2022-02-11 Fri
■ #4673. 言語の統計的必然性と偶然性 [chaos_theory][complex_system][computational_linguistics][statistics][zipfs_law]
本ブログでは,言語と複雑系,カオス理論,フラクタルの関係について,complex_system や chaos_theory などの記事で紹介してきた.しかし,とても関心はあるものの,私の頭の理解が伴っていかない分野のようで,なかなか深入りできない.文系頭にももう少し理解しやすい形で,上記の分野(一般的には数量言語学)の本などがあればよいのになぁと思っていたところ,昨年,田中久美子(著)『言語とフラクタル --- 使用の集積の中にある偶然と必然』が出版された.読みたいと思いつつ積ん読していたのだが,ようやくページ開く機会を得た.おもしろい.
なぜ私がこれまで深入りできなかったのか.その辺りの理由も,導入部から教えてくれていて,とても嬉しい(田中,pp. 10--11).
複雑系科学は自然・社会的な系に適用されてきたが,言語を捉える探求は,その中でも亜流であり,限定的であるといわざるをえない.その主な理由としては,物理学的方法論の対象は広いとはいってもまず自然であり,結果は人の解釈に依存しないものを目指すことがある.一方,言語の研究は,人の解釈を前提とした単語や文を探究してきた.統計力学的な方法論は,意味や解釈をめぐって,言語とは相性がよいとはいえなかったのである.その中で,物理学出身の研究者が言語を探究した報告があちこちに散乱しており,それは言語の諸研究の側からは見えない.本書はそのような既存研究に多くを拠っている.
とてもよく分かった.例えば Zipf's Law (cf. zipfs_law) という著名な語彙統計学上の法則ですら,突っ込んだ議論を読みたいと思えば,言語学から一歩外に出なければならない.多くの普通の言語学の徒にとって,なかなか手を出せないのである.
では,なぜ私は,理解するのが難しいと分かっていながらも,言語と複雑系などとの関係に心ひかれるのだろうか.その辺りのモヤモヤしたところも,田中 (11) が解消してくれた.
言語データを解析すると,統計的言語普遍としての性質が普遍的に立ち現れる.この事実から,統計的言語普遍は,言語が生み出す神秘の一つのように捉えられてきた側面がある.しかし,本書でも見るように,その因果関係はおそらく逆であると思われる.言語が統計的普遍を生み出すというよりは,統計的な性質がまずあり,言語はおそらくその性質を前提として成立している.つまり,統計的言語普遍は,言語を実現する前提となっていると思われる.ならばこの統計的必然性は,単語や統語構造などといった言語の諸性質に影響を及ぼしているはずである.そして,統計的必然の中で言語がどのような特殊性を持っているかを理解することは,言語の本質を捉える一つの手立てとなると思われる.
どこまでが言語の(統計的)必然なのかが分かれば,そこから逸脱したものこそが言語における偶然だと知れるだろう.そして,後者こそ,人間が言語に込めた意図を反映しているものである可能性が高い.田中 (5) は,このことを「Mallarmé の賽」として示している.
かつて,詩人 Stéphane Mallarmé が,詩作において「賽を投じる」ことに言及している〔中略〕.「賽の一投は偶然を決して廃さない」との Mallarmé のことばは,純粋な統計としては自明なだけであるが,言語や詩作についてとなると難しい.言葉が発せられる背景には意図があることが多く,偶然だけに基づくとは考えにくい.Mallarmé は,言葉を使うことも,賽を投じるように偶然性を廃さないことを暗示し,偶然性をふまえた言葉のアートを試行したかにみえる.意図があって発話する場合にも,文や単語を生成する時に偶然が排除できないなら,言語行為には偶然性と必然性が混ざっているだろう.言語の統計的特性を知ることで,言葉が前提とする偶然性について明らかになる.その残滓の中に,意図など人間の要因の本質がかすかに見えはしまいか.
私自身がなぜ言語の統計学に惹かれているのか,その辺りが読み進めるうちにどんどん分かってきたのが嬉しい.
・ 田中 久美子 『言語とフラクタル --- 使用の集積の中にある偶然と必然』 東京大学出版会,2021年.
2020-12-10 Thu
■ #4245. 頻度と漸近双曲線 (A-curve) [lexical_diffusion][zipfs_law][frequency][statistics][language_change][uniformitarian_principle]
variationist の立場を高度に押し進めた言語(変化)観を提案する,Kretzschmar and Tamasi の論考を読んだ."A-curve", "asymptotic hyperbolic distribution", "power law", "S-curve" などの用語が連発し思わず身構えてしまう論文だが,言わんとしていることは Zipf's Law (cf. zipfs_law) の発展版のように思われる.低頻度の言語項は多く,高頻度の言語項は少ないということだ.
ある英語コーパスにおいて,1度しか現われない語は相当数ある.一方,the, of, have などは超高頻度で現われるが,主として機能語であり種類数でいえば相当に限定される.例えば,1回しか現われない語 ( x = 1 ) は1000個 ( y = 1000 ) あるが,1000回も現われる語 ( x = 1000 ) は the の1語しかない ( y = 1 ) とすると,これを座標上にプロットしてみれば第1象限の左上と右下に点が打たれることになる.この2点を両端として,その間の点を次々と埋めていくと,y = 1/x で表わせるような漸近双曲線 (asymptotic hyperbolic curve) の片割れに近づくだろう.これを Kretzschmar and Tamasi は "A-curve" と呼んでおり,背後にある法則を "power law" (べき乗則)と呼んでいる.後者は "few realizations that occur very frequently and many realizations that occur infrequently" (384) ということである.
Kretzschmar and Tamasi は,アメリカ方言における訛語や調音の variants を調査し,各種の変異形について頻度の分布を取った.結果として,いずれのケースについても "A-curve" が観察されることを示した.
また,Kretzschmar and Tamasi は,語彙拡散 (lexical_diffusion) との関連でしばしば言及される "S-curve" と,彼らの "A-curve" との関係についても議論している.同一の言語変化を異なる軸に着目してプロットすると "S-curve" にも "A-curve" にもなり,両者は矛盾しないどころか,親和性が高いという.
私の拙い言葉使いでは上手く解説することができないのだが,言語体系や言語変化を徹底的に variationist に眺めようとすると,このような言語観あるいは言語理論になるのかと感心した.Kretzschmar and Tamasi (394) より,とりわけ重要と思われる箇所を引用する.
Our second observation, about the distribution of variants according to Zipf's Law, has the strongest set of implications for historical study of language. If we take the A-curve as the model for the frequency distribution of variants for any linguistic feature of interest to us at any moment in time, then we should expect that any particular variant of interest to us will have a particular rank along the A-curve. Therefore, one of the things that we should try to do for any given moment in time is to determine the place of our variant of interest on the curve; we need to know whether it is the most frequent variant in the set of possible realizations (at the top of the curve), or an infrequent variant (in the tail of the curve). Then, for any subsequent moment in time, we can again try to determine the location of our variant of interest along the curve, and so try to make a statement about whether the location of the variant has changed in the intervening time (see Figure 14). Since we hypothesize that an A-curve will exist for every feature at any moment in time (i.e., that language will not suddenly become invariant), we can define the notion "linguistic change" itself as the change in the location of the target variant at different heights along the curve. If a particular variant occurs at a higher place on the curve than it did before, it has become more frequent and so we can say that the direction of change for that variant is positive; if a variant occurs at a lower place on the curve than it did before, it has become less frequent and the direction of change is negative.
