hellog〜英語史ブログ / 2012-05
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
2026 : 01 02 03 04 05 06 07 08 09 10 11 12
2025 : 01 02 03 04 05 06 07 08 09 10 11 12
2024 : 01 02 03 04 05 06 07 08 09 10 11 12
2023 : 01 02 03 04 05 06 07 08 09 10 11 12
2022 : 01 02 03 04 05 06 07 08 09 10 11 12
2021 : 01 02 03 04 05 06 07 08 09 10 11 12
2020 : 01 02 03 04 05 06 07 08 09 10 11 12
2019 : 01 02 03 04 05 06 07 08 09 10 11 12
2018 : 01 02 03 04 05 06 07 08 09 10 11 12
2017 : 01 02 03 04 05 06 07 08 09 10 11 12
2016 : 01 02 03 04 05 06 07 08 09 10 11 12
2015 : 01 02 03 04 05 06 07 08 09 10 11 12
2014 : 01 02 03 04 05 06 07 08 09 10 11 12
2013 : 01 02 03 04 05 06 07 08 09 10 11 12
2012 : 01 02 03 04 05 06 07 08 09 10 11 12
2011 : 01 02 03 04 05 06 07 08 09 10 11 12
2010 : 01 02 03 04 05 06 07 08 09 10 11 12
2009 : 01 02 03 04 05 06 07 08 09 10 11 12
2012-05-31 Thu
■ #1130. gross の母音 [pronunciation][spelling][spelling_pronunciation_gap][etymology][spelling_pronunciation]
Carney (38) によると,gross は,<oss> の綴字で /əʊs/ と発音される唯一の英単語であるという.実際には,語源を同じくする engross も /əʊs/ をもっているが,ともかく他の <oss> をもつ語と一線を画することは確かだ.across, boss, cross, doss, dross, emboss, floss, gloss, goss, kaross, loss, moss, poss, toss などの語は,いずれもイギリス標準発音で /ɒs/ をもつ.
まず gross の語源を調べてみると,古典ラテン語にはなかったが,後のラテン語に grossum "thick, great" が文証される.古フランス語で gros あるいは grosse として現われ,これらの形態が14世紀に英語へ借用された.当初の意味は「大きい」だったが,英語では意味を発達させ,15世紀には「全般的な」や「野卑な」が生じている.
次に,綴字と発音の歴史をざっと調べてみたが,現在の特殊な関係に至った経緯はよく分からなかった.MED では,gros (adj.) の異綴りとして grosse や groce があったと記されており,OED でも同様の記述がある.groce の綴字は長母音を示唆するが,これが Carney (38) の述べているとおり "a common medieval spelling" だったかどうかは,両辞書の例数に基づいて判断するに,疑わしい.しかし,異綴りの存在は,問題の母音に長短の揺れがあったことを示唆する.<oss> の綴字をもつほとんどの語では,母音は短化して落ち着いたが,gross に限ってはどういうわけか長母音が選択され,後に二重母音化したということだろう.
現代英語で Gross! と感嘆すれば「ひどい,最悪」という俗語的表現となるが,中英語での gross の語感も「粗っぽい」という否定的な評価を伴うものだったようだ.顔をしかめながら感情たっぷりに発音する Gross! の母音が長い量になりやすいという事情が,かつてもあったのではないかと考えるのは speculation にすぎないだろうか.
ちなみに,人名としての Gross は,CEPD17 によれば,/grɒs, grəʊs/ の2種類があるという.前者の発音は,かつての母音の長短の揺れを反映しているのだろうか.あるいは,固有名詞としての spelling pronunciation の例と考えるべきだろうか.
・ Carney, Edward. "English Spelling is Kattastroffik." Language Myths. Ed. Laurie Bauer and Peter Trudgill. London: Penguin, 1998. 32--40.
・ Roach, Peter, James Hartman, and Jane Setter, eds. Cambridge English Pronouncing Dictionary. 17th ed. Cambridge: CUP, 2006.
2012-05-30 Wed
■ #1129. 印欧祖語の分岐は紀元前5800--7800年? [indo-european][archaeology][glottochronology][family_tree][lexicology]
印欧祖語の故郷と時代について,「#637. クルガン文化と印欧祖語」 ([2011-01-24-1]) 及び「#1117. 印欧祖語の故地は Anatolia か?」 ([2012-05-18-1]) の記事で,Gimbutas の唱道する Kurgan expansion hypothesis と Renfrew の唱道する Anatolian farming hypothesis をそれぞれ概観した.印欧祖語の分岐の時期について,前者は紀元前4千年紀,後者は紀元前6000--7500年に遡るとしており,深く対立している.
昨日の記事「#1128. glottochronology」 ([2012-05-29-1]) で触れたように,統計手法を用いた語彙研究を比較言語学へ応用する試みは様々な批判を受けてきた.しかし,語彙統計学者はその批判をエネルギーに替えて,次々と高度な手法を編み出してきた.近年では,Gray and Atkinson が,印欧語族の87言語について2449語を対象に,進化生物学のモデルに基づいて計算した例がある.
統計に当たっては常にそうであるように,何が前提とされているかが重要である.Gray and Atkinson の研究でも非常に多くの条件や情報が前提とされており,議論と結論を正しく評価するためには,そのいちいちの前提が妥当かどうかを確認してゆく必要がある.とりわけ,生物学の手法がそのまま比較言語学に応用できるのかどうか,生物と言語の類似点と相違点は何かという本質的な問題を論じる必要があるだろう([2011-07-13-1]の記事「#807. 言語系統図と生物系統図の類似点と相違点」を参照).以上の問題が山積しており,私には Gray and Atkinson の研究を適切に評価することはできないが,結論が興味深いので,少なくとも紹介するには値する.以下に,Gray and Atkinson の得た,分岐年代入りの印欧語系統樹を再掲しよう (437) .
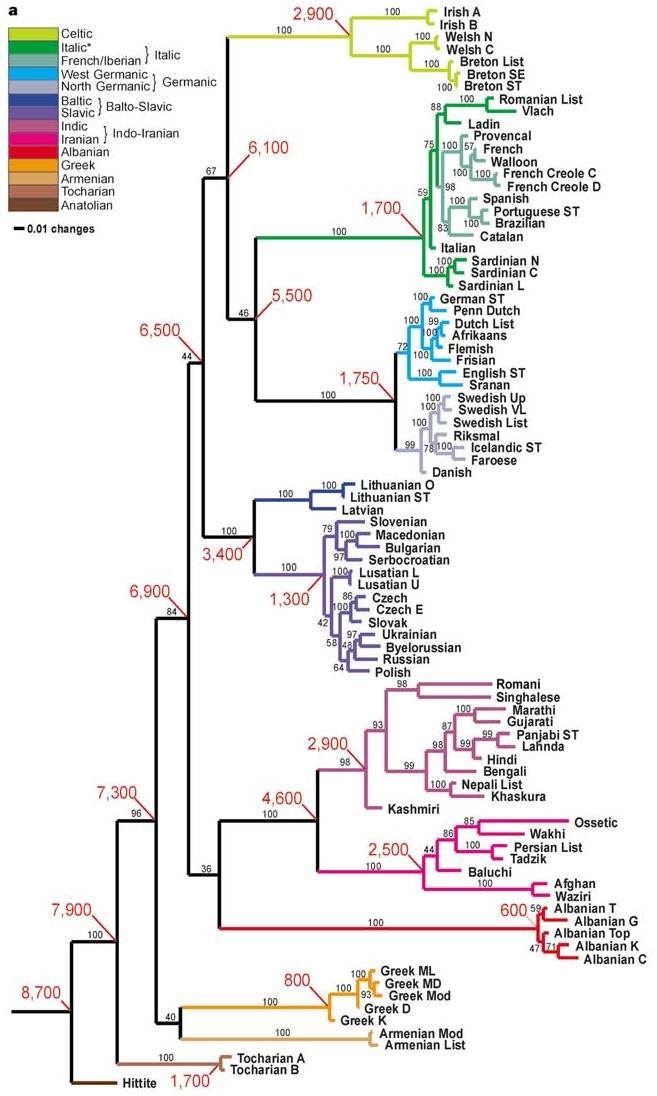
この図によると,印欧祖語が Hittite とその他の語群へ2分割したのは8700BP(=6700BC).Anatolia から農業が伝播し始めた時期に相当すると解釈できる.おもしろいのは,Italic, Celtic, Balto-Slavic そしておそらくは Indo-Iranian も含め,主立った語派が急速に分化してゆく時期が,紀元前5--4千年紀に観察されることだ.これは,時期的には Kurgan expansion hypothesis と符合する.とすると,両仮説は対立するものではなく,むしろ補完するものとも捉えられる (Gray and Atkinson 438) .
先にも述べたように,この結論を正しく評価できる立場にはない.しかし,進化生物学の知見を活かして語彙統計学の新手法を開発するというように,他分野と連係して学際的な難問に挑む試みはエキサイティングである.
・ Gray, Russell D. and Quentin D. Atkinson. "Language-Tree Divergence Times Support the Anatolian Theory of Indo-European Origin." Nature 426 (November 2003): 435--39.
2012-05-29 Tue
■ #1128. glottochronology [glottochronology][history_of_linguistics][family_tree][lexicology]
glottochronology (言語年代学)は,アメリカの言語学者 Morris Swadesh (1909--67) および Robert Lees (1922--65) によって1940年代に開かれた通時言語学の1分野である.その手法は lexicostatistics (語彙統計学)と呼ばれる.
人類言語学の知見によれば,人類文化の基礎的範疇を表わす語彙 (basic vocabulary) は言語間で共有されており,歴史的変化や外部からの影響を最も受けにくい単語群とされる.しかし,長期的にみれば,これらの基礎語彙もいずれ置換されてゆくものである.複数の関連する言語の間で共有されていた基礎的な同根語 (cognate) が,各言語において一定のゆっくりとした速度で非同根語に置換されてゆくこと (a constant rate of loss) を前提とし,それらの言語が互いに分岐した年代や速度を測ろうとするものが,glottochronology である.明らかに考古学の年代測定法にヒントを得ている.
glottochronology は上記のものを含む多くの前提の上に成り立っているが,そのいずれの前提もが激しく批判にさらされてきた.論争とされてきたのは次のような点である.
(1) Swadesh の基礎語彙 (basic vocabulary) 100語(以下に掲載)は,歴史や文化といった社会的な要因による変化を被りにくい語彙として選定されているが,これらは本当に特定の文化に依存しないと言い切れるのか.例えば,sun や moon は,文化によっては宗教的な意味を付されており,その意味において文化語ではないか.
I, you, we, this, that, who, what, not, all, many, one, two, big, long, small, woman, man, person, fish, bird, dog, louse, tree, seed, leaf, root, bark, skin, flesh, blood, bone, grease, egg, horn, tail, feather, hair, head, ear, eye, nose, mouth, tooth, tongue, claw, foot, knee, hand, belly, neck, breasts, heart, liver, drink, eat, bite, see, hear, know, sleep, die, kill, swim, fly, walk, come, lie, sit, stand, give, say, sun, moon, star, water, rain, stone, sand, earth, cloud, smoke, fire, ash, burn, path, mountain, red, green, yellow, white, black, night, hot, cold, full, new, good, round, dry, name
(2) 年代測定のための "a constant rate of loss" はすべての言語で同じであると前提できるのか.分岐して1000年たった2言語では86%の基礎語彙がいまだ共有されているといわれるが,分岐の歴史が先に分かっている多くの言語で検証すると,この率が当てはまらないケースもある.もし基礎語彙の分析について少数であったとしても誤りがあれば,この率に基づいて計算される年代は,古く溯れば溯るほど,大きな誤差を伴うことになる.
なお,以下のグラフは,2言語で共有されている基礎語彙のパーセンテージによって,分岐が少なくとも何世紀前にあったかが分かるという,glottochronology の理論的なツールである.例えば,2言語間で7割の基礎語彙が共有されていれば,その分岐の年代は少なくとも約1200年前であり,3割しか共有されていなければ,分岐年代は少なくとも約4000年前である.
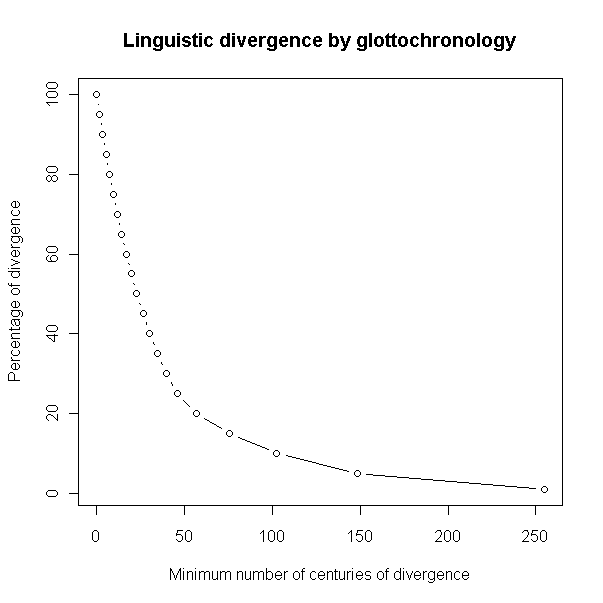
(3) cognate の同定に関わる多くの問題がある.異なる言語からの対応するとおぼしき2つの語が cognates であると言えるためには,音声的,意味的にどのような条件が必要だろうか.2語の関係が cognates ではなく loanwords であるという可能性が常にあるのではないか.これは比較言語学でも共有されている問題だが,時代を遡れば遡るほど,判別は難しい.また,古い言語では,基礎語彙のすべての語が文証されるわけではなく,言語間比較に証拠の穴が生じてしまうことがある.
glottochronology は,言語学史上,興味深い一幕を演出してくれたものの,その理論的妥当性は,現在では,ほとんどの言語学者によって疑われている.
以上,Crystal (333) などを参照して執筆した.
・ Crystal, David. The Cambridge Encyclopedia of Language. 2nd ed. Cambridge: CUP, 1997.
