2018-08-24 Fri
■ #3406. Levenshtein distance [cgi][web_service][spelling][shakespeare][levenshtein_distance]
文字列の類似度や相違度を測る有名な指標の1つに,標題の "Levenshtein distance" というものがある,「#3397. 後期中英語期の through のワースト綴字」 ([2018-08-15-1]),「#3398. 中英語期の such のワースト綴字」 ([2018-08-16-1]),「#3399. 綴字の類似度計算機」 ([2018-08-17-1]) でも前提としてきた指標であり,「#1163. オンライン語彙データベース DICT.ORG」 ([2012-07-03-1]) でもこの指標を利用して類似綴字語を取り出すオプションがある.
考え方は難しくない.もとの文字列から目標の文字列に変換するには,いくつの編集工程(挿入,削除,置換)が必要かを数えればよい.例えば,kitten から sitting へ変換するには,kitten →(k を s に置換)→ sitten →(e を i に置換)→ sittin →(g を挿入)→ sitting という3工程を踏む必要があるので,両綴字間の Levenshtein distance は3ということになる.通常は挿入,削除,置換の編集工程にそれぞれ1の値を割り当てるが,各々に異なる値を与える計算の仕方もある.
以下に,通常の重みづけで Levenshtein distance を計測する CGI を置いておく.試しに「#1720. Shakespeare の綴り方」 ([2014-01-11-1]) より25種類の異綴字を取り出して,カンマ区切りなどで下欄に入力してみてください(要するに以下をコピペ).Shakespeare, Schaksp, Shackespeare, Shackespere, Shackspeare, Shackspere, Shagspere, Shakespe, Shakespear, Shake-speare, Shakespere, Shakespheare, Shakp, Shakspe?, Shakspear, Shakspeare, Shak-speare, Shaksper, Shakspere, Shaxberd, Shaxpeare, Shaxper, Shaxpere, Shaxspere, Shexpere
綴字間の類似度や相違度の計測は,曖昧検索やスペリングチェックなどの実用的な目的にも応用されている.標準的な綴字がなかった古い英語の研究にも,ときに役立つことがありそうだ.
2018-08-17 Fri
■ #3399. 綴字の類似度計算機 [cgi][web_service][spelling][shakespeare][levenshtein_distance]
この2日間の記事「#3397. 後期中英語期の through のワースト綴字」 ([2018-08-15-1]),「#3398. 中英語期の such のワースト綴字」 ([2018-08-16-1]) で,異綴字間の類似性を計算するスクリプトを利用して,through と such の様々な綴字を比較した.このスクリプトは,ある程度使い勝手があるかもしれないと思い,より汎用的な形で CGI を組んでみた.
ところが,スクリプトの内部的な仕様の関係でサーバ上で動かないということが発覚.残念無念.公開しても無意味であることを承知のうえ,以下に置いておこうと思います(せっかく作ったのだし,私自身のローカルPCでは動いているので・・・).すみません.
と,これではあんまりなので,Shakespeare の異綴字を比較した結果を披露しておきます.「#1720. Shakespeare の綴り方」 ([2014-01-11-1]) で挙げた25種類の異綴字 Shakespeare, Schaksp, Shackespeare, Shackespere, Shackspeare, Shackspere, Shagspere, Shakespe, Shakespear, Shake-speare, Shakespere, Shakespheare, Shakp, Shakspe?, Shakspear, Shakspeare, Shak-speare, Shaksper, Shakspere, Shaxberd, Shaxpeare, Shaxper, Shaxpere, Shaxspere, Shexpere を入力して,ソートさせると,次のような出力が得られた.
| Similarity | Spellings |
|---|---|
| 1.0000 | Shakespeare |
| 0.9565 | Shackespeare, Shake-speare, Shakespheare |
| 0.9524 | Shakespear, Shakespere, Shakspeare |
| 0.9091 | Shackespere, Shackspeare, Shak-speare |
| 0.9000 | Shakspear, Shakspere |
| 0.8571 | Shackspere |
| 0.8421 | Shakespe, Shaksper |
| 0.8000 | Shagspere, Shaxpeare, Shaxspere |
| 0.7368 | Shaxpere, Shexpere |
| 0.7000 | Shakspe? |
| 0.6667 | Schaksp, Shaxper |
| 0.6250 | Shakp |
| 0.5263 | Shaxberd |
類似度が0.7以下のものは,およそ省略である.0.7を超えるものは,およそ許せるように感じられるのがおもしろい.
2018-01-11 Thu
■ #3181. Spelling/Pronunciation Search [spelling][pronunciation][orthography][web_service][cgi][dictionary][spelling_pronunciation_gap][silent_letter]
「#1191. Pronunciation Search」 ([2012-07-31-1]) で,The Carnegie Mellon Pronouncing Dictionary に基づくアメリカ英語発音検索ツールを作成した.そのデータベース (3MB+) の実体は,110935対の綴字と発音の組み合わせである.前回のツールは,Carnegie Mellon Pronouncing Dictionary の発音表記を正規表現で指定して,それを含む単語の綴字を返すものだったが,今回は綴字と発音のそれぞれに正規表現で条件を指定し,いずれにもマッチする単語を返すという仕様のツールを作ってみた.
正規表現は Perl 用のもので,大文字・小文字の別は最初から無視する仕様.発音表記の凡例は,本記事の末尾に掲げておいた.どちらか一方の検索欄を空にすれば,純粋な綴字検索あるいは発音検索になる.
2017-10-13 Fri
■ #3091. Baugh and Cable の英語史概説書の目次よりランダムにクイズを作成 [toc][quiz][hel_education][cgi][web_service]
英語史の流れをつかんでもらうために,授業で「#2089. Baugh and Cable の英語史概説書の目次」 ([2015-01-15-1]) を暗記してもらっているが,小テスト対策のために(というよりも実は問題作成の自動化のために)ランダムに穴を抜くツールを作ってみた.ブラウザで印刷すれば,そのまま小テスト.
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 6th ed. London: Routledge, 2013.