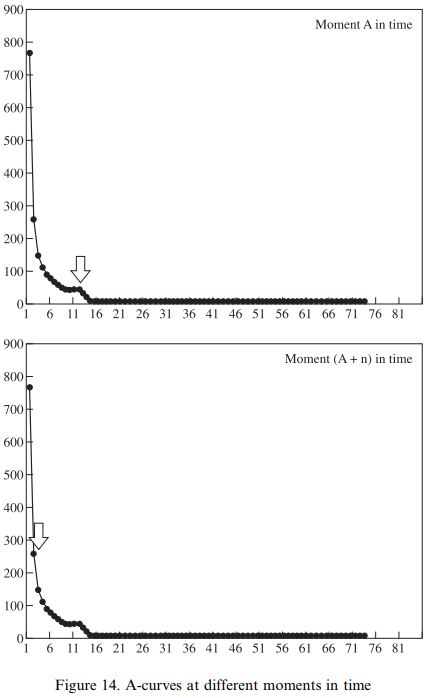
・ Kretzschmar, Jr.,William A and Susan Tamasi. "Distributional Foundations for a Theory of Language Change." World Englishes 22 (2003): 377--401.
2020-08-16 Sun
■ #4129. 「コロナ禍と英語」ならこれしかないでしょ! --- OED の記事より [oed][neologism][zipfs_law][covid]
OED が発信するコロナ関連語録の記事をいくつか読んだ.特集というよりは論文といってよい質の高さである.いずれにせよこれほどショッキングかつリアルタイムの社会言語学的論考は,あまり見たことがない.読んでいると苦しくなるかもしれないので要注意.以下,いくつか主要な記事をピックップする.
(1) New words list July 2020: この7月の新語(義)の一覧.
(2) Social change and linguistic change: the language of Covid-19: 目下のコロナ禍のみならず歴史的な疫病(14,17世紀ヨーロッパの惨禍を含む)に由来する語彙の歴史的解説もすばらしい.取り上げられている単語を列挙すると,Covid-19, WFH, elf-isolation, self-isolating, infodemic, shelter-in-place, social distancing, elbow bump, WFH, PPE, personal protective equipment, pestilence, pest, pox, pock, smallpox, epidemic, Black Plague, Black Death, self-quarantined, yellow fever, Spanish influenza, Spanish flu, poliomyelitis, polio, AIDS, SARS, coronaviruses となる.
(3) July 2020 update: scientific terminology of Covid-19: とりわけコロナ関連の医学的・科学的な用語が紹介されている.科学的事実が明らかになるにつれ語の定義も変わってくるという,まさに現在進行形の話題である.新型コロナウィルスを意味する語も Covid, C-19, CV-19, CV, corona など様々にあること,そして目下もう1つの省略語 rona がアメリカ英語やオーストラリア英語でトレンドになってきてことが取り上げられている (cf. 「#1102. Zipf's law と語の新陳代謝」 ([2012-05-03-1])) .なお,Covid-19, n. 自体の定義も最近書き換えられたようだ.
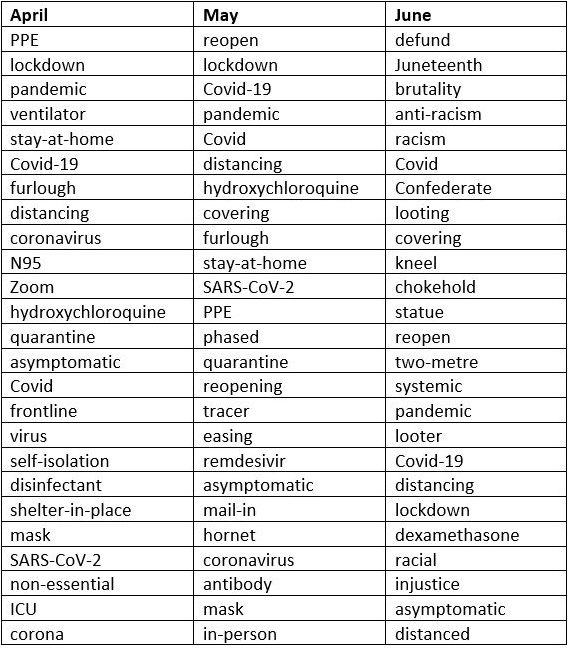
(4) Using corpora to track the language of Covid-19: update 2: コーパスを用いた,今年の4月から6月にかけてのトレンドワードの調査が紹介されている.トレンドワードのリストは,まさにその時代を映し出していることがよく分かる.これほど切実な生の単語リストを,私は見たことがない.社会と言語の驚くべき関係を見せつけられた感がする.
イギリス英語では Covid-19 の綴字が,アメリカ英語では COVID-19 の綴字が多いという結果も興味深い.6月のリストには,コロナ関連に紛れて "Black Lives Matter" に関する racism, injustice, police brutality, defund, Confederate statues なども現われる.いろいろな意味でため息が出てしまうリストである.
2018-03-25 Sun
■ #3254. 高頻度がもたらす縮小効果と保存効果 [frequency][grammaticalisation][auxiliary_verb][suppletion][zipfs_law]
言語項目は,高頻度であればあるほど形態がすり減って縮小するということはよく知られている.一方,言語項目は高頻度であればあるほど,新たな形態に取って代わられることが少なく,古い形態を保持しやすいこともしられている.高頻度性がもたらすそれぞれの効果は,"Reduction Effect" (縮小効果),"Conservation Effect" (保存効果)と呼ばれている (Hopper and Traugott 127--28) .
縮小効果は,文法化 (grammaticalisation) と関連が深い.代表的な例は,「#64. 法助動詞の代用品が続々と」 ([2009-07-01-1]) で示したような新種の法助動詞群である.used to [ju:stə], have to [hæftə], have got to [hævgɑtə], (be) supposed to [spoʊstə], (be) going to [gɑnə] などの音形が,オリジナルの音形からすり減って縮小しているのが確認される.この効果は,「#1101. Zipf's law」 ([2012-05-02-1]) や「#1102. Zipf's law と語の新陳代謝」 ([2012-05-03-1]) で取り上げた Zipf's law とも関係するだろう (cf. zipfs_law) .頻度と音形の長さには相関関係があるのだ(ただし,頻度と文法化の間には予想されるほどの関係はないと論じる,「#2176. 文法化・意味変化と頻度」 ([2015-04-12-1]) で紹介したような立場もあることを付け加えておこう).縮小効果の一般論としては,「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]) も参照されたい.
