2014-04-21 Mon
■ #1820. c-command [syntax][generative_grammar][terminology][ppcme2][ppceme][ppcmbe]
「#310. PPCMBE で広がる英語統語論の通時研究」 ([2010-03-03-1]) で,Penn Parsed Corpora of Historical English を紹介した.Helsinki Corpus をベースとしながらも拡張を加えた歴史英語コーパス群で,詳細に構文解析された Penn-Treebank format による統語ツリーもろとも検索できるのが最大の特徴である.タグや注釈の体系が複雑で,CorpusSearch なる特殊なプログラムを用いて検索する必要もあり,初心者が使いこなすには敷居が高いが,統語的に明確に規定された例文を集めるといった用途では,今のところ Penn 系の構文解析コーパス (PPC) にかなうものはない.
PPC の構文解析の理論的基盤は生成文法だが,用いられる術語は生成理論の特殊化したヴァージョンのものではなく,一般的・基本的なものなので,理論に精通していなくとも何とか利用はできる.例えば,CorpusSearch の命令群に,"Dominates", "iDominates" (=immediately dominates), "HasSister", "IsRoot" などがあるが,統語ツリーのいろはを知っていれば,これらの用語が指す統語関係を理解することは難しくない.
しかし,上に挙げたものよりも少し理論がかった命令に,"CCommands" というものがある.c-command あるいは c-統御とは,1980年代初期に発展した束縛理論 (binding theory) において広く言及された統語関係である.束縛理論は,UG (universal grammar) の一般原則のなかでも中核をなすものとして当時こぞって研究された理論であり,とりわけ再帰代名詞などに代表される照応形 (anaphora) ,代名詞,その他の名詞句と,それらの先行詞との関係を規定する原則を追究した.その理論的発展の過程で,とりわけ重要とされるようになった統語関係の1つが,c-統御である.ほかに,関連の深いものに束縛 (binding) と統率 (government) がある.
以下で,c-統御 (c-command) と束縛 (binding) について概説しよう.下の架空の統語ツリーにおいて,
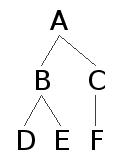
・ B は C と F を c-統御している
・ C と F はともに B, D, E を c-統御している
・ D は E を,E は D を c-統御している
と言われる.定義風にいえば,「節点 X を支配している最初の枝分かれ節点が別の節点 Y を支配しているとき,X は Y を c-command する」(渡辺,p. 86).
生成文法で理論上 c-統御が重要視されたのは,再帰代名詞とそれが指す先行詞の関係を規定するために,c-統御という統語関係が決定的な役割を果たすことがわかってきたからだ.以下の2つの文を考えよう.
(1) *John's mother criticized himself.
(2) John's mother criticized herself.
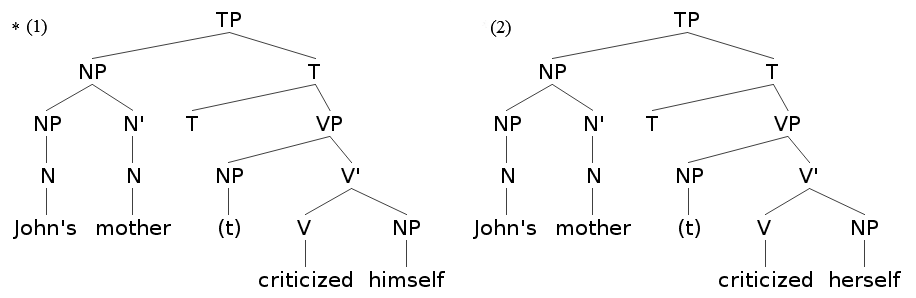
非文の (1) では,"John" に相当する NP を支配している最初の枝分かれ節点は TP のすぐ下の NP であるから,"John" は "mother" を c-command していることにはなっても,"himself" を c-command していることにはならない."himself" の立場からいえば,"John" に c-command されていないことになる.このような場合,すなわち "himself" が "John" に束縛されていない場合には,照応が成り立たないというのが,英語統語論でのルールである.
