hellog〜英語史ブログ / 2014-04
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
2026 : 01 02 03 04 05 06 07 08 09 10 11 12
2025 : 01 02 03 04 05 06 07 08 09 10 11 12
2024 : 01 02 03 04 05 06 07 08 09 10 11 12
2023 : 01 02 03 04 05 06 07 08 09 10 11 12
2022 : 01 02 03 04 05 06 07 08 09 10 11 12
2021 : 01 02 03 04 05 06 07 08 09 10 11 12
2020 : 01 02 03 04 05 06 07 08 09 10 11 12
2019 : 01 02 03 04 05 06 07 08 09 10 11 12
2018 : 01 02 03 04 05 06 07 08 09 10 11 12
2017 : 01 02 03 04 05 06 07 08 09 10 11 12
2016 : 01 02 03 04 05 06 07 08 09 10 11 12
2015 : 01 02 03 04 05 06 07 08 09 10 11 12
2014 : 01 02 03 04 05 06 07 08 09 10 11 12
2013 : 01 02 03 04 05 06 07 08 09 10 11 12
2012 : 01 02 03 04 05 06 07 08 09 10 11 12
2011 : 01 02 03 04 05 06 07 08 09 10 11 12
2010 : 01 02 03 04 05 06 07 08 09 10 11 12
2009 : 01 02 03 04 05 06 07 08 09 10 11 12
2014-04-30 Wed
■ #1829. 書き言葉テクストの3つの機能 [grammatology][writing][medium][speed_of_change]
エスカルピ著『文字とコミュニケーション』を読み,序論,第一章「文字」,第二章「読み」に文字論に関する啓発的な指摘をいくつか見つけた.以下に,備忘録的に書き留めておく.
著者は,文字,書き言葉,テキストの,話し言葉からの自立性を力説する.確かに書き言葉には話し言葉の写しとしての側面があり,その意味では依存しているとは言えるが,いったん書き言葉としての体系が発展すると,相当の自立性を獲得するというのも事実である.著者いわく,「文字法を,話し言葉を構成する音素の何かそのままの文字への置きかえ (transliteration) のように考えるのは錯覚である」 (22) ,さらに「文字を話し言葉の単なる道具と見なすことはできないといいたいし,また,言語学の伝統にみられる支配的傾向,「音声中心主義」 (phonocentrisme) を告発しよう」 (26) .エスカルピのこの主張について,私も賛同する.phonocentrisme については「#748. 話し言葉と書き言葉」 ([2011-05-15-1]) で,文字言語の独立性については「#1665. 話しことばと書きことば (4)」 ([2013-11-17-1]) や「#1655. 耳で読むのか目で読むのか」 ([2013-11-07-1]) の記事を参照されたい.
書き言葉が言語変化を抑止する,あるいは遅めるという点については,規範主義や教育という問題とも関わるが,エスカルピは文字そのものの本質,文字の記憶装置としての役割に帰せられるべきだと考えている.(36)
文字法の出現は話し言語を定着させ,あるいは少なくともその進化を著しくゆるめることに寄与したと指摘されているが,これはきわめて正しい.書かれない言語は急速に変わり,違ったものになっていく傾向があるために,一世代から次の世代にかけて理解しあうことが至難になった場合すら挙げられている.いうまでもなくこの定着は,痕跡の使用によって記憶が導入されたことによっている.とりわけ,何らかの形の痕跡がなければ,語彙総覧を作るこはできない./とくに単語というものは,本質的に文字言語がもたらしたもののように思われる.
文字が基本的に表語的 (logographic) な機能を果たすという指摘も重要である.アルファベットのような表音文字体系であっても,文字使用の主目的は表語にあると考えられる(「#1332. 中英語と近代英語の綴字体系の本質的な差」 ([2012-12-19-1]) や「#1386. 近代英語以降に確立してきた標準綴字体系の特徴」 ([2013-02-11-1]) も参照).
文字の語記号的性格はタイプライターでの打ち間違いによって証明される.手書きの草書体においては,語は連続したすじであって,書き手が自分のテクストと言説のあいだの絆を掌握していればいるだけ,それが単音文字へと分解されることは少ない.筆相鑑定家たちは,個別的なアルファベット符合が全体的な書き方のうちに消えていく《結合的》な筆蹟を知性のしるしと見なしている.ところで,タイプライターで書くときには単音文字への分解は避けられない.けれども,それは文字の継続的な選択に従ってなされはしない.少なくともいくらかの経験をもつタイピストの場合には.語全体が指の運動の内に《プログラム化》される.そしてこの運動がズレを起こしうるのである.その時 scripteur の代わりに spritceur と書かれることが起こる.語の要素はすべて出現している.外的な要素がまぎれ込むことは非常に珍しい.字の順序は狂うものの,その組成は変化を受けず,意味限定符は一般に無傷のまま残る./語記号――すなわちそれ自身の綴字で書かれた語――はゆえに,文字言語の最小有意味単位と考えねばならない.(38--39)
そして,何よりも啓発的なのは,文字の集合からなる書き言葉テクストには基本的な機能が2つあるという指摘である.1つは口頭の言説を写す言説的機能 (discursif) であり,もう1つは情報の記憶装置としての資料的機能 (documentaire) である(41) .前者は話し言葉に依存するが,後者は必ずしもそうではない.先に話題にした書き言葉が話し言葉の写しであるという見解は,テクストの言説的側面のみに着目した意見であり,テキストのもう1つの機能である資料的機能を考慮に入れていない点に問題がある.資料的機能が最大限に発揮されたテクストは,辞書やカタログなどのデータベースと呼びうる参考図書の類いである.そこでは情報が整理されており,相互参照などの機能も実装されている.このような機能は,話し言葉では容易にまねができない.
エスカルピ (44) は,もう1つ付け加えるべきテクストの機能として図像的機能 (iconique) を挙げている.これは,文字の形や大きさ,文字列の空間的な配列による書き言葉コミュニケーションの働きである.例えば新聞の1頁のレイアウトはテクストの読まれ方に影響を与えるが,これはテクストの図像的な働きゆえである.文字列の配置によって表現力を得ようとする具象詩においても,手紙の末尾の高い位置に宛名を大書する際にも,テクストの図像的機能が活用されている.この機能も,話し言葉に明確に対応するものはなく,書き言葉の自立性を示すものである.
・ ロベール・エスカルピ 著,末松 壽 『文字とコミュニケーション』 白水社〈文庫クセジュ〉,1988年.
2014-04-29 Tue
■ #1828. j の文字と音価の対応について再訪 [phonetics][french][latin][italian][spelling][pronunciation][consonant][j][grapheme]
「#1650. 文字素としての j の独立」 ([2013-11-02-1]) の記事の最後の段落で,<j> (= <i>) = /ʤ/ の対応関係が生まれた背景について触れた.ラテン語から古フランス語への発展期に,有声硬口蓋接近音 [j] が有声後部歯茎破擦音 [ʤ] へ変化したという件だ.この音韻変化と「#1651. j と g」 ([2013-11-03-1]) の記事の内容に関連して,田中 (138--39) によくまとまった記述があったので,引用する(OED の記述もほぼ同じ内容).
6世紀少し前に,後期ラテン語において,上述の [j] 音はしばしば発声上圧縮され,前舌面および舌尖を [j] の位置よりさらに高めることによってその前に d 音を発生させ iūstus > d-iūstus, māior > mā-d-ior, [dj] を経て [ʤ] に assibilate された.一方 g の古い喉音は前母音の前で口蓋化して [ʤ] に変わっていたので,consonantal i と 'soft' g はロマンス諸語では同一の音価をもつようになった.
イタリア語では,consonantal i から発展した新しい音 [ʤ] は e, i の前には g,そして a, o, u の前には gi- によって書き変えられることになって,j の綴りは捨てられた.〔中略〕
しかし,フランス語では i 文字は発展した音価をもってそのまま保存され,従って consonantal i と 'soft' g は等値記号であり,その差異は語の起源によるだけである.
L OF It. ModE iūstus iuste giusto just iūdic-cem iuge giudice judge Iēsus Iesu Gesù Jesus māior maire maggiore major gesta geste gesto gest (jest)
Norman Conquest 後,consonantal i はその古代フランス語の音価 [ʤ] をもって英語に輸入された.フランス語ではその後 [ʤ] はその第一要素を失って [ʒ] に単純化されたが,英語は今日に至るまでフランス起源の語においてその原音を保存している.
加えて,アルファベット <J> の呼称 /ʤeɪ/ について,田中 (141) の記述を引用しておこう.
J は古くは jy [ʤai] と呼ばれて左どなりの同族文字 I [ai] と押韻し,そしてフランス名 ji と呼応した.この呼び名は今でもスコットランドその他において普通である.近代イギリス名(17世紀)ja あるいは jay [ʤei] は,その a [ei] を右どなりの k に負う (O. Jespersen, B. L. Ullman) .ドイツ名 jot [jɔt] は,16世紀に j が初めて i から分化した時,セム名 yōd から取られた.
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
2014-04-28 Mon
■ #1827. magic <e> とは無関係の <-ve> [final_e][orthography][pronunciation][phonetics][silent_letter][spelling][grapheme][spelling_reform][webster][v]
昨日の記事「#1826. ローマ字は母音の長短を直接示すことができない」 ([2014-04-27-1]) で言及したが,現代英語の正書法についてよく知られた規則の1つに「#1289. magic <e>」 ([2012-11-06-1]) がある.take, mete, side, rose, cube など多くの <-VCe> をもつ英単語において,母音 V が長母音あるいは二重母音で読まれることを間接的に示す <e> の役割を呼んだものである.個々の例外はあるとしても,およそ規則と称して差し支えないだろう.
しかし,<-ve> で終わる単語に関して,dove, glove, shove, 形容詞接尾辞 -ive をもつ語群など,例外の多さが気になる.しかも,above, give, have, live (v.), love など高頻度語に多い.これらの語では, <ve> に先行する母音は短母音として読まれる.gave, eve, drive, grove など規則的なものも多いことは認めつつも,この目立つ不規則性はどのように説明されるだろうか.
実は,<-ve> 語において magic <e> の規則があてはまらないケースが多いのは,この <e> がそもそも magic <e> ではないからである.この <e> は,magic <e> とは無関係の別の歴史的経緯により発展してきたものだ.背景には,英語史において /v/ の音素化が遅かった事実,及び <v> の文字素としての独立が遅かった事実がある(この音素と文字素の発展の詳細については,「#373. <u> と <v> の分化 (1)」 ([2010-05-05-1]),「#374. <u> と <v> の分化 (2)」 ([2010-05-06-1]),「#1222. フランス語が英語の音素に与えた小さな影響」 ([2012-08-31-1]),「#1230. over と offer は最小対ではない?」 ([2012-09-08-1]) を参照されたい).結論を先取りしていえば,<v> は単独で語尾にくることができず,<e> のサポートを受けた <-ve> としてしか語尾にくることができない.したがって,この <e> はサポートの <e> にすぎず,先行する母音の量を標示する機能を担っているわけではない.以下に,2点の歴史的説明を与える(田中,pp. 166--70 も参照).
(1) 古英語では,[v] はいまだ独立した音素ではなく,音素 /f/ の異音にすぎなかった.典型的には ofer (over) など前後を母音に挟まれた環境で [v] が現れたが,直後に来る母音は弱化する傾向が強かったこともあり,中英語にかけては <e> で綴られることが多くなった.このようにして,[v] の音と <ve> の綴字が密接に関連づけられるようになった.<e> そのものは無音であり,あくまで寄生字母である.
(2) 先述のように,中英語期と初期近代英語期を通じて,<u> と <v> の文字としての分化は明瞭ではなかった.だが,母音字としての <u>,子音字としての <v> という役割分担が明確にできていなかった時代でも,不便はあったようである.例えば,完全に未分化の状況であれば,love と low はともに <lou> という綴字に合一してしまうだろう.そこで,とりあえずの便法として,子音 [v] を示すのに,無音の <e> を添えて <-ue> とした.3つの母音が続くことは少ないため,<loue> と綴られれば,中間の <u> は子音を表わすはずだという理屈になる.ここでも <e> そのものは無音であり,直前の <u> が子音字であることを示す役割を担っているにすぎない.やがて,子音字としての <v> が一般化すると,この位置の <u> そのまま <v> へと転字された.<v> が子音字として確立したのであれば <e> のサポートとしての役割は不要となるが,この <e> は惰性により現在まで残っている.
かくして,語尾の [v] は <-ve> として綴られる習慣が確立した.<-v> 単体で終わる語は,Asimov, eruv, guv, lav, Slav など,俗語・略語,スラヴ語などからの借用語に限定され,一般的な英語正書法においては浮いている.
Noah Webster や,Cut Speling の主唱者 Christopher Upward などは,give を <giv> として綴ることを提案したが,これは共時的には合理的だろう.一方で,上記のように歴史的な背景に目を向けることも重要である.
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
2014-04-27 Sun
■ #1826. ローマ字は母音の長短を直接示すことができない [grammatology][grapheme][latin][greek][alphabet][vowel][spelling][spelling_pronunciation_gap]
現代英語の綴字と発音を巡る多くの問題の1つに,母音の長短が直接的に示されないという問題がある.英語も印欧語族の一員として,母音の長短,正確にいえば短母音か長母音・二重母音かという区別に敏感である.換言すれば,母音の単・複が音韻的に対立する.ところが,この音韻対立が綴字上に直接的に反映していない.例えば,bat vs bate や give vs five では同じ <a> や <i> を用いていながら,それぞれ前者では短母音を,後者では二重母音を表わしている.確かに,bat vs bate のように,次の音節の <e> によって,母音がいかに読まれるかを間接的に示すヒントは与えられている(「#1289. magic <e>」 ([2012-11-06-1]) を参照).しかし,母音字そのものを違えることで音の違いを示しているのではないという意味では,あくまで間接的な標示法にすぎない.give vs five では,そのヒントすら与えられていない.
母音字を組み合わせて長母音・二重母音を表わす方法は広く採られている.また,長母音補助記号として母音字の上に短音記号や長音記号を付し,ā や ă のようにする方法も,正書法としては採用されていないが,教育目的では使用されることがある.もとより文字体系というものは音韻対立を常にあますところなく標示するわけではない以上,英語の正書法において母音の長短が文字の上に直接的に標示されないということは,特に驚くべきことではないのかもしれない.
しかし,この状況が,英語にとどまらず,ローマン・アルファベットを採用しているあらゆる言語にみられるという点が注目に値する.母音の長短が,母音字そのものによって示されることがないのである.母音字を重ねて長母音を表わすことはあっても,長母音が短母音とまったく別の1つの記号によって表わされるという状況はない.この観点からすると,ギリシア・アルファベットのε vs η,ο vs ωの文字の対立は,目から鱗が落ちるような革新だった.
アルファベット史上,ギリシア人の果たした役割は(ときに過大に評価されるが)確かに革命的だった.「#423. アルファベットの歴史」 ([2010-06-24-1]) で述べたように,ギリシア人は,子音文字だったセム系アルファベットに初めて母音文字を導入することにより,音素と文字のほぼ完全な結合を実現した.音韻対立という言語にとってきわめて本質的かつ抽象的な特徴を取り出し,それに文字という具体的な形をあてがった.これが第1の革命だったとすれば,それに比べてずっと地味であり喧伝されることもないが,同じくらい本質を突いた第2の革命もあった.それは,母音の音価ではなく音量(長さ)をも文字に割り当てようとした発想,先述の ε vs η,ο vs ω の対立の創案のことだ.ギリシア人はフェニキア・アルファベットのなかでギリシア語にとって余剰だった子音文字5種を母音文字(α,ε,ι,ο,υ)へ転用し,さらに余っていたηをεの長母音版として採用し,次いでωなる文字をοの長母音版として新作したのだった(最後に作られたので,アルファベットの最後尾に加えられた).
ところが,歴史の偶然により,ローマン・アルファベットにつながる西ギリシア・アルファベットにおいては,上記の第2の革命は衝撃を与えなかった.西ギリシア・アルファベットでは,η(大文字Η)は元来それが表わした子音 [h] を表わすために用いられたので,そのままラテン語へも子音文字として持ち越された(後にラテン語やロマンス諸語で [h] が消失し,<h> の存在意義が形骸化したことは実に皮肉である).また,ωの創作のタイミングも,ラテン語へ影響を与えるには遅すぎた.かくして,第2の革命は,ローマ字にまったく衝撃を与えることがなかった.以上が,後にローマ字を採用した多数の言語が母音の長短を直接母音字によって区別する習慣をもたない理由である.
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
2014-04-26 Sat
■ #1825. ローマ字 <F> の起源と発展 [grammatology][grapheme][latin][greek][alphabet][consonant][f][reduplication]
現代英語で <f> はほぼ常に /f/ に対応している(唯一の例外は of).この安定した関係は中英語にまで遡る.それ以前の古英語では <v> を欠いていたので,<f> は [f] とともに [v] にも対応していたが,中英語期にフランス語の綴字習慣に影響されて <v> が導入されることにより,<f> = /f/ の一意の関係が確立した.この経緯については,「#373. <u> と <v> の分化 (1)」 ([2010-05-05-1]),「#374. <u> と <v> の分化 (2)」 ([2010-05-06-1]),「#1222. フランス語が英語の音素に与えた小さな影響」 ([2012-08-31-1]),「#1230. over と offer は最小対ではない?」 ([2012-09-08-1]) を参照されたい.
英語史の範囲内で見る限り,<f> は特に問題となることはなさそうだが,この文字が無声唇歯摩擦音に対応するようになったのは,ラテン語における革新ゆえである.古代ギリシア語のアルファベットを知っている人は,<f> に対応する文字がないことに気づくだろう.しかし,古代ギリシア語でも西方言には <f> に相当する文字が残っていたし,東方言でも最初期の段階にはそれがあった.後に koiné となる東方言の1変種である Attic ではそれが失われていたので,現代に至るギリシア・アルファベットには <f> が含まれていないのである.
