hellog〜英語史ブログ / 2011-11
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
2026 : 01 02 03 04 05 06 07 08 09 10 11 12
2025 : 01 02 03 04 05 06 07 08 09 10 11 12
2024 : 01 02 03 04 05 06 07 08 09 10 11 12
2023 : 01 02 03 04 05 06 07 08 09 10 11 12
2022 : 01 02 03 04 05 06 07 08 09 10 11 12
2021 : 01 02 03 04 05 06 07 08 09 10 11 12
2020 : 01 02 03 04 05 06 07 08 09 10 11 12
2019 : 01 02 03 04 05 06 07 08 09 10 11 12
2018 : 01 02 03 04 05 06 07 08 09 10 11 12
2017 : 01 02 03 04 05 06 07 08 09 10 11 12
2016 : 01 02 03 04 05 06 07 08 09 10 11 12
2015 : 01 02 03 04 05 06 07 08 09 10 11 12
2014 : 01 02 03 04 05 06 07 08 09 10 11 12
2013 : 01 02 03 04 05 06 07 08 09 10 11 12
2012 : 01 02 03 04 05 06 07 08 09 10 11 12
2011 : 01 02 03 04 05 06 07 08 09 10 11 12
2010 : 01 02 03 04 05 06 07 08 09 10 11 12
2009 : 01 02 03 04 05 06 07 08 09 10 11 12
2011-11-30 Wed
■ #947. 現代英語の前置詞一覧 [preposition][conjunction]
前置詞,接続詞,助動詞,冠詞,代名詞,関係詞などは機能語 (function word) あるいは文法語 (grammatical word) と呼ばれ,語彙としては閉じた類 (closed class) を形成すると言われる.一方,名詞,動詞,形容詞,副詞は内容語 (content word) と呼ばれ,開いた類 (open class) を形成する.
理論上,閉じた類とは,そこに含まれる語の数が有限であり,新たな語彙項目が追加されることがなく,したがって網羅的な一覧を作ることができることを含意するが,実際には閉じた類へ新しい語彙項目が追加されるということはある.例えば,前置詞は,閉じた類の1つではあるが,含まれている語の数が比較的多く,なおかつその多くは歴史の過程でリストに加えられてきた語彙項目である.複合や他品詞からの派生により形成された前置詞も少なくない.
以下は,Quirk et al. (Sections 9.7--9.8, 9.10--9.11) に挙げられている独自の分類による前置詞の一覧を,整理したものである.英語にこれほど前置詞があったのかと驚くばかりだ.
1. Simple prepositions
(a) Monosyllabic prepositions
as, at, but, by, down, for, from, in, like, near (to), of, off, on, out, past, per, pro, qua, re, round, sans, since, than, through (thru), till, to, up, via, while, with
(b) Polysyllabic prepositions
about, above, across, after, against, agin, along, alongside, amid(st), among(st), anti, around, atop, before, behind, below, beneath, beside, besides, between (tween, twixt), beyond, circa, despite, during, except, inside, into, notwithstanding, onto, opposite, outside, outwith, over, pace, pending, throughout, toward(s), under, underneath, unlike, until, unto, upon, versus (v, vs), vis-à-vis, within, without
2. Marginal prepositions
bar, barring, excepting, excluding; save
concerning, considering, regarding, respecting, touching
failing, wanting
following, pending
given, granted, including
less, minus, plus, times, over
worth
3. Complex prepositions
(a) Two-word sequences
up against, as per
as for, but for, except for
apart from, aside from, away from, as from
ahead of, as of, back of, because of, devoid of, exclusive of, inside of, instead of, irrespective of, off of, out of, outside of, regardless of, upwards of, void of
according to, as to, close to, contrary to, due to, near(er) (to), next to, on to, owing to, preliminary to, preparatory to, previous to, prior to, pursuant to, subsequent to, thanks to, up to
along with, together with
à la, apropos (of)
(b) Three-word sequences
in aid of, (in) back of, in behalf of, in cause of, in charge of, in consequence of, in (the) face of, in favour of, in front of, in (the) light of, in lieu of, in need of, in place of, in (the) process of, in quest of, in respect of, in search of, (in) spite of, in view of
in accordance with, in common with, in comparison with, in compliance with, in conformity with, in contact with, in line with
by dint of, (by) means of, by virtue of, (by) way of
on account of, on behalf of, on (the) ground(s) of, on the matter of, (on) pain of, on the part of, on the strength of, on top of
as far as, at variance with, at the expense of, at the hands of, (for) (the) sake of, for/from want of, in exchange for, in return for, in addition to, in relation to, with/in regard to, with/in reference to, with/in respect to, with the exception of
この一覧には頻度,用法,使用域などの限られているものも含まれているが,異形を除くと194個の(群)前置詞が挙げられていることになる.閉じた類とはいえ,なかなか豊かな語類だ.
・ Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech, and Jan Svartvik. A Comprehensive Grammar of the English Language. London: Longman, 1985.
2011-11-29 Tue
■ #946. 名詞複数形の歴史の概要 [plural][number]
名詞複数形の発展(主として初期中英語期)を長らく研究しているのだが,入れ込みすぎているためか,かえってブログ記事として概要を書きづらい.しかし,概要くらいは書き留めておくとやはり便利なので,以下に教科書的な記述を与えておく.2つ引用を挙げるうち,先のものは簡易版要約として拙著論文 (Hotta, "Review") から,後のものは詳細版要約として Baugh and Cable のものからである.
The s-plural was fairly quickly generalised at the expense of other plural formations such as an n-ending, a vowel-ending, a zero-ending, and an i-mutation, first in the northern/eastern dialects of England in Late Old English (LOE). In the course of Early Middle English (EME), the trend was followed slowly but surely by the southern/western dialects. Although there long persisted older plural formations such as n- and vowel-endings and even unchanged forms, the s-form finally dominated the plural system by the end of ME, with the exception of a handful of "irregular plurals" that have survived to this day. (95)
In early Middle English only two methods of indicating the plural remained fairly distinctive: the -s or -es from the strong masculine declension and the -en (as in oxen) from the weak . . . . And for a time, at least in southern England, it would have been difficult to predict that the -s would become the almost universal sign of the plural that it has become. Until the thirteenth century the -en plural enjoyed great favor in the south, being often added to nouns which had not belonged to the weak declension in Old English. But in the rest of England the -s plural (and genitive singular) of the old first declension (masculine) was apparently felt to be so distinctive that it spread rapidly. Its extension took place most quickly in the north. Even in Old English many nouns originally of other declensions had gone over to this declension in the Northumbrian dialect. By 1200 -s was the standard plural ending in the north and north Midland areas; other forms were exceptional. Fifty years later it had conquered the rest of the Midlands, and in the course of the fourteenth century it had definitely been accepted all over England as the normal sign of the plural in English nouns. Its spread may have been helped by the early extension of -s throughout the plural in Anglo-Norman, but in general it may be considered as an example of the survival of the fittest in language. (160)
本当はこの記述のように簡単に説明しきれないからこそ突っ込んだ研究が成り立つのだが,概略としてはこの理解で間違いない.ただし,Baugh and Cable の引用の末尾に見られる,Anglo-Norman が英語の -s の発展に影響を与えた可能性があるという説は,今ではほぼ否定されており,私も否定されるべきと考える (Hotta, Development 154, 268 [Note 66]) .
・ Hotta, Ryuichi. "Review of The Development of the Nominal Plural Forms in Early Middle English." Studies in Medieval English Language and Literature 25 (2010): 95--112.
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
・ Hotta, Ryuichi. The Development of the Nominal Plural Forms in Early Middle English. Hituzi Linguistics in English 10. Tokyo: Hituzi Syobo, 2009.
2011-11-28 Mon
■ #945. either の2つの発音 [pronunciation][ame_bre]
現代英語 either の発音については,AmE /ˈiːðə/, BrE /ˈaɪðɚ/ が区別されると言われる.実際のところ,LPD3 の Preference polls では,AmE でも18%は /ˈaɪðɚ/ を用い,BrE でも13%は /ˈiːðə/ を用いるという.第1母音の音価の差は,英米変種を特徴づけているとは言えるかもしれないが,決定づけているとは言えないようだ.neither についても同様だろう.
近代英語期の問題の母音の変異についても,様々な言及がある.OED の説明を見てみよう.
The pronunciation (ˈaɪðə(r)), though not in accordance with the analogies of standard Eng., is in London somewhat more prevalent in educated speech than (ˈiːðə(r)). The orthoepists of 17th c. seem to give (ˈɛːðər, ˈeːðər); Jones 1701 has (ˈeːðər) and (ˈaɪðər), Buchanan (1766) has (ˈaɪðə(r)) without alternative (see Ellis, ''Early Eng. Pron.'' ix, x.). Walker (1791) says that (ˈiːðə(r)) and (ˈaɪðə(r)) are both very common, but gives the preference to the former on the ground of analogy and the authority of Garrick. Smart (1849) says that 'here is little in point of good usage to choose' between the two pronunciations, though in the body of his dictionary he, like earlier orthoepists, gives (ˈiːðə(r)) without alternative.
Jespersen は,/ˈiːðɚ/ の発音はスコットランド方言ではないかという説を紹介しながらも,20世紀半ばにおいては,その発音はむしろイングランドの南部方言で多く,北部方言では /ˈaɪðɚ/ が多いことを述べている (68) .この母音の歴史的な発達と分布については,わからないことが多い.
この語の古英語の形態は ǣȝhwæðer (ǣȝ "always" + hwæðer "whether") であり,"each of two" を意味した.しかし,14世紀初頭から選言的な "one or the other of two" の意味が発達した.これは,選言的意味をもっていた,似て非なる古英語の語 āhwæðer (ā "ever" + hwæðer "whether") との混同の結果だろう.古英語の副詞 ā "ever" は,every や each の語頭音にもその痕跡を残している([2011-08-07-1]の記事「#832. every と each」を参照).
関連して,says の母音の歴史については,[2010-10-20-1], [2010-10-22-1]の記事を参照.
・ Wells, J C. ed. Longman Pronunciation Dictionary. 3rd ed. Harlow: Pearson Education, 2008.
・ Jespersen, Otto. A Modern English Grammar on Historical Principles. Part 1. Sounds and Spellings. 1954. London: Routledge, 2007.
2011-11-27 Sun
■ #944. ration と reason [doublet][history_of_french][french][latin][etymology][loan_word]
英語語彙に散見される 2重語 (doublet) は,そのソース言語(方言)の組み合わせによって様々な種類がみられる.これまでの doublet の記事で取り上げてきた例は,フランス語絡みが多い.今回もフランス語からの借用語を扱うが,さらにその元であるラテン語の形態との間で2重語の関係を作っている例をみてみよう.
ラテン単語は,その娘言語であるフランス語へ伝わる際に音韻変化を経た.その音韻変化の1つに,ラテン語の典型的な名詞語尾 -tiō(nem) がフランス語で -son へと発達したというものがある.これにより,ラテン語 ratiōnem はフランス語 raison へ,同様に traditiōnem は trahison へ,pōtiōnem は poison へ,lectiōnem は leçon へと変化した.
音韻変化は原則として例外なしとすると,フランス語に -tion の形態は残らないはずだが,実際にはいくらでも存在する.それは,フランス語が,音韻変化を遂げた後に改めてラテン語から語源的な形態を借用した(あるいは復活させた)からである.その段階で,すでに,フランス語の内部において語源を一にする2つの異なる形態(フランス語形とラテン語形)が2重語として共存していたことになる.そして,フランス語におけるその2形態が,時期は必ずしも同じでないにせよ,そのまま英語へも借用され,2重語の関係がコピーされたのが,ration -- reason, tradition -- treason, potion -- poison, lection -- lesson のようなペアである.
ration -- reason には,ratio という同根語も英語に存在し,3重語 (triplet) を形成している.tradition はラテン語 trādere ("through" + "give") からの派生名詞で,「(次世代に)引き継ぐこと,明け渡すこと」が原義である.同語源の英単語 treason (裏切り)は「(人を)売り渡すこと」ほどの語義から発達した.英単語の tradition 自体も,15世紀末から17世紀までは「裏切り」の語義をもっていた.
