2026-01-06 Tue
■ #6098. 2025年度の朝カルシリーズ講座の第9回「one --- 単なる数から様々な用法へ広がった語」をマインドマップ化してみました [asacul][mindmap][notice][etymology][one][numeral][article][link][hel_education][one]
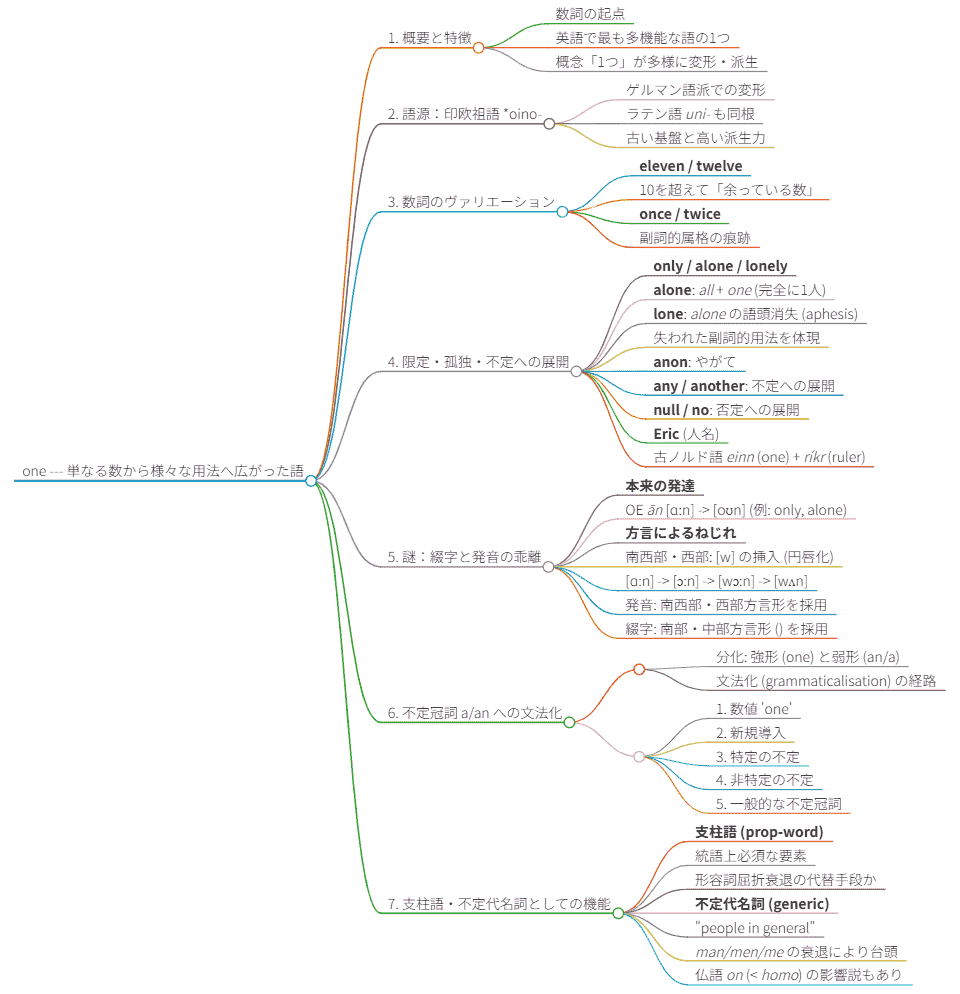
12月20日(土)に,今年度の朝日カルチャーセンターのシリーズ講座「歴史上もっとも不思議な英単語」の第9回が,秋期クールの第3回として開講されました.テーマは「one --- 単なる数から様々な用法へ広がった語」でした.
あまりに当たり前の単語ですが,英語史的には実に奥の深い語彙項目で,じっくり鑑賞するに値する対象です.いかにして基本的な数詞の役割から,文法化を経て不定冠詞となり,不定代名詞となり,支柱語となったのでしょうか.基本語だけに,そこから語形成を経て生じた関連語も多く,その1つひとつもやはり興味深い歴史をたどっています.実際,講義の90分では語りきれないほどでした.それほど one の世界は深くて広くて深いのです.
この朝カル講座第9回の内容を markmap によりマインドマップ化して整理しました.復習用にご参照いただければ.
なお,この朝カル講座のシリーズの第1回から第8回についてもマインドマップを作成しているので,そちらもご参照ください.
・ 「#5857. 2025年度の朝カルシリーズ講座の第1回「she --- 語源論争の絶えない代名詞」をマインドマップ化してみました」 ([2025-05-10-1])
・ 「#5887. 2025年度の朝カルシリーズ講座の第2回「through --- あまりに多様な綴字をもつ語」をマインドマップ化してみました」 ([2025-06-09-1])
・ 「#5915. 2025年度の朝カルシリーズ講座の第3回「autumn --- 類義語に揉み続けられてきた季節語」をマインドマップ化してみました」 ([2025-07-07-1])
・ 「#5949. 2025年度の朝カルシリーズ講座の第4回「but --- きわめつきの多義の接続詞」をマインドマップ化してみました」 ([2025-08-10-1])
・ 「#5977. 2025年度の朝カルシリーズ講座の第5回「guy --- 人名からカラフルな意味変化を遂げた語」をマインドマップ化してみました」 ([2025-09-07-1])
・ 「#6013. 2025年度の朝カルシリーズ講座の第6回「English --- 慣れ親しんだ単語をどこまでも深掘りする」をマインドマップ化してみました」 ([2025-10-01-1])
・ 「#6041. 2025年度の朝カルシリーズ講座の第7回「I --- 1人称単数代名詞をめぐる物語」をマインドマップ化してみました」 ([2025-11-10-1])
・ 「#6076. 2025年度の朝カルシリーズ講座の第8回「take --- ヴァイキングがもたらした超基本語」をマインドマップ化してみました」 ([2025-12-15-1])
シリーズは次回より冬期クールに入ります.次回の第10回は新年1月31日(土)に「very --- 「本物」から大混戦の強意語へ」と題して開講されます.開講形式は引き続きオンラインのみで,開講時間は 15:30--17:00 です.ご関心のある方は,ぜひ朝日カルチャーセンター新宿教室の公式HPより詳細をご確認の上,お申し込みいただければ幸いです.
2025-12-17 Wed
■ #6078. an one man --- an 単語が数詞ではなく不定冠詞と分かる例 [article][numeral][grammaticalisation][syntax][me]
歴史的に文法化 (grammaticalisation) を扱う研究をみていると,ある言語項が文法化したといえるのはいつか,どんな例が現われれば確実に文法化したと言い切れるか,という問題に出くわす機会がある.文法化は形式上の問題であると同時に意味の問題でもあるが,意味は研究者が自説に都合よく「読み込む」ことができてしまう.したがって,「この例文では文法化がすでに生じている」と主張するためには,なるべく主観を排して,客観的に確認でき,かつ説得力のある言語学的根拠を示す必要がある.特に形式的な観点から示せるとベストである.
例えば,数詞 one はいつから不定冠詞 (indefinite article) へ文法化したのか,という問題を考えてみる.音韻形態的には古英語 ān が弱まって an や a となったときだと考えたくなるが,中英語期には現代に連なる one を含め,多種多様な強形・弱形が現われており,それぞれが数詞とも不定冠詞とも解釈できる例があり,決着がつかない.1200年前後に書かれた討論詩 The Owl and the Nightingale の ll. 3--4 の "Iherde ich holde grete tale / An hule and one niȝtingale." などを参照されたい.
