2023-08-03 Thu
■ #5211. Innsbruck EDD Online 4.0 [dialect][web_service][corpus][lmode][lexicography][edd][dictionary][notice]
Joseph Wright による English Dialect Dictionary のオンライン版である EDD Online について,Manfred Markus が率いる Innsbruck 大学のチームがオンライン化プロジェクトの最終段階の成果として Version 4.0 を公表した,との情報を得ました.Innsbruck EDD Online 4.0 Based on Joseph Wright's English Dialect Dictionary (1898--1905) です.
私はまだ EDD Online の豊富な機能を使いこなせていないのですが,辞書の画像イメージを確認できたり,地図上に示してくれたり等,視覚化の機能が充実している印象です.
Markus 教授による使い方のイントロ動画(5分)もありますので視聴をお勧めします(辞書とは関係ありませんが,動画の最後のインスブルックの景色に心奪われて今すぐオーストリアに行きたい,などと妄想).
EDD については,hellog では以下の記事で取り上げてきましたので,そちらもご参照下さい.
・ 「#869. Wright's English Dialect Dictionary」 ([2011-09-13-1])
・ 「#868. EDD Online」 ([2011-09-12-1])
・ 「#2694. EDD Online (2)」 ([2016-09-11-1]) を参照.
2020-08-18 Tue
■ #4131. イギリスの世界帝国化の歴史を視覚化した "The OED in two minutes" [oed][map][lexicology][lexicography][philology][history][web_service]
昨日の記事「#4130. 英語語彙の多様化と拡大の歴史を視覚化した "The OED in two minutes"」 ([2020-08-17-1]) で紹介した同じコンテンツを,異なる角度から改めて眺めてみたい.The OED in two minutes で公開されている英語語彙史地図のコンテンツである.
中英語の始まりとなる1150年から再生して1年ごとに時間を進めていくと,しばらくは動きがヨーロッパ内部に限られており,さしておもしろくもないのだが,15世紀後半になってくると中東や北アフリカなどに散発的に点が現われてくる.そして,16世紀後半になると新大陸やインド方面にも点がポツポツしてきて,日本も舞台に登場してくる.この状況は17,18世紀にかけて稀ではなくなってくる.次に注目すべき動きが出てくるのは,18世紀後半のオセアニア,太平洋,南アフリカといった南半球を中心とした海洋地域である.19世紀に入るとアフリカや東南アジアを含めた世界の広域に点が打たれるようになり,同世紀後半には南アメリカも加わる.20世紀はまさにグローバルである.
実におもしろい.同時に,実に恐ろしい.16世紀後半から19世紀終わりまでの時間枠に関するかぎり,そのままイギリスの世界帝国化の足跡を語彙史の観点からパラフレーズしたコンテンツに見えてきたからだ.直接・間接にイギリスの支配権の及ぶ領土を塗りつぶした世界史の地図は「軍事的な」地図として見慣れているし,ある意味で分かりやすい.しかし,今回のような「語彙史的な」地図がそれと多かれ少なかれ一致するというのは,何とも薄気味悪い.そして,後者の地図が,OED という英語文献学の粋というべき学術的な成果物を利用して作成されていること,またその辞書それ自身が大英帝国の最盛期である19世紀半ばの企画の産物であることを思い出すとき,薄気味悪さ以上に,得体のしれない恐ろしさを感じる.
OED は学術的(文献学的)偉業を体現するツールであり,その点で私も賞賛を抑えることができない.しかし,その事実を認めつつ,それ自体が,毀誉褒貶相半ばする近代世界史の産物であることは肝に銘じておきたい.関連して以下の記事も参照.
・ 「#3020. 帝国主義の申し子としての比較言語学 (1)」 ([2017-08-03-1])
・ 「#3021. 帝国主義の申し子としての比較言語学 (2)」 ([2017-08-04-1])
・ 「#3376. 帝国主義の申し子としての英語文献学」 ([2018-07-25-1])
・ 「#3603. 帝国主義,水族館,辞書」 ([2019-03-09-1])
・ 「#3767. 日本の帝国主義,アイヌ,拓殖博覧会」 ([2019-08-20-1])
2020-08-17 Mon
■ #4130. 英語語彙の多様化と拡大の歴史を視覚化した "The OED in two minutes" [oed][map][lexicology][borrowing][lexicography][philology][statistics][web_service][hel_education]
The OED in two minutes に,中英語の始まる1150年から2010年までの英語(借用)語彙史を地図上で視覚化してダイジェストで示すコンテンツが公表されている.これは凄いコンテンツ.実にみごとに英語語彙の多様化と拡大の歴史が表現されており,しかもいろいろな意味で考えさせられる.こちらからどうぞ.
