2021-09-03 Fri
■ #4512. 英米英語と比較したカメルーン英語のキーワード [keyword][corpus][ice][flob][frown]
複数のコーパスを用いたキーワード分析は,私も何度か行なったことがある (cf. keyword) .特定のコーパスに特徴的に現われるキーワードを,別の一般的なコーパスとの対比によって統計的に抜き出してくる手法で,うまくいくと言語文化的な観点からおもしろい結果が出る.
今回は,Polzenhagen and Wolf の論考を読んでいて,ICE (International Corpus of English) が提供するカメルーン英語のコーパスからキーワードを抜き出した調査が紹介されているのを見つけたので,それを紹介したい.対比のための参照コーパスとして,イギリス英語の FLOB とアメリカ英語の FROWN が用いられている.
さて,調査の結果だが,カメルーン英語のキーワードとして以下の単語群が上位に浮かび上がってきたという (161) .
・ community
・ communal
・ family
・ relative
・ kin / kinship / kinsman / kinspeople
・ brotherhood
・ marriage
・ marry
・ marital
・ husband
・ wife
・ parent / parental / parenting
・ maternity / maternal
・ Birth
・ child / childhood / childless
・ Offspring
意味の場として共通項をくくり出せば「親族」と「共同体」といったところだろうか.カメルーン社会の顕点が明らかになっているといってよいだろう.民族誌や認知人類学にも洞察を与えてくれる興味深い結果といえる.ただし,対比のための参照ポイントが英米変種(文化)であること,つまり結果が相対的なものであることは,常に意識しておく必要があるだろう.
・ Polzenhagen, Frank and Hans-Georg Wolf, "World Englishes and Cognitive Linguistics." Chapter 8 of The Oxford Handbook of World Englishes. Ed. by Markku Filppula, Juhani Klemola, and Devyani Sharma. New York: OUP, 2017. 147--72.
2011-09-24 Sat
■ #880. いかにもイギリス英語,いかにもアメリカ英語の単語 [corpus][ame_bre][ame][bre][flob][frown][text_tool][keyword]
道具が揃っていれば簡単に実行でき,しかも結果がとてもおもしろいコーパスの使い方として,キーワード抽出がある.その原理については[2010-03-10-1]の記事「#317. 拙著で自分マイニング(キーワード編)」で概説し,[2010-09-27-1]の記事「#518. Singapore English のキーワードを抽出」でもキーワード抽出の事例を紹介した.
今回はより身近な疑問として,(1) アメリカ英語に対していかにもイギリス英語的な単語は何か,(2) イギリス英語に対していかにもアメリカ英語的な単語は何か,を FLOB と Frown の2コーパスを用いて取り出してみたい(両コーパスについては[2010-06-29-1]の記事「#428. The Brown family of corpora の利用上の注意」を参照).解析のお供は,以前と同様 WordSmith の KeyWords 抽出機能である.
両変種の語彙頻度表を互いに突き合わせ,それぞれキーワード性 (keyness) の高い順に上位500語を取り出した(全リストはこちらのテキストファイルを参照).ここでは,それぞれから上位50語のみを再掲しよう.すべて小文字で示す.
Q. (1) アメリカ英語に対していかにもイギリス英語的な単語は何か?
A. (1) 以下の通り.
cent, which, labour, uk, towards, london, per, centre, was, british, programme, behaviour, it, be, colour, britain, defence, favour, royal, there, been, round, bbc, thatcher, sir, mp, charter, nhs, realised, scottish, yesterday, lord, favourite, local, council, recognised, theatre, mr, being, fviii, tory, kinnock, mps, thalidomide, whilst, scotland, churches, should, programmes, parliament
Q. (2) イギリス英語に対していかにもアメリカ英語的な単語は何か
A. (2) 以下の通り.
percent, toward, program, programs, clinton, u, bush, labor, s, defense, president, american, states, center, washington, formula, federal, behavior, color, united, black, state, fiber, says, zen, americans, ó, california, congress, zach, san, o, white, presidential, pex, jell, women, treaty, favorite, said, bill, gray, colors, perot, favor, douglass, hershey, quayle, j, n
中には,それだけでは意味不明のものもある.BrE の第1位 cent などは何故かと思うかもしれないが,分かち書きをする per cent の2語目が抜き出された結果である.AmE では対応する percent が第1位である.他にも綴字の英米差はよく反映されており,behaviour, centre, colour, defence, favour, favourite, labour, programme(s) は互いのリストに現われる.
