2018-09-18 Tue
■ #3431. 各種の EEBO 検索インターフェース [eebo][corpus][emode][site][web_service][link][n-gram][kwic]
初期近代英語期の膨大なテキストを収録した EEBO (Early English Books Online) について,「#3117. EEBO corpus がリリース」 ([2017-11-08-1]) で BYU 提供の EEBO 検索インターフェース Early English Books Online corpus を紹介した.
それとは別に,Early Modern Print: Text Mining Early Printed English というサイトのプロジェクトで,n-gram や KWIC などの検索インターフェースが提供されていることを知ったので紹介しておきたい.全体的なイントロは,こちらのページをどうぞ.個々の具体的なツールは,次のリンクからアクセスできる.
・ EEBO N-Gram Browser (説明はこちら)
・ EEBO-TCP Key Words in Context (説明はこちら)
・ EEBO-TCP and ESTC Text Counts
・ EEBO-TCP Words Per Year
また,University of Michigan の提供する Early English Books Online の各種サーチや Lancaster University による EEBO on CQPweb (V3) も同様に有用.
各種インターフェースのいずれを用いるか迷うところだ.
2016-12-03 Sat
■ #2777. 語彙の14年周期説? [lexicology][language_change][speed_of_change][schedule_of_language_change][n-gram][corpus]
Language trends run in mysterious 14-year cycles と題する記事をみつけた.非常におもしろい. *
Marcelo Montemurro と Damián Zanette による調査結果である.2人は「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) とコンピュータ・プログラムを用いて,1700年から2008年の間の常用される名詞の "popularity" の推移を探った.すると,14年周期で英単語の "popularity" が上がっては下がるということが繰り返されていることが分かったという.意味的に関連する語群は盛衰をともにするというパターンも見つかっているし,英語に限らずフランス語,ドイツ語,イタリア語,ロシア語,スペイン語などの言語でも似たような周期が確認されるというから驚きだ.
では,なぜこのような周期があり,そしてなぜ14年前後という間隔なのか.いくつかの語については,政治を含めた社会的な変化との連動の可能性が指摘されうるが,一般論として,なぜこのような周期があるのかは不明である.もちろん,この周期が無作為変動の誤差の範囲にとどまっているのではないかという疑念は残っており,さらなる調査が必要ではあろう.しかし,もし何らかの要因があるとすれば,それはいったい何なのか.研究者の1人は "an obvious cultural connection" は見られないとしている.
人間行動の反復性,流行の周期,言語行動の慣れや飽き,などの問題と関わるのだろうか.いずれにせよ,非常に不思議で,興味をそそる現象である.
2016-09-07 Wed
■ #2690. N-gram Tool [cgi][n-gram][statistics][corpus][web_service][frequency][cgi]
n-gram は,言語統計やコーパス言語学の世界における基本的な概念・手段である(「#2324. n-gram」 ([2015-09-07-1]), 「#956. COCA N-Gram Search」 ([2011-12-09-1]) を参照).テキストを指定してその n-gram を得るツールはネットその他にも遍在しているが,あえて簡易ツールをCGIで実装してみた.バックエンドに Perl モジュールの Text::Ngrams を用いている.
使い方はおよそ自明だろう.適当な長さの英文テキストを投げ込めば,デフォルトでは単語ベースの 3-gram (およびそれ以下の 2-gram と 1-gram も含む)の一覧が絶対頻度の高い順に返される(出力行の制限はなし).オプションにより単語ベースではなく文字ベースにも変更でき,n-gram のサイズも変えられる.出力については,頻度順ではなくアルファベット順にすること,出力行に制限を設けること,絶対頻度ではなく相対頻度(各 n-gram 内で合計すると1.0となる)で返すことも可能.
なお,1-gram は入力テキストを構成する単語の頻度表となるので,その用途にも利用できる.簡易的な n-gram ツールとしてどうぞ.
