2025-01-25 Sat
■ #5752. 近代のフランス借用語 --- 月刊『ふらんす』の連載記事第11弾 [hakusuisha][french][rensai][furansu_rensai][contact][loan_word][borrowing][mode]

*
1月23日,白水社の月刊誌『ふらんす』2025年2月号が刊行されました.今年度,同誌で連載記事「英語史で眺めるフランス語」を寄稿していますが,今回は第11回「近代のフランス借用語」です.
1. 近代にフランス単語が借用された背景
フランス語からの借用は中英語期以降も継続的に行われ,特に17--18世紀にはフランス語がヨーロッパの知的共通語としての地位を確立した.この時期,イングランドではフランス借用語への反感も一部で示されたものの,受け入れの大きな阻害要因とはならなかった.
2. フランス語らしさをとどめる近代の借用語
近代の借用語は原語の形をほぼ保持したまま定着し,多くは貴族的・知的な印象を持つ単語群だった.また,借用時期の違いは単語の強勢パターンにも反映され,中世以前は第1音節,近代以降はフランス語本来の位置に強勢が置かれる傾向があった.
3. ロマンス諸語からの借用の窓口としてのフランス語
フランス語は直接の借用元としてだけでなく,イタリア語やスペイン語など他のロマンス諸語からの語彙を英語に導入する窓口としても機能した.ただし,ロマンス諸語は語形が似ているため,借用語の由来を特定することが難しい場合もある.近代英語期のフランス語借用は,18世紀以降,特に料理やファッション,文化・芸術分野で顕著となり,これらの借用語は既存の英語の語彙に新たなニュアンスを加えた.
4. 20世紀以降のフランス借用語
20世紀以降も garage や montage など多くの語が借用され続けており,21世紀に入ってからも parkour のような新しい借用語が登場している.約千年にわたるフランス語と英語の語彙的な関係は,今後も継続していくと予想される.
さらに詳しくは,直接『ふらんす』2月号を手に取ってお読みいただければと思います.過去10回の連載記事は hellog 記事群 furansu_rensai で紹介してきましたので,そちらもご参照ください.
これまで11回にわたって,千年以上にわたる英語の仏語との言語接触の歴史を眺めてきました.次号はいよいよ最終回となります.お楽しみに!
(以下,後記:2025/02/01(Sat))
今号と関連して,heldio でも「#1343. 近代のフランス借用語 --- 月刊『ふらんす』の連載記事第11弾」と題してお話ししていますので,こちらもお聴きください.
-->
・ 堀田 隆一 「英語史で眺めるフランス語 第11回 近代のフランス借用語」『ふらんす』2025年2月号,白水社,2025年1月23日.52--53頁.
2024-05-08 Wed
■ #5490. なぜ職業名を表わす姓の種類は近代英語期にかけて減少したのか? [onomastics][personal_name][name_project][by-name][me][mode][occupational_term]
「#5488. 中英語期の職業名(を表わす姓)の種類は驚くほど細分化されていて多様だった」 ([2024-05-06-1]) および「#5489. 古英語の職業名の種類は中英語と同じくらい多様だったか否か」 ([2024-05-07-1]) を受けての話題.前者の記事で,中英語期には多様だった職業名が,近代英語期にかけて種類を減らしていった事実に触れた.
同様に,職業名を表わす姓 (by-name) も,近代英語期にかけて種類を減らしていったという.これはなぜだろうか.Fransson (32) によれば,"by-name" が世襲の "family name" へ発展していく際に,一般的で短めの職業名が選択されたからではないかという.
As regards surnames of occupation we can notice that they become less specialized towards the end of the period, and if we examine rolls after 1350, we shall be surprised at the rarity of specialized names as compared with the earlier period. The reason for this has nothing to do with what has been said above about trades; it is connected with the heredity of surnames, which now begins to become prevalent. The specialized surname of occupation coincided with the trade of a person and, as a rule, does not seem to have been hereditary, which is probably due to its length and to the fact that it very easily calls to mind the trade itself. The surnames that became hereditary were usually short and denoted common trades, e.g. Smith, Cook, Tailor, Turner, etc.; it is almost exclusively names of this kind that one finds in later rolls. It is true that there are surnames of the specialized type that have survived to modern times, e.g. Arrowsmith, Cheesewright, but they are probably very rare; they owe their existence to the fact that the corresponding trade has died out or that the corresponding substantive has become extinct and its signification been forgotten, e.g. Billiter (= ME Belleyetere), Jenner (= ME Gynour), etc.
本来的には個人に属していた by-name が家に属する family name へ発展していくにつれて,硬直化し多様性が失われたということだろう.時代は多様性の中世から画一性の近代へと変化していった,とも議論できそうだ.
・ Fransson, G. Middle English Surnames of Occupation 1100--1350, with an Excursus on Toponymical Surnames''. Lund Studies in English 3. Lund: Gleerup, 1935.
2024-02-03 Sat
■ #5395. 2月24日(土),朝カルのシリーズ講座「文字と綴字の英語史」の第4回「近代英語の綴字 --- 標準化を目指して」 [asacul][notice][writing][spelling][orthography][mode][standardisation][etymological_respelling][link][voicy][heldio][chancery_standard][spelling_reform]
3週間後の2月24日(土)の 15:30--18:45 に,朝日カルチャーセンター新宿教室にてシリーズ講座「文字と綴字の英語史」の第4回となる「近代英語の綴字 --- 標準化を目指して」が開講されます.
今回の講座は,全4回のシリーズの第4回となります.シリーズのラインナップは以下の通りです.
・ 第1回 文字の起源と発達 --- アルファベットの拡がり(春・4月29日)
・ 第2回 古英語の綴字 --- ローマ字の手なずけ(夏・7月29日)
・ 第3回 中英語の綴字 --- 標準なき繁栄(秋・10月7日)
・ 第4回 近代英語の綴字 --- 標準化を目指して(冬・2月24日)
今度の第4回については,先日 Voicy heldio にて「#971. 近代英語の綴字 --- 2月24日(土)の朝カルのシリーズ講座第4回に向けて」として概要を紹介していますので,お聴きいただければ幸いです.
これまでの3回の講座では,英語綴字の標準化の前史を眺めてきました.今回はいよいよ近現代における標準化の実態に迫ります.まず,15世紀の Chancery Standard に始まり,16世紀末から17世紀にかけての Shakespeare,『欽定訳聖書』,初期の英語辞書の時代を経て,18--19世紀の辞書完成に至るまでの時期に注目し,英単語の綴字の揺れと変遷を追います.その後,アメリカ英語の綴字,そして現代の綴字改革の動きまでをフォローして,現代英語の綴字の課題について論じる予定です.各時代の英単語の綴字の具体例を示しながら解説しますので,迷子になることはありません.
本講座にご関心のある方は,ぜひこちらのページよりお申し込みください.講座当日は,対面のほかオンラインでの参加も可能です.また,参加登録されますと,開講後1週間「見逃し配信」を視聴できます.ご都合のよい方法でご参加いただければと思います.シリーズ講座ではありますが,各回の内容は独立していますので,今回のみの単発のご参加でもまったく問題ありません.なお,講座で用いる資料は,当日,参加者の皆様に電子的に配布される予定です.
本シリーズと関連して,以下の hellog 記事,および Voicy heldio 配信回もご参照ください.
