2025-12-05 Fri
■ #6066.take の多義性 [johnson][oed][loan_word][old_norse][polysemy][collocation][idiom][phrasal_verb][asacul]
動詞 take の多義性 (polysemy) について考えている.語義をどこで区分するのは意味論の古典的な難問とはいえ,どのような切り方をしても,take のような基本語は,多義語と言わざるを得ない.
手元の英和辞書でみてみると,『新英和大辞典』第6版では,他動詞項目だけで38の語義が立てられている.各語義には下位区分もある.分け方次第では,もっと細かくもなれば粗くもなるだろう.英英語辞書での扱いはといえば,OALD8 で42語義ある.歴史的な辞書をを見てみると,Johnson の辞書(1755年)で113語義ほど.OED 第2版で引くと,動詞 take の項は第17巻の pp. 557--72 にわたり,47コラムほどの分量がある.語義数でいえば94を数え,ページをめくっていくだけで壮観である.辞書には,そのほか take を用いた句動詞やイディオムなど,コロケーションの記載も豊富だ.
いちいちの動詞についてきちんと裏取りしたわけではないが,OED でみる限り,take は英語の一般動詞のなかでも群を抜いて記述が多く,その限りにおいて,ひとまず多義的といっておいて間違いない.対応する日本語の「とる」を考えても,これは十分に納得できるだろう.
現行の OED Online の take に比べ,冊子体の OED 第2版の記述がすぐれていると思うのは,同項目の冒頭に近いところで,膨大な多義性を整理し,12の大分類として簡潔に示してくれているところだ.OED Online も,ディスプレイ上で語義をある程度アウトライン化してくれるので,同様の情報は得られるのだが,積極的に取りに行かなければならない.
ここでは利便性を活かして第2版より,take の語義の大分類を示そう.
General arrangement of senses: I. To touch. II. To seize, grip, catch. III. Ordinary current sense, i. with material obj.; ii. with non-material obj. IV. To choose, take for a purpose, into use. V. To derive, obtain from a source. VI. To receive, accept, admit, contain. VII. To apprehend mentally, comprehend. VIII. To undertake, perform, make. IX. To convey, conduct, deliver, apply or betake oneself, go. X. Idiomatic uses with special obj. XI. Intransitive uses with preposition. XII. Adverbial combinations = compound verbs. XIII. Idiomatic phrases, and Phrase-key.
これらの多義をきっちり使いこなすのは非常に難しいことだ.
2025-12-04 Thu
■ #6065. Take an umbrella with you. の with you に見られる空間関係明示機能 [notice][sobokunagimon][collocation][polysemy][semantics][mond][helkatsu][aspect][preposition][reflexive_pronoun][personal_pronoun][aspect]
先日の記事「#6062. Take an umbrella with you. の with you はなぜ必要なのか? --- mond の問答が大反響」 ([2025-12-01-1]) と,それに先立つ mond での回答を受けて,この with you の役割について,さらに考察を深めてみる.
先の回答では,前置詞句 with you が,多義語 take の語義を限定する役割を担っていると解説した.この前置詞句の存在により, take が単なる「取る」ではなく「持っていく」を意味することが確定する.もちろん文脈によっても同様の役割は果たされ得るのだが,直接言語的に果たされるのであれば,それはそれで望ましいことだ.フレーズの意味は,構成要素の意味の単純な足し算で決まるというよりも,構成要素相互の共起 (collocation) それ自体によって定まる,と考えられる.これは,構造言語学的にも認知言語学的にも認められてきた捉え方だ.
さて,with you の役割は,上述の意味限定機能に尽きるだろうか.反響コメントを受けて改めて考えてみると,他にもありそうである.1つ考えたのは「空間関係明示機能」とでも名付けるべき機能だ.Take an umbrella with me. の類例,すなわち「前置詞+人称代名詞(再帰的)」を伴う他の文例を考えてみよう.例文は Quirk et al. を参照した過去の hellog 記事「#2322. I have no money with me. の me」 ([2015-09-05-1]) より再掲する.
(1) He looked about him.
(2) She pushed the cart in front of her.
(3) She liked having her grandchildren around her.
(4) They carried some food with them.
(5) Have you any money on you?
(6) We have the whole day before us.
(7) She had her fiancé beside her.
いくつかの例では,動詞の意味を限定する機能が発動されていると解釈できるが,多くの例で際立つのは,主語と目的語の指示対象各々の相対的な空間関係が明示・強調されていることだ.(6) については,その応用で時間関係にも同構文が用いられていると解せる.(1) の場合でいえば,空間関係が above him でも behind him でもなく about him なのだという,対比に近い強調の気味が感じられる.
関連してこの構文に特徴的な点は,前置詞句内の強勢は前置詞そのものに落ち,人称代名詞には落ちないことだ.つまり,表出していない他の前置詞との対比が意識されている,と考えられるのではないか.このことは,"Pat felt a sinking sensation inside (her)." のように人称代名詞が表出すらしないケースがあることからも疑われる.
Take an umbrella with you. の with you の問題に戻ると,先の意味限定機能の解釈によれば,「取る」だけでなく「取って,さらに携帯していく」という語義へ絞り込まれるというのがポイントだった.これは広い意味で動作のアスペクトに関する差異を生み出すとも解釈でき,今回新たに提案した空間関係記述機能とも無関係ではなさそうだ.むしろ,物理的な動作のアスペクトは,空間関係と密接な関係にあるはずだ.その点で,両機能は独立した別々の機能というよりは,連続体と捉える方がよいのかもしれない.
・ Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech, and Jan Svartvik. A Comprehensive Grammar of the English Language. London: Longman, 1985.
2025-12-01 Mon
■ #6062. Take an umbrella with you. の with you はなぜ必要なのか? --- mond の問答が大反響 [notice][sobokunagimon][collocation][polysemy][semantics][mond][helkatsu][aspect]
昨日に引き続いての話題.先週の金曜日に,私が知識共有プラットフォーム mond に投稿した回答が,X(旧 Twitter)上で驚くべき反響を呼んでいます.本日付でそのX投稿のインプレッション数が327万,mond 本体での「いいね」も800件に迫る勢いです.「英語に関する素朴な疑問」への関心の高さを改めて実感しています.
話題となっているのは,ある中学生から寄せられた次のような質問でした.
以前,中学生に英語を教えたとき,こーゆう質問されました.「Take an umbrella with you. の with you って何故必要なんですか?」確かに,Take an umbrella. だけでも通じるので,with NP は別にいらないんじゃないかと思ってしまいます.
実に鋭い質問です.確かに Take an umbrella. だけでも文脈上「傘を持っていきなさい」の意味となるので,基本的には通じるでしょう.辞書を引けば take には「持っていく」という語義が確かに載っているわけですから.では,なぜわざわざ with you という(一見すると冗長な)前置詞句を添えるのが自然な英語とされるのでしょうか.
