hellog〜英語史ブログ / 2010-03
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
2026 : 01 02 03 04 05 06 07 08 09 10 11 12
2025 : 01 02 03 04 05 06 07 08 09 10 11 12
2024 : 01 02 03 04 05 06 07 08 09 10 11 12
2023 : 01 02 03 04 05 06 07 08 09 10 11 12
2022 : 01 02 03 04 05 06 07 08 09 10 11 12
2021 : 01 02 03 04 05 06 07 08 09 10 11 12
2020 : 01 02 03 04 05 06 07 08 09 10 11 12
2019 : 01 02 03 04 05 06 07 08 09 10 11 12
2018 : 01 02 03 04 05 06 07 08 09 10 11 12
2017 : 01 02 03 04 05 06 07 08 09 10 11 12
2016 : 01 02 03 04 05 06 07 08 09 10 11 12
2015 : 01 02 03 04 05 06 07 08 09 10 11 12
2014 : 01 02 03 04 05 06 07 08 09 10 11 12
2013 : 01 02 03 04 05 06 07 08 09 10 11 12
2012 : 01 02 03 04 05 06 07 08 09 10 11 12
2011 : 01 02 03 04 05 06 07 08 09 10 11 12
2010 : 01 02 03 04 05 06 07 08 09 10 11 12
2009 : 01 02 03 04 05 06 07 08 09 10 11 12
2010-03-31 Wed
■ #338. Norman Conquest 後のイングランドのフランス語母語話者の割合 [french][demography][bilingualism]
1066年の Norman Conquest の後,イングランドはフランス語を母語とする者たちの支配下に入った.とはいっても,イングランドの居住者の大多数は相変わらずアングロサクソン系であり,フランスから渡ってきた者といえば王侯貴族,そのお仕えの者たち,高位聖職者が主だったが,その数は多くなかった.英語の復権の兆しが見えるまで Norman Conquest から優に300年はかかったが,英語が地下に潜りながらもたくましく生き延びた原因の一つは,英語母語話者の絶対数が圧倒的に多かったことである.では,ノルマン貴族とアングロサクソン庶民の人口比は具体的にはどれくらいだったのだろうか.
歴史人口統計学をもってしても11世紀後半における人口比を正確に知ることはできない.しかし,Blake によるおよその見積もりは参考になるかもしれない.
It would be reasonable to suggest that the number of native French speakers can never have been greater than 10 per cent of the total population of England, and a more realistic estimate is probably less than 5 per cent. The greatest part of the population in England at this time consisted of the peasants who tilled the land. They probably formed anything between 85 and 90 per cent of all people here, . . . . (107)
要するにフランス人は人口の約5%を占めたに過ぎないとの見積もりである.さらに Blake は,聖職者階級に入り込んだフランス人の人口比だけをとってもやはり非常に低いと見積もっている.
. . . the number of native French speakers in the clergy at any one time cannot have been very large. Perhaps it amounted to no more than 2 per cent of the total clergy. (108)
上記の人口統計を含め,当時の社会状況を考察した結果として導き出されるのは,イングランドは真の意味で bilingual ではなかったという主張である.
Although two languages, English and French, were spoken in England, it is doubtful whether it ever became a truly bilingual country. The majority of the population was monolingual and only used English. (109--10)
"truly bilingual" がどのような状況を指すのかが不明ではあるが,単純に人口の半々がそれぞれの言語を母語としており,かつ他の言語もある程度は理解可能であるという状況のことだと想定すると,中世イングランドを bilingual society とみなす慣習的なとらえ方は不適切ということになる.Blake 的な感覚でいえば,"barely bilingual" くらいの表現が適切なのかもしれない.
・ Blake, N. F. A History of the English Language. Basingstoke: Palgrave Macmillan, 1996.
2010-03-30 Tue
■ #337. egges or eyren [caxton][popular_passage][plural][me_dialect][inflection][spelling]
あまたある英語史の本のなかで繰り返し引用される,古い英語で書かれた一節というものがいくつか存在する.そういったパッセージを順次このブログに追加していき,いずれ popular_passage などというタグのもとで一覧できると,再利用のためにも便利かと思った.そこで,今日は「卵」を表す後期中英語の名詞の複数形の揺れについて Caxton が1490年に Eneydos の序文で挙げている逸話を紹介する.北部出身とおぼしき商人が,Zealand へ向かう海路の途中にケント海岸のとある農家に立ち寄り,夫人に卵を求めるという状況である.
And one of theym named Sheffelde, a mercer, cam in-to an hows and axed for mete; and specyally axed after eggys. And the goode wyf answerde, that she coude speke no frenshe. And the marchaunt was angry, for he also coude speke no frensche, but wolde have hadde egges, and she understode hym not. And thenne at laste a nother sayd that he wolde have eyren. Then the gode wyf sayd that she understode hym wel. Loo, what sholde a man in thyse dayes wryte, egges or eyren?
[2009-11-06-1]などで触れたとおり,中英語期は方言の時代である.イングランド各地に方言が存在し,いずれの方言も(ロンドンの方言ですら!)標準語としての地位を確立していなかった.したがって,例えば北部出身の話者と南部出身の話者とが会話する場合には,それぞれが自分の方言を丸出しにして話したのであり,時にコミュニケーションが成り立たないこともありえた.上の逸話では「卵」に当たる語の複数形が南部方言では eyren,北部方言では egges だったために,当初,互いにわかり合えなかったくだりが描写されている.
英語本来の複数形を代表しているのは南部の eyren である.古英語では「卵」を表す名詞の単数主格は ǣg という形態だった.これは r-stem と呼ばれるマイナーな屈折タイプに属する中性名詞で,その複数主格形は ǣgru のように -r- が挿入されていた.この点,child / children と同じタイプである ( see [2009-09-19-1], [2009-09-20-1], [2009-12-01-1] ).
初期中英語までは,語尾に -(e)n が付加された異形態も含めて,古英語由来の r をもつ形態がおこなわれていた.しかし,14世紀頃から,古ノルド語由来の硬い <g> をもつ形態が北部・東中部方言に現れ始めた.現代の我々が知っているとおり,最終的に標準英語に生き残ったのは舶来の新参者 eggs のほうであるから歴史はおもしろい.
綴字についても一言.Caxton の生きた時代は,印刷技術が登場した影響で綴字の固定化の兆しの見られる最初期であるが([2010-02-18-1]),上の短い一節のなかでも eggys, egges と語尾に異綴りが見られる.綴字の標準化は,この先150年以上かけて,17世紀から18世紀まで,ゆっくりと進行し,完成してゆくことになる.
(以下,後記:2025/01/19(Sun))
・ heldio 「#183. egges/eyren:卵を巡るキャクストンの有名な逸話」
2010-03-29 Mon
■ #336. Law French [me][french][reestablishment_of_english][norman_french][loan_word][law_french]
[2010-03-17-1]の記事で触れたが,法律文書の英語化は非常に緩慢としたプロセスだった.1362年に口頭の訴訟手続きこそフランス語から英語に切り替わったが,法律関係の文書にはまだまだフランス語が使用されていた.実に1731年まで使われ続けたのである.このフランス語は Law French と呼ばれ,Norman Conquest 以来の Norman French がもととなって確立された法律文章語である.
現在でも英語の法律用語の大半がフランス語由来であるのは,上述の歴史に負っている.法律関係の役職名と犯罪名だけをとってみても,英語の法律の世界がいかに French かが分かるだろう.
・ 役職名: advocate 「代言者」, attorney 「代理人」, bailiff 「執行吏」, coroner 「検視官」, counsel 「弁護人」, defendant 「被告」, judge 「裁判官」, jury 「陪審」, plaintiff 「原告」
・ 犯罪名: arson 「放火」, assault 「暴行」, felony 「重罪」, fraud 「詐欺」, libel 「文書誹毀」, perjury 「偽証」, slander 「口頭誹毀」, trespass 「侵害」
また,フランス語の統語では「名詞+形容詞」という語順が普通なので,これを反映した法律関係の句がたくさん存在する.
・ attorney general 「司法長官;法務長官」, court martial 「軍法会議」, fee simple 「単純封土権」, heir apparent 「法定推定相続人」, letters patent 「開封勅許状」, malice aforethought 「予謀の犯意」
英語で法律を勉強するのはものすごく大変そう・・・.
・McArthur, Tom, ed. The Oxford Companion to the English Language. Oxford: OUP, 1992. 591.
2010-03-28 Sun
■ #335. 日本語語彙の三層構造 [lexicology][japanese][kanji][loan_word][lexical_stratification]
昨日の記事[2010-03-27-1]で,類義語の豊富さに関しては英語は他言語と比べても異例だと述べた.しかし,もっと異例なことに,英語と日本語はこの点でよく似ているのである.英語では,アングロサクソン語(本来語),フランス語,ラテン・ギリシャ語の三層構造をなしているが,日本語では,和語(本来語),漢語,西洋語の三層構造をなしている.日本語の例(思いつき)を見てみよう.
| 和語 | 漢語 | 西洋語 |
|---|---|---|
| おおうなばら(大海原) | 大洋 | オーシャン |
| おかね(お金) | 金銭 | マネー |
| およぎ(泳ぎ) | 水泳 | スイミング |
| おんなのこ(女の子) | 女子 | ギャル |
| かみのけ(髪の毛) | 毛髪 | ヘアー |
| かわや(厠) | 便所 | トイレ |
| くすりや(薬屋) | 薬局 | ドラッグストア |
| くるま(車) | 乗用車 | カー |
| さくらんぼ | 桜桃 | チェリー |
| たたかい(戦い) | 戦闘 | バトル |
| たまご(卵) | 鶏卵 | エッグ |
| ひとつ(一つ) | 一 | ワン |
| ひるめし(昼飯) | 昼食 | ランチ |
| やど(宿) | 旅館 | ホテル |
英語の下層を構成する本来語と同様,和語はもっとも庶民的である.暖かく懐かしい響きがあり,感情に直接うったえかける力がある.「一,二,三」と数えるよりも,「ひとつ,ふたつ,みっつ」のほうが暖かく優しい.この階層の語彙は日常会話に頻出するが,学術論文にはあまり現れない類の語彙である.
学術論文などに代表される文語を主なフィールドとするのが,中層の漢語である.いや,学術論文ほどお堅くなくても日本語のあらゆる文章において漢語がなければ大変に不便である.本記事のここまでの文章だけでも,表中の語を除き,34種類の漢語がのべ50回も使用されている.漢語は日常会話でも頻度は低くない.この点,英語の中層を担うフランス語起源の語彙と機能がよく似ている.
