2025-10-08 Wed
■ #6008. 声の書評 --- khelf 泉類尚貴さんが紹介する『コーパスと英文法』 [khelf][hellive2025][review][voice_review][kenkyusha][heldio][voicy][corpus][collocation]
khelf(慶應英語史フォーラム)がお送りする https://voicy.jp/channel/1950] の「声の書評」シリーズ,第4弾です.今回は khelf 顧問で,関東学院大学で教鞭をとられている[[泉類尚貴さん|https://note.com/rui_hel/n/n4b3c4fa34656">heldioに,滝沢直宏(著)『〈英文法を解き明かす〉ことばの実際2 コーパスと英文法』(研究社,2017年)を紹介してもらいました.
泉類さんによれば,本書はコーパス言語学の入門書としてだけでなく,その応用までを視野に入れた実践的な1冊とのことです.コーパス (corpus) とは何か,という基礎的な解説から始まり,実際の研究でどのようにコーパスを活用するのか,具体例を交えて丁寧に説明されています.
特に,これまで感覚的に捉えられがちだった collocation (語と語の慣用的な結びつき)を,統計的な手法を用いて客観的に分析する方法が紹介されている点は,とても有益です.また,大規模なコーパスを利用する際の注意点や,自分でデータを収集する方法など,研究の現場で直面するであろう課題にも目配りされている点は,さすが専門家による解説書というべきでしょう.コーパスを使って本格的に言語研究に取り組みたいと考えている学生や研究者にとって,心強い味方となる1冊です.
収録参加者の khelf メンバーによる正規表現談義も聴き応えがありました.今回は,専門的な立場から本書の核心を解説してくれた泉類さんに感謝いたします.今回の「声の書評」は今朝の heldio 配信回「#1592. 声の書評 by khelf 泉類尚貴さん --- 滝沢直宏(著)『コーパスと英文法』(研究社,2017年)」でお聴きいただけます.

・ 滝沢 直宏 『〈英文法を解き明かす〉ことばの実際2 コーパスと英文法』 研究社,2017年.
2025-06-20 Fri
■ #5898. 英語史研究において「コーパスを用いる」ことの難しさ [corpus][historical_linguistics][speech][writing][methodology][register]
標題は,定期的に戻って考えておく必要のある問題である.先日も大学院の授業にて関連する議論が展開したので,ここで改めて検討しておきたい.
近年,英語史研究においてコーパスを用いることは,当たり前の手法となっている.現代英語ほどではないが,過去の英語においてもそれなりの規模のテキストデータにアクセスできるようになったことで,過去の言語現象を客観的かつ定量的に分析することが可能となり,多くの画期的な知見がもたらされている.
しかし,コーパスに基づく英語史研究の隆盛は,ある違和感を生み出してもいる.それは,データがあるものしか語られないし,語れない,という問題だ.歴史コーパスは,現存する書かれたテキストから構成される.これは,古英語から中英語を経て初期近代英語期までの言語資料は,書き言葉でしか残されていないという絶対的な制約がある以上,致し方のないことではある.歴史英語の大半は,原則として話し言葉ではなく書き言葉の情報しか与えてくれないのだ.
しかし,この制約は,古い英語に専門的に接していればいるほど,忘れられやすいものでもある.歴史コーパスには,あたかも当時の英語全体が,すなわち書き言葉の背後にあると仮定される話し言葉をも含めた英語資料が収められているかのような錯覚に陥りやすいのだ.実際には,コーパスのなかには,話し言葉は,少なくとも直接的には収められていないにもかかわらずだ.同様に,書き言葉に付されにくいジャンルの言語使用や,社会的に周縁化された人々の言語資料も,コーパスに含まれてないことが多い.コーパスを用いても,書かれなかったレジスターの英語の歴史にはアクセスできないのだ.コーパスを常用する英語史研究者は,書かれなかったものの歴史を語ることの難しさ,そしてその重要性を意識しておく必要がある.
このように議論するのは,コーパスの限界をネガティヴに指摘して終わるためではない.むしろコーパスを補完する他の視点をもつことの重要性を強調するためである. 言語学的素養,文献学的知識,社会的背景の理解などを組み合わせることで,コーパスデータだけでは見えてこない言語の歴史に光を当てようとすることが肝要である.
関連して,以下の記事も参照.
・ 「#307. コーパス利用の注意点」 ([2010-02-28-1])
・ 「#367. コーパス利用の注意点 (2)」 ([2010-04-29-1])
・ 「#428. The Brown family of corpora の利用上の注意」 ([2010-06-29-1])
・ 「#1280. コーパスの代表性」 ([2012-10-28-1])
・ 「#2584. 歴史英語コーパスの代表性」 ([2016-05-24-1])
・ 「#2779. コーパスは英語史研究に使えるけれども」 ([2016-12-05-1])
・ 「#3967. コーパス利用の注意点 (3)」 ([2020-03-07-1])
・ 「#4915. 英語史のデジタル資料 --- 大学院のデジタル・ヒューマニティーズ入門講義より」 ([2022-10-11-1])
・ 「#4916. デジタル資料を用いた研究の功罪について議論しました」 ([2022-10-12-1])
・ 「#5280. 本年度も大学院生とデジタル資料を用いた研究の功罪について議論しました」 ([2023-10-11-1])
2025-01-18 Sat
■ #5745. アルファベットの文字頻度 [corpus][link][alphabet][frequency][statistics][letter_frequency][bnc][morse_code]
AからZまでのアルファベット文字のなかで,最も頻度の高い文字,低い文字は何か.この文字頻度 (letter_frequency) の話題については,「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1]) の下部に Letter Frequencies (rankings for various languages) へのリンクを挙げたとおり,様々な言語やコーパスでの順位表が作り出されている.例えば,BNC に依拠すると "etaoinsrhldcumfpgwybvkxjqz" の順位表が得られる.
Crystal (277) には,The Cambridge Encyclopedia (1st ed.) の全テキスト,150万語をコーパスとした文字頻度表が掲げられている.累積頻度順位 (Cumulative) のみならず,文学,宗教,政治,物理学,化学の各々のテーマごとの頻度や Morse code (morse_code) の頻度も合わせて示されている.以下のグラフは,X軸に沿って累積頻度順 (= "eatinorslhdcmufpgbywvkxjq") に文字を並べ,Y軸を各テーマ内での頻度割合(百分率)としたものである(頻度表はソース HTML を参照).
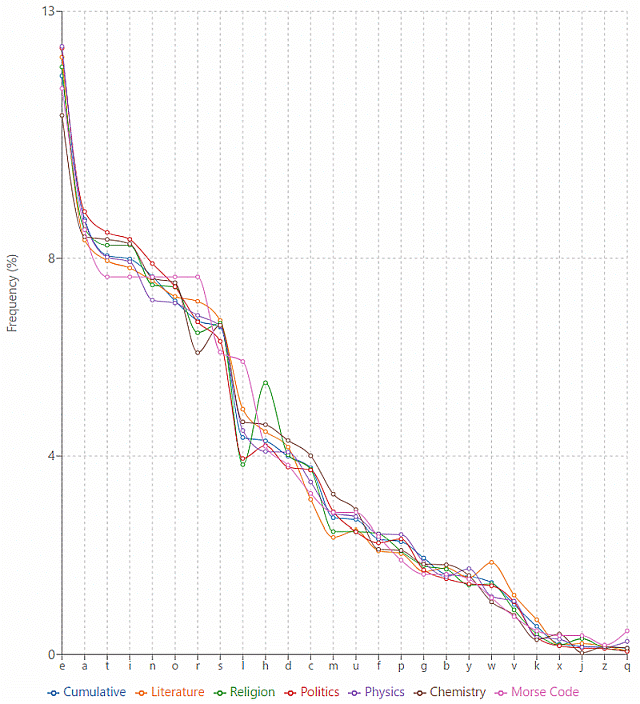
累積頻度順に照らしてテーマごとの特徴を見てみるとと,政治が最も標準的である.文学と政治がそれに続く.標準から遠ざかっていくのが,化学,物理学,そして Morse code となる.
