2014-07-25 Fri
■ #1915. 日本語における「女性語」 (2) [gender_difference][gender][japanese]
「#1905. 日本語における「女性語」」 ([2014-07-15-1]) について補足する.
日本語の性差を歴史的に考えるとき,まず思い浮かぶのは,男手(漢詩文)と女手(仮名文学)の文学伝統である.性差が,書き言葉というメディアにおける字種の対立として現われているのは興味深い.字種の違いは語彙にも反映され,その後の日本語史において,男性が漢語使用と,女性が和語使用と結びつけられる傾向を生み出した.
語彙に関して顕著な傾向は,先の記事でも触れたように,中世後期の女房詞の発達である.宮中の女性のあいだに,食物や生理現象などに対する婉曲語法として,「もじ」を添える文字詞や,接頭辞「お」を付す語形が発達した.前者は,髪を「かもじ」,鯉を「こもじ」,そなたを「そもじ」,鮒を「ふもじ」,杓子を「しゃもじ」,はずかしいを「はもじ」,ひだるい(空腹の)を「ひもじ」,お目にかかるを「お目文字」,湯具を「ゆもじ」という類いである.後者は,「おあし」「おいしい」「おいど」「おかか」「おかき」「おかず」「おから」「おぐし」「おこわ」「お湿り」「おじや」「おつくり」「おつむ」「おでん」「おなか」「おぬる」「おはぎ」「お歯黒」「お鉢」「お冷や」「おひろい」「おみおつけ」の類いである.これらが近世には公家の女性へ,さらに武家や町人の女性へと階級の階段を下りてゆき,現代の女性語として引き継がれている(加藤ほか, p. 207).苗村丈伯が元禄5年 (1692)に著した女性のための作法書 『女重宝記』によれば,「女のことばは,かた言まじりにやはらかなるこそよけれ,〔中略〕よろづの詞におともじとをつけてやはらかなるべし」(佐藤,p. 181)とあり,この頃から女性語が意識されていたことがわかる.
近世初期からは,別の系統の女性語として遊里語も発達し始めた.京都の島原から大阪新町を経て江戸吉原でも用いられ,吉原のものは江戸中期の宝暦明和に確立したともいわれる.「廓詞」「里なまり」「ありんす言葉」などとも呼ばれる.対称代名詞の「ぬし」「おまはん」,自称代名詞の「わちき」「わっち」,動詞の「ありんす」「おす」「ごぜいんす」,助動詞の「なます」など,特徴的な表現が用いられた(佐藤,p. 182) .撥音が多いので,「傾城は はねられるだけ はねるなり」という川柳が残っている.現在の「ござんす」「ざます」「ざんす」「おます」に痕跡を残している.
現代日本語で明確な男性語と女性語の区別を保っている言語項は,それほど多くない.「#1905. 日本語における「女性語」」 ([2014-07-15-1]) でもいくつか触れたが,それに補足しながら,性差の目立つ事項を列挙しよう(加藤ほか,pp. 208--09).
(1) 終助詞における「やるぞ」の「ぞ」や「出かけるぜ」の「ぜ」が男性用,「すてきだわ」の「わ」や「いいのよ」の「のよ」が女性用
(2) くだけた会話での「おれ」「ぼく」「おまえ」が男性用,「あたし」が女性用
(3) 男性は,感動詞の使用頻度が高く,種類も多い
(4) 男性は,あらたまった場面での漢語の使用頻度が高く,くだけた場面での俗語の使用頻度が高い
(5) 男性は,発話中で倒置構文が多い
(6) 女性は,問いかけで上昇調を用いることが多い
(7) 女性は,「お台所」「お勤め」といった美化語,「すてき」などの主観的な評価の形容詞の使用が多い
(8) 女性は,紋切り型の挨拶や相づちが多い
(9) 女性は,文末を言い切らない形で終わる例が多い
(10) 女性は,「わたし,くやしくてくやしくて」といった反復が多い
(11) 女性は,要求表現でぼかしや言いわけをまぜながら柔らかい形でもちかける
(12) 女性は,書き言葉において,形容詞,「とても」のような強意副詞,比喩表現,余韻をもたせる表現を多く用いる
(13) 男性は「行きますか」「来ますか」「居ますか」などと対者敬語を用いる場面で,女性は「いらっしゃる?」と素材敬語を用いることが多い
比較対照のために,現代英語の性差について,「#476. That's gorgeous!」 ([2010-08-16-1]) ,「#913. BNC による語彙の男女差の調査」 ([2011-10-27-1]) ,「#915. 会話における言語使用の男女差」 ([2011-10-29-1]) も参照されたい.
・ 加藤 彰彦,佐治 圭三,森田 良行 編 『日本語概説』 おうふう,1989年.
・ 佐藤 武義 編著 『概説 日本語の歴史』 朝倉書店,1995年.
2014-07-15 Tue
■ #1905. 日本語における「女性語」 [gender_difference][gender][japanese]
「#1887. 言語における性を考える際の4つの視点」 ([2014-06-27-1]) でみたように,性差の言語上への現われには様々なタイプがあり,多くの言語で語彙,文法,語法にみられるほか,最近の記事で取り上げたものとしては「#1900. 男女差の音韻論」 ([2014-07-10-1]) もある.現代英語において明確な性差を指摘することはそれほど簡単ではないが,それでも「#476. That's gorgeous!」 ([2010-08-16-1]) ,「#913. BNC による語彙の男女差の調査」 ([2011-10-27-1]) ,「#915. 会話における言語使用の男女差」 ([2011-10-29-1]) の記事や多くの研究で明らかとされているように,一般に信じられている以上に英語にも性差が反映されている.一方,現代日本語,少なくとも伝統的な変種では,男言葉(男性語)と女言葉(女性語)が明確に区別されるといわれる.日本語のように男女差が比較的明確な言葉は gender-exclusive speech,英語のように区別がそれほど明確ではないが,男女の使い分けの傾向はあるという言葉は gender-preferential speech と呼ばれている(東,p. 84).
しかし,日本語が gender-exclusive であり女言葉が男言葉から区別されるとはいっても,その現れ方は限定的である.例えば,典型的な女言葉の特徴としては,特有の終助詞・人称詞・間投詞の使用,命令形の不使用,平叙文の文末における終助詞「の」の使用(「わたし,ケーキ大好きなの」),主語・主題を表わす助詞「は」「が」の省略傾向などにおよそ限られている.しかも,近年,これらの伝統的な女言葉の使用は減少しており,伝統的な男言葉が女性話者に用いられる傾向とも相まって,日本語のユニセックス化が進んできているといわれる.近い将来,日本語を gender-exclusive speech と呼び続けるのは不適切な状況になってくるのかもしれない.だが,そもそも日本語の女言葉は歴史上いかにして生まれてきたのだろうか.
室町時代に,宮中の女官の間で「女房詞」と呼ばれる言葉遣いが現われた.もともとは性による方言というよりは,階級による方言として生じたものだった.この言葉遣いは,宮中の女性から公家の女性へと広がり,「女中ことば」と称されるようになる.さらに江戸時代には武家屋敷や富裕町人の娘へと拡がっていった.一方,江戸末期の遊郭の女性の用いる言葉使い(遊里語)が発達し,これら複数の水脈があいまって,明治の「婦人語」の母体を作った.婦人語は,良妻賢母を是とする明治の女子教育において,丁寧な響きをもつものとして推進された.もともとはエリート階層の女学生の言葉遣いだったが,後に一般に広まり,現代の「女性語」として確立していった.