2012-05-28 Mon
■ #1127. なぜ thou ではなく you が一般化したか? [pragmatics][personal_pronoun][honorific][t/v_distinction]
昨日の記事[2012-05-27-1]では「#1126. ヨーロッパの主要言語における T/V distinction の起源」を概説し,T/V distinction に関するかつての記事へのリンクを張った.英語における T/V distinction の最大の問題の1つとして,近代英語期以後に親称 thou と敬称 you の対立が解消される際に,なぜ thou ではなく you のほうが一般化したのかという問題がある.T/V distinction の解消については,初期近代英語期の社会に平等主義の潮流が生じてきたとする説があるが,仮にそれを受け入れるとしても,なぜ thou の方向ではなく you の方向へ解消したのかは不明である.平等主義が "power semantics" に基づく T/V distinction の排除を促したと考えるのであれば,"power semantics" を体現する you こそが切り捨てられて然るべきではないか.加えて,thou こそが古英語以来の純正の2人称単数代名詞であり,単数の「あなた」を表わすにはふさわしいはずである.実際に,人民の平等を目指したフランス革命期には,上流階級の頻用する vous は忌避され,tu が汎用の2人称単数代名詞として好まれた事実がある (Brown and Gilman 264--65) .
英語が you を一般化させた背景には,ある社会言語学的状況が関与していたのではないかという説がある.1650年代にイングランドの聖職者 George Fox (1624--91) が創始したキリスト教の一派フレンズ会 (The Society of Friends) の信徒たち(俗称 Quakers)は,習慣的に,互いに thou を用い合った.神の前には,信徒に上下はなく,みな平等であるという思想に基づいている.この点では,上述のフランス革命期の tu の一般化と軌を一にしていたことになる.現在でも多くのクエーカー教徒たちは thou や thee を用いており,なかには仲間内では thou を,外部の人々に対しては you を使い分ける者もいる.
さて,クエーカー教徒や,同じく平等主義を掲げるより急進的な水平派 (Leveller) は,社会の中では少数派であり,敵意をもって見られることもあった.そこで,多数派の社会は,クエーカー教徒たちの標榜する平等主義の象徴ともいえる特徴的な thou 使用を煙たがり,自らはそれを忌避したのではないか.social distancing の作用が働いて thou が消えていったとするこの説は,しばしば英語史概説書でも説かれるが,定説として受け入れられているわけではなく,1つの可能性として提示されていることに注意しておきたい.
Brown and Gilman (266) が合わせて触れているもう1つの要因として,"a general trend in English toward simplified verbal inflection" がある.[2010-02-12-1]の記事「#291. 二人称代名詞 thou の消失の動詞語尾への影響」では,「thou の消失が,英語の屈折衰退の流れに一押しを加えた」としたが,もしかすると因果関係は逆かもしれないということになる.動詞の屈折衰退の流れが2人称単数現在の屈折語尾 -(e)st にまで及び,その衰退とともに,対応する人称代名詞 thou も衰退した,という筋書きかもしれない.
いずれにせよ,標題の問いに対する定説といえるような答えは,いまだ提案されていない.2人称代名詞の you への一本化の問題は,英語史上の大きな課題である.
(後記 2013/06/30(Sun):solidarity を表わすのにフランス革命では上述のように T を双方向で用いたが,ロシア革命では V を双方向で用いたということが,Wardhaugh, Ronald. An Introduction to Sociolinguistics. 6th ed. Malden: Blackwell, 2010. p. 208 に書かれていた.)
・ Brown, R. W. and A. Gilman. "The Pronouns of Power and Solidarity." Style in Language. Ed. Thomas A. Sebeok. Cambridge, Mass.: MIT P, 1960. 253--76.
2012-05-27 Sun
■ #1126. ヨーロッパの主要言語における T/V distinction の起源 [pragmatics][personal_pronoun][honorific][latin][history][iconicity][t/v_distinction][solidarity]
[2012-03-21-1]の記事「#1059. 権力重視から仲間意識重視へ推移してきた T/V distinction」で Brown and Gilman の画期的な研究を間接的に紹介した.Brown and Gilman の論文には,ヨーロッパの主要な言語で T/V の区別が生じてきた経緯,諸言語間の用法の比較,英語での区別の喪失とその語用的な残滓などに至る話題がちりばめられており,非常に刺激的な論考である.
なぜヨーロッパの主要な言語で,2人称代名詞における T/V distinction の用法が共有されているのか.T/V distinction の起源についてはいくつかの説があるが,Brown and Gilman (255) による記述に従えば次のようになる.
古代のラテン語では,2人称単数を示す代名詞として tu のみが用いられていた.しかし,4世紀に,ローマ皇帝を指す代名詞として,対応する複数形 vos が特別に用いられるようになった.これには諸説あるが,当時,Constantinople とRome のそれぞれに皇帝がおり,皇帝は文字通り複数だったことが関与しているといわれる.Diocletian 皇帝の改革により,ローマ皇帝の座には2人が占めていたが,行政的には1つに統合されることになった.いずれかの皇帝に呼びかけることは,含みとして,2人の皇帝に呼びかけることと同じとされたのである.vos の使用は,この含みとしての複数性を反映しているといわれる.
また,別の説によれば,1人の皇帝が複数形と結びつけられたのは,統治される帝国民の統合と考えられたからではないか.イギリス君主が "royal we" を用いるのと同じ理屈で,ローマ皇帝は自らを指して nos と言ったのであり,それに対応して vos で呼びかけられたのだろう.もう1つの考え方として,指示対象が単数か複数かという文字通りの数とは別に,偉大な権力はそもそも複数性を喚起しやすいということがある.偉大であることと複数性は,iconicity により容易に結びつけられそうだ.
以上の説のいずれか,あるいは組み合わせにより,2人称複数形で1人の皇帝を指し示す慣用が発達した.やがて,この慣用は,皇帝のみならず権力者一般に適用されるようになった.ただし,その後発達したロマンス諸語においては,T/V distinction はそれほど体系的に守られていたわけではなく,数世紀の間,用法の揺れがみられた.言語間で時期に差はあるが,およそ12--14世紀に,"power semantics" に基づく体系的な T/V distinction が確立した.
英語へは中英語の時代に you と thou の区別が導入された.関連記事としては,以下の記事,あるいは personal_pronoun pragmatics 辺りを参照.
[2009-10-11-1]: #167. 世界の言語の T/V distinction
[2009-10-29-1]: #185. 英語史とドイツ語史における T/V distinction
[2010-02-12-1]: #291. 二人称代名詞 thou の消失の動詞語尾への影響
[2010-07-11-1]: #440. 現代に残る敬称の you
[2011-03-01-1]: #673. Burnley's you and thou
[2011-07-06-1]: #800. you による ye の置換と phonaesthesia
[2012-02-24-1]: #1033. 日本語の敬語とヨーロッパ諸語の T/V distinction
[2012-03-21-1]: #1059. 権力重視から仲間意識重視へ推移してきた T/V distinction
・ Brown, R. W. and A. Gilman. "The Pronouns of Power and Solidarity." Style in Language. Ed. Thomas A. Sebeok. Cambridge, Mass.: MIT P, 1960. 253--76.
2012-05-26 Sat
■ #1125. Chaucer による humility の美徳 [chaucer]
昨日の記事[2012-05-25-1]で,印欧祖語 *dhghem- から拡がる単語ネットワークを一覧した.human (人間)とは humus (腐植土)を這う humble (謙虚な)生き物ということになる.humility (謙虚,謙遜)といえば,すぐれて東洋的な美徳と考えられがちだが,当然ながら,西洋にもキリスト教にもとづいた humility を重んじる思想はある.Chaucer の The Parson's Tale (ll. 474--82) の説教を和訳つきで引用しよう(Riverside版および笹本訳より).
Now sith that so is that ye han understonde what is Pride, and whiche been the speces of it, and whennes Pride sourdeth and spryngeth,
now shul ye understonde which is the remedie agayns the synne of Pride; and that is humylitee, or mekenesse.
That is a vertu thurgh which a man hath verray knoweleche of hymself, and holdeth of hymself no pris ne deyntee, as in regard of his desertes, considerynge evere his freletee.
Now been ther three maneres of humylitee: as humylitee in herte; another humylitee is in his mouth; the thridde in his werkes.
The humilitee in herte is in foure maneres. That oon is whan a man holdeth hymself as noght worth biforn God of hevene. Another is whan he ne despiseth noon oother man.
The thridde is whan he rekketh nat, though men holde hym noght worth. The ferthe is whan he nys nat sory of his humiliacioun.
Also the humilitee of mouth is in foure thynges: in attempree speche, and in humblesse of speche, and whan he biknoweth with his owene mouth that he is swich as hym thynketh that he is in his herte. Another is whan he preiseth the bountee of another man, and nothyng therof amenuseth.
Humilitee eek in werkes is in foure maneres. The firste is whan he putteth othere men biforn hym. The seconde is to chese the loweste place over al. The thridde is gladly to assente to good conseil.
The ferthe is to stonde gladly to the award of his sovereyns, or of hym that is in hyer degree. Certein, this is a greet werk of humylitee.
さて,みなさんは何が〈傲慢〉であるか,どれがその類のものか,どこから〈傲慢〉は生じ,生まれるのかを理解したでしょうから,/今度はどれが〈傲慢〉の罪に対する救済策であるのかを理解すべきです,それは謙遜と温和なのです./それは,自分自信についての真の知識をもち,常に自分の欠点を考え,自分の長所に関しては,自惚れず威厳を持たない徳であります./さて,謙遜には三種類あります,一つは心の謙遜,もう一つは言葉の謙遜,三つ目は行為の謙遜です./心の謙遜には四種類あります.一つは天の神の前で自分自信価値がないものと思うことです.もう一つは他人を蔑まないことです./三つ目は人々が価値がない人だと思っていても,一向に気にしないことです.四つ目は屈辱を悲しまないことです./言葉の謙遜も四つあります.穏やかな言葉遣い,言葉のへりくだり,心の中で思っているとおりの人であることを自分の言葉で認めること,もう一つは他人のすばらしさを称え,それを少しも下げないことです./行為の謙遜も四種類あります.第一は他人を先に立てることであります.第二は最も下座を選ぶことであります.三つ目は良い意見に喜んで同意することであります./四つ目は支配者たち,あるいはより高い地位にいる人の決定に喜んで従うことであります.確かに,これは謙遜の大きな行為です.
いかにも parson(教区主任司祭)らしい説教である.humility, humiliation, humblesse のほかにも,meekness, not worth, attemper, lowest のような類義のキーワードが続き,印欧祖語 *dhghem- の道徳的な方面への意味の広がりを味わうことができる.
・ 笹本 長敬 訳 『カンタベリー物語(全訳)』 英宝社,2002年.
2012-05-25 Fri
■ #1124. 地を這う賤しくも謙虚な人間 [etymology][folk_etymology][loan_word][cognate][word_family]
印欧祖語で "earth" を意味する *dhghem- の派生語はおびただしい.天の神に対する,地の「人間」 (L homo) ,地は低きものという連想による「低い,賤しい,謙遜な」 (L humilis) 辺りを基本として,*dhghem- 単語群が生まれ,様々な経路で現代英語の語彙にも入り込んでいる.
ラテン語あるいは他のロマンス諸語から借用したものは,もっとも数が多い.対応する形態素の子音は h または h の脱落した無音である.ex. bonhomie, exhumation, exhume, homage, hombre, homicide, Hominidae, hominoid, homo, Homo sapiens, homunculus, human, humane, humane, humanism, humanist, humanistic, humanitarian, humanitarianism, humanities, humanity, humanization, humanize, humankind, humanly, humble, humbly, humiliate, humiliating, humiliation, humility, humility, humus, inhume, ombre, omerta, transhumance.
ギリシア語に由来するものは,形態素の頭の子音が /kh/ <ch> となっている(ただし,ラテン語を経由して g のものもある).ex. autochthon, chamae-, chamaephyte, chameleon, chamomile, chthonic, germander.
次に,土壌に関する専門用語 chernozem (チェルノーゼム,黒土), sierozem (シーロゼム,灰色土),また zemstvo (ゼムストボオ,帝政ロシアの地方自治体機関)は,対応する古ロシア語の z をもつ形態素から派生した語を借用したものである.同じく z をもつ zamindar (徴税請負人)はペルシア語からである.
最後に,英語本来語に遡れるものとしては bridegroom の第2要素がある.この語は,[2011-09-29-1]の記事「#885. Algeo の新語ソースの分類 (3)」の 50 で,folk_etymology (民間語源)の例として挙げられているもので,*dhghem- と直接の語源的関係はないが,間接的には関わっている.古英語で「人」を表わす語は様々あったが,その1つに *dhghem- に由来する guma があった.これと brȳd (花嫁)が合わさって複合語 brȳdguma (花嫁の人(男)=花婿)が古英語から用いられていた.他のゲルマン諸語にも,オランダ語 bruidegom,ドイツ語 Bräutigam,古ノルド語 brúðgumi などの同根語が確認される.この古英語形は,中英語へも bridgome などの形で受け継がれたが,15世紀には一旦廃れた.代わりに, bride が花嫁のみならず花婿も表わす語として用いられるようになった.そして,16世紀になって聖書のなかで bridegroom が突如として初出する.これが,後続の聖書や Shakespeare に継承され定着した.
15世紀に語源的な bridgome が消えて,16世紀に bridegroom が生じた経緯については不明な点が多い.第2要素 -gome が音声的な類似および意味の適合(groom は「若者」を意味した)から -groom に置換されたという一種の民間語源説が有力だが,bride が一時単独で「花婿」を表わした事実を考えると,-gome と -groom の置換ではなく,bride (花婿)と groom (若者)が新しく複合したのではないかという説もある.
本記事の内容と類似した語根ネットワークの話題については,[2012-03-05-1]の記事「#1043. mind の語根ネットワーク」も参照.
・ Watkins, Calvert, ed. The American Heritage Dictionary of Indo-European Roots. 2nd Rev. ed. Boston: Houghton Mifflin, 2000.