[ 第1回 文字の起源と発達 --- アルファベットの拡がり ]
・ heldio 「#668. 朝カル講座の新シリーズ「文字と綴字の英語史」が4月29日より始まります」(2023年3月30日)
・ hellog 「#5088. 朝カル講座の新シリーズ「文字と綴字の英語史」が4月29日より始まります」 ([2023-04-02-1])
・ hellog 「#5119. 朝カル講座の新シリーズ「文字と綴字の英語史」の第1回を終えました」 ([2023-05-03-1])
[ 第2回 古英語の綴字 --- ローマ字の手なずけ ]
・ hellog 「#5194. 7月29日(土),朝カルのシリーズ講座「文字と綴字の英語史」の第2回「古英語の綴字 --- ローマ字の手なずけ」」 ([2023-07-17-1])
・ heldio 「#778. 古英語の文字 --- 7月29日(土)の朝カルのシリーズ講座第2回に向けて」(2023年7月18日)
・ hellog 「#5207. 朝カルのシリーズ講座「文字と綴字の英語史」の第2回「古英語の綴字 --- ローマ字の手なずけ」を終えました」 ([2023-07-30-1])
[ 第3回 中英語の綴字 --- 標準なき繁栄 ]
・ hellog 「#5263. 10月7日(土),朝カルのシリーズ講座「文字と綴字の英語史」の第3回「中英語の綴字 --- 標準なき繁栄」」 ([2023-09-24-1])
・ heldio 「#848. 中英語の標準なき綴字 --- 10月7日(土)の朝カルのシリーズ講座第3回に向けて」(2023年9月26日)
[ 第4回 近代英語の綴字 --- 標準化を目指して ]
・ heldio 「#971. 近代英語の綴字 --- 2月24日(土)の朝カルのシリーズ講座第4回に向けて」(2024年1月27日)
多くの方々のご参加をお待ちしております.
2023-07-09 Sun
■ #5186. Voicy heldio に秋元実治先生が登場 --- 新刊『近代英語における文法的・構文的変化』についてお話しをうかがいました [voicy][heldio][review][mode][corpus][syntax][phrasal_verb][subjunctive][complementation][periodisation]
6月に開拓社より近代英語期の文法変化に焦点を当てた書籍が出版されました.『近代英語における文法的・構文的変化』です.秋元実治先生(青山学院大学名誉教授)が編者を務められ,他に6名の研究者が執筆に加わっています.本書については,すでにこのブログや YouTube 「井上逸兵・堀田隆一英語学言語学チャンネル」で紹介する機会がありました.
・ hellog 「#5166. 秋元実治(編)『近代英語における文法的・構文的変化』(開拓社,2023年)」 ([2023-06-19-1])
・ hellog 「#5167. なぜ18世紀に規範文法が流行ったのですか?」 ([2023-06-20-1])
・ hellog 「#5182. 大補文推移の反対?」 ([2023-07-05-1])
・ YouTube 「井上逸兵・堀田隆一英語学言語学チャンネル」より「#137. 辞書も規範文法も18世紀の産業革命富豪が背景に---故山本史歩子さん(英語・英語史研究者)に捧ぐ---」
このたび,本書をめぐって編者の秋元実治先生とじきじきに対談する機会に恵まれました.対談の様子は,今朝の Voicy チャンネル「英語の語源が身につくラジオ (heldio)」にて「#769. 『近代英語における文法的・構文的変化』 --- 秋元実治先生との対談」として配信しています.対談本体は27分ほどとなっています.お時間のあるときにゆっくりお聴きいただければ.
エンディングチャプター(第5チャプター)では,秋元先生から対談収録後にうかがった,本書の表紙下部のビッグベンの写真についての貴重な裏話を紹介しています.
皆さん,ぜひ近代英語の文法変化について関心を寄せていただければ!

・ 秋元 実治(編),片見 彰夫・福元 広二・田辺 春美・山本 史歩子・中山 匡美・川端 朋広・秋元 実治(著) 『近代英語における文法的・構文的変化』 開拓社,2023年.
2023-07-07 Fri
■ #5184. 秋元実治『イギリス哲学者の英語』(開拓社,2023年) [review][mode][philosophy][toc]
「#5166. 秋元実治(編)『近代英語における文法的・構文的変化』(開拓社,2023年)」 ([2023-06-19-1]) で紹介した編著者の秋元実治先生(青山学院大学名誉教授)が,今年,開拓社よりもう1冊の著書を出されています.『イギリス哲学者の英語 --- 通時的研究』です.ご献本いただき,ありがたき幸せです.

本書は開拓社の言語・文化選書の第99弾として出版されたものです(秋元先生は,2017年に同選書の第65弾『Sherlock Holmes の英語』を,2020年に第86弾『探偵小説の英語 --- 後期近代英語の観点から』を出版されています).
本書は,16--20世紀に生きた6人のイギリス哲学者に焦点を当て,彼らの英語を分析し,その文法的,文体的特徴を浮き彫りにしています.彼らの書いた英語を時系列に並べることで,主に近代英語期を通じての英語の通時的変化が俯瞰できるようになっています.英語史や英語の通時的変化に関心のある方はもちろん,イギリス経験哲学者の書いた英文に関心のある方にも,学べることが多いです.
以下に本書の章立てとともに,取り上げられた哲学者を列挙します.
第1章 概説 --- 哲学者を中心に
第2章 近代英語とは
第3章 哲学者の英語 (1) --- Francis Bacon(1561--1626)
第4章 哲学者の英語 (2) --- Thomas Hobbes(1588--1679)
第5章 哲学者の英語 (3) --- John Locke(1632--1704)
第6章 哲学者の英語 (4) --- David Hume(1711--1776)
第7章 哲学者の英語 (5) --- John Stuart Mill(1806--1873)
第8章 哲学者の英語 (6) --- Bertrand Russell(1872--1970)
第9章 通時的考察
・ 秋元 実治 『イギリス哲学者の英語 --- 通時的研究』 開拓社,2023年.
2023-07-05 Wed
■ #5182. 大補文推移の反対? [gcs][archer][corpus][mode][gerund][infinitive][complementation]
英語の統語論の歴史には,「#4635. "Great Complement Shift"」 ([2022-01-04-1]) という潮流がある,とされる.補文の構造 (complementation) が,もともとの that 節から不定詞へと推移し,さらに動名詞へと推移してきた変化である.古英語から現代英語に至るまでゆっくりと進行し続けてきており,非常に息が長い.
先日発売された「#5166. 秋元実治(編)『近代英語における文法的・構文的変化』(開拓社,2023年)」 ([2023-06-19-1]) で,編著者の秋元 (242--44) が,大補文推移 (gcs) の一種の反例のようにみえる興味深い例を示している.
近代英語期を通じて「~するために」を意味する in order ... の表現が,古くは動名詞をとっていたところ,そこへ不定詞が進出し,さらに that 節まで進出してきたというのである.その前段階の関連表現から始まる推移を概観すると,次のようになるという.
to the end that/to the end to V
↓
in order to NP/ing
↓
in order to V
↓
in order that ~ may
秋元によれば,これは ARCHER Corpus で検索した結果に基づいたシナリオということだ.推移の順序に従って代表的な例文が5つ挙げられているので,ここに再掲する.