2017-09-23 Sat
■ #3071. Pig Latin [cryptology][word_play][cgi][web_service]
英語の言葉遊びで Pig Latin というものがある.単語を一定の原則に基づいて変形する遊びだが,その原則は単純である.語頭の子音(群)を語尾に移し,さらにそこに <ay> /eɪ/ を追加する.語頭が母音の場合には,語尾に <way> /weɪ/ を追加するのみ.例えば,Pig Latin は Igpay Atinlay となり,I dont know. は Iway ontday nowkay. となる.語頭の子音(群)の扱いの差異や,語尾としての <way> /weɪ/ の代わりに <yey> /weɪ/ を用いるなどの変種もみられる.
慣れてしまえば即興で作れるが,慣れていない者にとって理解が難しいことから,言葉遊びにとどまらず,話し言葉における隠語やちょっとした暗号として用いることもできる.言葉遊びと暗号の距離は意外と近い.
Pig Latin のほか,より古い Hog Latin という呼称もある.前者は19世紀末,後者は19世紀初めに初出している.いずれも「崩れたラテン語」「偽のラテン語」ほどの意味である.実際にはラテン語と縁もゆかりもないが,格変化のような語尾が付き,理解しにくいという点で,ラテン語に擬せられたということだろう.なお,崩れたラテン語を表わす dog Latin という表現は17世紀半ばに初出しているが,こちらは変則的ながらも一応のところラテン語ベースである.
以下,Pig Latin 変換器を実装したのでお試しあれ.
2016-09-22 Thu
■ #2705. カエサル暗号機(hellog 版) [cryptology][grammatology][cgi][web_service][statistics]
「#2704. カエサル暗号」 ([2016-09-21-1]) と関連して,文字遊びのために「カエサル暗号機」を作ってみた.まずは,最も単純な n 文字シフトの方針により,入力文字列を符号化 (encipher) あるいは復号化 (decipher) するだけの機能.バックエンドに Perl の Text::Cipher::KeywordAlphabet モジュールを利用している.
次に,下の暗号機は復号機能のみを実装しているが,英語の各文字の出現頻度に基づいた統計を利用して,n の値が不明でもカエサル暗号を解読してしまうことができる.
このカエサル暗号とその発展形は,西洋の古代・中世を通じて1500年以上ものあいだ最も普通に用いられたが,原理は驚くほど単純である.現在では暗号学者ならずとも普通の人にもコンピュータを使って簡単に解読できてしまい,暗号とは呼べないほどに安全性は低いが,メッセージを隠したいという人間の欲求の生み出した,本格的な暗号文化の幕開きを代表する手法だった.歴史的意義は大きい.
[ 固定リンク | 印刷用ページ ]
2016-09-07 Wed
■ #2690. N-gram Tool [cgi][n-gram][statistics][corpus][web_service][frequency][cgi]
n-gram は,言語統計やコーパス言語学の世界における基本的な概念・手段である(「#2324. n-gram」 ([2015-09-07-1]), 「#956. COCA N-Gram Search」 ([2011-12-09-1]) を参照).テキストを指定してその n-gram を得るツールはネットその他にも遍在しているが,あえて簡易ツールをCGIで実装してみた.バックエンドに Perl モジュールの Text::Ngrams を用いている.
使い方はおよそ自明だろう.適当な長さの英文テキストを投げ込めば,デフォルトでは単語ベースの 3-gram (およびそれ以下の 2-gram と 1-gram も含む)の一覧が絶対頻度の高い順に返される(出力行の制限はなし).オプションにより単語ベースではなく文字ベースにも変更でき,n-gram のサイズも変えられる.出力については,頻度順ではなくアルファベット順にすること,出力行に制限を設けること,絶対頻度ではなく相対頻度(各 n-gram 内で合計すると1.0となる)で返すことも可能.
なお,1-gram は入力テキストを構成する単語の頻度表となるので,その用途にも利用できる.簡易的な n-gram ツールとしてどうぞ.
[ 固定リンク | 印刷用ページ ]
2016-09-07 Wed
■ #2690. N-gram Tool [cgi][n-gram][statistics][corpus][web_service][frequency][cgi]
n-gram は,言語統計やコーパス言語学の世界における基本的な概念・手段である(「#2324. n-gram」 ([2015-09-07-1]), 「#956. COCA N-Gram Search」 ([2011-12-09-1]) を参照).テキストを指定してその n-gram を得るツールはネットその他にも遍在しているが,あえて簡易ツールをCGIで実装してみた.バックエンドに Perl モジュールの Text::Ngrams を用いている.
使い方はおよそ自明だろう.適当な長さの英文テキストを投げ込めば,デフォルトでは単語ベースの 3-gram (およびそれ以下の 2-gram と 1-gram も含む)の一覧が絶対頻度の高い順に返される(出力行の制限はなし).オプションにより単語ベースではなく文字ベースにも変更でき,n-gram のサイズも変えられる.出力については,頻度順ではなくアルファベット順にすること,出力行に制限を設けること,絶対頻度ではなく相対頻度(各 n-gram 内で合計すると1.0となる)で返すことも可能.
なお,1-gram は入力テキストを構成する単語の頻度表となるので,その用途にも利用できる.簡易的な n-gram ツールとしてどうぞ.
[ 固定リンク | 印刷用ページ ]
2015-09-19 Sat
■ #2336. Text Analyser --- 簡易テキスト統計分析器 [cgi][text_tool][web_service][corpus]
最近では,テキスト分析のための高機能なツールが手軽に入手できるようになった.英語コーパスを分析するプログラムなどでは,使用語数に基づいて様々な統計値が計算され,見やすい形で提示される.そのようなツールを改めて公開する必要もないといえばないが,簡易テキスト統計分析器の CGI を作成してみたので,ここに hellog 版ということで設置しておきたい.テキストボックスに文章を投げ込むだけ.
背後では Perl モジュール Lingua::EN::Fathom を使用しているが,語や文の認識や音節カウントなど,自動では完全解決の難しい問題も多くあるため,結果としての統計値は近似的なものとして理解されたい.今回のバージョンでは,以下の14の統計値を示すことにした.