2012-05-24 Thu
■ #1123. 言語変化の原因と歴史言語学 [language_change][causation][prediction_of_language_change][historiography]
言語変化の原因はどこまで探ることができるのか,あるいはそもそも探ることができるものなのかどうか.これは,歴史言語学の本質的な疑問であり,本ブログでも causation の各記事で間接的に話題にしてきた.また,かつての言語変化の原因の解明は,今後の言語変化の予測可能性という問題にも関係するが,その議論は prediction_of_language_change で取り上げてきた.今回は,言語変化の原因を探ることに消極的な学者と積極的な学者の意見をそれぞれ紹介したい.前者を表明する Postal (283) は,言語変化は fashion であり,ランダムだという意見である.
. . . there is no more reason for languages to change than there is for automobiles to add fins one year and remove them the next, for jackets to have three buttons one year and two the next.
Postal によれば,言語変化の原因は探ることができないものであり,探ってもしかたのないものである.一方で,Smith はこの考え方を批判している.個々の言語変化の原因は究極的には解明できないかもしれないが,一般論として言語変化の原因は議論できるはずである.そして,歴史言語学が原因を探ることをやめてしまえば,ただの年表作成に終始してしまうだろうと,反論を繰り広げる.Smith より,2カ所を引用しよう.
. . . it is held here that an adequate history of English must attempt at least to take account of the 'why' as well as the 'how' of the changes the language has undergone; problems of causation must therefore be confronted in any historical account, however provisional the resulting explanations might be. (12)
Although it is not possible, given the limitations of the evidence, to offer absolute proof as to the motivation of a particular linguistic innovation, or to predict the precise development of linguistic phenomena, nevertheless a rationally arguable historical explanation can be offered for the kinds of changes which languages can undergo, and a broad prediction can be made about the kinds of change which are liable to happen. This seems a reasonable goal for any historical enquiry which seeks to go beyond the simple chronicle. (194)
Smith は,言語変化は言語内的および言語外的な複数の原因(あるいは条件的要素)が複雑に組み合わさって生じるという認識であり,それを積極的に探り,論じるのが歴史言語学者の仕事だと確信している.言語変化の予測 (prediction_of_language_change) にまで踏み込む言及があり,これには異論もあるに違いないが,私は概ね Smith の意見に賛成である.なお,Smith 先生は私の恩師です.
・ Postal, P. Aspects of Phonological Theory. New York: Harper & Row, 1968.
・ Smith, Jeremy J. An Historical Study of English: Function, Form and Change. London: Routledge, 1996.
2012-05-23 Wed
■ #1122. 協調の原理 [pragmatics][implicature][cooperative_principle][philosophy_of_language][tautology]
協調の原理 (cooperative principle) とは,哲学者 H. Paul Grice (1912?--88) によって提案された会話分析の用語で,会話において正しく効果的な伝達を成り立たせるために,話し手と聞き手がともに暗黙のうちに守っているとされる一般原則を指す.会話の含意 (conversational implicature) ,すなわち言外の意味が,なぜ適切に理解されるのかという問題にも関わる原則で,近年の語用論の発展の大きな拠り所となっている.Huang (25) に掲載されている "Grice's theory of conversational implicature" を示す.
Grice's theory of conversational implicature
a. The co-operative principle
Make your conversational contribution such as is required, at the state at which it occurs, by the accepted purpose or direction of the talk exchange in which you are engaged.
b. The maxims of conversation
Quality: Try to make your contribution one that is true.
(i) Do not say what you believe to be false.
(ii) Do not say that for which you lack adequate evidence.
Quantity:
(i) make your contribution as informative as is required (for the current purposes of the exchange).
(ii) Do not make your contribution more informative than is required.
Relation: Be relevant.
Manner: Be perspicuous.
(i) Avoid obscurity of expression.
(ii) Avoid ambiguity.
(iii) Be brief (avoid unnecessary prolixity).
(iv) Be orderly.
協調の原理は,4つの公理 (maxim) を履行することによって遵守されると言われる.その4つとは,質の公理,量の公理,関係の公理,様態の公理である.聞き手は,話し手が会話において協力的であること,上記の原則と公理を守っていることを前提として,話し手の発話を解釈する.例えば,話し手 A の "How is that hamburger?" という疑問に対して聞き手 B が "A hamburger is a hamburger." と答えたとする.B の発話はそれ自体では同語反復であり情報量はゼロだが,A は B が協調の原理を守っているとの前提のもとで B の言外の意味(会話の含意)を読み取ろうとする.協調の原理のもとでは,B は A の質問に対して relevant な答えを返しているはずであるから,A はその返答を「そのハンバーガーはごく平凡なハンバーガーであり,それ以上でも以下でもない」などと解釈することになる.この会話が有意味なものとして成り立つためには,A による会話の含意の読み取りが必要であり,読み取るに当たっては B が協力的であるという前提が必要である.この前提は事前に両者で申し合わせたものではなく,あくまで暗黙の了解であるから,これは会話の一般原則として仮定する必要がある,ということになる.
・ Huang, Yan. Pragmatics. Oxford: OUP, 2007.
2012-05-22 Tue
■ #1121. Grimm's Law はなぜ生じたか? [grimms_law][consonant][phonetics][germanic][sgcs][substratum_theory][causation]
標題の問題は,[2011-02-06-1]の記事「#650. アルメニア語とグリムの法則」で取り上げたが,そこで解説した基層言語影響説 (substratum theory) に対しては異論もある.今回は Grimm's Law の原因,より一般的にはゲルマン諸語に見られる子音推移の原因についての他説を紹介したい.
substratum theory に先だって提案されていた古典的な説によれば,ゲルマン語派に特徴的な子音推移は,主として山がちの地帯で生じており,山地の気候が強い帯気の調音を促すものとされた.この説は1901年に Meyer-Benfey によって主張されたものであり (Collitz 180) ,問題の推移が本質的に aspiration の程度の変化であると考えていた Grimm にとっても親しみやすかったかもしれない.
その後,1910年代に,Feist や Kauffmann などにより,"ethnological grounds" の仮説,すなわち現在でいう基層言語影響説が唱えられ出した (Collitz 181) .[2011-09-01-1]の記事「#857. ゲルマン語族の最大の特徴」で触れた通り,Meillet もその名著のなかで同仮説を支持している.
一方,Collitz は2つの説を批判している.まず,基層言語影響説を採らない理由としては,基層言語に,ゲルマン子音推移後の対応する子音がすべて先に揃っていたと仮定するのは難があることを挙げている.そうでないとすれば,基層言語が aspiration の程度についてある種の循環傾向をもっていたと考える必要があり,その循環傾向はなぜあるのかという問題に舞い戻ってくることになる.基層言語影響説は,問題の本質に触れていないというわけである (181--82) .
Collitz はどちらかといえば山地帯気説を支持している.というのは,Second Germanic Consonant Shift ([2010-06-06-1]) の地理的な分布を観察すると,アルプス,南ドイツ,中央ドイツ,北ドイツと北進するにつれて推移の完遂度が低くなっているという事実があるからだ.また,Meyer-Benfey が述べているように,同様の子音推移を経た Armenian やアフリカ Bantu 諸語でも,その舞台は山地に限定されていたという共通点もある.
しかし,Collitz は山地の帯気傾向のみが原因であるとは考えていない.第3の説とでもいうべきものとして,aspiration を減じる方向への一般的な調音傾向を土台としながらも,様々な方向への変化を可能ならしめる言語における "fashion" の働きが関与しているという説を提案している (183) .調音を緩めて "increased refinement" を得ようとするのが通常の発達だが,"fashion" の働きが関与すれば,その限りではなく,調音を強める方向の発達もあり得る,とするものだ.
. . . the phenomena generally designated by the term of Grimm's Law are plainly the outcome of a tendency towards vigorous articulation, the impression of vigor being effected partly by using an abundant amount of breath, partly by adding to the muscular effort. . . . It will readily be seen that, while the mountain climate may favor the tendency toward energetic articulation, it cannot be maintained that either one of the two modes of articulation is dependent exclusively on climatic conditions. (183)
しかし,fashion 説を認めとにしても,ある fashion がなぜその時その場所で生じたのかを探るのが,原因論ではないか.言語変化の原因を fashion や気まぐれに求める議論は古くよりあるが,これを採用すると常に議論はそこで止まってしまう.もう一歩先に進めないものか.
・ Collitz, Hermann. "A Century of Grimm's Law." Language 2 (1926): 174--83.
2012-05-21 Mon
■ #1120. Collitz による Grimm's Law の再解釈 [grimms_law][verners_law][sgcs][consonant][phonetics][germanic][aspiration]
昨日の記事「#1119. Rask's Law でなく Grimm's Law と呼ばれる理由」 ([2012-05-20-1]) で,Grimm's Law が法則と呼ばれる所以を Collitz に拠って示した.Collitz は Grimm の成果を賞賛してはいるが,Grimm's Law の問題点をも指摘している.Grimm's Law と,その音韻変化を延長させたとされる Second Germanic Consonant Shift ([2010-06-06-1]) とを合わせて考えると,media, tenuis, aspirate がこの順序で,一定の間隔を保ちながら循環するという図式は,必ずしも守られていないことがわかる.確かに,Grimm's Law に関連する Verner's Law なり,他のゲルマン諸語や方言における子音変化なりを見比べると,子音変化が循環する速度や角度は,それぞれのケースでまちまちである.むしろ,遅延があり,複雑で,むらのある循環変化ととらえるほうが自然ではないか.
Collitz (178) は,この問題を解決するために,media, tenuis, aspirate の3種のほかに,中間段階の子音を3種加え,循環の輪をきめ細かにつないだ.

さらに,Collitz (178--80) は,定説とされている印欧祖語の有声帯気音系列を,Prokosch の唱える通り,(4) の無声摩擦音系列とみるべきではないかという説を主張している.
従来の循環モデルでは p → f, b → p, bh → b のそれぞれの音韻変化については理解できたが,次のラウンドを始める際の鍵となる f と bh との関係が必ずしも明らかでなかった.しかし,Collitz 説のように後者を排除すれば,この問題はなくなる.Collitz の議論は高度に専門的であり,私には正確に評価することができないが,少なくとも,6段階を設定し,循環の速度が一定でないと仮定することによって,Grimm's Law や関連する音韻変化の見通しはよくなるように思われる.
ゲルマン諸語や方言の阻害音系列の音韻変化には,確かに一定の方向そして循環する性質がある.しかし,Grimm's Law, Verner's Law, Second Germanic Consonant Shift などの各々の推移について,その循環の速度や角度,すなわち6段階のどこで停止するかは異なる.循環パターンには様々な組み合わせがありえ,Grimm's Law もそのうちの1つを表わしたものとして解釈できるだろう.
・ Collitz, Hermann. "A Century of Grimm's Law." Language 2 (1926): 174--83.
2012-05-20 Sun
■ #1119. Rask's Law でなく Grimm's Law と呼ばれる理由 [grimms_law][verners_law][history_of_linguistics][consonant][phonetics][germanic][aspiration][sgcs]
Grimm's Law(グリムの法則)は,その発見者であるドイツの比較言語学者 Jakob Grimm (1785--1863) にちなんだ名称である.Grimm は,主著 Deutsche Grammatik 第1巻の第2版 (1822) でゲルマン諸語の子音と印欧諸語の対応する子音との音韻関係を確認し,それが後に法則の名で呼ばれるようになった.
しかし,言語学史ではよく知られているとおり,Grimm's Law が唱える同じ音韻変化は,デンマークの言語学者 Rasmus Rask (1787--1832) によって,すでに1818年に Undersøgelse om det gamle Nordiske eller Islandske Sprogs Oprindelse のなかで示されていた.フィン・ウゴル語族 (Finno-Ugric) や古いアイスランド語 (Old Icelandic) など多くの言語に通じていた Rask は,印欧祖語という可能性こそ抱いていなかったが,言語研究に歴史的基準を適用すべきことを強く主張しており,しばしば通時的言語学の創始者ともみなされている.
それにもかかわらず,法則の名前が Grimm に与えられることになったのはなぜか.Collitz (175) によれば,Grimm による同音韻変化のとらえ方が3つの点で体系的だったからだという.以下,"media" は有声破裂音,"tenuis" は無声破裂音,"aspirate" は帯気音をそれぞれ表わす.
(1) the second or High German shifting proceeds in general on the same lines as the first or common Germanic shifting;
(2) one and the same general formula is applicable to the various sets of consonants, whether they be labials or dentals or gutturals;
(3) the shifting proves to imply a fixed sequence of the principal forms of the shifting, based on the arrangement of the three classes of consonants involved in the order of media, tenuis, aspirate.
つまり,同音韻変化が,単発に独立して生じた現象ではなく,調音音声学的に一貫した性質をもち,決まった順序をもち,別の変化にも繰り返しみられる原理を内包していることを,Grimm は明示したのである.[2009-08-08-1]の記事「#103. グリムの法則とは何か」で示した2つの図で表わされる内容は,確かに法則の名にふさわしい.
Grimm's Law (1822) が公表されて以来,その部分的な不規則性は気付かれており,Grimm の没年である1863年には Hermann Grassmann が論考するなどしているが,最終的には1875年に Karl Verner (1846--96) による Verner's Law ([2009-08-09-1]) が提起されることによって,不規則性が解消された.
・ Collitz, Hermann. "A Century of Grimm's Law." Language 2 (1926): 174--83.
2012-05-19 Sat
■ #1118. Schleicher の系統樹説 [family_tree][wave_theory][indo-european][comparative_linguistics][history_of_linguistics]
印欧語族の系統図など,言語や方言の派生関係を表わした図 (family_tree は,現在の言語学を学ぶ者にとって見慣れた図である.言語には親娘関係があり,生物の進化と同様に系統樹で関係を描けるというこの考え方を最初に提示したのは,19世紀を代表するドイツの印欧語学者 August Schleicher (1821--68) だった.ダーウィンの進化論より多大な影響を受け,園芸と植物研究をも愛していた Schleicher にとって,言語の系統という思想,Stammbaumtheorie (系統樹説,pedigree theory とも)はごく自然なものだった.彼にとって,言語とは,自然の有機体であり,人間の意志によらずに生じ,一定の法則によって成長し,いずれ死滅するものだった.いわゆる,言語有機体説である.言語は発生以来,孤立語から膠着語を経て屈折語へと発展してきたのであり,歴史時代にあっては堕落の道をたどっているとすら考えた.これらはすぐれて19世紀的な言語観だが,それを最もよく代表していたのが Schleicher だった.