しかし,統語的な観点から迫る方法がありそうだ.それは標題の an one man のように,2つの "one" が並んで現われるケースだ.この場合,1つめの an が不定冠詞で,2つめの one が数詞である,と結論づけるのは自然であり異論はないだろう.前者は「初出・存在」を標示する文法的な機能を担っているのに対し,後者は「1人・個人」を意味する数詞として機能している語として解釈できる.これは架空の句ではなく,Mustanoja が後期中英語の Gower より引いた実在の表現である.以下に引用する (291) .
For thei be manye, and he [i.e., the king] is on; And rathere schal an one man With fals conseil, for oght he can, From his wisdom be maad to falle (Gower CA vii 4161)
現代英語では「不定冠詞 a + 数詞 one + 名詞」という句は許されないが,中英語にはこれがみられた(もっとも,非常にまれだったことは Mustanoja (291) も述べているが).ちなみに「定冠詞 the + 数詞 one + 名詞」は現代英語でも on the one hand, the one thing, the one exception などと普通にみられる.
・ Mustanoja, T. F. A Middle English Syntax. Helsinki: Société Néophilologique, 1960.
2025-12-16 Tue
■ #6077. 「ただ1人・1つ」を意味する副詞的な one [one][adjective][adverb][oe][me][article][numeral]
one について,現代英語では失われてしまった副詞的な用法がある.「ただ1人・1つ;~だけ」を意味する only や alone に近い用法だ.古英語や中英語では普通に見られ,同格的に名詞と結びつく場合には one は統語的に一致して屈折変化を示したので,起源としては形容詞といってよい.しかし,その名詞から遊離した位置に置かれることもあり,その点で副詞的ともいえるのだ.
Mustanoja は "exclusive use" と呼びつつ,この one の用法について詳述している.以下,一部を引用しよう (293--94) .
EXCLUSIVE USE. --- The OE exclusive an, calling attention to an individual as distinct from all others, in the sense 'alone, only, unique,' occurs mostly after the governing noun or pronoun (se ana, þa anan, God ana), but anteposition is not uncommon either (an sunu, seo an sawul, to þæm anum tacne). It has been suggested by L. Bloomfield (see bibliography) that anteposition of the exclusive an is due to the influence of the conventional phraseology of religious Latin writings (unus Deus, solus Deus, etc.). After the governing word the exclusive one is used all through the ME period: --- he is one god over alle godnesse; He is one gleaw over alle glednesse; He is one blisse over alle blissen; He is one monne mildest mayster; He is one folkes fader and frover; He is one rihtwis ('he alone is good . . .' Prov. Alfred 45--55, MS J); --- ȝe . . . ne sculen habben not best bute kat one (Ancr. 190); --- let þe gome one (Gaw. & GK 2118). Reinforced by all, exclusive one develops into alone in earliest ME (cf. German allein and Swedish allena), and this combination, after losing its emphatic character, is in turn occasionally strengthened by all: --- and al alone his wey than hath he nome (Ch. LGW 1777).
引用の最後のくだりでは,現代の alone や all alone の語源に触れられている.要するにこれらは,今はなき副詞的 one の用法を引き継いで残っている表現ということになる.そして,類義の only もまた one の派生語である.
・ Mustanoja, T. F. A Middle English Syntax. Helsinki: Société Néophilologique, 1960.
・ Bloomfield, L. "OHG Eino, OE Ana = Solus." Curme Volume of Linguistic Studies. Language Monograph VII, Linguistic Soc. of America, Philadelphia 1930. 50--59.
2025-12-11 Thu
■ #6072. 12月20日(土),朝カル講座の秋期クール第3回「one --- 単なる数から様々な用法へ広がった語」が開講されます [asacul][notice][one][numeral][indefinite_pronoun][kdee][hee][etymology][lexicology][spelling_pronunciation_gap][hel_education][helkatsu][prop_word][pronoun]

今年度,毎月1度の朝日カルチャーセンター新宿教室での英語史講座「歴史上もっとも不思議な英単語」シリーズも,これまで順調に進んでいます.来週末の12月20日(土),年内では最後となる,秋期クールの第3回(今年度通算第9回)が開講される予定です.今回は,一見すると何の変哲もない one という単語に注目します.
ただの数詞にすぎない,といえばそうなのですが,実はただものではありません.
・ one の綴字と発音の乖離
・ 不定冠詞 a/an への発達
・ 語源的関連語 any, alone, atone, only, other, none, no
・ 複合語 someone, anyone no one
・ 1つなのに複数形 ones がある?
・ 「屈折形」の one's, oneself
・ 代名詞としての one
・ 支柱語としての one
・ one of . . . の語法
one が数詞から尋常ならざる発達を遂げ,問題がありすぎる語へと変質してきたらしいことが見て取れるのではないでしょうか.むしろ卑近で高頻度で当たり前の単語だからこそ,様々な用法を生み出してきたといえます.講座では,この小さくも大きな語彙項目に,英語史の観点から90分じっくり向き合います.
講座への参加方法は,前回同様にオンライン参加のみとなっています.リアルタイムでのご参加のほか,2週間の見逃し配信サービスもありますので,ご都合のよい方法でご受講ください.開講時間は 15:30--17:00 です.講座と申込みの詳細は朝カルの公式ページよりご確認ください.
(以下,後記:2025/12/13(Sat)))
本講座の予告については heldio にて「「#1658. 12月20日の朝カル講座は one --- 単なる数から様々な用法へ広がった語」」としてお話ししています.ぜひそちらもお聴きください.
・ 寺澤 芳雄(編集主幹) 『英語語源辞典』新装版 研究社,2024年.
・ 唐澤 一友・小塚 良孝・堀田 隆一(著),福田 一貴・小河 舜(校閲協力) 『英語語源ハンドブック』 研究社,2025年.
2025-07-08 Tue
■ #5916. Jespersen による2桁の複合数詞の小史 [numeral][jespersen][compound][morphology][syntax][conjunction][word_order]
数詞「21」のことを英語で何というか? もちろん twenty-one である.しかし,歴史的には異なる表現法があった.伝統的には one and twenty が普通だったが,ときに twenty and one もあった.複合数詞は,1の位と10の位の数のどちらを前に置くのか,接続詞 and を用いるのか,といった観点から探ると,揺れ動いてきた歴史があることがわかる.身近に複合数詞を研究している大学院生がおり,私もこの問題にはアンテナを張っているのだが,切り口が豊富にあるなという印象をもっている.
2桁の複合数詞について,Jespersen (§§17.14--6) が歴史上の変化と変異を概観している.この問題を考察する手始めとして,引用しておこう.
17.14. In additions of 'tens' and 'ones' this 'one' now generally follows the 'ten' (twenty-one), but originally it always preceded it: one-and-twenty, a word-order which is still used except in numerals above 50.
The only examples I have noticed of the latter word-order in numerals above 50 are the following: Sheridan 197 she's six-and-fifty if she's an hour | Coleridge 452 in Köhln . . . I counted two and seventy stenches | Wells TB 163 Fifty-three days I had outward . . . three and fifty days of life cooped up | Walpole ST 285 never in all his five-and-fifty years.
17.15. We may find both types of word-order in close proximity: Sh H5 1.2.57 Untill foure hundred one and twentie yeeres . . . ib 61 Foure hundred twentie six | Defoe R 330 eight and twenty years . . . thirty and five years | Thack E 1.147 accepted the Thirty-nine Articles with all his heart, and would have signed and sworn to other nine-and-thirty with an entire obedience | Kipling PT 43 She was two-and-twenty, and he was thirty-three | Caine M 131 you are still so young. Let me see, is it eight-and-twenty? --- Twenty-six, said Philip | Jerome T 37 P. was forty-seven ... W. was three-and-twenty | Wells N 142 He was six and twenty, and I twenty-two | ib 199 I grew ... between three and twenty and twenty-seven.