私の回答の核心は「多義性の解消」にあります.動詞 take は英語でも屈指の多義語であり,基本義は「(手に)取る」 (= grab/grasp/seize) ほどです.文脈の補助がない場合,意地悪くすれば Take an umbrella. は単に「傘を手に取りなさい」とも解釈され得るのです.ここに with you を添えることで「携行」というアスペクト的な意味が明示されることになり,意味が「持っていく」に限定されるのです.これは I have money. 「お金持ちだ/いま所持金がある」と I have money on me. 「いま所持金がある」の違いにも通じる,英語の興味深いメカニズムです.
この解説の要点を,インフォグラフィック(生成AI作成)としてまとめてみました.視覚的に整理すると,with you の意味限定機能がよく分かると思います.

mond の本編では,この言語学的メカニズムについて,Pass me the salt. や日本語の補助動詞「~してくれる」との比較も交えながら,より詳しく解説しています.
今回の with you 問題については,意味限定機能という切り口から解説しましたが,ほかにアスペクト・空間関係記述機能という見方もできるのではないかと考えています.こちらはまた別の機会にご紹介したいと思います.
今回の中学生の素朴な疑問が,いかに英語の本質を突いているか.ぜひ以下のリンクから mond でのオリジナルの問答を読んで,英語の「なぜ」を深掘りしていただければ.
・ 「Take an umbrella with you. の with you って何故必要なんですか?」
2025-11-28 Fri
■ #6059. take --- 古ノルド語由来の big word の起源と発達 [etymology][loan_word][lexicology][grammaticalisation][phrasal_verb][asacul][polysemy][collocation][particle][idiom][old_norse][french][contact][borrowing]
明日29日(土)の朝日カルチャーセンター新宿教室での講座では,take という英単語に注目し,その驚くべき起源と発達をたどる予定でいる.この単語は,英語語彙のなかでも最も多義的な単語のひとつである.その意味の広がりと,しかも古ノルド語からの借用語であるという事実に,改めて驚かざるを得ない.
OED 第2版(冊子体)で調べると,動詞 take の項目だけで第17巻の pp. 557--72 を占める.あの OED の小さな文字まで,47コラムほどの分量である.日本語では一般に「取る」と訳されることが多いが,この「取る」という動作概念があまりにも一般的で抽象的であるがゆえに,そこから無数の意味的な発展や共起表現が派生してきた.まさに,英語語彙のなかでも有数の "big word"と言って差し支えないだろう.
この多義的な動詞の歴史をたどると,まず根源にあるのは積極的な行動としての「取る」という意味だ.場所や土地を目的語として「占拠する」といった軍事的な含みをもつ語義だ.ここから派生して,モノを「取る」ことは,それを「自分のものにする」こと,すなわち「所有権を得る」という意味が展開してくる.さらに,モノや人を目的語にとって,何かを「もっていく」,誰かを「連れて行く」へも発展する.
この「積極的に取りにいく」という性質が希薄化していくと,むしろ意味は反対の方向へと向かう.すなわち,「受け取る」「引き受ける」といった,比較的消極的な意味が生まれてくるのだ.
さらに興味深いのは,意味がより希薄化し,いわば文法化 (grammaticalisation) へと進むケースである.例えば,take a walk や take a bath のように,単に特定の動作を行うことを示す,あたかも do に近い補助動詞的な役割を帯び始めるのだ.ここでは「取る」や「受け取る」といった具体的な意味はもはや感じられず,文法的な機能を果たす道具として用いられているにすぎない.この現象は,動詞の語彙的意味が薄れていく過程を示している.
また,take の語彙的価値を高めているのは,句動詞 (phrasal_verb) を生み出す母体としての役割である.take away, take in, take off, take out など,後ろに小辞 (particle) を伴うことで,数限りない表現が生み出されている.これらは1つひとつが独立した意味を持つため,英語学習者にとっては厄介な暗記項目となるが,その豊かさが,英語という言語の表現力を支えている.
加えて,take effect, take place, take part in のように特定の名詞と結びついてイディオム (idiom) を形成する用法も,現代英語では多数存在する.この背景には,中英語期にフランス語の対応する動詞 prendre という単語がどのような目的語をとるのか,という文法的・語彙的な情報を,英語が積極的に参照し,取り入れてきた歴史が関わっていると考えられている.
しかし,この多義的で,これほどまでに英語の語彙体系に深く食い込み,核をなしている動詞 take が,実は英語本来語ではない,という点こそが最も驚くべき事実だ.古英語の本来の「取る」を意味する動詞は niman として存在したにもかかわらず,古英語後期以降に take が古ノルド語から借用されてきたのである.なぜ,古ノルド語からの借用語が,土着の日常的な動詞を駆逐し,英語のなかで最も多義的で強力な "big word" の地位を獲得するに至ったのか.
この現象は,単に語彙の取捨選択の問題にとどまらず,言語接触のメカニズムの複雑さと不思議さを私たちに教えてくれる.この謎について,明日の朝カル講座で考察していきたい.
2025-10-08 Wed
■ #6008. 声の書評 --- khelf 泉類尚貴さんが紹介する『コーパスと英文法』 [khelf][hellive2025][review][voice_review][kenkyusha][heldio][voicy][corpus][collocation]
khelf(慶應英語史フォーラム)がお送りする https://voicy.jp/channel/1950] の「声の書評」シリーズ,第4弾です.今回は khelf 顧問で,関東学院大学で教鞭をとられている[[泉類尚貴さん|https://note.com/rui_hel/n/n4b3c4fa34656">heldioに,滝沢直宏(著)『〈英文法を解き明かす〉ことばの実際2 コーパスと英文法』(研究社,2017年)を紹介してもらいました.
泉類さんによれば,本書はコーパス言語学の入門書としてだけでなく,その応用までを視野に入れた実践的な1冊とのことです.コーパス (corpus) とは何か,という基礎的な解説から始まり,実際の研究でどのようにコーパスを活用するのか,具体例を交えて丁寧に説明されています.
特に,これまで感覚的に捉えられがちだった collocation (語と語の慣用的な結びつき)を,統計的な手法を用いて客観的に分析する方法が紹介されている点は,とても有益です.また,大規模なコーパスを利用する際の注意点や,自分でデータを収集する方法など,研究の現場で直面するであろう課題にも目配りされている点は,さすが専門家による解説書というべきでしょう.コーパスを使って本格的に言語研究に取り組みたいと考えている学生や研究者にとって,心強い味方となる1冊です.
収録参加者の khelf メンバーによる正規表現談義も聴き応えがありました.今回は,専門的な立場から本書の核心を解説してくれた泉類さんに感謝いたします.今回の「声の書評」は今朝の heldio 配信回「#1592. 声の書評 by khelf 泉類尚貴さん --- 滝沢直宏(著)『コーパスと英文法』(研究社,2017年)」でお聴きいただけます.

・ 滝沢 直宏 『〈英文法を解き明かす〉ことばの実際2 コーパスと英文法』 研究社,2017年.
