hellog〜英語史ブログ / 2011-02
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
2026 : 01 02 03 04 05 06 07 08 09 10 11 12
2025 : 01 02 03 04 05 06 07 08 09 10 11 12
2024 : 01 02 03 04 05 06 07 08 09 10 11 12
2023 : 01 02 03 04 05 06 07 08 09 10 11 12
2022 : 01 02 03 04 05 06 07 08 09 10 11 12
2021 : 01 02 03 04 05 06 07 08 09 10 11 12
2020 : 01 02 03 04 05 06 07 08 09 10 11 12
2019 : 01 02 03 04 05 06 07 08 09 10 11 12
2018 : 01 02 03 04 05 06 07 08 09 10 11 12
2017 : 01 02 03 04 05 06 07 08 09 10 11 12
2016 : 01 02 03 04 05 06 07 08 09 10 11 12
2015 : 01 02 03 04 05 06 07 08 09 10 11 12
2014 : 01 02 03 04 05 06 07 08 09 10 11 12
2013 : 01 02 03 04 05 06 07 08 09 10 11 12
2012 : 01 02 03 04 05 06 07 08 09 10 11 12
2011 : 01 02 03 04 05 06 07 08 09 10 11 12
2010 : 01 02 03 04 05 06 07 08 09 10 11 12
2009 : 01 02 03 04 05 06 07 08 09 10 11 12
2011-02-28 Mon
■ #672. 構造主義的にみる中英語ロマンス [literature][romance][formula]
[2011-02-26-1], [2011-02-27-1]の記事で参照した Wittig は,中英語ロマンスの formula を機能的な単位として位置づけた研究者である.Wittig の議論には構造主義の視点が色濃く反映されており,それは特に次の2点において見られる.
1つは,formula を "a kind of mental template, in the mind of the poet, a pattern-making device which generates a series of derivative forms" (Wittig 29) とみなしている点である.この考えによると,formula とは統合関係 ( syntagm ) を表わす「型」のことであり,そこに選択関係 ( paradigm ) にある交替可能な語句群から1つを選んで流し込んでゆくことによってある表現が実現されるとする.例えば al thus in boke as as we rede という決まり文句は,以下の「型」の各スロットに適当な語句を選択して当てはめていった結果であると考える.
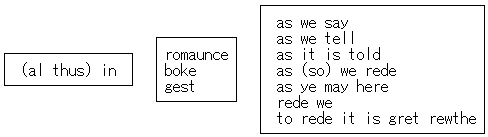
もう1つすぐれて構造主義的なのは,上記のような統語レベルの型を "syntagmeme" と名付けてロマンスの構造をなす最小単位と位置づけたあとで,「交替可能な選択肢の中からの選択」という考え方をより大きな単位へと拡張してゆく点である.例えば,ロマンスには「主人公の父の死」という場面がある.この場面を構成するのは「悪者による殺害の企み」「父の登場」「敵の挑戦」「敵との戦い」「死」という一連の出来事であり,それぞれの出来事の単位は "motifeme" と呼ばれる.各 motifeme には様々な variation が用意されており,また motifeme 間の順番は決まっている.型に流し込むかのように場面が構成されてゆく.次に,「主人公の父の死」という場面それ自体がより大きな構成単位 "type-scene" となり,「主人公の追放」というもう1つの type-scene と合わさって,さらに大きな構成単位 "type-episode" となる.いずれの規模の単位においても「交替可能な選択肢の中からの選択」という同一原則が適用されており,小さい単位の積み重ねにより最終的な物語が構成されるという意味で,きわめて構造主義的な考え方といえる.
Wittig は,"Dame," he said のような単純な formula の分析から始め,より大きな単位へと分析へと積み上げてゆき,結論として中英語ロマンスに共通する2対の type-episode 連鎖を突き止めた."love-marriage" 連鎖と "separation-restoration" 連鎖である.Wittig (177) は,中英語ロマンスの形式上の定義はこの2対の連鎖が組み合わさっているということであると言い切る.
中英語ロマンスでは,love と marriage の間に必ず困難が伴い,separation (追放によるアイデンティティの喪失)と restoration (その回復)にも苦難が付随する.2対の連鎖こそが中英語ロマンスの主要な "generating forces" であり,深層構造から,鋳型へ内容物を注入しつつ,表層構造を産出してゆく原動力なのである.
最後に,Wittig の議論は壮大な speculation へと及ぶ.中英語ロマンスの聴衆の関心の根底に love-marriage と separation-restoration があったと仮定すると,それはなぜなのか.その答えの1つとして,love-marriage が象徴する女系家族制と separation-restoration が象徴する男系家族制との融和が,かれらの大きな関心事だったからではないか.
formula の言語的分析から中世イングランドの家族観へと展開する Wittig の議論を読んで,構造主義というのは,小さな部品を1つの原理で組み合わせて大きな機械を作りあげることなのかと学んだ.
・ Wittig, Susan. Stylistic and Narrative Structures in the Middle English Romances. Austin and London: U of Texas P, 1978.
2011-02-27 Sun
■ #671. 中英語ロマンスにおける formula の機能 [literature][romance][auchinleck][formula]
昨日の記事[2011-02-26-1]で,中英語ロマンスの言語において formula がいかに大きな割合で用いられているかを見た.ロマンスに formula が多用される背景には,いくつかの説明が提案されている.1つは,有名な The Auchinleck Manuscript のロマンス群に関連して特に言われていることで,ロンドンの写本製作所が「売れ筋本」を大量生産するために,formula を機械的に多用したという "a theory of bookshop composition and extensive textual borrowing" である (Wittig 13) .もう1つは,ロマンスは,吟遊詩人が口頭で聴衆へ伝えるという意図で作成されたものであり,語りの効果と暗唱のために繰り返しが多くなるのは自然だとする "the oral-transmission theory" である (Wittig 14) .
しかし,Wittig は上の2つの説明では説得力がないと主張する.ロマンスが中世イングランドの聴衆に受けたのは,分かりきった物語の筋や予測可能な formula を何度も聞かされることにより,物語が描く社会の現状を確認し,是認し,安心感を得ることができたからではないか.ロマンスの語り手と聞き手はともに社会の秩序に対する信頼感をもっており,ロマンスを受容することによって,その秩序を保守することに賛意を表明しているのではないか.したがって,社会が変革すればロマンスというジャンル自体も変容を迫られるか衰退することになる.ロマンスの言語は,語り手と聞き手のスタンスの言語 "a language of stance" (Wittig 46) である.Wittig のこの主張が要約された一節を引く.
If the language does not serve to carry information, what then is its primary function? In addition to carrying a minimal amount of narrative information, the language carries at least one other level of social meaning as well. That is, it carries the additional messages which are encoded within the semiology of social gestures, the language of social ritual: leave-takings, greetings, meals and banquets, marriages and knightings and tournaments. Each one of the highly ritualized events to which the formulas themselves refer is also a kind of formulaic language, a complex system of significations which is as thoroughly understood and articulated in its own culture as that culture's natural language and which is indeed a language even though it may not be a verbal one. In the romances the language of the verse refers much of the time to this second-order system, and its message-bearing function is then doubled. The language of these narratives functions not only as a medium of narrative, but as a powerful social force which supports, reinforces, and perpetuates the social beliefs and customs held by the culture, perhaps long past their normal time of decline. (Wittig 45)
上で触れた The Auckinleck Manuscript については以下のサイトが有用である.
・ The Auchinleck Manuscript : National Library of Scotland
・ Auchinleck MS Home Page
・ Wittig, Susan. Stylistic and Narrative Structures in the Middle English Romances. Austin and London: U of Texas P, 1978.
2011-02-26 Sat
■ #670. 中英語ロマンスにおける formula の割合 [literature][romance][statistics][formula]
中世ロマンスの言語上の大きな特徴の1つに,formula の多用がある.stock phrase とも言われ「決まり文句,常套句」を指す.formula の定義には,表現の幅を限定したきわめて狭いものから,語彙や統語のレベルでの型に適合していればよいとする広いものまであるが,多くの formula 研究は Milman Parry の次の定義から出発している.
A formula is "a group of words which is regularly employed under the same metrical conditions to express a given essential idea." (qtd in Wittig, p. 15 as from "Studies in the Epic Technique of Oral Verse-Making. I: Homer and Homeric Style." Harvard Studies in Classical Philology 41 (1930). page 80.)
formula の具体例を挙げればきりがないが,"'Dame,' he said", "that hendi knight", "feyre and free" などの短いものから,"He was a bolde man and a stowt", "And he were neuer so blythe of mode", "For to make the lady glade / That was bothe gentyll and small" などの長いものまで様々である.Wittig によれば,中英語の韻文ロマンス25作品から Parry の条件を厳密に満たす formula を含む行を抜き出したところ,以下のような結果が得られた.
| POEM | LENGTH | VERSE TYPE | FORMULA RATE |
|---|---|---|---|
| Lai le freine | 340 lines | couplet | 10% |
| Sir Landeval | 500 | couplet | 11 |
| Sir Launfal | 1044 | tail-rhyme | 16 |
| King Horn | 1644 | couplet | 18 |
| Sir Degare | 1076 | couplet | 21 |
| Havelok | 2822 | couplet | 21 |
| Sir Isumbras | 804 | tail-rhyme | 22 |
| Sir Amadace | 864 | tail-rhyme | 22 |
| Sir Perceval | 2288 | tail-rhyme | 22 |
| Horn Child | 1138 | tail-rhyme | 24 |
| Roswall and Lillian | 885 | couplet | 25 |
| Ocatvian (southern) | 1962 | tail-rhyme | 25 |
| Sir Triamour | 1719 | tail-rhyme | 25 |
| Earl of Toulous | 1224 | tail-rhyme | 26 |
| Ywain and Gawayn | 4032 | couplet | 27 |
| Sir Eglamour | 1377 | tail-rhyme | 29 |
| Squyr of Lowe Degre | 1131 | couplet | 30 |
| Lebeaus Desconus | 2131 | tail-rhyme | 30 |
| Sir Torrent | 2669 | tail-rhyme | 31 |
| Bevis of Hampton | 4332 | couplet | 34 |
| Eger and Grime | 1474 | couplet | 35 |
| Sir Degrevant | 1920 | tail-rhyme | 38 |
| Octavian (northern) | 1731 | tail-rhyme | 39 |
| Floris and Blancheflur | 1083 | couplet | 41 |
| Emare | 1030 | tail-rhyme | 42 |
平均をとると,各テキストを構成する行数の26.56%が formula を含んでいることになる.couplet では平均が24.82%,tail-rhyme では27.93%だが,大差はない.また,テキストの長さと formula 行の割合には強い相関はない.Wittig の研究では,Arthur,Troy,Alexander ものなどの "cycle" は含まれていない.参照テキストを限定し,定義を厳密にし,あくまで低めに抑えられた数え上げなので,定義を緩くすれば相当に数値が上がるはずだという.
ロマンスのテキストの約1/4が formula から成っているとすると,聴衆にとって次にどのような文言が現われるかは予測可能ということになる.また,ロマンスは物語としての筋もおよそ決まっているので,聴衆にとって「新情報」を得る機会は非常に少ないと考えられる.では,そのようなロマンスが中世に大流行したのはなぜか.聴衆はロマンスに何を期待していたのだろうか.
・ Wittig, Susan. Stylistic and Narrative Structures in the Middle English Romances. Austin and London: U of Texas P, 1978.