・ ... they were all Committed to Newgate, in order to their being Tried next Sessions. (1682 2PROI.N1)
・ I know not whether it might not be worth a Poet's while, to travel in order to store is mind with ... (1714 BERK.X2)
・ ... every moral agent must exist forever, in order to the proper and full exercise of moral government. (1789 HOPK.H4)
・ ... consequently I cut away all the cerebrum until the corpus callosum appeared, in order that I might the more readily examine the lateral ventricles. (1820 A.M5)
・ Not because I want to undervalue the importance of these signs, but in order that I may impress upon you how important it is to Subject ...
確かに大補文推移を巻き戻したかのような順序の推移となっている.何か別の原理によるものなのか,あるいは偶発的な例外とみなすべきなのか,興味深い.
・ 秋元 実治(編),片見 彰夫・福元 広二・田辺 春美・山本 史歩子・中山 匡美・川端 朋広・秋元 実治(著) 『近代英語における文法的・構文的変化』 開拓社,2023年.
2023-06-19 Mon
■ #5166. 秋元実治(編)『近代英語における文法的・構文的変化』(開拓社,2023年) [review][mode][corpus][syntax][phrasal_verb][subjunctive][complementation][periodisation][youtube]
近代英語の文法変化についてコーパスを用いて実証的に研究した論考集が開拓社より出版されました.英語史分野の一線で活躍されている著者7名(片見彰夫氏,福元広二氏,田辺春美氏,山本史歩子氏,中山匡美氏,川端朋広氏,秋元実治氏)による書籍です.著者の方々よりご献本いただきました由,ここに感謝致します.
この本の最大の特徴は,各章が15--20世紀の各世紀を考察範囲としていることです.注目する話題は半ば固定されており,その点で定点観測となっているのですが,全体として整理された通時的な統語論の研究となっています.「はしがき」の冒頭に次のようにあります (v) .
本書は近代英語(1500--Present)における文法的・構文的変化についてコーパス等の使用による実証的研究である.
これまで英語史の記述において世紀別に述べることはあまりなかったように思われる.ひとつにはほとんどの言語変化は世紀を横断するため,各世紀の記述が難しいことがある.しかしながら,文学史などでは世紀別はきわめて普通であり(例えば,Oxford History of English Literature 12 volumes),このこともあってか英語史においても最近 Kytö et al. (2006), Mair (2006) などが出版され,それぞれ19世紀,20世紀の英語における変化・特徴に焦点をあてている.
本書では近代英語における上記のような変化の連続性と各世紀の特徴を捉えるために,以下の点を執筆者の間で共有した.
1. 全ての執筆者は共通項目,句動詞,仮定法,補文について述べる.
2. それ以外の項目で,その世紀の特徴と考えられる文法的・構文的変化について述べる.
3. 電子コーパス,テキスト等を使って,実証的に記述する.
英語史の時代区分 (periodisation) については,最近では「#5140. 「英語史の時代区分」月間の振り返り」 ([2023-05-24-1]) で取り上げるなどし,私自身も長らく考えてきました.「古英語」や「近代英語」などとラベルを貼るのではなく,きっぱりと世紀単位で切る,あるいは言及するというのは確かに一般的ではありませんでしたが,Curzan (33) が述べるように,ラベルを避けたい立場の論者は世紀単位を好むようです.一見すると無機質な時代区分のようでいて,むしろ読み手に世紀をまたいだ言語の連続性と断絶性を意識させるという効果があるのではないでしょうか.
本書ではコーパスを用いた具体的で実証的な研究が紹介されており,この分野を研究する学生や研究者には,手法も含めて直接参考になります.また,文法変化・構文変化といっても扱うべき話題は多岐にわたるものですが,各章では各世紀の英語を考察する上でとりわけ重要な項目が選ばれており,たいへん有用です.
最終章は全体のまとめとなっており,いったん各章のために世紀別に分けられたものが建て直され,読み手の視界がすっきりします.参考文献も充実しており,中英語末期から現代に至るまでの文法変化に関心のある方には,ぜひ手に取ってもらいたい一冊です.私も学生に薦めたいと思います.
著者の一人,山本史歩子さん(青山学院大学)におかれましては,本書の出版を見る前にご逝去されたとの報に接しました.悲しみでいっぱいです.ご冥福をお祈りいたします.
・ 秋元 実治(編),片見 彰夫・福元 広二・田辺 春美・山本 史歩子・中山 匡美・川端 朋広・秋元 実治(著) 『近代英語における文法的・構文的変化』 開拓社,2023年.
・ Curzan, Anne. "Periodization in the History of the English Language." Chapter 12 of The History of English. 1st vol. Historical Outlines from Sound to Text. Ed. Laurel J. Brinton and Alexander Bergs. Berlin: Mouton de Gruyter, 2017. 8--35.
2018-01-12 Fri
■ #3182. ARCHER で colour と color の通時的英米差を調査 [ame_bre][spelling][archer][corpus][mode][webster]
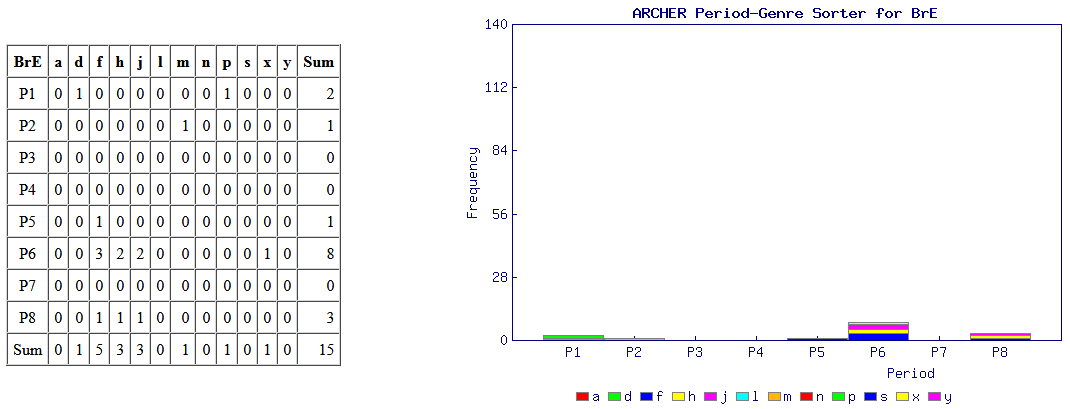
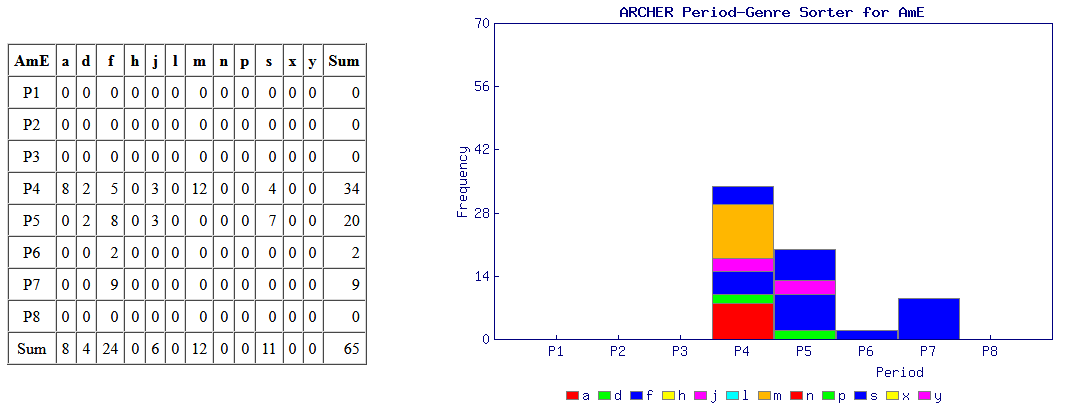
意外と簡単にできる調査として,標題の例を紹介したい.近代英米語コーパス「#1802. ARCHER 3.2」 ([2014-04-03-1]) を用いて,綴字の英米差の通時的な調査を手軽に行える.例として,最も知られている <colour> と <color> の英米差を調べてみよう.