[ 固定リンク | 印刷用ページ ]
2015-09-07 Mon
■ #2324. n-gram [corpus][information_theory][coca][bnc][google_books][statistics][n-gram][collocation][frequency][link]
情報理論や自然言語処理の分野で用いられる n-gram という分析手法がある.コーパス言語学でもすでにお馴染みの概念であり,共起表現 (collocation) の研究などでは当たり前のように用いられるようになった.種々のコーパスのインターフェースにおいても採用されており,「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) では名前に含まれているほどだし,本ブログでも COCA (Corpus of Contemporary American English) の N-gram データベースを用いて「#956. COCA N-Gram Search」 ([2011-12-09-1]) を実装してきた(その応用は,「#953. 頭韻を踏む2項イディオム」 ([2011-12-06-1]),「#954. 脚韻を踏む2項イディオム」 ([2011-12-07-1]),「#955. 完璧な語呂合わせの2項イディオム」 ([2011-12-08-1]) を参照).BNC では,Explore Words and Phrases from the BNC が利用できる.
コンピュータを用いた分析手法というと難しそうに聞こえるが,n-gram の考え方は至って単純である.文字レベルの 2-gram (bigram) を考えてみよう.最長の英単語といわれる pneumonoultramicroscopicsilicovolcanoconiosis (「#63. 塵肺症は英語で最も重い病気?」 ([2009-06-30-1])) を例にとる.まず,先頭の2文字1組の pn を取り出す.次に,2文字目に進んで同じように ne を取り出す.3文字目に進んで eu を,4文字目に進んで um を得る.同じように,1文字ずつ右にずらしながら,最後の is まで2文字1組を次々と拾っていく.これで44組の2文字を得たことになる.この組のなかで,ic と co という組み合わせは各々3回起こり,os, si, no, on の組み合わせは各々2回現われ,それ以外の組み合わせはいずれも1度きりである.したがって,この単語において最高頻度の2文字1組は ic と co となる.
n-gram の単位は,このように文字である必要はなく,音素でもよいし,より大きな単位である形態素や語でもよく,さらに大きな句などのより大きな単位でもよい.英語コーパス言語学では,語という単位で考えるのが普通だろう.Martin Luther King, Jr. の I Have a Dream の演説のテキストで語単位の 4-gram を取ると,最も多い4語の組み合わせは,予想通り "I have a dream" の8回だが,"will be able to" も同じく8回現われる."Let freedom ring from" も7回とよく現われる,等々の分析が可能となる.ここでは4語という「窓」を設定したので 4-gram と呼ばれるが,隣接するいくつの文字を考慮するかにより 1-gram (unigram), 2-gram (bigram), 3-gram (trigram),そして 5-gram 以上ももちろん考えることができる(1-gram の場合,得られるリストは,事実上各語の生起頻度表である).
巨大コーパスから得られた 2-gram や 3-gram の一覧は,それ自体が共起表現の研究などでは基本データとなるため,ウェブ上でもいろいろと公開されている.日本語では「N-gram コーパス - 日本語ウェブコーパス 2010」があるし,現代英語では COCA の n-gram データベース がある.また,Bigram Plus では,歴史英語コーパスを含めた各種英語コーパスから N-Gram Search を行なえる機能を提供している.ほかにも任意のテキストやコーパスを対象に n-gram を取る各種のツールやソフトも,ウェブ上で入手可能だ.
n-gram 分析の言語分野への応用範囲は広い.次に来る語(音,文字)は何か,という予測可能性とも関係が深いため,機械による音声認識,統語分析,言語判定,自動翻訳,スペルチェック,剽窃探知,全文検索用インデックスの作成などに活用される.もちろん,共起表現の研究では,基本にして不可欠の手段となっている.一方,n-gram はもっぱら言語として表面化されたテキストを対象とし,深層にある構造にまったく触れることがないため,生成文法のような言語理論の方面からは批判があるようだ.詳しくは,n-gram in Wikipedia を参照.
n-gram は工夫次第で,まだまだ使い道がありそうだ.歴史英語テキストにも,応用していきたい.
