2013-10-12 Sat
■ #1629. 和製漢語 [japanese][kanji][waseieigo][lexicology]
「#1624. 和製英語の一覧」 ([2013-10-07-1]) で和製英語の一覧を掲げたが,今回は和製漢語の例を列挙したい.英単語の借用に慣れた日本語が大正期に和製英語を作り出し始めたように,それにもまして長らく日本語になじんできた漢語がモデルとなって,数々の和製漢語が生み出されてきたことは,まったく自然なことである.和製英語の場合と同様に,ある漢語が和製であるか否かを定めるには日本語および中国語の双方における文献学的な考証が必要となり,たやすい問題ではないが,現代中国の専門家によれば,次の漢語は和製漢語である可能性が高いという(以下の例はすべて『日本語百科大事典』 pp. 1029--30 より).
備品,参看,参照,成因,寵児,単純,等外,敵視,読本,番号,方針,風位,服務,復式,副食,公立,公判,公認,公営,国立,集中,集結,記号,尖兵,堅持,簡単,金額,巨匠,巨星,克服,労作,落選,明確,内勤,農作物,権限,権益,人選,肉弾,実績,実権,私立,訴権,台車,特長,外勤,校訓,興信所,学会,学歴,訓話,訓令,銀翼,印鑑,原動力,原意,原作,陣容,支部,重点,手動,組成,座談
日本の文物を表す漢語も,和製と考えてよいだろう.例としては,和服,和文,人力車,浄瑠璃,能楽,三味線,茶道,弓道,柔道などがある.
また,以下の漢語も和製漢語の可能性をもつが,近代日本と中国の間での移入・移出の関係は複雑であり,一応のリストとして理解しておきたい.これらの多くは,近代期に,英語などを取り入れる際に漢訳して取り入れたことに由来する.
暗示,白金,半径,飽和,保険,悲劇,背景,本質,比重,必要,標語,表決,波長,不動産,財閥,挿話,成分,乗客,抽象,出版,触媒,大気,代議士,単元,蛋白質,道具,登記,低調,抵抗,地質,電波,電車,電話,電流,電子,動産,独占,隊商,対象,対照,法人,反動,反感,反射,反応,範疇,方程式,方式,雰囲気,否定,附着,複製,改編,改訂,概括,概略,概念,感性,幹部,幹線,高潮,高炉,歌劇,工業,公報,公称,公民,公僕,公訴,共産主義,共鳴,関係,観測,観念,光年,光線,広告,広義,帰納,国際,国庫,国税,寒帯,寒流,航空母艦,号外,化膿,化石,化学,化粧品,画廊,幻灯,幻想曲,回収,会話,会社,会談,活躍,火成岩,積極,基調,基準,集団,計画,技師,仮定,尖端,間接,建築,鑑定,講壇,交際,交響楽,膠着語,脚本,教科書,教養,酵素,接吻,結核,解放,解剖,介入,金剛石,金婚式,金牌,金融,緊張,進度,進化,進化論,進展,経験,景気,警察,警官,浄化,静脈,競技,就任,巨頭,決算,絶対,看護婦,看守,抗議,科学,可決,客観,客体,肯定,空間,会計,拡散,類型,冷蔵,冷蔵庫,理論,理念,理想,理智,力学,立憲,例会,了解,領海,領空,領主,領土,論理学,漫画,盲従,媒質,美感,密度,免許,民法,敏感,命題,黙示,母体,母校,目標,目的,内容,内在,能動,能率,擬人法,年度,暖流,派遣,判決,陪審,配給,批評,平面,評価,企業,気分,気体,気質,汽船,汽笛,契機,前線,強制,軽工業,清教徒,清算,情報,権威,熱帯,人格,人権,任命,溶体,入場券,入超,商法,商業,社交,審判,昇華,生理学,生態学,失恋,施工,施行,時間,実感,実業,使徒,士官,世界観,市場,市長,事態,手工業,受難,水素,思潮,死角,素材,素描,速度,速記,随員,索引,談判,探険,特権,体育,鉄血,統計,投影,投資,図案,外在,温床,温度,文庫,文学,無産者,物質,喜劇,系列,係数,細胞,狭義,繊維,現実,現象,現役,憲兵,相対,想像,象徴,消防,消費,消極,小夜曲,効果,協定,協会,心理学,信号,信託,性能,序幕,序曲,宣戦,旋盤,学位,血栓,血吸虫,巡洋艦,圧延,亜鉛,演出,演奏,燕尾服,陽極,要素,業務,液体,議会,議員,議院,意訳,因子,陰極,銀行,銀婚式,栄養,影像,優生学,油槽車,遊離,予後,元素,園芸,原理,原則,原子,原罪,遠足,運動,運動場,雑誌,債権,債務,展覧会,戦線,哲学,証券,政策,政党,支線,直観,直接,直径,直流,止揚,指標,指導,指数,制裁,制限,制約,質量,終点,仲裁,重工業,主筆,主観,資料,紫外線,宗教,総合,総動員,総理,作品
和製英語にせよ和製漢語にせよ,相手の言語からの直接の語彙借用に十分なじんでくると,今度はそれをモデルとして自家製の語彙を生み出そうとしてきた点が似ている.相手の言語に呑まれていると考えれば語彙借用反対論となるし,相手の言語を手なずけていると考えれば賛成論となる.私は,和製○語の存在は日本語が借用元言語の手なずけに成功し,高次に進んだ借用段階にあることを示すものとして解釈している.
・ 『日本語百科大事典』 金田一 春彦ほか 編,大修館,1988年.
2013-10-09 Wed
■ #1626. 現代日本語書き言葉均衡コーパス BCCWJ の各種インターフェース [web_service][corpus][link][japanese]
「#1567. 英語と日本語のオンラインコーパスをいくつか紹介」 ([2013-08-11-1]) で,現代日本語のコーパスとしてKOTONOHA 「現代日本語書き言葉均衡コーパス」に言及した.この『現代日本語書き言葉均衡コーパス』 (BCCWJ: Balanced Corpus of Contemporary Written Japanese) は,大学共同利用機関法人人間文化研究機構国立国語研究所と文部科学省科学研究費特定領域研究「日本語コーパス」プロジェクトが共同で開発した本格的なコーパスである.
コーパスの内容については,同サイトに「2012年3月現在,検索対象となっているのは,以下の11種のデータ,合計約1億500万語です」とある.サンプルは,1976--2008年にかけての文書で,その11のジャンルは書籍,雑誌,新聞,白書,教科書,広報紙,Yahoo!知恵袋,Yahoo!ブログ,韻文,法律,国会会議録にわたる.各テキストからは2種類のサンプルが取られており,「ひとつは長さを1000字に固定したサンプル (固定長サンプル),もうひとつは,節や章など文章の意味上のまとまりに対応した単位の全体です (可変長サンプル).これまでの調査によれば,可変長サンプルの平均長は新聞で約1000字,書籍で4000字弱です.」とある.
BCCWJ を利用する方法やインターフェースはいくつかあるが,もっとも簡便なものが,上にもリンクを張った少納言である.登録不要で,表層の文字列によるコーパスの全文検索ができる.出力は無作為の500件と制限があるが,お手軽に試すことができる.
一方,利用申請が必要な中納言では,同コーパスに対して,短単位・長単位・文字列の3つの方法により,形態論的な複雑な検索をかけることができる.
また別のインターフェーとして,NINJAL-LWP for BCCWJ (NLB) がある.現行の1.20版では,BBCWJ のほとんどのデータを対象として,検索をかけることができる.検索ページはこちら.
関連して,NLB と同じインターフェースで利用できるもう1つの日本語コーパスを紹介する.筑波大学がウェブサイトからテキストを収集して編纂した11億語からなる筑波ウェブコーパス (Tsukuba Web Corpus: TWC) へのインターフェース,NINJAL-LWP for TWC (NLT)である.検索ページはこちら.
2013-10-07 Mon
■ #1624. 和製英語の一覧 [waseieigo][japanese][katakana][borrowing][semantic_change][word_formation][lexicology][false_friend]
9月21--22日に,大連大学日本言語文化学院で開かれた第五回『中・日・韓日本言語文化研究国際フォーラム』に参加し,中央大学の同僚とチームを組んで「言語使用の前景と背景---言語研究と文学研究について」と題するパネルディスカッションを行った.私は「和製英語の自然さ・不自然さ」という題目で少し話しをした.専門外ではあるが,日本語学において和製英語や外来語の研究は,英語の研究者によるものが少なくないということなので,私もその立場からわずかばかり参与させていただいた,という次第である.
この発表のために,記事末に挙げたような参考図書等から和製英語といわれている表現を収集した.結果として231個が集まった.各々が本当に和製英語か否かという問題については,「#1492. 「ゴールデンウィーク」は和製英語か?」 ([2013-05-28-1]) で触れたように,本来,詳細な文献学的調査が必要だが,今回はそこまでは掘り下げていない.また,和製英語の厳密な定義が難しいという事情もある.したがって,以下の個々の例については疑問が呈されるかもしれないが,上記のような但し書きをつけたうえで,集めたものを一覧として公開しておくことは役に立つだろう.
和製英語の分類については,まだ仮のものにすぎないが,以下のように (1) 記号的和製英語,(2) 意味的和製英語,(3) 形態的和製英語に3分類してみた.分類の精緻化は今後の課題としたい.

