2023-06-16 Fri
■ #5163. 綴字体系とは何か? [laeme][spelling][grammatology][orthography][eme]
初期中英語期の方言地図 LAEME を編纂した Lass and Laing が,LAEME の前書きとした書いた長いイントロは,今のところ初期中英語の最良の導入的解説といってよい.執筆者の一人 Roger Lass は理論家として知られる学界の重鎮であり,このイントロにおいても,方言地図やコーパス編纂の方法論の理想と現実から,先発の後期中英語期の方言地図 LALME の学史的意義まで縦横無尽に論じており,面目躍如たるものがある.
"Interpreting Middle English" と題する第2章では,初期中英語期の綴字が詳細に論じられている.この章は,初期中英語期のみならず一般に英語の綴字の理論的解説となっており,この方面に関心のある向きには必読である.もっといえば,綴字とは何か,という本質的な問題を真正面から扱っているのである.Lass and Laing (3--4) の1節を引用する.
A spelling system is a mapping of some chosen set (or sets) of linguistic units into a set of visual signs.5 The standard inventory of linguistic units is the word, the morphophonemic representation, the syllable6 and the 'phoneme'. In relatively rare cases allophones of certain phonemes may be represented (e.g. the velar nasal in the elder Futhark, Gothic and Greek).
5 Just what kind of units is a complex matter. In the earlier part of this exposition we will be considering phonemes, allophones and other traditional kinds; later on we will adopt a more medieval and less anachronistic perspective. The mapping need not be one-to-one and in no case does it have to involve one level of unit only.
6 We will be concerned here only with segmental styles of representation, as syllabaries are not part of the Germanic tradition. Even the oldest Germanic writing, the runic inscriptions in the Elder Futhark, are in principle alphabetical, if often 'defectively' so.
綴字体系 ("spelling system") とは何か.上記の部分を一読するだけで,予想される以上に複雑な代物であることが伝わるだろう.高度に言語学的な分析を要する,1つの重要な領域である.
・ Lass, Roger and Margaret Laing. "Interpreting Middle English." Chapter 2 of "A Linguistic Atlas of Early Middle English: Introduction." Available online at http://www.lel.ed.ac.uk/ihd/laeme2/laeme_intro_ch2.html .
2023-01-10 Tue
■ #5006. YouTube 版,515通りの through の話し [spelling][me_dialect][lme][scribe][youtube][standardisation][oed][med][laeme][lalme][hc][through]
昨年2月26日に,同僚の井上逸兵さんと YouTube チャンネル「井上逸兵・堀田隆一英語学言語学チャンネル」を開始しました.以降,毎週レギュラーで水・日の午後6時に配信しています.最新動画は,一昨日公開された第91弾の「ゆる~い中世の英語の世界では綴りはマイルール?!through のスペリングは515通り!堀田的ゆるさベスト10!」です.
英語史上,前置詞・副詞の through はどのように綴られてきたのでしょうか? 後期中英語期(1300--1500年)を中心に私が調査して数え上げた結果,515通りの異なる綴字が確認されています.OED や MED のような歴史英語辞書,Helsinki Corpus, LAEME, LALME のような歴史英語コーパスや歴史英語方言地図など,ありとあらゆるリソースを漁ってみた結果です.探せばもっとあるだろうと思います.
標準英語が不在だった中英語期には,写字生 (scribe) と呼ばれる書き手は,自らの方言発音に従って,自らの書き方の癖に応じて,様々な綴字で単語を書き落としました.同一写字生が,同じ単語を異なる機会に異なる綴字で綴ることも日常茶飯事でした.とりわけ through という語は方言によって発音も様々だったため,子音字や母音字の組み合わせ方が豊富で,515通りという途方もない種類の綴字が生じてしまったのです.
関連する話題は hellog でもしばしば取り上げてきました.以下をご参照ください.
・ 「#53. 後期中英語期の through の綴りは515通り」 ([2009-06-20-1])
・ 「#54. through 異綴りベスト10(ワースト10?)」 ([2009-06-21-1])
・ 「#3397. 後期中英語期の through のワースト綴字」 ([2018-08-15-1])
・ 「#193. 15世紀 Chancery Standard の through の異綴りは14通り」 ([2009-11-06-1])
・ 「#219. eyes を表す172通りの綴字」 ([2009-12-02-1])
・ 「#2520. 後期中英語の134種類の "such" の異綴字」 ([2016-03-21-1])
・ 「#1720. Shakespeare の綴り方」 ([2014-01-11-1])
今回,515通りの through の話題を YouTube でお届けした次第ですが,その収録に当たって「小道具」を用意しました.せっかくですので,以下に PDF で公開しておきます.
・ 横置きA4用紙10枚に515通りの through の綴字を敷き詰めた資料 (PDF)
・ 横置きA4用紙1枚に1通りの through の綴字を大きく印字した全515ページの資料 (PDF)
・ 堀田の選ぶ「ベスト(ワースト)10」の through の綴字を印字した10ページの資料 (PDF)
ユルユル綴字の話題と関連して,同じ YouTube チャンネルより比較的最近アップされた第83弾「ロバート・コードリー(Robert Cawdrey)の英英辞書はゆるい辞書」もご覧いただければと(cf. 「#4978. 脱力系辞書のススメ --- Cawdrey さんによる英語史上初の英英辞書はアルファベット順がユルユルでした」 ([2022-12-13-1])).
2022-10-05 Wed
■ #4909. eWAVE は LAEME/LALME の現代世界英語版だった! [ewave][laeme][lalme][pde][eme][lme][world_englishes]
「#4902. eWAVE 3.0 の紹介 --- 世界英語の言語的特徴を格納したデータベース」 ([2022-09-28-1]) で,世界77変種の英語の統語形態情報を集積したデータベース eWAVE 3.0 (= The Electronic World Atlas of Varieties of English) を紹介した.言語項目に関する分布を世界地図上にプロットしてくれる優れものだが,どこか既視感のようなものを感じていた.
そして思い当たった.これは初期・後期中英語のイングランド方言地図 LAEME と LALME の現代世界英語版ではないかと.逆にいえば,LAEME/LALME は eWAVE の中英語版とみることができる.このことに気づいた瞬間,eWAVE と LAEME/LALME の英語史上の位置づけと意義が理解できた.
eWAVE と LAEME/LALME は対象とする時代や地理的な規模こそ異なっているが,狙いとしては類似している点が多い.いずれも当該時代の英語の特定の言語項目について,地域変種ごとにプロファイルをまとめてくれ,さらに地図上に分布をプロットしてくれる.そして,出力された結果を正しく解釈するためには高度な英語学・英語史の知識が必要であるという点も似ている.「標準変種」の概念が不在,あるいは少なくとも強く意識されていない,というのも共通点だ.
ただし,そもそも連携が意識されたプロジェクトではないわけで,当然ながら異なる点も多々ある.
・ eWAVE のターゲットは現代の世界英語というグローバルな規模,LAEME/LALME のターゲットは初期・後期中英語イングランドというローカルな規模
・ eWAVE のインフォーマントは各変種に精通した現代に生きる言語の専門家,LAEME/LALME のインフォーマントはたまたま現存している写本資料(eWAVE には "fit-technique" のような理論的な手法は不要)
・ eWAVE は統語形態項目に特化したプロファイルを,LAEME/LALME は音韻形態・綴字項目に特化したプロファイルを提供している
・ eWAVE のエンジンはデータベース,LAEME(体系的ではないが LALME も)のエンジンはコーパス(GloWbE のような世界英語コーパスは存在するが,eWAVE とは独立しているため,LAEME のように方言地図とコーパスとのシームレスな連携は望めない)
おもしろいのは,時代的に eWAVE と LAEME/LALME の間に位置する近代英語期について,類似の方言地図が作られていないことだ.近代英語期から現存する言語資料の大半が標準変種で書かれており,各地域変種の様子が見えてこないために,データベースもコーパスも編纂できないからだろう.地域変種の現われ方という観点からすると,時代を隔てた中英語と現代英語のほうがむしろ似ているのである.
2022-05-20 Fri
■ #4771. 古英語の3人称単数女性代名詞の対格 hie が与格 hire に飲み込まれた時期 [case][personal_pronoun][oe][inflection][paradigm][eme][laeme]
she の語源説について,連日 Laing and Lass の論文を取り上げてきた(cf. 「#4769. she の語源説 --- Laing and Lass による "Yod Epenthesis" 説の紹介」 ([2022-05-18-1]),「#4770. she の語源説 --- Laing and Lass による "Yod Epenthesis" 説の評価」 ([2022-05-19-1])) .
同論文の主な関心は3人称単数女性代名詞主格の形態についてだが,対格と与格の形態についても触れている.古英語の標準的なパラダイムによれば,対格は hīe,与格は hire の形態を取ったが,後の歴史をみれば明らかな通り,与格形が対格形を飲み込む形で「目的格 her」が生じることになった.この点でいえば,他の3人称代名詞でも同じことが起こっている.単数男性与格の him が対格 hine を飲み込み,複数与格の him が対格 hīe を飲み込んだ(後にそれ自身が them に置換されたが).
3人称代名詞に関して与格が対格を飲み込んだというこの現象(与格方向への対格の水平化)はあまり注目されず,およそいつ頃のことだったのだろうかと疑問が生じるが,単数女性に関しては Laing and Lass (209) による丁寧な説明があった.
