COCA ( Corpus of Contemporary American English ) に基づいた各種語彙リストが Corpus-based word frequency lists, collocates, and n-grams から入手できる.そのなかで最も基本的なリストが,こちらの最頻5000語リストである.列挙されているのは見出し語 ( lemma ) 単位で,順位はコーパスに現われる頻度と分散の関数で計算されている.UCREL CLAWS7 Tagset の品詞コード表に基づいた粗い品詞情報も付与されており,品詞別の頻度などを手軽に分析することができる.
今回は,500語ごとに区切って頻度の高い順にL1からL10までの階級を設け,それぞれの階級における品詞別割合を出した.品詞は開いた語類 ( open class ) を中心とし,noun, verb, adj., adv., others の5区分とした.(数値データはこのページのHTMLソースを参照.)
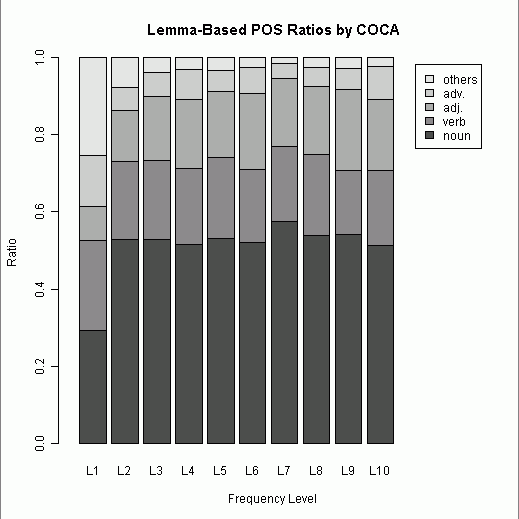
第1階級を除き,どの階級でも名詞が過半数を占めているのは予想できたことだが,第2階級以降に名詞の割合が思ったほど伸びていないことが分かった.動詞と形容詞が後半の階級でもおよそ一定の割合を占め続けているのも予想外だった.全体として,最頻5000語リストに限れば,名詞が飛び抜けつつも,開いた語類の内部比率はおよそ一定に保たれているといえよう.階級幅を様々に動かして試してみたが,およそ安定期に入るのは500語以降と見てよさそうだ.
[2011-02-16-1]の記事で中英語期のフランス借用語の品詞別割合をみたが,全体としての形容詞比率は0.1768だった.今回の現代英語の最頻5000語では,全体としての形容詞比率は0.1678.比べて意味のある数値かどうかは分からないが,英語(言語?)における品詞別比率の「安定感」のようなものはあるのだろうか.
COCA に基づくもの以外にオンラインで入手できる最頻英単語リストについては[2010-03-01-1]の記事を参照.頻度表を利用した別のパイロット・スタディとしては,単語の音節数を扱った[2010-04-17-1]の記事を参照.