初期ギリシア語には存在した <F> は,Γを上下にずらして2つ並べたような字形だったために,"digamma" として知られていた.これは,セム・アルファベットの第6番目の文字(Yに似た字形で,"wāu" と呼ばれる)を引き継いだもので,ギリシア語では半母音 [w] に近い摩擦音の音価を表わした.しかし,東方言ではこの音は消失し,その文字も捨て去られた.半母音 [w] に対して純正の母音 [u] は同起源のΥの文字で表わされ,これが後にラテン語以降の諸言語で <U>, <V>, <W>, <Y> へと分化していった.つまり,ローマ字の <F>, <U>, <V>, <W>, <Y> はすべてセム・アルファベットの wāu に起源をもつことになる.
さて,ラテン語はギリシア語西方言でまだ生き残っていた <F> = [w] の関係を取り入れた.しかし,ラテン語では [w] は <V> で表わす慣習が確立したので,<F> は不要となった.不要となった <F> はギリシア語東方言のときのように廃用となる可能性もあったが,ラテン語はこの余った文字をギリシア語にはなく,ラテン語にはあった無声唇歯摩擦音 [f] を表わすのに転用することを決めた.当初は,直接の転用には抵抗があったらしく,<F> 単体ではなく <FH> のように2文字を合わせて [f] を標示することを試みた証拠がある.例えば,紀元前7世紀の最古のラテン語で記された「マニオス刻文」には,右から左へ "IOISAMVN DEKAHFEHF DEM SOINAM" (Manios made me for Numasios) とあり,第3語目に "FHEFHAKED" (古典ラテン語の fecit に相当する古い加重形 reduplication)が見える(田中,p. 71).しかし,後には <F> 単体で [f] を表わすことになった.この関係が,ラテン語およびそれ以降の諸言語で保持されている.
ある言語のアルファベットが別の言語に移植される際に,不要な文字が廃用となったり,転用されたり,新しい文字が足されるなど,種々の変更が加えられることは,アルファベット史を通じて何度となく繰り返されてきた.文字と音化の関係は,ときに惰性で保持されることはあっても,その都度変化するのも普通のことだったことがわかるだろう.
以上,田中 (pp. 125--28) を参照して執筆した.
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
2014-04-25 Fri
■ #1824. <C> と <G> の分化 [grammatology][grapheme][latin][greek][alphabet][etruscan][rhotacism][consonant][c][g][q]
現代英語で典型的に <c> は /k/, /s/ に,<g> は /g/, /ʤ/ に対応する.それぞれ前者の発音は,古英語期に英語が Roman alphabet を受け入れたときのラテン語の音価に相当し,後者の発音は,その後の英語の歴史における発展を示す(<g> については,「#1651. j と g」 ([2013-11-03-1]) を参照).ラテン語から派生したロマンス諸語でも,種々の音変化の結果として,<c> や <g> が表わす音は,古典ラテン語のものとは異なっていることが多い.しかし,上で規範であるかのように参照したラテン語の <c> = /k/, <g> = /g/ という対応関係そのものも,ラテン語の歴史や前史における発展の結果,確立してきたものである.
ラテン語は,後にローマ字と呼ばれることになるアルファベットを,ギリシア語の西方方言からエトルリア語 (Etruscan) を介して受け取った.ギリシアとローマの両文明の仲介者であるエトルリア人とその言語は,「#423. アルファベットの歴史」 ([2010-06-24-1]) や「#1006. ルーン文字の変種」 ([2012-01-28-1]) でみたように,アルファベット史上に大きな役割を果たしたが,非印欧語であるエトルリア語について多くが知られているわけではない.しかし,エトルリア語の破裂音系列に有声・無声の音韻的対立がなかったことはわかっている.それにより,エトルリア語では,有声破裂音を表わすギリシア語のβとδは不要とされ廃用となった.しかし,γについては生き残り,これが軟口蓋破裂音 [k], [g] を表わす文字として用いられることとなった.
さて,エトルリア語から文字を受け取ったラテン語は,当初,γ = [k], [g] の関係を継続した.したがって,人名の省略形では,GAIUS に対して C. が,GNAEUS に対して CN. が当てられていた.しかし,紀元前300年頃に,この文字はとりわけ [k] に対応するようになり,純正に音素 /k/ を表わす文字として認識されるようになった.字体も rounded Γ と呼ばれる現代的な <C> へと近づいてゆき,<C> = /k/ の関係が確立すると,対応する有声音素 /g/ を表わすのに <C> に補助記号を伏した字形,後に <G> へ発展することになる字形が用いられるようになった.こうして紀元前300年頃に <C> と <G> が分化すると,後者はギリシア・アルファベットにおいてζが収っていた位置にはめ込まれた.ζは,ラテン語では後に <Z> として再採用されアルファベットの末尾に加えられることになったものの,[z] -> [r] の rhotacism を経て初期の段階で不要とされ廃用とされていたのである.
なお,ローマン・アルファベットでは無声軟口蓋破裂音を表わすのに <c>, <k>, <q> など複数の文字が対応しており,この点について英語を含めた諸言語は複雑な歴史を経験してきた.これは,英語の各文字の名称 /siː/, /keɪ/, /kjuː/ が暗示しているように,後続母音に応じた使い分けがあったことに起因する.エトルリア語では,前7世紀あるいはその後まで,CE, KA, QO という連鎖で用いられていた (cf. Greek kappa (Ka) vs koppa (Qo)) .現在にまで続く [k] を表わす文字の過剰は,ギリシア語やエトルリア語からの遺産を受け継いでいるがゆえである.
以上,田中 (pp. 76--79, 119) を参照して執筆した.
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
2014-04-24 Thu
■ #1823. ローマ数字 [numeral][latin][greek][grammatology][alphabet][etruscan]
現代の英語や日本語でも,時々ローマ数字 (Roman numerals) が使われる機会がある.例えば,番号,年号,本のページ,時計の文字盤などに現役で使用されている.現代英語からの例をいくつか挙げよう.
・ It was built in the time of Henry V.
・ For details, see Introduction page ix.
・ Do question (vi) or question (vii), but not both.
・ a fine XVIII-century' English walnut chest of drawers
ローマ数字は,ほんの数種類の文字と組み合わせ方の単純な原理さえ覚えれば,大きな数も難なく表わすことができるという長所をもち,ヨーロッパで2000年以上にわたる伝統を誇ってきた.10進法のなかに5進法が混在しており,後者にはギリシアのアッティカ式の影響が見られる.IV = 4, IX = 9 など減法も利用したやや特異な記数法である.以下に凡例を掲げよう.
| 1 | I |
| 2 | II |
| 3 | III |
| 4 | IV |
| 5 | V |
| 6 | VI |
| 7 | VII |
| 8 | VIII |
| 9 | IX |
| 10 | X |
| 11 | XI |
| 12 | XII |
| 13 | XII |
| 14 | XIV |
| 19 | XIX |
| 20 | XX |
| 21 | XXI |
| 30 | XXX |
| 40 | XL |
| 45 | XLV |
| 50 | L |
| 60 | LX |
| 90 | XC |
| 100 | C |
| 500 | D |
| 1000 | M |
| 1998 | MCMXCVIII |
ヨーロッパでアラビア数字 (Arabic numerals) の使用が最初に確認されるのは976年のウィギラム写本においてだが,13--14世紀以降に普及するまでは,ローマ時代以来,ローマ数字 (Roman numerals) が一般的に使用されてきた(カルヴェ,pp. 210--11) .それ以降も,上述のような限られた文脈においては,現在まで命脈を保っている.
では,ローマ数字の起源について考えよう.I が1を表わすというのは直感的に理解できるとしても,V, X, C などその他の単位の文字はどのように選ばれたのだろうか.明確なことはわかっていないが,ドイツの歴史家 Theodor Mommsen (1817--1903) の説が有名である.それによると,V は手をかたどった象形文字であり,指の本数である5を表わすという.Vを上下に向かい合わせて重ねると,X (10) となる.L, C, M は,エトルリア語や初期ラテン語を書き表すのに不要とされた西ギリシア文字のΨ (khi; 東ギリシア文字では khi はΧによって表わされるので注意),Θ (theta),Φ (phi) をそれぞれ 50, 100, 1000 の数に割り当てたのが起源とされる.後に字形の類似により,Ψ(後に字形が┴のように変形する)が L と,Θが C(ラテン語 centum の影響もあり)と,Φが M(ラテン語 mille の影響もあり)と結びつけられた.L (50) の字形が C (100) の下半分の字形に似ているという意識,さらに D (500) の字形が M (1000) の右半分の字形に似ているという意識も関与していたのではないかと言われる(田中,p. 75).
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
・ ルイ=ジャン・カルヴェ 著,矢島 文夫 監訳,会津 洋・前島 和也 訳 『文字の世界史』 河出書房,1998年.
2014-04-23 Wed
■ #1822. 文字の系統 [writing][grammatology][alphabet][kanji][history][runic][origin_of_language][family_tree][hieroglyph]
本ブログで,これまで文字論や文字の歴史に関する話題として,「#41. 言語と文字の歴史は浅い」 ([2009-06-08-1]),「#422. 文字の種類」 ([2010-06-23-1]),「#423. アルファベットの歴史」 ([2010-06-24-1]),「#490. アルファベットの起源は North Semitic よりも前に遡る?」 ([2010-08-30-1]),「#1006. ルーン文字の変種」 ([2012-01-28-1]) などを取り上げてきた.ほかにも,文字論について grammatology,アルファベットについて alphabet,ルーン文字について runic,漢字,ひらがな,カタカナについてそれぞれ kanji, hiragana, katakana で話題にした.
言語の発生 (origin_of_language) については,現在,単一起源説が優勢だが,文字の発生については多起源説を主張する論者が多い.古今東西で行われてきた種々の文字体系は,発生と進化の歴史によりいくつかの系統に分類することができるが,確かにそれらの祖先が単一の原初文字に遡るということはありそうにない.メソポタミア,エジプト,中国,アメリカなどで,それぞれの文字体系が独立して発生したと考えるのが妥当だろう.
最も古い文字体系は,メソポタミアに居住していたシュメール人による楔形文字である.紀元前4千年紀,おそらく紀元前3500年頃に,楔形文字の体系が整い始めた.楔形文字は,紀元前8000年頃にすでに見られたとされる,帳簿に数量を記録するのためのマークがその原型であるといわれ,数千年の時間をかけてゆっくりと文字体系へと成長していったものである.
同じ紀元前4千年紀,あるいはもう少し遅れて,比較的近いエジプトでもヒエログリフ (hieroglyphic) やそこから派生したヒエラティック (hieratic) が現れる.これらは初めて文証された段階で,すでにほぼ完全な文字体系として機能しており,メソポタミアの楔形文字のような漸次的発展の前史が確認されない.
アルファベットの発生については,「#423. アルファベットの歴史」 ([2010-06-24-1]) で概説したとおりなので記述は省略する.
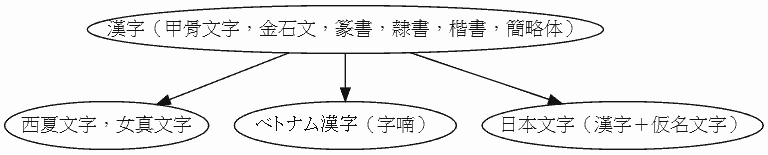
漢字は,紀元前2000年頃に現れ,紀元前1500年頃に文字としての体裁を整えた.文字体系として完成したのは,漢王朝 (BC202--220AD) の時代である.
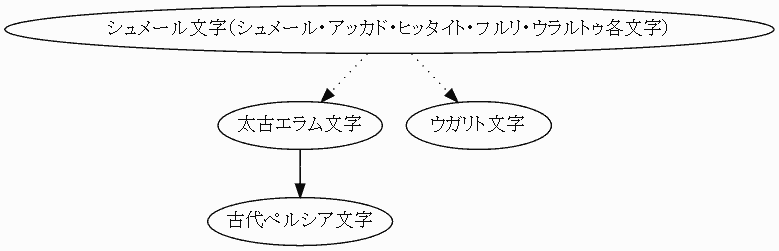
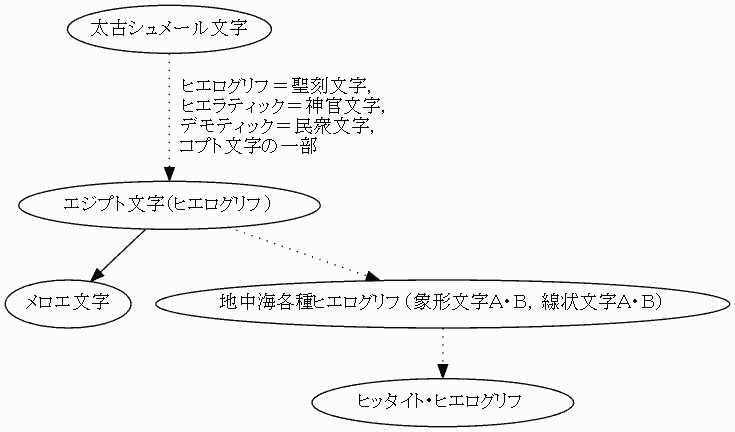
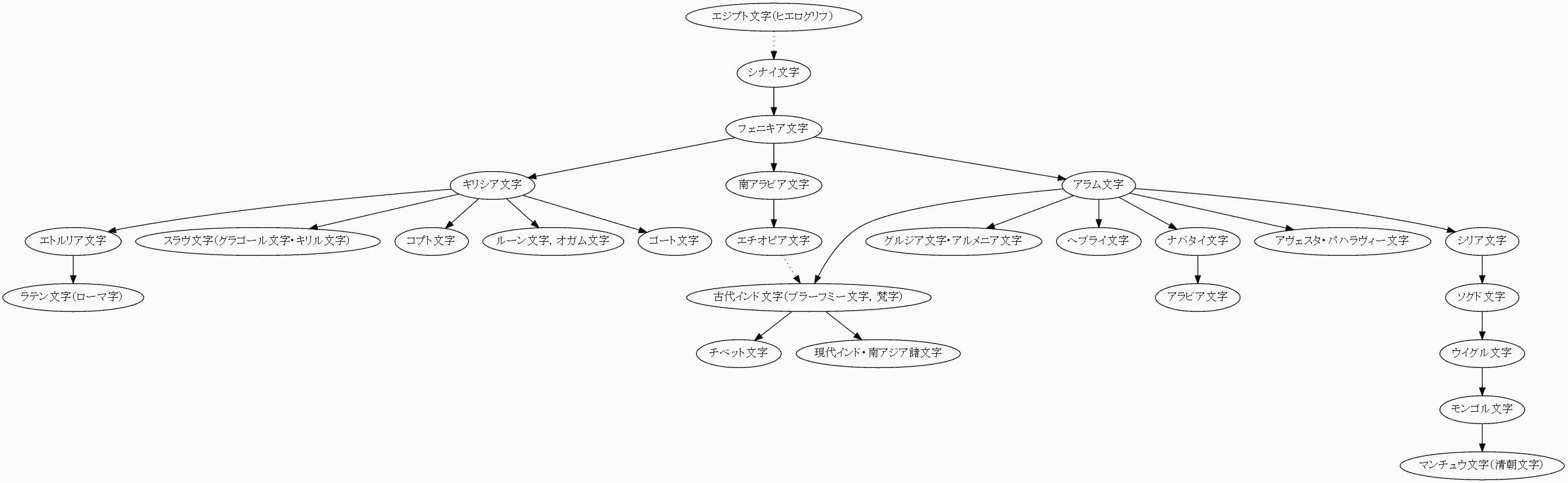
文字体系の系統としては,以上の4つ,(1) 楔形文字体系,(2) ヒエログリフ文字体系,(3) アルファベット体系,(4) 漢字体系が区別されることになる.ジョルジュ・ジャン (136--37) の図を参照して作った文字の系統図を示そう.実線矢印は直接的影響を,点線矢印は間接的影響を示す.
(1) 楔形文字体系
(2) ヒエログリフ文字体系
(3) アルファベット体系(図をクリックして拡大)
(4) 漢字体系
以上の4系統に収らないその他の文字体系もある.未解読文字を含むが,朝鮮文字(ハングル),ロロ文字,モソ文字,バヌム文字,インダス文字(紀元前3000年頃),マヤ・アステカ文字,イースター島文字などである.
古今東西の文字体系については,次のサイトが有用.
・ Omniglot: Writing Systems & Language of the World
・ A Compendium of World-Wide Writing Systems from Prehistory to Today
・ 世界の文字(各国文字)
・ ジョルジュ・ジャン 著,矢島 文夫 監修,高橋 啓 訳 『文字の歴史』 創元社,1990年.
2014-04-22 Tue
■ #1821. フランス語の復権と英語の復権 [french][latin][reestablishment_of_english][me][history][hfl]
中英語後期の,フランス語に対する英語の復権について,本ブログでは reestablishment_of_english の各記事で話題にしてきた.同じ頃,お隣のフランスでは,ラテン語に対するフランス語の復権が起こっていた.つまり,中世末期,イングランドとフランスの両国(のみならず実際にはヨーロッパ各国)で,相手にする言語こそ異なれ,大衆の言語 (vernacular) が台頭してきたのである.
中世後期のフランスで,フランス語がいかに市民権を得てきたか,行政・司法に用いられる言語という観点から概説しよう.中世フランスでは,行政・司法の言語としてラテン語が一般的であったことは間違いないが,13世紀中からフランス語の使用も始まっていた.特に Charles IV の治世 (1322--28) において行政・司法におけるフランス語の使用は,安定したものとはならなかったものの,進展した.その後14世紀末からは,フランス王国のアイデンティティと結びついた国語として,フランス語の存在感が確かに認められるようになってゆく.そして,ついに1539年8月15日,行政・司法におけるフランス語に,決定的なお墨付きが与えられることとなった.フランス語史上に名高いヴィレ・コトレの勅令 (l'ordonnance de Villers-Cotterêts) である.「#653. 中英語におけるフランス借用語とラテン借用語の区別」 ([2011-02-09-1]) で触れたように,それまで法曹界はラテン語とフランス語の2言語制で回っていたが,フランソワ1世 (Francis I; 1494--1547) が行政・司法でのラテン語使用を廃止したのである.Perret (47) より,勅令の関係する箇所を引こう.
