2015-09-19 Sat
■ #2336. Text Analyser --- 簡易テキスト統計分析器 [cgi][text_tool][web_service][corpus]
最近では,テキスト分析のための高機能なツールが手軽に入手できるようになった.英語コーパスを分析するプログラムなどでは,使用語数に基づいて様々な統計値が計算され,見やすい形で提示される.そのようなツールを改めて公開する必要もないといえばないが,簡易テキスト統計分析器の CGI を作成してみたので,ここに hellog 版ということで設置しておきたい.テキストボックスに文章を投げ込むだけ.
背後では Perl モジュール Lingua::EN::Fathom を使用しているが,語や文の認識や音節カウントなど,自動では完全解決の難しい問題も多くあるため,結果としての統計値は近似的なものとして理解されたい.今回のバージョンでは,以下の14の統計値を示すことにした.
(1) Number of characters
(2) Number of words (tokens)
(3) Number of types
(4) Type/token ratio
(5) Per cent of complex words
(6) Average syllables per word
(7) Number of sentences
(8) Average words per sentences
(9) Number of text lines
(10) Number of blank lines
(11) Number of paragraphs
(12) Fog index
(13) Flesch reading ease score
(14) Flesch-Kincaid grade level score
多くの統計値の意味は自明と思われるが,いくつかについて注記しておく.(4) Type/token ratio は,語彙の多様性を示す指標である.テキスト内のすべての語が各々1度きり現われる場合には,最大値 1.0 を示す.ただし,テキストの長さに大きく依存するため,この指標単体ではさほど情報量はない.
(5) Per cent of complex words の "complex words" とは,3音節以上の語の割合である.(12), (13), (14) は,テキストの読みやすさの指標であり,いずれも1文あたりの語数 (words_per_sentence) と1語あたりの音節数 (syllables_per_word) に基づいて計算されている.各指標の特徴と解釈の仕方を以下に略述する.
(12) The Fog index
読みやすさを表わす簡便な指標.( words_per_sentence + percent_complex_words ) * 0.4 で求めることができる.指標の数値は学年を表わし,その学年の標準的な生徒であれば,その文章を一度読んで理解できる水準といわれる.目安としては,8 = childish, 10 = acceptable, 12 = ideal, 14 = difficult, 18 = unreadable.
(13) The Flesch reading ease score
206.835 - (1.015 * words_per_sentence) - (84.6 * syllables_per_word) で求められる.最高点は100点で,指標が高ければ高いほど理解しやすいテキストである.60--70点が最適とされる.
(14) Flesch-Kincaid grade level score
(11.8 * syllables_per_word) + (0.39 * words_per_sentence) - 15.59 で求められる.指標は米国の学年を表わし,例えば 8.0 であれば,そのテキストは第8学年の生徒に理解できる水準ということになる.7.0--8.0 が最適値とされる.
2015-09-15 Tue
■ #2332. EEBO のキーワードを抽出 [eebo][lob][corpus][keyword][text_tool][emode]
コーパスからキーワードを拾うという分析を,「#317. 拙著で自分マイニング(キーワード編)」 ([2010-03-10-1]),「#518. Singapore English のキーワードを抽出」 ([2010-09-27-1]),「#880. いかにもイギリス英語,いかにもアメリカ英語の単語」 ([2011-09-24-1]) で紹介してきた.今回は初期近代英語を中心的に扱うテキスト・データベース EEBO (Early English Books Online) より,キーワードを拾ってみたい.
EEBO から個人的に収集した初期近代英語のテキスト集(全11億語以上)に対し,WordSmith の KeyWords 抽出機能を用いた.参照コーパスとしては,現代イギリス英語を代表するものとして LOB コーパスを指定した.本来は参照コーパスのほうがずっと大規模ではなければならないのだが,EEBO が大きすぎるということで,今回は目をつぶっておきたい.狙いは,現代英語と比べて使用頻度の著しく高い初期近代英語の語を拾い出すということである.当時の社会を特徴づける語彙が集まるはずである.
キーワード性を示す指標の高い順に,500語までのリストがたちどころに得られた.いずれも小文字で示す.