2011-02-25 Fri
■ #669. 発音表記と英語史 [phonetics][phonology][phoneme][ipa]
発音表記には,大きく分けて音声表記 ( phonetic transcription or narrow transcription ) と音素表記 ( phonemic transcription or broad transcription ) の2種類がある.前者は [ ] で囲み,後者は / / で囲むのが慣習である.音声表記と音素表記は見た目は似ているが,本質的にはまったく異なるものである.音声表記は,調音的,音響的な観点からの音の記述を目指しており,原則として当該の言語でその音が果たす機能は考慮していない.一方で,音素表記は,音の物理的な側面は捨象し,原則として当該の言語でその音が果たす役割を重視する.構造主義言語学によれば,当該言語で機能的な役割を果たしている音の単位は 音素 ( phoneme ) と呼ばれ,形態素の最小対 ( minimal pair ) に基づいた対立 ( opposition ) によって厳密に定義される.厳格な構造主義の立場からは,音素は調音的,音響的な性質とは無縁であり,Jakobson and Halle の言うように,"all phonemes denote nothing but mere otherness" (11) である.
しかし,実際のところ,発音表記は,音声表記と音素表記が互いに歩み寄ったところで実現されていることが多い.厳密に音声表記を目指そうとすれば,音の物理的な特性を余すところなく表現しなければならず,無数の数値や音響スペクトログラム ( spectrogram ) で表記しなければならなくなる.一方で,厳密に音素表記を目指そうとしても,音素の拠って立つ「機能的な対立」には論者によって複数の説があり得るし,調音的な観点が欠如しているために,機能的な対立をなしていない音どうしの関係は一切無視されてしまうことになる.そこで,語学学習や言語学の現場でも,音声と音素の両方の考え方を活かした broad phonetic transcription ともいうべき折衷案が利用されている.[ ] で囲まれていながら音素的であったり,/ / で囲まれていながら音声的であったりすることがあるのは,このためである.
英語史や歴史英語学でも,原則としてこの折衷案が採用されていると考えてよい.もとより,過去の発音を,厳密な音声表記で表わせるほど正確に復元することはできない.また,厳密な音素表記をするにも論者によって様々な立場があり得るのは現代の言語の場合と同じであるし,調音的な側面を無視していては有意義に音声変化を記述できないという決定的な事情がある.例えば,[i] が前舌高母音であることを明示しない限り i-mutation によって [o] が [e] に変化することはうまく説明できないが,厳密に構造主義的な立場では,[i] が前舌高母音であるという調音的な主張をすることができないのである.
正確には復元できない過去の音を扱うから,また音の変化を有意義に説明する必要があるから,歴史言語学ではことさらに折衷的な発音表記を採用することが避けられない.英語史の分野(そして本ブログ)に出てくる発音表記は,純粋な音声表記でも純粋な音素表記でもなく,原則として折衷的な "poorly resolved broad transcription" (Lass and Laing 20) だと考えてよい.
現在最も広く採用されている発音表記である IPA 「国際音標文字」は The International Phonetic Association のサイトから IPA: Alphabet を参照.
・ Jakobson, R. and Halle, M. Fundamentals of Language. The Hague: Mouton, 1965.
・ Lass, Roger and Margaret Laing. "Interpreting Middle English." Chapter 2 of "A Linguistic Atlas of Early Middle English: Introduction.'' Available online at http://www.lel.ed.ac.uk/ihd/laeme1/pdf/Introchap2.pdf .
2011-02-24 Thu
■ #668. Chaucer の knight との脚韻語 [chaucer][bnc][collocation][kyng_alisaunder]
Chaucer の全作品中,knight という語は90回以上,脚韻箇所に現われている.対応する脚韻語を調べ,さらにロンドンの方言で書かれた2つのロマンス Kyng Alisaunder と Arthur and Merlin でも同様に調べてみると,非常におもしろい事実が浮かび上がる.
Chaucer で knight と脚韻を踏む語として5回以上現われるものに,might (32), wight (22), night (9), right (8), bright (5) がある.Kyng Alisaunder では高頻度のものには wiȝth, fiȝth, riȝth / miȝth があり,同じく Arthur and Merlin では ''fiȝt, riȝt, riȝth がある.脚韻語の分布をまとめたのが以下の図である(Burnley, p. 130 の図をもとに作成).
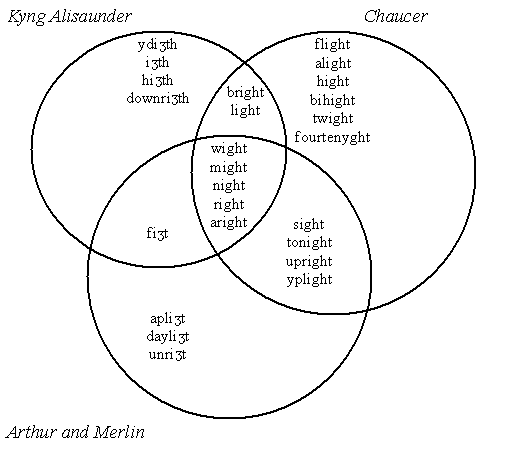
Chaucer の脚韻語は,高頻度のものを中心として大半が他の2つのロマンス作品と重複しており,全体として中英語ロマンスの伝統的な脚韻語を受け継いでいると解釈できる.一方で,Chaucer のみが用いている脚韻語もいくつか確認され,詩人の脚韻語の幅の広さが示唆される.
しかし,比較によってしか得られない非常に興味深い事実がある.他のロマンス2作品,ひいては中英語ロマンス全体として,最も頻度が高い脚韻語とみなしてもよいと思われる fight が,Chaucer には一度も現われないのである.knight と fight は縁語であり,collocation の度合いが高いことは自明であるから,Chaucer における不在は不自然とも思える.Burnley (131) は,脚韻語としての fight の不在は,Chaucer の選択した主題との関連もあるかもしれないが,おそらくは Chaucer が "a hackneyed rhyme" 「使い古された脚韻」とみなして意識的に避けたためだろうという.
Although he [Chaucer] was often content to employ familiar and traditional rhymes, there is also evidence of resourcefulness in seeking unusual rhymes, as well as of avoiding rhymes which might have proved unacceptable to his audience. (Burnley 131)
詩人が用いた脚韻語ではなく,用いなかった脚韻語を指摘することで,その詩人の特徴や詩の言語に対する態度が浮き彫りになりうる好例である.何が不在なのか,何を用いなかったのかを知るには,他と比較しなければならない.対象の本質を知るには,それが置かれている環境を広く見渡す必要がある.文献学の神髄を見せられるような印象的な例である.
ちなみに,knight と fight の collocation は強かったに違いないと述べたが,それは中世での話しである.現代英語における両語の collocation は BNCweb で調べたところそれほど顕著ではない.名詞 knight の前後5語以内に fight が現われる頻度はコーパス中で10回きりである.ただし,[2010-03-23-1]の記事で触れた MI と T-score の値を見ると,それぞれ 3.5415, 2.8907 であり,collocation と認めてよい水準ではある.
・ Burnley, David. The Language of Chaucer. Basingstoke: Macmillan Education, 1983. 13--15.
2011-02-23 Wed
■ #667. COCA 最頻50万語で品詞別の割合は? [lexicology][corpus][french][loan_word][adjective][statistics][coca]
昨日の記事[2011-02-22-1]に引き続き,COCA ( Corpus of Contemporary American English ) に基づく単語の頻度リストを利用したパイロット・スタディ.今回は,こちらで最近になって追加された最頻50万語のリストを用いて,昨日と同様の品詞別割合を調べた.昨日のリストは見出し語 ( lemma ) に基づいた最頻5000語,今日のリストは語形 ( word form ) に基づいた最頻50万語(正確には497187語)で,性格が異なることに注意したい.
昨日とほぼ同じ作業だが,今回は2万語ずつで階級を区切り,L1からL25までの階級のそれぞれにおいて noun, verb, adj., adv., others の5区分で品詞別割合を出した.(数値データはこのページのHTMLソースを参照.)
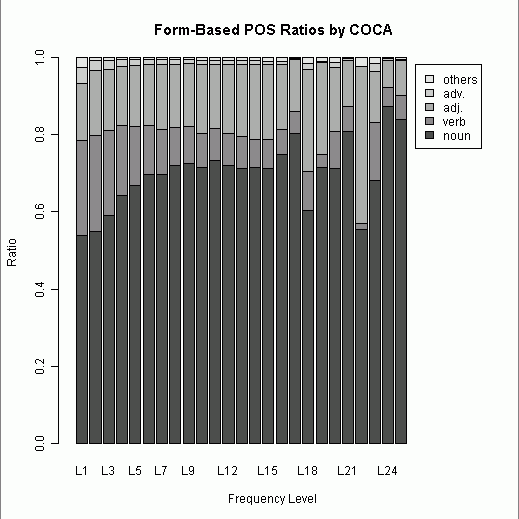
L6(12万語レベル)辺りから品詞別比率は安定期に入るといってよいだろう.L17(34万語レベル)辺りから変動期が始まるのが気になるが,階級幅を大きくしてみると(ならしてみると)直前のレベルから大きく逸脱していない.
[2011-02-16-1]の記事以来,形容詞の比率が気になっているが,今回のデータ全体から計算すると,0.1738という値がはじきだされた.昨日の lemma 調査では0.1678だったから,値は非常に近似している.ただし,名詞と動詞の lemma 対 word form の比率は,名詞が 0.5086 : 0.6985,動詞が 0.2000 : 0.1065 と大きく異なるので,形容詞の 0.1678 : 0.1738 という近似は偶然かもしれない.lemma 対 word form の品詞別割合には異なる傾向があるのかもしれないが,それでも大規模に調べると安定期と呼びうる区間が出現することは確かなようだ.
[2011-02-16-1]の記事で触れたように,中英語期のフランス借用語における形容詞比率は0.1768だった.今回の値0.1738と酷似しているが,主題の性質がまるで違うので,直接の関係を論じることは無理である.もとより昨日と今日の調査は,[2011-02-16-1]の調査とは無関係に始めたものである.しかし,偶然と思えるこの結果は,示唆的ではある.借用語彙といえば名詞が圧倒的なはずだと予想していたものの,フランス語や古ノルド語からはおよそ一定の割合の形容詞(それぞれ lemma 調査で0.1768と0.1817)が借用されていた.そして,その比率は時代が異なるとはいえ現代英語の比率と近似している.英語語彙全体における比率と借用語彙における比率が近似しているということは,もし偶然でないとしたら,何を意味するのだろうか.フランス借用語彙や古ノルド借用語彙が,英語に適応するような自然な比率で英語語彙へ溶け込んだということだろうか.これは,今回のパイロット・スタディの結果を受けての印象に基づく speculation にすぎない.今後も品詞別割合という観点に注目していきたい.
2011-02-22 Tue
■ #666. COCA 最頻5000語で品詞別の割合は? [lexicology][corpus][statistics][n-gram][coca]
COCA ( Corpus of Contemporary American English ) に基づいた各種語彙リストが Corpus-based word frequency lists, collocates, and n-grams から入手できる.そのなかで最も基本的なリストが,こちらの最頻5000語リストである.列挙されているのは見出し語 ( lemma ) 単位で,順位はコーパスに現われる頻度と分散の関数で計算されている.UCREL CLAWS7 Tagset の品詞コード表に基づいた粗い品詞情報も付与されており,品詞別の頻度などを手軽に分析することができる.
今回は,500語ごとに区切って頻度の高い順にL1からL10までの階級を設け,それぞれの階級における品詞別割合を出した.品詞は開いた語類 ( open class ) を中心とし,noun, verb, adj., adv., others の5区分とした.(数値データはこのページのHTMLソースを参照.)
