hellog〜英語史ブログ / 2012-06
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
2026 : 01 02 03 04 05 06 07 08 09 10 11 12
2025 : 01 02 03 04 05 06 07 08 09 10 11 12
2024 : 01 02 03 04 05 06 07 08 09 10 11 12
2023 : 01 02 03 04 05 06 07 08 09 10 11 12
2022 : 01 02 03 04 05 06 07 08 09 10 11 12
2021 : 01 02 03 04 05 06 07 08 09 10 11 12
2020 : 01 02 03 04 05 06 07 08 09 10 11 12
2019 : 01 02 03 04 05 06 07 08 09 10 11 12
2018 : 01 02 03 04 05 06 07 08 09 10 11 12
2017 : 01 02 03 04 05 06 07 08 09 10 11 12
2016 : 01 02 03 04 05 06 07 08 09 10 11 12
2015 : 01 02 03 04 05 06 07 08 09 10 11 12
2014 : 01 02 03 04 05 06 07 08 09 10 11 12
2013 : 01 02 03 04 05 06 07 08 09 10 11 12
2012 : 01 02 03 04 05 06 07 08 09 10 11 12
2011 : 01 02 03 04 05 06 07 08 09 10 11 12
2010 : 01 02 03 04 05 06 07 08 09 10 11 12
2009 : 01 02 03 04 05 06 07 08 09 10 11 12
2012-06-30 Sat
■ #1160. MRC Psychological Database より各種統計を視覚化 [lexicology][statistics][syllable][corpus]
[2012-06-28-1], [2012-06-29-1]と連日紹介してきた MRC Psycholinguistic Database に基づいて,4つの英語語彙統計を図示したい.原データファイルの仕様に示されている統計表をもとにグラフを作成しただけだが,別のコーパスに基づいて類似した調査を行なってきたものもあるので,比較に値するだろう.数値データは,HTMLソースを参照.
(1) 文字数による頻度
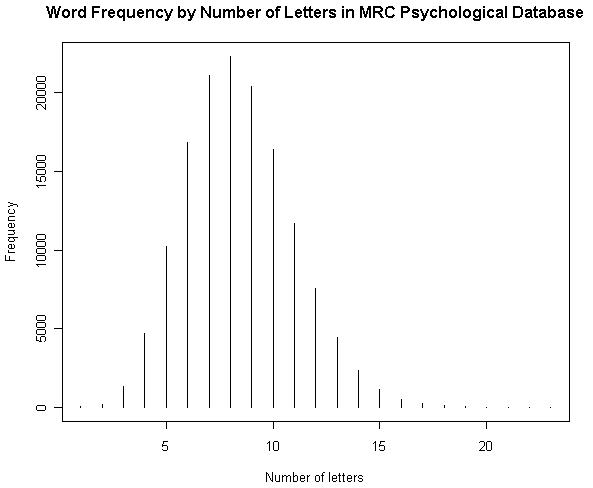
(2) 音素数による頻度
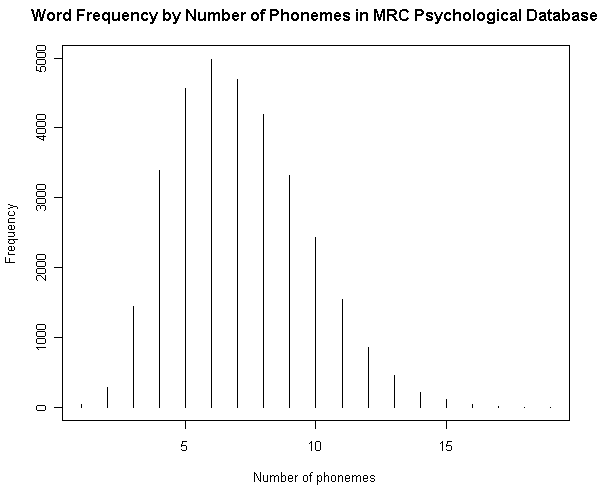
(参考)
・ [2012-02-13-1]: 「#1022. 英語の各音素の生起頻度」
(3) 音節数による頻度
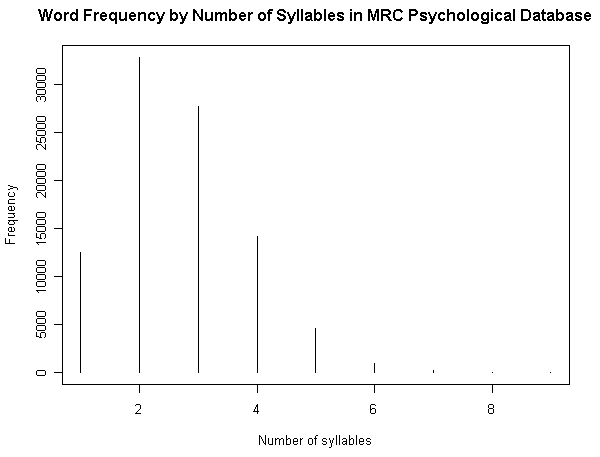
(参考)
・ [2010-04-09-1]: 「#347. 英単語の平均音節数はどのくらいか?」
・ [2010-04-10-1]: 「#348. BNC Word Frequency List による音節数の分布調査」
・ [2010-04-11-1]: 「#349. BNC Word Frequency List による音節数の分布調査 (2)」
・ [2010-04-17-1]: 「#355. COLT Word Frequency List による音節数の分布調査」
(4) 品詞による頻度
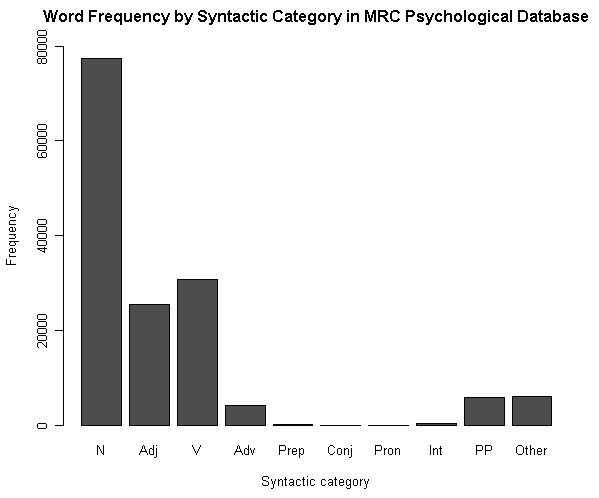
(参考)
・ [2012-06-02-1]: 「#1132. 英単語の品詞別の割合」
・ [2011-02-23-1]: 「#667. COCA 最頻50万語で品詞別の割合は?」
・ [2011-02-22-1]: 「#666. COCA 最頻5000語で品詞別の割合は?」
・ [2011-02-16-1]: 「#660. 中英語のフランス借用語の形容詞比率」
その他,語彙の頻度や,語種別の割合については以下の記事も参照.
・ [2010-03-01-1]: 「#308. 現代英語の最頻英単語リスト」
・ [2011-08-20-1]: 「#845. 現代英語の語彙の起源と割合」
・ [2012-01-07-1]: 「#985. 中英語の語彙の起源と割合」
2012-06-29 Fri
■ #1159. MRC Psycholinguistic Database Search [cgi][web_service][lexicology][frequency][statistics]
昨日の記事[2012-06-28-1]で紹介した英語語彙データベース MRC Psycholinguistic Database を,本ブログ上から簡易検索するツールを作成した.実際には検索ツールというよりは,MRC Psycholinguistic Database を用いると,こんなことができるということを示すデモ版にすぎず,出力結果は10行のみに限定してある.本格的な使用には,昨日示したページからデータベースと検索プログラムをダウンロードするか,ウェブ上のインターフェース (Online search (answers limited to 5000 entries) or Online search (limited search capabilities)) よりどうぞ.
以下,使用法の説明.SQL対応で,テーブル名は "mrc2" として固定.フィールドは以下の27項目:ID, NLET, NPHON, NSYL, K_F_FREQ, K_F_NCATS, K_F_NSAMP, T_L_FREQ, BROWN_FREQ, FAM, CONC, IMAG, MEANC, MEANP, AOA, TQ2, WTYPE, PDWTYPE, ALPHSYL, STATUS, VAR, CAP, IRREG, WORD, PHON, DPHON, STRESS.各パラメータが取る値の詳細については,原データファイルの仕様を参照のこと(仕様中に示されている各種統計値はそれ自身が非常に有用).select 文のみ有効.以下に,典型的な検索式を例として載せておく.
# 文字数で語彙を分別
select NLET, count(NLET) from mrc2 group by NLET;
# 音素数で語彙を分別
select NPHON, count(NPHON) from mrc2 group by NPHON;
# 音節数で語彙を分別
select NSYL, count(NSYL) from mrc2 group by NSYL;
# -ed で終わる形容詞を頻度順に
select WORD, K_F_FREQ from mrc2 where WTYPE = 'J' and WORD like '%ed' order by K_F_FREQ desc;
# 2音節の名詞,形容詞,動詞を強勢パターンごとに分別 (「#814. 名前動後ならぬ形前動後」 ([2011-07-20-1]) 及び「#801. 名前動後の起源 (3)」 ([2011-07-07-1]) を参照)
select WTYPE, STRESS, count(*) from mrc2 where NSYL = 2 and WTYPE in ('N', 'J', 'V') group by WTYPE, STRESS;
# <gh> の綴字で終わり,/f/ の発音で終わる語
select distinct WORD, DPHON from mrc2 where WORD like '%gh' and DPHON like '%f';
# 不規則複数形を頻度順に
select WORD, K_F_FREQ from mrc2 where IRREG = 'Z' and TQ2 != 'Q' order by K_F_FREQ desc;
# 馴染み深く,具体的な意味をもつ語
select distinct WORD, FAM from mrc2 where FAM > 600 and CONC > 600;
# イメージしやすい語
select distinct WORD, IMAG from mrc2 order by IMAG desc limit 30;
# 「有意味」な語
select distinct WORD, MEANC, MEANP from mrc2 order by MEANC + MEANP desc limit 30;
# 名前動後など品詞によって強勢パターンの異なる語
select WORD, WTYPE, DPHON from mrc2 where VAR = 'O';
2012-06-28 Thu
■ #1158. MRC Psycholinguistic Database [web_service][lexicology][frequency][statistics]
心理言語学の分野ではよく知られた英語の語彙データベースのようだが,「#1131. 2音節の名詞と動詞に典型的な強勢パターン」 ([2012-06-01-1]) と「#1132. 英単語の品詞別の割合」 ([2012-06-02-1]) で参照した Amano の論文中にて,その存在を知った.MRC Psycholinguistic Database は,150837語からなる巨大な語彙データベースである.各語に言語学的および心理言語学的な26の属性が設定されており,複雑な条件に適合する語のリストを簡単に作り出すことができるのが最大の特徴だ.特定の目的をもった心理言語学の実験に用いる語彙リストを作成するなどの用途に特に便利に使えるが,検索パラメータの組み合わせ方次第では,容易に語彙統計学の研究に利用できそうだ.
パラメータは実に多岐にわたる.文字数,音素数,音節数の指定に始まり,種々のコーパスに基づく頻度の範囲による絞り込みも可能.心理言語学的な指標として,語の familiarity, concreteness, imageability, meaningfulness なども設定されている.品詞などの統語カテゴリーはもちろん,接頭辞,接尾辞,略語,ハイフン形などの形態カテゴリーの指定もできる.発音や強勢パターンの指定にも対応している.組み合わせによって,およそのことができるのではないかと思わせる精緻さである.
全データベースと検索プログラムはこちらからダウンロードできるが,プログラムをコンパイルするなど面倒が多いので,ウェブ上のインターフェースを用いるのが便利である.2つのインターフェースが用意されており,それぞれ機能は限定されているが,通常の用途には十分だろう.
・ Online search (answers limited to 5000 entries): パラメータの細かい指定が可能だが,出力結果は5000語までに限られる.
・ Online search (limited search capabilities): 出力結果の数に制限はないが,言語学的なパラメータの細かい指定(綴字や発音のパターンの直接指定など)はできない.
