昨今,エントロピー (entropy) というキーワードをよく聞くようになったが,言語との関連で,この概念が話題にされることはあまりない.本ブログでは,「#838. 言語体系とエントロピー」 ([2011-08-13-1]) をはじめとして,##838,1089,1090,1587,1693 の各記事でこの用語に触れてきたが,まだ具体的な問題に適用したことはなかった.
エントロピーとは,体系としての乱雑さの度合いを示す指標である.データがいかに一様に散らばっているかを表わす尺度と言い換えてもよい.言語への応用は,Gries (112) が少し触れている.
A simple measure for categorical data is relative entropy Hrel. Hrel is 1 when the levels of the relevant categorical variable are all equally frequent, and it is 0 when all data points have the same variable level. For categorical variables with n levels, Hrel is computed as shown in formula (16), in which pi corresponds to the frequency in percent of the i-th level of the variable:
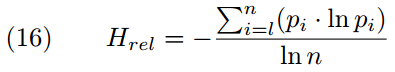
Gries は,300個の名詞句における冠詞の分布という例を挙げている.無冠詞164例,不定冠詞33例,定冠詞103例という内訳だった場合,Hrel = 0.8556091 となり,かなり不均質な分布を示すことになる.
ほかに散らばり具合が問題になるケースはいろいろと考えることができる.例えば,注目語句の出現頻度が,テキスト(のジャンル)に応じて一様か否かを測るということもできるだろう.
また,ある語に異形態や異綴字が認められる場合に,それぞれの変異形 (variants) の分布が均一か不均一かを計測することなどもできる.そのような変異の相対エントロピーが同時代の異なるテキスト(ジャンル)の間でどのくらい異なるのか,あるいは歴史的な関心からは,異なる時代のテキスト(ジャンル)の間でどのくらい異なるのかを,客観的に確かめることができるだろう.標準化その他の過程により,その変異が1つの形へ収斂してゆく場合,エントロピーが減少することになる.
具体的に考えるために,「#1773. ich, everich, -lich から語尾の ch が消えた時期」 ([2014-03-05-1]) で取り上げた,語尾の ch の脱落のデータを参照しよう.先の記事で Schlüter による集計結果の表を掲げたが,今回は,音声環境 (before V, before <h>, before C) の区別はせず,単純に ME II--ME IV の各時代に現れた変異形のトークン数のみを考慮に入れることにする.各変異形の各時代の Hrel を計算した結果の表を下に示す.
| I | 1150--1250 (ME I) | 1250--1350 (ME II) | 1350--1420 (ME III) | 1420--1500 (ME IV) |
|---|---|---|---|---|
| ich | 853 | 589 | 7 | 0 |
| I | 33 | 503 | 1397 | 2612 |
| Hrel | 0.2295 | 0.9955 | 0.04531 | 0.0000 |
| EVERY | 1150--1250 (ME I) | 1250--1350 (ME II) | 1350--1420 (ME III) | 1420--1500 (ME IV) |
| everich | - | 12 | 10 | 9 |
| everiche | - | 12 | 3 | 0 |
| every | - | 5 | 112 | 152 |
| Hrel | - | 0.9406 | 0.3550 | 0.1962 |
| -LY | 1150--1250 (ME I) | 1250--1350 (ME II) | 1350--1420 (ME III) | 1420--1500 (ME IV) |
| -lich | 106 | 33 | 31 | 3 |
| -''liche' | 689 | 168 | 70 | 44 |
| -ly | 12 | 19 | 1088 | 1444 |
| Hrel | 0.4225 | 0.6390 | 0.3123 | 0.1342 |
これの をプロットすると,次のようになる.
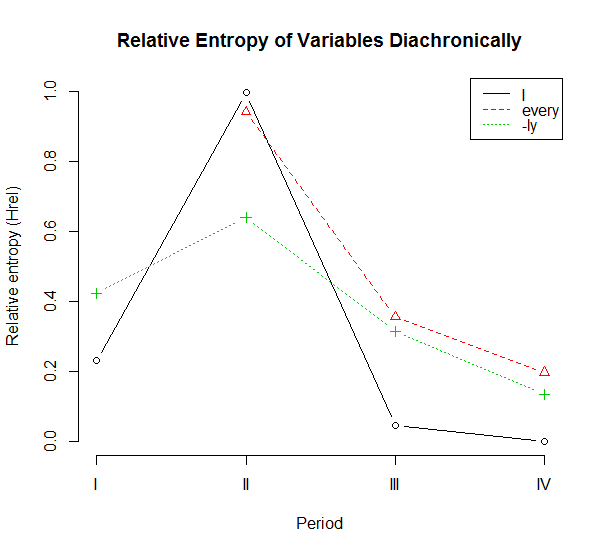
1人称単数代名詞主格 I の変異は,集束→発散→集束と推移しており,不安定期 II の突出が目立つ.安定していた体系が急激に乱され,そしてすぐに回復したという推移だ.第I期のデータを欠く every の変異は,I ほどではないものの,同じようにIIからIIIの時期にかけて急激な下落を示す.-ly の変異も,より緩やかではあるが,同時期に同様の下降を表わす.
Schlüter は,ich, everich, -lich の順で語尾の ch が脱落し,変異の収斂に向かっていったと評価しているが,これは第II期以降のエントロピーの減少率のことを指していると解釈できる.しかし,第I期からの推移も考慮に入れると,I の発散の開始は -ly の発散よりも後のようである.これは,早く始まった変化はゆっくりと進行するのに対し,遅く始まった変化は急速に進行するという,言語変化にしばしば見られるパターンを示唆する.エントロピー曲線の形状でいえば,前者は裾の長い富士山型,後者は先のとがったマッターホルン型ということになる.エントロピーという指標を用いて,言語変化のスピードについて何か一般化できることがあるかもしれない.
・ Gries, Stefan Th. Statistics for Linguistics with R: A Practical Introduction. Berlin: Mouton, 2009.
・ Schlüter, Julia. "Weak Segments and Syllable Structure in ME." Phonological Weakness in English: From Old to Present-Day English. Ed. Donka Minkova. Basingstoke: Palgrave Macmillan, 2009. 199--236.