英国の政治を特徴づける MP(s), NHS, Parliament, Royal, Scotland, Tory,対応する米国の Congress, Federal, President, State(s), Washington, White (House) などは,なるほどと頷かせる.両コーパスのテキスト年代である1990年代初頭(と少し以前の時期)を特徴づける Thatcher, Bush, Clinton も含まれている.
文法語としては,BrE の which や whilst ([2010-09-17-1]の記事「#508. Dracula に現れる whilst」を参照)が興味深い.
それにしても,それぞれ鼻につくほどの BrE あるいは AmE である.逆に,各変種の汎用コーパスからこのようにして抽出されたキーワードがどれくらい含まれているかによって,小説なり何なりのテキストがいかに BrE 的か AmE 的か,あるいはより中立な "World Standard English" に近いかということを測ることができるかもしれない.
キーワード抽出による「いかにも」シリーズは今後も続きそう.
2010-09-27 Mon
■ #518. Singapore English のキーワードを抽出 [text_tool][corpus][flob][ice][singapore_english][keyword]
昨日の記事[2010-09-26-1]で ICE ( International Corpus of English ) からいくつかの英語地域変種コーパスが手に入る旨を紹介したが,そのなかから Singapore English のコーパス ( ICE-SIN ) を少しいじってみた.
[2010-03-10-1]の記事で WordSmith の KeyWords 抽出機能を拙著の英文で試したが,今回は ICE-SIN で同様に試してみるとどうなるだろうかと思った.そこで今回も,1990年代初頭のイギリス英語を対象に編纂された比較可能な FLOB corpus ( see [2010-06-29-1] ) を参照コーパスとし,British English に照らして Singapore English に特徴的な語(=キーワード)を抽出してみた.キーワード性の高い上位20語について,WordSmith に出力された表を掲げよう(上位100語までのリストはこのページのHTMLソースを参照).
| n | word | ice-sin.freq. | ice-sin.lst % | flob.freq. | flob.lst % | keyness |
|---|---|---|---|---|---|---|
| 1 | uh | 8,230 | 0.74 | 8 | 19,246.0 | |
| 2 | you | 18,175 | 1.64 | 7,258 | 0.29 | 17,768.5 |
| 3 | uhm | 3,838 | 0.35 | 0 | 9,021.1 | |
| 4 | ya | 3,580 | 0.32 | 10 | 8,283.9 | |
| 5 | i | 15,166 | 1.37 | 12,230 | 0.49 | 7,051.3 |
| 6 | singapore | 3,041 | 0.27 | 64 | 6,570.0 | |
| 7 | word | 3,490 | 0.32 | 482 | 0.02 | 5,621.8 |
| 8 | know | 4,768 | 0.43 | 1,534 | 0.06 | 5,345.5 |
| 9 | okay | 2,296 | 0.21 | 28 | 5,112.0 | |
| 10 | so | 6,759 | 0.61 | 4,452 | 0.18 | 4,113.8 |
| 11 | lah | 1,747 | 0.16 | 2 | 4,074.4 | |
| 12 | it's | 3,585 | 0.32 | 1,186 | 0.05 | 3,949.9 |
| 13 | your | 3,485 | 0.31 | 1,642 | 0.07 | 2,972.2 |
| 14 | oh | 1,952 | 0.18 | 344 | 0.01 | 2,900.2 |
| 15 | think | 2,761 | 0.25 | 1,208 | 0.05 | 2,501.5 |
| 16 | ah | 1,288 | 0.12 | 142 | 2,204.9 | |
| 17 | we | 5,884 | 0.53 | 5,406 | 0.22 | 2,190.7 |
| 18 | is | 15,022 | 1.36 | 20,588 | 0.83 | 2,027.9 |
| 19 | don't | 2,372 | 0.21 | 1,196 | 0.05 | 1,904.9 |
| 20 | what | 4,635 | 0.42 | 4,072 | 0.16 | 1,865.8 |
上位リストを眺めていたら2つの特徴が浮かんできた.