・ Amano, Shuichi. "Rhythmic Alternation and the Noun-Verb Stress Difference in English Disyllabic Words." 『名古屋造形大学名古屋造形芸術大学短期大学部紀要』 15 (2009): 83--90.
2012-06-27 Wed
■ #1157. Welsh にみる音韻変化の豊富さ [phonetics][causation][i-mutation][suffix][germanic][dialect][grimms_law][gvs][compensatory_lengthening]
授業などで,グリムの法則 (Grimm's Law; [2009-08-08-1]) や大母音推移 (Great Vowel Shift; [2009-11-18-1]) などの体系的(とみられる)音韻変化を概説すると,なぜそのような変化が生じたのかという素朴な疑問が多く寄せられる.音韻変化の原因については諸家の意見が対立しており,はっきりしたことは言えないのが現状である.しかし,英語でも日本語でも,その他のあらゆる言語でも,話者の気付かぬところで音韻変化は現在もゆっくりと進行中である.ゲルマン語史や英語史に限っても,多数の音韻変化が理論的あるいは文献的に認められており,グリムの法則や大母音推移は,とりわけ著名ではあるが,多数のうちの2つにすぎない.したがって,グリムの法則についての「なぜ」を問うのであれば,同じように無数の音韻変化の「なぜ」も問わなければならなくなる.音韻変化の原因論はおくとしても,音韻変化がいかに日常的であり,豊富であるかということは気に留めておく必要がある.
例えば,現代英語 Welsh の発音を,ゲルマン祖語の再建形から歴史的に説明するには複数の音韻変化を前提としなければならない.そればかりか,ゲルマン祖語から古英語の West-Saxon 標準形である Wīelisc にたどり着くまでにも,5つもの音韻変化が関与しているのである (Hamer 34--35) .ゲルマン祖語形としては,語根 *walh に形容詞接尾辞 *-isk を付加した *walhisk が再建されている(対応する英語の接尾辞 -ish については,[2009-09-07-1]の記事「#133. 形容詞をつくる接尾辞 -ish の拡大の経路」を参照).

この図でいう "raising", "breaking", "sk > sc", "i-mutation", "loss of h and compensatory lengthening" が,それぞれの音韻変化に付けられた名称である.グリムの法則などと大仰な名前は付いていないが,それぞれが立派な1つの音韻変化である.
話しはここで終わらない.古英語 West-Saxon 標準形の Wīelisc にたどり着いたが,この語形は中英語以降には伝わらなかった.現在の標準形 Welsh に連なるのは,この West-Saxon 形ではなく,Anglian や Kentish 形である.古英語 Anglia 方言では,breaking が起こらず,むしろ第1母音は æ から a へ回帰した.これが,後に i-mutation により再び æ へ上がり,中英語ではそこから発展した e, a などの異形が並立した.16世紀以降は,e の母音で固まり,現在の Welsh が一般的な語形として定着した.
第2母音 i の消失については,古英語期に始まったらしいが,i の有無の揺れは中英語期にも激しかったようだ(MED の Welsh (adj.) を参照).なお,French も接頭辞 -ish の母音の省略された形態を伝えている([2009-10-09-1]の記事「#165. 民族形容詞と i-mutation」を参照).また,人名 Wallace, Wallis は Welsh の歴史的異形である.
このように,ある語のある時代における発音を歴史的に説明するには,数多くの音韻変化の跡を追うことが必要となる.類例として,近代英語の father が印欧祖語よりどのように音声的に発展してきたかを示した[2010-08-20-1]の記事「#480. father とヴェルネルの法則」も参照.
・ Hamer, R. F. S. Old English Sound Changes for Beginners. Oxford: Blackwell, 1967.
2012-06-26 Tue
■ #1156. admiral の <d> [etymological_respelling][loan_word][latin][etymology][spelling]
admiral (海軍大将,提督)の綴字には,興味深い歴史がある.アラビア語の amīr-al(-bahr) "the commander of (the sea)" が中世ラテン語に入ったものである.元来 d の発音も綴字も含まれていなかったが,中世ラテン語で,admīrābilis "admirable" との類推から,接頭辞 ad- が含まれているかのような admirālis という綴字が行なわれ出した.古フランス語では,この中世ラテン語を経由した綴字 admiral のほかに,アラビア語の原綴りを参照した amiral も見られた.この語は,1200年頃にフランス語から英語へ入ってきており,初期から <d> のある綴字もない綴字も併存していたが,amiral のほうが優勢だった.<d> 入りの admiral の綴字が定着するのは16世紀になってからである.(MED の amiral (n.) を参照.)
「海軍大将」の意味は,スペインやシチリアのアラビア人が「サラセンの海軍指揮者」を amīr-al-bahr と呼んだことに発し,キリスト教徒のシチリア王の呼称としても受け継がれた.後に,ジェノバ,フランス,イングランドへも伝わった.Edward III のもとで,Amyrel of the Se や admyrall of the navy として用いられている.
大槻 (105--06) では,admiral はルネサンス期の人文主義者による etymological_respelling の例の1つとして紹介されている.確かに etymological respelling の諸例は,ルネサンス期に特徴的なラテン語かぶれの現われとして言及されることが多いが,この説明には,注意すべき点が2つある.1つ目は,実はルネサンス期以前からの例が少なくないことである.つまり,ルネサンス期に特徴的ではあるかもしれないが,特有ではないということだ.2つ目は,フランス語でも比較される例が見られることから,英語に特有の現象ではないということである.むしろラテンかぶれの風潮はフランス語でこそ早く起こっていたのである([2011-02-09-1]の記事「#653. 中英語におけるフランス借用語とラテン借用語の区別」を参照).ある etymological respelling の事例が,フランス語史の中で語られるべきなのか,英語史の中で語られるべきなのか,あるいはその両者を区別する意味があるのかどうかも判然としないことがある.少なくとも,ルネサンス期の英語に特有の現象ではないということは銘記しておく必要があろう.
なお,emir, amir, emirate にも,アラビア語の同語根が共有されている.
・ 大槻 博,大槻 きょう子 『英語史概説』 燃焼社,2007年.
2012-06-25 Mon
■ #1155. Postal の言語変化観 [language_change][causation][generative_grammar][contact][sociolinguistics][rsr]
昨日の記事「#1154. 言語変化のゴミ箱としての analogy」 ([2012-06-24-1]) で言及した Postal は,「#1123. 言語変化の原因と歴史言語学」 ([2012-05-24-1]) で取り上げたように,言語変化の原因を fashion と考える論者である.同時に,言語変化とは "grammar change" (文法変化)にほかならなず,その文法変化は世代間で生じる規則の再解釈であるという生成的言語観の持ち主だ.そして,その文法変化の最初の段階を表わす "primary sound change which is independent of language contact" は,"'nonfunctional' stylistic change" であり,それ以外の原因説明はありえないとする.
Postal の議論は一見すると単純だが,実は但し書きがいろいろとついている.例えば,社会言語学的な差異化,言語変化の実現と拡散の区別,言語接触による言語変化,英語の Romance Stress Rule の歴史的獲得についても触れている.Postal の議論は,言語変化理論の大きな枠組みの1つとして注目すべきと考えるので,重要な1節 (283--85) の大部分を引用しよう.
SOME REMARKS ON THE 'CAUSES OF SOUND CHANGE'
It is perhaps not inappropriate to ask what implications the view that sound change consists in changes in grammars has for the much discussed and controversial question of the causes of sound change. Why should a language, independently of contact with other languages, add a new rule at a certain point? Of course there are some scholars who hold that all linguistic change is a result of language contact, but this position seems too radically improbable to demand serious consideration today. Assuming then that some if not all phonological changes are independent of contact, what is their basis? It seems clear to the present writer that there is no more reason for languages to change than there is for automobiles to add fins one year and remove them the next, for jackets to have three buttons one year and two the next, etc. That is, it seems evident within the framework of sound change as grammar change that the 'causes' of sound change without language contact lie in the general tendency of human cultural products to undergo 'nonfunctional' stylistic change. This is of course to be understood as a remark about what we might call 'primary change,' that is, change which interrupts an assumed stable and long-existing system. It is somewhat more plausible that such stylistic primary changes may yield a grammar which is in some sense not optimal, and that this may itself lead to 'functional' change to bring about an optimal state. Halle's suggestion that children may learn a grammar partially distinct from that underlying the utterances they hear and thus, from the point of view of the adult language, reformulate the grammar (while adults may only add rules), may be looked upon as a suggestion of this type. For as he noted, a grammar G2 which results from the addition of a rule to a grammar G1 may not be the optimal grammar of the set of sentences it generates. Hence one would expect that children learning the new language will internalize not G2 but rather the optimal grammar G3. It remains to be seen how many of the instances of so-called 'structural sound change,' discussed in the writings of scholars like A. Martinet, can be provided with a basis of this type.
It should be emphasized that the claim that contact independent sound change is due basically to the stylistic possibility for adults to add limited types of rules to their grammars does not preclude the fact that these changes may serve social functions, i.e. may be related to group differentiation, status differences, etc. That is, the claim that change is stylistic is not incompatible with the kinds of results reached by such investigators as Labov (1963). These latter matters concern more properly the social explanation for the spread of the change, a matter which seems more properly sociological than linguistic.
I have been careful above not to insist that all instances of what have been called sound change were necessarily independent of language contact. Although committed to the view that sound change can occur without contact, we can also accept the view that some changes result from borrowing. The view that sound change is grammar change in fact really eliminates much of the importance of this difference. For under the rule interpretation of change, the only issue is the forces which led to the grammar change. Studies of complex cases of phonological grammar change due to contact have actually been carried out recently within the framework of generative grammar. This work, to be reported in a forthcoming monograph (Keyser and Halle, to appear), shows quite clearly that English has borrowed a number of Romance phonological rules. In particular, English has incorporated essentially the Latin stress rule, that which softens Romance k to s in certain environments, etc. This work has important implications beyond the area of sound change and may affect radically concepts of genetic relationship, Mischsprache, etc., all of which will, I think, require reevaluation.
・ Postal, P. Aspects of Phonological Theory. New York: Harper & Row, 1968.
2012-06-24 Sun
■ #1154. 言語変化のゴミ箱としての analogy [analogy][lexical_diffusion][phonetics][neogrammarian]
analogy (類推作用)は,言語変化の原因として,最も広く知られているが,同時に最も軽視されているといってよい.「音韻変化に例外なし」と唱えた19世紀の青年文法学派 (Neogrammarians) は,法則から漏れる事例は,類推か借用によって個別に説明にできると主張した.これによって,とりわけ類推は,例外を投げ込むべきゴミ箱と化していった.
青年文法学派の音韻変化の考え方は "phonetically gradual and lexically abrupt" というものだが,現実の音韻変化のなかには "phonetically abrupt and lexically gradual" のものがあることが分かってきている.語彙拡散 (lexical diffusion) の諸事例だ.また,音韻変化から形態変化へ視野を広げると,むしろ "morphologically abrupt and lexically gradual" の事例が通常である.この性質は,まさに類推による言語変化に典型的に見られる性質である.伝統的な音韻法則の立場から見れば,類推はゴミ箱のようなものだが,逆に類推を中心とした視点からすると,音韻法則こそが特異な事例のように思えてくる.両者の性格の異同を整理した上で,より高次の音韻変化理論,さらには言語変化理論を作り出すことが必要なのではないか.
類推の置かれている不幸な立場について,また類推と音韻変化とが不当に対置されてきた不幸な状況について,Postal (234) の注3で,次のように述べられている.
'Analogy' is really an unfortunate term. There is reason to believe that rather than being some sharply defined process, analogy actually is a residual category into which is put every kind of linguistic change which does not meet some set of a priori notions about the nature of change. In particular, I think that the term 'analogy' has been used very misleadingly to refer to cases of perfectly regular phonological change in which part of the conditioning environment involves Surface Constituent Structure; i.e. changes which happen only in nouns, or only in verb stems, etc. I suspect that an analytic survey of cases which have been referred to as 'analogy' would yield many instances of regular phonological change with nonphonetic environments . . . .