2024-07-18 Thu
■ #5561. イディオムとは何か? [idiom][terminology][collocation][semantics][syntax]
先日,Voicy heldio で「#1139. イディオムとイディオム化 --- 秋元実治先生との対談 with 小河舜さん」をお届けしました.本編の冒頭で話題にしましたが,そもそもイディオム (idiom) とは何なのでしょうか?
上記の配信回でも参照した秋元 (33--34) によると,イディオムの定義は次の通りです.
イディオムの定義としては,意味上,統語上の基準に照らし合わせて,次のような特徴を持ち合わせたものと言える:
(i) 意味的不透明性,あるいは非合成性 (non-compositionality).イディオムの意味はその成分の総和から出てこない.よく知られている例として,
kick the bucket = die
がある.
(ii) 統語上の変形を許さない.すなわち,Chafe (1968) の言う 'transformational deficiency' である.上例のイディオムは「死ぬ」という意味では受動形は不可である:
*The bucket was kicked by Sam.
(iii) イディオム内の成分の語彙的代用はできない.すなわち,「語彙的完全無欠性」である.
have a crush on → *have a smash on
Numberg et al. (1994) はイディオム的意味が各成分に分配されていないイディオム(例:saw logs = snore)を 'idiomatic phrase',そしてイディオム的意味が各成分に分配されているイディオム(例:spill the beans = divulge the information) を 'idiomatic combination' と呼び,分けている.
ただし,ある表現がイディオムかどうかというのは,上記の条件から予想されるように自動的に,あるいはカテゴリカルに決まるような代物ではありません.イディオム性 (idiomaticity) という連続体の概念を念頭に置く必要がありそうです.
・ 秋元 実治 『増補 文法化とイディオム化』 ひつじ書房,2014年.
・ Chafe, Wallace. "Idiomaticity as an Anomaly in the Chomskyan Paradigm." Foundations of Language 4 (1968): 107--27.
・ Numberg, Geoffrey, Ivan A. Sag and Thomas Wasow. "Idioms." Language 70 (1994): 481--538.
2024-06-30 Sun
■ #5543. syntagmatic contamination と paradigmatic contamination [language_change][analogy][folk_etymology][contamination][assimilation][numeral][collocation][semantics][antonymy]
言語変化 (language_change) の基本的な原動力の1つである類推作用 (analogy) に関する本格的な研究書,Fertig の Analogy and Morphological Change についてはこちらの記事群で取り上げてきた.
今回は Fertig を参照し,contamination (混成)と呼ばれるタイプの類推作用について考えてみたい.「混成」とその周辺の現象が明確に分けられるかどうかについては議論があり,「#5419. blending と contamination」 ([2024-02-27-1]) でも関連する話題を取り上げたが,ひとまず contamination を区別できるものと理解し,そのなかに2つのタイプがあるという議論を導入したい.syntagmatic contamination と paradigmatic contamination である.具体例とともに Fertig からの関連箇所を引用する (64) .
Paul's initial conception of contamination (1886) involved influence attributable exclusively to paradigmatic (semantic) relations between forms, but he later (1920) recognized that lexical contamination often involves items that are not only semantically related but also frequently occur in close proximity in utterances. The importance of these syntagmatic relationships is emphasized in almost all modern accounts of contamination (Campbell 2004: 118--20 being the only exception that I am aware of). The most frequently cited examples involve adjacent numerals, which often influence each other's phonetic make-up: English eleven < Proto-Gmc. *ainlif under the influence of ten; Latin novem 'nine' instead of expected *noven under the influence of decem 'ten'; Greek dialectal hoktō 'eight' under the influence of hepta 'seven' (Osthoff 1878b; Trask 1996: 111--12; Hock and Joseph 2009: 163). Similar effects are attested in a number of languages among days of the week and months of the year, e.g. post-classical Latin Octember < Octōber under the influence of November and December.
Such contamination attributable to syntagmatic proximity of the affecting and affected items is often characterized as distant assimilation. Some scholars characterize contamination as a kind of assimilation even when it is purely paradigmatically motivated. Anttila calls it 'assimilation . . . toward another word in the semantic field' (1989: 76). Andersen (1980: 16--17) explicitly distinguishes such 'paradigmatic assimilation' from the more familiar 'syntagmatic assimilation'. As an unambiguous example of the latter, he mentions the influence of one word on another within a formulaic expression, such as French au fur et à mesure 'as, in due course' < Old French au feur et mesure (Wackernagel 1926: 49--50). Contamination involving antonyms, such as Late Latin sinexter < sinister 'left' under the influence of dexter 'right' or Vulgar Latin grevis < gravis 'heavy' under the influence of levis 'light', could be both paradigmatically and syntagmatically motivated since antonyms frequently co-occur in close proximity within an utterance, especially in questions: Is that thing heavy or light? Should I turn right or left? Wundt's view of paradigm leveling as a type of assimilation should also be mentioned in this context (Paul 1920: 116n 1).
syntagmatic contamination と paradigmatic contamination の2種類を区別しておくことは,理論的には重要だろう.しかし,実際的には両者は互いに乗り入れており,分別は難しいのではないかと思われる.paradigmatic な関係にある2者は syntagmatic には and などの等位接続詞で結ばれることも多いし,逆に syntagmatic に共起しやすい2者は paradigmatic にも意味論的に強固に結びつけられているのが普通だろう.
個々の事例が,いずれかのタイプの contamination であると明言することができるのかどうか,あるいはできるとしても,そう判断してよい条件は何か,という問題が残っているように思われる.
・ Fertig, David. Analogy and Morphological Change. Edinburgh: Edinburgh UP, 2013.
2023-02-19 Sun
■ #5046. silence と共起する形容詞 [adjective][collocation][bnc][corpus]
昨日の記事「#5045. deafening silence 「耳をつんざくような沈黙」」 ([2023-02-18-1]) で取り上げた共起表現について,BNCweb により例文を引き出してみた.いくつか挙げてみよう.
・ All that remained on the barren expanse was a deafening silence.
・ But the countryside! Absolute deafening silence. Not a tractor in sight. No buzzing saw mills, no electric milking machines humming away. Just horses and ploughs and, for want of a better word, peasants.
・ now there is almost a deafening silence, broken only by the odd apologetic cough as the minutes tick towards 8.30.
・ In the deafening silence inside the gallery she could hear her heart thumping madly against her ribs.
・ It was a relief when a couple of minutes later, amidst the deafening silence that had descended on the room, Mrs Aitken poked her head round the door. 'Dinner will be served whenever you're ready.'