(1) 当然ながら Singapore English としばしば結びつけられる表現が上位に食い込んでいる.例えば,11位の lah は日本語でいう終助詞「ね」「よ」や間投詞のような働きをする pragmatic marker で,Singapore (and Malaysian) English らしい表現として知られている.しかし,やはり局地的な表現だからか手元の英語辞書にはほとんど掲載されておらず,唯一 Macmillan English Dictionary for Advanced Learners, 2nd ed. で次のような説明があった.
adverb INFORMAL
used by people in Malaysia and Singapore for making something they are saying sound more friendly and informal
例文を挙げるには,ICE-SIN から直接拾ってくると早い.会話文ではもちろんのこと,次のような親しい手紙文でも使われている.
Anyway, life is getting colder here. Hottest degree - 16 degrees celcius, coldest so far is 8oc. Brr..rr!! I'm wearing 3 to 4 layers now, like I did in England. So heavy one lah! Get back ache, you know!
ほかには,Singapore が6位に入っていたり,dollar(s), Chinese, Singaporeans, Malay などが上位100語以内に入っている.
(2) lah の頻度の高さとも関係するが,口語性の高い語,会話で頻出すると考えられる語が目立つ.直示性を表わす人称代名詞や副詞,また語調を和らげる語 ( hedge ) が特に多い.広く語用論的な機能をもつ語群としてまとめてよいかもしれない.もっとも話し言葉と結びつけられるキーワードが多いことは予想されたことではある.書き言葉は標準に準拠しやすく,地域変種間の差が少ないのが普通だからである.とりわけ話し言葉に地域変種の差が出やすいということが,今回のキーワード抽出で確かめられたということだろう.
今回のようなキーワード抽出は,もちろん他の地域変種にも応用できる.参照コーパスをイギリス英語以外に動かして相対的に各変種の特徴をみるというのもおもしろそうだ.
2010-03-10 Wed
■ #317. 拙著で自分マイニング(キーワード編) [text_tool][flob][corpus][keyword]
昨日の記事[2010-03-09-1]に引き続き,拙著 The Development of the Nominal Plural Forms in Early Middle English で自分マイニング.WordSmith には KeyWords 抽出機能がある.単に単語リストを頻度順に並べた昨日のリストでもおよそのテキストの主題を読み取ることは可能だが,上位に機能語などの雑音が大量に入り込み,解釈しにくい.それに対して,キーワードリストでは対象テキストの主題をよく表す実質的なキーワードが上位に来るので,解釈しやすい.
考え方としては以下の通りである.巨大なコーパスなどを参照テキストとして使用し,そこから単語ごとに一般的な頻度を導き出す.次に,対象テキスト内で各単語について頻度を出す.ある語の対象テキスト内での頻度が,参照テキスト内での頻度よりも相当に大きい場合には,それは対象テキストに特有のキーワードとみなせる.そのようなキーワードを自動的に探し出してくれるのが,WordSmith の KeyWords 抽出機能である.拙著はイギリス英語で書いていることもあり,参照テキストとしては FLOB ( Freiburg-LOB corpus ) を使用した.以下,上位50語のキーワードである.
plural, english, s, n, old, nouns, norse, dialect, midland, middle, plurals, dialects, texts, language, forms, text, ending, diffusion, v, south, west, nominative, early, stem, the, spread, linguistic, singular, endings, inflectional, contact, accusative, o, system, weak, in, development, sec, change, fem, dative, morphological, languages, saxon, item, formation, period, transfer, germanic, strong
ずばり来てくれました plural .複数形の研究なのでそうでなければ困るところだ.昨日のリストよりも機能語の雑音がよくはじかれている.
WordSmith には各キーワードのファイル内での出現箇所を視覚的にプロットする機能もあり,上記の50語について以下のようなプロットが得られた.