Schleicher は Compendium のなかで次のような印欧諸語の系統関係を想定したが,これが現在の系統図のひな形であることを知るのは容易である(図は『新英語学辞典』 p. 211 より).
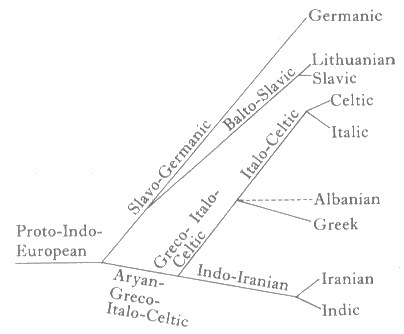
しかし,Schleicher の Stammbaumtheorie は,まもなく弟子の Johannes Schmidt (1843--1901) の唱えた Wellentheorie (the wave theory; [2012-01-21-1]の記事「#999. 言語変化の波状説」を参照) によって激しく批判を受け,様々な反証が提出されるに及んで,人気を失っていった.現在の言語学では,言語有機体説はおよそ葬り去られているし,系統樹説も数多くの但し書きのもとで解釈されなければならない.
それでも,一般の認識では,そして一部では言語学においてすら,言語有機体説や系統樹説への信仰は根深いものがある.言語は生き物であるという比喩は日常的にきかれるが,その限界を正しく見極めることは意外と難しい([2011-07-13-1]の記事「#807. 言語系統図と生物系統図の類似点と相違点」を参照).また,系統樹に関する様々な但し書きに注意が払われないことも少なくない.例えば,(1) 系統樹は万世一系に描かれるが,実際には,系統に対する影響という横のつながりが隠れている可能性が常にあるという点([2010-05-01-1]の記事「#369. 言語における系統と影響」および[2010-05-03-1]の記事「#371. 系統と影響は必ずしも峻別できない」を参照),(2) 祖語は一点として描かれるが,実際には祖語の内部にも変種があったはずだという点,などはとかく忘れられがちである.
英語史や言語学の概説書には必ずといってよいほど印欧語族の系統樹が描かれているが,この伝統が継承されているということは,Schleicher の思想が継承されているということにほかならない.言語学史では Schleicher の言語観は抹殺されたことになっているが,否,現在に至るまでその重要な一端は脈々と受け継がれているのである.
・ Schleicher, August. Compendium der vergleichenden Grammatik der indogermanischen Sprachen. Weimar: Böhlau, 1861--62.
・ 大塚 高信,中島 文雄 監修 『新英語学辞典』 研究社,1987年.
2012-05-18 Fri
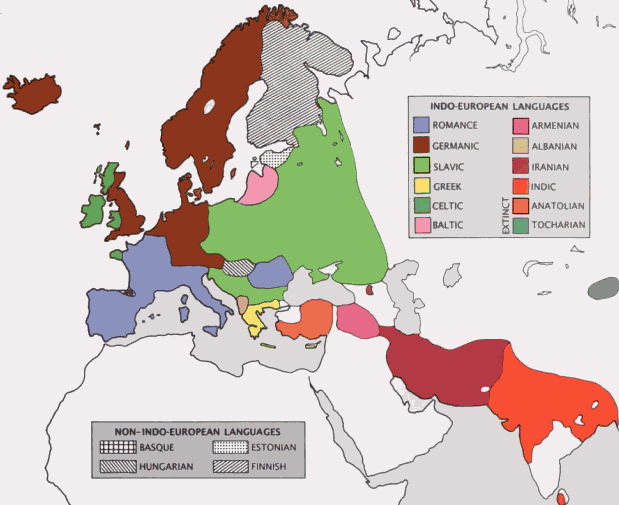
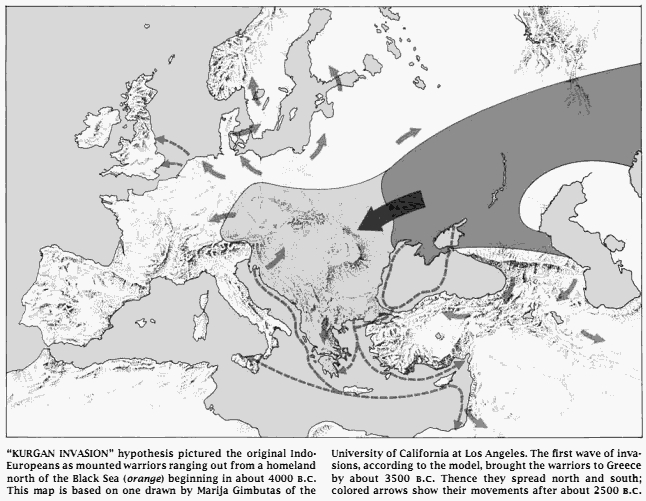
■ #1117. 印欧祖語の故地は Anatolia か? [indo-european][archaeology][map][pictish]
[2011-01-24-1]の記事「#637. クルガン文化と印欧祖語」で,印欧祖語の故地について,現時点で比較的有力な Gimbutas による説を紹介した.ウクライナ,ロシア南部,カザフスタンのステップ地帯に栄えていたクルガン文化 (the Kurgan culture) の担い手が,紀元前3500--2500年ほどの時期に東西への拡散を開始し,行く先々の先住民を矢継ぎ早に武力征服していったという筋書きである.
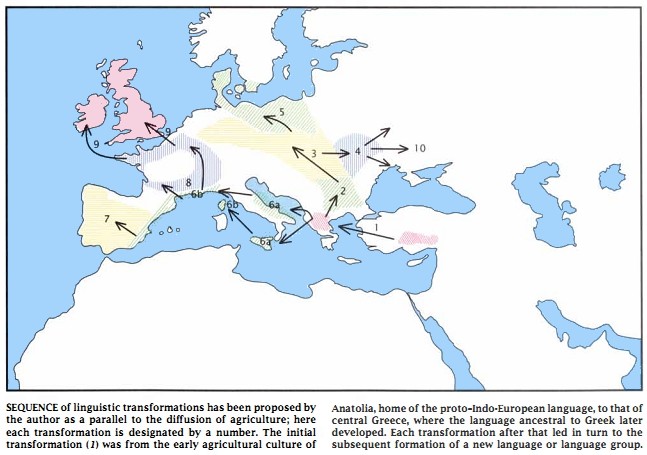
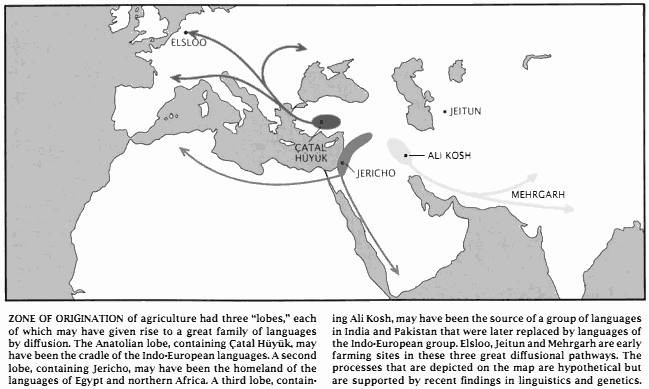
これに対して,考古学者 Renfrew は一貫して反対する論陣を張ってきた.Renfrew によれば,紀元前7千年紀までに遡りうる印欧祖語は Anatolia あるいは中東に端を発し,農業の伝播と相俟って民主的・平和的にゆっくりと各地に根付いていったという.Gimbutas 説と Renfrew 説は,故地,時期,言語拡散の方法のすべての点で真っ向から対立しており,印欧祖語を巡る議論としては,現在,最も注目すべき論争である.以下,Renfrew の主張のよくまとまった1989年の論文より,Renfrew 説の要点を示す.
(1) 1962年に V. Gordon Childe によって初めて提起された黒海北部のステップ地帯起源説が,近年 Gimbutas により補強され,多くの考古学者がこの説を受け入れているが,この説は,なぜ新石器時代末期に大規模民族移動が生じたかという根本的な問題に答えていない.(108--09)
(2) Gimbutas 説が前提としているようには,考古学的遺物と民族を一義的に結びつけることはできないし,民族と言語を一義的に結びつけることもできない.代わりに,文化が変化する過程に注目する必要がある.(109)
(3) ある地域で用いられる言語が替わる過程には4種類の方法がある.(a) "initial colonization", (b) Schleicher 的な "divergence", (c) Schmidt 的な "convergence", (d) "replacement" である.(109)
(4) replacement には4形態がある.(a) "elite dominance", (b) invaders that "take advantage of power vacuum", (c) pidgin 化や creole 化, (d) the introduction of a new "subsistence economy" ("the coming of farming"). (110)
(5) ヨーロッパに紀元前7千年紀にもたらされた農業は,Anatolia からもたらされた.(110)
(6) 上記 replacement の (a) は,征服者の優れた軍事技術および征服側と被征服側の双方の社会秩序が前提条件となるが,前者は Childe や Gimbutas ではあくまで仮説にすぎず,後者の確立はヨーロッパでは青銅器時代からのことである.(110)
(7) 農耕民とその子孫が,農業による人口増加にしたがって,農業を伝播させながら移動していったという "the wave-of-advance" model が,Ammerman and Cavalli-Sforza によって提起されている(111) .農業による人口増加率を狩猟の50倍と算定し,1世代を25年,各農耕民は成人して18km移動すると仮定して試算すると,1年に1kmの速度で移動と伝播の波が四方八方に拡がるとの結論を得た.これによれば,Anatolia から農業がヨーロッパ北部にたどりつくのは1500年ほどであり,考古学上の発見と合致する.(110--11)
(8) 実際には,農耕民移住者が先住民に農業を一方的に教えたのではなく,先住民が近隣の農耕民移住者から学び取ったというケースも多かったろう(ギリシア,バルカン半島,中欧,南イタリア以外ではこのケースだったと思われる).この場合には,言語交替の速度は鈍くなったはずである.そして,このような場合に,外来の印欧語を拒み続けて長く生き残った非印欧語が Basque, Estruscan, Iberian, Pictish などではないか.(111)
(9) この説では,農業がステップ地帯から Anatolia へ伝播したのではなく,その逆であることを唱えているが,ウクライナに初期農耕の証拠はあり,考古学的にも支持される.(113)
(10) 印欧語のヨーロッパへの到着は紀元前6500頃だろう.そうすると,ヨーロッパの先史はこれまで想定されてきたよりもはるかに長く連続性を保っていることになり,青銅器時代の到来にも鉄器時代の到来にも,"sudden discontinuity" はなかったことになる.(113)
(11) The Nostratic Theory ([2012-05-16-1]の記事「#1115. Nostratic 大語族」を参照)の主導者 Illich-Svitych と Dolgopolsky も印欧祖語の故地を Anatolia と考えていた.Afro-Asiatic, Indo-European, Dravidian の話者の遺伝学的な関係が強いことも証明されており,The Nostratic Theory と 印欧祖語 Anatolia 説とは調和する.(114)
以上の Renfrew 説のエッセンスは,次の2文に要約されるだろう.
Its [the new theory's] immigrants come from Anatolia rather than from the steppes and at a date (6500 B.C. or so) several thousand years earlier than has generally been suggested. My hypothesis also implies that the first Indo-European speakers were not invading warriors with a centrally organized society but peasant farmers whose societies were basically egalitarian and who in the course of an entire lifetime moved perhaps only a few kilometers. (113)
印欧語の故地を巡る論争の概要については,風間の第3章「考古学からの新しい提案---クルガン文化と近東説めぐって」(99--135) が読みやすい. *
*
*
*
・ Renfrew, Colin. "The Origins of the Indo-European Languages." Scientific American 261 (1989): 106--14.
・ 風間 喜代三 『印欧語の故郷を探る』 岩波書店〈岩波新書〉,1993年.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2012-05-17 Thu
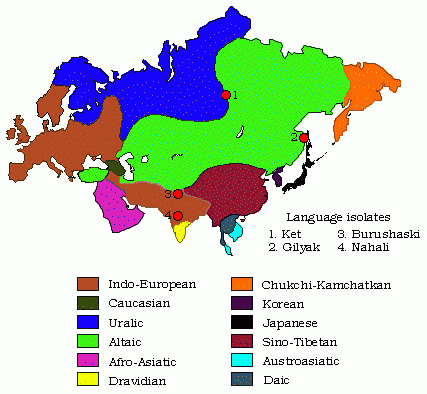
■ #1116. Nostratic を超えて Eurasian へ [language_family][indo-european][nostratic][eurasian][world_languages][map][family_tree][comparative_linguistics]
昨日の記事[2012-05-16-1]で「#1115. Nostratic 大語族」の仮説 (The Nostratic Theory) を紹介したが,現在,歴史言語学および言語類型論の関心から,さらに上を行く壮大な言語系統図の構想が抱かれている.
1つには,Nostratic 大語族とは独立した大語族として,North Caucasian, Sino-Tibetan, Yeniseian, Eyak-Athapascan の4語族を含む Sino-Caucasian あるいは Dene-Caucasian 大語族が提案されている([2011-02-08-1]の記事「#652. コーカサス諸語」の一番下の図を参照).それに加えて,アメリカ・インディアンのほとんどの言語を含むといわれる Amerind 大語族(この語族の設定自体が論争の的となっている)の仮説が唱えられている.Ruhlen は,究極の Eurasian 祖語を仮設し,上記の大語族間の系統関係を次のように想定した(Gelderen, pp. 31 の図をもとに作成).
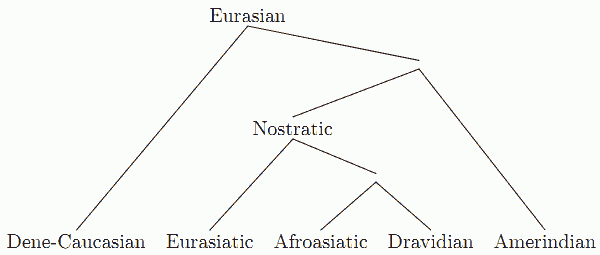
Eurasian を仮定したとしても,アフリカの3語族,オーストラリアの語群,太平洋の語群は,これに包含されず,孤立している.いずれも Eurasian 祖語以前に分裂したものと想定される.
