2025-01-18 Sat
■ #5745. アルファベットの文字頻度 [corpus][link][alphabet][frequency][statistics][letter_frequency][bnc][morse_code]
AからZまでのアルファベット文字のなかで,最も頻度の高い文字,低い文字は何か.この文字頻度 (letter_frequency) の話題については,「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1]) の下部に Letter Frequencies (rankings for various languages) へのリンクを挙げたとおり,様々な言語やコーパスでの順位表が作り出されている.例えば,BNC に依拠すると "etaoinsrhldcumfpgwybvkxjqz" の順位表が得られる.
Crystal (277) には,The Cambridge Encyclopedia (1st ed.) の全テキスト,150万語をコーパスとした文字頻度表が掲げられている.累積頻度順位 (Cumulative) のみならず,文学,宗教,政治,物理学,化学の各々のテーマごとの頻度や Morse code (morse_code) の頻度も合わせて示されている.以下のグラフは,X軸に沿って累積頻度順 (= "eatinorslhdcmufpgbywvkxjq") に文字を並べ,Y軸を各テーマ内での頻度割合(百分率)としたものである(頻度表はソース HTML を参照).
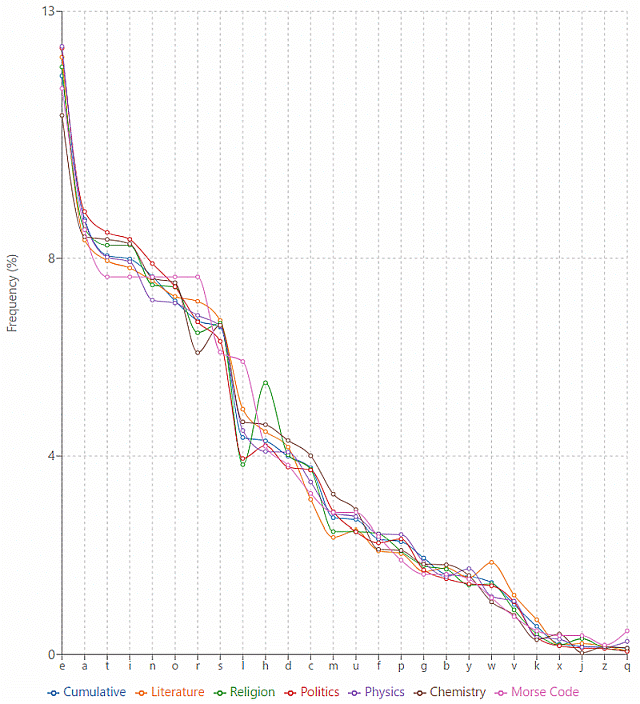
累積頻度順に照らしてテーマごとの特徴を見てみるとと,政治が最も標準的である.文学と政治がそれに続く.標準から遠ざかっていくのが,化学,物理学,そして Morse code となる.
個々の文字をみると興味深い点が多々ある.相対的に宗教では <h> が多く (holy?) <l> が少ないこと,文学では <w> が多いことは何を意味するのだろうか? 物理学や化学はラテン・ギリシア語系の単語が多く含まれているために,その他一般とは若干異なる文字頻度を示しているのかもしれない.人工的な Morse code は,他のテーマとは目に見えて異なる線を描いていることがわかる.
・ Crystal, D. The Cambridge Encyclopedia of the English Language. 3rd ed. CUP, 2018.
2023-02-19 Sun
■ #5046. silence と共起する形容詞 [adjective][collocation][bnc][corpus]
昨日の記事「#5045. deafening silence 「耳をつんざくような沈黙」」 ([2023-02-18-1]) で取り上げた共起表現について,BNCweb により例文を引き出してみた.いくつか挙げてみよう.
・ All that remained on the barren expanse was a deafening silence.
・ But the countryside! Absolute deafening silence. Not a tractor in sight. No buzzing saw mills, no electric milking machines humming away. Just horses and ploughs and, for want of a better word, peasants.
・ now there is almost a deafening silence, broken only by the odd apologetic cough as the minutes tick towards 8.30.
・ In the deafening silence inside the gallery she could hear her heart thumping madly against her ribs.
・ It was a relief when a couple of minutes later, amidst the deafening silence that had descended on the room, Mrs Aitken poked her head round the door. 'Dinner will be served whenever you're ready.'
この撞着語法 (oxymoron) の共起表現に関心を焚きつけられて,silence という名詞はほかにどのような形容詞で修飾されることが多いのだろうかと問いが湧いてきた.これは共起 (collocation) に関する初歩的な類いの疑問で,コロケーション辞書や活用辞書を引けば済む話しだが,行きがかり上 BNCweb で調べてみることにする."_AJ* {silence/N}" と検索した上で Frequency breakdown の機能を用い,50位までの頻度ランキングを出してみた.
| No. | Lexical items | No. of occurrences |
|---|---|---|
| 1 | long silence | 145 |
| 2 | stunned silence | 53 |
| 3 | complete silence | 44 |
| 4 | total silence | 43 |
| 5 | tense silence | 37 |
| 6 | awkward silence | 31 |
| 7 | brief silence | 28 |
| 8 | short silence | 27 |
| 9 | sudden silence | 23 |
| 10 | absolute silence | 22 |
| 11 | deafening silence | 22 |
| 12 | embarrassed silence | 22 |
| 13 | uncomfortable silence | 22 |
| 14 | shocked silence | 16 |
| 15 | stony silence | 15 |
| 16 | dead silence | 14 |
| 17 | deep silence | 13 |
| 18 | Eerie silence | 13 |
| 19 | heavy silence | 13 |
| 20 | small silence | 12 |
| 21 | thoughtful silence | 12 |
| 22 | uneasy silence | 12 |
| 23 | utter silence | 12 |
| 24 | ensuing silence | 11 |
| 25 | sullen silence | 11 |
| 26 | momentary silence | 10 |
| 27 | fraught silence | 9 |
| 28 | ominous silence | 9 |
| 29 | terrible silence | 9 |
| 30 | brooding silence | 8 |
| 31 | companionable silence | 8 |
| 32 | sponsored silence | 8 |
| 33 | virtual silence | 8 |
| 34 | dignified silence | 7 |
| 35 | horrified silence | 7 |
| 36 | Hushed Silence | 7 |
| 37 | lengthy silence | 7 |
| 38 | long silences | 7 |
| 39 | longer silence | 7 |
| 40 | strained silence | 7 |
| 41 | uncanny silence | 7 |
| 42 | awful silence | 6 |
| 43 | cold silence | 6 |
| 44 | comparative silence | 6 |
| 45 | continuing silence | 6 |
| 46 | embarrassing silence | 6 |
| 47 | gloomy silence | 6 |
| 48 | great silence | 6 |
| 49 | strange silence | 6 |
| 50 | angry silence | 5 |
deafening silence も10位タイに入っており,それなりに知られた共起表現だということがわかる.stunned silence, stony silence, dead silence など味わい深い表現があるものだ.
[ 固定リンク | 印刷用ページ ]
2023-01-20 Fri
■ #5016. 中英語の動名詞構文 there was ---ing 「---が行なわれた」 [gerund][construction][be][syntax][existential_sentence][bnc]
「#4995. 動名詞構文 there is no ---ing 「---することはできない」は中英語期から」 ([2022-12-30-1]) は現代英語にも続く構文として知られているが,中英語には there was ---ing という興味深い構文が存在した.「---が行なわれた」「---というということが起きた」ほどの意味である.Mustanoja (576) にいくつか例が挙げられている.