(後記 2015/09/12(Sat): Sketch Engine より N-grams も参照.)
2011-12-09 Fri
■ #956. COCA N-Gram Search [cgi][web_service][coca][corpus][collocation][n-gram]
##953,954,955 の記事で,最近公開された COCA ( Corpus of Contemporary American English ) の n-gram データベースを利用してみた.COCA に現われる 2-grams, 3-grams, 4-grams, 5-grams について,それぞれ最頻約100万の表現を羅列したデータベースで,手元においておけば,工夫次第で COCA のインターフェースだけでは検索しにくい共起表現の検索が可能となる.
ただし,各 n-gram のデータベースは,数十メガバイトの容量のテキストファイルで,直接検索するには重たい.そこで,SQLite データベースへと格納し,SQL 文による検索が可能となるように検索プログラムを組んだ.以下は,検索結果の最初の10行だけを出力する CGI である.
以下,使用法の説明.テーブル名は n-gram の "n" の値に応じて,"two", "three", "four", "five" とした.ちなみに,1-grams のデータベース(事実上,COCA に3回以上現われる語の頻度つきリスト)も付随しており,こちらもテーブル名 "one" としてアクセス可能にした.フィールドは,全テーブルに共通して "freq" (頻度)があてがわれているほか,"n" の値に応じて,"word1" から "word5" までの語形 (case-sensitive) と,"pos1" から "pos5" までの COCA の語類標示タグが設定されている.select 文のみ有効.以下に,典型的な検索式を例として載せておく.
# 1-grams で,前置詞を頻度順に取り出す(ただし,case-sensitive なので再集計が必要)
select * from one where pos1 like "i%" order by freq desc;
# 2-grams で,ハンサムなものを頻度順に取り出す
select * from two where word1 = "handsome" and pos1 = "jj" and pos2 like "nn_" order by freq desc;
# 2-grams で,"absolutely (adj.)" で強調される形容詞を頻度順に取り出す([2011-03-12-1]の記事「#684. semantic prosody と文法カテゴリー」を参照)
select * from two where word1 = "absolutely" and pos2 = "jj" order by freq desc;
# 3-grams で,高頻度の as ... as 表現を取り出す
select * from three where word1 = "as" and word3 = "as" order by freq desc;
# 4-grams で,高頻度の from ... to ... 表現を取り出す
select * from four where word1 = "from" and pos1 = "ii" and word3 = "to" and pos3 = "ii" order by freq desc;
# 5-grams で,死因を探る; "die of" と "die from" の揺れを観察する
select * from five where word1 in ("die", "dies", "died", "dying") and pos1 like "vv%" and word2 in ("of", "from") and pos2 like "i%" order by word3;
n-gram データベースを最大限に使いこなすには,このようにして得られた検索結果をもとにさらに条件を絞り込んだり,複数の検索結果を付き合わせるなどの工夫が必要だろう.
2011-12-08 Thu
■ #955. 完璧な語呂合わせの2項イディオム [binomial][rhyme][corpus][coca][collocation][euphony][n-gram][suffix][proverb]
[2011-12-06-1], [2011-12-07-1]の記事で,COCA ( Corpus of Contemporary American English ) の 3-gram データベースから取り出した,現代英語における頭韻を踏む2項イディオム (binomial) と脚韻を踏む2項イディオムの例を見てきた.分析するなかで,両リストのなかで重複する2項イディオムが散見されたので,取り出してみた.これぞ,頭韻と脚韻の両方を兼ねそなえた,完璧な語呂合わせとしての共起表現である.(検索結果を収めたテキストファイルはこちら.)整理した50表現を挙げよう.