[2011-02-09-1]の記事「#653. 中英語におけるフランス借用語とラテン借用語の区別」で見たように,フランス語とラテン語の語形は見分けるのが難しいことも多い.中世ではそれくらい両言語の差は小さく,それだけにラテン語にもある程度慣れていたフランスの書記たちは大いに混乱していた.古フランス語においては,フランス語形とラテン語形の併存は常態であり,その状況のなかで上記のような2重語が生み出された.そして,その余波は海峡を越えてイングランドへも伝わった.英語史の少なくとも一部は,このようにフランス語史と密接に関わっていることがわかるだろう.
このような2重語の例は,改めて英語語彙の多層性を見せてくれる例として覚えておきたい.
2011-11-26 Sat
■ #943. 頭韻の歴史と役割 [alliteration][reconstruction][germanic][glottal_stop]
[2011-07-02-1]の記事「#796. 中英語に脚韻が導入された言語的要因」で,ゲルマン語派に特徴的な韻の様式としての頭韻 (alliteration) について付随的に触れた.頭韻とは,古アイスランド語の韻文体 Edda や古英語の韻文に典型的に見られる「同一の子音(ときに母音)が近接して強勢を受ける音節に反復されること」(『新英語学辞典』)を特徴とする形式である.古英語の典型的な頭韻長行には aa:ax という構成が見られる.
中英語期には大陸より脚韻がもたらされ,頭韻は影が薄くなったが,14世紀にはイングランド中西部・北西部方言で限定的に復活した.そこでは,頭韻の前半行 (a-verse) の aa 型が標準化し,頭韻句 (alliterative phrase) と呼ばれる独特の固定表現が生まれた.例えば,いずれも "man on earth" を表わす gome vnder Gode, man vpon molde, segge vnder sunne などが繰り返し用いられた.中英語における頭韻の「復活」が文字通りの復活なのか,あるいは古英語の伝統の継承なのか,その背景については詳しく分かっておらず,英語史上,英文学史上の謎となっている.
近代英語期に入ると,頭韻は詩行の構成原理としては廃れ,もっぱら装飾的要素となった.しかし,チャイム効果 (chiming effect) をもたらす頭韻の技法は,ある意味では言語に普遍的とも言え,韻文に限らず,諺,慣用句,標語,表題,広告,早口ことばなどにおいて,現在にいたるまで広く利用され続けている.現代英語からの例を挙げよう.
(1) 語: flimflam, tittle-tattle
(2) 対句・慣用句: bed and breakfast, birds and beasts, cash and carry, confidence and cowardice, footloose and fancy-free, from top to toe, house and home, part and parcel, through thick and thin, with might and main
(3) 強意的直喩 (intensifying simile) あるいは俚諺的直喩 (proverbial simile): as blind as a bat, as bold as brass, as brisk as a bee, as clear as crystal, as cool as a cucumber, as dead as a door-nail, as dry as dust, as fit as a fiddle, as good as gold, as green as grass, as hungry as a hawk, as mad as a March hare, as queer as a Quaker, as strong as Samson, as sweet as summer
(4) 諺: Birth is much but breeding is more; Care killed the cat; Hold with the hare, and hunt with the hound; Look before you leap; Soon ripe, soon rotten; Wilful waste makes woeful want
(5) 早口ことば (tongue-twister): Peter Piper picked a peck of pickled peppers
(6) 公告・宣伝: Guinness is good for you, You can be sure of Shell
(7) 文学的修辞: fixed fate, free will, foreknowledge absolute (Milton); solid, so still and stable (J. Conrad); the great grey-green, greasy Limpopo River (Kipling)
(8) 表題: Love's Labour's Lost (Shakespeare); Mice and Men (J. Steinbeck); Pride and Prejudice (J. Austen); Twice-Told Tales (N. Hawthorne)
以上のように,現代でも頭韻には韻律的,修辞的,文体的な役割が認められるが,頭韻のもつゲルマン語比較言語学上の意義を忘れてはならない.古英語などで異なる母音により頭韻が形成されている事実は,母音に先行して声門閉鎖 (glottal stop) が行なわれていたことを示唆しており,文献には明示されない音韻の再建 (reconstruction) に寄与している.また,/sp/, /st/, /sk/ はそれ自身としか頭韻しないことから,2音合わせて音韻的単位をなしていたらしいことがわかる.頭韻は,このように古音の推定という比較言語学上の重要な問題に光を当ててくれるのである.
関連して,[2010-07-08-1]の記事「いかにして古音を推定するか」と[2011-05-25-1]の記事「#758. いかにして古音を推定するか (2)」を参照.
2011-11-25 Fri
■ #942. LAEME Index of Sources の検索ツール [laeme][web_service][cgi]
LAEME で Auxiliary Data Sets -> Index of Sources とメニューをたどると,LAEME が対象としているテキストソースのリスト (The LAEME Index of Sources) を,様々な角度から検索して取り出すことができる.LAEME のテキストデータベースを年代別,方言別,Grid Reference 別などの基準で分析したい場合に,適切なテキストの一覧を得られるので,LAEME 使いこなしのためには非常に重要な機能である.
しかし,もう少し検索式に小回りを利かせられたり,一覧の出力がコンパクトに表形式で得られれば使い勝手がよいだろうと思っていた.そこで,Index of Sources を独自にデータベース化し,SQL を用いて検索可能にしてみた.LAEME の使用者で,かつSQLを扱える人以外には何も役に立たないのだが,せっかく作ったので公開.
以下,使用法の説明.テーブル名は "ios" (for "Index of Sources") で固定.フィールドは,LAEME 本家の検索で対象となっている18のフィールドに加えて,整理番号としての "ID" と,テキスト情報の掲載されたオンラインページへの "URL" を加えた計20フィールド (ID, MS, TEXT_ID, FILE, DATE, TEXT, GRID, LOC, COMMENT, SAMPLING, TAGGED_WORDS, PLACE_NAMES, PERSONAL_NAMES, WORDS, SCRIPT, OTHER, STATUS, BIBLIO, CROSS_REF, URL) .select 文のみ有効.以下に,典型的な検索式を例として載せておく.
# Ancrene Wisse/Riwle のテキスト情報の取り出し
select TEXT_ID, MS, FILE, GRID, LOC, DATE, TEXT from ios where FILE like "%ar%t.tag" and TEXT like "%Ancrene%";
# Poema Morale のテキスト情報の取り出し
select TEXT_ID, MS, FILE, GRID, LOC, DATE, TEXT from ios where FILE like "%pm%t.tag" and TEXT like "%Poema%";
# Grid Reference の与えられているテキストの取り出し
select TEXT_ID, MS, FILE, GRID from ios where GRID != "000 000";
# DATE に "C13a" を含むテキストの取り出し
select TEXT_ID, DATE from ios where DATE like "%C13a%";
# 年代ごとに集計
select DATE, count(DATE) from ios group by DATE order by DATE;
# タグ付けされている語数をテキストごとに確認
select TEXT_ID, TAGGED_WORDS, PLACE_NAMES, PERSONAL_NAMES from ios;
# 全テキスト情報へのリンク集
select TEXT_ID, MS, FILE, URL from ios;
2011-11-24 Thu
■ #941. 中英語の言語変化はなぜ北から南へ伝播したのか [geography][me][wave_theory][geolinguistics][3sp]
古英語後期から中英語初期をへて中英語後期に至るまで,多くの言語変化がイングランドの北から南,より正確には北東から南西へと伝播していった.人称代名詞の she (she を参照)や they ([2011-04-10-1]を参照)の普及,3単現の -s の拡大,複数形の -s (Hotta の研究を参照)の伸長,古ノルド語からの多くの語彙の借用,そして英語史上最大の変化と言えるかもしれない屈折の水平化や文法性の消失も,北部・東部の方言が牽引した.現代のイギリス標準英語にかつての北部や東部の方言の痕跡が色濃いのは,中英語期に見られたこの「方向性」ゆえである.
しかし,なぜ北から南という方向なのか,伝播の原動力は何なのかという問題は,謎である.言語地理学 (linguistic geography or geolinguistics) では,言語変化は波紋状に伝播するという the wave theory が古くから唱えられている.それによれば,イングランドという池の北部に大きな石が投げ込まれ,その余波が何重もの波紋を描いて徐々に周囲へ,特に南部へと広がって行った,と説明できる.実際に,上記の諸変化は,概ね波状理論の示すとおりに伝播していったことが知られている(少なくとも,複数形の -s の伝播については拙著で確認した).だが,投げ込まれた石がなぜこれほどまでにエネルギーをもったのかが不明である.社会言語学では,通常,そのようなエネルギーは社会的に影響力のある地域(典型的には都市部)に発し,そこを起点として余波が地方へと伝播してゆくものと考えられており,南部のロンドンから北部の田舎へという方向ならば理解できるのだが,事実は逆である.なぜなのか.
この問題については拙著 (175) でも言及しているが,そこで引用した Thomason and Kaufman (274) からの一節を紹介しよう.
Until about 1225 innovations starting in the South were spreading northward (e.g., /aː/ > /oə/, 'ɣ' > w/y), after 1250 practically all innovations in English were starting in the North and spreading southward (e.g. lengthening of short stressed vowel in open syllable, dropping of final unstressed schwa, degemination, spread of third person singular present tense -es at the expense of -eth). No explanation (except that York, England's second city, is located in Deira) can as yet be offered for why the North should have been so influential on the Midlands and South from 1250 to 1400, since it was much poorer than the rest of England, and was constantly being raided by the Scots, with whom the Northerners (ruefully, one supposes) shared a dialect.
他所で,Thomason and Kaufman (289) は,Sawyer (174--75) を参照しながら次のようにも述べている.
. . . there was a great growth of quite profitable sheep-farming at the hands of Norse-origin or even Norse-speaking entrepreneurs in the eleventh century in the Lincolnshire Wolds (which lie in Lindsey, the major town being Louth) and in the Yorkshire Wolds (which lie in the East Riding of Yorkshire part of Deira, the major town being Bridlington), which lie right across the Humber from each other . . . .
こうした議論を受けながら,私は拙著 (175) において,しどろもどろに次のような意見を述べるにとどまった.
I cannot offer a strong alternative, but it is possible that as carriers of Norsified English in the North and East passed innovative linguistic features to neighbouring areas through person-to-person communication, the receiving areas willingly picked up the Norsified features as "faddish." For the time being, however, I would like to leave this question open.
この問題について最近 O'Neil (266) に見つけた別の意見を紹介しておこう.
Now why the northern Middle English system became that of all England is not at all clear. . . . After the return to English as the language of the English realm there may have been a (mistaken, note) feeling that it was in the north that real English resided, thus leading to it becoming the accepted model toward which the rest of England moved. This is an explanation of sorts, albeit not a very satisfactory one (1).
引用最後の (1) は脚注への参照で,その脚注には以下のようにある.
(1) It is, however, difficult to reconcile this explanation --- such as it is --- with the general London antipathy toward the northern dialects of Middle English. (266)
謎は深まる一方である.
・ Hotta, Ryuichi. The Development of the Nominal Plural Forms in Early Middle English. Hituzi Linguistics in English 10. Tokyo: Hituzi Syobo, 2009.
・ Thomason, Sarah Grey and Terrence Kaufman. Language Contact, Creolization, and Genetic Linguistics. Berkeley: U of California P, 1988.
・ Sawyer, P. H. The Age of the Vikings. 2nd ed. London: Edward Arnold, 1971.