上層を構成する西洋語は,主に英語由来のものが多い.英語の上層を担当するラテン・ギリシャ語由来の語彙の register のレベルが文字通りに上層であるのに対して,日本語の上層の西洋語は必ずしもお高い響きはない.むしろ,横文字は軽い響きがあると言われることすらある.この点で,上層に関しては英語と日本語の役割は異なっているようである.ただし,成長著しい科学や情報の分野では,英語の専門用語に対する日本語の訳語を作るのが追いつかず,そのまま英語を採用することも広く行われている.この場合,西洋語は専門性の響きを帯びるため,上層と呼ぶにふさわしいとも言える.
日本語では,各階層に対応する文字種がおよそ決まっているのが特徴である.和語はひらがな,あるいは漢字かな交じりで,漢語は漢字で,西洋語はカタカナ(あるいは最近はアルファベットそのままのケースもある)でというように,視覚的にも明確に区別される.
英語と日本語で各階層の機能に若干の差があることは認めるにせよ,ともにこれだけ明確な語彙の三層構造をもっているということは,稀なる偶然である.いや,もしかすると偶然以上のものがあるのかもしれない.歴史的に大陸からの影響を多く受けてきたのは,島国であるからこその特徴といえるかもしれない.
2010-03-27 Sat
■ #334. 英語語彙の三層構造 [lexicology][french][latin][register][thesaurus][loan_word][lexical_stratification]
類似概念を表すのに二つ以上の語が存在するという状況はどの言語でも珍しくない.確かに,完全な「同義語」というものが存在することは珍しいが,少し条件をゆるめて「類義語」ということであれば,多くの言語に存在する.とはいうものの,英語の類義語の豊富さは,多くの言語と比べても驚くべきほどである.このことは類義語辞典 ( thesaurus ) を開いてみれば,一目瞭然である.
英語史の観点から類義語の豊富さを説明すれば,それは英語が多くの言語と接触してきた事実に帰せられる.異なった言語から対応する語を少しずつ異なったニュアンスで取り入れ,語彙のなかに蓄積していったために,結果として英語は類義語の宝庫 ( thesaurus ) となったのである.
類義語を語源別にふるい分けてみると,そこに「層」があることがわかる.例えば,典型的な類義語のパターンとして「三層構造」とでも呼ぶべきものがある.下層が本来語,中層がフランス語,上層がラテン・ギリシャ語というパターンである.
| native | French | Latin/Greek |
|---|---|---|
| ask | question | interrogate |
| book | volume | text |
| fair | beautiful | attractive |
| fast | firm | secure |
| foe | enemy | adversary |
| help | aid | assistance |
| kingly | royal | regal |
| rise | mount | ascend |
下層は文字通り「レベルが低い」が,同時に「暖かみと懐かしさ」がある.本来のゲルマン系の語彙であるから,故郷の懐かしさのようなものが感じられるのは不思議ではない.
中層は多少なりとも権威と教養を感じさせるが,庶民が届かないほどレベルが高いものではない.歴史的には中世イングランドの公用語がフランス語だったことに対応するが,中英語期に借用されたフランス語彙のなかには特別な権威を感じさせず,十分に庶民化したといってよい語も多い ( ex. face, finish, marriage, people, story, use ) .
上層には,学問と宗教の言語,すなわち権威を体現したような言語たるラテン語(あるいはギリシャ語)が控えている.語の響きとしては厳格で近寄りがたく,音節数も多いのが普通である.
このように,語彙の三層構造が歴史的に育まれてきた英語では,階層間の使い分けが問題になる.特に微妙な意味の差や適切な 使用域 ( register ) の見極めが肝心である.例えば日常会話では下層や中層の語彙がふさわしいが,学術論文では中層や上層の語彙を使いこなす必要がある.気軽に尋ねるのに "May I interrogate you?" は妙だろう.
このような語彙の階層については,具体例を一覧表で列挙している橋本先生の英語史の第5章が参照に便利である.
・ 橋本 功 『英語史入門』 慶應義塾大学出版会,2005年.
2010-03-26 Fri
■ #333. イングランド北部に生き残る thou [personal_pronoun][dialect]
二人称単数代名詞の thou については,このブログでも何度か話題に取りあげた([2010-02-12-1], [2009-10-29-1], [2009-10-11-1]).現代標準英語では聖書や詩などの限られた register で生き残っているにすぎないが,地域変種を考慮に入れると,イングランド北部などで生き延びていることが確認される.通常,綴りは <tha>,発音は /ðə/ で,予想通り中英語以来の親近感のこめられた二人称単数代名詞として用いられているという.
次の用例は,ヨークシャー発の表現である (Svartvik and Leech 55).
Don't thou thou me, thou thou them as thous thee.
thou は,二人称親称代名詞としての用法のほか,「二人称親称代名詞 thou で呼びかける」という動詞の用法があり,ここでは "Please don't use thou in addressing me; use thou to address people who use thou in addressing you." ほどの意味になる.
・ Svartvik, Jan and Geoffrey Leech. English: One Tongue, Many Voices. Basingstoke: Palgrave Macmillan, 2006.
2010-03-25 Thu
■ #332. 「動物とその肉を表す英単語」の神話 [french][lexicology][loan_word][language_myth][lexical_stratification][animal]
昨日の記事[2010-03-24-1]に関連する話題.英語史で必ずといってよいほど取りあげられる「動物は英語,肉はフランス語」という区分は,語り継がれてきた神話であるという主張がある.OED の編集主幹を務めた Burchfield によると,"[an] enduring myth about French loanwords of the medieval period" だという.少し長いが,引用する (18).
The culinary revolution, and the importation of French vocabulary into English society, scarcely preceded the eighteenth century, and consolidated itself in the nineteenth. The words veal, beef, venison, pork, and mutton, all of French origin, entered the English language in the early Middle Ages, and would all have been known to Chaucer. But they meant not only the flesh of a calf, of an ox, of a deer, etc., but also the animals themselves. . . . The restriction of these French words to the sense 'flesh of an animal eaten as food' did not become general before the eighteenth century.
試しに beef を OED や MED で確認してみると,確かに動物そのものの語義も確認される.しかし,複数の例文を眺めてみると,動物本体と関連して肉が言及されているケースが多いようである.例えば,この語義での初例として両辞書ともに14世紀前半の次の例文を掲げている.
Hit mot boþe drink and ete .. Beues flesch and drinke þe broþt.
それでも,Burchfield の主張するように「動物は英語,肉はフランス語」という区分が一般的になったのは18世紀になってからということを受け入れるとするならば,それはなぜだろうか.18世紀には料理関係の語がフランス語から大量に入ってきたという事実もあり,これが関係しているかもしれない.
肉・動物の使い分けの始まりが中世であれ近代であれ,英語話者の意識下に「高きはフランス語,低きは英語」という印象が伝統的に定着してきたことは確かだろう.
・ Burchfield, Robert, ed. The New Fowler's Modern English Usage. 3rd ed. Oxford: Clarendon, 1996.
2010-03-24 Wed
■ #331. 動物とその肉を表す英単語 [french][lexicology][loan_word][etymology][popular_passage][lexical_stratification][animal]
中英語期を中心とするフランス語彙の借用を論じるときに,この話題は外せない.食用の肉のために動物を飼い育てるのはイギリスの一般庶民であるため,動物を表す語はアングロサクソン系の語を用いる.一方で,料理された肉を目にするのは,通常,上流階級のフランス貴族であるため,肉を表す語はフランス系の語を用いる.これに関しては,Sir Walter Scott の小説 Ivanhoe (38) の次の一節が有名である.
. . . when the brute lives, and is in the charge of a Saxon slave, she goes by her Saxon name; but becomes a Norman, and is called pork, when she is carried to the Castle-hall to feast among the nobles . . . .
具体的に例を示すと次のようになる.
| Animal in English | Meat in English | French |
|---|---|---|
| calf | veal | veau |
| deer | venison | venaison |
| fowl | poultry | poulet |
| sheep | mutton | mouton |
| swine ( pig ) | pork, bacon | porc, bacon |
| ox, cow | beef | boeuf |
「豚(肉)」について付け加えると,古英語では「豚」を表す語は swīn だった.pig は中英語で初めて現れた語源不詳の語である.また,後者が一般名称として広く使われるようになったのは19世紀以降である.bacon (豚肉の塩漬け燻製)は古仏語から来ているが,それ自身がゲルマン語からの借用であり,英語の back などと同根である.
・ Scott, Sir Walter. Ivanhoe. Copyright ed. Leipzig: Tauchnitz, 1845.
2010-03-23 Tue
■ #330. Cobuild Concordance and Collocations Sampler [corpus][bnc][cobuild][collocation]
本ブログでは,オンラインで利用できる現代英語のコーパスとして,簡便に使える BNC ( The British National Corpus ),より本格的に使える BNCWeb(要無料登録)を紹介してきた.BNC はその名の如くイギリス英語専門のコーパスで,ほぼ1975年以降の英語が約1億語おさめられている.そのうち9割は書き言葉,1割は話し言葉という構成である.現在オンラインで利用できる最大級の規模の英語コーパスである.
規模だけでいえば,もっと大きな英語コーパスが存在する.常に拡大を続けるモニターコーパス The Bank of English であり,その規模は5億5000万語にまで達する.BNC と異なり,イギリス英語だけでなくアメリカ英語を含めた他の変種もカバーしている.
このうちの一部,約5600万語が Cobuild Concordance and Collocations Sampler としてオンラインで無料で公開されている.コンコーダンス・ラインは40行まで,コロケーションのスコア・ランキングは100位までしか出力されない「デモ版」ではあるが,検索語に簡単なタグ指定ができるなど,手軽な目的であれば十分に使える仕様だろう(有料版 Collins WordbanksOnline もあり).
コロケーションのスコアとしては,T-score か MI ( Mutual Information ) かを選べる.[2010-03-04-1]でも触れたが,それぞれのスコアの特徴を簡単に述べる.
・ MI (mutual information): 共起する2語が持つ意味的特性に焦点が当てられる傾向がある.慣用句,ことわざ,複合語,専門用語など独特の言い回しを構成する語に高い値が与えられる.コーパスのサイズに依存しない.3以上の値をもって collocate しているとみなせるといわれる.イメージとしては,連想ゲーム的な語と語の関係が明らかになると考えるとよい ( = lexical collocation ).低頻度語が強調される傾向があり,独特でおもしろい結果になることがある.
・ T-score: collocation 強度そのものの指標というよりも,互いに関連があると言い切れる確信度の指標.コーパスのサイズが勘案されている.通常は,2以上の値でその collocation が統計的に有意とみなされる.特定の2語の共起頻度に焦点を当てるため,キーワードの前後に頻繁に生起する前置詞,不変化詞,人称代名詞,限定詞などの文法構造を満たすための語のほか,常套句や使い古されてしまった比喩,決まり文句などを構成する語が上位にランクインする.イメージとしては,主に文型や機能語の連語情報が明らかになると考えるとよい ( = grammatical collocation ) .