保存効果は,共時的には究極の不規則性を体現する形態,とりわけ補充法 (suppletion) の形態が,あちらこちらに残存していることから確認できる.人称代名詞の変化や be 動詞の活用など,超高頻度語においては古い形態がよく保持され,共時的にきわめて予測不可能な形態を示す.この点については,「#43. なぜ go の過去形が went になるか」 ([2009-06-10-1]),「#1482. なぜ go の過去形が went になるか (2)」 ([2013-05-18-1]),「#2090. 補充法だらけの人称代名詞体系」 ([2015-01-16-1]),「#2600. 古英語の be 動詞の屈折」 ([2016-06-09-1]),「#694. 高頻度語と不規則複数」 ([2011-03-22-1]) を参照.もちろん保存効果は形態のみならず語順などの統語現象にも見られるので,言語について一般にいえることだろう.
・ Hopper, Paul J. and Elizabeth Closs Traugott. Grammaticalization. 2nd ed. Cambridge: CUP, 2003.
2018-01-04 Thu
■ #3174. 高頻度語はスペリングが短い (2) [frequency][spelling][orthography][zipfs_law][statistics][lexicology][corpus]
昨日の記事 ([2018-01-03-1]) と同じ頻度とスペリングの長さに関するデータを,もう少し分析してみた.以下は,頻度ランキングのトップ100語,200語,500語,1000語,2000語,5000語,10000語,20000語,50000語について,それぞれ最低値,第1四分位数,中央値,平均値,第3四分位数,最大値を示した表である.英語の正書法を論じる上での基礎データとしてどうぞ.
| Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max. | |
|---|---|---|---|---|---|---|
| Top_100 | 1.0 | 2.0 | 3.0 | 3.1 | 4.0 | 5.0 |
| Top_200 | 1.00 | 3.00 | 4.00 | 3.77 | 4.00 | 10.00 |
| Top_500 | 1.000 | 4.000 | 4.000 | 4.498 | 5.000 | 10.000 |
| Top_1K | 1.000 | 4.000 | 5.000 | 4.968 | 6.000 | 15.000 |
| Top_2K | 1.000 | 4.000 | 5.000 | 5.406 | 7.000 | 15.000 |
| Top_5K | 1.000 | 5.000 | 6.000 | 6.014 | 7.000 | 16.000 |
| Top_10K | 1.000 | 5.000 | 6.000 | 6.488 | 8.000 | 16.000 |
| Top_20K | 1.000 | 5.000 | 7.000 | 6.954 | 8.000 | 17.000 |
| Top_50K | 1.000 | 6.000 | 7.000 | 7.622 | 9.000 | 20.000 |
これをもとに視覚化したのが,以下の箱ひげ図.
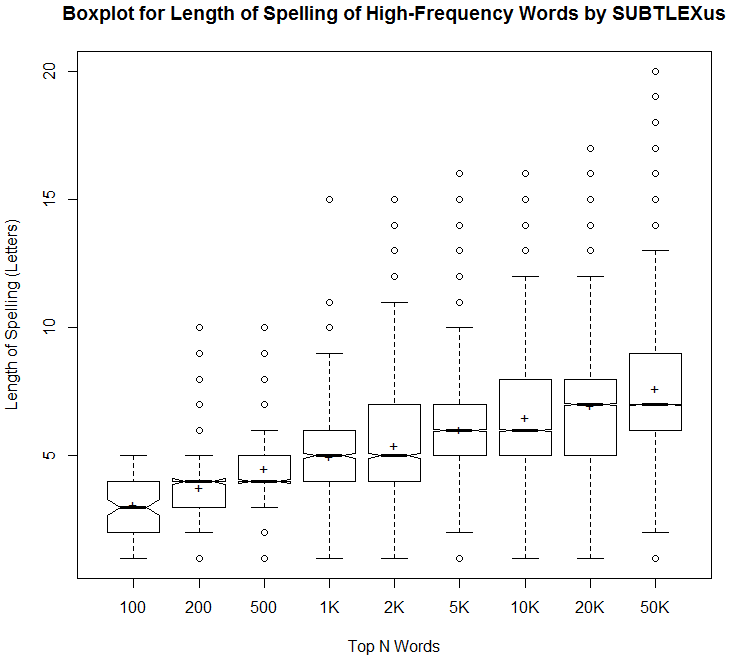
当然予想されたことだが,語数が増えるにしたがってスペリングの平均の長さは徐々に大きくなっていき,バラツキも広がっていく.しかし,トップ数万語でみても平均して7文字程度となっており,さほど長くないのだなという印象を受けた.
[ 固定リンク | 印刷用ページ ]
2018-01-03 Wed
■ #3173. 高頻度語はスペリングが短い (1) [frequency][spelling][orthography][zipfs_law][statistics][lexicology][corpus][three-letter_rule]
標題は特に目新しい指摘ではなく,英語を読み書きする者には直感されていることだと思われる.「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]) や「#1102. Zipf's law と語の新陳代謝」 ([2012-05-03-1]) でも指摘したように,よく読み書きする単語のスペリングは短いほうが効率がよいと考えられるからだ.逆に,滅多に読み書きしない単語であれば少々長くても我慢できる.単語のスペリングに限らず,単語の音形についても同様の原理が作用していると思われる.
また,英語の正書法には内容語は3文字以上で綴られなければならないという「#2235. 3文字規則」 ([2015-06-10-1]) がある.これは機能語という頻度のきわめて高い語類については適用されない.したがって,この規則は上記の効率の問題とも関わる実用的な側面をもつといえる.
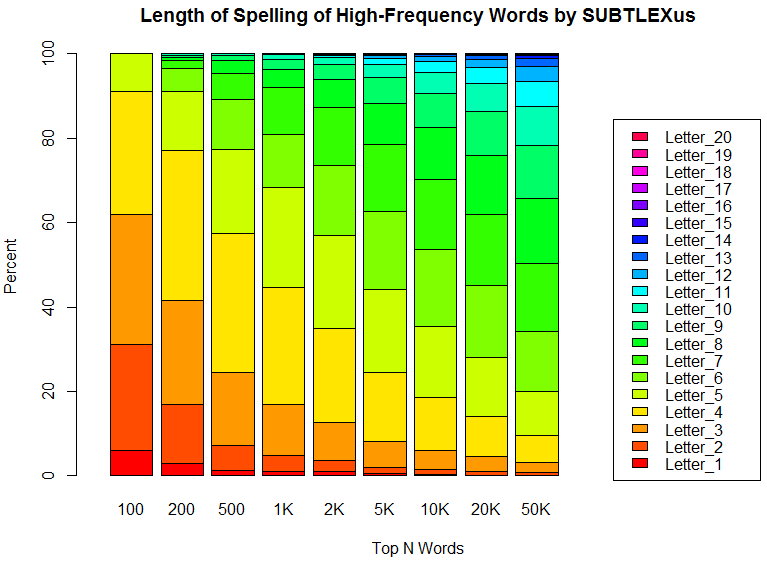
高頻度語であればあるほど,そのスペリングが平均的に短いことを示す方法の1つに,頻度ランキングのトップ100語,1000語,10000語などのリストに基づき,文字数別に単語を数え上げるというやり方がある.「#2096. SUBTLEX-US Word Frequency List」 ([2015-01-22-1]) から引き出した頻度ランキングを利用して,トップ100語,200語,500語,1000語,2000語,5000語,10000語,20000語,50000語について調査した.トップ100語のリストについては先の記事でリストを掲載している通りであり,なかには s, ll などコーパスの仕様に由来するとおぼしき怪しい「語」もあるが,結果の大勢には影響を及ぼさないだろう.