By the time ME proper begins to emerge, and to survive in the written record in the mid to late twelfth century, the new 'she' type for the subject pronoun already begins to be found. For the object pronoun the levelling of the 'her/hir' type from the OE DAT/GEN variants is also already the majority for direct object function. For the fem sg personal pronoun used as direct object ($/P13OdF), LAEME CTT has 60 tokens of the 'heo/hi(e)' type across only 7 texts. If one includes hi(e) spellings for IT ($/P13OdI) showing survival of feminine grammatical gender in inanimates, the total rises to 77 tokens across 14 texts. Only 2 texts (with 3 tokens between them) have 'heo/hie' exclusively in direct object function for HER. The other 5 texts show 'her/hir' types beside 'heo/hie' types. Against this are 494 tokens of the 'her/hir' type for HER found across 51 texts. Or, if one includes 'her/hir' type spellings for IT showing the survival of grammatical gender, the total rises to 590 across 58 texts.
要するに,対格の与格方向への水平化は,意外と早く初期中英語期の段階ですでに相当に進んでいたということになる.おそらく単数男性や複数でも似たような状況だったと想像されるが,これについては別に裏を取る必要がある.
この問題と関連して関連して,「#155. 古英語の人称代名詞の屈折」 ([2009-09-29-1]),「#975. 3人称代名詞の斜格形ではあまり作用しなかった異化」 ([2011-12-28-1]),「#4080. なぜ she の所有格と目的格は her で同じ形になるのですか?」 ([2020-06-28-1]) を参照.
2022-05-19 Thu
■ #4770. she の語源説 --- Laing and Lass による "Yod Epenthesis" 説の評価 [personal_pronoun][sound_change][phonetics][etymology][laeme][cone][orthography][epenthesis][she]
昨日の記事「#4769. she の語源説 --- Laing and Lass による "Yod Epenthesis" 説の紹介」 ([2022-05-18-1]) で,英語史における積年の問題に対する新説を簡単に紹介した.Laing and Lass 論文の結論箇所を引用すると,次のようになる (231) .
(a) For the history of she, we posit an approximant epenthesis of a type already found in OE, spreading to further items in ME, and occurring in all periods of Scots as well as PDE. This turns the word-onset into a consonant cluster with its own history, independent of that of the nuclear vowel (though it seems primarily to occur before certain nuclear types).
(b) The nuclear vowel derives in the normal way from OE [eo], with no need for 'resyllabification' or the creation of 'rising diphthongs'.
(c) This account allows an etymology with no interim generation of trimoric nuclei, or the problem of maintaining vowel length when the first element of the nucleus is the first vowel of the diphthong that constitutes it. It therefore allows for the unproblematic derivation of both [ʃe:] (required for PDE [ʃi:]) and [ʃo:] (required for some regional types such as [ʃu:]).
(d) We claim that the so-called 'she problem' has been a problem mainly because of a misconception of the kind of etymology it is. The literature (and this is true even of Britton's account, which is clearly the best) founders (sic) on the failure to separate the development of the word-onset and the development of the nuclear vowel.
The mistake has been the attempt to combine a vocalic story and a consonantal story and at the same time make phonological sense. We suggest that in this case it cannot be done, and that by separating the two stories we arrive at a clean and linguistically justifiable narrative.
ここで議論の詳細に立ち入ることはしないが,この新説に対する私自身の評価を述べるならば,これまで提案されてきた他の説よりも説得力があるとみている.
まず,LAEME という最新のツールを利用しつつ,圧倒的な質・量の資料に依拠している点が重要である.大きな視点からこの問題に取り組んでいるとよく分かるところからくる信頼感といえばよいだろうか.視野の広さと深さに驚嘆する.
上記と関連するが,LAEME と連携している CoNE (= A Corpus of Narrative Etymologies from Proto-Old English to Early Middle English) および CC (= the Corpus of Changes) の編纂という遠大な研究プロジェクトの一環として,she の問題を取り上げている点も指摘しておきたい.CoNE は,初期中英語に文証される単語のあらゆる異形態について,音変化や綴字変化の観点から説明尽くすそうという野心的な企画である(「初期中英語期を舞台とした比較言語学」と呼びたいほどだ).she についていえば,その各格形を含めたすべての異形態に説明を与えようとしており,[ʃ] を含む諸形態の扱いもあくまでその一部にすぎないのである.scha, þoe, þie, yo のような例外的な異形態についても,興味深い説明が与えられている.
そして,"Yod Epenthesis" 説の提案それ自体がコペルニクス的転回だった.she の語源を巡る論争史では [j] をいかに自然に導出させるかが重要課題の1つとなっていた.しかし,新説は [j] を自然に導出させることをある意味で潔く諦め,「ただそこに [j] が入ってしまった」と主張するのである.ただし,新説による [j] の挿入が必ずしも「不自然」というわけでもない.散発的ではあれ,類例があることは論文内で明確に示されているからだ.
理論的前提が多く,一つひとつの議論については著者らに問いただしてみたい点もあるのだが,全体として説得力があり,かつ刺激的な好論と評価したい.
・ Laing, Margaret and Roger Lass. "On Middle English she, sho: A Refurbished Narrative," Folia Linguistica Historica 35 (2014): 201-40.
・ Lass, Roger, Margaret Laing, Rhona Alcorn, and Keith Williamson. A Corpus of Narrative Etymologies from Proto-Old English to Early Middle English and accompanying Corpus of Changes, Version 1.1. Edinburgh: U of Edinburgh, 2013--. Available online at http://www.lel.ed.ac.uk/ihd/CoNE/CoNE.html.
2022-05-18 Wed
■ #4769. she の語源説 --- Laing and Lass による "Yod Epenthesis" 説の紹介 [personal_pronoun][sound_change][phonetics][etymology][laeme][epenthesis][she]
3人称単数女性代名詞 she の語源を巡って100年以上の論争が続いてきた.この問題については,hellog でも次の記事で取り上げてきた.
・ 「#792. she --- 最も頻度の高い語源不詳の語」 ([2011-06-28-1])
・ 「#793. she --- 現代イングランド方言における異形の分布」 ([2011-06-29-1])
・ 「#827. she の語源説」 ([2011-08-02-1])
・ 「#829. she の語源説の書誌」 ([2011-08-04-1])
この古い問題に LAEME という最新のツールを用いて挑んだのが,2014年の Laing and Lass の論文である(LAEME については,「#4086. 中英語研究における LAEME の役割」 ([2020-07-04-1]),「#4396. 初期中英語の方言地図とタグ付きコーパスを提供してくれる LAEME」 ([2021-05-10-1]) をはじめ laeme の各記事を参照).
she を巡る問題は,端的にいえば,初期中英語期より確認される異形態(現代の標準形 she に連なる形態も含む)に現われる (1) 子音 [ʃ],(2) [eː] および [oː],をどのように説明するのかという2点に集約される.とりわけ,問題解決の鍵となると目されている異形態 [hjoː] などに含まれる [j] が,どのように導出されるかが重要な問題となる.
従来の説では,問題の [j] は既存の音連続のなかから内在的に導出されることを前提としていた.一方,Laing and Lass の新しさは,[j] は内在的に導出されたのではなく,外在的に挿入されたにすぎないとしたことだ.簡単にいえば,ただそこに [j] が入ってしまったのだ,という説だ.これを前提とすれば上記の (1), (2) のも無理なく解決できるし,LAEME が示す異形態の方言分布の観点からも矛盾は生じないという.
「ただそこに [j] が入ってしまった」説は,同論文内では "Yod Epenthesis" (= YE) と名付けられている.古英語 [heo] が YE を経由して [hjeo] となり,その後 "eo-Monophthongisation/Merger" (= EOM) を通じて [hjeː] あるいは [hjoː] が導出されるという経路だ(実際には,この最後の過程の背景に中間的な [hjøː] が想定されているらしい).さらに,語頭の [hj] が "Fusional Assimilation" (= FA) を経て [ç] となり,最後に "Palatal Fronting" (= PF) の結果,[ʃ] が出力される,という道筋だ.
古英語からの流れを図示すれば次のようになる (Laing and Lass 217) .
*heo ((YE)) > *hjeo ((EOM)) >
1 *hjo: ((FA)) > [ço:] ((PF)) > [ʃo:]
2 *hje: ((FA)) > [çe:] ((PF)) > [ʃe:]
・ Laing, Margaret and Roger Lass. "On Middle English she, sho: A Refurbished Narrative," Folia Linguistica Historica 35 (2014): 201-40.
2021-05-10 Mon
■ #4396. 初期中英語の方言地図とタグ付きコーパスを提供してくれる LAEME [laeme][lalme][slide][corpus][academic_conference]
8ヶ月ほども前の話しで恐縮だが,昨年9月20日(日)にオンラインで開催された2020年度駒場英語史研究会にて,特別企画「電子コーパスやオンライン・リソースを使った英語史研究 ― その実践と可能性」に発表者として参加させていただいた.私の専門とする英語史の時代が中英語期なので,その時代の方言地図とタグ付きコーパスを紹介する趣旨で「LAEME & LALME を用いた英語史研究入門」と題して話す機会をいただいた.タイトルにある LAEME と LALME というものは,中英語を代表する2つの姉妹方言地図につけられた名前である.研究会では,とりわけ妹分である初期中英語期の LAEME の紹介に焦点を当てた,
研究会の様子はすでに「#4166. 英語史の各時代のコーパスを比較すれば英語史がわかる(かも)」 ([2020-09-22-1]) で簡単に報告したが,私の発表で用いたスライド資料について,活用されないよりはされたほうがよいと思ったので,こちらにて公表しておきたい.以下はスライドの各ページへのリンク.