The construction there was . . -ing is frequently used in ME for the expression of indefinite agency: --- þer was sobbing (Havelok 234); --- þer was sembling (Havelok 1018); --- thar wes oft bikkyring (Barbour ix 343); --- so greet wepyng was there noon, certayn, Whan Ector was ybroght, al fressh yslayn, To Troye, Allas, the pitee that was ther, Cracchynge of chekes, rentynge eek of heer (Ch. CT A Kn. 2831--4). A similar case is and thus the woful nyhtes sorwe To joie is torned on the morwe; Al was thonkinge, al was blessinge, Which erst was wepinge and cursinge (Gower CA ii 3317--18).
動名詞で表わされる動作の行為者は不定であり,動作そのものに焦点を当てたい場合に用いる構文なのだろう.OED の -ing, suffix1 には特にこの構文に関する記述はなく,MED -ing(e (suf.(1)) にも言及がない.
この構文は,現代でも特に目立った構文として言及されることはないものの,細々とは受け継がれているようだ.there is/was ---ing の例を BNCweb よりいくつか挙げてみよう.
・ 'Well, like I told the foreign gentleman, there was dancing in the sitting room, and this Mrs Heatherington-Scott she was dancing with Mr Merrivale.'
・ There is shooting almost daily in the capital as roaming snipers attack military checkpoints;
・ There was rationing at home and war in Ireland.
・ First there was cheering then jeering.
・ There was knocking on the front door.
・ Mustanoja, T. F. A Middle English Syntax. Helsinki: Société Néophilologique, 1960.
2021-08-18 Wed
■ #4496. two laps to go 「残り2週」の to go [sobokunagimon][infinitive][bnc]
先日,ゼミ生より陸上競技などで「残り2周」というのに英語では two laps to go などと言われるのを聞いたということで,to go の用法について質問があった.時間,距離,その他の量などについて「残り○○」として一般に用いられる日常的なフレーズだが,どのような由来なのだろうか.
OED の go, v. を調べてみると,語義 9c の下にこの用法が挙げられていた.挙げられている最初期の3例文とともに,以下に引用する.
c. intransitive. In the infinitive, used as a postpositive clause. Of a period of time: to be left, remain; to be required to elapse. Hence of a quantity of something: to remain to be dealt with.
Earliest in the context of marine racing.
Formally coincident with some uses of sense 2a(b): cf. quot. 1905 at that sense.
1881 'Rockwood' Stories Sc. Sports 91 Fifteen seconds to go, and it is all anxiety. Five seconds gone, and yet she is not there.
1892 J. G. Blaine Let. 26 Feb. in Fur-seal Arbitration: App. Case U.S. before Tribunal I. 354 Our consul at Victoria, telegraphs to-day that there are---Forty-six schooners cleared to date. Six or seven more to go.
1909 H. Sutcliffe Priscilla of Good Intent xvi. 241 There were five minutes to go before the signal for the start.
初例が19世紀後半ということなので,決して古い表現ではない.現代競技スポーツの文脈から生まれた表現と考えてよさそうで,今回のゼミ生の気づきも偶然ではなかったことになる.
go 「行く」という動詞は,古英語期より「(ある時間,距離,量を)進む,経る,踏破する,カバーする」ほどの語義で用いられてきた.例えば,現代英語でも "One of my favorite things to do was ice-skate on the beautiful St. Lawrence river... I'd go for miles and miles." などといえる.この用法の go が時間,距離,量を表わす表現の後ろに形容詞用法の不定詞として置かれ,「残り○○」の慣用表現を形成することになったのだろう.
ちなみに,BNCweb で "_CRD (more)? _NN* to go" と検索してみると422例が挙がってきた.単位の名詞は minutes, hours, days, weeks, months, years などの時間を表わすものが多いが,feet, yards, miles などの距離を表わすもの,また laps, holes, fenses, games などスポーツ競技を連想させるものも散見される.
2021-05-23 Sun
■ #4409. 色白で美しく公正な白雪姫 --- fair の語感 [khelf_hel_intro_2021][adjective][synonym][semantics][semantic_change][lexical_stratification][bnc][collocation][etymology]
「英語史導入企画2021」より今日紹介するコンテンツは,昨日学部生より公表された「この世で一番「美しい」のは誰?」です.ディズニー映画 Snow White and the Seven Dwarfs (『白雪姫』)の台詞 "Magic mirror on the wall, who is the fairest one of all?" で用いられている形容詞 fair の意味変化に焦点を当てた英語史導入コンテンツとなっています.
「美しい」といえばまず beautiful が思い浮かびますが,なぜ問題の台詞では fair なのでしょうか.まず,コンテンツでも解説されている通り fair には「色白の」という語義もありますので,Snow White とは相性のよい縁語といえます.さらに,beautiful が容姿の美しさを形容するのに特化している感があるのに対し,fair には「公正な,公平な」の語義を含め道徳的な含意があります (cf. fair trading, fair share, fair play) .白雪姫を形容するのにぴったりというわけです.
fair は古英語期より用いられてきた英語本来語で,古く清く温かい情感豊かな響きをもちます.一方,beautiful は,14世紀に古フランス語の名詞 beute を借用した後に,15世紀に英語側で本来語接尾辞 -ful を付加して作った借用語です.フランス借用語(正確には「半」フランス借用語)は相対的にいって中立的で無色透明の響きをもつことが多いのですが,beautiful についていえば確かに fair と比べて道徳的・精神的な深みは感じられません.(ラテン借用語 attractive と合わせた fair -- beautiful -- attractive の3語1組 (triset) と各々の使用域 (register) については,「#334. 英語語彙の三層構造」 ([2010-03-27-1]) をご覧ください.)
fair と beautiful のような類義語の意味・用法上の違いについて詳しく知りたい場合には,辞書やコーパスの例文をじっくりと眺め,どのような語と共起 (collocation) しているかを観察することをお薦めします.試しに約1億語からなるイギリス英語コーパス BNCweb で両語の共起表現を調べてみました.ここでは人物と容姿を形容する共起語に限って紹介しますが,fair とタッグを組みやすいのは hair と lady です.一方,beautiful とタッグを組む語としては woman, girl, young, hair, face, eyes, looks などが挙がってきます.気品を感じさせる fair lady に対して,あくまで容姿の良さを表わすことに特化した beautiful woman/girl という対立構造が浮かび上がってきます.白雪姫にはやはり fair がふさわしいのでしょうね.
fair に見られる白さと公正さの結びつきは,candid という形容詞にも見られます.candid は第一に「率直な」を意味しますが,やや古風ながらも「公平な」の語義がありますし,古くは「白い」の語義もありました.もともとの語源はラテン語 candidus で,まさに「白い」を意味しました.「白熱して輝いている」が原義で,candle (ロウソク)とも語根を共有しています.また,candidate (候補者)は,ローマで公職候補者が白いトーガを着る習わしだったことに由来します.ちなみに日本語でも「潔白」「告白」「シロ(=無罪)」などに白さと公正さの関係が垣間見えますね.
2021-05-14 Fri
■ #4400. 「犬猫」と cats and dogs の順序問題 [sound_symbolism][phonaesthesia][onomatopoeia][idiom][binomial][prosody][alliteration][phonetics][vowel][khelf_hel_intro_2021][clmet][coca][coha][bnc][sobokunagimon]
目下開催中の「英語史導入企画2021」より今日紹介するコンテンツは,学部生よりアップされた「犬猿ならぬ犬猫の仲!?」です.日本語ではひどく仲の悪いことを「犬猿の仲」と表現し,決して「犬猫の仲」とは言わないわけですが,英語では予想通り(?) cats and dogs だという興味深い話題です.They fight like cats and dogs. のように用いるほか,喧嘩ばかりして暮らしていることを to lead a cat-and-dog life などとも表現します.よく知られた「土砂降り」のイディオムも「#493. It's raining cats and dogs.」 ([2010-09-02-1]) の如くです.
これはこれとして動物に関する文化の日英差としておもしろい話題ですが,気になったのは英語 cats and dogs の語順の問題です.日本語では「犬猫」だけれど,上記の英語のイディオム表現としては「猫犬」の順序になっています.これはなぜなのでしょうか.
