2026-04-03 Fri
■ #6185. まだある,現代英語の綴字 <e> の役割 [spelling][graphemics][alphabet][orthography][final_e][silent_letter][three-letter_rule][voicy][heldio]
一度「#979. 現代英語の綴字 <e> の役割」 ([2012-01-01-1]) で取り上げた話題だが,そこで挙げた10件に尽きるわけではない.Carney を読んでいて分かったことだが,追加事項がある.まずは Carney より関連箇所を引用する (42) .
Empty letters are naturally a target for the spelling reformers, but one should not rush in with the scissors too hastily. A favourite target is final <-e>. The instances of <-e> at the end of copse, bottle, file, giraffe, are often referred to as 'silent' letters, but they are very different. The <-e> of copse marks the word as different from the plural cops. The word bottle cannot sensibly be spelt as *<bottl>, since syllabic consonants are always spelt with a vowel letter and a consonant letter, except for <sm> in sarcasm, prism. Similarly it might be thought that file could be spelt *<fil>. It would still be different from fill, as it is in filing, filling. However, some degree of redundancy is essential to human language and that justifies taking the unit of correspondence to be <i..e>≡/aɪ/. Even the <-e> at the end of giraffe has something to be said in its favour. It can be said to mark the unusual final stress of the noun as in the <-CCe> of brunette, cassette, corvette, largesse, bagatelle, gazelle.
bottle に関する解説が私にとっては目新しいものだった.この単語の音節主音の l について,音節主音的子音が用いられるときには,必ず <e> が付随するという.例外として <-sm> が挙げられているが,それ以外はどうやら <e> は必須のようだ.
もう1つ興味深いのが giraffe の語末の <e> である.brunette, cassette, corvette などの類例からもわかる通り,語末で <-VCCe> の綴字となる場合には,<V> を含む音節に強勢が落ちる.これは,<e> だけでというよりは <CCe> の全体で示唆されるというべきものだが,その一画に参与しているという点で,これを <e> の1つの役割と解釈することは可能である.
ほかには eye の語末の <e> のように,3文字規則 (three-letter_rule) を回避するためのダミーの <e> も,1つの役割としてリストに加えてよいだろう.
考え続けていくと,<e> の役割はもっと挙がってきそうだ.本記事と同じ趣旨で,3月30日の heldio にて「#1765. 英語綴字における <e> の役割」を配信しているので,そちらもお聴きいただければ.
・ Carney, Edward. A Survey of English Spelling. Abingdon: Routledge, 1994.
2026-03-08 Sun
■ #6159. 文字史における3つの重要な局面 [grammatology][writing][alphabet]
昨日の記事「#6158. Powell による文字の分類」 ([2026-03-07-1]) で参照・引用した Powell は,文字史における重大な転機が3つあったと記している.文字の分類を解説した直後に,次の文章が続く (51--52) .
Although this is a structural description, it is also a rough outline of the history of writing, understood as a technology that underwent broad and radical changes over millennia and came to serve ever more efficient and complex forms of communication and thought. The major changes were three.
First was the discovery of the phonetic principle, the representation of the sounds of speech by graphic means. This discovery appears to have been applied three times in a more or less systematic way: in southern Mesopotamia, in China, and in Mesoamerica. But all these systems are only partly phonetic.
The second major discovery was of a wholly phonetic writing. We cannot date the discovery, but perhaps as early as 1800 BC in the Near East and rather earlier in Crete, c.2100 BC (for the earliest "Cretan hieroglyphs"). While such writings are wholly phonetic, that is, most signs refer to sound and are not meaningful, they still cannot be pronounced except by a native speaker. Wholly phonetic writings made possible an immense constriction in the number of signs over the earlier logosyllabaries (made up of logograms and syllabograms) by focusing on a single semantic aspect of communication, namely sounds of the human voice speaking some "language." This advantageous constriction was gained at the loss of clarity provided by the many semantic nonphonetic elements of the earlier logosyllabaries.
The third major shift was the invention of the Greek alphabet around 800 BC, a system that atomized the sounds of human speech, utilized symbols for these sounds, and made possible the approximate reconstruction of the sound of human speech, even by someone who does not speak the language.
In studying the history of writing we must remember that a continuity of forms can mask an extreme shift in inner structure, while two sets of completely differing forms can function in the same way.
1つめの重要な局面は「表音原理そのものの発明」,2つめは「完全な表音文字の発明」,3つめは「音素文字の完全使用の発明」と要約しておいてよいだろう.Powell の文字論や文字観は洞察に満ちている.しかし,一方で文字の経済合理性の側面のみに注目しているように見受けられる.
第2の「完全な表音文字の発明」の局面について,中東でのアルファベットの発現だけでなく,さらに早い段階でのクレタ島のヒエログリフにも言及しているのは鋭い.
・ Powell, Barry B. Writing: Theory and History of the Technology of Civilization. Malden, MA: Wiley-Blackwell, 2009.
2026-03-07 Sat
■ #6158. Powell による文字の分類 [grammatology][terminology][writing][alphabet][phoneme]

上記は,Powell の文字論の本の扉に大きく図示されている "THE CATEGORIES OF WRITING" である.文字の分類の1つの考え方だ.この分類の解説は,p. 52 にまとめられている.
1 Semasiography: Writing in which the signs are not attached to necessary forms of speech. Sematograms, the elements of semasiography, may be arranged in any conventional way.
2 Lexigoraphy: Writing in which the signs are attached to necessary forms of speech. They are (usually) arranged in a linear sequence corresponding to sounds in speech. There are two divisions.
(i) Logography: the signs represent words (but not sounds), significant segments of speech. A logography would be a system in which logograms, the elements of logography, predominate (sometimes logograms do not follow the same order as words in speech).
(ii) Phonography: the signs represent sounds. Such sounds are ordinarily nonsignificant elements of speech. There are two kinds of phonographic systems.
・ Syllabography: the signs represent syllables, the smallest apprehensible elements of speech. A Syllabography would be a system in which syllabograms predominate.
・ Alphabetic writing: the signs represent elements of speech smaller than syllables, although such sounds do not exist in nature as separable elements of speech. In alphabetic writing letters predominate.
最後のアルファベット(単音文字)の解説において「単音などという単位は自然には存在しないのだが」というくだりにハッとさせられた.「単音文字」というよりは「音素文字」と捉えたほうがよいのだろう.音素 (phoneme) は人間による抽象化の産物であり,それを文字に当てたというところに,アルファベットの最大の言語学的な意義と価値があるのだと思う.
・ Powell, Barry B. Writing: Theory and History of the Technology of Civilization. Malden, MA: Wiley-Blackwell, 2009.