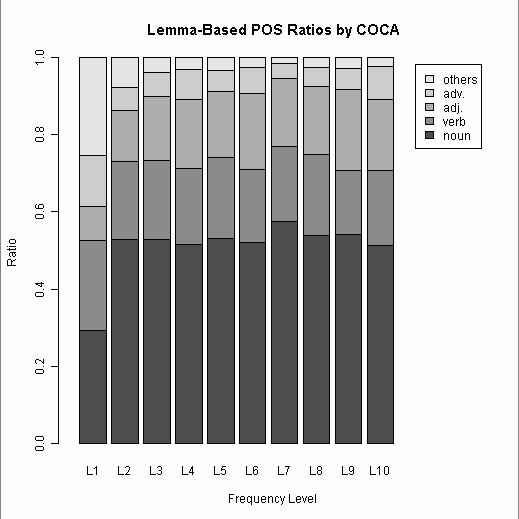
第1階級を除き,どの階級でも名詞が過半数を占めているのは予想できたことだが,第2階級以降に名詞の割合が思ったほど伸びていないことが分かった.動詞と形容詞が後半の階級でもおよそ一定の割合を占め続けているのも予想外だった.全体として,最頻5000語リストに限れば,名詞が飛び抜けつつも,開いた語類の内部比率はおよそ一定に保たれているといえよう.階級幅を様々に動かして試してみたが,およそ安定期に入るのは500語以降と見てよさそうだ.
[2011-02-16-1]の記事で中英語期のフランス借用語の品詞別割合をみたが,全体としての形容詞比率は0.1768だった.今回の現代英語の最頻5000語では,全体としての形容詞比率は0.1678.比べて意味のある数値かどうかは分からないが,英語(言語?)における品詞別比率の「安定感」のようなものはあるのだろうか.
COCA に基づくもの以外にオンラインで入手できる最頻英単語リストについては[2010-03-01-1]の記事を参照.頻度表を利用した別のパイロット・スタディとしては,単語の音節数を扱った[2010-04-17-1]の記事を参照.
2011-02-21 Mon
■ #665. Chaucer にみられる3人称代名詞の疑似指示詞的用法 [chaucer][personal_pronoun][demonstrative][french]
中英語では3人称代名詞を人名に先行させて,その代名詞に一種の指示的機能をもたせる特殊な用法がある.Chaucer の "The Knight's Tale", ll. 1209--10 からの例が Burnley (22--25) で論じられているので引用しよう(以下,引用は The Riverside Chaucer より).
This was the forward, pleynly for t'endite,
Bitwixen Theseus and hym Arcite:
幽閉されていた Arcite を条件つきで解放する契約に言及している箇所で,その契約が Theseus と hym Arcite の間で交わされた契約であることが示されている.ここで用いられている hym が,問題の疑似指示詞的な用法の3人称代名詞である.hym が Arcite という名前に先行しているのは,1つには韻律上の都合ということが考えられるが,ここでは「くだんのアルシータ,前述のアルシータ」ほどの意味で,hym は指示対象を限定し,明示していると解釈することができる.Horobin (95) では,指示詞 that ほどに置きかえられる hym だとしている.
人称代名詞には主として前方照応 ( anaphora ) の機能がある.前方照応の聞き手に及ぼす効果としては,(1) 前方照応の対象の存在を認知させ,(2) それが何・誰であるかを突き止めさせる,という2つの段階が考えられる.上記の hym Arcite で,hym は (1) の役割のみを担っており,照応対象として Arcite が直後に明示されているために,(2) までを担う必要がない.人称代名詞でありながらその本来の機能を半分しか果たしていない点が,疑似指示的と呼ばれる所以だろう.
しかし,韻律の都合は別として,文脈としては hym は不要なように思えるかもしれない.確かに Arcite だけでも解釈の上で何ら問題はないし,Arcite として示されている明確な指示対象を hym でさらに限定し,明示するというのも妙なものである.だが,ここでは「契約」が絡んでいるという点が重要である.
「契約」の関わる法律的な文言においては,問題になっているのが誰なのか,何なのかをことさらに明示する必要がある.そのために,法律文書では固有名詞にも指示詞的な要素が余剰的に先行することが多いのである.Burnley (24) が挙げている法律文書からの例としては,Petition of the Folk of Mercerye (1386) に he Nichol, hym Nichol, the forsaid Nichol (PDE (the) aforesaid), the same Nichol などが繰り返し現われるという.まさに「くだんのニコル,前述のニコル」である.
中世イングランドの法律語法は非常に多くをフランス語に負っており ( see [2010-03-29-1], [2010-07-04-1] ), 今回の問題の語法もフランス語の影響を多分に受けていると想定される.3人称代名詞を疑似指示詞として用いる hym Arcite のような「人称代名詞+固有名詞」という型に完全に対応する例はフランス語にはないが,機能的にほぼ対応する dit, le ditz, avaunt ditz, lequel などが影響を及ぼしたと考えられる.ラテン語の法律文書でも,フランス語法に対応する dictus, supradictus, ipse, idem などが見られる.
・ Burnley, David. The Language of Chaucer. Basingstoke: Macmillan Education, 1983.
・ Horobin, Simon. Chaucer's Language. Basingstoke: Palgrave Macmillan, 2007.
2011-02-20 Sun
■ #664. littera, figura, potestas [spelling_pronunciation_gap][grammatology][graphemics]
昨日の記事[2011-02-19-1]と関連して,中英語の綴字と発音の関係について.LAEME 編集者とその周辺では,4世紀のローマの文法家 Aelius Donatus による用語 littera, figura, potestas が,理論的な意味を付された書記素論の術語としてしばしば用いられてきた.Lass and Laing, p. 9 に引用されている原文および英訳を掲げよう.
Littera est pars minima vocis articulatae ... littera est vox, quae scribi potest individua ... accidunt cuique littera tria, nomen figura potestas, quaeritur enim, quid vocatur littera, qua figura sit, qua possit.
Littera is the smallest unit of articulated sound ... littera is (a) sound which is capable of being written alone ... littera has three properties: name, shape, power [= sound value]. For one must ask what the littera is called, what its shape is, and what its power is.
littera は書記素 ( grapheme ) ,figura は字形(=具体的な文字の現われ),potestas は音価にそれぞれ相当すると考えられる(書記素については[2010-12-02-1]の記事を参照).例えば,「`e' という littera は <e> という figura として書かれ,その potestas は [e] である」などと表現することができる.
さて,中英語では littera と potestas の対応が理想的な1対1でなかったが,これは現代英語でも同じ状況なので驚くには当たらない.現代英語でも1対1どころか多対多の対応が常態であり,本ブログでも spelling_pronunciation_gap の各記事で取り上げてきた問題である.上記の中英語書記素論の概念と Litteral Substitution Set (LSS) や Potestatic Substitution Set (PSS) と呼ばれる記法を利用すると,次に示すように現代英語の綴字の問題にも言及できるようになる.
[2010-11-13-1]の記事で触れた「 [ɪ] に対応する綴字」を取り上げよう.him, hymn, English, busy, spinach, been, sieve, build といった語例により,[ɪ] の LSS は以下のようになる(他にもあるかもしれない).
LSS of [ɪ]: { `i', `y', `e', `u', `a', `ee', `ie', `ui' }
逆の方向で「`a' に対応する発音」を試してみると,apple, age, sofa, image, mirage, any などの語例から,`a' の PSS は以下のようになる(他にもあるかもしれない).
PSS of `a': { [æ], [eɪ], [ə], [ɪ], [ɑː], [ɛ] }
上に示した LSS や PSS は標準現代英語における規範的な綴字とRPなどの準規範的な発音との対応にすぎないことに注意したい.各種の地理的方言や非標準変種を考慮すれば異なった LSS や PSS が見られるだろう.ましてや中英語(特に初期)に遡れば,規範が不在であるからテキスト ( scribal text ) ごとに個別の書記体系があると考えなければならない.中英語の書記体系の問題は想像以上に複雑であり,だからこそ Lass and Laing が提案しているように理論化を計る必要があるのだろう.
・ Lass, Roger and Margaret Laing. "Interpreting Middle English." Chapter 2 of "A Linguistic Atlas of Early Middle English: Introduction.'' Available online at http://www.lel.ed.ac.uk/ihd/laeme1/pdf/Introchap2.pdf .
2011-02-19 Sat
■ #663. 中英語方言学における綴字と発音の関係 [lalme][laeme][me_dialect][spelling_pronunciation_gap][grammatology][graphemics][x]
初期中英語の方言地図 LAEME の機能が向上してきた.その先輩でもあり生みの親でもある後期中英語の方言地図 LALME は,綴字と発音の関係を考察する上で重要な知見をもたらしてきた.中英語における綴字の地理的分布が,発音の地理的分布と同様に方言学的な価値をもっていることを明らかにした.それまでは,綴字は発音に従属する二次的な体系であり,綴字の地理的分布が本質的に重要な価値をもっているとはみなされていなかったが,LALME は綴字を独立して観察されるべき体系として位置づけたのである.綴字を発音から解放したとでも言おうか.
中英語方言学は,1986年の LALME の登場によって意表を突かれながら,新たな段階に入ることになった.ここに一種の解放感ならぬ開放感があったことは確かである.文書でしか残されていない中英語の言語的実態,ことに発音の実態を蘇らせたいと思えば,綴字の問題に行き着いてしまう.綴字がどのくらい忠実に発音を表わしているのかは,まさに隔靴掻痒たる問題である.例えば,悪名高いものに現代英語の shall に対応する後期中英語 East Anglia 地方の綴字 xul, xal がある(この語の他の奇妙な綴字は MED を参照).この <x> の文字で表わされる音価は [ks] なのか [ʃ] なのか,あるいは別の音なのか.このような難問が立ちはだかるなかで,綴字と発音を一度切り離して考えてみよう,綴字の側だけでも独立して考察してみよう,という研究上の選択肢が与えられることとなった.
しかし,発音の呪縛からの解放感は永久に続くわけではない.LALME の出版後,(時代としてはより古いが)その続編として LAEME のプロジェクトが始まったが,プロジェクトの後半から本格的に参加した歴史形態音韻論の理論家 Lass は,綴字と発音の関係を再考して次のように述べている.
The statement in LALME (vol. 1, 6) that the maps constitute 'a dialect atlas of written Middle English', and that texts are 'treated as examples of a system of written language in its own right' is often misinterpreted. The emphasis on the independent value of written evidence was particularly apposite two decades ago, given the post-Bloomfieldian view that was current then (and to a large extent still is) that writing is of no independent linguistic interest, but merely 'parasitic on' speech. But this must not be misunderstood and taken to imply that phonological interpretation is per se unnecessary. The LALME editors take no such line. They were fully aware of the potential phonological implications of their data. LALME is rich in phonological commentary, while the series of Dot Maps (vol. 1) crucially depends on acknowledging the relationship between sound and symbol. (Lass and Laing 11--12)
これは,20年ほどの解放感の後で xul の音価は何かという悪夢のような問題に立ち返らなければならないという宣言だろうか.上の論文でなされている Lass and Laing の文字論,書記素論の考察は,初期中英語の綴字問題にとどまらず,現代英語の綴字と発音の関係にも光を与えるものであり,読み応えがある.
・ Lass, Roger and Margaret Laing. "Interpreting Middle English." Chapter 2 of "A Linguistic Atlas of Early Middle English: Introduction." Available online at http://www.lel.ed.ac.uk/ihd/laeme1/pdf/Introchap2.pdf .
・ McIntosh, Angus, M. L. Samuels, and M. Benskin. A Linguistic Atlas of Late Mediaeval English. 4 vols. Aberdeen: Aberdeen UP, 1986.
2011-02-18 Fri
■ #662. sp-, st-, sk- が無気音になる理由 [phonetics][consonant][grimms_law][sgcs][germanic][aspiration][phonotactics]
[2011-01-28-1]の記事で,現代英語で強勢のある音節の最初にくる「 s+ 無声破裂音」の子音連鎖が気息 ( aspiration ) を伴わないことを取り上げた.この特徴は現代のゲルマン諸語に共通して見られることからゲルマン祖語にさかのぼる特徴と考えられ,印欧語祖語から分化した後に生じたとされる Grimm's Law ( see [2009-08-08-1], grimms_law ) や,後に高地ゲルマン語で生じたとされる Second Germanic Consonant Shift ( see [2010-06-06-1] ) などの子音推移に関与しているのではないかという議論だった.
