hellog〜英語史ブログ / 2010-03-10
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
2010-03-10 Wed
■ #317. 拙著で自分マイニング(キーワード編) [text_tool][flob][corpus][keyword]
昨日の記事[2010-03-09-1]に引き続き,拙著 The Development of the Nominal Plural Forms in Early Middle English で自分マイニング.WordSmith には KeyWords 抽出機能がある.単に単語リストを頻度順に並べた昨日のリストでもおよそのテキストの主題を読み取ることは可能だが,上位に機能語などの雑音が大量に入り込み,解釈しにくい.それに対して,キーワードリストでは対象テキストの主題をよく表す実質的なキーワードが上位に来るので,解釈しやすい.
考え方としては以下の通りである.巨大なコーパスなどを参照テキストとして使用し,そこから単語ごとに一般的な頻度を導き出す.次に,対象テキスト内で各単語について頻度を出す.ある語の対象テキスト内での頻度が,参照テキスト内での頻度よりも相当に大きい場合には,それは対象テキストに特有のキーワードとみなせる.そのようなキーワードを自動的に探し出してくれるのが,WordSmith の KeyWords 抽出機能である.拙著はイギリス英語で書いていることもあり,参照テキストとしては FLOB ( Freiburg-LOB corpus ) を使用した.以下,上位50語のキーワードである.
plural, english, s, n, old, nouns, norse, dialect, midland, middle, plurals, dialects, texts, language, forms, text, ending, diffusion, v, south, west, nominative, early, stem, the, spread, linguistic, singular, endings, inflectional, contact, accusative, o, system, weak, in, development, sec, change, fem, dative, morphological, languages, saxon, item, formation, period, transfer, germanic, strong
ずばり来てくれました plural .複数形の研究なのでそうでなければ困るところだ.昨日のリストよりも機能語の雑音がよくはじかれている.
WordSmith には各キーワードのファイル内での出現箇所を視覚的にプロットする機能もあり,上記の50語について以下のようなプロットが得られた.
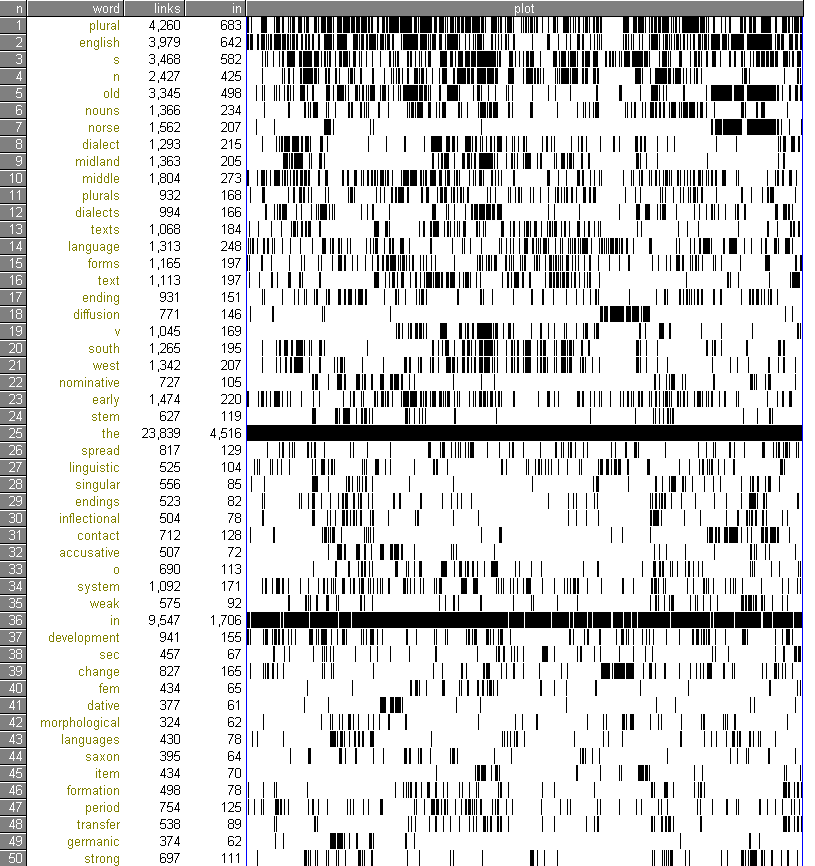
執筆者本人なので,なるほどと思えることが多い.最上位語はテキスト中にまんべんなく現れる傾向があるが,それでも分布が偏っているものもある.7位の norse は Old Norse について論じている7章に固まっているし,18位 diffusion は Lexical Diffusion を集中的に扱っている5章に集中している.
われながらの発見もあった.言語変化を論じているので development と change を多用しているが,執筆中にはそれほど意識して両語を使い分けていたわけではなかった.そうであればまんべんなく分布していそうなものだが,実際には change が5章辺りに偏在している.ということは,無意識のうちに使い分けていたということなのだろうか.無意識の癖とでもいうべきものが発見できておもしろい.
文章をこのように分析することで,実用的な効果がいろいろ考えられそうである.思いつきを記す.
・ 文体の統計を把握することで今後の文章改善に活かす(誰々の文体に近づきたい,ボキャ貧をなおしたい,パラグラフ構成の指針をもちたい,など)
・ 自分の過去の文章と比較し,文体の経年変化を観察する
・ 論文などを書き終えた後でタイトル候補が複数ある場合に,キーワードを参考にして決定する
・ 自分の過去の論文などをひっくるめて分析対象とし,「私の研究テーマは(キーワード)です」と言い切れるようになる
・ 相手の過去の論文などをひっくるめて分析対象とし,「あなたの研究テーマは(キーワード)です」と言い切れるようになる(←おせっかい)
・ 緩やかに関連する二つの論文 A と B を互いに参照テキストとしてそれぞれのキーワードを抽出し,A の特徴と B の特徴を比べる.共通点が多いことを前提としているので,キーワードによって逆に相違点が浮き彫りになる可能性がある.
2026 : 01 02 03 04 05 06 07 08 09 10 11 12
2025 : 01 02 03 04 05 06 07 08 09 10 11 12
2024 : 01 02 03 04 05 06 07 08 09 10 11 12
2023 : 01 02 03 04 05 06 07 08 09 10 11 12
2022 : 01 02 03 04 05 06 07 08 09 10 11 12
2021 : 01 02 03 04 05 06 07 08 09 10 11 12
2020 : 01 02 03 04 05 06 07 08 09 10 11 12
2019 : 01 02 03 04 05 06 07 08 09 10 11 12
2018 : 01 02 03 04 05 06 07 08 09 10 11 12
2017 : 01 02 03 04 05 06 07 08 09 10 11 12
2016 : 01 02 03 04 05 06 07 08 09 10 11 12
2015 : 01 02 03 04 05 06 07 08 09 10 11 12
2014 : 01 02 03 04 05 06 07 08 09 10 11 12
2013 : 01 02 03 04 05 06 07 08 09 10 11 12
2012 : 01 02 03 04 05 06 07 08 09 10 11 12
2011 : 01 02 03 04 05 06 07 08 09 10 11 12
2010 : 01 02 03 04 05 06 07 08 09 10 11 12
2009 : 01 02 03 04 05 06 07 08 09 10 11 12
最終更新時間: 2026-06-26 03:46
Powered by WinChalow1.0rc4 based on chalow