・ O'Neil, Wayne. "The Evolution of the Germanic Inflectional Systems: A Study in the Causes of Language Change." Orbis 27 (1980): 248--86.
2011-11-23 Wed
■ #940. 語形成の生産性と創造性 [productivity][word_formation][blend]
語形成の生産性について,##935,936,937,938 の記事で論じてきた.今回は,生産性 (productivity) と似て非なる概念である創造性 (creativity) を考える.両者の境目は必ずしも明確ではないが,創造性は,新語を形成する力の指標としては似ているものの,生産性よりも新奇さを求める意図が強い.
例えば,形容詞から名詞を作る接尾辞 -ness と -th を考えてみよう([2009-05-12-1]の記事「#14. 抽象名詞の接尾辞-th」を参照).現代英語では後者の生産性はほぼゼロであり,生産性の最も高い接辞の1つである前者とは比較にならない.しかし,話し手があえて形容詞 cool から派生名詞 *coolth を創造して使用したらどうなるだろうか.聞き手も -th の生産性のないことを知っているのだから,話し手の発した *coolth は,誤用でないとすれば,何らかの文体的効果,語用的効果を狙った意図的な言葉遣いとして理解するだろう.coolness にはない新奇さを求めたのかもしれないし,warmth との対比を際立たせようとしたのかもしれない.いずれにせよ,「冷涼」を意味する marked な表現となっていることは確かである.
話し手が特殊な意図で *coolth を産出する背景には,(1) -th の生産性が限りなくゼロに近いが,(2) -ness と同様に名詞を派生させる力が一応はある,ということを互いに理解しており,一方で (3) *coolth が言語共同体に広く認められることはないだろうという感覚も共有されている,ということがありそうだ.つまり,*coolth は,最初から臨時語 (nonce word) ,流行語,あるいは仲間うちでのみ通用する隠語 (jargon, argot) の域を出ないだろうという想定のもとで発せられている可能性が高い.*coolth のような語形成は,表面的には新語の形成であるかのように見えるものの,生産的 (productive) とは呼べず,むしろそれとは区別するために,創造的 (creative) と呼ぶべきではないか.
Lieber (70) は形態的な創造性について,以下のように説明している.
Morphological creativity . . . is the domain of unproductive processes like suffixation of -th or marginal lexeme formation processes like blending or backformation. It occurs when speakers use such processes consciously to form new words, often to be humorous or playful or to draw attention to those words for other reasons.
生産性と創造性の区別の問題は,[2011-09-20-1]の記事「#876. 現代英語におけるかばん語の生産性は本当に高いか?」で論じた問題とも関わる.そこでの問題は,現代英語では臨時語や流行語としてのかばん語の形成は日常茶飯事だが,これを「生産性が高い」と表現してよいのかというものだった.かばん語の形成は「創造性が高い」とは言えそうだが,広く用いられる語彙として定着しない限り,それについて生産性を論じるのは不適切ではないかということだ.実際,新語ウォッチサイト Word Spy には多くのかばん語が登録されている (かばん語を検索したリストを参照)が,このなかで次世代の辞書に登録されるほどに定着しうる語は一部だろう.多くは,臨時語とは言わないまでも,時代の流行語としていずれ消え去る運命にあると考えられる.生産性か創造性かという問題は,[2011-10-30-1], [2011-10-31-1]の記事で取り上げた bouncebackability の語形成にも関わりそうだ.
生産性と創造性の区別は,上記の *coolth の例からある程度直感的に理解できるが,客観的な線引きは難しいそうだ.ましてや,創造性の客観的な測定は生産性のそれ以上に困難だろう.
・ Lieber, Rochelle. Introducing Morphology. Cambridge: CUP, 2010.
2011-11-22 Tue
■ #939. 接尾辞 -dom をもつ名詞の通時的分布 (2) [suffix][oed][productivity]
[2011-04-28-1]の記事「#731. 接尾辞 -dom をもつ名詞の通時的分布」で,近代英語までに一度は廃れかけた接尾辞 -dom の生産性が19世紀に蘇った経緯を概観した(他の関連する記事は ##20,731,732 を参照).そこで掲げた -dom 語の通時的推移のグラフは OED による世紀ごとの見出し語検索に基づいたものだったが,同じく OED を利用してはいるが,世紀ごとの引用例数に基づいて -dom 語形成の生産性を割り出そうとした試みに Lieber (68--69) の調査がある.
Lieber は,引用例検索により初出世紀ごとに -dom 語のトークン数を集計し,各世紀からの引用例総数におけるその比率を計算した.私の[2011-04-28-1]での数値はタイプ数,Lieber の数値はトークン数という違いがあり,生産性を測るには後者のほうがきめ細かいことは言うまでもない.これによって得られた通時的推移のグラフは以下の通り(Lieber, p. 68 のグラフから目検討で数値を読み出し,それを頼りに再作成した).
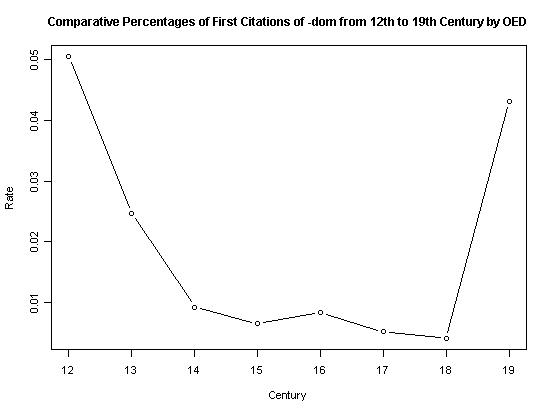
これによると,12--14世紀に -dom は没落の一途をたどったらしいことがわかる.
次に,19世紀の拡大に注目して,10年刻みで同様にまとめたのが以下である(Lieber, p. 69 のグラフから目検討で数値を読み出し,それを頼りに再作成した).
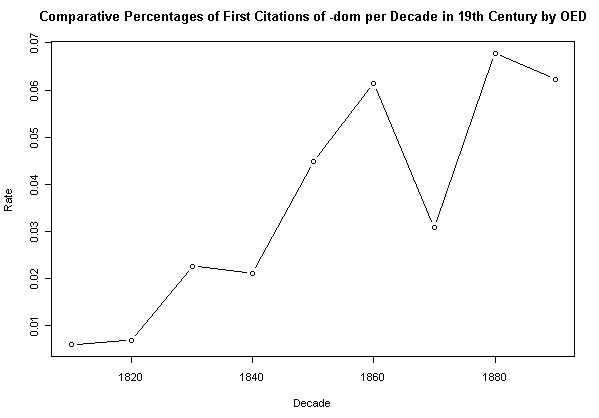
このグラフを見ると,19世紀の拡大とはいっても,著しい拡大は主として同世紀後半に起こったと考えてよさそうだ.その1世紀後,20世紀後半の状況を見ると,確かに新しい -dom 語は少なからず現われてはいるものの ([2011-04-29-1]) ,1880年代のような勢いはないようだ.
・ Lieber, Rochelle. Introducing Morphology. Cambridge: CUP, 2010.
2011-11-21 Mon
■ #938. 語形成の生産性 (4) [productivity][morphology][word_formation][affix][mental_lexicon][hapax_legomenon]
[2011-11-18-1], [2011-11-19-1], [2011-11-20-1]と,語形成の生産性の問題について理解を深めてきた.辞書を利用した生産性の測定はうまく行かないらしいことはわかったが,他にはどのような測定法があり得るだろうか.これまでに,次のような2つの提案がなされている (Lieber 66--67) .
(1) ある接辞添加により潜在的に形成され得る語の総数 (A) を出し,次にその接辞添加により実際に形成された語の総数 (B) を出し,A における B の割合を算出する.例えば,形容詞の基体に付加されて名詞を形成する接尾辞 -ness の場合,形容詞の総数が A となり,実際に文証される -ness 語の総数が B となる.
しかし,この測定法には問題がある.まず,形容詞の総数を把握することは難しい.辞書を参照するということになれば,昨日の記事[2011-11-20-1]で取り上げた諸問題の再来である.実際に文証される -ness 語の総数についても同様だ.-esque 語についていえば,[2011-11-19-1]の記事で触れた通り,この接尾辞は基体に主として多音節の固有名詞を要求するが,この条件に当てはまる基体の数を数え上げることは不可能に近い(まさか,世界人名辞典を参照する!?).
さらに,-esque に見られるような基体に課せられる諸制限は生産性の程度に影響するのであるから,基体に名詞を要求するという以外に制限のない -ness のような接辞の生産性との差異が浮き立つような測定法でなければならない.この測定法では,-esque のA値と -ness のA値に大差がある場合,その差が算入されないという問題がある.
(2) 巨大コーパスを用いて,token frequency に基づいて hapax legomenon の割合を算出する方法.従来の考え方とはまったく異なるこのアプローチは,生産的な語形成に見られる透明性 (transparency) と出現頻度の関係についての知見に基づいている.[2011-11-18-1]で述べたように,生産性の低い語形成は音韻的・意味的に透明性の低い語を生み出す.透明性の低い語は,辞書に (dictionary にも mental lexicon にも)登録されやすい,つまり語彙化 (lexicalize) されやすい.語彙化された語は,語彙化されていない語に比べて,平均してコーパス内のトークン頻度が高いという特徴が見られる.逆から見ると,生産性の高い語形成は透明性も高いゆえに,語彙化されることが少なく,平均してコーパス内のトークン頻度は低い傾向がある.実際のところ,コーパス内に1回しか現われない hapax legomenon である可能性も高い.
この知見に基づき,-ness の生産性の算出を考えてみよう.コーパス内に現われる -ness 語をトークン頻度で数え上げ,これを A とする.この中で hapax legomenon である -ness 語の数を B とする.A における B の比率を取れば,-ness の生産性(少なくとも,生産性を指し示すなにがしかの特徴)の指標となるだろう.
Baayen and Lieber で採用されたこの測定法は,生産性の完璧な指標ではないとしても,母語話者の直感する生産性を比較的よく反映していると考えられる.
・ Lieber, Rochelle. Introducing Morphology. Cambridge: CUP, 2010.
・ Baayen, Harald and Rochelle Lieber. "Productivity and English Derivation: A Corpus-Based Study." Linguistics 29 (1991): 801--43.
2011-11-20 Sun
■ #937. 語形成の生産性 (3) [productivity][morphology][word_formation][affix][dictionary]
[2011-11-18-1], [2011-11-19-1]に引き続き,語形成の生産性について.生産性の議論には様々な側面があるということを見てきたが,具体的に生産性を測る段には,何をどう測ればよいのだろうか.例えば,形容詞から名詞を作る接尾辞 -ness による語形成の生産性を測定するにはどうすればよいのか.
単純に考えると,辞書を参照して -ness 語を数え上げるという方法が挙げられるかもしれない.しかし,これでは正確に生産性を測ることはできない.なぜだろうか.
(1) 辞書ごとに掲載されている -ness 語の数はまちまちである.[2011-11-05-1]の記事「#922. 語の定義がなぜ難しいか (5)」を始めとして の各記事で触れたように,辞書はそれぞれ独自の方針で編纂されており,どれを選択するかによって数え上げる語数が著しく異なる可能性がある.
(2) 生産性は,問題の接辞を含む既存の語の数に依存するというよりは,むしろその接辞の添加によって派生される潜在的な語の数に依存すると考えられる.潜在的な語は辞書には載っていないので,辞書を参照しても無意味である.
(3) 生産性の高い語形成は,音韻・意味において透明性の高い(=予測可能性の高い)語形成であり ([2011-11-18-1]) ,予測可能性が高いということは,その語が辞書に掲載される必要も薄く,実際に掲載されることが少ないということである.一方,生産性の低い語形成は,音韻・意味において透明性の低い(=予測可能性の低い)語形成であり,その語はぜひとも辞書に掲載されるべき語であるということになる.つまり,以下の逆説が成立する."[L]ess productive processes would be represented by more entries in the dictionary than more productive processes!" (Lieber 66) .