2025-10-14 Tue
■ #6014. 表記スペースが足りないときには母音字を捨てる --- 英語史小ネタ from スーパー [writing][spelling][consonant][vowel][abbreviation][alphabet]
New Zealand は Christchurch に着いて2週間弱が経過した.お世話になっているいくつかのスーパーマーケットの1つが,"NZ's Lowest Food Prices" を謳うNZローカルのスーパー PAK'n'SAVE だ.倉庫型の巨大スーパーで,品揃えを眺めて歩くだけでも時間を忘れる.NZ的な野菜・肉・魚はもちろん,日本食材を含めアジアのものも手に入る.日常的なモノほど英語での表現が出てこないものなので,店内を歩き回るのは単純に英語学習によい.
日本食材の棚を眺めていたとき,背後の棚にあるメープルシロップが視界に入った.以下の写真の通りだが,左下のラベルを読んでみると,次のようにある:"PAMS FINEST / MPLE SYRP / CNDIAN A GRD / 250ML" .

ラベルの記入欄が狭いので,綴字を省略せざるを得ない.そこで何を省略するかといえば,典型的に母音字である.子音字は音節の骨格を形成するため,それさえ残せば読み手にとって十分なヒントになるからだ.実際に英語の知識があれば,商品そのものもそこにあるため,頭の中で展開するのは用意だ.フルに展開すると "PAMS FINEST / MAPLE SYRUP /CANADIAN A GRADE / 250ML" となる.
スーパーの英語綴字におけるこのような省略は,アルファベット文化圏では広く見られるものだろう.細かくみれば各言語の音素配列,音節構造,綴字体系に依存するものと思われるが,子音字を残すのが基本である.
この傾向は,文字,とりわけ表音文字の発展の経緯と連動しており意味深長だ.絵文字から発展した表語文字は,少なからぬ文字文化圏において,表音文字へと発展した.表音文字は,まず音節文字から始まるのが普通だ.例えば /ka/ という音節を「か」と仮名1文字で書くような発想だ.このような音節文字は,しばしば母音を無視して子音のみを標示する用法を発達させた.「か」と書いておきながら,これを /k/ という単独の子音として読ませるやり方だ.母音の「読み捨て」である.
ちなみに,アルファベット発達史を眺めても,子音字を重視する姿勢が一貫している.ここには,アルファベットという単音文字が,子音重視の音節構造をもつアフロアジア語族において発生・発達した事実が関係してくるだろう.相対的に母音字は軽視されてきたのである.アルファベット史でよく知られているように,母音字を積極的に「書き救う」動きが出たのは,フェニキア文字からギリシア文字が派生したときだった.以降,ローマ字の展開を経て,広くローマ字文化圏でも,原則として母音字を表記する綴字習慣が根付いた.
メープルシロップの例のように,表記スペースが足りないというやんごとなき事情がある場合に,子音字を残して母音字を捨てるというのは,ある意味で文字史を遡っているかのような現象なのである.振り返ったメープルシロップの棚の前で,(買わずに)アルファベット史3700年を振り返った次第.
2025-09-01 Mon
■ #5971. 602年,Kent でローマ字が採用される [alphabet][christianity][oe][anglo-saxon][st_augustine][history][writing][runic][kentish][oe_dialect][jute][100_places]
597年,Kent にキリスト教がもたらされた経緯については「#5444. 古英語の原文を読む --- 597年,イングランドでキリスト教の布教が始まる」 ([2024-03-23-1]) 等の記事で取り上げてきた.イングランド史上,そして英語史上,きわめて重大な出来事だったといってよい.
様々なインパクトがあったが,そのうちの1つはキリスト教とともにローマ字 (Roman alphabet) が導入されたことだ.古来,ゲルマン民族はローマ字と親戚関係にあったルーン文字 (runic script) をもっていたが,これを機に使用文字をローマ字へと乗り換えていくことになった.
そのローマ字の受容の象徴的な年として,602年を挙げることができる.Lucas and Mulvey (19) の "CANTERBURY --- The adoption of the Roman alphabet (602)" と題する節から,冒頭の3段落を引用する.
The Jutish kingdom of Kent is the first region of post-Roman Britannia to leave evidence of an organized realm. That is because Kent was the first area to be reconverted to Christianity. Sent by Pope Gregory, Augustine and fellow monks arrived in Canterbury in 597, bringing not only Christianity but also writing in the form of Roman script. In 602, King Ethelbert of Kent had the monks write down the laws of his people in that script.
Those laws, called 'dooms', had been brought to Kent from Continental Europe 150 years before. They are the first surviving example, in any Germanic language, of a legal document. They are the starting point of the Anglo-American common law and tradition. They are also of great importance in the history of the English language.
First, they show that within five years of the arrival of the Roman script, it had been adopted in place of the runic alphabet . . . . Second, they provide evidence of Kentish, a dialect of English that was to disappear altogether. Third, they are the beginning of regular and widespread written records in English, as the script of the dooms spread rapidly west and north.
ケント王 Ethelbert が602年に法律をローマ字で書き記させたというのが,その後の英語のローマ字使用の伝統にとって決定的な出来事だったことになる.英米法の歴史の観点からも非常に重要な年だったことが分かる.
それにしてもローマ字の広がり方が早いし速い.597年のたかだか5年後のことである.ローマ字は間違いなくキリスト教とともにもたらされたものなのだ.

・ Lucas, Bill and Christopher Mulvey. A History of the English Language in 100 Places. London: Robert Hale, 2013.
2025-03-19 Wed
■ #5805. Skeat の発見した幽霊語の一覧 [ghost_word][minim][spelling][alphabet][manuscript][palaeography][thorn][th][graphemics][editing]
昨日の記事「#5804. 中世写本で読み間違えられやすい文字(列) --- 幽霊語を生み出す元凶」 ([2025-03-18-1]) で,Skeat がまとめた読み違いしやすい文字(列)の一覧を示した.現代の中世写本の校訂者は原則として文献学のプロではあるが,そのプロですらはまってしまう文字の罠が多々あるということだ.Skeat は,そのような罠にはまった校訂者が,図らずも生み出してしまった幽霊語 (ghost_word) の数々を,自身の論文の最後で列挙している (373--74) .括弧のなかの綴字が,Skeat の考えるところによれば幽霊的でない正しい綴字である.