そもそも,英語(と他のゲルマン諸語)において s が先行すると p, t, k が無気音となるのがなぜなのか.これについて[2011-01-28-1]で生理学的な説明を加えたが,同僚の音声学者の先生に確認を取ってみたところ,説明に少々修正が必要となったので記しておく.先の説明では「気息は,破裂の開放後に遅れて呼気が漏れるという現象だが,/s/ はもともと呼気の漏れを伴っているために,その直後で呼気をいったん止め,あらためて遅らせて漏らすということがしにくい」としたが,英語の /s/ が(気息とみなされるほど強い)呼気の漏れを伴っているというのは正確な記述ではなかった./s/ 自体は aspirated ではない.ただし,同僚の先生の生理学的な説明は完全には理解できなかったものの,「 s を調音した直後の口腔内の気圧の状態が,後続する破裂音の aspiration に不利に作用する」ということは議論されているという.
一方で,この問題は必ずしも生理学的な問題ではないという議論もあるという.s に先行された無声破裂音を気息とともに調音することは決して不可能ではないし,単純に言語ごとの異音の分布の問題,音素配列論 ( phonotactics ) の問題であるという議論もあるという.生理学的な説明がどのくらい妥当であるかを判断するには広く通言語的に音素配列の分布をみる必要があるのだろう.
問題の子音連鎖がなぜ無気音となるのかはこのように未解決のままだが,グリムの法則との関連では,この問いに今すぐ究極の答えを出す必要はない.理由は分からないかもしれないが,ゲルマン祖語が他の印欧語派から分かれ,s に先行される破裂音系列は保持したものの,そうでない破裂音系列は独自の形で体系的に推移させたということは間違いないのである.
2011-02-17 Thu
■ #661. 12世紀後期イングランド人の話し言葉と書き言葉 [anglo-norman][writing][bilingualism][reestablishment_of_english][diglossia]
ノルマン征服によりイングランドの公用語が Old English から Norman French に切り替わった.イングランド内で後者は Anglo-French として発達し,Latin とともにイングランドの主要な書き言葉となった.ノルマン征服後の2世紀ほど,英語は書き言葉として皆無というわけではなかったが,ほとんどが古英語の伝統を引きずった文献の写しであり,当時の生きた中英語が文字として表わされていたわけではない.中英語の話し言葉を映し出す書き言葉としての中英語が本格的に現われてくるには,12世紀後半を待たなければならなかった.それまでは,イングランドの第1の書き言葉といえば英語ではなく,Anglo-French や Latin だったのである.
一方,ノルマン征服後のイングランドの話し言葉といえば,変わらず英語だった.フランス人である王侯貴族やその関係者は征服後しばらくはフランス語を母語として保持していたと考えられるし,イングランド人でも上流階級と接する機会のある人々は少なからずフランス語を第2言語として習得していただろう.しかし,イングランドの第1の話し言葉といえば英語に違いなかった ( see [2010-11-25-1] ) .
このように,ノルマン征服後しばらくの間は,イングランドにおける主要な話し言葉と書き言葉とは食い違っていた.12世紀後期において,イングランド人の書き手は普段は英語を話していながら,書くときには Anglo-French を用いるという切り替え術を身につけていたことになる.逆に言えば,12世紀後期までには,Anglo-French の書き手であっても主要な話し言葉は英語だった公算が大きい.Lass and Laing (3) を引用する.
By the early Middle English period, four generations after the Conquest, the high prestige languages in the written/spoken diglossia (though distantly cognate) were 'foreign': normally second and third languages, formally taught and learned. By the late 12th century it is virtually certain --- except in the case of scribes from continuingly bilingual families (and we do not have the information that would allow us to identify them) --- that none of the English scribes writing French were native speakers of French (though some may of course have been coordinate bilinguals). It is certain that none were native speakers of Latin, since after the genesis of the Romance vernaculars in the early centuries of this era it is most unlikely that there were any.
当時のイングランドの状況を日本の架空の状況に喩えてみれば,普段は日本語で話していながら,書くときには漢文を用いる(ただし中国語での会話は必ずしも得意ではないかもしれない)というような状況だろう.
12世紀後期イングランドにおける話し言葉と書き言葉の diglossia 「2言語変種使い分け」あるいは bilingualism については,Lass and Laing (p.3, fn. 3) に多くの参考文献が挙げられている.
・ Lass, Roger and Margaret Laing. "Interpreting Middle English." Chapter 2 of "A Linguistic Atlas of Early Middle English: Introduction.'' Available online at http://www.lel.ed.ac.uk/ihd/laeme1/pdf/Introchap2.pdf .
2011-02-16 Wed
■ #660. 中英語のフランス借用語の形容詞比率 [french][loan_word][adjective][statistics]
クレパン (p. 113) に次のような記述があった.
中英語では,ラテン語およびフランス語からの借用語の流入が特徴的である.フランス語の借用語は,次例にみられるように,形容詞の領分に,とくに明白なあらわれ方をしている.
able covetous gracious pertinent simple abundant coy hardy plain single active cruel hasty pliant sober actual curious honest poor solid amiable debonair horrible precious special amorous double innocent principal stable barren eager jolly probable stout blank easy large proper strange brief faint liberal pure sturdy calm feeble luxurious quaint subtle certain fierce malicious real sudden chaste final mean rude supple chief firm moist safe sure clear foreign natural sage tender common frail nice savage treacherous contrary frank obedient scarce universal courageous gay original second usual courteous gentle perfect secret
どの言語からであっても借用語彙はその大半が名詞であるという前提が染みこんでいたので,その陰で特に形容詞が顕著であるなどと借用語彙を品詞別に見る視点は欠けていた.確かに上のように例を列挙されるとそのようにも思われてくる.
ある時期にある言語から入った借用語彙全体を1としたときに品詞別の比率はどのくらいか.この観点からの研究があったかどうかすぐには思いつかなかったので,OED を用いて自分で軽く調べてみることにした.中英語期に入ったフランス借用語彙の形容詞比率がどのくらいかを調べるのが主目的だが,出された数値を解釈するためには,何らかの比較が必要である.今回は,古ノルド語の対応する比率と比べることにした.OED の Advance Search で,名詞,形容詞,動詞の主要3品詞ごとに検索することにし,"language names" にそれぞれ "French" と "ON" を,"earliest date" に "1101-1500" を入力してAND検索した.その結果を,[2011-01-05-1]の記事で紹介した「OED の検索結果から語彙を初出世紀ごとに分類する CGI」に流し込み,得た数値を品詞ごとの語数で整理し,2種類のグラフを作成した.両言語でスケールが異なっていることに注意.(数値データはこのページのHTMLソースを参照.)
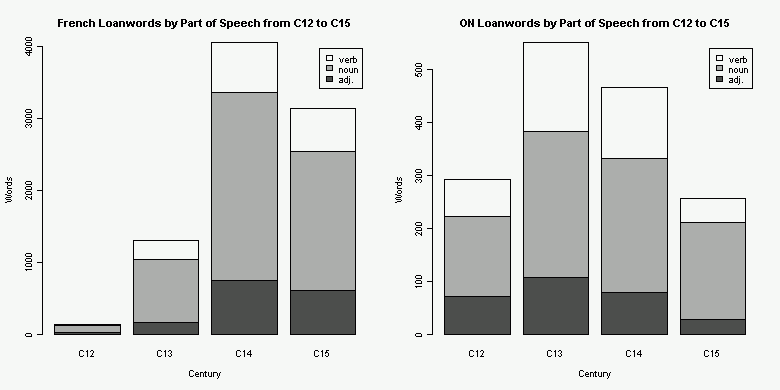
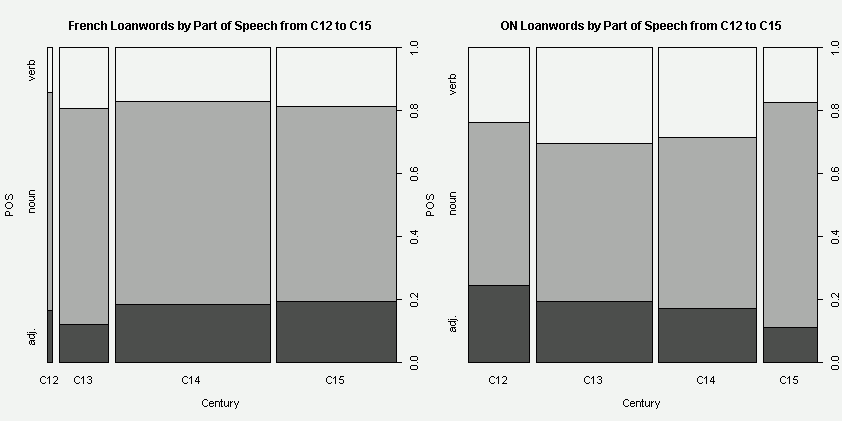
予想とはやや異なる結果が出た.前半2世紀でみたときには,形容詞比率に関しては古ノルド語のほうがフランス語よりも上回っている.一方,後半2世紀ではフランス語のほうが上回っている.両言語で借用語の最盛期が異なっていることを反映するかのように,フランス語ではおよそ上り調子,古ノルド語ではおよそ下り調子になっていることがわかるだろう.4世紀合計でみるとフランス語0.1768,古ノルド語0.1817で後者が僅差で勝っており,全体としてフランス語の形容詞が「とくに明白なあらわれ方をしている」ことは読み取れなかった.
ただし,これは荒いパイロット・スタディなので解釈には注意を要する.OED の検索には機能上の限界があり,そこから拾い出したデータには相当数の雑音が入っている.また,[2011-02-09-1]の記事で話題にしたように,ある借用語がフランス語からなのかラテン語からなのか区別がつけにくいケースも多いだろう.今回ラテン語借用語を比較対象に加えなかったのも同じ理由からである.
クレパンの「とくに明白なあらわれ方」とは,品詞別(特に対名詞)比率のことを指しているわけではないかもしれない.テキスト上での頻度が高いとか,目につく使われ方をしているとか,比率とは別の次元での顕著さのことを指しているのかもしれない.何よりも,形容詞の絶対数でいえばフランス語は古ノルド語の5倍以上もある.印象としては,Chaucer やロマンスのテキストでのフランス借用語形容詞の役割は確かに顕著だし,クレパンの指摘には首肯できる.
今後この問題を追究するのであれば,より精度の高い調査が必要だろう.手作業で借用元言語を確認し,古ノルド語だけでなくラテン語からの借用語彙も比較し,扱う時代範囲も前後に移動させる必要があろう.中英語テキストをジャンル別に検討するのもおもしろそうだ.
・ アンドレ・クレパン 著,西崎 愛子 訳 『英語史』 白水社〈文庫クセジュ〉,1980年.
2011-02-15 Tue
■ #659. 中英語 Romaunce の意味変化とジャンルとしての発展 [literature][romance][semantic_change]
[2010-11-06-1]の記事で romance という語の語源と romance という文学ジャンルの発生との関係を見た.ジャンルとしての romance は12世紀後半のフランスに始まり,英文学では13世紀終わりになってようやく現われた.フランスでもイギリスでも romans あるいは romaunce は,ジャンルとして成長するにつれ,多義的になっていった.逆にいえば語義の発展の仕方を見ることで,ジャンルとしてどのように発展していったかも分かるということである.