以下にグラフで整理した通り,結果は明白である(数値データはソースHTMLを参照).トップ100語の超高頻度語群では62.00%までが3文字以下のスペリングである.3文字以下の割合(下から3つ分のオレンジの帯まで)ということで比べていくと,トップ200語から50000語の調査結果まで,順に41.50%, 24.60%, 17.00%, 12.65%, 8.06%, 6.01%, 4.55%, 3.20%と目減りしていく.
2017-11-21 Tue
■ #3130. 複雑系言語学 [chaos_theory][complex_system][variety][zipfs_law][language_change][contact][methodology]
Kretzschmar は,言語を複雑系としてとらえ,言語変化を論じる研究者である.最近の論文で,複雑系の概念を用いて,アメリカ英語の諸変種がいかにして生じてきたかという問題を論じている.論文の冒頭 (251) で,発話を複雑系としてとらえる見方が端的に述べられている.
. . . language in use, speech as opposed to linguistic systems as usually described by linguists, satisfies the conditions for complex systems as defined in sciences such as physics, evolutionary biology, and economics . . . .
言語は複雑系とみなされるべき2つの特徴,すなわち "non-linear distribution" と "scaling" を備えているという (253) .前者 "non-linear distribution" は,具体的にいえば,漸近双曲線 (A-curve) の分布を指している.例としてすぐに思い浮かぶのは,「#1103. GSL による Zipf's law の検証」 ([2012-05-04-1]) や「#1101. Zipf's law」 ([2012-05-02-1]) で紹介した zipfs_law のグラフである.少数の高頻度語と多数の低頻度語により,右下へ長い尾を引くグラフが描かれる.Kretzschmar は,言語に関わる他の現象でもこのようなグラフが得られると主張する.
「言語=複雑系」に関するもう1つの特徴である "scaling" は,A-curve のような分布が言語の異なるレベルにおいて繰り返し現われる状況を指している.アメリカ東部諸州における方言単語(訛語)の頻度調査で,各形態について頻度順位の高い順に並べて頻度をプロットしていくと A-curve となるが,New York 州に限って同様のグラフを作成しても類似した曲線が得られるし,女性話者に限ったグラフでもやはり同様の曲線が得られるという (255) .
グラフが非線形でありスケール・フリーということになれば,当然ながら「#3123. カオスとフラクタル」 ([2017-11-14-1]) が想起される.関連して,「#3111. カオス理論と言語変化 (1)」 ([2017-11-02-1]),「#3112. カオス理論と言語変化 (2)」 ([2017-11-03-1]),「#3122. 言語体系は「カオスの辺縁」にある」 ([2017-11-13-1]) も参照されたい.
Kretzschmar (263--64) は論文の最後で,言語変種の生起・拡大を説明するのに複雑系の考え方が有用であると結論づけ,複雑系言語学を唱える.
Complexity science is the model that can cope successfully with the problems of language variation and change that we are interested in solving for the history of American English. Complexity science addresses the emergence of a new American variety, along with its component regional varieties, more adequately than traditional approaches. Complex systems replace the notion of monolithic "language contact" or Fischer's "cultural shift" with interaction between speakers. Complex systems can deal with the extension of existing varieties into new areas, and still account for the evident acquisition of new variants from important cultural groups in different areas. Finally, complex systems can cope with contemporary American cultural change and attendant language change, again without recourse to monolithic thinking. We are just at the beginning of research to understand the operation of the complex system of speech, but it is already clear that it gives us a good way to describe how the process of emergence and change really works.
従来のような "monolithic" な言語接触に基づいた理論ではなく,それを内に含み込むような複雑系の理論こそが,これからの言語変化研究を支えていくのではないかというわけだ.確かに刺激的な話題である.
・ Kretzschmar, William A., Jr. "Complex Systems in the History of American English." Chapter 4 of Developments in English: Expanding Electronic Evidence. Ed. Irma Taavitsainen, Merja Kytö, Claudia Claridge, and Jeremy Smith. Cambridge, 2015. 251--64.
2017-03-11 Sat
■ #2875. 英語語彙の頻度分布の格差をジニ係数とローレンツ曲線でみる [lexicology][statistics][frequency][zipfs_law][corpus]
「#1103. GSL による Zipf's law の検証」 ([2012-05-04-1]) で,General Service List (GSL) の最頻2000語余りの語彙頻度表を用いて,zipfs_law が成立する様子を実演した.頻度順位の高い少数の語がただの高頻度語ではなく超高頻度語であること,一方でそれ以外の大多数の語がおしなべて低頻度語であるということが確認された.このことは,英語(そして,おそらくあらゆる言語)の語彙の頻度分布がきわめて不平等・不均衡であり,大きなばらつきと格差に特徴づけられていることを示すものである.
このような分布の格差を示す代表的な指標に,イタリアの経済学者ジニが所得や資産の分布の不平等を計測する指標として1936年に考案したジニ係数 (Gini's coefficient) がある.考え方は次の通りだ.X軸に沿って左から右へ最も頻度の低い語から高い語へと順に並べ,その累積頻度のシェアをY軸方向に取っていく.この点をつなげると,何らかの形の右肩上がりの曲線となる.これをローレンツ曲線 (Lorenz curve) という.すべての語が同頻度で現われるときにはローレンツ曲線は45度の右肩上がりの直線となり「完全平等」を示す.逆に,極端な例として,1つの語のみが生起頻度のすべてを占有し,他のすべての語が頻度ゼロの場合に「完全不平等」となり,ローレンツ曲線は左右逆L字型となる.普通は,ローレンツ曲線は,45度の右肩上がりの線の下部に,三日月形の弧として描かれる.ジニ係数は,三日月の面積と,45度の右肩上がりの線を直角の対辺とする直角二等辺三角形の比率として表現される.したがって,値0が完全平等,値1が完全不平等ということになる.
さて,GSL のデータファイルで計算した結果,ジニ係数は0.812と出た.ローレンツ曲線を描くと,以下のようになる.