L'ordonnance de Villers-Cotterêts (1539) Articles 110 et 111
«Et afain qu'il n'y ait cause de douter sur l'intelligence desdits arrests, nous voulons et ordonnons qu'ils soient faits et escrits si clairement, qu'il n'y ait ne puisse avoir aucune ambiguïté ou incertitude, ne lieu à demander interprétation.
Et pour ce que de telles choses sont souvent advenues sur l'intelligence des mots latins contenus esdits arrests, ensemble toutes autres procédures, [...] soient prononcez, enregistrez et delivrez aux parties en langaige maternel françois et non autrement.»
この勅令は,ラテン語を扱えない官吏の業務負担を減らすためという実際的な目的もあったが,フランス語をフランスの国語として制定するという意味合いがあった.その後の歴史において,フランスは他言語や非標準方言を退け,標準フランス語の普及と拡大に突き進んでゆくが,その最初の決定的な一撃が1539年に与えられたことになる.実際に,17世紀中にこの勅令の内容は拡大し,フランス革命後も堅持されたことはいうまでもない.
一方,イングランドにおける英語の復権は,「#131. 英語の復権」 ([2009-09-05-1]) や「#706. 14世紀,英語の復権は徐ろに」 ([2011-04-03-1]) で示したように,あくまで徐々に進んでいった.確かに,「#324. 議会と法廷で英語使用が公認された年」 ([2010-03-17-1]) である1362年のような,英語の復権を象徴する契機はあるにはあるが,ヴィレ・コトレの勅令のような1つの決定的な出来事に相当するものはない.
近代ではイングランド,フランスともに標準語を巡る問題,規範の議論が持ち上がったが,諸問題への対処法や言語政策は両国間で大きく異なっていた.その差異の起源は,すでに中世後期における土着語の復権の仕方そのものにあったように思われる.
・ Perret, Michèle. Introduction à l'histoire de la langue française. 3rd ed. Paris: Colin, 2008.
2014-04-21 Mon
■ #1820. c-command [syntax][generative_grammar][terminology][ppcme2][ppceme][ppcmbe]
「#310. PPCMBE で広がる英語統語論の通時研究」 ([2010-03-03-1]) で,Penn Parsed Corpora of Historical English を紹介した.Helsinki Corpus をベースとしながらも拡張を加えた歴史英語コーパス群で,詳細に構文解析された Penn-Treebank format による統語ツリーもろとも検索できるのが最大の特徴である.タグや注釈の体系が複雑で,CorpusSearch なる特殊なプログラムを用いて検索する必要もあり,初心者が使いこなすには敷居が高いが,統語的に明確に規定された例文を集めるといった用途では,今のところ Penn 系の構文解析コーパス (PPC) にかなうものはない.
PPC の構文解析の理論的基盤は生成文法だが,用いられる術語は生成理論の特殊化したヴァージョンのものではなく,一般的・基本的なものなので,理論に精通していなくとも何とか利用はできる.例えば,CorpusSearch の命令群に,"Dominates", "iDominates" (=immediately dominates), "HasSister", "IsRoot" などがあるが,統語ツリーのいろはを知っていれば,これらの用語が指す統語関係を理解することは難しくない.
しかし,上に挙げたものよりも少し理論がかった命令に,"CCommands" というものがある.c-command あるいは c-統御とは,1980年代初期に発展した束縛理論 (binding theory) において広く言及された統語関係である.束縛理論は,UG (universal grammar) の一般原則のなかでも中核をなすものとして当時こぞって研究された理論であり,とりわけ再帰代名詞などに代表される照応形 (anaphora) ,代名詞,その他の名詞句と,それらの先行詞との関係を規定する原則を追究した.その理論的発展の過程で,とりわけ重要とされるようになった統語関係の1つが,c-統御である.ほかに,関連の深いものに束縛 (binding) と統率 (government) がある.
以下で,c-統御 (c-command) と束縛 (binding) について概説しよう.下の架空の統語ツリーにおいて,
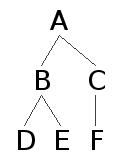
・ B は C と F を c-統御している
・ C と F はともに B, D, E を c-統御している
・ D は E を,E は D を c-統御している
と言われる.定義風にいえば,「節点 X を支配している最初の枝分かれ節点が別の節点 Y を支配しているとき,X は Y を c-command する」(渡辺,p. 86).
生成文法で理論上 c-統御が重要視されたのは,再帰代名詞とそれが指す先行詞の関係を規定するために,c-統御という統語関係が決定的な役割を果たすことがわかってきたからだ.以下の2つの文を考えよう.
(1) *John's mother criticized himself.
(2) John's mother criticized herself.
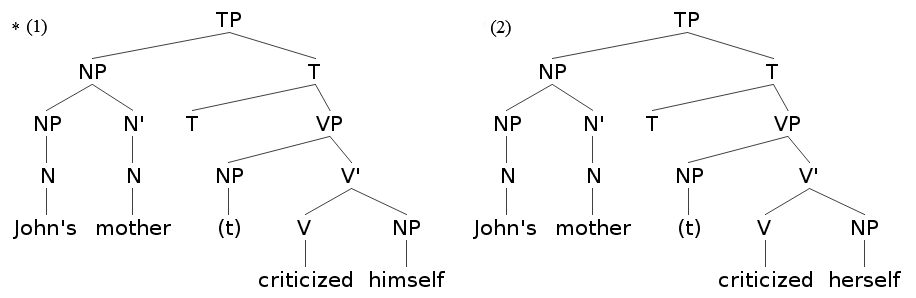
非文の (1) では,"John" に相当する NP を支配している最初の枝分かれ節点は TP のすぐ下の NP であるから,"John" は "mother" を c-command していることにはなっても,"himself" を c-command していることにはならない."himself" の立場からいえば,"John" に c-command されていないことになる.このような場合,すなわち "himself" が "John" に束縛されていない場合には,照応が成り立たないというのが,英語統語論でのルールである.
一方,正文の (2) では,再帰代名詞 "herself" は "John's mother" を表す NP を先行詞としているが,この NP を支配している最初の枝分かれ節点は TP であるから,"John's mother" は "herself" を c-command していることになる."herself" の立場からいえば,"John's mother" に c-command されており,束縛されているので,照応が成り立つ.生成文法家は,c-統御,さらに束縛という統語関係の規程を通じて,英語の照応に関する一般原則が見いだされたと考えた.
PPC の話に戻ると,例えば his ouermoch fearinge of you のような名詞句を検索するのに,"CCommands" という命令により「代名詞が別の代名詞を c-統御しているような名詞句」という統語条件を設定すればよい.複雑な統語条件のもとで,かつ authentic な例文を取り出したいときに,PPC と CorpusSearch は威力を発揮する.
・ 渡辺 明 『生成文法』 研究社,2009年.
2014-04-20 Sun
■ #1819. AHD Word History Note Search [etymology][dictionary][cgi][web_service]
「#1809. American Heritage Dictionary の Notes」 ([2014-04-10-1]) で,The Free Dictionary 上でアクセスできる Notes へのリンク集を作った(Notes 集そのものは,1.6MBあるこちらのページへ).今回は,そのなかから Word Histories に関する Notes を集めたものをデータベース化し,「#952. Etymology Search」 ([2011-12-05-1]) の要領で,検索ツール "AHD Word History Note Search" を作ってみた.
語源記事が登録されている見出し語を検索するだけであれば,上のリンク集で単語を検索すればよく,このツールの有用性はあまりない.このツールの特徴は,Notes の中身を正規表現で検索できる仕様(デフォルト)にある.例えば,日本に何らかの言及のある英単語の語源コラムを得たいのであれば,下の検索ボックスに Japan と入れればよいし,アイルランド関係であれば (Irish|Ireland) などだ.ほかには,search range を "Search for entry words" に入れ替えて,^[A-Z] と検索ボックスに入れると,固有名詞の語源コラムを集められる,等々.
2014-04-19 Sat
■ #1818. 日本語の /r/ [phonetics][consonant][japanese][phoneme][r][l]
「#1618. 英語の /l/ と /r/」 ([2013-10-01-1]) および昨日の記事「#1817. 英語の /l/ と /r/ (2)」 ([2014-04-18-1]) に引き続き,/r/ の話題.今回は日本語の /r/ の音声的実現についてである.
日本語のラ行の子音 /r/ は,典型的には,有声歯茎はじき音 [ɾ] として実現される.特に「あられ」のように,母音に挟まれた環境ではこれが普通である.この音は,BrE の merry や AmE の letter の第2子音として典型的に現れる音でもある.調音音声学的には,この音は有声歯茎閉鎖音 /d/ にかなり近いが,[ɾ] では舌尖と歯茎による閉鎖が弱く,その時間も短いという特徴がある.「ライオン」などの語頭や「アッラー」などの促音の後では接触が強くなり,/d/ にさらに近づくが,閉鎖の開放は弱めである.
意外と知られてないことだが,日本語母語話者の個人によっては,有声側面接近音 [l] に近い子音がラ行子音として用いられている.語頭や撥音の後で現われることが多いが,母音間でも側音に近くなる人もいる.ぴったりの音声標記はないが,有声そり舌破裂音 [ɖ] や 有声歯茎側面はじき音 [ɺ] や(接触が長い場合の)舌尖による有声歯茎側面接近音 [l̺] にも近いので,これらで代用する方法もある.有声歯茎側面はじき音 [ɺ] は,いわば [l] をはじき音化したものだが,タンザニアのチャガ語などで聞かれる子音である.
ほかにも「べらんめえ口調」に典型的とされる有声歯茎ふるえ音 [r] が,日本語 /r/ の自由異音として現れることがある.
以上,斉藤 (91) と佐藤 (43) を参照した.
・ 斉藤 純男 『日本語音声学入門』改訂版 三省堂,2013年.
・ 佐藤 武義(編著) 『展望 現代の日本語』 白帝社,1996年.
2014-04-18 Fri
■ #1817. 英語の /l/ と /r/ (2) [phonetics][consonant][rp][dialect][phoneme][r][l]
英語の /l/ と /r/ については,「#72. /r/ と /l/ は間違えて当然!?」 ([2009-07-09-1]),「#1597. star と stella」 ([2013-09-10-1]),「#1614. 英語 title に対してフランス語 titre であるのはなぜか?」 ([2013-09-27-1]) などで扱ってきた.とりわけ調音について「#1618. 英語の /l/ と /r/」 ([2013-10-01-1]) で概要を記したが,今回は一部重複するものの,それに補足する内容の記事を Crystal (245) に依拠して書く.
前の記事でも見たように,英語の音素 /l/ は,様々な音声として実現される.[l] の基本的な調音は,舌先を歯茎に接し,舌の側面から呼気を抜けさせるものだが,舌のとる形に応じて大きく2種類が区別される.それぞれ "clear l" と "dark l" と呼ばれる.前者 [l] は,前舌が硬口蓋に向かって上がるもので,前母音の響きをもち,RP では母音や [j] の前位置で起こる (ex. leap) .後者 [ɫ] は,後舌が軟口蓋に向かって上がるもので,後母音の響きをもち,RP ではそれ以外の位置で起こる (ex. pool) .ただし,clear l と dark l の分布は,諸変種において様々であり,例えば,Irish の一部であらゆる位置で clear l が聞かれたり,Scots や AmE の多くであらゆる位置で dark l が聞かれる.また,please, sleep のような無声子音の後位置では無声化した [l] が用いられる.そのほか,bottle のように音節主音的な l では,先行する [t] の側面破裂を伴う.Cockney 方言や一部 RP ですら,peel などの dark l が母音化し,[piːo] などとなる.
英語の音素 /r/ は,おそらく変種による差や個人差が最も多い子音だろう.最も普通には有声歯茎接近音 [ɹ] として実現される.d に後続する場合には,舌先が歯茎に限りなく接近し,摩擦音化が生じる (ex. drive) .母音に挟まれた位置やいくつかの子音の後位置で,日本語の典型的なラ行の子音と同じような有声歯茎はじき音 [ɾ] となる (ex. very, sorry, three) .気息を伴う [ph, th, kh] の後位置では無声摩擦音となる (ex. pry, try, cry) .
変種による異音としては,最も有名なのが有声そり舌接近音の [ɻ] で,先行する母音の音色を帯びる.General American に典型的だが,ほかにもイングランド南西部や東南アジアの変種でも聞かれる.有声歯茎ふるえ音の [r] は,Scots や Welsh の一部で聞かれるが,その他の変種でも格調高い発音において現れることがある.そのほか,フランス語やドイツ語で一般的に聞かれる有声口蓋垂摩擦音 [ʁ] あるいは有声口蓋垂ふるえ音 [ʀ] が,イングランド北東方言や一部スコットランド方言でも聞かれ,"Northumbrian burr" と呼ばれることがある(「#1055. uvular r の言語境界を越える拡大」 ([2012-03-17-1]) を参照).最後に,19世紀前半のイングランドで,red を [wed] と発音するように /r/ を [w] で代用することがはやったことを付け加えておこう.
なお,音素としては /r/ ではないが,AmE で matter の t は有声歯茎はじき音 [ɾ] として実現されることが多く,party の t は有声そり舌はじき音 [ɽ] で発音される.
・ Crystal, David. The Cambridge Encyclopedia of the English Language. 2nd ed. Cambridge: CUP, 2003.
2014-04-17 Thu
■ #1816. drift 再訪 [drift][gvs][germanic][synthesis_to_analysis][language_change][speed_of_change][unidirectionality][causation][functionalism]
Millar (111--13) が,英語史における古くて新しい問題,drift (駆流)を再訪している(本ブログ内の関連する記事は,cat:drift を参照).
Sapir の唱えた drift は,英語なら英語という1言語の歴史における言語変化の一定方向性を指すものだったが,後に drift の概念は拡張され,関連する複数の言語に共通してみられる言語変化の潮流をも指すようになった.これによって,英語の drift は相対化され,ゲルマン諸語にみられる drifts の比較,とりわけ drifts の速度の比較が問題とされるようになった.Millar (112) も,このゲルマン諸語という視点から,英語史における drift の問題を再訪している.
A number of scholars . . . take Sapir's ideas further, suggesting that drift can be employed to explain why related languages continue to act in a similar manner after they have ceased to be part of a dialect continuum. Thus it is striking . . . that a very similar series of sound changes --- the Great Vowel Shift --- took place in almost all West Germanic varieties in the late medieval and early modern periods. While some of the details of these changes differ from language to language, the general tendency for lower vowels to rise and high vowels to diphthongise is found in a range of languages --- English, Dutch and German --- where immediate influence along a geographical continuum is unlikely. Some linguists would suggest that there was a 'weakness' in these languages which was inherited from the ancestral variety and which, at the right point, was triggered by societal forces --- in this case, the rise of a lower middle class as a major economic and eventually political force in urbanising societies.
これを書いている Millar 自身が,最後の文の主語 "Some linguists" のなかの1人である.Samuels 流の機能主義的な観点に,社会言語学的な要因を考え合わせて,英語の drift を体現する個々の言語変化の原因を探ろうという立場だ.Sapir の drift = "mystical" というとらえ方を退け,できる限り合理的に説明しようとする立場でもある.私もこの立場に賛成であり,とりわけ社会言語学的な要因の "trigger" 機能に関心を寄せている.関連して,「#927. ゲルマン語の屈折の衰退と地政学」 ([2011-11-10-1]) や「#1224. 英語,デンマーク語,アフリカーンス語に共通してみられる言語接触の効果」 ([2012-09-02-1]) も参照されたい.
ゲルマン諸語の比較という点については,Millar (113) は,drift の進行の程度を模式的に示した図を与えている.以下に少し改変した図を示そう(かっこに囲まれた言語は,古い段階での言語を表わす).

この図は,「#191. 古英語,中英語,近代英語は互いにどれくらい異なるか」 ([2009-11-04-1]) で示した Lass によるゲルマン諸語の「古さ」 (archaism) の数直線を別の形で表わしたものとも解釈できる.その場合,drift の進行度と言語的な「モダンさ」が比例の関係にあるという読みになる.
この図では,English や Afrikaans が ANALYTIC の極に位置しているが,これは DRIFT が完了したということを意味するわけではない.現代英語でも,DRIFT の継続を感じさせる言語変化は進行中である.
・ Millar, Robert McColl. English Historical Sociolinguistics. Edinburgh: Edinburgh UP, 2012.
2014-04-16 Wed
■ #1815. 不定代名詞 one の用法はフランス語の影響か? [french][borrowing][personal_pronoun][numeral][contact][french_influence_on_grammar]
フランス語は英語の語彙や綴字には大きな影響を及ぼしてきたが,英文法に及ぼした直接の影響はほとんどないといわれる.「#1208. フランス語の英文法への影響を評価する」 ([2012-08-17-1]) で論じたように,間接的な影響ということでいえば,「#1171. フランス語との言語接触と屈折の衰退」 ([2012-07-11-1]) で取り上げた問題はおおいに議論に値するが,統語や形態へのフランス語の影響はほとんどないといってよい.数少ない例の1つとして,「#204. 非人称構文」 ([2009-11-17-1]) の記事でみたように,中英語期中の非人称動詞および非人称構文の増加はフランス語に負っていることが指摘されるが,せいぜいそれくらいのものだろう.
しかし,もう1つ,ときにフランス語からの文法的な影響として指摘される項目がある.One should always listen to what other people say. のように用いられる,不定代名詞 one である.これが,対応するフランス語の不定代名詞 on (< L homo) の借用ではないかという議論だ.最近では,Millar (126) が,次のように指摘している.