日本語が外国語としても学ばれるようになっている現在,「女性語」を推進し,男女差をことさらに際ただせることが果たして必要なのかどうかという議論が持ち上がってきている.一方で,柔らかい婉曲的な「女性語」を積極的に用いることによって自らの品位を示すことができるとして,これを肯定的に評価する向きもあるだろう.「女性語」の価値観は時代によっても変わる.現在の実情に合わせて「女性語」とは何かを解釈していくことが必要だろう.『日本語学研究事典』の「女性語」の項 (532--33) を参照されたい.
・ 東 照二 『社会言語学入門 改訂版』,研究社,2009年.
・ 『日本語学研究事典』 飛田 良文ほか 編,明治書院,2007年.
2014-07-06 Sun
■ #1896. 日本語に入った西洋語 [loan_word][borrowing][japanese][lexicology][borrowing][portuguese][spanish][dutch][italian][russian][german][french]
日本語に西洋語が初めて持ち込まれたのは,16世紀半ばである.「#1879. 日本語におけるローマ字の歴史」 ([2014-06-19-1]) でも触れたように,ポルトガル人の渡来が契機だった.キリスト教用語とともに一般的な用語ももたらされたが,前者は後に禁教となったこともあって定着しなかった.後者では,アルヘイトウ(有平糖)(alfeloa) ,カステラ (Castella),カッパ (capa),カボチャ(南瓜,Cambodia),カルサン(軽袗,calsãn),カルタ (carta),コンペイトウ(金平糖,confeitos),サラサ(更紗,saraça),ザボン (zamboa),シャボン (sabão),ジバン(襦袢,gibão),タバコ(煙草,tabaco),チャルメラ (charamela),トタン (tutanaga),パン (pão),ビイドロ (vidro),ビスカット(ビスケット,biscoito),ビロード (veludo),フラスコ (frasco),ブランコ (blanço),ボオロ (bolo),ボタン (botão) などが残った.16世紀末にはスペイン語も入ってきたが,定着したものはメリヤス (medias) ぐらいだった.
近世中期に蘭学が起こると,オランダ語の借用語が流れ込んでくる.自然科学の語彙が多く,後に軍事関係の語彙も入った.まず,医学・薬学では,エーテル (ether),エキス (extract),オブラート (oblaat),カルシウム (calcium),カンフル (kamfer, kampher),コレラ (cholera),ジギタリス (digitalis),スポイト (spuit),ペスト (pest),メス (mes),モルヒネ (morphine).化学・物理・天文では,アルカリ (alkali),アルコール (alcohol),エレキテル (electriciteit),コンパス (kompas),ソーダ (soda),テレスコープ (telescoop),ピント (brandpunt),レンズ (lenz).生活関係では,オルゴール (orgel),ギヤマン (diamant),コーヒ (koffij),コック (kok),コップ(kop; cf. 「#1027. コップとカップ」 ([2012-02-18-1])),ゴム (gom),シロップ (siroop),スコップ (schop),ズック (doek),ソップ(スープ,soep),チョッキ (jak),ビール (bier),ブリキ (blik),ペン (pen),ペンキ (pek), ポンプ (pomp),ホック (hoek),ホップ (hop),ランプ (lamp).軍事関係では,サーベル (sabel),ピストル (pistool),ランドセル (ransel).
明治時代には西洋語のなかでは英語が優勢となってくるが,明治初期にはいまだ「コップ」「ドクトル」などオランダ借用語の使用が幅を利かせていた.しかし,大正中期以降は英語系が大半を占めるようになり,オランダ風の「ソップ」が英語風の「スープ」へ置換されたように,発音も英語風へと統一されてくる.英語以外の西洋語としては,大正から昭和にかけてドイツ語(主に医学,登山,哲学関係),フランス語(主に芸術,服飾,料理関係),イタリア語(主に音楽関係),ロシア語も見られるようになった.それぞれの例を挙げてみよう.
・ ドイツ語:ノイローゼ(Neurose),カルテ(Karte),ガーゼ(Gaze),カプセル(Kapsel),ワクチン(Vakzin),イデオロギー(Ideologie),ゼミナール(Seminar),テーマ(Thema),テーゼ(These),リュックサック(Rucksack),ザイル(Seil),ヒュッテ(Hütte),オブラート (Oblate), クレオソート (Kreosot).
・ フランス語:デッサン(dessin),コンクール(concours),シャンソン(chanson),ロマン(roman),エスプリ(esprit),ジャンル(genre),アトリエ(atelier),クレヨン(crayon),ルージュ(rouge),ネグリジェ(néglige),オムレツ(omelette),コニャック(cognac),シャンパン(champagne),マヨネーズ(mayonnaise)
・ イタリア語:オペラ(opera),ソナタ(sonata),テンポ(tempo),フィナーレ(finale),マカロニ(macaroni),スパゲッティ(spaghetti)
・ ロシア語:ウォッカ(vodka),カンパ(kampaniya),ペチカ(pechka),ノルマ(norma)
今日,西洋語の8割が英語系であり,借用の対象となる英語の変種としては太平洋戦争をはさんで英から米へと切り替わった.
以上,佐藤 (179--80, 185--86) および加藤他 (74) を参照して執筆した.関連して,「#1645. 現代日本語の語種分布」 ([2013-10-28-1]),「#1526. 英語と日本語の語彙史対照表」 ([2013-07-01-1]),「#1067. 初期近代英語と現代日本語の語彙借用」 ([2012-03-29-1]) の記事も参照されたい.
・ 佐藤 武義 編著 『概説 日本語の歴史』 朝倉書店,1995年.
・ 加藤 彰彦,佐治 圭三,森田 良行 編 『日本語概説』 おうふう,1989年.
2014-07-03 Thu
■ #1893. ヘボン式ローマ字の <sh>, <ch>, <j> はどのくらい英語風か [alphabet][japanese][writing][grammatology][orthography][romaji][j][norman_french][digraph]
昨日の記事 ([2014-07-02-1]) の最後に,ヘボン式ローマ字の綴字のなかで,とりわけ英語風と考えられるものとして <sh>, <ch>, <j> の3種を挙げた.現代英語の正書法を参照すれば,これらの綴字が,共時的な意味で「英語風」であることは確かである.しかし,この「英語風」との認識の問題を英語史という立体的な観点から眺めると,問題のとらえ方が変わってくるかもしれない.歴史的には,いずれの綴字も必ずしも英語に本来的とはいえないからである.
まず,<sh> = /ʃ/ が正書法として確立したのは15世紀中頃のことにすぎない.古英語では,この子音は <sc> という二重字 (digraph) で規則的に綴られていた.この二重字は中英語へも引き継がれたが,中英語では様々な異綴りが乱立し,そのなかで埋没していった.例えば,現代英語の <ship> に対応するものとして,中英語では <chip>, <scip>, <schip>, <ship>, <sip>, <ssip> などの綴字がみられる.このなかで,中英語期中最もよく用いられたのは <sch> だろう.現代的な <sh> は,13世紀初頭に Orm が初めてかつ規則的に用いたが,ある程度一般的になったのは14世紀のロンドンで Chaucer などが <sh> を常用するようになってからである.その後,<sh> は15世紀中頃に広く受け入れられるようになり,17世紀までに他の異綴りを廃用へ追い込んだ.このように,二重字 <sh> の慣習は,英語の土壌から発したことは確かだが,中英語期の異綴りとの長い競合の末にようやく定まった慣習であり,英語の規準となってからの歴史はそれほど長いものではない (Upward and Davidson 157) .