まずフランスではどのように捉えられたか.[2010-11-06-1]の記事で見たとおり,romans は文字通りには「ロマンス語」を原義とした.具体的にはラテン語に対する土着語 ( vernacular language ) としての古フランス語 ( Old French ) を指す.フランスの書き手たちは,Statius の Thebaid, Virgil の Aeneid, Benoît de Sainte-Maure のトロイ陥落,Wace のブリテン史など,主にラテン語で伝えられた古代の物語 ( romans d'antiquité ) を,ラテン語を解さない人々にも理解できるように romans (土着のフランス語)で書き直した.ここから,romans は「フランス語で書かれた物語」を意味するようになった.この初期の romans の書き手たちは,後にジャンルとしてのロマンスと結びつけられる種々の特徴を特に意図していたわけではなかったが,情事,登場人物の心理,奇妙で不思議な出来事といった主題に光を当てる独創性を示していたのは確かである.romans の語義がある特徴をもった物語の主題を指すようになるのは12世紀の終わり,ロマンスのジャンルを明確に切り開いた Chrétien de Troyes 辺りからと考えられる.口承法と詩形の観点からも,歌われる chançon ではなく語られる物語として,武勲詩の節 laisse ではなく8音節詩行 ( octosyllabic ) として,romans は独自性を帯びてくるようになる.こうして,フランス語の romans は,「フランス語」,「フランス語で書かれた物語」,「内容的にある特徴をもった物語」,「形式的にある特徴をもった物語」へと意味を発展させ,文学ジャンルを表わす一般呼称として徐々に定着していった.
意味変化の用語で整理すると,「言語」から「その言語で書かれたもの」への換喩 ( metonymy ) と,「その言語で書かれたもの」から「内容的にある特徴をもった物語」への意味の特殊化 ( specialisation ) が生じていることになる.
次に,イギリスにおける romaunce の語義の発展はどうだったろうか.フランスの romans 作品は,Anglo-Norman という媒体を通じて早くからイギリスにもたらされていたが,英語という媒体に乗せられるのは13世紀も終わり頃のことである.ほぼすべてがフランス語からの翻訳であったので,英語 romaunce は当初は「フランス語で書かれた物語」を広く指す意味として出発した.しかし,時間をおかずに,媒体言語ではなく主題に注目する新たな語義も派生した.媒体言語が英語であっても,ある人物に焦点を当てた物語は広く romaunce と呼ばれるようになった.ある人物の人生が描かれる際に,しばしば幻想的な脚色や色事が付加されたが,説教文学はその点を取り上げて romaunce を世俗的なものとして非難した.興味深いことに,説教文学が自らを romaunce と対立させたその観点こそが romaunce という文学を後に特徴づけることになったのである.中世(そして現代)におけるロマンス文学の世俗的な人気を考えると,皮肉なことである.こうして,英語の romaunce は「フランス語で書かれた物語」,「ある人物に焦点を当てた物語」,「内容的にある特徴をもった物語」へと語義を発展させていった.ここでも,意味の特殊化 ( specialisation ) が生じている.
・ Strohm, Paul. "The Origin and Meaning of Middle English Romaunce." Genre 10.1 (1977): 1--28.
2011-02-14 Mon
■ #658. William Jones 以前の語族観 [indo-european][family_tree][comparative_linguistics][history_of_linguistics][hebrew][jones]
[2010-02-03-1]の記事で,Sir William Jones (1746--1794) によって印欧語比較言語学の端緒が開かれたことを見た.現在では前提とされている言語間の系統的関係,究極の祖語 ( proto-language ) ,語族 ( language family ) などという概念は,Jones 以前にはあくまでおぼろげなものでしかなかった.ただし,諸言語の親言語 ( parent language ) ほどの概念であれば,限られた範囲で論じられることは中世よりあった.以下,Perret (14--15) を参照して語族観に関する前史を箇条書きで概観する.
・ 10世紀,ユダヤやアラブの文法家がヘブライ語とアラビア語の類似を指摘し,後にセミ語族と認められるものの存在を予想した.
・ 13世紀,Roger Bacon (1220?--92) が古代ギリシア語と現代ギリシア語諸方言の系統関係を,Giraud de Cambrie がケルト諸語の系統関係を,指摘した.
・ 14世紀の最初,ダンテ (1265--1321) がロマンス諸語のラテン語起源に気付いた.
・ 16,17世紀に,印刷業者 H. Estienne や 辞書編纂者 Ménage などがそれぞれフランス語のラテン語起源を確証した.
・ 16世紀終わりから,探検家たちがインドの諸言語,ギリシア語,ラテン語,さらにペルシア語,ゲルマン諸語との関係について言及し始めた.
しかし,本格的な語族の探求の素地は,世界規模での探検や植民地貿易が開始された18世紀になってようやく築かれたといってよい.このような歴史の流れを受けて,18世紀の後半,サンスクリット語を研究した Jones による歴史的な講演が行なわれたのである.
・ Perret, Michèle. Introduction à l'histoire de la langue française. 3rd ed. Paris: Colin, 2008.
2011-02-13 Sun
■ #657. "English is the least typical Indo-European language." [germanic][indo-european][drift]
昨日の記事[2011-02-12-1]でも取り上げたが,ゲルマン語派の一般的特徴を詳説した Meillet は,英語が印欧語族のなかでいかに特異な変化を遂げた言語であるかを力説している.ゲルマン諸語の歴史は印欧祖語の原型からの逸脱の歴史であり,そのなかでも英語は特に逸脱の程度が激しいという.ここしばらく Meillet の Caracteres を読んでいたが,最後の1ページに上記のゲルマン語観,英語観が凝縮されている."CONCLUSION GÉNÉRALE" を拙訳つきで引用しよう.
Le germanique commun, fait à peu près tout entier d'éléments indo-européens, et dont l'aspect est à beaucoup d'égards encore tout indo-européen, était déjà en réalité un système nouveau. En développant les innovations qu'il présentait, les dialectes en lesquels il s'est différencié ont abouti à des états de choses qui s'éloignent de plus en plus de l'indo-européen. Le groupe de tous le plus conservateur, le groupe allemand, a pourtant une grammaire tout autre que la grammaire indo-européenne et un vocabulaire pénétré de mots étrangers, de valeurs étrangères de mots. Et, là où les circonstances historiques ont hâté le développement, presque rien n'est resté du type indo-européen de la langue : en anglais, la prononciation est éminemment singulière, la grammaire est d'un type qui est le plus loin possible du type indo-européen, et le vocabulaire ne laisse presque plus apparaître que bien peu de termes anciens avec leur sens ancien. A l'indo-européen, l'anglais est lié par une continuité historique; mais il n'a presque rien gardé du fonds indo-européen. (Meillet 221)
ゲルマン祖語は,ほとんどすべて印欧語の要素からなっており,その特徴は多くの点でいまだに印欧語的であったが,実際上はすでに新しい体系であった.ゲルマン祖語から分化した諸方言は,祖語が示していた革新を発展させながら,ますます印欧祖語から乖離された状態に到達した.そのなかで最も保守的な語群であるドイツ語群ですら,印欧祖語文法とはまったく異なる文法をもっており,外国語単語と外国語の語義に満たされた語彙をもっている.そして,歴史的な状況によりその発展が促進された言語では,印欧語タイプの特徴はほとんど残されていないのである.現に英語では,発音は著しく独特であり,文法は印欧語タイプから可能な限りかけ離れており,語彙は古い意味をもった古い語をほんの僅かばかり表わすにすぎない.英語は歴史的継続性によって確かに印欧祖語に結び付いている.しかし,英語は印欧祖語の本質をほとんど何も保っていないのである.
・ Meillet, A. Caracteres generaux des langues germaniques. 2nd ed. Paris: Hachette, 1922.
2011-02-12 Sat
■ #656. "English is the most drifty Indo-European language." [germanic][indo-european][drift][inflection][synthesis_to_analysis]
英語の文法史において,屈折の衰退の過程は最も大きな話題と言ってよいかもしれない.古英語後期から初期中英語にかけて生じた屈折の衰退により,英語は総合的な言語 ( synthetic language ) から分析的な言語 ( analytic language ) へと大きく舵を切ることになった.
英語以外のゲルマン諸語でも程度の差はあれ同じ傾向は見られ,これはしばしば drift 「漂流,偏流」と呼ばれる.いや,実は drift は印欧諸語全体に広く観察される大きな潮流であり,ゲルマン諸語に限定されるべき話題ではない.とはいえ,ゲルマン諸語でとりわけ顕著に drift が観察されることは事実である.そして,そのゲルマン諸語のなかでも,英語が最も顕著に drift の効果が見られるのである.
英語が "the most drifty Indo-European language" であることを示すには,本来は現存する印欧諸語のそれぞれについてどの程度 drift が進行しているのかを調査するという作業が必要だろうが,そうもいかないので今回は権威を引き合いに出して済ませておきたい.
La tendance à remplacer la flexion par l'ordre des mots et par des mots accessoires est chose universelle en indo-européen. Nulle part elle ne se manifeste plus fortement que dans les langues germaniques, bien que le germanique conserve encore un aspect alchaique. Nulle part elle n'a abouti plus complètement qu'elle n'a fait en anglais. L'anglais représente le terme extrême d'un développement: il offre un type linguistique différent du type indo-européen commun et n'a presque rien gardé de la morphologie indo-européenne. (Meillet 191--92)
屈折を語順や付随語で置きかえる傾向は,印欧語では普遍的なことである.ゲルマン祖語はいまだに古風な特徴を保持しているとはいえ,ゲルマン諸語以上に激しくその傾向の見られる言語はなく,英語以上に完全にその傾向が成功した言語はないのだ.英語はある発達の究極の終着点を示している.英語は印欧祖語の型とは異なった言語の型を提示しているのであり,印欧語的な形態論をほとんど保っていないのだ.
「付随語」と拙訳した des mots accessoires は,Meillet によれば,古英語 ge- などの動詞接頭辞,北欧語の -sk のような再帰代名詞的な動詞につく接尾辞,指示詞から発達した冠詞といった小辞を指す.
噂と違わず,現代英語は印欧語として相当の異端児であることは確かなようである.もっとも,ピジン英語 ( see [2010-08-03-1] ) などを含めれば,英語よりもさらに漂流的な言語はあるだろう.
・ Meillet, A. Caracteres generaux des langues germaniques. 2nd ed. Paris: Hachette, 1922.
2011-02-11 Fri
■ #655. 屈折の衰退=語根の焦点化 [conversion][drift][germanic][inflection]
近代英語以来の語形成の特徴として品詞転換 ( conversion ) が盛んであるということがある.品詞転換については[2009-11-03-1], [2009-11-01-1]の記事などで述べたが,これが形態的に可能となったのは,後期古英語から初期中英語にかけて起こった語尾の水平化とそれに続く消失ゆえである.古英語では,名詞や動詞は主に統語意味的な機能に応じて区別される特定の屈折語尾をとったが,屈折語尾の音声上の摩耗が進むにつれ,語類の区別がつけられなくなった.屈折語尾の衰退は,程度の差はあれ,第1音節にアクセントをおく特徴をもつゲルマン諸語に共通の現象である ( see [2009-10-26-1] (4) ) .
英語における品詞転換の発生は,上記のようにゲルマン諸語に共通する屈折語尾の衰退,いわゆる漂流 ( drift ) の延長線上にあるとして説明されることが多い.これは音韻形態的な説明といえるだろう.もう1つの説明としては,[2010-01-16-1]の記事で触れたように,語順規則の確立と関連づけるものがある.中英語以降,語順がおよそ定まったことにより,例えば動詞と名詞の区別は形態によらずとも語順によってつけることができるようになった.このことが品詞転換の発生に好意的に作用したとする説明がある.これは,統語的な説明といえる.
あまり指摘されたことはないように思われるが,もう1つ,意味的な説明があり得る.説明の出発点は,再びゲルマン諸語に共通する先述の drift である.ゲルマン諸語における drift の重要性は屈折の衰退にあると解釈されることが多いが,その裏返しとして同じくらい重要なのは,語彙的意味を担う語根に焦点が当てられることになったという点である.これによって,例えば love は,文中での統語的役割は何か,語類は何かであるかなどの可変の情報を標示する負担から解放され,「愛」という語彙的意味を標示することに集中することができるようになった.love という形態は「愛」という根源的主題を表わすのに特化した形態であり,それが文中で名詞として「愛」として用いられるのか,動詞として「愛する」として用いられているのかは,副次的な問題でしかない.いずれの品詞かは統語が決定してくれる.屈折の衰退という音韻形態的な過程には,語根の焦点化という意味論的な含蓄が付随していたということは注目に値するだろう.