Postal は,"the regularity of phonetic change と "its putative purely phonetic character" (281) とが混同されてきたという根本的な問題を指摘しながら,いわゆる音韻変化と類推との距離はそれほど大きくないのではないかと示唆している.
類推は,心理的で不規則的な作用として,言語変化の議論においても扱いが難しいとされてきた.しかし,伝統的な音韻法則にすら,心理的な解釈は提出されてきたし,実際には不規則性が見られるからこそ,ゴミ箱が必要とされてきたのである.analogy の復権は図られてしかるべきだろう.
・ Postal, P. Aspects of Phonological Theory. New York: Harper & Row, 1968.
2012-06-23 Sat
■ #1153. 名詞 advice,動詞 advise [spelling][etymological_respelling][etymology][metanalysis][caxton][loan_word][pronunciation_spelling][sobokunagimon]
名詞は <advice> /ədˈvaɪs/ で,動詞は <advise> /ədˈvaɪz/ と異なるのはなぜか.発音と綴字の両方にかかわる素朴な疑問が寄せられた.OED や語源辞典の記述を参考に,謎を解いてゆく.
まず,この語の成り立ちを振り返ってみる.ラテン語の接頭辞 ad- "to" に,vidēre "to see" の過去分詞 vīsum を加えたもので,原義は "according to one's view" ほどである.ここから,俗ラテン語へ *advīsu(m) "opinion" として伝わったのではないかと考えられている.古仏語における語形成もこれと平行的だったと想定されており,ce m'est à vis "this is according to my view" が ce m'est avis "this is my view" と異分析されたものと説明されることが多い.また,俗ラテン語や古仏語では,この名詞より *advīsāre > aviser という動詞が派生した.
英語へは,14世紀に古仏語から,名詞と動詞の両形が借用された.当初は,いずれの綴字にも,第1子音字として <d> は挿入されておらず,最終子音字も <c> ではなく <s> だった.一方,フランス語側では,14--16世紀に,写字生がラテン語形を参照して <d> を復活させた綴字 advis が現われる([2011-02-09-1]の記事「#653. 中英語におけるフランス借用語とラテン借用語の区別」を参照).これを15世紀に Caxton が英語へ導入し,定着させた.同じ15世紀には,第2母音が長音であることを明示するために語尾に <e> が添加された.そして,16世紀には,名詞形について,語尾子音が無声であることを明示するために <s> が <c> へ書き換えられた.まとめれば,14--16世紀にかけての avis > advis > advise > advice という発音および綴字の変化を追うことができる.
動詞については,フランス語 aviser に由来するものとして <s> は有声子音を表わしたので,上の経路の最終段階に見られる <c> への書き換えを被ることはなかった.もっとも,実際には,初期近代英語で,動詞形に <c> の綴字もあったようで,名詞形との多少の混同はあったようである.
名詞 advice と動詞 advise の綴字は,etymological_respelling や "pronunciation spelling" ([2011-07-05-1], [2011-07-31-1]) といった複雑な過程の結果であり,その区別は語源的なものではない.同様の例として,名詞 prophecy と動詞 prophesy もある.こちらも,18世紀に確立した非語源的な綴字の対立である.
2012-06-22 Fri
■ #1152. sneeze の語源 [etymology][spelling][onomatopoeia][alphabet][graphemics][palaeography]
sneeze 「くしゃみ(をする)」の初出は14世紀.中英語では snese(n) などの綴字で現われたが,語頭子音字が <s> でなく <f> である異形を考慮に入れれば,起源は古英語,そしてそれ以前にまで遡る.古英語では fnēosan が "to breathe hard, sneeze" ほどの意味で文証される.ゲルマン祖語では *fneusan が再建され,ゲルマン諸語の cognate では,語頭の <fn>- あるいは <f> の消失した <n>- が広く見られる (ex. MDu fniesen, ON fnýsa, Swed nysa, Ger niesen) .また,fn という語頭子音群はグリムの法則により規則的に印欧祖語 *pneu- "to breathe" の語頭子音に対応する.
語源辞典によると,中英語期における <fn>- から <sn>- への変形は,<f> と <s> の文字の古体を誤読したものという説が紹介されているが,字形の混同が変形の直接の原因となりうるのか疑問である.確かに[2010-12-02-1]の記事「#584. long <s> と graphemics」で紹介したように,<f> と long <s> が非常に良く似ていたことは事実である.しかし,聴覚に鮮烈な印象を与えるくしゃみという生理現象に対応する語が,音声レベルではなく綴字レベルで混同されて,変形したということは考えにくい.くしゃみは,綴字ベースの誤読を想定するにはあまりに聴覚的であるように思われる.むしろ,次のように考えたい.
問題の語頭子音の消失した nese のような形態が同じ14世紀から行なわれており,中英語の fnese はすでに発音を必ずしも正確に表わさない古めかしい綴字,徐々に廃れゆく綴字だったと思われる.一方で,語頭子音の落ちた nese に擬音的な効果を付すかのように,[s] 音が語頭に添加され,snese が一種の強調形として現われるようになったのではないか.この擬音の連想は,sn- を語頭にもつ snarl (うなる),sneer (あざ笑う,はなを鳴らす),sniff (くんくんかぐ), snore (いびきをかく),snort (鼻息を荒立てる),snout (ブタなどの鼻), snuff (吸う,かぐ)などの呼吸・鼻の関連語によって相互に強められていると想像される.これらのうち sneer や snore も古英語では fn- をもっていたので,問題の sneeze に限らず,fn- と sn- の混同は,中英語期には広く起こっていたに違いない.
語頭音 [f] が消えていったときに,綴字 <f> も徐々に消えゆく運命だった.しかし,古い綴字として <f> がしぶとく残るケースもあった.一方,発音としては擬音的な [s] の添加によってくしゃみの音声的イメージが強められ,綴字にも <s> が添加されるようになった.<f> で始まる fnese と <s> で始まる snese とは,音声レベルではともにおそらく /sneːze/ と発音されていた可能性がある.このような状況においては,<f> を <s> として「誤読した」と考えるよりも,発音に合わせて綴字を「差し替えた」と考える方が理に適っている.少なくとも,「誤読」説は,<fn>- から <sn>- への変形の直接の原因を説明するには,弱い議論のように思われる.
2012-06-21 Thu
■ #1151. 多くの謎を解き明かす軟口蓋唇音 [indo-european][comparative_linguistics][phonetics][etymology][assimilation][labiovelar]
昨日の記事「#1150. centum と satem」 ([2012-06-20-1]) で,印欧祖語に labiovelar (軟口蓋唇音)があったことに触れた.[k, g] のような軟口蓋音を調音する際に,同時に唇を丸めて出す音である.表記としては [kw, gw] などと示すのが通例である.2カ所の調音器官を同時に用いる独特な音であるため,調音にも聴解にもより簡便な,単なる唇音あるいは単なる軟口蓋音へと発達することも多い.異なる言語の同根語 (cognate) どうしの間で,/k, g/ が /w, b/ などに対応することになるわけだから,軟口蓋唇音は,大きな差を生み出しうる原因である.
例えば,フランス語の疑問詞に見られる語頭子音 [k] (ex. que, qui, quoi) に対して,英語の疑問詞に見られる語頭子音 [w] (ex. what, who) は音声的には著しく異なっているように見えるが,印欧祖語 *kw を想定すれば,同根語の対応がよく理解できる.英語本来語の名詞 cow (ウシ)とラテン語由来の形容詞 bovine (ウシ属の)の語頭子音の著しい差異も,PIE *gwōus を想定することで,意外と小さく見えてくる(この語の究極の語源については,『英語語源辞典』 pp. 1647--48 が詳しい).
音声環境によって [g] と [w] が非常に似ているということは,私も身近に体験したことがある.娘が幼児期に「レッグ・ウォーマー」を「レッグ・ゴーマー」と覚えてしまったという例がある.[regg(u) woːmaː] が [reggu goːmaː] と受け取られたのだろう.3拍目と4拍目の境に現われる軟口蓋唇音が,誤解の原因である.
子供の言い違え,聞き違いということでいえば,最近の次男による作品として「トイレット・テーパー」がある.トイレッ「ト」の [t] により,次に来るはずの [p] が調音点の同化(進行同化)を受けて [t] となったものと考えられる.これを聞いたときに頭をよぎったのは,[2009-07-26-1]の記事「#90. taper と paper」である.その記事では,同化 (assimilation) ではなくむしろ異化 (dissimilation) が説明原理だったわけだが・・・.
・ 寺澤 芳雄 (編集主幹) 『英語語源辞典』 研究社,1997年.
(後記 2022/10/02(Sun):この話題は 2022/05/01 に Voicy 「英語の語源が身につくラジオ (heldio)」にて「#335. cow と beef と butter が同語根って冗談ですか?」として取り上げました.以下よりどうぞ.)
2012-06-20 Wed
■ #1150. centum と satem [indo-european][comparative_linguistics][phonetics][palatalisation]
[2009-08-05-1]の記事「#100. hundred と印欧語比較言語学」で,印欧諸語を大きく2分する伝統的な方法として,「百」を表わすラテン語 (Latin) centum とアベスタ語 (Avestan) satem とで代表させる区分を見た.この区分は,Tocharian の帰属を巡る謎 ([2009-08-06-1], [2009-08-14-1]) や印欧語の故郷を巡る「ブナ問題」 ([2011-01-20-1]) などでも前提とされており,印欧語比較言語学では非常に重要なものとされてきた(この区分に関連する話題は,centum satem の各記事を参照).
しかし,この2分法は,これまで前提とされてきたほど必ずしも妥当ではないということがわかってきている.この状況を理解するためには,まず centum と satem の2分法の根拠を理解しなければならない.Fortson (53--54) によると,印欧祖語の軟口蓋閉鎖音には調音点により3系列が区別されていたとされる.無声音 k でいえば,plain *k, labiovelar *kw, palatal *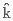 の3系列である.この3系列は,後のほとんどの印欧諸語において2系列へ再編成された.再編成には2通りあり,* が *k へ吸収された場合(centum 系)と,*kw が *k へ吸収された場合(satem 系)とがあった.結果として,前者では k, g, gh に対して kw, gw, gwh が,後者では k, g, gh に対して ,
の3系列である.この3系列は,後のほとんどの印欧諸語において2系列へ再編成された.再編成には2通りあり,* が *k へ吸収された場合(centum 系)と,*kw が *k へ吸収された場合(satem 系)とがあった.結果として,前者では k, g, gh に対して kw, gw, gwh が,後者では k, g, gh に対して , 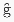 , h が区別されたことになる.PIE * に注目すれば,前者の再編成では典型的に k へ吸収されたが,後者の再編成では典型的に破擦音 /ʦ, ʧ/ や摩擦音 /s, ʃ/ へ変化した.こうして,「百」を表わす PIE
, h が区別されたことになる.PIE * に注目すれば,前者の再編成では典型的に k へ吸収されたが,後者の再編成では典型的に破擦音 /ʦ, ʧ/ や摩擦音 /s, ʃ/ へ変化した.こうして,「百」を表わす PIE 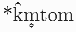 は,諸言語で centum 系か satem 系へと分化していったのである.k を代表として,再編成の様子を図式化すると以下のようになる.
は,諸言語で centum 系か satem 系へと分化していったのである.k を代表として,再編成の様子を図式化すると以下のようになる.
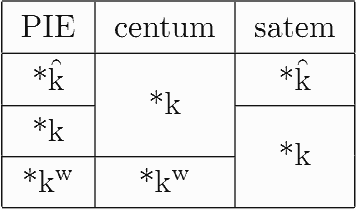
この2分法は全般的に見れば,非常にうまく印欧諸語の地理的な東西差を説明することができる.centum グループの語派 (Greek, Italic, Celtic, Germanic) は地理的に西に分布しており,satem グループの語派 (Indo-Iranian, Armenian, Balto-Slavic) は東に分布している.しかし,20世紀になって発見された Tocharian は印欧語の分布としては極東に位置するにもかかわらず,plain, labiovelar, palatal の3系列が保たれており,強いていえば centum 系の言語である.同様に,Anatolia 語派の Luvian にも3系列の区別が認められる.また,Balto-Slavic の諸語は一般的に satem 系とされるが,語によっては centum 系の子音を示すものも多い.Albanian は satem 系の言語だが,centum 系諸言語の地域に囲まれているという不可解な事実もある.