例えば,手持ちのどの辞書も bovine (ウシの)に対応する派生名詞 bovineness を掲載していないが,だからといって -ness がその分だけ生産性が低いかといえば,むしろ逆である.辞書にいちいち掲載する必要がないほどに,-ness による名詞派生が音韻的にも意味的にも透明だということであり,それだけ生産性が高いということだろう.
生産性を正確に測ることが難しいのは,それが「過去の実績」ではなく「将来性を見込んだ潜在力」の指標だからである.
・ Lieber, Rochelle. Introducing Morphology. Cambridge: CUP, 2010.
2011-11-19 Sat
■ #936. 語形成の生産性 (2) [productivity][morphology][word_formation][affix]
昨日の記事「#935. 語形成の生産性 (1)」 ([2011-11-18-1]) に続いて,productivity に関する話題.昨日,生産性を論じる視点の1つに "frequency of base type" があると紹介した.ある接辞が付加される基体の数や範囲が大きければその語形成の生産性は高いということになり,数や範囲が限定されていればその分だけ生産性が低いということになる,という考え方だ.
では,基体のタイプが限定される場合,限定の基準にはどのようなものがあるだろうか.以下に,Lieber (64--65) の解説を要約する.
(1) categorial restrictions: 品詞の限定.ほとんどの接辞は,基体が特定の品詞であることを要求する.-ness や -ity は原則として基体に形容詞を要求し,-ize は基体に名詞か形容詞を要求する,等々.
(2) phonological restrictions: 接辞のなかには,基体に特定の音韻構造を要求するものがある.例えば,-ize は基体に2音節以上からなる語で,かつ最終音節に主強勢の落ちない語を要求する.形容詞から動詞を作る -en は,末尾に阻害音をもつ基体に限定して付加される (ex. darken, brighten, deafen but not *slimmen, *tallen) .
(3) the meaning of the base: 否定の un- は,基体がすでに否定的な意味を帯びている場合には付加されない (ex. unlovely but not *unugly; unhappy but not *unsad) .
(4) etymological restrictions: 名詞から形容詞を作る -en は,基体に主として本来語を要求する (ex. wooden, waxen but not *metalen, *carbonen) .一方で,-ic は,基体に主としてフランス借用語あるいはラテン借用語を要求する (ex. parasitic, dramatic) .
(5) syntactic restrictions: -able は他動詞,より限定的には受動化できる他動詞に付加される傾向がある (ex. loveable but not *snorable ) .(これについては,[2011-10-30-1]の記事「#916. bouncebackability の運命と "non-lexicalizability" (1)」とその続編[2011-10-31-1]を参照.)
(6) pragmatic restrictions: 英語からの例ではないが,オーストラリア北東部で話される Dyirbal 語において,-ginay (?に覆われた)という接尾辞は,基体に汚いものや不快なものを表わす語を要求するという.ここには,当該言語の文化に根ざした語用論的な要因が作用していると考えられる.また,結果としてできる派生語の register が限定されるような接辞の存在も示唆される(例えば,-ish はくだけた文脈で使われがちな形容詞を派生させるなど).
語形成の生産性はすぐれて形態論的な問題ではあるが,それを論じるにあたって,音韻,語種,統語,意味・語用といった言語体系のあらゆる側面の考慮が必要になってくるというのが,難しいところであり,同時に魅力でもある.
・ Lieber, Rochelle. Introducing Morphology. Cambridge: CUP, 2010.
2011-11-18 Fri
■ #935. 語形成の生産性 (1) [productivity][morphology][word_formation][affix][frequency][mental_lexicon]
語形成の生産性 (productivity) については,productivity の各記事で話題にしてきた.そこでは,生産性をどのように定義するか,どのように測定するかは,形態理論における難問であると述べるにとどまったが,今回は,この問題にもう少し踏み込みたい.
まずは,Lieber (61) による,"productive" と "unproductive" の日常語による定義を挙げよう.
Processes of lexeme formation that can be used by native speakers to form new lexemes are called productive. Those that can no longer be used by native speakers, are unproductive; so although we might recognize the -th in warmth as a suffix, we never make use of it in making new words. The suffixes -ity and -ness, on the other hand, can still be used, although perhaps not to the same degree.
この定義により,生産性の指し示している概念は直感的に理解できるが,より専門的に定義しようとするとなかなか難しい.生産性に関与する要因としては,3点が考えられる (Lieber 61--64) .
(1) transparency: 音韻と意味の透明性が確保されており,基体と接辞が明確に区別される語形成は productive である.例えば,candidness や crudity において,それぞれ形態上 candid + -ness, crude + -ity と明確に線引きできるだけでなく,その意味も基体と接辞(「?である状態」)の純粋な和 (compositional) として解釈できる.この点で,-ness や -ity を用いた語形成は透明度が高いと言える.
しかし,-ity は -ness に比べて透明度が低い.1つには,rusticity において,綴字上は rustic + -ity と透明的に分析されるが,発音上は基体の最後の子音が /k/ から /s/ へ変化しており,その分だけ透明性が低くなる.別の例では,timid の強勢は第1音節だが,timidity の強勢は基体の第2音節へ移動しており,透明性が低くなっている.さらに,oddity は,odd + -ity から容易に想像されるとおり,透明的に「異常であること」を意味するのみならず,「変人」をも意味する.後者の語義については,予測可能性(=透明性)が低いとみなすことができる.最後に,dexterity では,基体として *dexter が予想されるところだが,これは実際には存在しない基体である.ここでは,透明性が確保されていない.
oddity (変人)の例で触れた意味の予測(不)可能性という指標は,その派生語が mental lexicon に登録されているかどうかという問題,語彙化 (lexicalization) の問題に関連する.この場合,「異常であること」の語義での oddity は語彙化されていないが,「変人」の意味でのoddity は語彙化されているということになる.したがって,透明性が高いほど語彙化されにくく,透明性が低いほど語彙化されやすいという関係が成り立つ.
(2) frequency of base type: 接辞の付加しうる基体の数や範囲が大きければ大きいほど,その語形成は生産的であるとみなすことができる.接尾辞 -esque (?風の)は名詞に付加されるが,主として固有名詞に限定される.単音節の基体には付加されにくいという条件もあるため,どんな名詞にも付加される接尾辞に比べれば,基体の範囲が狭い分,生産性が低いということになる.([2009-11-29-1]の記事「#216. 人名から形容詞を派生させる -esque の特徴」を参照.)
(3) usefulness: 語形成の有用性.常識的に,すべての形容詞について対応する名詞があることは有用であり,便利であると考えられる.この場合,形容詞を名詞化する接尾辞 -ness, -ity は有用であり,生産的であるということになる.反対に,女性を表わす接尾辞 -ess は,現代の性差別廃止の社会的な風潮により有用性が失われてきており,その分だけ生産性も低くなってきていると考えられる.
語形成の生産性は,少なくともこの3点に基づいて論じる必要がある.
音韻形態変化や意味変化によって (1) が,語彙の増加などによって (2) が,社会的な価値観の変化によって (3) が影響を受けるということを考えると,語形成の生産性もまた通時的な変化に晒されているということは明らかだろう.
・ Lieber, Rochelle. Introducing Morphology. Cambridge: CUP, 2010.
2011-11-17 Thu
■ #934. 借用の多い言語と少ない言語 (2) [loan_word][borrowing][french][geography]
[2011-10-17-1]の記事「#903. 借用の多い言語と少ない言語」の続編.言語によって借用語を受け入れる度合いが異なっている点について,Otakar Vočadlo という研究者が homogeneous, amalgamate, heterogeneous という3区分の scale of receptivity を設けていることに触れたが,同じ3区分法を採用している研究者に Décsy がいる.以下,下宮 (62--63) による Décsy の論の紹介を参照しつつ,3区分とそれぞれに属する主なヨーロッパ語を挙げよう.
(1) 借用に積極的な言語 "Mischsprachen" (混合語): English, French, Albanian, Romanian
(2) 借用に消極的な言語 "introvertierte Sprachen" (内向的な言語): German, Icelandic, Czech, Modern Greek
(3) 中間的な言語 "neutrale Sprachen" (中立的な言語): Polish, Danish, Swedish, Dutch
上で Mischsprachen として分類されている言語の借用元諸言語を記すと,以下の通り.
・ English: Old English, French, Celtic, Latin
・ French: Latin, Frankish, Celtic
・ Albanian: Illyrian, Latin, Slavic, Turkish
・ Romanian: Latin, Slavic, French
フランス語は近年英単語の借用を拒んでいるというイメージがあり,借用語の少ない言語かのように思われるかもしれないが,英語ほどとは言わずとも,かなりの Mischsprache である.基層のケルト語にラテン語が覆い被さったのみならず,フランク語からの借用語も少なくない.ゲルマン系とロマンス系が語彙的に同居しているという点では,英語とフランス語は一致している.
[2011-10-17-1]の記事でも触れたように,借用語の多寡は,その言語の構造的な問題というよりは,その言語の共同体の政治的・社会的な態度の問題としてとらえるほうが妥当のように思われる.もっと言えば,[2011-11-10-1]の記事「#927. ゲルマン語の屈折の衰退と地政学」で取り上げたように,共同体の地政学的な立ち位置に多く依存する問題なのではないか.
・ Vočadlo, Otakar. "Some Observations on Mixed Languages." Actes du IVe congrès internationale de linguistes. Copenhagen: 1937. 169--76.
・ 下宮 忠雄 『歴史比較言語学入門』 開拓社,1999年.
・ Décsy, Gyula. Die linguistische Struktur Europas. Wiesbaden: Kommissionsverlag O. Harrassowitz, 1973.
2011-11-16 Wed
■ #933. 近代英語期の英語話者人口の増加 [statistics][demography]
英語話者人口については共時的,通時的な側面から demography のいくつかの記事で取り上げてきた.特に以下を参照.
・ [2009-10-17-1]: #173. ENL, ESL, EFL の話者人口
・ [2010-03-12-1]: #319. 英語話者人口の銀杏の葉モデル
・ [2010-05-07-1]: #375. 主要 ENL,ESL 国の人口増加率
・ [2010-06-15-1]: #414. language shift を考慮に入れた英語話者モデル
・ [2010-06-28-1]: #427. 英語話者の泡ぶくモデル
通時的な英語話者人口の推移については,諸文献で様々な推測値が概数として挙げられている.[2010-03-12-1]の「銀杏の葉モデル」の図中に示されている数値もその一つである.値は大きく異ならないが,『英語史総合年表』に記されている概数をもとに,人口の推移グラフを作成してみた.1500年から1900年までの100年刻みでの人口統計である.
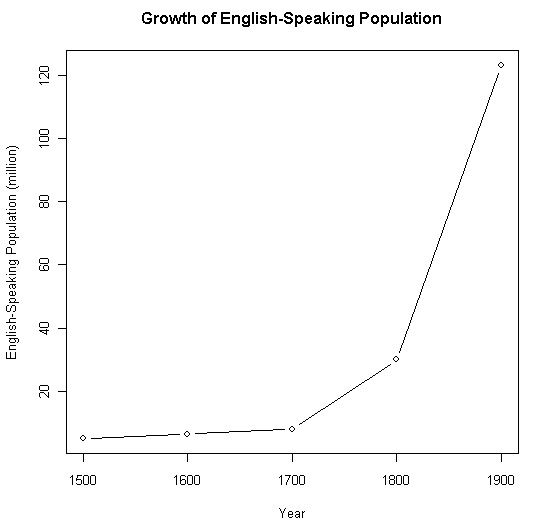
| Year | English-Speaking Population |
|---|---|
| 1500 | about 5 million |
| 1600 | about 6--7 million |
| 1700 | about 8 million (including about 2 million that had emigrated to the New World) |
| 1800 | 20--40 million |
| 1900 | about 123 million |
19世紀の爆発的増加が視覚的に表わされている.そして,20世紀のさらなる爆発により,2000年の段階で,上のグラフの高さを10倍にしても足りないほどの話者数を示すことになる.現在,第2言語話者,外国語話者を合わせて,英語を話す人口は15--20億と推定されている.