個々の文字をみると興味深い点が多々ある.相対的に宗教では <h> が多く (holy?) <l> が少ないこと,文学では <w> が多いことは何を意味するのだろうか? 物理学や化学はラテン・ギリシア語系の単語が多く含まれているために,その他一般とは若干異なる文字頻度を示しているのかもしれない.人工的な Morse code は,他のテーマとは目に見えて異なる線を描いていることがわかる.
・ Crystal, D. The Cambridge Encyclopedia of the English Language. 3rd ed. CUP, 2018.
2024-09-17 Tue
■ #5622. methoughts の用例を再び [3ps][impersonal_verb][verb][inflection][preterite][analogy][methinks][eebo][corpus][emode][comment_clause]
「#5385. methinks にまつわる妙な語形をいくつか紹介」 ([2024-01-24-1]) と「#5386. 英語史上きわめて破格な3単過の -s」 ([2024-01-25-1]) で触れたように,近代英語期には methoughts という英文法史上なんとも珍妙な動詞形態が現われます.過去形なのに -s 語尾が付くという驚きの語形です.
今回は,methoughts の初期近代英語期からの例を EEBO corpus より抜き出してみました(コンコーダンスラインのテキストファイルはこちら).10年刻みでのヒット数は,次の通りです.
| ALL | 1600s | 1610s | 1620s | 1630s | 1640s | 1650s | 1660s | 1670s | 1680s | 1690s | |
| METHOUGHTS | 184 | 1 | 6 | 6 | 18 | 37 | 75 | 41 |
15--16世紀中には1例も現われなかったので表中には示しませんでした.17世紀に入り,とりわけ後半以降に分布を伸ばしてきています.EEBO で追いかけられるのはここまでですが,この後の18世紀以降の分布も気になるところです.
コンコーダンスラインを眺めていると,methoughts は主節を担うというよりも,すでに評言節 (comment_clause) として挿入的に用いられている例が多いことが窺われます(これ自体は,対応する現在形 methinks の役割からも容易に予想されますが).
また,methoughts の近くに類義語というべき seem が現われる例もいくつか確認され,評言節からさらに発展して,副詞程度の役割に到達しているとすら疑われるほどです.
・ 1676: methoughts she seem'd though very reserv'd, and uneasie all the time i entertain'd her
・ 1678: methoughts my head seemed as it were diaphanous
・ 1679: nay, they so beautiful, so fair did seem, methoughts i took and eat'em in my dream
・ 1695: yet methoughts you seem chiefly to place this vacancy of the throne upon king iames's abdication
英語史上短命に終わった,きわめて珍妙なこの語形から目が離せません.
[ 固定リンク | 印刷用ページ ]
2024-01-28 Sun
■ #5389. 語用論的な if you like 「こう言ってよければ」の発展 (2) [pragmatics][discourse_marker][lmode][construction_grammar][politeness][comment_clause][syntax][constructionalisation][corpus][speed_of_change]
先日 Voicy heldio にて「#961. 評言節 if you like 「そう呼びたければ」と題して,口語の頻出フレーズ if you like の話題をお届けした.
実は私自身も忘れていたのだが,この問題については hellog で「#4593. 語用論的な if you like 「こう言ってよければ」の発展」 ([2021-11-23-1]) として取り上げていた.その過去の記事でも参照・引用した Brinton の論文を改めて読み直し,if you like および類義表現について興味深い歴史的事実を知ったので,ここに記しておきたい.
Brinton は挿入的に用いられる if you choose/like/prefer/want/wish の類いを "if-ellipitical clauses" (= "if-ECs") と名付けている (273) .意味論・語用論の観点から,2種類の if-ECs が区別される.1つめは省略されている目的語が前後のテキストから統語的に補えるタイプである ("elliptical form") .2つめは目的語を前後のテキストから補うことはできず,もっぱらメタ言語的な挿入説として用いられるタイプである ("metalinguistic parenthetical") .各タイプについて,Brinton (281) が歴史コーパスから拾った例を1つずつ挙げてみよう.
1. I said no, they are copper, but if you choose, you shall have them (1763 John Routh, Violent Theft; OBP)
2. I ought to occupy the foreground of the picture; that being the hero of the piece, or (if you choose) the criminal at the bar, my body should be had into court. (1822 De Quincy, Confessions of an English Opium Eater; CLMETEV)
いずれも choose という動詞を用いた例である.前者は if you choose to have them のようにテキストに基づいて目的語を補うことができるが,後者はそのようには補えない.あくまでメタ言語的に if you choose to say so ほどが含意されている用法だ.
歴史的には,前者のタイプの用例が,動詞を取り替えつつ18--19世紀に初出している.そして,おもしろいことに,後者のタイプの用例がその後数十年から100年ほど遅れて初出している.全体としては,類義の動詞が束になって,ゆっくりと似たような用法の拡張を遂げていることになる.Brinton (282) の "Dating of if-ECs" と題する表を掲げよう.近代英語期の様々なコーパスを用いた初出年調査の結果である.
| Earliest elliptical form | Earliest metalinguistic parenthetical | |
| if you choose | 1763 | 1822 |
| if you like | 1723 | 1823 |
| if you wish | 1819 | 1902/PDE |
| if you prefer | 1848 | 1900 |
| if you want | 1677/1824 | 1934 |
さらにおもしろいのは,メタ言語的な用法の初例を誇る if you choose は,現在までに人気を失っていることだ.一方,最も新しい if you want もメタ言語的な用法としての頻度は目立たない.安定感のあるのはその他の3種,like, wish, prefer 辺りのである.類義の動詞が束になって当該表現と用法を発展させてきたとしても,後の安定感に差が出たのはなぜなのだろうか.とても興味深い.
・ Brinton, Laurel J. "If you choose/like/prefer/want/wish: The Origin of Metalinguistic and Politeness Functions." Late Modern English Syntax. Ed. Marianne Hundt. Cambridge: CUP, 2014.
2023-10-11 Wed
■ #5280. 本年度も大学院生とデジタル資料を用いた研究の功罪について議論しました [methodology][corpus]
年に一度,人文系研究のためのデジタル資料の扱い方について大学院生と議論する機会があります.昨年度の議論の経緯は,以下の記事で報告しました.