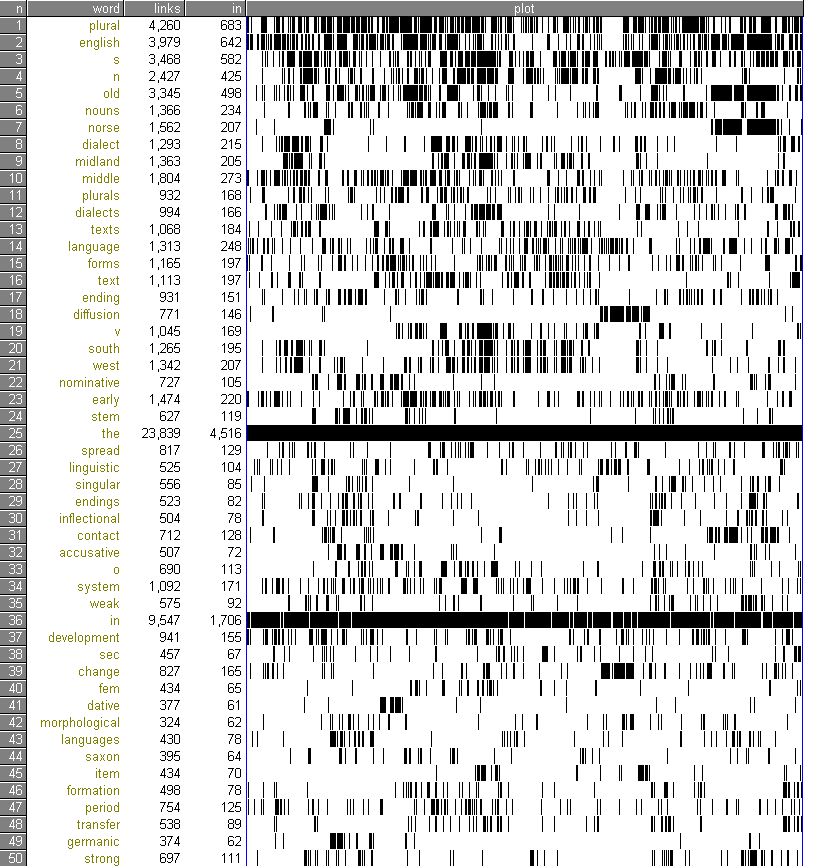
執筆者本人なので,なるほどと思えることが多い.最上位語はテキスト中にまんべんなく現れる傾向があるが,それでも分布が偏っているものもある.7位の norse は Old Norse について論じている7章に固まっているし,18位 diffusion は Lexical Diffusion を集中的に扱っている5章に集中している.
われながらの発見もあった.言語変化を論じているので development と change を多用しているが,執筆中にはそれほど意識して両語を使い分けていたわけではなかった.そうであればまんべんなく分布していそうなものだが,実際には change が5章辺りに偏在している.ということは,無意識のうちに使い分けていたということなのだろうか.無意識の癖とでもいうべきものが発見できておもしろい.
文章をこのように分析することで,実用的な効果がいろいろ考えられそうである.思いつきを記す.
・ 文体の統計を把握することで今後の文章改善に活かす(誰々の文体に近づきたい,ボキャ貧をなおしたい,パラグラフ構成の指針をもちたい,など)
・ 自分の過去の文章と比較し,文体の経年変化を観察する
・ 論文などを書き終えた後でタイトル候補が複数ある場合に,キーワードを参考にして決定する
・ 自分の過去の論文などをひっくるめて分析対象とし,「私の研究テーマは(キーワード)です」と言い切れるようになる
・ 相手の過去の論文などをひっくるめて分析対象とし,「あなたの研究テーマは(キーワード)です」と言い切れるようになる(←おせっかい)
・ 緩やかに関連する二つの論文 A と B を互いに参照テキストとしてそれぞれのキーワードを抽出し,A の特徴と B の特徴を比べる.共通点が多いことを前提としているので,キーワードによって逆に相違点が浮き彫りになる可能性がある.
2010-03-07 Sun
■ #314. -ise か -ize か (2) [spelling][bre][bnc][lob][flob][corpus][suffix][z]
[2010-02-26-1]の記事で取りあげた話題の続編.先日の記事では,単語によって比率は異なるものの,イギリス英語では -ise と -ize の両方の綴字が行われることを,BNC に基づいて明らかにした.高頻度20語については,おおむね -ise 綴りのほうが優勢ということだった.