(1) Number of characters
(2) Number of words (tokens)
(3) Number of types
(4) Type/token ratio
(5) Per cent of complex words
(6) Average syllables per word
(7) Number of sentences
(8) Average words per sentences
(9) Number of text lines
(10) Number of blank lines
(11) Number of paragraphs
(12) Fog index
(13) Flesch reading ease score
(14) Flesch-Kincaid grade level score
多くの統計値の意味は自明と思われるが,いくつかについて注記しておく.(4) Type/token ratio は,語彙の多様性を示す指標である.テキスト内のすべての語が各々1度きり現われる場合には,最大値 1.0 を示す.ただし,テキストの長さに大きく依存するため,この指標単体ではさほど情報量はない.
(5) Per cent of complex words の "complex words" とは,3音節以上の語の割合である.(12), (13), (14) は,テキストの読みやすさの指標であり,いずれも1文あたりの語数 (words_per_sentence) と1語あたりの音節数 (syllables_per_word) に基づいて計算されている.各指標の特徴と解釈の仕方を以下に略述する.
(12) The Fog index
読みやすさを表わす簡便な指標.( words_per_sentence + percent_complex_words ) * 0.4 で求めることができる.指標の数値は学年を表わし,その学年の標準的な生徒であれば,その文章を一度読んで理解できる水準といわれる.目安としては,8 = childish, 10 = acceptable, 12 = ideal, 14 = difficult, 18 = unreadable.
(13) The Flesch reading ease score
206.835 - (1.015 * words_per_sentence) - (84.6 * syllables_per_word) で求められる.最高点は100点で,指標が高ければ高いほど理解しやすいテキストである.60--70点が最適とされる.
(14) Flesch-Kincaid grade level score
(11.8 * syllables_per_word) + (0.39 * words_per_sentence) - 15.59 で求められる.指標は米国の学年を表わし,例えば 8.0 であれば,そのテキストは第8学年の生徒に理解できる水準ということになる.7.0--8.0 が最適値とされる.
2015-06-24 Wed
■ #2249. 綴字の余剰性 [spelling][orthography][cgi][web_service][redundancy][information_theory][punctuation][shortening][alphabet][q]
言語の余剰性 (redundancy) や費用の問題について,「#1089. 情報理論と言語の余剰性」 ([2012-04-20-1]),「#1090. 言語の余剰性」 ([2012-04-21-1]),「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]),「#1098. 情報理論が言語学に与えてくれる示唆を2点」 ([2012-04-29-1]),「#1101. Zipf's law」 ([2012-05-02-1]) などで議論してきた.言語体系を全体としてみた場合の余剰性のほかに,例えば英語の綴字という局所的な体系における余剰性を考えることもできる.「#1599. Qantas の発音」 ([2013-09-12-1]) で少しく論じた通り,例えば <q> の後には <u> が現われることが非常に高い確立で期待されるため,<qu> は余剰性の極めて高い文字連鎖ということができる.
英語の綴字体系は全体としてみても余剰性が高い.そのため,英語の語彙,形態,統語,語用などに関する理論上,運用上の知識が豊富であれば,必ずしも正書法通りに綴られていなくとも,十分に文章を読解することができる.個々の単語の綴字の規範からの逸脱はもとより,大文字・小文字の区別をなくしたり,分かち書きその他の句読法を省略しても,可読性は多少落ちるものの,およそ解読することは可能だろう.一般に言語の変化や変異において形式上の短縮 (shortening) が日常茶飯事であることを考えれば,非標準的な書き言葉においても,綴字における短縮が頻繁に生じるだろうことは容易に想像される.情報理論の観点からは,可読性の確保と費用の最小化は常に対立しあう関係にあり,両者の力がいずれかに偏りすぎないような形で,綴字体系もバランスを維持しているものと考えられる.
いずれか一方に力が偏りすぎると体系として機能しなくなるものの,多少の偏りにとどまる限りは,なんとか用を足すものである.主として携帯機器用に提供されている最近の Short Messages Service (SMS) では,使用者は,字数の制約をクリアするために,メッセージを解読可能な範囲内でなるべく圧縮する必要に迫られる.英語のメッセージについていえば,綴字の余剰性を最小にするような文字列処理プログラムにかけることによって,実際に相当の圧縮率を得ることができる.電信文体の現代版といったところか.
実際に,それを体験してみよう.以下の "Text Squeezer" は,母音削除を主たる方針とするメッセージ圧縮プログラムの1つである(Perl モジュール Lingua::EN::Squeeze を使用).入力するテキストにもよるが,10%以上の圧縮率を得られる.出力テキストは,確かに可読性は落ちるが,慣れてくるとそれなりの用を足すことがわかる.適当な量の正書法で書かれた英文を放り込んで,英語正書法がいかに余剰であるかを確かめてもらいたい.
2015-04-15 Wed
■ #2179. IPA の肺気流による子音の分類 (2) [phonetics][consonant][ipa][chart][hel_education][cgi][web_service]
「#1813. IPA の肺気流による子音の分類」 ([2014-04-14-1]) に引き続き,調音音声学に関する図表について.Carr (xx--xxi) の音声学の教科書に,調音器官の図とIPAの分節音の表が見開きページに印刷されているものを見つけたので,スキャンした(画像をクリックするとPDFが得られる).