次に,<ch> = /ʧ/ の対応の起源は,疑いなく外来である.この子音は,古英語では典型的に前舌母音の前位置に現われ,規則的に <c> で綴られた.しかし,音韻変化の結果,<c> は同じ音韻環境で /k/ をも表わすようになり,二重の役割をもつに至った.この両義性が背景にあったことと,中英語期に Norman French の綴字慣習が広範な影響力をもったことにより,英語では自然と Norman French の <ch> = /ʧ/ が受け入れられる結果となった.12世紀には,早くも古英語的な <c> = /ʧ/ の対応はほとんど廃れ,古英語由来の単語も以降こぞって <ch> で綴り直されるようになった.二重字 <ch> の受容には,文字と音韻の明確な対応を目指す言語内的な要求と,Norman French の綴字習慣の進出という言語外的な要因とが関与しているのである (Upward and Davidson 100) .
<j> については,「#1828. j の文字と音価の対応について再訪」 ([2014-04-29-1]) と「#1650. 文字素としての j の独立」 ([2013-11-02-1]) で見たように,フランス借用語を大量に入れた中英語期に,やはりフランス語の綴字習慣をまねたものが,後に英語でも定着したにすぎない.実際,<j> で始まる英単語は原則として英語本来語ではない.
以上のように,今では「英語風」と認識されている <sh>, <ch>, <j> も,定着するまでは不安定な綴字だったのであり,当初から典型的に「英語風」だったわけではない.<ch> と <j> の2つに至っては,当時のファッショナブルな言語であるフランス語の綴字習慣の模倣であった.英語が当時はやりのフランス語風を受容したように,日本語が現在はやりの英語風を受容したとしても驚くには当たらないだろう.綴字習慣や正書法も,時代の潮流とともに変化することもあれば変異もするのである.そして,言語接触における影響の方向は,流行や威信などの社会言語学的な要因に依存するのが常である.ローマ字の○○式の評価も,歴史的な観点を含めて立体的になされる必要があると考える.
・ Upward, Christopher and George Davidson. The History of English Spelling. Malden, MA: Wiley-Blackwell, 2011.
2014-07-02 Wed
■ #1892. 「ローマ字のつづり方」 [alphabet][japanese][writing][grammatology][orthography][romaji][language_planning]
「#1879. 日本語におけるローマ字の歴史」 ([2014-06-19-1]) の記事で触れたように,現代の日本語におけるローマ字使用の慣用は,概ね 1954年に政府が訓令として告示した「ローマ字のつづり方」に拠っている.これは様々な議論の末に昭和29年12月に告示されたものであり,それまでの慣用をも勘案して,第一表(=訓令式)と第二表(=ヘボン式と第一表にもれた日本式)を含めた折衷的な提案だった.「まえがき」によれば,第一表を基準としながらも,国際的関係や慣例によって改め難い場合には第二表によってもよいとしている.以下に,2つの表を掲げよう.
| 第1表 | (訓令式) | a | i | u | e | o | |||
| ア | イ | ウ | エ | オ | |||||
| ka | ki | ku | ke | ko | kya | kyu | kyo | ||
| カ | キ | ク | ケ | コ | キャ | キュ | キョ | ||
| sa | si | su | se | so | sya | syu | syo | ||
| サ | シ | ス | セ | ソ | シャ | シュ | ショ | ||
| ta | ti | tu | te | to | tya | tyu | tyo | ||
| タ | チ | ツ | テ | ト | チャ | チュ | チョ | ||
| na | ni | nu | ne | no | nya | nyu | nyo | ||
| ナ | ニ | ヌ | ネ | ノ | ニャ | ニュ | ニョ | ||
| ha | hi | hu | he | ho | hya | hyu | hyo | ||
| ハ | ヒ | フ | ヘ | ホ | ヒャ | ヒュ | ヒョ | ||
| ma | mi | mu | me | mo | mya | myu | myo | ||
| マ | ミ | ム | メ | モ | ミャ | ミュ | ミョ | ||
| ya | (i) | yu | (e) | yo | |||||
| ヤ | イ | ユ | エ | ヨ | |||||
| ra | ri | ru | re | ro | rya | ryu | ryo | ||
| ラ | リ | ル | レ | ロ | リャ | リュ | リョ | ||
| wa | (i) | (u) | (e) | (o) | |||||
| ワ | イ | ウ | エ | オ | |||||
| ga | gi | gu | ge | go | gya | gyu | gyo | ||
| ガ | ギ | グ | ゲ | ゴ | ギャ | ギュ | ギョ | ||
| za | zi | zu | ze | zo | zya | zyu | zyo | ||
| ザ | ジ | ズ | ゼ | ゾ | ジャ | ジュ | ジョ | ||
| da | (zi) | (zu) | de | do | (zya) | (zyu) | (zyo) | ||
| ダ | ジ | ズ | デ | ド | ジャ | ジュ | ジョ | ||
| ba | bi | bu | be | bo | bya | byu | byo | ||
| バ | ビ | ブ | ベ | ボ | ビャ | ビュ | ビョ | ||
| pa | pi | pu | pe | po | pya | pyu | pyo | ||
| パ | ピ | プ | ペ | ポ | ピャ | ピュ | ピョ |
| 第2表 | (標準式)〈ヘボン式〉 | sha | shi | shu | sho | |
| シャ | シ | シュ | ショ | |||
| tsu | ||||||
| ツ | ||||||
| cha | chi | chu | cho | |||
| チャ | チ | チュ | チョ | |||
| fu | ||||||
| フ | ||||||
| ja | ji | ju | jo | |||
| ジャ | ジ | ジュ | ジョ | |||
| (日本式) | di | du | dya | dyu | dyo | |
| ヂ | ヅ | ヂャ | ヂュ | ヂョ | ||
| kwa | ||||||
| クワ | ||||||
| gwa | ||||||
| グワ | ||||||
| wo | ||||||
| ヲ |
「ローマ字のつづり方」の告示に至るまでのローマ字の正書法を巡る議論は熾烈だった.その後も,○○式それぞれの支持者は主張を続けており,論争の火種は今もくすぶっている.昨今は,コンピュータのローマ字漢字変換の普及,日本語の国際化,「#1612. 道路案内標識,ローマ字から英語表記へ」 ([2013-09-25-1]) のような動向がみられることから,ローマ字に関する議論が再燃する可能性がある.
