2026-06-21 Sun
�� #6264. �űѸ�̾����ޤη��̤�������Ψ [oe][inflection][gender][paradigm][frequency][statistics]
����#6250. �ʤ��űѸ�ʸˡ��̾����ޤ����֤� stan �ʤΤ��� (2)�� ([2026-06-07-1]) �ǾҲ𤷤��̤ꡤ�إ�ᥤ�Ȥ� ykagata �����֡θűѸ��̾�����ɽ�� st���n �ǻϤޤ��ܡ��Ϥޤ�ʤ��ܡ����������Ƥ��롥������ Smith (66) �����Ѥ���Ƥ��롥�ʲ��˺ƷǤ��褦��
OE nouns can be classified into five groups, or declensions. In decreasing order of frequency of occurrence in OE, these declensions are:
(1) General Masculine Declension
(2) General Feminine Declension
(3) General Neuter Declension
(4) the -an Declension
(5) Irregular Declensions
�������ǡ�̾����ޤη��ˤĤ�������Ū���̻�Ū�ʥ�٥����Ѥ���������Ū������Ū�ʥ�٥����Ѥ��Ƥ��뤳�Ȥ�ykagata ����Ͼ�����Ƥ��롥
��(1) ���� (5) �����٤ι⤤����¤٤��Ƥ���Ȥ������Ȥ��������Ρ����١פΥ������Ϥɤ�������Ƥ���Τ��������������餯�����������ˤǤϤʤ������űѸ������Ū�������Quirk and Wrenn (20) �εƤ���������Ψ�ʤ��뤤�Ϥ������������������餫�Υ������ˤ˰͵Ƥ���ΤǤϤʤ������ˤ�Ǥ��롥���ο��ͤ�ɽ�ǤޤȤ��Ȱʲ��Τ褦�ˤʤ��ͽ�ۤ�����̤ꡤ����Ū���̻�Ū�ʥ�٥뤬�Ѥ����Ƥ����������աˡ�
| Noun Class | Value |
|---|---|
| masculine a-stems | 0.36 |
| masculine n-stems and minor declension | 0.09 |
| feminine o-stems | 0.25 |
| feminine n-stems and minor declension | 0.05 |
| neuter a-stems | 0.25 |
| neuter n-stems | insignificant |
����������1�ĵ��ˤʤ�Τϡ����� Qurik and Wrenn �ο��ͤ����˴�Ť��Ƥ���Τ���Ʊ�������������Ƥ��ʤ����Ȥ����ȡ��������٤ǤϤʤ����������٤ǿ����Ƥ�������ꤵ��뤬����¸�θűѸ켭���űѸ�ʸˡ��Υ����å���ʤɤ�ðǰ��Ĵ�٤��Τ���������
���� Smith, Jeremy J. Essentials of Early English. 2nd ed. London: Routledge, 2005.
���� Quirk, Randolph. and C. L. Wrenn. An Old English Grammar. 2nd ed. London: Methuen, 1957.
[ ������ | �����ѥڡ��� ]
2025-01-18 Sat
�� #5745. ����ե��٥åȤ�ʸ������ [corpus][link][alphabet][frequency][statistics][letter_frequency][bnc][morse_code]
��A����Z�ޤǤΥ���ե��٥å�ʸ���Τʤ��ǡ��Ǥ����٤ι⤤ʸ�����㤤ʸ���ϲ���������ʸ������ (letter_frequency) ������ˤĤ��Ƥϡ���#308. ����Ѹ�κ��ѱ�ñ��ꥹ�ȡ� ([2010-03-01-1]) �β����� Letter Frequencies (rankings for various languages) �ؤΥ����Ȥ��ꡤ�͡��ʸ���䥳���ѥ��Ǥν��ɽ�����Ф���Ƥ��롥�㤨�С�BNC �˰͵�� "etaoinsrhldcumfpgwybvkxjqz" �ν��ɽ�������롥
��Crystal (277) �ˤϡ�The Cambridge Encyclopedia (1st ed.) �����ƥ����ȡ�150������ѥ��Ȥ���ʸ������ɽ���Ǥ����Ƥ��롥�������ٽ�� (Cumulative) �Τߤʤ餺��ʸ�ء�������������ʪ���ء����ؤγơ��Υơ��ޤ��Ȥ����٤� Morse code (morse_code) �����٤��碌�Ƽ�����Ƥ��롥�ʲ��Υ���դϡ�X���˱�ä��������ٽ� (= "eatinorslhdcmufpgbywvkxjq") ��ʸ�����¤١�Y����ƥơ�����Ǥ����ٳ���ɴʬΨ�ˤȤ�����ΤǤ��������ɽ�ϥ����� HTML �ȡˡ�
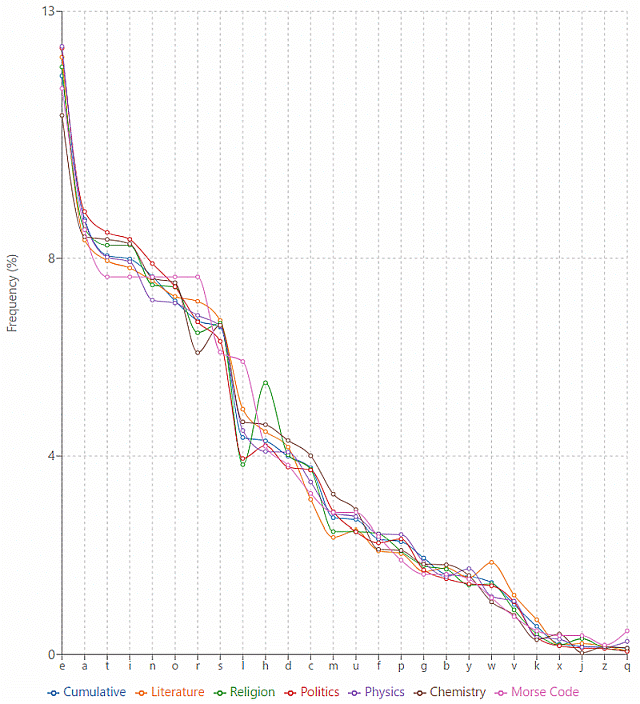
���������ٽ�˾Ȥ餷�ƥơ��ޤ��Ȥ���ħ�Ƥߤ�Ȥȡ��������Ǥ�ɸ��Ū�Ǥ��롥ʸ�ؤ������������³����ɸ�फ����äƤ����Τ������ء�ʪ���ء������� Morse code �Ȥʤ롥
���ġ���ʸ����ߤ�ȶ�̣��������¿�����롥����Ū�˽����Ǥ� <h> ��¿�� (holy?) <l> �����ʤ����ȡ�ʸ�ؤǤ� <w> ��¿�����Ȥϲ����̣����Τ�����������ʪ���ؤ䲽�ؤϥ�ƥ��ꥷ����Ϥ�ñ�줬¿���ޤޤ�Ƥ��뤿��ˡ�����¾���̤Ȥϼ㴳�ۤʤ�ʸ�����٤��Ƥ���Τ��⤷��ʤ�����Ū�� Morse code �ϡ�¾�Υơ��ޤȤ��ܤ˸����ưۤʤ����������Ƥ��뤳�Ȥ��狼�롥
���� Crystal, D. The Cambridge Encyclopedia of the English Language. 3rd ed. CUP, 2018.
2024-07-14 Sun
�� #5557. �����¼������ˡ����䡡ʸˡ���ȥ��ǥ����ಽ�١ʤҤĤ���˼��2014ǯ�� [toc][grammaticalisation][idiomatisation][idiom][composite_predicate][syntax][lexicology][frequency][lexicalisation][preposition][phrasal_verb][voicy][heldio]

�������������¼��������Ļ��ر����̾�������ˤ�ɸ���ν��ҤȤ��Ĥ����̤��ޤ����������ơ������ͻҤ����� Voicy heldio ����#1139. ���ǥ�����ȥ��ǥ����ಽ --- �����¼������Ȥ����� with ���Ͻؤ�����Ȥ����ۿ����ޤ�������Ȥ�ǻ�������Ԥ�22ʬ�ۤɤ����̲�ʤäƤ���ޤ������Ҥ����֤Τ���Ȥ��ˤ�İ������������
�������¼������ˡ����䡡ʸˡ���ȥ��ǥ����ಽ�١ʤҤĤ���˼��2014ǯ�ˤˤĤ��Ƥϡ�����ޤǤ⤤���Ĥ��ε����Ǽ��夲�Ƥ��Ƥ��ꡤ�Ȥ�櫓��#1975. ʸˡ�������ȯŸ�ȳ��� (2)�� ([2014-09-23-1]) ����1�Ϥ��ܼ���ޤ�����������Ϻ���λ��ȤΤ���ˤ��ܽ����Τ��ܼ���Ǥ��Ƥ����ޤ�������������̤�³�Ԥ��ۿ�����ͽ��Ǥ���
�����ǤϤ�����
�Ϥ�����
������
������1�ϡ���ʸˡ��
��������1.1������
��������1.2����ʸˡ���Ȥ��Υᥫ�˥���
������������1.2.1����������Ū���� (Pragmatic inferencing)
������������1.2.2����ɺ�� (Bleaching)
��������1.3������������ (Unidirectionality)
������������1.3.1�������̲� (Generalization)
������������1.3.2����æ���Ʋ� (Decategorialization)
������������1.3.3�������ز� (Layering)
������������1.3.4�����ݻ��� (Persistence)
������������1.3.5����ʬ���� (Divergence)
������������1.3.6�����ü첽 (Specialization)
������������1.3.7�����ƿ��� (Renewal)
��������1.4������Ѳ� (Subjectification)
��������1.5������ʬ�� (Reanalysis)
��������1.6�������饤���ʸˡ��Ϣ�� (Grammaticalization chains)
��������1.7����ʸˡ���ȥ��������� (Iconicity)
��������1.8����ʸˡ���ȳ�Ŭ�� (Exaptation)
��������1.9����ʸˡ���ȡָ��������� (Invisible hand) ����
��������1.10����ʸˡ���ȡ���ή�� (Drift) ��
����
������2�ϡ������ǥ����ಽ
��������2.1������
��������2.2�������ǥ�����Ȥ�
��������2.3�������ǥ����ಽ
��������2.4�������ǥ����ಽ���װ�
������������2.4.1��������Ū�������Ū
������������2.4.2����æ���Ʋ� (Decategorialization)
������������2.4.3������ʬ�� (Reanalysis)
������������2.4.4���������� (Frequency of occurrence)
��������2.5�������ǥ����ಽ��ʸˡ���ڤӸ��ò�
ʬ����
������1�ϡ����������Ѹ�ˤ�����ʣ��ư���ȯã
��������1.1������
��������1.2������Ը���
��������1.3�����ǡ���
��������1.4��������ʣ��ư��Υ��ǥ�����Ū��ħ
������������1.4.1����Give
������������1.4.2����Take
��������1.5����������֤���ӡ� The Cely Letters �� The Paston Letters
��������1.6��������
������2�ϡ����������Ѹ�ˤ�����ʣ��ư��
��������2.1������
��������2.2������Ը���
��������2.3�����ǡ���
��������2.4������¤����ħ
��������2.5�����ط���̾�첽
��������2.6������ư�����ħ
������������2.6.1����Do
������������2.6.2����Give
������������2.6.3����Have
������������2.6.4����Make
������������2.6.5����Take
��������2.7����ʣ��ư���ʸˡ��
��������2.8��������
����
������3�ϡ���Give ���ǥ�����η���
��������3.1������
��������3.2������Ը���
��������3.3�����ǡ����ڤ� give �ѥ���ε���
��������3.4��������
������������3.4.1����ʸˡ���ȥ��ǥ��������
������������3.4.2������ʬ�ϤȰ�̣��ɺ��
������������3.4.3�������ǥ����ಽ
������������3.4.4����̾����
������������3.4.5������ʸ��������
��������3.4��������
������������3.4.1����ʸˡ���ȥ��ǥ��������
������������3.4.2������ʬ�ϤȰ�̣��ɺ��
������������3.4.3�������ǥ����ಽ
������������3.4.4����̾����
������������3.4.5������ʸ��������
��������3.5��������
������4�ϡ���2�ĤΥ����פμ�ư��ʸ
��������4.1������
��������4.2������Ը���
��������4.3�����ǡ���
��������4.4�������ǥ����ಽ
��������4.5��������
������5�ϡ����Ƶ�ư��ȴ�Ϣ��ʸ
��������5.1������
��������5.2������Ը���
��������5.3�����ǡ���
������������5.3.1����Content oneself with
������������5.3.2����Avail oneself of