1つ考えられるのは,音韻上の要因です.2つの要素が結びつけられ対句として機能する場合に,音韻的に特定の順序が好まれる傾向があります.この音韻上の要因には様々なものがありますが,大雑把にいえば音節の軽いものが先に来て,重いものが後に来るというのが原則です.もう少し正確にいえば,音節の "openness and sonorousness" の低いものが先に来て,高いものが後にくるという順序です.イメージとしては,近・小・軽から遠・大・重への流れとしてとらえられます.音が喚起するイメージは,音象徴 (sound_symbolism) あるいは音感覚性 (phonaesthesia) と呼ばれますが,これが2要素の配置順序に関与していると考えられます.
母音について考えてみましょう.典型的には高母音から低母音へという順序になります.「#1139. 2項イディオムの順序を決める音声的な条件 (2)」 ([2012-06-09-1]) で示したように flimflam, tick-tock, rick-rack, shilly-shally, mishmash, fiddle-faddle, riffraff, seesaw, knickknack などの例が挙がってきます.「#1191. Pronunciation Search」 ([2012-07-31-1]) で ^([BCDFGHJKLMNPQRSTVWXYZ]\S*) [AEIOU]\S* ([BCDFGHJKLMNPQRSTVWXYZ]\S*) \1 [AEIOU]\S* \2$ として検索してみると,ほかにも chit-chat, kit-cat, pingpong, shipshape, zigzag などが拾えます.ding-dong, ticktack も思いつきますね.擬音語・擬態語 (onomatopoeia) が多いようです.
では,これを cats and dogs の問題に適用するとどうなるでしょうか.両者の母音は /æ/ と /ɔ/ で,いずれも低めの母音という点で大差ありません.その場合には,今度は舌の「前後」という対立が効いてくるのではないかと疑っています.前から後ろへという流れです.前母音 /æ/ を含む cats が先で,後母音 /ɔ/ を含む dogs が後というわけです.しかし,この説を支持する強い証拠は今のところ手にしていません.参考までに「#242. phonaesthesia と 遠近大小」 ([2009-12-25-1]) と「#243. phonaesthesia と 現在・過去」 ([2009-12-26-1]) をご一読ください.対句ではありませんが,動詞の現在形と過去形で catch/caught, hang/hung, stand/stood などに舌の前後の対立が窺えます.
さて,そもそも cats and dogs の順序がデフォルトであるかのような前提で議論を進めてきましたが,これは本当なのでしょうか.先に「英語のイディオム表現としては」と述べたのですが,実は純粋に「犬と猫」を表現する場合には dogs and cats もよく使われているのです.英米の代表的なコーパス BNCweb と COCA で単純検索してみたところ,いずれのコーパスにおいても dogs and cats のほうがむしろ優勢のようです.ということは,今回の順序問題は,真の問題ではなく見せかけの問題にすぎなかったのでしょうか.
そうでもないだろうと思っています.18--19世紀の後期近代英語のコーパス CLMET3.0 で調べてみると,cats and dogs が18例,dogs and cats が8例と出ました.もしかすると,もともと歴史的には cats and dogs が優勢だったところに,20世紀以降,最近になって dogs and cats が何らかの理由で追い上げてきたという可能性があります.実際,アメリカ英語の歴史コーパス COHA でざっと確認した限り,そのような気配が濃厚なのです.
「犬猫」か「猫犬」か.単なる順序の問題ですが,英語史的には奥が深そうです.
2021-01-02 Sat
■ #4268. -ly が2つ続く副詞 -lily は稀である [bnc][adverb][suffix][adjective][productivity][-ly][haplology]
接尾辞 -ly の周辺については -ly の多くの記事で扱ってきた.歴史的にみても話題が豊富な接尾辞で,「#1032. -e の衰退と -ly の発達」 ([2012-02-23-1]) や「#1189. 初期近代英語における -ly 副詞の規則化の背景」 ([2012-07-29-1]) などで,そのおもしろさを紹介してきた.
「#40. 接尾辞 -ly は副詞語尾か?」 ([2009-06-07-1]) で解説してきたように,現在では生産的な副詞語尾と考えられている接尾辞 -ly は,もともとは形容詞を作る接尾辞だった.その証拠に friendly, scholarly,womanly, daily, weekly, yearly などは主に形容詞として用いられる.しかし,これらの -ly 形容詞から対応する副詞を作るにはどうすればよいかと問われたら,答えられるだろうか.副詞語尾としての -ly をさらに加えて,friendlily などとするのだろうか.
きわめて生産的な副詞を作る接尾辞 -ly のことである,理屈上は確かに friendlily 等の形はあり得るし,事実,辞書に登録されているものもある.しかし,実際上は滅多にお目にかからない稀な語形である.形容詞と同形の friendly で代用したり,in a friendly manner などと迂言的に表現するのが普通だ./-lɪli/ と類似音が続くと調音的に語呂が悪い (cacophony) のが理由と思われる.結果として,haplology (重音脱落)が生じ,1つの -ly にまとめられてしまうのだろう(cf. 「#2362. haplology」 ([2015-10-15-1])).
-lily が稀であることは現代英語コーパスでも簡単に確認できる.例えば,BNCweb で "*l[i,y]ly_{ADV}" として単純検索してみると,106件が挙がってくる.各語形と頻度を列挙すると,slyly (90), jollily (4), sillily (4), surlily (2), beastlily (1), ghostlily (1), oilily (1), possiblily (1), seemlily (1), uglily (1) となる.最も頻度の高い slily の基体となる形容詞は sly /slaɪ/ であり,その ly はあくまで語幹の一部にすぎないため,今回の関心の対象から外してよい.2位タイの jollily, sillily についても,基体の形容詞 jolly, silly に含まれる -ly は,共時的にはおそらく接尾辞と感じられていないのではないか(語源的にいえば silly の -ly は確かに目下注目している接尾辞に由来するのだが).possiblily については,文脈を確認すると名詞 possibility のミススペリングであることが分かり,これも考慮から外してよい.結果として,-lily 副詞はきわめて稀であることがわかるだろう.
2020-12-17 Thu
■ #4252. COCA と BNCweb でみる color vs colour [coca][bnc][corpus][ame_bre][spelling]
アメリカ式綴字 color とイギリス式綴字 colour をめぐる問題について,本ブログでは何度も取り上げてきた.綴字の米英差の代表例としてよく知られており,分かりやすい問題であるということもあるが,英語史的には意外と深掘りできる魅力的な問題だからでもある.
しかし,最も基本的な事実確認 --- 現代のアメリカ英語とイギリス英語で color と colour の各々の分布はどうなっているのかの調査 --- を行なわずいたことに気づいた.ということで,今回は現代アメリカ英語の代表的コーパス COCA と,イギリス英語の BNCweb で調べてみることにした.colo(u)r の屈折形,派生語,複合語を含めて網羅的に行なうのが理想だが,今回はレンマ検索を利用して,colo(u)r, colo(u)rs, colo(u)red (以上は屈折形として), colo(u)rful, colo(u)rless, discolo(u)r の6種類の語形の取り出しにとどめた.
| COCA による <color> と <colour> の頻度 | |||
| 語形 | <or> | <our> | <or> 比率 |
| COLOR | 124,778 | 4,792 | 0.9630 |
| COLORS | 33,225 | 1,886 | 0.9463 |
| COLORED | 5,553 | 179 | 0.9688 |
| COLORFUL | 10,871 | 412 | 0.9635 |
| COLORLESS | 1,000 | 57 | 0.9461 |
| DISCOLOR | 110 | 0 | 1.0000 |
| BNCweb による <color> と <colour> の頻度 | |||
| 語形 | <or> | <our> | <our> 比率 |
| COLOR | 115 | 11,332 | 0.9900 |
| COLORS | 24 | 4,396 | 0.9946 |
| COLORED | 14 | 2,432 | 0.9943 |
| COLORFUL | 6 | 1,093 | 0.9945 |
| COLORLESS | 4 | 166 | 0.9765 |
| DISCOLOR | 1 | 19 | 0.9500 |
COCA を用いたアメリカ英語の調査によれば,アメリカ式の <or> が,予想通りに圧倒的な95%前後の比率で用いられている.しかし,逆にいえば,5%ほどはイギリス式とされる <our> が用いられているというのも,とりわけ次のイギリス英語の状況と比較すると興味深い.