コンコーダンスやコロケーションの出力は,英語の研究や学習のためだけでなく,汎用の発想ツール,連想ツールとしても使える.例えば,octopus のコロケーションの MI 値を出してみると,上位に squid, dried, october などが現れる.味わい深い.
・ 鷹家 秀史,須賀 廣 『実践コーパス言語学』 桐原ユニ,1998年.113--15頁.
2010-03-22 Mon
■ #329. 印欧語の右と左 [indo-european][etymology]
人類の文化はほとんどが右優位である.その根源には,人種・文化を越えてヒトの9割が右利きであるという事実がある.文化の右優位に例外がないわけではない.例えば,古代インカ帝国では左利きが幸運と考えられていたし,中国やその影響を受けた日本でも,時代によっては相対的に左が厚遇されたこともあった.しかし,印欧語をとりまく文化に限ると,右優勢・左劣勢の観念は根強い.今回は,印欧語に通底するこの観念を語源から探ってみたい.
英語の right は印欧語根の *reg- に遡る.原義は「まっすぐにする」で,同じ語根からはラテン語に由来する regular, reign, rule などが英語に入っている.この原義から様々に意味が発展し,「規準」「正義」「権利」「正しい」「正常な」「右の」などへ広がった.right の「右」の意味は古英語後期から現れ始め,それ以前には swīþra が用いられていた.これは,swīþ "strong" の比較級の形であり,"the stronger side" ほどの意味である.このように「右」にはまっすぐで,正しく,強いという思想がある.
一方 left は,種々の語源説があるが,低地ゲルマン諸語に確認される lucht "weak, useless" と同根とされる.古英語の lyftādl "paralysis" にみられるように,病気とも関連づけられている.「左」には弱いという思想がある.
フランス語に視点を移すと,droit 「右」には「法律」の意味がある.一方,gauche 「左」はそのまま英語に借用されて「不器用な」の意味を表す.ラテン語からは dexter 「右の」が dextrous 「器用な」として英語に借用されているし,sinister 「左の」が sinister 「不吉な」としてやはり英語に借用されている.
英語に入った単語を中心にして印欧諸語のごく一部だけを紹介したが,左右の差別は明らかだろう.
・ エド・ライト 『神々の左手?世界を変えた左利きたちの歴史?』 スタジオタッククリエイティブ,2009年.
2010-03-21 Sun
■ #328. 菌がもたらした(かもしれない) will / shall の誤用論争 [history][irish_english][ireland][auxiliary_verb]
昨日の記事[2010-03-20-1]で,アイルランドのジャガイモ大飢饉 ( Great Irish [Potato] Famine ) を契機として大量のアイルランド人がアメリカへ移住し,アイルランド英語の語法をアメリカ英語へもたらしたかもしれないという話題に触れた.例えば,shall の代わりに will を頻用するという AmE の特徴は,アイルランド英語の語法に由来するのではないかという.
話しをおもしろくするためにあえて歴史の因果関係をこじつけてみると,アイルランドの主食たるジャガイモを襲って大飢饉をもたらした疫病の元凶,Phytophthora infestans という菌こそが,現代米語の I will なる表現を定着させたともいえる.この舌をかみそうな名前の菌は,皮肉なことに北米から運ばれてきたものだった.結果としてみれば,アメリカはアイルランドに菌を送り出し,代わりに大量のアイルランド移民と(おそらく)アイルランド英語語法を迎え入れたことになる.[2009-08-24-1]の「英語を世界語にしたのはクマネズミである」的な強引さではあるが,biohistory of English (?) なる観点からするとストーリーとしておもしろいのではないか.
ところで,BrE では will と shall は主語の人称によって使い分けられるのが規範文法の建前である.それを犯すと誤用のレッテルを貼られる可能性がある.[2010-02-22-1]でみた BBC による誤用ランキングでは,この使い分けは堂々の第7位である.もしこの誤用がアメリカ語法に後押しされているという部分があるのであれば,言語的影響が Irish -> American -> British と回ってきたことによりヒートアップした誤用論争ということになるのかもしれない.
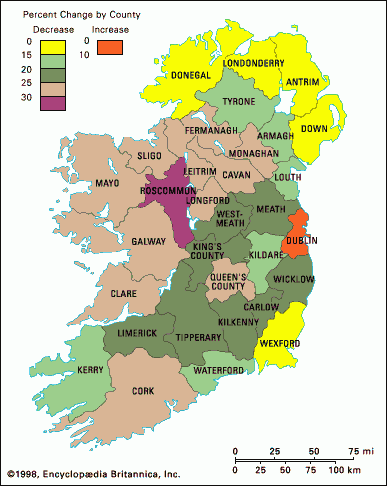
以下に,アイルランド大飢饉について簡単に説明.19世紀ヨーロッパに起こった最大の飢饉.特にジャガイモ依存率の高かったアイルランドでは,1845--49年のジャガイモ疫病による大凶作により,大量の人民が被害を被った.1844年には840万人いた人口が,大飢饉直後の1851年には660万人にまで減っていた.餓死したものも多かったし,北米や英国へ移民したものも多かった.移民は飢饉の期間のみで150万人.それ以降も続いた.下図は,1841--51年の地域別の人口減少率を示す.西部の貧しいエリアが甚大な被害を被ったことがよくわかる.
2010-03-20 Sat
■ #327. Irish English が American English に与えた影響 [ame][irish_english][ireland][contact][history]
19世紀半ば,アイルランド大飢饉 ( 1845--48 ) を受けてアイルランド人のアメリカへの大移住 ( The Great Irish Immigration ) が起こった.その結果,いくつかのアイルランド英語の語法がアメリカ英語に持ち込まれ,後にアメリカ語法として定着したという.松浪有編『英語史』によれば,例えば,次のような項目が挙げられている.
・ shall の用法が will にほとんど取って代わられた(早くも1855年頃にすでに確立)
・ the measles などのように定冠詞を用いる用法(アイルランド英語の基層にあるゲール語の影響か)
・ 接頭辞・接尾辞の頻繁な使用( anti-, semi-, -ster, -eer などの接辞による造語は AmE に顕著.このケースではアイルランド英語の影響はあくまで可能性とのこと.)
・ 強意語の多用
いずれも知らなかった.これらの影響が言語事実からどれだけ客観的に裏付けられるのか確認する必要があるが,しばしば指摘される英語の英米差の一端が Irish English に帰せられるとすれば,アメリカ移民史とも関連して興味深い.
・ 松浪 有 編,秋元 実治,河井 迪男,外池 滋生,松浪 有,水鳥 喜喬,村上 隆太,山内 一芳 著 『英語史』 英語学コース[1],1986年,大修館書店.159--60頁.
2010-03-19 Fri
■ #326. The subjunctive forms die hard. [subjunctive][drift][mandative_subjunctive]
昨日の記事[2010-03-18-1]で,mandative subjunctive がアメリカ英語のみならずイギリス英語でも勢いを増してきていることに触れた.英語史の大きな流れからすると,屈折の種類は減少する方向へ推移し続けていくだろうと予想されるところだが,mandative subjunctive が拡大している状況を知ると,大きな流れのなかの小さな逆流を見ているかのようである.100年以上も前,Bradley は英語史の流れを意識して,次のような予測を立てていた.
The only formal trace of the old subjunctive still remaining, except the use of be and were, is the omission of the final s in the third person singular of verbs. And even this is rapidly dropping out of use, its only remaining function being to emphasize the uncertainty of a supposition. Perhaps in another generation the subjunctive forms will have ceased to exsit except in the single instance of were, which serves as a useful function, although we manage to dispense with a corresponding form in other verbs.
約100年後の現在,Bradly の予測がみごとに外れたことがわかる.ではなぜ,しばしば drift と呼ばれる英語の屈折衰退の傾向に対して,逆行するかのような言語変化が起こっているのか.これは今後の研究課題であるが,英米差であるとか米から英への影響であるとか以外にも,考えるべきパラメータは多そうである.浦田和幸先生の論文を読んだが,そこから思いつく限りでも,以下のパラメータが関与している可能性がある.
・ that 節を従える動詞の語義(特に insist, suggest などは factive な語義と suasive な語義が区別されるべき)
・ that 節内の動詞が,be 動詞か一般動詞か(一般に be 動詞の頻度が高いといわれる)
・ 文が否定文かどうか
・ 文が疑問文かどうか
・ that 節内の be が not で否定されている場合の,両者の統語的な前後関係
・ 話者の年齢
・ 語用の formality
・ that 節内の主語(動作主)の volition
・ that 節を従える動詞から派生した名詞とともに使われる mandative subjunctive の頻度
・ Bradley, Henry. The Making of English. New York: Dover, 2006. 95. New York: Macmillan, 1904.
・ 浦田 和幸 「現代イギリス英語に於ける Mandative Subjunctive の用法」 『帝京大学文学部紀要 英語英文学・外国語外国文学』18号,1987年,123--36頁.
2010-03-18 Thu
■ #325. mandative subjunctive と should [ame_bre][subjunctive][mandative_subjunctive]
現代英語において,特定の動詞や形容詞と関連づけられた that 節内の動詞が接続法 ( subjunctive mood ) の屈折形態をとるという文法がある.学校文法で一般に仮定法現在 ( subjunctive present ) と呼ばれている現象である.特に,このような that 節内に現れるケースを mandative subjunctive と呼ぶ.
この話題については[2009-08-17-1]で軽く触れた.またその使用頻度の英米差については[2010-03-08-1], [2010-03-05-1]で触れた.かいつまんでいえば,AmE ではいまなお接続法が一般的だが,BrE では代わりに should を用いることが多い.しかし,AmE の影響で BrE でも接続法の使用が増えてきている.
学校文法では,AmE 型の mandative subjunctive は BrE 型の should の省略であると説明されることがある.
AmE: I advised that John read more books.
BrE: I advised that John should read more books.
共時的には省略であるとする記述も可能なのかもしれないが,歴史的にはこの記述は不適当である.歴史的には,現代の AmE 型の subjunctive のほうが古い.古英語以来 Shakespeare の時代でも,mandative subjunctive は広く使われていた.この Shakespeare 時代の用法がそのままアメリカに渡り,AmE では現在まで変わらずに受け継がれているのである.一方,BrE では Shakespeare より後の時代に mandative subjunctive の用法が廃れ,当該の動詞形が不定詞形と再解釈されたうえで,直前に法助動詞 should が挿入されたのである.