������������5.3.3����Devote oneself to
������������5.3.4����Apply oneself to
������������5.3.5����Attach oneself to
������������5.3.6����Address oneself to
������������5.3.7����Confine oneself to
������������5.3.8����Concern oneself with/about/in
������������5.3.9����Take (it) upon oneself to V
��������5.4�����Ƶ�ư���ʸˡ���ڤӥ��ǥ����ಽ
��������5.5�����Ƶ�ư������ư���ڤ�ʣ��ư��
������������5.5.1����Prepare
������������5.5.2����Interest
��������5.6��������
������6�ϡ���Far from ��ʸˡ�������ǥ����ಽ
��������6.1������
��������6.2������Ը���
��������6.3�����ǡ���
��������6.4����ʸˡ���ȥ��ǥ����ಽ
������������6.4.1����ʸˡ��
������������6.4.2������̣�Ѳ��������Ѳ��δط������ǥ����ಽ
��������6.5��������
������7�ϡ���ʣ�����ֻ�
��������7.1������
��������7.2������Ը���
��������7.3�����ǡ���
��������7.4����ʣ�����ֻ��ȯã
������������7.4.1����Instead of
������������7.4.2����On account of
��������7.5��������ط� (Rivalry)
������������7.5.1����In comparison of/in comparison with/in comparison to
������������7.5.2����By virtue of/in virtue of
������������7.5.3����In spite of/in despite of
��������7.6�������õ�ǽ��ȯã
��������7.7����ʸˡ�������ò������ǥ����ಽ
��������7.8��������
������8�ϡ���ư���������ֻ�
��������8.1������
��������8.2������Ը���
��������8.3�����ǡ����ڤ�ʬ��
������������8.3.1����Concerning
������������8.3.2����Considering
������������8.3.3����Regarding
������������8.3.4����Relating to
������������8.3.5����Touching
��������8.4����ư���������ֻ��ʸˡ��
��������8.5��������
����
������9�ϡ���ư�� pray ��ʸˡ��
��������9.1������
��������9.2������Ը���
��������9.3�����ǡ���
��������9.4����15����
��������9.5����16����
��������9.6����17����
��������9.7����18����
��������9.8����19����
��������9.9����ʸˡ��
������������9.9.1�����������ʸˡ��
������������9.9.2������ǫɸ����ʸˡ��
��������9.10��������
������10�ϡ���'I'm afraid' ��������Ūȯã
��������10.1������
��������10.2������Ը���
��������10.3�����ǡ����ڤӤ���ʸˡ
��������10.4����ʸˡ��---Hopper (1991) ���濴��
��������10.5��������
������11�ϡ���'I dare say' ��������Ūȯã
��������11.1������
��������11.2������Ը���
��������11.3�����ǡ�����ʬ��
��������11.4����ʸˡ����ʸ��
��������11.5��������
������12�ϡ�����ư��ˤ����� after �� forth �ο���
��������12.1������
��������12.2����For �ˤ�� after �θ���
������������12.2.1������Ը���
������������12.2.2����ư�������������
������������12.2.3����After �� for �ΰ�̣����ǽ���Ѳ�
��������12.3����Forth ���
������������12.3.1������Ը���
������������12.3.2����Forth �ȶ�������ư��μ���
������������12.3.3����Out �ˤ�� forth �θ���
��������12.4��������
������13�ϡ���Wanting �����פ�ư��֤˸����붥�� --- desire, hope, want �ڤ� wish ���濴�� ---
��������13.1������
��������13.2������Ը���
��������13.3���������Ѳ�
������������13.3.1����Desire
������������13.3.2����Hope
������������13.3.3����Want
������������13.3.4����Wish
��������13.4����4�Ĥ�ư�������Ū����̣Ū��ħ
������������13.4.1������°����ˤ�����ˡ�ڤӻ���
����������������13.4.1.1����Desire + that/Ø
����������������13.4.1.2����Hope + that/Ø
����������������13.4.1.3����Wish + that/Ø
������������13.4.2����Desire, hope, want �ڤ� wish �� to ����칽¤
������������13.4.3����That �ξ�ά
��������13.5���������������ƥ�˻���Ѳ��ڤӺ�����
��������13.6��������
����
���
����ʸ��
����
������̾����
�����������
���� ���� �¼��������䡡ʸˡ���ȥ��ǥ����ಽ�١��ҤĤ���˼��2014ǯ��
2024-01-18 Thu
�� #5379. blend �Ϸ��������䱤Χ�����ˤȤäƤ�ͭ�յ��ʸ��ݤǤ��� [blend][morphology][frequency][word_formation][prosody][analogy]
����ǯ���Ѹ���ä� blend �ʺ�����ˤ��������Ƥ�����¤ˤĤ��Ƥϡ����Ǥ� hellog �Ǥⷫ���֤����夲�Ƥ�����
���� ��#631. blending ���� ([2011-01-18-1])
���� ��#876. ����Ѹ�ˤ����뤫�Ф����������������˹⤤������ ([2011-09-20-1])
���� ��#4369. Brexit --- �����������ͷ�Ӥθ������ ([2021-04-13-1])
���츫����� blend �Ͽ��ܤ��������ͷ�Ӥˤ��������������夢���ޤǼ���Ū�ʸ��ݤˤȤɤޤ�Ȼפ��뤫�⤷��ʤ�������������ǯ�αѸ������ˤ����뤽���������ι⤵�ϡ�����θ������Ѥ��ĤĤ��롥�㤨�С�Fertig (70) �ϡ������Ȥ��������������Ū�ʰյ����Ĥ��ȤΤ褦�����⤷�Ƥ��롥
Blends are often treated as a marginal phenomenon (Haspelmath and Sims 2010:40). Aronoff discusses them under the heading 'oddities' and considers them 'words which have no recognizable internal structure or constituents'; they are 'opaque, and hence uncommon' (1976: 20). Recent developments suggest that Aronoff may have had the relationship between opacity and frequency backwards here. Blends may have been rather opaque in 1976 precisely because they were still relatively uncommon. Today, at least in English, blends (of certain types) can hardly be called uncommon, and we generally seem to have little trouble parsing and processing them. As we will see in §7.3.8, this issue of the relationship between the frequency of a morphological pattern and its transparency/opacity has implications for some fundamental theoretical issues of great relevance to morphological change.
To the extent that some types of blending have become productive and predictable morphological operations in present-day English, it is no longer accurate to classify them as non-proportional. They amount to a kind of compounding with the two elements overlapping in accordance with well defined constraints. Within Paul's proportional theory, they could thus be handled by an extension of the (syntagmatic) proportional equations that he proposes for syntax (see §6.2 below). Blending as a type of word formation would fit even more easily into certain other theories of morphology. Insights and analytical tools from Prosodic Morphology (McCarthy and Prince 1995) have made it clear that (most) blends absolutely do have 'recognizable internal structure'. They are a type of non-concatenative morphology. Instead of combining two words into a linear string as in compounding, blends superimpose one word onto the prosodic structure of another (Piñeros 1998, 2004).
�����衤������Ϸ�����Ū�ˤ�������¤����Ʃ���Ȥߤʤ���Ƥ�����������������Ϻ����ˤ�����������������ޤ��㤫�ä�����˽�ʬ�˲�������Ƥ��餺������Ʃ���פȤΥ�åƥ��Ž���Ƥ��������ʤΤǤϤʤ����������줬����Ƥ��븽�ߡ����ѼԤ⤹�ä��괷�졤�ष��Ʃ�������⤯�ʤäƤ����Ȥ�����ΤǤϤʤ����������ơ��٤�Ф��ʤ��顤���������䲻�������ˤ������Υ������Ϥ�ΤǤϤʤ������Ȥ��Τ褦�ʵ����Ǥ��롥
����Χ������ (Prosodic Morphology) �Ȥ���ʬ�����Ƥ���褦�Ǥ��ꡤ����ˡ�#3722. ������ϱ�¦�������β�����Ȱ��פ���� ([2019-07-06-1]) �Ǥߤ��̤ꡤ���������ħŪ�ʱ�Χ������¤�Τ��ˤ���褦��������κ��������ؤ�Ÿ���˴��Ԥ�������
���� Fertig, David. Analogy and Morphological Change. Edinburgh: Edinburgh UP, 2013.