この撞着語法 (oxymoron) の共起表現に関心を焚きつけられて,silence という名詞はほかにどのような形容詞で修飾されることが多いのだろうかと問いが湧いてきた.これは共起 (collocation) に関する初歩的な類いの疑問で,コロケーション辞書や活用辞書を引けば済む話しだが,行きがかり上 BNCweb で調べてみることにする."_AJ* {silence/N}" と検索した上で Frequency breakdown の機能を用い,50位までの頻度ランキングを出してみた.
| No. | Lexical items | No. of occurrences |
|---|---|---|
| 1 | long silence | 145 |
| 2 | stunned silence | 53 |
| 3 | complete silence | 44 |
| 4 | total silence | 43 |
| 5 | tense silence | 37 |
| 6 | awkward silence | 31 |
| 7 | brief silence | 28 |
| 8 | short silence | 27 |
| 9 | sudden silence | 23 |
| 10 | absolute silence | 22 |
| 11 | deafening silence | 22 |
| 12 | embarrassed silence | 22 |
| 13 | uncomfortable silence | 22 |
| 14 | shocked silence | 16 |
| 15 | stony silence | 15 |
| 16 | dead silence | 14 |
| 17 | deep silence | 13 |
| 18 | Eerie silence | 13 |
| 19 | heavy silence | 13 |
| 20 | small silence | 12 |
| 21 | thoughtful silence | 12 |
| 22 | uneasy silence | 12 |
| 23 | utter silence | 12 |
| 24 | ensuing silence | 11 |
| 25 | sullen silence | 11 |
| 26 | momentary silence | 10 |
| 27 | fraught silence | 9 |
| 28 | ominous silence | 9 |
| 29 | terrible silence | 9 |
| 30 | brooding silence | 8 |
| 31 | companionable silence | 8 |
| 32 | sponsored silence | 8 |
| 33 | virtual silence | 8 |
| 34 | dignified silence | 7 |
| 35 | horrified silence | 7 |
| 36 | Hushed Silence | 7 |
| 37 | lengthy silence | 7 |
| 38 | long silences | 7 |
| 39 | longer silence | 7 |
| 40 | strained silence | 7 |
| 41 | uncanny silence | 7 |
| 42 | awful silence | 6 |
| 43 | cold silence | 6 |
| 44 | comparative silence | 6 |
| 45 | continuing silence | 6 |
| 46 | embarrassing silence | 6 |
| 47 | gloomy silence | 6 |
| 48 | great silence | 6 |
| 49 | strange silence | 6 |
| 50 | angry silence | 5 |
deafening silence も10位タイに入っており,それなりに知られた共起表現だということがわかる.stunned silence, stony silence, dead silence など味わい深い表現があるものだ.
[ 固定リンク | 印刷用ページ ]
2023-02-18 Sat
■ #5045. deafening silence 「耳をつんざくような沈黙」 [oxymoron][voicy][heldio][collocation][rhetoric][pragmatics][ethnography_of_speaking][prosody][syntagma_marking][sociolinguistics][anthropology][link][collocation]
今週の Voicy 「英語の語源が身につくラジオ (heldio)」にて,「#624. 「沈黙」の言語学」と「#627. 「沈黙」の民族誌学」の2回にわたって沈黙 (silence) について言語学的に考えてみました.
hellog としては,次の記事が関係します.まとめて読みたい方はこちらよりどうぞ.
・ 「#1911. 黙説」 ([2014-07-21-1])
・ 「#1910. 休止」 ([2014-07-20-1])
・ 「#1633. おしゃべりと沈黙の民族誌学」 ([2013-10-16-1])
・ 「#1644. おしゃべりと沈黙の民族誌学 (2)」 ([2013-10-27-1])
・ 「#1646. 発話行為の比較文化」 ([2013-10-29-1])
heldio のコメント欄に,リスナーさんより有益なコメントが多く届きました(ありがとうございます!).私からのコメントバックのなかで deafening silence 「耳をつんざくような沈黙」という,どこかで聞き覚えたのあった英語表現に触れました.撞着語法 (oxymoron) の1つですが,英語ではよく知られているものの1つのようです.
私も詳しく知らなかったので調べてみました.OED によると,deafening, adj. の語義1bに次のように挙げられています.1968年に初出の新しい共起表現 (collocation) のようです.
b. deafening silence n. a silence heavy with significance; spec. a conspicuous failure to respond to or comment on a matter.
1968 Sci. News 93 328/3 (heading) Deafening silence; deadly words.
1976 Survey Spring 195 The so-called mass media made public only these voices of support. There was a deafening silence about protests and about critical voices.
1985 Times 28 Aug. 5/1 Conservative and Labour MPs have complained of a 'deafening silence' over the affair.
例文から推し量ると,deafening silence は政治・ジャーナリズム用語として始まったといってよさそうです.
関連して想起される silent majority は初出は1786年と早めですが,やはり政治的文脈で用いられています.
1786 J. Andrews Hist. War with Amer. III. xxxii. 39 Neither the speech nor the motion produced any reply..and the motion [was] rejected by a silent majority of two hundred and fifty-nine.
最近の中国でのサイレントな白紙抗議デモも記憶に新しいところです.silence (沈黙)が政治の言語と強く結びついているというのは非常に示唆的ですね.そして,その観点から改めて deafening silence という表現を評価すると,政治的な匂いがプンプンします.
oxymoron については.heldio より「#392. "familiar stranger" は撞着語法 (oxymoron)」もぜひお聴きください.
2023-02-18 Sat
■ #5045. deafening silence 「耳をつんざくような沈黙」 [oxymoron][voicy][heldio][collocation][rhetoric][pragmatics][ethnography_of_speaking][prosody][syntagma_marking][sociolinguistics][anthropology][link][collocation]
今週の Voicy 「英語の語源が身につくラジオ (heldio)」にて,「#624. 「沈黙」の言語学」と「#627. 「沈黙」の民族誌学」の2回にわたって沈黙 (silence) について言語学的に考えてみました.
hellog としては,次の記事が関係します.まとめて読みたい方はこちらよりどうぞ.
・ 「#1911. 黙説」 ([2014-07-21-1])
・ 「#1910. 休止」 ([2014-07-20-1])
・ 「#1633. おしゃべりと沈黙の民族誌学」 ([2013-10-16-1])
・ 「#1644. おしゃべりと沈黙の民族誌学 (2)」 ([2013-10-27-1])
・ 「#1646. 発話行為の比較文化」 ([2013-10-29-1])
heldio のコメント欄に,リスナーさんより有益なコメントが多く届きました(ありがとうございます!).私からのコメントバックのなかで deafening silence 「耳をつんざくような沈黙」という,どこかで聞き覚えたのあった英語表現に触れました.撞着語法 (oxymoron) の1つですが,英語ではよく知られているものの1つのようです.
私も詳しく知らなかったので調べてみました.OED によると,deafening, adj. の語義1bに次のように挙げられています.1968年に初出の新しい共起表現 (collocation) のようです.
b. deafening silence n. a silence heavy with significance; spec. a conspicuous failure to respond to or comment on a matter.
1968 Sci. News 93 328/3 (heading) Deafening silence; deadly words.
1976 Survey Spring 195 The so-called mass media made public only these voices of support. There was a deafening silence about protests and about critical voices.
1985 Times 28 Aug. 5/1 Conservative and Labour MPs have complained of a 'deafening silence' over the affair.
例文から推し量ると,deafening silence は政治・ジャーナリズム用語として始まったといってよさそうです.