・ 1. 駒場英語史研究会特別企画「電子コーパスやオンライン・リソースを使った英語史研究 ― その実践と可能性」LAEME & LALME を用いた英語史研究入門
・ 2. 本スライド資料
・ 3. 中英語 =「方言の時代」
・ 4. LAEME & LALME =「方言の時代」に使える最強の研究ツール
・ 5. LALME (書籍版)の外観
・ 6. LAEME & LALME との私的なお付き合い
・ 7. LAEME & LALME が提供してくれるもの
・ 8. LAEME & LALME のすごい点(学史上の意義)
・ 9. LAEME & LALME の強みと弱み
・ 10. LAEME のデータ点とサイズ (cf. #856)
・ 11. LAEME コーパスの「代表性」 (#1263)
・ 12. LAEME のタグ体系
・ 13. The Owl and the Nightingale (MS Cotton) の冒頭2行
・ 14. 対応する LAEME の tag file
・ 15. LAEME で(やろうと思えば)できることの例
・ 16. LAEME でやりにくいことの例
・ 17. LAEME の機能紹介
・ 18. お題1 3単現語尾の通時・方言分布 (#2142)
・ 19. お題2 nighti(n)gale の n (#797)
・ 20. お題3 through の異綴字はどれだけあったか? (#53)
・ 21. お題4 between の異形態はどれだけあったか?
・ 22. お題5 third の音位転換はいつ,どこで起こったか?
・ 23. お題6 初期中英語の「キーワード」抽出
・ 24. LAEME & LALME を利用したその他のミニ研究
・ 25. 参考文献・サイト
高度に専門的なツールなので取っつきにくいのは承知ながらも,LAEME を用いるとこんなことができますよ,ということでブレストしてみた「15. LAEME で(やろうと思えば)できることの例」に目を通していただければと.
2020-11-13 Fri
■ #4218. colour の最初期の異綴字 [spelling][laeme][ame_bre]
昨日の記事「#4217. 後期近代英語期のイギリス英語における colour vs color」 ([2020-11-12-1]) に引き続き,colour の綴字の話題.OED の colour | color, n.1 によると,この語は名詞として1300年頃に以下のように初出する.
c1300 St. Patrick's Purgatory (Laud) l. 562 in C. Horstmann Early S.-Eng. Legendary (1887) 216 He..axede him of ȝwuch colur were heuene op-riȝt þere.
colur という綴字がみえるが,これは最初期の綴字の典型的なものの1つである.この語はラテン語 color から直接,あるいはフランス語 colur を経由して借り入れられたものとされる.少なくとも上記の最初例の綴字は,フランス語経由のルートを示唆するようにみえるが,事はそれほど単純ではない.フランス語における綴字も諸変種間で様々で,OED の語源欄によれば,次のように variants はきわめて豊富だ.
Anglo-Norman colur, culur, coler, coloure, coleure, collour, Anglo-Norman and Old French, Middle French color, colour, coulour, Old French coulor, Old French, Middle French, couleur, coleur, Middle French colleur, coullour, etc.
フランス語側でのこのような綴字の多様性がみられるが,英語側も負けていない.OED より異綴字を覗いてみよう.
ME coleour, ME coleure, ME colewre, ME colovre, ME coulur, ME culur, ME kolour, ME-15 collore, ME-15 colowr, ME-15 colowre, ME-15 culoure, ME-16 coler, ME-16 coleur, ME-16 colore, ME-16 coloure, ME-16 colur, ME-16 colure, ME-16 cullour, ME-16 culour, ME- color (now U.S.), ME- colour, lME clour, lME (in a late copy) 15-16 collor, 15 colloure, 15 collyr, 15 cooler, 15 cooller, 15 coollor, 15 coollour, 15 coollur, 15 coolore, 15 cooloure, 15 coullar, 15 coulloure, 15 coulore, 15 cowler, 15-16 coller, 15-16 coolor, 15-16 coolour, 15-16 couler, 15-16 coullour, 15-16 coulor, 15-16 couloure, 15-16 culler, 15-16 cullor, 15-16 culloure, 15-17 collour, 15-17 couller, 15-17 coullor, 15-17 coulour; Scottish pre-17 coiller, pre-17 coller, pre-17 colleur, pre-17 collor, pre-17 collour, pre-17 colloure, pre-17 colore, pre-17 coloure, pre-17 colowr, pre-17 colowre, pre-17 colur, pre-17 couler, pre-17 couller, pre-17 coullour, pre-17 coulour, pre-17 culler, pre-17 cullor, pre-17 cullour, pre-17 culloure, pre-17 culour, pre-17 17-18 color, pre-17 17- colour.
中英語での出現形に注目すると,MED の colour n. では,見出しとして colour のほか culur, colur, coler の形態が挙げられている.また,LAEME からは,最初期の例として,13世紀後半(OED の初出年代より若干早いか)からの culur, colur,また14世紀前半からの colurs, colour, colures の計5件が得られた.
このような多様で複雑きわまりない状況を前にして,容易に有意義な傾向を指摘することはできない.しかし一つ言えることは,この語が英語に出現した最初期より,すでに第2音節母音を1母音字で綴るか,2母音字で綴るかという変異 --- 現代の colour vs color 問題の元祖 --- が確認されるということだ.したがって,この問題の淵源は「フランス語綴字 vs ラテン語綴字」に,もしくは「フランス語変種のある異綴字 vs フランス語変種の別の異綴字」にあるといってよい.関連して「#4161. アメリカ式 color はラテン語的,イギリス式 colour はフランス語的」 ([2020-09-17-1]) も参照.
2020-09-22 Tue
■ #4166. 英語史の各時代のコーパスを比較すれば英語史がわかる(かも) [academic_conference][corpus][eebo][glowbe][laeme][lalme][historiography][standardisation]
一昨日の9月20日(日),2020年度駒場英語史研究会にて,特別企画「電子コーパスやオンライン・リソースを使った英語史研究 ― その実践と可能性」に発表者として参加しました.Zoom でのオンライン大会でしたが,円滑に会が進行しました.(企画のご提案から会の主催までお世話になりました寺澤盾先生(東京大学),発表者の家入葉子先生(京都大学)と菊地翔太先生(明海大学),および参加者すべての方々には,貴重な機会とインスピレーションをいただきました.お礼申し上げます.)
トップバッターの私自身の発表では「LAEME & LALME を用いた英語史研究入門」と題して,中英語を代表する2つの姉妹コーパス LAEME と eLALME を紹介しました.続いて,家入先生の「データベースの利用によるコーパス言語学 --- Early English Books Online を中心に」と題する発表では,初期近代英語期を代表するコーパス EEBO corpus が紹介されました.最後に,菊地先生による「Corpus of Global Web-Based English(GloWbE)を用いた World Englishes 研究の可能性」という発表により,21世紀の World Englishes 時代を象徴する GloWbE が導入されました(←私にとって未知だったので驚きの連続でした).
各々の発表はコーパスの紹介とデモにとどまらず,その可能性や「利用上の注意」にまで触れた内容であり,発表後のディスカッションタイムでは,英語史研究においてコーパス利用はどのような意義をもつのかという方法論上の肝心な議論にまで踏み込めたように思います(時間が許せば,もっと議論したいところでした!).
中英語,近代英語,21世紀英語という3つの異なる時代の英語を対象としたコーパスを並べてみたわけですが,研究会が終わってからいろいろと考えが浮かんできました.同じ英語のコーパスとはいえ,対象とする時代が異なるだけで,なぜ検索の仕方も検索の結果もインターフェースもここまで異なるのだろうかということです.その答えは「各々の時代における英語の(社会)言語学的事情が大きく異なっているから,それと連動して(現代の研究者が編纂する)コーパスのあり方も大きく異ならざるを得ない」ということではないかと思い至りました.
逆からみれば,各時代のコーパスがどのように編纂され,どのように使用されているかを観察することにより,その時代の英語の(社会)言語学的事情が浮き彫りになってくるのではないか,ということです.そうして時代ごとの特徴がきれいに浮き彫りになってくるようであれば,それを並べてみれば,ある種の英語史記述となるにちがいない.換言すれば,各時代のコーパス検索に伴うクセや限界みたいなものを指摘していけば,その時代の背後にある言語事情が透けて見えてくるのではないかと.ここから「コーパスのあり方からみる英語史」のような試みが可能となってきそうです.
時代順にみていきます.中英語期は標準形が不在なので,ある単語を検索しようとしても,そもそもどの綴字で検索すればよいのかという出発点からして問題となります (cf. 「#1450. 中英語の綴字の多様性はやはり不便である」 ([2013-04-16-1])).実際,中英語辞書 MED である単語を引くにしても,そこそこ苦労することがあります.LAEME や LALME でも検索インターフェースには様々な工夫はなされていますが,やはり事前の知識や見当づけが必要ですので,検索が簡単であるとは口が裂けても言えません.現実に標準形がないわけですから,致し方がありません.