[ Top 100 ]
amp, note, god, and, that, hath, them, christ, shall, haue, thou, they, thy, so, all, our, not, their, upon, doth, vnto, of, unto, his, king, yet, or, hee, eacute, vs, ye, him, lord, thee, which, bee, doe, saith, men, onely, but, vpon, be, nor, de, c, gods, by, faith, holy, great, church, your, o, as, selfe, wee, owne, ad, con, est, things, then, such, therefore, himselfe, may, y, to, sin, grace, cause, tis, us, mr, ther, kings, thereof, let, spirit, man, al, vp, yea, any, this, ac, s, pro, ing, com, thus, e, against, forth, re, shew, whom, l, wherein
[ -- 200 ]
loue, ly, selves, scripture, self, law, st, those, thing, cor, sinne, being, glory, euery, death, good, sonne, true, neuer, whereof, iohn, againe, psal, pope, religion, ed, hym, soule, hast, lib, ex, heaven, agrave, whiche, pray, neither, downe, acirc, tion, quod, my, sed, fore, soul, nature, euen, dayes, is, p, apostles, euer, till, feare, chap, ver, rom, vnder, ma, qui, vse, according, giue, power, ouer, mans, egrave, lesse, se, doctrine, ne, ment, meanes, themselues, shal, d, sins, viz, prince, did, vertue, wicked, honour, earth, ut, blessed, princes, ter, apostle, th, persons, que, thinke, same, others, lords, ought, pag, truth, none, kingdome
[ -- 300 ]
tho, si, cap, goe, if, beene, flesh, et, christs, make, fathers, concerning, reason, body, mercy, selues, enemies, bishops, farre, v, bishop, ar, hearts, wil, likewise, other, rome, name, obedience, en, wise, cum, speake, finde, nay, iesus, we, conscience, manner, non, heart, sinnes, it, yt, hauing, saints, generall, mat, contrary, worke, wit, sayd, whereby, covenant, wherefore, gen, passe, poore, lorde, publick, word, mens, suffer, na, heare, mee, ei, heb, divers, christians, therein, theyr, minde, shalt, bloud, shewed, certaine, vers, un, son, amongst, ibid, ca, jesus, betwixt, quae, scriptures, say, divine, thine, rest, countrey, besides, di, heauen, cannot, qu, therfore, godly, sent
[ -- 400 ]
m, moses, these, christian, called, n, vn, false, should, paul, also, discourse, meane, without, booke, whence, shee, emperour, souls, place, thereby, yeares, tyme, lawes, peace, what, dis, behold, foure, citie, giuen, israel, anno, liberty, thence, gospel, cast, ograve, aboue, souldiers, tooke, sa, priests, gaue, fol, maketh, places, pardon, te, warre, saviour, wayes, saint, thinges, will, themselves, kinde, suche, bene, love, salvation, yeare, towne, spirituall, esse, fa, duke, majesty, brethren, laws, alwayes, workes, ab, lest, for, wrath, wordes, soules, done, sunt, angels, vel, ry, liue, ted, ty, looke, repentance, dr, beare, prayer, keepe, faire, ii, parts, helpe, iudge, no, churches, r
[ -- 500 ]
dy, vsed, prophet, outward, ble, ap, spake, sect, armes, notwithstanding, come, h, naturall, maner, crosse, popes, sayth, pa, papists, whatsoever, gospell, iudgement, writ, noble, hoc, par, sacrifice, dye, worship, ons, af, eternal, leaue, ob, euill, am, sacrament, diuers, both, ghost, quam, lye, yee, comming, secondly, how, iustice, sword, daies, father, vi, before, prayers, bodie, whome, councell, nec, though, faithfull, lawe, humane, aut, wel, mi, hir, iii, worthy, isa, easie, ugrave, nowe, lawfull, ere, seene, priest, glorious, serue, commanded, earle, forme, thither, eternall, prophets, turne, iewes, mo, im, halfe, matth, manifest, wilt, are, words, iust, betweene, affections, ocirc, li, ned, creatures
対象としたのは EEBO から収集した平テキストであり,そこには多くの注記やタグも含まれている.それを除去するなどの特別なテキスト処理は施していないので,雑音も相当混じっていることに注意したい.実際,1位の amp はタグの一部であり,2位の note も注記を表わす記号と考えてよいので,いずれも無視すべきだが,ここではキーワード抽出結果をそのまま提示することにした.