abacot (a bicocket)
abofted (abosted)
allryn (alkyn)
belene (beleue)
beuen (benen)
bewunus (bewunne)
bolueden (bolneden)
bouchen (bonchen)
char (thar)
chek yn a tyde (chek-matyde),
chesse (chese)
chichingis (thithingis, error for tithingis)
clamupe (claurnpe)
cleue (clene)
conise (comse)
conisyng (comspg)
coppin (croppin)
corves (cornes)
couuen (coxmen)
cronde (croude)
culde (tulde)
culpis (cuupis ? for coupis ?),
degontit (degoutit)
desouled (defouled)
dimnede (diuinede)
dolf (douf)
dolp (doup)
drinen (driuen)
dymnede (dyuinede)
eftures (esteres, estres)
enchausyt (enchaufyt)
encortif (encorcif)
flocced (flotted)
folloke (wilfolloker)
forbusur (forbusne)
forgalbed (forgabbed)
fonngit (foriugit)
fouk (fonk)
founed (fonned)
galbert (gabbert)
golk (gouk)
gramity (graunty)
havin (harm)
hetheued (heued)
holk (houk)
howen, howne (howue)
kimes (knives)
lath (lay)
lessyt (leffyt)
lohe (lome)
maused (mansed)
monelich (menelich)
morse (nurse)
moyt (mo þat)
nalle (ualle)
nolt (nout)
onen (ouen)
ouershuppe (ouerhuppe)
owery (dwerþ)
palke (pakke)
palpis (paupis)
panfray (paufray)
pantener (pautener)
pavade (panade)
polien (þolien)
polk (pouk)
porcours (portours)
punniten (permuten)
rendit (vondit)
rentful (reuful)
renthe (reuthe)
reuk (renk)
rolkis (rokkis)
roned (roued)
sangtle (saughtle)
satoure (fatoure)
scharpe (schappe)
sharter (Charter)
skowurand (skownrand)
slalk (slakk)
soket (Coket)
sordid (fordid)
spelk (spekk)
stone (schon)
succh (sutth)
suten (sitten)
Syvewarm (Fysewarin)
talbart (tabbart)
tavart (tabart)
thame (tharne)
treryn (temp)
tyre (cyre)
ulode (correct; u=v)
ullorxa (?)
vyt (rycht)
walk (wakk, later wauk)
walkrif (wakkrif, later waukrif)
walknit (wakknit, later wauknit)
watte (waite)
wayne (wayue)
wok (woux)
ytoped (ycoped)
yvete (ybete)
Skeat は,校訂者のミスによって生じるこのような幽霊語が,後に定着し,辞書に採録までされてしまう可能性に強い危機感を抱いていた.文献学のプロとしての矜持なのだろう.
・ Skeat, Walter W. "Report upon 'Ghost-words,' or Words which Have no Real Existence." in the President's Address for 1886. Transactions of the Philological Society for 1885--87. Vol. 2. 350--80.
2025-03-18 Tue
■ #5804. 中世写本で読み間違えられやすい文字(列) --- 幽霊語を生み出す元凶 [minim][spelling][alphabet][manuscript][ghost_word][palaeography][thorn][th][graphemics][punctuation]
最近いくつかの記事で,幽霊語 (ghost_word) の話題を取り上げてきた.この用語の生みの親である Skeat は,「幽霊語」論文のなかで,幽霊語の出現の背後にある写本上の文字(列)の読み違いを詳細に論じている.とりわけ読み間違えられやすい文字(列)のリストが示されているので,その部分を引用しよう (372) .
I now proceed to make a list of the symbols which, in the foregoing examples, have been misread and confused. The following groups denote the confused symbols: b, v; c, t; d, o; e, o, s; f, s; k, lr; m, ui, in; n, u; o, d, e; p, þ (th); r, v; s, C, e, f; y, þ (th). Also mi, un; mu, um; ni, in; rp, pp; tt, it; ur, ne; unn, erm; vin, rm. Also lb, bb; lk, kk. Very few of these mistakes result from the misreading of marks of contraction. If I were to add examples of this character, the number of ghost-words would be very largely increased.
少なからぬ例が,縦棒 (minim) で構成される文字(列)を含んでいる.minim の害悪(?)に関心をもった方は,「#4134. unmummied --- 縦棒で綴っていたら大変なことになっていた単語の王者」 ([2020-08-21-1]) や「#5215. 句動詞から品詞転換した(ようにみえる)名詞・形容詞の一覧」 ([2023-08-07-1]) などからどうぞ.
また,<th> に相当する古英語・中英語の文字 <þ> (thorn) については,「#1428. ye = the」 ([2013-03-25-1]) などを参照ください.
・ Skeat, Walter W. "Report upon 'Ghost-words,' or Words which Have no Real Existence." in the President's Address for 1886. Transactions of the Philological Society for 1885--87. Vol. 2. 350--80.
2025-01-18 Sat
■ #5745. アルファベットの文字頻度 [corpus][link][alphabet][frequency][statistics][letter_frequency][bnc][morse_code]
AからZまでのアルファベット文字のなかで,最も頻度の高い文字,低い文字は何か.この文字頻度 (letter_frequency) の話題については,「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1]) の下部に Letter Frequencies (rankings for various languages) へのリンクを挙げたとおり,様々な言語やコーパスでの順位表が作り出されている.例えば,BNC に依拠すると "etaoinsrhldcumfpgwybvkxjqz" の順位表が得られる.
Crystal (277) には,The Cambridge Encyclopedia (1st ed.) の全テキスト,150万語をコーパスとした文字頻度表が掲げられている.累積頻度順位 (Cumulative) のみならず,文学,宗教,政治,物理学,化学の各々のテーマごとの頻度や Morse code (morse_code) の頻度も合わせて示されている.以下のグラフは,X軸に沿って累積頻度順 (= "eatinorslhdcmufpgbywvkxjq") に文字を並べ,Y軸を各テーマ内での頻度割合(百分率)としたものである(頻度表はソース HTML を参照).
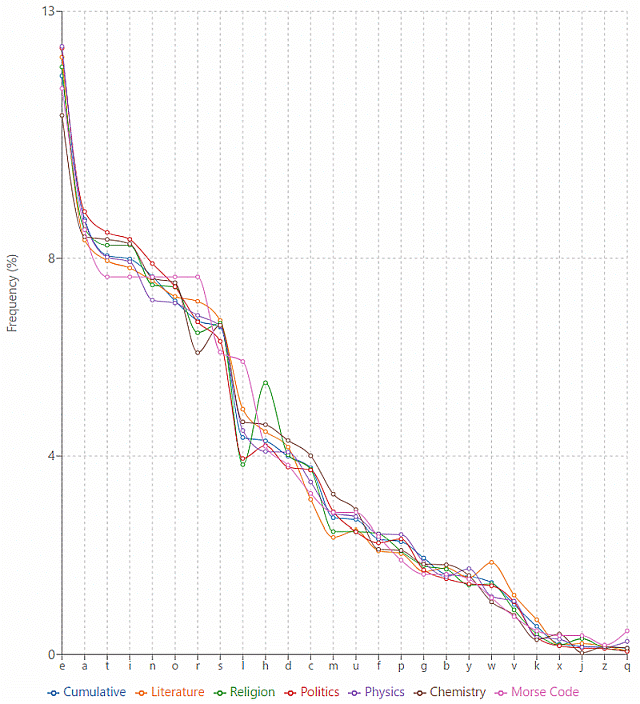
累積頻度順に照らしてテーマごとの特徴を見てみるとと,政治が最も標準的である.文学と政治がそれに続く.標準から遠ざかっていくのが,化学,物理学,そして Morse code となる.