2023-11-12 Sun
�� #5312. �֤�����إ饸���ǿ���ϡ��Ե�§ư��Ϥʤ�¸�ߤ���Τ����� [yurugengogakuradio][verb][inflection][conjugation][sobokunagimon][frequency][voicy][heldio][youtube][link][notice][numeral][suppletion][analogy]
���������͵� YouTube/Podcast �����ͥ��֤�����إ饸�����κǿ����ۿ�����ޤ���������ϱѸ�ˤȤ⤪�����˴ط��������Ե�§ư��Ϥʤ�¸�ߤ���Τ����ڥ����륷����ʸˡ_�Ե�§ư���#280���Ǥ���
��������إ饸���ο�����������ˤϡ�������Voicy �ֱѸ�θ츻���ȤˤĤ��饸���� (heldio)������� YouTube �����ͥ��ְ���ʼ������δ��Ѹ�ظ���إ����ͥ���Τ����Ĥ��δ�Ϣ����ƥ�Ĥ˸��ڤ��Ƥ��������ޤ�����ȴ����ȯ���Ϥ��Ĥ�����إ饸������ˡ����αѸ�˾��������������夲�Ƥ����������ȤƤ���Ǥ������Υȥԥå���̥�Ϥ����������ޤ��褦�ˡ�
��������˷Ǻܤ��Ƥ�������������ƥ�����ؤΥ������ˤ�ƷǤ��Ƥ����ޤ���
���� ���� �رѸ�Ρ֤ʤ����פ�������Ϥ���ƤαѸ�ˡ١ʸ���ҡ�2016ǯ��
���� ���� �رѸ�ˤDzۤ����Ѹ�θ��� --- Ǽ�����ƱѸ��ؤ֤���ˡ١������ؽ�������2011ǯ��
���� heldio ��#58. �ʤ������ٸ�ˤ��Ե�§�ʤ��Ȥ�¿���ΤǤ�������
���� YouTube �ֿ��⡪ go �β����� went ����ͳ�� (cf. ��#4774. go/went �ϼҲ�����Ū��ȥޥ����Ǥ���� ([2022-05-23-1])��
���� YouTube �ֱѸ���Ե�§����ư��ΤҤ����⤴�� --- �����������о졪�� (cf. hellog ��#4810. sing �β����� sang �Ǥ⤢�� sung �Ǥ⤢�롪�� ([2022-06-28-1])��
���� YouTube ���ΤαѸ���Ե�§ư����餱���� (cf. ��#4807. -ed �ˤ��������뵬§ư��νи��ϳ�̿Ū���ä����� ([2022-06-25-1])��
���� heldio ��#9. first �� -st �ϺǾ����ä�����
���� heldio ��#10. third �� three + th ���ѷ��ʤΤǽ൬§Ū��
���� heldio ��#11. �ʤ��� second ��2���ܤΡפϼ��Ѹ졪��
�����Ե�§ư��Ϥʤ�¸�ߤ���Τ����פȤ����Ѹ�˴ؤ������Ѥʵ��䤫���⤭���������佼ˡ (suppletion) ������ʡ֥�������������С��סˤ�Ƴ��������ˡ��Ե�§���μҲ�����Ū�յ����ͳ���Ĥġ����ΤȤ��Ƹ���ˤ�����ֵ�§�פ��뤤�ϡ��Ե�§�פȤϲ��ʤΤ��Ȥ����礭�ʵ��������Ƥ��������ޤ�����������ٸ������꤬�Ȥ��������ޤ���������#5130. �֤�����إ饸�����������ȥ���� ([2023-05-14-1]) �⤼�Ҥ����Ȥ���������
2022-05-01 Sun
�� #4752. which vs that --- �ط���̾�������α��ˤҤ�����Ѱ� [relative_pronoun][frequency][corpus][youtube][syntax][genre][ame_bre]
��4��27���ʿ�ˤ˸������줿 YouTube �����ְ���ʼ������δ��Ѹ�ظ���إ����ͥ���Ǥ��ּ������Τߤʤ����ط���̾���ʸˡ�����ְ㤨�������н�ˡ�Ǥ��衼�ڰ���ʼ������δ��Ѹ�ظ���إ����ͥ� # 18 �ۡ����ꤷ�ƴط���̾����������夲�ޤ������ʤ��ʤ�¿����İ����Ƥ���褦�ǡ����꤬�����¤�Ǥ������ºݤ�2�ͤǤ��⤷�������Ȥ�٤äƤ��ޤ��ʾСˡ����Ҥ�������������
��ɸ��Ѹ�Ǵط���̾��Ȥ����� which, who, whom, that, �����ƥ����ʤ�����ط���̾��ξ�ά���դ꤬���ޤ��������Τ����줬�Ѥ����뤫�Ȥ�������ˤϡ�ʣ���Υѥ�����ʣ���˴ؤ�äƤ��ޤ����ط���̾����������Ǥ���䤬��ʤʤΤ���Ū�ʤʤΤ��Ȥ������ȤϤ���������¡���������ˡ�ΰ㤤����Ի줬ͭ����̵�����ʤɤ������̣��Ū�ѥ�����ʣ���˴�Ϳ���Ƥ��ޤ�������ˡ����ޤ����ܤ���ޤ����¤ϻ��Ѱ� (register) �Ȥ���������Ū�ѥ������������ط���̾�������ˤȤƤ���פ�����̤����Ƥ���ΤǤ���
��Longman Grammar of Spoken and Written English (608--21) �ˤϡ������ѥ����Ѥ����ط���̾������˴ؤ���Ĵ����̤��ܺ٤˼�����Ƥ��ޤ�������Ϥ�����Ȥ��ʤ��顤���ΤȤ��ƺǤ�������٤ι⤤�Ȥ���� which �� that �˾��������ơ�ξ�Ԥ�ʬ�ۤ���٤Ƥߤޤ��礦��
��which �� that ��¿���ξ�������ؤ���ǽ�Ǥ������ع�ʸˡ�Ƕ����Ȥ��ꡤ��§�Ȥ��� which ����Ի줬̵���ξ��˸¤�졤�ޤ�������ˡ�Τߤʤ餺��������ˡ�Ȥ��Ƥ�Ȥ���Ȥ�����ħ���ߤ��ޤ���������that ����Ի�����Ӥޤ���������ˡ�˸��ꤵ��ޤ���
����������which �� that ��ʬ�ۤΰ㤤�ˤĤ��Ƥ��⤷�����Τϡ����Τ褦�������̣��Ū���װ���Ʊ�����餤���Ѱ�Ȥ����װ�������Ƥ���Ȥ������ȤǤ���which ���ݼ�Ū�dzؽ�Ū�ʴޤߤ����ꡤ�ؽѻ�ʸ�Ǥ���������ˡ�˸��ꤹ��С�70%����ᡤthat ���ݤ��Ƥ��ޤ���������that �ϸ���Ū�Ǥ��������ޤߤ����ꡤ�㤨�Хե��������Ǥ���������ˡ�˸��ꤹ��ȡ�75%�����ޤ���
���ޤ�������ꥫ�Ѹ줫�����ꥹ�Ѹ줫�Ȥ����㤤�⡤which vs that ������Ǥ��ޤ����˥塼���Ǥ���������ˡ�����ܤ���ȡ�����ꥫ�Ѹ�Τۤ������餫�� that �ߡ������ꥹ�Ѹ�Ǥ� which �ߤޤ������ä���٤�ȡ��ޤ��ޤ�����ꥫ�Ѹ�Ǥ� that �����ޤ졤�����ꥹ�Ѹ��2�ܤ����٤��Ѥ����ޤ���
�����ΤȤ��ơ�LGSWE (616) �� which vs that �з�ˤĤ��Ƽ��Τ褦�����礷�Ƥ��ޤ���
The AmE preference for that over which reflects a willingness to use a form with colloquial associations more widely in written contexts than BrE.
���ط���̾�������α��ˤϻ��Ѱ�Ȥ����ե����������Ҥ���Ǥ����ΤǤ���
�����ʤߤˡ�����18:00�˸�������� YouTube #19 �ϴط���̾��������³�ԤȤʤ�ޤ������ڤ��ߤˡ�
���� Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad, and Edward Finegan, eds. Longman Grammar of Spoken and Written English. Harlow: Pearson Education, 1999.
2022-02-17 Thu
�� #4679. ����ˤ���������ݤȤ�餮 [complex_system][computational_linguistics][statistics][frequency][1/f][terminology][keyword]
�������ε�����#4678. ����ˤ���������ݤ�Ĺ��ء� ([2022-02-16-1]) �ǡ�����ˤ���������ݤ��Ĺ��ءפδ�������ߤ���������Ϥ⤦1�Ĥδ����Ǥ���֤�餮�פ����ܤ��褦����餮���ϤˤĤ��ơ����� (112) �ϼ��Τ褦���������Ƥ��롥
���Τ褦�ʲ����ݤ�ª���뼫������ˡ�ΰ�ĤȤ��ơ����������ϰ���˽и�����ñ������٤�ʬ����Ĵ�٤뤳�Ȥ����롥����ñ��νи��ˤ�餮������ΤǤ���С����������ϰ���ˤ���ñ�줬�и����ʤ���礬���ꡤ�ޤ������Ǥ���ñ�줬��¿���и�������⤢�ꡤ�������٤�ʬ�����礭���ʤ�Ϥ��Ǥ��롥
�����ϸ����Ȥ��Ƥ�ʬ����䤹��������ʸ�����ɽ������ä�ǰƬ�ˤ�����硤��餮���ϸ�ˤ�äưۤʤ뤬�����⤷�������Ȥˡ������륭����ɤϤ��Ф��Ф�餮���礭���Ȥ��������桤p. 118�ˡ�����ϡ�����Ū�ʥ�����ɤ�Ʊ��ʤɤ˹��������ʶ�̣���������Ǥ��롥
���ޤ����ʹָ���ˤ��ʸ�Ϥȥ�����ʸ�����ʸ�ϤȤǤ�餮����٤�ȡ����餫�����Ԥ�������餮���礭�������Τ��ȤϿʹָ������ħ�ΰ�ü�����롥����ˡ�ʸ�ϤΥ�����ˤ�äƤ��餮�ϰۤʤ뤿��ˡ����桤p. 120�ˡ���餮���ٹ礤��ʸ����Ū�ʻ�ɸ�Ȥ�ʤ����롥
���͡��ʲ�ǽ����������ˤ�����֤�餮�פ˥���ƥʤ�ĥ�äƤ�����������Ϣ���ơ�1/f ��餮�� (1/f) �������ܡ�
���� ���� �����ҡ��ظ���ȥե饯���� --- ���Ѥν��Ѥ���ˤ��������ɬ���١������ؽ��Dz�2021ǯ��
2022-02-16 Wed
�� #4678. ����ˤ���������ݤ�Ĺ��� [complex_system][computational_linguistics][statistics][frequency][information_structure][article][terminology]
������ˤϡ�¾��¿���μ������Ҳݤˤ�ߤ���ֲ����ݡפȤ�����Τ��ѻ�����롥���� (98) ����������Ѥ��롥
���η����ϰ���Ǹ����Сֲ����ݡס��Ĥޤ�ñ�줬�ǤޤäƸ���뤳�ȡ�����ñ�줬��ö�����Ȥ��Ф餯�δ֤����ˤ˽и���������ǡ��������ȤۤȤ�ɽи����ʤ��ʤ뷹�������뤳�ȤȤ���ľ��Ū��ª���뤳�Ȥ��Ǥ��롥�����ݤ����������Ǥϡ�û���ֳ֤�³������ˤ�û���ֳ֤����졤�ޤ��դ�Ĺ���ֳ֤�³������ˤ�Ĺ���ֳ֤�������ǽ�����⤤�����Τ褦�ʸ���β����ݤ��װ��ΰ�Ĥϡ������Τ��Ȥʤ���ʸ̮���Ѳ��ˤ��롥
�������ݤϡ���������ͻ�ʤɡ����ޤ��ޤ�ʣ���Ϥˤ����ƤϤ褯�Τ������ά�͡����Ȥ��С��籫���Ͽ̤��ǤޤäƸ���뤳�ȤϷи����̤���ï�����ΤäƤ�����������Ҳ�Ū���оݤˤ����Ƥ⡤���Ȥ��С�������ˤϡ���������������Ȥʤäơ���Ϣ���������Ԥ��뤿�ᡤ��Ϥ�����ݤ������뤳�Ȥ��Τ��롥Ʊ�ͤˡ�ñ��⤢��ñ�줬������Ȥʤꡤ����ñ��ʤ�Ӥ˴�Ϣ����ñ��β����и����롥