What is noteworthy about these large-scale French-induced changes is that they are dependent upon the massive lexical borrowing. Other structural changes not connected to this are limited (and also contested), such as the origin of the Modern English impersonal pronoun one in the ancestor of Modern French on.
OED の one, adj., n., and pron. によると,フランス語影響説は必ずしも妥当ではないかもしれない旨が示唆されている.
The use as an indefinite generic pronoun (sense C. 17), which replaced ME pron.2, MEN pron. in late Middle English, may have been influenced by Anglo-Norman hom, on, un, Old French, Middle French on (12th cent.; mid 9th cent. in form om ; French on; ultimately < classical Latin homō: see HOMO n.1), though this is not regarded as a necessary influence by some scholars.
C. 17 に挙げられている初例は,MED ōn (pron) の語義2からの初例を取ったものである.
a1400 (a1325) Cursor Mundi (Vesp.) 1023 (MED), Of an [a1400 Gött. ane; a1400 Trin. Cambr. oon] qua siþen ete at þe last, he suld in eild be ai stedfast.
Mustanoja (223--24) が,後期中英語における one のこの用法の発生について,まとまった議論を展開している.やや長いが,すべて引用しよう.
'ONE.' --- The origin of the one used for the indefinite person has been the subject of some scholarly dispute. Some grammarians believe that it developed from the indefinite one (originally a numeral . . .) meaning 'a person,' just as man expressing the indefinite person developed from man meaning 'a human being.' It has also been suggested that the one used for the indefinite person is in reality French on (from Latin homo), though influenced by the native indefinite one. This view, first expressed by R. G. Latham (The English Language, Vol. II, London 1855), has been more recently advocated by G. L. Trager and H. Marchand . . . . The case of those who maintain that one is a direct loan from French is, however, somewhat weakened by the fact that in the two earliest known instances of this use one occurs as an object of the verb and as an attributive genitive ('possessive dative'); one of these is doo thus fro be to be; thus wol thai lede oon to thaire dwelliyng place (Pall. Husb. v 181). The earliest examples of one as an indefinite subject are recorded in works of the late 15th century: --- he herde a man say that one was surer in keping his tunge than in moche speking, for in moche langage one may lightly erre (Earl Rivers Dicts 57); --- every chambre was walled and closed rounde aboute, and yet myghte one goo from one to another (Caxton En. 117). It is not until the second half of the 16th century that the use of one in this sense becomes common.
From all we know about the first appearance and the subsequent development of one expressing the indefinite person it seems that this use arose as a synthesis of native one and French on. This view is further supported by the fact that in Anglo-Norman the spelling un is used not only for the numeral un but also for the indefinite person, as in the proverb un vout pendre par compaignie.
標記の問題は,いまだ決着がついていない.
・ Millar, Robert McColl. English Historical Sociolinguistics. Edinburgh: Edinburgh UP, 2012.
・ Mustanoja, T. F. A Middle English Syntax. Helsinki: Société Néophilologique, 1960.
2014-04-15 Tue
■ #1814. 18--19世紀の be 完了の衰退を CLMET で確認 [perfect][clmet][corpus][syntax][be][auxiliary_verb][aspect][participle][lmode]
「#1653. be 完了の歴史」 ([2013-11-05-1]) で,変移動詞 (mutative verb) は,18世紀末まで,通常 be + 過去分詞というかたちで完了形を作っていたことを見た.英語史では,この be 完了が18世紀末辺りを境に衰退の一途をたどることになったとされている.「#1637. CLMET3.0 で between と betwixt の分布を調査」 ([2013-10-20-1]) で紹介した CLMET3.0 は,1710--1920年をカバーする約3,400万語からなる大型バランスコーパスであり,この種の言語変化を追うには最適なリソースと思われるので,これを用いて be 完了の衰退を確認してみた.
今回は,先の記事でも取り上げた7つの変移動詞 (arrive, become, come, fall, flee, grow; go) に限定し,CLMET3.0 の3つの時代区分 (1710--1780, 1780--1850, 1850--1920) と6つのジャンル分け (Narrative fiction, Narrative non-fiction, Drama, Letters, Treatise, Other) にしたがって,コーパスから用例を拾った.3つの時期のサブコーパスの規模はおよそ同程度だが,ジャンル別のサブコーパスは,[2013-10-20-1]の表で示したように,Narrative fiction に大きく偏っているので,その解釈には注意を要する.以下,(1)--(7) に各動詞に関する推移の積み上げ棒グラフ,(8), (9) に7動詞をひっくるめたジャンル別,動詞別のシェアを示す積み上げ棒グラフを示す.(1)--(6) については,比較のためにY軸の最大値を揃えてある.データファイルと頻度表はソースHTMLを参照されたい.
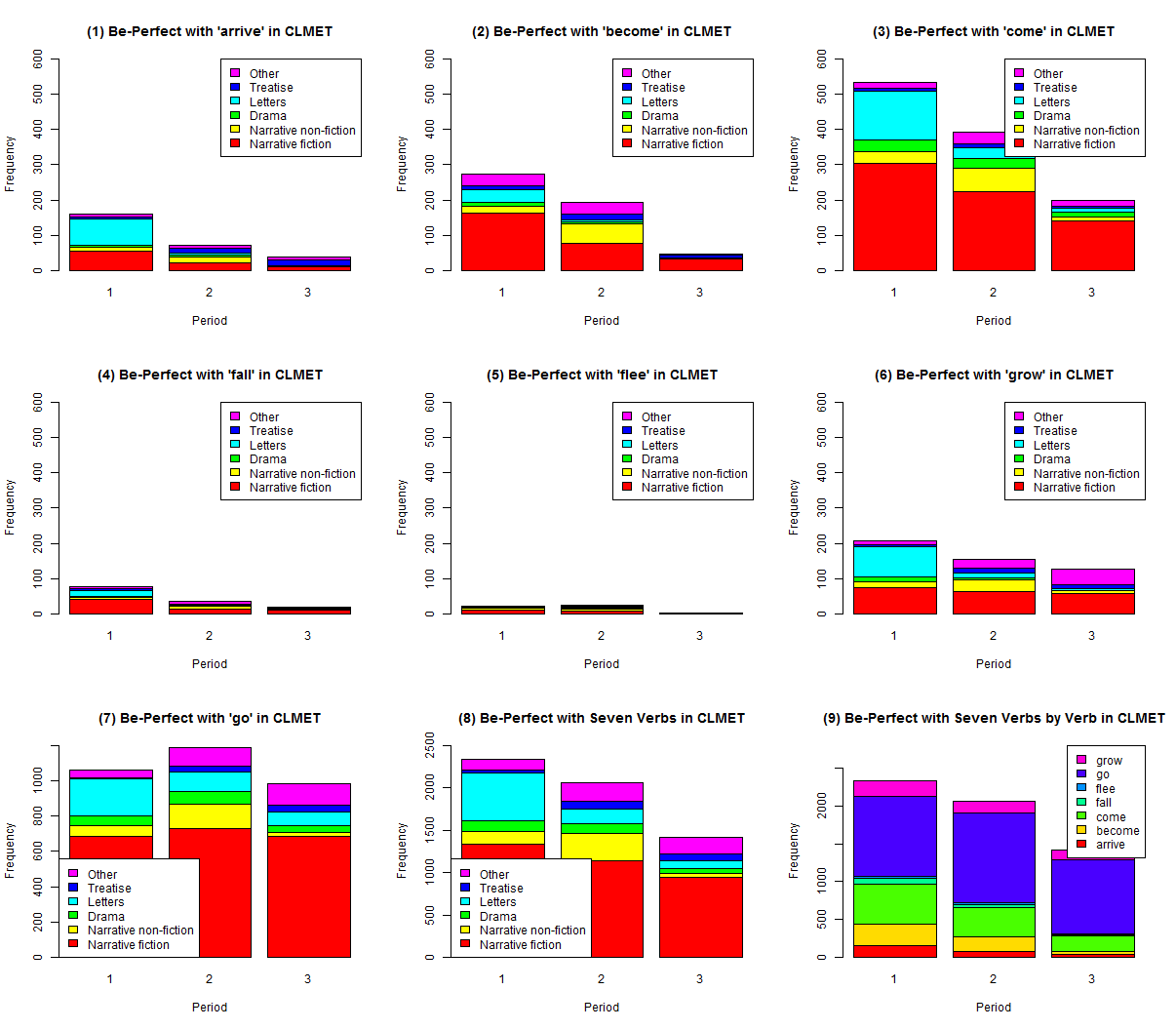
動詞によって衰退のスピードに若干の違いがみられるが,全体として急激に衰退したというよりは,比較的穏やかに,着実に衰退していったという印象を受ける.ただし,(7) の go は(現代英語でも be gone がイディオム化して残っていることから分かるように)後期近代英語期中にはそれほど落ち込んでおらず,しかも用例数が他の動詞よりも大きく上回っているために,(8) や (9) に示されるような be 完了の衰退の全体像を多少なりとも歪めていることには注意する必要がある.
2014-04-14 Mon
■ #1813. IPA の肺気流による子音の分類 [phonetics][consonant][ipa][chart][link]
標題の内容に入る前に,関連する過去の記事へリンクを張っておく.
・ 「#251. IPAのチャート」 ([2010-01-03-1])
・ 「#669. 発音表記と英語史」 ([2011-02-25-1])
・ 「#822. IPA の略史」 ([2011-07-28-1])
・ 「#1376. 音声器官の図」 ([2013-02-01-1])
・ 「#31. 現代英語の子音の音素」 ([2009-05-29-1])
では,本題へ.以下の IPA の2005年度版 (PDF; 58KB) の肺気流(「#1672. 気流機構」 ([2013-11-24-1]) を参照)による子音表で,行と列はそれぞれ何を表わしているだろうか.
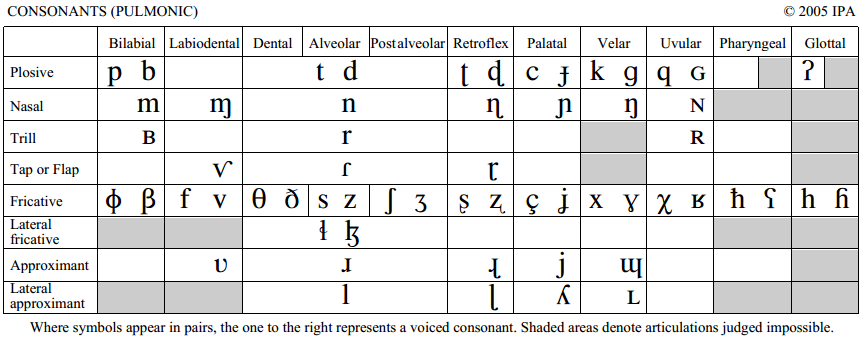
まず,列は調音点 (place of articulation) を表わし,左端の唇から右端の声門まで,声道内の各器官に対応する.左を向いた顔の横顔ととらえればよい.
一方,行は調音様式 (manner of articulation) を表わし,上から下へ,およそ呼気に対する妨害の程度の高いものから順に並んでいる.ここで妨害の種類は8つに区分されているが,この配列にも実は一定の論理がある.その論理は,斉藤 (21) による図をみれば一目瞭然だ.分節音の種類に英語訳をつけつつ,その図を再現しよう.
┌─ 破裂[口]音 (plosive)
┌─ 破 裂 ─┤
│ └─ [破裂]鼻音 (nasal)
│
口腔内に閉鎖がつくられるもの ─┼─ ふるえ ─── ふるえ音 (trill)
│
└─ はじき ─── はじき音 (tap or flap)
┌─ [中線的]摩擦音 (fricative)
┌─ 摩 擦 ─┤
│ └─ 側面[的]摩擦音 (lateral fricative)
口腔内に隙間が残されるもの ──┤
│ ┌─ [中線的」接近音 (approximant)
└─ 接 近 ─┤
└─ 側面[的]接近音 (lateral approximant)
大きく2系列に分かれる.口腔内に完全な閉鎖が作られて,気流が一時止められるものと,閉鎖が不完全で隙間が残り,気流がせき止められないものとである.前者は広い意味での破裂を表わし,閉鎖の形成,持続,開放の3段階からなる.しっかりした持続が1回はあるもの,と言い換えてもよい.気流の開放が口のみで生じれば破裂[口]音 (plosive) ,鼻でも生じれば[破裂]鼻音 (nasal) となる.一方,持続の極めて短い閉鎖と破裂が複数回繰り返されると,例えば巻き舌音のような,ふるえ音 (trill) となる.また,極めて短い閉鎖と破裂が一度だけ生じる場合には,日本語のラ行の子音に現れるような,はじき音 (tap or flap) となる.厳密に言えば,tap と flap は異なり,「tap は舌(動的調音器官)がそれ自体の運動の目的として上歯茎など(静的調音器官)に接触してもどるもの,flap は舌がもとの位置にもどる運動の途中で上歯茎などに1回触れるものをさす」(斉藤,p. 40).
もう1つの系列,すなわち口腔内に隙間が残される音には,調音器官のあいだを通る気流の摩擦の強いものと,そのような摩擦がほとんどなく,調音器官間がある程度接近しているにすぎないものとが区別される.また,それぞれについて,気流が口腔内の真ん中を通るか脇を通るかに応じて,中線的と側面的な音が区別される.結果として,[中線的]摩擦音 (fricative) ,側面[的]摩擦音 (lateral fricative) ,[中線的」接近音 (approximant) ,側面[的]接近音 (lateral approximant) の4種類が分けられることになる.
IPA の子音分類は,したがって,調音音声学の観点からきわめて論理的になされていることになる.全体として,肺気流による子音の分類は,以下の5つの観点からなされているといえる(斉藤,p. 25).
(1) 声門の状態(声帯の振動の有無)
(2) 調音の場所(どの部分で空気の流れを妨害するか)
(3) 気流の通路(気流は口腔内の真ん中を通るか脇を通るか)
(4) 接近の度合いなど(気流に対してどのように妨害を作るか)
(5) 口蓋帆の位置(気流は鼻腔に抜けるか抜けないか)
IPA や音声学の学習には,音声を聴くこともできる以下のページをどうぞ.
・ 東京外国語大学による IPA モジュール
・ Department of Language and Communication Studies, Norges Teknisk-Naturvitenskapelige Universitet による A Sound Reference to the IPA: active, sound-enabled version of the International Phonetic Alphabet
・ Department of Phonetics and Linguistics, University College London による IPA: Alphabet
・ The UCLA Phonetics Lab
・ Institute of Phonetic Sciences, University of Amsterdam による Phonetic Sciences, Amsterdam
・ 東北大学の後藤斉教授による 音声学と音響音声学のリンク集
・ 斉藤 純男 『日本語音声学入門』改訂版 三省堂,2013年.
2014-04-13 Sun
■ #1812. 6単語の変異で見る中英語方言 [me_dialect][spelling][map][isogloss][dialect][bre]
本ブログでは,中英語方言に関して,特定の語,形態素,音素の分布に注目した記事として,方言地図とともに「#562. busy の綴字と発音」 ([2010-11-10-1]),「#790. 中英語方言における動詞屈折語尾の分布」 ([2011-06-26-1]),「#1320. LAEME で見る most の異形態の分布」 ([2012-12-07-1]),「#1622. eLALME」 ([2013-10-05-1]) などを書いてきた(ほかにも,me_dialect の記事を参照).また,一般的な中英語の方言区分図を「#130. 中英語の方言区分」 ([2009-09-04-1]) で示した.
中英語方言に限らないが,方言間を区別する音韻対応と方言線 (isogloss) の複雑さはよく知られている.中英語では LALME や LAEME という詳細な言語地図が出版されているので,その具体的な地図を覗いてみれば一目瞭然である.そこで,大雑把にでも主たる変異や音韻対応(及びそれを反映していると考えられる綴字対応)を理解していると便利だろう.そのような目的で「#1341. 中英語方言を区分する8つの弁別的な形態」 ([2012-12-28-1]) が役立つが,Lerer (92) の示している簡易方言図も役に立ちそうだ.Lerer は,高い弁別素性をもつ6語 ("stone", "man", "heart", "father", "them", "hill") を選んで,中英語5方言を簡易的に図示した.以下は,Lerer のものを参照して作った図である.
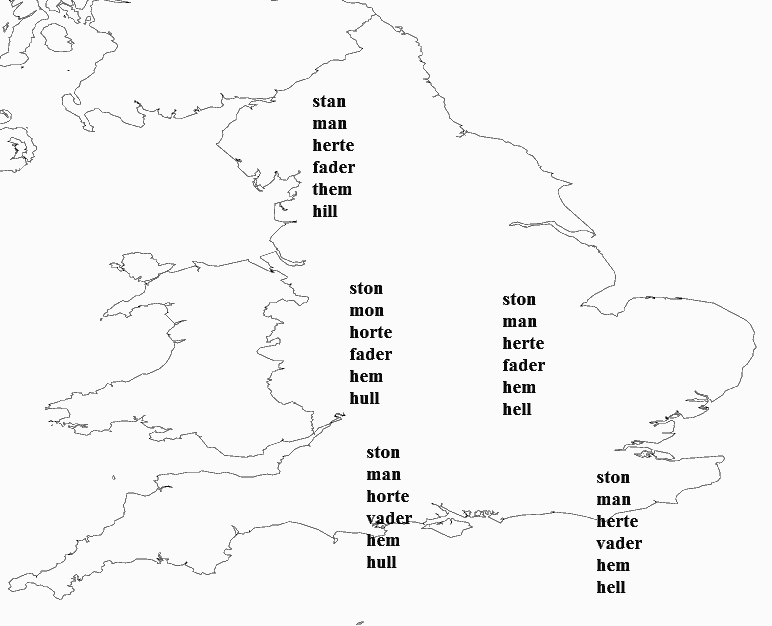
じっくり眺めていると,架空の方言線があちこちに走っているのが 見えてきそうだ.hill -- hell -- hull に見られる母音の変異については,関連して「#562. busy の綴字と発音」 ([2010-11-10-1]) を参照.