関連して想起される silent majority は初出は1786年と早めですが,やはり政治的文脈で用いられています.
1786 J. Andrews Hist. War with Amer. III. xxxii. 39 Neither the speech nor the motion produced any reply..and the motion [was] rejected by a silent majority of two hundred and fifty-nine.
最近の中国でのサイレントな白紙抗議デモも記憶に新しいところです.silence (沈黙)が政治の言語と強く結びついているというのは非常に示唆的ですね.そして,その観点から改めて deafening silence という表現を評価すると,政治的な匂いがプンプンします.
oxymoron については.heldio より「#392. "familiar stranger" は撞着語法 (oxymoron)」もぜひお聴きください.
2022-10-08 Sat
■ #4912. 意味調整における前景化と背景化 [semantics][modulation][collocation][metonymy]
昨日の記事「#4911. 意味調整における昇格と降格」 ([2022-10-07-1]) に引き続き,文脈が語に与える意味調整 (semantic modulation) について.
意味調整には,昇格 (promotion) や降格 (demotion) と似てはいるが別種のタイプがある."highlighting" と "backgrounding" と言われるものだ.当面,それぞれを「前景化」「背景化」と和訳しておく.Cruse (53) の説明と例が分かりやすい.
Another effect of contextual modulation on the sense of a lexical unit involves the relative highlighting or backgrounding of semantic traits. Different sorts of trait can be affected in this way. Two examples will suffice. First, some part of an object (or process, etc.) may be thrown into relief relative to other parts. For instance, The car needs servicing and The car needs washing highlight different parts of the car. (This is not to say that car refers to something different in each of these sentences --- in both cases is is the whole car which is referred to.) Second, it is commonly the case that what is highlighted or backgrounded is an attribute, or range of attributes, of the entity referred to. For instance, We can't afford that car highlights the price of the car, Our car crushed Arthur's foot its weight. It is in respect of 'contextually modulated sense' that a lexical unit may be justifiably said to have a different meaning in every distinct context in which it occurs.
文脈に応じて同じ car という語に意味調整が働き,注目点が精妙に操作されているわけだ.前景化(および背景化)は,指示対象の特定の「部分」や「属性」に注目する点で,メトニミー (metonymy) と関係が深い.
・ Cruse, D. A. Lexical Semantics. Cambridge: CUP, 1986.
2022-10-07 Fri
■ #4911. 意味調整における昇格と降格 [semantics][modulation][collocation]
語の意味が文脈によって調整される現象は,意味調整 (semantic modulation) と呼ばれる.意味調整は本質として連続的かつ流動的で,それだけ精妙なものである.意味調整の種類1つに昇格 (promotion) と降格 (demotion) がある.文脈によりある語の特定の意味特徴が "canonical" になった場合,その意味特徴は昇格されたといわれる.反対に,ある意味特徴があり得なくなった場合,それは降格されたといわれる.Cruse (52) より例を挙げよう.
(1) A nurse attended us.
(2) A pregnant nurse attended us.
(1) の nurse には,多くの場合「女性」という意味特徴が含まれているだろうと予期される.おそらく女性でありそうだ,おそらく男性ではなさそうだ,ほどの予期である.
一方 (2) の nurse にあっては,「女性」という意味特徴は "canonical" である,つまり解釈する上で必須の意味特徴である.文脈(あるいは pregnant との共起)によって,意味特徴「女性」が,単にありそうだという地位から,そうでなければならないという地位に昇格されるということだ.逆にいえば,「男性」という意味特徴は,場合によってはあり得るという地位から,絶対にあり得ないという地位に降格されることになる.
もう1つ例を挙げれば,
(3) Arthur poured the butter into a dish.
という文において,butter は必然的に「液体性」という意味特徴を帯びる.通常は butter の液体性は,場合によってはあり得る程度の意味特徴にすぎないが,この文脈(あるいは poured との共起)にあっては,そうでなければならないという地位に昇格されているのである.
・ Cruse, D. A. Lexical Semantics. Cambridge: CUP, 1986.
2021-05-23 Sun
■ #4409. 色白で美しく公正な白雪姫 --- fair の語感 [khelf_hel_intro_2021][adjective][synonym][semantics][semantic_change][lexical_stratification][bnc][collocation][etymology]
「英語史導入企画2021」より今日紹介するコンテンツは,昨日学部生より公表された「この世で一番「美しい」のは誰?」です.ディズニー映画 Snow White and the Seven Dwarfs (『白雪姫』)の台詞 "Magic mirror on the wall, who is the fairest one of all?" で用いられている形容詞 fair の意味変化に焦点を当てた英語史導入コンテンツとなっています.
「美しい」といえばまず beautiful が思い浮かびますが,なぜ問題の台詞では fair なのでしょうか.まず,コンテンツでも解説されている通り fair には「色白の」という語義もありますので,Snow White とは相性のよい縁語といえます.さらに,beautiful が容姿の美しさを形容するのに特化している感があるのに対し,fair には「公正な,公平な」の語義を含め道徳的な含意があります (cf. fair trading, fair share, fair play) .白雪姫を形容するのにぴったりというわけです.
fair は古英語期より用いられてきた英語本来語で,古く清く温かい情感豊かな響きをもちます.一方,beautiful は,14世紀に古フランス語の名詞 beute を借用した後に,15世紀に英語側で本来語接尾辞 -ful を付加して作った借用語です.フランス借用語(正確には「半」フランス借用語)は相対的にいって中立的で無色透明の響きをもつことが多いのですが,beautiful についていえば確かに fair と比べて道徳的・精神的な深みは感じられません.(ラテン借用語 attractive と合わせた fair -- beautiful -- attractive の3語1組 (triset) と各々の使用域 (register) については,「#334. 英語語彙の三層構造」 ([2010-03-27-1]) をご覧ください.)
fair と beautiful のような類義語の意味・用法上の違いについて詳しく知りたい場合には,辞書やコーパスの例文をじっくりと眺め,どのような語と共起 (collocation) しているかを観察することをお薦めします.試しに約1億語からなるイギリス英語コーパス BNCweb で両語の共起表現を調べてみました.ここでは人物と容姿を形容する共起語に限って紹介しますが,fair とタッグを組みやすいのは hair と lady です.一方,beautiful とタッグを組む語としては woman, girl, young, hair, face, eyes, looks などが挙がってきます.気品を感じさせる fair lady に対して,あくまで容姿の良さを表わすことに特化した beautiful woman/girl という対立構造が浮かび上がってきます.白雪姫にはやはり fair がふさわしいのでしょうね.
fair に見られる白さと公正さの結びつきは,candid という形容詞にも見られます.candid は第一に「率直な」を意味しますが,やや古風ながらも「公平な」の語義がありますし,古くは「白い」の語義もありました.もともとの語源はラテン語 candidus で,まさに「白い」を意味しました.「白熱して輝いている」が原義で,candle (ロウソク)とも語根を共有しています.また,candidate (候補者)は,ローマで公職候補者が白いトーガを着る習わしだったことに由来します.ちなみに日本語でも「潔白」「告白」「シロ(=無罪)」などに白さと公正さの関係が垣間見えますね.
