2026-06-21 Sun
■ #6264. 古英語名詞屈折の型別の頻度比率 [oe][inflection][gender][paradigm][frequency][statistics]
「#6250. なぜ古英語文法で名詞屈折の定番が stan なのか? (2)」 ([2026-06-07-1]) で紹介した通り,ヘルメイトの ykagata さんが,「[古英語]名詞屈折表が stān で始まる本,始まらない本」を公開されている.そこで Smith (66) が引用されている.以下に再掲しよう.
OE nouns can be classified into five groups, or declensions. In decreasing order of frequency of occurrence in OE, these declensions are:
(1) General Masculine Declension
(2) General Feminine Declension
(3) General Neuter Declension
(4) the -an Declension
(5) Irregular Declensions
ここで,名詞屈折の型について伝統的・通時的なラベルを採用せず,教育的・共時的なラベルを採用していることを,ykagata さんは賞賛されている.
(1) から (5) は頻度の高い順に並べられているということだが,この「頻度」のソースはどこから来ているのだろうか.おそらくだが,完全にではないが,古英語の伝統的な入門書,Quirk and Wrenn (20) の挙げている頻度比率(あるいはそこから派生した何らかのソース)に依拠しているのではないかと睨んでいる.その数値を表でまとめると以下のようになる(予想される通り,伝統的・通時的なラベルが用いられている点に注意).
| Noun Class | Value |
|---|---|
| masculine a-stems | 0.36 |
| masculine n-stems and minor declension | 0.09 |
| feminine o-stems | 0.25 |
| feminine n-stems and minor declension | 0.05 |
| neuter a-stems | 0.25 |
| neuter n-stems | insignificant |
ただし,1つ気になるのは,この Qurik and Wrenn の数値が何に基づいているのかが同書内で明記されていないことだ.トークン頻度ではなくタイプ頻度で数えていると想定されるが,既存の古英語辞書や古英語文法書のグロッサリーなどを丹念に調べたのだろうか.
・ Smith, Jeremy J. Essentials of Early English. 2nd ed. London: Routledge, 2005.
・ Quirk, Randolph. and C. L. Wrenn. An Old English Grammar. 2nd ed. London: Methuen, 1957.
[ 固定リンク | 印刷用ページ ]
2026-05-23 Sat
■ #6235. 基本語順の類型論 (5) [word_order][syntax][typology][world_languages][statistics][nazesantangen]
世界の言語の基本語順の類型論,とりわけ S, V, O の3要素の並び順のパターンについて,以下の記事などで扱ってきた.
・ 「#137. 世界の言語の基本語順」 ([2009-09-11-1])
・ 「#2786. 世界言語構造地図 --- WALS Online」 ([2016-12-12-1])
・ 「#3124. 基本語順の類型論 (1)」 ([2017-11-15-1])
・ 「#3125. 基本語順の類型論 (2)」 ([2017-11-16-1])
・ 「#3128. 基本語順の類型論 (3)」 ([2017-11-19-1])
・ 「#3129. 基本語順の類型論 (4)」 ([2017-11-20-1])
・ 「#4316. 日本語型 SOV 言語は形態的格標示をもち,英語型 SVO 言語はもたない」 ([2021-02-19-1])
・ 「#3734. 島嶼ケルト語の VSO 語順の起源」 ([2019-07-18-1])
・ 「#5585. 『子供の科学』9月号で小5生からの「なぜ,日本語と英語では語順が違うのですか?」に回答しました」 ([2024-08-11-1])
今回は,The World Atlas of Language Structures (WALS Online) の Feature 81A: Order of Subject, Object and Verb に基づいて作成した表を掲げたい.「#3128. 基本語順の類型論 (3)」 ([2017-11-19-1]) でも同趣旨の記事を書いたが,今回は数字を整理し,具体的な言語例もいくつか添えたので,より参照しやすくなっていると思う.
| 語順 | 割合 | 言語例 |
|---|---|---|
| SOV | 41% | 日本語,アイヌ語,トルコ語,ヒンディー語,バスク語 |
| SVO | 35% | 英語,中国語,フィンランド語,スワヒリ語,ベトナム語 |
| VSO | 7% | アイルランド語,ハワイ語,マオリ語 |
| VOS, OVS, OSV | 3% | マラガシ語;ツバル語;トバティ語 |
| 基本語順なし | 14% | ハンガリー語,フィジー語,チェロキー語,ジルバル語 |
基本語順の話題は,近刊『英語史で解く 英文法の謎 --- なぜ「3単現の s」をつけるのか』の第1章第1節でも取り上げられる.
・ Matthew S. Dryer. 2013. Order of Subject, Object and Verb. In: Dryer, Matthew S. & Haspelmath, Martin (eds.) WALS Online (v2020.4) [Data set]. Zenodo. https://doi.org/10.5281/zenodo.13950591. (Available online at http://wals.info/chapter/81, Accessed on 2026-05-14.)
[ 固定リンク | 印刷用ページ ]
2025-07-09 Wed
■ #5917. 『英語史新聞』第12号が公開されました [hel_herald][notice][khelf][hel_education][link][helkatsu][etymological_respelling][relative_pronoun][loan_word][borrowing][lexicology][statistics][negative_cycle][syntax][helvillian]

7月7日の七夕,khelf(慶應英語史フォーラム)による『英語史新聞』シリーズの第12号がウェブ上で公開されました.こちらよりPDFで自由に閲覧・ダウンロードできます.
数ヶ月前から,七夕の日を公開日と定め,執筆陣や編集陣が協力して準備を進めてきました.例によって公開前夜はぎりぎりまで最終調整に追われていましたが,できあがった紙面については,どうぞご安心ください.珠玉のコンテンツが満載です.企画,執筆,編集と今号の制作に関わったすべての khelf メンバーに,まずは労いと感謝の言葉を述べたいと思います.よく頑張ってくれました,ありがとうございます!
さて,今号も4面構成となっています.どのような記事が掲載されているか,具体的に紹介していきましょう.まず第1面は,七夕の公開日に合わせ「星を見ながら語源をめぐろう」と題するロマンチックな巻頭記事です.執筆者は,本ブログや heldio でも語源的綴字 (etymological_respelling) に関する研究でお馴染みの,khelf の寺澤志帆さんです.彦星(わし座のアルタイル)と織姫(こと座のベガ)にちなみ,2つの星座にまつわる単語の歴史をたどります.「こと座」 (Lyra) に関しては,lyre の綴りが中英語期の lire から,語源のギリシャ語に近づけるために16世紀に y を用いる形へ変更されたという語源的綴字の実例にも触れられており,執筆者の専門知識が活かされた記事となっています.
続く第2面の記事は,「wh から始まる関係代名詞の歴史」です.こちらは学部4年生の Y. T. さんによる本格的な英語史コンテンツです.私たちが当然のように使っている who や which は,古英語の時代には,「誰」「どれ」を意味する疑問詞でしかありませんでした.関係代名詞としては指示詞に由来する that の祖先などが用いられていましたが,中英語期以降,which を皮切りに wh 疑問詞が,関係代名詞の用法を獲得してきました.ただし,who については,関係代名詞として定着するのは意外にも17世紀に入ってからと,比較的遅いのです.その過渡期には,Shakespeare の作品で,人を先行詞にとる場合に which が感情的な文脈で用いられていました.関係代名詞をめぐる歴史には,単なる文法規則の変化にとどまらない,社会言語学的にダイナミックな変化の過程が関わっていたのです.