Mr. Walt Arneson states: "Used in U.S. only occasionally, for stylistic effect or facetiously."
17.16. Compounds of two numerals denoting a number below one hundred have and between the two members if the small numeral precedes: one-and-twenty. If it follows the higher numeral, there is generally no connecting word: twenty-one. Especially in early authors we may find the type twenty-and-two, e.g. Malory 101 xx & viij knyghtes | AV Luke 15.7 ninety and nine iust persons | Swift P 132 there are thirty-and-two good bits in a shoulder of veal | Fielding T 1.17 | Goldsm 645 | Carlyle S 16 | Bennett A 50.
If two neighbouring numerals are to be used, the type with the small number first is commonest, as in this case the higher numeral need not be repeated: Thack E 2.150 though now five or six and forty years | Locke CA 315 Between Nadia and him there was but a separation of two or three years; between Nadia and myself two or three and twenty | Crofts Cask 220 a girl of perhaps two or three-and-twenty.
現代でも古風な表現として用いられる one-and-twenty が,50以上の数については,これが見られないというのが不可思議である.また,同一の文脈で異なるパターンの複合数詞が現われるというのは興味深い.統語論の話題でありながら形態論にも深く関わっており,問題の位置づけについても考察に値する.
・ Jespersen, Otto. A Modern English Grammar on Historical Principles. Part 7. Syntax. 1954. London: Routledge, 2007.
2024-11-07 Thu
■ #5673. 10月,Mond で5件の質問に回答しました [mond][sobokunagimon][hel_education][notice][link][helkatsu][numeral][grammaticalisation][number][category][dual][negation][perfect][subjunctive][heldio]
先月,知識共有サービス Mond にて5件の英語に関する質問に回答しました.新しいものから遡ってリンクを張り,回答の要約も付します.
(1) なぜ数量詞は遊離できるのに,冠詞や所有格は遊離できないの?
回答:理論的には数量詞句 (QP) と限定詞句 (DP) の違いによるものと説明できそうですが,一筋縄では行きません.歴史的にいえば,古英語から現代英語に至るまで,数量詞遊離は常に存在していましたが,時代とともに制限が厳しくなってきているという事実があります.詳しくは新刊書の田中 智之・縄田 裕幸・柳 朋宏(著)『生成文法と言語変化』(開拓社,2024年)をご参照ください.
(2) have got to の got とは何なのでしょうか?
回答:have got は本来「獲得したところだ」という現在完了の意味でしたが,16世紀末から「持っている」という単純な意味に転じました.文法化 (grammaticalisation) の過程を経て,口語で have の代用として定着しています.「#5657. 迂言的 have got の発達 (1)」 ([2024-10-22-1]),「#5658. 迂言的 have got の発達 (2)」 ([2024-10-23-1]) を参照.
(3) 英語では単数形,複数形の区別がありますが,なぜ「1とそれ以外」なのでしょうか?
回答:「1」が他の数と比べて特に基本的で重要な数であるためと考えられます.古英語には双数形もありましたが,中英語以降は単数・複数の2区分となりました.世界の言語では最大5区分まで持つものもあります.「#5660. なぜ英語には単数形と複数形の区別があるの? --- Mond での質問と回答より」 ([2024-10-25-1]) を参照.
(4) 完了形はなぜ動作の継続を表現できるのでしょうか?
回答:完了形の諸用法の共通点は「現在との関与」です.継続の意味は主に状態動詞で現われ,動作動詞では完了の意味が表出します.また「時間的不定性」も完了形の重要な特徴と考えられます.「#5651. 過去形に対する現在完了形の意味的特徴は「不定性」である」 ([2024-10-16-1]) を参照.
(5) subjunctive mood (仮定法・接続法)の現在完了について
回答:仮定法現在完了は理論上存在可能で実例も見られますが,比較的まれです.仮定法の体系は「現在・過去・過去完了」の3つ組みとして理解するのが妥当で,その中で完了相が必要な場合に現在完了形が使用される,と解釈するのはいかがでしょうか.
以上です.11月も Mond にて英語(史)に関する素朴な疑問を受け付けています.気になる問いをお寄せください.
2024-06-30 Sun
■ #5543. syntagmatic contamination と paradigmatic contamination [language_change][analogy][folk_etymology][contamination][assimilation][numeral][collocation][semantics][antonymy]
言語変化 (language_change) の基本的な原動力の1つである類推作用 (analogy) に関する本格的な研究書,Fertig の Analogy and Morphological Change についてはこちらの記事群で取り上げてきた.
今回は Fertig を参照し,contamination (混成)と呼ばれるタイプの類推作用について考えてみたい.「混成」とその周辺の現象が明確に分けられるかどうかについては議論があり,「#5419. blending と contamination」 ([2024-02-27-1]) でも関連する話題を取り上げたが,ひとまず contamination を区別できるものと理解し,そのなかに2つのタイプがあるという議論を導入したい.syntagmatic contamination と paradigmatic contamination である.具体例とともに Fertig からの関連箇所を引用する (64) .
Paul's initial conception of contamination (1886) involved influence attributable exclusively to paradigmatic (semantic) relations between forms, but he later (1920) recognized that lexical contamination often involves items that are not only semantically related but also frequently occur in close proximity in utterances. The importance of these syntagmatic relationships is emphasized in almost all modern accounts of contamination (Campbell 2004: 118--20 being the only exception that I am aware of). The most frequently cited examples involve adjacent numerals, which often influence each other's phonetic make-up: English eleven < Proto-Gmc. *ainlif under the influence of ten; Latin novem 'nine' instead of expected *noven under the influence of decem 'ten'; Greek dialectal hoktō 'eight' under the influence of hepta 'seven' (Osthoff 1878b; Trask 1996: 111--12; Hock and Joseph 2009: 163). Similar effects are attested in a number of languages among days of the week and months of the year, e.g. post-classical Latin Octember < Octōber under the influence of November and December.
Such contamination attributable to syntagmatic proximity of the affecting and affected items is often characterized as distant assimilation. Some scholars characterize contamination as a kind of assimilation even when it is purely paradigmatically motivated. Anttila calls it 'assimilation . . . toward another word in the semantic field' (1989: 76). Andersen (1980: 16--17) explicitly distinguishes such 'paradigmatic assimilation' from the more familiar 'syntagmatic assimilation'. As an unambiguous example of the latter, he mentions the influence of one word on another within a formulaic expression, such as French au fur et à mesure 'as, in due course' < Old French au feur et mesure (Wackernagel 1926: 49--50). Contamination involving antonyms, such as Late Latin sinexter < sinister 'left' under the influence of dexter 'right' or Vulgar Latin grevis < gravis 'heavy' under the influence of levis 'light', could be both paradigmatically and syntagmatically motivated since antonyms frequently co-occur in close proximity within an utterance, especially in questions: Is that thing heavy or light? Should I turn right or left? Wundt's view of paradigm leveling as a type of assimilation should also be mentioned in this context (Paul 1920: 116n 1).
syntagmatic contamination と paradigmatic contamination の2種類を区別しておくことは,理論的には重要だろう.しかし,実際的には両者は互いに乗り入れており,分別は難しいのではないかと思われる.paradigmatic な関係にある2者は syntagmatic には and などの等位接続詞で結ばれることも多いし,逆に syntagmatic に共起しやすい2者は paradigmatic にも意味論的に強固に結びつけられているのが普通だろう.