さて,ここではいずれの方式を採るべきかという問題の核心には入り込むことはせずに,英語の正書法に近いとされるヘボン式のどこが英語的なのかを確認するにとどめよう.訓令式と比較するとすぐにわかるが,ヘボン式が体系的に英語風といえるのは,シャ行,チャ行,ジャ行である.訓令式の <sya>, <syu>, <syo>, <tya>, <tyu>, <tyo>, <zya>, <zyu>, <zyo> は,ヘボン式では <sha>, <shu>, <sho>, <cha>, <chu>, <cho>, <ja>, <ju>, <jo> に対応する.また,これと関連して,体系的というよりは個別的だが,訓令式 <si>, <ti>, <zi> は,ヘボン式 <shi>, <chi>, <ji> に対応する.ほかにヘボン式には <fu> や <tsu> もあるが,ヘボン式の体系的かつ顕著な「英語風」は,とりわけ <sh>, <ch>, <j> の3種の綴字といってよいだろう.しかし,実は,これらの綴字を「英語風」と認識するのは,あくまで近現代の発想である.英語史の観点からみると,これらは必ずしも典型的に「英語風」といえるものではない.これについては,明日の記事で.
2014-06-19 Thu
■ #1879. 日本語におけるローマ字の歴史 [alphabet][japanese][writing][grammatology][orthography][romaji][language_planning]
ローマン・アルファベット誕生の歴史については,アルファベットの派生を扱った「#423. アルファベットの歴史」 ([2010-06-24-1]),「#1822. 文字の系統」 ([2014-04-23-1]),「#1834. 文字史年表」 ([2014-05-05-1]),「#1849. アルファベットの系統図」 ([2014-05-20-1]),「#1853. 文字の系統 (2)」 ([2014-05-24-1]) の記事で概観してきた.ラテン語を書き表すために発展したローマン・アルファベットは,その後,西ヨーロッパを中心に広がり,さらに世界史の経緯とともにヨーロッパ外へ拡散し,「#1861. 英語アルファベットの単純さ」 ([2014-06-01-1]) も相まって,現在では世界化している(関連して「#1838. 文字帝国主義」 ([2014-05-09-1]) を参考).日本語におけるローマ字の使用は室町時代後期に遡るが,これもローマン・アルファベットの世界的拡散の歴史の一コマである.以下,日本語におけるローマ字の歴史を,古藤 (118--24) に拠って要約しよう.
日本に初めてローマ字が伝えられたのは,16世紀後半,室町時代の末である.キリスト教の宣教師とともにもたらされた.1590年(天正18年),イタリア人のワリニャーニ (1539--1609) が島原に活字印刷機をもたらし,それでローマ字による初の書『サントスの御作業の内抜書き』 (1591) を刊行した.続いて,長崎,天草,京都などで数多くのローマ字書きの「キリシタン資料」が出版されることになったが,『ドチリナ・キリシタン(吉利支丹教義)』 (1592) などでは,ポルトガル語の発音に基づいて日本語が表記されており,当時の日本語の発音を知る上で貴重な資料となっている.
続く江戸時代には鎖国が行われ,一時期,ローマ字の普及が妨げられることとなった.その間に,新井白石 (1657--1725) が1708年(宝永5年)に屋久島に漂流したローマ人宣教師シドッチを訊問してローマ字その他の知識を得て,洋語に対して初めて一貫してカタカナを当てた『西洋紀聞』を世に送ったが,日本におけるローマ字の発展に直接は貢献しなかった.江戸時代後期には蘭学が盛んになるとともにオランダ語式のローマ字が用いられ,やがてドイツ語式やフランス語式も現われたが,明治維新のころには英語式が最も優勢となっていた.英語式ローマ字が一般化したのは,1767年(慶応3年)にアメリカの眼科医・宣教師のヘボン (James Curtis Hepburn; 1815--1911) が著わした日本初の和英辞典『和英語林集成』に負うところが大きい.この第3版で採用されたローマ字表記が「ヘボン式(標準式)」の名で広く普及することになった.
明治時代になると,ローマ字を国字にしようという運動が高まったが,英語表記に近いヘボン式(標準式)をよしとせず,日本語表記に特化した「日本式」こそを採用すべしと田中館愛橘 (1856--1952) が提唱するに至り,両派閥の対立が始まった.この対立はその後も長く続くことになり,大正時代には文部省,外務省などがヘボン式を,陸海軍,逓信省などは日本式をそれぞれ支持した.政府は統一を目指して臨時ローマ字調査会を組織し,6年の議論の末,1937年に日本式を基礎にヘボン式を多少取り入れた「訓令式」を公布した.
だが,議論は収まらず,1954年に,政府は第一表(=訓令式)と第二表(=ヘボン式と第一表にもれた日本式)を収録した「ローマ字のつづり方」を訓令として告示することになった.すでに駅名やパスポートの人名に採用されていたヘボン式にも配慮しつつの折衷的な方式だったが,その後,ある程度の承認を得たとはいえるだろう.現在の教育では,ローマ字は小学校4年生で学ぶことになっている.
町の看板にローマ字があふれ(「#1746. 看板表記のローマ字」 ([2014-02-06-1])),コンピュータのローマ字漢字変換が普及し,日本語の国際化も進んでいる現在,新たな観点から日本語におけるローマ字使用の問題を論じる時期が来ているように思われる.
・ 古藤 友子 『日本の文字のふしぎふしぎ』 アリス館,1997年.
2014-06-18 Wed
■ #1878. 国訓,そして記号のリサイクル [kanji][japanese][sign][semiotics]
6月はアユのおいしい季節である.その香ばしさゆえに香魚とも呼ばれ,英語では sweetfish (or ayu) と称する.漢字では「鮎」と書くが,これを「アユ」と読むのはいわゆる国訓(あるいは和訓)であり,中国での字義は別の淡水魚ナマズである.ほかに,中国で「偲ぶ」はツトメル,「萩」はヨモギ,「社」は土神,「串」はツラヌク,「淋」は霖雨を意味し,日本語での意味とは異なっている.近代の「米」(メートル),「瓦」(グラム),「弗」(ドル)もこの類いと考えられる.『日本語学研究事典』 (118) によれば,国訓とは「漢字本来の字義に関係なく,あるいは原義を転用して日本語に当てたもの」で,広い意味で国字の一種と解することができよう.
国訓という術語は日本語における漢字の転用のみに限定されるが,一般的な観点からみると,表意文字の原義の転用という現象は日本語に限定されない.英語を含む印欧諸語を表記するアルファベットはそもそも表音文字なので直接これらの言語から類例を探すことは困難だが,関連する現象はある.「#1823. ローマ数字」 ([2014-04-24-1]) で述べたように,西ギリシア文字のΨ (khi) ,Θ (theta),Φ (phi) の3文字は,エトルリア語やラテン語へ移植されたときに,それぞれ 50, 100, 1000 の数字を表わすのに転用された.また,%は一般的に百分率の記号だが,コンピュータ言語では剰余算の演算子として用いられることがある.国訓と同じではないが,類する現象とはいえるのではないだろうか.
これらに共通しているように思われる特徴は,新たに記号化したい記号内容 (signifié) があるときに,必ずしも新しい記号表現 (signifiant) を作らずにすむという点だ.すでに存在している文字を取り出し,それに新たな意味・機能を担わせてしまうのが簡便である.場合によっては新旧の意味・機能のあいだに衝突や両義性が生じてしまうかもしれないが,たいてい大きな問題とはならず,簡便さのメリットのほうが大きいだろう.新しい語を作るよりも,可能な範囲で既存の語の意味スペースを有効利用するのが便利なのと同じである.