このような事実を見ると,印欧祖語の軟口蓋閉鎖音系列の歴史的な変化は,少なくとも部分的には,独立して生じたのではないかという可能性が濃厚になってくる.現在では,centum と satem による2分法は,かつてのように,印欧諸語の絶対的な区分とはみなされなくなってきている.とはいっても,便利な区分には違いなく,今後も言及され続けてゆくだろう.
・ Fortson IV, Benjamin W. Indo-European Language and Culture: An Introduction. Malden, MA: Blackwell, 2004.
2012-06-19 Tue
■ #1149. The Aldbrough Sundial [inscription][old_norse][oe][inflection][contact][personal_pronoun]
古英語と古ノルド語の言語接触を直接に文証する記録はほとんど残されていない.イングランド東部や北部から接触当時の碑文が見つかっているが,指折り数えられるほどにすぎない.
その少数の碑文のなかでもよく知られているものの1つが,The Aldbrough Sundial と呼ばれる日時計の円周部に刻まれている銘である.East Yorkshire の小さな町 Aldbrough にある St. Bartholomew's church の内壁にはめ込まれているもので,碑文はノルマン・コンクェスト以前に刻まれたものと考えられている.University of Pennsylvania の Anthony Kroch のページで画像と説明を閲覧できる. *
そのページにも一部引用のある,Page の論文を読んだ.この日時計の碑文には,古英語と古ノルド語の言語接触を示唆する貴重な言語特徴が見られるという.その文の翻字と現代英語訳を添えよう.
{kind=link}
+VLF LET (?HET) ARŒRAN CYRICE FOR HANVM 7 FOR GVNWARA SAVLA
"+Ulf had this church built for his own sake and for Gunnvǫr's soul."
古英語の屈折体系が崩れていることが,CYRICE や SAVLA からわかる.Late West-Saxon の標準であれば,*cirican や *saule となるはずのところである.ただし,Northumbrian 方言では古英語後期にはすでにこの種の屈折の水平化は進行しており,これだけをもって古ノルド語との言語接触による影響を論じることはできないだろう.GVNWARA については,統語的に属格形と考えられるが,英語化した屈折形を示しているようだ.なお,固有名詞 GVNWARA と VLF はともに北欧系の名前である.
屈折体系の崩壊を示唆する語形以上に興味深いのは,再帰代名詞の与格を表わすとおぼしき HANVM という語形である.古英語では3人称男性単数代名詞の与格としてこの形態は確認されていないが,古ノルド語ではまさにこの形態が用いられていた.したがって,この語形が古ノルド語から借用されたという仮説は受け入れてよいだろう.しかし,3人称代名詞が再帰的に用いられている今回のような文脈では,古ノルド語であれば再帰代名詞形 sér の用いられるのが常である.一方,古英語では,再帰代名詞と非再帰代名詞の形態的な区別はなかった.以上を考え合わせると,この例は,古英語の3人称男性単数代名詞の機能と用法は保ったままに,その形態 him が古ノルド語の対応形 HANVM に置き換わった例ということになる.
VLF と GVNWARA なる人物,そしてこの碑文を刻んだ人物は,いずれも古ノルド語話者の末裔だった可能性がある.彼らは,古英語話者との数世代の融合のうちに,この碑文に示唆されるような,言語接触によって変形した英語を話すようになっていたのかもしれない.しかし,Page (178) は,少ない証拠からそのような可能性を引き出すことには注意を要すると述べている.
Even in the highly Scandinavianized York, people with Norse names need not be of Norse descent. Surviving English inhabitants may have given their children fashionable Norse names in imitation of a Norse dominant class.
Page の論題は「イングランドで古ノルド語はいつまで話されていたか」というものだが,明確な結論は提示せずに論を閉じている.ただし,Page の全体的な論調からは,あまり長くもたなかったのではないかという見解が読み取れる.
・ Page, R. I. "How Long Did the Scandinavian Language Survive in England? The Epigraphical Evidence." England Before the Conquest: Studies in Primary Sources Presented to Dorothy Whitelock. Ed. P. Clemoes and K. Hughes. Cambridge: CUP, 1971. 165--81.
2012-06-18 Mon
■ #1148. 古英語の豊かな語形成力 [oe][lexicology][derivation][compound][compounding][word_formation][productivity][kenning]
古英語の語形成 (word formation) が,派生 (derivation) や複合 (compounding) により,著しく豊かであることは,古英語の文法書や英語史の概説書を通じてよく知られている.Baugh and Cable (64--65) では,印象的な例として,古英語 mōd "mood, heart, mind, spirit; boldness, courage, pride, haughtiness" という1つの語根から,100以上の語が形成されるという事実が紹介されている.100個とまではいかないが,そこで挙げられている語を,意味とともに列挙してみよう.
・ mōdig "spirited, bold, high-minded, arrogant, stiff-necked"
・ mōdiglic "magnanimous"
・ mōdiglīce "boldly; proudly"
・ mōdignes "magnanimity; pride"
・ mōdigian "to bear oneself proudly or exultantly; to be indignant, to rage"
・ gemōdod "disposed; minded"
・ mōdfull "haughty"
・ mōdlēas "spiritless"
・ mōdsefa "mind, thought, understanding"
・ mōdgeþanc "mind, thought, understanding"
・ mōdgeþoht "mind, thought, understanding"
・ mōdgehygd "mind, thought, understanding"
・ mōdgemynd "mind, thought, understanding"
・ mōdhord "mind, thought, understanding"
・ mōdcræft "intelligence"
・ mōdcræftig "intelligent"
・ glædmōdnes "kindness"
・ mōdlufu "affection"
・ unmōd "despondency"
・ mōdcaru "sorrow"
・ mōdlēast "want of courage"
・ mādmōd "folly"
・ ofermōd "pride"
・ ofermōdigung "pride"
・ ofermōdig "proud"
・ hēahmōd "proud; noble"
・ mōdhete "hate"
・ micelmōd "magnanimous"
・ swīþmōd "great of soul"
・ stīþmōd "resolute; obstinate"
・ gūþmōd "warlike"
・ torhtmōd "glorious"
・ mōdlēof "beloved"
Hall の古英語辞書(第2版)で mōdig 周辺をのぞくと,ほかにも関連語のあることがわかる.

確かに古英語の語形成の "resourcefulness" には驚く.複合に関しては,その延長線上に kenning という文飾的技巧のあることを指摘しておこう.
ただし,この "resourcefulness" が古英語の共時的な生産性を表わすものかどうかという点については熟慮を要する.[2011-05-28-1]の記事「#761. 古英語の derivation は死んでいたか」で考察したように,この "resourcefulness" は,古英語以前からの通時的な派生・複合の結果が累々と蓄積され,豊かな語彙ネットワークとして古英語に共時的に現われているということではないか.synchronic productivity と diachronic productivity とを分けて考える必要があるのではないか.
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
・ Hall, John Richard Clark, ed. A Concise Anglo-Saxon Dictionary. 2nd ed. New York: Macmillan, 1916.
2012-06-17 Sun
■ #1147. 印欧諸語の音韻対応表 [indo-european][phonetics][grimms_law]
印欧諸語(主要な古語)の音韻対応の一覧表があると便利だと思い,Watkins (146--47) の表を再現してみた.語頭音節の最初の子音と母音についての対応表であり,あくまで簡便なものである.なお,Germanic 諸語については mutation は考慮されていない.
横長の表なので,以下の縮小画像をクリックして,PDF版で拡大しながらご覧ください.
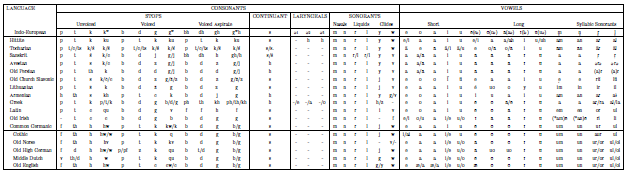
・ Watkins, Calvert, ed. The American Heritage Dictionary of Indo-European Roots. 2nd Rev. ed. Boston: Houghton Mifflin, 2000.
2012-06-16 Sat
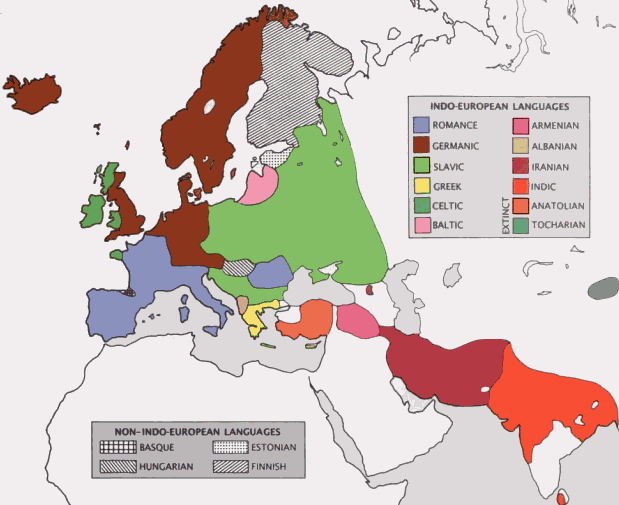
■ #1146. インドヨーロッパ語族の系統図(Fortson版) [indo-european][family_tree][flash]
印欧語族の系統図や地図については,本ブログでも何度か触れてきた.
・ [2009-06-17-1]: 「#50. インドヨーロッパ語族の系統図をお遊びで」(Flash版)
・ [2010-07-26-1]: 「#455. インドヨーロッパ語族の系統図(日本語版)」(Flash版)
・ [2012-05-19-1]: 「#1118. Schleicher の系統樹説」
・ [2012-05-30-1]: 「#1129. 印欧祖語の分岐は紀元前5800--7800年?」
・ [2011-04-12-1]: 「#715. Britannica Online で参照できる言語地図」.特に現代における印欧諸語の地理的分布については Approximate locations of Indo-European languages in contemporary Eurasia を参照. *
上記に加えて,今回,新たに Fortson (10) の系統図を3種類の方法で再現してみる.もとより網羅的ではないが,これまでの系統図に比べれば詳しい.* 印のあるものは,死語,あるいは現代語の古い段階を表わす.
複数の印欧語系統図を示す意義は,研究者ごとに諸言語の分類や図の描き方の異なる点を強調することにより,言語の系統というものが絶対的なものではないことを確認する点にある.この点については,「#807. 言語系統図と生物系統図の類似点と相違点」 ([2011-07-13-1]) や「#1118. Schleicher の系統樹説」 ([2012-05-19-1]) も参照.