Le développement grammatical du germanique est donc commandé par deux grands faits: l'intensité initiale a donné aux radicaux une importance nouvelle, la dégradation des finales a tendu à ruiner la flexion, et l'a en effet ruinée dans des langues comme l'anglais et le danois. (Meillet 100)
したがって,ゲルマン語の文法の発達は2つの重要な事実に支配されている.1つは語頭の強勢が語根に新たな重要性を与えたということであり,もう1つは語尾の衰退が屈折を崩壊させがちであり,実際に英語やデンマーク語などの言語では崩壊させてしまったということである.
・ Meillet, A. Caracteres generaux des langues germaniques. 2nd ed. Paris: Hachette, 1922.
2011-02-10 Thu
■ #654. ヨーロッパのライバル辞書と比べた OED の特徴 [oed][lexicography][ghost_word]
[2011-01-31-1]の記事で参照した Osselton の論文の pp. 72--75 から,歴史的原則に則ったヨーロッパのライバル辞書3点 ( DWB, Littré, WNT ) と比較した OED の特徴について箇条書きする.
(1) 借用語 ( loanwords ), 臨時語 ( nonce-words ), 幽霊語 ( ghost words ) などを一貫して寛容に採用している.DWB と WNT は,初期には借用語について不寛容だった.
(2) 同義語 ( synonyms ) を援用した定義や,collocation pattern への言及が,他の辞書に比べて弱い.
(3) 多義語の語義配列は,論理と時系列を折衷したバランスの取れた順番となっている.
(4) 語法についてのコメントは最も記述的である.他の辞書はいずれも規範的・権威的である.
(5) OED は編纂時期が長かったにもかかわらず,短期間でほぼ独力で作業した Littré と比べられるほどに,アルファベット全体にわたって記述が一貫している.
(6) 1150年より前に廃語となった語彙を除くが,古英語から現代英語までにわたる最長の時間幅から語彙と引用例を収集している.DWB は1550年ほどの Luther から19世紀前半の Goethe まで(19世紀の扱いは弱い),Littré は1600年から,WNT は1500年から(当初は1637年の欽定訳聖書から)である.
(7) 綴字の歴史的異形を一貫して一覧している.(例えば,neighbour に429通りの綴字の可能性があることが示唆される.)
(8) 引用例が簡潔であり,かつ年代が明記されている.DWB と WNT は,引用例への年代付与は後の巻のみである.
上記の点の多くは OED の特徴というよりは特長というべきかもしれない.Osselton の論文には OED 贔屓の視点が幾分あるだろうし,他の辞書の特長も挙げて比較しなければ不公平だろう.しかし,上記の OED の多くの特徴は言語史研究にとって確かに必要不可欠な要素である.特に (1), (4), (6), (7), (8) などは,他の言語の歴史家にとって喉から手が出るほど欲しい特徴ではないだろうか.
・ Osselton, Noel. "Murray and his European Counterparts." Lexicography and the OED : Pioneers in the Untrodden Forest. Ed. Lynda Mugglestone. Oxford: OUP, 2000. 59--76.
2011-02-09 Wed
■ #653. 中英語におけるフランス借用語とラテン借用語の区別 [etymological_respelling][history_of_french][french][latin][loan_word][etymology]
中英語期のフランス語借用については,本ブログでも[2009-08-22-1]の記事を始めとして様々な形で触れてきた.同じく,中英語期のラテン語借用についても[2009-08-25-1]の記事で扱った.さらに,現代英語語彙に占める両言語からの借用語の比率が高いことは,[2010-06-30-1], [2009-11-14-1], [2009-08-15-1]で話題にした.フランス語とラテン語の借用は英語史ではよく取りあげられるトピックであり,借用語の数が問題になる場合に「フランス・ラテン借用語」として合わせて数えられることも多い.確かにフランス語とラテン語はロマンス語群のなかで親子関係にある言語どうしではあるが,一応は別々の言語として区別がつけられるはずである.それにもかかわらず,合わせて扱われることが多いのはなぜだろうか.
1つには,予想されるとおり,中英語期に相当する時代では,フランス語はいまだラテン語から別れて久しくなかったということがある.確かに種々の音声変化によってフランス語はラテン語から区別されるようになっていたが,両言語の形態はいまだに似通っていることが多かった.さらに,中世イングランドと同様に,中世フランスではフランス語と並んでラテン語も書き言葉として用いられていたので,両言語の形態がなまじ似ている分,その混用も頻繁だったのである.英語では中英語後期から近代英語初期にかけてラテン語源かぶれの綴字 ( see etymological_respelling ) が増したが,同じ傾向がフランスでは早く13世紀後半から現われていた.既存のフランス語をラテン語形に近づける方向へ少しだけ変化させたのである.その新しい語形は,従来のフランス語でもないし厳密なラテン語でもない中途半端な語形となり,いずれかに分類するのは困難であり,無意味でもあるということになる(バケ,pp. 72--73).
ホームズとシュッツ (pp. 78--80) を参考に,フランス語とラテン語の混用の状況を概観しておこう.聖王ルイと呼ばれたルイ9世 (Louis IX; 1214--70) は,1260年頃から法律制度改革に乗り出していた.改革の主眼は証言を文書で提出することを許可にした点にあり,これにより代理人としての職業的法律家が台頭してくることになった.法律家たちはそれぞれ書記を雇っており,その書記たちは basoche と呼ばれる組織を構成し,フランス語の綴字に大きな影響を及ぼす集団となった.当時,告訴状はフランス語で書かれたが,法令はぞんざいなラテン語で書かれており,法曹界は2言語制で回っていた.この状況は,フランソワ1世 (Francis I; 1494--1547) が法廷でのラテン語使用をヴィレ・コトレ ( Villers-Cotterêts ) で廃止した1539年まで続いた.このような時代背景で,書記たちはなにがしかのラテン語の教養を身につけている必要があったわけだが,その教養とて大したものではなく,フランス語とラテン語の綴字が混用されるのが常だった.フランス語の dit 「上述の,くだんの」がラテン語風に dict と綴られたり,doit 「指」もラテン語 digitus の影響で doigt と綴られたりした.
一方で,14世紀にはシャルル5世 (1338--80) の学芸奨励によりラテン語が重んじられた.実際,14--15世紀にわたる中世フランス語後期の借用語の半数以上がラテン語からのものとされる.それに加えて,既存のフランス語単語をラテン語の形に近づけた etymological respelling の例も少なからずあった.delitier を delecter などとする例である ( see [2010-02-04-1] ) .
以上が,中英語期に大量に英語に流入した Latin, Latinised French, and French loanwords を別々に扱うのではなく「フランス・ラテン借用語」として一緒くたに扱うのが妥当である理由だ.ラテン語に基づく etymological respelling は英語だけでなくフランス語でも起こっていたこと,後者ではラテン語となまじ似ているがゆえの語形の混用も大いに絡んでいたことに注意する必要がある.
・ ポール・バケ 著,森本 英夫・大泉 昭夫 訳 『英語の語彙』 白水社〈文庫クセジュ〉,1976年.
・ U. T. ホームズ,A. H. シュッツ 著,松原 秀一 訳 『フランス語の歴史』 大修館,1974年.
2011-02-08 Tue
■ #652. コーカサス諸語 [caucasian][language_family][map]
[2011-02-05-1], [2011-02-06-1]の記事でアルメニア語 ( Armenian ) と,そのグリムの法則への含蓄を話題にした.アルメニア語に基層言語として影響を与えたと推測される南コーカサス諸語 ( the Southern Caucasian languages ) は,より広範なコーカサス諸語 ( the Caucasian languages ) の1部である.コーカサス諸語は,周囲に分布するインドヨーロッパ語族の言語やチュルク語派の言語から区別される独特な言語特徴をもつ40言語ほどの言語群で,19世紀始めに宣教師や民族学者たちの記録により知られるようになって以来,言語学者に注目されてきた.
コーカサス諸語とは純粋に地理的な呼称であり,互いに系統的な関係にあるとは限らない.主要な語族としては,南コーカサス語族を構成するカルトゥヴェリ語族 ( Kartvelian ),北コーカサス語族を構成する北西グループのアブハズ・アディゲ語族 ( Abkhazo-Adyghian ) ,北東グループのナフ・ダゲスタン語族 ( Nakho-Dagestanian ) の3つがある.以下は,Caucasian languages -- Britannica Online Encyclopedia からのコーカサス諸語の分布地図である.
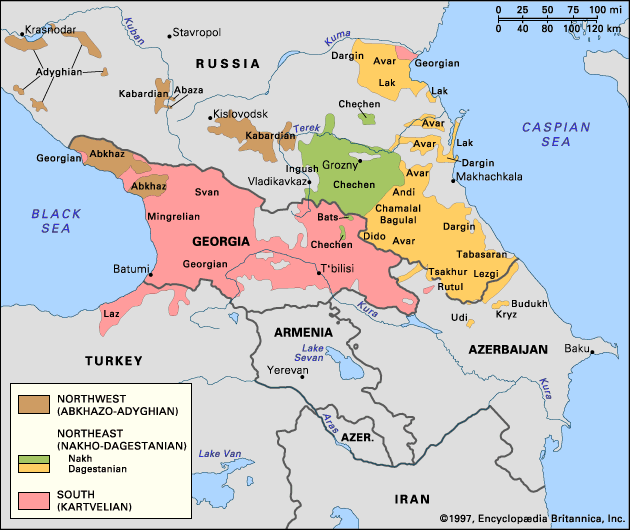
上記3語族の関係についてはよく分かっていないことが多いが,北コーカサス語族の北西と北東の語派は互いに緩い系統関係を示すという.一方で,北コーカサス語属と南コーカサス語族は互いに独立しているとするのが現在の有力な見方である.『新訂世界言語文化図鑑』 (p. 51) から諸言語の関係をまとめたのが下図である.
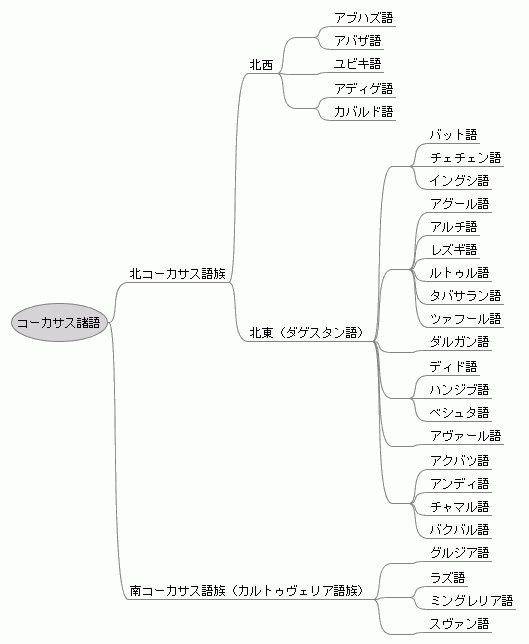
ちなみに,以下の系統図に示した壮大なデネ・コーカサス仮説 ( the Dene-Caucasian hypothesis ) によると,北コーカサス語族とシナ・チベット語族 ( Sino-Tibetan ) および北米のナ・デネ語族 ( Na-Dene ) とは遠くつながっているとされる.少なくともナ・デネ語族とエニセイ語族 ( Yeniseian ) の間には堅固な文法・語彙上の対応が見られると言われるが,この大胆な仮説には大いに議論の余地がある.