次に初期近代英語期ですが,EEBO は検索インターフェースが格段にとっつきやすく,一見すると検索そのものに問題があるようには見えません.しかし,英語史的にはあくまで標準化を模索している時代にとどまり,標準化が達成された現代とは事情が異なります.つまり,標準形とおぼしきものを検索欄に入れてクリックしたとしても,実は拾い漏れが多く生じてしまうのです.公式には実装されているとされる lemma 検索も,実際には思うほど精度は高くありません.落とし穴がいっぱいです.
最後に,21世紀英語の諸変種を対象とする GloWbE については,(ポスト)現代英語が相手ですから,当然ながら標準形を入力して検索できます.しかし,BNC や COCA のような「普通の」コーパスと異なるのは,返される検索結果が諸変種に由来する多様な例だということです.
大雑把にまとめると次のようになります.
| 代表コーパス | 検索法などに反映される「コーパスのあり方」 | (社会)言語学的事情 | |
|---|---|---|---|
| 中英語 | LAEME, LALME | 検索法が難しい | 標準形がない |
| 初期近代英語 | EEBO | 検索法が一見すると易しい | 標準形が中途半端にしかない |
| 21世紀英語 | GloWbE | 検索法が易しい | 標準形はあるが,その機能は変種によって多様 |
異なる時代のコーパスを比べてみると,英語史がみえてくるということがよく分かりました.駒場英語史研究会での発表の機会をいただき,改めて感謝します.
2020-07-04 Sat
■ #4086. 中英語研究における LAEME の役割 [laeme][lalme][me_dialect][dialectology][eme][manuscript][scribe]
昨日の記事「#4085. 中英語研究における LALME の役割」 ([2020-07-03-1]) に引き続き,LALME の姉妹版である初期中英語の方言地図 LAEME についても,研究史上の重要な位置づけを紹介しておこう.
LAEME は,時代としては LALME よりも古い時代を扱うが,プロジェクトとしてはそのの後継として開始されたために「後発の利点」を活かしうる立場にあった.とはいえ,編者の1人 Laing は,初期中英語の呈する特殊事情ゆえに深い悩みを抱えていた.後期中英語よりもテキストの量がずっと少なく,分布も偏っており,そもそも方言同定の最初の頼みとなる "anchor texts" が得にくい.とりわけ初期のテキストは,古英語の West-Saxon Schriftsprache に影響されたものが多く,そのスペリングを方言同定のために利用することはできない.しかし,Laing はテキスト産出に貢献した写字生を丁寧に選り分け,どの写字生の関わったどの部分のスペリングがその写字生の出所を示している可能性が高いか,等の知見を粘り強く蓄積していった.結果として,何とか少数の "anchor texts" を得ることに成功し,それをもとに LALME 以来洗練されてきた "fit-technique" を適用して,他のテキストを地図上にプロットしていった --- 今回はデジタルの力を借りて --- のである.
LAEME の新機軸は,LALME に付随する積年の問題だった質問項目 (questionnaire) の設定を放棄したことにあった.語彙・文法的タグを付しながらテキストを電子コーパス化し,即席の質問項目に対応できるように準備したのである.もっとも,対象としたテキストの全文に対して完全なるタグ付けを行なったわけではなく,時に写字(生)に関する込み入った事情ゆえに不完全にとどまるなど困難な経緯もあったようだ.プロジェクトの時間上の制約もあり,最終的には初期中英語の網羅的なコーパスとはならなかったものの,タグ付けされた65万語からなる,堂々たる研究ツールに仕上がった.とりわけ同時代の英語の正書法,音韻論,形態論のためには,なくてはならない必須ツールである.
研究ツールとしての LAEME の最大の長所は,テキストが徹頭徹尾 "diplomatic" であることだ.デジタルでありながら写本の綴字に限りなく忠実であろうとする,この原文に対する "diplomatic" な態度は,他ではほとんど例を見出すことができない.私自身も博士論文研究で大変お世話になった,ありがたいツールである.以上,Lowe (1126) に依拠して執筆した.
・ Lowe, Kathryn A. "Resources: Early Textual Resources." Chapter 71 of English Historical Linguistics: An International Handbook. 2 vols. Ed. Alexander Bergs and Laurel J. Brinton. Berlin: Mouton de Gruyter, 2012. 1119--31.
2020-05-30 Sat
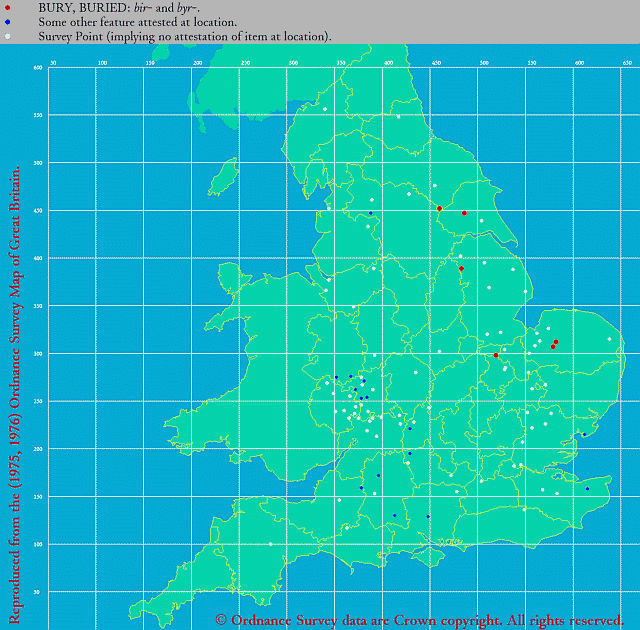
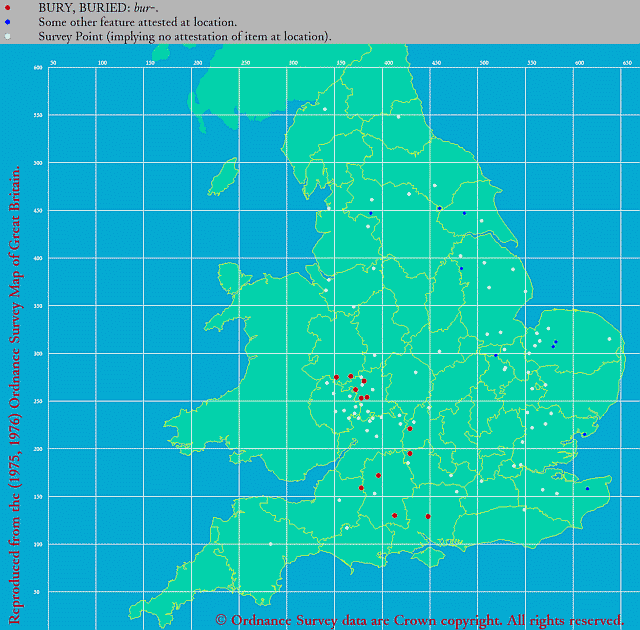
■ #4051. 中英語方言における bury の綴字の方言地図 --- LAEME より [laeme][me_dialect][dialectology][vowel][map][isogloss][eme][lalme]
中英語方言学でよく知られている方言間の母音変異の事例として,北部・東部方言の <i> = [i(ː)],中西部方言の <u> = [y(ː)],南東部方言の <e> = [e(ː)] というものがある.これは,古英語ウェストサクソン方言において典型的に <y> で綴られた母音(初期には [y(ː)],後期には [i(ː)] だったとされる)が,中英語の諸方言でどのような対応形を示しているかを図式的に整理したものである.
現代英語の単語でいえば busy, merry などが典型的に上記の方言分布と関連している. 関連する話題は以下の記事で扱ってきた.
・ 「#562. busy の綴字と発音」 ([2010-11-10-1])
・ 「#563. Chaucer の merry」 ([2010-11-11-1])
・ 「#570. bury の母音の方言分布」 ([2010-11-18-1])
・ 「#1341. 中英語方言を区分する8つの弁別的な形態」 ([2012-12-28-1])
・ 「#1434. left および hemlock は Kentish 方言形か」 ([2013-03-31-1])
・ 「#4048. much, shut, such, trust の母音と中英語方言学」 ([2020-05-27-1])
今回はとりわけ bury に焦点を当て,初期中英語の諸方言における第1母音(字)の変異を LAEME の Dot Map により示したい.この問題は,上の 「#562. busy の綴字と発音」 ([2010-11-10-1]) や「#570. bury の母音の方言分布」 ([2010-11-18-1]) でも扱ってきたが,今回は専門的なツールを用いて信頼に足る証拠を示すことに重点を置く.以下,当該母音(字)として <i, y> を用いる分布図の Dot Map を最初に挙げ,続いて2つ目に <u>,3つ目に <e> に関する Dot Map を示す.