BNCweb を用いたイギリス英語の調査結果をみてみると,99%ほどというほぼ完全な比率でイギリス式の <our> が用いられている.アメリカ綴字を用いている少数の例を確認してみると,引用符に囲まれた短いタイトルらしきもの(アメリカ系由来の可能性があるもの)のなかで用いられているのが散見され,それを差し引いて考えることが許されるのであれば,さらに <our> は100%に近づく.この点では,イギリス英語のほうが綴字慣習についてより一貫しており,アメリカ英語は若干の寛容さを示すといえるかもしれない.
以上,標題の米英差の問題について事実確認した.
[ 固定リンク | 印刷用ページ ]
2020-12-03 Thu
■ #4238. oddly enough, interestingly enough などの表現における enough (1) [adverb][semantics][bnc][corpus][collocation][eurhythmy]
以前より不思議に思っていた表現がある.enough という卑近な副詞を用いた表現なのだが,典型的に -ly 副詞に enough が後置され,文頭位置あるいは挿入句として生起するものだ.例をみるのが早い.BNCweb より挙げてみよう(問題の句はイタリック体にしてある).なお,検索窓には "*ly_{ADV} enough" と入力した.
・ Oddly enough, many parliaments expect to modify government plans, which takes time.
・ Her large grin and knotted black curls were, strangely enough, more memorable.
・ I had a dream last night funnily enough about Leeds (I dont normally --- honest!).
・ Interestingly enough, even hens and rats have been found to consume more calories when they are offered a varied diet than when they are fed `the same old thing' all the time.
・ Naturally enough, those who commit crimes will tend to conceal their actions and protect themselves.
それぞれ「妙なことに」「奇妙なことに」「滑稽なことに」「興味深いことに」「当然のことに」を意味する,いわゆる文修飾の副詞句である.文修飾であるから,統語的には文頭に現われたり,挿入的に用いられたりすることは不思議ではない.理解しかねるのは,enough の役割である.なぜ「十分に」が添えられているのだろうか.enough が省略されたところで,前置されている副詞単体でも文修飾として同じように機能するのだ.副詞単体ではやや寂しく感じられ,たいした強調ともならない enough を添えることでリズムを良くする程度の効果 (eurhythmy) はありそうだが.
enough に前置されることの多い副詞の種類としては,ヒット数の多い順に20個を挙げると oddly, quickly, strangely, funnily, interestingly, early, easily, naturally, curiously, clearly, appropriately, only, seriously, barely, ironically, nearly, surprisingly, badly, reasonably, hardly となる.しかし,quickly, early, easily などは,今回注目する用法としてではない例(つまり「十分に素早く」などの通常の用法)によって頻度が高くなっているにすぎない.注目する用法で現われる最も典型的な10語を選べば,oddly, strangely, funnily, interestingly, naturally, curiously, appropriately, ironically, surprisingly, reasonably あたりとなる.
この用法が生起する分布に注意すると,書き言葉にも話し言葉にも現われており,メディアによる違いはないといってよい(いずれも 18 wpm 程度).使用者の男女差や世代差でみても,特に目立った分布上の特徴ははない.テキストタイプとしては Fiction and verse で相対的に高い値 (27.01 wpm) を示すが,際立っているわけでもない.多くの異なるレジスターで用いられているのが実態である.
改めて enough の意味の問題に立ち戻ろう.この enough は意味論的にはかなり薄いものと言わざるを得ない.実際『ジーニアス英和大辞典』によれば,この enough には「十分に」の意味はほどんどない旨,言及がある.また,OED の enough, adj., pron., and n., and adv. の C. adv. 2 にも "With the idea of satisfying a requirement reduced or absent." とあり,何のために「十分な」のかについて「何」の前提が薄くなってしまった語義が立てられている.その下位区分 (b) として与えられているのが,まさに今問題にしている用法で,次のように説明がある.
(b) With a sentence adverb, as in aptly enough.
See also funnily enough at FUNNILY adv. 2, oddly enough at ODDLY adv. 5b.
1704 W. Nicolson Diary 22 Nov. in London Diaries (1985) 231 The Text of the Book (whimsically enough) in Vermilion-Letters, instead of an Italic Character.
1783 Ld. Hailes Disquis. Antiq. Christian Church ii. 15 Which, aptly enough, might be denominated the journals of the senate.
1912 E. V. Baxter & L. J. Rintoul Rep. Sc. Ornithol. 3 Curiously enough, both the Common Nightingale .. and the Northern Nightingale .. were added in spring to the Scottish list.
2015 H. Scales Spirals in Time ix. 249 A mollusc named, appropriately enough, the Windowpane Oyster.
この用法での初例が1704年となっているので,はるばる古英語 geōg にさかのぼる古参の副詞とはいえ,別の副詞に前置される問題の表現は,なかなかモダンらしい.
2020-05-15 Fri
■ #4036. stay at home か stay home か --- コーパス調査 [sobokunagimon][phraseology][preposition][bnc][coca][coha][clmet][ame_bre]
昨日の記事 ([2020-05-14-1]) で,目下世界のキーフレーズとなっている stay at home と stay home について英語史の観点から考察した.今回はいくつかのコーパスでざっと調査した結果を報告する.以下,細かい文脈調査や統計処理はしていないのであしからず.
まずは現代のイギリス英語とアメリカ英語について,それぞれ BNCweb と COCA (Corpus of Contemporary American English) から stay (at) home をレンマ検索で拾い出してみた.結果は,イギリス英語では stay at home が86.9%で優勢,逆にアメリカ英語では stay home が74.6%で優勢と出た.英米差が分かりやすく現われていることになる.
次に,通時的な分布の推移をみてみよう.イギリス英語については後期近代英語コーパス CLMET3.0 を利用し,アメリカ英語には1810年以降のテキストを収めた COHA (Corpus of Historical American English) を利用した.
CLMET では第1期 (1710--1780),第2期 (1780--1850),第3期 (1850--1920) のサブコーパスごとに stay (at) home をレンマ検索してみたところ,どの時期においても stay at home が事実上唯一の表現だった.第2期 (1780--1850) に staying home が1例現われるのみで,19世紀までは stay home はほとんど知られていなかったといってよさそうだ.上でみた BNCweb から分かった現代イギリス英語の状況を勘案すると,おそらく20世紀中に stay home が少し増えてきたということになろう.
一方,アメリカ英語での分布の推移がおもしろい.アメリカ英語でも,もともと stay at home が事実上唯一の表現だったが,19世紀中に stay home もちらほら現われてくる.20世紀に入ると stay home は急速に伸び始め,1940年代には従来の stay at home を頻度の上で逆転するに至った.そして,現在にかけて圧倒的な優位を確立してきたということになる.
簡単な調査なので証拠の穴はところどころに残っているものの,以上より両表現の分布の推移についておよその見当がつけられる.まとめると次のようになる.19世紀までは,英米両変種ともに歴史的により古い stay at home がデフォルトで,stay home はほとんど知られていなかった.ところが,20世紀にかけて stay home が少しずつ増えてきた.とりわけアメリカ英語では20世紀後半に古株の stay at home を抑えて躍進し,現在までに一気に普及してきた.