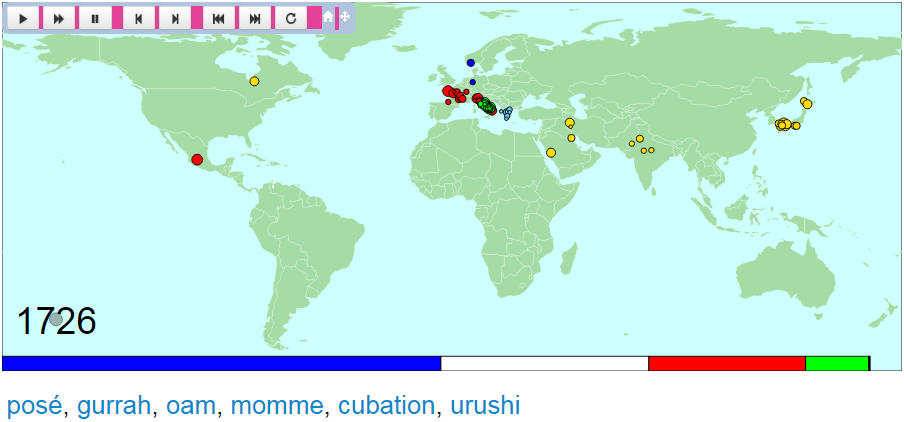
地図の下にある色付きの帯は,現代英語における語種ごとの総トークン頻度を表わしている(背後で利用されているデータベースは Google Ngrams の1970--2008年の部分だという).試しに2010年現在の地図に示される統計をみてみると,総トークン頻度にして,ゲルマン系の語彙(青帯)が49%,英語要素に基づく複合語など(白帯)が26%なので,ここまでで全体の3/4である.ロマンス系の語彙(赤帯)が18%,ラテン語が7%,そしてその他が0.2%だ.英語史では語彙の歴史は借用の歴史であるというのが定番だが,トークン頻度で考える限り,現在でも英語の語彙は圧倒的にアングロサクソン(あるいはゲルマン)的であるといってよいことになる.この事実については「#3400. 英語の中核語彙に借用語がどれだけ入り込んでいるか?」 ([2018-08-18-1]) と,そこに張ったリンク先の記事を参照.
地図左下の年号に重なって描かれている灰色のバブルは,高頻度かつ多数の単語が加わった年ほど大きくなり,低頻度かつ少数の単語が加わったにすぎない年には小さくなる.17世紀を通じて相対的に大きかったバブルが,18世紀にかけてしぼんでいく様子も興味深い (cf. 「#2995. Augustan Age の語彙的保守性」 ([2017-07-09-1]),「#203. 1500--1900年における英語語彙の増加」 ([2009-11-16-1]),「#4070. 18世紀の語彙的低迷のなぞ」 ([2020-06-18-1])) .
英語(語彙)史を大づかみするには,このようなダイジェストの視覚コンテンツが威力を発揮する.
2020-08-09 Sun
■ #4122. 物凄いツールが現われた --- OED Text Visualizer (beta) [web_service][oed][etymology]
OED が OED Text Visualizer という物凄いツールを作っている.入力欄に英文テキストを放り投げると,OED の情報に基づいて背後で各単語にタグが付され,初出年代と語源をタイムラインで視覚的に表現してくれるというものだ.いつかこのようなツールが作れたら(あるいは誰かが作ってくれたら)いいなと私が夢見ていたような語源表示ツールである.これまでも技術的には十分に可能だったろうが,本格的に取り組む者が現われなかった.それを OED が実装してくれたというのは,さすがである.開発中のベータ版ということで,入力する英文は500語まで,また1750年以後の英文でないと精度が下がるなどの制限はあるようだが,十分に楽しめる.
百聞は一見に如かず.「#3276. Churchill の We Shall Fight on the Beaches 演説」 ([2018-04-16-1]) より,308語からなる英文の1節を放り込んでみた.1940年の演説なので,その年代も添えつつ Vizualize ボタンをクリックすると,次のような図が返される(画像クリックで拡大).
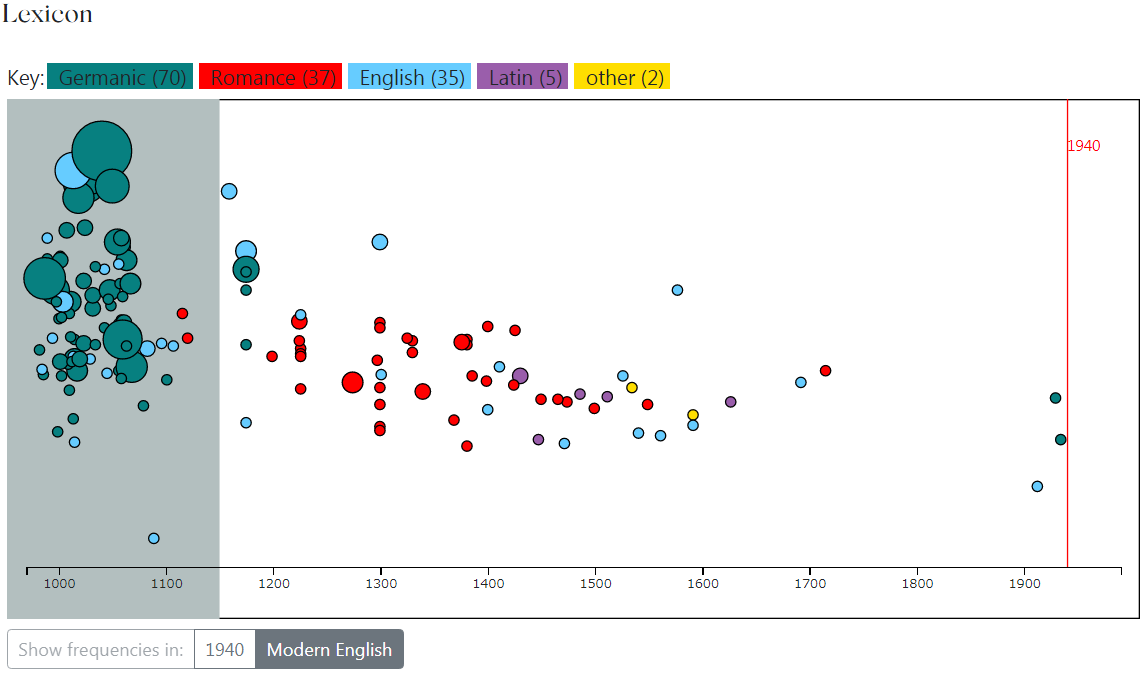
テキストに現われる各単語(レンマ)がバブルで表現されている.バブルの左右の位置はその語の初出年代に対応し,色は語源に,大きさは同テキスト内の頻度に対応する.バブルにマウスを乗せれば,その語の詳しい情報が得られる.スゴい.