現代でも高頻度語ではあるが,初期近代では綴字が異なる hath, haue, doth, hee, vs, bee などが上位に来ることは理解できるだろう.また,現代では古風となっている2人称単数代名詞 thou, thy, thee の顕著なことも理解できる.
おもしろいのは,現在でも現役ではあるが,それほど顕著ではなくなっている語である.例えば,リストの上位にキリスト教的な語が多いことに気づく.200位以内に限ってざっと拾うだけでも,god, christ, gods, faith, holy, church, grace, spirit, loue, scripture, sinne, glory, death, pope, religion, soule, heaven, pray, soul, apostles, vertue, wicked, honour, blessed, apostle などが挙がる.チューダー朝,スチュアート朝ともに,キリスト教に翻弄され続けた時代だったことも関係するだろう.逆にいえば,現代がいかに世俗化したか,ということでもある.
綴字としては,無音の <e> の自由な付加・脱落,<u> と <v> 及び <i> と <j> の混在,shall の顕著な使用,ye の残存などが挙げられるだろう (see 「#373. <u> と <v> の分化 (1)」 ([2010-05-05-1]),「#374. <u> と <v> の分化 (2)」 ([2010-05-06-1]); 「#1650. 文字素としての j の独立」 ([2013-11-02-1])) .また,現在では堅苦しい機能語も多い (ex. upon, vnto, nor, therefore, thereof, whereof) .
2012-03-03 Sat
■ #1041. COCA の "ANALYZE TEXT" [coca][corpus][web_service][academic_word_list][text_tool]
COCA ( Corpus of Contemporary American English ) を運営する Mark Davies 氏が,[2012-01-08-1]の記事「#986. COCA の "WORD AND PHRASE . INFO"」で紹介した機能 (Frequency List) に加え,英文を投げ込むとCOCAベースで各語に関する諸情報を色づけして返してくれるサービス WORD AND PHRASE . INFO, ANALYZE TEXT を公開した.
適当な英文を投げ込むと,各単語が頻度レベルによって色分けされた状態で返される.上位500語までの超高頻度語は青,3,000語までの高頻度語は緑,それ以下の頻度の語は黄色で示されるほか,academic word が赤字として返される.文章内でのそれぞれの割合も示され,その語彙リストを出すことも容易だ.各語はクリッカブルで,クリックすると用例のサンプルが KWIC で右下ペインに表示される.また,左下ペインには類義語が現われる.以下は,昨日の記事「#1040. 通時的変化と共時的変異」 ([2012-03-02-1]) に引用した英文を投げ込んでのスクリーンショット.
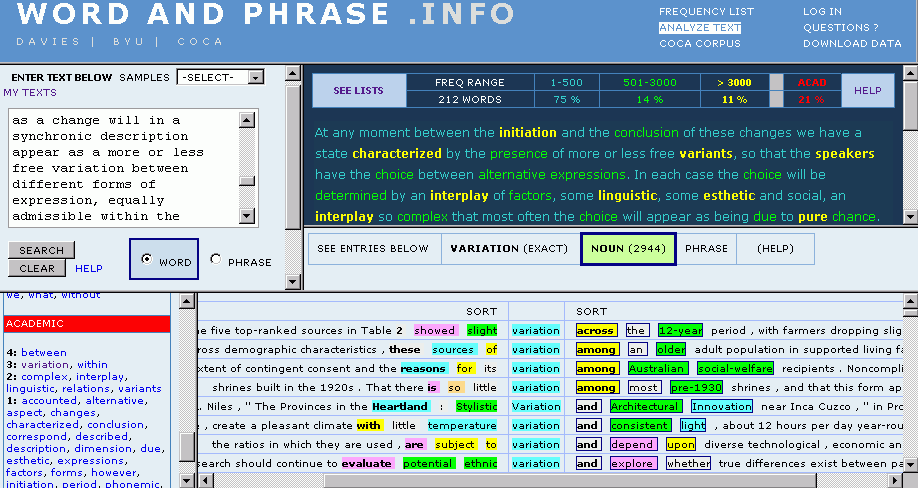
英文を書くときには collocation や synonym を調べながら書くことが多いので,使い方次第では英作文学習に威力を発揮しそうだ.ある文章の academic 度を判定するのにも使える.Academic Word List に含まれる語彙の含有度ということでいえば,[2010-12-30-1]の記事「#612. Academic Word List」で挙げた The AWL Highlighter も類似ツールだ.