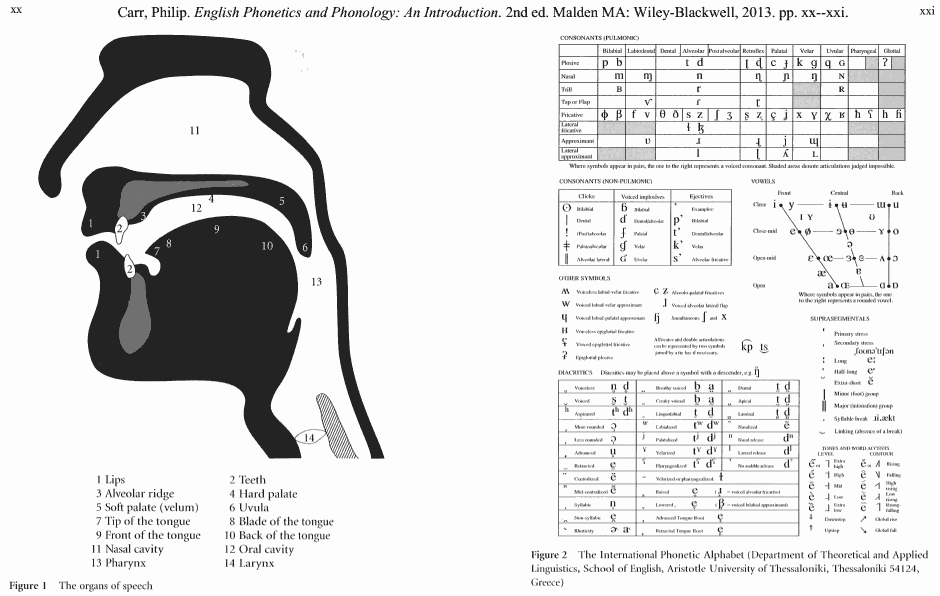
特に右上にある肺気流による子音の分類表について,学習の一助になるようにと,表の穴埋め問題生成ツールを以下に作ってみた.調音音声学の学習の一助にどうぞ.
・ Carr, Philip. English Phonetics and Phonology: An Introduction. 2nd ed. Malden MA: Wiley-Blackwell, 2013.
[ 固定リンク | 印刷用ページ ]
2015-01-22 Thu
■ #2096. SUBTLEX-US Word Frequency List [frequency][statistics][corpus][lexicology][zipfs_law][cgi][web_service]
従来の英語学研究において,権威ある語彙頻度表といえばアメリカ英語に関する Kucera and Francis (1967) のものや,イギリス英語に比重を置いたより新しいものとして CELEX (1993) やその2版 (cf. 「#1424. CELEX2」 ([2013-03-21-1])) がよく用いられてきた.しかし,最近,これらを批判し,新しい手法に基づいたアメリカ英語の語彙頻度表が現われた.ベルギー,ヘント大学の実験心理学科の提供する SUBTLEXus である.左のHPから,SUBTLEXus の一群の頻度表のファイルや記述がダウンドーロできる.
SUBTLEXus の基盤にあるコーパスは,8388件の映画の字幕の集成であり,総語数は5100万語に及ぶ.SUBTLEXus の頻度表は,Kucera and Francis や CELEX の頻度表と比べて,いくつかの算出された指標においてすぐれていると主張されている.頻度は,見出し語 (lemma) ごとではなく語形 (word form) ごとに数えられており,例えば名詞であれば単数形と -s 語尾などをもつ複数形は別扱いされる(異なる語形は74,286種類).名詞と動詞など複数の品詞として用いられる語形については,それぞれの品詞ごとの頻度にもアクセスできるし,より優勢な品詞 (Dominant POS) のほうへ合算した頻度へもアクセスできる.データには,ほかに何件の映画に現われているか,小文字として現われているのは何回か,頻度の対数を取った指標,Zipf 指標 (cf. 「#1101. Zipf's law」 ([2012-05-02-1])) なども含まれている.これだけの種類のデータが含まれていると,目的とアイデア次第でおおいに有効に利用できるだろう.話し言葉ベースであることも顕著な特徴だ.
ダウンロードできるいくつかのデータのなかで "a zipped Excel file of SUBTLEX-US with the Zipf values included" をダウンロードし,少しいじってみた.例えば,(1) 全体的に多く現われ,かつ (2) 多くの映画にも現われる語形は,総合的な意味で頻度が高いと考えられるだろう.そこで (1) と (2) に関する対数の指標を掛け合わせて,それを降順に並べて最初の100語を取ると,正真正銘の最頻単語100語が得られるはずだ.省略形の片割れなども含まれているが,以下がそのリストである.
you, I, the, to, s, a, it, t, that, and, of, what, in, me, is, we, this, he, on, for, my, m, your, don, have, do, re, no, be, know, was, not, can, are, all, with, just, get, here, but, there, ll, so, they, like, right, out, go, up, about, she, if, him, got, at, now, come, oh, one, how, well, want, yeah, her, think, good, see, let, did, why, who, as, going, his, will, from, when, back, time, yes, look, d, take, an, where, man, would, them, been, some, or, tell, us, had, were, say, could, gonna, didn, hey
ほかには,最頻10語,25語,50語,100語,250語,500語,1,000語,2,500語,5,000語,10,000語,25,000語,50,000語,100,000語について,Dominant POS ごとに数え上げてみることもたやすい.「#666. COCA 最頻5000語で品詞別の割合は?」 ([2011-02-22-1]),「#667. COCA 最頻50万語で品詞別の割合は?」 ([2011-02-23-1]),「#1132. 英単語の品詞別の割合」 ([2012-06-02-1]) の記事でも,別のコーパスにより似たような調査を行ったが,SUBTLEX-US 版の調査結果は次のグラフにまとめられる.
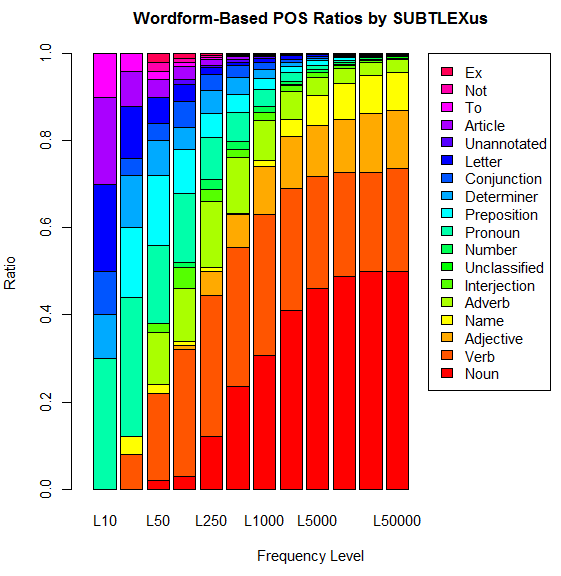
以下はおまけの検索ツール (SUBTLEX-US Word Frequency Extractor) .おまけなので,10例までしか結果が出力されない仕様です.SUBTLEXus の提供する複雑な検索も可能な,SUBTLEXus Online Search もどうぞ.