個々の事例が,いずれかのタイプの contamination であると明言することができるのかどうか,あるいはできるとしても,そう判断してよい条件は何か,という問題が残っているように思われる.
・ Fertig, David. Analogy and Morphological Change. Edinburgh: Edinburgh UP, 2013.
2024-06-27 Thu
■ #5540. Chancery English にみる数詞のスペリングの揺れ [chancery_standard][spelling][numeral]
昨日の記事「#5539. Chancery English にみる語源的綴字」 ([2024-06-26-1]) や,少し前の「#5535. 接頭辞 en- と in- の揺れを Chancery English でみる」 ([2024-06-22-1]) で,Chancery English におけるスペリングの揺れを観察してきた.今回も Fisher et al. によるアンソロジーの "Glossary of Forms" を利用して,今度は数詞 (numeral) という別の語類のスペリング変異を拾い上げてみた.アンソロジーには,主要な数詞のすべてが現われるわけではないので,あくまで Chancery English における数詞のスペリングの揺れの部分集合を確認するにとどまる.参考まで.
- one n. and adj. (17) P3, C3; on (9) P3, C3; oon (4) C8, S1; oone (1) C4; oo (5) P2 (D.122); o (3) C8, S1.
- first adj. (9), adv. (7) S1, P2; firste (1) C5; furst (9) S1, S2; ffirst (2) P2; ferst (2) C3, C5; ferste (2) C1, C3; fyrst (1) N8; furste (1) C3. There are no distinctions between adj. and adv. usage.
- two adj. (24) S1, P1; twoo (3) C5; too (5) P3, C3; twey (2) C1, C5; tweye (1) P5.
- twayn adj. two. (1) C3; tweyn (1) C3.
- twelve n. and adj. (1) C1 (D.163.47); twelf (2) C2, N5.
- twelfemonethe n. (1) C3; tuelfmoneth (1) C3; twolfmonth (1) P2.
- twenty adj. (2) N5 (D.240).
- second adj. (6) S1, C1; seconde (5) P3, C3; secund(e) (2) P3, C3.
- three adj. and n. (1) P2; thre (3) P3, C3; þre (2) P3, C3.
- third adj. (3) C5; thridde (9) C3, P4; thrid (3) P4; þrydde (2) N2; thirde (1) N2; thryd (1) N8, C3; þredde (1) P5 (D.159.33); pl. thriddes (3) P4 (D.156).
- thirdly adv. thirdly. (1) S2 (D.78.7).
- four(e) adj. (3) C1, C2.
- fourthe ordinal adj. (2) P3, N2 (D.144.9, 234.1); four (1) C1 (D.163.4).
- fourtieth adj. (2) N6.
- fifte adj. fith. (2) P3, N5; fyfte (2) C3.
- sixt adj. (1) N5; syxth (3) N5 (D.241); sext (2) N2; sixte (1) C3; sexte (1) N2.
- tenthe n. (1) P5 (D.159,36).
- hundred numeral (2) P3, N5; hundreth (1) P3 (D.143.3); hundred n. subdivision of a county. (1) C3; pl. hundredes (2) P3. C3.
とりわけ third については「#92. third の音位転換はいつ起こったか」 ([2009-07-28-1]) や 「#93. third の音位転換はいつ起こったか (2)」 ([2009-07-29-1]) でも中英語スペリングの揺れを列挙した.15世紀の Chancery English でも,数詞という語類において揺れはまだかなり残っている.
ちなみに,去る6月23日(日)に開催された近代英語協会第41回大会(日本大学)のシンポジウム「初期近代英語期におけるスペリング」において,第3発表者として「数詞のスペリングの揺れと標準化 --- 後期中英語から初期近代英語へ」をお話ししました.昨日と今日の記事は,その内容からということです.
・ Fisher, John H., Malcolm Richardson, and Jane L. Fisher, comps. An Anthology of Chancery English. Knoxville: U of Tennessee P, 1984. 392.
2024-06-16 Sun
■ #5529. なぜ once の -ce が古英語属格の -es 由来であるなら,語末子音は /z/ にならず /s/ なの? [sobokunagimon][numeral][reanalysis][inflection][genitive][adverbial_genitive][adverb][verners_law]
今回は英語の先生より寄せられた疑問を紹介します.標題はもはや素朴な疑問 (sobokunagimon) の域を超えており,高度な英語史リテラシーを持っていて初めて生ずる疑問だろうと思います.
まず歴史的事実として,頻度・度数の副詞 once や twice の -ce は古英語の男性・中性の単数属格語尾 -es に遡ります.歴史的には副詞的属格の典型例となります.この件については「#84. once, twice, thrice」 ([2009-07-20-1]) と「#4081. once や twice の -ce とは何か (2)」 ([2020-06-29-1]) で話題にしました.
once の語末子音が古英語の属格の -es(現代英語の所有格の 's に相当)に起源をもつのであれば,once の発音は現代の one's /wʌnz/ と同じになりそうなものですが,実際には語末子音は無声音で /wʌns/ となります.これはどうしたことか,という高度な疑問です.
今回の素朴な疑問については,先に挙げた2つめの hellog 記事「#4081. once や twice の -ce とは何か (2)」 ([2020-06-29-1]) の後半でも少し触れています.その部分を引用すると,問題のこの単語は
中英語では ones, twies, thrise などと s で綴られるのが普通であり,発音としても2音節だったが,14世紀初めまでに単音節化し,後に s の発音が有声化する契機を失った.それに伴って,その無声音を正確に表わそうとしたためか,16世紀以降は <s> に代わって <ce> の綴字で記されることが一般的になった.
ここで言わんとしていることは,副詞の once, twice, thrice は,その起源や語形成の観点からは属格と結びつけられるものの,おそらく中英語期にはすでにその発想が忘れ去られ,one + -es としては(少なくとも明確には)分析されないようになり,全体が1つの語幹であると意識されるに至ったのだろう,ということです.折しも中英語後期には -es の母音が弱化・消失し,単語全体が1音節となったことにより,1つの語幹としての意識がますます強くなったと思われます.だからこそ,続く近代英語期には,もはや屈折語尾を想起させる -<(e)s> と綴るのはふさわしくなく,同部分があくまで語幹の一部であるという解釈を促す -<ce> という綴字へと差し替えられたのではないでしょうか.
最後に語末子音の有声・無声の問題について触れます.古英語から中英語にかけて,屈折語尾として解釈された -(e)s は /(ə)s/ のように無声子音を示していました.ところが,近代英語期にかけて,この屈折語尾音節の /s/ が /z/ へと有声化します(これについては「#858. Verner's Law と子音の有声化」 ([2011-09-02-1]) を参照).これにより,現代では(後の歴史的な事情により,有声音に先行される場合に限ってとなりますが)所有格語尾の -'s は /z/ で発音されることになっています.
しかし,副詞 once の類いは,この一般的な音変化の流れに,どうも乗らなかったようなのです.それは,先にも述べたように,早い段階から,問題の語尾が屈折語尾ではなく語幹の一部として認識されるようになっていたこと,また単語が1音節に縮まっていたことが関係していると思われます.