第3面の上部にみえるのは「英語史ラウンジ by khelf」の連載コーナーです.今回は,青山学院大学の寺澤盾先生へのインタビューの後編をお届けします.記事執筆者は khelf 会長の青木輝さんです.寺澤先生の「推し本」として,中島文雄『英語発達史』や H. Bradley 『英語発達小史』など,英語史研究における古典的名著が複数紹介されます.また,英語史を学ぶ魅力について,「面白い」で終わらず「なぜ」と問い続けることの重要性が説かれており,研究者を志す学生には特に示唆に富む内容となっています.
そして,3面の下部では,第2面でちらっと出題されている「英語史クイズ BASIC」の答えと詳しい解説を読むことができます.現代英語の語彙における借用語の割合に関するクイズですが,問いも答えも,ぜひ記事を熟読していただければ.記事執筆者は,大学院生の小田耕平さんです.
最後の第4面には,大学院生の疋田海夢さんによる本格的な英語史の記事「Not は否定の「強調」!? ~Jespersen's Cycle と「古都」としての言語観~」が掲載されています.これは,英語の否定文の発達を説明する "Jespersen's Cycle" に関する解説と論考です.ここで紹介される「否定辞の弱化→強調語の追加→強調語の否定辞化」というサイクルはフランス語やドイツ語でも見られる現象ですが,記事ではさらに,現代アメリカ英語のスラング squat (例: Claudia saw squat.) の事例を取り上げ,このサイクルが現代,そして未来へと続いている可能性を示唆しています.
このように,今号もすべての記事が khelf メンバーの熱意と探究心の結晶です.英語史を研究する学生たちが本気で作り上げた『英語史新聞』第12号を,ぜひじっくりとお読みいただければ幸いです.
最後に,hellog 読者の皆さんへ1点お伝えします.もし学校の授業などの公的な機会(あるいは,その他の準ずる機会)にて『英語史新聞』を利用される場合には,ぜひ上記 heldio 配信回のコメント欄より,あるいはこちらのフォームを通じてご一報くださいますと幸いです.khelf の活動実績となるほか,編集委員にとっても励みともなりますので,ご協力のほどよろしくお願いいたします.ご入力いただいた学校名・個人名などの情報につきましては,khelf の実績把握の目的のみに限り,記入者の許可なく一般に公開するなどの行為は一切行なわない旨,ここに明記いたします.フィードバックを通じ,khelf による「英語史をお茶の間に」の英語史活動(hel活)への賛同をいただけますと幸いです.
最後に『英語史新聞』のバックナンバー(号外を含む)も紹介しておきます.こちらも合わせてご一読ください(khelf HP のこちらのページにもバックナンバー一覧があります).
・ 『英語史新聞』第1号(創刊号)(2022年4月1日)
・ 『英語史新聞』号外第1号(2022年4月10日)
・ 『英語史新聞』第2号(2022年7月11日)
・ 『英語史新聞』号外第2号(2022年7月18日)
・ 『英語史新聞』第3号(2022年10月3日)
・ 『英語史新聞』第4号(2023年1月11日)
・ 『英語史新聞』第5号(2023年4月10日)
・ 『英語史新聞』第6号(2023年8月14日)
・ 『英語史新聞』第7号(2023年10月30日)
・ 『英語史新聞』第8号(2024年3月4日)
・ 『英語史新聞』第9号(2024年5月12日)
・ 『英語史新聞』第10号(2024年9月8日)
・ 『英語史新聞』号外第3号(2024年9月8日)
・ 『英語史新聞』第11号(2024年12月30日)
2025-03-11 Tue
■ #5797. 言語年代学は後世の言語学に何を残したか? --- いのほた最新回 [glottochronology][history_of_linguistics][statistics][inohota][youtube][voicy][heldio][helwa][linguistics][link]
YouTube 「いのほた言語学チャンネル」の最新回が公開されています.お題は「#317. 言語年代学は後世の言語学に何を残したか?」です.
本ブログでも言語年代学 (glottochronology) について様々な記事を書いてきました.いくつかピックアップしてみます.
・ 「#1128. glottochronology」 ([2012-05-29-1])
・ 「#1729. glottochronology 再訪」 ([2014-01-20-1])
・ 「#2659. glottochronology と lexicostatistics」 ([2016-08-07-1])
・ 「#2660. glottochronology と基本語彙」 ([2016-08-08-1])
・ 「#4685. Campbell による glottochronology 批判」 ([2022-02-23-1])
音声配信 heldio/helwa でも,以下の回で言語年代学についてお話ししています.
・ helwa 「【英語史の輪 #91】否定された「言語年代学」」 (2024/02/08)
・ heldio 「#1339. 言語年代学 --- 言語学史の一幕」 (2025/01/28)
・ heldio 「#1340. 言語年代学への批判から学べること」 (2025/01/29)
この言語学の分野は,今では言語学史の一コマとして見られることが多いですが,アイディア自体は斬新だったと私は考えています.批判の多い学説でしたが,その鋭い批判のなかから数々のインスピレーションが飛び出し,言語学の一角に若い種が蒔かれたのでした.印欧語比較言語学が新たな刺激を獲得し,語彙統計学 (lexicostatistics) が発展し,基本語彙とは何かという問いが生じ,意味素に関する議論も見直されました.批判される学説にも中長期的にはポジティヴな意義があることを教えてくれる好例です.
歴史的な学説の掘り起こし,ポジティヴな再解釈,現代的応用は,有益な試みですね.
2025-01-18 Sat
■ #5745. アルファベットの文字頻度 [corpus][link][alphabet][frequency][statistics][letter_frequency][bnc][morse_code]
AからZまでのアルファベット文字のなかで,最も頻度の高い文字,低い文字は何か.この文字頻度 (letter_frequency) の話題については,「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1]) の下部に Letter Frequencies (rankings for various languages) へのリンクを挙げたとおり,様々な言語やコーパスでの順位表が作り出されている.例えば,BNC に依拠すると "etaoinsrhldcumfpgwybvkxjqz" の順位表が得られる.
Crystal (277) には,The Cambridge Encyclopedia (1st ed.) の全テキスト,150万語をコーパスとした文字頻度表が掲げられている.累積頻度順位 (Cumulative) のみならず,文学,宗教,政治,物理学,化学の各々のテーマごとの頻度や Morse code (morse_code) の頻度も合わせて示されている.以下のグラフは,X軸に沿って累積頻度順 (= "eatinorslhdcmufpgbywvkxjq") に文字を並べ,Y軸を各テーマ内での頻度割合(百分率)としたものである(頻度表はソース HTML を参照).