このように考えてくると,国訓とは決して特異な現象ではなく,一般的にみられる記号のリサイクルにすぎないということになる.媒体が文字であれ音声であれ,記号というものは,空間や時間を隔てて異なる言語文化へ移植されると,元の記号内容から逸脱してしまう可能性が十分にある.実際に,意味のズレがしばしば問題となる和製英語(「#1624. 和製英語の一覧」 ([2013-10-07-1]))は多数あるし,印欧祖語の故地を巡る大論争「ブナ問題」(「#633. beech と印欧語の故郷」 ([2011-01-20-1]))では,beech の意味・指示対象のズレが論点であった.国訓が特別に感じられるのは,記号のリサイクルが文字という次元で生じていること,そして現代世界に表意文字が比較的珍しいことによるのだろう.記号の現象としては,平凡なのかもしれない.
・ 『日本語学研究事典』 飛田 良文ほか 編,明治書院,2007年.
2014-06-16 Mon
■ #1876. 言霊信仰 [kotodama][japanese][taboo][sound_symbolism][arbitrariness][semiotics]
言霊(ことだま)とは,言葉に宿る霊力を指し,古代日本人は言葉を神秘的な働きをするものと信じていた.秋山・三好 (19) による説明を引こう.
呪言や呪詞など日常の言葉とは異なる働きをする言葉には,不思議な霊力が宿ると考えられていた.口に出して言い立てた言葉は,そのまま事実として実現され,よい言葉・美しい言葉はサキハヒ(幸)をもたらし,悪い言葉はワザハヒ(禍)をもたらすという,“言”と“事”の同一性が信じられていたのである.こうした言葉に宿る霊力(言霊)に対する信仰を言霊信仰と呼んでいる.
言霊という語は,『万葉集』に3例現われる.
・ そらみつ 倭(やまと)の国は 皇神(すめがみ)の 厳(いつく)しき国 言霊の 幸(さき)はふ国と 語り継ぎ 言ひ継がひけり (巻五・山上憶良の長歌の一部)
・ 言霊の 八十(やそ)の衢(ちまた)に 夕占(ゆうけ)問ふ 占(うら)正(まさ)に告(の)る 妹(いも)はあひ寄らむ (巻十一・柿本人麻呂歌集)
・ 磯城島(しきしま)の 日本(やまと)の国は 言霊の 幸(さきは)ふ国ぞ ま幸(さき)くありこそ (巻十三・柿本人麻呂歌集)
最初と最後の歌は,いずれも遣唐使派遣にかかわる歌であり,「対外的な緊張の中で,国家意識の目ざめとともに〈言霊〉への信仰が自覚された」(秋山・三好,p. 19)とされる.最後の歌を参照して,日本は「言霊の幸ふ国」(言霊の霊妙な働きによって栄える国)と呼ばれることがあるが,実際には言霊への信仰は日本(語)に限らず,古今東西に例がある.むしろ,言語をもつ人類にとって一般的な現象と考えられる.
祝詞,神託,呪文はとりわけ古代社会で重視された言霊信仰の反映であるし,忌詞 (taboo) の慣習と,それによって引き起こされる婉曲語法 (euphemism) の発達は,現代の諸言語にも広く見られる.記号の恣意性 (arbitrariness) への反例として広く観察される音象徴 (sound_symbolism) やオノマトペ (onomatopoeia) ,また古代ギリシアで起こった「#1315. analogist and anomalist controversy (1)」 ([2012-12-02-1]) の論争も,記号とその指示対象とを同一視しようとする傾向と深く関係している.五十音図の並びに深遠な意義があると説く江戸時代の音義説や,ユダヤ教で発展した「#1455. gematria」 ([2013-04-21-1]) などの言葉占いも,言霊信仰の現われである.Ogden and Richards の「#1770. semiotic triangle の底辺が直接につながっているとの誤解」 ([2014-03-02-1]) への警鐘も,人々が「記号=指示対象」と同一視してしまう根強い性向への危機感からであった.言霊信仰は,決して前近代的な慣習ではなく,現代でも息づいている「言語の盲信」である.
言語情報にあふれた現代には,一方で「言語の不信」という問題がある.言語の盲信と不信という問題を意味論や記号論の立場で解決しようとするならば,まずは記号と指示対象との関係を正しく理解することから始める必要があろう.言霊信仰という話題は,この議論に絶好の材料を提供してくれる.
・ 秋山 虔,三好 行雄(編著) 『原色シグマ新日本文学史』 文英堂,2000年.
2014-06-15 Sun
■ #1875. acrostic と折句 [word_play][japanese][acronym][word_play]
acrostic とは,各行頭の文字を綴ると語になる詩や言葉遊びをいう.行末や中間の文字を集める場合もあり,行末のものは telestich とも呼ばれる.『ランダムハウス英和辞典』に掲載されていた acrostic の例を挙げよう.行頭の文字を集めると COMET となる.
Composed of vapors, shining bright,
Of wondrous size, yet harmless light.
Men view thee as a burning ball,
Expecting soon to see thee fall
To this world, kill us all. (R. Blackwell)
西洋では,acrostic はギリシャ神話の巫女 Sibyl (シビュラ)の神託のなかに初めて現われ,ギリシア人の間で流行したという.中世ヨーロッパにも伝わり,現在でも言語遊戯として親しまれている.OED によると,英語における acrostic という語の最初期(16世紀後半)の例は,Sibyl への言及を含む文だ.
1587 Sir P. Sidney & A. Golding tr. P. de Mornay Trewnesse Christian Relig. xxxii. 591 Cicero..maketh mention of Sibils Acrosticke [Fr. l'Acrostiche de la Sybille], that is to say, of certeyne verses of hirs whose first letters made the name of that King.
現在,acrostic は暗記に用いられることがある.例えばト音記号の五線譜上の音を覚えるのに,"Every Good Boy Deserves Favour" の頭文字を利用する方法などがある (Crystal 116) .
日本語では,和歌・俳句・川柳などに使われる同様の様式として,折句(おりく)がある.その源流は在原業平の『伊勢物語』に詠まれた「かきつばた」を折り込んだ和歌「から衣きつつなれにし妻しあればはるばる来ぬる旅をしぞ思ふ」にあり,江戸時代には雑俳様式として流行し,五七五各句に折り込む三字折や七七各句に折り込む二字折など様々な種類が現われた.さらに手の込んだ,行頭音と行末音を折り込んだ沓冠(くつかぶり) (=double acrostic) という様式もある.以下は,吉田兼好の作品で,「米(よね)たまへ銭(ぜに)も欲し」と読める.
よもすずし
ねざめのかりほ
たまくらも
ま袖も秋に
へだてなきかぜ
・ Crystal, David. The English Language. 2nd ed. London: Penguin, 2002.
2014-06-09 Mon
■ #1869. 日本語における仏教語彙 [japanese][kanji][loan_word][religion][buddhism][lexicology]
宗教の伝来が受け入れ側の言語に著しい影響を及ぼすことについて,「#296. 外来宗教が英語と日本語に与えた言語的影響」 ([2010-02-17-1]) で取り上げた.その記事では,日英において顕著な類似点があることを指摘した.ユーラシア大陸の両端で,時をほぼ同じくする6世紀という時期に,それぞれ大陸から仏教とキリスト教が伝わった.各々,漢字とローマ字を受容して本格的な文字文化が始まり,その宗教と関連した種々の文物や語彙が流入した.新宗教は乗り物として機能しており,語彙はそれに乗って,日本とイングランドへ到着したのである.