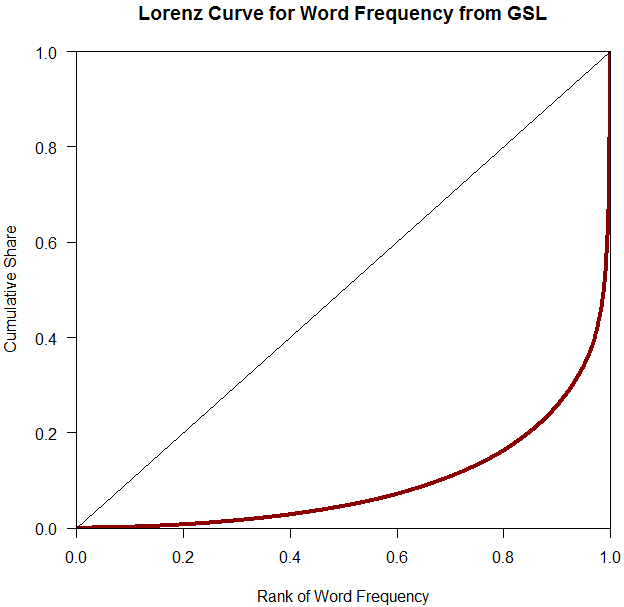
明らかに不平等な分布といえる.ちなみに,GSL よりも巨大なコーパスの語彙頻度表を使うと,さらにジニ係数は上がる(例えば,1790万語からなるコーパス「#1424. CELEX2」 ([2013-03-21-1]) に基づいた計算では,0.950 というすさまじい値が出た!).
参考までに,吉川 (122) に拠って2010年の諸国の所得格差を示すジニ係数をいくつか挙げると,日本が 0.336,アメリカが 0.380,チリが 0.510,アイスランドが 0.246 である.語彙の社会が極めて不平等な社会であることが分かるだろう.
・ 吉川 洋 『人口と日本経済』 中央公論新社〈中公新書〉,2016年.
2015-10-16 Fri
■ #2363. hapax legomenon [hapax_legomenon][terminology][lexicology][lexicography][word_formation][productivity][bible][zipfs_law][frequency][corpus][shakespeare][chaucer]
昨日の記事「#2362. haplology」 ([2015-10-15-1]) でギリシア語の haplo- (one, single) に触れたが,この語根に関連してもう1つ文献学や辞書学の用語としてしばしば出会う hapax (legomenon) を取り上げよう.ある資料のなかで(タイプ数えではなくトークン数えで)1度しか用いられていない語(句)を指す.ギリシア語の hapax (once) + legomenon (something said) からなる複合語だ.複数形は hapax legomena という.
"nonce word" を hapax legomenon と同義としている辞書もあるが,前者は「臨時語」と訳され「その時限りに用いる語」を指す.nonce-word は新語の臨時的な生産性を念頭に用いられることが多いのに対し,hapax legomenon は文献に現われる回数が1度であることに焦点が当てられているという違いが感じられる.nonce (その場限りの)という語の語源については,「#1306. for the nonce」 ([2012-11-23-1]) を参照.
hapax legomenon は,聖書の注釈との関連で,しばしば言及されてきた歴史がある.OED によると英語における初例は1692年のことで,"J. Dunton Young-students-libr. 242/1 There are many words but once used in Scripture, especially in such a sence, and are called the Apax legomena." とある.
文献学や語源学において,hapax legomenon はしばしば問題となる.その語の語源はおろか,意味すら不明であることが少なくない.語彙論や辞書学では,それを一人前の「語」として認めてよいのか,何かの間違いではないか,辞書に掲載すべきか否か,という頭の痛い問題がある (see 「#912. 語の定義がなぜ難しいか (3)」 ([2011-10-26-1])) .一方で,語形成やその生産性という観点からは,hapax legomenon は重要な考察対象となる.というのは,1度だけ臨時的に出現するためには,話者の生産的な語形成機構が前提とされなければならないからである (see 「#938. 語形成の生産性 (4)」 ([2011-11-21-1])) .
だが,実際のところ halax legomenon は決して少なくない.このことは,ジップの法則に照らせば驚くべきことではないだろう (see 「#1101. Zipf's law」 ([2012-05-02-1]), 「#1103. GSL による Zipf's law の検証」 ([2012-05-04-1])) .英語の例としては,Chaucer の用いたnortelrye (education) や Shakespeare の honorificabilitudinitatibus, また Dickens の sassigassity (audacity?) などが挙げられる.
2015-04-14 Tue
■ #2178. 新グライス学派語用論の立場からみる意味の一般化と特殊化 [semantic_change][pragmatics][cooperative_principle][implicature][zipfs_law][information_theory][hyponymy]
Grice の協調の原理 (cooperative_principle) と会話的含意 (implicature) について,「#1122. 協調の原理」 ([2012-05-23-1]),「#1133. 協調の原理の合理性」 ([2012-06-03-1]),「#1134. 協調の原理が破られるとき」 ([2012-06-04-1]),「#1976. 会話的含意とその他の様々な含意」 ([2014-09-24-1]),「#1984. 会話的含意と意味変化」 ([2014-10-02-1]) などの記事で話題にしてきた.Grice の理論は語用論に革命をもたらし,その後の研究の進展にも大きな影響を及ぼしたが,なかでも新グライス学派 (Neo-Gricean) による理論の発展は注目に値する.
新グライス学派を牽引した Laurence R. Horn は,Grice の挙げた4つの公理 (Quality, Quantity, Relation, Manner) を2つの原理へと再編成した.Q[uantity]-principle と R[elation]-principle とである.両原理の定式化は,以下の通りである (Huang 38 より).
Horn's Q- and R-principles
a. The Q-principle
Make your contribution sufficient;
Say as much as you can (given the R-principle)
b. The R-principle
Make your contribution necessary;
Say no more than you must (given the Q-principle)
Q-principle はより多くの情報を提供しようとする原理であり,R-principle はより少ない情報で済ませようとする原理である.この観点からは,会話の語用論とは両原理のせめぎ合いにほかならない.ここには言語使用における "most effective, least effort" の思想が反映されており,言語使用の経済的な原理であるジップの法則(Zipf's Law;cf. 「#1101. Zipf's law」 ([2012-05-02-1]))とも深く関係する.Huang (39--40) 曰く,
Viewing the Q- and R-principles as mere instantiations of Zipfian economy . . ., Horn explicitly identified the Q-principle ('a hearer-oriented economy for the maximization of informational content') with Zipf's Auditor's Economy (the Force of Diversification) and the R-principle ('a speaker-oriented economy for the minimization of linguistic form') with Zipf's Speaker's Economy (the Force of Unification).
さて,意味変化の代表的な種類として,一般化 (generalization) と特殊化 (specialization) がある.それぞれの具体例は,「#473. 意味変化の典型的なパターン」 ([2010-08-13-1]),「#2060. 意味論の用語集にみる意味変化の分類」 ([2014-12-17-1]),「#2102. 英語史における意味の拡大と縮小の例」 ([2015-01-28-1]) で挙げた通りであり,繰り返さない.ここでは,意味の一般化と特殊化が,新グライス学派の語用論の立場から,それぞれ R-principle と Q-principle に対応するものしてとらえることができる点に注目したい.
ある語が意味の一般化を経ると,それが使用される文脈は多くなるが,逆説的にその語の情報量は小さくなる.つまり,意味の一般化とは情報量が小さくなることである.すると,この過程は,必要最小限の情報を与えればよいとする R-principle,すなわち話し手の側の経済によって動機づけられているに違いない.
一方で,ある語が意味の特殊化を経ると,それが使用される文脈は少なくなるが,逆説的にその語の情報量は大きくなる.つまり,意味の特殊化とは情報量が大きくなることである.すると,この過程は,できるだけ多くの情報を与えようとする Q-principle,すなわち聞き手の側の経済によって動機づけられているに違いない (Luján 293--95) .