したがって,歴史的にみれば,AmE 型の mandative subjunctive の使用は should の省略などではまったくない.むしろ正反対で,BrE 型の should こそが後付の挿入なのである.[2010-03-08-1]でも触れたが,この例は AmE が保守的で BrE が革新的であるという,一見すると意外な例の一つである.
こうした歴史的経緯を踏まえると,現在 BrE でも mandative subjunctive が復活しつつあるという状況が俄然おもしろく見えてくるだろう.
・ 児馬 修 『ファンダメンタル英語史』 ひつじ書房,1996年.60--65頁.
2010-03-17 Wed
■ #324. 議会と法廷で英語使用が公認された年 [history][reestablishment_of_english][me]
[2009-09-05-1]の記事などで,中英語期の英語の復権を話題にしてきた.その記事に掲げた年表では,1362年に議会の開会が英語で宣言され,1363年に法廷での使用言語が英語と記した.ところが,後者の法廷での英語使用が1363年ではなく,議会での英語使用と同じ,前年の1362年と結びつけられている記述を別で見つけ,この辺りの事情をきちんと理解していなかったので,正確なところを調べ直してみた.
結論をいえば,1362年の秋に開かれた議会で「訴答手続き法」 ( Statute of Pleading ) が制定され,施行がその翌年1月だったということである.英語の復活にかかわる英語史的意義としては,制定年をとれば象徴的,施行年をとれば実質的ということになろう.いずれにせよ,議会の開会が初めて英語で行われた年と重なることからも,1362年を英語の公的な復活を象徴する年とみなしてよいだろう.この英語の復活までに,Norman Conquest から実に296年の歳月が流れていた.
さて,London や Middlesex の州裁判所においては,英語による訴訟手続きは一足先の1356年に始まっていたが,全国的な法律としては上記の通り1362年に制定された.それ以前は,手続きはフランス語で行われていたのである.また,同法の制定・施行後も,記録自体はいまだラテン語で行われていたことも銘記すべきである.つまり,立証,弁護,答弁,論争など,口頭の訴訟手続きこそ英語に切り替わったが,それが文書化される段には英語の地位はいまだゼロだった.英語が法律の書き言葉としては認められたのは,それから126年後の1488年のことである(1489年1という記述もあり,これも制定・施行の差だろうか?).その140年後,1628年にようやく英語で書かれた最初の法典が編纂され,さらにその103年後,1731年に法律文書がラテン語ではなく英語で書かれることが義務づけられた.法律の分野での英語化の速度がいかに遅々としたものであったかが知れよう.逆にいえば,この分野でのフランス語やラテン語の影響力が,中世以来いかに大きいものであったかがわかる.
・ 寺澤 芳雄,川崎 潔 編 『英語史総合年表?英語史・英語学史・英米文学史・外面史?』 研究社,1993年.
・ 渡部 昇一 『英語の歴史』 大修館,1983年.174--75頁.
2010-03-16 Tue
■ #323. 英語史のイントロクイズ(2009年度版)の解答 [flash][quiz][hel_education]
昨日[2010-03-15-1]のクイズの解答は,こちらの Flash のスライドでどうぞ.(ファイルが500KB強とやや重いので,本記事には貼りつけなかった.直接,PDFのスライドとして落としたい方はこちらからどうぞ.)
スライドでは,各問題の次のページが解答(と補足)になっている.昨日も述べた通り,クイズ自体は荒っぽいし,数値も数年前のものでありアップデートされていないので,あくまで参考までに.クイズ作成に利用した参考資料はいくつかあるが,Graddol を参照することが多かった.
・ Graddol, David. The Future of English? The British Council, 1997. Digital version available at http://www.britishcouncil.org/learning-research-futureofenglish.htm.
2010-03-15 Mon
■ #322. 英語史のイントロクイズ(2009年度版) [flash][quiz][hel_education]
毎年度始め,英語史の初回の授業で以下のようなクイズを試している(全25問).かなり荒っぽいクイズではあるがそこそこ好評なので,1年ほど前に使用した2009年度版のクイズを以下に掲載する(全画面モードでどうぞ).直接,PDFのスライドとして落としたい方はこちらからどうぞ.答えは,明日の記事で.
2010-03-14 Sun
■ #321. controversy over controversy [pronunciation][rp][stress]
controversy 「論争」という語には,英米で標準とされる変種をとってもいくつかの発音がありうる.LPD ( Longman Pronunciation Dictionary ) の記述によると,以下の発音がある.
(BrE) /ˈkɒntəvɜːsi/ or /ˈkɒntəvəsi/: RP ( Received Pronunciation ) で優勢とされる発音.
(BrE) /kənˈtrɒvəsi/: RP 以外で広く使われている発音.教養層では第1音節に第2アクセントをおく発音 /ˌkɒnˈtrɒvəsi/ もきかれる.
(AmE) /ˈkɑːntrəvɜːsi/: 米語では唯一の発音.
AmE では選択肢はないが,BrE ではアクセントを第1音節におくものと第2音節におくものとで variation が見られる.LPD の傾向調査によると,BrE での揺れの度合いは以下の通りである.
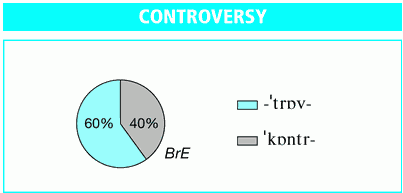
イギリスの国民的な机上辞書といわれる COD ( The Concise Oxford English Dictionary. 11th rev. ed. ) を参照してみると,標準変種では /kənˈtrɒvəsi/ は誤りであると記されているが,実際のところ,むしろこちらのほうがよく使われているということになる.しばらく時間が経ち,こちらの発音がさらに優勢になってゆけば,英米変種間の差が明確になることになる.だが,今のところは,BrE では controversy の発音に関する controversy は継続中である.
この問題についておもしろいのは,イギリスで,伝統的な /ˈkɒntəvɜ:si/ と異なる /kənˈtrɒvəsi/ という変種がきかれるようになったとき,後者はアメリカ英語かぶれの崩れた発音であるという認識が一部の BrE 話者に存在したことである ( Algeo 177 ).BrE 話者には AmE 英語を蔑視するという伝統がある.近年は AmE の世界的な影響力のもとにその伝統は弱まってきているとはいうものの,根底には存続していると考えられる.しかし,上で見たようにAmE では,BrE の伝統的な発音に対応する,第1音節に強勢のある発音しか存在しないのであり,この認識には事実の裏付けがない.偏見と直感にすぎなかったわけである.[2010-03-08-1]で触れたように,BrE は保守的で由緒正しく,AmE は革新的にすぎて軽蔑に値するという神話が生きている証拠でもある.実際には,この語の発音に関する限り,BrE こそが第2音節に強勢をおく革新的な発音を生み出したのであった.
アクセントの位置に関連する話題としては,名前動後 ( diatones ) も要参照 ([2009-11-01-1], [2009-11-02-1]).
・ Wells, J C. ed. Longman Pronunciation Dictionary. 3rd ed. Harlow: Pearson Education, 2008.
・ Soanes, Catherine and Angus Stevenson, eds. Concise Oxford English Dictionary. 11th rev. ed. Oxford: OUP, 2008.
・ Algeo, John. "America is Ruining the English Language." Language Myths. Ed. Laurie Bauer and Peter Trudgill. London: Penguin, 1998. 176--82.
2010-03-13 Sat
■ #320. The Untrue-Born English Language [contact][elf]
Robinson Crusoe の著者 Daniel Defoe (1660-1731) が,その出版よりずっと前の1701年に The True-Born Englishman という風刺詩を書いている.当時,イギリスは James II を廃して(名誉革命),オランダからやってきた William of Orange が William III として,Mary II との共同統治という形で王位についていた.政治パンフレット作家で William III の支持派であった Defoe は,外国人が我が国を治めているということに不満を抱く人々に対抗する目的で,本書を世に出した.要するに,生粋のイングランド人などというものはありえない.歴史を見れば分かるとおりイングランド人は雑種なのだから,外国人の王を黙って受け入れよ,というメッセージである.当時これは飛ぶように売れ,現在でも人種・国籍差別廃止の観点からその内容は色あせていないと評価されている.
イングランド人が雑種であることと英語が雑種であることは,ぴたりと符合している.かつての征服や移住などによる多民族との接触の結果として,イングランドが今ある姿になり,英語が今ある姿になった (see [2009-06-04-1]).イングランドの多民族性,英語の雑種性を説明するには,当の Defoe の言葉をして語らしめるのが一番よさそうだ.少し長いが 1703年版に基づくオンラインの Luminarium Edition から引用する.
The Romans first with Julius Cæsar came,
Including all the nations of that name,
Gauls, Greeks, and Lombards, and, by computation,
Auxiliaries or slaves of every nation.
With Hengist, Saxons; Danes with Sueno came,
In search of plunder, not in search of fame.
Scots, Picts, and Irish from the Hibernian shore,
And conquering William brought the Normans o'er.
All these their barbarous offspring left behind,
The dregs of armies, they of all mankind;
Blended with Britons, who before were here,
Of whom the Welsh ha' blessed the character.
From this amphibious ill-born mob began
That vain ill-natured thing, an Englishman.
The customs, surnames, languages, and manners
Of all these nations are their own explainers:
Whose relics are so lasting and so strong,
They ha' left a shibboleth upon our tongue,
By which with easy search you may distinguish
Your Roman-Saxon-Danish-Norman English.
さしずめ英語は,"this amphibious ill-born language" ということになろうか.あるいは,"The Untrue-Born English Language" と呼んでもよい.
今後,非母語話者からの強力な圧力により英語が変容してゆく可能性があるが ( see [2009-10-07-1] ),新たに現われてくる雑種的な英語に対して母語話者(や伝統文法を重んじる世界中の英語教師)はどのような反応を示してゆくことになるだろうか.
2010-03-12 Fri
■ #319. 英語話者人口の銀杏の葉モデル [elf][model_of_englishes][statistics][demography]
近代以降,特に19世紀から20世紀にかけて英語の話者人口が爆発的に増えてきたことは,本ブログでもたびたび話題に取りあげている.例えば,英語話者人口の様々な分類の仕方と問題点は[2009-10-17-1], [2009-11-30-1], [2009-12-05-1], [2010-01-24-1]で扱った.英語話者の分類はともかくとして話者人口そのものが増えてきた点に焦点をあてたとき,よく引き合いに出されるのがマッシュルームモデルである.最近では,Svartvik and Leech (8) でも掲載されたモデルである.
子供に図を見せて何に見えるかと尋ねたら,マッシュルームではなくイチョウの葉だというので,ここでは名称を改め「銀杏の葉モデル」と呼んでおきたい.これの意味するところは図を見れば一目瞭然だろう.