ARCHER Untagged にアクセスし,検索欄に "colour*" と "color*" 入れ,それぞれの結果を取り出す.それを「#1808. ARCHER 検索結果の時代×ジャンル仕分けツール (ARCHER Period-Genre Sorter)」 ([2014-04-09-1]) にかけて,自動的に4つの図表を作成させる.この図表により,両綴字の英米差について,1600--1999年を8区分した時代別に,そして12のジャンル別に比較することが可能となる.時代区分とジャンルは以下の通り.
・ P1 = 1600--49, P2 = 1650--99, P3 = 1700--49, P4 = 1750--99, P5 = 1800--49, P6 = 1850--99, P7 = 1900--49, P8 = 1950--99
・ a = advertising, d = drama, f = fiction, h = sermons, j = journals, l = legal, m = medicine, n = news, p = early prose, s = science, x = letters, y = diaries
では,まずイギリス英語からみていこう.上の図表が伝統的なイギリス式の <colour> の数値を示し,下が典型的にアメリカ式スペリングといわれる <color> の数値である.期待を裏切らず,イギリス英語では時代にかかわらず,ほぼ <colour> 一辺倒といってよい.
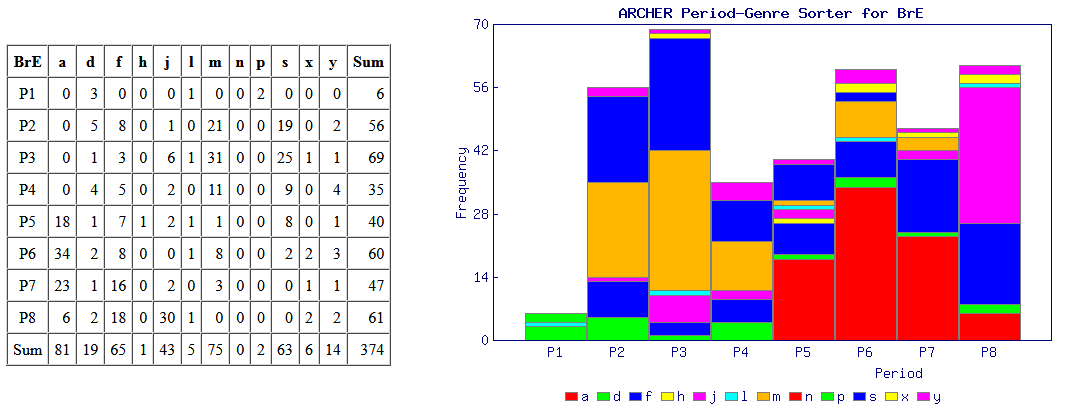
次にアメリカ英語の結果だが,こちらも英語史の期待を裏切らない.P4(1750--99年)までは伝統を受け継ぐ <colour> の綴字が圧倒的だが,P5 以降は著しく衰退し,代わりに <color> が伸びていく.P5 といえば,Noah Webster が An American Dictionary of the English Language を出版した1828年を含む半世紀の時代区分であり,米国式スペリングがその後数十年の時間をかけつつ定着していく様をよく表わしている.
現在は超巨大な Google Books Ngram Viewer に簡単にアクセスできるため,ARCHER よりもさらに簡便に同じような調査を行えるようになっている.しかし,ARCHER ではコンコーダンス・ラインを引き出せるために文の中身を吟味することもできるし,ヒット件数が手作業でまかなえるほどに抑えられるというのも,考えようによっては利点といえる.要は使い方次第だ.ARCHER を使用した他の調査例として,「#1806. ARCHER で shew と show」 ([2014-04-07-1]),「#1807. ARCHER で between と betwixt」 ([2014-04-08-1]),「#1752. interpretor → interpreter (2)」 ([2014-02-12-1]) も参照.
2016-11-05 Sat
■ #2749. "Present Perfect Puzzle" --- 近現代英語からの「違反」例 [perfect][aspect][tense][adverb][present_perfect_puzzle][mode]
「#2492. 過去を表わす副詞と完了形の(不)共起の歴史 」 ([2016-02-22-1]),「#2633. なぜ現在完了形は過去を表わす副詞と共起できないのか --- Present Perfect Puzzle」 ([2016-07-12-1]) で紹介したように,現代英語には,現在完了と過去の特定の時点を表わす副詞語句は共起できないという規則がある.ところが,近代英語やとりわけ中英語では,このような共起の例が散見される.現代英語にかけて,なぜこのような制限規則が定まったのかという問題,いわゆる "Present Perfect Puzzle" については,様々な提案がなされてきたが,完全には解明されていない.
Visser (2197) より,近代英語期,さらに20世紀を含む時代からの例をいくつか引こう.
・ 1601 Shakesp., All's Well IV, iii, 3, I have delivered it an hour since.
・ 1669 Pepys's Diary April 11th, which I have forgot to set down in my Journal yesterday.
・ 1777 Sheridan, School f. Sc. I, i, I am told he has had another execution in the house yesterday.
・ 1820 Scott. Monastery XXX, The Englishman . . . has murdered young Halbert . . . yesterday morning.
・ 1847 Ch. Brontë, Jane Eyre XVI, Indeed I have seen Blanche, six or seven years ago, when she was a girl of eighteen.
・ 1912 Standard, Aug. 16, Prince Henry has decided to travel to Tokio by the overland route. Twice already he has visited Japan, in 1892 and 1900 (Kri).
・ 1920 Galsworthy, In Chancery IV, I have been to Richmond last Sunday.
・ 1962 Everyman's Dictionary of Literary Biography p. 609--10, He [sc. Shakespeare] is, of course, unmeasurably the greatest of all English writers, and has been so recognized even in those periods that were antipathetic to the Elizabethan genius.
このような現代的な規則から逸脱している例について,Visser (2197) は他の研究者を参照しつつ次のように述べている.
Several scholars (e.g. 1958 F. T. Wood; 1926 Poutsma) account for these idioms by suggesting that the writer or speaker has embarked on the given form before the idea of a temporal adjunct comes into his mind, and then adds this adjunct as a kind of afterthought. Another explanation is based on the assumption that instances like those quoted here may be seen as survivals of a usage that formerly---when there was not yet the strict line of demarcation between the different uses---occurred quite normally.
ここでは2つの提案がなされているが,前者の "afterthought" 説は理解しやすい.しかし,上記の例のすべてが,後から思いついての付け足しとして説明できるかどうかは,客観的に判断できないように思われる.第2の「古くからの残存」説は,その通りなのかもしれないが,現代英語にかけてくだんの共起制限が課されたのはなぜかという "Present Perfect Puzzle" に直接に迫るものではない.