個々の文字をみると興味深い点が多々ある.相対的に宗教では <h> が多く (holy?) <l> が少ないこと,文学では <w> が多いことは何を意味するのだろうか? 物理学や化学はラテン・ギリシア語系の単語が多く含まれているために,その他一般とは若干異なる文字頻度を示しているのかもしれない.人工的な Morse code は,他のテーマとは目に見えて異なる線を描いていることがわかる.
・ Crystal, D. The Cambridge Encyclopedia of the English Language. 3rd ed. CUP, 2018.
2024-09-12 Thu
■ #5617. 「古英語LINEスタンプ」をリリース --- アングロサクソン戦士 Winewulf くんとともに古英語の挨拶を楽しもう! [oe][hellive2024][ole_english_stickers][winewulf][khelf][calligraphy][alphabet][greetings]

今回はとてもエキサイティングなお知らせです.heldio/helwa で企画立案された「古英語LINEスタンプ」が,有志の手により完成しました.先日9月8日の「英語史ライヴ2024」の正午の番組にてお披露目となりましたが,そのときには皆でその場で当該スタンプを購入し,オープンチャット「古英語スタンプお試し会」にてスタンプを交わし合うというイベントも実施しました.ぜひ皆さんも「古英語スタンプ」をご覧になり,よろしければ入手して日常的にお使いください.
メインキャラ Winewulf くん
このスタンプのメインキャラクターはアングロサクソン戦士 Winewulf (ウィネウルフ)くんです.その名は古英語で「友の戦士(狼)」を意味します.彼は勇敢で心優しいアングロサクソンの戦士です.槍と盾を持ち,赤いマントをなびかせた頼もしい戦士の姿ですが,それでいて親しみやすい表情が特徴です.母語である古英語を織り交ぜながら,皆さんのトークに英語史の風を吹き込んでくれます.
上記のイラストでは,Winewulf くんは Ic eom Winewulf 「私はウィネウルフです」と自己紹介をしています.スタンプでは,他の日常使いできる挨拶や感謝の気持ちを母語の古英語で発しています.例えば「おはよう」の意味で Godne morȝen を,感謝の気持ちを込めて Ic ðancie ðe を唱えています.英語史好きの方にはぴったりのスタンプです!
「古英語LINEスタンプ」の試み
「古英語LINEスタンプ」の制作は,他に類を見ない本気の試みでした.スタンプに使用されている古英語の文言は,古英語研究者である小河舜さん(上智大学)と khelf の藤原郁弥さん(慶應義塾大学大学院生),および私自身も補佐的に監修しました.そして,その文言は,古英語の代表的な書体である "Insular Minuscule" で綴られており,まるで中世の古文書を手に取るような感覚を味わえます.日本語訳も付されていますので,大丈夫.日常遣いできます.
こんなシーンで使えます!
・ 友達との日常会話に英語史的なアクセントを加えたいとき
・ 言語 and/or 歴史に興味のある仲間とユニークなやり取りを楽しむ場面で
・ 普段の挨拶や感謝の気持ちを,特殊な言語・文字で伝えてみたいとき
・ Winewulf くんを人気キャラに成長させるために!
古英語の魅力を伝える Winewulf くんの「古英語スタンプ」を使って,いつものトークが一気に特別なものに変わるでしょう.Winewulf くんと一緒に友達や家族とのコミュニケーションを楽しんでみませんか? 他に例のない本格的なスタンプで,メッセージに英語史の深みを加えてください!
入手はこちらからどうぞ
「古英語スタンプ」は,LINEストアにて好評発売中です.最低金額に設定しています.Winewulf くんが登場するスタンプ8個のセットは,古英語文言とキャラ・デザインの両方を楽しめる一品です.ぜひチェックしてみてください!
イラストレーターと監修者への感謝
スタンプのイラストレーターは,heldio の有料版,プレミアムリスナー限定配信チャンネル「英語史の輪」 (helwa) の有志リスナーお二方,Lilimi さんと MISATO (Galois) さんです.監修の小河舜さんと藤原郁弥さんを含め,制作班の皆の尽力に感謝いたします.
2023-10-10 Tue
■ #5279. Z の推し活 [notice][z][alphabet][ame_bre][greek][latin][french][academy][shakespeare][consonant][youtube][grapheme][link][spelling][helsta]
一昨日配信した YouTube の「井上逸兵・堀田隆一英語学言語学チャンネル」の最新回は「#169. なぜ Z はアルファベットの最後に追いやられたのか? --- 時代に翻弄された日陰者 Z の物語」です.歴史的に「日陰者 Z」と称されてきたかわいそうな文字にスポットライトを当て,12分ほど集中して語りました.これで Z が多少なりとも汚名返上できればよいのですが.
z の文字については,この hellog,および Voicy 「英語の語源が身につくラジオ (heldio)」等の媒体でも,様々に取り上げてきました.Z の汚名返上のために助力してきた次第ですが,さすがに Z に関する話題はこれ以上見つからなくなってきましたので,ネタとしてはいったん打ち切りになりそうです.
これまでの Z の推し活の履歴を列挙します.
[ hellog ]
・ 「#305. -ise か -ize か」 ([2010-02-26-1])
・ 「#314. -ise か -ize か (2)」 ([2010-03-07-1])
・ 「#446. しぶとく生き残ってきた <z>」 ([2010-07-17-1])
・ 「#447. Dalziel, MacKenzie, Menzies の <z>」 ([2010-07-18-1])
・ 「#799. 海賊複数の <z>」 ([2011-07-05-1])
・ 「#964. z の文字の発音 (1)」 ([2011-12-17-1])
・ 「#965. z の文字の発音 (2)」 ([2011-12-18-1])
・ 「#1914. <g> の仲間たち」 ([2014-07-24-1])
・ 「#2916. 連載第4回「イギリス英語の autumn とアメリカ英語の fall --- 複線的思考のすすめ」」 ([2017-04-21-1])
・ 「#2925. autumn vs fall, zed vs zee」 ([2017-04-30-1])
・ 「#4990. 動詞を作る -ize/-ise 接尾辞の歴史」 ([2022-12-25-1])
・ 「#4991. -ise か -ize か問題 --- 2つの論点」 ([2022-12-26-1])
・ 「#5042. 『中高生の基礎英語 in English』の連載第24回(最終回)「アルファベット最後の文字 Z のミステリー」」 ([2023-02-15-1])
[ heldio (Voicy) ]
・ 「#171. z と r の発音は意外と似ていた!」 (2021/11/18)
・ 「#540. Z について語ります」 (2022/11/22)
・ 「#541. Z は zee か zed か問題」 (2022/11/23)
[ helsta (stand.fm) ←数日前に始めました ]
・ 「#3. 動詞を作る接尾辞 -ize の裏話」 (2023/10/08)
ただし,いずれ Z に関する新ネタを仕込むことができれば,もちろん Z の汚名返上活動に速やかに戻るつもりです.皆様,これからも Z にはぜひとも優しく接してあげてくださいね.