キリスト教が英語に与えた語彙上の影響については,「#32. 古英語期に借用されたラテン語」 ([2009-05-30-1]) や「#1439. 聖書に由来する表現集」 ([2013-04-05-1]) で触れ,日英の語彙史の比較対照は「#1526. 英語と日本語の語彙史対照表」 ([2013-07-01-1]) や「#1049. 英語の多重語と漢字の異なる字音」 ([2012-03-11-1]) で言及した.今回は,日本語における仏教語の受容について取り上げる.以下,『日本語学研究事典』 (407--08) を参照して記す.
6世紀半ばに仏教が伝来すると,以降,多くの仏教語(あるいは仏語)が日本語へ流入した.聖徳太子以後,仏教を振興した上代には「香炉」「蝋燭」「脇息」「高座」「功徳」「供養」などが入り,天台・真言の二宗の栄えた中古には「大徳」「修法」「念誦」「新発意」「持仏」「名号」「数珠」「加持」「精進」「彼岸」「布施」「回向」「出家」,また「道理」「本意」「世界」「世間」「孝養」「懈怠」「道心」「変化」「稀有」「愛敬」「執念」などが見られた.中古から中世にかけては,信仰がいっそう深まり,仏教説話も多く現われ,「諸行無常」「盛者必衰」「煩悩」「衆生」「修行」「三界」「智慧」「過去」,また「発心」「悲願」「勧進」「微塵」「安穏」など300語以上が借用されている.中世から近世にかけては,臨済・曹洞などの禅宗の伝来とともに使用の拡がった「挨拶」「以心伝心」「向上」「到底」「到頭」「端的」「滅却」「毛頭」「行脚」「看経」に加え,「一得一失」「主眼」「自粛」「体得」「打開」「単刀直入」「門外漢」「老婆心」のように日常化したものも多い.また,インドの経論が漢文に音訳された,いわゆる梵語も「閼伽」「伽藍」「娑婆」「卒塔婆」「荼毘」「檀那」のように日本語へ入ってきている.
仏教語はその他多数あるが,以下に『学研 日本語「語源」辞典』に挙げられている仏教語・梵語に由来することばを列挙しよう.借用された時期はまちまちだが,仏教が日本語の語彙や表現に与えてきた影響の甚大さが知られる.
愛敬〔あいきょう〕,挨拶〔あいさつ〕,愛着〔あいちゃく〕,阿吽〔あうん〕,閼伽〔あか〕,悪魔〔あくま〕,阿修羅〔あしゅら〕,痘痕〔あばた〕,尼〔あま〕,行脚〔あんぎゃ〕,安心〔あんしん〕,意識〔いしき〕,以心伝心〔いしんでんしん〕,一大事〔いちだいじ〕,一念発起〔いちねんほっき〕,一蓮托生〔いちれんたくしょう〕,衣鉢〔いはつ〕,因果〔いんが〕,因業〔いんごう〕,引導〔いんどう〕,因縁〔いんねん〕,有為転変〔ういてんぺん〕,有象無象〔うぞうむぞう〕,有頂天〔うちょうてん〕,優曇華〔うどんげ〕,優婆夷・優婆塞〔うばい・うばそく〕,盂蘭盆〔うらぼん〕,雲水〔うんすい〕,会釈〔えしゃく〕,縁起〔えんぎ〕,往生〔おうじょう〕,応用〔おうよう〕,お題目〔おだいもく〕,億劫〔おっくう〕,餓鬼〔がき〕,加持祈祷〔かじきとう〕,呵責〔かしゃく〕,火宅〔かたく〕,我慢〔がまん〕,空念仏〔からねんぶつ〕,伽藍〔がらん〕,迦陵頻伽〔かりょうびんが〕,瓦〔かわら〕,観念〔かんねん〕,甘露〔かんろ〕,伽羅〔きゃら〕,経木〔きょうぎ〕,行住坐臥〔ぎょうじゅうざが〕,苦界〔くがい〕,愚痴〔ぐち〕,功徳〔くどく〕,供養〔くよう〕,庫裏〔くり〕,紅蓮〔ぐれん〕,怪訝〔けげん〕,袈裟〔けさ〕,解脱〔げだつ〕,外道〔げどう〕,玄関〔げんかん〕,香典〔こうでん〕,虚仮〔こけ〕,居士〔こじ〕,後生〔ごしょう〕,乞食〔こつじき〕,御来迎〔ごらいごう〕,御利益〔ごりやく〕,権化〔ごんげ〕,言語道断〔ごんごどうだん〕,金輪際〔こんりんざい〕,散華〔さんげ〕,懺悔〔ざんげ〕,三途の川〔さんずのかわ〕,三昧〔さんまい〕,四苦八苦〔しくはっく〕,獅子身中の虫〔しししんちゅうのむし〕,竹篦返し〔しっぺがえし〕,七宝〔しっぽう〕,慈悲〔じひ〕,娑婆〔しゃば〕,舎利〔しゃり〕,出世〔しゅっせ〕,修羅〔しゅら〕,精進〔しょうじん〕,正念場〔しょうねんば〕,所詮〔しょせん〕,新発意〔しんぼち〕,随喜〔ずいき〕,頭陀袋〔ずだぶくろ〕,世間〔せけん〕,世知〔せち〕,殺生〔せっしょう〕,雪隠〔せっちん〕,刹那〔せつな〕,専念〔せんねん〕,禅問答〔ぜんもんどう〕,相好〔そうごう〕,息災〔そくさい〕,作麼生〔そもさん〕,醍醐味〔だいごみ〕,大衆〔たいしゅう〕,荼毘〔だび〕,他力本願〔たりきほんがん〕,旦那〔だんな〕,断末魔〔だんまつま〕,知恵〔ちえ〕,長広舌〔ちょうこうぜつ〕,長者〔ちょうじゃ〕,爪弾き〔つまはじき〕,道具〔どうぐ〕,堂堂巡り〔どうどうめぐり〕,道楽〔どうらく〕,内緒〔ないしょ〕,南無三〔なむさん〕,奈落〔ならく〕,涅槃〔ねはん〕,拈華微笑〔ねんげみしょう〕,暖簾〔のれん〕,馬鹿〔ばか〕,彼岸〔ひがん〕,比丘・比丘尼〔びく・びくに〕,非業〔ひごう〕,火の車〔ひのくるま〕,不思議〔ふしぎ〕,普請〔ふしん〕,布施〔ふせ〕,分別〔ふんべつ〕,法師〔ほうし〕,坊主〔ぼうず〕,方便〔ほうべん〕,菩提〔ぼだい〕,法螺〔ほら〕,煩悩〔ぼんのう〕,摩訶不思議〔まかふしぎ〕,魔羅〔まら〕,曼荼羅〔まんだら〕,満遍なく〔まんべんなく〕,微塵〔みじん〕,未曾有〔みぞう〕,冥利〔みょうり〕,未来〔みらい〕,無垢〔むく〕,無残〔むざん〕,無常〔むじょう〕,無尽蔵〔むじんぞう〕,冥土〔めいど〕,滅相もない〔めっそうもない〕,滅法〔めっぽう〕,妄想〔もうそう〕,野狐禅〔やこぜん〕,夜叉〔やしゃ〕,唯我独尊〔ゆいがどくそん〕,遊山〔ゆさん〕,律儀〔りちぎ〕,輪廻〔りんね〕,流転〔るてん〕,瑠璃〔るり〕,老婆心〔ろうばしん〕,渡りに船〔わたりにふね〕
上述のとおり,日本では仏教が国民生活に深く浸透したために,仏教語は日本語語彙に広く見られるだけでなく,転義を生じて俗語となったものも多い.英語側でも同様に,「#32. 古英語期に借用されたラテン語」 ([2009-05-30-1]) や「#1439. 聖書に由来する表現集」 ([2013-04-05-1]) の語彙・表現リストに見られるように,当初はキリスト教の専門用語として始まったものの,後に専門的な響きを弱め,使用域 (register) を拡げた語 (ex. candle, master, noon, school, verse) も少なくない.この点でも,日英両言語において宗教伝来と語彙史の関連を比較対照することは意義深い.