一方,正文の (2) では,再帰代名詞 "herself" は "John's mother" を表す NP を先行詞としているが,この NP を支配している最初の枝分かれ節点は TP であるから,"John's mother" は "herself" を c-command していることになる."herself" の立場からいえば,"John's mother" に c-command されており,束縛されているので,照応が成り立つ.生成文法家は,c-統御,さらに束縛という統語関係の規程を通じて,英語の照応に関する一般原則が見いだされたと考えた.
PPC の話に戻ると,例えば his ouermoch fearinge of you のような名詞句を検索するのに,"CCommands" という命令により「代名詞が別の代名詞を c-統御しているような名詞句」という統語条件を設定すればよい.複雑な統語条件のもとで,かつ authentic な例文を取り出したいときに,PPC と CorpusSearch は威力を発揮する.
・ 渡辺 明 『生成文法』 研究社,2009年.
2013-03-25 Mon
■ #1428. ye = the [palaeography][spelling][thorn][th][pub][alphabet][graphemics][ppcme2][ppceme][ppcmbe][corpus]
「#13. 英国のパブから ye が消えていくゆゆしき問題」 ([2009-05-11-2]) で,ye や ye が定冠詞 the の代わりに用いられる擬古的な綴字について触れた.
þ (thorn) と y との字形の類似による混同は中英語期から見られたが,この混乱がいわば慣習化したのは þ が衰退してからである.þ が廃れていったのは,「#1329. 英語史における eth, thorn, <th> の盛衰」 ([2012-12-16-1]) や「#1330. 初期中英語における eth, thorn, <th> の盛衰」 ([2012-12-17-1]) で確認したように,Helsinki Corpus の時代区分によるME第4期 (1420--1500) 以降である.それに呼応して,擬古的な定冠詞 ye は近代英語期に入ってから頻度を増してきた.OED を参照すると,ye の使用は中英語から17世紀にかけて,とある.
では,中英語から初期近代英語にかけて,具体的にどの程度 ye が用いられたのだろうか.これを調べるために PPCME2, PPCEME, PPCMBE のPOSファイル群で "ye/D" を検索してみた.MEからは1例のみ,EModEから1259例,LModEから5例が挙がった.各コーパスはおよそ130万語,180万語,100万語からなるが,総語数を考えずとも,傾向は歴然としている.初期近代英語で急激に現われだし,一気に衰微したということである.ただし,PPCEME の1259例のうち975例は,The Journal of George Fox (1673--74) という1作品からである.ほかには10例以上現われるテキストが4つあるのみで,残りは20テキストに少数例ずつ散らばっているにすぎないという分布ではある.隆盛を極めたというよりは,地味な流行といった感じだろうか.
先日,ロンドンを訪れた際に,145 Fleet St の老舗パブ "Ye Olde Cheshire Cheese" と 42 Ludgate Hill の "Ye Olde London" の看板を撮影してきた.残念ながらここでエールを一杯やる機会はなかったけれども,別のパブでは一杯(だけではなく)やりました.


2013-03-13 Wed
■ #1416. shew と show (2) [spelling][corpus][ppcmbe][johnson][pronunciation_spelling]
昨日の記事「#1414. shew と show (1)」 ([2013-03-12-1]) の続編.昨日は Helsinki Corpus を用いて初期近代英語期までの shew と show の分布を調査したが,今回は後期近代英語期における分布を PPCMBE (Penn Parsed Corpus of Modern British English; see [2010-03-03-1]) によって簡単に調査した.