画面のさらに下には,各単語が token ベース,および lexeme ベースでタグ付けされた情報が一覧され,CSV や JSON でダウンロードできるので,後からプログラムを用いて詳しく分析することも可能である.
いや,驚いた.英語史の研究方法もどんどん変わっていきそうだ.
2018-09-18 Tue
■ #3431. 各種の EEBO 検索インターフェース [eebo][corpus][emode][site][web_service][link][n-gram][kwic]
初期近代英語期の膨大なテキストを収録した EEBO (Early English Books Online) について,「#3117. EEBO corpus がリリース」 ([2017-11-08-1]) で BYU 提供の EEBO 検索インターフェース Early English Books Online corpus を紹介した.
それとは別に,Early Modern Print: Text Mining Early Printed English というサイトのプロジェクトで,n-gram や KWIC などの検索インターフェースが提供されていることを知ったので紹介しておきたい.全体的なイントロは,こちらのページをどうぞ.個々の具体的なツールは,次のリンクからアクセスできる.
・ EEBO N-Gram Browser (説明はこちら)
・ EEBO-TCP Key Words in Context (説明はこちら)
・ EEBO-TCP and ESTC Text Counts
・ EEBO-TCP Words Per Year
また,University of Michigan の提供する Early English Books Online の各種サーチや Lancaster University による EEBO on CQPweb (V3) も同様に有用.
各種インターフェースのいずれを用いるか迷うところだ.
2018-08-24 Fri
■ #3406. Levenshtein distance [cgi][web_service][spelling][shakespeare][levenshtein_distance]
文字列の類似度や相違度を測る有名な指標の1つに,標題の "Levenshtein distance" というものがある,「#3397. 後期中英語期の through のワースト綴字」 ([2018-08-15-1]),「#3398. 中英語期の such のワースト綴字」 ([2018-08-16-1]),「#3399. 綴字の類似度計算機」 ([2018-08-17-1]) でも前提としてきた指標であり,「#1163. オンライン語彙データベース DICT.ORG」 ([2012-07-03-1]) でもこの指標を利用して類似綴字語を取り出すオプションがある.
考え方は難しくない.もとの文字列から目標の文字列に変換するには,いくつの編集工程(挿入,削除,置換)が必要かを数えればよい.例えば,kitten から sitting へ変換するには,kitten →(k を s に置換)→ sitten →(e を i に置換)→ sittin →(g を挿入)→ sitting という3工程を踏む必要があるので,両綴字間の Levenshtein distance は3ということになる.通常は挿入,削除,置換の編集工程にそれぞれ1の値を割り当てるが,各々に異なる値を与える計算の仕方もある.
以下に,通常の重みづけで Levenshtein distance を計測する CGI を置いておく.試しに「#1720. Shakespeare の綴り方」 ([2014-01-11-1]) より25種類の異綴字を取り出して,カンマ区切りなどで下欄に入力してみてください(要するに以下をコピペ).Shakespeare, Schaksp, Shackespeare, Shackespere, Shackspeare, Shackspere, Shagspere, Shakespe, Shakespear, Shake-speare, Shakespere, Shakespheare, Shakp, Shakspe?, Shakspear, Shakspeare, Shak-speare, Shaksper, Shakspere, Shaxberd, Shaxpeare, Shaxper, Shaxpere, Shaxspere, Shexpere
綴字間の類似度や相違度の計測は,曖昧検索やスペリングチェックなどの実用的な目的にも応用されている.標準的な綴字がなかった古い英語の研究にも,ときに役立つことがありそうだ.
2018-08-17 Fri
■ #3399. 綴字の類似度計算機 [cgi][web_service][spelling][shakespeare][levenshtein_distance]
この2日間の記事「#3397. 後期中英語期の through のワースト綴字」 ([2018-08-15-1]),「#3398. 中英語期の such のワースト綴字」 ([2018-08-16-1]) で,異綴字間の類似性を計算するスクリプトを利用して,through と such の様々な綴字を比較した.このスクリプトは,ある程度使い勝手があるかもしれないと思い,より汎用的な形で CGI を組んでみた.
ところが,スクリプトの内部的な仕様の関係でサーバ上で動かないということが発覚.残念無念.公開しても無意味であることを承知のうえ,以下に置いておこうと思います(せっかく作ったのだし,私自身のローカルPCでは動いているので・・・).すみません.