・ 寺澤 芳雄,川崎 潔 編 『英語史総合年表?英語史・英語学史・英米文学史・外面史?』 研究社,1993年.
2011-11-15 Tue
■ #932. neutralization は異形態の縮減にも貢献した [oe][old_norse][inflection][conjugation][paradigm][contact][language_change][analogy]
[2011-11-11-1]の記事「#928. 屈折の neutralization と simplification」と[2011-11-14-1]の記事「#931. 古英語と古ノルド語の屈折語尾の差異」で,古ノルド語との言語接触に起因する古英語の屈折体系の簡単化について取り上げてきた.O'Neil が neutralization と呼ぶ,この英語形態論の再編成については,両言語話者による屈折語尾の積極的な切り落としという側面が強調されることが多いが,より目立たない側面,allomorphy の縮減という側面も見逃してはならない.
昨日の記事で示したパラダイムの対照表を見れば,屈折語尾の差異を切り落とし,ほぼ同一の語幹により語を識別するという話者の戦略が有効そうであることが分かるが,語幹そのものの同一性が必ずしも確保できないケースがある.パラダイムのスロットによっては,語幹が異形態 (allomorph) として現われることがある.昨日の例では,drīfan の過去形においては,単数1・3人称 (drāf) で ā の語幹母音を示すが,単数2人称および複数 (drife,drifon) で i の語幹母音を示す.
他にも,現在単数2・3人称の屈折において語幹母音が i-mutation を示す古英語の動詞は少なくない.OE lūcan "to lock" の現在形の活用表を示すと,以下のように語幹母音が変異する (O'Neil 262) .
| Old English | |
| Inf | lūcan 'lock' |
| Pres. Sing. 1. | lūce |
| 2. | lȳc(e)st |
| 3. | lȳc(e)ð |
| Plur. | lūcað |
ところが,中英語の典型的なパラダイムでは,現在単数2・3人称の語幹は他のスロットと同じ語幹を取るようになっている.ここで生じたのは allomorphy の縮減であり,結果として,不変の語幹が現在形のパラダイムを通じて用いられるようになった.動機づけのない allormophy をこのように縮減することは,当時,互いに意志疎通を図ろうとしていた古英語や古ノルド語の話者にとっては好意的に迎え入れられただろうし,それ以上にかれらが縮減を積極的に迎え入れたとすら考えることができる.
I think it clear that working from quite similar, often identical, underlying forms but with different sets and intersecting sets of endings associated with them and bewildering allomorphies as a result of the conditions established by the endings, the basic underlying sameness of Old English and Old Norse had become somewhat distorted and thus a superficial barrier to communication between speakers of the two languages had arisen. It is not surprising then that the inflections of the languages were rapidly and radically neutralized, for they were the source of nearly all difficulty. (O'Neil 262--63)
allormophy の縮減は,言語接触による neutralization の過程としてだけでなく,言語内的な類推 (analogy) や 単純化 (simplification) の過程としても捉えることができる.実際には,片方のみが作用していたと考えるのではなく,両者が共に作用していたと考えるのが妥当かもしれない.
allomorphy の縮減は,パラダイム内の levelling (水平化)と読み替えることも可能だろう.この用語については,[2010-11-03-1]の記事「#555. 2種類の analogy」を参照.
・ O'Neil, Wayne. "The Evolution of the Germanic Inflectional Systems: A Study in the Causes of Language Change." Orbis 27 (1980): 248--86.
2011-11-14 Mon
■ #931. 古英語と古ノルド語の屈折語尾の差異 [oe][old_norse][inflection][conjugation][paradigm][contact][language_change]
[2011-11-11-1]の記事「#928. 屈折の neutralization と simplification」では,古英語の言語体系が古ノルド語との接触により簡単化していった過程を,O'Neil の用語を用いて neutralization と呼んだ.この過程の要諦は,古英語と古ノルド語との間で,対応する語幹はほぼ同一であるにもかかわらず,対応する屈折語尾は激しく異なっていたために,後者が積極的に切り落とされたということだった.
では,具体的にどのように両言語の屈折体系が混乱を招き得るものだったかを確かめてみよう.以下は,典型的な強変化動詞,弱変化動詞,弱変化名詞,強変化女性名詞 (o-stem) の屈折の対照表である (O'Neil 257--59) .
Strong Verb
| Old English | Old Norse | |
| Inf | drīfan 'drive' | drífã |
| Pres. Sing. 1. | drīfe | dríf |
| 2. | drīfest | drífR |
| 3. | drīfeð | drífR |
| Plur. 1. | drīfað | drífom |
| 2. | drīfað | drífeð |
| 3. | drīfað | drífã |
| Past Sing. 1. and 3. | drāf | dreif |
| 2. | drife | dreift |
| Plur. 1. | drifon | drifom |
| 2. | drifon | drifoð |
| 3. | drifon | drifð |
| Pres. pple. | drīfende | drífande |
| Past pple. | drifen | drifenn |
Weak Verb
| Old English | Old Norse | |
| Inf | tellan 'count' | teljã |
| Pres. Sing. 1. | telle | tel |
| 2. | telest | telR |
| 3. | telð | telR |
| Plur. 1. | tellað | teljom |
| 2. | tellað | teleð |
| 3. | tellað | teljã |
| Past Sing. 1 | talde | talda |
| 2. | taldest | talder |
| 3. | talde | talde |
| Plur. 1. | taldon | tǫldom |
| 2. | taldon | tǫldoð |
| 3. | taldon | tǫldõ |
| Pres. pple. | tellende | teljande |
| Past ppl.e | tald | tal(e)ð |
Weak Noun
| Old English | Old Norse | |
| Sing. Nom. | guma 'man' | gume |
| Oblique | guman | gumã |
| Plur. Nom. | guman | gumaR |
| Acc. | guman | gumã |
| Gen. | gumena | gum(n)a |
| Dat. | gumum | gumon |
Strong Noun (Feminine ō-stems)
| Old English | Old Norse | |
| Sing. Nom. | bōt 'remedy' | bót |
| Acc. | bōte | bót |
| Gen. | bōte | bótaR |
| Dat. | bōte | bót |
| Plur. Nom. | bōta | bótaR |
| Acc. | bōta | bótaR |
| Gen. | bōtena | bóta |
| Dat. | bōtum | bótom |
語幹はほぼ同一であり,わずかに異なるとしても「訛り」の許容範囲である.ところが,対応する屈折語尾を比べると,類似よりも相違のほうが目立つ.対応するスロットに異なる語尾が用いられているということはさることながら,形態的に同一の語尾が異なるスロットに用いられているというのも混乱を招くに十分だったろう.例えば,古英語の drīfeð は現在3人称単数だが,同音の古ノルド語 drífeð は現在2人称複数である.
このように屈折表を見比べると,両言語話者の混乱振りが具体的に見えてくるのではないか.
・ O'Neil, Wayne. "The Evolution of the Germanic Inflectional Systems: A Study in the Causes of Language Change." Orbis 27 (1980): 248--86.
2011-11-13 Sun
■ #930. a large number of people の数の一致 [agreement][number][syntax][bnc][corpus]
現代英語で「a (large) number of + 複数名詞」が主語に立つとき,動詞は複数に一致するのが原則である.完全にこの理解でいたのだが,先日次のような文に出くわした.
A large number of native speakers is perhaps a pre-requisite for a language of wider communication . . . . (Graddol 12)
そこで,数々の辞書や文法書をひっくり返してみた.ほとんどすべての参考書がこの句を複数扱いとしており,統語分析を与えているものについては,number ではなくこの場合で言えば native speakers を主要部 (head) とみなしている.特に,OALD8, LDOCE5, COBUILD English Usage といった典型的な学習者用英英辞書では,複数形の動詞で一致するよう明示的に注記を与えている.また,規範文法のご意見番 Fowler ("number" の項)によると次の通りで,単数一致については明示的な言及はなかった.
. . . as a noun of multitude in the type 'a number of + pl. noun', normally governs a plural verb both in BrE and AmE.
調べたレファレンスのなかで,単数一致について言及していたのは以下のものである.
・ CGEL: "A (large) number of people have applied for the job. [2]" という例文について,"Use of the singular . . . would be considered pedantic in [2] . . . ." (765) と述べている.
・ CALD3: 単数一致を示す例文を "(slightly formal)" というレーベルを与えつつ挙げていた."A large number of invitations has been sent."
・ 『ジーニアス英和大辞典』: 単数一致を「((正式))」としていた."A ? of passengers were [((正式)) was] injured in the accident."
これで,formal or pedantic という register でまれに使用されるらしいということは分かった.では,BNCWeb で確かめてみようと,"a (very)? (large|great|good|small)? number of ((_AV*)? _AJ*)* _NN2 (_VHZ|_VBZ|was_VBD|_VDZ|_VVZ)" として検索し,該当する例のみを手作業で拾い出してみた.全部で25例あったが,1例を除いてすべてが書き言葉からの文例であり,そのうち12例が Academic prose からのものだった.全体として,この表現が academic or pedantic へ強い傾向を示すことは確かなようだ.
・ Graddol, David. The Future of English? The British Council, 1997. Digital version available at http://www.britishcouncil.org/learning-research-futureofenglish.htm.
・ Burchfield, Robert, ed. Fowler's Modern English Usage. Rev. 3rd ed. Oxford: OUP, 1998.
・ Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech, and Jan Svartvik. A Comprehensive Grammar of the English Language. London: Longman, 1985.
2011-11-12 Sat
■ #929. 中英語後期,イングランド中部方言が標準語の基盤となった理由 [popular_passage][me_dialect][standardisation][chancery_standard]
中英語は「方言の時代」と呼ばれるほど,方言が花咲き,それが書き言葉にも如実に反映された時期である.それほど異なっていたのであれば,はたして当時のイングランド各地の人々は互いにコミュニケーションを取ることができたのだろうか,という素朴な疑問が持ち上がる.[2010-03-30-1]の記事「#337. egges or eyren」で紹介した Caxton の有名な逸話を読むと,少なくともイングランドの南北方言間では部分的な意志疎通の障害があったことが具体的に理解できる.日本語の方言事情を考えれば,逸話内の夫人の当惑も手に取るように分かるだろう.
中英語も後期になってくると,緩やかな書き言葉の標準というべきものが現われてくる.現在の書き言葉標準のような固定化した (fixed) 標準ではなく,むしろ現在の話し言葉標準のような中心を指向する (focused) 標準に近い.当時現われ始めた書き言葉標準は,諸方言の混じり合ったものではあったが,その中でも基盤となった方言は中部方言である.これはなぜだろうか.なぜ北部や南部の方言がベースとならなかったのだろうか.
1つには,政治や文化の中心地としてのロンドンで話され,書かれていた英語,特に公文書に用いられていた Chancery Standard の影響力がある.言語的標準を目指す上で,社会的権威を付されている首都の公式の語法を参照するというのは自然な発想である.ロンドンの方言は,方言学的には中部と南部の両方言の境目に当たるのだが,少なくとも北部方言に対する中部・南部方言の優位性はこれで確保される.
2つ目として,中部方言が,教養の香りを漂わせる London, Oxford, Cambridge の作る三角地帯で用いられていた方言と重なっていたという事情がある.これによって,中部方言は学問的,文化的な権威をも付されることとなった.