2023-07-30 Sun
■ #5207. 朝カルのシリーズ講座「文字と綴字の英語史」の第2回「古英語の綴字 --- ローマ字の手なずけ」を終えました [asacul][writing][grammatology][alphabet][notice][spelling][oe][literature][beowulf][runic][christianity][latin][alliteration][distinctiones][punctuation][standardisation][voicy][heldio]
先日「#5194. 7月29日(土),朝カルのシリーズ講座「文字と綴字の英語史」の第2回「古英語の綴字 --- ローマ字の手なずけ」」 ([2023-07-17-1]) でご案内した通り,昨日,朝日カルチャーセンター新宿教室にてシリーズ講座「文字と綴字の英語史」の第2回となる「古英語の綴字 --- ローマ字の手なずけ」を開講しました.多くの方々に対面あるいはオンラインで参加いただきまして感謝申し上げます.ありがとうございました.
古英語期中に,いかにして英語話者たちがゲルマン民族に伝わっていたルーン文字を捨て,ローマ字を受容したのか.そして,いかにしてローマ字で英語を表記する方法について時間をかけて模索していったのかを議論しました.ローマ字導入の前史,ローマ字の手なずけ,ラテン借用語の綴字,後期古英語期の綴字の標準化 (standardisation) ,古英詩 Beowulf にみられる文字と綴字について,3時間お話ししました.
昨日の回をもって全4回シリーズの前半2回が終了したことになります.次回の第3回は少し先のことになりますが,10月7日(土)の 15:00~18:45 に「中英語の綴字 --- 標準なき繁栄」として開講する予定です.中英語期には,古英語期中に発達してきた綴字習慣が,1066年のノルマン征服によって崩壊するするという劇的な変化が生じました.この大打撃により,その後の英語の綴字はカオス化の道をたどることになります.
講座「文字と綴字の英語史」はシリーズとはいえ,各回は関連しつつも独立した内容となっています.次回以降の回も引き続きよろしくお願いいたします.日時の都合が付かない場合でも,参加申込いただけますと後日アーカイブ動画(1週間限定配信)にアクセスできるようになりますので,そちらの利用もご検討ください.
本シリーズと関連して,以下の hellog 記事をお読みください.
・ hellog 「#5088. 朝カル講座の新シリーズ「文字と綴字の英語史」が4月29日より始まります」 ([2023-04-02-1])
・ hellog 「#5194. 7月29日(土),朝カルのシリーズ講座「文字と綴字の英語史」の第2回「古英語の綴字 --- ローマ字の手なずけ」」 ([2023-07-17-1])
同様に,シリーズと関連づけた Voicy heldio 配信回もお聴きいただければと.
・ heldio 「#668. 朝カル講座の新シリーズ「文字と綴字の英語史」が4月29日より始まります」(2023年3月30日)
・ heldio 「#778. 古英語の文字 --- 7月29日(土)の朝カルのシリーズ講座第2回に向けて」(2023年7月18日)
2023-05-12 Fri
■ #5128. 17世紀の普遍文字への関心はラテン語の威信の衰退が一因 [writing_system][alphabet][latin][prestige][emode][history_of_linguistics][orthoepy][orthography][pictogram]
スペリングの英語史を著わした Horobin によると,17世の英語社会には従来のローマン・アルファベットではなく万国共通の普遍文字を考案しようとする動きが生じていた.
16--17世紀には正音学 (orthoepy) が発達し,それに伴って正書法 (orthography) への関心も高まった時代だが,そこで常に問題視されたのはローマン・アルファベットの不完全性だった.この問題意識のもとで,完全なる普遍的な文字体系が模索されることになったことは必然といえば必然だった.しかし,17世紀の普遍文字の考案の動きにはもう1つ,同時代に特有の要因があったのではないかという.それは長らくヨーロッパ社会で普遍言語として認識されてきたラテン語の衰退である.古い普遍「言語」が失われかけたときに,新しい普遍「文字」が模索されるようになったというのは,時代の流れとしておもしろい.Horobin (25) より引用する.
Attempts have also been made to devise alphabets to overcome the difficulties caused by this mismatch between figura and potestas. In the seventeenth century, a number of scholars attempted to create a universal writing system which could be understood by everyone, irrespective of their native language. This determination was motivated in part by a dissatisfaction with the Latin alphabet, which was felt to be unfit for purpose because of its lack of sufficient letters and because of the differing ways it was employed by the various European languages. The seventeenth century also witnessed the loss of Latin as a universal language of scholarship, as scholars increasingly began to write in their native tongues. The result was the creation of linguistic barriers, hindering the dissemination of ideas. This could be overcome by the creation of a universal writing system in which characters represented concepts rather than sounds, thereby enabling scholars to read works composed in any language. This search for a universal writing system was prompted in part by the mistaken belief that the Egyptian system of hieroglyphics was designed to represent the true essence and meaning of an object, rather than the name used to refer to it. Some proponents of a universal system were inspired by the Chinese system of writing, although this was criticized by others on account of the large number of characters required and for the lack of correspondence between the shapes of the characters and the concepts they represent.
21世紀の現在,普遍文字としての絵文字やピクトグラム (pictogram) の可能性に注目が寄せられている.現代における普遍言語というべき英語が17世紀のラテン語のように衰退しているわけでは必ずしもないものの,現代の普遍文字としてのピクトグラムの模索への関心が高まっているというのは興味深い.17世紀と現代の状況はどのように比較対照できるだろうか.
関連して「#2244. ピクトグラムの可能性」 ([2015-06-19-1]),「#422. 文字の種類」 ([2010-06-23-1]) を参照.
・ Horobin, Simon. Does Spelling Matter? Oxford: OUP, 2013.
・ サイモン・ホロビン(著),堀田 隆一(訳) 『スペリングの英語史』 早川書房,2017年.
2023-05-03 Wed
■ #5119. 朝カル講座の新シリーズ「文字と綴字の英語史」の第1回を終えました [asacul][writing][grammatology][alphabet][notice]
去る4月29日(土),朝日カルチャーセンター新宿教室にて新シリーズ講座「文字と綴字の英語史」がオープンしました.向こう1年ほどかけて春夏秋冬の全4回,英語の文字と綴字の歴史についてお話ししていきます.
初回は「文字の起源と発達 --- アルファベットの拡がり」と題して,文字の起源と発達,とりわけアルファベットの世界的拡がりを概観しました.2回目以降,英語の綴字の話題を本格的に導入していくことになりますが,初回はその下準備として,そもそも文字とは何かを問い,文字の役割・種類・歴史について議論しました.