(1) 記号的和製英語
アイスキャンディー (popsicle),アイドリングストップ (shutting off the engines),アウトコース (outside),アパート (apartment, apartmenthouse),アフターケア/アフターサービス (after-sales service, after-the-sale service),アフレコ (post recording),アメリカン(コーヒー) ((regular) coffee),イメージアップ (improve one's image),イメージチェンジ (change one's image),ウェストバッグ (fanny bag, bum bag),エステ (beauty salon, beauty spa, beauty-treatment clinic),エッチ (dirty-minded, sex-mad, have a one-track mind, indecent, salacious, pervert, abnormal),オーエル(オフィスレディ) (office worker),オーダーメード (custom-made, made-to-order),オートバイ (motorbike, motorcycle),オービー (alumnus, alumna, graduate),オーブントースター (toaster oven),オープンカー (convertible),オールバック (combed (straight) back, combed towards the back),カフスボタン (cuff links),ガード (overpass),ガードマン ((security) guard, watchman),ガソリンスタンド (gas station),ガッツポーズ (victory pose),キッチンペーパー (paper towel),キャッチコピー (slogan),キャッチホン (call-waiting),キャッチボール (play catch),クーラー (air conditioner),グラビア (glamour photos, cheesecake, Page Threes),グレードアップ (upgrade),ゲームセンター (amusement arcade),コインランドリー (launderette),コストダウン (lower costs, reduce costs),コンセント (outlet, outlet box, receptacle, wall outlet, wall socket),コンビニ (drugstore, grocery),ゴールデンアワー (prime time),ゴールデンウィーク (holidays in May),サイドビジネス (side job),サラリーマン (company employee),シーズンオフ (off-season),シーチキン (canned tuna),シェイプアップ (become thin, lose weight),システムキッチン (organized kitchen),シティホテル (big hotel),シャーペン (mechanical pencil, automatic pencil),シャッターチャンス (the right moment on film),シルバーウィーク (holidays in November),シルバーシート (priority seat),ジージャン (denim jacket, jeans jacket),ジーパン (jeans),ジェットコースター (roller coaster),ジューサー (blender),スーパー (supermarket),スキンシップ (touching, bonding, physical contact),スクールカラー (the traditional feature of a school),スケールメリット (economies of scale),スタメン (starting lineup),スタンドプレー (grandstand play),スピードダウン (slow down),スリーサイズ ((bust-waist-hip) measurement),ゼネコン (big construction company, large construction company),ソーラーシステム (solar power),ソフト (software),ソフトクリーム (soft-serve ice cream, ice cream cone, swirl ice-cream cone),ターミナルホテル (station hotel),タイムサービス (blue-light special, limited time offer (special)),タイムリーヒット (RBI hit),タッチアウト (tagged and out),ダイニングキッチン (kitchenette),ダンプカー (dump truck),チアガール (cheerleader a),チャンスメーカー (table setters),テーブルスピーチ (speech at a party),テレビゲーム (video game),テンキー (numeric keypad),デコレーションケーキ (birthday cake, decorated cake),デッドボール (hit by (a) pitch),デリバリーヘルス (massage parlor),トレーニングパンツ(トレパン) (sweat pants),ドクターストップ (doctor's orders),ドライブイン (rest area, rest stop),ナイター (night game),ニューハーフ (drag queen, transvestite),ネイティヴチェッカー (proof reader, native-speaking proof reader),ネットショッピング (on-line shopping),ノーカット (uncut (movie)),ノースリーブ (sleeveless dress),ノータイ(ノーネクタイ) (without a tie),ノートパソコン (laptop),ノンステップバス (bus without steps),ノンセクション (trivia),ハートフル (heartwarming),ハーフ (someone of mixed race),ハイソックス (knee socks),ハイティーン (late teens),ハイテンション (excitable, overexcited, carried away),ハローワーク (Job Centre),バックミラー (rearview mirror),バトンガール (baton twirler),バトンタッチ (baton pass, hand over),パタンナー (pattern maker),パトカー (police car),パネラー (panelist),パンチパーマ (tight-perm, short-perm),ビーチパラソル (beach umbrella),ビジネスホテル (economy hotel, budget hotel),フィールドアスレチック (obstacle course),フォアボール (base on balls, walk),フライドポテト (French fries, chips),フライング (false start),フリーサイズ (one-size-fits-all),フリーダイヤル (toll-free number),フロントガラス (windshield),ブックカバー (book jacket, dust jacket),プレーガイド (booking office),ヘアヌード (full-frontal nudity (photo)),ヘディングシュート (header),ヘルスメーター (bathroom scale),ベースアップ (raise of the wage base),ベッドタウン (bedroom suburb),ベビーサークル (playpen),ペーパーカンパニー (shell company),ペーパードライバー (person with a driving licence but no practice, driver in name only),ペアルック (dressed in matching outfits),ペットボトル (plastic bottle),ホーム (platform),ホットカーペット (electric carpet),ホットケーキ (pancake),ボディチェック (frisk, security check, body search),マイカー (one's own car),マイナスイメージ (negative image),マイペース (go one's own way),マカロニウェスタン (spaghetti Western),マグカップ (mug),マザコン (mummy's boy),マンツーマン (one-on-one (one-to-one) lesson, private lesson),ミシン (sewing machine),ミニコミ (free paper),ミルクティー (tea with milk),メタボ (big, overweight, fat),モーニングコール (wake-up call),モーニングサービス (breakfast special),ライブハウス (club with live music, live music club),ラブホテル (hot-pillow hotel, no-tell motel),ランニングシャツ (undershirt),ランニングホームラン (inside-the-park home run),リクルートスーツ (suit for an interview),リサイルクルショップ (secondhand shop, recycled-goods shop),リップクリーム (lip balm, chapstick),リフティング (keepy-uppy),ルーズソックス (loose-fitting socks),ローティーン (early teens),ロスタイム (additional time, injury time, stoppage time),ワイシャツ (business shirt),ワイドショー (talk and variety (TV) show, tabloid show, TV magazine show),ワンパターン (predictable, routine)
(2) 意味的和製英語
アイドル (pop idol),アットホーム (cozy, homey),アバウト (irresponsible),(イベント)コンパニオン (booth girl, promotional model, trade show model),カンニング (cheating),クラクション (car horn),クレーム (complaint),サイン (autograph, signature),シール (sticker),スタンド (grandstand),スナック (bar, pub),スマート (slender, slim),センス(服装) (good dress sense, well-dressed, stylish),ソープ(風俗) (bordello, house of ill repute, whorehouse, knocking shop),タレント (celebrity, entertainer, TV personality),ダッチワイフ (blow-up doll),チャック (zipper, zip-fastener),トランプ ((playing) cards),ドライ (businesslike),ドライバー(工具) (screwdriver),ナイーブ (uncorrupted, unspoiled),ネック (weak link, dead wood, disadvantage, burden),ハンドル ((steering) wheel),バーコード(髪型) (Bobby Charlton),バイキング (buffet),パワーアップ (build),ファイト (Go for it, Do your best),フロント (front desk, reception),ブーム (fad),プリント (handout, printout),プロデューサー (coordinator),マジック (felt tip pen, marker pen),マンション (condominium, apartment),メリット/デメリット (pros and cons, advantages and disadvantages),モニター (test user, product tester),ヤンキー (good-for-nothings, layabouts, hooligans, thugs),リフォーム (alteration, refurbish, renovate),リベンジ (rematch),ルーズ (lax, careless, negligent, irresponsible)
(3) 形態的和製英語
アイロン (flat iron),アクセル (accelerator),アプリ (application),アポ/アポイント (appointment),ウイルス (virus),エンスト (engine stall),オンザロック (on the rocks),カレーライス (curry and rice, curry with rice),コーンビーフ (corned beef),コネ (connection),サンオイル (suntan oil),スモークハム (smoked ham),セクハラ (sexual harassment),セットローション (setting lotion),デパート (department store),トイレ (bathroom, restroom),ドンマイ (Don't worry about it, Never mind),ニス (varnish),ネーブル (navel orange),ノート (notebook),ノンプロ (nonprofessional),パーマ (permanent),パソコン (personal computer),パンク (flat tyre, puncture),ビタミン (vitamin),ビル (building),ファンタジック (fantastic),プリン (pudding, custard pudding),プロレスラー (professional wrestler),マイク (microphone),マスコミ (mass communication, mass media, the media),マニア (maniac, fan),リストアップ (list),リストラ (restructuring, corporate downsizing),レジ (cash register)
・ スティーブン・ウォルシュ 『恥ずかしい和製英語』 草思社,2005年.
・ 桐生 りか 『カタカナ語・外来語事典』 汐文社,2006年.
・ 『新版日本語教育事典』 日本語教育学会 編,大修館書店,2005年.
・ デイビッド・セイン 『日本人がつい間違えるNGカタカナ英語』 主婦と生活社,2012年.
・ 『日本語学研究事典』 飛田 良文ほか 編,明治書院,2007年.
・ 『日本語百科大事典』 金田一 春彦ほか 編,大修館,1988年.
・ 村石 利夫 『カタカナ語おもしろ辞典』 さ・え・ら書房,1990年.
・ 山口 理 『国語おもしろ発見クラブ 外来語・和製英語』 2012年.