このパズルは未解決と言わざるを得ない.
・ Visser, F. Th. An Historical Syntax of the English Language. 3 vols. Leiden: Brill, 1963--1973.
2014-05-15 Thu
■ #1844. ドイツ語式の名詞語頭の大文字使用は英語にもあった (2) [punctuation][printing][mode][writing][standardisation][lexical_diffusion][swift][capitalisation]
「#583. ドイツ語式の名詞語頭の大文字使用は英語にもあった」 ([2010-12-01-1]) で話題にしたように,Addison, Dryden, Swift などの活躍した17--18世紀には,名詞の語頭大文字化がはやった.当初の書き手の趣旨はキーワードとなる名詞を大文字化することだったが,一時期,名詞であれば何であれ大文字化するという慣習が芽生えた.Horobin (157) によれば,この慣習の背後には植字工の介入があったという.
The convention seems to have been for a writer to leave the business of spelling to the compositors who were responsible for setting the type for printed texts. This practice led to the introduction of a distinctive feature of punctuation found in this period: the capitalization of nouns. This practice has its origins in an author's wish to stress certain important nouns within a piece of writing. Because ultimate authority for spelling and punctuation lay with compositors, who were often unable to distinguish capital letters from regular ones in current handwriting, they adopted a policy of capitalization of nouns by default.
「#1829. 書き言葉テクストの3つの機能」 ([2014-04-30-1]) の記事で参照したエスカルピ (45--46) は,印刷業者が現代においてもテクストの諸機能に影響を及ぼしていることを指摘している.
印刷されたテキストでは,資料機能のレヴェルでは部分的に,図像機能のレヴェルではほとんどもっぱら産業機構が介入し,それに対して書き手は必ずしも力をもたない.実はそれゆえに,自分の本が印刷されたのを読む作家は,自分が手で書いたのとは別の本を前にしている感じを抱くのである.印刷されたものから出てくる権威は彼の外にある.
その後,名詞の語頭はすべて大文字化するという句読法の慣習は長続きせず,ついに標準化されることはなかった.しかし,書き言葉の標準化における植字工や印刷家の潜在的な役割には注意しておく必要があるだろう.なお,最近の研究では印刷業者の書き言葉標準化への関与を従来よりも小さめに見積もる傾向が認められるが,彼らの関与そのものを否認しているわけではない.一定の介入は間違いなくあったろう.関連して,cat:printing standardisation のいくつかの記事を参照されたい.
英語では途中で断ち切れになったが,名詞大文字化の慣習はドイツ語では標準化している.私はドイツ語史には暗いが,昨年8月に Oslo 大学で開かれた ICHL 21 (International Conference on Historical Linguistics) に参加した折りに,ドイツ語におけるこの句読法の発展についての研究発表があり,興味深く聴いた.手元に残っているメモによると,ドイツ語では16--17世紀にこの慣習が発展したが,最初からすべての名詞が大文字化されたわけではなく,[+animal] の意味素性をもつ名詞から始まり,[+agentive], [+material] などの順で進行したという.統語的にも,主語としてのほうが目的語としてよりも名詞の大文字化が早かったという.綴字習慣の変化も語彙拡散 (lexical_diffusion) に従い得るのかと関心したのを覚えている.
ローマ字における大文字と小文字の区別の発生については,「#1309. 大文字と小文字」 ([2012-11-26-1]) を参照.
・ Horobin, Simon. Does Spelling Matter? Oxford: OUP, 2013.
・ ロベール・エスカルピ 著,末松 壽 『文字とコミュニケーション』 白水社〈文庫クセジュ〉,1988年.
2014-04-09 Wed
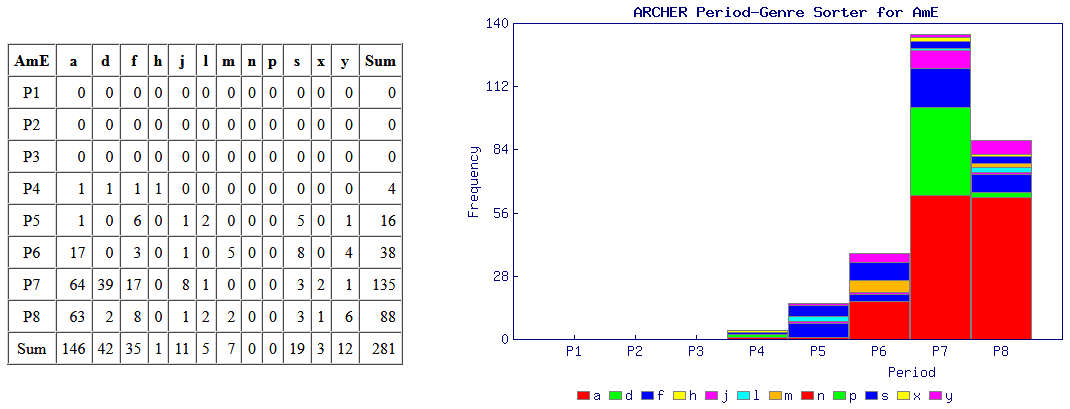
■ #1808. ARCHER 検索結果の時代×ジャンル仕分けツール (ARCHER Period-Genre Sorter) [cgi][web_service][corpus][archer][mode]
この2日間の記事「#1806. ARCHER で shew と show」 ([2014-04-07-1]) と「#1807. ARCHER で between と betwixt」 ([2014-04-08-1]) で,ARCHER の Untagged 版 を用いて,語の変異形の頻度が通時的にどのように推移してきたかを調査した.
近代英語の初期から後期を含むコーパスとしては,ほかに CEECS (The Corpus of Early English Correspondence, LC (The Lampeter Corpus of Early Modern English Tracts), CLMET3.0 (The Corpus of Late Modern English Texts, version 3.0), PPCMBE, COHA などがあり,それぞれに特徴があるが,ARCHER は,1600--1999年というまとまった期間をカバーし,英米変種それぞれについてジャンル分けがなされており,比較的大型の歴史コーパスとして価値が高い.しかし,「#1802. ARCHER 3.2」 ([2014-04-03-1]) で紹介した通り,現在ウェブ上で一般公開されている版については,いまだタグ検索などが実装されておらず,可能性を最大限に利用することはできない.しかし,工夫次第でいろいろと活用できる.実装されている Frequency lists や Keywords の機能はアイディア次第で有効に使えそうだし,コーパス全体の単語頻度リスト (TXT)も公開されている.
通時的な言語変化という観点から ARCHER に望む機能は,この2日間の記事で調査したように,ある検索語の頻度が時期を追って(ついでにジャンル別に)どのように推移してきたかを,簡単に確認できるようにすることだ.Restricted query で時期とジャンルを絞り,検索欄に検索語を入力してヒット数を数えてゆくということは手作業でできるが,時間がかかるし面倒だ.「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) や COHA では,この通時的な一覧を可能にする機能が実装されているので,ARCHER でも余計に同様の機能が欲しくなる.そこで,欲しいのならば作ってしまおうということで,簡単なスクリプトを組んだ.ARCHER の検索結果のコンコーダンス・ラインには,テキストを表わすファイル名が付されているが,ファイル名の仕様によれば,末尾3文字がそれぞれジャンル,時期,英米変種のいずれかを表わす記号となっている.そこで,検索結果をコピーして,以下のテキストボックスに貼り付けてやると,適切にファイル名を解析し,時期,ジャンル,変種ごとにヒット数を整理してくれ,グラフ化してくれるというツール (ARCHER Period-Genre Sorter) を作成した.ARCHER での出力結果が数ページにまたがる場合には,少し手数がかかるが,各ページをコピペして累積していけばよい.