当然ながら,中英語の方言区分は,現代イングランド英語の方言区分とも無縁ではない.8つの語による現代の区分は,「#1030. England の現代英語方言区分 (2)」 ([2012-02-21-1]) を参照されたい.
・ Lerer, Seth. Inventing English. New York: Columbia UP, 2007.
2014-04-12 Sat
■ #1811. "The later a change begins, the sharper its slope becomes." [lexical_diffusion][speed_of_change][language_change][entropy][do-periphrasis][schedule_of_language_change]
昨日の記事「#1810. 変異のエントロピー」 ([2014-04-11-1]) の最後で,「遅く始まった変化は急速に進行するという,言語変化にしばしば見られるパターン」に言及した.これは必ずしも一般的に知られていることではないので,補足説明しておきたい.実はこのパターンが言語変化にどの程度よく見られることなのかは詳しくわかっておらず,この問題は私の数年来の研究テーマともなっている.
言語変化のなかには,進行速度が slow-quick-quick-slow と変化する語彙拡散 (lexical_diffusion) と呼ばれるタイプのものがある.語彙拡散の研究によると,変化を開始するタイミングは語によって異なり,比較的早期に変化に呑み込まれるものから,比較的遅くまで変化に抵抗するものまで様々である.Ogura や Ogura and Wang の指摘で興味深いのは,このタイミングの早い遅いによって,開始後の変化の進行速度も異なる可能性があるということだ.早期に開始したもの (leaders) はゆっくりと進む傾向があるのに対して,遅れて開始したもの (laggers) は急ピッチで進む傾向があるという.譬えは悪いが,早起きしたけれども歩くのが遅いので遅刻するタイプと,寝坊したけれども慌てて走るので間に合うタイプといったところか.標記に挙げた "the later a change begins, the sharper its slope becomes" は,Ogura (78) からの引用である.
私自身,初期中英語諸方言における複数形の -s の拡大に関する2010年の論文で,この傾向を明らかにした.その論文から,Ogura と Ogura and Wang へ言及している部分など2箇所を引用する.
In their series of studies on Lexical Diffusion, Ogura and Wang discussed whether leaders and laggers of a change are any different from one another in terms of the speed of diffusion. In case studies such as the development of periphrastic do and the development of -s in the third person singular present indicative, they proposed that the later the change, the more items change and the faster they change . . . . (12)
. . . the laggers catching up with the leaders in SWM C13b and in SEM C13b concurs with the recent proposition of Lexical Diffusion that "the later a change begins, the sharper its slope becomes." (14)
変化に参与する各語をそれぞれS字曲線として表わすと,例えば以下のような非平行的なS字曲線の集合となる.
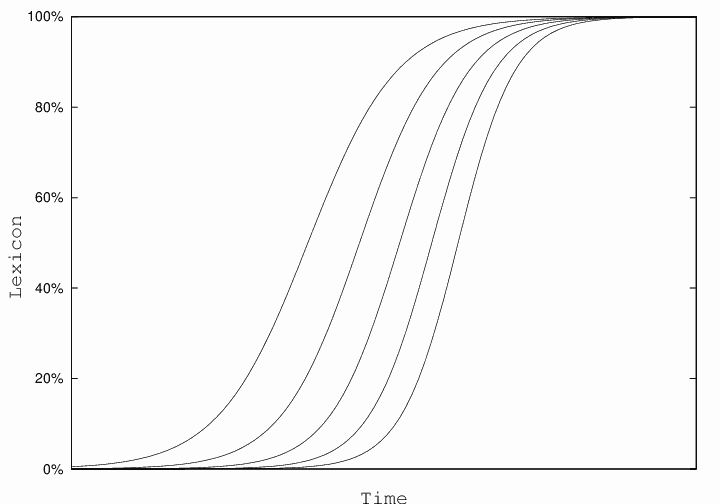
ここで昨日の相対エントロピーの話に戻ろう.上のようなグラフを,Y軸を相対エントロピーの値として描き直せば,スタートは早いが進みは遅い語は,長い裾を引く富士山型の線を,スタートは遅いが進みは速い語は,尖ったマッターホルン型の線を描くことになるだろう.
語彙拡散のS字曲線,エントロピー,[2013-09-09-1]の記事で触れた「#1596. 分極の仮説」などは互いに何らかの関係があると見られ,言語変化のスピードやスケジュールという一般的な問題に迫るヒントを与えてくれるだろう.
・ Ogura, Mieko. "The Development of Periphrastic Do in English: A Case of Lexical Diffusion in Syntax." Diachronica 10 (1993): 51--85.
・ Ogura, Mieko and William S-Y. Wang. "Snowball Effect in Lexical Diffusion: The Development of -s in the Third Person Singular Present Indicative in English." English Historical Linguistics 1994. Papers from the 8th International Conference on English Historical Linguistics. Ed. Derek Britton. Amsterdam: John Benjamins, 1994. 119--41.
・ Hotta, Ryuichi. "Leaders and Laggers of Language Change: Nominal Plural Forms in -s in Early Middle English." Journal of the Institute of Cultural Science (The 30th Anniversary Issue II) 68 (2010): 1--17.
2014-04-11 Fri
■ #1810. 変異のエントロピー [statistics][entropy][variation][consonant][speed_of_change][language_change][schedule_of_language_change][-ly]
昨今,エントロピー (entropy) というキーワードをよく聞くようになったが,言語との関連で,この概念が話題にされることはあまりない.本ブログでは,「#838. 言語体系とエントロピー」 ([2011-08-13-1]) をはじめとして,##838,1089,1090,1587,1693 の各記事でこの用語に触れてきたが,まだ具体的な問題に適用したことはなかった.
エントロピーとは,体系としての乱雑さの度合いを示す指標である.データがいかに一様に散らばっているかを表わす尺度と言い換えてもよい.言語への応用は,Gries (112) が少し触れている.
A simple measure for categorical data is relative entropy Hrel. Hrel is 1 when the levels of the relevant categorical variable are all equally frequent, and it is 0 when all data points have the same variable level. For categorical variables with n levels, Hrel is computed as shown in formula (16), in which pi corresponds to the frequency in percent of the i-th level of the variable:
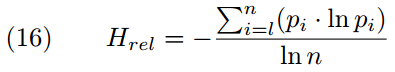
Gries は,300個の名詞句における冠詞の分布という例を挙げている.無冠詞164例,不定冠詞33例,定冠詞103例という内訳だった場合,Hrel = 0.8556091 となり,かなり不均質な分布を示すことになる.
ほかに散らばり具合が問題になるケースはいろいろと考えることができる.例えば,注目語句の出現頻度が,テキスト(のジャンル)に応じて一様か否かを測るということもできるだろう.
また,ある語に異形態や異綴字が認められる場合に,それぞれの変異形 (variants) の分布が均一か不均一かを計測することなどもできる.そのような変異の相対エントロピーが同時代の異なるテキスト(ジャンル)の間でどのくらい異なるのか,あるいは歴史的な関心からは,異なる時代のテキスト(ジャンル)の間でどのくらい異なるのかを,客観的に確かめることができるだろう.標準化その他の過程により,その変異が1つの形へ収斂してゆく場合,エントロピーが減少することになる.
具体的に考えるために,「#1773. ich, everich, -lich から語尾の ch が消えた時期」 ([2014-03-05-1]) で取り上げた,語尾の ch の脱落のデータを参照しよう.先の記事で Schlüter による集計結果の表を掲げたが,今回は,音声環境 (before V, before <h>, before C) の区別はせず,単純に ME II--ME IV の各時代に現れた変異形のトークン数のみを考慮に入れることにする.各変異形の各時代の Hrel を計算した結果の表を下に示す.
| I | 1150--1250 (ME I) | 1250--1350 (ME II) | 1350--1420 (ME III) | 1420--1500 (ME IV) |
|---|---|---|---|---|
| ich | 853 | 589 | 7 | 0 |
| I | 33 | 503 | 1397 | 2612 |
| Hrel | 0.2295 | 0.9955 | 0.04531 | 0.0000 |
| EVERY | 1150--1250 (ME I) | 1250--1350 (ME II) | 1350--1420 (ME III) | 1420--1500 (ME IV) |
| everich | - | 12 | 10 | 9 |
| everiche | - | 12 | 3 | 0 |
| every | - | 5 | 112 | 152 |
| Hrel | - | 0.9406 | 0.3550 | 0.1962 |
| -LY | 1150--1250 (ME I) | 1250--1350 (ME II) | 1350--1420 (ME III) | 1420--1500 (ME IV) |
| -lich | 106 | 33 | 31 | 3 |
| -''liche' | 689 | 168 | 70 | 44 |
| -ly | 12 | 19 | 1088 | 1444 |
| Hrel | 0.4225 | 0.6390 | 0.3123 | 0.1342 |
これの をプロットすると,次のようになる.
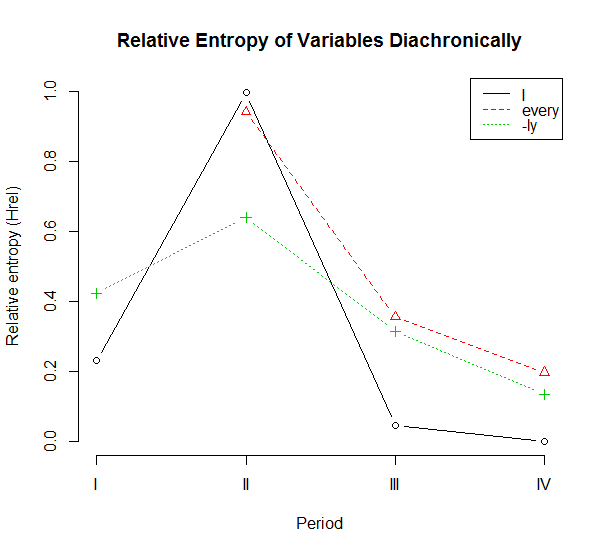
1人称単数代名詞主格 I の変異は,集束→発散→集束と推移しており,不安定期 II の突出が目立つ.安定していた体系が急激に乱され,そしてすぐに回復したという推移だ.第I期のデータを欠く every の変異は,I ほどではないものの,同じようにIIからIIIの時期にかけて急激な下落を示す.-ly の変異も,より緩やかではあるが,同時期に同様の下降を表わす.
Schlüter は,ich, everich, -lich の順で語尾の ch が脱落し,変異の収斂に向かっていったと評価しているが,これは第II期以降のエントロピーの減少率のことを指していると解釈できる.しかし,第I期からの推移も考慮に入れると,I の発散の開始は -ly の発散よりも後のようである.これは,早く始まった変化はゆっくりと進行するのに対し,遅く始まった変化は急速に進行するという,言語変化にしばしば見られるパターンを示唆する.エントロピー曲線の形状でいえば,前者は裾の長い富士山型,後者は先のとがったマッターホルン型ということになる.エントロピーという指標を用いて,言語変化のスピードについて何か一般化できることがあるかもしれない.
・ Gries, Stefan Th. Statistics for Linguistics with R: A Practical Introduction. Berlin: Mouton, 2009.
・ Schlüter, Julia. "Weak Segments and Syllable Structure in ME." Phonological Weakness in English: From Old to Present-Day English. Ed. Donka Minkova. Basingstoke: Palgrave Macmillan, 2009. 199--236.
2014-04-10 Thu
■ #1809. American Heritage Dictionary の Notes [dictionary][etymology][link][synonym][thesaurus]
「#485. 語源を知るためのオンライン辞書」 ([2010-08-25-1]) で触れたが,American Heritage Dictionary of the English Language, 4th ed. (AHD) とその他の辞書に基づいた The Free Dictionary というオンライン辞書がある.AHD は,アメリカの辞書らしく百科事典的な情報や視覚資料が豊富で,私もよく使うお気に入りの辞書だ.紙版は大型だが,読む辞書としてお薦めである.(なお,The Free Dictionary Encyclopedia の Article of the Day というフィードもお気に入り.)
特に注目したいのが,Notes と呼ばれるコラム的な記事が充実していることだ.Usage Notes, Synonym Notes, Word Histories, Our Living Language, Regional Notes といった5種類の Notes が,延べ1,700以上,辞書中にちりばめられている.以下では,取りこぼれもあるとは思われるが,その大多数へのリンクを拾い出した.長いリストなので,ジャンプのための目次を挙げておく.
・ Usage Notes 一覧
・ Synonym Notes 一覧
・ Word Histories 一覧
・ Our Living Language 一覧
・ Regional Notes 一覧
ほかにも,リンク先の Notes 部分のみを抜き出した Notes 集そのものもブラウザ上で閲覧できるように作ってみたが,1.6MBと重めなので,必要に応じてどうぞ.