2013-09-30 Mon
■ #1617. 日本語における外来語の氾濫 [japanese][katakana][loan_word][lexicology][language_planning]
日本語における「外来語の氾濫」の問題は,長らくメディアを賑わわせている.最近目についたところでは,9月4日(水)の朝日新聞朝刊13面に「耕論 カタカナ語の増殖」として3名の識者による議論が掲載されていた.「フランス語の未来」協会長のアルベール・サロン氏による「過剰な英語化,無味乾燥」,英語言語帝国主義批判の論客,津田幸男氏による「「言語法」で日本語を守れ」,クリエーティブディレクター岡康道氏による「取り込んで,面白がろう」の3論である.サロン氏は英語支配の観点から,津田氏は英語支配および日本の伝統維持という立場からそれぞれカタカナ語の氾濫を厳しく批判しているが,岡氏は日本語の同化力と創造力を評価して外来語の流入を歓迎している. *
確かに,戦前から戦後を経て21世紀初頭の現在に至るまで,主として英語起源のカタカナ語の流入はおびただしい.この「氾濫」に対して,上記の議論のように様々な立場から反論が加えられてきたし,逆に擁護論が展開されたりもしてきた.しかし,とりわけ目につくのは反対論のほうである.このような問題における支持論は,およそ反対論に対する反論として唱えられるのが常であるようだ.
『新版日本語教育事典』 (261) によると,外来語問題とは次の通りである.
「カタカナ語の氾濫」として問題にされ,急増している外来語への対応がさまざまな角度から議論される.背景には,英語とアメリカ文明の圧倒的な優位があるといってよい.議論の方向は,大きく2つの立場に分かれる.一つは,日本語そのものが良き文化的伝統とともに崩壊するのではないかと懸念する伝統重視の立場からのもの,もう一つは,一般になじみのうすい外来語が出まわることによって,基本的な情報のやりとりや意志疎通に支障が生ずることを問題視する機能重視の立場からのものである.後者に関しては,とくに公共性の高い場面における外来語使用について,個々の語の定着度に配慮した適切な対応を求める動きが国のレベルでも見られる.
このような問題意識を受けて,昨日の記事「#1616. カタカナ語を統合する試み,2種」 ([2013-09-29-1]) でも触れたとおり,2002年より国立国語研究所の「外来語」委員会が「外来語」言い換え提案について議論することになった次第である.委員会設立趣意書では,機能主義の立場から外来語の問題点を指摘している.
外来語・外国語の問題点
近年,片仮名やローマ字で書かれた目新しい外来語・外国語が,公的な役割を担う官庁の白書や広報紙,また,日々の生活と切り離すことのできない新聞・雑誌・テレビなどで数多く使われていると指摘されています.例えば,高齢者の介護や福祉に関する広報紙の記事は,読み手であるお年寄りに配慮した表現を用いることが,本来何よりも大切にされなければならないはずです.多くの人を対象とする新聞・放送等においても,一般になじみの薄い専門用語を不用意に使わないよう十分に注意する必要があります.ところが,外来語・外国語の使用状況を見ると,読み手の分かりやすさに対する配慮よりも,書き手の使いやすさを優先しているように見受けられることがしばしばあります.
日本語教育の立場からも,外来語の問題点が指摘されている.以下,遠藤(編) (205--06) より引用するが,これも広い意味では機能主義的な議論の一種だろう.
日本語の中に外来語が多いことは,日本人にとってだけでなく,日本語学習者にとっても,いろいろな問題を生んでいる.
日本人にとっては,次々に生まれるカタカナの外来語の意味するところがわからなくて,困惑する人が多くなっている.政府関係の白書に使われる外来語の多さが,論議を呼び,外来語使用を自粛するように通達も出されたこともある.しかし,減る気配はいっこうに見えなくて,意思疎通に支障を来すことをおそれて国立国語研究所が言い換え案を出すことになった.その効果についてはまだ,報告されていない.
ショートステイ・ケアマネージャー・ケアプログラム・バリアフリーなど,福祉関係の用語が外来語で占められているが,これではその主な対象者である高齢者にはわかりにくい.ノーマライゼーション・アカウンタビリティなどのように新しい概念を移入するとき,原語をそのままカタカナにするために,外来語が増えるのであるが,そのカタカナの表す音と原語の発音の差が大きすぎて,原語のわかる人にもそのカタカナ語はわからない.まして,日本で適当に原語を組み合わせて作られる語(=和製語)は,原語を知っている人でもまったく類推が利かない.
そのために,英語の話者は倍の苦労をする.日本人はカタカナの語を見ると,英語だと思い,外国人には英語で言えば通じると思う.しかし,それは英語でも何でもない日本での造語である.英語話者に通じるはずがないのに,通じると思われて多く使ってこられるとしたら,ますます負担は大きくなるのである.
発音のわかりにくい,英語もどきのことばより,いっそ本来の日本語で言ってくれたほうがはるかにわかりやすいと,日本語を知る英語話者は嘆いているのである.
日本語を教える際に,カタカナ外来語は,原語とは関連がなく,まったく新たな日本語であるということを認識しておく必要がある.
このように外来語の氾濫は様々な批判の対象とはなっているが,実際のところ,多くの日本語母語話者は外来語の受容と使用について議論こそすれ,本格的に敵視し排除しようというわけではなさそうだ.外来語を法によって規制しようという動きにまで発展したことはないし,今後もそこまで行くかどうかは疑問だ.全体として現状肯定,あるいは消極的な支持という向きが支配的のように思う.
・ 『新版日本語教育事典』 日本語教育学会 編,大修館書店,2005年.
・ 遠藤 織枝(編) 『日本語教育を学ぶ 第二版』 三修社,2011年.
2013-09-29 Sun
■ #1616. カタカナ語を統合する試み,2種 [japanese][katakana][loan_word][lexicography][lexicology][language_planning][binomial]
昨日の記事「#1615. インク壺語を統合する試み,2種」 ([2013-09-28-1]) で,16世紀に大量にラテン語から流入したインク壺語の理解を促すための主たる方法として,辞書の出版と言い換え表現があったことを述べた.おもしろいことに,現代日本語におけるカタカナ語の大増殖にも,ほとんど同じことがいえる.大正以降,とりわけ戦後の洋語(ほとんどが英語)の語彙借用はおびただしいが,それを日本語語彙に統合しようとする試みの1つとして,カタカナ語辞書の出版が目につく.図書検索サイトなどで,「カタカナ語」や「外来語」を題名に含む本を検索すると,非常に多くの参考図書がヒットする.地元の公立図書館のこども用書棚をちょっとのぞくだけでも,例えば『カタカナ語おもしろ辞典』(村石 利夫,さ・え・ら書房,1990年)や『カタカナ語・外来語事典』(桐生 りか,汐文社,2006年)が簡単に見つかる.この日本の著者たちの意図は,かつてのイングランドの Mulcaster, Cawdrey, Bullokar, Cockeram の意図と重ね合わせることができるだろう.
インク壺語統合のために用いられたもう1つの方法,すなわち言い換え表現もまた,カタカナ語統合のために利用されている.ただし,カタカナ語の場合には,近年,より公的な言語政策が関与していることに注意したい.2002--06年,国立国語研究所の「外来語」委員会が「外来語」言い換え提案の活動を行い,その成果を公開した.言い換え手引きは書籍としても出版されたし,オンラインでも公開されている.委員会設立趣意書や提案した語の一覧ほか,様々な参考資料や研究論文がオンラインで閲覧できる.趣意書に「緩やかな目安・よりどころを具体的に提案することを目指しています」とあるとおり,強制力のない提案ではあるが,公的な機関が策定しているという点で,国による言語政策の一環(とりわけ corpus planni ng と呼ばれるもの)と考えてよいだろう.「アーカイブ〔保存記録〕」「インフォームドコンセント〔納得診療〕」「ワーキンググループ〔作業部会〕」などの表記は,かつてのイングランドにおける "education or bringing up of children", "agility and nimbleness" を想起させる.かっこ付きで補助的に表記するとき,それは一種の日本語版 2項イディオム (binomial idiom) であるといえる.
時代も言語も異なるが,インク壺語もカタカナ語も,その統合のための努力と手段については大きく変わるところがない.個々の語が定着するか廃用となるかが時間の問題であることも,変わらないだろう.
2013-09-21 Sat
■ #1608. multilingualism は世界の常態である (2) [bilingualism][japanese][world_languages][sign_language][language_or_dialect]
[2013-05-30-1]の記事の続編.多言語使用が世界の常態であるという事実について,Crystal (409--10) に言及を見つけたので,追加したい.
[M]ultilingualism is the normal human condition. It is a principle which often takes people by surprise. If you have lived your whole life in a monolingual environment, you could easily come to believe that this is the regular way of life around the world, and that people who speak more than one language are the exceptions. Exactly the reverse is the case.
Speaking two or more languages is the natural way of life for three-quarters of the human race. There are no official statistics, but with over 6,000 languages co-existing in fewer than 200 countries . . . it is obvious that an enormous amount of language contact must be taking place; and the inevitable result of languages in contact is multilingualism, which is most commonly found in an individual speaker as bilingualism.
There is no such thing as a totally monolingual country. Even in countries that have a single language used by the majority of the population, such as Britain, the USA, France, and Japan, there exist sizeable groups that use other languages. In the USA, around 10% of the population regularly speak a language other than English. In Britain, over 350 minority languages are in routine use. In Japan, one of the most monolingual of countries, there are substantial groups of Chinese and Korean speakers. In Ghana, Nigeria, and many other African countries that have a single official language, as many as 90% of the population may be regularly using more than one language. (409--10)
引用にもあるとおり,日本は世界でも最も典型的な単一言語国家とみなされるがちだ.しかし,少数言語としてアイヌ語や,朝鮮・韓国語その他の移民言語,日本手話などの手話言語も行われている.また,琉球語なのか琉球方言なのかという問いの答えいかんによっては,その話者のすべてが標準日本語を理解するという意味において,2言語使用者と呼びうる.また,ビジネスなどで英語や中国語などを常用する多くの日本語母語話者の日本人も,日本国内外の多言語使用に貢献している人々であるとみなすことができる.程度の差こそあれ,日本も世界の他の地域と同様に多言語使用地域であるという認識は重要だろう.