Geldren (29--32) は,英語史概説書としては珍しく,このような大語族の仮説にまで踏み込んで記述しており,有用.世界の諸語族については,[2010-05-30-1]の記事「#398. 印欧語族は世界人口の半分近くを占める」や,Ethnologue より language family index が参考になる.Oxford 提供のユーラシア大陸の簡単な言語地図も参照. *
・ Gelderen, Elly van. A History of the English Language. Amsterdam, John Benjamins, 2006.
・ Ruhlen, Merritt. The Origin of Language. New York: Wiley, 1994.
{kind=link}
2012-05-16 Wed
■ #1115. Nostratic 大語族 [language_family][indo-european][nostratic][comparative_linguistics][reconstruction][world_languages][map]
19世紀,印欧語比較言語学は飛躍的に進歩を遂げたが,印欧語族内にとどまらず,語族と語族の間の2言語を比較する試みは,すでに同世紀より見られた.しかし,異なる語族からの2言語の比較ではなく,語族レベルでの比較が本格的になされたのは20世紀後半になってからのことである.1964年,Illich-Svitych と Dolgopolsky という2人の比較言語学者が,独立して重要な論文を発表した.そこでは,Indo-European, Afro-Asiatic (Hamito-Semitic), Kartvelian, Uralic, Altaic, Dravidian の6つの主要語族が比較され,その同系が唱えられた.これらを包括する大語族の名前として,1903年に Pedersen が提案していた "Nostratic" というラベルが与えられた.現在,Nostratic 大語族には,さらに5つの語族 (Eskimo-Aleut, Chukchi-Kamchatkan, Niger-Kordofanian, Nilo-Saharan, Sumerian) が付け加えられている.
Nostratic 大語族を比較言語学的に検証する上での大きな問題の1つは,比較する語彙素の選定である.Dolgopolsky は,もっとも借用されにくく安定性のある語彙素として15語を選び出した ("I, me", "two, pair", "thou, thee", "who, what", "tongue", "name", "eye", "heart", "tooth", verbal NEG (negation and prohibition), "finger/toe nail", "louse", "tear" (n.), "water", "dead") .それから各言語の対応する語彙素を比較し,祖語の形態を再建 (reconstruction) していった.
一方,Illich-Svitych は,Nostratic 祖語の形態と統語の再建も試み,次のような銘句を作詩すらしている.

Nostratic 大語族の仮説 (The Nostratic Theory)は,単一語族を超える規模の比較として,ある程度の根拠に支えられているものとしては,現在,唯一のものである.しかし,比較すべき語彙素の選定や,再建の各論は激しい論争の的となっている.この仮説に熱心な研究者もいれば,比較言語学の限界の前にさじを投げる研究者も多い.19世紀,20世紀と踏み固められてきたようにみえる印欧語比較言語学ですら多くの問題を残しており,その起源について決定的な説がない([2011-01-24-1]の記事「#637. クルガン文化と印欧祖語」を参照)のだから,Nostratic の仮説など途方もないと考えるのも無理からぬことである.しかし,ズームアウトして視野を広げることで見えてくる細部の特徴もあるかもしれない.それが,野心的な Nostratic 仮説の謙虚な狙いの1つといえるかもしれない.
以上は Kaiser and Shevoroshkin の論文を参照して執筆した. *
・ Kaiser, M. and V. Shevoroshkin. "Nostratic." Annual Review of Anthropology 17 (1988): 309--29.
2012-05-15 Tue
■ #1114. 草仮名の連綿と墨継ぎ [punctuation][grammatology][japanese][hiragana][katakana][writing][manuscript][syntagma_marking][distinctiones]
[2012-05-13-1], [2012-05-14-1]の記事で,分かち書きについて考えた.英語など,アルファベットのみを利用する言語だけでなく,日本語でも仮名やローマ字のみで表記する場合には,句読法 (punctuation) の一種として分かち書きするのが普通である.これは,表音文字による表記の特徴から必然的に生じる要求だろう.おもしろいことに,日本語において漢字をもとに仮名が発達していた時代にも,分かち書きに緩やかに相当するものがあった.
例えば,天平宝字6年(762年)ごろの正倉院仮名文書の甲文書では,先駆的な真仮名の使用例が見られる(佐藤,pp. 54--55).そこでは,墨継ぎ,改行,箇条書き形式,字間の区切りなど,仮名文を読みやすくする工夫が多く含まれているという.一方,真仮名(漢字)を草書化した草仮名の最初期の例は9世紀後半より見られるようになる.当初は字間の区切りの傾向が見られたが,時代と共に語句のまとまりを意識した「連綿」と呼ばれる続け書きへと移行していった.これは,統語的な単位を意識した書き方であり,syntagma marking を標示する手段だったと考えてよい.また,仮名文とはいっても,平仮名のみで書かれたものはほとんどなく,少数の漢字を交ぜて書くのが現実であり,現在と同じように読みにくさを回避する策が練られていたことにも注意したい.
連綿と関連して発達したもう1つの syntagma marker に「墨継ぎ」がある.佐藤 (59) を参照しよう.
墨継ぎでは,筆のつけはじめは墨が濃く、次第に枯れて細く薄くなり,また墨をつけて書くと濃いところと薄いところが生じる.その濃淡の配置は大体において文節あるいは文に対応しているのである.連綿もあるまとまりをつけるものであるが,やはり,語あるいは文節に対応していることが多い.これらはある種の分かち書きの機能を果たしていると考えられる.
ところで,字と字をつなげて書く習慣や連綿は,もっぱら平仮名書きに見られることに注目したい.一方で,片仮名と続け書きとは,現在でも相性が悪い.これは,片仮名が基本的には漢字とともに用いられる環境から発達してきたからである.片仮名は,発生当初から,現在のような漢字仮名交じり文として用いられており,昨日の記事[2012-05-14-1]で説明したように,字種の配列パターンにより文節区切りが容易に推知できた.したがって,syntagma marking のために連綿という手段に訴える必要が特になかったものと考えられる(佐藤, pp. 60--61).
・ 佐藤 武義 編著 『概説 日本語の歴史』 朝倉書店,1995年.
2012-05-14 Mon
■ #1113. 分かち書き (2) [punctuation][grammatology][japanese][kanji][hiragana][writing][syntagma_marking][distinctiones]
昨日の記事[2012-05-13-1]に引き続き,分かち書きの話し.日本語の通常の書き表わし方である漢字仮名交じり文では,普通,分かち書きは行なわない.昨日,べた書きは世界の文字をもつ言語のなかでは非常に稀だと述べたが,これは,漢字仮名交じり文について,分かち書きしない積極的な理由があるというよりは,分かち書きする必要がないという消極的な理由があるからである.
1つは,漢字仮名交じり文を構成する要素の1つである漢字は,本質的に表音文字ではなく表語文字である.仮名から視覚的に明確に区別される漢字1字あるいは連続した漢字列は,概ね語という統語単位を表わす.昨日述べた通り,語単位での区別は,書き言葉において是非とも確保したい syntagma marking であるが,漢字(列)は,その字形が仮名と明確に異なるという事実によって,すでに語単位での区別を可能にしている.あえて分かち書きという手段に訴える必要がないのである.漢字の表語効果は,表音文字である仮名と交じって書かれることによって一層ひきたてられているといえる.
もう1つは,日本語の統語的特徴として「自立語+付属語」が文節という単位を形成しているということがある(橋本文法に基づく文節という統語単位は,理論的な問題を含んでいるとはいえ,学校文法に取り入れられて広く知られており,日本語母語話者の直感に合うものである).そして,次の点が重要なのだが,自立語は概ね漢字(列)で表記され,付属語は概ね仮名で表記されるのが普通である.通常,文は複数の文節からなっているので,日本語の文を表記すれば,たいてい「漢字列+仮名列+漢字列+仮名列+漢字列+仮名列+漢字列+仮名列…….」となる.漢字仮名交じり文においては,仮名と漢字の字形が明確に異なっているという特徴を利用して,文節という統語的な区切りが瞬時に判別できるようになっているのだ.漢字仮名交じり文のこの特徴は,より親切に読み手に統語的区切りを示すために分かち書きする可能性を拒むものではないが,スペースを無駄遣いしてまで分かち書きすることを強制しない.
日本語の漢字仮名交じり文とべた書きとの間に,密接な関係のあることがわかるだろう.このことは,漢字使用の慣習が変化すれば,べた書きか分かち書きかという選択の問題が生じうることを含意する.戦後,漢字仮名交じり文において漢字使用が減り,仮名で書き表わされる割合が増えてきている.特に自立語に漢字が用いられる割合が少なくなれば,上述のような文節の区切りが自明でなくなり,べた書きのままでは syntagma marking 機能が確保されない状態に陥るかもしれない.そうなれば,分かち書き化の議論が生じる可能性も否定できない.例えば,29年ぶりに見直された2010年11月30日告示の改訂常用漢字表にしたがえば,「文書が改竄され捏造された」ではなく「文書が改ざんされねつ造された」と表記することが推奨される.しかし,後者は実に読みにくい.読点を入れ「文書が改ざんされ,ねつ造された」としたり,傍点を振るなどすれば読みやすくなるが,別の方法として「文書が 改ざんされ ねつ造された」と分かち書きする案もありうる.いずれにせよ,日本語の書き言葉は,syntagma marking を句読点に頼らざるを得ない状況へと徐々に移行しているようである.分かち書きは,純粋に文字論や表記体系の問題であるばかりではなく,読み書き能力や教育の問題とも関与しているのである.
なお,日本語表記に分かち書きが体系的に導入されたのは室町時代末のキリシタンのローマ字文献においてだが,後代には伝わらなかった.仮名の分かち書きの議論が盛んになったのは,明治期からである.現代では,かな文字文,ローマ字文において,それぞれ文節単位,語単位での分かち書きが提案されているが,正書法としては確立しているとはいえない.日本語の表記体系は,今なお,揺れ動いている.
2012-05-13 Sun
■ #1112. 分かち書き (1) [punctuation][grammatology][alphabet][japanese][kanji][hiragana][writing][syntagma_marking][distinctiones]
分かち書きとは,読みやすさを考慮して,その言語の特定の統語形態的な単位(典型的には語や文節)で区切り,空白を置きながら書くことである.「分け書き」「分別書き」「付け離し」とも呼ばれ,世界のほとんどすべての言語の正書法に採用されている.対する「べた書き」は日本語や韓国語に見られ,日本語母語話者には当然のように思われているが,世界ではきわめて稀である.
では,日本語ではなぜ分かち書きをしないのだろうか.そして,例えば,英語ではなぜ分かち書きをするのだろうか.それは,表記に用いる文字の種類および性質の違いによる([2010-06-23-1]の記事「#422. 文字の種類」を参照).日本語では,表音文字(音節文字)である仮名と表語文字である漢字とを混在させた漢字仮名交じり文が普通に用いられるのに対して,英語は原則としてアルファベットという表音文字(音素文字)のみで表記される.この違いが決定的である.
説明を続ける前に,書き言葉の性質を確認しておこう.書き言葉の本質的な役割は話し言葉を写し取ることだが,写し取る過程で,話し言葉においては強勢,抑揚,休止などによって標示されていたような多くの言語機能が捨象される.話し言葉におけるこのような言語機能は,メッセージの受け手にとって,理解を助けてくれる大きなキューである.聞こえている音声の羅列に,形態的,統語的,意味的な秩序をもたらしてくれるキューである.別の言い方をすれば,話し言葉には,文の構造の理解にヒントを与えてくれる,様々な syntagma marker ([2011-12-29-1], [2011-12-30-1]) が含まれている.書き言葉は,話し言葉とは異なるメディアであり,寸分違わず写し取ることは不可能なので,話し言葉のもっている機能の多くを捨象せざるを得ない.どこまで再現し,どこから捨象するのかという程度は文字体系によって異なるが,最低限,特定の統語的単位の区切りは示すのが望ましい.それは,多くの場合,語という単位であり,ときには文節のような単位であることもあるが,いずれにせよ文字をもつほとんどの言語で,ある統語的単位の区切りが syntagma marking されている.
さて,表音文字のみで表記される英語を考えてみよう.語の区切りがなく,アルファベットがひたすら続いていたら,さぞかし読みにくいだろう.書き手は頭の中にある統語構造を連続的に書き取っていけばよいだけなので楽だろうが,読み手は連続した文字列を自力で統語的単位に分解してゆく必要があるだろう.読み手を考慮すれば,特定の統語的単位(典型的には語)ごとに区切りをつけながら書いてゆくのが理に適っている.その方法はいくつか考えられる.各語を枠でくくるという方法もあるだろうし,(中世の英語写本にも実際に見られるように)語と語の間に縦線を入れるという方法もあるだろう.しかし,なんといっても簡便なのは,空白で区切ることである.これは話し言葉の休止にも相似し,直感的でもある.したがって,表音文字のみで表記される書き言葉では,分かち書きは syntagma marking を確保する最も普通のやり方なのである.
同じことは,日本語の仮名書きについても言える.漢字を用いず,平仮名か片仮名のいずれかだけで書かれる文章を考えてみよう.小学校一年生の入学当初,国語の教科書の文章は平仮名書きである.ちょうど娘がその時期なので光村図書の教科書「こくご 一上」の最初のページを開いてみると次のようにある.
はる
はるの はな
さいた
あさの ひかり
????????????
?????壔?????
?????壔?????
みんな ともだち
いちねんせい
一種の詩だからということもあるが,空白と改行を組み合わせた,文節区切りの分かち書きが実践されている(初期の国定教科書では語単位の分かち書きだったが,以後,現在の検定教科書に至るまで文節主義が採用されている).これがなければ「はるのはなさいたあさのひかりきらきらおはようおはようみんなともだちいちねんせい」となり,ひどく読みにくい.そういえば,娘が初めて覚え立ての平仮名で文を書いたときに,分かち書きも句読点もなしに(すなわち読み手への考慮なしに),ひたすら頭の中にある話し言葉を平仮名に連続的に書き取っていたことを思い出す.ピリオド,カンマ,句点,読点などの句読法 (punctuation) の役割も,分かち書きと同じように,syntagma marking を確保することであることがわかる.