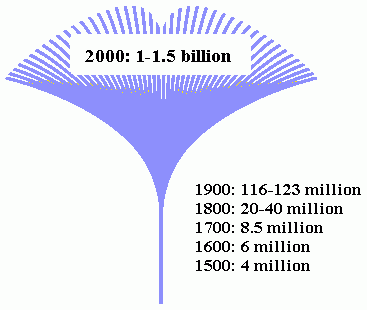
図中の数値は ENS, ESL, EFL を含めた概数だが,過去2世紀の間に約40倍も増えているのだから驚きだ.この図を見て思うところが3点あるので,コメントしておきたい.
(1) 話者人口数を表すこの銀杏の葉モデルを側面図ととらえて,立体的に真上からのぞき込むと,話者人口の分類を表す同心円モデル([2009-11-30-1])に近くなるのではないか.透明の円錐をとがった方を下にして,上からのぞき込んだ感じである.話者人口増加にもっとも貢献しているのは,Outer Circle 及び Expanding Circle に所属する人々である.
(2) 銀杏の葉の上端にある筋状の葉脈の一つひとつが,英語の変種 ( variety ) に相当すると見ることができるのではないか.上端に近いほど筋は互いに離れていくが,実際には葉っぱ本体に埋め込まれている筋なので,つながっている.現代の英語の変種間に働く遠心力と求心力を思い起こさせる.
(3) 近代以前と以降とで英語史が二分されるというイメージ.近年,英語史研究の世界では,特に近代英語期以降に関する研究において,話者と言語との関係を意識した社会言語学なアプローチが活気づいている.また,変種間の微妙な違いに留意する研究も増えてきている.話者が増え,その分だけ変種も増え,現在に近いだけに言語現象の背後にある社会言語学的な情報にもアクセスできる,ということが関与していると思われる.
それに対して,中英語期の研究は,確かに社会言語学的な視点からのアプローチが増えてきているとはいえ,アクセスできる情報には限りがある.変種も地域変種(方言)の研究は盛んだが,地理的な広がりといえばイングランド(とせいぜいその周辺)に限られ,近代以降の世界中に展開する複雑きわまれる変種の分布とは規模が異なる.
だが,英語史をこのように二分する考え方が必ずしもいいとは思っていない.変種の規模や広がりこそ大きく異なるが,変種のあり方については近代も中世も古代もそれほど変わらない点があるのではないか.
あれやこれやと,この図から想像してみた.
・ Svartvik, Jan and Geoffrey Leech. English: One Tongue, Many Voices. Basingstoke: Palgrave Macmillan, 2006.
2010-03-11 Thu
■ #318. 地下に潜った英語と潜らなかった日本語 [japanese][me][sociolinguistics][reestablishment_of_english]
[2009-09-05-1]の記事で,英語の復権について述べた.1066年のノルマン人の征服 ( Norman Conquest ) 以降,1362年辺りにいたるまで,イングランドでは公の場で英語が用いられることはほぼなかった.確かに初期中英語期と呼ばれるこの時期にも英語で書かれた文書は存在するが,あくまで非公的文書である.文学的にもあまり洗練されていないと評価されることが多い.公用語フランス語のくびきのもとで,庶民の言語である英語はまさに地下に潜っていたのである.
さて,日本語史をみてみると,平安初期に一見すると英語と似通った事情があった.日本語で書かれた文学は,『万葉集』の作られたと考えられる760年頃から,勅撰の『古今集』の作られた905年までのあいだに空白がある.この時代は漢文が全盛の時代で,男性貴族が『凌雲集』『経国集』『文華秀麗集』などの漢詩集を著し,漢文の秀才振りを示した.公の書の最たるものである『日本書紀』『日本後記』『続日本後記』『文徳実録』『三大実録』などの国史も,すべて漢文で書かれていた.書き言葉でみる限り,日本全体があたかも漢語に乗っ取られたかのような様相を呈していたのである.土着の言語が公の書き言葉としてほとんど現れてこない点で,時代こそ異なれ,英語と日本語の状況は似ているように見える.
しかし,大きく異なる点がある.日本では,ある意味でもっとも公的な意味合いを帯びた文章が,漢語文ではなく,紛れもない日本語文として記されていたのである.天皇の祝詞(のりと)である.祝詞は天皇によって口頭で読み上げられる大和言葉である.いくら貴族が競って漢文を書こうが,日本の公世界の頂点たる天皇の口から発せられた言葉は日本語そのものであった.祝詞の文章は宣命体という形式で書かれており,そこでは漢字が中心であることは間違いないが,助詞・助動詞の類が万葉仮名で示され,語順も日本語そのものである.漢字文ではあるが,紛れもない日本語の文章である.日本では,天皇をはじめ貴族の話し言葉が日本語だったことは疑いをいれない.それに対して,中世初期のイギリスでは,王侯貴族の日常的な話し言葉は英語ではなくフランス語だった.
当時の両国で,社会的地位の高い言語(日本では漢語,イギリスではフランス語)を上層言語,低い言語(日本では日本語,イギリスではフランス語)を下層言語と呼ぶことにすると,当時の状況は以下の表のようにまとめられる.
| 日本 | イギリス | |
|---|---|---|
| 庶民の話し言葉 | 下層 | 下層 |
| 公の書き言葉 | 上層 | 上層 |
| 王侯貴族の話し言葉 | 下層 | 上層 |
日本とイギリスの状況が一見共通しているように見えるのは上二段のゆえである.だが,最下段の「王侯貴族の話し言葉」では対照をなす.この違いを一言でいえば,当時のイギリスの言語状況は王朝の征服の結果として生じたものだが,日本の言語状況は征服によるものではなく,あくまで中国からの甚大な文化的な影響によるものだったということだろう.日本語は,英語と同じ意味で「地下に潜った」わけではない.
・ 渡部 昇一 『アングロサクソンと日本人』 新潮社〈新潮選書〉,1987年.72--75頁.
・ 山口 仲美 『日本語の歴史』 岩波書店〈岩波新書〉,2006年. 54, 71--72頁.
[ 固定リンク | 印刷用ページ ]
2010-03-10 Wed
■ #317. 拙著で自分マイニング(キーワード編) [text_tool][flob][corpus][keyword]
昨日の記事[2010-03-09-1]に引き続き,拙著 The Development of the Nominal Plural Forms in Early Middle English で自分マイニング.WordSmith には KeyWords 抽出機能がある.単に単語リストを頻度順に並べた昨日のリストでもおよそのテキストの主題を読み取ることは可能だが,上位に機能語などの雑音が大量に入り込み,解釈しにくい.それに対して,キーワードリストでは対象テキストの主題をよく表す実質的なキーワードが上位に来るので,解釈しやすい.
考え方としては以下の通りである.巨大なコーパスなどを参照テキストとして使用し,そこから単語ごとに一般的な頻度を導き出す.次に,対象テキスト内で各単語について頻度を出す.ある語の対象テキスト内での頻度が,参照テキスト内での頻度よりも相当に大きい場合には,それは対象テキストに特有のキーワードとみなせる.そのようなキーワードを自動的に探し出してくれるのが,WordSmith の KeyWords 抽出機能である.拙著はイギリス英語で書いていることもあり,参照テキストとしては FLOB ( Freiburg-LOB corpus ) を使用した.以下,上位50語のキーワードである.
plural, english, s, n, old, nouns, norse, dialect, midland, middle, plurals, dialects, texts, language, forms, text, ending, diffusion, v, south, west, nominative, early, stem, the, spread, linguistic, singular, endings, inflectional, contact, accusative, o, system, weak, in, development, sec, change, fem, dative, morphological, languages, saxon, item, formation, period, transfer, germanic, strong
ずばり来てくれました plural .複数形の研究なのでそうでなければ困るところだ.昨日のリストよりも機能語の雑音がよくはじかれている.
WordSmith には各キーワードのファイル内での出現箇所を視覚的にプロットする機能もあり,上記の50語について以下のようなプロットが得られた.
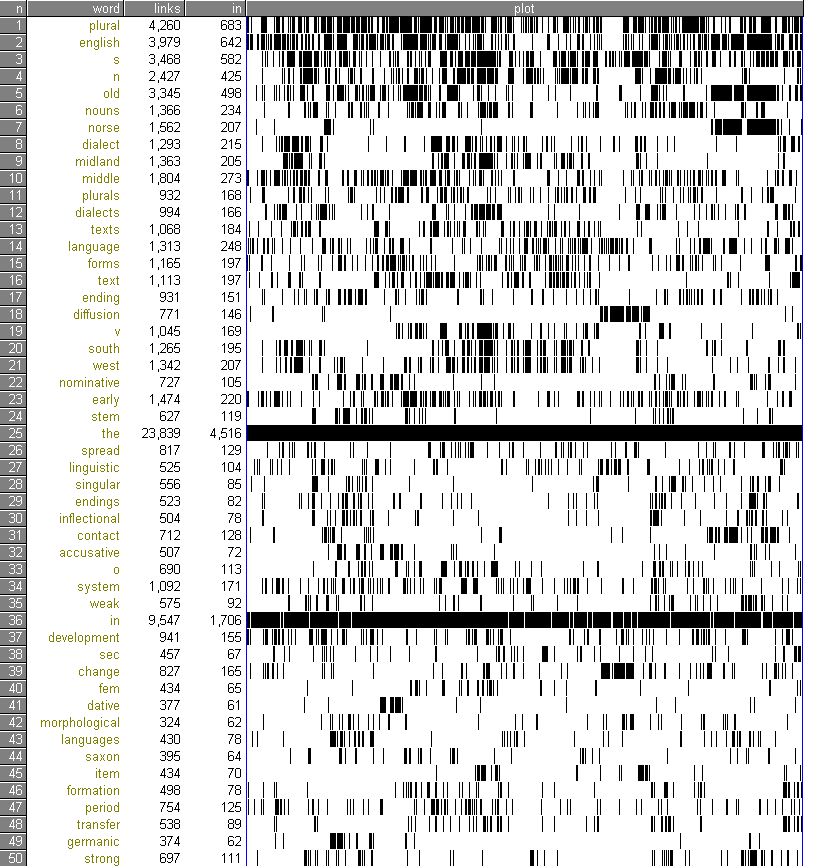
執筆者本人なので,なるほどと思えることが多い.最上位語はテキスト中にまんべんなく現れる傾向があるが,それでも分布が偏っているものもある.7位の norse は Old Norse について論じている7章に固まっているし,18位 diffusion は Lexical Diffusion を集中的に扱っている5章に集中している.
われながらの発見もあった.言語変化を論じているので development と change を多用しているが,執筆中にはそれほど意識して両語を使い分けていたわけではなかった.そうであればまんべんなく分布していそうなものだが,実際には change が5章辺りに偏在している.ということは,無意識のうちに使い分けていたということなのだろうか.無意識の癖とでもいうべきものが発見できておもしろい.