と,これではあんまりなので,Shakespeare の異綴字を比較した結果を披露しておきます.「#1720. Shakespeare の綴り方」 ([2014-01-11-1]) で挙げた25種類の異綴字 Shakespeare, Schaksp, Shackespeare, Shackespere, Shackspeare, Shackspere, Shagspere, Shakespe, Shakespear, Shake-speare, Shakespere, Shakespheare, Shakp, Shakspe?, Shakspear, Shakspeare, Shak-speare, Shaksper, Shakspere, Shaxberd, Shaxpeare, Shaxper, Shaxpere, Shaxspere, Shexpere を入力して,ソートさせると,次のような出力が得られた.
| Similarity | Spellings |
|---|---|
| 1.0000 | Shakespeare |
| 0.9565 | Shackespeare, Shake-speare, Shakespheare |
| 0.9524 | Shakespear, Shakespere, Shakspeare |
| 0.9091 | Shackespere, Shackspeare, Shak-speare |
| 0.9000 | Shakspear, Shakspere |
| 0.8571 | Shackspere |
| 0.8421 | Shakespe, Shaksper |
| 0.8000 | Shagspere, Shaxpeare, Shaxspere |
| 0.7368 | Shaxpere, Shexpere |
| 0.7000 | Shakspe? |
| 0.6667 | Schaksp, Shaxper |
| 0.6250 | Shakp |
| 0.5263 | Shaxberd |
類似度が0.7以下のものは,およそ省略である.0.7を超えるものは,およそ許せるように感じられるのがおもしろい.
2018-02-04 Sun
■ #3205. スライドできる英語史年表 (3) [timeline][web_service][hel_education]
「#2358. スライドできる英語史年表」 ([2015-10-11-1]),「#2871. 古英語期のスライド年表」 ([2017-03-07-1]),「#3164. スライドできる英語史年表 (2)」 ([2017-12-25-1]) に引き続き,もう1つのスライド英語史年表を提示する.
最近の記事で,Algeo and Pyles の英語史概説書に基づく年表を掲載した (see 「#3193. 古英語期の主要な出来事の年表」 ([2018-01-23-1]),「#3196. 中英語期の主要な出来事の年表」 ([2018-01-26-1]),「#3197. 初期近代英語期の主要な出来事の年表」 ([2018-01-27-1]),「#3200. 後期近代英語期の主要な出来事の年表」 ([2018-01-30-1])).今回のスライドは,この Algeo and Pyles 版をもとに作成した.項目数は比較的少いながらも,説明書きが長いので,読みながら学習できるだろう.

・ Algeo, John, and Thomas Pyles. The Origins and Development of the English Language. 5th ed. Thomson Wadsworth, 2005.
2018-01-11 Thu
■ #3181. Spelling/Pronunciation Search [spelling][pronunciation][orthography][web_service][cgi][dictionary][spelling_pronunciation_gap][silent_letter]
「#1191. Pronunciation Search」 ([2012-07-31-1]) で,The Carnegie Mellon Pronouncing Dictionary に基づくアメリカ英語発音検索ツールを作成した.そのデータベース (3MB+) の実体は,110935対の綴字と発音の組み合わせである.前回のツールは,Carnegie Mellon Pronouncing Dictionary の発音表記を正規表現で指定して,それを含む単語の綴字を返すものだったが,今回は綴字と発音のそれぞれに正規表現で条件を指定し,いずれにもマッチする単語を返すという仕様のツールを作ってみた.
正規表現は Perl 用のもので,大文字・小文字の別は最初から無視する仕様.発音表記の凡例は,本記事の末尾に掲げておいた.どちらか一方の検索欄を空にすれば,純粋な綴字検索あるいは発音検索になる.
2017-12-25 Mon
■ #3164. スライドできる英語史年表 (2) [timeline][web_service][hel_education]
英語史に関連する種々の年表をこれまで timeline の各記事で示してきたが,今回は「#2562. Mugglestone (編)の英語史年表」 ([2016-05-02-1]) をスライド化してみた.スライドの仕様によりすべてが反映されているわけではないが,とりあえず遊びながら眺められる.14世紀くらいから,だんだんゴチャゴチャしてくる.

関連して,「#2358. スライドできる英語史年表」 ([2015-10-11-1]),「#2871. 古英語期のスライド年表」 ([2017-03-07-1]) も参照.
・ Mugglestone, Lynda, ed. The Oxford History of English. Oxford: OUP, 2006.
2017-11-08 Wed
■ #3117. EEBO corpus がリリース [eebo][corpus][web_service][site]
本ブログでも何度か利用していたテキスト・データベース EEBO (Early English Books Online) が,BYU の Mark Davies 氏によりコーパス化され,この10月にオンラインで公開された.Early English Books Online corpus よりアクセスできる.
簡単にこのコーパスを紹介すると,まず規模としては "755 million words in more than 25,000 texts from the 1470s to the 1690s" を含む,巨大コーパスであることがわかる.時代としては初期近代英語をまるまるカバーしている.BYU系の他のコーパスと同様に,見出し語化がなされており,品詞タグや意味タグも賦与されている.コンコーダンス・ラインを出したり,共起表現を分析することはもとより,10年ごとに検索語句の頻度を自動的にグラフ化するなど,様々な機能が備わっている.