日本語を音素文字であるローマ字で書く場合も,仮名の場合と同様である.海外から日本に電子メールを送るとき,PCが日本語対応でない場合にローマ字書きせざるを得ない状況は今でもある.その際には,語単位あるいは文節単位で日本語を区切りながら書かないと,読み手にとって相当に負担がかかる.いずれの単位で区切るかは方針の問題であり,日本語の正書法としては確立していない.
それでは,日本語を書き表わす通常のやり方である漢字仮名交じり文では,どのように状況が異なるのか.明日の記事で.
2012-05-12 Sat
■ #1111. Graddol による熟達度を重視した英語話者モデル [elf][model_of_englishes][language_shift][native_speaker_problem]
1985年に Kachru によって提案された「#217. 英語話者の同心円モデル」 ([2009-11-30-1]) は,現代における英語使用を理解するためのモデルとして,広く受け入れられてきた.しかし,とりわけ21世紀が近づくにつれて,様々な批判が湧き出てきた.異論や代案は model_of_englishes の各記事で紹介してきたが,最近では Modiano による別の同心円モデルを示した ([2012-04-27-1], [2012-05-07-1]) .今回は,Kachru モデルを再解釈した Graddol の見解を紹介しよう.
Graddol (English Next 110) は,Kachru の歴史地理的な観点に基づく階層よりも,英語の熟達度に基づくモデルのほうが20世紀の英語使用の現状をよく反映していると考え,それに対応する図式を描いた(下図参照).また,熟達度の各階層は明確に区別されるというよりは,グラデーションを描く連続体だろうと考えた.Inner という用語こそ残したが,新しくここに含まれるのは「最も熟達度の高い階層」を構成する5億人ほどの英語話者ということになる.
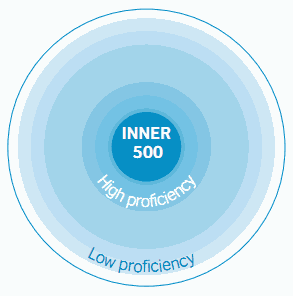
Kachru の名誉のために述べれば,彼自身も近年は Graddol のような熟達度に依拠するモデルを念頭においているようだ (Graddol, English Next 110) .
このモデルは,英語の熟達度を重視する点で Modiano の同心円モデル([2012-04-27-1]) とも比較されるが,後者はとりわけ "international English" の熟達度を問題にしている.Graddol には,"international English" に相当するものへの言及はない.また,Graddol モデルは,話者の "bilingual status" (English Next 110) という観点を,熟達度ほど重視していないが,Jenkins モデル ([2010-01-24-1]) では "bilingual status" の有無こそが肝要である.Jenkins モデルは,"the native speaker problem" を指摘しやすいモデルともいえる.
提案されてきた現代の英語使用のモデルは,それぞれ力点の置き方に差がある.そこには,英語使用の現状という以上に,提案者の英語史観や将来の英語使用への期待と希望が反映されている.したがって,私は,これらを広い意味での英語史記述であると考えている.だからこそ,様々なモデルに関心がある.
さて,Graddol といえば,前著 The Future of English? で,言語交替 (language shift) を考慮に入れた動的なモデルも提案している.そちらについては,[2010-06-15-1]の記事「#414. language shift を考慮に入れた英語話者モデル」で取り上げたので,要参照.
・ Graddol, David. English Next. British Council, 2006. Digital version available at https://www.teachingenglish.org.uk/article/english-next .
・ Graddol, David. The Future of English? The British Council, 1997. Digital version available at https://www.teachingenglish.org.uk/article/future-english .
2012-05-11 Fri
■ #1110. Guiraud による言語学の構成部門 [linguistics]
「#377. 英語史で話題となりうる分野」 ([2010-05-09-1]) および「#378. 語用論は言語理論の基本構成部門か否か」 ([2010-05-10-1]) の記事で,言語学の基本構成部門を紹介した.伝統的な分類として現代のほとんどの言語学で採用されている言語(学)のモデルだが,必ずしもバランスがよいとはいえない.音声学・音韻論 (phonetics, phonology) ,形態論 (morphology) ,統語論 (syntax) は主として言語の形態を,意味論 (semantics) , 語用論 (pragmatics) は主として言語の意味を扱うのだが,形態と意味の関係が明示されていない.言語学において発達してきた時代順に部門を並べただけ,という印象である.
ギロー (124--29) は,ソシュールの眺望にしたがって,言語学の構成部門を体系的に整理した.伝統的な見方とは異なる点が少なくないが,構造言語学の筋の通ったモデルである.以下は,ギロー (130) の「言語:意味作用の実体と形態」 の図をもとに作成したものである.
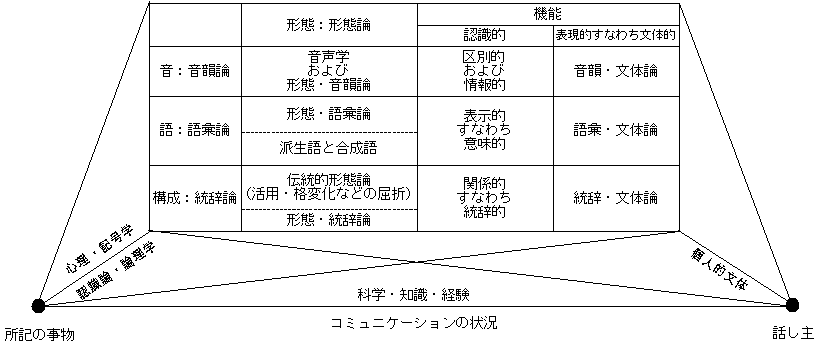
まず,ギローは言語を構成する大項目として,音韻論,語彙論,統辞論の3つを区別した.そして,それぞれに形態的側面と機能的側面があるとし,後者には認識的なものと文体的なものとがあるとした.形態的側面では,伝統的な「音韻論」と「統語論」の領域はそのままギローの「音韻論」と「統辞論」に包含されると考えてよいが,伝統的な「形態論」に含まれていた屈折 (inflection) は,語幹と語尾の組み合わせ(統辞)として再解釈されており,「統辞論」の1部へ取り込まれている.また,派生や合成は,語彙論と統辞論にまたがる性質をもつとされる.
ギローのモデルの面目躍如たるは,3項目に対応する機能的側面の記述である.音韻論で扱われる音素という単位は,意味こそ担っていないが,区別する機能を担っている.また,情報的というのは,情報理論的と読み替えてよく,音素が最小努力の法則 (the Principle of Least Effort) に従って配分されており,経済的な情報伝達を確保しているという点に注目した記述である(ギローは情報理論の言語学への応用に関心が深い).語彙論における機能とは語の意味を表わす機能のことであり,「意味論」とは原則としてこの領域のみを扱うものでなければならない.統辞論における機能とは記号と記号の関係を確定する機能であり,広義には「意味」と読み替えられるかもしれないが,上記の意味論的な意味とは区別して理解しておく必要がある.以上の機能は認識的な側面について述べたものだが,機能には別に文体的な側面という付加的な価値も認められており,音韻論,語彙論,統辞論の3項目それぞれに対応する文体的機能が割り当てられている(ギローは文体論者でもある).
・ ピエール・ギロー 著,佐藤 信夫 訳 『意味論』 白水社〈文庫クセジュ〉,1990年.
2012-05-10 Thu
■ #1109. 意味変化の原因の分類 [semantics][semantic_change][prediction_of_language_change]
[2010-08-13-1]の記事では「#473. 意味変化の典型的なパターン」をみたが,意味変化の原因にはどのような種類があるのだろうか.ギロー (82--84) は,メイエやニュロップの考察に基づいて,4種類の分類を示している.
a) 歴史的原因:すなわち科学,技術,制度,風俗などの変化が,名前の変化を伴わずに事物の変化をもたらす.したがってそれは言語の体系に直接的には影響しない./この種類は,ほとんどすべての意味論学者が認めている.
b) 言語的原因:すなわち音韻的,形態的,あるいは統辞的な諸原因に由来する変化,伝染,通俗語源,同音の衝突,省略.
c) 社会的原因:「社会的借用語」や,語の社会的な有効範囲の移動,語の意味の有効範囲の移動(緊縮あるいは拡張)を惹き起こすような専門化と一般化.
d) 心理的原因:表現性の探究,タブーと婉曲法,情動の力(この第4類別はメイエのもとの分類にはなかった).
分類の見た目は単純だが,実際の意味変化は種々の原因が重なって生じるものである.因果関係の連鎖の輪が1つでも不明であれば,意味変化を追うことはできない.したがって,個々の語の意味変化の仮説には,常に危険が伴っている.
上記の原因の大前提となる意味変化の原理として,昨日の記事「#1108. 言語記号の恣意性,有縁性,無縁性」 ([2012-05-09-1]) で示した言語記号の有縁化と無縁化のサイクルがある.では,意味変化の原因の分類や原理が得られた今,その法則を確立することはできるのだろうか.
語の意味変化は定義可能な原因により生じるのであるから,そこには法則といった観念も含まれている.しかし,昨日の記事でみたように,語の signifiant と signifié の関係は限定的でも被限定的でもなく,常に自由である.したがって,有限の手段により関係が変化してゆくということはわかっていても,それを予見することは不可能である.手段は有限だが,その使い道は自由であるということは,事実上,無限で無法則であると考えてよい.意味変化においては(そして言語変化一般においても),せいぜい傾向が見いだされるにすぎず,確率の問題にとどまるだろう.
・ ピエール・ギロー 著,佐藤 信夫 訳 『意味論』 白水社〈文庫クセジュ〉,1990年.
2012-05-09 Wed
■ #1108. 言語記号の恣意性,有縁性,無縁性 [semantics][semantic_change][language_change][arbitrariness][sound_symbolism][phonaesthesia][onomatopoeia][saussure][sign][root_creation]
ソシュール (Ferdinand de Saussure; 1857--1913) が言語の恣意性 (arbitrariness) を公準として唱えて以来,恣意性を巡る無数の論争が繰り返されてきた.例えば,恣意性の原理に反するものとして,オノマトペ (onomatopoeia) や音象徴 (sound_symbolism) がしばしば挙げられてきた.しかし,ギローは,これらの論争は不毛であり,規約性と有縁性という2つの異なる性質を区別すれば解決する問題だと主張した.
ギロー (24--27) によれば,記号の本質として規約性があることは疑い得ない.記号の signifiant と signifié は,常に社会的な規約によって結びつけられている.規約による結合というと,「でたらめ」や「ランダム」のような恣意性を思い浮かべるかもしれないが,必ずしも有縁性を排除するわけではない.むしろ,「どんな語もみな語源的には有縁的である」 (25) .有縁的というときには,自然的有縁性と言語的有縁性を区別しておく必要がある.前者は自然界にきこえる音を言語音に写し取る onomatopoeia の類であり,後者は派生や複合などの形態的手段によって得られる相互関係(例えば,possible と impossible の関係)である.まれな語根創成 (root_creation) の例を除いて,すべての語はいずれかの種類の有縁性によって生み出されるという事実は注目に値する.
重要なのは,有縁性は限定的でもなければ被限定的でもなく,常に自由であるという点だ.限定的でないというのは,いったん定まった signifiant と signifié の対応は不変ではなく,自由に関係を解いてよいということである.被限定的でないというのは,比喩,派生,複合,イディオム化など,どんな方法を用いても,命名したり意味づけしたりできるということである.
したがって,ほぼすべての語は様々な手段により有縁的に生み出され,そこで signifiant と signifié の対応が確定するが,確定した後には再び対応を変化させる自由を回復する.換言すれば,当初の有縁的な関係は時間とともに薄まり,忘れられ,ついには無縁的となるが,その無縁化した記号が出発点となって再び有縁化の道を歩み出す.有縁化とは意識的で非連続の個人の創作であり,無縁化とは無意識的で連続的な集団の伝播である (45) .有縁化と無縁化のあいだの永遠のサイクルは,意味論の本質にかかわる問題である.語の意味変化を有縁性という観点から図示すれば,以下のようになろう.
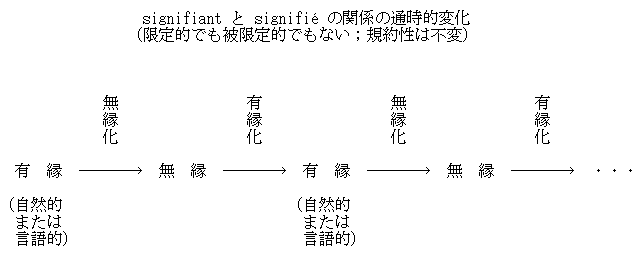
ギローにとって,ソシュールのいう恣意性とは,いつでも自由に有縁化・無縁化することができ,なおかつ常に規約的であるという記号の性質を指すものなのである.
「#1056. 言語変化は人間による積極的な採用である」 ([2012-03-18-1]) や「#1069. フォスラー学派,新言語学派,柳田 --- 話者個人の心理を重んじる言語観」 ([2012-03-31-1]) の記事でみた柳田国男の言語変化論は,上のサイクルの有縁化の部分にとりわけ注目した論ということになるだろう.
・ ピエール・ギロー 著,佐藤 信夫 訳 『意味論』 白水社〈文庫クセジュ〉,1990年.
2012-05-08 Tue
■ #1107. farther and further [comparison][superlative][etymology][i-mutation][suppletion]
規範文法によれば,副詞・形容詞 far の比較級(および最上級)には標題のとおり2種類があり,用法の区別が説かれる.Usage and Abusage より,その区別をみてみよう.
farther, farthest; further, furthest. 'Thus far and no farther' is a quotation-become-formula; it is invariable. A rough distinction is this: farther, farthest, are applied to distance and nothing else; further, furthest, either to distance or to addition ('a further question').
規範文法ではなく記述文法でいえば,口語や特に BrE では farther, farthest は廃れる傾向にあり,用法の区別も失われてきているという.