・ PNG画像版の系統図(=以下の画像の拡大版)
・ ノードを開閉できるFLASH版の系統図
・ ノードを開閉できるHTML版のリスト型系統図
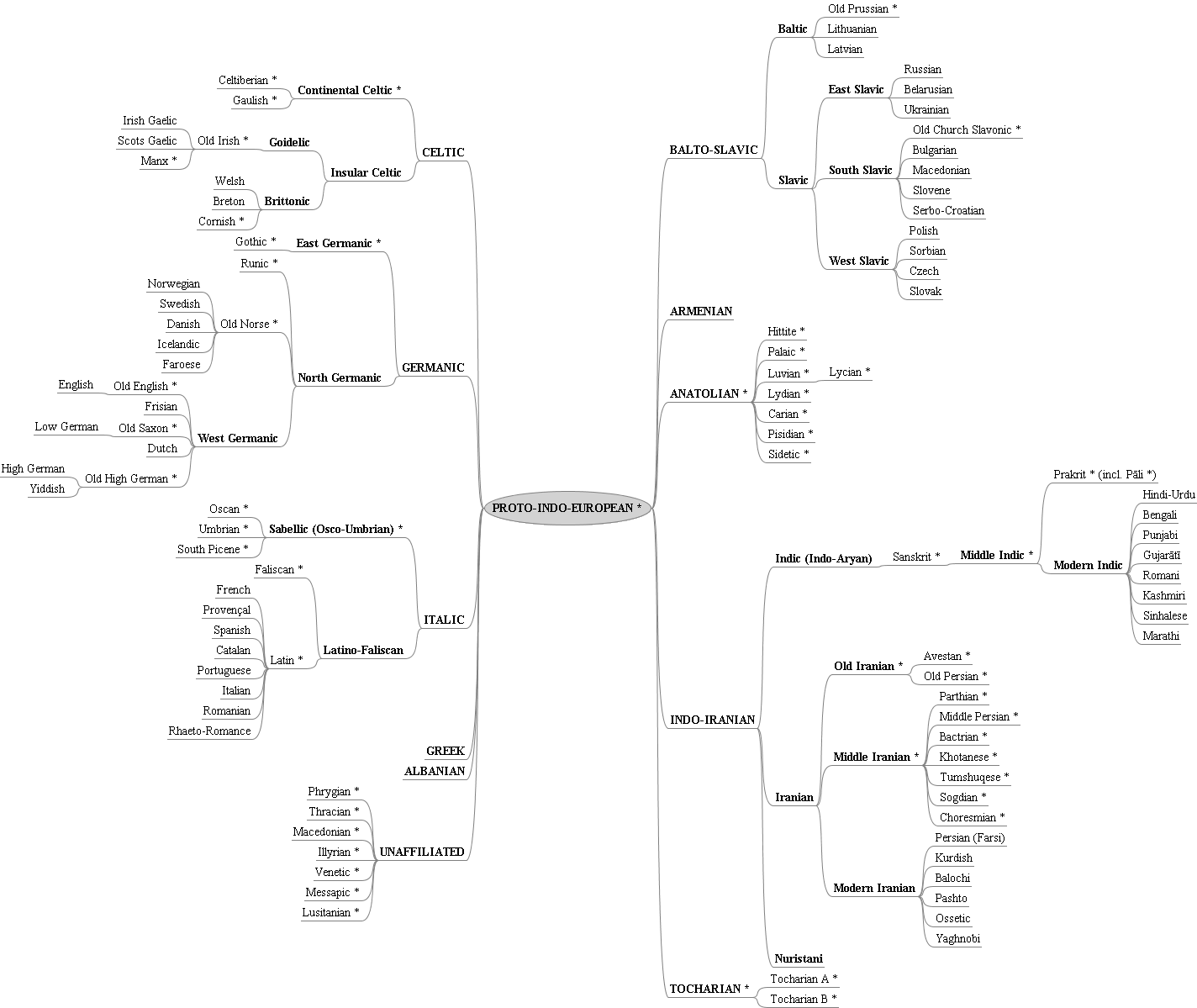
・ Fortson IV, Benjamin W. Indo-European Language and Culture: An Introduction. Malden, MA: Blackwell, 2004.
{kind=link}
2012-06-15 Fri
■ #1145. English と England の名称 [anglo-saxon][history][toponymy][etymology][haplology][ethnonym]
[2010-05-21-1]の記事「#389. Angles, Saxons, and Jutes の故地と移住先」で概観したように,英語史は通例,西ゲルマン系の諸部族が5世紀中葉にブリテン島に渡り,ケルト系先住民を辺境へ追いやって,定住し始めた時期をもって始まるとされる.この西ゲルマン系の民族には,アングル人,サクソン人,ジュート人のほか,フランク族やフリジア人など他の低地ゲルマン系の人々も多少は交じっていた可能性があるが,はたから見れば全体として似通った部族であり,1つの名称で呼ばれることが多かった.そして,ブリテン島に渡ってからは,多かれ少なかれ,仲間うちでも1つの名前で自称する習慣が発達した.今回は,ブリテン島に渡った西ゲルマン諸部族の名称,彼らが打ち立てた国の名称,かれらの話していた言語の名称の由来について,Baugh and Cable (50--51) にしたがって概略したい.
追い立てられたケルト系先住民は,この野蛮な部族の集合を一括して Saxons として言及していた.なぜ Saxons が包括的な民族名として選ばれたのかは不明だが,ケルト人にとって,とりわけサクソン人による略奪が悪夢の印象を与えたということだろうか.一方,西ゲルマン系の侵略者は,ケルト系先住民を一括して Wealas 「外国人たち」と呼んだ.現代の Welsh の起源である.
さて,ラテン語でも,当初は,西ゲルマン系の侵略者は一括して Saxones と呼ばれ,彼らの侵略した土地は Saxonia として言及されていた.しかし,じきに民族名は Angli として,土地名は Anglia としても言及されるようになってきた.例えば,Pope Gregory は,601年,ケント王 Æþelberht を rex Anglorum と称しているし,Bede は自らの手になる歴史書を Historia Ecclesiastica Gentis Anglorum と呼んでいる.結果として,ラテン語では Angli と Anglia が,件の民族と土地名を指す名称として Saxones と Saxonia を置き換えた.
一方,西ゲルマン系の侵略者は,当初から,自らの言語を Englisc として言及していた.アングル人を指す Engle からの派生である([2009-09-07-1]の記事「#133. 形容詞をつくる接尾辞 -ish の拡大の経路」を参照).彼等らは,土地の名前にも Angelcynn とアングル人びいきの名称を用いていたが,およそ1000年を境に,Englaland (後にその haplology の結果としての England) が地歩を占めるようになった.このアングル人びいきの理由の1つとして,Baugh and Cable (51) は次のように述べている.
It is not easy to say why England should have taken its name from the Angles. Possibly a desire to avoid confusion with the Saxons who remained on the continent and the early supremacy of the Anglian kingdoms were the predominant factors in determining usage.
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
2012-06-14 Thu
■ #1144. 現代英語における数の不一致の例 [number][agreement][prescriptive_grammar][syntax][singular_they]
主語となる名詞の示す数と,対応する動詞の示す数が一致しない例は,古い段階の英語にも現代英語にも数多く認められる.現代英語におけるこの問題の代表としては,[2012-03-16-1]の記事で取り上げた singular they などが挙げられよう.Reid に基づいた武藤 (85--86) によれば,数の不一致の例は,3種類に分けられる.以下,各例文で,不一致の部分を赤で示した.
(A型) 実体の焦点は単数;数の焦点は複数
・ At ADT (security systems) 98 years' experience have taught us that no one alarm device will foil a determined burglar.
・ Five years ago 5 per cent of tax returns were subject to review. Today, only one per cent are subject to review.
・ The whole process of learning a first and second language are so completely different. (Laura Holland)
・ Rudolph is especially effective in crowd scenes like the opening, where movement of people and camera are delicately braided, where odd characters flutter through the background unemphasized. (Stanley Kauffman, The New Republic)
(B型) 実体の焦点は複数;数の焦点は単数
・ The sex lives of Roman Catholic nuns does not, at first blush, seem like promising material for a book. (Newsweek)
・ Two million dollars comes from corporations and foundations, but almost $400,000 from private gifts. (The New York Times)
・ Two drops deodorizes anything in your home. (Air freshner advertisement)
・ For one thing, the player is much closer to the instrument than the listener, and the sounds he hears is thus a different sound. (John Holt, Instead of Education)
(C型) and で連結された2個の実体;数の焦点は単数
・ Gas and excess acid in your stomach is what we call Gasid Indigestion. (Alka-Seltzer commercial)
・ We know that the company's destiny and ours is the same.
・ Galloping horses and thousands of cattle is not necessary to cinema; I call that photography. (Alfred Hitchcock, radio interview)
・ I just want you to know that this whole Watergate situation and the other opportunities was a concerted effort by a number of people. (Jeb Magruder, Newsweek)
以上の例は,いずれも実体の数と,観念の上で焦点化される数との不一致として説明される.A型の各例文でいえば,主語となる名詞句の主要部が指している実体は単数だが,共起している 98 years', tax returns, a first and second language, people and camera が複数を喚起するため,それに引かれて動詞も複数で呼応しているということである.
言語の社会的,規範遵守的,論理的な側面と,個人的,規範逸脱的,文体的な側面とのせめぎ合いと言ったらよいだろうか.武藤 (87) のことばを借りれば,次のようになる.
名詞形の数の話者が置く焦点によって動詞との呼応が何れかに分れるのはそれなりの根拠が存在している点を考えると,この呼応は話者の idiosyncratic な言語感覚,stylistic な好みによっているとも思われるが,もっと大きな言語行為として把えると,話者が形態上の呼応にとらわれずに自由に,単数あるいは複数の呼応を決めて行こうとする言語表現の1つの傾向だと思われる.
・ 武藤 光太 「英語の単数形対複数形について」『プール学院短期大学研究紀要』33,1993年,69--88頁.
・ Reid, Wallis. Verb and Noun Number in English: A Functional Explanation. London: Longman, 1991.
2012-06-13 Wed
■ #1143. 中英語期はいつ始まったか (2) [me][periodisation][inflection][analogy][me_dialect]
昨日の記事[2012-06-12-1]に引き続き,中英語の開始時期の話題.古英語と中英語の境を1000年頃におく Malone の見解は,極端に早いとして,現在,ほとんど受け入れられていない.その対極にあるのが,1200年頃におくべきだとする Kitson の論考である.
Kitson (221--22) は,まず,現在の主流の見解である1100年あるいは1150年という年代が,どのような議論から生み出されてきたかを概説している.[2009-12-19-1]の記事「#236. 英語史の時代区分の歴史 (5)」で示したように,Henry Sweet の3区分は後に圧倒的な影響力をもつことになったが,Sweet 自身の中英語期の開始時期についての意見は揺れていた.1888年の段階では1150年,それから4年後の1892年の段階では1200年に区切りを設定していたからである(後者は[2009-12-20-1]の記事「#237. 英語史の時代区分の歴史 (6)」で示されている見解).その後,1150年とする見解は比較的多くの支持者を得たが,現在では Hogg (9) の "by about 1100 the structure of our language was beginning to be modified to such a considerable degree that it is reasonable to make that the dividing line between Old English and Middle English" との見解が広く受け入れられているようだ.いずれの場合も,試金石は,屈折語尾の母音がいつ [ə] へ水平化したかという点である.
Kitson の議論を要約すれば,中英語の開始時期を巡る問題が難しいのは,母音の水平化が一夜に生じたものではなく,時間をかけて,方言によって異なる速度で進行したからである.また,母音の水平化は,ただ機械的な音韻変化として進行したわけではなく,複雑な類推作用 (analogy) の絡んだ形態変化として進行したのであり,その過程を跡づけることは余計にややこしい.そこで,中英語の開始時期を決めるにあたっては,(1) どの方言における母音水平化を中心に据えるか,(2) 母音水平化の始まった時期を重視するのか,あるいは完了した時期を重視するのか,あるいは中間時期を重視するのか,などの基本方針を決めなければならない.
Kitson (222--23) は,(1) の方言の問題については,後期古英語の標準語の中心が Winchester だったこと,初期中英語の標準化された言語の代表例として South-West Midland 方言の "AB-language" があったこと,母音水平化を詳細に跡づけることが可能なほどに多くの写本がこの方言から現存していること,Sweet の区分でも South-West Midland 方言の Laȝamon を基準として用いていることなどを指摘しながら,"the area between, broadly, Wiltshire and Herefordshire" あるいは "the north Wessex--south-west midland area" (223) を基本に据えるべきだと結論づけている.(2) の母音水平化の完了の程度という問題については,音韻形態変化としての母音水平化が決して逆行しえない段階,すなわち完全に終了した段階をもって中英語の開始を論じるのが理に適っていると結論している.