10年のまとまりごとのテキスト数や総語数の情報は,上のページのインフォメーションから容易に得られるが,第4列に1テキスト辺りの平均語数を加えた表を示そう.
| Decade | #words | #texts | #words/#texts |
|---|---|---|---|
| 1470s | 712,130 | 18 | 39,562.8 |
| 1480s | 3,706,937 | 43 | 86,207.8 |
| 1490s | 1,992,503 | 49 | 40,663.3 |
| 1500s | 1,288,091 | 45 | 28,624.2 |
| 1510s | 946,117 | 35 | 27,031.9 |
| 1520s | 3,042,934 | 73 | 41,684.0 |
| 1530s | 7,099,997 | 181 | 39,226.5 |
| 1540s | 8,709,681 | 239 | 36,442.2 |
| 1550s | 7,219,423 | 283 | 25,510.3 |
| 1560s | 16,084,901 | 361 | 44,556.5 |
| 1570s | 26,927,229 | 442 | 60,921.3 |
| 1580s | 31,955,245 | 558 | 57,267.5 |
| 1590s | 24,105,385 | 723 | 33,340.8 |
| 1600s | 40,031,223 | 898 | 44,578.2 |
| 1610s | 42,901,535 | 894 | 47,988.3 |
| 1620s | 38,550,967 | 994 | 38,783.7 |
| 1630s | 42,826,013 | 1,036 | 41,337.9 |
| 1640s | 47,129,000 | 3,805 | 12,386.1 |
| 1650s | 99,452,875 | 2,416 | 41,164.3 |
| 1660s | 63,491,742 | 2,481 | 25,591.2 |
| 1670s | 74,600,805 | 2,421 | 30,814.0 |
| 1680s | 92,583,947 | 3,977 | 23,279.8 |
| 1690s | 79,719,722 | 2,999 | 26,582.1 |
| TOTAL | 755,078,402 | 24,971 | 30,238.2 |
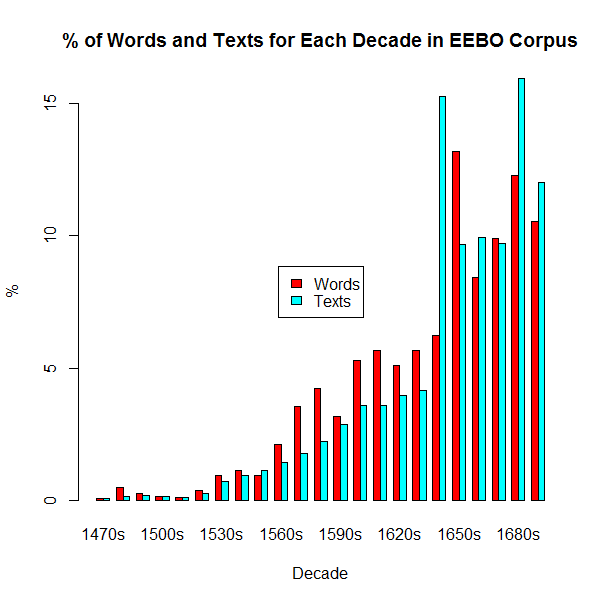
全期間にしめる各10年間の値を百分率でグラフ化してみた.赤は単語数,水色はテキスト数に基づいた数値である.いずれも16世紀から17世紀にかけてサブコーパスが大きくなっているのが分かるが,単語数は1650年代と1680年代,テキスト数は1640年代と1680年代が際立っていることを気に留めておきたい.
2017-10-13 Fri
■ #3091. Baugh and Cable の英語史概説書の目次よりランダムにクイズを作成 [toc][quiz][hel_education][cgi][web_service]
英語史の流れをつかんでもらうために,授業で「#2089. Baugh and Cable の英語史概説書の目次」 ([2015-01-15-1]) を暗記してもらっているが,小テスト対策のために(というよりも実は問題作成の自動化のために)ランダムに穴を抜くツールを作ってみた.ブラウザで印刷すれば,そのまま小テスト.
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 6th ed. London: Routledge, 2013.
2017-09-23 Sat
■ #3071. Pig Latin [cryptology][word_play][cgi][web_service]
英語の言葉遊びで Pig Latin というものがある.単語を一定の原則に基づいて変形する遊びだが,その原則は単純である.語頭の子音(群)を語尾に移し,さらにそこに <ay> /eɪ/ を追加する.語頭が母音の場合には,語尾に <way> /weɪ/ を追加するのみ.例えば,Pig Latin は Igpay Atinlay となり,I dont know. は Iway ontday nowkay. となる.語頭の子音(群)の扱いの差異や,語尾としての <way> /weɪ/ の代わりに <yey> /weɪ/ を用いるなどの変種もみられる.
慣れてしまえば即興で作れるが,慣れていない者にとって理解が難しいことから,言葉遊びにとどまらず,話し言葉における隠語やちょっとした暗号として用いることもできる.言葉遊びと暗号の距離は意外と近い.