2014-04-20 Sun
■ #1819. AHD Word History Note Search [etymology][dictionary][cgi][web_service]
「#1809. American Heritage Dictionary の Notes」 ([2014-04-10-1]) で,The Free Dictionary 上でアクセスできる Notes へのリンク集を作った(Notes 集そのものは,1.6MBあるこちらのページへ).今回は,そのなかから Word Histories に関する Notes を集めたものをデータベース化し,「#952. Etymology Search」 ([2011-12-05-1]) の要領で,検索ツール "AHD Word History Note Search" を作ってみた.
語源記事が登録されている見出し語を検索するだけであれば,上のリンク集で単語を検索すればよく,このツールの有用性はあまりない.このツールの特徴は,Notes の中身を正規表現で検索できる仕様(デフォルト)にある.例えば,日本に何らかの言及のある英単語の語源コラムを得たいのであれば,下の検索ボックスに Japan と入れればよいし,アイルランド関係であれば (Irish|Ireland) などだ.ほかには,search range を "Search for entry words" に入れ替えて,^[A-Z] と検索ボックスに入れると,固有名詞の語源コラムを集められる,等々.
2014-04-09 Wed
■ #1808. ARCHER 検索結果の時代×ジャンル仕分けツール (ARCHER Period-Genre Sorter) [cgi][web_service][corpus][archer][mode]
この2日間の記事「#1806. ARCHER で shew と show」 ([2014-04-07-1]) と「#1807. ARCHER で between と betwixt」 ([2014-04-08-1]) で,ARCHER の Untagged 版 を用いて,語の変異形の頻度が通時的にどのように推移してきたかを調査した.
近代英語の初期から後期を含むコーパスとしては,ほかに CEECS (The Corpus of Early English Correspondence, LC (The Lampeter Corpus of Early Modern English Tracts), CLMET3.0 (The Corpus of Late Modern English Texts, version 3.0), PPCMBE, COHA などがあり,それぞれに特徴があるが,ARCHER は,1600--1999年というまとまった期間をカバーし,英米変種それぞれについてジャンル分けがなされており,比較的大型の歴史コーパスとして価値が高い.しかし,「#1802. ARCHER 3.2」 ([2014-04-03-1]) で紹介した通り,現在ウェブ上で一般公開されている版については,いまだタグ検索などが実装されておらず,可能性を最大限に利用することはできない.しかし,工夫次第でいろいろと活用できる.実装されている Frequency lists や Keywords の機能はアイディア次第で有効に使えそうだし,コーパス全体の単語頻度リスト (TXT)も公開されている.
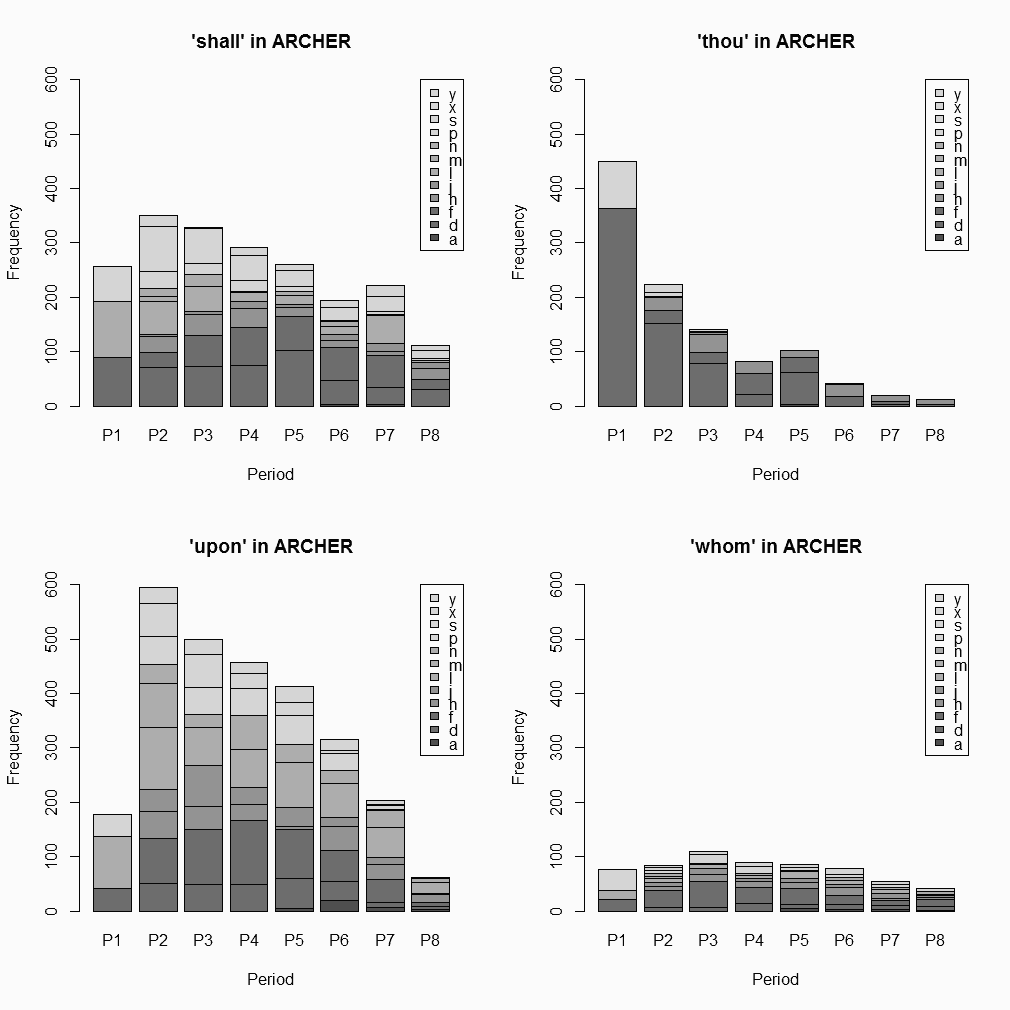
通時的な言語変化という観点から ARCHER に望む機能は,この2日間の記事で調査したように,ある検索語の頻度が時期を追って(ついでにジャンル別に)どのように推移してきたかを,簡単に確認できるようにすることだ.Restricted query で時期とジャンルを絞り,検索欄に検索語を入力してヒット数を数えてゆくということは手作業でできるが,時間がかかるし面倒だ.「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) や COHA では,この通時的な一覧を可能にする機能が実装されているので,ARCHER でも余計に同様の機能が欲しくなる.そこで,欲しいのならば作ってしまおうということで,簡単なスクリプトを組んだ.ARCHER の検索結果のコンコーダンス・ラインには,テキストを表わすファイル名が付されているが,ファイル名の仕様によれば,末尾3文字がそれぞれジャンル,時期,英米変種のいずれかを表わす記号となっている.そこで,検索結果をコピーして,以下のテキストボックスに貼り付けてやると,適切にファイル名を解析し,時期,ジャンル,変種ごとにヒット数を整理してくれ,グラフ化してくれるというツール (ARCHER Period-Genre Sorter) を作成した.ARCHER での出力結果が数ページにまたがる場合には,少し手数がかかるが,各ページをコピペして累積していけばよい.