・ 「#4915. 英語史のデジタル資料 --- 大学院のデジタル・ヒューマニティーズ入門講義より」 ([2022-10-11-1])
・ 「#4916. デジタル資料を用いた研究の功罪について議論しました」 ([2022-10-12-1])
先日,今年度も改めて同じ趣旨で議論する機会を得ました.参加者の大学院生は昨年度とは異なるメンバーで,それぞれ人文系の様々な分野に所属しています.まず私自身が英語史を専攻していることもあり英語史分野におけるデジタル資料の利用とその課題について概要をお話しました.その上で,各大学院生に,自身の分野に引きつけてデジタル資料の利用法について顧みてもらい,その功罪を箇条書きで挙げてもらいました.おもしろい見解がたくさん出てきましたので,以下に列挙し,本ブログ読者の皆さんと共有したいと思います.
功:地理的に閲覧が難しい史料を扱えるようになった
罪:デジタル化されている史資料のみを扱う傾向が加速する
罪:デジタル化が進んでいる地域の言語のみで研究が発達し,言語帝国主義が加速する
罪:物質的に書いてある文字を画像にスキャンする際に失われてしまう情報がある(インクの染みなのか句読点なのかがわかりにくい,透かしのデザインに気が付かないなど)
功:デジタル化される際に何らかのフォーマットで統一されるため,データ同士の参照がしやすくなった
功:1人の手作業では絶対にできなかった研究が容易にできるようになった
罪:逆引き辞典により,古典語の実際の学習効率が落ちている(自分で覚えようという気にならない).また,逆引きの間違いに気づかない.
罪:地域によっては,資料のデジタル化のばらつきが激しい
功:言語哲学においてコーパスの使用により実証的な概念分析ができるようになった
罪:デジタル化されている資料とそうでない資料の間の参照される度合いに格差が生じてしまった
罪:研究に要求される調査範囲が,デジタル化で際限なく拡大してしまった
罪:データを収集する際に,サービス提供側のルールが急に変わったりすることがある(例:X(旧Twitter)ツイートの収集)
功:特定の言葉について長い期間で意味の変化を追うことができるようになった
罪:実物資料から読み解けることに対する理解が乏しくなる可能性がある
罪:あまり質の良くない論文(査読無し)も見つかる
罪:提供されているデータの範囲や性質について考えずに使っても,一見それなりの結果を出せてしまうので,研究の目的から見たときのデータの妥当性について考えない場合も出てきてしまう(研究する側の問題ですが)
罪:データ閲覧に端末の種類,スペックに制限がある
功:量的分析に取り組みやすくなる
罪:質的分析の方が適切な場合でも,量的分析を選びがちになってしまうおそれがある
功:書籍の中の語句を検索できることにより,参照したい箇所をすぐに見つけられるようになった
功:時期やテーマと言った研究範囲を指定しやすくなった
罪:デジタル化される際に行われた編集作業を把握するのが難しいため,本来の資料と編集者の意図が一体化してしまう
罪:参照すべきと思わせる文献が増えた
功:情報がリンク化されていれば,素早くアクセスできる.
罪:出てくるデータ量が大きすぎて事後処理に時間がかかるようになってしまった
功:API を用いて大規模なデータの取得ができるようになった
功:逆引き辞典により,古典語学習初期段階から読める一次史料が増える
功:臨床群等の貴重なデータを使用することができる
功:3Dスキャンによって,実物資料にアクセスしなくても資料閲覧ができるようになった.
功:作品における一つの言葉について注目し研究したい場合,検索をかけることで簡単に調べられる(一作品において特定の単語が何回使用されたか等)
罪:用例や言葉が多すぎて,調べた結果をまとめるだけでも,時間がかかる
功:提供されるデジタル化された文献に関連する文献を探しやすくなった
功:ファンダム研究において,ブログなどのSNSにより,ファンの声が記録でき,貴重なデータベースである
功:デジタル化により資料の共有・二時配布が容易になった(著作権侵害も容易になりこれは罪でもある)
功:一般人でも一次史料にアクセスできるようになった
罪:コーパスで調べても,当時の具体的な意味については同時代の史料を読む必要があり,便利になったとは言い切れない
罪:捏造,やらせ,デマを飛ばすような信ぴょう性の低い内容もデータになってしまう
罪:アーカイブ調査では,資料同士の物理的な距離感を知ることから得られる情報もあるため,個々人がデジタル化されたもののうち必要な箇所だけを見ることで「資料間の距離感」が失われるのではないか
全38件中,功18件に対して罪20件となりました.思いのほか罪がよく挙がるのは昨年も同様でした.私自身も思い当たるところがありますが,このお題を示されると,問題意識が呼び覚まされるのかもしれません.非常に気づきの多いブレストでした.
2023-09-10 Sun
■ #5249. 川端朋広先生と現代英語の言語変化をいかに研究するかについて対談しました [voicy][heldio][review][corpus][pde][syntax][philology][methodology][link]

『近代英語における文法的・構文的変化』が,6月に開拓社より出版されています.15--20世紀の英文法およびその変化が実証的に記述されています.本書のユニークな点は,6名の研究者の各々が各世紀の言語事情を定点観測的に調査していることです.個々の章を読むのもよいですし,ある項目に注目して章をまたいで読むのもよいと思います.
本書については,本ブログ,Voicy heldio,YouTube で様々にご紹介してきました.昨日の heldio では川端朋広先生(愛知大学)との対談回の第2弾「#831. 『近代英語における文法的・構文的変化』 --- 川端朋広先生との対談 (2)」を配信しました.今回は,現代英語の言語変化を研究する際の難しさ,悩み,魅力などに注目し,最終的には研究法をめぐる談義に発展しました.35分ほどの音声となります.お時間のあるときにどうぞ.
こちらの回をもって,本書紹介シリーズが出そろったことになります.改めてこれまでの関連コンテンツへのリンクを張っておきます.著者の先生方の声を聴きつつ本書を読んでいくというのも,一つの味わい方かと思います.
・ YouTube 「井上逸兵・堀田隆一英語学言語学チャンネル」より「#137. 辞書も規範文法も18世紀の産業革命富豪が背景に---故山本史歩子さん(英語・英語史研究者)に捧ぐ---」
・ hellog 「#5166. 秋元実治(編)『近代英語における文法的・構文的変化』(開拓社,2023年)」 ([2023-06-19-1])
・ hellog 「#5167. なぜ18世紀に規範文法が流行ったのですか?」 ([2023-06-20-1])
・ hellog 「#5182. 大補文推移の反対?」 ([2023-07-05-1])
・ hellog 「#5186. Voicy heldio に秋元実治先生が登場 --- 新刊『近代英語における文法的・構文的変化』についてお話しをうかがいました」 ([2023-07-09-1])
・ hellog 「#5208. 田辺春美先生と17世紀の英文法について対談しました」 ([2023-07-31-1])
・ hellog 「#5224. 中山匡美先生と19世紀の英文法について対談しました」 ([2023-08-16-1])
・ hellog 「#5235. 片見彰夫先生と15世紀の英文法について対談しました」 ([2023-08-27-1])
・ hellog 「#5242. 川端朋広先生と20世紀の英文法について対談しました」 ([2023-09-03-1])
・ hellog 「#5249. 川端朋広先生と現代英語の言語変化をいかに研究するかについて対談しました」 ([2023-09-09-1])
・ heldio 「#769. 『近代英語における文法的・構文的変化』 --- 秋元実治先生との対談」
・ heldio 「#772. 『近代英語における文法的・構文的変化』 --- 16世紀の英語をめぐる福元広二先生との対談」
・ heldio 「#790. 『近代英語における文法的・構文的変化』 --- 田辺春美先生との対談」
・ heldio 「#806. 『近代英語における文法的・構文的変化』 --- 中山匡美先生との対談」
・ heldio 「#824. 『近代英語における文法的・構文的変化』 --- 川端朋広先生との対談 (1)」
・ heldio 「#831. 『近代英語における文法的・構文的変化』 --- 川端朋広先生との対談 (2)」
・ heldio 「#837. 18世紀の英語の文法変化 --- 秋元実治先生との対談」(←こちらは 2023/09/15(Fri) の後記)
・ 秋元 実治(編),片見 彰夫・福元 広二・田辺 春美・山本 史歩子・中山 匡美・川端 朋広・秋元 実治(著) 『近代英語における文法的・構文的変化』 開拓社,2023年.