����������Ƥߤ�С���äȤ�Ȥ������ݤǤϤ��롥���β����ݤΰ���Ū�ʸ���ˤ���ˤ����뤬������˱��Ѥ�������Ͼ��ʤ��褦��������ˡ�Ȥ��Ƥϡ��礭��ʬ���ơ�Ĺ��ءפȡ֤�餮�פ����ܤ���2���ब����Ȥ����������Ǥ����ԤƤ�������
����Ĺ��ءפˤ����Ϥϡ��֤��������Ρ���Ĥ���ʬ�����ؤ���������ʬ��ε�Υ s �˰�¸���ƤɤΤ褦���Ѳ����뤫��Ĵ�٤���ϡפǤ�������桤p. 99�ˡ��ߤ���Υ�줿2�Ĥ���ʬ���������¤��������Ƥ����Ĺ��ؤ�����Ȥ������Ȥˤʤ��cf. ��#4675. �����ʣ���ϡ� ([2022-02-13-1]) �Ǹ��ڤ�����Ĺ�������סˡ�
���Ѹ�ˤ�������Ѹ�Ǥ����괧�� the �ˤĤ��ơ�Ĺ��ʸ�Ϥ�Ĺ��ز��Ϥ��ߤ�ȡ��ɤ����夤Ĺ��ؤ�����褦�������桤p. 105�ˡ��������������ޤǼ夤Ĺ��ؤ�����ˤȤɤޤꡤ�٤����ߤ�� the �ˤ��餢�����٤β����ݤ��ߤ��뤳�Ȥ�Ƚ�����롥�ä����Ȥˡ�the �⸽����Ȥ��ϸǤޤäƸ���졤�����ʤ��Ȥ��ˤϤ��Ф餯�����ʤ����Ȥ������Ȥ��������ٴѻ������ΤǤ��롥���� (109�ˤϡ���Ը���˽��������λ��¤Τ褦�˲�ᤷ�Ƥ��롥
k �Ĥ�û���ֳ֤�����ȡ�³�� k + 1���ܤδֳ֤�û����k �Ĥ�Ĺ���ֳ֤�����ȡ������³�� k + 1���ܤδֳ֤�Ĺ�������ˤ��롥û���ֳ֤�³�����Ȥϡ��оݤȤʤ�ñ�줬�ǤޤäƸ���뤳�Ȥ��Ƥ��롥����ά�ͤ��Τ褦�ʲ����ݤ��طʤˤ�ʸ̮���Ѳ������롥the �ˤĤ��Ƥϡ��ޤ����괧����濴�Ȥ��ư���Ū�ʳ�ǰ��Ƴ���������θ塤Ƴ�����줿��ǰ�ˤĤ��Ƶ������Ԥ�졤���κݤ� the ��¿�Ѥ���롥
������ϡ����äˤ��������¤ (information_structure) �����ܤ�����the �ˤĤ��Ƥβ����ݤ��ɤ߲Ȥ��äƤ褤��������
���� ���� �����ҡ��ظ���ȥե饯���� --- ���Ѥν��Ѥ���ˤ��������ɬ���١������ؽ��Dz�2021ǯ��
2021-08-01 Sun
�� #4479. �Ե�§ư��β�����ľ�ܵ�����¸����Ƥ��� [frequency][suppletion][verb][inflection][be][preterite]
������Ū�Ե�§������Ϲ����ٸ�˽��椷�Ƥ��롥����ŵ�����Ե�§ư��Ǥ��롥��§Ū�� -ed ���դ��Ʋ������밵��Ū¿����ư����Ф��ơ��Ե�§ư��Ͽ����ʤ����������Ƥ�����Ū�����٤ι⤤ư��Ǥ��롥�Ե�§����Ե�§�Ȥ����� go �� be �β��� went, was/were �ʤɤϡ��佼ˡ (suppletion) �ˤ���ΤǤ��ꡤ�ŵ����Ƥ��ʤ������������Ǥ��Ǥ��ʤ�������ϡ��������Ķ�����ٸ�Ǥ��뤳�Ȥ��ط����Ƥ��롥�����դ�λ���ϰʲ��ε����Ǥ���夲�Ƥ�����
���� �֤ʤ������ٸ�ˤ��Ե�§�ʤ��Ȥ�¿���ΤǤ������� �ʵ��7��29���դ��ֱѸ�θ츻���ȤˤĤ��饸�����ˤƲ��������
���� ��#3859. �ʤ�����ˤ��Ե�§�ʸ��ݤ�����ΤǤ������� ([2019-11-20-1])
���� ��#43. �ʤ� go �β����� went �ˤʤ뤫�� ([2009-06-10-1])
���� ��#1482. �ʤ� go �β����� went �ˤʤ뤫 (2)�� ([2013-05-18-1])
���� ��#3284. be ư����ü����� ([2018-04-24-1])
���Ǥϡ��ʤ����٤ι⤤ư��ˤ��Ե�§���Ѥ���Τ�¿���Τ������������� (memory) ����֤ο�Ūɽ�� (mental representation) ���ʤ�������������Ū�Ǥ��롥Smith (1535) �β������Ѥ��롥
The relationship between high frequency and irregularity has to do with memory in so far as those verbs that are used frequently have strong mental representations such that the irregular past forms are stored autonomously and thus accessed independently of the present stem. Such items are said to have become "entrenched" in storage . . . . On the other hand, a low frequency form does not necessarily have its past form stored autonomously and does not allow for direct access to that past form. Thus, its use in the past involves access to the present stem and rule application . . . .
�����٤ι⤤ư��β����ϡ����ˤ˻��Ѥ��뤿��ˡ������Τʤ���ľ�ܥ��������Ǥ�������Ф��ˤ��ޤäƤ����Τ������Ǥ��롥go �Ȥ������߷���������ˤ��� went �ˤ��ɤ��夯�褦�Ǥϡ��٤������Ω���ʤ���go ���ͳ�����ˡ�ľ�� went �ΰ����Ф��ˤ��ɤ��夭���������������٤��㤤ư��Ǥ���С����߷���������ˤ��ơ������ -ed ���դ��Ȥ�����§Ŭ�Ѥη��⡤���ޤΤ��Ȥˤ����ʤ��Τ��Ѥ����롥�Ĥޤꡤ�����Ф����٤˱�����ľ�ܥ��������ȴ��ܥ���������2�����ʬ���Ƥ����Τ���ΨŪ�Ǥ��롥
���Ǥϡ�-ed ���դ��Ʋ������뵬§ư��Ͼ�˷���ȼ�����ܥ��������ʤΤ��Ȥ����ȡ�ɬ�����⤽���ǤϤʤ��褦����Smith (1535) �ǾҲ𤵤�Ƥ��뤢�븦��ˤ��ȡ�Ʊ����Ǥ��� kneaded �� needed ���︳�Ԥ�ȯ�����Ƥ��ä��Ȥ���������Ū�����٤��㤤���Ԥ� -ed �����Τۤ��������٤ι⤤��Ԥθ������⡤ʿ�Ѥ��ƿ��ߥ���Ĺ��ȯ�����줿�Ȥ���������ϡ�needed �Τۤ��������������ưפǤ��뤳�ȡ������餯���ľ�ܤ˵�����¸����Ƥ��뤳�Ȥ����롥
���� Smith, K. Aaron. "New Perspectives, Theories and Methods: Frequency and Language Change." Chapter 97 of English Historical Linguistics: An International Handbook. 2 vols. Ed. Alexander Bergs and Laurel J. Brinton. Berlin: Mouton de Gruyter, 2012. 1531--46.
2021-07-31 Sat
�� #4478. ���٤Ǥߤ� be ��λ�ο������� [perfect][be][verb][aspect][tense][auxiliary_verb][frequency]
���Ѹ�ˤǤϡ����űѸ����ꡤ��λ��ɽ�魯�Τ� have ��λ�� be ��λ��2���ब�Ԥʤ��Ƥ�������������be ��λ�ϼ�ư�졤���褽��ưư��˸��ꤵ�졤have ��λ����٤�Ф�Ȥ����Ω���ʤ�¸�ߤǤϤ��ä�������Ѹ���ˤ����� have ��λ���ޤ��ޤ������������ˤ���ӡ���ưư��� have ��λ�ؤȾ�괹���Ƥ��ä���
���嵭�ϡ�be ��λ�ο������ˤζ��ʽ�Ū�ʳ��ѤǤ��롥��Ϣ���뵭���Ȥ��ơ�#1653. be ��λ����ˡ� ([2013-11-05-1])����#1814. 18--19������ be ��λ�ο���� CLMET �dz�ǧ�� ([2014-04-15-1])����#3031. have ��λ�� be ��λ�� --- Auxiliary Selection Hierarchy�� ([2017-08-14-1]) �⻲�Ȥ��줿����
���Ƕ� be ��λ�� have ��λ����Ψ���̻�Ū��ܤ����餫�ˤ��� Smith (2012: 1537) ��Ĵ����ߤĤ����Τǡ��Ҳ𤷤Ƥ����������头�Ȥ� type ���٤� token ���٤���Ψ�ʤ���ӳ��������١ˤ�������Ƥ���ʴ�ȤʤäƤ���Τ� Smith ���̤�2001ǯ�� "Role" ��ʸ�ˡ�
| Type | Token | |||
| Be | have | Be | have | |
| OE | 16% (11) | 84% (57) | 21% (18) | 79% (85) |
| EME | 11% (12) | 89% (92) | 24% (69) | 76% (214) |
| LME | 11% (9) | 89% (70) | 11% (12) | 89% (96) |
| EModE | 8% (10) | 92% (115) | 4% (13) | 96% (319) |
| 19th C | 3% (8) | 97% (311) | 4% (38) | 96% (839) |
��have ��λ��Ȥ�ư��μ�����������٤⡤��Ȥ�갵��Ū¿���ɤ��ä����Ȥ�ʬ���뤬�����夬����ˤĤ�ƽ����������Ƥ������Ȥ�褯ʬ���롥�����ޤǽ����������Ƥ����Ȥ����������פǤ��롥�դ���ߤ�С���Ȥ�� be ��λ��ȤäƤ���������ư�줬��have ��λ���ˤ�������趯�����Ƥ����Ȥ������Ȥˤʤ뤫�����
������ޤǤ� be ��λ�� be gone �Τ褦���귿��Ȥ����Ѥ�����ˤȤɤޤꡤ���¾�ܴۤ����˿��ष�Ƥ��ޤä��Ȥ��äƤ褤�����ʤߤˡ�He is gone. �� He has gone. �ΰ㤤�ˤĤ��Ƥ��������Ԥ� be ��λ�Ǥϡ��ԤäƤ��ޤä����ߤη�̡����ʤ���ֺ��Ϥ⤦���ʤ��פȤ���¦�̤˾��������Ƥ���Ȥ���롥��������Ԥ� have ��λ�ϡ�����Ū����Ԥ���Ԥ��Ȥ���ư��Τ�Ρ�����Ӥ��θ��ߤؤδ�Ϳ�Ȥ���¦�̤˾��������Ƥ���졤���褽�ֹԤä����Ȥ�����פ˶ᤤ��̣�Ȥʤ롥��λ��Τ�Ȥ�Ȥΰ�̣�ϡַ�̡פǤ��ꡤ�������ǤϷ���Ū�˸Ť� be gone ����̣Ū�˸Ť��ַ�̡פ�ô�äƤ��ꡤ����Ū�˿����� have gone ����̣Ū�˿�������������פ�ô�äƤ���Ȥ���ʿ�����Ϥ��⤷���� (Smith, "New" 1537--38) ����Ϣ���ơ�#3631. �ʤ���?�˹Ԥä����Ȥ�����פ� have gone to . . . �ǤϤʤ� have been to . . . �ʤΤ����� ([2019-04-06-1]) �⻲�ȡ�
���� Smith, K. Aaron. "New Perspectives, Theories and Methods: Frequency and Language Change." Chapter 97 of English Historical Linguistics: An International Handbook. 2 vols. Ed. Alexander Bergs and Laurel J. Brinton. Berlin: Mouton de Gruyter, 2012. 1531--46.