2021-04-15 Thu
■ #4371. 価値なきもの イチジク,エンドウ,ピーナッツ,ネギ,マメ,ワラ [negative][idiom][collocation][proverb][khelf_hel_intro_2021]
英語における「取るに足りないもの」の物尽し.
価値なきもの
イチジク,エンドウ,ピーナッツ,
ネギ,マメ,ワラ
この物尽しの果実・野菜・豆などを表わす植物名を英単語に置き換え,not worth a に後続させると,いずれも「?ほどの価値もない,取るに足りない」を意味する慣用句 (idiom) となる.not worth a fig/pea/peanut/leek/bean/straw の如くだ.
私などは,ワラを除いて,すべて旨い食べ物ではないか,とりわけ酒のつまみに良さそうではないか(イチジクはよしておこう)と評価したいところだが,英語文化においてはどうやら軽視される存在のようだ.
日本語では,例えば「豆」は接頭辞として「豆電球」「豆台風」などと用いるが,物理的に小さいことを示しこそすれ,軽視のコノテーションは感じられない.また,日本語の「溺れる者は藁をも掴む」という諺は,窮地に陥っている人はワラのように頼りにならないものにも救いを求めるものだという教えで,一見すると「ワラ=取るに足りない」が成立しそうだが,この諺は実は英語の A drowning man will catch at a straw. の直訳にすぎず,日本語発の諺ではない.この辺りの感覚は,日英語でかなり異なるらしい.
英語のこのような「価値なきもの」を表わす種々の慣用句の役割は「文彩的否定」(figurative negation)呼ばれるという.これは「英語史導入企画2021」の一環として昨日アップされた院生によるコンテンツ「否定と植物」から学んだことである.文彩的否定の表現には様々な「取るに足りない」植物の名前が用いられてきたようで,歴代引き合いに出されてきた植物としては cress (カラシナ)や sloe (リンボク)なども含まれ,何だかよく分からないリストとなっている.
同コンテンツによると,このような表現は中英語期に続々と生まれたという.植物のみならず動物,昆虫,魚なども引き合いに出されたというから,こうした名詞の一覧を整理してみれば,英語文化において何が軽視されてきたかが概観できそうである.たいへん洞察に富むコンテンツ.
2021-01-29 Fri
■ #4295. Porzig の「意味の場」 [semantics][semantic_field][collocation][cognitive_linguistics][terminology]
一昨日と昨日の記事「#4292. Trier の「意味の場」の言語学史上の意義 (1)」 ([2021-01-27-1]) と「#4293. Trier の「意味の場」の言語学史上の意義 (2)」 ([2021-01-28-1]) では,Trier の「意味の場」 (semantic_field) の学史的背景をみた.今回は,Trier と同じ時代にかなり異なる種類の「意味の場」を提起した Porzig に注目してみたい.参照する論文は昨日と同じ Öhman である.
Trier の「意味の場」が paradigmatic な視点からのものであるのに対し,Porzig の「意味の場」は syntagmatic である.現代の術語でいえば語の共起 (collocation),あるいは共起制限の発想に近い.また,Trier は「意味の場」を論じるのに名詞を重視するが,Porzig は動詞や形容詞などの述語的な語彙を重視する.
The field concept of Porzig is of quite a different type than Trier's. Porzig finds certain "essential semantic relationships" between verbs and nouns or between adjectives and nouns. 'To go' presupposes 'the feet', 'to grasp' presupposes 'the hand', and 'blond' (in German and English) presupposes 'the hair'. These relationships form the basic articulations of the meaning system and therefore Porzig calls them "elementary semantic fields" (elementare Bedeutungsfelder). The nucleus of such a semantic field can only consist of a verb or an adjective, because these classes of words have a predicative function and are therefore less ambiguous than nouns. One can grasp with the hand only, but one can do many things with the hand. (129)
両者のもう1つの大きな違いは,Trier の「意味の場」が最終的には意味や語彙の全体を覆う大構造を前提としているのに対して,Porzig のそれは基本的で具体的な場に主たる関心があるという点だ.後者には現代の認知意味論的な風味も感じられる.
Trier protests against Porzig's use of the term "field" in this new sense. Trier based his theory on the entire vocabulary, dividing it into large field units, and subdividing these until he reached the smallest entities---single words. Porzig's field, on the other hand, is conceived as primitive concrete situations linguistically designated. By means of it the speech community succeeds in grasping higher and more abstract spheres.
現在の言語学でも「意味の場」の概念・用語は,かなり緩いものとして用いられているように見受けられる.この緩さの背景を理解するのに学史を振り返ってみることも重要だと,今回感じた.
・ Öhman, Suzanne. "Theories of 'the Linguistic Field'." Word 9 (1953): 123--34.
2020-12-03 Thu
■ #4238. oddly enough, interestingly enough などの表現における enough (1) [adverb][semantics][bnc][corpus][collocation][eurhythmy]
以前より不思議に思っていた表現がある.enough という卑近な副詞を用いた表現なのだが,典型的に -ly 副詞に enough が後置され,文頭位置あるいは挿入句として生起するものだ.例をみるのが早い.BNCweb より挙げてみよう(問題の句はイタリック体にしてある).なお,検索窓には "*ly_{ADV} enough" と入力した.
・ Oddly enough, many parliaments expect to modify government plans, which takes time.
・ Her large grin and knotted black curls were, strangely enough, more memorable.
・ I had a dream last night funnily enough about Leeds (I dont normally --- honest!).
・ Interestingly enough, even hens and rats have been found to consume more calories when they are offered a varied diet than when they are fed `the same old thing' all the time.
・ Naturally enough, those who commit crimes will tend to conceal their actions and protect themselves.
それぞれ「妙なことに」「奇妙なことに」「滑稽なことに」「興味深いことに」「当然のことに」を意味する,いわゆる文修飾の副詞句である.文修飾であるから,統語的には文頭に現われたり,挿入的に用いられたりすることは不思議ではない.理解しかねるのは,enough の役割である.なぜ「十分に」が添えられているのだろうか.enough が省略されたところで,前置されている副詞単体でも文修飾として同じように機能するのだ.副詞単体ではやや寂しく感じられ,たいした強調ともならない enough を添えることでリズムを良くする程度の効果 (eurhythmy) はありそうだが.
enough に前置されることの多い副詞の種類としては,ヒット数の多い順に20個を挙げると oddly, quickly, strangely, funnily, interestingly, early, easily, naturally, curiously, clearly, appropriately, only, seriously, barely, ironically, nearly, surprisingly, badly, reasonably, hardly となる.しかし,quickly, early, easily などは,今回注目する用法としてではない例(つまり「十分に素早く」などの通常の用法)によって頻度が高くなっているにすぎない.注目する用法で現われる最も典型的な10語を選べば,oddly, strangely, funnily, interestingly, naturally, curiously, appropriately, ironically, surprisingly, reasonably あたりとなる.