2024-05-17 Fri
■ #5499. 古英語の数詞 [oe][numeral][voicy][heldio][link]
Sweet's Anglo-Saxon Primer (20--21) より古英語の数詞 (numeral) を挙げる.基数詞 (cardinal numbers) と序数詞 (ordinal numbers) の各々を列挙する.
| Cardinal | Ordinal | |
| 1(st) | ān | forma |
| 2(nd) | twā | ōþer |
| 3(rd) | þrēo | þridda |
| 4(th) | fēower | fēorþa |
| 5(th) | fīf | fīfta |
| 6(th) | siex | siexta |
| 7(th) | seofon | seofoþa |
| 8(th) | eahta | eahtoþa |
| 9(th) | nigon | nigoþa |
| 10(th) | tīen | tēoþa |
| 11(th) | en(d)leofon | en(d)leofta |
| 12(th) | twelf | twelfta |
| 13(th) | þrēo-tīene | þrēo-tēoþa |
| ... | ... | ... |
| 19(th) | nigon-tīene | nigon-tēoþa |
| 20(th) | twen-tiġ | twentigoþa |
| 30(th) | þrī-tiġ | þrītigoþa |
| 40(th) | fēower-tiġ | fēowertigoþa |
| 50(th) | fīf-tiġ | fīftigoþa |
| 60(th) | siex-tiġ | siextigoþa |
| 70 | hund・seofon-tiġ | |
| 80 | hund・eahta-tiġ | |
| 90 | hund・nigon-tiġ | |
| 100 | hund, hundred, hund・tēon-tiġ | |
| 110 | hund・endleofon-tiġ | |
| 120 | hund・twelf-tiġ | |
| 1000 | þūsend |
これまでも hellog や Voicy heldio で英語の数詞に関する話題を多々取り上げてきた.以下に主なコンテンツへのリンクを張っておく.
・ hellog 「#67. 序数詞における補充法」 ([2009-07-04-1])
・ hellog 「#68. first は何の最上級か」 ([2009-07-05-1])
・ hellog 「#69. second の世界の広がり」 ([2009-07-06-1])
・ hellog 「#646. billion の値」 ([2011-02-02-1])
・ hellog 「#647. million 以上の大きな単位」 ([2011-02-03-1])
・ hellog 「#1080. なぜ five の序数詞は fifth なのか?」 ([2012-04-11-1])
・ hellog 「#1823. ローマ数字」 ([2014-04-24-1])
・ hellog 「#2240. thousand は "swelling hundred"」 ([2015-06-15-1])
・ hellog 「#2285. hundred は "great ten"」 ([2015-07-30-1])
・ hellog 「#2286. 古英語の hundseofontig (seventy), hundeahtatig (eighty), etc.」 ([2015-07-31-1])
・ hellog 「#2304. 古英語の hundseofontig (seventy), hundeahtatig (eighty), etc. (2)」 ([2015-08-18-1])
・ hellog 「#2477. 英語にみられる20進法の残滓」 ([2016-02-07-1])
・ hellog 「#3104. なぜ「ninth(ナインス)に e はないんす」かね?」 ([2017-10-26-1])
・ hellog 「#3105. tithe と tenth」 ([2017-10-27-1])
・ hellog 「#4046. 歴史的に妙な ten の短母音」 ([2020-05-25-1])
・ hellog 「#4248. なぜ three と thirteen では r の位置が異なるのですか? --- hellog ラジオ版」 ([2020-12-13-1])
・ hellog 「#4429. 序数詞 third の d と fourth の th の関係」 ([2021-06-12-1])
・ heldio 「#10. third は three + th の変形なので準規則的」
・ heldio 「#419. 23 が「three and twenty」!?」
・ heldio 「#440. なぜ oneteen, twoteen ではなく eleven, twelve というの?」
・ heldio 「#442. 英語における12進法的発想」
・ heldio 「#443. 英語における20進法的発想」
・ Davis, Norman. Sweet's Anglo-Saxon Primer. 9th ed. Oxford: Clarendon, 1953.
2023-11-12 Sun
■ #5312. 「ゆる言語学ラジオ」最新回は「不規則動詞はなぜ存在するのか?」 [yurugengogakuradio][verb][inflection][conjugation][sobokunagimon][frequency][voicy][heldio][youtube][link][notice][numeral][suppletion][analogy]
昨日,人気 YouTube/Podcast チャンネル「ゆる言語学ラジオ」の最新回が配信されました.今回は英語史ともおおいに関係する「不規則動詞はなぜ存在するのか?【カタルシス英文法_不規則動詞】#280」です.
ゆる言語学ラジオの水野太貴さんには,拙著,Voicy 「英語の語源が身につくラジオ」 (heldio),および YouTube チャンネル「井上逸兵・堀田隆一英語学言語学チャンネル」のいくつかの関連コンテンツに言及していただきました.抜群の発信力をもつゆる言語学ラジオさんに,この英語史上の第一級の話題を取り上げていただき,とても嬉しいです.このトピックの魅力が広く伝わりますように.
概要欄に掲載していただいたコンテンツ等へのリンクを,こちらにも再掲しておきます.
・ 拙著 『英語の「なぜ?」に答えるはじめての英語史』(研究社,2016年)
・ 拙著 『英語史で解きほぐす英語の誤解 --- 納得して英語を学ぶために』(中央大学出版部,2011年)
・ heldio 「#58. なぜ高頻度語には不規則なことが多いのですか?」
・ YouTube 「新説! go の過去形が went な理由」 (cf. 「#4774. go/went は社会言語学的リトマス試験紙である」 ([2022-05-23-1]))
・ YouTube 「英語の不規則活用動詞のひきこもごも --- ヴァイキングも登場!」 (cf. hellog 「#4810. sing の過去形は sang でもあり sung でもある!」 ([2022-06-28-1]))
・ YouTube 「昔の英語は不規則動詞だらけ!」 (cf. 「#4807. -ed により過去形を作る規則動詞の出現は革命的だった!」 ([2022-06-25-1]))
・ heldio 「#9. first の -st は最上級だった!」
・ heldio 「#10. third は three + th の変形なので準規則的」
・ heldio 「#11. なぜか second 「2番目の」は借用語!」
「不規則動詞はなぜ存在するのか?」という英語に関する素朴な疑問から説き起こし,補充法 (suppletion) の話題(「ヴィヴァ・サンバ!」)を導入した後に,不規則形の社会言語学的意義を経由しつつ,全体として言語における「規則」あるいは「不規則」とは何なのかという大きな議論を提示していただきました.水野さん,堀元さん,ありがとうございました! 「#5130. 「ゆる言語学ラジオ」周りの話題とリンク集」 ([2023-05-14-1]) もぜひご参照ください.
2023-10-13 Fri
■ #5282. Jespersen の「近似複数」の指摘 [plural][number][numeral][personal_pronoun][personal_name][plural_of_approximation][semantics][pragmatics]
昨日の記事「#5281. 近似複数」 ([2023-10-12-1]) で話題にした近似複数 (plural_of_approximation) について,最初に指摘したのは Jespersen (83--85) である.この原典は読み応えがあるので,そのまま引用したい.
Plural of Approximation
4.51 The sixties (cf. 4.12) has two meanings, first the years from 60 to 69 inclusive in any century; thus Seeley E 249 the seventies and the eighties of the eighteenth century | Stedman Oxford 152 in the "Seventies" [i.e. 1870, etc.] | in the early forties = early in the forties. Second it may mean the age of any individual person, when he is sixty, 61, etc., as in Wells U 316 responsible action is begun in the early twenties . . . Men marry before the middle thirties | Children's Birthday Book 182 While I am in the ones, I can frolic all the day; but when I'm in the tens, I must get up with the lark . . . When I'm in the twenties, I'll be like sister Joe . . . When I'm in the thirties, I'll be just like Mama.
4.52. The most important instance of this plural is found in the pronouns of the first and second persons: we = I + one or more not-I's. The pl you (ye) may mean thou + thou + thou (various individuals addressed at the same time), or else thou + one or more other people not addressed at the moment; for the expressions you people, you boys, you all, to supply the want of a separate pl form of you see 2.87.