(1) BURY, BURIED: bir- and byr-. (Map No. 16255502)
(2) BURY, BURIED: bur-. (Map No. 16255503)
(3) BURY, BURIED: ber-. (Map No. 16255501)
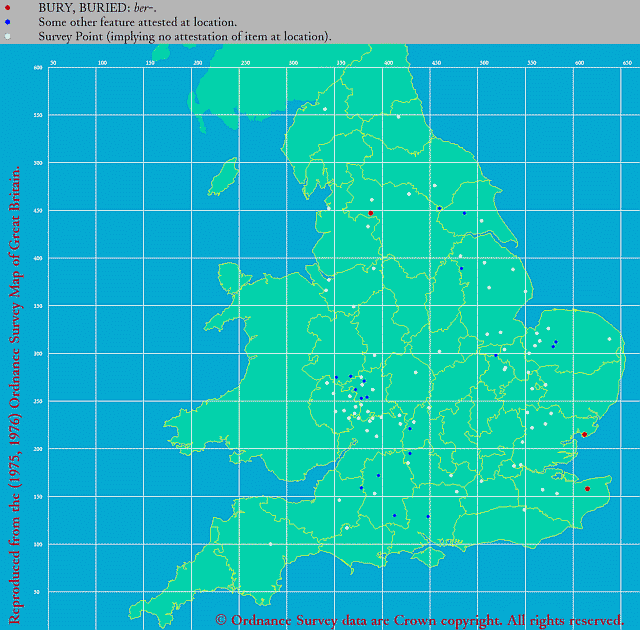
「#1262. The LAEME Corpus の代表性 (1)」 ([2012-10-10-1]),「#1263. The LAEME Corpus の代表性 (2)」 ([2012-10-11-1]) でみたように,LAEME の扱う(および初期中英語期一般についていえる)テキスト分布の事情により,全体として調査点 (dots) の数は多くはないものの,本記事の冒頭に示した伝統的な図式は,上の3つの地図により概ね支持されているといえよう.
なお,続く後期中英語における状況は,LAEME の姉妹版 LALME の Dot Map で確認できるが,後期には諸方言形が互いに激しく「乗り入れ」しており,初期ほど明確な分布は現われない.
[ 固定リンク | 印刷用ページ ]
2020-04-25 Sat
■ #4016. 中英語研究のための基本的なオンライン・リソース [bibliography][website][link][corpus][dictionary][hel_education][auchinleck][oed][htoed][laeme][lalme][med][ceec][me]
標記について,Smith (47--48) の参考文献表よりいくつか抜き出し,整理し,リンクを張ってみた(現時点で生きたリンクであることを確認済み).本ブログでは,その他各種のオンライン・リソースも紹介してきたが,まとめきれないので link を参照.とりわけ Chaucer 関連のリンクは「#290. Chaucer に関する Web resources」 ([2010-02-11-1]) をどうぞ.
・ AM = Burnley, David and Alison Wiggins, eds. Auchinleck Manuscript. National Library of Scotland, 2003. Available online at http://www.nls.uk/auchinleck/ .
・ CEEC = Nevalainen, Terttu, Helena Raumolin-Brunberg, Jukka Keränen, Minna Nevala, Arja Nurmi, and Minna Palander-Collin. Corpus of Early English Correspondence (CEEC). Department of English, U of Helsinki. Available online at https://varieng.helsinki.fi/CoRD/corpora/CEEC/index.html .
・ CSC = Meurman-Solin, Anneli. Corpus of Scottish Correspondence. U of Helsinki, 2007. Available online at https://varieng.helsinki.fi/CoRD/corpora/CSC/ .
・ CTP = Robinson, Peter and Barbara Bordalejo. The Canterbury Tales Project. Institute of Textual Scholarship and Electronic Editing, U of Birmingham, 1996--. Available online at http://server30087.uk2net.com/canterburytalesproject.com/index.html .
・ HTOED = Kay, Christian, Jane Roberts, Michael Samuels, and Irené Wotherspoon, eds. Historical Thesaurus of the Oxford English Dictionary. Oxford: OUP, 2009. Available online via http://www.oed.com/ .
・ LAEME = Laing, Margaret and Roger Lass. LAEME: A Linguistic Atlas of Early Middle English, 1150--1325. U of Edinburgh, 2007. Available online at http://www.lel.ed.ac.uk/ihd/laeme2/laeme2.html .
・ LALME = McIntosh, Angus, Michael Samuels, and Michael Benskin, with Margaret Laing and Keith Williamson. A Linguistic Atlas of Late Mediaeval English (LALME). Aberdeen: Aberdeen UP, 1986. Available online as eLALME at http://www.lel.ed.ac.uk/ihd/elalme/elalme_frames.html .
・ LAOS = Williamson, Keith. A Linguistic Atlas of Older Scots, Phase 1: 1380--1500 (LAOS). 2007. Available online at http://www.lel.ed.ac.uk/ihd/laos1/laos1.html .
・ MEC = McSparran, Frances, ed. Middle English Compendium. Ann Arbor: U of Michigan P, 2006. Available online at http://quod.lib.umich.edu/m/mec/ .
・ MED = Kurath, Hans, Sherman M. Kuhn, John Reidy, and Robert E. Lewis. Middle English Dictionary. Ann Arbor: U of Michigan P, 1952--2001. Available online at http://quod.lib.umich.edu/m/med/ .
・ MEG-C = Stenroos, Merja, Martti Mákinen, Simon Horobin, and Jeremy Smith. The Middle English Grammar Corpus (MEG-C). Version 2011.2. Available online at https://www.uis.no/research/history-languages-and-literature/the-mest-programme/the-middle-english-grammar-corpus-meg-c/ .
・ OED = Simpson, John, ed. The Oxford English Dictionary. 3rd ed. Oxford UP, 2000--. Available online at http://www.oed.com/.
・ TOE = Edmonds, Flora, Christian Kay, Jane Roberts, and Irené Wotherspoon. Thesaurus of Old English. U of Glasgow, 2005. Available online at https://oldenglishthesaurus.arts.gla.ac.uk/ .
・ VARIENG = Nevalainen, Terttu, Irma Taavitsainen, and Sirpa Leppänen. The Research Unit for Variation, Contacts and Change in English (VARIENG). Department of English, U of Helsinki. Available online at https://varieng.helsinki.fi/index.html .
・ Smith, Jeremy J. "Periods: Middle English." Chapter 3 of English Historical Linguistics: An International Handbook. 2 vols. Ed. Alexander Bergs and Laurel J. Brinton. Berlin: Mouton de Gruyter, 2012. 32--48.
2019-12-01 Sun
■ #3870. 中英語の北部方言における wh- ならぬ q- の綴字 [spelling][me_dialect][labiovelar][lalme][laeme][map]
中英語方言学ではよく知られているが,イングランドの北部や東部の方言では,疑問詞に典型的に現われる軟口蓋唇音 (labiovelar) が,一般的な wh- などの綴字ではなく,quh-, qvh, qwh, qh などの綴字で現われることが多い.たとえば what に対応する綴字をいくつか挙げてみると,qwhat, qwat, quat, quad, qhat のごとくである.これは問題の子音の調音が北部系方言と南部系方言の間で異なっていたことを示唆するが,具体的にどのような違いだったのかについては議論がある.(なお,北部系方言においては wh- などの綴字も普通に使われており,それと平行して q- もよく使われていたということである.)
後期中英語における q- の地理的な分布は,実にきれいである.eLALME の Item 44 として取り上げられている,"WH-: q-, all spellings." と題された Dot Map を以下に再掲しよう.
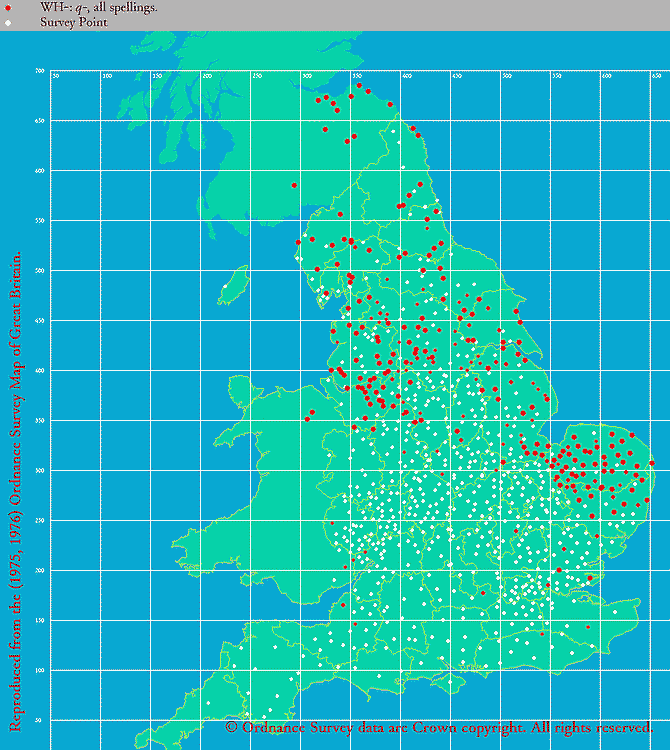
少しさかのぼって初期近代英語においても,LAEME の Map 28285405 の Dot Map を見るとわかるように,数こそ少ないが,やはり北部と東部に分布している.
当時,イングランド北部と地続きのスコットランドでも quh- などの綴字が一般的に用いられていた.しかし,16世紀以降になると,イングランドの標準的綴字の影響により,スコットランド英語でも quh- の立場は弱まっていった.そのくだりについては明日の記事で.