And bearing in mind that the linguistic processes of the transition were to a large extent analogical rather than strictly regular sound-changes, it seems most reasonable to date the beginning of Middle English, as against Old English whether or not with a sub-period specified as Transitional, to the point of time from which even if external events influencing linguistic change had taken so different a course as to lead to directions of analogy violently different from the actual ones, reduction of inflectional variety to the single-un-stressed-vowel level characteristic of actual Middle English was irrevocable. (223)
Kitson は,この移行期間に南部方言で書かれた文書における綴字と発音の関係を精密に調査し,1200年頃までは,いまだ前舌母音と後舌母音の区別が残っていたと主張し,次のように結論づけている.
. . . even at the end of the twelfth century the replacement of language with at least some variety of inflections by language with fully levelled inflections was not absolutely irrevocable. . . . Granting the level of fuzziness at the edges inescapable in all tidy divisions of linguistic periods, Sweet's 1892 dating really is right after all.
・ Malone, Kemp. "When Did Middle English Begin?" Language 6 (1930): 110--17.
・ Kitson, Peter R. "When did Middle English begin? Later than you think!." Studies in Middle English Linguistics. Ed. Jacek Fisiak. Berlin: Mouton de Gruyter, 1997. 221--269.
・ Hogg, Richard M., ed. The Cambridge History of the English Language: Vol. 1 The Beginnings to 1066. Cambridge: CUP, 1992.
2012-06-12 Tue
■ #1142. 中英語期はいつ始まったか (1) [me][periodisation][inflection]
言語変化は連続的であるため,言語内的な観点のみにより,ある言語の歴史を時代区分することは不可能である.言語内的な観点に加え,多分に言語外的な観点をも含めて,時代区分してゆくのが通例である.また,ある区分がいったん定まってしまうと,慣例や定説となって無批判に受け継がれてゆくことになる.確立された時代区分は研究の範囲や方法を決定づける力があり,研究の動向に勢いを与えるプラスの側面があると同時に,研究の幅を狭めてしまうマイナスの側面ももっている.したがって,時代区分を批判的に見ておくことは非常に重要である.
英語史の時代区分の歴史的変遷については,##232,233,234,235,236,237 の連続記事で取り上げてきた.Henry Sweet の提示した3区分方式が現在に至るまで伝統的に受け継がれているが,とりわけ中英語期の始まりをどの年代に当てるかという点については,いまだに専門家の間でも見解が揺れている.多くの概説書では,1100年あるいは1150年という年代がよくみられる.しかし,互いに半世紀も異なるというのは,議論を巻き起こすに十分である.
古くはあるが,よく引用される議論として,思い切った提言をした Malone の論考をのぞいてみよう.まず,Malone は,Sweet の原典を引きながら,伝統的な3区分が屈折の残存の程度によるものであることを確認した.
I propose, therefore, to start with the three main divisions of Old, Middle and Modern, based mainly on the inflectional characteristics of each stage. Old English is the period of full inflections (nama, gifan, caru), Middle English of levelled inflections (naame, given, caare), and Modern English of lost inflections (naam, giv, caar). (qtd in Malone, p. 110 as from Sweet, A History of English Sounds, printed on p. 160 of the Transactions of the Philological Society for 1873--74.)
Sweet の古英語と中英語を区別する基準は,屈折語尾が水平化されているかどうかという点にある.より具体的にいえば,屈折語尾に現われる,様々な母音字で表わされる母音が,それぞれに特徴的な音価を保っていたか,あるいは [ə] へと曖昧化していたかという点にある.曖昧化それ自体がすぐれて連続的であるため,それが始まった年代も終わった年代も正確に限定することはできない.しかし,およその限定ということでいえば,多くの論者が12世紀辺りだろうと踏んでおり,それが現在おおむね受け入れられている1100年や1150年などの区切り年代に反映されている.
Malone は,Sweet に従って,屈折語尾の母音の [ə] 化の年代が,すなわち古英語と中英語を分ける年代であるとするのであれば,それは1000年頃にまでさかのぼらせる必要があると論じている.というのは,10世紀のものとされる南部の4写本 (the Vercelli Book, the Exeter Book, the Junius Codex, the Beowulf Codex) における屈折母音字の分布を詳細に検討すると,すでに屈折母音の [ə] 化が進んでいる様子が "scribal error" を通じて窺えるからだ.
この議論は,同時期のテキストの言語がどこまで後期ウェスト・サクソン方言の Schriftsprache を反映しているのか,発音と綴字の関係がどこまで正確に突き止められるのかという問題に密接に関わっている.綴字のみを考えるのであれば,母音字の明らかな <e> 化は11世紀あるいは12世紀を待つ必要があるのかもしれない.しかし,発音を推し量るのであれば,母音の [ə] 化の兆しは,早くも10世紀に見られるということになる.既存の説の中では極端に早い年代ではあるが,この議論を通じて,中英語期はいつ始まったかという問いの難しさの要因をのぞき見ることができるように思われる.
・ Malone, Kemp. "When Did Middle English Begin?" Language 6 (1930): 110--17.
2012-06-11 Mon
■ #1141. なぜ mama と papa なのか? (2) [phonetics][consonant][vowel]
昨日の記事[2012-06-10-1]の続編.Jespersen の唱えた説や,そこで言及されているかつての諸説を,いずれも「俗説」として退けたのは,プラーグ学派 (The Prague School) の領袖 Roman Jakobson (1896--1982) である.Jakobson には,この問題に理論的に迫った論考がある.Murdock の通言語的な mama, papa 語の調査結果に基づいて,次のように考察している.
(1) Murdock が諸言語から集めた母親と父親を表わす1072種類の語の音声の分布を統計的に分析したところ,子音連続を含むものは全体の1.1%ほどであり,母音単独のものはほとんどなかった.つまり,父母両語について,単子音と母音の組み合わせが圧倒的だった (540) .
(2) 子音については,調音様式としては閉鎖音と鼻音が合わせて85%を占め,調音点としては,唇音と歯音が合わせて76%を占めた.とりわけ子音性の高い閉鎖唇音が高い割合を示していることになる (540) .
(3) 母音については,正確な割合は出せないが,すぐれて母音的な /a/ が際立っていることは確かである."the optimal consonant" と "the optimal vowel" との組み合わせが多いことは,幼児の言語獲得の観点からも理に適っている (540--41) .
(4) 子音と母音の組み合わせの順序について,例えば /am/ ではなく /ma/ であるのはなぜか.というのは,喃語期の発音では,開いた口を閉じるという /am/ の順序のほうが自然だからだ.しかし,子音の音素を弁別する段には,幼児は子音から母音へのわたりにヒントを求め,徐々に子音+母音の音連鎖に馴染んでゆく./ma/ や /pa/ などの音節構造は,この過程の反映ではないか (541) .
(5) 歯子音と硬口蓋子音のあとでは口蓋母音が続きやすく(例「ちち」),唇子音と軟口蓋子音のあとでは続きにくい(例「はは」).この母音の差異は調音点の同化によるものであり,そこに音素としての区別が確立していることを必ずしも意味するものではない.有意味な音素上の区別は,子音にこそある (541) .
(6) mama, papa などの同じ音節の繰り返し (reduplication) は,その音節が喃語としての偶然の産物ではなく,意味のある単位であることを表わすという点で,幼児の言語獲得にあたっては義務的ですらある (542) .
そして,きわめつけは,なぜ母親を表わす語が /m/ を始めとする鼻子音を伴いやすいかを説明するくだりである.従来の様々な「俗説」を退けながら,Jakobson は哺乳に際して口腔が塞がるために鼻音を伴わざるをえないという驚くべき説を提唱している.なるほど,口腔が塞がった状態で声を発しようとすれば,ハミングにならざるをえない.こうした /m/ などの鼻音が,定常的に母乳,食物,そしてすべての望みをかなえてくれる母親と結びついてゆくのではないか.そして,その存在と対置される父親が,/m/ の弁別素性 [nasal] を逆転させた /p/ などの子音と結びつけられることになるのではないか (542--44) .
感心することが2点.1つは,これだけよく理屈づけたということ.もう1つは,弁別素性で説明をくくる辺り,いかにも Jakobson 的だということ.切り口が鮮やか.
(後記 2013/03/28(Thu):中央大学の増田桂子氏による最初の一語―なぜ母親は「ママ」,父親は「パパ」なのか―も参照.)
・ Jakobson, Roman. "Why 'Mama' and 'Papa'?" Phonological Studies. 2nd ed. Vol. 1 of Roman Jakobson Selected Writings. The Hague and Paris: Mouton, 1971. 538--45.
・ Jespersen, Otto. Language: Its Nature, Development, and Origin. 1922. London: Routledge, 2007.
2012-06-10 Sun
■ #1140. なぜ mama と papa なのか? (1) [phonetics][consonant][phonaesthesia]
[2012-06-06-1]の記事「#1136. 異なる言語の間で類似した語がある場合」で,(3) 言語普遍性 (language universals) の1例として,「非常に多くの言語で,母親を表わす語に ma, ba, da, ta が現われるのも,偶然の一致とは考えられず,何らかの言語普遍性が関与しているとされる」と述べたが,なぜ言語を超えて普遍的なのかの合理的な説明には触れなかった.母親が mama で,父親が papa なのはなぜか.
様々な説が提案されてきた.かつてよく唱えられたのは,英語の papa や mam(m)a や,ドイツ語,デンマーク語,イタリア語等々の対応語は,いずれもフランス語からの借用であるという説である.しかし,現代のヨーロッパの諸言語のみならず,古代ギリシア語にも,そして世界中の言語にも類例がみられることから,フランス語借用説を受け入れるわけにはいかない.確かに,特に17世紀にヨーロッパに広まっていたフランス文化の流行が,ヨーロッパの近隣の言語において papa や mam(m)a などの使用を促したということはあったかもしれない.しかし,これらの語の発生は,通言語的に独立したものであると考えるべきだろう (Jespersen, VIII. 8 (p. 159)) .
また,父母を表わすそれぞれの語は,幼児による創出ではなく,他の語彙と同様に,世代から世代へと受け継がれているにすぎないとした研究者もいた.だが,Jespersen (VIII. 8 (p. 160)) も切り捨てているように,多くの言語で類似した子音をもつこれらの語が確認されることから,この説も受け入れがたい.
では,papa と mama の独立発生を前提とすると,それはどのように合理的に説明されるだろうか.phonaesthesia の観点から,m 音節は求心的かつ情緒的であり,p 音節は遠心的かつ意志的であり,それぞれ母と父のイメージに適合するという説が唱えられたことがある.しかし,広く知られるようになったのは, Jespersen (VIII. 8 (p. 154)) の唱えるような,次の説である.
In the nurseries of all counties a little comedy has in all ages been played---the baby lies and babbles his 'mamama' or 'amama' or 'papapa' or 'apapa' or 'bababa' or 'ababab' without associating the slightest meaning with his mouth-games, and his grown-up friends, in their joy over the precocious child, assign to these syllables a rational sense, accustomed as they are themselves to the fact of an uttered sound having a content, a thought, an idea, corresponding to it.
幼児が何気なく発したいまだ言語的意味をもたない音のつながりを,親が自分を指示しているものと勘違いする,という説である.幼児による言語習得の研究の知見からも支持される説であり説得力はあるが,半ば普遍的に母が /m/ で父が /p/ に対応するのはなぜなのか,その説明が与えられていない.
・ Jespersen, Otto. Language: Its Nature, Development, and Origin. 1922. London: Routledge, 2007.
2012-06-09 Sat
■ #1139. 2項イディオムの順序を決める音声的な条件 (2) [phonetics][syllable][binomial][idiom][prosody][alliteration][phonaesthesia]
昨日の記事[2012-06-08-1]に続いて,binomial (2項イディオム)の構成要素の順序と音声的条件の話題.昨日は「1音節語 and 第1音節に強勢のある2音節語」という構成の binomial が多く存在することを見た.この著しい傾向の背景には,強弱強弱のリズムに適合するということもあるが,Bolinger の指摘するように,「短い語 and 長い語」という一般的な順序にも符合するという要因がある.もっとも典型的な長短の差異は2要素の音節数の違いということだが,音節数が同じ(単音節の)場合には,長短の差異は音価の持続性や聞こえ度の違いとしてとらえることができる.Bolinger の表現でいえば,"openness and sonorousness" (40) の違いである.