日本の多言語使用状況については,Ethnologue の Japan を参照されたい.
・ Crystal, David. How Language Works. London: Penguin, 2005.
2013-09-14 Sat
■ #1601. 英語と日本語の母音の位置比較 [phonetics][japanese][vowel][rp]
英語と日本語の調音の異同については,どの音声学の教科書でも詳述されているが,母音を調音する際の舌の位置については母音四辺形で対比的に示すのが最もわかりやすい.今井 (2) より,短母音と長母音の図を掲載する.

上記の母音調音位置はそれぞれの言語の標準変種に基づいているが,その内部において,異音の幅もあれば,個人差もある.しかし,この図をみれば,日本語を母語とする英語学習者が,発音上,一般的に気をつけるべき点を多く見いだすことができるだろう.日本語の [エ] はやや高いので,ときに英語の [e] ではなく [ɪ] に近づくこと.英発音の [ʌ] は,案外と日本語の [ア] に近いこと.日本語の [ウ] と [オ] の差は比較的少ないが,英語で対応するとみなされている [uː] や [ʊ] と [ɔː] の差は比較的大きいこと.「ア(ー)」と音訳される [ɑː], [ɑ], [ɒ] は,いずれも英語では相当に奥まっていること,等々.
概して,英語には周辺部や突端部で調音する母音が多く,口腔内が広く使われるという印象だ.一方,日本語の母音調音は,口腔の中央寄りにこじんまりと分布しているようだ.ぼそぼそ感といおうか,確かに口をあまり動かさずに「アイウエオ」と発音できてしまう.
ただし,上の図の調音位置を不変の静的なものととらえるのは誤りである.この100年ほどの間の英語における調音位置の変化をみてみると,意外と変化の幅は大きい.Bauer (121) によると,RP をとってみても,[uː] の調音は上の図で表わされるよりも顕著に前寄りになってきているという.[ʌ] についても,明らかに前舌化が進んできているし,[æ] も図よりも若干後ろ寄りでの調音の傾向を示す証拠がある.言語変化は常に進行してるために避けられないことではあるが,概説書などの調音図は,原則として多少なりとも時代遅れの調音を表わすものだと考えておいてよい.
・ 今井 邦彦 『ファンダメンタル音声学』 ひつじ書房,2007年.
・ Bauer, Laurie. Watching English Change: An Introduction to the Study of Linguistic Change in Standard Englishes in the Twentieth Century. Harlow: Longman, 1994.
2013-08-11 Sun
■ #1567. 英語と日本語のオンラインコーパスをいくつか紹介 [web_service][corpus][efl][link][japanese]
ウェブ上で用いることのできるコーパスをいくつか紹介したい.
まず,「#1441. JACET 8000 等のベース辞書による語彙レベル分析ツール」 ([2013-04-07-1]) で取り上げた染谷泰正氏は,Business Letter Corpus のオンライン・コンコーダンサーをこちらで公開している.27種のコーパスからの検索が選択可能となっているが,メインは100万語超からなる Business Letter Corpus (BLC2000) とそれにタグ付けした POS-tagged BLC の2つだ.これは1970年代以降の英米その他の出版物から収集したデータである.
Instructions for the First-Time User でまとめられているように,種々のコーパスのなかには,167万語を超える State of the Union Address (1790--2006) などデータをダウンロードできるものもあり,有用である.英作文の学習・教育や,独自データベースのコンコーダンサー作成のために参考になる.
なお,同サイトでは,上述の各種コーパスから N-Gram Search を行なえる Bigram Plus の機能も提供している.N-Gram の検索には,本ブログより「#956. COCA N-Gram Search」 ([2011-12-09-1]) も参照.
次は,英国のリーズ大学 (University of Leeds) が作成した大規模な Leeds collection of Internet corpora.英語を始め,フランス語,日本語などの様々な言語のコーパスをオンラインで検索できる.
日本語のコーパスの情報については詳しくないが,KOTONOHA 「現代日本語書き言葉均衡コーパス」は充実しているようだ.ほかの日本語コーパスの情報源としては,コーパス日本語学のための情報館 --- コーパス紹介が有用.
2013-08-02 Fri
■ #1558. ギネスブック公認,子音と母音の数の世界一 [phonology][phoneme][vowel][consonant][altaic][japanese][language_family][world_languages][austronesian]
日本語のルーツについての有力な説の1つに,オーストロネシア系 (Austronesian) とアルタイ系 (Altaic) の言語が融合したとする説がある.オーストロネシア語族の音韻論的な特徴としては,開音節が多い,区別される音素が少ないというものがあり,確かに日本語の比較的単純な音素体系にも通じる.
日本語の音素が比較的少ない点については「#1021. 英語と日本語の音素の種類と数」 ([2012-02-12-1]) および「#1023. 日本語の拍の種類と数」 ([2012-02-14-1]) で触れたが,そこでは関連してハワイ語にも触れた.ハワイ語もオーストロネシア語族に属する言語で,8つの子音 /w, m, p, l, n, k, h, ʔ/ と5つの母音 /a, i, u, e, o/ を区別するにすぎない(コムリー,p. 95).ところが,世界にはもっと音素が少ない言語があるのである.
地理的にオーストロネシア語族と隣接しているパプア諸語も,音韻体系は単純である.そのなかでも,東パプアニューギニアの Bougainville Province で4千人ほどの話者によって話されているロトカス語 (Rotokas) は,6つの子音 /b, g, k, p, r, t/ と5つの母音 /a, e, i, o, u/ の計11音素(と対応する11の文字)しかもたない(Ethnologue より,関連する言語地図はこちら).コムリー (106) によれば,これは世界最少の音素数であり,とりわけ子音の少なさについては1985年のギネスブック (199) に登録されているほどである.
子音についていえば,最多を誇るのは「#1021. 英語と日本語の音素の種類と数」 ([2012-02-12-1]) でも触れたウビフ語である.80--85個の子音をもつという.母音の最少は,コーカサス地方のアブハズ語で2母音しかもたない.母音音素の最多はベトナム中央部のセダン語で,明確に区別できる55の母音をもつという.世界は広い.
同じギネスブック (198--201) では,言語についての興味深い「世界一」が,他にもいろいろと挙げられており,一見の価値がある.言語のびっくり統計は,Language statistics & facts も参考になる.
・ バーナード・コムリー,スティーヴン・マシューズ,マリア・ポリンスキー 編,片田 房 訳 『新訂世界言語文化図鑑』 東洋書林,2005年.
・ ノリス・マクワーター 編,青木 栄一・大出 健 訳 『ギネスブック』 講談社,1985年.
2013-07-23 Tue
■ #1548. アルタイ語族 [altaic][family_tree][japanese][language_family][map][mongolian]
「#496. ウラル語族」 ([2010-09-05-1]) と合わせてウラル・アルタイ大語族の仮説を構成するアルタイ語族 (Altaic) について,バーナード・コムリー他 (46--47) より紹介する.アルタイ語族は,実証されてはいないものの朝鮮語や日本語が所属するとも提案されてきた重要な語族である.コムリーの与えているアルタイ語系統図を見てみよう.
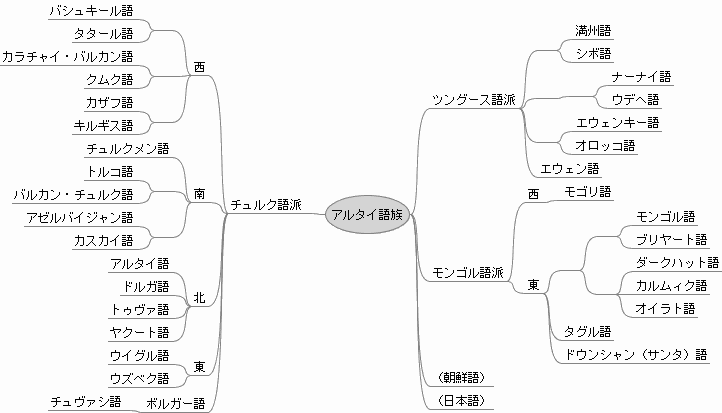
この語族の故地はアルタイ山脈付近(下図参照)にあるとされ,西のチュルク語派 (Turkic),中央のモンゴル語派 (Mongolian),東のツングース語派 (Tungus) が区分される.その後,担い手である遊牧民によって拡散し,現在ではトルコからシベリア北東部にいたる大草原地帯に広く分布する.
アルタイ諸語のあいだの系統関係は,語彙よりも文法上の類似に基づくものが多く,研究者間で必ずしも意見の一致を見ているわけではない.共通する特徴として指摘されるのは,語順が SOV であること,膠着語であること,母音調和をもっていることが挙げられるが,後者2点についてはウラル語族の特徴とも一致する.日本語の所属が提案されているのも,これらの特徴ゆえである.主流派の見解によれば,日本語はアルタイ語族とオーストロネシア語族の混成語とも言われるが,証明は難しい.
満州語は,中国最後の皇帝の言語であり,清王朝 (1644--1911) のもとで優遇されたが,現在では大多数の話者が中国語へ言語交替したため,消滅の危機に瀕している.
アルタイ語族の各言語の詳細については,Ethnologue report for Altaic を参照.