2019-06-16 Sun
■ #3702. 中英語の3人称複数対格代名詞 es はオランダ語からの借用か? (2) [personal_pronoun][laeme][lalme][me_dialect][clitic][map][dutch]
昨日の記事 ([2019-06-15-1]) に引き続き,中英語の them の代わりに用いられる es という人称代名詞形態について.Bennett and Smithers の注を引用して,およそ "SE or EMidl" に使用が偏っていると述べたが,LAEME と eLALME を用いて,初期・後期中英語における状況を確認しておこう.
LAEME では Map No. 00064420 として "THEM dir obj: 's' forms (sometimes cliticised), e.g. as, es, is, ys, hes, his." が挙げられており(下左図),eLALME では Item 8 として "THEM: 'his' type (incl as, es, is and enclitic -(e)s)." が挙げられている(下右図).ここでは縮小して掲げているので,詳しくはクリックして拡大を.
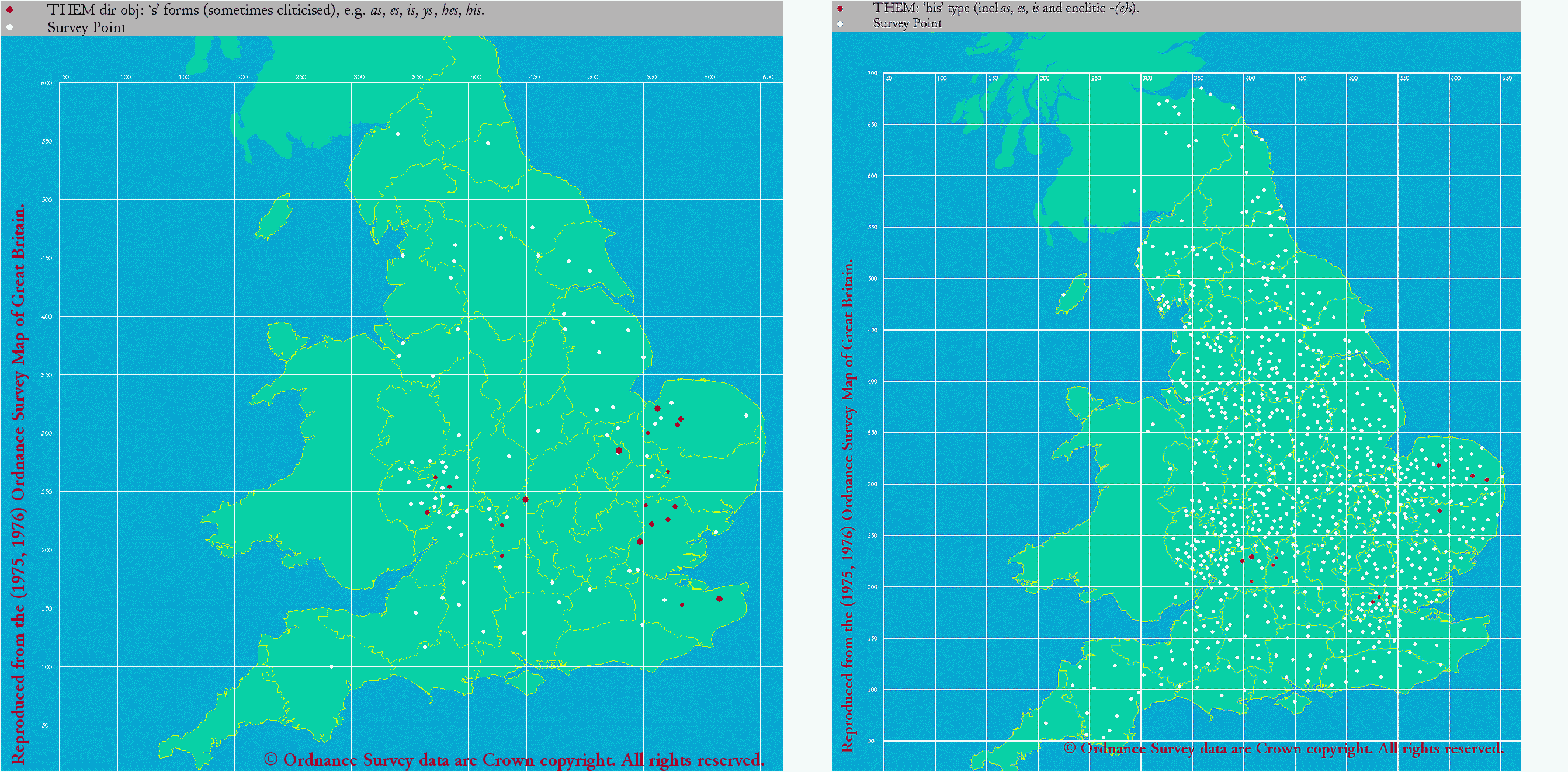
全体として例が多いわけではないが,中英語期を通じて East Midland と Southeastern を中心として,部分的には内陸の West Midland にも散見されるといった分布を示していることが分かる.
オランダ語との関連を議論するためには,当時のオランダ語話者集団のイングランドへの移民状況などの歴史社会言語学的な背景を調べる必要がある.一般的にいえば,「#3435. 英語史において低地諸語からの影響は過小評価されてきた」 ([2018-09-22-1]) でみたように,14世紀辺りには毛織物貿易の発展によりフランドルと東イングランドの関係は緊密になったことから,East Midland における es や類似形態の分布に関しては,オランダ語影響説を論じ始めることができるかもしれない.しかし,West Midland の散発的な事例については,別に考えなければならないだろう.
・ Bennett, J. A. W. and G. V. Smithers, eds. Early Middle English Verse and Prose. 2nd ed. Oxford: OUP, 1968.
2018-04-22 Sun
■ #3282. The Parsed Corpus of Middle English Poetry (PCMEP) [corpus][me][hc][ppcme][laeme][link]
中英語の韻文を集めた統語タグ付きコーパスをみつけた.The Parsed Corpus of Middle English Poetry より編纂者 Richard Zimmermann 氏の許可を得て利用できる.
現段階で,同コーパスは41のテキスト,160,432語からなっている(テキスト・リストはこちら).カバーする時代範囲は c. 1150--1420年,すなわち Helsinki Corpus の区分でいえば M1, M2, M3 に相当する時代である.統語タグは Penn Parsed Corpora of Historical English と同じ方法で付されており,Corpus Search 2 などのツールを用いて解析できる.
Related Corpora のページの情報も有用.そこにある中英語に関する各種コーパスやデータベースへのリンクを,以下にも張りつけておきたい.
・ The Penn-Parsed Corpus of Middle English
・ The Corpus of Middle English Prose and Verse
・ The Innsbruck Corpus of Middle English Prose
・ A Parsed Linguistic Atlas of Early Middle English (P-LAEME)
・ Database of Middle English Romance
アンテナ張りを怠っているうちに,いろいろなプロジェクトや成果物が現われていたのだなという感慨.
2018-01-24 Wed
■ #3194. ノルマン征服後,英語が用いられなくなったことへの嘆き [norman_conquest][me_text][scribe][manuscript][alliteration][laeme][bible]
Worcester Cathedral, Dean and Chapter Library F 174 という写本の Fol. 63r, lines 14--28 に,緩い頭韻を示す短いテキストが収められている.オリジナルは古英語で書かれていたようだが,このテキストの言語はすでに初期中英語的な特徴を示している.写本はおそらく13世紀の第2四半世紀 (C13a2) に成立した.このテキストの直前には Ælfic の Grammar と Glossary が,直後には "Body and Soul" に関する頭韻詩が収められている.写本全体が "Worcester tremulous hand" として知られる写字生によって書かれている.
テキストの内容は,標題に示唆したように,ノルマン征服後に教育などの公的な場面で英語が用いられなくなってしまったことへの嘆きである.征服前の古英語期には英語で教育が行なわれ,イングランドは文化的に反映していたのに,今や英語を話さないノルマン人が教師となってしまっている,嗚呼,嘆かわしいことよ,という趣旨だ.
ポイントは,l. 15 と l. 18 の対比である.古英語期にはアングロサクソン人の教師が英語で人々を教育していたが (l. 15),ノルマン征服後の今では「他の人々」,すなわち大陸から渡ってきたノルマン人が(他の言語で)人々を教育していると,書き手は嘆いている.英語が公的な地位から振り落とされ,学問からも遠ざけられた様子がわかる.Dickins and Wilson 版 (2) のテキストを示そう.