用法の区別の前提となっているのが形態の区別だが,そもそもなぜ2つの異なる形態が生じたのだろうか.far の比較級,最上級の形態については,2つの問題がある.1つは,なぜ原級には含まれない th が挿入されているのか,もう1つは,なぜ第1母音(字)の異形として u が現われたのか.
far の古英語の形態は feor(r) だった.さらに語源を遡れば,「#68. first は何の最上級か」 ([2009-07-05-1]) および「#695. 語根 fer」 ([2011-03-23-1]) で見たように,印欧語根 *per にたどりつく.古英語での比較級,最上級はウムラウト (i-mutation) 母音を示す fierr, fi(e)rrest だったが,これは12世紀以後には廃れた.代わって,原級の母音を反映した類推形 ferrer, farrer また ferrest, farrest が勢力を得て,17世紀頃まで用いられた.
さて,古英語には,究極的な語源こそ同じ *per に遡るが,独立して発達してきた forþ "forth" という語があった.この比較級が furþor という形態だった."far" の比較級としての fierr と "forth" の比較級としての furþor は,意味の上では「さらに先(の),さらに遠く(の)」と類似しているので,形態的に混同が生じた.そうして,"far" の系列に非語源的な th が挿入され,"forth" の系列に非語源的な母音 e が侵入した.中英語では ferther などの形態が広く行なわれたが,近代英語の17世紀以後は,母音変化を経て生じた farther の形態が標準化された.これと平行して,混同以前の語形を伝える最も語源的といってよい further も存続した.こうして,farther と further が,ともに far の比較級と解釈されつつ生き残ってきたのである.最上級の形態も,同様に説明される.
近代以後,両者の並立を支えてきたのは規範文法に基づく用法の区別であると推測されるが,用法の区別それ自体にある程度の歴史的な根拠のあることが,上述の語史からわかる.母音に注目すれば,farther は far の比較級であり,further は forth の比較級であるから,前者が物理的距離の意味に,後者が比喩的な順番などの意味に対応するのは理解しやすい.
・ Partridge, Eric. Usage and Abusage. 3rd ed. Rev. Janet Whitcut. London: Penguin Books, 1999.
2012-05-07 Mon
■ #1106. Modiano の同心円モデル (2) [elf][model_of_englishes][wsse][linguistic_imperialism][variety]
[2012-04-27-1]の記事「#1096. Modiano の同心円モデル」で,Modiano の論文 "International English in the Global Village" に示された実用主義的英語使用のモデルを紹介した.Modiano は,批評家たちの反応を受けて,数ヶ月後に,別の論文 "Standard English(es) and Educational Practices for the World's Lingua Franca." を発表した.そこでは,改訂版モデルが示されている(以下,同論文 p. 10 の図をもとに作成).
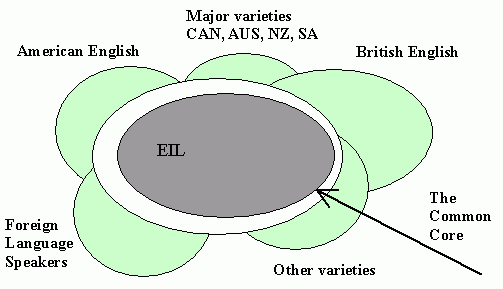
改訂版では,具体的な英語変種が周囲に配されており,それぞれが異なった比率ではあるが "The Common Core" に属する特徴とそこから逸脱した特徴を合わせもっていることが強調されている.この点では,British English や American English のような伝統的な主要変種と,EFL変種を含めたそれ以外の変種との間に差はなく,いずれも周縁部にフラットに位置づけられている.中央の The Common Core の外側を取り巻く狭い白の領域は,今後 The Common Core に入り込んでくる可能性のある特徴や今後 The Common Core から外れる可能性のある特徴の束を表わし,The Common Core が流動性をもった中心部であることを示唆する.そして,EIL (English as an International English) は,この The Common Core をもとに定義される変種として描かれている.このモデルは,Svartvik and Leech による「#426. 英語変種のピラミッドモデル」 ([2010-06-27-1]) と比較されるが,The Common Core の流動性をより適格に表現している点では評価できる.
以上はモデルを図示したものだが,これを文章として表現するのは難しい.Modiano の前の論文に対する批判の1つに,EIL (English as an International Language) がどのような変種を指すのかわからないというものがあった.その批判に応えて,Modiano はその基盤は "standard English" にあるとした上で,次のように表現している.
. . . the designation "standard English" includes those features of English which are both used and easily recognized by the majority of people who speak the language (what is operative in a lingua franca context). (11)
Standard English should be a composite of those features of English which are comprehensible to a majority of native and competent non-native speakers of the language . . . . (12)
前の論文よりも定義が進歩しているわけではない.EIL なり "standard English" なり "the common core" (11) なりの用語を定義することの難しさが改めて知られる.だが,この理想化された英語変種の特徴は,まさに,とらえどころがないという点にある.それは,伸縮自在のゴムのようなものである.このゴムに明確な形を与えようとすれば,外から prescription を投与するしか方法がない.なるべく独断的にならないように prescription を用意するためには,精密な description に基づいていなければならない.だが,輪郭の不定なものを describe するのは骨が折れる.description と prescription を繰り返して螺旋状に上って行き,広く合意が得られる状態に達するというのが現実的な目標となるのではないか.あるいは,その合意が自然に形成されるのを待つという方法もあるだろう.その場合には,EIL や "standard English" という概念は密かに暖めているにとどめておくのが得策ということになるかもしれない.
Modiano の後の論文は,全体として前の論文から大きく発展しているわけではないが,実用主義に反するところの伝統的な英米主体の英語観に対する舌鋒は,鋭く激しくなっている.例えば,次の如くである.
A linguistic chauvinism, or if you will, ethnocentricity, is so deeply rooted, not only in British culture, but also in the minds and hearts of a large number of language teachers working abroad, that many of the people who embrace such bias find it difficult to accept that other varieties of English, for some learners, are better choices for the educational model in the teaching of English as a foreign or second language. (6)
A great many people in the UK do not speak "standard English" if by standard English we mean forms of the language which are comprehensible in the international context. (7--8)
Modiano の英語モデルに賛否両論が出されるのは,現状を表わすモデルであるという以上に,近未来の英語使用を先取りしようとするモデルであり,理想の含まれたモデルだからだ.モデルとは,いつでもその観点こそが注目される.Jenkins (22--23) の批評も要参照.
・ Modiano, Marko. "International English in the Global Village." English Today 15.2 (1999): 22--28.
・ Modiano, Marko. "Standard English(es) and Educational Practices for the World's Lingua Franca." English Today 15.4 (1999): 3--13.
・ Jenkins, Jennifer. World Englishes: A Resource Book for Students. 2nd ed. London: Routledge, 2009.
2012-05-06 Sun
■ #1105. 美女の形容としての grey eyes (2) [romance][adjective][collocation][bnc][corpus]
昨日の記事[2012-05-05-1]に引き続き grey eyes の話題.昨日は,中英語ロマンスの grey eyes について考えたが,この共起表現は現代にも続いている.BNCWeb で,"(grey|gray) {eye/N}" として検索すると,287例がヒットした.grey eyes がさらに別の形容詞に先行されている例をみると,clear, dark, deep, pale が比較的多い.beautiful や bright の例もわずかながらあった.
このような例から判断すると,grey 自体は輝きの有無を表わす意味を担当していないように思われる.もし担当しているとすれば,むしろ pale 寄りの「薄い,輝きのない」という解釈に引き寄せられるだろう.英英辞書で確認する限り,現代英語の grey の一般的な語感は,日本語のそれとよく似て,negative だからだ.老年,陰気,病気,憂鬱,退屈,悪天候のイメージだ.したがって,現代英語の grey eyes は,negative なニュアンスを特に含意しない読みを求めるとするならば,純粋に色としての「灰色」あるいは「青みのいくぶん混じった灰色」を表わすものと考えられる.あるいは,grey eyes は,意味の薄まった共起表現の伝統として用いられているにすぎないという可能性もあるかもしれない.
すると,ますます中英語の美女の典型的な描写としての grey eyes がわからない.もし,MED や Silverstein が述べている通り,中英語の grey が輝きを表わしたのだとすれば,現代英語の輝きのない grey は180度の意味変化を経たことになる.
色は gradation を描くものであり,かつて覆っていた範囲や意味を推定して復元することは,なかなか難しい.英語のみならず日本語においても,色彩語を巡る議論は厄介である.
なお,中世の美女の典型的な描写を示しておこう.Brewer (258) は,Matthew of Vandôme による Helen of Troy の描写が,以下の要約の通り,1つの型であるとしている.
. . . her hair is golden, forehead white as paper, eyebrows black and thin. The space between the eyes (in contrast to the Greek ideal) is white and clear, a 'milky way'; the face is a shining star; the eyes are like stars. She has a little smile, a nose neither too big nor too small. Her face is rosy, her colouring white and red, like rose and snow. Teeth are like ivory, lips are small, slightly swelling, honeyed. Her mouth smells like a rose, her neck is smooth, shoulders radiant, well-spaced (dispatiati), breasts small, and figure incomparable.
こんな女性,いるんでしょうか,ぜひ会ってみたい・・・.
・ Silverstein, Theodore, ed. Sir Gawain and the Green Knight. Chicago: U of Chicago P, 1983.
・ Brewer, D. S. "The Ideal of Feminine Beauty in Medieval Literature, Especially 'Harley Lyrics', Chaucer, and Some Elizabethans." The Modern Language Review 50 (1955): 257--69.
2012-05-05 Sat
■ #1104. 美女の形容としての grey eyes (1) [romance][adjective][sggk]
中英語ロマンスを読んでいると,ヒロインが grey eyes をもつ美女として描写されることが多い.美女の描写であるから,grey eyes が具体的にどのような瞳を表わしているのか,ぜひ知りたいと思うのだが,これが案外と難しい問題である.中世と現代とで美的感覚が異なることはおおいにあり得るとしても,「灰色の瞳」とは本当に美しいものなのだろうか.あるいは,中英語の grey の表わす意味が,現代英語の grey とは異なっていたという可能性はないだろうか.
例えば,Sir Gawain and the Green Knight の ll. 81--84 の "wheel" 部では,アーサー王妃 Guenevere が grey eyes をもつ美女として描かれている(Andrew and Waldron 版より引用).
Þe comlokest to discrye
Þer glent with yȝen gray;
A semloker þat euer he syȝe
Soth moȝt no mon say.
この gray の解釈は,編者によっても異なっている.Andrew and Waldron はグロッサリーで "(of eyes) blue-grey" としており,「青みがかった灰色」と解釈している.Gollancz, Barron, Tolkien and Gordon は,現代英語の grey と同一であるとしており,「青み」を積極的に排除しているわけではないが,基本的には「灰色」とみなしていることになる.grey eyes は灰色の瞳を指すという素直な解釈は,OED でも語義3において "Having a grey iris" として採用されている.
しかし,MED では grei (adj. & n.) では,異なる解釈が示されている.語義 2 (b) で,"of eyes: bright, gleaming (of indeterminate color)" とあり,色合いではなく光り輝く様を記述する形容詞とされている.同じ解釈は Silverstein によっても示されており,"With lively, sparkling eyes" として注が与えられている.中英語には,greye as glas (The General Prologue, l. 152 の Prioress や,The Reeve's Tale, l. 3974 の粉屋の娘の形容)や grey as crystalle stone などの表現もみつかるし,「星のような目」という描写も広く見られることから,瞳の色合いそのものよりはその輝きに注目して美しさを表現するという伝統があったのかもしれない.
西洋中世における美女描写の伝統については Brewer が詳しいが,12世紀より前には,文学上,さして重要な伝統とはされていなかったという.しかし,以降は,典型的な描写の伝統が中世の終わりまで続いた.その伝統の上に,時に革新的な表現が現われた.例えば,"whiter than the swan" のような美女の形容は中英語における創案とされる (Brewer 262) .一方,grey eyes はフランス語で創案された des yeux vaires の翻訳だろうといわれている.ただし,この vaires なる形容詞の解釈も,色合いと輝きのいずれを表わしたのか不明であり,grey eyes の解釈に必ずしもヒントを与えてくれない.
・ Andrew, Malcolm and Ronald Waldron, eds. The Poems of the Pearl Manuscript. 3rd ed. Exeter: U of Exeter P, 2002.
・ Gollancz, Israel, ed. Sir Gawain and the Green Knight. EETS os 250. 1950.
・ Tolkien, J. R. R. and E. V. Gordon, eds. Sir Gawain and the Green Knight. 2nd ed. Rev. Norman Davis. Oxford: Clarendon, 1967.
・ Barron, W. R. J., ed. Sir Gawain and the Green Knight. Manchester: Manchester UP, 1974.
・ Silverstein, Theodore, ed. Sir Gawain and the Green Knight. Chicago: U of Chicago P, 1983.
・ Brewer, D. S. "The Ideal of Feminine Beauty in Medieval Literature, Especially 'Harley Lyrics', Chaucer, and Some Elizabethans." The Modern Language Review 50 (1955): 257--69.
2012-05-04 Fri
■ #1103. GSL による Zipf's law の検証 [lexicology][statistics][frequency][zipfs_law][corpus]
[2012-05-02-1], [2012-05-03-1]の記事で取り上げてきた Zipf's law を検証(というよりは体験)するために,General Service List (GSL) の最頻2000語余りのデータを利用して計算してみた(データファイルはこちら).
![]()
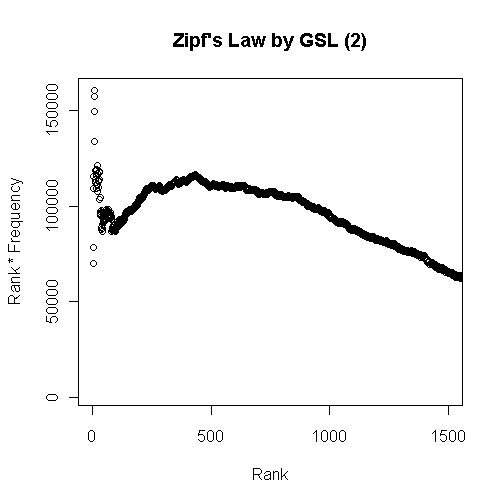
最初のグラフは頻度順位と頻度を掛け合わせたグラフで,頻度順で100位ほどまでの語を対象とした.以下はひたすら漸減してゆくのみなので省略.累積頻度のグラフを作成するまでもなく,最頻の数十語ほどで延べ語数のほとんどを覆ってしまう様子がよくわかる.