���� Smith, K. Aaron. "The Role of Frequency in the Specialization of the English Anterior." Frequency and the Emergence of Linguistic Structure. Ed. by Joan Bybee and Paul Hopper. Amsterdam/Philadelphia: Benjamins, 2001. 361--82.
[ ������ | �����ѥڡ��� ]
2021-01-07 Thu
�� #4273. the --- �Ѹ�ǺǤ���פʸ� [article][frequency][hellog_entry_set][definiteness]
���Ѹ�ǺǤ����٤ι⤤��ϡ��괧�� the �Ǥ��롥��#308. ����Ѹ�κ��ѱ�ñ��ꥹ�ȡ� ([2010-03-01-1]) �Τɤ�����ɽ��ߤƤ⡤����Ū��1�̤Ǥ��롥�Ȥ�����������ۤɽ��פʸ�Ǥ���ʤ���ָ���Ū�ʰ�̣�פϤʤ�������Τϡ�ʸˡŪ�ʵ�ǽ�פΤߤǤ��롥the �ϡ����̤ˤ�����Τ�Τ���ΤΤ�Τ�ؼ���������ô�äƤ���Ȥ��졤ʸˡŪ�Ǥ����Ʊ��������Ū������Ū�ʸ�Ǥ⤢�롥
�����̤��괧������֤����Τ����괧�� a(n) ��̵�������ˡ�����������δ֤λȤ�ʬ���������ȤϤĤȤ��Τ��Ƥ��롥��§�Ǥ����뤳�Ȥ��Ǥ���������㳰��¸�ߤ��롥�ޤ���Ʊ���Ѹ�Ǥ��Ѽ�֤ǻȤ�ʬ�����ۤʤ롥�֥��������Ƥ��פ� play the guitar �ʤΤ� play guitar �ʤΤ������������ơפ� in hospital �ʤΤ� in the hospital �ʤΤ���
���Ѽ�֡ʤ������üԸĿʹ֡ˤǰۤʤ�Τϡ��Ȥ����ˤȤɤޤ�ʤ���ȯ���� [ðə], [ði], [ðiː] �ʤɤ��Ѱۤ��롥���Τ褦�ʸ줬����ȥĤ�Ķ�����ٸ�Ǥ���Ȥ����Τ⡤�ͤ��Ƥߤ�Ф����ؤä��ä��Ǥ��롥
����ˤˤĤ��ƤϤɤ������űѸ�䡤��������Ǥ��륲��ޥ��ĸ졤�����Ƶ�ˤ����Ĥ�����������ĸ�Ǥ⡤��������������ΤϤʤ��ä����Ѹ����ˤ�ߤƤ⡤���ꡦ����˴���Ȥ�������ϡ��űѸ���ˤ�¸�ߤ�������Ѹ���ʹߤ�ȯã���Ƥ��������ԤǤ��롥�űѸ�ˤ� this �� that ����������ؼ����¸�ߤ��Ƥ��ꡤ��˸�Ԥ�������������Ǵ��줬���ޤ�Ƥ����Ȥ����аޤ����롥���줬������Ѹ�ʹߤˤϡ��ʤ��ƤϤʤ�ʤ����Ū�ʸ���ؤ��Ф�ͤ�Ƥ����櫓�����顤�ԻĤ��ä���
��the �ˤĤ������ܤ���30ʬ��Υ饸�����Ȥ�Ҳ𤷤褦��BBC Radio 4's Word of Mouth: The Most Powerful Word �Ǥ��롥�Ѹ�ˤ�����Ȥ�������the ���ԻĤ�̥�Ϥ�;���Ȥ����ʤ���äƤ��롥���Ȥ����Ƥ�ޤȤ��������ɤ��ᤷ�������Ѹ�ˤδ�������ϡ��Ȥ�櫓��Ⱦ�� "Origins" ���ͭ�ѡ�
���ʤ����ܥ֥����Ǥ� the �ˤĤ����͡��˰��äƤ���������##3831,154,156,2144,2855,2856,906,907,2236,4132�ε������å���ɤ�����
2020-12-10 Thu
�� #4245. ���٤������ж��� (A-curve) [lexical_diffusion][zipfs_law][frequency][statistics][language_change][uniformitarian_principle]
��variationist ��Ω�����٤˲����ʤ������Ѳ��˴Ѥ���Ƥ��롤Kretzschmar and Tamasi �����ͤ��ɤ����"A-curve", "asymptotic hyperbolic distribution", "power law", "S-curve" �ʤɤ��Ѹ줬Ϣȯ���פ鷺�ȹ����Ƥ��ޤ���ʸ�����������Ȥ��Ƥ��뤳�Ȥ� Zipf's Law (cf. zipfs_law) ��ȯŸ�ǤΤ褦�˻פ��롥�����٤θ�����¿���������٤θ����Ͼ��ʤ��Ȥ������Ȥ���
������Ѹ쥳���ѥ��ˤ����ơ�1�٤��������ʤ�������������롥������the, of, have �ʤɤ�Ķ�����٤Ǹ����뤬����Ȥ��Ƶ�ǽ��Ǥ��������Ǥ����������˸��ꤵ��롥�㤨�С�1�������ʤ��� ( x = 1 ) ��1000�� ( y = 1000 ) ���뤬��1000��⸽����� ( x = 1000 ) �� the ��1�줷���ʤ� ( y = 1 ) �Ȥ���ȡ�������ɸ��˥ץ��åȤ��Ƥߤ����1�ݸ¤κ���ȱ����������Ǥ���뤳�Ȥˤʤ롥����2����ξü�Ȥ��ơ����δ֤����������Ƥ����ȡ�y = 1/x ��ɽ�碌��褦�������ж��� (asymptotic hyperbolic curve) ���ҳ��˶�Ť�������������� Kretzschmar and Tamasi �� "A-curve" �ȸƤ�Ǥ��ꡤ�ظ�ˤ���ˡ§�� "power law" �ʤ٤���§�ˤȸƤ�Ǥ��롥��Ԥ� "few realizations that occur very frequently and many realizations that occur infrequently" (384) �Ȥ������ȤǤ��롥
��Kretzschmar and Tamasi �ϡ�����ꥫ�����ˤ������¸��Ĵ���� variants ��Ĵ�������Ƽ���Ѱ۷��ˤĤ������٤�ʬ�ۤ��ä�����̤Ȥ��ơ�������Υ������ˤĤ��Ƥ� "A-curve" ���ѻ�����뤳�Ȥ�����
���ޤ���Kretzschmar and Tamasi �ϡ����óȻ� (lexical_diffusion) �Ȥδ�Ϣ�Ǥ��Ф��и��ڤ���� "S-curve" �ȡ����� "A-curve" �Ȥδط��ˤĤ��Ƥ�������Ƥ��롥Ʊ��θ����Ѳ���ۤʤ뼴�����ܤ��ƥץ��åȤ���� "S-curve" �ˤ� "A-curve" �ˤ�ʤꡤξ�Ԥ�̷�⤷�ʤ��ɤ����������������⤤�Ȥ�����
������ۤ����ջȤ��ǤϾ�꤯���⤹�뤳�Ȥ��Ǥ��ʤ��Τ����������ηϤ�����Ѳ���Ű��Ū�� variationist ��į��褦�Ȥ���ȡ����Τ褦�ʸ���Ѥ��뤤�ϸ��������ˤʤ�Τ��ȴ���������Kretzschmar and Tamasi (394) ��ꡤ�Ȥ�櫓���פȻפ���ս����Ѥ��롥
Our second observation, about the distribution of variants according to Zipf's Law, has the strongest set of implications for historical study of language. If we take the A-curve as the model for the frequency distribution of variants for any linguistic feature of interest to us at any moment in time, then we should expect that any particular variant of interest to us will have a particular rank along the A-curve. Therefore, one of the things that we should try to do for any given moment in time is to determine the place of our variant of interest on the curve; we need to know whether it is the most frequent variant in the set of possible realizations (at the top of the curve), or an infrequent variant (in the tail of the curve). Then, for any subsequent moment in time, we can again try to determine the location of our variant of interest along the curve, and so try to make a statement about whether the location of the variant has changed in the intervening time (see Figure 14). Since we hypothesize that an A-curve will exist for every feature at any moment in time (i.e., that language will not suddenly become invariant), we can define the notion "linguistic change" itself as the change in the location of the target variant at different heights along the curve. If a particular variant occurs at a higher place on the curve than it did before, it has become more frequent and so we can say that the direction of change for that variant is positive; if a variant occurs at a lower place on the curve than it did before, it has become less frequent and the direction of change is negative.
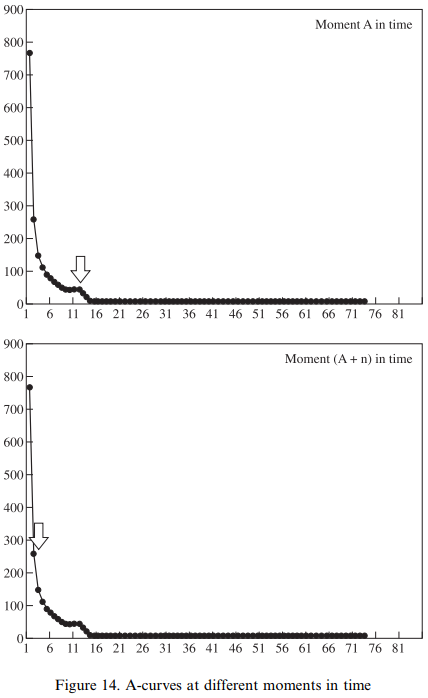
���� Kretzschmar, Jr.,William A and Susan Tamasi. "Distributional Foundations for a Theory of Language Change." World Englishes 22 (2003): 377--401.
2019-12-22 Sun
�� #3891. ����Ѹ���͡��ʶ��ɵ���λ������� [punctuation][alphabet][diacritical_mark][net_speak][brown][corpus][frequency][statistics][exclamation_mark]
���Ѹ��Ʊ�������ޥ���ե��٥åȤ��Ѥ���ʸ�����Τʤ��Ǥ⡤����ˡ (punctuation) �˴ؤ��Ƥ����Ūñ�����������롥����Ū�ʶ��ɵ��椬�Ф����ä��Τ�500ǯ�����餤�Ǥ��ꡤ���ο���¿���ʤ� (cf. ��#575. ����Ū�� punctuation ����ˤ�500ǯ�ۤɡ� ([2010-11-23-1])) ���ޤ���ʸ�����Τ�Τ�26ʸ�������ʤ���ˡ��ե���ɥ��ĸ�ʤɤˤߤ��롤ʸ���μ��դ��դ��ü��ȯ��������ʹ�� (diacritical mark; cf. ��#870. diacritical mark�� ([2011-09-14-1])) �⸶§�Ȥ����Ѥ����ʤ�������ˡ�����ΰ���ʸ���Ǥ϶��ɵ��椬������˻Ȥ���褦�ˤʤäƤ��Ƥ���Ȥ�����롥������net_speak �ʤɤǤϡ������ʶ��ɵ���λ���ˡ�����߽Ф���Ƥ��뤳�Ȥ�Τ��Ǥ��ꡤ����ˡ��ȯŸ���ߤޤäƤ��ޤä��櫓�ǤϤʤ��褦�� (cf. ��#808. smileys or emoticons�� ([2011-07-14-1])) ��
�����ơ���100����Υ���ꥫ�Ѹ�ν��ե����ѥ� Brown Corpus ���Ѥ���Ĵ���ˤ��ȡ��Ѹ�μ��פʶ��ɵ���λ������� (%) �ϼ����̤���Ȥ��� (Cook 92) ��
| Commas | 47 |
| Full stops | 45 |
| Dashes | 2 |
| Parentheses | 2 |
| Semi-colons | 2 |
| Question marks | 1 |
| Colons | 1 |
| Exclamation marks | 1 |
���Ѥ����Ƥ�����ɵ����9��ʾ夬 <,> �� <.> �Ǥ���Ȥ����Τϡ��Ѹ���ɤꡦ���ľ���Ȥ��Ƥ��ʤŤ��롥�Ѹ���ɤ߽ؽ��δ������餤���С��ޤ��Ϥ���2�Ĥζ��ɵ���˽��Ϥ��뤳�Ȥ��ؤ��Ф褤���Ȥˤʤ롥
�������ޥ���ե��٥å�ʸ�����ζ��ɵ�����ѰۤˤĤ��ƴؿ��Τ������ϡ�Character design standards - Punctuation for Latin 1 �ʤɤȤ��줿����
���� Cook, Vivian. The English Writing System. London: Hodder Education, 2004.