このようなとらえ方は,意味変化の類型について語用論の立場から議論できる可能性を示している.
・ Huang, Yan. Pragmatics. Oxford: OUP, 2007.
・ Luján, Eugenio R. "Semantic Change." Chapter 16 of Continuum Companion to Historical Linguistics. Ed. Silvia Luraghi and Vit Bubenik. London: Continuum International, 2010. 286--310.
2015-01-22 Thu
■ #2096. SUBTLEX-US Word Frequency List [frequency][statistics][corpus][lexicology][zipfs_law][cgi][web_service]
従来の英語学研究において,権威ある語彙頻度表といえばアメリカ英語に関する Kucera and Francis (1967) のものや,イギリス英語に比重を置いたより新しいものとして CELEX (1993) やその2版 (cf. 「#1424. CELEX2」 ([2013-03-21-1])) がよく用いられてきた.しかし,最近,これらを批判し,新しい手法に基づいたアメリカ英語の語彙頻度表が現われた.ベルギー,ヘント大学の実験心理学科の提供する SUBTLEXus である.左のHPから,SUBTLEXus の一群の頻度表のファイルや記述がダウンドーロできる.
SUBTLEXus の基盤にあるコーパスは,8388件の映画の字幕の集成であり,総語数は5100万語に及ぶ.SUBTLEXus の頻度表は,Kucera and Francis や CELEX の頻度表と比べて,いくつかの算出された指標においてすぐれていると主張されている.頻度は,見出し語 (lemma) ごとではなく語形 (word form) ごとに数えられており,例えば名詞であれば単数形と -s 語尾などをもつ複数形は別扱いされる(異なる語形は74,286種類).名詞と動詞など複数の品詞として用いられる語形については,それぞれの品詞ごとの頻度にもアクセスできるし,より優勢な品詞 (Dominant POS) のほうへ合算した頻度へもアクセスできる.データには,ほかに何件の映画に現われているか,小文字として現われているのは何回か,頻度の対数を取った指標,Zipf 指標 (cf. 「#1101. Zipf's law」 ([2012-05-02-1])) なども含まれている.これだけの種類のデータが含まれていると,目的とアイデア次第でおおいに有効に利用できるだろう.話し言葉ベースであることも顕著な特徴だ.
ダウンロードできるいくつかのデータのなかで "a zipped Excel file of SUBTLEX-US with the Zipf values included" をダウンロードし,少しいじってみた.例えば,(1) 全体的に多く現われ,かつ (2) 多くの映画にも現われる語形は,総合的な意味で頻度が高いと考えられるだろう.そこで (1) と (2) に関する対数の指標を掛け合わせて,それを降順に並べて最初の100語を取ると,正真正銘の最頻単語100語が得られるはずだ.省略形の片割れなども含まれているが,以下がそのリストである.
you, I, the, to, s, a, it, t, that, and, of, what, in, me, is, we, this, he, on, for, my, m, your, don, have, do, re, no, be, know, was, not, can, are, all, with, just, get, here, but, there, ll, so, they, like, right, out, go, up, about, she, if, him, got, at, now, come, oh, one, how, well, want, yeah, her, think, good, see, let, did, why, who, as, going, his, will, from, when, back, time, yes, look, d, take, an, where, man, would, them, been, some, or, tell, us, had, were, say, could, gonna, didn, hey
ほかには,最頻10語,25語,50語,100語,250語,500語,1,000語,2,500語,5,000語,10,000語,25,000語,50,000語,100,000語について,Dominant POS ごとに数え上げてみることもたやすい.「#666. COCA 最頻5000語で品詞別の割合は?」 ([2011-02-22-1]),「#667. COCA 最頻50万語で品詞別の割合は?」 ([2011-02-23-1]),「#1132. 英単語の品詞別の割合」 ([2012-06-02-1]) の記事でも,別のコーパスにより似たような調査を行ったが,SUBTLEX-US 版の調査結果は次のグラフにまとめられる.
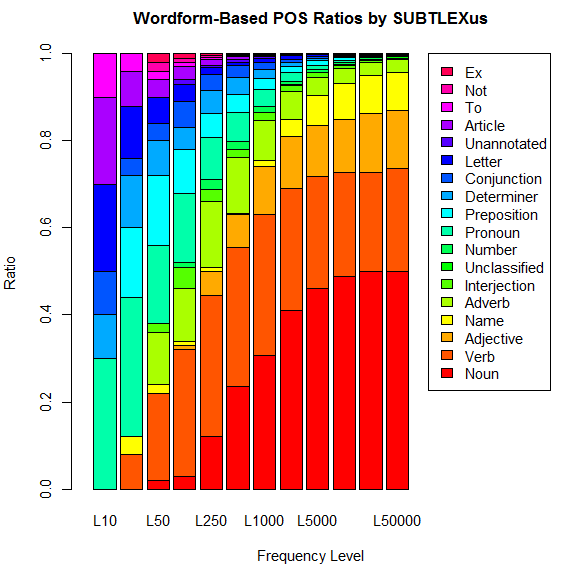
以下はおまけの検索ツール (SUBTLEX-US Word Frequency Extractor) .おまけなので,10例までしか結果が出力されない仕様です.SUBTLEXus の提供する複雑な検索も可能な,SUBTLEXus Online Search もどうぞ.
2014-09-18 Thu
■ #1970. 多義性と頻度の相関関係 [polysemy][zipfs_law][information_theory][frequency][statistics]
基本語彙と呼ばれるものの多面的な性質について「#1960. 英語語彙のピラミッド構造」 ([2014-09-08-1]) で触れた.基本語彙とは,日常的で頻度が高く,早期に習得され,変化しにくく,意味・用法が多岐にわたるなどの特徴をもつ.関連する話題は,「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1]),「#1089. 情報理論と言語の余剰性」 ([2012-04-20-1]),「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]),「#1101. Zipf's law」 ([2012-05-02-1]),「#1874. 高頻度語の語義の保守性」 ([2014-06-14-1]),「#1961. 基本レベル範疇」 ([2014-09-09-1]),「#1965. 普遍的な語彙素」 ([2014-09-13-1]) その他の記事でいろいろと扱ってきた.
今回は,この問題と関連して,高頻度語は多義的であるという命題について考えてみたい.頻度の高い語ほど語義を多くもち,頻度の低い語は語義を多くもたないということは言語使用の事実に照らして実証されるだろうか.また,理論的にいかに説明されるだろうか.Zipf's law で知られる Zipf は,情報理論の立場からこの課題に挑んだ.
Zipf は,E. L. Thorndike の英語最頻20,000語と Thorndike-Century Senior Dictionary に基づき,語の頻度と語義数の相関関係を探った.この辞書は,古語や廃語などの特殊な register をもつ語義は掲載しておらず,一般的に用いられる語義のみを掲載している.丹念に調査した結果,ある頻度域と,そこに属する語が示す平均語義数との間に,明らかな相関関係が見いだされた.以下は,Zipf (253) に示されているグラフを再現したものである.両軸ともに対数軸であり,X軸は頻度順位を,Y軸は頻度域の平均語義数を表わす.