[ Usage Notes ]
!Kung, -ee, -ess, -wise, .gov, a, A.M., aberrant, able, about, absolute, absolutely, accessory, acquiesce, act, acumen, ad hominem, admission, adopt, advance, advise, affect, affinity, agenda, aggravate, ain't, alibi, all, all right, alleged, allude, alongside, also, alternative, although, altogether, alumnus, Amerasian, Amerindian, and, and/or, Anglo, anticipate, antidote, anxious, any, anyone, apparent, archetype, as, as far as, Asian, Asiatic, assure, author, awhile, backward, bad, bait, baleful, banal, barbarism, barbiturate, be, bear, because, behalf, berdache, besides, best, between, bi-, black, Black English, blatant, boast, both, bring, but, callous, can, cannot, capital, careen, celebrant, celibate, center, certain, challenged, Chicano, child-directed speech, claustrophobic, cohort, collective noun, color, colored, compact disk, compare, complected, complement, complete, comprise, conflicted, contact, contemporary, continuance, contrast, controller, convince, council, couple, craft, credential, credible, crescendo, criterion, critique, culture, czar, dare, data, deaf, debut, deceptively, decimate, definite, demagogue, denote, depend, deprecate, dialogue, different, dilemma, disabled, discomfit, disingenuous, disinterested, disinvent, distinct, dive, domestic partner, double negative, doubt, dour, drunk, due to, each, each other, either, elder, else, empower, enervate, enormity, enthuse, envelope, epicenter, epithet, equal, err, escape, Eskimo, Eurasian, every, everyplace, except, exceptionable, fact, factoid, farther, February, few, finalize, First Nation, firstly, flammable, flaunt, flotsam, follow, foot, foregone, former, formidable, forte, fortuitous, founder, fulsome, fun, gambit, gay, gender, General American, get, glamour, good, gourmet, government, graduate, graffito, grieve, group, grow, handicapped, hang, harass, hardly, harebrained, have, he, headquarter, headquarters, healthy, hegemony, height, help, herb, hero, Hispanic, historic, hoi polloi, holocaust, homosexual, hopefully, host, however, hyphenated, I, identical, identify, if, impact, impeach, important, impracticable, include, Indian, individual, infer, infinite, infrastructure, input, insignia, intense, interface, intrigue, intuit, Inuit, ironic, irregardless, its, Jew, Jewess, kabbalah, Kanaka, kilometer, knot, kudos, lack, lady, late, Latina, lay, leave, legend, liable, lifestyle, light, like, likely, literally, literate, loan, look, majority, man, master, masterful, materialize, mean, medium, men, methodology, mid-, migrate, minimal, mistress, momentarily, month, moot, Ms., mute, mutual, myriad, myself, native, Native American, nauseous, need, neither, Net, none, nonstandard, nonwhite, nor, not, nothing, nuclear, number, oblivious, octoroon, of, off, officiate, often, old, on, one, only, or, oriental, ought, over-, pair, paradigm, parameter, participle, party, pass, people, percent, percentage, perfect, periodic, permit, person, peruse, phenomenon, pill bug, plead, plus, politics, poor, possessed, practicable, practically, precipitate, premiere, preposition, presently, principal, prioritize, process, protagonist, prove, quarter, queer, quick, quote, race, rarely, rather, redundancy, regard, replete, repulse, responsible, restive, sacrilegious, safe sex, said, salutation, same, saving, scarcely, schism, Scottish, seasonal, series, service, set, shall, she, short-lived, should, slow, sneak, so, so-called, someday, sometime, sonorous, soon, split infinitive, Standard English, status, staunch, stomp, stratum, strength, such, suffer, than, that, themed, there, they, this, Three Age system, thusly, tight, till, together, too, tortuous, toward, transpire, try, un-, unaware, unexceptionable, unique, utilize, various, verbal, very, victual, virtual, wake, want, way, we, wean, web, website, well, what, whatever, when, whence, where, which, who, whose, why, wish, with, wreak, Xmas, ye, yet, zoology
[ Synonym Notes ]
ability, abolish, abstinence, abuse, accidental, accompany, acknowledge, active, adapt, admonish, adulterate, advance, adventurous, advice, advise, affair, affect, affectation, afflict, afraid, ageless, agitate, agree, aim, airy, allocate, alone, amateur, ambiguous, ambush, amenity, amiss, amuse, analyze, ancestor, anger, angry, announce, annoy, answer, anxiety, apology, apparent, appear, appendage, applaud, appoint, appreciate, apprehend, appropriate, approve, arbitrary, argue, argument, argumentative, arrange, art, artificial, ask, assent, assistant, attack, attribute, authentic, authorize, average, aware, band, banish, banter, bargain, barrage, base, baseless, batter, bear, beat, beautiful, beg, begin, beginning, behavior, belief, belligerent, bend, beneficial, benefit, benevolent, besiege, bet, bias, binge, bite, bitter, blackball, blackout, blame, blameworthy, blast, blemish, blink, block, bloom, blunder, boast, bodily, boil, book, boor, border, boring, botch, branch, brave, brawl, breach, break, breeze, bright, broach, broad-minded, brood, brush, bulge, bulwark, burden, burdensome, burn, business, busy, cadge, calculate, call, calm, campaign, care, careful, careless, caress, caricature, catch, cause, celebrity, center, certain, certainty, chafe, chance, charge, charm, chief, choice, chronic, circumference, citizen, claim, clean, clear, clever, cliché, clothe, coagulate, cold, collision, comfort, comfortable, comment, commit, common, complete, complex, conceit, condemn, conduct, confidence, confirm, conflict, confuse, consider, contain, contaminate, contemporary, continual, convert, convey, cool, correct, corrupt, count, crisis, criticize, crowd, crude, cruel, crush, cry, cure, curious, dark, daze, dead, decay, deceive, decide, decision, decisive, decrease, decry, defeat, defend, defer, defy, degrade, delicate, delicious, demand, demote, deny, dependent, deplete, depressed, describe, desire, despise, despondent, development, deviation, devote, dexterous, dialect, dictate, dictatorial, differ, difference, difficulty, dip, dirty, disadvantage, disappear, discord, discourage, discover, discuss, disguise, disgust, dishonest, dismay, dismiss, display, disposition, dissuade, distinct, distort, distribute, doctrine, dominant, dry, dull, earn, easy, eat, echo, effect, effective, eject, elaborate, element, elevation, eliminate, embarrass, emphasis, empty, enclose, encourage, endanger, enemy, engagement, enmity, enormous, enrapture, envy, equipment, erase, escape, estimate, estrange, evoke, exaggerate, example, excel, excessive, existence, expect, explain, explicit, expressive, extemporaneous, extricate, fair, faithful, faithless, fantastic, fashion, fashionable, fast, fasten, fat, fatal, favorable, fawn, fear, feat, feeling, female, fertile, fidelity, field, figure, flagrant, flash, flexible, flirt, flock, flourish, flow, follow, foolish, forbid, force, foreign, foretell, forgive, form, forte, found, fragile, fragrance, frank, freedom, frighten, frown, function, furnish, futile, gather, gaudy, gaze, general, gesture, ghastly, giddy, glad, glib, gossip, gracious, grand, graphic, grieve, gruff, guide, habit, hamper, handle, happen, happy, harass, hard, harden, haste, hateful, healthy, heap, heavy, help, heritage, hesitate, hide, hinder, honor, humane, idea, ideal, imagination, imitate, immaterial, impetuous, importance, impression, improper, improve, inactive, incalculable, incisive, incline, include, increase, indicate, indispensable, infinite, inflexible, injustice, innate, inquiry, insanity, instinctive, insubordinate, intelligent, intense, intention, interfere, intimidate, introduce, irrelevant, isolate, item, jealous, jerk, join, joke, judge, justify, keep, kind, knowledge, lack, large, last, latent, lazy, lean, learned, lethargy, letter, level, liberal, lie, lift, likeness, limit, limp, living, logical, loose, loud, love, lure, luxury, makeshift, male, malign, malleable, manipulate, mark, mature, living, logical, mercy, method, meticulous, mind, miscellaneous, mix, mixture, moderate, moment, monopolize, mood, moral, morale, moving, multitude, muscular, mysterious, naive, native, nautical, neat, negligent, new, news, noise, noted, noticeable, nuance, nurture, object, oblige, observe, obstacle, obstinate, occurrence, offend, offensive, offer, old, opinion, opportunity, oppose, opposite, orderly, origin, outline, overthrow, pacify, pain, palliate, pamper, partner, passion, pathetic, patience, pause, pedantic, penitence, pensive, perceptible, perfect, perform, period, periodic, permission, persuade, phase, pity, plain, plan, plausible, please, plentiful, poisonous, polite, poor, possible, posture, practice, praise, predicament, predict, predilection, preliminary, presume, prevailing, prevent, produce, proficient, profuse, promise, proportion, propose, proud, provoke, prudence, pull, punish, pure, push, puzzle, quality, qualm, quibble, range, reach, real, reap, reason, recede, reciprocate, reckless, recover, refer, refrain, refuse, regard, regret, relevant, reliable, relieve, religious, relinquish, rely, remember, reparation, repeat, replace, represent, resort, responsible, restrain, revere, reverse, revive, rich, ridicule, right, rise, rival, room, rough, rude, ruin, rural, sad, sarcastic, satisfy, save, saying, scatter, scold, secret, see, seem, send, sensuous, sentimental, separate, series, serious, severe, shade, shake, shameless, shapeless, sharp, shelter, shorten, shout, show, showy, shrewd, shy, sign, silent, sinister, slant, sleek, slide, sloppy, slow, small, smell, social, solitude, solve, sour, spacious, sparing, speak, speed, spend, spontaneous, stain, standard, state, stay, steal, steep, stem, stench, stiff, still, stoop, stop, strange, streak, strength, subject, substance, sufficient, suggest, summit, superfluous, supervise, support, supposed, sure, surprise, surrender, surround, swerve, swing, tact, tardy, task, taste, teach, tear, teem, temporary, tend, tendency, theoretical, think, think, tight, tire, tireless, tool, touch, treat, trial, trivial, trouble, trust, truth, turn, ugly, uncertainty, unctuous, unfortunate, unruly, unspeakable, urgent, use, usual, vain, valid, vent, versatile, vertical, victory, vigor, vociferous, voluntary, voracious, wander, waste, way, weak, weird, wet, whole, wile, wit, wonder, wordy, work, yield, young, zest
[ Word Histories ]
abacus, abracadabra, accolade, acorn, adder, adolescent, agnostic, alcohol, Allegheny River, alligator, amateur, Amazon, an, anesthesia, appendicitis, arena, arrowroot, artery, artichoke, Aryan, asparagus, assassin, automatic, avocado, baby-sit, badger, ballyhoo, banquet, barnacle, bayonet, beef, belfry, berserk, Betelgeuse, bigot, bless, Bolshevik, book, boomerang, boycott, Brazil, brickbat, broker, buccaneer, buffalo, bumpkin, bury, butterfly, bylaw, Canada, canter, cappuccino, caricature, carouse, casino, caterpillar, caviar, chagrin, chameleon, chaperon, check, Chicago, china, chivalry, chortle, churl, ciao, circus, cleric, cockroach, codex, cologne, comet, comrade, coroner, cot, coupon, coward, crayfish, croissant, crucial, cuckold, cushy, cute, cynic, dandelion, debunk, deer, delta, dervish, desert, diabetes, diatribe, digitalis, dinner, dirge, ditto, do-gooding, Don River, drench, dress, dungeon, dynamite, easel, economy, edit, eleven, empty, encyclopedia, English, ennui, enthusiasm, erudite, ethnic, eunuch, exorcise, fascism, fear, fee, fellow, fey, fiction, film, fire, fizzle, flunky, fool, fornication, fraction, freeze, friend, fuck, funky, garage, gauntlet, geezer, gerrymander, giddy, glitch, goatee, goodbye, gorilla, Gothic, grass widow, Greenland, gremlin, gringo, guillotine, hall, hamburger, harlot, hassle, haywire, hectic, helicopter, hell, helpmate, hex, high muckamuck, hobnob, holocaust, hooker, Hoosier, hubbub, husband, iconoclast, ilk, impeach, industry, inkling, interloper, internecine, island, item, janitor, Japan, jaunty, junk, kangaroo, ketchup, kidnap, kiosk, kith and kin, laconic, landscape, larva, lava, lemon, leprechaun, lieutenant, limbo, lingo, lion, loaf, lobster, long-lived, lucre, macabre, maharajah, malaprop, mannequin, mantis, marshal, mascot, mattress, mealy-mouthed, Melba toast, menu, mesmerism, metal, midwife, milquetoast, Minnesota, misericord, Mississippi, modern, mortgage, mosquito, Muse, mutt, namby-pamby, nap, naughty, neighbor, nerd, nest, New Jersey, noise, nonchalant, numb, OK, ombudsman, one, opossum, orange, orgy, oscillate, otorhinolaryngology, Ouse River, outlaw, oyez, Pakistan, pal, pant, paradise, pariah, pay, peeping Tom, penthouse, period, petard, Philistine, pickle, pilot, plane, Platonic, plumber, Plymouth, poison, pollster, Pomerania, posh, posthumous, powwow, premise, pretzel, prison, prude, Pueblo, Punjab, Quaalude, quark, queen, queue, quiz, raid, rajah, rankle, rapt, read, reindeer, resent, rhinestone, Riot Act, robot, role, rose, roster, rune, sack, salad, sanction, sanguine, Sanskrit, sarcophagus, scan, scarce, scold, scuba, séance, seersucker, senile, serendipity, shadow, shambles, sherbet, short shrift, shyster, Singapore, slave, sleuth, slivovitz, soldier, soothsayer, Sophocles, south, speak, speed, spill, spoof, spree, stampede, stove, sunbeam, superman, surly, syphilis, taboo, tangerine, tattoo, tea, telephone, temple, testis, testy, Thames, theater, they, third, ticket, tin, tithe, toady, Tokyo, tomato, tooth, trek, trivial, true, tulip, tweed, tycoon, typhoon, umpire, underling, uranium, valentine, vegetable, vixen, vogue, vulgar, Wales, wallflower, war, water, Wednesday, went, werewolf, whiskey, whore, wigwam, window, winsome, worry, write, xylophone, Yankee, Zeus, zipper, zloty
[ Our Living Language ]
a-, agreement, all, as far as, ax, bad, basket case, be, breathe, call, cent, chill, comparative, cool, dig, downsize, dude, dumb, foot, geek, go, gung ho, hisself, historical present, hornswoggle, I'm, igg, it, izzard, knockout, like, me, might, mine, Ocracoke Island, of, plural, rap, redundancy, rent, right, schlock, sleigh, Smith Island, strike, trashed, were, za, zero copula
[ Regional Notes ]
absquatulate, agin, andiron, anymore, as, bare-naked, beignet, birth, bodacious, boughten, cayuse, chaw, chesterfield, chirren, clever, critter, damned, dogie, dope, dornick, dragonfly, drudge, everwhere, fair, faubourg, favor, feist, ferninst, fix, frosting, frying pan, gallery, goober, greasy, gum band, gunnysack, gutter, hey, highfalutin, holler, hosey, intervale, johnnycake, juke, kindling, krewe, krumkake, lagniappe, light bread, lightning bug, loblolly, luminaria, milk shake, mill, mozo, mud dauber, muffuletta, need, neutral ground, Old Scratch, old-field colt, olla, parking, pocosin, poke, pone, possum, powerful, preacher, purty, quoit, ramada, redd, reeling, run, scoot, shivaree, slatch, smart, so, spa, stateside, stob, stoop, submarine, summercater, tarnation, ted, teeter-totter, thataway, tit, tonic, tule, tumbleset, ugly, ukulele, vaquero, vum, wake, wanigan, whiffletree, woodchuck, yonder, you-all, you-uns
2014-04-09 Wed
■ #1808. ARCHER 検索結果の時代×ジャンル仕分けツール (ARCHER Period-Genre Sorter) [cgi][web_service][corpus][archer][mode]
この2日間の記事「#1806. ARCHER で shew と show」 ([2014-04-07-1]) と「#1807. ARCHER で between と betwixt」 ([2014-04-08-1]) で,ARCHER の Untagged 版 を用いて,語の変異形の頻度が通時的にどのように推移してきたかを調査した.
近代英語の初期から後期を含むコーパスとしては,ほかに CEECS (The Corpus of Early English Correspondence, LC (The Lampeter Corpus of Early Modern English Tracts), CLMET3.0 (The Corpus of Late Modern English Texts, version 3.0), PPCMBE, COHA などがあり,それぞれに特徴があるが,ARCHER は,1600--1999年というまとまった期間をカバーし,英米変種それぞれについてジャンル分けがなされており,比較的大型の歴史コーパスとして価値が高い.しかし,「#1802. ARCHER 3.2」 ([2014-04-03-1]) で紹介した通り,現在ウェブ上で一般公開されている版については,いまだタグ検索などが実装されておらず,可能性を最大限に利用することはできない.しかし,工夫次第でいろいろと活用できる.実装されている Frequency lists や Keywords の機能はアイディア次第で有効に使えそうだし,コーパス全体の単語頻度リスト (TXT)も公開されている.
通時的な言語変化という観点から ARCHER に望む機能は,この2日間の記事で調査したように,ある検索語の頻度が時期を追って(ついでにジャンル別に)どのように推移してきたかを,簡単に確認できるようにすることだ.Restricted query で時期とジャンルを絞り,検索欄に検索語を入力してヒット数を数えてゆくということは手作業でできるが,時間がかかるし面倒だ.「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) や COHA では,この通時的な一覧を可能にする機能が実装されているので,ARCHER でも余計に同様の機能が欲しくなる.そこで,欲しいのならば作ってしまおうということで,簡単なスクリプトを組んだ.ARCHER の検索結果のコンコーダンス・ラインには,テキストを表わすファイル名が付されているが,ファイル名の仕様によれば,末尾3文字がそれぞれジャンル,時期,英米変種のいずれかを表わす記号となっている.そこで,検索結果をコピーして,以下のテキストボックスに貼り付けてやると,適切にファイル名を解析し,時期,ジャンル,変種ごとにヒット数を整理してくれ,グラフ化してくれるというツール (ARCHER Period-Genre Sorter) を作成した.ARCHER での出力結果が数ページにまたがる場合には,少し手数がかかるが,各ページをコピペして累積していけばよい.
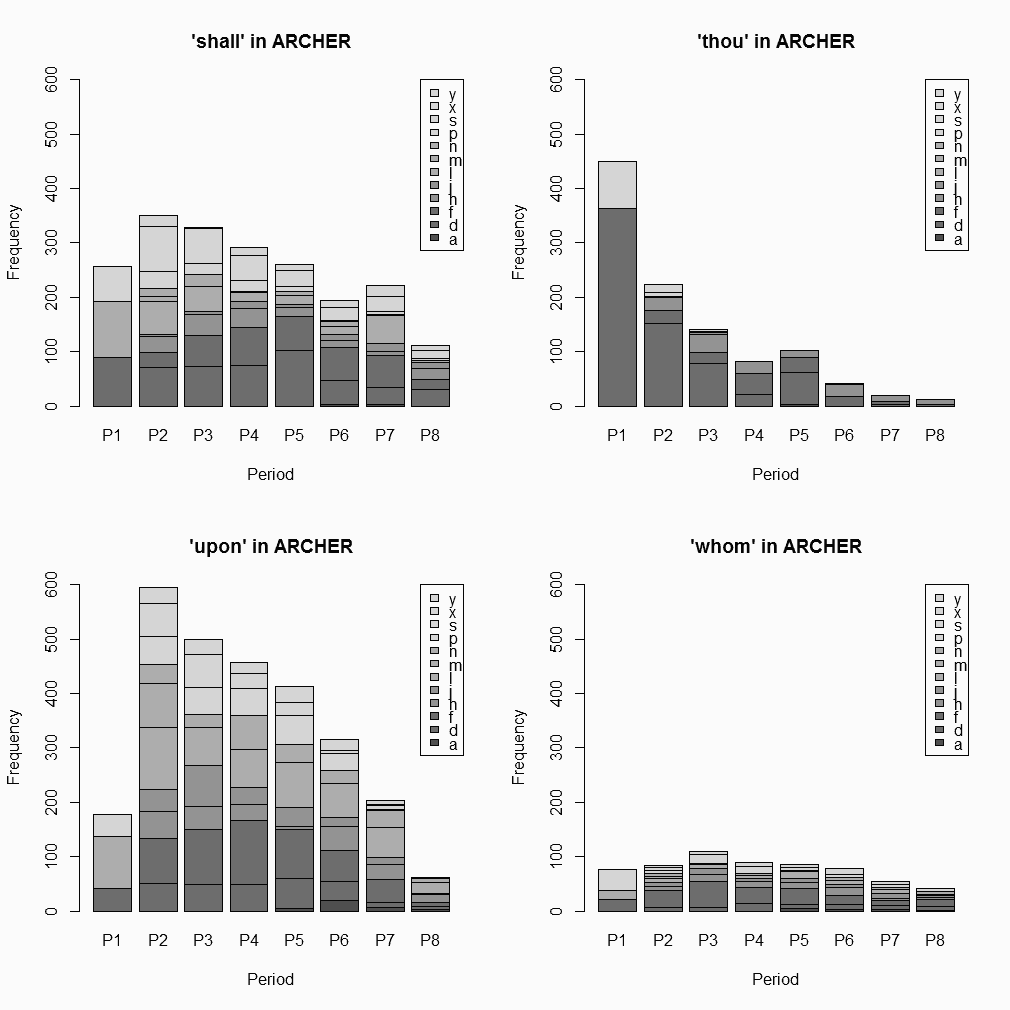
このツールの使用の応用例として,ここ数世紀の間で使用頻度が衰退しただろうと疑われる4語,shall, thou (= thou, thy, thee, thine), upon, whom を取り上げる.今回は,イギリス英語のサブコーパスのみに限定した.以下は,ツールが返した集計表をもとにグラフ化したものである.(ツールがどのように機能するかを確認するために,試しに ARCHER による 'thou' の出力結果のテキストファイル (194KB) の内容を上のテキストボックスにコピペされたい.)
2014-04-08 Tue
■ #1807. ARCHER で between と betwixt [spelling][corpus][archer][mode]
昨日の記事「#1806. ARCHER で shew と show」 ([2014-04-07-1]) に引き続き,[2014-04-03-1]の記事で紹介した「#1802. ARCHER 3.2」を利用して,別の問題に臨む.標記の between と betwixt の後期近代英語における分布について,「#1637. CLMET3.0 で between と betwixt の分布を調査」 ([2013-10-20-1]) で話題にしたが,ARCHER の Untagged 版ではどのような調査結果が出るだろうか.