2019-12-15 Sun
�� #3884. ʸ�����ɤΡ�2��ϩ�פ����� [spelling][grammatology][alphabet][reading][writing][psycholinguistics][kanji][frequency]
����#3881. ʸ���ɲ�Ρ�2��ϩ��ǥ�ס� ([2019-12-12-1]) �ε����Ǥߤ��褦�ˡ�ʸ�����ɤˤϡֲ����롼�ȡ� (phonological route) �ȡָ�롼�ȡ� (lexical route) ��2��ϩ����������ꤵ��Ƥ��롥ŵ��Ū�ˤϳơ�����ե��٥åȤȴ����ʷ��ɤߡˤ˷�ӤĤ���Τ�ʬ����䤹����������ե��٥åȤ��֤�줿ñ�줬��롼�Ȥ��ɲ�뤳�Ȥ⤢��С�����ʸ���δ����������롼�Ȥ��ɲ�뤳�Ȥ⤢������Τǡ�����ñ��ǤϤʤ���Cook (25) �ϡ�2�ĤΥ롼�Ȥ�ʲ��Τ褦�����椷�Ƥ��롥
| Phonological route | Lexical route | |
|---|---|---|
| Converts written units | To phonemes | To meanings |
| Also known as | Assembled phonology | Addressed phonology |
| Needs | Mental rules | Mental lexicon of items |
| Works by | Correspondence rules | Matching |
| Can handle | Any novel combination | Only familiar symbols |
| Used with | Any words | High frequency words |
���Ǹ��2�Ԥλ�Ŧ����̣��������롼�Ȥϡ����Ǥ��ΤäƤ���졤�Ȥ�櫓���٤ι⤤����������褤�Ȥ����������դˤ����С�̤�Τθ�������٤θ�Ȥ������������Ȥ������Ȥ����Τ��˴�������˳ؤ�Ǥ��ʤ��¤��ɤळ�ȤϤǤ��ʤ����������٤δ����Ϥʤ��ʤ����夷�ʤ��Τ��ɤ߽�˺�줬���Ǥ��롥����������ե��٥åȤǽ줿��ϡ����Ȥ�̤�Τǰ�̣�����Ǥ��äƤ⡤���褽�ɤळ�ȤϤǤ��롥�ޤ�������ե��٥åȤǽ�Ƥ���ȤϤ�����the �� very �ʤɤι����ٸ�ϡ������餯��롼�Ȥ��ɲ�Ƥ����������
�����Ѥ��Ȥ���С������롼�Ȥ�ɮ���������������뤳�Ȥˡ���롼�Ȥϰŵ����Ƥ��뤫��������ľ�ܲ����˥����������뤳�Ȥ���������Ȥ��ä���褤����������
���� Cook, Vivian. The English Writing System. London: Hodder Education, 2004.
2019-11-20 Wed
�� #3859. �ʤ�����ˤ��Ե�§�ʸ��ݤ�����ΤǤ����� [sobokunagimon][frequency][suppletion]
���Ѹ�ˤ�Ѹ�ؤιֵ��ǥꥢ������ڡ��ѡ���Ƥ�餦�ȡ֤ʤ��Ѹ�ˤϡ����Τ褦���Ե�§�ʸ��ݤ�¿���ΤǤ����פȤ������䤬¿�����ޤ����Τ��˱Ѹ�ؽ��ˤ����Ƥϡ��Ե�§��ư����ѡ��Ե�§��̾���ʣ�������Ե�§�ʥ��ڥ�ʤɤ�Ω��³���˸���졤���Τ��Ӥ˰ŵ������ޤ������٤Ƥ���§Ū�Ǥ���Ф����ΤˤȻפ��Τ�̵������̤��ȤǤ����Ѹ����2����Ȥ��Ƴؤֺݤˤ��Τ褦���������뤳�Ȥϡ��ޤä�����ä����̤δ��ФǤ��礦��
�������������Ǥ���1����Ȥ��ƶ�ϫ�ʤ��������Ƥ��ޤäƤ������ܸ��ͤ��Ƥ⡤��Ϥ��Ե�§���������Ƥ��ޤ������ܸ�����üԤϡ����ʳ��ѡ�����ʳ��ѡ������ʳ��ѡ�����ѳʳ��ѡ������ѳʳ��Ѥζ�ϫ��ʤ��Ȥ����ʤ��Ƥ��ޤ����������Ȥ������ܸ��ؤ�Ǥ���ؽ��ԤˤȤäƤϡ��ʤ����٤Ƥ�ư�줬���ʳ��ѤǤ��äƤ���ʤ��Τ����������⤷��ޤ����Ѥ䥵�Ѥϡ��ѳʡפ��ʤ�����Ե�§�פʤ櫓�Ǥ����顤�ؽ��ԤˤȤäƤ����ǤǤ��礦���Ѹ�ؽ��ԤˤȤäƤ� thing -- thought -- thought �� go -- went -- gone ���纹����ޤ���
������ˤ��Ե�§���դ���ΤǤ����Ե�§���ϸź������ν����������Ū�ʸ��ݤʤΤǤ�������˳����ؽ��ԤˤȤäƵ�����������¤���������С�����Ū������Ū�������٤ι��ܤǤ���Ф���ۤ��Ե�§�����⤤�ΤǤ����Ĥޤꡤ�����볰���ؽ��ˤ����ƽ���٥�ۤɰŵ����٤��Ե�§����¿������顦����٥�˶�Ť��Ƥ���ȵ�§���������Ƥ��ޤ�����˾Ū�Ȥ⤤������¤Ǥ��������줬����Ȥ�����ΤǤ���
������ϡ��ʤ��Ե�§�������뤫�Ȥ������ȤǤ����������٤��Ե�§�����ź������ν�������̤�������Ū�Ǥ���Ȥ���С�����ˤ����Ƥϡ����٤Ƥ���§Ū���Ȥष���Թ�ΰ������Ȥ�����Τ������ꤻ����ޤ��������٤��Ե�§�������ä��ۤ����������ʲ���������Ȥ������ȤǤ����Ǥϡ�����ϲ��ʤΤǤ��礦����
����������ˤĤ��ƹͤ����餻�ʤ���ֺ�ȴ���ʸ˼��פ����Ȥ˻פ����ޤ�������������ʸ�Ϥ�Ƥ��뼫��δ��ն�ˤ��͡���ʸ˼����ޤ��������˼�Ф����Ȥ����ˤ������Υڥ�Ω�Ƥ���ˤϡ��Ƽ�Υڥ�Τۤ����Ϥ��ߡ����å������구���ۥå������οij���������ޤ���Ʊ�������ʤȤ����ˤϡ��ݥ��ȥ��åȤȥ��ѥåɤ�����ޤ����������ܤ����ˤ��͡���ʸ˼����Ǽ�Ǥ�������Ф�ê�����ꡤ�����ˤϸҡ������ơ��ס��ä����ࡤ����å��ࡤ�ۥå����������Ƥʤɤ����äƤ��ޤ������������դ��ΰ����Ф��ϡ��ɤ���Ȥ��ˤ�������ˤ��ޤ����Ѥ��Ƥ��ޤ��������Ƥߤ����ǯɮ�ѤΥ����緿�ۥå��������ꤢ���ѥ����Ĺ���구�ʤɤ����äƤ��ޤ���
�������֤äƤߤ�ȡ��ǽ餫���Τ褦�����֤�ʸ˼������������櫓�ǤϤ���ޤ���Ǥ�����Ĺ�����֤��ơ���ˤȤäƻ�̳��Ⱦ��Թ�Τ褤���֤ˤʤäƤ�����ΤȻפ��ޤ����Ϥ��ߤ�ۥå������οij����ϡ���ˤȤäƻ������٤��⤤�ΤǼ��ˤ��ä��ۤ����������Ȥ������Ȥǡ���˻��Υڥ�Ω�Ƥ��꽻����˻�ä��ΤǤ��礦���������ꤢ���ѥ���ϤۤȤ�ɻȤ�ʤ��Τǡ�������°�ΰ����Ф��κǤ����̲�äƤ���ΤǤ��礦���������٤ι⤤ʸ˼��ϡ��Ȥˤ��������˼���Ϥ����ˤʤ������Ω���ޤ��������ۤȤ�ɻ��Ѥ��ʤ�ʸ˼��ϡ��ष�������Ф��α������Ǥ��äƤ⤭�������������Ǽ����Ƥ���ۤ������������嵤�����褤�Ǥ��������ޤ˻Ȥ����餤�Ǥ���Фष�������ʤΤǤ���
���������٤��㤤ʸ˼��Ǥ���С֤������ΰ����Ф��פΡֱ������פȤ���2�ʹ����θ�����ˡ�Ǥ⽽ʬ�Ѥ����ޤ������ޤλ��ѤǤ����顤õ���Τ˾����λ��֤ȹ������������äƤ�����Ǥ��ޤ������������������٤ι⤤ʸ˼��Ϥ����⤤���ޤ����줤�˼�Ǽ����Ƥ��ʤ��Ȥ⡤�ڥ��ݥ��ȥ��åȤϡ���Ϥꤹ���긵�ˤʤ�������Ω���ʤ��ΤǤ���̵¤��Ǥ��ޤ�ʤ����Ȥˤ���������������Τ˻��֤ȹ����������ʤ��ۤ����褤�ΤǤ���
��������Ѥˤ�����ñ��⡤����ʸ˼���Ʊ�����ȤǤ�������Ѹ�Ҳ�ˤ����ư��̤� go �ʹԤ��ˤ� locomote �ʼ��Ϥ�ư���ˤȤǤ����٤����餫�˰ۤʤ�ޤ������ޤˤ����Ȥ�ʤ�ư��ˤĤ��Ƥϡ���§Ū�˳��Ѥ����롤���ʤ�� locomote + ed �Τ褦�˷�������Ȥ������ݤˤ��Ѥ����ޤ����������٤�ư��ˤĤ��ơ�Ʊ���褦�ˤ����������������Ʒ�������Τϡ����餫�˸�Ψ�������Ǥ��礦��go �Ȥ����� went �Ȥ����褦�ˡ����������Τ褦�ˤ������������Ф�ۤ��������Ǥ����Τ��˺ǽ�˰ŵ����륳���ȤϹ⤯�Ĥ��ޤ��������ä���ꥢ���Ƥ��ޤ��С����θ�����λ��Ѥ˺ݤ��Ƹ�Ψ�Τ褤�ѥե����ޥ������ޤ����ޤ���������礭���ۤʤ뤳�Ȥˤ�ꡤ�����ְ㤤��ʹ���ְ㤤�β�ǽ�����㤯�ʤ�Ȥ��������⤢��ޤ����Ե�§�����餳�������Ȥ������Ȥ⤢��ΤǤ���
�����٤Ƥ�ñ�줬Ʊ���٤��Ѥ�����褦�ʸ���Ϥ���ޤ������Τ褦�ʸ��줬�Ѥ�����ʹּҲ�������Ǥ��ޤ��褯�Ȥ�ʤ�ñ��ȤۤȤ�ɻȤ�ʤ�ñ�줬Ʊ�路�Ƥ���Τ�����Ȥ�����ΤǤ����⤷��˽Ҥ٤�������̤ꡤñ��ˤ�����٤κ����Ե�§�����ط����Ƥ���Τ��Ȥ���С��ʤ��ź������θ���ˤ������Ե�§�ʸ��ݤ��ߤ���Τ�������Ǥ��ޤ���
2019-05-07 Tue
�� #3662. "Recency Illusion" �� "Frequency Illusion" [language_myth][language_change][frequency]