文章をこのように分析することで,実用的な効果がいろいろ考えられそうである.思いつきを記す.
・ 文体の統計を把握することで今後の文章改善に活かす(誰々の文体に近づきたい,ボキャ貧をなおしたい,パラグラフ構成の指針をもちたい,など)
・ 自分の過去の文章と比較し,文体の経年変化を観察する
・ 論文などを書き終えた後でタイトル候補が複数ある場合に,キーワードを参考にして決定する
・ 自分の過去の論文などをひっくるめて分析対象とし,「私の研究テーマは(キーワード)です」と言い切れるようになる
・ 相手の過去の論文などをひっくるめて分析対象とし,「あなたの研究テーマは(キーワード)です」と言い切れるようになる(←おせっかい)
・ 緩やかに関連する二つの論文 A と B を互いに参照テキストとしてそれぞれのキーワードを抽出し,A の特徴と B の特徴を比べる.共通点が多いことを前提としているので,キーワードによって逆に相違点が浮き彫りになる可能性がある.
2010-03-09 Tue
■ #316. 拙著で自分マイニング(文体統計と単語リスト編) [text_tool]
自分で書いた文章をいろいろと分析することを自分マイニングというが,今回は僭越ながら拙著 The Development of the Nominal Plural Forms in Early Middle English の英文を材料にして,自分の英作文の傾向(と対策)を調べてみたい.今回使用したツールは,コーパス研究用に開発された WordSmith Version 3 である.
まず準備として,手元にある拙稿を収めた LaTeX ファイルから図表部や Bibliography 部などをそぎ落とし,おおかた本文だけが含まれるような平テキストを得る.それを WordSmith にかけて,文体に関わる統計値を出してみた.
| Tokens | 58,535 |
| Types | 4,805 |
| Type/Token Ratio | 8.21 |
| Standardised Type/Token | 37.81 |
| Ave. Word Length | 4.88 |
| Sentences | 1,745 |
| Sent.length | 22.49 |
| sd. Sent. Length | 12.36 |
| Paragraphs | 865 |
| Para. length | 67.67 |
| sd. Para. length | 48.26 |
| 1-letter words | 3,239 |
| 2-letter words | 9,619 |
| 3-letter words | 10,771 |
| 4-letter words | 7,996 |
| 5-letter words | 5,657 |
| 6-letter words | 4,938 |
| 7-letter words | 5,220 |
| 8-letter words | 3,747 |
| 9-letter words | 2,594 |
| 10-letter words | 2,043 |
| 11-letter words | 1,224 |
| 12-letter words | 857 |
| 13-letter words | 304 |
| 14(+)-letter words | 203 |
本文は6万語弱 ( tokens ) からなり,使用している単語の種類 ( types ) は lemmatise されていない状態で 5千語弱.平均的な一文の長さは22語ほど.一段落は68語ほど.当然ながら,お手本となる英文の基準統計値がないと,いずれの数値もどう判断してよいかはわからない.いずれ尊敬する研究者や好きな作家の文体と比べてみたい.
次に,WordList を作成.頻度順に並び替えれば拙著の主題が見えてくるはずである.上位50語を小文字化された状態で以下に掲載.
the, of, in, to, and, a, is, plural, as, english, that, s, for, old, was, n, it, be, from, i, this, are, with, by, on, middle, language, but, or, nouns, not, early, dialect, norse, west, midland, were, forms, text, south, texts, more, have, we, system, than, which, an, may, v
大部分は機能語だが,内容語としては plural, english, middle, nouns, early, forms がちゃんと出てきてくれた.ちゃんとというのは,タイトルを構成する単語が上位に出てきてくれないとタイトルの付けかたが悪かったということになりかねないからだ.development は56位,nominal は189位だったが・・・.
2010-03-08 Mon
■ #315. イギリス英語はアメリカ英語に比べて保守的か [ame_bre]
英語の英米差については,これまでもいくつかの記事で取り上げてきた ( see ame_bre ).広く信じられている「神話」によれば,アメリカ英語 ( AmE ) が革新的で,イギリス英語 ( BrE ) が保守的ということになっている.国民性についてのステレオタイプに基づく神話といっていいだろう.英語史ではよく取り上げられることであるが,実際には,AmE に古い語法が残っていたり,BrE に革新的な語法が見られることも少なくない.そもそも英語史の舞台の大半はイギリスであり,AmE の誕生につながる近代英語期まで,英語という言語はまさにそのイギリスで数々の言語変化を経てきたのである.歴史的にみて BrE が絶対的に保守的であるということはできない.
生きた言語である以上,AmE も BrE もある意味では革新的であり,ある意味では保守的である.今回は,AmE と BrE の標準的な変種がそれぞれどのような古い語法を保ち続けているかについて代表的なものを列挙する.以下,典拠は Algeo .
[ AmE のほうが保守的である点 ]
(1) more, mother などの /r/ .BrE では発音しない方向へ変化し,現在にいたっている.
(2) path, calf, class などの /æ/ .BrE では /ɑ:/ へと変化し,現在にいたっている.
(3) secretary /ˈsekrəˌteri/ などで最後から二番目の音節に第2アクセントをもつ.BrE では,通常 /ˈsekrətri/ と母音が消失し,3音節語になる.
(4) Chaucer も愛用した I guess を I think の意味で頻用する.BrE では guess はもっぱら「言い当てる」の意.
(5) get の過去分詞としての gotten の使用.BrE では got のみ.ちなみに AmE でも got を使わないわけではないが,gotten とは意味が異なる.例えば,I've got a cold = I have a cold だが,I've gotten a cold = I've caught a cold .( see also [2010-03-05-1] )
(6) They insisted that he leave. などにおける仮定法の使用.BrE では should を用いるのが通例.( see also [2010-03-05-1], [2009-08-17-1] )
[ BrE のほうが保守的である点 ]
(1) atom と Adam など母音間の /t/ と /d/ を明確に区別する.AmE では弾音化 ( flap ) して両語が同じ発音になる.
(2) callous と Alice などが韻を踏まない(最終音節が異なる発音を保っている).AmE では,最終音節の母音が曖昧母音 /ə/ へ融合するため,韻を踏む.
(3) father /ˈfɑ:ðə/ と fodder /ˈfɒdə/ などで強勢音節の母音が異なる.AmE では /ɑ:/ へ融合.
(4) I reckon を I think の意味で使用する.AmE では,reckon は通常「計算する,見積もる」の意.
(5) fortnight 「二週間」, corn 「穀物」などの使用と意味.AmE では通常,前者は使わず,後者は「トウモロコシ」の意に限定.
(6) Have you the time? など一般動詞としての have を助動詞のように前置する文法.AmE では Do you have the time?
いずれの変種にも革新性と保守性は備わっており,どちらがより革新的なのか保守的なのかは判然としないというのが事実だろう.一方で,Algeo の次の見解にも留意しておきたい.
Perhaps Americans do innovate more; after all, there are four to five times as many English speakers in the United States as in the United Kingdom. So one might expect, on the basis of population size alone, four to five times as much innovation in American English. Moreover, Americans have been disproportionately active in certain technological fields, such as computer systems, that are hotbeds of lexical innovation. (182)
・ Algeo, John. "America is Ruining the English Language." Language Myths. Ed. Laurie Bauer and Peter Trudgill. London: Penguin, 1998. 176--82.
2010-03-07 Sun
■ #314. -ise か -ize か (2) [spelling][bre][bnc][lob][flob][corpus][suffix][z]
[2010-02-26-1]の記事で取りあげた話題の続編.先日の記事では,単語によって比率は異なるものの,イギリス英語では -ise と -ize の両方の綴字が行われることを,BNC に基づいて明らかにした.高頻度20語については,おおむね -ise 綴りのほうが優勢ということだった.
通時的な観点がいつも気になってしまう性質なので,そこで新たな疑問が生じた.-ise / -ize のこの比率は,過去から現在までに多少なりとも変化しているのだろうか.大昔までさかのぼらないまでも,現代英語の30年間の分布変化だけを見ても有意義な結果が出るかもしれないと思い,1960年代前半のイギリス英語を代表する LOB ( Lancaster-Oslo-Bergen corpus ) と1990年代前半のイギリス英語を代表する FLOB ( Freiburg-LOB corpus ) を比較してみることにした.
それぞれのコーパスで,前回の記事で取りあげた頻度トップ20の -ise / -ize をもつ動詞について,その変化形(過去形,過去分詞形,三単現の -s 形,-ing(s) )を含めた頻度と頻度比率を出してみた(下表参照).
| item | LOB: rate (freq) | FLOB: rate (freq) | ||
| -ise | -ize | -ise | -ize | |
| recognise | 59.6% (99) | 40.4% (67) | 71.8% (127) | 28.2% (50) |
| realise | 63.2% (134) | 36.8% (78) | 68.7% (125) | 31.3% (57) |
| organise | 65.6% (42) | 34.4% (22) | 67.2% (43) | 32.8% (21) |
| emphasise | 37.7% (20) | 62.3% (33) | 62.9% (39) | 37.1% (23) |
| criticise | 52.0% (13) | 48.0% (12) | 80.0% (24) | 20.0% (6) |
| characterise | 0.0% (0) | 100.0% (4) | 56.3% (18) | 43.8% (14) |
| summarise | 35.3% (6) | 64.7% (11) | 64.7% (11) | 35.3% (6) |
| specialise | 56.3% (18) | 43.8% (14) | 81.8% (27) | 18.2% (6) |
| apologise | 68.8% (11) | 31.3% (5) | 70.6% (12) | 29.4% (5) |
| advertise | 100.0% (41) | 0.0% (0) | 100.0% (55) | 0.0% (0) |
| authorise | 77.4% (24) | 22.6% (7) | 68.2% (15) | 31.8% (7) |
| minimise | 90.0% (9) | 10.0% (1) | 80.0% (16) | 20.0% (4) |
| surprise | 100.0% (182) | 0.0% (0) | 100.0% (173) | 0.0% (0) |
| supervise | 100.0% (10) | 0.0% (0) | 100.0% (9) | 0.0% (0) |
| utilise | 70.0% (7) | 30.0% (3) | 83.3% (5) | 16.7% (1) |
| maximise | 50.0% (2) | 50.0% (2) | 50.0% (9) | 50.0% (9) |
| symbolise | 50.0% (3) | 50.0% (3) | 40.0% (4) | 60.0% (6) |
| mobilise | 66.7% (2) | 33.3% (1) | 20.0% (1) | 80.0% (4) |
| stabilise | 58.3% (7) | 41.7% (5) | 33.3% (3) | 66.7% (6) |
| publicise | 81.8% (9) | 18.2% (2) | 84.6% (11) | 15.4% (2) |
いずれも100万語規模のコーパスなので,トップ20とはいっても下位のほうの語の頻度はそれほど高くない.だが,全体的な印象としては,-ise の綴字が30年のあいだにじわじわと増えてきているようである.頻度比率に大きな変化の見られないものも確かにあるが,著しく伸びたものとして emphasise, criticise, characterise, summarise, specialise などがある.ただ,これはあくまで印象なので,全体的に,あるいは個別の単語について統計的な有意差があるのかどうかは別に検証する必要がある.また,LOB には characterise は一例も例証されないが characterisation は確認されたことからも,動詞だけでなく名詞形の -isation / -ization も合わせて調査する必要がある.さらには,対応するアメリカ英語の状況も調査し,イギリス英語の通時的変化(もしあるとすればであるが)と関係があるのかどうかを探る必要がある.