Saturday and Sunday, personal and professional, himself or herself, quantity and quality, morbidity and mortality, quantitative and qualitative, security and stability, best and brightest, latitude and longitude, sixteenth and seventeenth, whenever and wherever, sensitivity and specificity, watching and waiting, majority and minority, basketball and baseball, fight or flight, ranting and raving, forties and fifties, cooperation and coordination, nature and nurture, pushing and pulling, tossing and turning, twisting and turning, grandchildren and great-grandchildren, skiers and snowboarders, communication and collaboration, cooking and cleaning, psychiatrists and psychologists, biggest and best, development and deployment, slipping and sliding, communication and cooperation, Dungeons and Dragons, heterosexual and homosexual, healthier and happier, grandmother and grandfather, stopping and starting, sixteen or seventeen, hooting and hollering, competence and confidence, stalactites and stalagmites, waxing and waning, positive and productive, reading and rereading, patience and perseverance, bedroom and bathroom, consultation and collaboration, going and getting, grandfather and grandmother, protection and promotion
多くは,頭韻と脚韻が語呂として偶然に一致したと考えるよりは,語幹どうしに語源的な関連があるがゆえに頭韻を踏んでいるのであり,同じ接尾辞を用いているがゆえに脚韻を踏んでいるのだ,と解釈すべきだろう.
単なる語呂遊びというなかれ.上記の例は,音と意味の調和をいやおうなく感じさせ,2項の間に一種の必然性すら呼び起こすかのような,高度に修辞的な表現といえるだろう.fight or flight, nature and nurture, competence and confidence, positive and productive などは,単なる高頻度の共起表現であるという以上に,教訓的,ことわざ的ですらある.
2011-12-07 Wed
■ #954. 脚韻を踏む2項イディオム [binomial][rhyme][corpus][coca][collocation][euphony][n-gram][suffix][compound]
昨日の記事「#953. 頭韻を踏む2項イディオム」 ([2011-12-06-1]) に引き続き,今回は,脚韻を踏む高頻度の binomial を COCA ( Corpus of Contemporary American English ) の n-gram データベースにより拾い出したい.昨日と同様に,3-gram を用い,"A and/but/or B" の形の共起表現で,かつ A と B が脚韻を踏んでいるような例を取りだした.検索結果を納めたテキストファイルはこちら.
検索結果を眺めていて今更ながら気付いたことなのだが,脚韻は頭韻に比べてパターンが見つけやすい.特に顕著なのは,脚韻の多くが,語幹の語尾に依存しているというよりは,接尾辞に依存していることだ.-ing, -ed, -ly, -al, -y, -ion, -er などの屈折接尾辞や派生接尾辞が活躍している.
positive and negative, national and international, internal and external, Friday and Saturday, teaching and learning, gifted and talented, elementary and secondary, hunting and fishing, personal and professional, presence or absence, reliability and validity, coming and going, winners and losers, physical and psychological, formal and informal, directly and indirectly, advantages and disadvantages, rising and falling, physically and mentally, buyers and sellers
また,これも考えてみれば,さもありなんという事例なのだが,複合語の第2要素に同じ形態素を用いることにより韻を踏んでいる例も多い.一種の self-rhyme ではある.
Friday and Saturday, children and grandchildren, Saturday and Sunday, hardware and software, himself or herself, formal and informal, parents and grandparents, direct and indirect, buyers and sellers, mother and grandmother, father and grandfather, Afghanistan and Pakistan, anything and everything, football and basketball, indoor and outdoor, direct or indirect, servicemen and women, likes and dislikes, urban and suburban, indoor and outdoor
接尾辞を多用する屈折や派生,そして right-headed な複合を好む英語においては,脚韻を利用した2項イディオムの形成が容易であり,頻繁であることは,自然に理解できそうだ.逆から見れば,語幹の語頭音を利用する頭韻の2項イディオムの形成は,相対的に難しいということになるのかもしれない.