[S]anctus Beda was iboren her on Breotene mid us, And he wisliche [bec] awende Þet þeo Englise leoden þurh weren ilerde. And he þeo c[not]ten unwreih, þe questiuns hoteþ, Þa derne diȝelnesse þe de[or]wurþe is. 5 Ælfric abbod, þe we Alquin hoteþ, He was bocare, and þe [fif] bec wende, Genesis, Exodus, Vtronomius, Numerus, Leuiticus, Þu[rh] þeos weren ilærde ure leoden on Englisc. Þet weren þeos biscop[es þe] bodeden Cristendom, 10 Wilfrid of Ripum, Iohan of Beoferlai, Cuþb[ert] of Dunholme, Oswald of Wireceastre, Egwin of Heoueshame, Æld[elm] of Malmesburi, Swiþþun, Æþelwold, Aidan, Biern of Wincæstre, [Pau]lin of Rofecæstre, S. Dunston, and S. Ælfeih of Cantoreburi. Þeos læ[rden] ure leodan on Englisc, 15 Næs deorc heore liht, ac hit fæire glod. [Nu is] þeo leore forleten, and þet folc is forloren. Nu beoþ oþre leoden þeo læ[reþ] ure folc, And feole of þen lorþeines losiæþ and þet folc forþ mid. Nu sæiþ [ure] Drihten þus, Sicut aquila prouocat pullos suos ad volandum, et super eo[s uolitat.] 20 This beoþ Godes word to worlde asende, Þet we sceolen fæier feþ [festen to Him.]
l. 20 のラテン語は,Deuteronomy 32:11 より.The King James Version から対応箇所を引用すると "As an eagle stirs up her nest, flutters over her young, spreads abroad her wings, takes them, bears them on her wings: / So the Lord alone did lead him, and there was no strange god with him." (ll. 11--12) とある.よそから来た「神」が疎ましい,という引っかけか.
この写本については,LAEME よりこちらの情報も参照.
・ Dickins, Bruce and R. M. Wilson, eds. Early Middle English Texts. London: Bowes, 1951.
2016-11-22 Tue
■ #2766. 初期中英語における1人称代名詞主格の異形態の分布 [laeme][eme][map][personal_pronoun][owl_and_nightingale][compensatory_lengthening]
初期中英語のテキスト The Owl and the Nightingale を Cartlidge 版で読んでいる.868行にこのテキストからの唯一例として,1人称代名詞主格として ih の綴字が現われる.梟が歌のさえずり方について議論しているシーンで,Ne singe ih hom no foliot! として用いられている.この綴字はC写本のものであり,対するJ写本ではこの箇所に一般的な綴字 ich が用いられている.
この事実から,初期中英語における1人称代名詞主格の異形態の分布に関心をもった.そこで,LAEME で分布をさっと調べてみることにした.特に気になっているのは語末の子音の有無,およびその子音の種類である.母音を無視して典型的な綴字タイプを取り出してみると,ich, ik, ih, i 辺りが挙がる.細かく見ればほかにもありうるが,当面この4系列の綴字について出現分布を大雑把にみておきたい.
LAEME のプログラムはよくできているので,私の行なったことといえば,該当する形態に関して地図を表示させることのみだ.以下に4枚の方言分布図をつなぎ合わせたものを掲載する.キャンプションが小さくて読みにくいが,位置関係は次の表に示した通り(画像をクリックすれば拡大版が現われる).
| 以下の合成地図での位置 | Map No. | 説明 |
|---|---|---|
| 左上 | 00001312 | I: Ih, ih and yh |
| 右上 | 00001305 | I: 'ik', all k forms, incl icke. |
| 左下 | 00001302 | I: '(h)ich' and 'ych' incl iich and ichs |
| 右下 | 00001308 | I: I. |
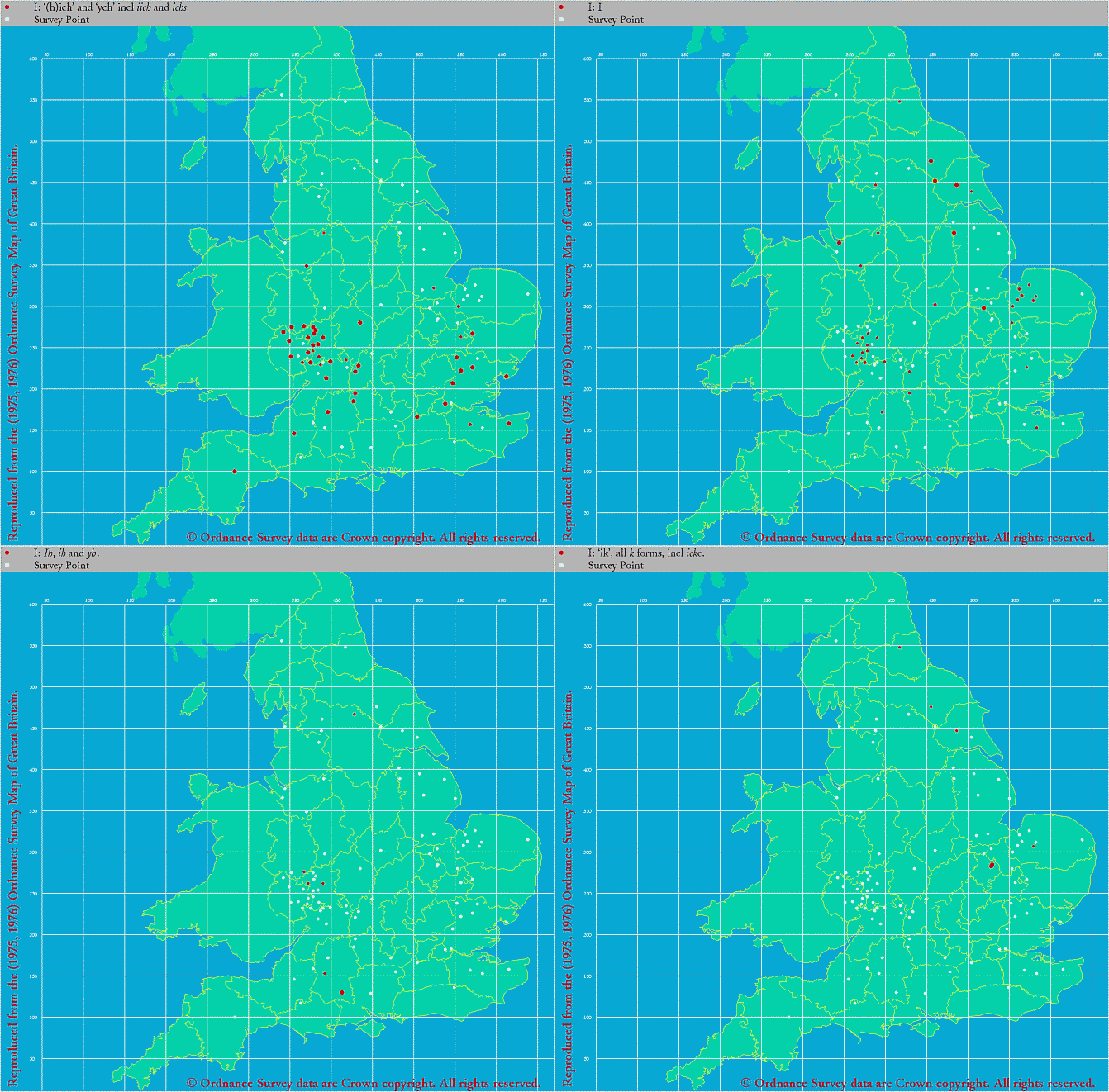
分布としては,左上の伝統的な ich 系が最も普通に南中部に広がっているのが分かる.右上の子音の落ちた i 系の綴字も普通であり,主として中部から北部に広がっている.左下の ih 系が今回注目した綴字を表わすが,西中部や南西部の,いわゆる最も保守的と言われる方言部分に散見される程度である.右下の ik 系は,東中部や北部に散在する程度で,一般的ではない.
The Owl and the Nightingale の方言については様々な議論がなされてきたが,いずれの写本の方言も,南西中部のものという解釈が一般的である.その点からすると,C写本で ih が現われたということは,初期中英語の全体の方向性と一致するだろう.
この問題に関心をもっているのは,伝統的な ich かいかなる経路を辿って後の I へと変化していったかという歴史的な問題に関係するからだ.この問題の周辺について,「#1198. ic → I」 ([2012-08-07-1]),「#1773. ich, everich, -lich から語尾の ch が消えた時期」 ([2014-03-05-1]) で簡単に話題にしたが,単に /ʧ/ と想定される語末子音が消失し,先行母音が代償延長 (compensatory_lengthening) したと考えておくだけでよいのか,疑念が残るのである.周辺的な方言に散見される ih や ik の語末子音は,/ʧ/ と通時的・共時的にどのような関係にあるのか.ih の子音は /ʧ/ の弱化した音で,消失への途中段階を表わすものではないか等々,いろいろな可能性が頭に浮かぶ.
・ Cartlidge, Neil, ed. The Owl and the Nightingale. Exeter: U of Exeter P, 2001.
[ 固定リンク | 印刷用ページ ]
2016-06-07 Tue
■ #2598. 古ノルド語の影響力と伝播を探る研究において留意すべき中英語コーパスの抱える問題点 [old_norse][loan_word][me_dialect][representativeness][geography][lexical_diffusion][lexicology][methodology][laeme][corpus]
「#1917. numb」 ([2014-07-27-1]) の記事で,中英語における本来語 nimen と古ノルド語借用語 taken の競合について調査した Rynell の研究に触れた.一般に古ノルド語借用語が中英語期中いかにして英語諸方言に浸透していったかを論じる際には,時期の観点と地域方言の観点から考慮される.当然のことながら,言語項の浸透にはある程度の時間がかかるので,初期よりも後期のほうが浸透の度合いは顕著となるだろう.また,古ノルド語の影響は the Danelaw と呼ばれるイングランド北部・東部において最も強烈であり,イングランド南部・西部へは,その衝撃がいくぶん弱まりながら伝播していったと考えるのが自然である.