Pig Latin のほか,より古い Hog Latin という呼称もある.前者は19世紀末,後者は19世紀初めに初出している.いずれも「崩れたラテン語」「偽のラテン語」ほどの意味である.実際にはラテン語と縁もゆかりもないが,格変化のような語尾が付き,理解しにくいという点で,ラテン語に擬せられたということだろう.なお,崩れたラテン語を表わす dog Latin という表現は17世紀半ばに初出しているが,こちらは変則的ながらも一応のところラテン語ベースである.
以下,Pig Latin 変換器を実装したのでお試しあれ.
2017-03-07 Tue
■ #2871. 古英語期のスライド年表 [timeline][web_service][oe][anglo-saxon]
「#2358. スライドできる英語史年表」 ([2015-10-11-1]) にならい,Mitchell (361--64) の古英語期の年表をスライド化してみました.以下の画像をクリックしてご覧ください.スライド年表では,出来事のジャンル別に Lay = 緑,Religious = 赤,Literary = 青で色分けしています.

以下は,スライド年表のベースとした通常の表形式の年表です.参考までに.
| Date | Lay | Religious | Literary |
| 449 | Traditional date of coming of Angles, Saxons, and Jutes. | The legend of Arthur may rest on a British leader who resisted the invaders. | |
| c. 547 | Gildas writes De excidio Britanniæ. | ||
| 560--616 | Æthelbert King of Kent. | ||
| c. 563 | St Columba brings Celtic Christianity to Iona. | ||
| 597 | St Augustine brings Roman Christianity to Kent. | ||
| 616--632 | Edwin King of Northumbria. | ||
| c. 625 | Earliest possible date for Sutton Hoo ship-burial. | ||
| 627 | Edwin converted to Christianity. | ||
| 632 | Edwin killed by heathen King Penda of Mercia. | ||
| 635 | Aidan settles in Lindisfarne, bringing Celtic Christianity. | ||
| 635 | King Cynegils of Wessex converted. | ||
| 641 | Oswald King of Northumbria killed by Penda. | ||
| 654 | Penda killed by Oswy King of Northumbria. | ||
| 664 | Synod of Whitby establishes supremacy of Roman Christianity. | ||
| 664 | St Chad becomes bishop. | ||
| 657--680 | Hild Abbess of Whitby. | Cædmon uses Germanic alliterative verse for religious subjects during this period. | |
| c. 678 | English missions to the continent begin. | ||
| 680 | Approximate earliest date for composition of Beowulf. | ||
| c. 700 | Date of first linguistic records. | ||
| 709 | Death of Aldhelm, Bishop of Sherborne. | ||
| 731 | Bede completes Historia gentis Anglorum ecclesiastica. | ||
| 735 | Death of Bede. | ||
| c. 735 | Birth of Alcuin. | ||
| 757--796 | Offa King of Mercia. | ||
| 782 | Alcuin settles at Charlemagne's court. | ||
| 793 | Viking raids begin. | Sacking of Lindisfarne. | |
| fl. 796 | Nennius, author or reviser of Historia Britonum. | ||
| 800 | Four great kingdoms remain --- Northumbria, Mercia, East Anglia, Wessex. | ||
| 780--850 | Cynewulf probably flourishes some time in this period. | ||
| 804 | Death of Alcuin. | ||
| 851 | Danes' first winter in England. | ||
| 865 | Great Danish Army lands in East Anglia. | ||
| 867 | Battle of York. End of Northumbria as a political power. | ||
| 870 | King Edmund of East Anglia killed by Danes. East Anglia overrun. | ||
| 871 | Alfred becomes King of Wessex. | ||
| 874 | Danes settle in Yorkshire. | ||
| 877 | Danes settle in East Mercia. | ||
| 880 | Guthrum and his men settle in East Anglia. Only Wessex remains of the four Kingdoms. | ||
| ?886 | Boundaries of Danelaw agreed with Guthrum. Alfred occupies London. | The period of the Alfredian translations and the beginning of the Anglo-Saxon Chronicle. | |
| 892 | Further Danish invasion. | ||
| 896 | Alfred builds a fleet. | ||
| 899 | Death of King Alfred. | ||
| 899--954 | The creation of the English Kingdom. | ||
| c. 909 | Birth of Dunstan. | ||
| 937 | Battle of Brunanburh. | Poem commemorates the battle. | |
| 954 | The extinction of the Scandinavian kingdom of York. | ||
| 959--975 | Edgar reigns. | ||
| 960 | Dunstan Archbishop of Canterbury. The period of the Monastic Revival. | ||
| c. 971 | The Blickling Homilies. | ||
| 978 or 979 | Murder of King Edward. | ||
| 950--1000 | Approximate dates of the poetry codices --- Junius MS, Vercelli Book, Exeter Book, and Beowulf MS. | ||
| 978--1016 | Ethelred reigns. | ||
| 988 | Death of Dunstan. | ||
| 991 | Battle of Maldon. | Poem commemorates the battle. | |
| 990--992 | Ælfric's Catholic Homilies. | ||
| 993--998 | Ælfric's Lives of the Saints. | ||
| 1003--1023 | Wulfstan Archbishop of York. | ||
| c. 1014 | Sermo Lupi ad Anglos. | ||
| 1005--c. 1012 | Ælfric Abbot of Eynsham. | ||
| 1013 | Sweyn acknowledged as King of England. | ||
| 1014 | Sweyn dies. | ||
| 1016 | Edmund Ironside dies. | ||
| 1016--1042 | Canute and his sons reign. | ||
| 1042--1066 | Edward the Confessor. | ||
| 1066 | Harold King. Battle of Stamford Bridge. Battle of Hastings. William I king. |
・ Mitchell, Bruce. An Invitation to Old English and Anglo-Saxon England. Oxford: Blackwell, 1995.