2011-09-24 Sat
■ #880. いかにもイギリス英語,いかにもアメリカ英語の単語 [corpus][ame_bre][ame][bre][flob][frown][text_tool][keyword]
道具が揃っていれば簡単に実行でき,しかも結果がとてもおもしろいコーパスの使い方として,キーワード抽出がある.その原理については[2010-03-10-1]の記事「#317. 拙著で自分マイニング(キーワード編)」で概説し,[2010-09-27-1]の記事「#518. Singapore English のキーワードを抽出」でもキーワード抽出の事例を紹介した.
今回はより身近な疑問として,(1) アメリカ英語に対していかにもイギリス英語的な単語は何か,(2) イギリス英語に対していかにもアメリカ英語的な単語は何か,を FLOB と Frown の2コーパスを用いて取り出してみたい(両コーパスについては[2010-06-29-1]の記事「#428. The Brown family of corpora の利用上の注意」を参照).解析のお供は,以前と同様 WordSmith の KeyWords 抽出機能である.
両変種の語彙頻度表を互いに突き合わせ,それぞれキーワード性 (keyness) の高い順に上位500語を取り出した(全リストはこちらのテキストファイルを参照).ここでは,それぞれから上位50語のみを再掲しよう.すべて小文字で示す.
Q. (1) アメリカ英語に対していかにもイギリス英語的な単語は何か?
A. (1) 以下の通り.
cent, which, labour, uk, towards, london, per, centre, was, british, programme, behaviour, it, be, colour, britain, defence, favour, royal, there, been, round, bbc, thatcher, sir, mp, charter, nhs, realised, scottish, yesterday, lord, favourite, local, council, recognised, theatre, mr, being, fviii, tory, kinnock, mps, thalidomide, whilst, scotland, churches, should, programmes, parliament
Q. (2) イギリス英語に対していかにもアメリカ英語的な単語は何か
A. (2) 以下の通り.
percent, toward, program, programs, clinton, u, bush, labor, s, defense, president, american, states, center, washington, formula, federal, behavior, color, united, black, state, fiber, says, zen, americans, ó, california, congress, zach, san, o, white, presidential, pex, jell, women, treaty, favorite, said, bill, gray, colors, perot, favor, douglass, hershey, quayle, j, n
中には,それだけでは意味不明のものもある.BrE の第1位 cent などは何故かと思うかもしれないが,分かち書きをする per cent の2語目が抜き出された結果である.AmE では対応する percent が第1位である.他にも綴字の英米差はよく反映されており,behaviour, centre, colour, defence, favour, favourite, labour, programme(s) は互いのリストに現われる.
英国の政治を特徴づける MP(s), NHS, Parliament, Royal, Scotland, Tory,対応する米国の Congress, Federal, President, State(s), Washington, White (House) などは,なるほどと頷かせる.両コーパスのテキスト年代である1990年代初頭(と少し以前の時期)を特徴づける Thatcher, Bush, Clinton も含まれている.
文法語としては,BrE の which や whilst ([2010-09-17-1]の記事「#508. Dracula に現れる whilst」を参照)が興味深い.
それにしても,それぞれ鼻につくほどの BrE あるいは AmE である.逆に,各変種の汎用コーパスからこのようにして抽出されたキーワードがどれくらい含まれているかによって,小説なり何なりのテキストがいかに BrE 的か AmE 的か,あるいはより中立な "World Standard English" に近いかということを測ることができるかもしれない.
キーワード抽出による「いかにも」シリーズは今後も続きそう.