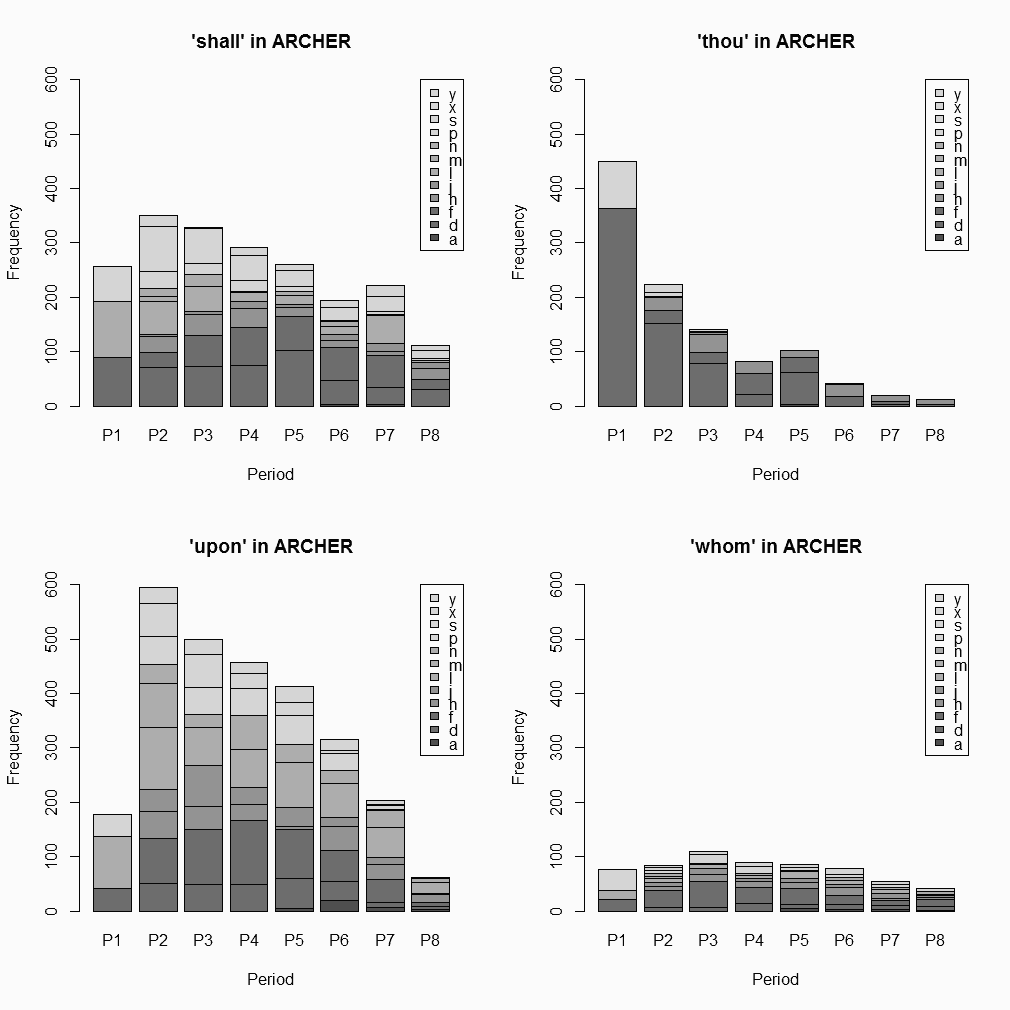
このツールの使用の応用例として,ここ数世紀の間で使用頻度が衰退しただろうと疑われる4語,shall, thou (= thou, thy, thee, thine), upon, whom を取り上げる.今回は,イギリス英語のサブコーパスのみに限定した.以下は,ツールが返した集計表をもとにグラフ化したものである.(ツールがどのように機能するかを確認するために,試しに ARCHER による 'thou' の出力結果のテキストファイル (194KB) の内容を上のテキストボックスにコピペされたい.)
2014-04-08 Tue
■ #1807. ARCHER で between と betwixt [spelling][corpus][archer][mode]
昨日の記事「#1806. ARCHER で shew と show」 ([2014-04-07-1]) に引き続き,[2014-04-03-1]の記事で紹介した「#1802. ARCHER 3.2」を利用して,別の問題に臨む.標記の between と betwixt の後期近代英語における分布について,「#1637. CLMET3.0 で between と betwixt の分布を調査」 ([2013-10-20-1]) で話題にしたが,ARCHER の Untagged 版ではどのような調査結果が出るだろうか.
検索にあたっては,とりわけ17世紀の段階では綴字が完全に定まっていたわけではないため,それぞれの語の異綴字も考慮に入れた.具体的には,between 系列として between, betweene, betwen, betwene, betwn が,betwixt 系列として betwixt, betwext が異綴字として挙がってきた.昨日と同様に,ヒット数を12ジャンルおよび1600--1999年を50年刻みにした8期に分けて数え上げた.以下に,集計結果のグラフのみ示す(データファイルと頻度表はソースHTMLを参照されたい).なお,betwixt and between の形では1例も現れていない.
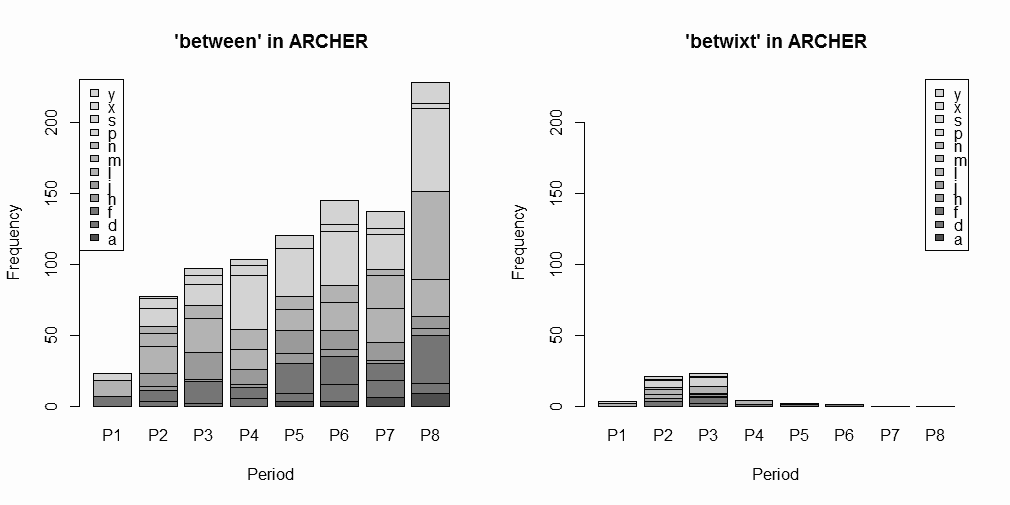
全体として,17--19世紀のどの時期においても between が圧倒していることは,以前の CLMET3.0 による調査結果からも予想されたことである.しかし,P2--P3 (1650--1749) の時期に限ってではあるが,betwixt が20%ほどのシェアを占めていたという事実は注目してよい(P1のサブコーパスは他の各時期のサブコーパスの1/3ほどの規模であることにも注意).CLMET3.0 による調査でも18世紀中までは bewixt が10%ほどのシェアを占めていたという結果が出ているから,大雑把にいって1750年くらいまでは betwix は between の異形としてそれなりの存在感を示していたことが確認できた.