2011-12-06 Tue
■ #953. 頭韻を踏む2項イディオム [binomial][alliteration][corpus][coca][collocation][euphony][n-gram]
[2011-07-26-1]の記事「#820. 英仏同義語の並列」で,2項イディオム (binomial idiom) を紹介した.and, but, or などの等位接続詞で結ばれる2項からなる表現は現代英語でも顕在であり,よく見られるものには,語呂のよいもの (euphony) が多い.英語において語呂の良さといえば,[2011-11-26-1]の記事「#943. 頭韻の歴史と役割」で取り上げた頭韻 (alliteration) が,典型の1つとして挙げられる.
ところで,11月22日に,大規模オンライン・コーパス COCA ( Corpus of Contemporary American English ) などで知られるコーパス言語学者 Mark Davies が,COCA に基づく n-gram を無償で公開した.2, 3, 4, 5語からなる,それぞれ最頻100万の共起表現 (collocation) を,頻度数とともに列挙したデータベースで,ダウンロードしてオフラインで自由に処理できる.
・ Visit N-GRAMS: from the COCA and COHA corpora of American English. For downloading, directly visit Free lists.
・ Also visit Word frequency lists and dictionary: from the Corpus of Contemporary American English for other COCA-derived n-grams and frequency lists.
ここで,COCA n-gram から現代英語の2項イディオムに見られる頭韻を探して出してみようと思い立った.3-gram データベースを利用し,"A and/but/or B" の形の共起表現を探った.話者の意識していないところでも,頭韻は日常表現のなかに相当活用されているはずだとの予想のもとでの検索だったが,実際に多数の例を拾い出すことができた.検索結果のテキストファイルはこちら.2項の語頭の子音字が一致しているものを取り出しただけなので,それが表わす子音が一致しているとは限らず,注意が必要である.それでも,相当数の生きた日常的な頭韻の例を拾い出すことができた.
検索結果上位には,his or her, four or five, six or seven, this or that, Saturday and Sunday など,なるほどとは思わせるが,それほど興味深く感じられない例が少なくない.しかし,イディオム的な性格のもう少し強い,次のような共起表現も次々と挙がり,検索の甲斐があったと満足した.
public and private, rules and regulations, pots and pans, command and control, flora and fauna, free and fair, death and destruction, go and get, safety and security, signs and symptoms, fame and fortune, families and friends, fresh or frozen, peace and prosperity, past and present, quantity and quality, morbidity and mortality, slowly but surely, professional and personal, name and number, facts and figures, pencil and paper, state and society, small but significant, clear and convincing
n-gram については,[2010-12-25-1]の記事「#607. Google Books Ngram Viewer」も参照.
2011-09-16 Fri
■ #872. -ick or -ic [suffix][johnson][webster][corpus][google_books][spelling][n-gram]
現代英語の動詞 panic や picnic は,屈折語尾や派生語尾が付加されると,panicking, panicky, picnicked, picnicker などと <k> が挿入される.また,brick, kick, stick などの接尾辞ではない,語根の一部としての /-ɪk/ にも <k> が現われる.しかし,一般に接尾辞としての /-ɪk/ が語末に現われる場合,対応する綴字は -ick ではなく -ic である (ex. public, music, specific, basic, domestic, traffic, democratic, scientific, characteristic, academic) .
しかし,Johnson の A Dictionary of the English Language (1755) では,-ic 語はすべて,いまだ -ick として綴られていた.これを現代風の -ic へと改めたのはアメリカの辞書編纂者 Noah Webster だった.彼が The American Dictionary of the English Language (1828) で体現した改革により public の綴字が定着し,そのほかの多くの -ic 語の綴字も定着した.そして,これがアメリカ英語のみならずイギリス英語へも拡大していったのである (Potter 41) .