2016-12-12 Mon
■ #2786. 世界言語構造地図 --- WALS Online [web_service][syntax][evolution][typology][word_order]
The World Atlas of Language Structures (WALS Online) というサイトがある.世界中の多くの言語を様々な観点から記述したデータベースに基づき,その地理的分布を世界地図上にプロットしてくれる機能を有するツールである.進化人類学の成果物として提供されており,進化言語学や言語類型論にも貢献し得るデータベースとなっている.
検索できる言語的素性の種類は豊富で,音韻,形態,統語,語彙と多岐にわたる.表をクリックしていくことで,簡単に分布図を表示してくれるという優れものだ.素性を組み合わせて分布図を示すこともでき,素性間の相関関係を探るのにも適している.例えば,VO/OV 語順と接置詞 (adposition) 語順の相関について,Feature 83A と 85A を組み合わせると,こちらの分布図が得られる.青と黄緑のマークが目立つが,青は日本語型の「OV語順かつ後置詞使用」を示す言語,黄緑は英語型の「VO語順かつ前置詞使用」を示す言語である.同じように VO/OV と NA/AN の素性 (Feature 83A と 87A) の組み合わせで地図を表示させることもできる(こちら).なお,この2つの例は,名古屋大学を中心とする研究者の方々により出版された『文法変化と言語理論』のなかの若山論文で参照され,論じられているものである.
いろいろな素性を,単体で,あるいは組み合わせで試しながら遊べそうだ.WALS Online は,本ブログでは「#1887. 言語における性を考える際の4つの視点」 ([2014-06-27-1]) でも触れているので,ご参照を.
・ 若山 真幸 「言語変化における主要部媒介変数の働き」『文法変化と言語理論』田中 智之・中川 直志・久米 祐介・山村 崇斗(編),開拓社.294--308頁.
2016-09-22 Thu
■ #2705. カエサル暗号機(hellog 版) [cryptology][grammatology][cgi][web_service][statistics]
「#2704. カエサル暗号」 ([2016-09-21-1]) と関連して,文字遊びのために「カエサル暗号機」を作ってみた.まずは,最も単純な n 文字シフトの方針により,入力文字列を符号化 (encipher) あるいは復号化 (decipher) するだけの機能.バックエンドに Perl の Text::Cipher::KeywordAlphabet モジュールを利用している.
次に,下の暗号機は復号機能のみを実装しているが,英語の各文字の出現頻度に基づいた統計を利用して,n の値が不明でもカエサル暗号を解読してしまうことができる.
このカエサル暗号とその発展形は,西洋の古代・中世を通じて1500年以上ものあいだ最も普通に用いられたが,原理は驚くほど単純である.現在では暗号学者ならずとも普通の人にもコンピュータを使って簡単に解読できてしまい,暗号とは呼べないほどに安全性は低いが,メッセージを隠したいという人間の欲求の生み出した,本格的な暗号文化の幕開きを代表する手法だった.歴史的意義は大きい.
[ 固定リンク | 印刷用ページ ]
2016-09-11 Sun
■ #2694. EDD Online (2) [dialect][web_service][corpus][lmode][lexicography][edd][dictionary]
「#868. EDD Online」 ([2011-09-12-1]) で紹介したように,Joseph Wright による The English Dialect Dictionary の電子化プロジェクトが Innsbruck 大学で進められていたが,つい最近完成したとの知らせを受けた.これまでウェブ上のサービスではアカウント取得が必要だったが,これで直接自由にアクセスできるようになった.こちらの EDD Online からどうぞ.
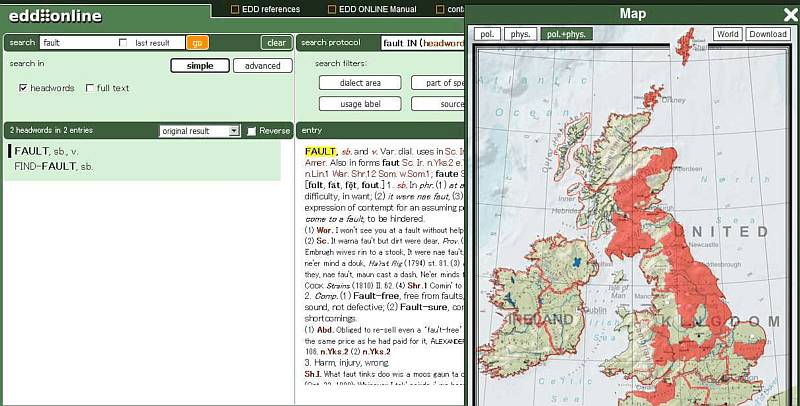
機能も充実しており,例えば上のスクリーンショットのように,検索語と関連して辞書内に言及されている方言地域を地図上で確認できる機能がある.ちょうど語源的綴字 (etymological_respelling) に関する調査の関係で,言及されている方言地域が地図上で確認できれば便利だろうと思っていた矢先だったので,嬉しい.