当日は,新宿教室での対面およびオンラインにて多くの方に参加していただきました.ありがとうございます.講座中にご質問を寄せていただいたのみならず,講座後も居残りで文字の話題で盛り上がりました.次回以降もよろしくお願いいたします.
今後開講する各回は互いに関連しつつも独立していますので,ご関心のある回のみの参加でも問題ありません.日時の都合が付かない場合でも,申し込みいただけますと後日アーカイブ動画(1週間限定配信)にアクセスできるようになりますので,そちらの利用もご検討ください.
シリーズ全体の概要を以下に示します.
アルファベットは現代世界で最も広く用いられている文字体系であり,英語もそれを受け入れてきました.しかし,そのような英語もアルファベットとは歴史の過程で出会ったものにすぎず,綴字として手なずけていくのに千年以上の年月を要しました.本講座では,英語が文字や綴字と格闘してきた歴史をたどります.
全4回のタイトルは以下の通りです.
・ 第1回 文字の起源と発達 --- アルファベットの拡がり(春・4月29日に開講済み)
・ 第2回 古英語の綴字 --- ローマ字の手なずけ(夏・7月29日に開講予定)
・ 第3回 中英語の綴字 --- 標準なき繁栄(秋・未定)
・ 第4回 近代英語の綴字 --- 標準化を目指して(冬・未定)
シリーズ紹介として,Voicy 「英語の語源が身につくラジオ (heldio)」にて「#668. 朝カル講座の新シリーズ「文字と綴字の英語史」が4月29日より始まります」も配信していますので,ぜひお聴きください.
2023-04-29 Sat
■ #5115. アルファベットの起源と発達についての2つのコンテンツ [voicy][heldio][start_up_hel_2023][hel_contents_50_2023][alphabet][grammatology][etruscan][greek][latin][history][khelf]
4月も終わりに近づき,GW が始まりました.この新年度,khelf(慶應英語史フォーラム)では「英語史スタートアップ」企画 (cat:start_up_hel_2023) の一環として「英語史コンテンツ50」を開催中です.コツコツとコンテンツが積み上がり,すでに14本が公開されています.連休中は休止しますが,これからもまだまだ続きます.
今日はこれまでのストックのなかから,アルファベットの歴史に関する大学院生のコンテンツを紹介しましょう.4月19日に公開された「#6. <b> と <d> は紛らわしい!」です.タイトルからは想像できないかもしれませんが,コンテンツの前半はアルファベットの起源と発達,とりわけローマ字の歴史に焦点が当てられています.

このたび,同コンテンツを作成者との対談という形でラジオ化しました.Voicy [「英語の語源が身につくラジオ (heldio)」より「#698. 先生,アルファベットの歴史を教えてください! --- 寺澤志帆さんとの対談」として配信していますので,そちらを合わせてお聴きください.
本ブログよりアルファベットの歴史に関する記事としては以下を参照ください.
・ 「#423. アルファベットの歴史」 ([2010-06-24-1])
・ 「#490. アルファベットの起源は North Semitic よりも前に遡る?」 ([2010-08-30-1])
・ 「#2888. 文字史におけるフェニキア文字の重要性」 ([2017-03-24-1])
・ 「#1849. アルファベットの系統図」 ([2014-05-20-1])
2023-02-15 Wed
■ #5042. 『中高生の基礎英語 in English』の連載第24回(最終回)「アルファベット最後の文字 Z のミステリー」 [notice][sobokunagimon][rensai][z][ame_bre][alphabet][voicy][heldio]
昨日『中高生の基礎英語 in English』の3月号が発売となりました.今回で丸2年続いた連載「歴史で謎解き 英語のソボクな疑問」も第24回で,最終回となります.取り上げる話題は,最終回にふさわしく「アルファベット最後の文字 Z のミステリー」です.よろしければ手に取っていただければと思います.

冒頭の節「Z はもっとも出番の少ない文字」では,Z が英語のアルファベット26文字中最も頻度の低い文字であることが述べられます.続く「Z を含む英単語を挙げてみると」では,Z を含む英単語が列挙されていきますが,パッとしないものばかりです.S と Z の守備範囲についても触れられます.次の「日陰者の人生」では,いよいよ Z の悲哀の歴史が明らかにされます.最終節「発音は「ズィー」か「ゼッド」か」の節では,この文字をどう呼ぶかに関する混乱と競合の歴史が描かれ,英語の英米差に話が及びます.
24回続いた連載は今回の Z の話題で幕を閉じます.読者より寄せられた疑問にお答えする回もあり,毎月,執筆者としても楽しみながら筆を執ることができました.編集者さんの丁寧なお仕事に助けられ,そしてイラストレーターさんの確立した探偵スタイルにも元気づけられ,24回を完走できました.関係の皆様に感謝致します.2年間のご愛読,ありがとうございました.
振り返りの意味も込め,Voicy 「英語の語源が身につくラジオ (heldio)」で昨年10月22日で公開した放送回「#509. 毎月,中高生のために英語史連載を書いています」もお聴きいただければとと思います.
連載「歴史で謎解き 英語のソボクな疑問」はこれにて終了となりますが,英語の歴史の謎解き自体は,この hellog でも,その他の媒体でも,続けていきます.引き続きよろしくお願いいたします.
2023-02-07 Tue
■ #5034. ヘボン式ローマ字表記は本当に英語に毒されている? [youtube][notice][romaji][digraph][h][spelling][orthography][french][norman_conquest][link][alphabet]
一昨日公開された YouTube 「井上逸兵・堀田隆一英語学言語学チャンネル」の最新回では,英語史の観点から日本語を表記するためのローマ字について,とりわけヘボン式ローマ字について語っています.「最近よく見かける shi,chi,ji などのローマ字表記は,実は英語的ではない!」です.17分弱の動画となっております.どうぞご視聴ください.
今回依拠したローマ字使用に関するデータは,昨年9月30日に文化庁より公開された,2021年度の「国語に関する世論調査」の結果です.詳細は「令和3年度「国語に関する世論調査」の結果について」 (PDF) よりご確認いただけます.
日本語を表記するためのローマ字の使用については,これまでも様々な議論があり,本ブログでも romaji の記事群で多く取り上げてきました.今回の YouTube 動画ととりわけ関連の深い記事へのリンクを張っておきますので,合わせてご参照ください.