残る問題は stay home が英語史のどの段階で姿を現わしてきたかである.OED の home, adv. の 1e では,移動動詞を伴わない副詞 home の初出こそc1580年となっているが,stay home という句自体の初出がいつかは教えてくれない(keep home や be home などの表現は1600年前後に出ているようである.「#2237. I'm home.」 ([2015-06-12-1]) も参照).
さらに調べる必要があるが,場合によってはずっと遅れて後期近代英語期のことである可能性もある.stay home は実はかなり新しい表現なのではないか.
2019-07-10 Wed
■ #3726. Just The Word --- 英作文の強力なお供 [collocation][bnc][webservice]
英作文のお供といえば『新編英和活用大辞典』(研究社)などを用いてきたが,中田 (125) で紹介されているオンラインツールの Just The Word なども素晴らしい使い勝手だ.適当な語を入力欄に入れて "combinations" のボタンを押すと,構文パターン別に頻度の高い collocation が表示されるという代物だ.さらに,適当な collocation をクリックすると,その例文が KWIC でいくつか示されるというから,至れり尽くせりだ.
Just The Word のもう1つの便利な使い途は,適切な英語表現を見つけようとする際のやり方である.「冗談を言う」に対応する英語表現を知りたいときに,半信半疑ながらも,まずは "say joke" と入力した上で "alternatives from thesaurus" をクリックしてみる.すると "say joke" は悪いコロケーションとして赤で表示されるが,その下に "tell joke" が良いコロケーションとして緑で表示されるのだ.そこをクリックすれば,やはり KWIC で "tell a joke" や "tell jokes" などの例文が多く得られる.
こちらの説明書きによれば,背後に控えているのは BNC のようだ.そして,コロケーションの「良さ」は T-score の数値に依存しているという(「#1283. 共起性の計算法」 ([2012-10-31-1])).
コーパスを用いた研究や技術の成果が,ここまで応用されているのかと驚くばかりである.
・ 中田 達也 『英単語学習の科学』 研究社,2019年.
2019-07-09 Tue
■ #3725. 語彙力診断テストや語彙関連ツールなど [lexicology][bnc][coca][corpus][webservice][link]
以前「#833. 語彙力診断テスト」 ([2011-08-08-1]) を紹介したが,今回は中田(著)『英単語学習の科学』 (12) で取り上げられていた別の語彙診断力テスト Test Your Vocabulary Online With VocabularySize.com を紹介しよう.140問の4択問題をクリックしながら解き進めていくことで,word family ベースでの語彙力が判定できる.母語を日本語に設定して診断する.また,英語での出題のみとなるが,同じ語彙セットを用いた100問からなる語彙診断テストの改訂版もある.
関連して中田 (13) では,英単語の頻度レベルを調べるツールとして,Compleat Lexical Tutor の VocabProfilers が便利だとも紹介されている.BNC や COCA などを利用して,入力した単語(群)の頻度を1000語レベル,2000語レベルなどと千語単位で教えてくれる.ある程度の長さの英文を放り込むと,各単語を語彙レベルごとに色づけしてくれたり,分布の統計を返してくれる優れものだ.ただし,インターフェースがややゴチャゴチャしていて分かりにくい.
日本人の英語学習者にとっては,「標準語彙水準 SVL 12000」などに基づいて英文の語彙レベルを判定してくれる Word Level Checker も便利である.単語ごとにレベルを返してくれるわけではなく,入力した英文内の語彙レベルとその分布を返してくれるというツールである.
英文を入力すると,単語の語注をアルファベット順に自動作成してくれる Apps 4 EFL の Text to Flash というツールも便利だ.さらにこれの応用版で,単語をクリックすると意味がポップアップ表示される英文読解ページを簡単に作れる Pop Translation なるツールもある.世の中,便利になったものだなあ.
・ 中田 達也 『英単語学習の科学』 研究社,2019年.
2019-01-27 Sun
■ #3562. may 祈願文の生産性 [optative][productivity][frequency][bnc][auxiliary_verb][may]
may 祈願文の歴史や現代での事例について may や optative の記事で扱ってきた.松瀬 (78) が引用している Declerck (416) によると,may 祈願文の特徴として4点が指摘されている.
a. In a main clause, a wish (malediction or benediction) is introduced by may.
b. This use of may is very formal and rarely found in modern English, except in standing expressions.
c. May always expresses a present wish with future actualisation.
d. Might cannot be used in a similar way.
a, c, d については問題なく受け入れられるが,b についてはどうだろうか.誤りとはいわずとも,補足が必要なように思われる.
may 祈願文の現状をみるために,BNCweb で例を集めてみた.ただし,助動詞の may (検索式に "may_VM0" と指定)は,3,537のテキストから112,397例がヒットし,そのなかから少数派の祈願用法の例を漏れなく探すのにはあまりに骨が折れる.そこで,may 祈願文の典型的な統語パターンや感嘆符の存在などを頼りに,なるべく多くの例が網にかかるはずという次善の策で今回は満足することにした.その上で,手作業にて確かな文例を拾い出した.
結果として取り出せたのは100個ほどの例文である(結果をまとめたテキストファイルはこちら).取り残しも相当数あるだろうが,1億語からなるコーパスから100例ということは,頻度として相当に貧弱とはいえる.また,定型表現 (Declerck の "standing expressions")に多いということも確認された.もっとも,上述のように定型表現などの「型」を頼りに検索しているので,この結果は当然といえば当然である.たとえば May God bless/forgive/rest . . . や Long may it flourish/continue/last . . . や May . . . be with you . . . や Much good may it do . . . などは,明らかなパターンを示している.
しかし,これらの型にはまりきったものばかりではない.may 祈願文は,上のようなお決まりのパターンに基づいて語句を入れ替えただけの「パロディ」の枠をはみ出し,数は多くないとはいえ,新たなタイプの文を確かに生産しているのである.その意味で,「頻度」は低くとも「生産性」は必ずしも衰えていないと言えるのではないか.次のような例を挙げておこう.
・ Happy days, Jack, and may all your troubles be little ones!' (A73 91)
・ AN OLD CAMBRIDGE toast is, 'Here's to pure mathematics - may she never be of any use to anyone!' (B7C 2026)
・ St Augustine taught that God had created man in his own image and so it was by looking at his own soul that man would discover God: 'May I know myself! may I know thee!' he had cried. (CD4 417)
・ May you be doing so well into the next century! (CGB 37)
・ With joy may we burn and cleanse!' (CM4 255)
・ May all dealers have this problem! (EBU 2407)
・ May you take that knowledge to your grave!' (HGV 6054)
もう1つ authentic な例を.1ヶ月ほど前,年始に海外から次のような文で始まるメールを受け取った.
We hope this email finds you all well and settling in to the New Year. May it be a productive and enjoyable one for one and all!
・ 松瀬 憲司 「"May the Force Be with You!"――英語の may 祈願文について――」『熊本大学教育学部紀要』64巻,2015年.77--84頁.
・ Declerck, R. A Comprehensive Descriptive Grammar of English. Tokyo: Kaitaku-sha, 1991.
2018-01-10 Wed
■ #3180. 徐々に高頻度語の仲間入りを果たしてきたフランス・ラテン借用語 [french][latin][loan_word][borrowing][frequency][statistics][lexicology][hc][bnc]
英語史では,中英語から初期近代英語にかけて,フランス語とラテン語から大量の語彙借用がなされた.それらのうち現在常用されるものについては,おそらく借用時点からスタートして時間とともに使用頻度が増してきたものと想像される.というのは,借用された当初から高頻度で用いられたとは考えにくく,徐々に英語に同化し,日常化してきたととらえるのが自然だからだ.