3つ目に,中部方言は地理的にも南北両方言の中間に位置しているため,両方言の要素を兼ね備えており,方言の花咲くイングランドにおいてリンガフランカとして機能し得たと考えられる.この点については,Ranulph Higden (c. 1280--1364) によるラテン語の歴史書 Polychronicon を1387年に英語へ翻訳した John of Trevisa (1326--1402) より,Mossé 版 (288--89) から次の箇所を引用しよう.
. . . for men of þe est wiþ men of þe west, as hyt were undur þe same party of hevene, acordeþ more in sounyng of speche þan men of þe north wiþ men of þe souþ; þerfore hyt ys þat Mercii, þat buþ men of myddel Engelond, as hyt were parteners of þe endes, undurstondeþ betre þe syde longages, Norþeron and Souþeron, þan Norþeron and Souþeron understondeþ eyþer oþer.
[2011-11-10-1]の記事「#927. ゲルマン語の屈折の衰退と地政学」で北西ヨーロッパにおける地理と言語の間接的な結びつきを話題にしたが,イングランド国内というより小さなレベルでも地理が言語において間接的な意味をもつということを,この3つ目の事情は示しているのではないか.
・ Mossé, Fernand. A Handbook of Middle English. Trans. James A. Walker. Baltimore: Johns Hopkins, 1952.
2011-11-11 Fri
■ #928. 屈折の neutralization と simplification [inflection][contact][language_change][germanic][old_norse]
英語史では,古英語から中英語にかけて起こった屈折体系の簡単化を,屈折の水平化 (levelling) や単純化 (simplification) という用語で表現するのが普通である.同様の現象が多かれ少なかれ他のゲルマン諸語でも生じてきたことは,昨日の記事「#927. ゲルマン語の屈折の衰退と地政学」 ([2011-11-10-1]) や「#656. "English is the most drifty Indo-European language."」 ([2011-02-12-1]) で話題にしてきたが,ここでも水平化や単純化という用語が適用されるだろう.
しかし,O'Neil は,ゲルマン諸語に見られる屈折の衰退は,明確に区別されるべき2つの用語 neutralization と simplification によって記述されるべきだと強調している.それぞれの定義は,O'Neil (283) によると次の通り.
(A) If there is significant and more-or-less permanent contact between two closely related languages differing for the most part only in superficial aspects of their grammars (inflections, accent, tone, etc.), these superficial differences will be rapidly neutralized or erased. (283)
(B) Without language contact, inflectional systems will simplify only so far as there is room available for easing learning without greatly decreasing perceptibility. (283)
つまるところ,言語接触が契機となって文法カテゴリーの区別が失われるような言語体系の簡単化を neutralization と呼び,言語接触とは関係なく,学習や知覚に関わる話者の言語心理学的な要求に基づいて自然に進行する言語体系の簡単化を simplification と呼び分けるべきだと,O'Neil は主張している.比喩的に言えば,neutralization は突如として激しく作用するデジタルな力,simplification は常に少しずつ作用しているアナログな力と捉えられるだろうか.
この用語でゲルマン諸語の屈折体系の簡単化を改めて記述すると,次のようになるだろう.Icelandic や High German などの相対的に保守的な言語では,主として simplification による屈折体系の簡単化のみが観察されるのに対して,著しく簡単化した英語,大陸スカンジナビア諸語,アフリカーンス語などでは,simplification に加えて,言語接触によって引き起こされた neutralization が作用した.
古英語後期から言語内的に進行していた屈折の簡単化が古ノルド語との接触により著しく加速したという歴史的な説明は,今では広く受け入れられているが,それを明確に区別される2つの用語により説明しなおしたという点に,O'Neil の意義がある.既に進行していたプロセス (simplification) がそのまま延長されたのではなく,簡単化という意味では一緒にくくることができるものの,古ノルド語との接触により誘発された別のプロセス (neutralization) によって後押しされたと考えている点が重要である.
・ O'Neil, Wayne. "The Evolution of the Germanic Inflectional Systems: A Study in the Causes of Language Change." Orbis 27 (1980): 248--86.
2011-11-10 Thu
■ #927. ゲルマン語の屈折の衰退と地政学 [germanic][inflection][synthesis_to_analysis][contact][geography][map][dutch][german][faroese][icelandic][danish][afrikaans]
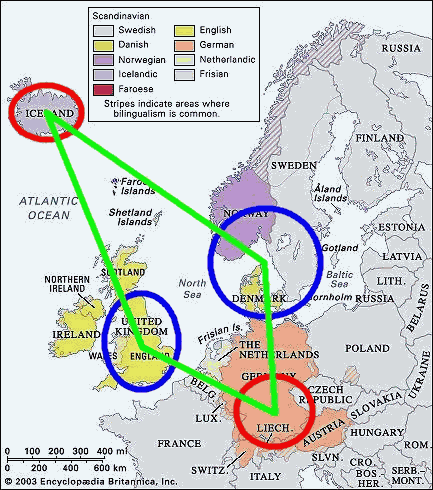
中世のゲルマン語派の話者の分布を地図に示すと,北東端を Continental Scandinavian,南東端を High German,南西端を English,北西端を Icelandic にもつ四辺形が描かれる.この地図が示唆する興味深い点は,青で示した English と Continental Scandinavia は歴史的に屈折を激しく摩耗させてきたゲルマン語であり,赤で示した Icelandic と High German は歴史的に屈折を最もよく残してきたゲルマン語であるという事実だ.そして,革新的な北東・南西端と保守的な北西・南東端に囲まれた,緑で示した四辺形の中程に含まれる Faroese, Dutch, Frisian, Low German は,屈折をある程度は摩耗させているが,ある程度は保持しているという中間的な性格を示す.この地理と言語変化の相関関係は見かけだけのものだろうか,あるいは実質的なものだろうか.
この点について好論を展開しているのが,O'Neil である.
Now from the point of view of their inflectional systems, it is in the languages of the extreme southwest and northeast areas, among the Scandinavians and the English, that things are farthest from the state of the old languages, where --- in fact --- the old inflectional system has become so simplified that the languages can barely be said to be inflected at all. It is in the other two areas, in the northwest in Iceland and in the southeast among the High Germans (but most especially in Iceland) that an older inflectional system is best preserved. Between these two extremes and their associated corners or areas and languages, lie other Germanic languages (Faroese, Frisian, Dutch, etc.) of neither extreme characteristic: i.e. not stripped (essentially) of their inflections, nor heavily inflected like the older languages. (250)
地理が直接に言語の変化に影響を及ぼすということはあり得ない.しかし,地理が言語話者の地政学的な立場に影響を及ぼし,地政学的な立場が歴史に影響を及ぼし,歴史が言語の発展に影響を及ぼすという間接的な関係を想定することは可能だろう.
屈折が大いに単純化した英語の場合,古ノルド語 (Old Norse) との接触が単純化の決定的な引き金となったという論は,今では広く受け入れられている([2009-06-26-1]の記事「#59. 英語史における古ノルド語の意義を教わった!」を参照).一方で,アイスランド語 (Icelandic) が地理的に孤立しているがゆえに,古い屈折を現代までよく残しているということもよく言われる([2010-07-01-1]の記事「#430. 言語変化を阻害する要因」を参照).いずれも歴史的に経験してきた言語接触の程度との関数として説明されているが,その言語接触の歴史とは地政学上の要因によって大いに条件付けられているのである.ここでは言語変化が地理的条件により間接的に動機づけられているといえるだろう.
では,英語やアイスランド語以外のゲルマン諸語についても,同様の説明が可能だろうか.O'Neil は,大陸スカンジナビア諸語の屈折の単純化も英語のそれと平行的な関係にあると主張する.この場合,大陸スカンジナビア諸語が接触したのは低地ドイツ語 (Middle Low German) である.
It is clear then that Continental Scandinavian is inflectionally simple like English, with --- however --- its idiosyncratic sense of simplicity. The reasons for its simplicity seem to be exactly those that led to the development of the neutralized northern Middle English inflectional system: language contact between Middle Low German and Danish in the countryside and between Middle Low German and all Continental Scandinavian languages in the centers of trade. (267)
さらに,英語や大陸スカンジナビア諸語と同じように単純化した屈折をもつアフリカーンス語 (Afrikaans) についても,同様の議論が成り立つ.ここでは,オランダ語 (Dutch) と低地ゲルマン語 (Low German) との接触が関与している.
. . . the original population that settled Capetown and then the Cape was not a homogeneous Dutch-speaking population. The group of people that arrived in Capetown in 1652 was first of all predominantly German (Low German mercenaries) and the Dutch part of it was of mixed Dutch dialects. Thus just the right conditions for the neutralization of inflections existed in Capetown at the time of its settlement. (268--69)
他にも,フリジア語 (Frisian) とオランダ語 (Dutch) とが都市部で言語接触を経験した結果としての "Town Frisian" (268) の例も挙げられる.
反対に,複雑な屈折を比較的よく保っている例として,アイスランド語の他に挙げられているのが高地ドイツ語 (High German) である.ここでも O'Neil は,高地ドイツ語もアイスランドほどではないが,地政学的に見て隔離されていると論じている.
. . . High German has not been so completely isolated as Icelandic. But then neither is its inflectional system as conservative. Yet in fact the area of High German has been generally isolated from other Germanic contact --- the sort of contact that would lend to neutralization, for the general motion of High German has always been away from the Germanic area and onto its periphery among non-Germanic peoples. (277)
最後に,地図上の四辺形の内部に納まる中間的な屈折度を示す言語群についても O'Neil は地政学的な相関関係を認めているので,指摘しておこう.以下は,フェロー語 (Faroese) の屈折の中間的な特徴を説明づけている部分からの引用である.
. . . the Faroese fished and worked among the Icelanders and still do, at the same time being administered, educated, and exploited by continental Scandinavians. Thus for centuries was Faroese exposed to the simplified inflectional systems of continental Scandinavia while in constant contact with the conservative system of Icelandic. Unless this conflict was resolved Faroese could neither move toward Continental Scandinavian, say, nor remain essentially where it began like Icelandic: neither completely neutralize its inflections, nor simplify them trivially. The conflict was not resolved and as a consequence Faroese moved in a middle state inflectionally. (280)
・ O'Neil, Wayne. "The Evolution of the Germanic Inflectional Systems: A Study in the Causes of Language Change." Orbis 27 (1980): 248--86.
2011-11-09 Wed
■ #926. 強勢の本来的機能 [stress][prosody][diatone]
言語において強勢の機能は何か.Martinet (105--06) によれば,それは複数あるが,最も基本的な機能は "contrastive" あるいはより正確に "culminative" であるという.拙訳とともに,関連箇所を引用する.
La fonction de l'accent est essentiellement contrastive, c'est-à-dire qu'il contribue à individualiser le mot ou l'unité qu'il caractérise par rapport aux autres unités du même énoncé; une langue a un accent; et non des accents. Lorsque, dans une langue donnée, l'accent se trouve toujours sur la première ou la dernière syllabe du mot, cette individualisation est parfaite puisque le mot est ansi bien distingué de ce qui précède ou ce qui suit. Lá où la place de l'accent est imprévisible, doit être apprise pour chaque mot et ne marque pas la fin et le début de l'unité accentuelle, l'accent a une fonction dite culminative: il sert à noter la présence dans l'énoncé d'un certain nombre d'articulations importante; il facilite ainsi l'analyse du message. Que sa place soit prévisible ou non, l'accent permet, en faisant varier l'importance respective des mises en valeur successives, de préciser ce message.