もっとも,Webster 以前に -ic の綴字がなかったわけではない.むしろ,ある程度の市民権を得ていたからこそ,Webster の一押しが効いたという側面がある.[2010-12-25-1]の記事で紹介した Google Books Ngram Viewer による public と publick の頻度の変遷を見れば,この状況が把握できる.AmE の変遷グラフ と BrE の変遷グラフ を確認されたい.同じデータを Mark Davies による Google Books: American English 経由で10年刻みに見ると,publick は1810--29年までは100万語辺りで20回以上現われていたが,1830年代には4.15回へ激減しているのが分かる.
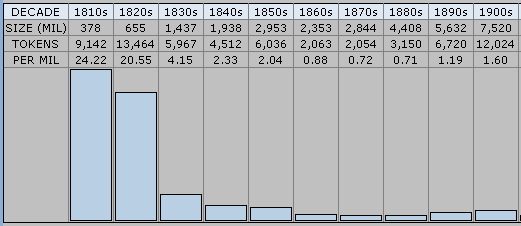
接尾辞 -ic に関連する話題としては,次の記事も参照.
・ [2009-08-02-1]: #97. 借用接尾辞「チック」
・ [2009-08-03-1]: #98. 「リック」や「ニック」ではなく「チック」で切り出した理由
・ [2009-08-10-1]: #105. 日本語に入った「チック」語
・ Potter, Simon. Changing English. London: Deutsch, 1969.
2011-02-22 Tue
■ #666. COCA 最頻5000語で品詞別の割合は? [lexicology][corpus][statistics][n-gram][coca]
COCA ( Corpus of Contemporary American English ) に基づいた各種語彙リストが Corpus-based word frequency lists, collocates, and n-grams から入手できる.そのなかで最も基本的なリストが,こちらの最頻5000語リストである.列挙されているのは見出し語 ( lemma ) 単位で,順位はコーパスに現われる頻度と分散の関数で計算されている.UCREL CLAWS7 Tagset の品詞コード表に基づいた粗い品詞情報も付与されており,品詞別の頻度などを手軽に分析することができる.
今回は,500語ごとに区切って頻度の高い順にL1からL10までの階級を設け,それぞれの階級における品詞別割合を出した.品詞は開いた語類 ( open class ) を中心とし,noun, verb, adj., adv., others の5区分とした.(数値データはこのページのHTMLソースを参照.)
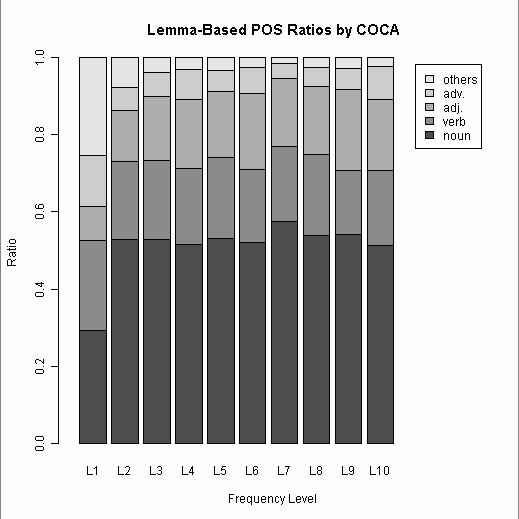
第1階級を除き,どの階級でも名詞が過半数を占めているのは予想できたことだが,第2階級以降に名詞の割合が思ったほど伸びていないことが分かった.動詞と形容詞が後半の階級でもおよそ一定の割合を占め続けているのも予想外だった.全体として,最頻5000語リストに限れば,名詞が飛び抜けつつも,開いた語類の内部比率はおよそ一定に保たれているといえよう.階級幅を様々に動かして試してみたが,およそ安定期に入るのは500語以降と見てよさそうだ.
[2011-02-16-1]の記事で中英語期のフランス借用語の品詞別割合をみたが,全体としての形容詞比率は0.1768だった.今回の現代英語の最頻5000語では,全体としての形容詞比率は0.1678.比べて意味のある数値かどうかは分からないが,英語(言語?)における品詞別比率の「安定感」のようなものはあるのだろうか.