2023-09-03 Sun
■ #5242. 川端朋広先生と20世紀の英文法について対談しました [voicy][heldio][review][corpus][pde][syntax][phrasal_verb][subjunctive][complementation][preposition]
こちらの本は6月に開拓社より出版された『近代英語における文法的・構文的変化』です.6名の研究者の各々が,15--20世紀の各世紀の英文法およびその変化について執筆されています.
本書については本ブログや Voicy heldio で何度かご紹介してきましたが,今回は,第6章「20世紀の文法的・構文的変化」を執筆された川端朋広先生(愛知大学)との heldio 対談をご案内します.「#824. 『近代英語における文法的・構文的変化』 --- 川端朋広先生との対談 (1)」と題し,40分超でじっくりお話しをうかがっています.
2023年の現在,20世紀の英語は正確にいえば「過去の英語」となりますが,事実上は私たちが日常的に触れている英語と同じものと考えられます.しかし,100年余の時間を考えれば,当然ながら細かな言語変化はたくさん起こってきたはずです.1901年と2023年の英語とでは,お互いに通じないことはないにせよ,やはり微妙なズレはあるはずです.現代英語の文法にも確かに変化が生じてきたのです.
英語史ときくと,古英語や中英語のような古文を研究する分野という印象があるかもしれませんが,直近数十年に生じた英語の変化を追うのも立派な英語史研究の一部です.今回の川端先生のお話しからも,言語変化のダイナミックさと複雑さが伝わるのではないでしょうか.
本書についてご関心をもった方は,ぜひ以下のコンテンツも訪問していただければと思います.
・ YouTube 「井上逸兵・堀田隆一英語学言語学チャンネル」より「#137. 辞書も規範文法も18世紀の産業革命富豪が背景に---故山本史歩子さん(英語・英語史研究者)に捧ぐ---」
・ hellog 「#5166. 秋元実治(編)『近代英語における文法的・構文的変化』(開拓社,2023年)」 ([2023-06-19-1])
・ hellog 「#5167. なぜ18世紀に規範文法が流行ったのですか?」 ([2023-06-20-1])
・ hellog 「#5182. 大補文推移の反対?」 ([2023-07-05-1])
・ hellog 「#5186. Voicy heldio に秋元実治先生が登場 --- 新刊『近代英語における文法的・構文的変化』についてお話しをうかがいました」 ([2023-07-09-1])
・ hellog 「#5208. 田辺春美先生と17世紀の英文法について対談しました」 ([2023-07-31-1])
・ hellog 「#5224. 中山匡美先生と19世紀の英文法について対談しました」 ([2023-08-16-1])
・ hellog 「#5235. 片見彰夫先生と15世紀の英文法について対談しました」 ([2023-08-27-1])
・ heldio 「#769. 『近代英語における文法的・構文的変化』 --- 秋元実治先生との対談」
・ heldio 「#772. 『近代英語における文法的・構文的変化』 --- 16世紀の英語をめぐる福元広二先生との対談」
・ heldio 「#790. 『近代英語における文法的・構文的変化』 --- 田辺春美先生との対談」
・ heldio 「#806. 『近代英語における文法的・構文的変化』 --- 中山匡美先生との対談」
・ heldio 「#817. 『近代英語における文法的・構文的変化』 --- 片見彰夫先生との対談」
・ 秋元 実治(編),片見 彰夫・福元 広二・田辺 春美・山本 史歩子・中山 匡美・川端 朋広・秋元 実治(著) 『近代英語における文法的・構文的変化』 開拓社,2023年.
2023-08-27 Sun
■ #5235. 片見彰夫先生と15世紀の英文法について対談しました [voicy][heldio][review][corpus][lme][syntax][phrasal_verb][subjunctive][complementation][caxton][malory][negative][impersonal_verb][preposition][periodisation]
6月に開拓社より出版された『近代英語における文法的・構文的変化』について,すでに何度かご紹介してきました.6名の研究者の各々が,15--20世紀の各世紀の英文法およびその変化について執筆するというユニークな構成の本です.
本書の第1章「15世紀の文法的・構文的変化」の執筆を担当された片見彰夫先生(青山学院大学)と,Voicy heldio での対談が実現しました.えっ,15世紀というのは伝統的な英語史の時代区分では中英語期の最後の世紀に当たるのでは,と思った方は鋭いです.確かにその通りなのですが,対談を聴いていただければ,15世紀を近代英語の枠組みで捉えることが必ずしも無理なことではないと分かるはずです.まずは「#817. 『近代英語における文法的・構文的変化』 --- 片見彰夫先生との対談」をお聴きください(40分超の音声配信です).
私自身も,片見先生と対談するまでは,15世紀の英語はあくまで Chaucer に代表される14世紀の英語の続きにすぎないという程度の認識でいたところがあったのですが,思い違いだったようです.近代英語期への入り口として,英語史上,ユニークで重要な時期であることが分かってきました.皆さんも15世紀の英語に関心を寄せてみませんか.最初に手に取るべきは,対談の最後にもあったように,Thomas Malory による Le Morte Darthur 『アーサー王の死』ですね(Arthur 王伝説の集大成).
時代区分の話題については,本ブログでも periodisation のタグのついた多くの記事で取り上げていますので,ぜひお読み下さい.
さて,今回ご案内した『近代英語における文法的・構文的変化』については,これまで YouTube 「井上逸兵・堀田隆一英語学言語学チャンネル」,hellog, heldio などの各メディアで紹介してきました.以下よりご参照ください.
・ YouTube 「井上逸兵・堀田隆一英語学言語学チャンネル」より「#137. 辞書も規範文法も18世紀の産業革命富豪が背景に---故山本史歩子さん(英語・英語史研究者)に捧ぐ---」
・ hellog 「#5166. 秋元実治(編)『近代英語における文法的・構文的変化』(開拓社,2023年)」 ([2023-06-19-1])
・ hellog 「#5167. なぜ18世紀に規範文法が流行ったのですか?」 ([2023-06-20-1])
・ hellog 「#5182. 大補文推移の反対?」 ([2023-07-05-1])
・ hellog 「#5186. Voicy heldio に秋元実治先生が登場 --- 新刊『近代英語における文法的・構文的変化』についてお話しをうかがいました」 ([2023-07-09-1])
・ hellog 「#5208. 田辺春美先生と17世紀の英文法について対談しました」 ([2023-07-31-1])
・ hellog 「#5224. 中山匡美先生と19世紀の英文法について対談しました」 ([2023-08-16-1])
・ heldio 「#769. 『近代英語における文法的・構文的変化』 --- 秋元実治先生との対談」
・ heldio 「#772. 『近代英語における文法的・構文的変化』 --- 16世紀の英語をめぐる福元広二先生との対談」
・ heldio 「#790. 『近代英語における文法的・構文的変化』 --- 田辺春美先生との対談」
・ heldio 「#806. 『近代英語における文法的・構文的変化』 --- 中山匡美先生との対談」
・ heldio 「#817. 『近代英語における文法的・構文的変化』 --- 片見彰夫先生との対談」
・ 秋元 実治(編),片見 彰夫・福元 広二・田辺 春美・山本 史歩子・中山 匡美・川端 朋広・秋元 実治(著) 『近代英語における文法的・構文的変化』 開拓社,2023年.