強勢の機能は本質的に対比の機能である.すなわち,強勢は,それに特徴づけられている語や単位を,同じ発話内の他の単位との対比により個別化することに貢献する.したがって,言語は1つの強勢をもつのであり,複数の強勢をもつものではない.所与の言語において,強勢が常に語の最初あるいは最終の音節に落ちるとき,語は先行するものや後続するものから明確に区別されるのであるから,この個別化の機能は完全となる.強勢の位置が予測不能であり,単語ごとに学習されねばならず,強勢を受ける単位の最後と最初を明示しない場合には,強勢は頂点表示と呼ばれる機能をもつ.つまり,強勢は,発話の中にいくつかの重要な調音が存在するということを気づかせる働きをしているのであり,それによってメッセージの分析を容易にしているのである.強勢の位置が予測可能であれ不可能であれ,強勢は,連続する音価それぞれの重要性を違えさせながら,このメッセージを明確にしてくれる.
しかし,Martinet (106) は,英語などの言語では強勢の位置によって語を区別する (distinctive) 例があり,これは強勢の副次的な機能を示すものであるとも述べている.強勢の位置によって品詞の変わる increase, permit の類 (diatone) がその典型だ.しかし,強勢を示すすべての言語に共通する特徴として考えるのであれば,強勢の主たる機能は "contrastive" あるいは "culminative" といってしかるべきだろう.このような言語一般の大局観を通じて,英語における強勢の特徴が浮き彫りになるように思われる.
・ Martinet, André. Éléments de linguistique générale. 5th ed. Armand Colin: Paris, 2008.
2011-11-08 Tue
■ #925. conversion の方向は共時的に同定できるか? [conversion][word_formation][diatone][semantic_change][affix]
[2009-11-03-1]の記事「#190. 品詞転換」ほか conversion の諸記事では,conversion を主として歴史的過程として解釈してきたが,共時的な語彙間の関係として解釈することもできる.ただし,その場合にも conversion の方向は意識されているように思われる.conversion を zero-derivation と考えると,その出発点を基体 (base) ,到着点を派生形 (derivative) と呼び分けることができるが,形態的には同一である base と derivative を共時的に区別する手がかりはどこにあるのだろうか.大石 (167--73) および Lieber (49--50) を参照し,主要な方法について要約しよう.
(1) 意味を参照する方法.名詞と動詞の用法をもつ net を例に取ると,名詞としての「網」を基準とすると,動詞形は "put into a net" として容易に定義できるが,その逆は簡単ではない.名詞としての net がより一般的な意味をもっているということであり,こちらを基準と考えるべき共時的な根拠を提供している.反対に,動詞から名詞への転換を表わす(通時的に確認されている)例としては,wash や throw がある.それぞれの名詞の意味は,対応する動詞を X とすると "an instance of X-ing" として定義されるのが普通であり,逆にこの典型に適合していれば動詞から名詞への転換である可能性が高い.
(2) 接辞(特に接尾辞)を参照する方法.問題の語形に,特定の品詞と典型的に結びつけられる接辞がすでに付加されている場合には,その品詞としての用法が基準であると考えられる.例えば,commission は典型的な名詞接尾辞をもっているので,名詞用法が基準で,動詞用法が派生であると想定される.
(3) 純粋な conversion ではないが,強勢の交替を伴う名前動後 (diatone の語では,原則として基体は動詞であると考えられる.Sherman (53) が述べている通り,第1音節に強勢をもつのが普通である名詞が基体である場合には,動詞化したときに強勢の交替が生じる確率は低い ("the creation of stress alternation is more likely to occur as stress-retraction in an oxytonic pair than to occur as stress-advancement in a paroxytonic pair") .関連して,abstráct (抽出する)→ ábstract (抜粋)→ ábstract (抜粋する)のように2段階の conversion ([2011-07-30-1]の記事「#824. smoke --- 2重の品詞転換」を参照)を経た語に注意.
(4) 固有名詞が基体となっている場合には,比較的,区別がつきやすい.boycott (ボイコットする), lynch (リンチを加える), meander (曲がりくねる), shanghai (意識を失わせて船に連れ込んで水夫にする), japan (漆を塗る)など.
(5) 閉じた語類と開いた語類が conversion の関係にある場合,前者から後者への方向の転換である可能性が高い.But me no buts. (しかし,しかしと言うな)など.
(6) 動詞から作られた派生名詞以外では,名詞は項をとることができないという性質に基づく方法.the robber of the bank は可能だが,*the thief of the bank は不可能である.これは,thief が派生名詞でなく本来の名詞だからであると考えられる.この性質を利用すると,his release by the government や the government's release of the prisoners では release は項をとっているので派生名詞だと判断される.
(7) conversion にかかわるゼロ接辞は,理論上クラスII接辞であると議論することができるため,クラスI接辞が付加できるかどうかで基体の区別が可能である.figure は形容詞接尾辞 -al を付加して figural が派生されるので,本来的には名詞であると考えられる.picture は,動詞接尾辞 -ize を付加して picturize が派生されるので,本来的には動詞であると考えられる,等々.
・ Lieber, Rochelle. Introducing Morphology. Cambridge: CUP, 2010.
・ 大石 強 『形態論』 開拓社,1988年.
2011-11-07 Mon
■ #924. 複合語の分類 [compound][word_formation][morphology]
複合語 (compound) の分類にはいくつかの観点がある.Lieber (46--49) を以下に要約する.
(1) right-headed compound or left-headed compound: head (主要部)とは,複合語を構成する2つの語彙素のうち,意味および統語の範疇を決定づける要素を指す.例えば,greenhouse, sky blue では,それぞれ house, blue が head である.greenhouse は家の一種かつ名詞であり,sky blue は青色の一種かつ形容詞である.ここでは主要部が右側要素であるため,right-headed と呼ばれる.英語の複合語は典型的に right-headed だが,フランス語の複合語は timbre-poste (切手)に典型的に見られるように left-headed である.したがって,フランス語から借用された複合語 court martial (軍法会議)などは英単語であっても left-headed ということになる ([2010-03-29-1]の記事「#336. Law French」の複合語を参照).
(2) root (or primary) compound or synthetic (or deverbal) compound: 主要部の語彙素が動詞由来であり,非主要部がその動詞の項となっているような複合語は synthetic compound と呼ばれる.一方,2つの語彙素の意味的な関係がより自由である複合語は root compound と呼ばれる.ここでは主要部が動詞由来でないのが普通である.synthetic compound の例として dog walker, hand washing, home made が挙げられ,root compound の例として windmill, ice cold, hard hat, red hot が挙げられる.
(3) attributive compound, coordinative compound, or subordinative compound: attributive compound は,非主要部が緩い意味的連関により主要部を修飾している複合語である.緩い意味的連関とは,例えば school book は「学校で使われる本」,yearbook は「1年の出来事を記す帳面」,notebook は「ノートとして使われる帳面」といったように,同じ主要部 book を持っていてもそれぞれ語彙素間の関係は固定していないことを指す.
coordinative compound は,producer-director, prince consort, blue-green などの両語彙素が対等の関係で結びつけられている複合語のことである.また,doctor-patient confidentiality に見られる doctor-patient のような「関係」を表わす coordinative compound もある.いずれの場合でも,意味的には各語彙素が主要部とされる.
subordinative compound は,(典型的に動詞由来の)主要部とその非主要部が項の関係にある複合語で,(2) で見た synthetic (or deverbal) compound の守備範囲とほぼ重複する.truck driver, food shopping, meal preparation, cost containment などが例となる.しかし,pickpocket のように,両語彙素が subordinative な関係にありながら (to pick pockets) ,主要部である pocket の側が動詞由来ではないという点で synthetic compound ではない例もあるので,「subordinative compound = synthetic compound」は必ずしも成り立たない.
(4) endocentric compound or exocentric compound: 複合語の指示対象がその主要部の指示対象と同一であるような複合語が endocentric であり,そうでないものが exocentric である.windmill, producer-director, truck driver はいずれも複合語の指示対象は主要部の指示対象と同一なので endocentric である.一方,air head (頭が空っぽの人),parent-child (親子の),pickpocket (スリ)では同一ではないので exocentric である.
特に (3) と (4) の観点を組み合わせた複合語の分類を図でまとめると,以下のようになる.
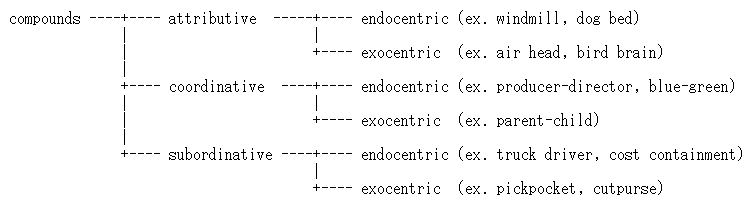
・ Lieber, Rochelle. Introducing Morphology. Cambridge: CUP, 2010.
2011-11-06 Sun
■ #923. 意味範疇による接辞の分類 [affix][word_formation][morphology][polysemy]
接辞 (affix) には様々な種類がある.品詞を変える transpositional affix (or category-changing affix) もあれば,意味を変える meaning-changing affix もある.後者について意味範疇によって接辞を分類すると,主要なものは以下のようになる (Lieber 40) .
(1) personal affixes: 典型的に動作主 (agent) を表わす -er (ex. lover, philosopher) や,典型的に受動者 (patient) を表わす -ee (ex. employee, interviewee) など.
(2) negative and privative affixes: 否定を表わす un-, in-, non- (ex. unable, infinite, non-smoker のほか,欠性を表わす -less, de- (ex. hopeless, debug) など.
(3) prepositional and relational affixes: 空間や時間の意味を表わす over-, out- (ex. overfill, outrun) など.
(4) quantitative affixes: 量に関わる意味を表わす -ful, multi-, re- (ex. handful, multifaceted, reread) など.
(5) evaluative affixes: 指小辞 (diminutive) として -let (ex. booklet) ,増大辞 (augmentative) として mega- (ex. megastore) など.前者は愛情を含意し,後者は軽蔑を含意する傾向がある.
以上のうちのいくつかは,意味を変えるだけでなく統語範疇をも変える機能を持っていることに注意されたい( -er は動詞から名詞を,de- は名詞から動詞を派生させることができる).
意味範疇による接辞の分類は,より詳細にもなしうる.例えば,上では動作主を表わす -er を personal affix と呼んだが,printer (印刷機), freighter (貨物船)における同接尾辞は「道具」と呼ぶのがふさわしいだろう.loaner (賃貸人), fryer (フライ用若鶏)は「受動者」,diner (食堂車)は「場所」と呼べるだろう.同じ -er という接尾辞でも実に多義的 (affixal polysemy) であり,はたしてこれを1つの範疇にくくることができるのか,基体の動詞の統語的な項構造と多義性は対応するのか,などの理論的な問題が生じている (Lieber 193--95) .
・ Lieber, Rochelle. Introducing Morphology. Cambridge: CUP, 2010.
2011-11-05 Sat
■ #922. 語の定義がなぜ難しいか (5) [word][dictionary][lexicography][mental_lexicon]
標題の話題について,##910,911,912,921 の記事の続編.言語学の研究者は例外なく辞書好き人間だが,辞書が絶対的ではないということもよく知っている.自分が語とは何かという究極の問いに対する答えを知らないにもかかわらず,辞書編纂に関わる可能性すらあるからだ.
市販の辞書 (dictionary) は,理論と現実の妥協の産物であり,脳内の語彙目録 (lexicon) を反映しているわけではない.前者は,あくまで現実的な諸事情を反映した便宜的な語彙リストである.というのは,辞書編纂者は,編集に際して以下の条件に縛られるからである.Lieber (27) より,辞書編纂者が考慮しなければならない要点を引用しよう.
・ the size of the dictionary, which determines the number of words it can hold;
・ the intended audience of the dictionary (adults, children, language learners, etc.);
・ whether a word has a sufficiently broad base of usage;
・ whether it's likely to last;
・ whether it's too specialized or technical for the intended audience;
・ for a word borrowed from another language, whether it's assimilated enough to be considered part of English.
近年の online dictionary の興隆により,紙幅の都合という従来の辞書の旧弊は克服されつつある.しかし,online とはいえども,辞書としてある種の読者を対象とする以上,他の条件は満たさざるを得ない.