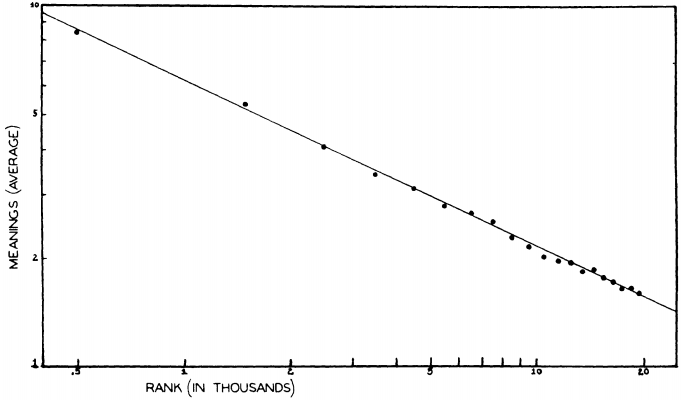
傾きはほぼ0.5に等しく,これは話者の発話と聴者の聴解にかかる費用に関する理論の予測と符合するという.その理論の数学的裏付けは私の理解を超えるので解説できないが,Zipf は結論として語の語義数と頻度(順位)の関係について次のように定式化した (Zipf 255) .
. . . different meanings of a word will tend to be equal to the square root of its relative frequencies (with the possible exception of the few dozen most frequent words)
背景には,多義の定義やある語の語義をいかに区分するかといった意味論の側で問うべき問題もおおいにあるが,示唆に富んだ結論である.関連して,「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]) や zipfs_law の各記事も参照されたい.
・ Zipf, G. K. "The Meaning-Frequency Relationship of Words." Journal of General Psychology 33 (1945): 251--66.
2012-05-04 Fri
■ #1103. GSL による Zipf's law の検証 [lexicology][statistics][frequency][zipfs_law][corpus]
[2012-05-02-1], [2012-05-03-1]の記事で取り上げてきた Zipf's law を検証(というよりは体験)するために,General Service List (GSL) の最頻2000語余りのデータを利用して計算してみた(データファイルはこちら).
![]()
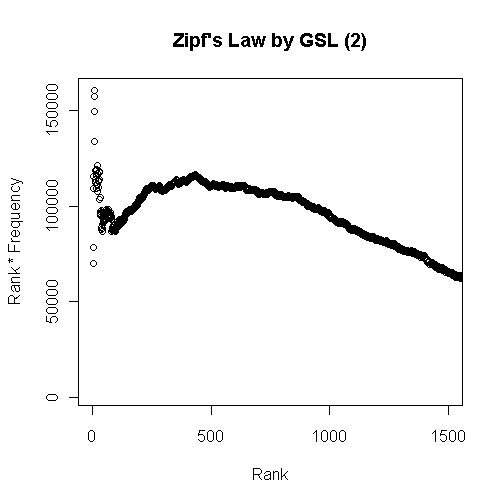
最初のグラフは頻度順位と頻度を掛け合わせたグラフで,頻度順で100位ほどまでの語を対象とした.以下はひたすら漸減してゆくのみなので省略.累積頻度のグラフを作成するまでもなく,最頻の数十語ほどで延べ語数のほとんどを覆ってしまう様子がよくわかる.
次のグラフは,Zipf's law によると定数になるとされる頻度順位と頻度の積を縦軸にとったものである.上位数十語までは「定数」は上下に大きく揺れて安定しないが,以後1000語ぐらいまでは,緩やかな増減はあるものの,落ち着く.その後のグラフ外ではひたすら漸減を続ける.したがって,「定数」を云々できるのは大目に見ても上位1000語ぐらいまでだろう.
これを法則と呼ぶのはあまりに外れていると考えるか,統計的傾向がよく出ているととらえるかは,観察者の見方ひとつである.Zipf's law における「定数」は「およそ定数」と解釈するのが暗黙の了解だが,「およそ」の幅がどの程度であるのかは明示されていない.また,Zipf's law が主張しているのと異なり,グラフの線は頻度をとるコーパスのサイズにも依存するようだ.
2012-05-03 Thu
■ #1102. Zipf's law と語の新陳代謝 [information_theory][frequency][statistics][zipfs_law][shortening][language_change]
昨日の記事[2012-05-02-1]で Zipf's law について概説した.Zipf's law には派生した「法則」が多くあり,その1つに,[2012-04-22-1]の記事「#1091. 言語の余剰性,頻度,費用」でも指摘した「言語要素は,頻度が高ければ音形が短い」というものがある.これを,より動的に,通時的に表現すると「言語要素は,頻度が高くなれば音形が短くなる」となる.ある語の頻度が高くなってゆくと,ある程度の遅延はあるものの,その音形が短くされてゆく傾向のあることは,私たちも経験的によく知っていることである.「#878. Algeo と Bauer の新語ソース調査の比較」([2011-09-22-1]) や「#879. Algeo の新語ソース調査から示唆される通時的傾向」([2011-09-23-1]) で見たとおり,現代英語の新語ソースとして短縮 (shortening) による語形成が増加しており,例には事欠かない.
この Zipf's law の派生法則のもつ共時的意義と通時的意義を合わせて考えると,語の頻度と長さによって,それが老いゆく語 (senescent word) なのか,生まれつつある語 (nascent word) なのかを区別できるという可能性が生じる.Zipf 著 Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology の書評を著わした Chao (399) より,関連箇所を引用しよう.
A very interesting application of the tool analogy is that of senescent and nascent tools in connection with the Principle of Economical Specialization. Reasoning from tool efficiency yields the result that 'whenever we find a tool (or word) whose magnitude is smaller than that of its neighbors in the frequency range, we may conclude that the tool (or word) of below-average size is an older tool (or word) whose usage is on the decrease (hereinafter we shall call this a senescent tool)', and 'whenever we find a tool (or word) whose magnitude is above average for its frequency, we may conclude not only that it is a newer tool (or word), but that its usage may well be directed toward an increase (hereinafter we shall call this a nascent tool)' (72). The application to words is verified to a fair degree for English of various periods (111). By regarding all behavior as work and words as tools, the analogy becomes a case and the qualifier 'or word' can be omitted.
音形の比較的短いある単語 A を考える.Zipf's law によれば,A は比較的頻度の高い語だと予想されるが,実際には同程度の頻度を示す他の多くの語に比べると音形が短すぎたとする.この場合,おそらく A はさかりを過ぎて頻度が徐々に低まってきた senescent word と考えてよいだろう.反対に,音形の比較的長いある単語 B を考える.Zipf's law によれば,B は比較的頻度の低い語だと予想されるが,実際には同程度の頻度を示す他の多くの語に比べると音形が長すぎたとする.この場合,おそらく B はこれから頻度がますます増してゆき,短縮を起こしてゆくと予想される nascent word と考えてよいだろう.これは,Zipf's law に,冒頭に述べた時間的遅延とを掛け合わせた応用法則といってよい.