2010-12-30 Thu
■ #612. Academic Word List [lexicology][lexicography][academic_word_list][web_service][text_tool][elt]
英語教育や辞書学の分野で Academic Word List (AWL) という語彙集が知られている.1998年に Avril Coxhead が The Academic Corpus という350万語からなる独自コーパスをもとに英語教育用に開発した570語とその派生語(合わせて word family と呼ばれる)からなる語彙集で,高等教育で用いられる頻度の高い語からなっている.
もう少し詳しく AWL の語彙選定基準を記せば次のようになる.(1) 各 word family がコーパスの Arts, Commerce, Law, Science 部門のサブセットすべてにおいて生起し,かつ細分化された28分野のサブセットの過半数に生起する.(2) 各 word family の出現頻度がコーパス全体で100回を超える.(3) 各 word family がコーパスの各部門で最低10回は生起する.(4) GSL ( General Service List ) (1953) の最頻2000語は除く ( see [2010-03-02-1] ) . (5) 固有名詞は除く.(6) et al, etc, ibid などの最頻ラテン語表現は除く.
こうして厳選された語彙集が AWL で,AWL Headwords から閲覧およびダウンロードできる.word family の頻度の高い順に1から10の Sublists としてグループ分けされており,すべて合わせるとコーパス全体に生起する語の9.8%を覆うという.
最近の上級者用英英辞書は軒並み AWL の重要性を認識しているようだ.2006年出版の Longman Exams Dictionary を皮切りに,2007年の Longman Advanced American Dictionary, 2nd ed.,2009年 Longman Dictionary of Contemporary English, 5th ed. など売れ筋辞書でも AWL が考慮されている ( Dohi et al., p. 174 ) .Macmillan, Collins COBUILD 系でも同様である.目下の AWL の評価は Dohi et al. によると以下の通りである.
It remains to be seen whether Coxhead's AWL will continue to be used, will be revised or replaced in future advanced learners' dictionaries, because not all scholars concur with her AWL. . . . The AWL could be regarded for the time being as "a quick reference" for academic vocabulary until more research bears fruit . . . . (100)
関連して The AWL Highlighter なるツールがあり,ここに英文テキストを入れると,AWL 語彙をハイライトしてくれる.私が最近書いた英語論文のイントロ部の1235語で試してみたら,Sublist 10 までのレベルで128語がハイライトされた.これは全体の10.36%であり,academic 度は合格か!?
・ Dohi, Kazuo, Tetsuo Osada, Atsuko Shimizu, Yukiyoshi Asada, Rumi Takahashi, and Takashi Kanazashi. "An Analysis of Longman Dictionary of Contemporary English, Fifth Edition." Lexicon 40 (2010): 85--187.
2010-09-27 Mon
■ #518. Singapore English のキーワードを抽出 [text_tool][corpus][flob][ice][singapore_english][keyword]
昨日の記事[2010-09-26-1]で ICE ( International Corpus of English ) からいくつかの英語地域変種コーパスが手に入る旨を紹介したが,そのなかから Singapore English のコーパス ( ICE-SIN ) を少しいじってみた.
[2010-03-10-1]の記事で WordSmith の KeyWords 抽出機能を拙著の英文で試したが,今回は ICE-SIN で同様に試してみるとどうなるだろうかと思った.そこで今回も,1990年代初頭のイギリス英語を対象に編纂された比較可能な FLOB corpus ( see [2010-06-29-1] ) を参照コーパスとし,British English に照らして Singapore English に特徴的な語(=キーワード)を抽出してみた.キーワード性の高い上位20語について,WordSmith に出力された表を掲げよう(上位100語までのリストはこのページのHTMLソースを参照).