このツールの使用の応用例として,ここ数世紀の間で使用頻度が衰退しただろうと疑われる4語,shall, thou (= thou, thy, thee, thine), upon, whom を取り上げる.今回は,イギリス英語のサブコーパスのみに限定した.以下は,ツールが返した集計表をもとにグラフ化したものである.(ツールがどのように機能するかを確認するために,試しに ARCHER による 'thou' の出力結果のテキストファイル (194KB) の内容を上のテキストボックスにコピペされたい.)
2014-04-06 Sun
■ #1805. Morse code [semiotics][sign][double_articulation][cgi][web_service][morse_code]
標題は,アメリカの画家・発明家 Samuel Finley Breese Morse (1791--1872) が発明した電信用の符合.トン・ツーとも称される.短点 (dot),その3倍の長さからなる長点 (dash),空白 (space) の組み合わせからなり,その組み合わせがアルファベットや数字に対応する.
Morse は,1830年代に電信符号の着想を得て,1838年に後のモールス符号の原型を築いた.その後,1844年に Baltimore から Washington への最初の電信を開通させ,歴史的な最初のメッセージ "What has God wrought!" を送信した.彼の発明は世界的な反響を呼び,その後,ヨーロッパで改訂が加えられ,1851年に国際会議により International (or Continental) Morse Code が制定された.1938年に小さな変更が加えられたが,現在に至るまで国際的には国際版が原則として用いられている(ただし,アメリカはオリジナル版の使用にこだわり続けた).モールス符号による電信は,電話やラジオの発明により世界的に影が薄くなったが,劣悪な通信環境でも最低限の情報交換が可能であることから,21世紀の現在でも完全に無用となったわけではない.別途,和文モールス符合などの言語別変種も現れたが,現在ではアマチュア無線家による利用などに使用範囲が限られている.
記号論的には,モールス符号はいくつかの特徴をもった記号体系である.最たる特徴は,言語,とりわけ文字言語に大きく依存した記号体系であるということだろう.自立した記号体系というよりは,言語の代用記号といってよく,その点では点字や手旗信号やタムタムの太鼓言語と同様である.Saussure や「#1074. Hjelmslev の言理学」 ([2012-04-05-1]) の用語でいえば,実質 (substance) が変わっただけで,形相 (form) は変わっていないということになる.モールス符号では,あるトン・ツーの組み合わせが,アルファベット1文字に厳密に対応しており,それがもとの文字列と同じ順序で時間上あるいは空間上に配列される.そこに並び順という統辞論はあるにはあるが,それは自立した固有の統辞論ではなく,背後にある文字言語の統辞論をなぞったものにすぎない(池上,p. 125).
モールス符号のもう1つの特徴は,言語の写しであるとはいいつつも,言語とは異なる二重分節 (double_articulation) をもっていることだ.言語のように二重分節を有する記号体系というのは珍しいが,モールス符号は人工的な記号体系であるから,そこに二重分節の経済性が意図的に組み込まれたということは驚くべきことではないだろう(二重分節をもつほかの記号体系として,遺伝子の情報伝達,楽譜,電話番号などもある).しかし,言語とは異なる形で二重分節が組み込まれていることは注目に値する.モールス符号では,言語の音素に相当するものはトンとツーの2種類である.この2種類の「音素」を決まった順序で決まった個数組み合わせることで,1つの文字に対応する「形態素」を作りだし,そのような「形態素」を上記の言語依存の統辞論に則って配列してゆくのだ(池上,p. 87).ほかには,コードの規程が強い,余剰性が低いなどの特徴も挙げられよう.
では,国際モールス符号の実際をみてみよう.規約の詳細は,Recommendation ITU-R M.1677-1 (10/2009) International Morse code (PDF) より確認できる.一般の(英文)テキストと国際モールス符合の変換器は,ウェブ上に Morse Code Translator などいろいろなものがあるが,以下に hellog 版を作ってみた.テキストあるいはモールス符号を入力すると,他方へ変換される仕様.
例えば,What has God wrought! を入力すると,.-- .... .- - .... .- ... --. --- -.. .-- .-. --- ..- --. .... - -.-.-- が得られる.そして,... --- ... と入力すると,SOS が返される.なお,SOS はモールス符号として打ちやすく聞きやすい文字を並べたものであり,それ自体に意味があるものではない.
・ ピエール・ギロー 著,佐藤 信夫 訳 『記号学』 白水社〈文庫クセジュ〉,1972年.
・ 池上 嘉彦 『記号論への招待』 岩波書店〈岩波新書〉,1984年.