通常 Zipf's law は静的で共時的な統計的法則ととらえられているが,動的で通時的な観点から,語の新陳代謝の法則として再解釈してみるとおもしろい.
・ Chao, Y. R. "Review of Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology by George Kingsley Zipf." Language 26 (1950): 394--401.
2012-05-02 Wed
■ #1101. Zipf's law [information_theory][frequency][statistics][language_change][zipfs_law][shortening][pragmatics][zipfs_law]
##1089,1090,1091,1098 の記事で,情報理論 (information theory) が言語学に与えてくれる知見について,いくつか見てきた.情報理論からの貢献として,最もよく知られているものの1つに,アメリカの言語学者 George Kingsley Zipf (1902--50) が1949年に Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology において提唱した Zipf's law (ジップの法則)がある.語の頻度についての経験的な法則であり,語の頻度を f とし,その頻度の順位を r とすると,その積 C はほぼ定数となるという.
r × f = C
この法則は,言語,テキストの主題,著者,その他の言語的な変数にかかわらず成り立つとされるが,実際には頻度が最高および最低の語群については誤差の大きいことがわかっており,信頼性は高くないとして批判も多い.また,r (頻度順位)は当然ながら f (頻度)に依存しており,f が増えれば r が減るのは自明であるから,その積が近似値をとるということは驚くべき帰結ではない,一種のトートロジーであるという批判がある.しかし,経験的事実に照らして法則とまではいわずとも傾向をよく表わしているということはでき,これを明示的に指摘した意義は大きい.
Zipf's law の波及効果は多岐にわたる.例えば,この法則によれば,使用頻度の高い語からその使用頻度の累計を求めて行くと比較的少数の語で延べ語数の大部分を占めることから,学習基本語彙の設定に根拠を与えるものとなる.また,この法則に適合しない頻度分布を示す語彙があるとすれば,他の特殊な要因が関与している可能性が疑われるとされる(少数の語の頻度があまりに高すぎれば語彙の貧弱化が生じていると診断されるし,頻度の低いはずの語が高頻度で用いられている場合には爆発的な新造語彙や精神分裂症が原因と想定される等々).
Zipf's law は,人間の行動を司るとされるより大きな原則,the Principle of Least Effort (最小努力の原則)の一部であり,その言語への応用は,上記の最もよく知られた頻度と頻度順の関係の公式化のみならず,他の公式の提案にも及んでいる.例えば,語の頻度と語の長さは反比例の関係にある,というものもある.最頻語は単音節であることが多いという事実(音節数の分布調査については ##348,349,355 を参照)や,頻度が高くなると頭字語などのように短縮・省略されることが多いという事実も,この公式で説明される.ほかには,ある頻度範囲とそれに属する語の数の関係を表わす公式,調音の難しい音素は頻度が低いとする原則など,派生した法則は数多い.語用論の cooperative principle (協調の原則)における量の格律「(その状況において)必要とされている(だけの)情報を与えよ」とも関与するだろう."effort" の定義などの難しい問題が残っており,また最小努力が人間の行動を司る唯一の原則であるとは考えることもできないが,真理の一面をついたものとして重要な学説であることは間違いない.
なお,諸文献では,上記のいずれの原則も Zipf's law として言及されることがあり,また Zipf's laws と複数形でまとめられたり,the Principle of Least Effort と総括されたりすることもあるので注意が必要である.Zipf の著書の書評としては Chao を参照.類似の統計的法則については,Crystal (86--87) を参照.
・ Chao, Y. R. "Review of Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology by George Kingsley Zipf." Language 26 (1950): 394--401.
・ Crystal, David. The Cambridge Encyclopedia of Language. 2nd ed. Cambridge: CUP, 1997.
2012-05-02 Wed
■ #1101. Zipf's law [information_theory][frequency][statistics][language_change][zipfs_law][shortening][pragmatics][zipfs_law]
##1089,1090,1091,1098 の記事で,情報理論 (information theory) が言語学に与えてくれる知見について,いくつか見てきた.情報理論からの貢献として,最もよく知られているものの1つに,アメリカの言語学者 George Kingsley Zipf (1902--50) が1949年に Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology において提唱した Zipf's law (ジップの法則)がある.語の頻度についての経験的な法則であり,語の頻度を f とし,その頻度の順位を r とすると,その積 C はほぼ定数となるという.
r × f = C
この法則は,言語,テキストの主題,著者,その他の言語的な変数にかかわらず成り立つとされるが,実際には頻度が最高および最低の語群については誤差の大きいことがわかっており,信頼性は高くないとして批判も多い.また,r (頻度順位)は当然ながら f (頻度)に依存しており,f が増えれば r が減るのは自明であるから,その積が近似値をとるということは驚くべき帰結ではない,一種のトートロジーであるという批判がある.しかし,経験的事実に照らして法則とまではいわずとも傾向をよく表わしているということはでき,これを明示的に指摘した意義は大きい.
Zipf's law の波及効果は多岐にわたる.例えば,この法則によれば,使用頻度の高い語からその使用頻度の累計を求めて行くと比較的少数の語で延べ語数の大部分を占めることから,学習基本語彙の設定に根拠を与えるものとなる.また,この法則に適合しない頻度分布を示す語彙があるとすれば,他の特殊な要因が関与している可能性が疑われるとされる(少数の語の頻度があまりに高すぎれば語彙の貧弱化が生じていると診断されるし,頻度の低いはずの語が高頻度で用いられている場合には爆発的な新造語彙や精神分裂症が原因と想定される等々).
Zipf's law は,人間の行動を司るとされるより大きな原則,the Principle of Least Effort (最小努力の原則)の一部であり,その言語への応用は,上記の最もよく知られた頻度と頻度順の関係の公式化のみならず,他の公式の提案にも及んでいる.例えば,語の頻度と語の長さは反比例の関係にある,というものもある.最頻語は単音節であることが多いという事実(音節数の分布調査については ##348,349,355 を参照)や,頻度が高くなると頭字語などのように短縮・省略されることが多いという事実も,この公式で説明される.ほかには,ある頻度範囲とそれに属する語の数の関係を表わす公式,調音の難しい音素は頻度が低いとする原則など,派生した法則は数多い.語用論の cooperative principle (協調の原則)における量の格律「(その状況において)必要とされている(だけの)情報を与えよ」とも関与するだろう."effort" の定義などの難しい問題が残っており,また最小努力が人間の行動を司る唯一の原則であるとは考えることもできないが,真理の一面をついたものとして重要な学説であることは間違いない.
なお,諸文献では,上記のいずれの原則も Zipf's law として言及されることがあり,また Zipf's laws と複数形でまとめられたり,the Principle of Least Effort と総括されたりすることもあるので注意が必要である.Zipf の著書の書評としては Chao を参照.類似の統計的法則については,Crystal (86--87) を参照.
・ Chao, Y. R. "Review of Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology by George Kingsley Zipf." Language 26 (1950): 394--401.
・ Crystal, David. The Cambridge Encyclopedia of Language. 2nd ed. Cambridge: CUP, 1997.
Powered by WinChalow1.0rc4 based on chalow