この仮説を実証するのにいくつかの方法がありそうだが,Durkin があるやり方で調査を行なっている.中英語,初期近代英語,現代英語のそれぞれにおいてコーパスに基づく最高頻度語リストを作り,そのなかにフランス・ラテン借用語がどのくらいの割合で含まれているかを調べ,その割合の通時的推移を比較するという手法だ.古い時代のコーパスでは綴字の変異という問題が関わるため,厳密に調査しようとすれば単純にはいかないが,Durkin はとりあえずの便法として,中英語と初期近代英語については Helsinki Corpus の 1150--1500年と1500--1710年のセクションを用いて,現代英語については BNC を用いて異綴字ベースで調査した.それぞれ頻度ランキングにして900--1000位ほどまでの単語(綴字)リストを作り,そのなかでフランス・ラテン語借用語が占める割合をはじき出した.
結果は,中英語セクションでは7%ほどだったものが,初期近代英語セクションでは19%まで上昇し,さらに現代英語セクションでは38%までに至っている.粗い調査であることは認めつつも,フランス・ラテン借用語で現在頻用されているものの多くについては,歴史のなかで徐々に頻度を上げてきた結果として,現在の日常的な性格を示すことがよくわかった.
さらにおもしろいことに,初期近代英語のセクション(1500--1710年)に関する数値について,高頻度語リストに含まれるフランス・ラテン借用語のすべてが1500年より前に借用されたものであり,しかもその2/3ほどは確実にフランス借用語であるという事実が確認される (Durkin 338--39) .
また,中英語と初期近代英語の高頻度語リストに含まれるフランス・ラテン借用語の多くが,現代英語の高頻度語リストにも再現されている事実にも触れておこう.古い2期には現われるが現代期からは漏れている語群を眺めると,なんとも時代の変化を感じさせてくれる.例えば,honour, justice, manner, noble, parliament, pray, prince, realm, religion, supper, treason, usury, virtue である (Durkin 340) .
時代によって最頻語リストやキーワードが異なることは当然といえば当然だが,歴史英語コーパスを用いて様々な時代を比較してみるとおもしろそうだ.例えば,初期近代英語コーパスに基づくキーワード・リストについて「#2332. EEBO のキーワードを抽出」 ([2015-09-15-1]) を参照.また,頻度と歴史の問題については「#1243. 語の頻度を考慮する通時的研究のために」 ([2012-09-21-1]) も参照されたい.
・ Durkin, Philip. Borrowed Words: A History of Loanwords in English. Oxford: OUP, 2014.
2015-09-07 Mon
■ #2324. n-gram [corpus][information_theory][coca][bnc][google_books][statistics][n-gram][collocation][frequency][link]
情報理論や自然言語処理の分野で用いられる n-gram という分析手法がある.コーパス言語学でもすでにお馴染みの概念であり,共起表現 (collocation) の研究などでは当たり前のように用いられるようになった.種々のコーパスのインターフェースにおいても採用されており,「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) では名前に含まれているほどだし,本ブログでも COCA (Corpus of Contemporary American English) の N-gram データベースを用いて「#956. COCA N-Gram Search」 ([2011-12-09-1]) を実装してきた(その応用は,「#953. 頭韻を踏む2項イディオム」 ([2011-12-06-1]),「#954. 脚韻を踏む2項イディオム」 ([2011-12-07-1]),「#955. 完璧な語呂合わせの2項イディオム」 ([2011-12-08-1]) を参照).BNC では,Explore Words and Phrases from the BNC が利用できる.
コンピュータを用いた分析手法というと難しそうに聞こえるが,n-gram の考え方は至って単純である.文字レベルの 2-gram (bigram) を考えてみよう.最長の英単語といわれる pneumonoultramicroscopicsilicovolcanoconiosis (「#63. 塵肺症は英語で最も重い病気?」 ([2009-06-30-1])) を例にとる.まず,先頭の2文字1組の pn を取り出す.次に,2文字目に進んで同じように ne を取り出す.3文字目に進んで eu を,4文字目に進んで um を得る.同じように,1文字ずつ右にずらしながら,最後の is まで2文字1組を次々と拾っていく.これで44組の2文字を得たことになる.この組のなかで,ic と co という組み合わせは各々3回起こり,os, si, no, on の組み合わせは各々2回現われ,それ以外の組み合わせはいずれも1度きりである.したがって,この単語において最高頻度の2文字1組は ic と co となる.
n-gram の単位は,このように文字である必要はなく,音素でもよいし,より大きな単位である形態素や語でもよく,さらに大きな句などのより大きな単位でもよい.英語コーパス言語学では,語という単位で考えるのが普通だろう.Martin Luther King, Jr. の I Have a Dream の演説のテキストで語単位の 4-gram を取ると,最も多い4語の組み合わせは,予想通り "I have a dream" の8回だが,"will be able to" も同じく8回現われる."Let freedom ring from" も7回とよく現われる,等々の分析が可能となる.ここでは4語という「窓」を設定したので 4-gram と呼ばれるが,隣接するいくつの文字を考慮するかにより 1-gram (unigram), 2-gram (bigram), 3-gram (trigram),そして 5-gram 以上ももちろん考えることができる(1-gram の場合,得られるリストは,事実上各語の生起頻度表である).
巨大コーパスから得られた 2-gram や 3-gram の一覧は,それ自体が共起表現の研究などでは基本データとなるため,ウェブ上でもいろいろと公開されている.日本語では「N-gram コーパス - 日本語ウェブコーパス 2010」があるし,現代英語では COCA の n-gram データベース がある.また,Bigram Plus では,歴史英語コーパスを含めた各種英語コーパスから N-Gram Search を行なえる機能を提供している.ほかにも任意のテキストやコーパスを対象に n-gram を取る各種のツールやソフトも,ウェブ上で入手可能だ.
n-gram 分析の言語分野への応用範囲は広い.次に来る語(音,文字)は何か,という予測可能性とも関係が深いため,機械による音声認識,統語分析,言語判定,自動翻訳,スペルチェック,剽窃探知,全文検索用インデックスの作成などに活用される.もちろん,共起表現の研究では,基本にして不可欠の手段となっている.一方,n-gram はもっぱら言語として表面化されたテキストを対象とし,深層にある構造にまったく触れることがないため,生成文法のような言語理論の方面からは批判があるようだ.詳しくは,n-gram in Wikipedia を参照.
n-gram は工夫次第で,まだまだ使い道がありそうだ.歴史英語テキストにも,応用していきたい.
(後記 2015/09/12(Sat): Sketch Engine より N-grams も参照.)
2015-05-22 Fri
■ #2216. 研究社Webマガジンの記事「コーパスで探る英語の英米差 ―― 実践編 ――」 [link][corpus][bnc][coca][ame_bre][sociolinguistics][language_change][gender_difference][link]
一ヶ月前の「#2186. 研究社Webマガジンの記事「コーパスで探る英語の英米差 ―― 基礎編 ――」」 ([2015-04-22-1]) に引き続き,5月20日付で「実践編」が公開されました.研究社WEBマガジン Lingua リンガより,こちらをご覧ください. *
今回は,複数のコーパスを用いることの利点やおもしろさを押し出しました.また,英語の英米差という一見すると静的な話題にも,動的あるいは通時的に迫ることにより,新たな見方が得られる点も強調しました.
記事のなかでも触れましたが,実際には今回の「実践編」で述べた結論に至るには,もっと詳しく調査しなければなりません.しかし,コーパスを用いて,例えばこのような言語変化の徴候をとらえることができるかもしれないという可能性を感じ取ってもらえれば,という気持ちで執筆しました.基礎編,実践編で私の執筆担当は完結ですが,来月以降も引き続き研究社WEBマガジン Lingua リンガの記事にご注目ください.バックナンバーも非常に有用です.以下,改めて研究社WEBマガジン Lingua リンガの各記事へのリンク(最新版)を張っておきます.