・ 「#3427. 訓令式・日本式・ヘボン式のローマ字つづり対照表」 ([2018-09-14-1])
・ 「#1892. 「ローマ字のつづり方」」 ([2014-07-02-1])
・ 「#1879. 日本語におけるローマ字の歴史」 ([2014-06-19-1])
・ 「#2550. 宣教師シドッチの墓が発見された?」 ([2016-04-20-1])
・ 「#4905. 「愛知」は Aichi か Aiti か?」 ([2022-10-01-1])
・ 「#4925. ローマ字表記の揺れと英語スペリング慣れ」 ([2022-10-21-1])
・ 「#1893. ヘボン式ローマ字の <sh>, <ch>, <j> はどのくらい英語風か」 ([2014-07-03-1])
・ 「#3251. <chi> は「チ」か「シ」か「キ」か「ヒ」か?」 ([2018-03-22-1])
日本語社会がいかにしてローマ字というアルファベット文字体系を受容し,改変し,手なずけようとしてきたかを振り返ることは,これから英語を始めとする世界中の言語や文字とどう付き合っていくかを考える上でも大事なことだと考えます.今回の動画を通じて,日本語を表記するためのローマ字使用について改めて考えてみてはいかがでしょうか.
2023-02-05 Sun
■ #5032. 取材記事のご案内 産経新聞の連載「テクノロジーと人類」の最新回「文字の発明」 [notice][speech][writing][medium][alphabet][kanji][grammatology]
昨日2月4日の産経新聞の朝刊に,連載「テクノロジーと人類」の最新回となる記事「文字の発明」が掲載されました.先日,産経新聞の科学部編集委員会の記者(長内洋介さん)より文字の歴史について取材を受けまして,今回それが記事となりました.他の専門家の方にも取材した上で,文字の特性を浮き彫りにした記事を書かれています.ウェブでは後日公開ということです.機会を見つけてお読みいただければと. *

先日,私の研究室で取材を受けまして2時間近く,楽しくお話ししました.連載「テクノロジーと人類」を20回にわたり続けてきた記者さんをして「やはり文字が人類の最大の発明」と言わせしめたことは功績でした.私もそう考えていますので (^^;; 取材ではたいへんお世話になりました!
先日「#5022. hellog より文字(論)に関する記事を厳選」 ([2023-01-26-1]) と題してリンクを整理しましたが,今回の取材との関連でまとめたものです.改めて産経新聞の「文字の発明」記事とともに,そちらもご覧いただければと存じます.
ウェブ時代の21世紀も,文字は間違いなく人類の最強ツールであり続けます!
2023-01-26 Thu
■ #5022. hellog より文字(論)に関する記事を厳選 [link][grammatology][speech][writing][medium][alphabet][alphabet][punctuation][kanji]
本ブログでは広く文字論 (grammatology) に関する話題を多く取り上げてきた.標題に掲げているタグなどを辿っていくと多くの記事にアクセスできるが,それでも数が多くて選びにくいと思われるので,ここに記事タイプごとにお勧め記事を厳選し,リンクを整理しておきたい.「文字」に関心のある方にとって,参考になると思います.
[ 話し言葉と書き言葉,文字の性質 ]
・ 「#230. 話しことばと書きことばの対立は絶対的か?」 ([2009-12-13-1])
・ 「#748. 話し言葉と書き言葉」 ([2011-05-15-1])
・ 「#849. 話し言葉と書き言葉 (2)」 ([2011-08-24-1])
・ 「#1001. 話しことばと書きことば (3)」 ([2012-01-23-1])
・ 「#1664. CMC (computer-mediated communication)」 ([2013-11-16-1])
・ 「#1665. 話しことばと書きことば (4)」 ([2013-11-17-1])
・ 「#1829. 書き言葉テクストの3つの機能」 ([2014-04-30-1])
・ 「#2301. 話し言葉と書き言葉をつなぐスペクトル」 ([2015-08-15-1])
・ 「#2417. 文字の保守性と秘匿性」 ([2015-12-09-1])
・ 「#2701. 暗号としての文字」 ([2016-09-18-1])
・ 「#3274. 話し言葉と書き言葉 (5)」 ([2018-04-14-1])
・ 「#3886. 話しことばと書きことば (6)」 ([2019-12-17-1])
[ 文字の種類・歴史 ]
・ 「#422. 文字の種類」 ([2010-06-23-1])
・ 「#1822. 文字の系統」 ([2014-04-23-1])
・ 「#1834. 文字史年表」 ([2014-05-05-1])
・ 「#1849. アルファベットの系統図」 ([2014-05-20-1])
・ 「#1853. 文字の系統 (2)」 ([2014-05-24-1])
・ 「#2389. 文字体系の起源と発達 (1)」 ([2015-11-11-1])
・ 「#2390. 文字体系の起源と発達 (2)」 ([2015-11-12-1])
・ 「#2398. 文字の系統 (3)」 ([2015-11-20-1])
・ 「#2399. 象形文字の年表」 ([2015-11-21-1])
・ 「#2414. 文字史年表(ロビンソン版)」 ([2015-12-06-1])
・ 「#2416. 文字の系統 (4)」 ([2015-12-08-1])
・ 「#3443. 表音文字と表意文字」 ([2018-09-30-1])
[ アルファベットの歴史・特徴 ]
・ 「#423. アルファベットの歴史」 ([2010-06-24-1])
・ 「#490. アルファベットの起源は North Semitic よりも前に遡る?」 ([2010-08-30-1])
・ 「#1861. 英語アルファベットの単純さ」 ([2014-06-01-1])
・ 「#2105. 英語アルファベットの配列」 ([2015-01-31-1])
・ 「#2888. 文字史におけるフェニキア文字の重要性」 ([2017-03-24-1])
[ 文字の伝播と文字帝国主義 ]
・ 「#1838. 文字帝国主義」 ([2014-05-09-1])
・ 「#2429. アルファベットの卓越性という言説」 ([2015-12-21-1])
・ 「#850. 書き言葉の発生と論理的思考の関係」 ([2011-08-25-1])
・ 「#2577. 文字体系の盛衰に関わる社会的要因」 ([2016-05-17-1])
・ 「#3486. 固有の文字を発明しなかったとしても……」 ([2018-11-12-1])
・ 「#3700. 「アルファベットと鉄による文明の大衆化」論」 ([2019-06-14-1])
・ 「#3768. 「漢字は多様な音をみえなくさせる,『抑制』の手段」」 ([2019-08-21-1])
・ 「#3837. 鈴木董(著)『文字と組織の世界史』 --- 5つの文字世界の発展から描く新しい世界史」 ([2019-10-29-1])
[ 絵文字と句読法 ]
・ 「#808. smileys or emoticons」 ([2011-07-14-1])
・ 「#2244. ピクトグラムの可能性」 ([2015-06-19-1])
・ 「#2400. ピクトグラムの可能性 (2)」 ([2015-11-22-1])
・ 「#574. punctuation の4つの機能」 ([2010-11-22-1])
・ 「#575. 現代的な punctuation の歴史は500年ほど」 ([2010-11-23-1])
・ 「#3045. punctuation の機能の多様性」 ([2017-08-28-1])
2023-01-26 Thu
■ #5022. hellog より文字(論)に関する記事を厳選 [link][grammatology][speech][writing][medium][alphabet][alphabet][punctuation][kanji]
本ブログでは広く文字論 (grammatology) に関する話題を多く取り上げてきた.標題に掲げているタグなどを辿っていくと多くの記事にアクセスできるが,それでも数が多くて選びにくいと思われるので,ここに記事タイプごとにお勧め記事を厳選し,リンクを整理しておきたい.「文字」に関心のある方にとって,参考になると思います.