2010-03-06 Sat
■ #313. Canadian English の二峰性 [canadian_english]
カナダ英語 (CanE) についてよく指摘される特徴として,アメリカ英語 (AmE) とイギリス英語 (BrE) の両方の特徴が混在していることが挙げられる.CanE の発音は概ね AmE に沿っている点で,両変種の上位に Northern American English という変種を設ける場合もある.しかし,綴字や語法などでは BrE に従うことも少なくなく,全体として CanE は英米変種の混合のように見えることは確かである.
この状況は,歴史的に説明される.アメリカ独立戦争では必ずしもすべてのアメリカ人がイギリスに対抗したわけではなく,Loyalists と呼ばれるイギリス支持派も存在した. アメリカ独立後,Loyalists は Nova Scotia などのカナダ方面に逃れ,後のカナダ英語の形成に大きく貢献した.イギリスとの親密な連携が伝統的に続いていることが一つ,絶大な影響力を誇る隣国アメリカとの日常的な接触が一つ,この二つの背景が絡み合って,カナダ英語が現在の姿へと発展してきた.
昨日の記事[2010-03-05-1]で典型的な文法上の英米差を列挙したが,それを同僚のカナダ人(音声学者)に尋ねてみたところ,ケースごとに AmE 的だったり BrE 的だったりとまちまちだった.昨日の記事の連番と対応させて,同僚カナダ人の示した反応のうち特に興味深かったものを挙げる.
(3) AmE 型に,集合名詞には単数で一致する.BrE 型を用いる習慣はない.
(4) BrE の口語できかれることのある They insist that she accepts the offer. のような直説法の使用は「とんでもない」とのこと.
(7) AmE 型の二人称複数代名詞 y'all は,家庭では regular に使用する.
(8) Have you eaten yet? などの文で,現在完了と過去を場合によって使い分ける.Did you eat yet? を用いるのが普通だが,If no, then will you eat? などを含意する場合には現在完了を用いる.
(9) look out (of) the window では AmE 型( of なし)を用いるが,get off (of) the sofa では BrE 型( of なし)を用いる.(彼の英米間の分裂症を指摘してあげたところ,自分は怠けものだから一貫して短いほうを選んでいるのだ,とか・・・)
(10) dived ではなく dove を使う.rang も rung も両方用いるが,書くときは絶対に前者.sank と sunk も同様.しかし,swam の代わりに swum とは言わない.
もちろんカナダ英語と一括りにすることはできず,様々なレベルの変種がありうるだろうが,カナダ英語の混合性がよく示されている.Chambers は英米両変種の混在を「二峰性の伝統」 ( bimodal tradition ) と呼んでいる.
Why do we find ourselves in this apparent state of confusion? As in so many other dilemmas, it follows from the crux of our history as British North America. Our venerable historical allegiance to Britain pulls us one way but our geographical attachment to the United States pushes us the other. . . . English spelling conventions were stabilized in England just before the American Revolution and then reformed in the U.S. at a time when belligerence had cooled into disdain. The result was not exactly two traditions but a bi-modal tradition. (cited from Chambers in Svartvik and Leech, p. 97)
・ Svartvik, Jan and Geoffrey Leech. English: One Tongue, Many Voices. Basingstoke: Palgrave Macmillan, 2006.
2010-03-05 Fri
■ #312. 文法の英米差 [ame_bre][grammar]
綴字の英米差([2009-12-27-1][2009-12-23-1]),発音の英米差([2009-11-24-1])に続き,今回は文法の英米差について主要なものを10点挙げる.
(1) gotten (AmE) / got (BrE)
AmE: She's gotten into trouble in school.
BrE: She's got into trouble in school.
(2) from ... through ... (AmE) / from ... to ... (BrE).AmE で through を使うと8月を含む意味になる.BrE ではこの慣用がないため,to だけでは8月を含むのか否かが不明.BrE で「含める」読みにするには,明示的に inclusive を使うことが多い.
AmE: The tour lasted from May through August.
AmE and BrE: The tour lasted from May to August.
BrE: The tour lasted from May to August inclusive.
(3) 集合名詞の数の一致.AmE では形態が単数である限り単数扱いだが,BrE では形態が単数でも意味が複数であれば後者を重視して複数扱い.team, audience, board, committee, government, the public など.
AmE: The Government has been considering further tax cuts.
BrE: The Government have been considering further tax cuts.
(4) insist, recommend, suggest などが従える従属節における仮定法 (AmE) と should (BrE) の使用.ただし,BrE でも AmE の影響で仮定法の使用が普通になってきている.(see [2009-08-17-1])
AmE: They insist that she accept the offer. (also increasing in BrE)
BrE: They insist that she should accept the offer. (getting unacceptable in AmE)
BrE (colloquial): They insist that she accepts the offer. (not accepted in AmE)
(5) AmE で副詞の代用としての形容詞.good, slow, awful, sure など.
AmE: They pay them pretty good. (non-standard in BrE)
BrE: They pay them pretty well.
(6) AmE で like の接続詞としての使用.BrE では as if が普通.
AmE: It seems like we've made another mistake. (non-standard in BrE)
BrE: It seems as if we've made another mistake.
(7) AmE のいくつかの変種で明示的な二人称複数代名詞 you all, y'all, yous(e) の頻用.
AmE: I'll see y'all later. (South)
AmE: How much did yous want? (Northeast, esp. New York City)
AmE: We'll see you guys Sunday, okay? (informal)
(8) 現在完了と過去.AmE ではしばしば過去形が代用される.
AmE: Dolly just finished her homework.
BrE: Dolly has just finished her homework.
(9) AmE で out の前置詞としての使用.BrE では out of を用いる.
AmE: I always look out the window.
BrE: I always look out of the window.
(10) AmE で用いられる動詞の過去形の異形.BrE では括弧内の形態しかとらないが,AmE の口語では両方とりうる.
dove ( dived ), fit ( fitted ), pled ( pleaded ), rung ( rang ), sung ( sang ), sunk ( sank ), snuck ( sneaked ), swum ( swam )
・ Svartvik, Jan and Geoffrey Leech. English: One Tongue, Many Voices. Basingstoke: Palgrave Macmillan, 2006. 166--69.
2010-03-04 Thu
■ #311. girl とよく collocate する形容詞は何か [corpus][collocation][bnc]
コーパスを使った collocation 研究は多い.しかし自分では行ったことがなかったので,McEnery et al. (56--57, 210--20) を参考にしつつ,自らお題を一つ掲げて collocation 研究のさわりを試してみた.特に collocation にかかわる様々な統計指標の特徴に注意してみたい.
お題は「girl とよく collocate する形容詞は何か」.使用するコーパスは BNCWeb .girl の左側3語までに現れる形容詞を検索対象とし,collocation の強度を示す様々な指標を出して,指標ごとに上位20個までの形容詞を一覧にしたのが下表である.
| Rank | raw frequency | observed/expected | t-score | z-score | log-likelihood | MI | MI3 |
|---|---|---|---|---|---|---|---|
| 1 | little | 15-year-old | little | little | little | 15-year-old | little |
| 2 | young | 16-year-old | young | young | young | 16-year-old | young |
| 3 | that | dark-haired | good | 15-year-old | good | dark-haired | good |
| 4 | this | 13-year-old | that | dark-haired | clever | 13-year-old | clever |
| 5 | good | nine-year-old | this | 16-year-old | poor | nine-year-old | pretty |
| 6 | one | 14-year-old | old | clever | pretty | 14-year-old | that |
| 7 | old | four-year-old | poor | pretty | old | four-year-old | 15-year-old |
| 8 | other | year-old | other | teenage | that | year-old | dark-haired |
| 9 | poor | clever | clever | 13-year-old | beautiful | clever | poor |
| 10 | clever | teenage | one | nine-year-old | lovely | teenage | 16-year-old |
| 11 | beautiful | blonde | pretty | four-year-old | golden | blonde | this |
| 12 | pretty | pretty | beautiful | head | nice | pretty | old |
| 13 | small | head | nice | 14-year-old | 15-year-old | head | beautiful |
| 14 | any | little | lovely | poor | teenage | little | teenage |
| 15 | nice | wee | big | blonde | dark-haired | wee | lovely |
| 16 | big | eldest | small | good | head | eldest | head |
| 17 | another | brave | golden | golden | 16-year-old | brave | golden |
| 18 | lovely | golden | tall | beautiful | tall | golden | nice |
| 19 | new | silly | dear | lovely | this | silly | tall |
| 20 | golden | young | teenage | year-old | dear | young | blonde |
各指標の読み方を以下にメモ.
・ raw frequency: コーパス内の総頻度.統計計算を加える前のベースとなる値で,それ自体は collocation の強度計測にはほとんど役に立たない.
・ observed/expected: 偶然に collocate している可能性からどれだけ隔たっているか.collocation の指標としては粗い.
・ t-score: 広く使われる指標.コーパスのサイズが勘案されている.通常は,2以上の値でその collocation が統計的に有意とみなされる.collocation 強度そのものの指標というよりも,互いに関連があると言い切れる確信度の指標.(後記 2010/03/21(Sun):特定の2語の共起頻度に焦点を当てるため,キーワードの前後に頻繁に生起する前置詞,不変化詞,人称代名詞,限定詞などの文法構造を満たすための語のほか,常套句や使い古されてしまった比喩,決まり文句などを構成する語が上位にランクインする.つまり,主に文型や機能語の連語情報 [ grammatical collocation ] に寄与する.)
・ z-score: 両語それぞれのコーパス中の全頻度を勘案したうえで,その collocation が期待値よりどれだけ高い頻度で現れているかを示す.広く使われている指標だが,データが正規分布をなすとの前提に立っており,多くの場合に必ずしも適切でない.コーパスが巨大か,あるいは(たいてい関心を引かない)超高頻度語を対象にするのでない限り,問題が生じうる.低頻度語が強調される傾向がある.