2014-04-07 Mon
■ #1806. ARCHER で shew と show [spelling][corpus][archer][mode]
標記の語を巡る綴字の変異について,「#1415. shew と show (1)」 ([2013-03-12-1]),「#1416. shew と show (2)」 ([2013-03-13-1]),「#1716. shew と show (3)」 ([2014-01-07-1]) で取り上げてきた.今回は,[2014-04-03-1]の記事で紹介した「#1802. ARCHER 3.2」を利用して,近代英語期における両綴字の分布を改めて確認しよう.
ARCHER: A Representative Corpus of Historical English Registers の Untagged 版で,shew 系列 (shew, shews, shewed, shewn, shewing) と show 系列 (show, shows, showed, shown, showing) の語形を検索し,ヒット数を12ジャンルおよび1600--1999年を50年刻みにした8期に分けて数え上げた.データファイルと頻度表はソースHTMLを参照してもらうとして,結果をグラフ化したもののみ示そう.
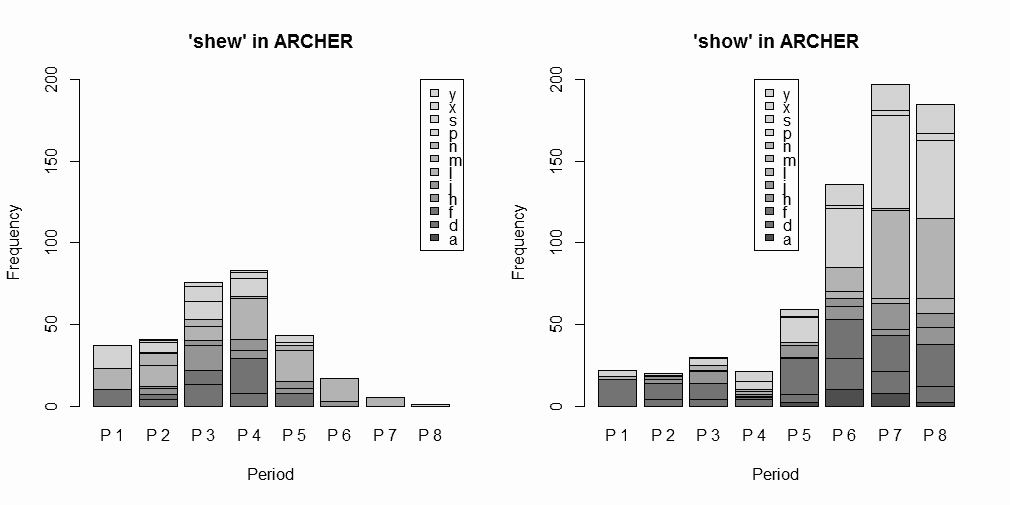
ジャンルの考慮はおいておくとして,通時的な推移に注目しよう.P1 (1600--49) から P4 (1750--99) まで,つまり17--18世紀には,絶対頻度で shew のほうが show より優勢だが,P5 (1800--49) に両者がおよそ肩を並べ,P6 以降には show が一気に shew を駆逐してゆく過程が見てとれる.この推移の概要は,過去の記事で調査した Helsinki Corpus および PPCMBE の結果とは符合するが,CLMET3.0 の結果とは少々異なる.CLMET3.0 では,[2014-01-07-1]の記事で見たように,18世紀中から絶対頻度で show が shew を圧倒的に上回っていたのである.このコーパス間の違いが,各コーパスの代表性の違いによるものなのか,それともジャンル分け等が関与しているのか,あるいは複数の語形を一括して数えたことに由来するものなのか,詳しくは調査していない(P1のサブコーパスについては,他の各時期のサブコーパスの1/3ほどの規模であることに注意).しかし,両系列の相対的な盛衰ではなく,shew 系列の衰退という観点で考えるのであれば,いずれのコーパスを参照しても,それは19世紀前半の出来事とみなしてよいだろう.
2014-04-03 Thu
■ #1802. ARCHER 3.2 [corpus][archer][mode][frequency]
昨年末のことになるが,近代英米語コーパス ARCHER: A Representative Corpus of Historical English Registers の Untagged 版が公開された.詳細は,公式の Documentation,あるいは VARIENG によるコーパスの解説からどうぞ.英語史研究会のオンライン会報より,三浦あゆみさんの記事「ARCHERの新版公開」も参考になる.
ARCHER は,1990年代初頭より Biber and Finegan が編纂してきたもので,現在では14の大学が合同で管理している.2013年に公開されたこの3.2版は Manchester 大学 ( David Denison and Nuria Yáñez-Bouza) による提供である.コーパスの内容と用途を端的に表現すれば,"a multi-genre historical corpus of British and American English covering the period 1600--1999. The corpus has been designed as a tool for the analysis of language change and variation in a range of written and speech-based registers of English." ということである.
コーパスの規模は1,710ファイル,3,298,080語からなり,語数での英米比は6:4ほど.また,時期として8期,内容により12種類にジャンル分けされている (a = advertising, d = drama, f = fiction, h = sermons, j = journals, l = legal, m = medicine, n = news, p = early prose, s = science, x = letters, y = diaries) .ファイル数と語数の内訳は以下の通り.