A 'normal' plural of I is only thinkable, when I is taken as a quotation-word (cf. 8.2), as in Kipl L 66 he told the tale, the I--I--I's flashing through the record as telegraph-poles fly past the traveller; cf. also the philosophical plural egos or me's, rarer I's, and the jocular verse: Here am I, my name is Forbes, Me the Master quite absorbs, Me and many other me's, In his great Thucydides.
4.53. It will be seen that the rule (given for instance in Latin grammars) that when two subjects are of different persons, the verb is in "the first person rather than the second, and in the second rather than the third" 'si tu et Tullia valetis, ego et Cicero valemus, Allen and Greenough, Lat. Gr. §317) is really superfluous, as a self-evidence consequence of the definition that "the first person plural is the first person singular plus some one else, etc." In English grammar the rule is even more superfluous, because no persons are distinguished in the plural of English verbs.
When a body of men, in response to "Who will join me?", answer "We all will", their collective answers may be said to be an ordinary plural (class 1) of I (= many I's), though each individual "we will" means really nothing more than "I will, and B and C . . . will, too" in conformity with the above definition. Similarly in a collective document: "We, the undersigned citizens of the city of . . ."
4.54. The plural we is essentially vague and in no wise indicates whom the speaker wants to include besides himself. Not even the distinction made in a great many African and other languages between one we meaning 'I and my own people, but not you', and another we meaning 'I + you (sg or pl)' is made in our class of languages. But very often the resulting ambiguity is remedied by an appositive addition; the same speaker may according to circumstances say we brothers, we doctors, we Yorkshiremen, we Europeans, we gentlemen, etc. Cf. also GE M 2.201 we people who have not been galloping. --- Cf. for 4.51 ff. PhilGr p. 191 ff.
4.55. Other examples of the pl of approximation are the Vincent Crummleses, etc. 4.42. In other languages we have still other examples, as when Latin patres many mean pater + mater, Italian zii = zio + zia, Span. hermanos = hermano(s) + hermana(s), etc.
複数形といっても,その意味論は複雑であり得る.これは,一見して形態論の話題とみえて,本質的には意味論と語用論の問題なのだと思う.
・ Jespersen, Otto. A Modern English Grammar on Historical Principles. Part 2. Vol. 1. 2nd ed. Heidelberg: C. Winter's Universitätsbuchhandlung, 1922.
2023-10-12 Thu
■ #5281. 近似複数 [plural][number][numeral][personal_pronoun][personal_name][plural_of_approximation][metonymy][t/v_distinction]
近似複数 (plural_of_approximation) なるものがあるが,ご存じだろうか.以下『新英語学辞典』に依拠して説明する.
英語の名詞の複数形は,一般的に -s 語尾を付すが,通常,同じもの,同種のものが2つ以上ある場合に現われる形式である.これを正常複数 (normal plural) と呼んでおこう.一方,同種ではなく,あくまで近似・類似しているものが2つ以上あるという場合にも,-s のつく複数形が用いられることがある.厳密には同じではないが,そこそこ似ているので同じものととらえ,それが2つ以上あるときには -s をつけようという発想である.これは近似複数 (plural_of_approximation) と呼ばれており,英語にはいくつかの事例がある.
例えば,年代や年齢でいう sixties を取り上げよう.1960年代 (in the sixties) あるいは60歳代 (in one's sixties) のような表現は,sixty に複数語尾の -(e)s が付いている形式だが「60年(歳)」そのものが2つ以上集まったものではない.60,61,62年(歳)のような連番が69年(歳)まで続くように,60そのものと60に近い数とが集まって,sixties とひっくるめられるのである.いわばメトニミー (metonymy) によって,本当は近似・類似しているにすぎないものを,同じ(種類の)ものと強引にまとめあげることによって,sixties という一言で便利な表現を作り上げているのである.少々厳密性を犠牲にすることで得られる経済的な効果は大きい.
他には人名などに付く複数形の例がある.例えば the Henry Spinkers といえば,Mr. and Mrs. Spinker 「スピンカー夫妻」の省略形として用いられる.この表現は事情によっては「スピンカー兄弟(姉妹)」にもなり得るし「スピンカー一家」にもなり得る.家族として「近似」したメンバーを束ねることで,近似複数として表現しているのである.
さらに本質的な近似複数の例として,I の複数形としての we がある.1人称代名詞の I は話し手である「自己」を指示するが,複数形といわれる we は,決して I 「自己」を2つ以上束ねたものではない.「自己」と「あなた」と「あなた」と「あなた」と・・・を合わせたのが we である.同一の I がクローン人間のように複数体コピーされているわけではなく,あくまで I とその側にいる仲間たちのことを慣習上,近似的な同一人物とみなして,合わせて we と呼んでいるのである.本来であれば「1人称の複数」という表現は論理的に矛盾をはらんでいるものの,上記の応用的な解釈を採用することで言葉を便利に使っているのである.
もともと複数の「あなた」を意味する you を,1人の相手に対して用いるという慣行も,もしかすると近似複数の発想に基づいた応用的な用法といってしかるべきものなのかもしれない.
「同じとは何か」という哲学的問題が脳裏にちらついてくるが,言語における近似複数はおもしろい事象である.
・ 大塚 高信,中島 文雄(監修) 『新英語学辞典』 研究社,1982年.
2023-05-19 Fri
■ #5135. 不定冠詞の発達の一般経路 [grammaticalisation][article][pragmatics][semantics][historical_pragmatics][unidirectionality][numeral]
Heine and Kuteva (92) によると,諸言語において不定冠詞 (indefinite article) が発達してきた経路をたどってみると,しばしばそこには意味論的・語用論的な観点から一連の段階が確認されるという.
1 An item serves as a nominal modifier denoting the numerical value 'one' (numeral).
2 The item introduces a new participant presumed to be unknown to the hearer and this participant is then taken up as definite in subsequent discourse (presentative marker).
3 The item presents a participant known to the speaker but presumed to be unknown to the hearer, irrespective of whether or not the participant is expected to come up as a major discourse participant (specific indefinite marker).
4 The item presents a participant whose referential identity neither the hearer nor the speaker knows (nonspecific indefinite marker).
5 The item can be expected to occur in all contexts and on all types of nouns except for a few contexts involving, for instance, definiteness marking, proper nouns, predicative clauses, etc. (generalized indefinite article).
英語の不定冠詞の発達においても,この一連の段階が見られたのかどうかは,詳細に調査してみなければ分からない.しかし,少なくとも発達の開始に相当する第1段階は的確である.つまり,数詞 one (古英語 ān) から始まったことは疑い得ない.2--5の各段階が実証されれば,文法化 (grammaticalisation) の一方向性 (unidirectionality) を支持する事例として取り上げられることにもなろう.注目すべき時代は,おそらく中英語期から近代英語期にかけてとなるに違いない.
関連して「#2144. 冠詞の発達と機能範疇の創発」 ([2015-03-11-1]) も参照.
・ Heine, Bernd and Tania Kuteva. "Contact and Grammaticalization." Chapter 4 of The Handbook of Language Contact. Ed. Raymond Hickey. 2010. Malden, MA: Wiley-Blackwell, 2013. 86--107.
2022-03-15 Tue
■ #4705. 『中高生の基礎英語 in English』の連載第13回「なぜ one, two はこの綴字でこの発音なの?」 [notice][sobokunagimon][rensai][numeral][spelling][pronunciation][spelling_pronunciation_gap][hellog-radio]
この新年度も,1年間続いてきたNHKラジオ講座「中高生の基礎英語 in English」での連載「英語のソボクな疑問」が継続されることになりました.読者の方々に毎月ご愛読いただいたおかげと感謝しております.ありがとうございました.ソボクな疑問を歴史的な観点からなるべくわかりやすく解説するというのが連載の趣旨です.引き続きご愛読のほど,よろしくお願いいたします.