・ 『日本語学研究事典』 飛田 良文ほか 編,明治書院,2007年.
2014-06-04 Wed
■ #1864. ら抜き言葉と頻度効果 [frequency][lexical_diffusion][japanese][ranuki][japanese]
言語変化における項目の頻度 (frequency) の役割について,frequency の各記事,とりわけ「#694. 高頻度語と不規則複数」 ([2011-03-22-1]),「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]),「#1239. Frequency Actuation Hypothesis」 ([2012-09-17-1]),「#1242. -ate 動詞の強勢移行」 ([2012-09-20-1]),「#1243. 語の頻度を考慮する通時的研究のために」 ([2012-09-21-1]),「#1265. 語の頻度と音韻変化の順序の関係に気づいていた Schuchardt」 ([2012-10-13-1]),「#1286. 形態音韻変化の異なる2種類の動機づけ」 ([2012-11-03-1]),「#1287. 動詞の強弱移行と頻度」 ([2012-11-04-1]) で様々に議論してきた.
理論的な扱いとしては Phillips による「#1239. Frequency Actuation Hypothesis」 ([2012-09-17-1]) に関心を抱いているが,先日,現代日本語(東京共通語)のら抜き言葉 (innovative potential) の拡散を頻度の観点から調査した論文を見つけ,そこで提起されている "Revised Frequency Hypothesis of Analogical Leveling (RFH)" に目を引かれた.
その論文で,著者の Matsuda はこれまでに指摘されてきた様々な言語学的,社会言語学的,文体的な要因がいかに関与的かを量的に明らかにしようとした.考慮されている変数は以下の通りである (12) .
I. Linguistic
1. Length of the stem [measured in mora]
2. Conjugation type of the verb: i-stem/e-stem
3. Conjugation form following the potential suffix: Negative/Others
4. Morphological structure of the preceding stem: Monomorphemic verb/Compound verb/Auxiliary verb/Causative verb
5. Type of clause in which the potential form is embedded:
Main clause
Semi-embedded clause (Adverbial clause/Gerund)
Embedded clause (Quote/Relative clause/Predicate complement clause/Noun complement clause)
II. Social
1. Age
2. Sex
3. Area of residence: Uptown/Downtown
III. Style (taken from Labov & Sankoff, 1988)
Casual (narrative, group, kids, tangent)
Careful (response, language, soapbox, careful)
Matsuda はこれらの変数(の組み合わせ)の効き目を量的に確かめていき,概ね各々がら抜き言葉の革新に関与的であることを示したが,Sex や Area of residence など有意差の出ない変数もあった.そして,これらの分析のあとで,従来の研究では考慮されてこなかった頻度という変数を導入した.Matsuda は,頻度効果というものを考えようとするときに,いったい何の頻度を考慮すればよいのかという本質的な問題に言及している.例えば mirare(ru)/mire(ru) (見られ(る)/見れ(る))の場合には,語幹 mir- の頻度を数えるべきのか,あるいは問題の接辞 -are/-e の頻度を数えるべきなのか.前者であれば,mir- のトークン頻度とタイプ頻度のどちらを問題にすべきなのか.英語の drive--drove など不規則変化動詞に見られる屈折現象を頻度の観点から分析する場合には,屈折した語形そのものの頻度を問題にすればよさそうだが,膠着的な日本語の mir-e(-ru) (見れ(る))の場合には,どの形態素の頻度を数えればよいのだろうか.
以上のような考察を経て,Matsuda は屈折型と膠着型とでは考慮すべき頻度の単位が異なっているのではないかという仮説を唱える.これが上述の "Revised Frequency Hypothesis of Analogical Leveling (RFH)" (24) である.
In analogical leveling, the token frequency of the unit undergoing the leveling and its degree/rate of leveling tend to show an inverse correlation, where the "unit" is defined according to the degree of fusion of the form undergoing the leveling with its neighboring morpheme(s). If the form is highly fused with the neighboring morpheme, the whole (morpheme, form) combination counts as a "unit" whose frequency is to be measured. If it is not, the form alone counts as a "unit," and its own frequency suffices as a correlate of the rate of leveling.
この仮説を採用すれば,今回のら抜き言葉の調査の結果が無理なく解釈できるという.つまり,ら抜き言葉の拡散に対して(反比例的に)関与的な頻度とは,問題の可能を表わす接辞 -are/-e それ自体のトークン頻度であり,前接する動詞語幹のトークン頻度やタイプ頻度ではない,と.
おもしろい仮説のようにも思えるが,素朴な疑問として,頻度の低い接辞だからといって,なぜそれ自身の水平化(ら抜き化)が進むことになるのだろうか.-are にしても -e にしても頻度が低いのであれば,なぜ前者が後者に置換されてゆくことになるのだろうか.
・ Matsuda, Kenjiro. "Dissecting Analogical Leveling Quantitatively: The Case of the Innovative Potential Suffix in Tokyo Japanese." Language Variation and Change 5 (1993): 1--34.
2014-06-04 Wed
■ #1864. ら抜き言葉と頻度効果 [frequency][lexical_diffusion][japanese][ranuki][japanese]
言語変化における項目の頻度 (frequency) の役割について,frequency の各記事,とりわけ「#694. 高頻度語と不規則複数」 ([2011-03-22-1]),「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]),「#1239. Frequency Actuation Hypothesis」 ([2012-09-17-1]),「#1242. -ate 動詞の強勢移行」 ([2012-09-20-1]),「#1243. 語の頻度を考慮する通時的研究のために」 ([2012-09-21-1]),「#1265. 語の頻度と音韻変化の順序の関係に気づいていた Schuchardt」 ([2012-10-13-1]),「#1286. 形態音韻変化の異なる2種類の動機づけ」 ([2012-11-03-1]),「#1287. 動詞の強弱移行と頻度」 ([2012-11-04-1]) で様々に議論してきた.
理論的な扱いとしては Phillips による「#1239. Frequency Actuation Hypothesis」 ([2012-09-17-1]) に関心を抱いているが,先日,現代日本語(東京共通語)のら抜き言葉 (innovative potential) の拡散を頻度の観点から調査した論文を見つけ,そこで提起されている "Revised Frequency Hypothesis of Analogical Leveling (RFH)" に目を引かれた.