| n | word | ice-sin.freq. | ice-sin.lst % | flob.freq. | flob.lst % | keyness |
|---|---|---|---|---|---|---|
| 1 | uh | 8,230 | 0.74 | 8 | 19,246.0 | |
| 2 | you | 18,175 | 1.64 | 7,258 | 0.29 | 17,768.5 |
| 3 | uhm | 3,838 | 0.35 | 0 | 9,021.1 | |
| 4 | ya | 3,580 | 0.32 | 10 | 8,283.9 | |
| 5 | i | 15,166 | 1.37 | 12,230 | 0.49 | 7,051.3 |
| 6 | singapore | 3,041 | 0.27 | 64 | 6,570.0 | |
| 7 | word | 3,490 | 0.32 | 482 | 0.02 | 5,621.8 |
| 8 | know | 4,768 | 0.43 | 1,534 | 0.06 | 5,345.5 |
| 9 | okay | 2,296 | 0.21 | 28 | 5,112.0 | |
| 10 | so | 6,759 | 0.61 | 4,452 | 0.18 | 4,113.8 |
| 11 | lah | 1,747 | 0.16 | 2 | 4,074.4 | |
| 12 | it's | 3,585 | 0.32 | 1,186 | 0.05 | 3,949.9 |
| 13 | your | 3,485 | 0.31 | 1,642 | 0.07 | 2,972.2 |
| 14 | oh | 1,952 | 0.18 | 344 | 0.01 | 2,900.2 |
| 15 | think | 2,761 | 0.25 | 1,208 | 0.05 | 2,501.5 |
| 16 | ah | 1,288 | 0.12 | 142 | 2,204.9 | |
| 17 | we | 5,884 | 0.53 | 5,406 | 0.22 | 2,190.7 |
| 18 | is | 15,022 | 1.36 | 20,588 | 0.83 | 2,027.9 |
| 19 | don't | 2,372 | 0.21 | 1,196 | 0.05 | 1,904.9 |
| 20 | what | 4,635 | 0.42 | 4,072 | 0.16 | 1,865.8 |
上位リストを眺めていたら2つの特徴が浮かんできた.
(1) 当然ながら Singapore English としばしば結びつけられる表現が上位に食い込んでいる.例えば,11位の lah は日本語でいう終助詞「ね」「よ」や間投詞のような働きをする pragmatic marker で,Singapore (and Malaysian) English らしい表現として知られている.しかし,やはり局地的な表現だからか手元の英語辞書にはほとんど掲載されておらず,唯一 Macmillan English Dictionary for Advanced Learners, 2nd ed. で次のような説明があった.
adverb INFORMAL
used by people in Malaysia and Singapore for making something they are saying sound more friendly and informal
例文を挙げるには,ICE-SIN から直接拾ってくると早い.会話文ではもちろんのこと,次のような親しい手紙文でも使われている.
Anyway, life is getting colder here. Hottest degree - 16 degrees celcius, coldest so far is 8oc. Brr..rr!! I'm wearing 3 to 4 layers now, like I did in England. So heavy one lah! Get back ache, you know!
ほかには,Singapore が6位に入っていたり,dollar(s), Chinese, Singaporeans, Malay などが上位100語以内に入っている.
(2) lah の頻度の高さとも関係するが,口語性の高い語,会話で頻出すると考えられる語が目立つ.直示性を表わす人称代名詞や副詞,また語調を和らげる語 ( hedge ) が特に多い.広く語用論的な機能をもつ語群としてまとめてよいかもしれない.もっとも話し言葉と結びつけられるキーワードが多いことは予想されたことではある.書き言葉は標準に準拠しやすく,地域変種間の差が少ないのが普通だからである.とりわけ話し言葉に地域変種の差が出やすいということが,今回のキーワード抽出で確かめられたということだろう.
今回のようなキーワード抽出は,もちろん他の地域変種にも応用できる.参照コーパスをイギリス英語以外に動かして相対的に各変種の特徴をみるというのもおもしろそうだ.
2010-03-10 Wed
■ #317. 拙著で自分マイニング(キーワード編) [text_tool][flob][corpus][keyword]
昨日の記事[2010-03-09-1]に引き続き,拙著 The Development of the Nominal Plural Forms in Early Middle English で自分マイニング.WordSmith には KeyWords 抽出機能がある.単に単語リストを頻度順に並べた昨日のリストでもおよそのテキストの主題を読み取ることは可能だが,上位に機能語などの雑音が大量に入り込み,解釈しにくい.それに対して,キーワードリストでは対象テキストの主題をよく表す実質的なキーワードが上位に来るので,解釈しやすい.