2014-02-03 Mon
■ #1743. ICE Frequency Comparer [corpus][web_service][cgi][frequency][new_englishes][variety][ice]
「#1730. AmE-BrE 2006 Frequency Comparer」 ([2014-01-21-1]), 「#1739. AmE-BrE Diachronic Frequency Comparer」 ([2014-01-30-1]) で,the Brown family of corpora ([2010-06-29-1]の記事「#428. The Brown family of corpora の利用上の注意」を参照)を利用した,変種間あるいは通時的な頻度比較ツールを作った.Brown family といえば,似たような設計で編まれた ICE (International Corpus of English) も想起される([2010-09-26-1]の記事「#517. ICE 提供の7種類の地域変種コーパス」を参照).1990年以降の書き言葉と話し言葉が納められた100万語規模のコーパス群で,互いに比較可能となるように作られている.
そこで,手元にある ICE シリーズのうち,Canada, Jamaica, India, Singapore, the Philippines, Hong Kong の英語変種コーパス計6種を対象に,前と同じように頻度表を作り,データベース化し,頻度比較が可能となるツールを作成した.使い方については,「#1730. AmE-BrE 2006 Frequency Comparer」 ([2014-01-21-1]) を参照されたい.
どんな使い道があるかは,アイデア次第だが.例えば,"^snow(s|ed|ing)?$", "^Japan(ese)?$", "^bananas?$", "^Asia(n?)s?$" などで検索してみるとおもしろいかもしれない.
2014-01-30 Thu
■ #1739. AmE-BrE Diachronic Frequency Comparer [corpus][ame_bre][web_service][cgi][frequency][representativeness]
「#1730. AmE-BrE 2006 Frequency Comparer」 ([2014-01-21-1]) で,2006年前後の書き言葉テキストを編纂した英米各変種コーパスを紹介し,それに基づいた頻度比較ツールを作成・公開した.そのツールを作成しながら気づいたのだが,同じ方法で編纂され,規模も同じく100万語程度の the Brown family of corpora (「#428. The Brown family of corpora の利用上の注意」 ([2010-06-29-1]))と連携させれば,直近50年間ほどの通時的な英米間頻度比較が容易に可能となる.
そこで,前の記事で紹介した Professor Paul Baker - Linguistics and English Language at Lancaster University による AmE06 と BrE06 に加えて,書き言葉アメリカ英語を代表する Brown (1961), Frown (1992),書き言葉イギリス英語を代表する LOB (1961), FLOB (1991) より語形頻度表を抽出し,合わせてデータベース化した.利用の仕方は,AmE-BrE 2006 Frequency Comparer とほぼ同じなので,そちらの取説 ([2014-01-21-1]) を参照されたい.ただし,出力される表では,問題の語形が出現するテキストの数や頻度順位は省いており,純粋に約100万語当たりの頻度を表示するにとどめているので,AmE06 と BE06 について前者の情報が必要な場合には,AmE-BrE 2006 Frequency Comparer をどうぞ.
例えば,^movies?$ と入力してみると,伝統的にアメリカ英語的とされてきたこの語の分布が,過去50年ほどの間に,イギリス英語にも浸透してきている様子がわかる.
英米差の通時的な変化を調査したいのであれば,単語だけではなく語句も受けつけ,かつ規模も巨大な「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) のほうが簡便だろう.しかし,今回のツールは,the Brown family of corpora をベースにしているがゆえに,(1) 均衡かつ比較可能であり,(2) 「素性」がわかっている(再現可能性が確保されている)という利点があることは指摘しておきたい.望ましいのは,小型できめ細かなコーパスと,大型で傾向を大づかみにするコーパスとを上手に連携させることだろう.
2014-01-21 Tue
■ #1730. AmE-BrE 2006 Frequency Comparer [corpus][ame_bre][web_service][cgi][frequency][spelling]
先日,Professor Paul Baker - Linguistics and English Language at Lancaster University というページを教えてもらった.Baker 氏の編纂した現代英語・米語コーパス BE06 と AmE06 の情報と,そこから抽出した単語リストが得られる.当該のコーパス自体は,ユーザIDを請求すれば,ランカスター大学の CQP (Corpus Query Processor) system よりアクセスできる.
BE06 と AmE06 は,2006年前後に出版されたイギリス変種とアメリカ変種の書き言葉均衡コーパスである.編纂方式や構成は「#428. The Brown family of corpora の利用上の注意」 ([2010-06-29-1]) で紹介した The Brown family に準じており,500テキスト×2000語の計100万語ほどの規模だ.
さて,上のページからダウンロードできる BE06 Wordlist in WordSmith 5 format と AmE06 Wordlist in WordSmith 5 format より(見出し語ではなく)語形による頻度表を抽出し,それぞれをデータベース化して,英米変種の語の頻度を比較してくれる AmE-BrE Frequency 2006 Comparer なるツールを作成してみた.
入力するのは原則としてPerl5相当の正規表現だが,カンマ,タブ,改行などで区切った(非正規表現の)単語リストも受け付ける.1つの語形のみを入力したい場合には ^ と $ で挟んで ^loves$ のようにするか,あるいは "nothing (non-regex mode only)" のラジオボックスをオンにする.
出力形式は,デフォルトではアメリカ英語コーパスにおける頻度の高い順でソートされるようになっている ("by AmE freq") が,イギリス英語コーパスの頻度順 ("by BrE freq"),語形のアルファベット順 ("alphabetically") も可能.単語リストで入力した場合に,入力したそのままの順序で出力したいときには,"nothing (non-regex mode only)" をオンにする.
いずれも100万語規模の(今となっては)小さめのコーパスなので,語形によっては十分な頻度が得られないこともあるが,簡便に英米差をチェックしたいときには便利だろう.出力結果の WORD, AME_2006, BRE_2006 の3列を切り出して,最後の行にコーパスサイズとして "total\t1000000\t1000000" と補ったうえで,Log-Likelihood Tester, Ver. 1 に放り込めば,英米差を統計的に検定することができる.