また,紙媒体の元祖 The English Dialect Dictionary のページをイメージとして確認することもできる.検索については,dialect area, part of speech, phonetic, etymology, usage label, source, morphemic, time span など各種カテゴリーによるサーチが可能.
利用マニュアルも閲覧できるので,参照しながらあれこれといじってみることをお薦めする.
・ Wright, Joseph, ed. The English Dialect Dictionary. 6 vols. Henry Frowde, 1898--1905.
2016-09-07 Wed
■ #2690. N-gram Tool [cgi][n-gram][statistics][corpus][web_service][frequency][cgi]
n-gram は,言語統計やコーパス言語学の世界における基本的な概念・手段である(「#2324. n-gram」 ([2015-09-07-1]), 「#956. COCA N-Gram Search」 ([2011-12-09-1]) を参照).テキストを指定してその n-gram を得るツールはネットその他にも遍在しているが,あえて簡易ツールをCGIで実装してみた.バックエンドに Perl モジュールの Text::Ngrams を用いている.
使い方はおよそ自明だろう.適当な長さの英文テキストを投げ込めば,デフォルトでは単語ベースの 3-gram (およびそれ以下の 2-gram と 1-gram も含む)の一覧が絶対頻度の高い順に返される(出力行の制限はなし).オプションにより単語ベースではなく文字ベースにも変更でき,n-gram のサイズも変えられる.出力については,頻度順ではなくアルファベット順にすること,出力行に制限を設けること,絶対頻度ではなく相対頻度(各 n-gram 内で合計すると1.0となる)で返すことも可能.
なお,1-gram は入力テキストを構成する単語の頻度表となるので,その用途にも利用できる.簡易的な n-gram ツールとしてどうぞ.
[ 固定リンク | 印刷用ページ ]
2015-10-11 Sun
■ #2358. スライドできる英語史年表 [timeline][web_service]
SIMILE が提供する Timeline API というものを利用して,ブラウザ上でスムーズに動かせる年表を作成できるといううことを知ったので,スライドできる英語史年表を作ってみた.年表データは,「#777. 英語史略年表」 ([2011-06-13-1]) で掲げた Crystal 版を利用することにした.
スライド年表そのものは,こちらからアクセスしてください(あるいは以下の画像をクリック).今後,これを基本にして改訂を加え,見栄えや使い勝手のよい年表に仕上げていきたいところ.

・ Crystal, David. The English Language. 2nd ed. London: Penguin, 2002.
2015-09-19 Sat
■ #2336. Text Analyser --- 簡易テキスト統計分析器 [cgi][text_tool][web_service][corpus]
最近では,テキスト分析のための高機能なツールが手軽に入手できるようになった.英語コーパスを分析するプログラムなどでは,使用語数に基づいて様々な統計値が計算され,見やすい形で提示される.そのようなツールを改めて公開する必要もないといえばないが,簡易テキスト統計分析器の CGI を作成してみたので,ここに hellog 版ということで設置しておきたい.テキストボックスに文章を投げ込むだけ.
背後では Perl モジュール Lingua::EN::Fathom を使用しているが,語や文の認識や音節カウントなど,自動では完全解決の難しい問題も多くあるため,結果としての統計値は近似的なものとして理解されたい.今回のバージョンでは,以下の14の統計値を示すことにした.
(1) Number of characters
(2) Number of words (tokens)
(3) Number of types
(4) Type/token ratio
(5) Per cent of complex words
(6) Average syllables per word
(7) Number of sentences
(8) Average words per sentences
(9) Number of text lines
(10) Number of blank lines
(11) Number of paragraphs
(12) Fog index
(13) Flesch reading ease score
(14) Flesch-Kincaid grade level score
多くの統計値の意味は自明と思われるが,いくつかについて注記しておく.(4) Type/token ratio は,語彙の多様性を示す指標である.テキスト内のすべての語が各々1度きり現われる場合には,最大値 1.0 を示す.ただし,テキストの長さに大きく依存するため,この指標単体ではさほど情報量はない.
(5) Per cent of complex words の "complex words" とは,3音節以上の語の割合である.(12), (13), (14) は,テキストの読みやすさの指標であり,いずれも1文あたりの語数 (words_per_sentence) と1語あたりの音節数 (syllables_per_word) に基づいて計算されている.各指標の特徴と解釈の仕方を以下に略述する.
(12) The Fog index
読みやすさを表わす簡便な指標.( words_per_sentence + percent_complex_words ) * 0.4 で求めることができる.指標の数値は学年を表わし,その学年の標準的な生徒であれば,その文章を一度読んで理解できる水準といわれる.目安としては,8 = childish, 10 = acceptable, 12 = ideal, 14 = difficult, 18 = unreadable.
(13) The Flesch reading ease score
206.835 - (1.015 * words_per_sentence) - (84.6 * syllables_per_word) で求められる.最高点は100点で,指標が高ければ高いほど理解しやすいテキストである.60--70点が最適とされる.
(14) Flesch-Kincaid grade level score
(11.8 * syllables_per_word) + (0.39 * words_per_sentence) - 15.59 で求められる.指標は米国の学年を表わし,例えば 8.0 であれば,そのテキストは第8学年の生徒に理解できる水準ということになる.7.0--8.0 が最適値とされる.
Powered by WinChalow1.0rc4 based on chalow