考え方としては以下の通りである.巨大なコーパスなどを参照テキストとして使用し,そこから単語ごとに一般的な頻度を導き出す.次に,対象テキスト内で各単語について頻度を出す.ある語の対象テキスト内での頻度が,参照テキスト内での頻度よりも相当に大きい場合には,それは対象テキストに特有のキーワードとみなせる.そのようなキーワードを自動的に探し出してくれるのが,WordSmith の KeyWords 抽出機能である.拙著はイギリス英語で書いていることもあり,参照テキストとしては FLOB ( Freiburg-LOB corpus ) を使用した.以下,上位50語のキーワードである.
plural, english, s, n, old, nouns, norse, dialect, midland, middle, plurals, dialects, texts, language, forms, text, ending, diffusion, v, south, west, nominative, early, stem, the, spread, linguistic, singular, endings, inflectional, contact, accusative, o, system, weak, in, development, sec, change, fem, dative, morphological, languages, saxon, item, formation, period, transfer, germanic, strong
ずばり来てくれました plural .複数形の研究なのでそうでなければ困るところだ.昨日のリストよりも機能語の雑音がよくはじかれている.
WordSmith には各キーワードのファイル内での出現箇所を視覚的にプロットする機能もあり,上記の50語について以下のようなプロットが得られた.
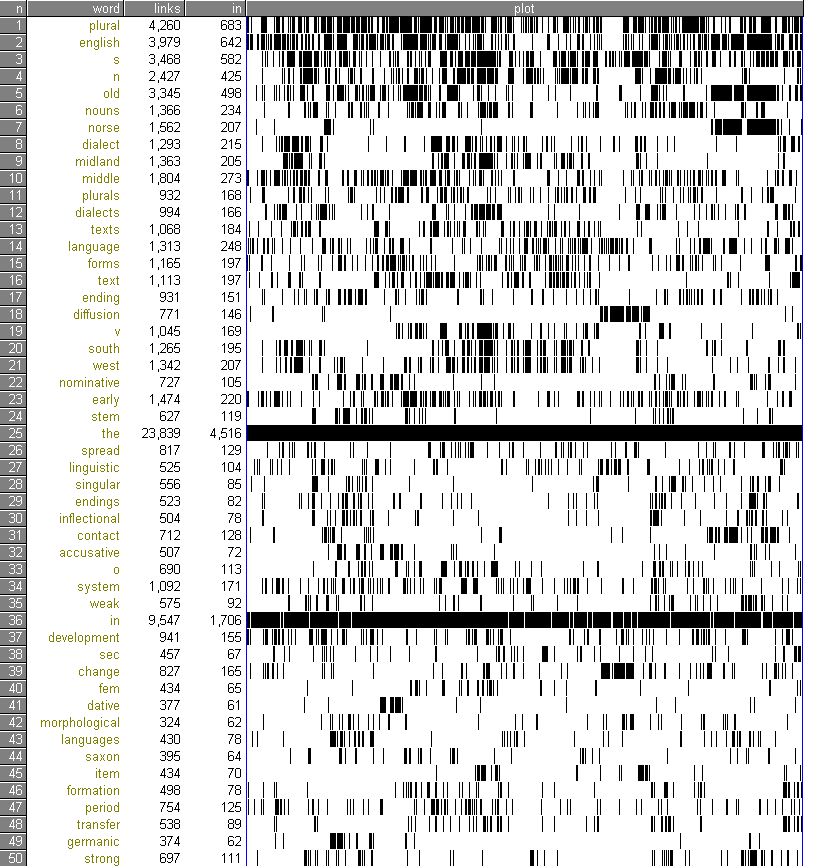
執筆者本人なので,なるほどと思えることが多い.最上位語はテキスト中にまんべんなく現れる傾向があるが,それでも分布が偏っているものもある.7位の norse は Old Norse について論じている7章に固まっているし,18位 diffusion は Lexical Diffusion を集中的に扱っている5章に集中している.