分節音を "open and sonorous" 度の高いほうから低いほうへと分類すると,(1) 母音,(2) 有声持続音,(3) 有声閉鎖音・破擦音,(4) 無声持続音,(5) 無声閉鎖音・破擦音,となる.この観点から「短い語 and 長い語」を言い換えれば,「openness and sonorousness の低い語 and 高い語」ということになろう.Bolinger (40--44) は,現実には存在しない語により binomial 形容詞をでっちあげ,構成要素の順序を替えて,英語母語話者の被験者にどちらが自然かを選ばせた."He lives in a plap and plam house." vs "He lives in a plam and plap house." のごとくである.結果は,統計的に必ずしも著しいものではなかったが,ある程度の傾向は見られたという.
でっちあげた binomial による実験以上に興味深く感じたのは,p. 40 の注記に挙げられていた一連の頭韻表現である(関連して,[2011-11-26-1]の記事「#943. 頭韻の歴史と役割」を参照).flimflam, tick-tock, rick-rack, shilly-shally, mishmash, fiddle-faddle, riffraff, seesaw, knickknack. ここでは,2要素の並びは,それぞれの母音の聞こえ度が「低いもの+高いもの」の順序になっている.この順序については,phonaesthesia の観点から,心理的に「近いもの+遠いもの」とも説明できるかもしれない (see ##207,242,243) .
音節数,リズム,聞こえ度,頭韻,phonaesthesia 等々,binomial という小宇宙には英語の音の不思議がたくさん詰まっているようだ.
・ Bolinger, D. L. "Binomials and Pitch Accent." Lingua (11): 34--44.
2012-06-08 Fri
■ #1138. 2項イディオムの順序を決める音声的な条件 (1) [phonetics][stress][binomial][idiom][prosody]
同じ形態類の2語から成る表現を (2項イディオム)と呼ぶ.##953,954,955 の記事では,押韻に着目して数々の binomial を紹介した.binomial は "A and B" のように典型的に等位接続詞で結ばれるが,構成要素の順序はたいてい固定している.必ずしもイディオムとして固定していない場合にも,傾向として好まれる順序というものがある.なぜある場合には "A and B" が好まれ,別の場合には "D and C" が好まれるのだろうか.音節数や音価など,特に音声的な条件というものがあるのだろうか.
Bolinger は,現代英語の傾向として「短い語 and 長い語」の順序が好まれることを指摘している.この長短の差は,典型的に音節数の違いとして現われる.その典型は「1音節語 and 第1音節に強勢のある2音節語」である.名詞を修飾する形容詞の例をいくつか挙げれば,a bows-and-arrows project, cold and obvious fact, drum-and-bugle corps, floor-to-ceiling window, fresh and frisky pups, furred and feathered creatures, a red and yellow river, strong and bitter political factor, up-and-coming writer などがある (Bolinger 36) .他にも例はたくさんある.
black and sooty, blue and silver, bright and rosy, bright and shiny, bruised and battered, cheap and nasty, cloak and dagger, drawn and quartered, fast and furious, fat and fulsome, fat and sassy, fine and dandy, fine and fancy, free and easy, full and equal, gay and laughing, grim and weary, hale and hearty, high and handsome, high and mighty, hot and bothered, hot and healthy, hot and heavy, hot and spicy, lean and lanky, long and lazy, low and lonely, married or widowed, plain and fancy, poor but honest, pure and simple, rough and ready, rough and tumble, slick and slimy, slow and steady, straight and narrow, strong and stormy, tried and tested, true and trusty, warm and winning, wild and woolly
一覧してすぐにわかるが,いずれの binomial も強弱強弱の心地よいリズムとなる.もちろん tattered and torn, peaches and cream, merry and wise, open and shut, early and later などのように,強弱弱強となる binomial もあるにはあるが,例外的と考えてよさそうだ.
この「1音節語 and 第1音節に強勢のある2音節語」という順序の傾向について,Bolinger (36--40) は母語話者の実験によっても確認をとっている.イディオムというほどまでには固定されていない2項について,"A and B" と "B and A" の並びを両方示して,どちらがより自然かを母語話者に選ばせるという実験である.いくつかの条件で実験を施したが,傾向は明らかだった.binomial において,prosody の果たしている役割は大きい.
・ Bolinger, D. L. "Binomials and Pitch Accent." Lingua (11): 34--44.
2012-06-07 Thu
■ #1137. prophet の原義と文献学 [etymology][greek][philology]
prophet には,「預言者」および「予言者」の両方の意味がある.その語源は,ギリシア語 prophḗtēs に遡り,pro- "before, forth" + -phḗtēs "sayer" という語形成である.後半要素は,動詞 phēmí "I say" に基づく派生名詞であり,つまるところ prophet の原義は "one who speaks before/forth" 辺りであると想像される.
だが,pro- に割り当てられた2つの現代英語訳語 "before" と "forth" とでは,全体の解釈が異なってくる."before" をとれば「前もって言い当てる人」となり,「予言者」に等しい,"forth" をとれば「公言(公表)する人」となり,むしろ「預言者」に近い.預言はたいてい予言でもあるので,両者の語義は近く,原義がいずれであったかを定めること難しい問題である.ところが,ギリシア語には動詞 prophēmi があり,そこでの意味は「予言する」である.とすると,prophḗtēs は,この動詞から派生した名詞であると考えるのが妥当であり,その原義は対応する「予言」に違いない,と考えられる.
しかし,ここからが文献学の出番である.Fortson (7) によれば,テキストからの証拠に従うと,名詞 prophḗtēs は動詞 prophēmi よりも700年も前に現われるのである.また,pro- をもつ他の語を調べると,この接頭辞の原義は "before" ではなく,"before" の語義の発達は prophḗtēs の出現の後の出来事らしいことがわかってくる.このように見ると,本来 prophḗtēs とは "one who speaks forth or announces the will of the gods" の意であり,"one who foretells the future" の意は後世の発達であると結論づけることができる.語の原義や意味の発達を正確に跡づけるために,文献学的な様々の証拠を援用する必要があることを教えてくれる好例だろう.
なお,接頭辞 pro- については,[2011-03-23-1]の記事「#695. 語根 fer」を参照.
・ Fortson IV, Benjamin W. Indo-European Language and Culture: An Introduction. Malden, MA: Blackwell, 2004.
2012-06-06 Wed
■ #1136. 異なる言語の間で類似した語がある場合 [comparative_linguistics][arbitrariness][onomatopoeia][phonaesthesia][sound_symbolism]
ランダムに選んだ言語Aと言語Bの単語リストを見比べて,意味も形態も十分に似通った語があったとする.このような場合には,4つの可能性のいずれか,あるいは複数の組み合わせが想定される.Fortson (1--3) を参考に説明しよう.
(1) 偶然の一致 (chance) .言語記号は恣意的 (arbitrary) であり,犬のことを「イヌ」と呼ぶ必然性もなければ,dog と呼ぶ必然性もない.したがって,2つの異なる言語で同じ(あるいは類似した)意味をもつ語が同じ(あるいは類似した)形態をもつ可能性は低いと考えられるが,ゼロではない.無数の単語の羅列を見比べれば,たまたま意味と形態が一致するような項目も2,3は見つかるだろう.よくあることではないが,偶然の一致という可能性を排除しきることはできない.
(2) 借用 (borrowing) .言語Aが言語Bからその語を借用した,あるいはその逆の場合,当然ながら,借用されたその語の意味と形態は両言語で共有されることになる.日本語「コンピュータ」は英語 computer からの借用であり,意味と形態が(完全に同じではないとしても)似ていることはいうまでもない.
(3) 言語普遍性 (language universals) .言語の恣意性の反例としてしばしば出される onomatopoeia や phonaesthesia を含む sound_symbolism の例.ある種の鳥は英語で cuckoo,フランス語で coucou,ドイツ語で Kuckuck,非印欧語である日本語で「カッコウ」である.非常に多くの言語で,母親を表わす語に ma, ba, da, ta が現われるのも,偶然の一致とは考えられず,何らかの言語普遍性が関与しているとされる.
(4) 同系 (genetic relation) .(2), (3) の可能性が排除され,かつ言語間で多くの単語が共有されている場合,(1) の偶然の一致である可能性も限りなく低い.この場合に可能な唯一の説明は,それらの言語がかつては1つであったと仮定すること,言い換えれば互いに同系統であると仮定することである.
比較言語学の再建 (reconstruction) の厳密な手続きによる同系証明は,理論上,(1), (2), (3) の可能性の否定の上に成り立っているということに注意したい.(1) と (3) には言語の恣意性 (arbitrariness) の問題がかかわっており,(2) と (4) の区別には,系統と影響の問題 (##369,371) がかかわっている.言語の同系証明とは,言語の本質に迫った上での真剣勝負なのである.
・ Fortson IV, Benjamin W. Indo-European Language and Culture: An Introduction. Malden, MA: Blackwell, 2004.
2012-06-05 Tue
■ #1135. 印欧祖語の文法性の起源 [gender][indo-european][hittite]
標記の問題は,多くの人が関心をもつ問題である.[2010-08-27-1]の記事「#487. 主な印欧諸語の文法性」でみたように,現代英語や少数の言語は例外として,印欧諸語の大部分が文法的な性 (grammatical gender) の体系を保持している.この自然性 (natural gender) とは一致しない,不合理にみえる名詞の分類法はいったいどのような動機づけで発生したのだろうか.諸説紛々としているが,1つの説として Szemerényi (155--57) の論に耳を傾けよう.
再建された形態論に従えば,印欧祖語には男性 (masculine) ,女性 (feminine) ,中性 (neuter) の3性があったとされる.この3性体系は,Balto-Slavic や Germanic を中心に多く保持されているが,中性名詞が男性と女性へ割り振られて2性体系へと再編成された言語も,Lithuanian やロマンス諸語など,少なくない.
さて,印欧祖語の3性体系は,その前段階として想定される共性 (common) と中性 (neuter) の2性体系から分化・発達したものと考えられる.というのは,古代の屈折クラスでは,男性と女性とは類似した屈折要素を示しているが (ex. patēr, mētēr; see also ##698,699) ,中性はそれらと対立していたからである.印欧祖語の段階ではすでに,共性から分化する形で女性が確立していたと考えてよいが,共性と中性の2性体系が前段階にあったという仮説には一理ある.
共性から女性が分化・発達したのはなぜかという問題についても百家争鳴だが,伝統的な見解によれば,たまたま特定の音形をもっていた「女性」などを意味する語の形態がモデルとなり,そこに含まれる母音などが,他の名詞においても女性名詞を標示するものとして機能するようになったのではないかといわれる.
では,原初の共生と中性の2性システムが,そもそも最初に生じたのはなぜだろうか.Meillet の見解はこうである.印欧祖語では,いくつかの重要な概念に対して,有生的 (animate) なとらえ方と無生的 (inanimate) なとらえ方の2種類が区別されており,それぞれに異なる形態が割り当てられていた.例えば,「火」はラテン語では ignis だが,ギリシア語には,まったく異なる語根を反映する pûr がある.同様に,「水」はラテン語 aqua に対してギリシア語 húdōr がある,等々.森羅万象を有生に見立てるか,無生に見立てるかという世界観に基づいて,共性と中性という2性体系が生じたということではないか.
なお,文証される印欧語として最も古い Hittite は,共性と中性の2性体系である.これほど古い段階の印欧語が2性体系だったということは,印欧祖語の性体系の議論にも大きな影響を及ぼす.Hittite の2性体系は,印欧祖語の3性体系から女性が失われた結果を示すのか,あるいは印欧祖語がいまだ2性体系だった早い時代に分岐したことを示すのか.比較言語学のミステリーである.