COCA に基づくもの以外にオンラインで入手できる最頻英単語リストについては[2010-03-01-1]の記事を参照.頻度表を利用した別のパイロット・スタディとしては,単語の音節数を扱った[2010-04-17-1]の記事を参照.
2010-12-25 Sat
■ #607. Google Books Ngram Viewer [corpus][web_service][ame_bre][google_books][n-gram][statistics][frequency][lexicology]
Google がものすごいコーパスツールを提供してきた.Google Books Ngram Viewer は Google Labs 扱いだが,その規模と可能性の大きさに驚いた.2004年以来1500万冊の本をデジタル化してきた Google が,そのサブセットとなる520万冊の本,5000億語をコーパス化した.英語のほかフランス語,ドイツ語,ロシア語,スペイン語,中国語が含まれているが,英語では British English, American English, English, English Fiction, English One Million からサブコーパスを選択できる.最大の特徴は,指定した5語までの検索語の頻度を過去5世紀(1500--2008年)にわたって追跡し,グラフで表示してくれることだ.Google からの公式な説明はこちらの記事にある.
規模が大きすぎてコーパスとしてどう評価すべきかも分からないが,ひとまずはいじるだけで楽しい.上記の記事内にいくつかのサンプルがあるが,英語史的な関心を引くサンプルとして burnt と burned の分布比較があったので,English, American English, British English の3サブコーパスをグラフを出してみた.
次に,本年度の卒論ゼミ生の扱った話題を拝借し,一般に AmE on the street, BrE in the street とされる前置詞使用の差異を Google Books Ngram Viewer で確認してみた.American English と British English のそれぞれのサブコーパスから出力されたグラフは以下の通り.
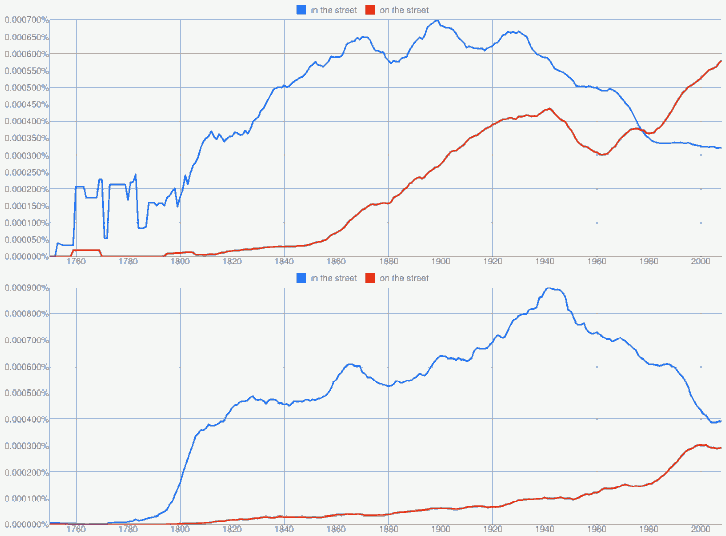
in と on の選択は句の意味(「街路で」か「失業して」か)などにも依存するため単純な形態の頻度比較では不十分だが,傾向はつかめる.
[2010-08-16-1], [2010-08-17-1]の記事で扱った gorgeous についても調べてみた.19世紀には流行っていたが20世紀には落ち目であったこの形容詞が,American English において1980年代以降,再び勢いを盛り返してきている状況がよくわかる.British English でも復調の兆しがあるだろうか?
コーパス言語学一般にいえるが,ツールの使用はアイデア次第である.文化史的な観点からは,[2009-12-28-1]の記事で紹介した American Dialect Society による "Words of the Century" や "Words of the Millennium" のノミネート語句を検索してみるとおもしろい.
他のオンラインコーパスについては[2010-11-16-1]を参照.
Powered by WinChalow1.0rc4 based on chalow