1. なぜコーパスか? (赤須 薫)
2. 英語コーパス体験ツアー ― BNCweb を検索してみる ―(前編) (石井 康毅)
3. 英語コーパス体験ツアー ― BNCweb を検索してみる ―(後編) (石井 康毅)
4. Google をコーパスに見立てる (仁科 恭徳)
5. 言語統計の基礎(前編) ― 頻度差の検定 ― (小林 雄一郎 )
6. 言語統計の基礎(後編) ― 共起尺度 ― (小林 雄一郎)
7. コーパスを活用した古くて新しい学問領域:フレイジオロジー ― 理論編 ― (井上 亜依)
8. コーパスを活用した古くて新しい学問領域:フレイジオロジー ― 実践編 ― (井上 亜依)
9. 学習者コーパスとは何か? (鎌倉 義士)
10. 学習者コーパスで何ができるのか? (鎌倉 義士)
11. パラレルコーパスの可能性 (仁科 恭徳)
12. 日本語コーパスに見られる慣用句の用法 (石田 プリシラ)
13. 日本語コーパスに見られる慣用句の変化可能性 (石田 プリシラ)
14. COCA を使ったコロケーションの検索 (内田 諭)
15. COCA を使った類義語の検証 (内田 諭)
16. コーパスで話し言葉を探る ― 基礎編 ― (青木 理香)
17. コーパスで話し言葉を探る ― 実践編 ― (青木 理香)
18. 学習者の話し言葉コーパスを使った語用論分析 (1)談話標識 well, I mean, kind of, like の使い方 (三浦 愛香)
19. 学習者の話し言葉コーパスを使った語用論分析 (2)買い物での要求の表現 (三浦 愛香)
20. 認知言語学を用いてコーパスから意味を探る― 入門編 ― (大谷 直輝)
21. 認知言語学を用いてコーパスから意味を探る― 前置詞・句動詞編 ― (大谷 直輝)
22. コーパスで探る英語の英米差 ―― 基礎編 ―― (堀田 隆一)
23. コーパスで探る英語の英米差 ―― 実践編 ―― (堀田 隆一)
なお,今回の実践編で注目した gorgeous に関しては,本ブログでも以下の記事で扱ってきましたのでご参照ください.
・ 「#476. That's gorgeous!」 ([2010-08-16-1])
・ 「#477. That's gorgeous! (2)」 ([2010-08-17-1])
・ 「#607. Google Books Ngram Viewer」 ([2010-12-25-1])
また,英語(言語)の男女差についても gender_difference の各記事で扱ってきました.特に言語の男女差とコーパス利用を絡めた記事として,「#913. BNC による語彙の男女差の調査」 ([2011-10-27-1]) をご覧ください.
2014-12-01 Mon
■ #2044. なぜ mayn't が使われないのか? (1) [auxiliary_verb][negative][tag_question][bnc][corpus][sobokunagimon]
なぜ may not の短縮形 mayn't が現代英語では一般的に用いられないのかという質問をいただいた.確かに不思議だと思っていたのだが,これまで扱わずにきたので少し考えてみたい.
法助動詞が否定辞を伴う形には,たいてい対応する短縮形がある.can't, couldn't, won't, wouldn't, shouldn't, mightn't, mustn't, needn't, use(d)n't, oughtn't 等々だ.しかし,mayn't はあまりお目にかからない.実際のところ大きな辞書には記載があるのだが,レーベルとしては口語的であるとか古風であるとか,特殊な用法とされている.OED でも mayn't は "(colloq., now rare)" や "rare in all varieties of English" とあり,標準英語をターゲットとする英語教育において教えられていないのも無理からぬことである.Quirk et al. (122) でも,mayn't が shan't とともに用いられなくなってきていることが述べられている.
Every auxiliary except the am form of BE has a contracted negative form . . ., but two of these, mayn't and shan't, are now virtually nonexistent in AmE, while in BrE shan't is becoming rare and mayn't even more so.
また Quirk et al. (811--12) は,付加疑問において mayn't I? などの形が使いにくい現状のぎこちなさにも言い及んでいる.mightn't I? や can't I? で代用する話者もいるようだが,スマートではない.may I not? は常に可能だが,堅苦しすぎて多くの文脈にはふさわしくない.
The negative tag question following a positive statement with modal auxiliary may poses a problem because the abbreviated form mayn't is rare (virtually not found in AmE). There is no obvious solution for the tag question, though some speakers will substitute mightn't or can't or --- when the reference is future --- won't:
?I may inspect the books, | mightn't I?
| can't I?
?They may be here next week, | mightn't they?
| won't they?
The abbreviated form is fully acceptable, but limited to formal usage:
I may inspect the books, may I not?
They may be here next week, may they not?
さて,BNC で mayn't を検索すると7例のみヒットした.話し言葉サブコーパスからは2例のみだが,書き言葉サブコーパスからの5例も口語的な文脈において生起している.7例中3例が mayn't you?, mayn't it?, mayn't there といった付加疑問のなかで現われており,一応は使用されていることがわかるが,1億語規模のコーパスでこれだけの例数ということは,やはり事実上の不使用といってよいだろう.
can't や mightn't との平行性を断ち切り,かつ付加疑問におけるそのぎこちなさを甘受してまでも mayn't の使用は避けるというこの状況は,いったいどのように理解すればよいのだろうか.歴史的に何か解明できるのだろうか.歴史的な事情について,明日の記事で考察したい.
・ Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech, and Jan Svartvik. A Comprehensive Grammar of the English Language. London: Longman, 1985.
2014-09-11 Thu
■ #1963. 構文文法 [bnc][construction_grammar][syntax][cognitive_linguistics][prototype][web_service][speech_act][generative_grammar]
構文文法 (construction grammar) は,この四半世紀の間で発展してきた認知言語学に基づく文法理論である.Lakoff, Fillmore, Goldberg, Kay などによって洗練されてきた.
構文という捉え方そのものは,統語論において長い伝統がある.構造言語学では当然視されていたし,その流れを汲んだ「文型」の考え方も,語学教育を通じて広く知られている.しかし,生成文法の登場により,従来の構文や文型は相対化され,二次的な付帯現象として扱われるようになった.
しかし,1970年代後半の認知言語学の誕生により,構文は単に形式的な観点からだけではなく,機能的・意味的な観点からアプローチされるようになった.特定の構文は,深層構造から生成されるのではなく,それ自身の資格において特定の意味に直接貢献する単位であるという考え方だ.例えば,Me write a novel?! という一見すると破格的な構文は,それ自体が独自の韻律(主部と述部が上昇調のイントネーションを帯びる)を伴い,「あざけり」を含意する.また,There's the bell! のような構文は,人差し指を上げる動作とともに用いられることが多く,「知覚の直示性」を表わす,といった具合だ.構文文法では,構文そのものが意味,語用,韻律などを規定していると捉える.
ただし,構文が意味などを規定しているといっても,その規定の強さは変異する.例えば,Is A B? の構文は典型的に質問の発話行為を表わすが,Is that a fact? は,通常,質問ではなく話者の驚きを表わす(いわゆる間接的発話行為 (indirect speech_act)) .このように,構文文法は,構文とその意味の関係もプロトタイプ的に考える必要があると主張する.また,定型構文となると,そのなかの語句を他のものに交換できなくなるなど,意味的,統語的に融通のきかなくなるケースもある.例えば,Thanks a lot, Thanks a million からの発展で Thanks a billion は可能だが,*Thanks a hundred は不可能となる.day in day out, month in month out は可だが,minute in minute out や century in century out は不可である,等々 (Taylor 225--28) .
構文文法は上記のように生成文法へのリアクションとして生じてきたが,近年では生成文法の側でも構文文法と親和性のある反語彙論や分散形態論などの理論が発展してきている.構文復権の徴候が顕著になってきたといえるだろう.