例として,「#244. 綴字の英米差のリスト」 ([2009-12-27-1]) のうち,とりわけよく知られている類の米英綴字のペアを抜き出したリストを挙げよう.以下をコピーして,上のテキストボックスに放り込み,"nothing (non-regex mode only)" を選択して実行すると,数値として米英差が実感できる.
acknowledgment, acknowledgement, aging, ageing, aluminum, aluminium, analyze, analyse, apologize, apologise, armor, armour, behavior, behaviour, center, centre, civilization, civilisation, color, colour, defense, defence, disk, disc, endeavor, endeavour, favor, favour, favorite, favourite, fiber, fibre, flavor, flavour, fulfill, fulfil, gray, grey, harbor, harbour, honor, honour, humor, humour, inquiry, enquiry, judgment, judgement, labor, labour, license, licence, liter, litre, marvelous, marvellous, mold, mould, mom, mum, neighbor, neighbour, neighborhood, neighbourhood, odor, odour, organize, organise, pajamas, pyjamas, parlor, parlour, program, programme, realize, realise, recognize, recognise, skeptic, sceptic, specter, spectre, sulfur, sulphur, theater, theatre, traveler, traveller, tumor, tumour
これまでは,語彙や綴字に関する英米差のコーパスによる比較は,「#708. Frequency Sorter CGI」 ([2011-04-05-1]) を用いたり,「BNC Frequency Extractor」 ([2012-12-08-1]) と「#1322. ANC Frequency Extractor」 ([2012-12-09-1]) を組み合わせたり,the Brown Family corpora を併用するなど,各変種コーパスの個別比較により対処してきたが,今回のツールにより多少便利な環境ができた.
2013-09-22 Sun
■ #1609. Cawdrey の辞書をデータベース化 [cawdrey][lexicography][dictionary][cgi][web_service][inkhorn_term][lexicology]
英語史上初の英英辞書 Robert Cawdrey の A Table Alphabeticall (1604) について,cawdrey の各記事で話題にしてきた.オンライン版をもとに,語彙項目記述を検索可能とするために,簡易データベースをこしらえた.半ば自動でテキストを拾ってきたものなので細部にエラーがあるかもしれないが,とりあえず使えるようにした.
データベースの内容をブラウザ上でテキスト形式にて閲覧したい方は,こちらをどうぞ(あるいはテキストファイルそのものはこちら).
以下,使用法の説明.SQL対応で,テーブル名は "cawdrey" として固定.select 文のみ有効.フィールドは7項目で,ID (整理番号),LEMMA (登録語),INITIAL (登録後の頭文字1文字),LENGTH (登録後の文字数),LANGUAGE (借用元言語),DEFINITION (定義語句),DEF_WC (定義語句の語数).典型的な検索式を例として挙げておこう.
# データベース全体を表示
select * from cawdrey
# 登録語をイニシャルにしたがってカウント
select INITIAL, count(*) from cawdrey group by INITIAL
# 登録語を文字数にしたがってカウント
select LENGTH, count(*) from cawdrey group by LENGTH
# 登録語を語源にしたがってカウント
select LANGUAGE, count(*) from cawdrey group by LANGUAGE
# 語源と語の長さの関係
select LANGUAGE, avg(LENGTH) from cawdrey group by LANGUAGE
# 登録語を定義語数にしたがってカウント
select DEF_WC, count(*) from cawdrey group by DEF_WC
# 語源と定義語数の関係
select LANGUAGE, avg(DEF_WC) from cawdrey group by LANGUAGE
# 定義に "(k)" (kind of) を含むもの
select LEMMA, DEFINITION from cawdrey where DEFINITION like '%(k)%'
# 定義に " or " を含むもの
select LEMMA, DEFINITION from cawdrey where DEFINITION like '% or %'
# 定義に " and " を含むもの
select LEMMA, DEFINITION from cawdrey where DEFINITION like '% and %'
# 定義がどんな句読点で終わっているか集計
select substr(DEFINITION, -1, 1), count(*) from cawdrey group by substr(DEFINITION, -1, 1)
・ ポール・バケ 著,森本 英夫・大泉 昭夫 訳 『英語の語彙』 白水社〈文庫クセジュ〉,1976年.
2013-06-19 Wed
■ #1514. Sonority Analyser [phonetics][sonority][syllable][web_service][cgi]
昨日の記事「#1513. 聞こえ度」 ([2013-06-18-1]) で,音節を定義づけるに当たっての聞こえ度の役割を解説した.また,Sonority Sequencing Generalisation (SSG) という原則を導入し,分節音が聞こえ度の原則に従って配置されることを示した.聞こえ度の果たすこのような役割を理解し,確認するために,昨日の記事ではいくつかの単語による分析を示したが,任意の単語で分析できると便利である.
そこで,正書法にしたがって単語を入力すると,自動的にその発音を分節音へ分解し,各分節音へ sonority scale に即した聞こえ度の値を割り振り,山と谷を図示してくれるツールを作成した.以下に,"Sonority Analyser" を公開する.1つの語でもよいし,カンマ区切りで複数の語を見出し語の形で入力してもよいが,聞こえ度の山と谷の図が適切に出力される仕様である.
発音データベースには「#1159. MRC Psycholinguistic Database Search」 ([2012-06-29-1]) を用いており,たまたまそこに登録されていない語(綴字)は当然ながら出力は得られない.1つの正書法に対して複数のエントリーがある場合(同綴異義語や品詞違いなど)には,それぞれが図示される.音声表記については,MRC の原データファイルの仕様に基づいたものをそのまま使用した.
sonority scale には,原則として昨日の記事で示したものを利用しているが,(1) /w, j/ を聞こえ度8として挿入し,もともとの高母音,中母音,低母音の値は繰り上げて,それぞれ9, 10, 11とし,(2) 2重母音は下降2重母音 (falling diphthong) を前提とし,第1母音の聞こえ度の値を2重母音全体に割り当てることとした.厳密ではなくとも,プレゼンや確認の用途には十分だろう.
[ 固定リンク | 印刷用ページ ]
Powered by WinChalow1.0rc4 based on chalow