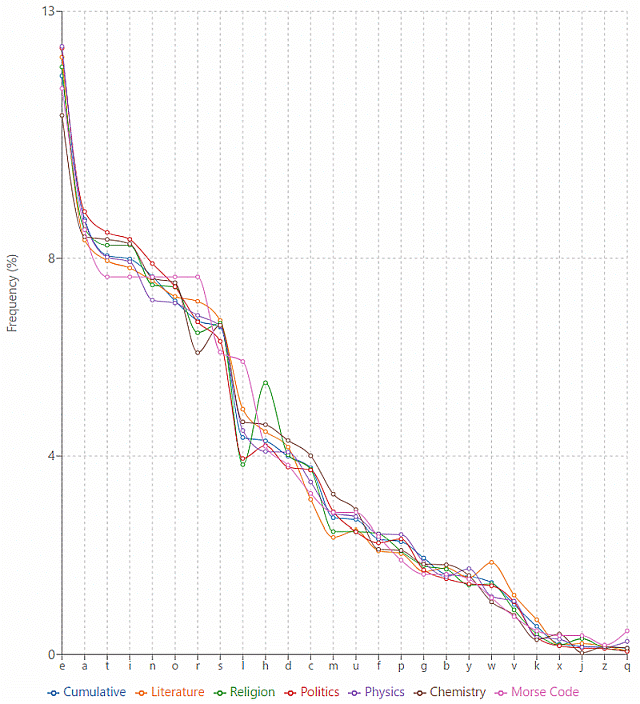
累積頻度順に照らしてテーマごとの特徴を見てみるとと,政治が最も標準的である.文学と政治がそれに続く.標準から遠ざかっていくのが,化学,物理学,そして Morse code となる.
個々の文字をみると興味深い点が多々ある.相対的に宗教では <h> が多く (holy?) <l> が少ないこと,文学では <w> が多いことは何を意味するのだろうか? 物理学や化学はラテン・ギリシア語系の単語が多く含まれているために,その他一般とは若干異なる文字頻度を示しているのかもしれない.人工的な Morse code は,他のテーマとは目に見えて異なる線を描いていることがわかる.
・ Crystal, D. The Cambridge Encyclopedia of the English Language. 3rd ed. CUP, 2018.
2024-12-26 Thu
■ #5722. Shakespeare は1591--1611年の間にラテン語由来の単語を600語取り込んだ [renaissance][shakespeare][emode][latin][greek][borrowing][loan_word][neologism][statistics][neo-latin][scientific_name][scientific_english][word_formation]
16--17世紀の初期近代英語期は,大部分が英国ルネサンスの最盛期に当たり,古典語(ラテン語とギリシア語)が尊ばれ,そこから大量の単語が英語語彙に取り込まれた時期である.同時代の代表的な文人が Shakespeare なのだが,Durkin によればこの劇作家のみに注目したとしても,短期間に相当数のラテン語由来の新語 ("latinate neologisms") が英語に流入したことが確認されるという.
The peak period of the Literary Renaissance was C.1590--1600. The Primary author was Shakespeare who, between 1591 and 1611, introduced no fewer than six hundred latinate neologisms, fifty-three of which occur in Hamlet alone. Many of these became everyday words, e.g. addiction, assassination, compulsive, domineering, obscene, sanctimonious, traditional. (226--27)
この点で Shakespeare は同時代的に著しい造語力を体現しているといえるが,さらに重要なのは,その後の新古典主義新語ブームに前例を与えたという功績なのではないか.Shakespeare に代表されるルネサンス期に火のついた古典語からの語彙借用の慣習は,続く時代にも勢いが緩まるどころか,むしろ拡張しつつ受け継がれていったからである.Durkin はこう続けている.
After the Renaissance, a vast amount of technical and scientific vocabulary flooded into English from both Greek and Latin, hence words like carnivorous, clitoris, formula, hymen, nucleus. In the next century, Linnaeus [1707--78] introduced numerous biological terms, like chrysanthemums and rhododendron. The Scientific period, which peaked C.1830, featured many Neolatin terms like am(o)eba, bacterium, flagellum. Finally, the modern technical/technological period featured words like floccilation. (227)
これは Shakespeare が英語語彙史上に果たした役割の1つとみてよいだろう.
・ Durkin, Philip. Borrowed Words: A History of Loanwords in English. Oxford: OUP, 2014.
2024-05-13 Mon
■ #5495. インド憲法第343条に記載されている連邦の公用語 [hindi][india][statistics][official_language][demography]
1950年に定められたインド憲法(英語版)の第343条の第1項によれば,連邦の公用語 (official_language) はデーヴァナーガリー文字 (Devanagari) で書かれたヒンディー語 (hindi) とされている.しかし,向こう15年間は英語の暫定的使用も認める,という但し書き条項が加えられていた.さらに,その15年の後にも,英語を引き続き公的に使用することができる選択肢は開かれていた.インドの公用語をめぐる問題は,すでに憲法制定時より,このように奥歯に物が挟まったような言い方で始まっていたということだ.英語版より343条を引用しよう.
343. Official language of the Union.---(1) The official language of the Union shall be Hindi in Devanagari script.
The form of numerals to be used for the official purposes of the Union shall be the international form of Indian numerals.
(2) Notwithstanding anything in clause (1), for a period of fifteen years from the commencement of this Constitution, the English language shall continue to be used for all the official purposes of the Union for which it was being used immediately before such commencement:
Provided that the President may, during the said period, by order authorise the use of the Hindi language in addition to the English language and of the Devanagari form of numerals in addition to the international form of Indian numerals for any of the official purposes of the Union.
(3) Notwithstanding anything in this article, Parliament may by law provide for the use, after the said period of fifteen years, of---
(a) the English language, or
(b) the Devanagari form of numerals,
for such purposes as may be specified in the law.
憲法上の記載の順序でいえば,ヒンディー語が筆頭の公用語である.実際,インド国内ではヒンディー語は話者が最も多く,2020年の時点で約6億人以上を数えるという(大石(編),p. 70).さらにいえば,ヒンディー語は,世界の中でも3番目に話者の多い超大言語である.2020年のこちらのニュース記事によると,Ethnologue による統計に基づき,次のような解説がなされている.
Hindi is the 3rd most spoken language of the world in 2019 with 615 million speakers. The 22nd edition of the world language database Ethnologue stated English at the top of the list with 1,132 million speakers. Chines Mandarin is at the second position with 1,117 million speakers.
今後もインドの人口増加と連動してヒンディー語の話者人口は増えていくものと思われる.インドのダイナミックな言語事情からは目を離せない.
関連して Ethnologue の言語話者人口について「#3009. 母語話者数による世界トップ25言語(2017年版)」 ([2017-07-23-1]) を,多言語国家の公用語の話題として「#3291. 11の公用語をもつ南アフリカ共和国」 ([2018-05-01-1]) を参照.
・ 大石 晴美(編) 『World Englishes 入門』 昭和堂,2023年.
2023-10-04 Wed
■ #5273. 英語に関する最新統計 --- 大石晴美(編)『World Englishes 入門』(昭和堂,2023年)の序章より [world_englishes][notice][hel_education][hel][statistics][demography][review][we_nyumon]
先日の記事「#5268. 大石晴美(編)『World Englishes 入門』(昭和堂,2023年)」 ([2023-09-29-1]) で紹介したこちらの本,一般発売が開始となったようです.

これまで本ブログでもWorld Englishes (世界英語')については多く取り上げてきました (cf. (world_englishes)) .21世紀に入ってから英語学・英語史でも驚くほど注目されるようになった今をときめく話題です.この15年ほどを振り返ってみても,英語学・英語史を専攻する大学生の研究テーマとして大人気のトピックといってよいでしょう.この World Englishes の人気の高まりには,間違いなく社会的な背景があると考えています.この問題についていろいろな機会に書いたり話したりしてきましたが,今後も注目していく予定です.