通時的な観点がいつも気になってしまう性質なので,そこで新たな疑問が生じた.-ise / -ize のこの比率は,過去から現在までに多少なりとも変化しているのだろうか.大昔までさかのぼらないまでも,現代英語の30年間の分布変化だけを見ても有意義な結果が出るかもしれないと思い,1960年代前半のイギリス英語を代表する LOB ( Lancaster-Oslo-Bergen corpus ) と1990年代前半のイギリス英語を代表する FLOB ( Freiburg-LOB corpus ) を比較してみることにした.
それぞれのコーパスで,前回の記事で取りあげた頻度トップ20の -ise / -ize をもつ動詞について,その変化形(過去形,過去分詞形,三単現の -s 形,-ing(s) )を含めた頻度と頻度比率を出してみた(下表参照).
| item | LOB: rate (freq) | FLOB: rate (freq) | ||
| -ise | -ize | -ise | -ize | |
| recognise | 59.6% (99) | 40.4% (67) | 71.8% (127) | 28.2% (50) |
| realise | 63.2% (134) | 36.8% (78) | 68.7% (125) | 31.3% (57) |
| organise | 65.6% (42) | 34.4% (22) | 67.2% (43) | 32.8% (21) |
| emphasise | 37.7% (20) | 62.3% (33) | 62.9% (39) | 37.1% (23) |
| criticise | 52.0% (13) | 48.0% (12) | 80.0% (24) | 20.0% (6) |
| characterise | 0.0% (0) | 100.0% (4) | 56.3% (18) | 43.8% (14) |
| summarise | 35.3% (6) | 64.7% (11) | 64.7% (11) | 35.3% (6) |
| specialise | 56.3% (18) | 43.8% (14) | 81.8% (27) | 18.2% (6) |
| apologise | 68.8% (11) | 31.3% (5) | 70.6% (12) | 29.4% (5) |
| advertise | 100.0% (41) | 0.0% (0) | 100.0% (55) | 0.0% (0) |
| authorise | 77.4% (24) | 22.6% (7) | 68.2% (15) | 31.8% (7) |
| minimise | 90.0% (9) | 10.0% (1) | 80.0% (16) | 20.0% (4) |
| surprise | 100.0% (182) | 0.0% (0) | 100.0% (173) | 0.0% (0) |
| supervise | 100.0% (10) | 0.0% (0) | 100.0% (9) | 0.0% (0) |
| utilise | 70.0% (7) | 30.0% (3) | 83.3% (5) | 16.7% (1) |
| maximise | 50.0% (2) | 50.0% (2) | 50.0% (9) | 50.0% (9) |
| symbolise | 50.0% (3) | 50.0% (3) | 40.0% (4) | 60.0% (6) |
| mobilise | 66.7% (2) | 33.3% (1) | 20.0% (1) | 80.0% (4) |
| stabilise | 58.3% (7) | 41.7% (5) | 33.3% (3) | 66.7% (6) |
| publicise | 81.8% (9) | 18.2% (2) | 84.6% (11) | 15.4% (2) |
いずれも100万語規模のコーパスなので,トップ20とはいっても下位のほうの語の頻度はそれほど高くない.だが,全体的な印象としては,-ise の綴字が30年のあいだにじわじわと増えてきているようである.頻度比率に大きな変化の見られないものも確かにあるが,著しく伸びたものとして emphasise, criticise, characterise, summarise, specialise などがある.ただ,これはあくまで印象なので,全体的に,あるいは個別の単語について統計的な有意差があるのかどうかは別に検証する必要がある.また,LOB には characterise は一例も例証されないが characterisation は確認されたことからも,動詞だけでなく名詞形の -isation / -ization も合わせて調査する必要がある.さらには,対応するアメリカ英語の状況も調査し,イギリス英語の通時的変化(もしあるとすればであるが)と関係があるのかどうかを探る必要がある.
Powered by WinChalow1.0rc4 based on chalow