この用法が生起する分布に注意すると,書き言葉にも話し言葉にも現われており,メディアによる違いはないといってよい(いずれも 18 wpm 程度).使用者の男女差や世代差でみても,特に目立った分布上の特徴ははない.テキストタイプとしては Fiction and verse で相対的に高い値 (27.01 wpm) を示すが,際立っているわけでもない.多くの異なるレジスターで用いられているのが実態である.
改めて enough の意味の問題に立ち戻ろう.この enough は意味論的にはかなり薄いものと言わざるを得ない.実際『ジーニアス英和大辞典』によれば,この enough には「十分に」の意味はほどんどない旨,言及がある.また,OED の enough, adj., pron., and n., and adv. の C. adv. 2 にも "With the idea of satisfying a requirement reduced or absent." とあり,何のために「十分な」のかについて「何」の前提が薄くなってしまった語義が立てられている.その下位区分 (b) として与えられているのが,まさに今問題にしている用法で,次のように説明がある.
(b) With a sentence adverb, as in aptly enough.
See also funnily enough at FUNNILY adv. 2, oddly enough at ODDLY adv. 5b.
1704 W. Nicolson Diary 22 Nov. in London Diaries (1985) 231 The Text of the Book (whimsically enough) in Vermilion-Letters, instead of an Italic Character.
1783 Ld. Hailes Disquis. Antiq. Christian Church ii. 15 Which, aptly enough, might be denominated the journals of the senate.
1912 E. V. Baxter & L. J. Rintoul Rep. Sc. Ornithol. 3 Curiously enough, both the Common Nightingale .. and the Northern Nightingale .. were added in spring to the Scottish list.
2015 H. Scales Spirals in Time ix. 249 A mollusc named, appropriately enough, the Windowpane Oyster.
この用法での初例が1704年となっているので,はるばる古英語 geōg にさかのぼる古参の副詞とはいえ,別の副詞に前置される問題の表現は,なかなかモダンらしい.
2020-10-30 Fri
■ #4204. コーパス言語学の基本的な用語を解説 --- concordance [terminology][corpus][hel_education][collocation]
昨日の記事 ([2020-10-29-1]) に引き続き,コーパス周りの用語を解説する.
concordance とは,もともとは「用語索引」ほどを意味し,ある本に出てくる単語を1つ1つ取り出してアルファベット順にリスト化したものである.その本に例えば the という単語が何回出現したか,さらに具体的にどこに出現したがが分かるような作りになっていることもあり,文献学研究や言語研究では馴染みのツールだった.聖書のコンコーダンスやChaucer のコンコーダンスなどがよく知られている.
しかし,電子コーパスが普及してからは,concordance という用語は別の意味でも用いられるようになった.昨今の電子コーパスで何らかの語なり表現なりを検索式の形にして検索すると,その条件にあった形式を含む例文がコーパス全体から収集され,ずらっと画面上に提示される.この全体が,その形式の concordance ということになる.そして,例文を含む個々の行のことを concordance line と呼ぶ.たとえていえば,ある単語を Google 検索して1万件ヒットしたという場合,その1万件全体が concordance ということになり,その1件1件が concordance line ということになる.
たいていのコーパス検索では,注目している形式の前後にどのような語が共起しているかを知りたいことが多いので,注目する形式が各 concordance line の中央に位置するように表示されると都合がよい.前後の文脈 (context) も合わせてその形式の用例を確認できることから,この表示法はコーパス研究ではある種のデフォルトといってよく,KWIC (= Key Word in Context) という名前すらついている.
昨日の記事で取り上げたが,BNCweb で "{love/V}" として検索してみると,14,195行もの concordance lines が得られる.その先頭の10行ほどを KWIC で表示すると,次のようになる.読みやすいし分析しやすい表示法であることがわかるだろう.
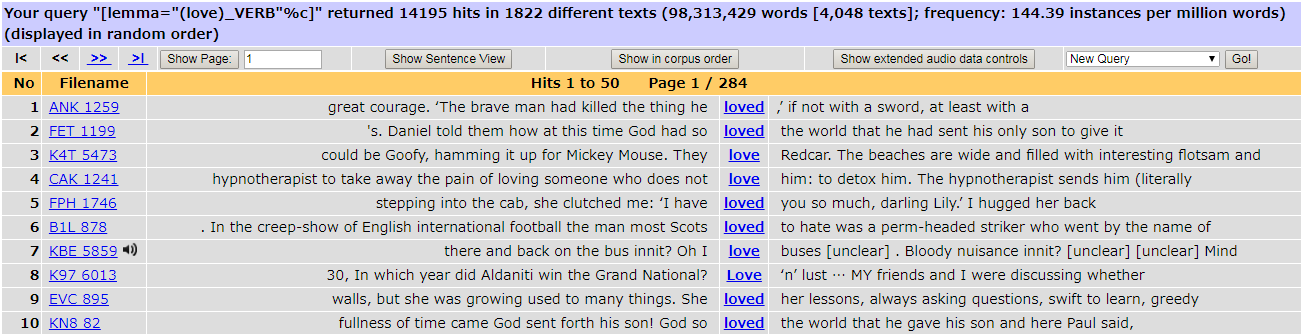
このように電子コーパスでは,ある形式の concordance が容易に得られる.もちろん concordance を産出するプログラムが背後で動いてくれているおかげであり,そのようなプログラムやアプリケーションを concordancer と呼んでいる.
2019-07-10 Wed
■ #3726. Just The Word --- 英作文の強力なお供 [collocation][bnc][webservice]
英作文のお供といえば『新編英和活用大辞典』(研究社)などを用いてきたが,中田 (125) で紹介されているオンラインツールの Just The Word なども素晴らしい使い勝手だ.適当な語を入力欄に入れて "combinations" のボタンを押すと,構文パターン別に頻度の高い collocation が表示されるという代物だ.さらに,適当な collocation をクリックすると,その例文が KWIC でいくつか示されるというから,至れり尽くせりだ.
Just The Word のもう1つの便利な使い途は,適切な英語表現を見つけようとする際のやり方である.「冗談を言う」に対応する英語表現を知りたいときに,半信半疑ながらも,まずは "say joke" と入力した上で "alternatives from thesaurus" をクリックしてみる.すると "say joke" は悪いコロケーションとして赤で表示されるが,その下に "tell joke" が良いコロケーションとして緑で表示されるのだ.そこをクリックすれば,やはり KWIC で "tell a joke" や "tell jokes" などの例文が多く得られる.
こちらの説明書きによれば,背後に控えているのは BNC のようだ.そして,コロケーションの「良さ」は T-score の数値に依存しているという(「#1283. 共起性の計算法」 ([2012-10-31-1])).
コーパスを用いた研究や技術の成果が,ここまで応用されているのかと驚くばかりである.
・ 中田 達也 『英単語学習の科学』 研究社,2019年.