2023-08-16 Wed
■ #5224. 中山匡美先生と19世紀の英文法について対談しました [voicy][heldio][review][corpus][lmode][syntax][phrasal_verb][subjunctive][complementation]
6月に開拓社より近代英語期の文法変化に焦点を当てた『近代英語における文法的・構文的変化』が出版されました.秋元実治先生(青山学院大学名誉教授)による編著です.6名の研究者の各々が,15--20世紀の各世紀の英文法およびその変化について執筆しています.
このたび,本書の第5章「19世紀の文法的・構文的変化」の執筆を担当された中山匡美先生(神奈川大学ほか)と,Voicy heldio での対談が実現しました.19世紀は,英語史全体からみると現代に非常に近い時期ですので,それほど大きな違いはないと思われがちです.確かに現代英語を読めるのであれば19世紀の英語もおおよそ読めてしまうというのは事実です.しかし,それだからこそ,小さな違いを見過ごしてしまい,大きな誤解に陥ってしまう危険性があるのです.似ているだけに,落とし穴にはまらないよう,注意深く意識的な観察が必要ということにもなります.この辺りの事情を,19世紀の英語の専門家にお聴きしました.「#806. 『近代英語における文法的・構文的変化』 --- 中山匡美先生との対談」です.どうぞご聴取ください(27分ほどの音声配信です).
中山先生とは,これまでも2回の heldio 対談を行ない,配信しています.
・ 「#803. 中山匡美先生にとって英語とは何ですか? --- 「英語は○○です」企画の関連対談回」(2023/08/12 配信)
・ 「#323. 中山匡美先生との対談 singular "they" は19世紀でも普通に使われていた!」 (2022/04/19 配信)
今回ご案内した『近代英語における文法的・構文的変化』については,すでに YouTube 「井上逸兵・堀田隆一英語学言語学チャンネル」,hellog, heldio などの各メディアで紹介してきましたので,以下よりご参照いただければ幸いです.
・ YouTube 「井上逸兵・堀田隆一英語学言語学チャンネル」より「#137. 辞書も規範文法も18世紀の産業革命富豪が背景に---故山本史歩子さん(英語・英語史研究者)に捧ぐ---」
・ hellog 「#5166. 秋元実治(編)『近代英語における文法的・構文的変化』(開拓社,2023年)」 ([2023-06-19-1])
・ hellog 「#5167. なぜ18世紀に規範文法が流行ったのですか?」 ([2023-06-20-1])
・ hellog 「#5182. 大補文推移の反対?」 ([2023-07-05-1])
・ hellog 「#5186. Voicy heldio に秋元実治先生が登場 --- 新刊『近代英語における文法的・構文的変化』についてお話しをうかがいました」 ([2023-07-09-1])
・ hellog 「#5208. 田辺春美先生と17世紀の英文法について対談しました」 ([2023-07-31-1])
・ heldio 「#769. 『近代英語における文法的・構文的変化』 --- 秋元実治先生との対談」
・ heldio 「#772. 『近代英語における文法的・構文的変化』 --- 16世紀の英語をめぐる福元広二先生との対談」
・ heldio 「#790. 『近代英語における文法的・構文的変化』 --- 田辺春美先生との対談」
・ heldio 「#806. 『近代英語における文法的・構文的変化』 --- 中山匡美先生との対談」
・ 秋元 実治(編),片見 彰夫・福元 広二・田辺 春美・山本 史歩子・中山 匡美・川端 朋広・秋元 実治(著) 『近代英語における文法的・構文的変化』 開拓社,2023年.
2023-08-03 Thu
■ #5211. Innsbruck EDD Online 4.0 [dialect][web_service][corpus][lmode][lexicography][edd][dictionary][notice]
Joseph Wright による English Dialect Dictionary のオンライン版である EDD Online について,Manfred Markus が率いる Innsbruck 大学のチームがオンライン化プロジェクトの最終段階の成果として Version 4.0 を公表した,との情報を得ました.Innsbruck EDD Online 4.0 Based on Joseph Wright's English Dialect Dictionary (1898--1905) です.
私はまだ EDD Online の豊富な機能を使いこなせていないのですが,辞書の画像イメージを確認できたり,地図上に示してくれたり等,視覚化の機能が充実している印象です.
Markus 教授による使い方のイントロ動画(5分)もありますので視聴をお勧めします(辞書とは関係ありませんが,動画の最後のインスブルックの景色に心奪われて今すぐオーストリアに行きたい,などと妄想).
EDD については,hellog では以下の記事で取り上げてきましたので,そちらもご参照下さい.
・ 「#869. Wright's English Dialect Dictionary」 ([2011-09-13-1])
・ 「#868. EDD Online」 ([2011-09-12-1])
・ 「#2694. EDD Online (2)」 ([2016-09-11-1]) を参照.
2023-07-31 Mon
■ #5208. 田辺春美先生と17世紀の英文法について対談しました [voicy][heldio][review][corpus][emode][syntax][phrasal_verb][subjunctive][complementation]
6月に開拓社より近代英語期の文法変化に焦点を当てた『近代英語における文法的・構文的変化』が出版されました.秋元実治先生(青山学院大学名誉教授)による編著です.6名の研究者の各々が,15--20世紀の各世紀の英文法およびその変化について執筆しています.
このたび,本書の第3章「17世紀の文法的・構文的変化」の執筆を担当された田辺春美先生(成蹊大学)と,Voicy heldio での対談が実現しました.17世紀は英語史上やや地味な時代ではありますが,着実に変化が進行していた重要な世紀です.ことさらに取り上げられることが少ない世紀ですので,今回の対談はむしろ貴重です.「#790. 『近代英語における文法的・構文的変化』 --- 田辺春美先生との対談」をお聴き下さい(21分ほどの音声配信です).
田辺先生の最後の台詞「17世紀も忘れないでね~」が印象的でしたね.
本書については,すでに YouTube 「井上逸兵・堀田隆一英語学言語学チャンネル」,hellog, heldio などの各メディアで紹介してきましたので,そちらもご参照いただければ幸いです.