そんな折りに,この『World Englishes 入門』が出版されました.これから,本書を参照しつつ本ブログや Voicy 「英語の語源が身につくラジオ (heldio)」にて,関連する話題を取り上げていくつもりですので,ぜひ伴走していただければ.
大石晴美・梅谷博之氏による「序章 World Englishes---世界諸英語」では,世界の言語や英語に関する最新の事実や統計が示されています.いくつか引用します.
・ 現在,世界には196か国が存在し,7000以上の言語が使われている.(p. 6)
・ 2022年11月,世界の総人口は80億人を超えた(世界人口推計 2022).そのうち英語を使用する人口(母語,第二言語,外国語としての英語使用者)は約14億5000万人,そのうち母語話者が約3億7000万,第二言語,外国語としての使用者は約10億8000万人である (Ethnologue 2022) .このことから非母語話者の数が母語話者の数をはるかに上回っていることがわかる.(p. 9--10)
・ 世界で,英語を公用語もしくは準公用語と定めている国は54か国である.4か国のうち1か国が英語を公用語や準公用語にしていることになる.(p. 10)
・ 世界のインターネット総人口は,約41億6000万人(全人口の69%)である (Internet World Stats 2023) .そのうち,26%が英語仕様人口であり,インターネット普及率が英語の広がりにつながっている.(p. 10)
・ 世界で上映されている映画のうち英語が用いられているのは8割以上である. (p. 10)
本書はコラムも充実しています.例えば,序章のなかの2つめのコラムにおいて「世界の英語を映画で学ぶ研究会」(京都府立大学)が紹介されています.すべての映画が観たくなってしまい,たいへん困っています.
・ 大石 晴美(編) 『World Englishes 入門』 昭和堂,2023年.
2022-06-05 Sun
■ #4787. 英語とフランス語の間には似ている単語がたくさんあります [french][latin][loan_word][borrowing][notice][voicy][link][hel_education][lexicology][statistics][hellog_entry_set][sobokunagimon]
一昨日の Voicy 「英語の語源が身につくラジオ (heldio)」 にて「#368. 英語とフランス語で似ている単語がある場合の5つのパターン」という題でお話ししました.この放送に寄せられた質問に答える形で,本日「#370. 英語語彙のなかのフランス借用語の割合は? --- リスナーさんからの質問」を公開しましたので,ぜひお聴きください.
英語とフランス語の両方を学んでいる方も多いと思います.Voicy でも何度か述べていますが,私としては両言語を一緒に学ぶことをお勧めします.さらに,両言語の知識をつなぐものとして「英語史」がおおいに有用であるということも,お伝えしたいと思います.英語史を学べば学ぶほど,フランス語にも関心が湧きますし,その点を押さえつつフランス語を学ぶと,英語もよりよく理解できるようになります.そして,それによってフランス語がわかってくると,両言語間の関係を常に意識するようになり,もはや別々に考えることが不可能な境地(?)に至ります.英語学習もフランス語学習も,ともに楽しくなること請け合いです.
実際,語彙に関する限り,英語語彙の1/3ほどがフランス語「系」の単語によって占められます.フランス語「系」というのは,フランス語と,その生みの親であるラテン語を合わせた,緩い括りです.ここにフランス語の姉妹言語であるポルトガル語,スペイン語,イタリア語などからの借用語も加えるならば,全体のなかでのフランス語「系」の割合はもう少し高まります.
さて,その1/3のなかでの両言語の内訳ですが,ラテン語がフランス語を上回っており 2:1 あるいは 3:2 ほどいでしょうか.ただし,両言語は同系統なので語形がほとんど同一という単語も多く,英語がいずれの言語から借用したのかが判然としないケースもしばしば見られます.そこで実際上は,フランス語「系」(あるいはラテン語「系」)の語彙として緩く括っておくのが便利だというわけです.
このような英仏語の語彙の話題に関心のある方は,ぜひ関連する heldio の過去放送,および hellog 記事を通じて関心を深めていただければと思います.以下に主要な放送・記事へのリンクを張っておきます.実りある両言語および英語史の学びを!
[ heldio の過去放送 ]
・ 「#26. 英語語彙の1/3はフランス語!」
・ 「#329. フランス語を学び始めるならば,ぜひ英語史概説も合わせて!」
・ 「#327. 新年度にフランス語を学び始めている皆さんへ,英語史を合わせて学ぶと絶対に学びがおもしろくなると約束します!」
・ 「#368. 英語とフランス語で似ている単語がある場合の5つのパターン」
[ hellog の過去記事(一括アクセスはこちらから) ]
・ 「#202. 現代英語の基本語彙600語の起源と割合」 ([2009-11-15-1])
・ 「#429. 現代英語の最頻語彙10000語の起源と割合」 ([2010-06-30-1])
・ 「#845. 現代英語の語彙の起源と割合」 ([2011-08-20-1])
・ 「#1202. 現代英語の語彙の起源と割合 (2)」 ([2012-08-11-1])
・ 「#874. 現代英語の新語におけるソース言語の分布」 ([2011-09-18-1])
・ 「#2162. OED によるフランス語・ラテン語からの借用語の推移」 ([2015-03-29-1])
・ 「#2357. OED による,古典語およびロマンス諸語からの借用語彙の統計」 ([2015-10-10-1])
・ 「#2385. OED による,古典語およびロマンス諸語からの借用語彙の統計 (2)」 ([2015-11-07-1])
・ 「#117. フランス借用語の年代別分布」 ([2009-08-22-1])
・ 「#4138. フランス借用語のうち中英語期に借りられたものは4割強で,かつ重要語」 ([2020-08-25-1])
・ 「#660. 中英語のフランス借用語の形容詞比率」 ([2011-02-16-1])
・ 「#1209. 1250年を境とするフランス借用語の区分」 ([2012-08-18-1])
・ 「#594. 近代英語以降のフランス借用語の特徴」 ([2010-12-12-1])
・ 「#1225. フランス借用語の分布の特異性」 ([2012-09-03-1])
・ 「#1226. 近代英語期における語彙増加の年代別分布」 ([2012-09-04-1])
・ 「#1205. 英語の復権期にフランス借用語が爆発したのはなぜか」 ([2012-08-14-1])
・ 「#2349. 英語の復権期にフランス借用語が爆発したのはなぜか (2)」 ([2015-10-02-1])
・ 「#4451. フランス借用語のピークは本当に14世紀か?」 ([2021-07-04-1])
・ 「#1638. フランス語とラテン語からの大量語彙借用のタイミングの共通点」 ([2013-10-21-1])
・ 「#1295. フランス語とラテン語の2重語」 ([2012-11-12-1])
・ 「#653. 中英語におけるフランス借用語とラテン借用語の区別」 ([2011-02-09-1])
・ 「#848. 中英語におけるフランス借用語とラテン借用語の区別 (2)」 ([2011-08-23-1])
・ 「#3581. 中英語期のフランス借用語,ラテン借用語,"mots savants" (1)」 ([2019-02-15-1])
・ 「#3582. 中英語期のフランス借用語,ラテン借用語,"mots savants" (2)」 ([2019-02-16-1])
・ 「#4453. フランス語から借用した単語なのかフランス語の単語なのか?」 ([2021-07-06-1])
・ 「#3180. 徐々に高頻度語の仲間入りを果たしてきたフランス・ラテン借用語」 ([2018-01-10-1])
2022-02-21 Mon
■ #4683. 異なる言語の間で「偶然」類似した語がある場合 [comparative_linguistics][statistics][lexicology][sound_change][arbitrariness][methodology]
「#1136. 異なる言語の間で類似した語がある場合」 ([2012-06-06-1]) の (1) で「偶然の一致」という可能性に言及した.2つの言語の系統的な関係を同定することを目指す比較言語学 (comparative_linguistics) にとって,2言語からそれぞれ取り出された1対の語が,言語の恣意性 (arbitrariness) に基づき,たまたま似ているにすぎないのではないか,という疑念は常に脅威的である.類似性の偶然と必然をどう見分けるのか,これは比較言語学の方法論においても,あるいはそれを論駁しようとする陣営にとっても,等しく困難な問題である.