�����߿ʹ���θ����Ѳ�����Ȥ��ˡ��褯�ֿ������Ѳ��סֺǶ���Ѳ��פȸƤ֤��Ȥ����롥���ܸ�Ǥ����С֤�ȴ�����աפ�ŵ������������θ����Ѳ��Ϸ褷�ƿ������Ϥʤ�����#2132. ��ȴ�����ա�ar ȴ�����ա�eru �դ����ա� ([2015-02-27-1]) �ǿ��줿�褦�ˡ�����ǤϾ��½�����鵭Ͽ�����ꡤ�����餯���������鵯����Ϥ�Ƥ������Ѹ�˴ؤ��Ƥ⡤���Ȥ��� often �� /t/ ��ȯ�������褦�ˤʤäƤ������Ȥ����߿ʹ�����Ѳ��Ȥ������ܤ���뤬��/t/ �����ȯ�����Τ�Τ���������Ϣ�ʤ�³���Ƥ����ΤǤ��ꡤ��̩�ˤ����Сֿ������Ѳ��פȤϸƤӤˤ��������������⡤���ߤ�ʹ�����Ѳ��ǤϤ���ˤϰ㤤�ʤ���������˻Ϥޤä��Ѳ��ǤϤʤ�������ǯ�ʾ塤���ˤ�äƤϿ������ʾ��������³���Ƥ����Ѳ��Ȥ⤤�������ˤ��äƤ���ΤǤ����cf. ��#860. ����Ѹ���Ѳ����Ѱۤΰ����� ([2011-09-04-1])�ˡ�
������Ū�ˤ����С�¿���ο͡����������Ѳ��Ȥߤʤ��Ƥ����Τϡ������Ƥ����Ǥˤ���ʤ����ˤΤ���Ť��Ѳ��Ǥ��롥�����Ѳ��˾�˥���ƥʤ�ĥ�äƤ������ؼԤǤ��顤���Ф��Ф���櫤α¿��ˤʤ롥Arnold Zwicky �Ϥ���櫤� "the Recency Illusion" �ȸƤ�����¤˸�������̯����Denison (158) �� Zwicky �ˤ��"Just Between Dr. Language and I" ���ꤹ�뵭�����鼡�ΰ��������Ƥ��롥
[...] the Recency Illusion, the belief that things YOU have noticed only recently are in fact recent. This is a selective attention effect. Your impressions are simply not to be trusted; you have to check the facts. Again and again---retro not, double is, speaker-oriented hopefully, split infinitives, etc.---the phenomena turn out to have been around, with some frequency, for very much longer than you think. It's not just Kids These Days. Professional linguists can be as subject to the Recency Illusion as anyone else.
����Ϣ���ơ�Zwicky �� "Frequency Illusion" �ˤ���ڤ��Ƥ��롥
[...] Another selective attention effect, which tends to accompany the Recency Illusion, is the Frequency Illusion: once you've noticed a phenomenon, you think it happens a whole lot, even "all the time." Your estimates of frequency are likely to be skewed by your noticing nearly every occurrence that comes past you. People who are reflective about language---professional linguists, people who set themselves up as authorities on language, and ordinary people who are simply interested in language---are especially prone to the Frequency Illusion.
������ˤ����ƤϤ��Ф��Сֿ������Ѳ��ϻפä����Ť��Ѳ��פǤ��ꡤ�����ˤʸ��ݤϻפä���굩�ʸ��ݡסʤ���ˤĤ��Ƥϡ��դ�ޤ����ʤ�ˤǤ��뤳�Ȥ��õ����Ƥ���������
���� Denison, David. "Word Classes in the History of English" Chapter 13 of Approaches to Teaching the History of the English Language: Pedagogy in Practice. Introduction. Ed. Mary Heyes and Allison Burkette. Oxford: OUP, 2017. 157--71.
���� Zwicky, Arnold. "Just between Dr. Language and I." Language Log. 2005. Accessed May 4, 2006, http://itre.cis.upenn.edu/~myl/languagelog/archives/002386.html .
2019-01-27 Sun
�� #3562. may ����ʸ�������� [optative][productivity][frequency][bnc][auxiliary_verb][may]
��may ����ʸ����ˤ丽��Ǥλ���ˤĤ��� may �� optative �ε����ǰ��äƤ��������� (78) �����Ѥ��Ƥ��� Declerck (416) �ˤ��ȡ�may ����ʸ����ħ�Ȥ���4������Ŧ����Ƥ��롥
��a. In a main clause, a wish (malediction or benediction) is introduced by may.
��b. This use of may is very formal and rarely found in modern English, except in standing expressions.
��c. May always expresses a present wish with future actualisation.
��d. Might cannot be used in a similar way.
��a, c, d �ˤĤ��Ƥ�����ʤ�����������뤬��b �ˤĤ��ƤϤɤ���������������ȤϤ��鷺�Ȥ⡤����ɬ�פʤ褦�˻פ��롥
��may ����ʸ�θ�����ߤ뤿��ˡ�BNCweb �����Ƥߤ�������������ư��� may �ʸ������� "may_VM0" �Ȼ���ˤϡ�3,537�Υƥ����Ȥ���112,397�㤬�ҥåȤ������Τʤ����龯���ɤε�����ˡ�����ϳ��ʤ�õ���ΤˤϤ��ޤ�˹����ޤ�롥�����ǡ�may ����ʸ��ŵ��Ū������ѥ�����䴶ò���¸�ߤʤɤ����ˡ��ʤ�٤�¿�����㤬�֤ˤ�����Ϥ��Ȥ��������κ��Ǻ���������뤳�Ȥˤ��������ξ�ǡ����ȤˤƳΤ���ʸ����Ф�����
����̤Ȥ��Ƽ��Ф����Τ�100�Ĥۤɤ���ʸ�Ǥ���ʷ�̤�ޤȤ�ƥ����ȥե�������������ˡ����Ĥ����������������������1���줫��ʤ륳���ѥ�����100��Ȥ������Ȥϡ����٤Ȥ����������ϼ�ȤϤ����롥�ޤ����귿ɽ�� (Declerck �� "standing expressions"�ˤ�¿���Ȥ������Ȥ��ǧ���줿����äȤ⡤��ҤΤ褦���귿ɽ���ʤɤΡַ��פ����˸������Ƥ���Τǡ����η�̤������Ȥ����������Ǥ��롥���Ȥ��� May God bless/forgive/rest . . . �� Long may it flourish/continue/last . . . �� May . . . be with you . . . �� Much good may it do . . . �ʤɤϡ����餫�ʥѥ�������Ƥ��롥
���������������η��ˤϤޤ꤭�ä���ΤФ���ǤϤʤ���may ����ʸ�ϡ���Τ褦�ʤ���ޤ�Υѥ�����˴�Ť��Ƹ��������ؤ��������Ρ֥ѥ��ǥ��פ��Ȥ�Ϥ߽Ф�������¿���ʤ��ȤϤ����������ʥ����פ�ʸ��Τ����������Ƥ���ΤǤ��롥���ΰ�̣�ǡ������١פ��㤯�Ȥ���������פ�ɬ������ꤨ�Ƥ��ʤ��ȸ�����ΤǤϤʤ��������Τ褦�����Ƥ�������
���� Happy days, Jack, and may all your troubles be little ones!' (A73 91)
���� AN OLD CAMBRIDGE toast is, 'Here's to pure mathematics - may she never be of any use to anyone!' (B7C 2026)
���� St Augustine taught that God had created man in his own image and so it was by looking at his own soul that man would discover God: 'May I know myself! may I know thee!' he had cried. (CD4 417)
���� May you be doing so well into the next century! (CGB 37)
���� With joy may we burn and cleanse!' (CM4 255)
���� May all dealers have this problem! (EBU 2407)
���� May you take that knowledge to your grave!' (HGV 6054)
���⤦1�� authentic �����1����ۤ�����ǯ�Ϥ˳������鼡�Τ褦��ʸ�ǻϤޤ���������ä���
We hope this email finds you all well and settling in to the New Year. May it be a productive and enjoyable one for one and all!
���� ���� ���ʡ���"May the Force Be with You!"�����Ѹ�� may ����ʸ�ˤĤ��ơ����סط�����ض���������ס�64����2015ǯ��77--84�ǡ�
���� Declerck, R. A Comprehensive Descriptive Grammar of English. Tokyo: Kaitaku-sha, 1991.