・ バーナード・コムリー,スティーヴン・マシューズ,マリア・ポリンスキー 編,片田 房 訳 『新訂世界言語文化図鑑』 東洋書林,2005年.
2011-02-07 Mon
■ #651. 公文書の原文を巧みに扱う外交官 [etymology][greek][semantic_change]
diploma 「免状,資格免許状;卒業証書,学位記」と diplomacy 「外交」の間に形態的関連を見て取ることはたやすいが,意味的関連を想像することは難しい.diploma 関連語は,意味の共時的・通時的な広がりを味わわせる好例である.語源からひもといてみよう.
英語の diploma はギリシア語 díplōma からラテン語 diplōma を経て17世紀に「公文書;免許状,学位免状」として英語に入ってきた.ギリシア語 díplōma は,di- 「2つの」+ ploûn 「たたむ」と分析され,「二つ折り(の紙)」を意味した.免状は二つ折りにした紙や羊皮紙として授与されたために,免状やその他の公文書が diploma と呼ばれることになった.
diploma から派生した形容詞 diplomatic は「公文書の」を原義としていたが,そこから「原文のままの」「文献上の」の語義を発展させた ( ex. diplomatic copy, diplomatic edition ) .一方で,diploma 「公文書」が主に「外交文書」を指すようになり,18世紀終わりから diplomatic が「外交(文書)の」の語義を帯びてくる.そこから,「外交」を意味する diplomacy や「外交文書を発行する人(=外交官)」を意味する diplomat が生まれた.最後に,19世紀に diplomatic の第3の語義「外交的な,人使いの巧みな,如才ない」が発展した.
ギリシア語 di- + ploûn に対応するラテン語の形態素からは double 「二倍の」, duple 「二重の」, duplex 「二連の」, duplicate 「倍にする」, duplicity 「二面性;不誠実」などが派生し,英語に入ってきている.
2011-02-06 Sun
■ #650. アルメニア語とグリムの法則 [grimms_law][substratum_theory][armenian][gender]
昨日の記事[2011-02-05-1]で比較的影の薄い印欧語であるアルメニア語 ( Armenian ) を取り上げたが,この言語は英語史(ゲルマン語史)研究にある重要な示唆を与えてくれる.それは,ゲルマン語史上に名高いグリムの法則 ( Grimm's Law ) という音韻変化に関する問題である ( see [2009-08-08-1], grimms_law ) .
グリムの法則は,印欧祖語の3系列の閉鎖音がゲルマン諸語でそれぞれ無気音化,無声音化,摩擦音化した一連の音韻変化を指す.これは,[2009-10-26-1]の記事の (5) で見たように,ゲルマン諸語にみられる顕著な特徴の1つである.この音韻変化は歴史時代以前に生じたため,なぜ,どのように生じたかについては文献の証拠に基づいて考察することはできない.ゲルマン諸語の最も重要な特徴について憶測しかできないというこの状況は非常にもどかしいものだが,この問題に一条の光を投げかける意外な言語がある.それがアルメニア語だ.
アルメニア語では,ゲルマン語派に生じたグリムの法則とほぼ同じ音韻変化が歴史時代に生じた.例えば,印欧祖語の閉鎖音を保存している Sanskrit や Latin の語形と比べると Arm. berem / Skr. bhárāmi "I bear", Arm. kin / Skr. gn![]() "woman", Arm. khan / Latin quam "what" などである.時間的にも空間的にも両方の音韻変化のあいだに因果関係はなく,あくまで独立して生じたと考えなければならないが,アルメニア語の変化はゲルマン語の変化よりも状況証拠が揃っているので,後者の解明にもヒントを与えてくれるのではないかと期待されるのである.
"woman", Arm. khan / Latin quam "what" などである.時間的にも空間的にも両方の音韻変化のあいだに因果関係はなく,あくまで独立して生じたと考えなければならないが,アルメニア語の変化はゲルマン語の変化よりも状況証拠が揃っているので,後者の解明にもヒントを与えてくれるのではないかと期待されるのである.
アルメニア語の周囲の言語を観察すると,閉鎖音の系列が,印欧祖語の系列ではなく,音韻変化後に得られる系列に似通っている.つまり,アルメニア語はコーカサス地方の諸言語から音韻的な影響を受け,印欧風の音韻体系からコーカサス風の音韻体系へと推移したのではないか.より具体的には,アルメニア語話者によって征服されたコーカサス先住民がもとの言語の音韻体系を引きずったままアルメニア語に乗り換えたのではないか.これは,[2010-06-17-1]や[2011-01-24-1]の記事でも触れた基層言語影響説 ( substratum theory ) と呼ばれる仮説である.これ自体は推測でしかないものの,仮定されている基層言語が当時だけでなく現在でもコーカサス地方に確認できるという点が重要である.
一方,ゲルマン語派に生じたグリムの法則についても substratum theory は提案されているものの,こちらは基層言語と仮定される言語が現在は周囲に存在しない.あくまで弱い仮説である.しかし,比較される音韻変化が時間も空間も隔たったアルメニア語で生じており,そこでの仮説はもう少し基盤の強い仮説だということになれば,グリムの法則についての基層言語影響説にも勢いがつくというものである.Meillet は次のように述べている.
Quant à l'Arménie, l'introduction d'un parler indo-européen s'y est produite à date historique; et, d'autre part, le système des occlusives arméniennes, qui est tout à fait particulier, est identique à celui d'un groupe de langues voisines, de famille autre, le groupe caucasique du Sud, dont le représentant le plus connu est le géorgien. L'action étrangère, que la théorie seule fait supposer pour le germanique, est donc indiquée par des faits positifs pour l'arménien. On conclura de là que la mutation consonantique du germanique est due au maintien de leurs habitudes d'articulation par les populations qui ont reçu et adopté le dialecte indo-européen appelé à devenir le germanique. (40--41)
アルメニアについていえば,印欧語の一方言がもたらされたのは歴史時代のことである.その上,アルメニア語の閉鎖音の体系は,完全に独自ではあるが,別の語族に属する近隣語群の体系,最もよく知られた代表言語としてグルジア語を挙げることができる南コーカサス諸語の体系と同一である.したがって,ゲルマン語については理論的な仮定にとどまらざるを得ない外国語の影響が,アルメニア語については積極的な事実によって示唆されるのである.ここから次のように結論づけることができる.ゲルマン語の子音推移は,ゲルマン語と呼ばれることになる印欧語一方言を受け入れて取り込んだ人々が自らの発音習慣を保持したことに起因するのだ,と.
・ Meillet, A. Caracteres generaux des langues germaniques. 2nd ed. Paris: Hachette, 1922.
2011-02-05 Sat
■ #649. アルメニア語 [armenian][indo-european][map][indo-european_sub-family]
印欧諸語のなかでもアルメニア語 ( Armenian ) は影が薄い.印欧語系統図 ( see [2009-06-17-1], [2010-07-26-1] ) で1つの独立した語派を形成していながら類縁関係のある言語が他にないというのがその理由だろう.(1875年に独立した語派として認められるまでは,イラン語群に区分されていた.)
アルメニア語はコーカサス山脈 ( the Caucasus Mountains ) の南に位置するアルメニア共和国( the Republic of Armenia; 1991年独立)の公用語である.コーカサス山脈地帯,トルコ東部,ロシア南部などで有史以前の前8世紀頃より話されていたとされる.現存する最古の文献は5世紀に古典アルメニア語で訳された聖書である(アルメニアは,紀元300年頃,正式にキリスト教を受け入れた世界最初の国である).現在は東西2方言に分かれており,東方言が主流をなす.話者人口は約670万人で,アルメニア国内にその過半数がいる.
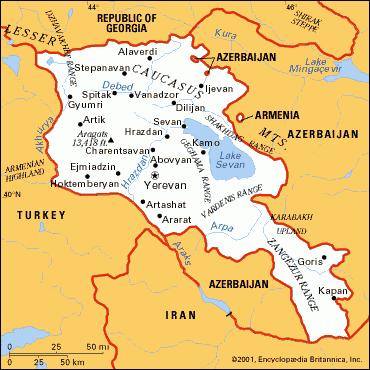
様々な民族に征服されてきたため諸言語からの影響が強く,語彙ではトルコ語,セミ諸語,ギリシア語,そして特にペルシア語からの借用語を多く取り込んでいる.また,非印欧語族であるコーカサス諸語に囲まれているために,これらの言語から文法や音韻への強い影響が認められる.例えば,アルメニア語は現代英語と同様に印欧諸語には珍しく文法性 ( grammatical gender ) を欠いているが ( see [2010-08-27-1] ) ,これは文法性をもたない南コーカサス諸語の影響と考えられている (Baugh and Cable 24--25) (格については7格が残存しているので,文法性の消失を,英語史にみられるような一般的な屈折の衰退の一環として説明するのは難しい).
類縁の言語がないと上述したが,実は,小アジア中部・北西部にわたっていた古代王国フリギア ( Phrygia; 前11世紀頃から) で話されていたフリギア語 ( Phrygian ) との関係が,少ない証拠から示唆されている.
印欧語族の遠い親戚であるという点を除けば,アルメニア語と英語に接点はほとんどない(ただし heathen の語源にアルメニア語が関係しているという説がある).しかし,アルメニア語は,英語史(より正確にはゲルマン語史)上のある大きな変化を解明するのに非常に重要な示唆を与えてくれる.それについては明日の記事で.
アルメニア(語)については,以下の記事を参照.
・ Ethnologue report for Armenian
・ Armenia -- Britannica Online Encyclopedia
・ Armenia -- CIA: The World Factbook
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
2011-02-04 Fri
■ #648. 古英語の語彙と廃語 [oe][lexicology][word_formation][thesaurus][synonym]
古英語の語彙が現代までにどれだけ残存しているか,どれだけ消失したかについては[2010-07-21-1]の記事で話題にした.古英語語彙の大規模な消失は,英語が中英語期以降にフランス語を始めとする様々な外国語から語彙的な影響を受け,多くの本来語が借用語で置き換えられるに至ったとして説明されることが多いが,消失傾向を促進するある特徴が古英語語彙体系に内在していたと考えることもできるかもしれない.バケから,古英語語彙の消失について述べている箇所を引用しよう.
もう一つの消失の原因は,疑いもなく,同じ概念系統の語形の中に存在していた封建的関係である.ある語が消失していく度に,語群全体がそれとともに分解してきた.これは情熱を抱くに足る研究であり,ぜひとも奨励しておきたい.古期英語の実詞 þeod 「国民,種族」およびその複合語あるいは派生語は,発生的に þeoden 「首長,王子,王」および( geþeode 「(話し)ことば」と結びついていたが,それらの政治・文化上のすべての親族関係語とともに消えてしまった.Wer 「男,英雄,亭主」および werod 「大勢,軍団」についても同様である.この点について,古期英語辞典を引くこと以上に示唆を得るものはない.ある用語が衰えると語彙面全体が崩れ落ちてしまう.その原因は多様で,しばしば社会学的であったり,政治的であったりする.(22)
þeod は古英語では高頻度語かつ基本語であり,これに基づいた複合語や派生語が数多く存在した.þeod を中心とした関連語彙が,古英語話者の「国」観,「民族」観,ひいては世界観を表現していたといっても過言ではない.しかし,þeod という語自体が何らかの事情で徐々に衰退し,ついには消失してしまうと,独特な世界観を構成していた扇の要が壊れてしまうことになり,関連語彙もその存在基盤を失うことになる.はたして,þeod の世界観全体が忘れられることになるのである.皮肉なことに,古英語の語形成は基底となる語を元にした複合 ( composition ) と派生 ( derivation ) によって特徴づけられるために,基底語が消失してしまうと関連語彙も総崩れとなりがちだということである.
バケが基底語(主)と関連語彙(従)との関係を「封建的関係」と呼んでいるのは興味深い.君主が崩れることによって家臣すべてが総崩れとなり,封建制(=世界観)そのものが機能しなくなるという巧みな比喩が,この表現に隠されている.