この問題について,Campbell (275--76) が "Chance Similarities" と題する1節で Doerfer の先行研究に言及しながら論じている.偶然性には2種類あるという趣旨だ.
Doerfer (1973: 69--72) discusses two kinds of accidental similarity. "Statistical chance" has to do with what sorts of words and how many might be expected to be similar by chance; for example, the 79 names of Latin American Indian languages which begin na- (e.g., Nahuatl, Naolan, Nambicuara, etc.) are similar by sheer happenstance, statistical chance. "Dynamic chance" has to do with forms becoming more similar through convergence, that is, lexical parallels (known originally to have been different) which come about due to sounds converging through sound change. Cases of non-cognate similar forms are well known in historical linguistic handbooks, for example, French feu 'fire' and German Feuer 'fire' . . . (French feu from Latin focus 'hearth, fireplace' [-k- > -g- > -ø; o > ö]; German Feuer from Proto-Indo-European *pūr] [< *puHr-, cf. Greek pür] 'fire,' via Proto-Germanic *fūr-i [cf. Old English fy:r]).
共時的・通言語的な偶然の一致が "statistical chance" であり,通時的な音変化の結果,形態が似てしまったという偶然が "dynamic chance" である.比較言語学で2言語からそれぞれ取り出された1対の語を比べる際に,だまされてはいけない2つの注意すべき点として銘記しておきたい.
"dynamic chance" の1例として「#4072. 英語 have とラテン語 habere, フランス語 avoir は別語源」 ([2020-06-20-1]) を参照.
・ Campbell, Lyle. "How to Show Languages are Related: Methods for Distant Genetic Relationship." Handbook of Historical Linguistics. Ed. Brian D. Joseph and Richard D. Janda. Oxford: Blackwell, 262--82.
・ Doerfer, Gerhard. Lautgesetz und Zufall: Betrachtungen zum Omnikomparatismus. Innsbruck: Institut für vergleichende Sprachwissenschaft der Universität Innsbruck, 1973.
2022-02-17 Thu
■ #4679. 言語における塊現象とゆらぎ [complex_system][computational_linguistics][statistics][frequency][1/f][terminology][keyword]
昨日の記事「#4678. 言語における塊現象と長相関」 ([2022-02-16-1]) で,言語における塊現象を「長相関」の観点からみたが,今回はもう1つの観点である「ゆらぎ」に注目しよう.ゆらぎ解析について,田中 (112) は次のように説明している.
このような塊現象を捉える自然な方法の一つとして,ある一定の範囲内に出現する単語の頻度の分散を調べることが挙げられる.ある単語の出現にゆらぎがあるのであれば,ある一定の範囲内にその単語が出現しない場合があり,また一方でその単語が数多く出現する場合もあり,その頻度の分散は大きくなるはずである.
解析原理としては分かりやすい.ある文章中に表われる語彙を念頭におく場合,ゆらぎ方は語によって異なるが,おもしろいことに,いわゆるキーワードはしばしばゆらぎが大きいという(田中,p. 118).これは,機械的なキーワードの同定などに貢献しそうな興味深い傾向である.
また,人間言語による文章とランダム文字列の文章とでゆらぎを比べると,明らかに前者の方がゆらぎが大きく,このことは人間言語の特徴の一端を示唆する.さらに,文章のジャンルによってもゆらぎは異なるために(田中,p. 120),ゆらぎの度合いは文体論的な指標ともなり得る.
様々な可能性を秘めた言語における「ゆらぎ」にアンテナを張っておきたい.関連して「1/f ゆらぎ」 (1/f) も要注目.
・ 田中 久美子 『言語とフラクタル --- 使用の集積の中にある偶然と必然』 東京大学出版会,2021年.
2022-02-16 Wed
■ #4678. 言語における塊現象と長相関 [complex_system][computational_linguistics][statistics][frequency][information_structure][article][terminology]
言語には,他の多くの自然・社会現象にもみられる「塊現象」というものが観察される.田中 (98) の説明を引用する.
その傾向は一言で言えば「塊現象」,つまり単語が固まって現れること,ある単語が一旦現れるとしばらくの間は頻繁に出現する一方で,それを過ぎるとほとんど出現しなくなる傾向があることとして直感的に捉えることができる.塊現象が見られる系列では,短い間隔が続いた後には短い間隔が現れ,また逆に長い間隔が続いた後には長い間隔が現れる可能性が高い.このような言語の塊現象の要因の一つは,当然のことながら文脈の変化にある.
塊現象は,自然,金融など,さまざまな複雑系においてはよく知られる〔中略〕.たとえば,大雨や地震が固まって現れることは経験を通して誰しも知っているだろう.社会的な対象においても,たとえば,株取引には,ある取引が引き金となって,関連する取引が行われるため,やはり塊現象が生じることが知られる.同様に,単語もある単語が引き金となり,その単語ならびに関連する単語の塊が出現する.
説明されてみれば,もっともという現象ではある.この塊現象の一般的な研究には歴史があるが,言語に応用した研究は少ないようだ.解析法としては,大きく分けて「長相関」と「ゆらぎ」に着目する2種類があるという.ここでは前者を見ていこう.
「長相関」による解析は,「ある系列中の,二つの部分列の相関が,その部分列の距離 s に依存してどのように変化するかを調べる解析」である(田中,p. 99).互いに離れた2つの部分列の内部構造が類似していれば長相関があるということになる(cf. 「#4675. 言語と複雑系」 ([2022-02-13-1]) で言及した「長期記憶」).
英語における最頻語である定冠詞 the について,長い文章で長相関解析を試みると,どうやら弱い長相関があるようだ(田中,p. 105).しかし,あくまで弱い長相関があるにとどまり,細かくみれば the にすらある程度の塊現象がみられることが判明する.驚くことに,the も現われるときは固まって現われ,現われないときにはしばらく現われない,ということがある程度観察されるのである.田中 (109)は,先行研究に従い,この事実を次のように解釈している.
k 個の短い間隔があると,続く k + 1番目の間隔も短く,k 個の長い間隔があると,それに続く k + 1番目の間隔も長い傾向にある.短い間隔が続くことは,対象となる単語が固まって現れることを示している.〔中略〕このような塊現象の背景には文脈の変化がある.the については,まず不定冠詞を中心として一般的な概念を導入し,その後,導入された概念について議論が行われ,その際は the が多用される.