このように古ノルド語の言語的影響の強さについては,時期と地域方言の間に密接な相互関係があり,その分布は明確であるとされる.実際に「#818. イングランドに残る古ノルド語地名」 ([2011-07-24-1]) や「#1937. 連結形 -son による父称は古ノルド語由来」 ([2014-08-16-1]) に示した語の分布図は,きわめて明確な分布を示す.古英語本来語と古ノルド語借用語が競合するケースでは,一般に上記の分布が確認されることが多いようだ.Rynell (359) 曰く,"The Scn words so far dealt with have this in common that they prevail in the East Midlands, the North, and the North West Midlands, or in one or two of these districts, while their native synonyms hold the field in the South West Midlands and the South."
しかし,事情は一見するほど単純ではないことにも留意する必要がある.Rynell (359--60) は上の文に続けて,次のように但し書きを付け加えている.
This is obviously not tantamount to saying that the native words are wanting in the former parts of the country and, inversely, that the Scn words are all absent from the latter. Instead, the native words are by no means infrequent in the East Midlands, the North, and the North West Midlands, or at least in parts of these districts, and not a few Scn loan-words turn up in the South West Midlands and the South, particularly near the East Midland border in Essex, once the southernmost country of the Danelaw. Moreover, some Scn words seem to have been more generally accepted down there at a surprisingly early stage, in some cases even at the expense of their native equivalents.
加えて注意すべきは,現存する中英語テキストの分布が偏っている点である.言い方をかえれば,中英語コーパスが,時期と地域方言に関して代表性 (representativeness) を欠いているという問題だ.Rynell (358) によれば,
A survey of the entire material above collected, which suffers from the weakness that the texts from the North and the North (and Central) West Midlands are all comparatively late and those from the South West Midlands nearly all early, while the East Midland and Southern texts, particularly the former, represent various periods, shows that in a number of cases the Scn words do prevail in the East Midlands, the North, and the North (and sometimes Central) West Midlands and the South, exclusive of Chaucer's London . . . .
古ノルド語の言語的影響は,中英語の早い時期に北部・東部方言で,遅い時期には南部・西部方言で観察される,ということは概論として述べることはできるものの,それが中英語コーパスの時期・方言の分布と見事に一致している事実を見逃してはならない.つまり,上記の概論的分布は,たまたま現存するテキストの時間・空間的な分布と平行しているために,ことによると不当に強調されているかもしれないのだ.見えやすいものがますます見えやすくなり,見えにくいものが隠れたままにされる構造的な問題が,ここにある.
この問題は,古ノルド語の言語的影響にとどまらず,中英語期に北・東部から南・西部へ伝播した言語変化一般を観察する際にも関与する問題である (see 「#941. 中英語の言語変化はなぜ北から南へ伝播したのか」 ([2011-11-24-1]),「#1843. conservative radicalism」 ([2014-05-14-1])) .
関連して,初期中英語コーパス A Linguistic Atlas of Early Middle English (LAEME) の代表性について「#1262. The LAEME Corpus の代表性 (1)」 ([2012-10-10-1]),「#1263. The LAEME Corpus の代表性 (2)」 ([2012-10-11-1]) も参照.
・ Rynell, Alarik. The Rivalry of Scandinavian and Native Synonyms in Middle English Especially taken and nimen. Lund: Håkan Ohlssons, 1948.
2016-03-22 Tue
■ #2521. 初期中英語の113種類の "such" の異綴字 [spelling][eme][laeme][corpus][scribe][me_dialect][representativeness]
昨日の記事「#2520. 後期中英語の134種類の "such" の異綴字」 ([2016-03-21-1]) に続き,今回は初期中英語コーパス LAEME で "such" の異綴字を取り出してみたい (see 「#1262. The LAEME Corpus の代表性 (1)」 ([2012-10-10-1])) .この語は,初期中英語では形容詞,副詞,接続詞として用いられ,形容詞の場合には屈折もするので,全体として様々な形態が現われる.アルファベット順に一覧しよう(かっこ内の数値は文証される頻度).
hsƿucche (1), schilke (1), schuc (3), scli (1), scuche (1), sec (1), secc (1), secche (1), sech (2), seche (1), selk (1), selke (1), shuc (1), shuch (1), siche (1), silc (1), silk (3), sli (1), slic (5), sliik (1), slik (3), slike (1), slk (1), sly (1), soch (5), soche (1), solchere (1), suc (2), sucche (2), such (51), suche (1), suecche (1), suech (1), sueche (1), sueh (1), sug (1), suic (1), suicchne (1), suich (12), suiche (3), suilc (14), suilce (1), suilch (1), suilk (1), suilke (2), sulch (1), sulche (1), sulk (1), sulke (1), suuche (1), suweche (1), suwilk (1), suyc (1), suych (4), suyche (1), svich (2), sƿche (1), sƿic (3), sƿicche (1), sƿich (1), sƿiche (14), sƿichne (1), sƿilc (30), sƿilch (22), sƿilche (1), sƿilcne (1), sƿilk (14), sƿillc (10), sƿillke (2), sƿi~lch (1), sƿlche (1), sƿuc (4), sƿucch (1), sƿucche (4), sƿucches (1), sƿuch (1), sƿuche (1), sƿuchne (1), sƿuilc (1), sƿulc (8), sƿulce (1), sƿulche (9), swch (1), swecche (1), swech (1), sweche (2), swich (5), swiche (1), swics (1), swil (1), swilc (5), swilce (1), swilk (2), swilke (2), swilkee (2), swlc (1), swlch (1), swlche (1), swlchere (1), swlcne (1), swuche (2), swuh (1), swulcere (1), swulch (3), swulchen (1), swulchere (1), swulke (1), swulne (1), zuich (10), zuiche (14), zuichen (3), zuych (10), zuyche (2)
大文字と小文字の区別はつけずに,合計113種類の綴字が文証される.そのなかで頻度にしてトップ5の綴字を抜き出すと,such, sƿilc, sƿilch, sƿilk, sƿiche となり,この5種類だけで全用例369個のうち131個 (35.5%) を占める.
昨日の後期中英語からの134種類と合わせ,重複綴字を減算すると,中英語全体として247種類の異綴字があることになる.使用した方言地図やコーパスも必ずしも網羅的ではないので,これは控えめな数値と思われる.例えば,MED の swich (adj.) に掲げられている異綴字を加えれば,種類はもう少し増えるだろう.
2015-04-09 Thu
■ #2173. gospel から d が脱落した時期 [phonetics][consonant][etymology][loan_translation][folk_etymology][laeme]
福音(書)を意味する gospel の語源はよく知られている.この語は,ラテン語 evangelium (これ自体はギリシア語 euaggélion "good news" に由来する)からの翻訳借用 (loan_translation) であり,古英語期に取り入れられた.古英語 godspel (good news) の第1要素は gōd (good) に等しく,本来は長母音をもっていたが,god (God) との類推から短母音も早くから行われていたようだ.これは,一種の民間語源 (folk_etymology) といってよいだろう.OED や Jespersen (126) もこの民間語源説を支持している.しかし,もう1つの説明として,「#2063. 長母音に対する制限強化の歴史」 ([2014-12-20-1]) で触れたように,この短母音は3子音前位置短化という音韻過程の結果と考えることもできるかもしれない.中尾 (142) は,この過程がすでに初期古英語から始まっていたと述べている.
母音の量については上のような説明が与えられているが,古英語 godspel からの d の脱落についてはどうだろうか.中尾 (405) によれば,13世紀に,子音の後続する d の削除の過程がいくつかの語において観察されるという.例を挙げると,an (and), handeselle > hanselle (handsel), wenesday (Wednesday), godspell > gospel, andswerian > answerie (answer) である(cf. 「#1261. Wednesday の発音,綴字,語源」 ([2012-10-09-1])).
d の脱落という問題に関心をもったのは,Wordorigins.org の gospel に関する記事に,13世紀末に godspel から d が突如として消えたとの記述があったからである.突如としてということであれば,注目に値する.LAEME で簡単に調べてみた.
結果は,当該語の種々の異形を含む合計213例のうち,18例において問題の破裂音 (多数の d に加えて t の例も1つあった)の脱落が見られた(脱落率は8.45%).これらの例は6テキストに集中しており,方言は North, South-West Midland, Southwestern とばらばらだが,時期的には13世紀前半からの1例を除いてすべて13世紀後半から14世紀前半について,つまり1300年を挟む時期である.ただし,1300年以降にも d を示す例のほうが多数派ではあるし,d に関して揺れを示すテキストもある.全体として,Wordorigins.org の上の記事で述べられているように13世紀末に d が脱落したという形跡はなかったし,脱落が突如として生じたというわけでもなさそうだ.おそらくは中尾の言及にもある通り,13世紀中に d の削除が始まったが,その削除は突如として起こったわけではなく,14世紀以降に向けて徐々に進行したと考えるのが妥当だろう.MED の gospel (n) も参照されたい.
・ Jespersen, Otto. A Modern English Grammar on Historical Principles. Part 1. Sounds and Spellings. 1954. London: Routledge, 2007.
・ 中尾 俊夫 『音韻史』 英語学大系第11巻,大修館書店,1985年.
Powered by WinChalow1.0rc4 based on chalow