昨日発売された4月号テキストに,連載の第13回が掲載されました.新年度に向けての一発目は「なぜ one, two はこの綴字でこの発音なの?」という綴字と発音の乖離に関する話題です.皆さん,すでに見慣れ,読み慣れている単語ですので不思議など感じないかと思いますが,普通であれば one で「ワン」,two で「トゥー」などとはひっくり返っても読めないはずです.なぜ素直に「オネ」や「トゥウォー」などとならないのでしょうか.そこには,あっと驚く歴史的な理由があったのです.

one, two に限らず,英語には発音と綴字がかみ合っていない単語がごまんとあります.実のところ基本的な単語であればあるほどチグハグなケースが多いので,初学者にとっては特にキツいのです.規則から入るのではなく,いきなり不規則から入るに等しいわけですから.
連載記事ではできる限り丁寧な説明を心がけました.同じ問題について本ブログや音声メディアでも取り上げたことがありますので,そちらも合わせて参照し,理解を深めていただければと思います.関連する記事セットよりどうぞ.音声メディアについては,以下より直接お聴きください.
2022-01-15 Sat
■ #4646. 『中高生の基礎英語 in English』の連載第11回「なぜ eleven, twelve というの?」 [notice][sobokunagimon][rensai][numeral][metathesis]
NHKラジオ講座「中高生の基礎英語 in English」の2月号のテキストが発売されました.本年度連載中の「英語のソボクな疑問」の第11回の話題は「なぜ eleven, twelve というの?」です.13から19までは X-teen という語形成で「X + 10」という構成原理がわかりやすいのですが,11と12については期待される *oneteen, *twoteen とはなりません.これはなぜなのでしょうか.

本ブログでは「#3279. 年度初めの「素朴な疑問」を3点」 ([2018-04-19-1]) にて,この問題に簡単に触れました.わからないことも多々あるのですが,そこでの説明を膨らませたのが今回の連載記事です.記事では,その他 thirteen と fifteen についての謎にも迫っています.なぜ素直に *threeteen や *fiveteen とならないのか,という素朴な疑問です.ぜひテキストを手に取っていただければと思います.
数詞というのは非常に身近な語彙ですが,eleven, twelve の問題に関わらず謎が多い語群でもあります.むしろ日常的で頻度が高すぎるからこそ,イレギュラーなことが多いのだろうと思われます.数詞の不思議については,本ブログでも numeral の各記事で取り上げてきましたので,そちらもご覧ください.
2021-06-22 Tue
■ #4439. 古英語は混合方言として始まった? [dialectology][dialect][oe_dialect][anglo-saxon][dialect_contact][dialect_mixture][numeral][superlative][be][suppletion]
一般的な英語史記述によると,古英語は,5世紀半ばにアングル人,サクソン人,ジュート人など西ゲルマンの近親諸民族が,互いに少々異なった方言を携えてブリテン島に渡ってきたところから始まる.当初の「英語」は,これらの民族ごとの諸方言をひっくるめて総称したものと理解してよい.その後,古英語期中に各方言はそれぞれの土地に根付きつつ発展し,ある意味では現代にまで続くイングランド諸方言の土台を築いた.
上記の見方は,諸方言が5世紀半ば以来,互いに(まったくとはいわずとも)それほど交わってこなかったことを前提としている.しかし,「#2868. いかにして古英語諸方言が生まれたか」 ([2017-03-04-1]) で紹介したように,古英語はそもそも方言接触 (dialect_contact) と方言混合 (dialect_mixture) の産物ではないかという議論もある.8世紀頃の古英語にはまだかなりの言語的多様性が観察されるが,これは古い諸方言が相互接触を通じて新しい諸方言へと生まれ変わる際に典型的にみられる現象といえるのではないか.
Trudgill (2045--46) は Nielsen を参照しつつ,方言混合に起因するとみられる古英語の言語的多様性の具体例を3点挙げている.
1) Old English had a remarkable number of different, alternative forms corresponding to Modern English 'first', and, crucially, more than any other continental Germanic language. This variability, moreover, would appear to be linked, although in some way that is not entirely clear, to variability and differentiation on the European mainland: ærest (cf. Old High German eristo); forma (cf. Old Frisian forma); formest (cf. Gothic frumists); and fyrst (cf. Old Norse fyrst).
2) Similarly, OE had two different paradigms for the present tense of the verb to be, one derived from Indo-European *-es- and apparently related to Old Norse and Gothic; and the other deriving from Indo-European *bheu and relating to Old Saxon and Old High German. The relevant singular forms in Table 130.1
Table 130.1: Singular forms of the present tense of the verb to be (Nielsen 1998: 80)
Gothic Old Norse Old English I Old English II Old Saxon Old High German 1SG im em eom beom bium bim 2SG is es eart bist bist bist 3SG ist es is bið is(t) ist
3) Old English also exhibited variability, in all regions, in the form of the interrogative pronoun meaning 'which of two'. This alternated between hwæðer which relates to Gothic hvaóar and W. Norse hvaðarr, on the other hand, and hweder which corresponds to O. Saxon hweðar, on the other.
上記 1) の "first" に相当する序数詞の形態的多様性については,中英語の話題ではあるが「#1307. most と mest」 ([2012-11-24-1]) も関係する.2) の be 動詞が示す共時的な補充法 (suppletion) については,その起源が方言混合にあるかもしれないという洞察は鋭い.一般に補充法の事例を考察する際のヒントになるだろう.
古英語における言語上の問題は,文献的にそれ以上遡れないという理由で積極的に話題にするのが難しく,所与のものとして受け入れてしまうことが多い.しかし,文献に先立つ時代に,思いのほか多くの方言接触や方言混合があった可能性を想定してみると,新たな視野が開けてくるように思われる.
方言接触や方言混合の一般的な解説は「#1671. dialect contact, dialect mixture, dialect levelling, koineization」 ([2013-11-23-1]) をどうぞ.
・ Trudgill, Peter. "Varieties of English: Dialect Contact." Chapter 130 of English Historical Linguistics: An International Handbook. 2 vols. Ed. Alexander Bergs and Laurel J. Brinton. Berlin: Mouton de Gruyter, 2012. 2044--59.
・ Nielsen, Hans Frede. The Continental Backgrounds of English and its Insular Development until 1154. Odense: Odense UP, 1998.
2021-06-12 Sat
■ #4429. 序数詞 third の d と fourth の th の関係 [indo-european][germanic][numeral][grimms_law][verners_law][suffix][metathesis]
6月2日より,音声配信プラットフォーム Voicy にて「英語の語源が身につくラジオ」と題するチャンネルをオープンしています.日々10分弱の英語史の話題を配信していますが,昨日は「third は three + the の変形なので準規則的」という話題を取り上げました(cf. 「#92. third の音位転換はいつ起こったか」 ([2009-07-28-1]),「#93. third の音位転換はいつ起こったか (2)」 ([2009-07-29-1]),「#60. 音位転換 ( metathesis )」 ([2009-06-27-1])).この話題について専門的な補足を加えたいと思います.
third の末尾の -d は fourth など4以上の序数詞の末尾に現われる -th と起源的に同一物であり,それが変形したものであるという趣旨で話しました.大雑把にいえば上記の通りに理解しておいてよいのですが,厳密に議論すればそれなりに込み入った事情があります.