これは,談話における情報構造 (information_structure) に着目した,the についての塊現象の読み解きといってよいだろう.
・ 田中 久美子 『言語とフラクタル --- 使用の集積の中にある偶然と必然』 東京大学出版会,2021年.
2022-02-11 Fri
■ #4673. 言語の統計的必然性と偶然性 [chaos_theory][complex_system][computational_linguistics][statistics][zipfs_law]
本ブログでは,言語と複雑系,カオス理論,フラクタルの関係について,complex_system や chaos_theory などの記事で紹介してきた.しかし,とても関心はあるものの,私の頭の理解が伴っていかない分野のようで,なかなか深入りできない.文系頭にももう少し理解しやすい形で,上記の分野(一般的には数量言語学)の本などがあればよいのになぁと思っていたところ,昨年,田中久美子(著)『言語とフラクタル --- 使用の集積の中にある偶然と必然』が出版された.読みたいと思いつつ積ん読していたのだが,ようやくページ開く機会を得た.おもしろい.
なぜ私がこれまで深入りできなかったのか.その辺りの理由も,導入部から教えてくれていて,とても嬉しい(田中,pp. 10--11).
複雑系科学は自然・社会的な系に適用されてきたが,言語を捉える探求は,その中でも亜流であり,限定的であるといわざるをえない.その主な理由としては,物理学的方法論の対象は広いとはいってもまず自然であり,結果は人の解釈に依存しないものを目指すことがある.一方,言語の研究は,人の解釈を前提とした単語や文を探究してきた.統計力学的な方法論は,意味や解釈をめぐって,言語とは相性がよいとはいえなかったのである.その中で,物理学出身の研究者が言語を探究した報告があちこちに散乱しており,それは言語の諸研究の側からは見えない.本書はそのような既存研究に多くを拠っている.
とてもよく分かった.例えば Zipf's Law (cf. zipfs_law) という著名な語彙統計学上の法則ですら,突っ込んだ議論を読みたいと思えば,言語学から一歩外に出なければならない.多くの普通の言語学の徒にとって,なかなか手を出せないのである.
では,なぜ私は,理解するのが難しいと分かっていながらも,言語と複雑系などとの関係に心ひかれるのだろうか.その辺りのモヤモヤしたところも,田中 (11) が解消してくれた.
言語データを解析すると,統計的言語普遍としての性質が普遍的に立ち現れる.この事実から,統計的言語普遍は,言語が生み出す神秘の一つのように捉えられてきた側面がある.しかし,本書でも見るように,その因果関係はおそらく逆であると思われる.言語が統計的普遍を生み出すというよりは,統計的な性質がまずあり,言語はおそらくその性質を前提として成立している.つまり,統計的言語普遍は,言語を実現する前提となっていると思われる.ならばこの統計的必然性は,単語や統語構造などといった言語の諸性質に影響を及ぼしているはずである.そして,統計的必然の中で言語がどのような特殊性を持っているかを理解することは,言語の本質を捉える一つの手立てとなると思われる.
どこまでが言語の(統計的)必然なのかが分かれば,そこから逸脱したものこそが言語における偶然だと知れるだろう.そして,後者こそ,人間が言語に込めた意図を反映しているものである可能性が高い.田中 (5) は,このことを「Mallarmé の賽」として示している.
かつて,詩人 Stéphane Mallarmé が,詩作において「賽を投じる」ことに言及している〔中略〕.「賽の一投は偶然を決して廃さない」との Mallarmé のことばは,純粋な統計としては自明なだけであるが,言語や詩作についてとなると難しい.言葉が発せられる背景には意図があることが多く,偶然だけに基づくとは考えにくい.Mallarmé は,言葉を使うことも,賽を投じるように偶然性を廃さないことを暗示し,偶然性をふまえた言葉のアートを試行したかにみえる.意図があって発話する場合にも,文や単語を生成する時に偶然が排除できないなら,言語行為には偶然性と必然性が混ざっているだろう.言語の統計的特性を知ることで,言葉が前提とする偶然性について明らかになる.その残滓の中に,意図など人間の要因の本質がかすかに見えはしまいか.
私自身がなぜ言語の統計学に惹かれているのか,その辺りが読み進めるうちにどんどん分かってきたのが嬉しい.
・ 田中 久美子 『言語とフラクタル --- 使用の集積の中にある偶然と必然』 東京大学出版会,2021年.
2022-01-08 Sat
■ #4639. 近代英語期にかけて増えてきた受動文 [passive][syntax][word_order][information_structure][statistics][hc]
一般に言語において,情報構造 (information_structure) の観点から,主題となる項(主語とは限らない)は文頭,文の前寄りに置くのが望ましいとされる.日本語のような自由な語順をもつ言語であれば,これを実現することはたやすい.実際,日本語と同様に語順が比較的自由だった古英語でも,この情報構造上の要求に応えることは難しくなかった.
しかし,近現代英語のようなおよそ固定化した語順をもつ言語の場合には,何らかの工夫をこらさなければならない.古英語から中英語期にかけて文の文法としてのV2規則が失われ,語順が固定化していくにつれて,主題となる項を文頭にもってくるための方法が手薄になった.このような状況にあって,重要な手段の1つと目されるようになったのが受動文である.能動文における目的語が主題となる場合,その能動文を受動文に換えることにより,元の目的語が主語となり,問題なく文頭に置けるようになるからだ.
語順の固定化と受動文の多用化という一見すると独立した2つの統語的現象は,情報構造という語用論的な概念を仲立ちとして関連づけられ得るのである.これは「#4561. 語順問題は統語論と情報構造の交差点」 ([2021-10-22-1]) で論じた通りである.少なくとも仮説としては興味深い.
この仮説を実証しようとした研究に Seoane がある.Helsinki Corpus の15世紀初期から18世紀初期までの部分(すなわちV2規則が失われた後の時代のサブコーパス)を用いた調査によれば,以下の通り,時代を追って受動文の比率が漸増していることが分かる (Seoane 371) .
| Words | Actives | Percent active | Passives | Percent passive | |
| M4 (1420--1500) | 44,000 | 2,928 | 81.9 | 647 | 18.0 |
| E1 (1500--1570) | 50,000 | 2,236 | 78.5 | 612 | 21.4 |
| E2 (1570--1640) | 48,000 | 2,550 | 77.9 | 722 | 22.0 |
| E3 (1640--1710) | 55,000 | 2,893 | 78.5 | 2,903 | 21.3 |
| Total | 197,000 | 10,607 | 78.5 | 2,903 | 21.3 |
ただし,この表の背景にあるコーパスの扱い方,データの拾い方については注記が必要だろう.Seoane によれば,能動文の収集は受動文化できるタイプのものに限っているという.また,現代英語でもよく知られている通り,受動文の生起頻度はテキストタイプに大きく依存するため,その考慮も必要である.また,受動文で行為者を示す by 句の有無も,考慮すべきパラメータとなる(実際,Seoane 論文ではこれらの観点にも注意が払われている).
この表はあくまで大雑把な調査結果と解釈すべきであり,上記の仮説を実証したとまではいえないだろう.しかし,コーパスを大きくし,種々のパラメータを検討することによって,実証に近づくことはできるかもしれない.だが,何よりもこの仮説のキモは,語順の固定化と受動文の多用化の関係だったことを思い出したい.両者の因果関係を実証するには,どの時代について何をどの程度明らかにすればよいのだろうか.