検索にあたっては,とりわけ17世紀の段階では綴字が完全に定まっていたわけではないため,それぞれの語の異綴字も考慮に入れた.具体的には,between 系列として between, betweene, betwen, betwene, betwn が,betwixt 系列として betwixt, betwext が異綴字として挙がってきた.昨日と同様に,ヒット数を12ジャンルおよび1600--1999年を50年刻みにした8期に分けて数え上げた.以下に,集計結果のグラフのみ示す(データファイルと頻度表はソースHTMLを参照されたい).なお,betwixt and between の形では1例も現れていない.
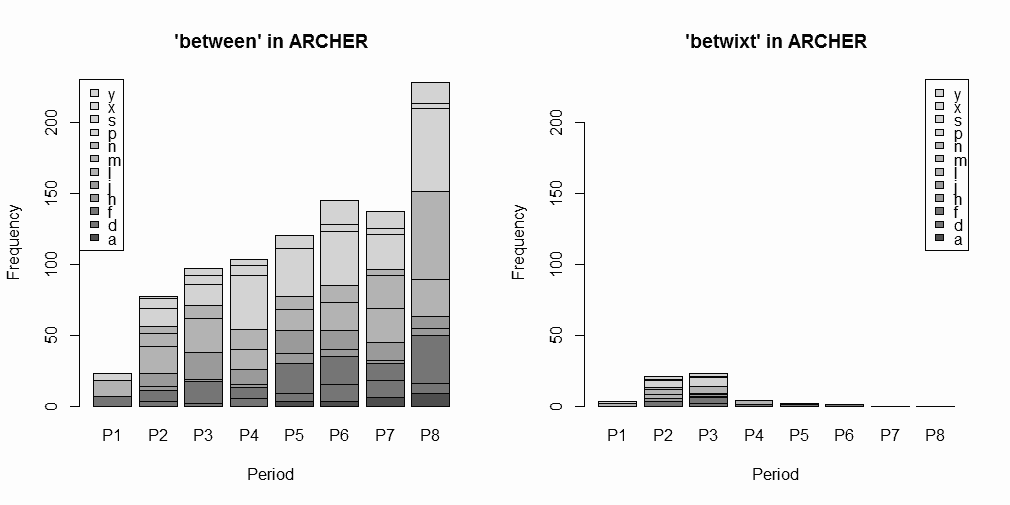
全体として,17--19世紀のどの時期においても between が圧倒していることは,以前の CLMET3.0 による調査結果からも予想されたことである.しかし,P2--P3 (1650--1749) の時期に限ってではあるが,betwixt が20%ほどのシェアを占めていたという事実は注目してよい(P1のサブコーパスは他の各時期のサブコーパスの1/3ほどの規模であることにも注意).CLMET3.0 による調査でも18世紀中までは bewixt が10%ほどのシェアを占めていたという結果が出ているから,大雑把にいって1750年くらいまでは betwix は between の異形としてそれなりの存在感を示していたことが確認できた.
2014-04-07 Mon
■ #1806. ARCHER で shew と show [spelling][corpus][archer][mode]
標記の語を巡る綴字の変異について,「#1415. shew と show (1)」 ([2013-03-12-1]),「#1416. shew と show (2)」 ([2013-03-13-1]),「#1716. shew と show (3)」 ([2014-01-07-1]) で取り上げてきた.今回は,[2014-04-03-1]の記事で紹介した「#1802. ARCHER 3.2」を利用して,近代英語期における両綴字の分布を改めて確認しよう.
ARCHER: A Representative Corpus of Historical English Registers の Untagged 版で,shew 系列 (shew, shews, shewed, shewn, shewing) と show 系列 (show, shows, showed, shown, showing) の語形を検索し,ヒット数を12ジャンルおよび1600--1999年を50年刻みにした8期に分けて数え上げた.データファイルと頻度表はソースHTMLを参照してもらうとして,結果をグラフ化したもののみ示そう.
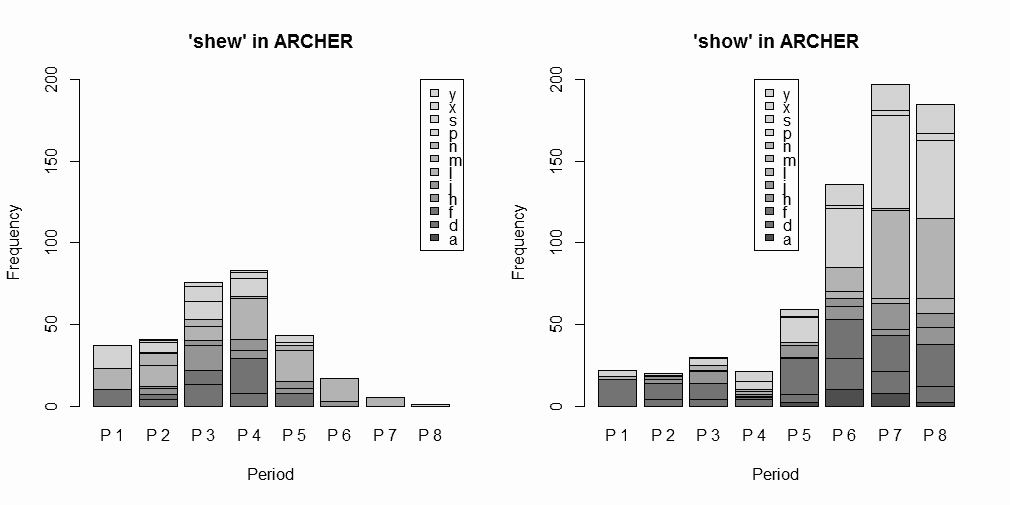
ジャンルの考慮はおいておくとして,通時的な推移に注目しよう.P1 (1600--49) から P4 (1750--99) まで,つまり17--18世紀には,絶対頻度で shew のほうが show より優勢だが,P5 (1800--49) に両者がおよそ肩を並べ,P6 以降には show が一気に shew を駆逐してゆく過程が見てとれる.この推移の概要は,過去の記事で調査した Helsinki Corpus および PPCMBE の結果とは符合するが,CLMET3.0 の結果とは少々異なる.CLMET3.0 では,[2014-01-07-1]の記事で見たように,18世紀中から絶対頻度で show が shew を圧倒的に上回っていたのである.このコーパス間の違いが,各コーパスの代表性の違いによるものなのか,それともジャンル分け等が関与しているのか,あるいは複数の語形を一括して数えたことに由来するものなのか,詳しくは調査していない(P1のサブコーパスについては,他の各時期のサブコーパスの1/3ほどの規模であることに注意).しかし,両系列の相対的な盛衰ではなく,shew 系列の衰退という観点で考えるのであれば,いずれのコーパスを参照しても,それは19世紀前半の出来事とみなしてよいだろう.
2014-04-06 Sun
■ #1805. Morse code [semiotics][sign][double_articulation][cgi][web_service][morse_code]
標題は,アメリカの画家・発明家 Samuel Finley Breese Morse (1791--1872) が発明した電信用の符合.トン・ツーとも称される.短点 (dot),その3倍の長さからなる長点 (dash),空白 (space) の組み合わせからなり,その組み合わせがアルファベットや数字に対応する.
Morse は,1830年代に電信符号の着想を得て,1838年に後のモールス符号の原型を築いた.その後,1844年に Baltimore から Washington への最初の電信を開通させ,歴史的な最初のメッセージ "What has God wrought!" を送信した.彼の発明は世界的な反響を呼び,その後,ヨーロッパで改訂が加えられ,1851年に国際会議により International (or Continental) Morse Code が制定された.1938年に小さな変更が加えられたが,現在に至るまで国際的には国際版が原則として用いられている(ただし,アメリカはオリジナル版の使用にこだわり続けた).モールス符号による電信は,電話やラジオの発明により世界的に影が薄くなったが,劣悪な通信環境でも最低限の情報交換が可能であることから,21世紀の現在でも完全に無用となったわけではない.別途,和文モールス符合などの言語別変種も現れたが,現在ではアマチュア無線家による利用などに使用範囲が限られている.
記号論的には,モールス符号はいくつかの特徴をもった記号体系である.最たる特徴は,言語,とりわけ文字言語に大きく依存した記号体系であるということだろう.自立した記号体系というよりは,言語の代用記号といってよく,その点では点字や手旗信号やタムタムの太鼓言語と同様である.Saussure や「#1074. Hjelmslev の言理学」 ([2012-04-05-1]) の用語でいえば,実質 (substance) が変わっただけで,形相 (form) は変わっていないということになる.モールス符号では,あるトン・ツーの組み合わせが,アルファベット1文字に厳密に対応しており,それがもとの文字列と同じ順序で時間上あるいは空間上に配列される.そこに並び順という統辞論はあるにはあるが,それは自立した固有の統辞論ではなく,背後にある文字言語の統辞論をなぞったものにすぎない(池上,p. 125).
モールス符号のもう1つの特徴は,言語の写しであるとはいいつつも,言語とは異なる二重分節 (double_articulation) をもっていることだ.言語のように二重分節を有する記号体系というのは珍しいが,モールス符号は人工的な記号体系であるから,そこに二重分節の経済性が意図的に組み込まれたということは驚くべきことではないだろう(二重分節をもつほかの記号体系として,遺伝子の情報伝達,楽譜,電話番号などもある).しかし,言語とは異なる形で二重分節が組み込まれていることは注目に値する.モールス符号では,言語の音素に相当するものはトンとツーの2種類である.この2種類の「音素」を決まった順序で決まった個数組み合わせることで,1つの文字に対応する「形態素」を作りだし,そのような「形態素」を上記の言語依存の統辞論に則って配列してゆくのだ(池上,p. 87).ほかには,コードの規程が強い,余剰性が低いなどの特徴も挙げられよう.
では,国際モールス符号の実際をみてみよう.規約の詳細は,Recommendation ITU-R M.1677-1 (10/2009) International Morse code (PDF) より確認できる.一般の(英文)テキストと国際モールス符合の変換器は,ウェブ上に Morse Code Translator などいろいろなものがあるが,以下に hellog 版を作ってみた.テキストあるいはモールス符号を入力すると,他方へ変換される仕様.
例えば,What has God wrought! を入力すると,.-- .... .- - .... .- ... --. --- -.. .-- .-. --- ..- --. .... - -.-.-- が得られる.そして,... --- ... と入力すると,SOS が返される.なお,SOS はモールス符号として打ちやすく聞きやすい文字を並べたものであり,それ自体に意味があるものではない.
・ ピエール・ギロー 著,佐藤 信夫 訳 『記号学』 白水社〈文庫クセジュ〉,1972年.
・ 池上 嘉彦 『記号論への招待』 岩波書店〈岩波新書〉,1984年.
2014-04-05 Sat
■ #1804. gradable antonym の意味論 [markedness][antonymy][semantics][pragmatics]
「#1800. 様々な反対語」 ([2014-04-01-1]) の記事で,もっとも典型的な反対語として "gradable antonym" と称される種類について触れた."contrary" とも呼ばれるが,典型的な程度の形容詞のペアを思い浮かべればよい.good / bad, big / small, hot / cold, old / young, long / short, happy / sad, clean / dirty 等々である.それぞれ見かけは単純なペアだが,意味論的に本格的に扱おうとすると,なかなか複雑な問題を含んでいる.
これらの反意語ペアについてよく知られている現象は,先の記事でも触れたように,ペアのうち一方が無標 (unmarked) で,他方が有標 (marked) であることだ.例えば,年齢を尋ねる疑問文では,How old are you? と old を用いるのが普通である.How young are you? と young をあえて用いる場合には,「あなたが若いということはすでに知っているが,尋ねたいのはどれだけ若いかだ」という特殊な前提を含んだ疑問となる.old の場合にはそのような前提はなく,通常,中立的に使われる.一見すると old と young はそれぞれ同等の資格でペアをなしている反意語のように見えるが,実際には old は中立的な働きも担っており無標であるのに対して,young は場合によっては特殊な前提を要求する点で有標である.old と young に見られるこのような差は,語用論的に現れる差ではなく,意味論的に規定されている差であると考えられ,意味論の領域の問題とされる.
反意語の有標と無標の対立が表出するのは,程度を尋ねる疑問文という文脈に限らない.例えば,派生名詞も,反意語形容詞の無標メンバーに基づくものが多い.long / short に対応する中立的な名詞は length だ.shortness としてしまうと,意味の重心が短い方へ傾き,中立的ではない.同様に,deep / shallow に対して depth が,strong / weak に対して strength が,それぞれ中立的な派生名詞だろう.
有標と無標の対立が表出する環境として疑問文と派生名詞の2点を上で挙げたが,Lehrer (400) はさらに6つの項目を挙げて,この対立が反意語の意味論に深く根を下ろしていることを論じた.全8項目を以下に示す.
I Neutralization of an opposition in questions by unmarked member.
II Neutralization of an opposition in nominalizations by unmarked member.
III Only the unmarked member appears in measure phrases of the form Amount Measure Adjective (e.g. three feet tall).
IV If one member of the pair consists of an affix added to the antonym, the affix form is marked.
V Ratios can be used only with the unmarked member (e.g. Twice as old).
VI The unmarked member is evaluatively positive; the marked is negative.
VII The unmarked member denotes more of a quality; the marked denotes less.
VIII If there are asymmetrical entailments, the unmarked member is less likely to be 'biased' or 'committed'. Cf.
A is better than B. A and B could be bad.
B is worse than A. B must be bad, and A may be as well.
I と II についてはすでに触れた.III は,five feet tall, two years old, three metres wide などの単位量にかかわる表現で通常用いられるのが無標メンバーとされる.
IV は,典型的に否定接頭辞のつくメンバーが有標であるということで,lucky / unlucky, important / unimportant などの例がある.ただし,impartial / partial や unbiased / biased のペアでは,他の属性に照らすと,むしろ否定接頭辞のつく前者が無標となり,反例を構成する.
V は,twice as long as . . ., ten times as heavy as . . . などの倍数表現で用いられるメンバーが無標ということである.
VI は,ポジティヴな評価を担当するメンバーが無標であるというものだ.good, strong, happy, clean などをみる限り,確かにその傾向が強いように思われるが,文化による揺れや語用による変異はあり得るだろう.たとえば,clean / dirty の対立において,ポルノ雑誌の編集者にとってポジティヴな評価を担当するのは dirty のほうだろう.
VII は,客観的に量化した場合に,より大きくなるほうが無標であるというものだ.big, long, heavy, wide などについてはこの基準はよく当てはまるが,clean / dirty の場合,前者が後者に比べて何の量が大きいのかはよく分からない.ちらかっているゴミの量でいえば,dirty のほうが大きいということになる.safe / dangerous, sober / drunk, pure / impure, accurate / inaccurate にも同様の問題が生じる.
VIII は,含意 (entailment) に関わる興味深い観点だ.例えば good / bad の対立において,The steak is better than the chicken, but both are bad. は許容されるが,* The chicken is worse than the steak, but both are good. は許容されないという.これは,good が bad と異なり,中立的な意味を担うことができることを表わす.逆に,bad は非中立的であり,特定の方向を向いているということになる.bad のこのような特性は,"committed" と表現される.この点で,hot / cold, happy / sad などでは両メンバーとも "committed" であるから,片方のメンバーのみが "committed" である good / bad, long / short のようなペアとは性質が異なることになる.
上記8項目は,全体として gradable antonyms が無標と有標の対立を有する傾向があることを示すものにとどまり,すべてのペアが必ず8項目のすべてを満たすということにはならない.I を最も強力な属性とみなすことまではできるが,それ以外の属性は個々の反意語ペアに応じて満たされたり満たされなかったりとまちまちだ.
上記が英語以外の言語にも広く観察される現象なのか,またそもそもなぜ反意語ペアに無標と有標の対立があるものなのかという,一般的な問題も浮かんでくる.反意語の意味論は,見かけ以上に深遠である.
・ Lehrer, A. "Markedness and Antonymy." Journal of Linguistics 21 (1985): 397--429.
2014-04-04 Fri
■ #1803. Lord's Prayer [bible][popular_passage][hel_education][book_of_common_prayer]
イエスが弟子たちに教えた祈りで,「主の祈り」「主祷文」とも言われる.ラテン語より paternoster とも.キリスト教において最も重要な祈りの文句である.聖書では Matt 6:9--13(簡約版が Luke 11:2--4)に現われる.the Lord's Prayer という英語表現はラテン語 ōrātiō Dominica のなぞりで,1548--49年に The Book of Common Prayer の中に the Lordes prayer として初めて現われる.
「#1427. 主要な英訳聖書に関する年表」 ([2013-03-24-1]) で見たように英語訳聖書の歴史は長く,Lord's Prayer も古英語版から21世紀の最新版まで各種そろっている.英語の通時的変化を見るための素材としてうってつけなので,以下に (1) 1000年頃の West-Saxon Gospels より古英語版を,(2) 1388--95年の Wycliffite Bible の後期訳より中英語版を,(3) 1611年の The Authorised Version (The King James Version [KJV]) より初期近代英語版を,(4) 1989年の The New Revised Standard Version より現代英語版を,(5) 参考までに新共同訳の日本語版を,それぞれ掲げる.引用は,Matt 6:9--13 の Lord's Prayer を含む箇所である.これらの詳しい解説については,寺澤盾先生の『聖書でたどる英語の歴史』2--5章を参照されたい.
(1) 1000年頃の古英語訳 West-Saxon Gospels より.
Fæder ūre þū þe eart on heofonum, Sī þīn nama gehālgod. Tō becume þīn rīce. Gewurþe ðīn willa on eorðan swā swā on heofonum. Ūrne gedæghwāmlīcan hlāf syle ūs tōdæg. And forgyf ūs ūre gyltas, swā swā wē forgyfað ūrum gyltendum. And ne gelǣd þu ūs on costnunge, ac ālȳs ūs of yfele. Sōþlīce.
(2) 1388--95年の Wycliffite Bible (Later Version) より.