印欧語族の序数詞の語尾にはいくつかの種類があり,英語の -th に連なる語尾が唯一のものではありませんでした.3の序数詞についていえば,再建された形態としては,-th に連なる語尾を含む *tri-to- もあれば,別に *triy-o という形態もありましたし,さらにこれらの複雑な混成形と考えられる *t(e)r(e)tiyo- もありました.この最後のものが,現代英語の third (< OE þridda) を出力することになります.したがって,third の d は -th の起源である *-to- と直系の関係にはなく,あくまで「混成」を経由しての間接的な関係というのが正確なところです.典拠として,Mallory and Adams (311) を引用しておきます.
The number 'three', *tréyes (neuter: triha), is also marked by different forms for the different genders and was declined as an -i-stem plural (e.g. OIr trī, Lat trēs, NE three, Lith trỹs, OCS trije [m.], tri [f./nt.], Alb tre [m.], tri [f.], Grk treîs, Arm erek ̔, Hit tēri-, Av θrayō [m./f.], θri [nt.], Skr tráyas [m./f.], trī [nt.], Toch B trai [m.], tarya ([f.]). In some languages we have reflections of a very unusual feminine form, *t(r)is(o)res, i.e. OIr teōir, Av tišrō, Skt tisrás. The underlying derivation of *tréyes is generally sought in either *ter 'further', i.e. the number beyond 'two', or from a *ter- 'middle, top, protruding', i.e. the middle finger, assuming one counted on one's fingers in Proto-Indo-European. Again, the probability that either suggestion is correct is very low. The ordinal number is indicated by a variety of forms similar to *triy-o (e.g. Arm eri 'third', Hit teriyan 'third', tariyanalli- '賊 third officer'), or *tri-to- (e.g. Alb tretê, Grk trítos, Skt tritá-, Toch B trite), or finally *t(e)r(e)tiyo- (e.g. NWels tryddyd, Lat teritius, NE third, Lith trẽčias, Rus trétij, Av θritiya-, Skt tr̥tíya-) which is presumably a conflation of sorts, in various ways, of the previous two while *tris supplies the multiplicative (e.g. Lat ter, Grk trís, Av θriš, Skt tríṣ; despite its apparent phonetic similarity, NE thrice is of a different origin.
上記の通り,現代英語 third そして古英語 tridda の祖形は *t(e)r(e)tiyo- にあったと想定され,問題の語尾の子音は t だったことになります.この子音は順当に発達すればグリムの法則 (grimms_law) により θ に発達していたはずと想定されますが,強勢が後続していたために同発達がブロックされ,ヴェルネルの法則 (verners_law) に従って有声化して ð となり,これが後に脱摩擦音化して d となりました.この一連の流れは,古英語 fæder (> PDE father) に d が確認されるのとまったく同じ流れです(cf. 「#480. father とヴェルネルの法則」 ([2010-08-20-1])).この点については Lass (214) より引用しておきましょう.
3rd. Go þridja, OE þridda, OIc þriþe. This is not entirely suppletive, as it still obviously contains the root for '3'. But the formation is different from that of the other ordinals, involving a suffix */-tjo:-/ (cf. L ter-ti-us). The E, WGmc forms must go back to a variant with an accented suffix, hence the voiced dental from Verner's Law. ModE third is metathesized from þridda (cf. bird < OE bridd, dirt < Osc drit).
なお,印欧祖語レベルでは,英語の -th 語尾に連なる */-to-/ は4,5,6の序数詞のみに当てはまり,ゲルマン語において7以上の序数詞にも付されるようになったのは,後の類推 (analogy) によるものです (Lass 215) .現代英語では4以上の序数詞は -th できれいに揃っているように見えますが,もともとはそうではなかったことになります.
・ Mallory, J. P. and D. Q. Adams. The Oxford Introduction to Proto-Indo-European and the Proto-Indo-European World. Oxford: OUP, 2006.
・ Lass, Roger. Old English: A Historical Linguistic Companion. Cambridge: CUP, 1994.
2020-12-13 Sun
■ #4248. なぜ three と thirteen では r の位置が異なるのですか? --- hellog ラジオ版 [hellog-radio][sobokunagimon][metathesis][numeral]
語源的に明らかに関連していると思われる語なのに,発音や綴字が微妙に異なっているというのは,よくある話しです.three 「3」を基本として,thirteen 「13」,thirty 「30」,third 「第3の」はそこから派生した語であることは間違いなさそうですが,r の位置が異なっています.基本の three では「th + r + 母音」となっていますが,派生語では「th + 母音 + r」となっています.これはどういうわけでしょうか.音声解説をお聴きください.
古英語では「3」は þrēo,「13」は þrēo-tīene,「30」は þrī-tiġ,「第3の」は þridda という綴字でした(<þ> は古英語の文字で th を表わします).つまり,すべて「th + r + 母音」だったのです.ところが,中英語期から近代英語期にかけて,派生語における「r + 母音」が位置を逆転させて「母音 + r」に変化していったのです.
これは「ろれつ」が回らず,発音し損ねたという一種の言い間違いから生じたもので,古今東西でしばしば観察される音位転換 (metathesis) という現象です.通常であれば一過性の言い間違いで終わるところですが,どういうわけか間違った発音のほうが正しい発音として定着してしまうこともあるのです.
英語の場合,とりわけ r と母音の関与する例が圧倒的に多く,ほかにも bird, grass, horse などが挙げられます.これらは古英語では各々 brid, gærs, hros というように,r と母音の位置が逆転した綴字で現われていました.
日本語からも例は豊富に挙がります.「さんざか」(山茶花)が「さざんか」となったり,「したづつみ」(舌鼓)が「したつづみ」となったり,昨今「ふんいき」(雰囲気)が「ふいんき」と発音されることが多くなってきているのも,音位転換のなせる技です.
音位転換という興味深い話題については,##60,92,93,2809の記事セットをご覧ください.多くの例が挙げられています.
2020-08-26 Wed
■ #4139. なぜ数詞 two は「トゥー」と発音するのですか? --- hellog ラジオ版 [hellog-radio][sobokunagimon][hel_education][pronunciation][numeral][phonetics][spelling_pronunciation_gap]
hellog ラジオ版の第19回は,前回の「#4135. なぜ数詞 one は「ワン」と発音するのですか? --- hellog ラジオ版」 ([2020-08-22-1]) に続いて数詞 (numeral) の話題です.前回は one は綴字のどこにも <w> がないのに発音には /w/ が現われる,けしからん,という趣旨でしたが,今回はさらに不審な点を指摘したいと思います.two は綴字に <w> が現われるのに発音には /w/ が出てこないのです.英語がいかに妙ちくりんな言語であるかが,よくわかるかと思います.
しかし,ここにもちゃんと歴史的背景があります.では,音声の解説をどうぞ.

two の関連語で /w/ の後に前舌母音が続く twelve, twenty, twin, twain 等ではしっかり /w/ が発音されるのですが,たまたま後舌母音が続いた two については,母音と /w/ との音声学的な特徴が似ているために,歴史の過程で /w/ が脱落してしまったということです.この脱落は中英語期にはすでに始まっていたようです.
このように発音はどんどん変わっていくものですが,綴字はその変化のスピードに付いていけず,古い発音を表わした状態に据え置かれることが多いのです.英語における綴字と発音の乖離の問題の大半は「発音は変わったけれども,綴字は昔の状態に取り残されてきた」過程の結果として説明できます.
この話題について,詳しくは##184,1324,51,3630の記事セットをご覧ください.
Powered by WinChalow1.0rc4 based on chalow