・ Seoane, Elenna. "Information Structure and Word Order Change: The Passive as an Information-Rearranging Strategy in the History of English." Chapter 15 of The Handbook of the History of English. Ed. Ans van Kemenade and Bettelou Los. Malden, MA: Blackwell, 2006. 360--91.
[ 固定リンク | 印刷用ページ ]
2021-09-11 Sat
■ #4520. Oxford 3000, Oxford 5000, OPAL の語彙 [lexicology][lexicography][dictionary][keyword][statistics]
「#4518. OALD10 の世界英語のレーベル15種」 ([2021-09-09-1]) でも紹介したが,昨年 Oxford Advanced Learner's Dictionary of Current English (通称 OALD)の第10版が出版された.改訂とともに進化し続けるこの辞書のファンの1人としては,辞書本文以上に付録的な部分にも注目してしまうのだが,関連して Oxford 3000, Oxford 5000, OPAL と呼ばれる英語学習・教育上の有用な語彙一覧を紹介したい.OALD10 の x--xi に各々の解説がある.
・ The Oxford 3000TM
20億語からなる巨大な The Oxford English Corpus における生起頻度に基づいた,英語学習者を意識して編まれた英単語3000個の一覧.同コーパスは,イギリス英語とアメリカ英語のみならず世界英語を網羅している.最頻2000語で英語テキストの8割の語彙をカバーしているともいわれるが,この3000語の一覧は CEFR (= Common European Framework of Reference) の A1 から B2 までの水準を念頭においた頼りになるリストだ.こちらより一覧をダウンロードできる.
・ The Oxford 5000TM
The Oxford 3000 よりも水準の高い,CEFR の B2 から C1 までの語彙を含めた拡張版の単語一覧.上記と同様こちらから一覧にアクセスできる.
・ The Oxford Phrasal Academic LexiconTM
"OPAL" と略称されている,学術英語 (English for Academic Purposes) に有用な語彙.大学の講義,セミナー,レポート,卒論などの英語を念頭に編まれた単語一覧である.この一覧は,書き言葉コーパス The Oxford Corpus of Academic English (= OCAE) と話し言葉コーパス The British Academic Spoken English (= BASE) をソースとしたキーワード (keyword) 分析に基づくもので,学術英語の習得に役立つ単語一覧である.こちらからアクセスできる.
昨今の英語学習・教育は実に統計的・科学的になっているなあと感心するばかりだが,英語学・英語史のアカデミックな研究においても語彙の頻度情報というのは基本事項であるから,おおいに活用したい.
・ Oxford Advanced Learner's Dictionary of Current English. 10th ed. Ed. A. S. Hornby. Oxford: Oxford UP, 2020.
2021-08-05 Thu
■ #4483. Shakespeare の語彙はどのくらい豊か? [sobokunagimon][shakespeare][statistics][lexicology]
Shakespeare の語彙の豊かさはつとに知られているが,具体的にいくつの単語を使用しているのだろうか.ある言語の語彙全体にせよ,ある作家の用いている語彙全体にせよ,語彙の規模を正確に計ることは難しい.それは,そもそも数えるべき単位である「語」 (word) の定義が言語学的に定まっていないからである.この本質的な問題については,本ブログでも「語の定義がなぜ難しいか」の記事セットで論じてきた.
それでも,概数でもよいので知りたいというのが人情である.Shakespeare の語彙の豊かさはしばしば桁外れとして言及され,なかば伝説と化している気味もあるが,実際のところ,論者の間で与えられる具体的な数には大きな相違がある.比較的広く知られているのは「3万語程度」という説だろうか.一方,「2万語程度」と見積もる論者も少なくないようである.では,昨日取り上げた Crystal による The Oxford Dictionary of Original Shakespearean Pronunciation (xv) を参考にするとどうなるだろうか.
同辞書が語彙収集の対象としているのは (1) 第1フォリオの全部,および (2) それ以外のソースからの脚韻に関わる語である(つまり,Shakespeare のテキスト全体ではないことに注意).その上で同辞書の見出し語の数を数えると,相互参照を除いて20,672語が挙がってくる..ただし,この中には1,809の固有名詞,495語の外国語単語(ラテン語など),29の "non-sense words",84のフォリオ外からの脚韻語が含まれている.これらを引き算すると,「正規」の語彙は18,255語となる.厳密にいえば,植字上のミスによる語ならぬ語も入っていると思われるし,複合語らきしものを複合語とみなすかどうかという頭の痛い問題もあるが,この数は「2万語程度」説に近いものとして参考になる.
関連して,Shakespeare にまつわる数字については,「#1763. Shakespeare の作品と言語に関する雑多な情報」 ([2014-02-23-1]) も参照.
・ Crystal, David. The Oxford Dictionary of Original Shakespearean Pronunciation. Oxford: OUP, 2016.
2021-07-04 Sun
■ #4451. フランス借用語のピークは本当に14世紀か? [french][loan_word][borrowing][statistics][lexicology][hybrid][personal_name][onomastics][link]
中英語期にフランス語からの借用語が大量に流入したことは,英語史ではよく知られている.とりわけ中期から後期にかけて,およそ1250--1400年の時期に,数としてピークに達したことも,英語史概説書では広く記述されてきた.本ブログでも以下の記事などで,幾度となく取り上げてきた話題である.
・ 「#117. フランス借用語の年代別分布」 ([2009-08-22-1])
・ 「#1205. 英語の復権期にフランス借用語が爆発したのはなぜか」 ([2012-08-14-1])
・ 「#1209. 1250年を境とするフランス借用語の区分」 ([2012-08-18-1])
・ 「#1638. フランス語とラテン語からの大量語彙借用のタイミングの共通点」 ([2013-10-21-1])
・ 「#2349. 英語の復権期にフランス借用語が爆発したのはなぜか (2)」 ([2015-10-02-1])
・ 「#2162. OED によるフランス語・ラテン語からの借用語の推移」 ([2015-03-29-1])
・ 「#2357. OED による,古典語およびロマンス諸語からの借用語彙の統計」 ([2015-10-10-1])
・ 「#2385. OED による古典語およびロマンス諸語からの借用語彙の統計 (2)」 ([2015-11-07-1])
・ 「#4138. フランス借用語のうち中英語期に借りられたものは4割強でかつ重要語」 ([2020-08-25-1]),
フランス借用語の数についていえば,OED などを用いた客観的な調査に裏づけられた事実であり,上記の「定説」に異論はない.しかし,当然ながらすべて書き言葉に基づく調査結果であることに注意が必要である.もし話し言葉におけるフランス借用語のピークを推し量ろうとするならば,ピークはもっと早かった可能性が高い.Trotter (1789) が次のように論じている.
In charting the chronology of the process, we are again at the mercy of the documentary evidence. The key period of lexical transfer appears to be the 14th century; but that may be, as much as anything else, because of the explosion of available documentation in both Anglo-French and, more particularly, Middle English at that time. In other words, the real dates of the transfers may not be the dates at which they are documented. Some evidence that this is not so is available in the form of English surnames, of Anglo-French origin . . . , and indeed in the capacity of some early Middle English texts to generate hybrids from Anglo-French and Middle English (forpreiseð; propreliche; priveiliche from Ancrene Wisse . . .).