Oure fadir that art in heuenes, halewid be thi name; thi kyngdoom come to; be thi wille don in erthe as in heuene; ȝyue to vs this dai oure breed ouer othir substaunce; and forȝyue to vs oure dettis, as we forȝyuen to oure dettouris; and lede vs not in to temptacioun, but delyuere vs fro yuel. Amen.
(3) 1611年の The Authorised Version (The King James Version)より.
Our father which art in heauen, hallowed be thy name. Thy kingdome come. Thy will be done, in earth, as it is in heauen. Giue vs this day our daily bread. And forgiue vs our debts, as we forgiue our debters. And lead vs not into temptation, but deliuer vs from euill: For thine is the kingdome, and the power, and the glory, for euer, Amen.
(4) 1989年の The New Revised Standard Version より.
Our Father in heaven, hallowed be your name. Your kingdom come. Your will be done, on earth as it is in heaven. Give us this day our daily bread. And forgive us our debts, as we also have forgiven our debtors. And do not bring us to the time of trial, but rescue us from the evil one. [For the kingdom and the power and the glory are yours forever. Amen.]
(5) 新共同訳より.
天におられるわたしたちの父よ,御名が崇められますように.御国が来ますように.御心が行われますように,天におけるように地の上にも.わたしたちに必要な糧を今日与えてください.わたしたちの負い目を赦してください,わたしたちも自分に負い目のある人を/赦しましたように.わたしたちを誘惑に遭わせず,悪い者から救ってください.[国と力と栄えとは永遠にあなたのものです.アーメン.]
なお,古英語の Lord's Prayer について,YouTube で The Lords Prayer in Old English from the 11th century なる映像を見つけたので,参考までに.
・ 寺澤 盾 『聖書でたどる英語の歴史』 大修館書店,2013年.
2014-04-03 Thu
■ #1802. ARCHER 3.2 [corpus][archer][mode][frequency]
昨年末のことになるが,近代英米語コーパス ARCHER: A Representative Corpus of Historical English Registers の Untagged 版が公開された.詳細は,公式の Documentation,あるいは VARIENG によるコーパスの解説からどうぞ.英語史研究会のオンライン会報より,三浦あゆみさんの記事「ARCHERの新版公開」も参考になる.
ARCHER は,1990年代初頭より Biber and Finegan が編纂してきたもので,現在では14の大学が合同で管理している.2013年に公開されたこの3.2版は Manchester 大学 ( David Denison and Nuria Yáñez-Bouza) による提供である.コーパスの内容と用途を端的に表現すれば,"a multi-genre historical corpus of British and American English covering the period 1600--1999. The corpus has been designed as a tool for the analysis of language change and variation in a range of written and speech-based registers of English." ということである.
コーパスの規模は1,710ファイル,3,298,080語からなり,語数での英米比は6:4ほど.また,時期として8期,内容により12種類にジャンル分けされている (a = advertising, d = drama, f = fiction, h = sermons, j = journals, l = legal, m = medicine, n = news, p = early prose, s = science, x = letters, y = diaries) .ファイル数と語数の内訳は以下の通り.
| BRITISH | a | d | f | h | j | l | m | n | p | s | x | y | TOTAL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1600--49 | files | 0 | 10 | 0 | 0 | 0 | 10 | 0 | 0 | 10 | 0 | 0 | 0 | 30 |
| words | 0 | 32,342 | 0 | 0 | 0 | 21,026 | 0 | 0 | 32,741 | 0 | 0 | 0 | 86,109 | |
| 1650--99 | files | 0 | 10 | 11 | 10 | 10 | 10 | 21 | 10 | 0 | 10 | 75 | 10 | 177 |
| words | 0 | 30,328 | 41,667 | 21,818 | 21,186 | 20,466 | 23,811 | 22,304 | 0 | 21,427 | 38,767 | 20,488 | 262,262 | |
| 1700--49 | files | 0 | 10 | 11 | 10 | 11 | 10 | 14 | 10 | 0 | 10 | 77 | 10 | 173 |
| words | 0 | 27,862 | 44,057 | 21,511 | 23,265 | 21,315 | 22,066 | 21,612 | 0 | 20,812 | 33,896 | 20,495 | 256,891 | |
| 1750--99 | files | 10 | 10 | 10 | 10 | 10 | 10 | 20 | 10 | 0 | 10 | 70 | 11 | 181 |
| words | 25,386 | 27,484 | 45,198 | 21,752 | 21,284 | 20,367 | 21,002 | 23,172 | 0 | 20,599 | 29,589 | 23,043 | 278,876 | |
| 1800--49 | files | 10 | 10 | 10 | 10 | 11 | 10 | 10 | 10 | 0 | 10 | 25 | 10 | 126 |
| words | 30,804 | 31,211 | 45,107 | 21,777 | 23,249 | 20,531 | 20,286 | 22,951 | 0 | 21,015 | 12,671 | 20,883 | 270,485 | |
| 1850--99 | files | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 0 | 10 | 26 | 10 | 126 |
| words | 30,684 | 34,856 | 43,427 | 21,322 | 21,243 | 20,757 | 22,265 | 23,072 | 0 | 21,810 | 10,819 | 21,789 | 272,044 | |
| 1900--49 | files | 10 | 11 | 10 | 10 | 10 | 10 | 10 | 10 | 0 | 10 | 29 | 10 | 130 |
| words | 26,717 | 31,391 | 45,408 | 21,123 | 22,208 | 21,160 | 20,213 | 21,977 | 0 | 21,664 | 12,529 | 22,424 | 266,814 | |
| 1950--99 | files | 10 | 11 | 10 | 10 | 10 | 10 | 13 | 10 | 0 | 10 | 28 | 10 | 132 |
| words | 23,437 | 32,200 | 45,109 | 21,093 | 22,723 | 20,721 | 20,994 | 22,935 | 0 | 21,385 | 11,361 | 22,060 | 264,018 | |
| TOTAL | files | 50 | 82 | 72 | 70 | 72 | 80 | 98 | 70 | 10 | 70 | 330 | 71 | 1,075 |
| words | 137,028 | 247,674 | 309,973 | 150,396 | 155,158 | 166,343 | 150,637 | 158,023 | 32,741 | 148,712 | 149,632 | 151,182 | 1,957,499 | |
| AMERICAN | a | d | f | h | j | l | m | n | p | s | x | y | TOTAL | |
| 1750--99 | files | 3 | 10 | 10 | 10 | 10 | 12 | 9 | 10 | 0 | 10 | 58 | 10 | 152 |
| words | 9,214 | 29,980 | 38,980 | 21,271 | 21,896 | 41,177 | 23,541 | 22,265 | 0 | 20,668 | 27,860 | 21,315 | 278,167 | |
| 1800--49 | files | 1 | 10 | 10 | 0 | 10 | 12 | 0 | 10 | 0 | 10 | 10 | 10 | 83 |
| words | 2,822 | 40,568 | 44,676 | 0 | 21,476 | 33,409 | 0 | 37,107 | 0 | 20,904 | 20,739 | 20,695 | 242,396 | |
| 1850--99 | files | 8 | 10 | 11 | 10 | 10 | 10 | 10 | 10 | 0 | 10 | 28 | 11 | 128 |
| words | 24,480 | 32,721 | 44,394 | 21,056 | 22,436 | 28,506 | 20,547 | 21,994 | 0 | 21,311 | 11,361 | 23,419 | 272,225 | |
| 1900--49 | files | 10 | 10 | 10 | 0 | 10 | 11 | 0 | 15 | 0 | 10 | 52 | 10 | 138 |
| words | 30,460 | 52,514 | 53,430 | 0 | 21,661 | 21,607 | 0 | 22,802 | 0 | 20,984 | 25,021 | 20,731 | 269,210 | |
| 1950--99 | files | 10 | 10 | 10 | 10 | 10 | 12 | 10 | 10 | 0 | 12 | 30 | 10 | 134 |
| words | 29,563 | 31,037 | 44,382 | 21,051 | 22,109 | 25,517 | 22,617 | 23,069 | 0 | 25,623 | 11,961 | 21,654 | 278,583 | |
| TOTAL | files | 32 | 50 | 51 | 30 | 50 | 57 | 29 | 55 | 0 | 52 | 178 | 51 | 635 |
| words | 96,539 | 186,820 | 225,862 | 63,378 | 109,578 | 150,216 | 66,705 | 127,237 | 0 | 109,490 | 96,942 | 107,814 | 1,340,581 | |
Documentation のページより,完全単語リストをダウンロード可能.タグ付きの検索が可能な版もいずれ公開されるということなので,期待したい.「#1752. interpretor → interpreter (2)」 ([2014-02-12-1]) の記事で少し使ってみたので,そちらも参照を.
2014-04-02 Wed
■ #1801. homonymy と polysemy の境 [semantics][homonymy][polysemy][semantic_change][lexeme][componential_analysis]
homonymy (同義)と polysemy (多義)の区別が難しいことについては,「#286. homonymy, homophony, homography, polysemy」 ([2010-02-07-1]) や「#815. polysemic clash?」 ([2011-07-21-1]) の記事で話題にした.同形態の2つの語彙素が2つの同義語であるのか,あるいは1つの多義語であるのかは,一方は通時的な意味の変遷を参考にして,他方では話者の共時的な直感を参考にして判断するというのが通常の態度だろう.しかし,2つの視点が食い違うこともある.
例えば,(トランプの)組札,(衣服の)スーツ,訴訟の3つの語義をもつ suit という語を考えよう.3者は語源的には関連があり,核となる意味として "a following or natural sequence of things or events" ほどをもつ.「組札」と「スーツ」は一組・一続きという共通項でくくられそうだが,「訴訟」は原義からが逸脱しているように思われる.「訴訟」は「不正をただす目的で自然な流れとして法廷に訴える」に由来し,本来的には原義とつながりは保っているのだが,共時的な感覚としては逸脱としているといってよいだろう.Voyles (121--22) は,生成意味論の立場から,3つの語義が1つの語として共存しえた段階の意味規則を (1) として,2つの語に分かれたというに近い現代の段階の意味規則を (2) として定式化した.

(1) が polysemous,(2) が homonymous ということになるが,(2) も全体をひとくくりにしているという点では,必ずしも2つの別の語とみなしているわけではないのかもしれない.ポイントは,homonymy か polysemy かの区別は程度の問題ということである.Voyles (122) 曰く,
We are suggesting that for most contemporary speakers the meaning of suit as a set of cards or a set of clothes is an instance of polysemy: these two meanings share certain semantic markers in common. The other meaning of 'legal action' has become completely divorced from the meaning of 'collection' in that it has virtually no features in common with this meaning. This is then an instance of homonymy. The question of whether two or more different sense of a word should be considered the same or separate lexical items is, we believe, a function of the number of semantic features shared by the two (or more) senses. Often such a question does not admit of a simple yes or no; rather, the answer is one of degree.
生成意味論での意味変化の考え方について,一言述べておこう.Voyles によれば,意味素性の束から成る語の意味表示に対して,ある意味素性を加えたり,脱落させたりする規則を適用することによって,その語の意味が変化すると考えた.生成文法が意味を扱う際に常にアキレス腱となるのは,どの意味素性を普遍的な意味素性として設定するかという問題である.Voyles (122) も,結局,同じ問題にぶつかっているようだ.Williams (462) による Voyles の論文に対する評は,否定的だ.
A formal system for representing semantic structure is no less a prerequisite to describing most patterns in change of meaning. Voyles 1973 has attempted to represent change of meaning, building on the formal semantic theory of features and markers first proposed by Katz & Fodor 1963. He tries to demonstrate that semantic change can be systematically explained by changes in rules that generate semantic representations, much as phonological change can be represented as rule change. But a great deal of investigation is still necessary before we understand what should go into a semantic representation, much less what one should look like and how it might change.
生成意味論は理論的には過去のものといってよいだろう.しかし,homonymy と polysemy のような個別の問題については,どんな理論も何らかのヒントは与えてくれるものである.
・ Voyles, Joseph. "Accounting for Semantic Change." Lingua 31 (1973): 95--124.
・ Williams, Joseph M. "Synaesthetic Adjectives: A Possible Law of Semantic Change." Language 52 (1976): 461--78.
2014-04-01 Tue
■ #1800. 様々な反対語 [semantics][markedness][antonymy][lexicology]
反対語 (opposite) には反意語,反義語などの呼び名があるが,用語の不安定さもさることながら,何をもって反対とするかについての理解も様々である.
黒の反対は白か,しかし白の反対は紅(赤)とも考えられるのではないか.だが『赤と黒』という組み合わせもあるし,信号機を思い浮かべれば赤と青(実際の色は緑)という対立も考え得る.また「高い」の反対には「低い」と「安い」の2つがあるが,「低い」の反対には「高い」1つしかない.兄の反対は弟か,あるいは姉か,はたまた妹か.犬に対する猫,タコに対するイカは反対語といえるのか.happy の反対は unhappy か,それとも sad か.長いと短い,生と死,山と海,北と南,夫と妻は,それぞれ同じ基準によって反対語と呼べるのだろうか.
意味論では,反対語にも様々な種類があることが認められている.以下に Hofmann (40--46, 57--60) に拠って,代表的なものをまとめよう.
(1) (gradable) antonym
最も典型的な反対語は,high / low,long / short, old / new, hot / cold のような程度を表わす形容詞の対である.これらの反対語形容詞は,英語でいえば比較級や最上級にできる,very で程度を強められるなどの特徴をもつ.程度を尋ねる疑問や名詞形に使用されるのは,対のうちいずれかであり,そちらが一時的に中立的な意味を担うことになる.例えば,long / short の対に関しては long が無標となり,How long is the train? や the length of the train などと中和した意味で用いられる.日本語でも「どのくらい長いのか」と尋ねるし,名詞は「長さ」という.漢字では「長短」「大小」「寒暖」などと対にして中立的な程度を表わすことができるのがおもしろい.
(2) complementary
on / off,true / false, finite / infinite, mortal / immortal, single / married などの二律背反の対を構成する.(1) の対と異なり,very などで強めることはできず,程度として表現できないデジタルな関係である.一般的に,否定の接頭辞が付加されている場合を除いて,どちらが無標であるかを決めることができない.ただし,対の一方が (1) の性質をもち,他方が (2)の性質をもつケースもある.例えば,open / shut, cooked / raw, invisible / visible は,それぞれのペアのうち前者は gradable である.
他の品詞では,male / female, stop / move などが挙げられる.
(3) antonymous group
black / white / red / blue / green のように,「反対」となりうるものが集まって一連の語群(この場合には色彩語彙)を形成するもの.これらは反対語というよりは,むしろ同じ語群に属するという意味では類義語とも言うべきである.互いに同類でありながらも,その属の内部では固有の地位を占めており互いに差異的であるという点で,見方によっては「反対語」ともされるにすぎない.dog と cat はそれぞれ同類でありながら,同属の内部で相互に異なっているので,antonymous group の一部をなしているといえる.犬と猫は日本語でも英語でも慣用的にペアをなすので対語と見なされるが,同じグループの構成員としては,鼠,豚,狐,鹿を含めた多くの動物を挙げることができる.形容詞の例としては,big / small であれば (1) の例と同様にみえるが,huge / big / small / tiny という4段階制のなかで考えれば (3) を問題にしていることがわかる.つまり,(3) は,(1) や (2) の2項対立とは異なり,複数項対立と言い換えてもよいだろう.north / south / east / west の4項目など,方向に関して内部構造をもっているようなグループもある.
日本語で山の反対は海(あるいは川?)が普通だが,アメリカでは mountain に対しては valley が普通である.このように,グルーピングに文化的影響が見られるものも多い.
(4) reversative
動詞の動作について,逆転関係を表わす.tie (結ぶ)と untie (ほどく),clothe (着せる)と unclothe (脱がせる)など.過去分詞形容詞にして tied / untied, clothed / unclothed の対立へ転化すると,(1) や (2) の例となる.appear / disappear, enable / disable も同様.
(5) converse
husband / wife, parent / child のような相互に逆方向でありながら補い合う関係."X is the (husband) of Y." のとき,"Y is the (wife) of X." が成り立つ.だが,son / father は上の言い換えが必ずしもできないので,見せかけの converse である (ex. "X is the father of Liz") .
性質は異なるが,buy / sell, lend / borrow のように単一の出来事を反対の観点で見るものや,above / below, in front of / behind, north of / south of, right / left のように空間的位置関係を表わすものも,converse といえる.
上記のようにきれいに分類できないような「反対語」もあるはずだが,一応の区分として参考になるだろう.
・ Hofmann, Th. R. Realms of Meaning. Harlow: Longman, 1993.
2026 : 01 02 03 04 05 06 07 08 09 10 11 12
2025 : 01 02 03 04 05 06 07 08 09 10 11 12
2024 : 01 02 03 04 05 06 07 08 09 10 11 12
2023 : 01 02 03 04 05 06 07 08 09 10 11 12
2022 : 01 02 03 04 05 06 07 08 09 10 11 12
2021 : 01 02 03 04 05 06 07 08 09 10 11 12
2020 : 01 02 03 04 05 06 07 08 09 10 11 12
2019 : 01 02 03 04 05 06 07 08 09 10 11 12
2018 : 01 02 03 04 05 06 07 08 09 10 11 12
2017 : 01 02 03 04 05 06 07 08 09 10 11 12
2016 : 01 02 03 04 05 06 07 08 09 10 11 12
2015 : 01 02 03 04 05 06 07 08 09 10 11 12
2014 : 01 02 03 04 05 06 07 08 09 10 11 12
2013 : 01 02 03 04 05 06 07 08 09 10 11 12
2012 : 01 02 03 04 05 06 07 08 09 10 11 12
2011 : 01 02 03 04 05 06 07 08 09 10 11 12
2010 : 01 02 03 04 05 06 07 08 09 10 11 12
2009 : 01 02 03 04 05 06 07 08 09 10 11 12
最終更新時間: 2026-05-16 23:43
Powered by WinChalow1.0rc4 based on chalow