・ バーナード・コムリー,スティーヴン・マシューズ,マリア・ポリンスキー 編,片田 房 訳 『新訂世界言語文化図鑑』 東洋書林,2005年.
2013-07-01 Mon
■ #1526. 英語と日本語の語彙史対照表 [word_formation][japanese][timeline][lexicology][loan_word][borrowing][compounding][affix][buddhism]
以下に,英語と日本語の語彙史,語形成の歴史を比較対照できるような表を作成した.それぞれの時代における語彙や語形成の特徴を箇条書きにしたものである.「#1524. 英語史の時代区分」 ([2013-06-29-1]) と「#1525. 日本語史の時代区分」 ([2013-06-30-1]) でそれぞれの言語の時代区分を示したが,両者がきれいに重なるわけではないので,表ではおよその区分で横並びにした.英語の側では特定の典拠を参照したわけではないが,その多くは本ブログ内でも様々な形で触れてきたので,キーワード検索やカテゴリー検索を利用して関連する記事にたどりつくことができるはずである.とりわけ現代英語の語形成については,「#883. Algeo の新語ソースの分類 (1)」 ([2011-09-27-1]) を中心として記事で細かく扱っているので,要参照.日本語の側は,『シリーズ日本語史2 語彙史』 (p. 7) の語彙史年表に拠った.
| Old English | * Germanic vocabulary | 上代 | ○和語(やまとことば)が大部分を占めた. |
| * monosyllabic bases | ○2音節語が基本. | ||
| * derivation and compounding | ○中国との交流の中で漢語が借用された.例:茶 胡麻 銭 (なお,仏教とともに伝えられたことばの中には「卒塔婆」「曼荼羅」のような梵語(古代インド語=サンスクリット語)も含まれている.) | ||
| * Christianity-related vocabulary from Latin (some via Celtic) | 中古 | ○漢語が普及した.例:案内(あない) 消息(せうそこ) 念ず 切(せち)に 頓(とみ)に | |
| * few Celtic words | ○和文語と漢文訓読語との文体上の対立が見られる.例:カタミニ〈互に〉←→タガヒニ(訓読語) ク〈来〉←→キタル(訓読語) | ||
| Middle English | * Old Norse loanwords including basic words | ○派生・複合によって,形容詞が大幅に造成された. | |
| * a great influx of French words | 中世 | ○漢語が一般化した. | |
| * an influx of Latin technical words | ○古語・歌語・方言・女房詞など,位相差についての認識が広く存在した. | ||
| Modern English | * a great influx of Latin loanwords | ○禅宗の留学僧たちが,唐宋音で読むことばを伝えた.例:行燈(あんどん) 椅子(いす) 蒲団(ふとん) 饅頭(まんぢゅう) | |
| * Greek loanwords directly | ○キリスト教の宣教師の伝来,また通商関係などにより,ポルトガル語が借用された.例:パン カルタ ボタン カッパ〈合羽〉 | ||
| * loanwords from various languages | 近世 | ○漢語がより一般化し,日常生活に深く浸透した. | |
| * Shakespeare's vocabulary | ○階層の分化に応じて語彙の位相差が深まった. | ||
| * scientific vocabulary | ○蘭学との関係でオランダ語が借用された.例:アルコール メス コップ ゴム | ||
| Present-Day English | * shortening | 近代 | ○西欧語の訳語として,新造漢語が急激に増加する.例:哲学 会社 鉄道 市民 |
| * many Japanese loanwords | ○英米語を筆頭として,フランス語,ドイツ語,イタリア語などからの外来語が増加する. | ||
| * compounding revived | ○長い複合語を省略した略語が多用される. | ||
| * loanwords decreased |
両言語ともに借用という手段で語彙を豊かにしてきたことがわかるだろう.文化史と語の借用の歴史は常に密接な関係にあるが,英語と日本語の語彙史以上にこのことを如実に示すものはあまりない.言語類型的にも地理的にも著しくかけ離れた両言語が,語彙史において多くの共通点をもっていることは銘記しておきたい.
・ 安部 清哉,斎藤 倫明,岡島 昭浩,半沢 幹一,伊藤 雅光,前田 富祺 『シリーズ日本語史2 語彙史』 岩波書店,2009年.
2013-06-30 Sun
■ #1525. 日本語史の時代区分 [periodisation][historiography][timeline][japanese]
昨日の記事「#1524. 英語史の時代区分」 ([2013-06-29-1]) を受けて,今日は日本語史の時代区分を示す.日本語についても,細かい時代区分は研究者の数だけあるといって過言ではないが,そのうち2つの時代区分の例を示したい.1つ目は『日本語概説』 (pp. 282--83) に示されている時代区分をもとにしたもの.フラットに区分と名称が与えられている.
| 1. | 古代 | B.C. 13000 ? A.D. 600 | 縄文・弥生・古墳時代 |
| 2. | 上代 | 600 ? 784 | 飛鳥・奈良時代 約200年間 |
| 3. | 中古 | 784 ? 1184 | 平安・院政時代 約400年間 |
| 4. | 中世 | 1184 ? 1603 | 鎌倉・室町時代 約400年間 |
| 5. | 近世 | 1603 ? 1867 | 江戸時代 約300年間 |
| 6. | 近代 | 1868 ? 1945 | 明治・大正・昭和前半時代 約80年間 |
| 7. | 現代 | 1946 ? | 昭和後半・平成時代 約70年間 |
次に,『概説 日本語の歴史』 (p. 14) の表をもとにしたものを掲げる.
| I | II | III | IV | V |
| 古代 | 古代 | 上代 | 上代 | 奈良時代とそれ以前 |
| 中古 | 中古 | 平安時代 | ||
| 中世 | 中世前期 | 中世前期 | 院政・鎌倉時代 | |
| 近代 | 中世後期 | 中世後期 | 室町時代 | |
| 近代 | 近世 | 近世前期 | 江戸時代前期 | |
| 近世後期 | 江戸時代後期 | |||
| 現代 | 現代 | 明治以降 |
ここでは,階層上に入り組んだ区分と名称が用いられている.最も大雑把には I のレベルの区分により古代と近代が区別されるが,一般的には III や IV のレベルの区分と名称が用いられることが多い.
日本史の時代区分を2例ほど挙げたが,相互に時代の呼称が入り乱れていることからも推察されるように,時代区分はその研究者の言語史観を如実に表わすものとして研究上重要な意味をもつが,一方で参照ポイントとしてはあくまで便宜的なものにすぎないことに注意されたい.
・ 加藤 彰彦,佐治 圭三,森田 良行 編 『日本語概説』 おうふう,1989年.
・ 佐藤 武義 編著 『概説 日本語の歴史』 朝倉書店,1995年.
2013-06-09 Sun
■ #1504. 日本語の階層差 [japanese][sociolinguistics][variation][link]
階級による英語の言語的な差異については,例えば次の記事で扱ってきた.
・ 「#1359. 地域変異と社会変異」 ([2013-01-15-1])
・ 「#1481. カンナダ語にみる社会方言差と地域方言差の逆ピラミッド」 ([2013-05-17-1])
・ 「#1370. Norwich における -in(g) の文体的変異の調査」 ([2013-01-26-1])
・ 「#406. Labov の New York City /r/」 ([2010-06-07-1])
・ 「#1371. New York City における non-prevocalic /r/ の文体的変異の調査」 ([2013-01-27-1])
・ 「#1363. なぜ言語には男女差があるのか --- 女性=保守主義説」 ([2013-01-19-1])
・ 「#1203. 中世イングランドにおける英仏語の使い分けの社会化」 ([2012-08-12-1])
・ 「#1292. 中英語から近代英語にかけての h の位置づけ」 ([2012-11-09-1])
現代日本語では階級による言語の差異が明確にはみられないので,英語での差異について直感的に理解しにくいが,明治以前には日本語にも階級差が明確に存在した.『新版日本語教育事典』 (468) より,関連する箇所を引用する.
士農工商という身分制度が存在した江戸時代には,日本語も同様であった.福沢諭吉は『旧藩情』(1877) のなかで,旧中津藩において士農商のことばにはっきりした差異があったことを,具体例を挙げて記述している.さらに,このような言語の変異は身分の違いに起因するものであり,このような状況は,他藩でも同じだろうとも述べている.〔中略〕日本語の社会階層差は,明治時代に入り,いわゆる身分制度が廃止された後も,教育・職業などによることばの違いとして存続してきた./近世・近代に比べると,高学歴化が進み,階層が固定的でなくなった現代では,社会階層間の格差の現象を反映して,日本語の階層による違いも,小さくなってきているといえよう.しかし,音声上の諸特徴,使用する語彙の選択,表現の方法などから,話者の職業などをある程度特定することは可能である.
青空文庫より『旧藩情』を参照したところ,例えば「見てくれよ」というのに,上士は「みちくれい」,下士は「みちくりい」,商人は「みてくりぃ」,農民は「みちぇくりい」の如く変異を示したという.
同じく『日本語学研究事典』 (176) より引用.