1つは,一般的にピークとされてきた14世紀は,たまたま書き言葉の記録が多く残された時代であり,そのためにフランス借用語の規模も大きく見えがちになるということだ.
もう1つは,書き言葉に初出した年代をもって,そのまま英語に初出した年代と理解することはできないということだ(cf. 「#2375. Anglo-French という補助線 (2)」 ([2015-10-28-1])).普通の語ではなく姓(人名)として借用されたフランス語要素を考え合わせるならば,より早い時期に入っていた証拠がある.また,初期中英語期に文証される混種語の存在は,通常のフランス借用語が当時までにそれだけ多く流通していたことを示唆する(cf. 「#96. 英語とフランス語の素材を活かした 混種語 ( hybrid )」 ([2009-08-01-1])).
英語史におけるフランス借用語のピークは,書き言葉の証拠から量的に調査した限りにおいては,従来通りに14世紀といってよいが,話し言葉を含めた実態としては,それより早い時期にあったものと推測されるのである.
・ Trotter, David. "English in Contact: Middle English Creolization." Chapter 114 of English Historical Linguistics: An International Handbook. 2 vols. Ed. Alexander Bergs and Laurel J. Brinton. Berlin: Mouton de Gruyter, 2012. 1781--93.
2021-02-17 Wed
■ #4314. 能格言語は言語の2割を占める [ergative][case][world_languages][statistics][typology][caucasian][language_family][terminology]
世界の諸言語について,主要な格 (case) のあり方という観点から分類するとき,英語のような nominative-accusative タイプの言語と,バスク語やグルジア語のような absolutive-ergative タイプの言語に大きく分けられる.前者は対格言語 (accusative language),後者は能格言語 (ergative language) と呼ばれる.
英語のような対格言語の格体系は,私たちが当然視しているものであり,ほとんど説明を要しないだろう.He opened the door. と The door opened. の2文において,各々文頭に立っている名詞句 He と The door が主語の役割を果たす主格 (nominative case) に置かれているのに対し,第1文の the door は目的語の役割を果たす対格 (accusative case) に置かれているといわれる.
しかし,能格言語においては,第1文と第2文の両方の the door が絶対格 (absolutive case) に置かれ,第2文の He は能格 (ergative case) に置かれる.いずれの文でも,自然に開こうが誰かが開こうが,結果的に開いている「扉」は絶対格に置かれ,第2文のみに明示されている,その状態を能動的に引き起こした「彼」が能格に置かれるのだ.
類型論などでしばしば言及される能格言語というものは,世界の諸言語のなかでは稀なタイプの言語だと思い込んでいたが,それほど稀でもないようだ.対格言語に比べれば圧倒的な少数派であることは間違いないが,世界言語の2割ほどはこのタイプだと知って驚いた.Blake (121) によると,分布は世界中に広がっている.
Ergative systems are often considered rare and remote, but in fact they make up at least twenty per cent of the world's languages. Ergative systems are to be found in all families of the Caucasian phylum, among the Tibeto-Burman languages, in Austronesian, in most Australian languages, in some languages of the Papuan families, in Zoque and the Mayan languages of Central America and in a number of language families in South America: Jé, Arawak, Tupí-Guaraní, Panoan, Tacanan, Chibchan and Carib. Outside these phyla and families where ergative systems of marking are common, ergativity is also to be found in some other languages including Basque, Hurrian and a number of other extinct languages of the Near East, Burushaski (Kashmir, Tibet), Eskimo, Chukch, and Tsimshian and Chinook (these last two being Penutian languages of British Columbia).
ちなみに,英語は能格言語ではないが,上の例で挙げた open(ed) のように自動詞にも他動詞にも用いられる動詞を指して能格動詞 (ergative verb) と呼ぶことがある.
・ Blake, Barry J. Case. 2nd ed. Cambridge: CUP, 2001.
2021-01-06 Wed
■ #4272. 世界に言語はいくつあるのですか? --- hellog ラジオ版 [hellog-radio][sobokunagimon][world_languages][statistics][demography][language_death][hellog_entry_set]
英語も1つの言語,日本語も1つの言語なので,合わせて2言語ですね.ほかにフランス語,スペイン語,ドイツ語,ロシア語,中国語,韓国語など知っている言語名を挙げ,足し合わせていくと,はたして現代世界にはいくつの言語があることになるでしょうか.100個くらい? あるいは1,000個? もしかして10,000個? このような疑問は抱いたこともなく,見当がつかないという方も多いかもしれません.
実は専門の言語学においても,様々な理由により,正確な数を出すことはできません.論者によって相当な揺れがみられるのです.この辺りの事情も含めて,音声で解説していきましょう.以下をお聴きください.
言語学者が時間とお金をかけて世界中を調査し,頑張って言語を数えていけば,いずれは正確な数が出るのではないかと疑問に思うかもしれませんが,その答えは No です.いくら言語学者が頑張っても,正確な言語数を得ることは不可能です.というのは,これは言語の問題ではないからです.政治の問題なのです.世界の言語を数えるということは,いったいどのような行為なのか.この問いこそが重要なように思われます.
それでも数が知りたいというのが人情です.試しに Ethnologue (第23版,2020年)を参照してみますと,世界の言語の数は7,117とカウントされています.ただし,これとて1つの参考値にすぎませんのでご注意を.今回の素朴な疑問に対しては,私としては「数千個程度」と答えて逃げておきたいと思います.
言語を数えるという問題,およびそれに関連する話題として,##3009,270,1060,274,401,1949の記事セットも合わせてお読みください.
2020-12-21 Mon
■ #4256. 「言語の死」の記事セット [hellog_entry_set][language_death][statistics][world_languages][linguistic_right][language_shift][dialect][linguistic_imperialism][ecolinguistics][sociolinguistics]
社会言語学の授業等で「言語の死」 (language_death) の話題に触れると,関心をもつ学生が多い.目下,世界中で12日に1言語というハイペースで言語が失われているという事実を知ると,当然ながらショックを受けるのだろう.今のところ安泰な立場にある日本語という大言語を常用しており,さらに世界第一の通用度を誇る超大言語である英語を義務教育のなかで学習してきた者にとって,絶滅危機に瀕した言語が世界にそれほど多く存在するということは,容易に想像もできないにちがいない.平均的日本人にとって「言語の死」とはある意味で遠い国の話しだろう.
しかし,日本国内にも危機に瀕する言語は複数ある.また,言語を方言と言い換えれば,方言の死,少なくとも方言の衰退という話題は聞いたことがあるだろう.
英語を筆頭とする世界的な影響力をもつ超強大な言語は,多くの弱小言語の死を招いているのか否か,という問題もある.もしそうだとすれば,英語のような言語は殺人的な言語であり,悪者とみなすべきなのか.もし弱小言語を救うというのであれば,誰がどのように救うのか.そもそも救う必要があるのか,ないのか.一方,自らが用いる言語を選ぶ「権利」(言語権)を個人に認めるとするならば,その個人に課せられる「義務」は何になるだろうか.
このように「言語の死」を考え始めると,議論すべき点が続々と挙がってくる.社会言語学の論点として第一級のテーマである.議論に資する参考記事として「言語の死」の記事セットをどうぞ.
Powered by WinChalow1.0rc4 based on chalow