2018-12-08 Sat
�� #3512. ǧ��ư��μ�������٤��̻�Ū�Ѳ� [frequency][verb][comment_clause][semantic_field]
������ (162) ������Ѹ줫�鸽��Ѹ�ˤ�����ǧ��ư��μ�������١פ�ɽ��Ǥ��褦��ɽ�� (p) �� "personal"��(i) �� "impersonal" ����ˡ�����ʤ�������ɽ�ϡֳƻ���ǰ���줿ư������ٽ�ˤ������äѤ˼�������ΡפȤΤ��ȤǤ��롥
| 14th | 15th | 16th | 17th | 18th | 19th | 20th |
| knowe | suppose | know | know | think | think | think |
| witen | trust | think | think | believe | suppose | know |
| thinke (p) | trow | trow | find suppose | know | suppose | |
| seme | understand | trust/wot | believe | know | believe | believe |
| wene | wot | believe | suppose | guess | guess | guess |
| trowe | hope | wene | fancy | |||
| thinke (i) | know | suppose | guess | |||
| understonde | deme/think/wene | guess | trust | |||
| deme | deme | |||||
| mene | doubt | |||||
| trust | believe | |||||
| hope | guess | |||||
| gessen | ||||||
| leve | ||||||
| undertake | ||||||
| suppose | ||||||
| beleven |
���̻�Ū�ʷ����Ȥ��Ƥϡ���������ǧ�����ʽ�����p. 162--63�ˡ�
1. think �� know ����Ӥ���¿���Ȥ��Ƥ��롥
2. suppose ��15�����ˤϺǤ�¿���Ȥ�줿�������θ�Ƥ�18�����ʹߤ�¿���ʤäƤ��ä���
3. believe ����Ѹ� (Chaucer)��15�����ˤϤۤȤ�ɻȤ��ʤ��ä�����17�����ʹ�¿���Ȥ���褦�ˤʤä���
4. guess �ϰ�Ӥ��Ƥ���ۤ�¿���Ϥʤ���
5. witen, wene, wot ��17���������˻Ȥ��ʤ��ʤä���
6. trowe ��17���������˻Ȥ��ʤ��ʤä����ޤ�����ư��ϤۤȤ�� as ? �η��ǻȤ�줿��
7. ɽ�ˤϤϤä���Ȥ�ɽ��Ƥ��ʤ�����fancy �ϸ���Ѹ�ǤϻȤ��ʤ��ʤä���
������ (170) �ϡ�������ư����̻�Ū�������̣�� (semantic_field) ���붥��Ȱ��֤Ť��Ƥ��롥
witan, wene �ο���� think �����礬�ط������ޤ� know ������η�̤Ǥ⤢��ȹͤ����롥Fancy ��17�����������餷�Ф餯�Ȥ��Ƥ�������20����������ȡ�epistemic phrase �Ȥ��ƻȤ��ʤ��ʤä��Τϡ�imagine �ʤɤ�ư����ɤ����줿�ꡤ���뤤�Ϥ��θ켫�Ȥ�¾����ˡ��fancy restaurant �Τ褦��̾�졤���ƻ�Ū��ˡ�ˤ�ȯã����������Ǥ���ȹͤ����롥�դ˶���ط����ݤ���Ƥ���Τϡ���Ʊ�Τ����������ʬ����ԤäƤ��ꡤ���ΥХ�ξ�˵�ǽ���Ƥ��뤫����ȹͤ����롥Think, believe, suppose, know, guess �� comment cl �Ϥ��Τ褦������ʬ����줿���֤ˤ����Ƶ�ǽ���Ƥ��뤫��Ǥ�������
��ǧ��ư��Ȥ��������٤η���������ȤäƤ⡤�̻�Ū�˼�������٤��ɤäƤߤ뤳�Ȥǡ���̣�ξ�ζ���Ȥ��������ʥߥå��ʸ��ݤ��ѻ�����뤳�Ȥ˴���������
���� ���� �¼�������8�ϡ�Comment clause �ΤޤȤ�ס�Comment Clause �λ�Ū���桡�������ε�ǽ��ȯã�����ٽ��� �¼����ԡˡ���Ĭ�ҥե��˥å�����2010ǯ��161--72�ǡ�
2018-03-25 Sun
�� #3254. �����٤��⤿�餹�̾����̤���¸���� [frequency][grammaticalisation][auxiliary_verb][suppletion][zipfs_law]
��������ܤϡ������٤Ǥ���Ф���ۤɷ��֤����긺�äƽ̾�����Ȥ������ȤϤ褯�Τ��Ƥ��롥������������ܤϹ����٤Ǥ���Ф���ۤɡ������ʷ��֤˼�ä������뤳�Ȥ����ʤ����Ť����֤��ݻ����䤹�����Ȥ⤷���Ƥ��롥�����������⤿�餹���줾��θ��̤ϡ�"Reduction Effect" �ʽ̾����̡ˡ�"Conservation Effect" ����¸���̡ˤȸƤФ�Ƥ��� (Hopper and Traugott 127--28) ��
���̾����̤ϡ�ʸˡ�� (grammaticalisation) �ȴ�Ϣ����������ɽŪ����ϡ���#64. ˡ��ư��������ʤ�³���ȡ� ([2009-07-01-1]) �Ǽ������褦�ʿ����ˡ��ư�췲�Ǥ��롥used to [ju:stə], have to [hæftə], have got to [hævgɑtə], (be) supposed to [spoʊstə], (be) going to [gɑnə] �ʤɤβ����������ꥸ�ʥ�β������餹�긺�äƽ̾����Ƥ���Τ���ǧ����롥���θ��̤ϡ���#1101. Zipf's law�� ([2012-05-02-1]) ���#1102. Zipf's law �ȸ�ο�����ա� ([2012-05-03-1]) �Ǽ��夲�� Zipf's law �Ȥ�ط���������� (cf. zipfs_law) �����٤Ȳ�����Ĺ���ˤ���شط�������Τ��ʤ����������٤�ʸˡ���δ֤ˤ�ͽ�ۤ����ۤɤδط��Ϥʤ��������롤��#2176. ʸˡ������̣�Ѳ������١� ([2015-04-12-1]) �ǾҲ𤷤��褦��Ω��⤢�뤳�Ȥ��դ��ä��Ƥ������ˡ��̾����̤ΰ������Ȥ��Ƥϡ���#1091. �����;���������١����ѡ� ([2012-04-22-1]) �⻲�Ȥ��줿����
����¸���̤ϡ�����Ū�ˤϵ�ˤ��Ե�§�����θ�������֡��Ȥ�櫓�佼ˡ (suppletion) �η��֤��������餳����˻�¸���Ƥ��뤳�Ȥ����ǧ�Ǥ��롥�;���̾����Ѳ��� be ư��γ��Ѥʤɡ�Ķ�����ٸ�ˤ����ƤϸŤ����֤��褯�ݻ����졤����Ū�ˤ�����ͽ¬�Բ�ǽ�ʷ��֤����������ˤĤ��Ƥϡ���#43. �ʤ� go �β����� went �ˤʤ뤫�� ([2009-06-10-1])����#1482. �ʤ� go �β����� went �ˤʤ뤫 (2)�� ([2013-05-18-1])����#2090. �佼ˡ���餱�ο;���̾���ηϡ� ([2015-01-16-1])����#2600. �űѸ�� be ư��ζ��ޡ� ([2016-06-09-1])����#694. �����ٸ���Ե�§ʣ���� ([2011-03-22-1]) �ȡ����������¸���̤Ϸ��֤Τߤʤ餺���ʤɤ����츽�ݤˤ⸫����Τǡ�����ˤĤ��ư��̤ˤ����뤳�Ȥ�������
���� Hopper, Paul J. and Elizabeth Closs Traugott. Grammaticalization. 2nd ed. Cambridge: CUP, 2003.
2018-01-10 Wed
�� #3180. �����˹����ٸ����������̤����Ƥ����ե����ƥ���Ѹ� [french][latin][loan_word][borrowing][frequency][statistics][lexicology][hc][bnc]
���Ѹ�ˤǤϡ���Ѹ줫��������Ѹ�ˤ����ơ��ե��ȥ�ƥ�줫�����̤θ��ü��Ѥ��ʤ��줿�������Τ������߾��Ѥ�����ΤˤĤ��Ƥϡ������餯���ѻ������饹�����Ȥ��ƻ��֤ȤȤ�˻������٤������Ƥ�����Τ���������롥�Ȥ����Τϡ����Ѥ��줿���餫������٤��Ѥ���줿�ȤϹͤ��ˤ����������˱Ѹ��Ʊ���������ﲽ���Ƥ����ȤȤ館��Τ��������������
�����β����¾ڤ���Τˤ����Ĥ�����ˡ�����ꤽ��������Durkin ������������Ĵ����ԤʤäƤ��롥��Ѹ졤�������Ѹ졤����Ѹ�Τ��줾��ˤ����ƥ����ѥ��˴�Ť��ǹ����ٸ�ꥹ�Ȥ��ꡤ���Τʤ��˥ե����ƥ���Ѹ줬�ɤΤ��餤�γ��Ǵޤޤ�Ƥ��뤫��Ĵ�١����γ����̻�Ū��ܤ���Ӥ���Ȥ�����ˡ�����Ť�����Υ����ѥ��Ǥ��ֻ����ѰۤȤ������꤬�ؤ�뤿�ᡤ��̩��Ĵ�����褦�Ȥ����ñ��ˤϤ����ʤ�����Durkin �ϤȤꤢ��������ˡ�Ȥ��ơ���Ѹ�Ƚ������Ѹ�ˤĤ��Ƥ� Helsinki Corpus �� 1150--1500ǯ��1500--1710ǯ�Υ����������Ѥ��ơ�����Ѹ�ˤĤ��Ƥ� BNC ���Ѥ��ư��ֻ��١�����Ĵ�����������줾�����٥�ˤ���900--1000�̤ۤɤޤǤ�ñ����ֻ��˥ꥹ�Ȥ��ꡤ���Τʤ��ǥե����ƥ����Ѹ줬�������Ϥ����Ф�����
����̤ϡ���Ѹ쥻�������Ǥ�7%�ۤɤ��ä���Τ����������Ѹ쥻�������Ǥ�19%�ޤǾ徺��������˸���Ѹ쥻�������Ǥ�38%�ޤǤ˻�äƤ��롥�Ƥ�Ĵ���Ǥ��뤳�Ȥ�ǧ��ĤĤ⡤�ե����ƥ���Ѹ�Ǹ������Ѥ���Ƥ����Τ�¿���ˤĤ��Ƥϡ���ˤΤʤ��ǽ��������٤�夲�Ƥ�����̤Ȥ��ơ����ߤ�����Ū�����ʤ����Ȥ��褯�狼�ä���
������ˤ��⤷�������Ȥˡ��������Ѹ�Υ���������1500--1710ǯ�ˤ˴ؤ�����ͤˤĤ��ơ������ٸ�ꥹ�Ȥ˴ޤޤ��ե����ƥ���Ѹ�Τ��٤Ƥ�1500ǯ������˼��Ѥ��줿��ΤǤ��ꡤ�����⤽��2/3�ۤɤϳμ¤˥ե���Ѹ�Ǥ���Ȥ������¤���ǧ����� (Durkin 338--39) ��
���ޤ�����Ѹ�Ƚ������Ѹ�ι����ٸ�ꥹ�Ȥ˴ޤޤ��ե����ƥ���Ѹ��¿����������Ѹ�ι����ٸ�ꥹ�Ȥˤ�Ƹ�����Ƥ�����¤ˤ��Ƥ��������Ť�2���ˤϸ����뤬����������ϳ��Ƥ���췲��į���ȡ��ʤ�Ȥ������Ѳ��������Ƥ���롥�㤨�С�honour, justice, manner, noble, parliament, pray, prince, realm, religion, supper, treason, usury, virtue �Ǥ��� (Durkin 340) ��
������ˤ�äƺ��Ѹ�ꥹ�Ȥ䥭����ɤ��ۤʤ뤳�Ȥ������Ȥ�����������������˱Ѹ쥳���ѥ����Ѥ����͡��ʻ������Ӥ��Ƥߤ�Ȥ��⤷�����������㤨�С��������Ѹ쥳���ѥ��˴�Ť�������ɡ��ꥹ�ȤˤĤ��ơ�#2332. EEBO �Υ�����ɤ���С� ([2015-09-15-1]) �ȡ��ޤ������٤���ˤ�����ˤĤ��Ƥϡ�#1243. ������٤��θ�����̻�Ū����Τ���ˡ� ([2012-09-21-1]) �⻲�Ȥ��줿����
���� Durkin, Philip. Borrowed Words: A History of Loanwords in English. Oxford: OUP, 2014.
Powered by WinChalow1.0rc4 based on chalow