この2日間の記事「#1806. ARCHER で shew と show」 ([2014-04-07-1]) と「#1807. ARCHER で between と betwixt」 ([2014-04-08-1]) で,ARCHER の Untagged 版 を用いて,語の変異形の頻度が通時的にどのように推移してきたかを調査した.
近代英語の初期から後期を含むコーパスとしては,ほかに CEECS (The Corpus of Early English Correspondence, LC (The Lampeter Corpus of Early Modern English Tracts), CLMET3.0 (The Corpus of Late Modern English Texts, version 3.0), PPCMBE, COHA などがあり,それぞれに特徴があるが,ARCHER は,1600--1999年というまとまった期間をカバーし,英米変種それぞれについてジャンル分けがなされており,比較的大型の歴史コーパスとして価値が高い.しかし,「#1802. ARCHER 3.2」 ([2014-04-03-1]) で紹介した通り,現在ウェブ上で一般公開されている版については,いまだタグ検索などが実装されておらず,可能性を最大限に利用することはできない.しかし,工夫次第でいろいろと活用できる.実装されている Frequency lists や Keywords の機能はアイディア次第で有効に使えそうだし,コーパス全体の単語頻度リスト (TXT)も公開されている.
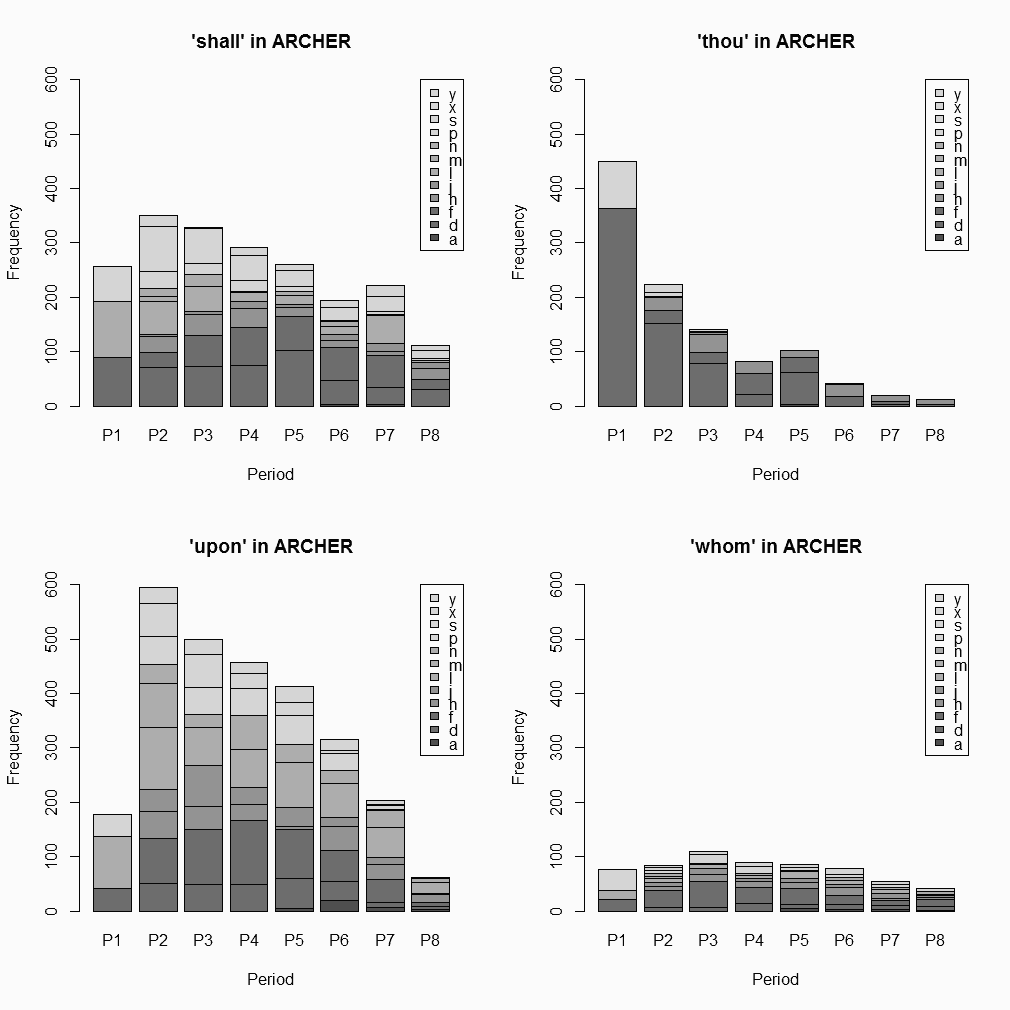
通時的な言語変化という観点から ARCHER に望む機能は,この2日間の記事で調査したように,ある検索語の頻度が時期を追って(ついでにジャンル別に)どのように推移してきたかを,簡単に確認できるようにすることだ.Restricted query で時期とジャンルを絞り,検索欄に検索語を入力してヒット数を数えてゆくということは手作業でできるが,時間がかかるし面倒だ.「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) や COHA では,この通時的な一覧を可能にする機能が実装されているので,ARCHER でも余計に同様の機能が欲しくなる.そこで,欲しいのならば作ってしまおうということで,簡単なスクリプトを組んだ.ARCHER の検索結果のコンコーダンス・ラインには,テキストを表わすファイル名が付されているが,ファイル名の仕様によれば,末尾3文字がそれぞれジャンル,時期,英米変種のいずれかを表わす記号となっている.そこで,検索結果をコピーして,以下のテキストボックスに貼り付けてやると,適切にファイル名を解析し,時期,ジャンル,変種ごとにヒット数を整理してくれ,グラフ化してくれるというツール (ARCHER Period-Genre Sorter) を作成した.ARCHER での出力結果が数ページにまたがる場合には,少し手数がかかるが,各ページをコピペして累積していけばよい.
このツールの使用の応用例として,ここ数世紀の間で使用頻度が衰退しただろうと疑われる4語,shall, thou (= thou, thy, thee, thine), upon, whom を取り上げる.今回は,イギリス英語のサブコーパスのみに限定した.以下は,ツールが返した集計表をもとにグラフ化したものである.(ツールがどのように機能するかを確認するために,試しに ARCHER による 'thou' の出力結果のテキストファイル (194KB) の内容を上のテキストボックスにコピペされたい.)