・ YouTube 「井上逸兵・堀田隆一英語学言語学チャンネル」より「#137. 辞書も規範文法も18世紀の産業革命富豪が背景に---故山本史歩子さん(英語・英語史研究者)に捧ぐ---」
・ hellog 「#5166. 秋元実治(編)『近代英語における文法的・構文的変化』(開拓社,2023年)」 ([2023-06-19-1])
・ hellog 「#5167. なぜ18世紀に規範文法が流行ったのですか?」 ([2023-06-20-1])
・ hellog 「#5182. 大補文推移の反対?」 ([2023-07-05-1])
・ hellog 「#5186. Voicy heldio に秋元実治先生が登場 --- 新刊『近代英語における文法的・構文的変化』についてお話しをうかがいました」 ([2023-07-09-1])
・ heldio 「#769. 『近代英語における文法的・構文的変化』 --- 秋元実治先生との対談」
・ heldio 「#772. 『近代英語における文法的・構文的変化』 --- 16世紀の英語をめぐる福元広二先生との対談」
・ heldio 「#790. 『近代英語における文法的・構文的変化』 --- 田辺春美先生との対談」
・ 秋元 実治(編),片見 彰夫・福元 広二・田辺 春美・山本 史歩子・中山 匡美・川端 朋広・秋元 実治(著) 『近代英語における文法的・構文的変化』 開拓社,2023年.
2023-07-09 Sun
■ #5186. Voicy heldio に秋元実治先生が登場 --- 新刊『近代英語における文法的・構文的変化』についてお話しをうかがいました [voicy][heldio][review][mode][corpus][syntax][phrasal_verb][subjunctive][complementation][periodisation]
6月に開拓社より近代英語期の文法変化に焦点を当てた書籍が出版されました.『近代英語における文法的・構文的変化』です.秋元実治先生(青山学院大学名誉教授)が編者を務められ,他に6名の研究者が執筆に加わっています.本書については,すでにこのブログや YouTube 「井上逸兵・堀田隆一英語学言語学チャンネル」で紹介する機会がありました.
・ hellog 「#5166. 秋元実治(編)『近代英語における文法的・構文的変化』(開拓社,2023年)」 ([2023-06-19-1])
・ hellog 「#5167. なぜ18世紀に規範文法が流行ったのですか?」 ([2023-06-20-1])
・ hellog 「#5182. 大補文推移の反対?」 ([2023-07-05-1])
・ YouTube 「井上逸兵・堀田隆一英語学言語学チャンネル」より「#137. 辞書も規範文法も18世紀の産業革命富豪が背景に---故山本史歩子さん(英語・英語史研究者)に捧ぐ---」
このたび,本書をめぐって編者の秋元実治先生とじきじきに対談する機会に恵まれました.対談の様子は,今朝の Voicy チャンネル「英語の語源が身につくラジオ (heldio)」にて「#769. 『近代英語における文法的・構文的変化』 --- 秋元実治先生との対談」として配信しています.対談本体は27分ほどとなっています.お時間のあるときにゆっくりお聴きいただければ.
エンディングチャプター(第5チャプター)では,秋元先生から対談収録後にうかがった,本書の表紙下部のビッグベンの写真についての貴重な裏話を紹介しています.
皆さん,ぜひ近代英語の文法変化について関心を寄せていただければ!
・ 秋元 実治(編),片見 彰夫・福元 広二・田辺 春美・山本 史歩子・中山 匡美・川端 朋広・秋元 実治(著) 『近代英語における文法的・構文的変化』 開拓社,2023年.
2023-07-05 Wed
■ #5182. 大補文推移の反対? [gcs][archer][corpus][mode][gerund][infinitive][complementation]
英語の統語論の歴史には,「#4635. "Great Complement Shift"」 ([2022-01-04-1]) という潮流がある,とされる.補文の構造 (complementation) が,もともとの that 節から不定詞へと推移し,さらに動名詞へと推移してきた変化である.古英語から現代英語に至るまでゆっくりと進行し続けてきており,非常に息が長い.
先日発売された「#5166. 秋元実治(編)『近代英語における文法的・構文的変化』(開拓社,2023年)」 ([2023-06-19-1]) で,編著者の秋元 (242--44) が,大補文推移 (gcs) の一種の反例のようにみえる興味深い例を示している.
近代英語期を通じて「~するために」を意味する in order ... の表現が,古くは動名詞をとっていたところ,そこへ不定詞が進出し,さらに that 節まで進出してきたというのである.その前段階の関連表現から始まる推移を概観すると,次のようになるという.
to the end that/to the end to V
↓
in order to NP/ing
↓
in order to V
↓
in order that ~ may
秋元によれば,これは ARCHER Corpus で検索した結果に基づいたシナリオということだ.推移の順序に従って代表的な例文が5つ挙げられているので,ここに再掲する.
・ ... they were all Committed to Newgate, in order to their being Tried next Sessions. (1682 2PROI.N1)
・ I know not whether it might not be worth a Poet's while, to travel in order to store is mind with ... (1714 BERK.X2)
・ ... every moral agent must exist forever, in order to the proper and full exercise of moral government. (1789 HOPK.H4)
・ ... consequently I cut away all the cerebrum until the corpus callosum appeared, in order that I might the more readily examine the lateral ventricles. (1820 A.M5)
・ Not because I want to undervalue the importance of these signs, but in order that I may impress upon you how important it is to Subject ...
確かに大補文推移を巻き戻したかのような順序の推移となっている.何か別の原理によるものなのか,あるいは偶発的な例外とみなすべきなのか,興味深い.
・ 秋元 実治(編),片見 彰夫・福元 広二・田辺 春美・山本 史歩子・中山 匡美・川端 朋広・秋元 実治(著) 『近代英語における文法的・構文的変化』 開拓社,2023年.
2023-06-19 Mon
■ #5166. 秋元実治(編)『近代英語における文法的・構文的変化』(開拓社,2023年) [review][mode][corpus][syntax][phrasal_verb][subjunctive][complementation][periodisation][youtube]
近代英語の文法変化についてコーパスを用いて実証的に研究した論考集が開拓社より出版されました.英語史分野の一線で活躍されている著者7名(片見彰夫氏,福元広二氏,田辺春美氏,山本史歩子氏,中山匡美氏,川端朋広氏,秋元実治氏)による書籍です.著者の方々よりご献本いただきました由,ここに感謝致します.
この本の最大の特徴は,各章が15--20世紀の各世紀を考察範囲としていることです.注目する話題は半ば固定されており,その点で定点観測となっているのですが,全体として整理された通時的な統語論の研究となっています.「はしがき」の冒頭に次のようにあります (v) .
本書は近代英語(1500--Present)における文法的・構文的変化についてコーパス等の使用による実証的研究である.
これまで英語史の記述において世紀別に述べることはあまりなかったように思われる.ひとつにはほとんどの言語変化は世紀を横断するため,各世紀の記述が難しいことがある.しかしながら,文学史などでは世紀別はきわめて普通であり(例えば,Oxford History of English Literature 12 volumes),このこともあってか英語史においても最近 Kytö et al. (2006), Mair (2006) などが出版され,それぞれ19世紀,20世紀の英語における変化・特徴に焦点をあてている.
本書では近代英語における上記のような変化の連続性と各世紀の特徴を捉えるために,以下の点を執筆者の間で共有した.
1. 全ての執筆者は共通項目,句動詞,仮定法,補文について述べる.
2. それ以外の項目で,その世紀の特徴と考えられる文法的・構文的変化について述べる.
3. 電子コーパス,テキスト等を使って,実証的に記述する.