2016-03-07 Mon
■ #2506. 英語の2項イディオムと日本語の文選読み [binomial][japanese][kanji][lexicology][borrowing][lexicology][collocation]
2項イディオムとも呼ばれる英語の word pair あるいは binomial について,本ブログでも「#820. 英仏同義語の並列」 ([2011-07-26-1]),「#1443. 法律英語における同義語の並列」 ([2013-04-09-1]),「#2157. word pair の種類と効果」 ([2015-03-24-1]) をはじめ,いくつかの記事で話題にしてきた.
この語法は,特に中英語以降,フランス語やラテン語からの借用語が増えてきたときに,本来語にそれを並置する習慣から生じた.日本語も英語と同じように,諸言語,特に漢語からの借用を広く受け入れてきた経緯があるので,歴史的に似たような状況があったに違いない.この点について,齋藤 (10 fn.) に関連する言及があった.
Cf. "The inaudible and noiseless foot of Time" (Shakespeare: All's Well That Ends Well, V. iii. 41)
"The dark backward and abysm of Time" (Shakespeare: The Tempest, I. ii. 50)
これは昔,わが国の学者が「詩経」の冒頭にある
関関雎鳩,...窈窕淑女,
を,「クヮンクヮンとやはらぎなけるショキウのみさごは,...エゥテゥとゆほびかなるシュクヂョのよきむすめ」と,いわゆる「文選(もんぜん)読み」をしたのに似ている.
文選読みとは,同一の漢語を音と訓で2度読むことで,「豺狼 (サイラウ) のおほかみ」,「蟋蟀 (シッシュツ) のきりぎりす」,「芬芳(フンポウ)トカウバシ」などがこれに当たる.漢文訓読に由来する読み方で,平安時代に流行した,中国の周から梁に至る千年間の詩文集『文選』を読むときにとりわけ用いられたので,この名前がある.英語における本来語と借用語のペアには,後者の意味を理解させるための前者の並置という動機づけがしばしばあったが,文選読みでも同様に,一般には難しく馴染みの薄い漢語を理解しやすくするために和語の訓読を添えるという習慣が発達したものと思われる.これまで話題にしてきた英仏や英羅の単語ペアは,日本語の発想でいうと「音訓複読」というべきものだったわけだ.日英両言語にこのような類似点のあることは,あまり気づかれていないが,ともに豊富な語彙借用の歴史を歩んできたことを考えれば,ある程度は必然的といってもよいのかもしれない(『日本語学研究事典』 p. 117 も参照).
日本語での "binomial" については,「#1616. カタカナ語を統合する試み,2種」 ([2013-09-29-1]) で触れた「アーカイブ〔保存記録〕」「インフォームドコンセント〔納得診療〕」「ワーキンググループ〔作業部会〕」などの表記も,その一例となるだろう.
・ 齋藤 勇 『英文学史概説』 研究社,1963年.
・ 『日本語学研究事典』 飛田 良文ほか 編,明治書院,2007年.
2015-09-07 Mon
■ #2324. n-gram [corpus][information_theory][coca][bnc][google_books][statistics][n-gram][collocation][frequency][link]
情報理論や自然言語処理の分野で用いられる n-gram という分析手法がある.コーパス言語学でもすでにお馴染みの概念であり,共起表現 (collocation) の研究などでは当たり前のように用いられるようになった.種々のコーパスのインターフェースにおいても採用されており,「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) では名前に含まれているほどだし,本ブログでも COCA (Corpus of Contemporary American English) の N-gram データベースを用いて「#956. COCA N-Gram Search」 ([2011-12-09-1]) を実装してきた(その応用は,「#953. 頭韻を踏む2項イディオム」 ([2011-12-06-1]),「#954. 脚韻を踏む2項イディオム」 ([2011-12-07-1]),「#955. 完璧な語呂合わせの2項イディオム」 ([2011-12-08-1]) を参照).BNC では,Explore Words and Phrases from the BNC が利用できる.
コンピュータを用いた分析手法というと難しそうに聞こえるが,n-gram の考え方は至って単純である.文字レベルの 2-gram (bigram) を考えてみよう.最長の英単語といわれる pneumonoultramicroscopicsilicovolcanoconiosis (「#63. 塵肺症は英語で最も重い病気?」 ([2009-06-30-1])) を例にとる.まず,先頭の2文字1組の pn を取り出す.次に,2文字目に進んで同じように ne を取り出す.3文字目に進んで eu を,4文字目に進んで um を得る.同じように,1文字ずつ右にずらしながら,最後の is まで2文字1組を次々と拾っていく.これで44組の2文字を得たことになる.この組のなかで,ic と co という組み合わせは各々3回起こり,os, si, no, on の組み合わせは各々2回現われ,それ以外の組み合わせはいずれも1度きりである.したがって,この単語において最高頻度の2文字1組は ic と co となる.
n-gram の単位は,このように文字である必要はなく,音素でもよいし,より大きな単位である形態素や語でもよく,さらに大きな句などのより大きな単位でもよい.英語コーパス言語学では,語という単位で考えるのが普通だろう.Martin Luther King, Jr. の I Have a Dream の演説のテキストで語単位の 4-gram を取ると,最も多い4語の組み合わせは,予想通り "I have a dream" の8回だが,"will be able to" も同じく8回現われる."Let freedom ring from" も7回とよく現われる,等々の分析が可能となる.ここでは4語という「窓」を設定したので 4-gram と呼ばれるが,隣接するいくつの文字を考慮するかにより 1-gram (unigram), 2-gram (bigram), 3-gram (trigram),そして 5-gram 以上ももちろん考えることができる(1-gram の場合,得られるリストは,事実上各語の生起頻度表である).
巨大コーパスから得られた 2-gram や 3-gram の一覧は,それ自体が共起表現の研究などでは基本データとなるため,ウェブ上でもいろいろと公開されている.日本語では「N-gram コーパス - 日本語ウェブコーパス 2010」があるし,現代英語では COCA の n-gram データベース がある.また,Bigram Plus では,歴史英語コーパスを含めた各種英語コーパスから N-Gram Search を行なえる機能を提供している.ほかにも任意のテキストやコーパスを対象に n-gram を取る各種のツールやソフトも,ウェブ上で入手可能だ.
n-gram 分析の言語分野への応用範囲は広い.次に来る語(音,文字)は何か,という予測可能性とも関係が深いため,機械による音声認識,統語分析,言語判定,自動翻訳,スペルチェック,剽窃探知,全文検索用インデックスの作成などに活用される.もちろん,共起表現の研究では,基本にして不可欠の手段となっている.一方,n-gram はもっぱら言語として表面化されたテキストを対象とし,深層にある構造にまったく触れることがないため,生成文法のような言語理論の方面からは批判があるようだ.詳しくは,n-gram in Wikipedia を参照.
n-gram は工夫次第で,まだまだ使い道がありそうだ.歴史英語テキストにも,応用していきたい.
(後記 2015/09/12(Sat): Sketch Engine より N-grams も参照.)
Powered by WinChalow1.0rc4 based on chalow