・ Szemerényi, Oswald J. L. Introduction to Indo-European Linguistics. Trans. from Einführung in die vergleichende Sprachwissenschaft. 4th ed. 1990. Oxford: OUP, 1996.
2012-06-04 Mon
■ #1134. 協調の原理が破られるとき [pragmatics][cooperative_principle][implicature][rhetoric]
協調の原理 (the Cooperative Principle) について,[2012-05-23-1], [2012-06-03-1]の記事で取り上げてきた.談話の参加者が暗黙のうちに遵守しているとされるルールのことであるが,あくまで原則として守られるものとしてと捉えておく必要がある.原則であるから,ときには意識的あるいは無意識的に破られることもある.例えば,Grice (30) によれば,原理 (principle) あるいは公理 (maxims) は以下のような場合に破られることがある.適当な例を加えながら解説しよう.
(1) 相手に知られずに公理を犯す場合.結果として,聞き手の誤解を招くことが多い.嘘をつくことがその典型である.嘘は,質の公理を犯すことによって,聞き手に誤ったメッセージを信じさせる行為である.嘘に限らず,誤解を生じさせることを目的とした意地悪な物言いなども,このタイプである.
(2) 原理や公理から意図的に身を引く場合.質問に対して「その質問には答えません」と返したり,「ところで・・・」と話しをそらすようなケース.
(3) ある公理に従うことで他の公理を犯すことになってしまう場合.「○○さんはどこに住んでいるんだろうね?」に対して,具体的な住所は知らずに「東北地方のどこか」と答えるようなケース.量の公理によれば,質問に対して必要なだけ詳しい回答を与えることが期待されるが,質の公理によれば,知らないものは口にすべきではないということになり,後者の遵守が前者の遵守を妨げる結果となる.
(4) 公理をあえて無視し,それにより特定の含意 (implicature) を生み出す場合.[2012-05-23-1]の記事で挙げた,"How is that hamburger?" --- "A hamburger is a hamburger." のような例.別の例を挙げよう.
A: Smith doesn't have a girlfriend these days.
B: He has been paying a lot of visits to New York lately.
このやりとりで,B の発言は額面通りに取れば A の発言に呼応しておらず,関係の公理を犯しているかのようにみえる.しかし,B が対話から身を引いているようには思われない以上,B は A の発言に有意味な発言をしているにちがいない.B はあえて関係の公理を破り,そのことを A もわかっているはずだとの前提のもとに,A に言外の意味を推測するよう駆り立てているのである.「Smith はニューヨークに新しい彼女がいる」という含意 (implicature) が生まれるのは,このためである.公理の力を利用した裏技といえるだろう.皮肉や機知や各種の修辞的技法はこのタイプである.
原理とは,破られるときにこそ,その力がはっきりと理解されるものかもしれない.
・ Grice, Paul. "Logic and Conversation." Studies in the Way of Words. Cambridge, Mass.: Harvard UP, 1989. 22--40.
2012-06-03 Sun
■ #1133. 協調の原理の合理性 [pragmatics][cooperative_principle]
[2012-05-23-1]の記事で紹介した「#1122. 協調の原理」 (the Cooperative Principle) は,語用論における重要な原理として広く認められており,直感や会話の実際にも沿うものである.しかし,それを遵守することが話し手と聞き手のあいだで暗黙のうちに前提とされているのはなぜだろうか.協調の原理には,合理的な根拠があるのだろうか.
経験から導かれる答えは以下のようなものだろう.人々は協調の原理にもとづいて行動している.子供の頃からそのように行動しているし,大人になってからもその習慣を捨てていない.むしろ,この習慣から大きく逸脱するには多大な労力が必要だろう.例えば,質の公理に従って真実を述べ続けることのほうが,嘘をつき続けるよりも楽なはずである.しかし,この回答は,惰性により習慣を守り続ける説明にはなっていても,協調の原理がなぜ最初に存在するのかの合理的な説明にはなっていない.
Grice は,協調の原理を最初に提起した1975年の論文(1989年の論文集で再掲された)で,合理性の問題を論じている.Grice は,当初,談話における協調の原理を,他の人間活動にもみられるような契約の一種としてとらえた.談話の参加者は,ある目的を共有し,その目的を達成するために互いに貢献し合い,しばしば暗黙のうちにそのやりとりを打ち切る合意ができるまで継続する.
目的達成のための暗黙の契約であるとするこの見方は,確かに合理的ではあるが,これが当てはまらないやりとりは数多く存在する.例えば,口喧嘩や手紙を書くという行為は,共通の目的を達成するための契約という考え方とどのように関わり合うのか不明である.そこで,Grice は次のように考え直した.
So I would like to be able to show that observance of the Cooperative Principle and maxims is reasonable (rational) along the following lines: that anyone who cares about the goals that are central to conversation/communication (such as giving and receiving information, influencing and being influenced by others) must be expected to have an interest, given suitable circumstances, in participation in talk exchanges that will be profitable only on the assumption that they are conducted in general accordance with the Cooperative Principle and the maxims. (29--30)
先の契約論では参加者の共通の目的が強調されていたが,新しい説では必ずしも共通で同一の目的は仮定されておらず,極端な場合には参加者によって具体的な目的の異なっていることもありうるだろう.より一般的な "the goals that are central to conversation/communication" が共有されていさえすればよい.これは,より自己中心主義の説ということができるかもしれない.なお,Grice も,この説はいまだ仮説の段階であるとしている.
Grice の協調の原理は言語学というよりも哲学の議論から生じてきたものであり,原理の見かけは単純だが,原文に戻るとなかなか難解である.
・ Grice, Paul. "Logic and Conversation." Studies in the Way of Words. Cambridge, Mass.: Harvard UP, 1989. 22--40.
2012-06-02 Sat
■ #1132. 英単語の品詞別の割合 [lexicology][corpus][statistics]
昨日の記事で,MRC Psycholinguistic Database (全150837語を含む)を利用した Amano の研究を参照した.Amano では,名詞と動詞の stress typicality の調査の副産物として,同データベースに基づいた語の品詞別割合の表が示されていたので,今回はそれをメモしておきたい.
Amano (86) は,データベースより計10894個の2音節語を抜き出した.複数の品詞の機能をあわせもつ語については,それぞれの品詞のもとで1個として加えた(その他,詳しい作業手順は p. 86 に明記されている).結果として得られた品詞別の個数と割合は以下の通りである.
| POS | FREQ | % |
| noun | 7326 | 57.04% |
| verb | 2501 | 19.47% |
| adjective | 2420 | 18.84% |
| adverb | 291 | 2.27% |
| preposition | 68 | 0.53% |
| conjunction | 21 | 0.16% |
| pronoun | 15 | 0.12% |
| interjection | 37 | 0.29% |
| past participle | 57 | 0.44% |
| others | 108 | 0.84% |
品詞別の割合の算出は,用いるデータベースやコーパスの性質や規模,word form で数えるか lemma で数えるかなどの「語」の定義の問題に左右されるが,複数の調査結果を比較すれば,ある程度は信頼できる値が得られるだろう.本ブログ内でこれまでに紹介した品詞別の割合については,以下を参照.
・ [2011-02-23-1]: 「#667. COCA 最頻50万語で品詞別の割合は?」
・ [2011-02-22-1]: 「#666. COCA 最頻5000語で品詞別の割合は?」
・ [2011-02-16-1]: 「#660. 中英語のフランス借用語の形容詞比率」
・ Amano, Shuichi. "Rhythmic Alternation and the Noun-Verb Stress Difference in English Disyllabic Words." 『名古屋造形大学名古屋造形芸術大学短期大学部紀要』 15 (2009): 83--90.
2012-06-01 Fri
■ #1131. 2音節の名詞と動詞に典型的な強勢パターン [stress][diatone][statistics]
「名前動後」の現象について,diatone の各記事で触れてきた.Kelly and Bock の研究によれば,2音節語における名前動後の強勢パターンは,一般的な強勢位置の傾向を反映しているという.すなわち,2音節の名詞では第1音節に強勢のおちる強弱型 (trochaic) ,2音節の動詞では第2音節に強勢の落ちる弱強型 (iambic) が普通とされる.この傾向は stress typicality と呼ばれるが,率でいえばどの程度の傾向を示すのだろうか.
Amano は,Kelly and Bock や Sereno の調査結果を参照しながら,MRC Psycholinguistic Database を用いた独自の調査をおこなった.調査間の比較が可能となるように,純粋な名詞(他の品詞機能をもたないもの)と純粋な動詞に限定しての数え上げだが,次のような結果となった.他の調査と合わせて,Amano (86) の調査の統計を挙げよう.
| researcher | category | result |
| Sereno (1986) | noun | out of 1425 nouns, 93% are trochaic |
| verb | out of 523 verbs, 76% are iambic | |
| Kelly & Bock (1988) | noun | out of 3202 nouns, 94% are trochaic |
| verb | out of 1021 verbs, 69% are iambic | |
| Amano (2009) | noun | out of 5766 nouns, 92.92% are trochaic |
| verb | out of 1184 verbs, 72.65% are iambic |
(注記.Sereno の値は Brown Corpus によるものであり,Amano (86) より孫引きしたものである.しかし,直接 Sereno の原典に当たったところ,名詞が92%,動詞が85%と異なる値が示されていた.)
調査間に大きな差異はなく,名詞の約93%が trochaic,動詞の約73%が iambic という事実が確認された.対比的に評価すれば,品詞ごとに stress typicality があることは,疑いえない.なぜこのような傾向があるのかという問題については,Kelly and Bock および Amano で論じられている.要約すれば,2音節名詞を強弱型に,2音節動詞を弱強型にそれぞれはめ込むことにより,周囲の語とともに,強勢と無強勢の交替のリズムを作りやすくなるからである.名詞は無強勢の冠詞が前置されることが多いので,あわせて「弱強弱」となりやすく,動詞は1音節の屈折語尾(-ing および語幹の一定の音声環境のもとでの ed や -es)を伴う頻度が名詞よりも高いので,あわせて「弱強弱」となりやすい,等々.
名前動後の問題を考える際にも,2音節語の名詞・動詞に関するこの一般的な傾向を念頭に置いておく必要があるだろう.
・ Kelly, Michael H. and J. Kathryn Bock. "Stress in Time." Journal of Experimental Psychology: Human Perception and Performance 14 (1988): 389--403.
・ Sereno, J. A. "Stress Pattern Differentiation of Form Class in English." The Journal of the Acoustical Society of America 79 (1986): S36.
・ Amano, Shuichi. "Rhythmic Alternation and the Noun-Verb Stress Difference in English Disyllabic Words." 『名古屋造形大学名古屋造形芸術大学短期大学部紀要』 15 (2009): 83--90.
2026 : 01 02 03 04 05 06 07 08 09 10 11 12
2025 : 01 02 03 04 05 06 07 08 09 10 11 12
2024 : 01 02 03 04 05 06 07 08 09 10 11 12
2023 : 01 02 03 04 05 06 07 08 09 10 11 12
2022 : 01 02 03 04 05 06 07 08 09 10 11 12
2021 : 01 02 03 04 05 06 07 08 09 10 11 12
2020 : 01 02 03 04 05 06 07 08 09 10 11 12
2019 : 01 02 03 04 05 06 07 08 09 10 11 12
2018 : 01 02 03 04 05 06 07 08 09 10 11 12
2017 : 01 02 03 04 05 06 07 08 09 10 11 12
2016 : 01 02 03 04 05 06 07 08 09 10 11 12
2015 : 01 02 03 04 05 06 07 08 09 10 11 12
2014 : 01 02 03 04 05 06 07 08 09 10 11 12
2013 : 01 02 03 04 05 06 07 08 09 10 11 12
2012 : 01 02 03 04 05 06 07 08 09 10 11 12
2011 : 01 02 03 04 05 06 07 08 09 10 11 12
2010 : 01 02 03 04 05 06 07 08 09 10 11 12
2009 : 01 02 03 04 05 06 07 08 09 10 11 12
最終更新時間: 2026-05-16 23:43
Powered by WinChalow1.0rc4 based on chalow