【階層差】宮廷・貴族の言葉と庶民の言葉,武家の言葉と町人の言葉など,身分・階級によって,言葉の様相に大きな差異がみられる.落語の『たらちね』は,宮仕えをしていた公家の娘を妻に迎えた,長屋住まいの八五郎夫婦の言葉の行き違いを描いたものであり,『八五郎出世』には,殿様の側室になった妹を訪ねた八五郎が武家言葉に戸惑うおかしみが描かれている.こうした,言語の階層差には,かつてイギリスやロシアの貴族社会ではフランス語が使われていたというような極端な例もある.江戸時代,各藩の武家社会の言葉は,「ご家中言葉(家中語)」などと呼ばれたが,そこには,改易や移封によって,地域住民の言葉とは全く別の地域の言語が行なわれていることが珍しくなかった.また,武家の女性たちの用いる,上品な言葉遣いは「お屋敷言葉・大和言葉」などと呼ばれ,庶民の言葉の純化に貢献した.例えば上田万年・保科孝一らの「東京の中流社会の言葉」をもとにして標準語を作ろうといった言説にも見られるように,言語に上流・中流・下流などの階層差を意識する傾向は,かなり強く残っている.
明治以前の日本語でも,現在のイングランドの場合と同様に,上層の階級では地域による変異が小さいが,下層では変異が大きいピラミッド構造を示す([2013-01-15-1]の記事「#1359. 地域変異と社会変異」の図を参照).ただし,部分的にその逆のパターンを示すカンナダ語のような例があることは,「#1481. カンナダ語にみる社会方言差と地域方言差の逆ピラミッド」 ([2013-05-17-1]) で触れたとおりである.
・ 『新版日本語教育事典』 日本語教育学会 編,大修館書店,2005年.
・ 『日本語学研究事典』 飛田 良文ほか 編,明治書院,2007年.
2013-05-28 Tue
■ #1492. 「ゴールデンウィーク」は和製英語か? [japanese][borrowing][semantic_change][word_formation][terminology][sign][loan_translation][lexicology][morphology][false_friend][waseieigo]
「#1471. golden を生み出した音韻・形態変化」 ([2013-05-07-1]) の記事で,「ゴールデンウィーク」 (Golden Week) という日本語表現に触れたとき,それを和製英語として紹介した.後日,同記事へのコメントがあり,英語教育に関する質疑応答・情報共有サイトの「Is ゴールデンウィーク wasei-eigo?」という記事へのリンクをいただいた(ありがとうございました!).その記事によると,Google Books Ngram Viewer (see [2010-12-25-1]) で検索をかけると,golden week という共起表現が1951年以前に英語に存在したということがわかる(こちらのページを参照).[2010-12-25-1]の記事で述べたように,正直のところ Google Books のコーパスとしての評価はしにくいと考えているが,少なくとも同句の存在は事実であると受け入れてよいだろう.だが,英語の golden week に「大型連休」なる語義があったわけではなく,あくまで「(黄金のように)素晴らしい週間」ほどの意味で用いられているようだ.さて,このような状況に鑑みて,はたして日本語の「ゴールデンウィーク」は和製英語とみなしてよいのかどうか.
この問いには様々な側面があると思われるが,整理すると (1) 語形成論・通時態の側面と (2) 記号論・共時態の側面がある.「ゴールデンウィーク」は和製英語かどうかという問いは,もっぱら (1) の視点から発せられる問いであり,日本語語彙史や日本語語源学においては重要な問題だろう.一方,(2) の視点からはこの問いはあまり本質的ではないものの,間接的に日本語語彙論に理論的な問題を投げかけるという点では同じくらい興味深い.以下で (1) と (2) のそれぞれについて記す.
(1) 語形成論・通時態の側面
日本語学用語として和製英語の厳密な定義が何であるのかはいくつかの用語辞典を参照しても判然としなかったが,和製英語の典型として挙げられる「ナイター」「バックミラー」のような例からその特徴を抽出すれば,「英語(由来)の形態素を英語の規則に概ね則って組み合わせることによって形成した日本語としての語句」ということになりそうだ.この定義は,音形 (signifiant) 形成が日本語体系内で行なわれている点,英語のモデルを参照していない点に焦点を当てた定義である.また,この定義は,その後意味が変化したかどうか,英語へ逆借用されたかどうかなどの後の発展には言及しない定義であり,もっぱら形成過程に注目した定義といえる.
上の定義の和製英語と対立する過程は,借用 (borrowing) である.英語側のモデルとなる記号 (signe) を参照し,それをほぼそのまま日本語語彙体系のなかに取り込む過程である.
さて,ある英語風日本語句が和製英語であるか英語借用語であるかは,既存の英語モデルを参照したかどうかにかかっている.「ゴールデンウィーク」の例でいえば,英語にすでに存在していたらしいモデル golden week を参照し借用したのか,あるいは英語側のモデルの有無はどうであれ,参照せずに日本語内部で独自に作り上げたものなのか.英語側にモデルがある以上,それを参照したと考えるのが自然と思われかもしれないが,必ずしもそうとはいえない.nighter などの形態規則のたまものとは異なり,golden week は統語規則のたまものであり,このような統語的共起表現が英語側と日本語側で独立して発生する可能性は十分にある.問題の語彙革新者がモデルの存在を知らなかったという可能性も捨てきれないのではないか.結局のところ,この問題への答えは,その語彙革新者が英語モデルの存在を知っており,それを参照したか否かという一点にかかっているのであり,それを知ることが現実的には難しい以上,この問いには「わからない」としか答えようがない.さらにいえば,その語彙革新者がモデルの存在を知っているか否かも,実際のところ,yes か no かで切り分けられる問題ではないかもしれない.英語の golden week をどこかで見聞きしたことがあるような・・・というおぼろげな記憶にすぎないかもしれないし,そもそも英語にはきっとモデルがありそうだという感覚さえあれば和製英語の形成に踏み切るには十分なのである.
語源学上,「ゴールデンウィーク」を日本語内部での形成と考えるか,英語からの借用および意味の特殊化と考えるかは大きな違いである.語源欄に書くべきことが変わってくるからだ.英語にモデルが存在しない「ナイター」のように,明らかな和製英語の例が一方の端にある.借用過程がわかっている「コーパス」のように,明らかな借用の例が他方の端にある.その両端の間に,歴史的事情がよくわからないグレーゾーンが広がっており,良心的な語源学者であれば無理にどちらかに所属させることには躊躇するだろう.代わりに,和製英語から借用語へと続くこの連続体そのものに何かラベルを当てるというのが1つの解決法になるかもしれない.モデル参照の有無にかかわらず signifiant が英語風であるという共通点があるので,「英語横文字(カタカナ)語」などとしておくのが無難かもしれない.
(2) 記号論・共時態の側面
記号論の観点から「ゴールデンウィーク」を考えると,上述とは違った見方が可能になる.英語の干渉を受けて形成された語は,記号 (signe) の観点から4つのタイプに分類される.
(a) 英語に対応する signe が存在するタイプ(借用語に典型的)
(b) 英語に対応する signifié は存在するが signifiant は異なるタイプ(翻訳借用語に典型的)
(c) 英語に対応する signifiant は存在するが signifié は異なるタイプ("false friends" あるいは "faux amis" に典型的)
(d) 英語に対応する signe が存在しないタイプ(和製英語に典型的)
(c) の "false friends" とは,言語教育などで指摘されている「諸言語間で,形態は対応するが意味は異なるために注意を要する語句」である.不完全な借用過程や,借用後に生じた意味変化によってもたらされることが多いが,モデルの存在に気づかずに作られた和製英語などでこのタイプに属するものがあるかもしれない.
和製英語にまとわりつくイメージとして「英語では通じないもの」があるが,実際には「英語では通じないもの」は,(c) と (d) に区別して捉えておく必要がある.(c) には「(自動車の)ハンドル」,授業をサボるの意での「エスケープする」,女性に親切な男を指す「フェミニスト」などが,(d) には「サラリーマン」「オールバック」「ベッドタウン」「シルバーシート」などがあり,通じなさの質が異なる.この類型に従えば「ゴールデンウィーク」は (c) となるだろう.この類型はあくまで共時的な類型であり,(1) で扱った形成過程に重きを置いた通時的な観点とは対照される点に注意されたい.
上では,いくつかの角度から和製英語を他の語彙(過程)と対比的に位置づけようと試みてきた.さらに議論の整理が必要だが,「和製英語」とは本質的に (1) の観点から名付けられた用語であるらしいことがわかってきた.一方,「英語では通じないもの」という問題は,(2) に属する話題である.「和製英語」と「英語では通じないもの」とは,通時態と共時態の区別と同様に,いったん切り分けて議論したほうがよいのではないか.
明日は,関連する英語の話題を取り上げる.
2013-04-14 Sun
■ #1448. wanna go と「行かまほし」 [japanese][assimilation][grammaticalisation][auxiliary_verb]
現代英語の口語において,want to の省略形としての wanna が勢力を得てきている.「#914. BNC による語彙の世代差の調査」 ([2011-10-28-1]) でも,wanna は gonna (< going to) とともに若い世代を特徴づける表現であることが示されていた.また,この省略ないし変化は「#624. 現代英語の文法変化の一覧」 ([2011-01-11-1]) で簡単に触れたように,法助動詞化(より一般的には文法化)の過程としてみることもできる.wanna において want と to は音韻的,形態的に同化しており,話者は使用にあたって分析していないと想定される.もしそうだとすれば,wanna は「#64. 法助動詞の代用品が続々と」 ([2009-07-01-1]) のリストに加えて然るべきということになろう.