PPCMBE は,1700年から1914年までの総語数948,895語のコーパスである.これを約70年ずつの3期に分け,見出し語化された pos ファイル群を対象に検索することで shew 系列と show 系列の token 数を数え上げた.結果は以下の通り.
| shew 系列 | show 系列 | 総語数 | |
|---|---|---|---|
| 1700--1769 | 80 | 25 | 298,764 |
| 1770--1839 | 79 | 86 | 368,804 |
| 1840--1914 | 17 | 162 | 281,327 |
大雑把な数え上げではあるが,第1期と第3期は明らかに分布に有意差が出る.1800年前後を境に形勢が逆転し,show が優勢になってきたことがわかるだろう.なぜ形勢が逆転したかという理由については,Johnson の Dictionary (1755) の記述が参考になる."To SHOW" の見出しのもとに次のようにあるので,引用しておこう.
This word is frequently written shew; but since it is always pronounced and often written show, which is favoured likewise by the Dutch schowen, I have adjusted the orthography to the pronunciation.
つまり,spelling_pronunciation ならぬ pronunciation_spelling の例ということになるのだろうか.show ほどの高頻度語でこのような一種の理性的な過程が作用したというのは不思議にも思えるが,中英語期以来,劣勢とはいえ show 系列が一応は行なわれていたという事実が背景にあったことは,確かに効いているだろう.
2011-06-09 Thu
■ #773. PPCMBE と COHA の比較 [corpus][coha][ppcmbe][lmode][adjective][comparison][inflection][representativeness]
本ブログでも何度か取り上げている2つの歴史英語コーパス PPCMBE ( Penn Parsed Corpus of Modern British English; see [2010-03-03-1]. ) と COHA ( Corpus of Historical American English; see [2010-09-19-1]. ) について,塚本氏が『英語コーパス研究』の最新号に研究ノートを発表している.両者とも2010年に公開された近代英語後期のコーパスだが,それぞれ英米変種であること,また編纂目的が異なることから細かな比較の対象には適さない.しかし,代表性をはじめとするコーパスの一般的な特徴を比べることは意味があるだろう.
PPCMBE は1700--1914年のイギリス英語テキスト約949,000語で構成されており,Parsed Corpora of Historical English の1部をなす.同様に構文解析されたより古い時代の対応するコーパスとの接続を意識した作りである.有料でデータを入手する必要がある.一方,COHA は1810--2009年のアメリカ英語テキスト4億語を収録した巨大コーパスである.こちらは,構文解析はされていない.COHA は無料でオンラインアクセスできるため使いやすいが,インターフェースが固定されているので柔軟なデータ検索ができないという難点がある.
コーパスの規模とも関係するが,PPCMBE は代表性 (representativeness) の点で難がある.PPCMBE のコーパステキストを18ジャンルへ細かく分類し,テキスト年代を10年刻みでとると,サイズがゼロとなるマス目が多く現われる.これは,区分を細かくしすぎると有意義な分析結果が出ないということであり,使用に際して注意を要する.
一方,COHA のコーパステキストは Fiction, Popular Magazines, Newspapers, Non-Fiction Books の4ジャンルへ大雑把に区分されている.細かいジャンル分けの研究には利用できないが,10年刻みでも各マス目に適切なサイズのテキストが配されており,代表性はよく確保されている.ただし,Fiction の構成比率がどの時代も約50%を占めており,Fiction の言語の特徴(特に語彙)がコーパス全体の言語の特徴に影響を与えていると考えられ,分析の際にはこの点に注意を要する.
塚本氏は,両コーパスの以上の特徴を,後期近代英語における形容詞の比較級・最上級の問題によって示している.CONCE (Corpus of Nineteenth-Century English) を用いた Kytö and Romaine の先行研究によれば,19世紀の間,比較級の迂言形に対する屈折形の割合は,30年刻みで世紀初頭の57.1%から世紀末の67.8%へと増加しているという.同様の調査を COHA と PPCMBE で10年刻みに施したところ,前者では1810年の64.7%から1910年の74.3%へ着実に増加していることが確かめられたが,後者では1810年の79.4%から1910年の78.0%まで増減の揺れが激しかったという(塚本,p. 56).しかし,CONCEと同様の30年刻みで分析し直すと,PPCMBE でも有意な変化をほぼ観察できるほどの結果がでるという.