・ log-likelihood (LL test): データの正規分布を前提としない.コーパスのサイズが小さめでも有効.高頻度語にも低頻度語にも有効.手堅い統計値.
・ MI (mutual information): LL ほど統計的に厳格ではないが,z-score や LL の代替指標として広く使われている.3以上の値をもって collocate しているとみなせるといわれる.負の値が出ると,むしろ両語が背反し合うという意味になる.コーパスのサイズに依存しない.z-score と同様に低頻度語が強調される傾向がある.unique collocation を知るなど辞書学的な用途には役立つ指標だが,英語教育用には不向き.(後記 2010/03/21(Sun):共起する2語が持つ意味的特性に焦点が当てられる傾向がある.慣用句,ことわざ,複合語,専門用語など独特の言い回しを構成する語に高い値が与えられる.)
・ MI3: MI の低頻度語を強調しがちな傾向を補正した指標の一つ.英語教育用に向いている.同様の趣旨の指標として,log-log test というものもある.
正直なところ,どう読み解けばいいのかよくわからない(あくまで練習題なので・・・).little, young, good, clever などいずれの指標でもランクの高いものはあり,これらは明らかに強い collocation ありとみなしてよいだろう.ほかには, z-score や MI が 15-year-old などの影響を激しく反映しているのに対して,手堅い log-likelihood や補正済みの MI3 の値は -year-old を比較的よくはじいていることがわかる.このことから,-year-old は girl とよく collocate することは確かながらも,いくつかの指標が示唆するような最上位のランクであるというのは言い過ぎであるといえそうである.MI値の上位にはやや個性的と思われる形容詞も含まれており,若干くせのある値だということも肌で感じることができた.だが,統計値の解読はなかなかに難しい・・・.
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
2010-03-03 Wed
■ #310. PPCMBE で広がる英語統語論の通時研究 [corpus][ppcmbe][syntax]
Penn Parsed Corpora of Historical English のプロジェクトの成果として,University of Pennsylvania から PPCMBE ( Penn Parsed Corpus of Modern British English ) が出版された.これにより,以下の通り,古英語から現代英語にわたる各時期のイギリス英語の統語タグ付きコーパスが出そろったことになる.
・ YCOE: Taylor, Ann, Anthony Warner, Susan Pintzuk, and Frank Beths. York-Toronto-Helsinki Parsed Corpus of Old English Prose, first edition. Oxford Text Archive, 2003. (1.5 million words)
・ PPCME2: Kroch, Anthony and Ann Taylor. Penn-Helsinki Parsed Corpus of Middle English, second edition. University of Pennsylvania, 2000. (1.3 million words)
・ PPCEME: Kroch, Anthony, Beatrice Santorini, and Ariel Diertani. Penn-Helsinki Parsed Corpus of Early Modern English, first edition. University of Pennsylvania, 2004. (1.8 million words)
・ PPCMBE: Kroch, Anthony, Beatrice Santorini, and Ariel Diertani. Penn-Hensinki Parsed Corpus of Modern British English, first edition. University of Pennsylvania, 2010. (1.0 million words)
いずれも Helsinki Corpus をベースとしたソースに対して同一の annotation scheme による統語的タグが付加されており,互いに連携できるように作られている.視点は異なるが,およそ1410年から1695年までのあいだの書簡集となるコーパス PCEEC も同様の annotation scheme でタグ付けされており,やはり連携が可能である(ただし利用は限定的).
・ PCEEC: Taylor, Ann, Arja Nurmi, Anthony Warner, Susan Pintzuk, and Terttu Nevalainen. Parsed Corpus of Early English Correspondence, first edition. Oxford Text Archive, 2006. (2.2 million words)
現時点で,あわせて 7.8 million words が通時的かつ統語的な視点からタグ付けされ,一般に利用可能になったことになる.
一昨日と昨日と,東京外国語大学のグローバルCOEプログラム「コーパスに基づく言語学教育研究拠点」 ( Corpus-based Linguistics and Language Education ) 主催で,"Corpus Analysis and Diachronic Linguistics" と題する国際シンポジウムが同大学で開かれ,Anthony Kroch や Merja Kytö など英語史コーパス言語学の著名な学者も講演した(ポスターはこちら).PPCMBE の出版直後ということもあったので,特に Anthony Kroch が何を話すかに興味をもっていた.一連の歴史英語コーパスを使った統語研究の一端でも見せてくれるのかなと期待していたが,驚いたことに,歴史英語コーパスと歴史フランス語コーパスを組み合わせた「英仏対照通時統語コーパス言語学」とでもいうべき研究の可能性を示す発表だった.今や University of Pennsylvania は英語に限らず諸言語のコーパス作成の拠点となっており,あれやこれやと組み合わせるとこんなこともあんなこともできるんだぞというところを見せつけられたとでもいおうか.
ちなみに,取り上げられた話題は英仏の direct object topicalization の歴史で,英語の場合には 1151--1250 年期から 1251--1350 年期にかけて,直接目的語の前置される頻度が一気に減少したという.
2010-03-02 Tue
■ #309. 現代英語の基本語彙100語の起源と割合 [loan_word][lexicology][statistics][pde]
昨日の記事[2010-03-01-1]で,現代英語の最頻英単語リストをいくつか紹介した.そのなかで,やや古いが広く参照されている GSL ( General Service List ) に基づき,最頻100語の語源別の内訳を調べてみた.
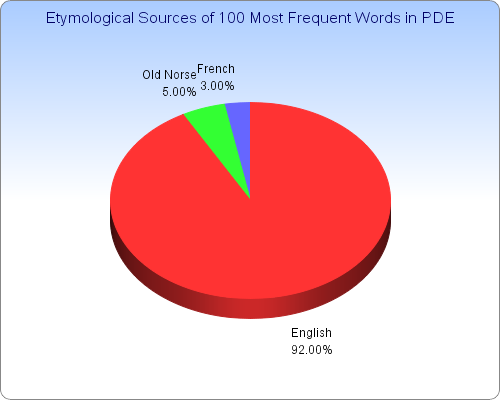
英語の本来語 ( native words ) の一人勝ちであることは一目瞭然である.借用語 ( loan words ) はわずかである.最頻語彙の血は紛れもなく Anglo-Saxon である.
古ノルド語由来の語は they, she, take, get, give の5語のみ.ただし,she の語源にはイングランド北部方言説など諸説がある.また,get と give については,語頭子音 /g/ こそ古ノルド語形に由来すると言ってよいが,対応する語は古英語にもあり,考え方によってはどちらの言語にも帰せられる.ここでは,いずれも古ノルド語由来として数えた.
フランス語由来の語は,state, use, people の3語のみ.
過去の記事でも類似する統計をいくつか載せているので,そちらも要参照.
・ [2009-11-15-1]: 現代英語の基本語彙600語の起源と割合
・ [2009-11-14-1]: 現代英語の借用語の起源と割合 (2)
・ [2009-08-15-1]: 現代英語の借用語の起源と割合
2010-03-01 Mon
■ #308. 現代英語の最頻英単語リスト [lexicology][corpus][link][academic_word_list][alphabet][frequency][statistics][letter_frequency]
現代英語の最頻英単語は何か.この話題についてはコーパス言語学,辞書学,計算機の発展により,様々な頻度表が作られてきた.ウェブ上でも簡単に手に入るので,いくつか代表的なリストや情報源へのリンクを掲げておく.語彙研究に活用したい.
[主要な頻度表]
・ GSL ( General Service List ): 最頻2000語を掲げたリスト.出版が1953年と古いが,現在でも広く参照されているリスト.
・ AWL ( Academic Word List ): 学術テキストに限定した最頻語リスト.2000年に出版され,GSLに含まれる語と重複しないように選ばれた570語を掲載.10のサブリストに分かれている.AWL の前身となる,1984年に出版された808語のリスト UWL ( University Word List ) も参照.
・ BNC Word Frequency Lists: BNC ( The British National Corpus ) による最頻6318語のリスト.頻度表の直接ダウンロードはこちらから.
・ Top 1000 words in UK English: 18人の著者,29作品,460万語のコーパスから抽出したイギリス英語の最頻1000語リスト.
・ Brown Corpus List: Brown Corpus によるアルファベット順リスト.
・ The Longman Defining Vocabulary: LDOCE の1988年版の定義語彙リスト.2000語以上.
[他のリストへのリンク集]
・ Work/Frequency List: 様々な頻度表へのリンク集.(2010/09/10(Fri)現在リンク切れ)
・ Famous Frequency Lists: 様々な頻度表へのリンク集.
・ Basic English and Common Words: ML上の最頻語頻度表についての議論.
[アルファベットの文字の頻度表]
・ Letter Frequencies (rankings for various languages): いくつかのランキング表がある.BNCでは "etaoinsrhldcumfpgwybvkxjqz" の順とある.
(後記 2010/03/07(Sun):American National Corpus に基づいた頻度表を見つけた.Written と Spoken で分別した頻度表もあり.)
(後記 2010/04/12(Mon):COLT: The Bergen Corpus Of London Teenage Language に基づいた最頻1000語のリストを見つけた.)
(後記 2011/02/14(Mon):Corpus of Contemporary American English (COCA) に基づいた Corpus-based word frequency lists, collocates, and n-grams を見つけた.Top 5,000 lemma, Top 500,000 word forms など.)
2026 : 01 02 03 04 05 06 07 08 09 10 11 12
2025 : 01 02 03 04 05 06 07 08 09 10 11 12
2024 : 01 02 03 04 05 06 07 08 09 10 11 12
2023 : 01 02 03 04 05 06 07 08 09 10 11 12
2022 : 01 02 03 04 05 06 07 08 09 10 11 12
2021 : 01 02 03 04 05 06 07 08 09 10 11 12
2020 : 01 02 03 04 05 06 07 08 09 10 11 12
2019 : 01 02 03 04 05 06 07 08 09 10 11 12
2018 : 01 02 03 04 05 06 07 08 09 10 11 12
2017 : 01 02 03 04 05 06 07 08 09 10 11 12
2016 : 01 02 03 04 05 06 07 08 09 10 11 12
2015 : 01 02 03 04 05 06 07 08 09 10 11 12
2014 : 01 02 03 04 05 06 07 08 09 10 11 12
2013 : 01 02 03 04 05 06 07 08 09 10 11 12
2012 : 01 02 03 04 05 06 07 08 09 10 11 12
2011 : 01 02 03 04 05 06 07 08 09 10 11 12
2010 : 01 02 03 04 05 06 07 08 09 10 11 12
2009 : 01 02 03 04 05 06 07 08 09 10 11 12
最終更新時間: 2026-06-26 03:46
Powered by WinChalow1.0rc4 based on chalow