興味深いことに,日本語の古語で希望を表わす助動詞「まほし」は,その形成過程が wanna の場合とそっくりである.例えば,「行かまほし」は「行かまくほし」の縮約形であり,後者を歴史的,形態的に分析すると,「行く」の未然形+推量の助動詞「む」の未然形+名詞をつくる接尾辞「く」(ク語法)+形容詞「ほし」となる.音韻的に示せば,/ma ku FoSi/ がつづまって /maFoSi/ となり,この形態音韻連鎖が独立した希望の助動詞として認識されるようになったということである.実際に,上代ではまだ「まくほし」の形が見られる.「まほし」は中世まで主として仮名文学作品の散文で用いられたが,近世以降は現在の「たい」に連なる「たし」が優勢となり,「まほし」を置き換えた.
wanna go と「行かまほし」の形成過程の類似はこれだけにとどまらない.英語の不定詞 to は,後続する動詞を未来志向を込めた名詞へと作り替える働きをしている(反対に動名詞は過去志向の名詞を作るといわれる).同様に,「まほし」の前身「まくほし」に含まれる「まく」は,先述の通り,推量の助動詞「む」の未然形+名詞をつくる接尾辞「く」(ク語法)である.推量の助動詞「む」は未来をも表わす.形態素の並びの方向こそ,英語と日本語とで逆向きではあるが,対応する意味を担った形態素が並び,縮約され,結果として分析されない1つの助動詞として解されるようになった点が酷似している.
2012-10-19 Fri
■ #1271. 日本語の唇音退化とその原因 [phonetics][japanese][grimms_law][causation][anthropology]
[2012-02-12-1]の記事「#1021. 英語と日本語の音素の種類と数」で軽く言及したのみだが,日本語は通時的に唇音退化 (delabialisation) を経たとされている.現在のハ行の子音は,かつては [p] だったという説である.[p] が摩擦音化し,さらに摩擦そのものが弱くなり,調音点が [h] へと後退したという.異論もないわけではないが,今や学界ではほぼ定説として受け入れられている.
[p] > [f] の変化といえば,英語史(正確には印欧語史というべきか)におけるグリムの法則 (Grimm's Law; [2009-08-08-1]) がすぐに想起される.ただし,グリムの法則の示す変化は,調音点においても調音様式においても,広範かつ体系的であり,単発の日本語の唇音退化とは性質が大きく異なる.しかし,[2012-05-22-1]の記事「#1121. Grimm's Law はなぜ生じたか?」などで,グリムの法則の変化の起源が謎であるのを見たとおり,日本語の唇音退化を引き起こした要因も謎であるという点で,両者は共通している.
大野 (95--96) は,場合によっては胡散臭い印象を与えかねない人類学的な要因を提案している.
この〔F〕の音は,奈良時代をさかのぼるもっと以前の時代には唇の合わせ方がもっと強くて〔p〕の音であったろうと推定されている.ちょうど現代の沖縄の八重山方言で歯を pa,花を pana,蠅を pai,墓を paka,骨を puni,帆を pu: というように,奈良時代よりずっと以前の本土の日本語でも,舟を puna などと言っていたのだろうという.これは今日の学界の定説である./(では〔p〕→〔F〕→〔h〕という変化は何故起こったのかについて従来説をとなえる人がいないが,私はこれが日本人の顎の骨の後退という骨格の年台的変化と密接な関係があるのだろうと考えている.日本の縄文式時代の人骨では上歯と下歯とはぴったり咬み合わさっているが,弥生式時代以降,下顎が後に退き,相対的に上歯が前方に出る傾向がある.そして鎌倉時代の人骨,徳川時代の人骨と時代がくだるにつれて,下顎が小さくなり,下後方にさがって行く.そして出歯やそっ歯が多くなりつつある.これは元来上唇の短い傾きのある日本人の上下の唇の合わせ方をしにくくする原因となる骨格的変化である.この変化の漸進と,ハ行子音の〔p〕→〔F〕→〔h〕の変化とは平行しており,次に述べる〔w〕子音の脱落も,発音機構の変化としては全く同一の原因によってひき起こされている.)
この提案は学界ではほとんど相手にされなかったというが,小松 (125) はこのような胡散臭い提案を,胡散臭さのみを理由に,頭ごなしに否定するのは科学的な態度ではなく,きちんと検証しようとする姿勢が必要だと考えているようだ.結論としては小松は大野の下顎骨後退説を否定しているが,私も少なくとも検証する価値はあるという意見だ.確かに,胡散臭い,怪しい,荒唐無稽と思われる.だが,本当のところはどこまで笑って済ませられる問題なのか,専門家の助けを得ながら,ぜひ知りたいと思うからだ.
なぜこの説が胡散臭く聞こえるかといえば,人類学的な要因とは人種的な差に訴えかける説明のことであり,それは人種差別につながりうる危険をはらんでいるからだ.言語の起源論については人類学的な知見が不可欠であることは誰しもが認めていながら,形質人類学的な特徴と諸言語の特徴が相関している可能性があるという議論は一種のタブーとされている観がある.
この点で,私はマルティネの科学的リアリズムを評価したい.以下は,ムーナン (281--82) からのマルティネ(『音声変化の経済』)評である.
マルティネはさらに,見ならってよい科学的リアリズムをもって,ある種の生物学的原因の働く可能性を検討することさえ認めている.なにしろ生物学的原因というのは,醜悪なイデオロギー的論法に利用された過去があるために毛嫌いされる場合がきわめて多いのである.彼はこう書いている,「人種の影響という一つの独立した問題が提起される.その問題を一挙に退けてしまうわけにはいかないのだ.[口の器官の一般に見られる非対称性は,形態的類型に応じて変わっている可能性があるし,生理的な人体構造によって,たとえばある種の言語にはある種の音素が欠如しているとか,まれであるということが説明されるかもしれない].しかし,[その問題]を解くためには,どんな種類の先入観ももたずに長い忍耐づよい調査研究を進め,身体的な特性以外の何ものも介入させないよう綿密に配慮することが要求されるだろう.」
・ 大野 晋 『日本語をさかのぼる』 岩波書店,1974年.
・ 小松 秀雄 『日本語の歴史 青信号はなぜアオなのか』 笠間書院,2001年.
・ ジョルジュ・ムーナン著,佐藤 信夫訳 『二十世紀の言語学』 白水社,2001年.
2012-08-06 Mon
■ #1197. 英語の送り仮名 [grammatology][japanese][hiragana][katakana][kanji][writing][punctuation]
日本語の漢字表記には,送り仮名という慣習がある.送り仮名の重要な役割の1つは,原則として直前の漢字が訓読みであることを示すことである.もう1つの重要な役割は,用言の場合に,活用形を示すことである.例えば「語る」の送り仮名「る」は,この漢字が音読みで「ご」ではなく訓読みで「かた」と読まれるべきこと,およびこの動詞が終止・連用形として機能していることを明示している.1つ目の役割は用言以外にも認められ,とりわけ肝要である.「二」であれば「に」と読むが,「二つ」であれば「ふたつ」と読む必要がある.送り仮名は,音訓の問題 ([2012-03-04-1])や分かち書きの問題 ([2012-05-13-1], [2012-05-14-1]) とも関わっており,特異な書記慣習といってよいだろう.
しかし,特異とはいっても,古今東西に唯一の慣習ではない.例えば,シュメール人 (Sumerian) によって紀元前4千年紀の終わりに発明されたとされるメソポタミアの楔形文字 (cuneiform) を紀元前2400年頃に継承したアッカド人 (Akkadian) は,シュメール語に基づく表意文字に,アッカド語の屈折語尾に対応する「送り仮名」を送り,アッカド語として読み下していた.この「送り仮名」は phonetic complement と呼ばれている.紀元前1600年までには,アッカド語を記した楔形文字の一種がヒッタイト語 (Hittite) へも継承され,そこでも似たような phonetic complement が付された (Fortson 160) .
とはいっても,"phonetic complement" あるいは「送り仮名」は,やはり珍しい.そもそも音訓の区別がごく周辺的にしか存在しない英語にあっては([2012-03-04-1]の記事「#1042. 英語におけるの音読みと訓読み」を参照),送り仮名に相当するものなどあるわけがないと思われるが,実は,さらに周辺的なところに類似した現象が見られるのである.一種の略記として広く行なわれている 1st, 2nd, 3rd などの例だ.「二」であれば「に」と読んでください,「二つ」であれば「ふたつ」と読んでください,という日本語の慣習と同じように,1 であれば "one" と読んでください,1st であれば "first" と読んでください,という慣習である.同じ「二」なり 1 なりという(表意)文字を用いているが,送り仮名の「つ」や st の有無によって,発音が予想もつかないほどに大きく異なる.st, nd, rd は,それぞれ,直前の表意文字を「訓読み」してくださいというマーカーとして機能している.
時々,1st, 2nd, 3rd と「送り仮名」部分が上付きで書かれるのを見ることがある.これは,ちょうど漢文で送り仮名をカタカナで小書きするのに似ていておもしろい.メインは表意文字であり,送り仮名はあくまでサブであるという点が共通している.また,この観点から "(phonetic) complement" という用語の意味を考えると味わい深い.OALD8 によると,complement とは "a thing that adds new qualities to sth in a way that improves it or makes it more attractive" である.送り仮名は,チビだが良い奴ということだろうか.
だが,日本語の漢字書きで話題になる送り仮名の揺れの問題(「行なう」あるいは「行う」?)は,さすがに英語にはなさそうだ.1t とか 1rst は見たことがない.
・ Fortson IV, Benjamin W. Indo-European Language and Culture: An Introduction. Malden, MA: Blackwell, 2004.