次のグラフは,Zipf's law によると定数になるとされる頻度順位と頻度の積を縦軸にとったものである.上位数十語までは「定数」は上下に大きく揺れて安定しないが,以後1000語ぐらいまでは,緩やかな増減はあるものの,落ち着く.その後のグラフ外ではひたすら漸減を続ける.したがって,「定数」を云々できるのは大目に見ても上位1000語ぐらいまでだろう.
これを法則と呼ぶのはあまりに外れていると考えるか,統計的傾向がよく出ているととらえるかは,観察者の見方ひとつである.Zipf's law における「定数」は「およそ定数」と解釈するのが暗黙の了解だが,「およそ」の幅がどの程度であるのかは明示されていない.また,Zipf's law が主張しているのと異なり,グラフの線は頻度をとるコーパスのサイズにも依存するようだ.
2012-05-03 Thu
■ #1102. Zipf's law と語の新陳代謝 [information_theory][frequency][statistics][zipfs_law][shortening][language_change]
昨日の記事[2012-05-02-1]で Zipf's law について概説した.Zipf's law には派生した「法則」が多くあり,その1つに,[2012-04-22-1]の記事「#1091. 言語の余剰性,頻度,費用」でも指摘した「言語要素は,頻度が高ければ音形が短い」というものがある.これを,より動的に,通時的に表現すると「言語要素は,頻度が高くなれば音形が短くなる」となる.ある語の頻度が高くなってゆくと,ある程度の遅延はあるものの,その音形が短くされてゆく傾向のあることは,私たちも経験的によく知っていることである.「#878. Algeo と Bauer の新語ソース調査の比較」([2011-09-22-1]) や「#879. Algeo の新語ソース調査から示唆される通時的傾向」([2011-09-23-1]) で見たとおり,現代英語の新語ソースとして短縮 (shortening) による語形成が増加しており,例には事欠かない.
この Zipf's law の派生法則のもつ共時的意義と通時的意義を合わせて考えると,語の頻度と長さによって,それが老いゆく語 (senescent word) なのか,生まれつつある語 (nascent word) なのかを区別できるという可能性が生じる.Zipf 著 Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology の書評を著わした Chao (399) より,関連箇所を引用しよう.
A very interesting application of the tool analogy is that of senescent and nascent tools in connection with the Principle of Economical Specialization. Reasoning from tool efficiency yields the result that 'whenever we find a tool (or word) whose magnitude is smaller than that of its neighbors in the frequency range, we may conclude that the tool (or word) of below-average size is an older tool (or word) whose usage is on the decrease (hereinafter we shall call this a senescent tool)', and 'whenever we find a tool (or word) whose magnitude is above average for its frequency, we may conclude not only that it is a newer tool (or word), but that its usage may well be directed toward an increase (hereinafter we shall call this a nascent tool)' (72). The application to words is verified to a fair degree for English of various periods (111). By regarding all behavior as work and words as tools, the analogy becomes a case and the qualifier 'or word' can be omitted.
音形の比較的短いある単語 A を考える.Zipf's law によれば,A は比較的頻度の高い語だと予想されるが,実際には同程度の頻度を示す他の多くの語に比べると音形が短すぎたとする.この場合,おそらく A はさかりを過ぎて頻度が徐々に低まってきた senescent word と考えてよいだろう.反対に,音形の比較的長いある単語 B を考える.Zipf's law によれば,B は比較的頻度の低い語だと予想されるが,実際には同程度の頻度を示す他の多くの語に比べると音形が長すぎたとする.この場合,おそらく B はこれから頻度がますます増してゆき,短縮を起こしてゆくと予想される nascent word と考えてよいだろう.これは,Zipf's law に,冒頭に述べた時間的遅延とを掛け合わせた応用法則といってよい.
通常 Zipf's law は静的で共時的な統計的法則ととらえられているが,動的で通時的な観点から,語の新陳代謝の法則として再解釈してみるとおもしろい.
・ Chao, Y. R. "Review of Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology by George Kingsley Zipf." Language 26 (1950): 394--401.
2012-05-02 Wed
■ #1101. Zipf's law [information_theory][frequency][statistics][language_change][zipfs_law][shortening][pragmatics][zipfs_law]
##1089,1090,1091,1098 の記事で,情報理論 (information theory) が言語学に与えてくれる知見について,いくつか見てきた.情報理論からの貢献として,最もよく知られているものの1つに,アメリカの言語学者 George Kingsley Zipf (1902--50) が1949年に Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology において提唱した Zipf's law (ジップの法則)がある.語の頻度についての経験的な法則であり,語の頻度を f とし,その頻度の順位を r とすると,その積 C はほぼ定数となるという.
r × f = C
この法則は,言語,テキストの主題,著者,その他の言語的な変数にかかわらず成り立つとされるが,実際には頻度が最高および最低の語群については誤差の大きいことがわかっており,信頼性は高くないとして批判も多い.また,r (頻度順位)は当然ながら f (頻度)に依存しており,f が増えれば r が減るのは自明であるから,その積が近似値をとるということは驚くべき帰結ではない,一種のトートロジーであるという批判がある.しかし,経験的事実に照らして法則とまではいわずとも傾向をよく表わしているということはでき,これを明示的に指摘した意義は大きい.
Zipf's law の波及効果は多岐にわたる.例えば,この法則によれば,使用頻度の高い語からその使用頻度の累計を求めて行くと比較的少数の語で延べ語数の大部分を占めることから,学習基本語彙の設定に根拠を与えるものとなる.また,この法則に適合しない頻度分布を示す語彙があるとすれば,他の特殊な要因が関与している可能性が疑われるとされる(少数の語の頻度があまりに高すぎれば語彙の貧弱化が生じていると診断されるし,頻度の低いはずの語が高頻度で用いられている場合には爆発的な新造語彙や精神分裂症が原因と想定される等々).
Zipf's law は,人間の行動を司るとされるより大きな原則,the Principle of Least Effort (最小努力の原則)の一部であり,その言語への応用は,上記の最もよく知られた頻度と頻度順の関係の公式化のみならず,他の公式の提案にも及んでいる.例えば,語の頻度と語の長さは反比例の関係にある,というものもある.最頻語は単音節であることが多いという事実(音節数の分布調査については ##348,349,355 を参照)や,頻度が高くなると頭字語などのように短縮・省略されることが多いという事実も,この公式で説明される.ほかには,ある頻度範囲とそれに属する語の数の関係を表わす公式,調音の難しい音素は頻度が低いとする原則など,派生した法則は数多い.語用論の cooperative principle (協調の原則)における量の格律「(その状況において)必要とされている(だけの)情報を与えよ」とも関与するだろう."effort" の定義などの難しい問題が残っており,また最小努力が人間の行動を司る唯一の原則であるとは考えることもできないが,真理の一面をついたものとして重要な学説であることは間違いない.
なお,諸文献では,上記のいずれの原則も Zipf's law として言及されることがあり,また Zipf's laws と複数形でまとめられたり,the Principle of Least Effort と総括されたりすることもあるので注意が必要である.Zipf の著書の書評としては Chao を参照.類似の統計的法則については,Crystal (86--87) を参照.
・ Chao, Y. R. "Review of Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology by George Kingsley Zipf." Language 26 (1950): 394--401.
・ Crystal, David. The Cambridge Encyclopedia of Language. 2nd ed. Cambridge: CUP, 1997.
2012-05-01 Tue
■ #1100. Farsi の形容詞区分の通時的な意味合い [adjective][loan_word][lexicology][suffix][semantic_change][prediction_of_language_change][register][lexical_stratification]
昨日の記事[2012-04-30-1]で Farsi による「#1099. 記述の形容詞と評価の形容詞」の区分を見た.記述的な Class A,評価的な Class B,両性質を兼ね備えた Class C という区分は,共時的な観点からの区分だが,それぞれのクラスに属する形容詞を対照して眺めていると,通時的な意味合いが浮き上がってくる.Farsi は次の2点を指摘する (56--58) .
(1) Class A から Class C へと所属変更した形容詞がいくつかある.もともとは記述的な "concerning X" ほどの語義を有していた Class A 形容詞が,評価的な "worthy of X" ほどの語義を獲得し,新旧の語義を合わせもつ結果となっている.English, American, Christian, logical, philosophical, scientific などが,このような通時的経過をたどった.
(2) 上記のような例から推測するに,現在 Class A に属する形容詞が,将来,評価的な意味を獲得して Class C へ移行するということがあり得るのではないか.例えば,phonemic は「音素の」という記述的な語義をもつ典型的な Class A 形容詞だが,音素という考え方を軽視する音韻論を批判的に指して *unphonemic と表現すれば,その裏返しとしての *phonemic も評価的な語義を獲得することになり,Class C と認定されることになる.Class A に属するどの形容詞にも,評価的語義を獲得する機会は開かれている.
Class A から Class C への通時的移行,あるいは意味の発展は,使用域 (register) に応じてみられる記述的語義と評価的語義のあいだの揺れという共時的な事実として表出してくる.例えば,mental は標準的な用法では記述的だが,非標準的な用法では評価のこもった「精神のおかしい」という意味を帯びる.aesthetic は通常は記述的にも評価的にも用いられるが,美学の文脈では,もっぱら記述的に用いられるだろう.
Farsi は,Class A から Class C への方向しか取り上げていないが,論理的にはそれ以外の方向の変化もあり得るとは述べている.しかし,非評価的な語が評価的な語義を帯びるという意味変化は,その逆よりも遥かに多いだろうと直感される.客観から主観への方向を主張する文法化 (grammaticalisation) しかり,[2011-03-11-1]の記事「#683. semantic prosody と性悪説」で示唆した人間の批判精神しかり.Hotta (2011) で調査した形容詞接尾辞 -ish の軽蔑的意味の獲得でも,関連する問題を扱った([2009-09-07-1]の記事「#133. 形容詞をつくる接尾辞 -ish の拡大の経路」も参照).Farsi の形容詞の分類は,このように,意味変化の方向の問題,意味変化と使用域の問題などにも示唆を与えてくれる.
もう1つ,通時態との関連で議論しておきたいのは,Farsi の分類と借用あるいは語種との関係である.昨日の記事の冒頭でも述べたが,「#334. 英語語彙の三層構造」 ([2010-03-27-1]) やその他の三層構造の記事で見てきたとおり,本来語は評価的で,(Greco-Latin 系)借用語は記述的であるような語のペアが多い.このような共時的な分布を通時的な観点から解釈すると,次のような歴史を仮定することができるのではないか.古英語では,形容詞はほぼ本来語のみであり,意味にしたがって Class A, B, C の3種類があった.中英語以降,フランス語やラテン語から大量の形容詞が借用され([2011-02-16-1]の記事「#660. 中英語のフランス借用語の形容詞比率」),その多くは記述的語義をもっていたため,Class A や Class C に属していた本来語はその圧力に屈して対応する記述的語義を失っていった.つまり,本来語は主として評価的語義をもった Class B に閉じ込められた.一方,借用語も次第に評価的語義を帯びて Class B や Class C へ侵入し,そこでも本来語を脅かした.その結果としての現在,借用語はクラスにかかわらず広く分布しているが,本来語は主要なものが Class B に属しているばかりである.
以上が大雑把な仮説である.「本来語」や「借用語」は,より正確には「本来形態素」や「借用形態素」と呼ぶほうがよいかもしれないし,behavioural や mannerly などの混種語 ( hybrid ) の扱いを仮説内でどのように位置づけるべきかも考える必要がある.昨日掲げた Farsi の形容詞リストがどのように作成されたもので,どの程度網羅的なのかなども検証する必要があろう.
評価的語義の獲得,使用域,本来語と借用語―――このような問題の交差点として,Farsi の形容詞分類をとらえなおすことができるように思われる.英語語彙の三層構造を理解するためにも,そして日本語語彙の三層構造([2010-03-28-1]の記事「#335. 日本語語彙の三層構造」)の理解のためにも,魅力あるテーマとなりそうだ.
・ Farsi, A. A. "Classification of Adjectives." Language Learning 18 (1968): 45--60.
・ Hotta, Ryuichi. "The Suffix -ish and Its Derogatory Connotation: An OED Based Historical Study." Journal of the Faculty of Letters: Language, Literature and Culture 108 (2011): 107--32.
2026 : 01 02 03 04 05 06 07 08 09 10 11 12
2025 : 01 02 03 04 05 06 07 08 09 10 11 12
2024 : 01 02 03 04 05 06 07 08 09 10 11 12
2023 : 01 02 03 04 05 06 07 08 09 10 11 12
2022 : 01 02 03 04 05 06 07 08 09 10 11 12
2021 : 01 02 03 04 05 06 07 08 09 10 11 12
2020 : 01 02 03 04 05 06 07 08 09 10 11 12
2019 : 01 02 03 04 05 06 07 08 09 10 11 12
2018 : 01 02 03 04 05 06 07 08 09 10 11 12
2017 : 01 02 03 04 05 06 07 08 09 10 11 12
2016 : 01 02 03 04 05 06 07 08 09 10 11 12
2015 : 01 02 03 04 05 06 07 08 09 10 11 12
2014 : 01 02 03 04 05 06 07 08 09 10 11 12
2013 : 01 02 03 04 05 06 07 08 09 10 11 12
2012 : 01 02 03 04 05 06 07 08 09 10 11 12
2011 : 01 02 03 04 05 06 07 08 09 10 11 12
2010 : 01 02 03 04 05 06 07 08 09 10 11 12
2009 : 01 02 03 04 05 06 07 08 09 10 11 12
最終更新時間: 2026-06-26 03:46
Powered by WinChalow1.0rc4 based on chalow