[ 話し言葉と書き言葉,文字の性質 ]
・ 「#230. 話しことばと書きことばの対立は絶対的か?」 ([2009-12-13-1])
・ 「#748. 話し言葉と書き言葉」 ([2011-05-15-1])
・ 「#849. 話し言葉と書き言葉 (2)」 ([2011-08-24-1])
・ 「#1001. 話しことばと書きことば (3)」 ([2012-01-23-1])
・ 「#1664. CMC (computer-mediated communication)」 ([2013-11-16-1])
・ 「#1665. 話しことばと書きことば (4)」 ([2013-11-17-1])
・ 「#1829. 書き言葉テクストの3つの機能」 ([2014-04-30-1])
・ 「#2301. 話し言葉と書き言葉をつなぐスペクトル」 ([2015-08-15-1])
・ 「#2417. 文字の保守性と秘匿性」 ([2015-12-09-1])
・ 「#2701. 暗号としての文字」 ([2016-09-18-1])
・ 「#3274. 話し言葉と書き言葉 (5)」 ([2018-04-14-1])
・ 「#3886. 話しことばと書きことば (6)」 ([2019-12-17-1])
[ 文字の種類・歴史 ]
・ 「#422. 文字の種類」 ([2010-06-23-1])
・ 「#1822. 文字の系統」 ([2014-04-23-1])
・ 「#1834. 文字史年表」 ([2014-05-05-1])
・ 「#1849. アルファベットの系統図」 ([2014-05-20-1])
・ 「#1853. 文字の系統 (2)」 ([2014-05-24-1])
・ 「#2389. 文字体系の起源と発達 (1)」 ([2015-11-11-1])
・ 「#2390. 文字体系の起源と発達 (2)」 ([2015-11-12-1])
・ 「#2398. 文字の系統 (3)」 ([2015-11-20-1])
・ 「#2399. 象形文字の年表」 ([2015-11-21-1])
・ 「#2414. 文字史年表(ロビンソン版)」 ([2015-12-06-1])
・ 「#2416. 文字の系統 (4)」 ([2015-12-08-1])
・ 「#3443. 表音文字と表意文字」 ([2018-09-30-1])
[ アルファベットの歴史・特徴 ]
・ 「#423. アルファベットの歴史」 ([2010-06-24-1])
・ 「#490. アルファベットの起源は North Semitic よりも前に遡る?」 ([2010-08-30-1])
・ 「#1861. 英語アルファベットの単純さ」 ([2014-06-01-1])
・ 「#2105. 英語アルファベットの配列」 ([2015-01-31-1])
・ 「#2888. 文字史におけるフェニキア文字の重要性」 ([2017-03-24-1])
[ 文字の伝播と文字帝国主義 ]
・ 「#1838. 文字帝国主義」 ([2014-05-09-1])
・ 「#2429. アルファベットの卓越性という言説」 ([2015-12-21-1])
・ 「#850. 書き言葉の発生と論理的思考の関係」 ([2011-08-25-1])
・ 「#2577. 文字体系の盛衰に関わる社会的要因」 ([2016-05-17-1])
・ 「#3486. 固有の文字を発明しなかったとしても……」 ([2018-11-12-1])
・ 「#3700. 「アルファベットと鉄による文明の大衆化」論」 ([2019-06-14-1])
・ 「#3768. 「漢字は多様な音をみえなくさせる,『抑制』の手段」」 ([2019-08-21-1])
・ 「#3837. 鈴木董(著)『文字と組織の世界史』 --- 5つの文字世界の発展から描く新しい世界史」 ([2019-10-29-1])
[ 絵文字と句読法 ]
・ 「#808. smileys or emoticons」 ([2011-07-14-1])
・ 「#2244. ピクトグラムの可能性」 ([2015-06-19-1])
・ 「#2400. ピクトグラムの可能性 (2)」 ([2015-11-22-1])
・ 「#574. punctuation の4つの機能」 ([2010-11-22-1])
・ 「#575. 現代的な punctuation の歴史は500年ほど」 ([2010-11-23-1])
・ 「#3045. punctuation の機能の多様性」 ([2017-08-28-1])
2022-05-15 Sun
■ #4766. 『中高生の基礎英語 in English』の連載第15回「なぜ I は大文字で書くの?」 [notice][sobokunagimon][rensai][minim][spelling][orthography][punctuation][capitalisation][alphabet][hel_contents_50_2022][hellog_entry_set]
『中高生の基礎英語 in English』の6月号が発売となりました.連載「歴史で謎解き 英語のソボクな疑問」の第15回は,英語史上の定番ともいえる素朴な疑問を取り上げています.なぜ1人称単数代名詞 I は常に大文字で書くのか,というアノ問題です.

関連する話題は,本ブログでも「#91. なぜ一人称単数代名詞 I は大文字で書くか」 ([2009-07-27-1]) をはじめ様々な形で取り上げてきましたが,背景には中世の小文字の <i> の字体に関する不都合な事実がありました.上の点がなく <ı> のように縦棒 (minim) 1本で書かれたのです.これが数々の「問題」を引き起こすことになりました.連載記事では,このややこしい事情をなるべく分かりやすく解説しましたので,どうぞご一読ください.
実は目下進行中の khelf イベント「英語史コンテンツ50」において,4月15日に大学院生により公開されたコンテンツが,まさにこの縦棒問題を扱っています.「||||||||||←読めますか?」というコンテンツで,これまでで最も人気のあるコンテンツの1つともなっています.連載記事と合わせて,こちらも覗いてみてください.
連載記事では,そもそもなぜアルファベットには大文字と小文字があるのかという,もう1つの素朴な問題にも触れています.これについては以下をご参照ください.
・ hellog-radio: #1. 「なぜ大文字と小文字があるのですか?」
・ heldio: 「#50. なぜ文頭や固有名詞は大文字で始めるの?」
・ heldio: 「#136. 名詞を大文字書きで始めていた17-18世紀」
・ 関連する記事セット
ほぼ1年ほど前のことになりますが,2021年5月14日(金)に NHK のテレビ番組「チコちゃんに叱られる!」にて「大文字と小文字の謎」と題してこの話題が取り上げられ,私も監修者・解説者として出演しました(懐かしいですねぇ). *
Powered by WinChalow1.0rc4 based on chalow