英語史の時代区分 (periodisation) については,最近では「#5140. 「英語史の時代区分」月間の振り返り」 ([2023-05-24-1]) で取り上げるなどし,私自身も長らく考えてきました.「古英語」や「近代英語」などとラベルを貼るのではなく,きっぱりと世紀単位で切る,あるいは言及するというのは確かに一般的ではありませんでしたが,Curzan (33) が述べるように,ラベルを避けたい立場の論者は世紀単位を好むようです.一見すると無機質な時代区分のようでいて,むしろ読み手に世紀をまたいだ言語の連続性と断絶性を意識させるという効果があるのではないでしょうか.
本書ではコーパスを用いた具体的で実証的な研究が紹介されており,この分野を研究する学生や研究者には,手法も含めて直接参考になります.また,文法変化・構文変化といっても扱うべき話題は多岐にわたるものですが,各章では各世紀の英語を考察する上でとりわけ重要な項目が選ばれており,たいへん有用です.
最終章は全体のまとめとなっており,いったん各章のために世紀別に分けられたものが建て直され,読み手の視界がすっきりします.参考文献も充実しており,中英語末期から現代に至るまでの文法変化に関心のある方には,ぜひ手に取ってもらいたい一冊です.私も学生に薦めたいと思います.
著者の一人,山本史歩子さん(青山学院大学)におかれましては,本書の出版を見る前にご逝去されたとの報に接しました.悲しみでいっぱいです.ご冥福をお祈りいたします.
・ 秋元 実治(編),片見 彰夫・福元 広二・田辺 春美・山本 史歩子・中山 匡美・川端 朋広・秋元 実治(著) 『近代英語における文法的・構文的変化』 開拓社,2023年.
・ Curzan, Anne. "Periodization in the History of the English Language." Chapter 12 of The History of English. 1st vol. Historical Outlines from Sound to Text. Ed. Laurel J. Brinton and Alexander Bergs. Berlin: Mouton de Gruyter, 2017. 8--35.
2023-03-12 Sun
■ #5067. 自然言語処理の前処理 [nlp][corpus]
自然言語処理 (nlp) の対象となるほとんどすべてのテキストのソースは,そのまま自然言語処理にフィードするわけにはいかない.適切な「前処理」を施して入力に相応しい形に整えた上でフィードすることが求められる.典型的な前処理としては,Vajjala (52ff) によれば次のようなものがある.それぞれタスクとして難易度の差があり,テキストソースの特徴や施したい処理の目的に応じて,必要なタスクと不要なタスクがあることに注意したい.
・ 文の分割
・ 単語への分割
・ ストップワード (stop word) の除去
・ ステミング
・ 見出し語化
・ 数字・句読点の除去
・ 小文字化
・ テキストの正規化 (text normalization)
・ 言語検出
・ コードミキシング
・ 翻字 (transliteration)
・ 品詞タグ付け
・ 構文解析
・ 共参照解決 (coreference resolution)
・ 関係抽出 (relation extraction)
・ 固有表現認識 (named entity recognition)
昨今は,多くの前処理タスクが,簡単なスクリプトにより,かなりの程度自動化できるようになってきているのでありがたい.ただし,既製の自動化スクリプトの利用はブラックボックスとなりがちなので,例えばコーパスの自作や編纂などをしようと思うのであれば,前処理の基本的な考え方は知っているほうがよいだろう.
・ Vajjala, Sowmya, Bodhisattwa Majumder, Anuj Gupta, Harshit Surana (著),中山 光樹(訳) 『実践 自然言語処理 --- 実世界 NLP アプリケーション開発のベストプラクティス』 オライリー・ジャパン,2022年.
2023-03-10 Fri
■ #5065. 自然言語処理 (NLP) の基本タスク [nlp][corpus][history_of_linguistics]
私の直接の専門からはほど遠いが,今をときめく言語に関する分野の1つに自然言語処理 (Natural Language Processing) がある.これ自体がとてつもなく広い領域を扱うし,来たるべきAI時代にあっては応用範囲も無限大だろう.コンピュータ・サイエンス,AI,機械学習,ディープ・ラーニングなどとも関連をもつ,この分野の本を読み出している.
私の専攻する英語史や歴史言語学の分野では,どのような話題が自然言語処理と関係してきただろうかと問うてみると,おおよそコーパス周りの技術だろう.正規化,レマ化,品詞タグ付け,コンコーダンスなど自然言語処理のタスクのなかでは最も基本的な部類に入るタスクだ.より直接的には,近代英語より前の時代のスペリングの正規化・標準化などの問題に関心がある.
入門書によれば,自然言語処理の基本タスクには様々なものがある.Vajjala 他の pp. 6--7 には,主要なものが列挙されている.
言語モデル
言語モデルは,単語の履歴に基づいて,次の単語を予測するタスクです.このタスクの目標は,ある言語における単語系列の出現確率を学習することです.言語モデルは,音声認識,光学式文字認識,手書き文字認識,機械翻訳,スペル修正など,幅広い問題のソリューションを構築するのに役立ちます.
テキスト分類
テキスト分類は,テキストをその内容に基づいて,事前に定義したカテゴリへ分類するタスクです.テキスト分類は NLP でもっとも一般的なタスクであり,電子メールのスパム識別からセンチメント分析まで,さまざまなツールで使われています.
情報抽出
情報抽出は,その名が示すように,テキストから関連情報を抽出するタスクです.たとえば,電子メールから予定を抽出したり,ソーシャルメディアの投稿で言及されている人名などの抽出に使えます.
情報検索
情報検索は,ユーザーのクエリに関連する文書を大規模な文書集合から検索するタスクです.よく知られたユースケースとして,Google 検索があります.
会話エージェント
会話エージェントは,自然言語での会話が可能な対話システムを構築するタスクです.よく知られたアプリケーションとして,Alexa や Siri があります.
テキスト要約
テキスト要約は,テキストの主な事柄と全体的な意味を維持しながら,元のテキストより短い要約を作成するタスクです.
質問応答
質問応答は,自然言語で尋ねられた質問に自動的に回答できるシステムを構築するタスクです.
機械翻訳
機械翻訳は,テキストをある言語から別の言語に変換するタスクです.よく知られたアプリケーションとして,Google 翻訳があります.
トピックモデル
トピックモデルは,大規模な文書集合のトピック構造を明らかにするタスクです.トピックモデルはテキストマイニングツールとしてよく使われており,文学からバイオインフォマティクスまで,幅広い分野で使われています.
自然言語処理は実用的なタスクをこなすための技術だが,そのベースには当然ながら言語学の知見が多く含まれている.そこから再出発して,自然言語処理の技術によって可能となった問題解決の手法が,いかにして英語史や歴史言語学の学術的問題に適用され得るのか.この辺りを考察していくことが,今後エキサイティングな課題となりそうだ.
・ Vajjala, Sowmya, Bodhisattwa Majumder, Anuj Gupta, Harshit Surana (著),中山 光樹(訳) 『実践 自然言語処理 --- 実世界 NLP アプリケーション開発のベストプラクティス』 オライリー・ジャパン,2022年.