基底となる þeod が消失した原因は様々だろうが,1つには次々に現われてきた類義語からの圧力が作用したと思われる.Historical Thesaurus of the Oxford English Dictionary によると,þeod の類義語は "the external world > the living world > people > people > [noun]" の項に見つけることができる.18語の歴史的類義語を初出年とともに提示しよう.
| word | first year |
|---|---|
| thede | 855 |
| folk | c888 |
| lede | 971 |
| mannish | OE |
| birth | a1300 |
| nation | c1330 |
| people | a1375 |
| tongue | 1382 |
| race | 1572 |
| family | 1582 |
| the mass | 1621 |
| public | 1709 |
| nationality | 1832 |
| peoplet | 1872 |
| peoplehood | 1879 |
| La Raza | 1927 |
| ethnic minority (group) | 1945 |
| ethnogenesis | 1962 |
þeod という語の消失は,実際には徐々に進行しており,1400年くらいまでは使用されていた.上の表を眺めると,þeod は突如消えたわけではなく,中英語期に他の類義語とのせめぎ合いのなかで徐々に忘れられていったというシナリオが描けそうである.
・ ポール・バケ 著,森本 英夫・大泉 昭夫 訳 『英語の語彙』 白水社〈文庫クセジュ〉,1976年.
2011-02-03 Thu
■ #647. million 以上の大きな単位 [numeral][bre][blend]
昨日の記事[2011-02-02-1]で,billion 以上の単位の表わす値が現代英語と古風なイギリス英語の間で食い違っており,使用には注意を要することについて述べた.billion を話題にしたついでに,million 以上の大きな単位の英語表現について表でまとめてみた.
million の -on はフランス語の増大辞 ( augmentative ) で,「大きな mille (千)」の意である ( see [2009-08-30-1] ) .それより大きい単位では,million から -(i)llion が切り出され,それにラテン語の数詞接頭辞が前置されるという語形成になっている.ただし,-(i)llion が生産的な形態素として切り出されたと解釈するのではなく,bi- + million が縮約された一種のblend 「混成語」であるという解釈もありうる ( see [2011-01-18-1] ) .
| AmE and BrE | old-fashioned BrE | 日本語 | |
|---|---|---|---|
| million | 106 | million | 百万 |
| billion | 109 | milliard | ?????? |
| trillion | 1012 | billion | 一兆 |
| quadrillion | 1015 | ?????? | |
| quintillion | 1018 | trillion | 百京 |
| sextillion | 1021 | ?????? | |
| septillion | 1024 | quadrillion | 一 |
| octillion | 1027 | 千 | |
| nonillion | 1030 | quintillion | 百穰 |
| decillion | 1033 | 十溝 | |
| undecillion | 1036 | sextillion | 一澗 |
| duodecillion | 1039 | 千澗 | |
| tredecillion | 1042 | septillion | 百正 |
| quattuordecillion | 1045 | 十載 | |
| quindecillion | 1048 | octillion | 一極 |
| sexdecillion | 1051 | 千極 | |
| septendecillion | 1054 | nonillion | 百恒河沙 |
| octodecillion | 1057 | 十阿僧祇 | |
| novemdecillion | 1060 | decillion | 一那由他 |
| vigintillion | 1063 | 千那由他 | |
| 1069 | undecillion | 十無量大数 | |
| 1072 | duodecillion | ||
| 1078 | tredecillion | ||
| 1084 | quattuordecillion | ||
| 1090 | quindecillion | ||
| 1096 | sexdecillion | ||
| 10102 | septendecillion | ||
| 10108 | octodecillion | ||
| 10114 | novemdecillion | ||
| 10120 | vigintillion | ||
| centillion | 10303 | ||
| 10600 | centillion |
2011-02-02 Wed
■ #646. billion の値 [numeral][bre]
どの言語でも,数詞や数詞を含む句は頻度が高く,発音や語法において不規則であることが多い.日本語では「ひとり」「ふたり」に対して「さんにん」,「しちじ」(七時)に対して「ななかい」(七階),「ようか」(八日)や「はたち」(二十歳)など,例は尽きない.
英語での形態的な問題を指摘すると,通常 hundred, thousand, million は two hundred, three thousand, four million のように -s のつかない単複同形だが,概数表現としては hundreds of students, thousands of fans, millions of years のように -s を伴う.
さて,million の上の単位である billion も上記のように振る舞うが,こちらは指す値に注意する必要がある.billion は一般的には「10億」 ( = one thousand million ) を意味するが,古風なイギリス英語では「1兆」 ( = one million million ) を意味した.同様に,次の単位である trillion は一般的には「1兆」だが,古風なイギリス英語では「100京」である.さらに上の単位である quadrillion, quintillion などでも,現代英語と古風なイギリス英語の指示する値に差が見られる.つまるところ,現代語法では「100万」を基準として次々に1000倍してゆく計算であるのに対して,古風なイギリス語法では「100万」のべき乗で計算するということである.
billion = 「1兆」の対応関係は古風なイギリス語法であるとはいっても,20世紀半ばまで実際に用いられていたので注意を要する.billion は17世紀の終わりころにフランス語から借用された.フランス語の原義は100万の2乗を表わす「1兆」であり,それが英語やドイツ語に入った.ところが,後にフランスやアメリカは3桁ずつ数字を区切る慣習を発達させ,100万の1000倍を表わす「10億」の意味を採用することになる.ここに「英独1兆」対「米仏10億」という対立が生じることになった.しかし,話しはここで終わらない.イギリス英語は20世紀半ばからアメリカ式の「10億」の意味を一般化させ,フランス語は1949年以降もとの「1兆」に回帰した.このような複雑な過程を経て,現在は「英米10億」対「仏独1兆」という図式に落ち着いている.
イギリス英語では,上記のように比較的近年まで billion が「1兆」を指していたこともあり,現在でも意味の曖昧さを排除すべき文脈では billion の使用は避けるべきともされる.Quirk et al. (6.63n [p. 394]) の説明を引用する.
One thousand million (1,000,000,000) is called one billion in the American system of numeration. In the UK, billion has traditionally been used for 1,000,000,000,000 (1012), corresponding to one trillion in the US. However, the American usage where billion = 109 is now often used also in the UK by people who are ignorant of the double meaning of the word. It is not used by scientists, engineers, and mathematicians according to the British Standards Institution, which recommends that the use of billion, together with the equally ambiguous trillion (1012 or 1015) and quadrillion (1015 or 1018), should be avoided.
引用の最後の "together with . . ." 句は,現代英語語法と古風なイギリス語法との対比という文脈ということであれば,"together with the equally ambiguous trillion (1012 or 1018) and quadrillion (1015 or 1024)" (赤字引用者)となるべきところではないだろうか.
・ Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech, and Jan Svartvik. A Comprehensive Grammar of the English Language. London: Longman, 1985.
2011-02-01 Tue
■ #645. 死語と廃語 [language_death][lexicology]
日本語の「死語」は,英語でいう "dead language" と "obsolete word" の2つの語義を兼ねる.『明鏡国語辞典』によると,
(1) 昔は使われていたが,現在では使用されていない言語.古代ギリシア語・ヒッタイト語など.
(2) 昔は使われていたが,現在,一般には使用されなくなった語.廃語.
以下,この記事では (1) を「死語」,(2) を「廃語」と呼び分けることにする.死語については,このブログでも language_death の各記事で取り上げてきた.ある言語が死滅するという場合には,生物種の絶滅と同様に,センチメンタルな感情が伴うものである(と信じたい).言語にはその話者共同体の思想,文化,歴史が詰まっており,言語が消滅するということは(記録が残されていない限り)その知的遺産が永遠に失われるということである.言語の死は人類にとっての損失である.
一方,廃語についてはブログで明示的に話題にしたことはあまりなかった.言語の死に比べれば,単語レベルの消滅は通常センチメンタルな現象とはとらえられないだろう.言語そのものが消滅するわけではなく,小さな断片が失われるだけなので,至極当然かもしれない.しかし,単語にも言語共同体の思想,文化,歴史が凝縮されているのであり,その消滅は,取り戻すことの難しい知的遺産の消滅であると考えることができる.話題性の大小はあるものの,豊かな言語的感受性をもってすれば,死語も廃語も質的には同等の損失なのかもしれない.
このように思ったのは,豊かな言語的感受性を示すポール・バケの文章に出会ったからである.バケは,語の消失や語義の変化について次のように評している.
しかし消失の過程の期間がどうであれ,語の死滅は決定的と言わぬまでも現実のものであり,その死なるものが人間や文明に訪れるときと同じように,ここでも人の心を打つのである.この死とともに,ある世界全体が,あるいは文化的,感情的,概念的存在の一断片が姿を消していくのである.たとえある別の1語あるいは数語が遺棄された土地を引き受け,失われた語の意味領域を取戻すことがあるにせよ.たとえ意義の上から実際には何も失われていないにせよ,文脈はもはや同一ではなく,意味の移行がなされるのは数年のうちのことでしかない.それ故,すべてが変貌し,そして人々が変わり,世代もまた代わって,語の意味は,このしばしば無意識であるとはいえ,たゆみなき進化の影響を受けるのである.(16--17)
語の消失や語義の変化にいちいち感傷的になっていては言語生活を営むことすらおぼつかないと言ってしまえばそうなのだが,語の研究に関する限りこのような感受性は必要なのだろうなと思う.
さて,「廃」を表わす英語の obsolete は,ラテン語 obsolescere の過去分詞 obsolētus に由来し,16世紀に英語に借用された.ob- 「完全に」+ sol(ere) 「慣れる」 + ēscere 「?し始める」と形態分析され,その過去分詞形は全体として "grown out, worn out, fallen into disuse" ほどの意となる.OED では,廃語の見出しには短剣符 ( dagger or obelisk ) と呼ばれる「†」の標識がつけられる.短剣符は十字架の立った墓の象形に由来すると思われ,慣習的に没年を表わすのに用いられるので,廃語を標示するのにもふさわしいということだろうか.
余談だが,近年の日本語の死語(=廃語)を収集したサイト死語's HomePageを発見した.その「ナウな死語辞典」に収録されている語句の数々に共感を覚えた.あったなあ,あんな言葉,こんな言葉.
・ ポール・バケ 著,森本 英夫・大泉 昭夫 訳 『英語の語彙』 白水社〈文庫クセジュ〉,1976年.
2026 : 01 02 03 04 05 06 07 08 09 10 11 12
2025 : 01 02 03 04 05 06 07 08 09 10 11 12
2024 : 01 02 03 04 05 06 07 08 09 10 11 12
2023 : 01 02 03 04 05 06 07 08 09 10 11 12
2022 : 01 02 03 04 05 06 07 08 09 10 11 12
2021 : 01 02 03 04 05 06 07 08 09 10 11 12
2020 : 01 02 03 04 05 06 07 08 09 10 11 12
2019 : 01 02 03 04 05 06 07 08 09 10 11 12
2018 : 01 02 03 04 05 06 07 08 09 10 11 12
2017 : 01 02 03 04 05 06 07 08 09 10 11 12
2016 : 01 02 03 04 05 06 07 08 09 10 11 12
2015 : 01 02 03 04 05 06 07 08 09 10 11 12
2014 : 01 02 03 04 05 06 07 08 09 10 11 12
2013 : 01 02 03 04 05 06 07 08 09 10 11 12
2012 : 01 02 03 04 05 06 07 08 09 10 11 12
2011 : 01 02 03 04 05 06 07 08 09 10 11 12
2010 : 01 02 03 04 05 06 07 08 09 10 11 12
2009 : 01 02 03 04 05 06 07 08 09 10 11 12
最終更新時間: 2026-06-26 03:46
Powered by WinChalow1.0rc4 based on chalow