市販の辞書は多かれ少なかれ複数の言語使用者をターゲットにするが,mental lexicon は言語使用者一人ずつに存在するものである.この両者を調和させるということ自体が,無理な注文なのかもしれない.dictionary と (mental) lexicon という用語の間に横たわる考え方の違いを認識することが重要である.
・ Lieber, Rochelle. Introducing Morphology. Cambridge: CUP, 2010.
2011-11-04 Fri
■ #921. 語の定義がなぜ難しいか (4) [word][dictionary][lexicography][oed][mental_lexicon]
[2011-10-26-1]の記事「#912. 語の定義がなぜ難しいか (3)」の (2) で触れたが,辞書には意味が不詳であるにもかかわらず見出し語として掲げられているものがありうる.語の意味が不詳であるということは辞書編纂者の情報収集の問題であるという可能性は排除できないにせよ,その語が一般的に知られていない語であるということは恐らく間違いないだろう.
OED では,そのような語が少なくとも77個は登録されている.以下は,OED の定義部検索で "meaning obscure" あるいは "obscure meaning" というキーワードにより引き出された語である.Lieber (26) では,OED での同種の検索により87語が引き出されたとしているが,ここには語義の1つのみが意味不明というものも含まれている.それを手作業で排除した結果の77語だ.
†cremitoried (ppl. a.), †emporture (v.), †gestyll (v.), †leary (a.), †leg-saw, †minority waiter, notchet, †rag (v.4), †reordi (a.), †reprobitant (a.), †resaille, †residence (v.), †rok, †romb (v.), †rompering, †rownfol(d, †rubell, †rum (n.3), †ruvell, †ryne2, scuncheon anglers, -crest, †sheer-point, short-coat vicarage, †shreake, shuffle-breeches, †sidder (v.), †sithy-coat, †skyvald, †slampamb, †slope (v.3), †smazky (a.), †spanner2, †sparth2, †spen (n.), †spencer (v.), †spene (n.), †sperring (vbl. n.), †sperware, †splet (n.), †splete, †spleyer, †spyccard, †squaleote (v.), †squalm, †squirgliting (a.), †start-rope, †strothe (a.), †threte (n.), †thwerl (v.), †traythly (adv.), †trice (n.3), umbershoot, †unbrede (v.), †uncape (v.), †underdrawn (ppl. a.), †uniable (a.), †unthwyuond (pres. pple.), †untwitten (ppl. a.), †val-dunk, †ver (n.2), †verge-salt, †verling-line, †versing box, †very(e), †vezon, †viridary (a.), †vitremyte, †vounde (a.), †vowgard, †vrycloth, †wandclot, †way-flax, Welsh brief, †werder, †wesel, †wranchevel, †wrast (? n.)
71語が廃語というのが現実だが,要点はこのような語が辞書にエントリーされているという事実があることである.dictionary の見出し語と mental lexicon の登録が必ずしも一致しないということは,これらの例からも明らかだろう.語とは何かという問いへの答えを辞書編集者に任せるわけにはいかないということを示す好例だ.
・ Lieber, Rochelle. Introducing Morphology. Cambridge: CUP, 2010.
2011-11-03 Thu
■ #920. The Gavagai problem [psycholinguistics][language_acquisition][mental_lexicon][philosophy_of_language][translation]
人はどのようにして多くの語を記憶語彙 (mental lexicon) へ蓄積してゆくのか,という問題は言語習得 (language acquisition) の分野における大きな問題である.大人になるにつれ音韻,形態,統語の規則の習得能力は落ちて行くと考えられているが,語彙の習得能力は維持されるという.子供にせよ大人にせよ,新しい語彙をどのように習得してゆくのか.意識的な語彙学習は別として,日常生活のなかでの語彙習得については,いまだに謎が多い.
哲学者 W. O. Quine が議論した以下のような状況に言及して,心理言語学者が the Gavagai problem と称している語彙習得上の問題がある.
Picture yourself on a safari with a guide who does not speak English. All of a sudden, a large brown rabbit runs across a field some distance from you. The guide points and says "gavagai!" What does he mean? / One possibility is, of course, that he's giving you his word for 'rabbit'. But why couldn't he be saying something like "There goes a rabbit running across the field"? or perhaps "a brown one," or "Watch out!," or even "Those are really tasty!"? How do you know? / In other words, there may be so much going on in our immediate environment that an act of pointing while saying a word, phrase, or sentence will not determine clearly what the speaker intends his utterance to refer to. (Lieber 16)
普通であれば,上記の場合には gavagai をウサギと解釈するのが自然のように思われるが,この直感的な「自然さ」はどこから来るものだろうか.心理言語学者は,人は語彙習得に関するいくつかの原則をもっていると仮定する (Lieber 17--18) .
(1) Lexical Contrast Principle: 既知のモノに混じって未知のモノが目の前にあり,未知の語が発せらるのを聞くとき,言語学習者はその未知のモノとその未知の語を結びつける.
(2) Whole Object Principle: 未知の語を未知のモノと結びつけるとき,言語学習者はその語をその未知のモノ全体を指示するものとして解釈する.未知のモノの一部,一種,色,形などを指示するものとしては解釈しない.
(3) Mutual Exclusivity Principle: 既知のモノだけが目の前にあり,未知の語が発せられるのを聞くとき,言語学習者は周囲に未知のモノを探してそれと結びつけるか,あるいは既知のモノの一部や一種を指示するものとして解釈する.
この仮説は多くの実験によって支持されている.現実には稀に the Gavagai problem が生じるとしても,上記のような戦略的原則を最優先させることによって,我々は多くの語彙を習得しているのである.確かに,このような効率的な戦略がなければ,言語学習者は数万という語彙を習得できるはずもないだろう.
・ Lieber, Rochelle. Introducing Morphology. Cambridge: CUP, 2010.
2011-11-02 Wed
■ #919. Asia の発音 [pronunciation][diachrony][variation]
少し前だが10月19日に,中央大学で駐日英国大使 David Warren 氏による講演会が開かれた(案内のチラシ).1952年ロンドン生まれの Warren 氏の講演内では,Asia(n) という語が頻出したが,/eiʃə(n)/ と発音されていた.この発音は時々聞かれることはあっても,現在では概ね /eiʒə(n)/ と発音されるものだろうと認識していたので,大使の発音が耳についた.Asia は,[2010-08-28-1]の記事「#488. 発音の揺れを示す語の一覧」にも含まれており,発音の揺れを示す語の典型のようなので,少し調べてみた.
LDP3 によれば,AmE ではほぼ /eiʒə/ だが,BrE では揺れが激しいという.Preference Poll の結果は,次の通り.
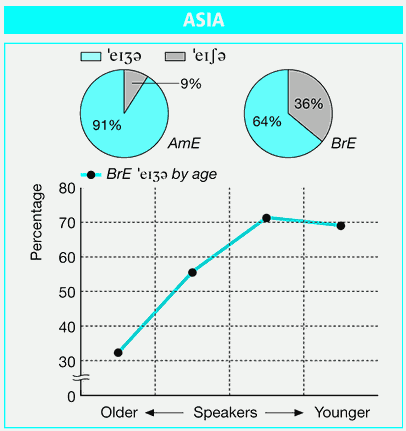
また,1942年より前に生まれた人々は,有声子音が 32%,無声子音が 68% という統計も示されていた.Warren 氏は上述の通り1952年生まれではあるが,この世代のイギリス英語母語話者ではまだ /eiʃə/ も珍しくはないということが予想される.
[2011-10-28-1]の記事「#914. BNC による語彙の世代差の調査」でも触れたが,現時点での発音の年齢差を調べることで,擬似的に過去数十年の通時的変化を観察することができる.前者は "apparent time",後者は "real time" と呼ばれ,共時的変異 (synchronic variation) と通時的変化 (diachronic change) を結びつける手法が,近年の社会歴史言語学で確立されてきた.両者を完全に同一視できるわけではないが,慎重に扱えば,通時的変化を間接的に観察する方法として有効である.
・ Wells, J C. ed. Longman Pronunciation Dictionary. 3rd ed. Harlow: Pearson Education, 2008.
2011-11-01 Tue
■ #918. sow, swine, hog, pig の語源 [etymology][i-mutation]
先日,中英語のテキストで sow (雌豚)に出くわし,[sū] と音読していたところ,この母音が swine の母音と i-mutation の関係にあるなと気づき,語源辞典を繰ってみた(i-mutation については,[2009-10-01-1]の記事「#157. foot の複数はなぜ feet か」を参照).以下,調べた内容をメモ.
成長した繁殖用の雌豚を表わす sow [saʊ] の語源をたどると,ME soue < OE sugu < Gmc *suȝō < IE *sū- "pig" へと遡る.関連する諸語における cognate は,G Sau, ON sýr, L sūs, Gr hûs など.(/h/ と /s/ の対応については[2010-04-14-1]の記事「#352. ラテン語 /s/ とギリシャ語 /h/ の対応」を参照.)
主として集合的に用いられる古風あるいは専門的な語としての豚を表わす swine (豚)については,OE swīn < Gmc *swīnam < IE *suəīno- "pertaining to swine" へと遡る.IE の形態は,*sū- に接尾辞がついたもので,同種の接尾辞は OE gǣten "of goats" などにも見られる.この接尾辞は,[2010-04-18-1]の記事「#356. 動物を表すラテン語形容詞」で挙げた bovine や feline に見られるラテン語の形容詞接尾辞とも同根だろう.案の定,この接尾辞に含まれる前母音が i-mutation を引き起こした元凶だったのだ.
BrE pig の代わりに AmE で通常に食用の雄豚の意味で用いられる hog も,語源的には IE *sū- に遡る.Celt. *hukk- から後期古英語へ hogg として借用されたものである.
この印欧語根と関係する意外な語に,hyena (ハイエナ)がある.この語は古フランス語から中英語へ hiene として入ったもので,遡れば上記の Gr hûs に女性語尾 -ainā が付加された派生形にたどり着く.
さて,現代英語で最も一般的に豚を表わす語である pig はというと,詳しい語源は分かっていない.初出は中英語で,古英語に遡る形態はないものの,docga "dog" や frocga "frog" との比例で *picga が提案されている.また,突き出た鼻との連想から pick や pike との関連を指摘する説もある.古英語,中英語では swine, hog が一般的に用いられていたが,19世紀以降に pig が優勢となった.
2026 : 01 02 03 04 05 06 07 08 09 10 11 12
2025 : 01 02 03 04 05 06 07 08 09 10 11 12
2024 : 01 02 03 04 05 06 07 08 09 10 11 12
2023 : 01 02 03 04 05 06 07 08 09 10 11 12
2022 : 01 02 03 04 05 06 07 08 09 10 11 12
2021 : 01 02 03 04 05 06 07 08 09 10 11 12
2020 : 01 02 03 04 05 06 07 08 09 10 11 12
2019 : 01 02 03 04 05 06 07 08 09 10 11 12
2018 : 01 02 03 04 05 06 07 08 09 10 11 12
2017 : 01 02 03 04 05 06 07 08 09 10 11 12
2016 : 01 02 03 04 05 06 07 08 09 10 11 12
2015 : 01 02 03 04 05 06 07 08 09 10 11 12
2014 : 01 02 03 04 05 06 07 08 09 10 11 12
2013 : 01 02 03 04 05 06 07 08 09 10 11 12
2012 : 01 02 03 04 05 06 07 08 09 10 11 12
2011 : 01 02 03 04 05 06 07 08 09 10 11 12
2010 : 01 02 03 04 05 06 07 08 09 10 11 12
2009 : 01 02 03 04 05 06 07 08 09 10 11 12
最終更新時間: 2026-06-26 03:46
Powered by WinChalow1.0rc4 based on chalow