2023-02-26 Sun
■ #5053. None but the brave deserve(s) the fair. 「勇者以外は美人を得るに値せず」 [pronoun][indefinite_pronoun][number][agreement][negative][proverb][clmet][coha][corpus]
昨日の記事「#5052. none は単数扱いか複数扱いか?」 ([2023-02-25-1]) で,none に関する数の一致の歴史的な揺れを覗いた.その際に標題の諺 (proverb) None but the brave deserve(s) the fair. 「勇者以外は美人を得るに値せず」を挙げた.この諺の出所は,17世紀後半の英文学の巨匠 John Dryden (1631--1700) である.詩 Alexander's Feast (1697) に,この表現が現われており,the brave = 「アレクサンダー大王」,the fair = 「アテネの愛人タイース」という構図で用いられている.
Happy, happy, happy pair!
None but the brave
None but the brave
None but the brave deserves the fair!
つまり,「原典」では3単現の -s が見えることから none が単数として扱われていることがわかる.the brave と the fair の各々について指示対象が個人であることが関係しているように思われる.
一方,Dryden の表現を受け継いだ後世の例においては,Speake の諺辞典,CLMET3.0,COHA などでざっと確認した限り,複数扱いが多いようである.19世紀からの例を3点ほど挙げよう.
・ 1813 SOUTHEY Life of Horatio Lord Nelson It is your sex that makes us go forth, and seem to tell us, 'None but the brave deserve the fair';
・ 1829 P. EGAN Boxiana 2nd Ser. II. 354 The tender sex . . . feeling the good old notion that 'none but the brave deserve the fair', were sadly out of temper.
・ 1873 TROLLOPE Phineas Redux II. xiii. All the proverbs were on his side. 'None but the brave deserve the fair,' said his cousin.
諺として一般(論)化したことで,また「the + 形容詞」の慣用からも,the brave や the fair がそれぞれ集合名詞として捉えられるようになったということかもしれない.いずれにせよ none の扱いの揺れを示す,諺の興味深いヴァリエーションである.
・ Speake, Jennifer, ed. The Oxford Dictionary of Proverbs. 6th ed. Oxford: OUP, 2015.
2023-02-19 Sun
■ #5046. silence と共起する形容詞 [adjective][collocation][bnc][corpus]
昨日の記事「#5045. deafening silence 「耳をつんざくような沈黙」」 ([2023-02-18-1]) で取り上げた共起表現について,BNCweb により例文を引き出してみた.いくつか挙げてみよう.
・ All that remained on the barren expanse was a deafening silence.
・ But the countryside! Absolute deafening silence. Not a tractor in sight. No buzzing saw mills, no electric milking machines humming away. Just horses and ploughs and, for want of a better word, peasants.
・ now there is almost a deafening silence, broken only by the odd apologetic cough as the minutes tick towards 8.30.
・ In the deafening silence inside the gallery she could hear her heart thumping madly against her ribs.
・ It was a relief when a couple of minutes later, amidst the deafening silence that had descended on the room, Mrs Aitken poked her head round the door. 'Dinner will be served whenever you're ready.'
この撞着語法 (oxymoron) の共起表現に関心を焚きつけられて,silence という名詞はほかにどのような形容詞で修飾されることが多いのだろうかと問いが湧いてきた.これは共起 (collocation) に関する初歩的な類いの疑問で,コロケーション辞書や活用辞書を引けば済む話しだが,行きがかり上 BNCweb で調べてみることにする."_AJ* {silence/N}" と検索した上で Frequency breakdown の機能を用い,50位までの頻度ランキングを出してみた.
| No. | Lexical items | No. of occurrences |
|---|---|---|
| 1 | long silence | 145 |
| 2 | stunned silence | 53 |
| 3 | complete silence | 44 |
| 4 | total silence | 43 |
| 5 | tense silence | 37 |
| 6 | awkward silence | 31 |
| 7 | brief silence | 28 |
| 8 | short silence | 27 |
| 9 | sudden silence | 23 |
| 10 | absolute silence | 22 |
| 11 | deafening silence | 22 |
| 12 | embarrassed silence | 22 |
| 13 | uncomfortable silence | 22 |
| 14 | shocked silence | 16 |
| 15 | stony silence | 15 |
| 16 | dead silence | 14 |
| 17 | deep silence | 13 |
| 18 | Eerie silence | 13 |
| 19 | heavy silence | 13 |
| 20 | small silence | 12 |
| 21 | thoughtful silence | 12 |
| 22 | uneasy silence | 12 |
| 23 | utter silence | 12 |
| 24 | ensuing silence | 11 |
| 25 | sullen silence | 11 |
| 26 | momentary silence | 10 |
| 27 | fraught silence | 9 |
| 28 | ominous silence | 9 |
| 29 | terrible silence | 9 |
| 30 | brooding silence | 8 |
| 31 | companionable silence | 8 |
| 32 | sponsored silence | 8 |
| 33 | virtual silence | 8 |
| 34 | dignified silence | 7 |
| 35 | horrified silence | 7 |
| 36 | Hushed Silence | 7 |
| 37 | lengthy silence | 7 |
| 38 | long silences | 7 |
| 39 | longer silence | 7 |
| 40 | strained silence | 7 |
| 41 | uncanny silence | 7 |
| 42 | awful silence | 6 |
| 43 | cold silence | 6 |
| 44 | comparative silence | 6 |
| 45 | continuing silence | 6 |
| 46 | embarrassing silence | 6 |
| 47 | gloomy silence | 6 |
| 48 | great silence | 6 |
| 49 | strange silence | 6 |
| 50 | angry silence | 5 |
deafening silence も10位タイに入っており,それなりに知られた共起表現だということがわかる.stunned silence, stony silence, dead silence など味わい深い表現があるものだ.
[ 固定リンク | 印刷用ページ ]
2023-02-02 Thu
■ #5029. 家入先生と Voicy 対談の第2弾 --- 新著『文献学と英語史研究』より英語史コーパスのいま・むかし [voicy][heldio][bunkengaku][notice][corpus][history_of_linguistics][hel_education][link][hel_herald]
昨日の Voicy 「英語の語源が身につくラジオ (heldio)」にて,新著『文献学と英語史研究』(開拓社)の共著者である家入葉子先生(京都大学)との対談の第2弾をお届けしました.「#611. 家入葉子先生との対談の第2弾:新著『文献学と英語史研究』より英語史コーパスについて語ります」と題して,英語史コーパスの世代変化についての20分ほどの対談です.凝縮した英語史コーパス論となっております.ぜひお聴きください.
対談の後半では,現在の英語史研究ではコーパス利用が当たり前になってきているという点に話が及びました.コーパス言語学 (corpus linguistics) は発展的解消の段階にある,とみることができそうです.その一方で,コーパスが当たり前の道具になってきているからこそ,コーパスの落とし穴に気づきにくくなってきているようにも思えます.どんな道具もそうですが,道具は上手に使うことが大事です.
今回の対談を通じて英語(史)のコーパスに関心を持った方は,hellog より「#3676. 英語コーパスの使い方」 ([2019-05-21-1]) を始めとして corpus の各記事をお読みいただければと思います.
khelf(慶應英語史フォーラム)発行の『英語史新聞』の最新号(第4号)の1面コラム「英語コーパスをもっと気軽に」も英語コーパス超入門として一読ください.
新著『文献学と英語史研究』(開拓社)もどうぞよろしくお願いいたします!

Powered by WinChalow1.0rc4 based on chalow