コーパスはそれぞれ独自の特徴をもっている.よく把握して利用する必要があることを確認した.関連して,[2010-06-04-1]の記事「流れに逆らっている比較級形成の歴史」を参照.
・ 塚本 聡 「2つの指摘コーパス---その代表性と類似性」『英語コーパス研究』第18号,英語コーパス学会,2011年,49--59頁.
・ Kytö, M. and S. Romaine. "Adjective Comparison in Nineteenth-Century English." Nineteenth-Century English: Stability and Change. Ed. M. Kytö, M. Rydén, and E. Smitterberg. Cambridge: CUP, 2006. 194--214.
2010-03-03 Wed
■ #310. PPCMBE で広がる英語統語論の通時研究 [corpus][ppcmbe][syntax]
Penn Parsed Corpora of Historical English のプロジェクトの成果として,University of Pennsylvania から PPCMBE ( Penn Parsed Corpus of Modern British English ) が出版された.これにより,以下の通り,古英語から現代英語にわたる各時期のイギリス英語の統語タグ付きコーパスが出そろったことになる.
・ YCOE: Taylor, Ann, Anthony Warner, Susan Pintzuk, and Frank Beths. York-Toronto-Helsinki Parsed Corpus of Old English Prose, first edition. Oxford Text Archive, 2003. (1.5 million words)
・ PPCME2: Kroch, Anthony and Ann Taylor. Penn-Helsinki Parsed Corpus of Middle English, second edition. University of Pennsylvania, 2000. (1.3 million words)
・ PPCEME: Kroch, Anthony, Beatrice Santorini, and Ariel Diertani. Penn-Helsinki Parsed Corpus of Early Modern English, first edition. University of Pennsylvania, 2004. (1.8 million words)
・ PPCMBE: Kroch, Anthony, Beatrice Santorini, and Ariel Diertani. Penn-Hensinki Parsed Corpus of Modern British English, first edition. University of Pennsylvania, 2010. (1.0 million words)
いずれも Helsinki Corpus をベースとしたソースに対して同一の annotation scheme による統語的タグが付加されており,互いに連携できるように作られている.視点は異なるが,およそ1410年から1695年までのあいだの書簡集となるコーパス PCEEC も同様の annotation scheme でタグ付けされており,やはり連携が可能である(ただし利用は限定的).
・ PCEEC: Taylor, Ann, Arja Nurmi, Anthony Warner, Susan Pintzuk, and Terttu Nevalainen. Parsed Corpus of Early English Correspondence, first edition. Oxford Text Archive, 2006. (2.2 million words)
現時点で,あわせて 7.8 million words が通時的かつ統語的な視点からタグ付けされ,一般に利用可能になったことになる.
一昨日と昨日と,東京外国語大学のグローバルCOEプログラム「コーパスに基づく言語学教育研究拠点」 ( Corpus-based Linguistics and Language Education ) 主催で,"Corpus Analysis and Diachronic Linguistics" と題する国際シンポジウムが同大学で開かれ,Anthony Kroch や Merja Kytö など英語史コーパス言語学の著名な学者も講演した(ポスターはこちら).PPCMBE の出版直後ということもあったので,特に Anthony Kroch が何を話すかに興味をもっていた.一連の歴史英語コーパスを使った統語研究の一端でも見せてくれるのかなと期待していたが,驚いたことに,歴史英語コーパスと歴史フランス語コーパスを組み合わせた「英仏対照通時統語コーパス言語学」とでもいうべき研究の可能性を示す発表だった.今や University of Pennsylvania は英語に限らず諸言語のコーパス作成の拠点となっており,あれやこれやと組み合わせるとこんなこともあんなこともできるんだぞというところを見せつけられたとでもいおうか.
ちなみに,取り上げられた話題は英仏の direct object topicalization の歴史で,英語の場合には 1151--1250 年期から 1251--1350 年期にかけて,直接目的語の前置される頻度が一気に減少したという.
Powered by WinChalow1.0rc4 based on chalow