われながらの発見もあった.言語変化を論じているので development と change を多用しているが,執筆中にはそれほど意識して両語を使い分けていたわけではなかった.そうであればまんべんなく分布していそうなものだが,実際には change が5章辺りに偏在している.ということは,無意識のうちに使い分けていたということなのだろうか.無意識の癖とでもいうべきものが発見できておもしろい.
文章をこのように分析することで,実用的な効果がいろいろ考えられそうである.思いつきを記す.
・ 文体の統計を把握することで今後の文章改善に活かす(誰々の文体に近づきたい,ボキャ貧をなおしたい,パラグラフ構成の指針をもちたい,など)
・ 自分の過去の文章と比較し,文体の経年変化を観察する
・ 論文などを書き終えた後でタイトル候補が複数ある場合に,キーワードを参考にして決定する
・ 自分の過去の論文などをひっくるめて分析対象とし,「私の研究テーマは(キーワード)です」と言い切れるようになる
・ 相手の過去の論文などをひっくるめて分析対象とし,「あなたの研究テーマは(キーワード)です」と言い切れるようになる(←おせっかい)
・ 緩やかに関連する二つの論文 A と B を互いに参照テキストとしてそれぞれのキーワードを抽出し,A の特徴と B の特徴を比べる.共通点が多いことを前提としているので,キーワードによって逆に相違点が浮き彫りになる可能性がある.
2010-03-09 Tue
■ #316. 拙著で自分マイニング(文体統計と単語リスト編) [text_tool]
自分で書いた文章をいろいろと分析することを自分マイニングというが,今回は僭越ながら拙著 The Development of the Nominal Plural Forms in Early Middle English の英文を材料にして,自分の英作文の傾向(と対策)を調べてみたい.今回使用したツールは,コーパス研究用に開発された WordSmith Version 3 である.
まず準備として,手元にある拙稿を収めた LaTeX ファイルから図表部や Bibliography 部などをそぎ落とし,おおかた本文だけが含まれるような平テキストを得る.それを WordSmith にかけて,文体に関わる統計値を出してみた.
| Tokens | 58,535 |
| Types | 4,805 |
| Type/Token Ratio | 8.21 |
| Standardised Type/Token | 37.81 |
| Ave. Word Length | 4.88 |
| Sentences | 1,745 |
| Sent.length | 22.49 |
| sd. Sent. Length | 12.36 |
| Paragraphs | 865 |
| Para. length | 67.67 |
| sd. Para. length | 48.26 |
| 1-letter words | 3,239 |
| 2-letter words | 9,619 |
| 3-letter words | 10,771 |
| 4-letter words | 7,996 |
| 5-letter words | 5,657 |
| 6-letter words | 4,938 |
| 7-letter words | 5,220 |
| 8-letter words | 3,747 |
| 9-letter words | 2,594 |
| 10-letter words | 2,043 |
| 11-letter words | 1,224 |
| 12-letter words | 857 |
| 13-letter words | 304 |
| 14(+)-letter words | 203 |
本文は6万語弱 ( tokens ) からなり,使用している単語の種類 ( types ) は lemmatise されていない状態で 5千語弱.平均的な一文の長さは22語ほど.一段落は68語ほど.当然ながら,お手本となる英文の基準統計値がないと,いずれの数値もどう判断してよいかはわからない.いずれ尊敬する研究者や好きな作家の文体と比べてみたい.
次に,WordList を作成.頻度順に並び替えれば拙著の主題が見えてくるはずである.上位50語を小文字化された状態で以下に掲載.
the, of, in, to, and, a, is, plural, as, english, that, s, for, old, was, n, it, be, from, i, this, are, with, by, on, middle, language, but, or, nouns, not, early, dialect, norse, west, midland, were, forms, text, south, texts, more, have, we, system, than, which, an, may, v
大部分は機能語だが,内容語としては plural, english, middle, nouns, early, forms がちゃんと出てきてくれた.ちゃんとというのは,タイトルを構成する単語が上位に出てきてくれないとタイトルの付けかたが悪かったということになりかねないからだ.development は56位,nominal は189位だったが・・・.
Powered by WinChalow1.0rc4 based on chalow