構文文法の枠組みで BNC の例文に構文情報を付したデータベースが,http://framenet.icsi.berkeley.edu/ で公開されており,こちらのインターフェースよりアクセスできる.数十の注目すべき英語構文が登録されている.
・ Taylor, John R. Linguistic Categorization. 3rd ed. Oxford: OUP, 2003.
2012-12-08 Sat
■ #1321. BNC Frequency Extractor [cgi][web_service][frequency][corpus][bnc]
Adam Kilgarriff が公開している BNC database and word frequency lists から,見出し語化されていない頻度表 (unlemmatised lists) をダウンロードし,検索できるようにデータベースをこしらえた.
仕様の説明.データベースには SQLite を用いており,SQL対応.select 文のみ有効.テーブルは "bnc" (コーパス全体),"written" (書き言葉コーパス),"demog" ('demographic' spoken material) ,"cg" ('context-governed' spoken material) ,"variances" (計算された分散その他の値を含む)の5種類.variances を除く4テーブルについては,フィールドは "freq" (頻度), "word" (語形), "pos" (品詞;BNC CLAWS POS-tags の一覧を参照), "files" (その語形が生起しているテキスト数)の4つ.variances のテーブルについては,上記4フィールドに加えて,"mean" (= freq / files) ,"variance" (分散),"variance_to_mean" (= variance / mean) の3つが設定されている.variances の計算基準となっているサブコーパスは,5000語以上を含む書き言葉テキストということで,全体としては約1千万語(BNC全体の約1割)である.具体的には,"select * from bnc limit 10" や "select * from variances limit 10" などとすれば,データの格納のされ方を確かめることができる.
以下に,典型的な検索式を挙げておこう.
# 書き言葉テキストで,英米差があるとされる "diarrhoea" vs. "diarrhea" の綴字の生起頻度を確認
select * from written where word like "diarrh%"
# s で始まる語形を分散の高い順に
select * from variances where word like "s%" order by variance desc limit 100
# 母音変異の複数形を示す語の単数形の頻度(cf. 「#708. Frequency Sorter CGI」([2011-04-05-1]) の例では lemma 検索だった)
select * from bnc where word in ("foot", "goose", "louse", "man", "mouse", "tooth", "woman") and pos = "nn1" order by freq desc
# 母音変異の複数形の頻度
select * from bnc where word in ("feet", "geese", "lice", "men", "mice", "teeth", "women") and pos = "nn2"
# POSでまとめて頻度の高い順に(話し言葉 'demog')
select pos, sum(freq) from demog group by pos order by sum(freq) desc
# 最も広く多く使われる名詞
select * from variances where pos like "n%" order by variance desc limit 100
# 最も広く多く使われる形容詞
select * from variances where pos like "aj%" order by variance desc limit 100
なお,見出し語化されている頻度表 (lemmatised list) については,頻度にして800回以上現われる,上位6318位までの見出し語のみに限定されており,その検索ツールは「#708. Frequency Sorter CGI」 ([2011-04-05-1]) として実装してある.関連して,「#956. COCA N-Gram Search」 ([2011-12-09-1]) も参照.
2012-10-31 Wed
■ #1283. 共起性の計算法 [corpus][statistics][bnc][collocation][lltest]
[2010-03-04-1]の記事「#311. girl とよく collocate する形容詞は何か」で,語と語の共起 (collocation) を測る計算法 (association measure) にはいくつかの種類があることを見た.コーパス言語学では,Log-Likelihood Test という検定にかかわる計算法が比較的よく使われているが,それぞれの計算法には特徴があるので,なるべく複数の方法を試すのがよい.今回は[2010-03-04-1]の内容と重複する部分もあるが,BNCweb で実装されている7種類の計算法の各々について Hoffmann et al. (149--58) を参照しながら,特徴および利用のヒントを示したい.
各種の計算法は,(a) 共起頻度 (frequency of co-occurrence),(b) 共起有意性 (significance of co-occurrence),(c) エフェクト・サイズ (effect-size) の1つ,あるいは複数の組み合わせに基づいている.(b) は,共起が統計的に有意であるとの確信度を表わす指標であり,共起の強さを表わすものではないことに注意する必要がある.(c) は,観察頻度と期待頻度との比を計算の基本とする指標である.
(1) Rank by frequency
観察される共起頻度そのものを用いる,最も単純で直感的な尺度.他の計算法のような複雑な統計処理はほどこされておらず,指標としては最も粗い.機能語や句読記号などが上位に来ることが多い.通常の共起分析には用いられない.
(2) Log-likelihood
共起有意性を用いる.BNCweb のデフォルトの計算法で,コーパス研究で広く用いられている.機能語や句読記号などの極めて高頻度の語との共起や,逆に極めて低頻度の語(1, 2回など)との共起をはじく傾向がある.しかし,共起頻度の高い組み合わせに高得点を与えるという特徴があり,解釈には注意を要する.
(3) Mutual information (MI)
エフェクト・サイズを用いる.非常によく用いられている計算法だが,利用に当たっては多くの注意を要する.機能語や句読記号などとのありふれた共起を効果的に排除してくれる点はよいが,反面,低頻度の共起表現への偏りが激しい.この偏りの影響を減じるために,BNCweb では "Freq(node, collocate) at least" を10以上に設定することが推奨される.これにより,"conspicuous and intuitively appealing collocations involving words of intermediate frequency" (Hoffmann et al. 154) が浮き彫りとなる.
(4) T-score
共起頻度と共起有意性を考慮する計算法.期待頻度が1以下程度の稀な共起表現については Rank by frequency と似たような振る舞いをし,頻度の高い共起表現については共起有意性を反映した振る舞いをする.また,観察頻度が期待頻度よりも必ず高くなる.Log-likelihood と類似した結果となることが多いが,高頻度へのバイアスは一層強くなる.ノードそのものが1000回を大きく下回る場合に,効果を発揮することがある.
(5) Z-score
共起有意性とエフェクト・サイズを考慮する計算法.高頻度の共起表現にはエフェクト・サイズをより重視するが,低頻度の共起表現にはそこまでエフェクト・サイズに寄りかからない.Log-likelihood と MI の両特徴を兼ね備えたような,バランスの取れた指標である.ただし,MI と同様に,低頻度の共起表現へのバイアスがみられるので,"Freq(node, collocate) at least" を5程度に設定するのがよいとされる.
(6) MI3
共起頻度とエフェクト・サイズを考慮する計算法.MI のもつ低頻度表現への偏重を取り除くべく改善されている.低頻度共起表現にはエフェクト・サイズが,高頻度共起表現には共起頻度が,比較的よく反映される.POS による限定とともに用いると効果的.複数語からなる用語などの取り出しに威力を発揮する.しかし,全体としては高頻度共起表現へのバイアスが強く,一般的な共起分析には向かない.
(7) Dice coefficient
MI3 と同様に,共起頻度とエフェクト・サイズを考慮する計算法.しかし,MI3と異なり,低頻度共起表現には共起頻度が,高頻度共起表現にはエフェクト・サイズがよく反映され,両者の切り替えが急なのが特徴的である.切り替えは,ノードそのものの頻度が共起表現の頻度の10倍ほどの点で起こるとされる.経験的に,Z-score と似たような結果が得られるが,Z-score ほど頻度に基づくバイアスが見られない.
以上のように多種類あって目移りするが,Hoffmann et al. の見解によれば,単一基準の計算法としては Log-likelihood と MI がお勧めで,混合基準の計算法としては Z-score と Dice がお勧めとのことである.
共起性の様々な計算法については,Association measures を参照.
・ Hoffmann, Sebastian, Stefan Evert, Nicholas Smith, David Lee, and Ylva Berglund Prytz. Corpus Linguistics with BNCweb : A Practical Guide. Frankfurt am Main: Peter Lang, 2008.
Powered by WinChalow1.0rc4 based on chalow