| BRITISH | a | d | f | h | j | l | m | n | p | s | x | y | TOTAL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1600--49 | files | 0 | 10 | 0 | 0 | 0 | 10 | 0 | 0 | 10 | 0 | 0 | 0 | 30 |
| words | 0 | 32,342 | 0 | 0 | 0 | 21,026 | 0 | 0 | 32,741 | 0 | 0 | 0 | 86,109 | |
| 1650--99 | files | 0 | 10 | 11 | 10 | 10 | 10 | 21 | 10 | 0 | 10 | 75 | 10 | 177 |
| words | 0 | 30,328 | 41,667 | 21,818 | 21,186 | 20,466 | 23,811 | 22,304 | 0 | 21,427 | 38,767 | 20,488 | 262,262 | |
| 1700--49 | files | 0 | 10 | 11 | 10 | 11 | 10 | 14 | 10 | 0 | 10 | 77 | 10 | 173 |
| words | 0 | 27,862 | 44,057 | 21,511 | 23,265 | 21,315 | 22,066 | 21,612 | 0 | 20,812 | 33,896 | 20,495 | 256,891 | |
| 1750--99 | files | 10 | 10 | 10 | 10 | 10 | 10 | 20 | 10 | 0 | 10 | 70 | 11 | 181 |
| words | 25,386 | 27,484 | 45,198 | 21,752 | 21,284 | 20,367 | 21,002 | 23,172 | 0 | 20,599 | 29,589 | 23,043 | 278,876 | |
| 1800--49 | files | 10 | 10 | 10 | 10 | 11 | 10 | 10 | 10 | 0 | 10 | 25 | 10 | 126 |
| words | 30,804 | 31,211 | 45,107 | 21,777 | 23,249 | 20,531 | 20,286 | 22,951 | 0 | 21,015 | 12,671 | 20,883 | 270,485 | |
| 1850--99 | files | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 0 | 10 | 26 | 10 | 126 |
| words | 30,684 | 34,856 | 43,427 | 21,322 | 21,243 | 20,757 | 22,265 | 23,072 | 0 | 21,810 | 10,819 | 21,789 | 272,044 | |
| 1900--49 | files | 10 | 11 | 10 | 10 | 10 | 10 | 10 | 10 | 0 | 10 | 29 | 10 | 130 |
| words | 26,717 | 31,391 | 45,408 | 21,123 | 22,208 | 21,160 | 20,213 | 21,977 | 0 | 21,664 | 12,529 | 22,424 | 266,814 | |
| 1950--99 | files | 10 | 11 | 10 | 10 | 10 | 10 | 13 | 10 | 0 | 10 | 28 | 10 | 132 |
| words | 23,437 | 32,200 | 45,109 | 21,093 | 22,723 | 20,721 | 20,994 | 22,935 | 0 | 21,385 | 11,361 | 22,060 | 264,018 | |
| TOTAL | files | 50 | 82 | 72 | 70 | 72 | 80 | 98 | 70 | 10 | 70 | 330 | 71 | 1,075 |
| words | 137,028 | 247,674 | 309,973 | 150,396 | 155,158 | 166,343 | 150,637 | 158,023 | 32,741 | 148,712 | 149,632 | 151,182 | 1,957,499 | |
| AMERICAN | a | d | f | h | j | l | m | n | p | s | x | y | TOTAL | |
| 1750--99 | files | 3 | 10 | 10 | 10 | 10 | 12 | 9 | 10 | 0 | 10 | 58 | 10 | 152 |
| words | 9,214 | 29,980 | 38,980 | 21,271 | 21,896 | 41,177 | 23,541 | 22,265 | 0 | 20,668 | 27,860 | 21,315 | 278,167 | |
| 1800--49 | files | 1 | 10 | 10 | 0 | 10 | 12 | 0 | 10 | 0 | 10 | 10 | 10 | 83 |
| words | 2,822 | 40,568 | 44,676 | 0 | 21,476 | 33,409 | 0 | 37,107 | 0 | 20,904 | 20,739 | 20,695 | 242,396 | |
| 1850--99 | files | 8 | 10 | 11 | 10 | 10 | 10 | 10 | 10 | 0 | 10 | 28 | 11 | 128 |
| words | 24,480 | 32,721 | 44,394 | 21,056 | 22,436 | 28,506 | 20,547 | 21,994 | 0 | 21,311 | 11,361 | 23,419 | 272,225 | |
| 1900--49 | files | 10 | 10 | 10 | 0 | 10 | 11 | 0 | 15 | 0 | 10 | 52 | 10 | 138 |
| words | 30,460 | 52,514 | 53,430 | 0 | 21,661 | 21,607 | 0 | 22,802 | 0 | 20,984 | 25,021 | 20,731 | 269,210 | |
| 1950--99 | files | 10 | 10 | 10 | 10 | 10 | 12 | 10 | 10 | 0 | 12 | 30 | 10 | 134 |
| words | 29,563 | 31,037 | 44,382 | 21,051 | 22,109 | 25,517 | 22,617 | 23,069 | 0 | 25,623 | 11,961 | 21,654 | 278,583 | |
| TOTAL | files | 32 | 50 | 51 | 30 | 50 | 57 | 29 | 55 | 0 | 52 | 178 | 51 | 635 |
| words | 96,539 | 186,820 | 225,862 | 63,378 | 109,578 | 150,216 | 66,705 | 127,237 | 0 | 109,490 | 96,942 | 107,814 | 1,340,581 | |
Documentation のページより,完全単語リストをダウンロード可能.タグ付きの検索が可能な版もいずれ公開されるということなので,期待したい.「#1752. interpretor → interpreter (2)」 ([2014-02-12-1]) の記事で少し使ってみたので,そちらも参照を.
2013-04-15 Mon
■ #1449. 言語における「範疇」 [category][number][gender][tense][aspect][person][mode][terminology][sapir-whorf_hypothesis][linguistic_relativism]
言語学では範疇 (category) という術語が頻用される.もともとは哲学用語であり,日本語の「範疇」は,中国の『書経』の「洪範九疇」ということばをもとに,英語 category やドイツ語 Kategorie の訳語として,明治時代の西洋哲学の移入時に,井上哲次郎(一説に西周)が作ったものとされる.原語はギリシア語の katēgoríā であり,その動詞 katēgoreîn は kata- (against) + agoreúein (to speak in the assembly) から成る.「公の場で承認されうる普遍的な概念の下に包みこんで訴える」ほどの原義に基づいて,アリストテレスは「分類の最も普遍的な規定,すなわち最高類概念」の語義を発展させ,以降,非専門的な一般的な語義「同じ種類のものの所属する部類・部門」も発展してきた.
英語の category も,まずは16世紀末に哲学用語としてラテン語から導入され,17世紀中葉から一般用語として使われ出した.現在では,OALD8 の定義は "a group of people or things with particular features in common" とあり,日常化した用語と考えてよい.
では,言語学で用いられる「範疇」とは何か.さすがに専門用語とだけあって,日常的な単なる「部類・部門」の語義で使われるわけではない.では,言語的範疇の具体例を見てみよう.英文法では文法範疇 (grammatical category) ということが言われるが,例えば数 (number) ,人称 (person) ,時制 (tense) ,法 (mode) などが挙げられる.これらは動詞を中心とする形態的屈折にかかわる範疇だが,性 (gender or sex) など語彙的なものもあるし,定・不定 (definiteness) や相 (aspect) などの統語的なものもある.これらの範疇は英文法の根本にある原理であり,文法記述に欠かせない概念ととらえることができる.これで理解できたような気はするが,では,言語的範疇をずばり定義せよといわれると難しい.このもやもやを解決してくれるのは,Bloomfield の定義である.以下に引用しよう.
Large form-classes which completely subdivide either the whole lexicon or some important form-class into form-classes of approximately equal size, are called categories. (270)
文法性 (gender) で考えてみるとわかりやすい.名詞という語彙集合を前提とすると,例えばフランス語には形態的,統語的な振る舞いに応じて,規模の大きく異ならない2種類の部分集合が区別される.一方を男性名詞と名付け,他方を女性名詞と名付け,この区別の基準のことを性範疇を呼ぶ,というわけである.
category の言語学的用法が一般的用法ではなく哲学的用法に接近していることは,言語的範疇がものの見方や思考様式の問題と直結しやすいからである.この点についても,Bloomfield の説明がすばらしい.
The categories of a language, especially those which affect morphology (book : books, he : she), are so pervasive that anyone who reflects upon his language at all, is sure to notice them. In the ordinary case, this person, knowing only his native language, or perhaps some others closely akin to it, may mistake his categories for universal forms of speech, or of "human thought," or of the universe itself. This is why a good deal of what passes for "logic" or "metaphysics" is merely an incompetent restating of the chief categories of the philosopher's language. A task for linguists of the future will be to compare the categories of different languages and see what features are universal or at least widespread. (270)
・ Bloomfield, Leonard. Language. 1933. Chicago and London: U of Chicago P, 1984.
Powered by WinChalow1.0rc4 based on chalow