2012-07-15 Sun
■ #1175. ロマンス系動詞借用以前の副詞の役割 [romancisation][lexicology][latin][french][adverb][synonym][japanese][onomatopoeia][lexical_stratification]
英語語彙の三層構造について,「#334. 英語語彙の三層構造」 ([2010-03-27-1]) を始めとする記事で取り上げてきた.本来語とロマンス系借用語との差は,意味や語法上の微妙な差として現われることが多い.例えば,本来語動詞 beat が "to defeat, to win against sb" であるのに対して,フランス語動詞 vanquish は "to defeat sb completely" である.また,本来語動詞 wet が "to make sth wet" であるのに対して,フランス語形容詞から派生した動詞 moisten は "to make sth slightly wet" である.動詞についていえば,類義語間の差異は,多くの場合,迂言的に言い換えた場合の副詞(相当語句)の差異や有無であることが多い.
このことを逆からみれば,ロマンス系動詞が借用される以前の時代(古英語や初期中英語)には,類義語は貧弱であり,表現力を求めるのであれば,副詞(相当語句)により迂言的に表現せざるを得なかったということになる.特に文学の文体における副詞の役割は大きかったに違いない.Donner (2) は,次のように指摘している.
In a period of the language antecedent to the influx of Latin verbs that allow modern authors so readily both to designate an act and to characterize its quality within a single word, modal qualifiers are likely to play rather a more important role than they currently do in literary rhetoric, which largely avoids them . . . .
中英語期以降,法 (mood) を含意する副詞の役割が大きくなっていることは,Killie (127) などの言及している "adverbialization process" として認められるが,それ以前の時代にも,それとは異なる意味においてではあるが,上記の動詞語彙の貧弱さとの関連において,副詞の役割は重要だったと考えられる.
ここで思い出すのは,日本語における動詞の貧弱さと擬音語様態副詞の豊富さだ.和語の動詞は比較的少なく,多くは漢語に補助動詞「する」を付加した派生的な動詞である.漢語が借用される以前の日本語では,先述の諸期中英語以前の状況と同様に,表現力を求めるかぎり,副詞的な役割をもつ語に依存せざるを得なかった.日本語の場合,副詞的な役割をもつ語として,擬音語が異常に発達していたことは広く知られている.現代の「ゴロゴロ」「スヤスヤ」「ジリジリ」「プンプン」「シトシト」「ベロンベロン」等々.漢語の動詞が大量生産された後もこれらの擬音語は遺産として引き継がれ,拡大すらしたが,動詞の表現力を補う副詞としての役割は,相対的に減じているのかもしれない.同様に,英語の副詞はロマンス系動詞の大量借用後も遺産として引き継がれ,拡大すらしたが,動詞の表現力を補う副詞としての役割は,相対的に減じてきたのではないか.
ただし,これは,Donner も触れているとおり,"literary rhetoric" というレジスターにおいてのみ有効な議論かもしれない.いや,それすらも危うい.英語の副詞や日本語の擬音語の多用は幼稚な印象を与えかねない一方で,時にこれらの表現は驚くほど印象的な修辞を生み出すこともあるからだ.しかし,この問題は,英語史にとっても,日英語の比較にとっても,エキサイティングなテーマとなるに違いない.
・ Killie, Kristin. "The Spread of -ly to Present Participles." Advances in English Historical Linguistics. Ed. Jacek Fisiak and Marcin Krygier. Mouton de Gruyter: Berlin and New York: 1998. 119--34.
・ Donner, Morton. "Adverb Form in Middle English." English Studies 72 (1991): 1--11.
2012-07-01 Sun
■ #1161. 英語と日本語における語彙の音節数別割合 [lexicology][statistics][syllable][corpus][japanese]
昨日の記事「#1160. MRC Psychological Database より各種統計を視覚化」 ([2012-06-30-1]) の (3) で,英語語彙を音節数により分別して,それぞれの頻度を出した.それによると,対象となった92767語の語彙全体における1音節語,2音節語,3音節語,4音節語の占める割合は,それぞれ13.46%,35.40%,29.91%,15.26%であり,合わせて94.03%に達する.とりわけ2音節語と3音節語を合わせて65.31%である.9万余という大規模な語彙で調査する限り,英語語彙の3分の2近くは2--3音節語であるということになる.
一方,##348,349,355 の記事では,BNC や COLT のコーパスを用いて,最も頻度の高い数百語から数千語を対象に音節数調査を行なった.調査対象となる語彙の規模は格段に小さく,それに従って音節数別の割合も変わる.1音節語と2音節語が優勢であり,最大の6000語規模の調査でもこの2種類だけで68.7%を占める(「#349. BNC Word Frequency List による音節数の分布調査 (2)」 ([2010-04-11-1]) のグラフを参照).対象とする語彙規模により,優勢な占有率を示す音節数が変動することがわかるが,全般的に,英語語彙においては1--3音節語が主要であることは間違いないだろう.
では,日本語の語彙について,音節数別の割合はどうだろうか.加藤ほか (80) では,林大氏による『日本語アクセント辞典』の見出し語形に基づく拍数の分布の調査結果が要約されている.辞典の見出し語形であるから対称語彙は数万語の規模と思われる.以下のような結果が出た.
| 1拍 | 2拍 | 3拍 | 4拍 | 5拍 | 6拍 | 7拍 | 8拍 | 9拍 | 10拍 | 計 |
| 0.3 | 4.8 | 22.7 | 38.8 | 17.7 | 11.0 | 3.3 | 1.2 | 0.2 | 0.1 | 100 |
割合のピークは4拍語にあり,その前後の3拍語と5拍語を合わせて79.2%,6拍語を加えれば90.2%になる.英語の語彙の主たる構成要素が1--3音節語とすれば,日本語の語彙の主たる構成要素は3--5拍語となる.音節数でみる限り,英単語は相対的に短く,日本語単語は相対的に長いことがよくわかる.
両言語間の際だった差異は,音韻数の差と音節構造の差に起因するといってよいだろう.音韻数については,[2012-02-12-1]の記事「#1021. 英語と日本語の音素の種類と数」で見たとおり,著しい差がある.また,音節構造については,日本語の音節がほぼ「子音+母音」の1形式だけであるのに対して,英語の音節は,[2012-02-14-1]の記事「#1023. 日本語の拍の種類と数」で示唆したとおり,数万形式がある.
日本語の語彙は,2拍語を基本としていると考えられる.和語でも漢語でも2±1拍語が多く,語彙の膨張に従って,その結合が増え,結果として4±1拍語が主流となってきた経緯がある.洋語についても,優勢な4拍語に合わせて「マスコミュニケーション」→「マスコミ」,「ハンガーストライキ」→「ハンスト」,「エンジンストップ」→「エンスト」と省略されることが多い.2拍語を基本とした日本語語彙の成立と,その後の発展については,小松 (48--62) が詳しい.
・ 加藤 彰彦,佐治 圭三,森田 良行 編 『日本語概説』 おうふう,1989年.
・ 小松 秀雄 『日本語の歴史 青信号はなぜアオなのか』 笠間書院,2001年.
[ 固定リンク | 印刷用ページ ]
2012-05-15 Tue
■ #1114. 草仮名の連綿と墨継ぎ [punctuation][grammatology][japanese][hiragana][katakana][writing][manuscript][syntagma_marking][distinctiones]
[2012-05-13-1], [2012-05-14-1]の記事で,分かち書きについて考えた.英語など,アルファベットのみを利用する言語だけでなく,日本語でも仮名やローマ字のみで表記する場合には,句読法 (punctuation) の一種として分かち書きするのが普通である.これは,表音文字による表記の特徴から必然的に生じる要求だろう.おもしろいことに,日本語において漢字をもとに仮名が発達していた時代にも,分かち書きに緩やかに相当するものがあった.
例えば,天平宝字6年(762年)ごろの正倉院仮名文書の甲文書では,先駆的な真仮名の使用例が見られる(佐藤,pp. 54--55).そこでは,墨継ぎ,改行,箇条書き形式,字間の区切りなど,仮名文を読みやすくする工夫が多く含まれているという.一方,真仮名(漢字)を草書化した草仮名の最初期の例は9世紀後半より見られるようになる.当初は字間の区切りの傾向が見られたが,時代と共に語句のまとまりを意識した「連綿」と呼ばれる続け書きへと移行していった.これは,統語的な単位を意識した書き方であり,syntagma marking を標示する手段だったと考えてよい.また,仮名文とはいっても,平仮名のみで書かれたものはほとんどなく,少数の漢字を交ぜて書くのが現実であり,現在と同じように読みにくさを回避する策が練られていたことにも注意したい.
連綿と関連して発達したもう1つの syntagma marker に「墨継ぎ」がある.佐藤 (59) を参照しよう.
墨継ぎでは,筆のつけはじめは墨が濃く、次第に枯れて細く薄くなり,また墨をつけて書くと濃いところと薄いところが生じる.その濃淡の配置は大体において文節あるいは文に対応しているのである.連綿もあるまとまりをつけるものであるが,やはり,語あるいは文節に対応していることが多い.これらはある種の分かち書きの機能を果たしていると考えられる.
ところで,字と字をつなげて書く習慣や連綿は,もっぱら平仮名書きに見られることに注目したい.一方で,片仮名と続け書きとは,現在でも相性が悪い.これは,片仮名が基本的には漢字とともに用いられる環境から発達してきたからである.片仮名は,発生当初から,現在のような漢字仮名交じり文として用いられており,昨日の記事[2012-05-14-1]で説明したように,字種の配列パターンにより文節区切りが容易に推知できた.したがって,syntagma marking のために連綿という手段に訴える必要が特になかったものと考えられる(佐藤, pp. 60--61).
・ 佐藤 武義 編著 『概説 日本語の歴史』 朝倉書店,1995年.
Powered by WinChalow1.0rc4 based on chalow