その論文で,著者の Matsuda はこれまでに指摘されてきた様々な言語学的,社会言語学的,文体的な要因がいかに関与的かを量的に明らかにしようとした.考慮されている変数は以下の通りである (12) .
I. Linguistic
1. Length of the stem [measured in mora]
2. Conjugation type of the verb: i-stem/e-stem
3. Conjugation form following the potential suffix: Negative/Others
4. Morphological structure of the preceding stem: Monomorphemic verb/Compound verb/Auxiliary verb/Causative verb
5. Type of clause in which the potential form is embedded:
Main clause
Semi-embedded clause (Adverbial clause/Gerund)
Embedded clause (Quote/Relative clause/Predicate complement clause/Noun complement clause)
II. Social
1. Age
2. Sex
3. Area of residence: Uptown/Downtown
III. Style (taken from Labov & Sankoff, 1988)
Casual (narrative, group, kids, tangent)
Careful (response, language, soapbox, careful)
Matsuda はこれらの変数(の組み合わせ)の効き目を量的に確かめていき,概ね各々がら抜き言葉の革新に関与的であることを示したが,Sex や Area of residence など有意差の出ない変数もあった.そして,これらの分析のあとで,従来の研究では考慮されてこなかった頻度という変数を導入した.Matsuda は,頻度効果というものを考えようとするときに,いったい何の頻度を考慮すればよいのかという本質的な問題に言及している.例えば mirare(ru)/mire(ru) (見られ(る)/見れ(る))の場合には,語幹 mir- の頻度を数えるべきのか,あるいは問題の接辞 -are/-e の頻度を数えるべきなのか.前者であれば,mir- のトークン頻度とタイプ頻度のどちらを問題にすべきなのか.英語の drive--drove など不規則変化動詞に見られる屈折現象を頻度の観点から分析する場合には,屈折した語形そのものの頻度を問題にすればよさそうだが,膠着的な日本語の mir-e(-ru) (見れ(る))の場合には,どの形態素の頻度を数えればよいのだろうか.
以上のような考察を経て,Matsuda は屈折型と膠着型とでは考慮すべき頻度の単位が異なっているのではないかという仮説を唱える.これが上述の "Revised Frequency Hypothesis of Analogical Leveling (RFH)" (24) である.
In analogical leveling, the token frequency of the unit undergoing the leveling and its degree/rate of leveling tend to show an inverse correlation, where the "unit" is defined according to the degree of fusion of the form undergoing the leveling with its neighboring morpheme(s). If the form is highly fused with the neighboring morpheme, the whole (morpheme, form) combination counts as a "unit" whose frequency is to be measured. If it is not, the form alone counts as a "unit," and its own frequency suffices as a correlate of the rate of leveling.
この仮説を採用すれば,今回のら抜き言葉の調査の結果が無理なく解釈できるという.つまり,ら抜き言葉の拡散に対して(反比例的に)関与的な頻度とは,問題の可能を表わす接辞 -are/-e それ自体のトークン頻度であり,前接する動詞語幹のトークン頻度やタイプ頻度ではない,と.
おもしろい仮説のようにも思えるが,素朴な疑問として,頻度の低い接辞だからといって,なぜそれ自身の水平化(ら抜き化)が進むことになるのだろうか.-are にしても -e にしても頻度が低いのであれば,なぜ前者が後者に置換されてゆくことになるのだろうか.
・ Matsuda, Kenjiro. "Dissecting Analogical Leveling Quantitatively: The Case of the Innovative Potential Suffix in Tokyo Japanese." Language Variation and Change 5 (1993): 1--34.
2014-05-07 Wed
■ #1836. viz. と「流石」 [latin][grapheme][grammatology][japanese][kanji][spelling_pronunciation_gap]
昨日の記事「#1835. viz.」 ([2014-05-06-1]) に引き続き,英語で namely と読み下す viz. について.今回は,文字論の立場から論じる.
英語において viz. と表記される語の構成要素である3文字(省略を表わす period を除く)は,当然ながらいずれもアルファベット文字(=表音文字)である.しかし,個々の文字で考えても,3文字が合わさった全体で考えても,まるで /neɪmli/ の発音を示唆するところがない.<viz.> はこの点において非表音的である.意味についても同様に,字面を個々に考えても全体で考えても,とうてい「すなわち」の意味は浮かび上がってこない.<viz.> はこの点において非表意的である.つまり,英語の <viz.> は,語源形であるラテン語 videlicet を想起するまれな場合を除き,通常は音も意味も示唆しない.
にもかかわらず,<viz.> は英語の副詞 namely と同等であるとして,英語使用者の意識のなかでは密接に結びついている.言い換えれば,<viz.> は,3文字全体としてむりやりに namely を表語している.<viz.> の綴字は,表音 (phonographic) でも表意 (ideographic) でもなく,表語 (logographic) の機能を果たしているのであり,記号論の用語を使えば,<viz.> が指し示しているものは,namely という記号 (signe) の能記 (signifiant) でも所記 (signifié) でもなく,namely という記号そのものである,ということになる.むりやりの結びつきであるから,英語使用者は,この <viz.> = namely の関係を暗記しなければならない.<viz.> のもつこの表語機能は,「#1042. 英語における音読みと訓読み」 ([2012-03-04-1]) で挙げた,<e.g.> (for example), <i.e.> (that is) にも見られる.
そこで,典型的に表語文字といわれる漢字を使いこなす日本語において,これと比較される類例があるだろうかと考えてみた.しかし,案外と見つからないものだ.漢字は確かに表語的ではあるが,同時に表意機能も果たすのが普通だし,形声文字の場合には表音機能も備わっている.英語の <viz.> の場合のように,発音も意味も示唆すらしないという徹底的な例は,なかなかない.
頭をひねってやっと思いついたのが,熟字訓として /さすが/ と読ませる <流石> という例だ.<流> も <石> も,さらにはそれを組み合わせた <流石> 全体も,なんら /さすが/ の発音を示唆するところがないし,「何といってもやはり」の意味を匂わせるところがない.<流石> は表音的でも表意的でもなく,副詞「さすが」をむりやりに表語しているのである.<viz.> と <流石> の唯一の差異は,前者の構成要素であるアルファベット文字が本質的に表音的であるのに対して,後者の構成要素である漢字は本質的に表語・表意的であるという点だろう.しかし,いずれの表記も全体としては結局のところ非表音的かつ非表意的であり,発現している機能はもっぱら表語機能である点では同じだ.
一見すると,「流石」 に代表される熟字訓は,純粋な表語機能(=非表音かつ非表意かつ表語)の好例を提供してくれそうだが,<私語> /ささやき/,<五月雨> /さみだれ/,<海苔> /のり/,<紅葉> /もみじ/ などでは,漢字の組み合わせが意味を匂わせてしまっており(しかも美しく詩的に),<viz.> = namely の純粋な表語機能には達していない.むしろ英語はアルファベットという表音文字体系をベースに置いている言語であるからこそ,<viz.> = namely のような例において,稀ではあるが純粋な表語機能を獲得し得たのかもしれない.文字論の観点からは,この逆説は興味深い.
なお,<流石> を /さすが/ と訓読するのは,以下の故事によるものとするのが通説である(『学研 日本語「語源」辞典』より).
中国,西晋の国の孫楚が「石に枕し,流れに漱ぐ」というべきところを,誤って「石に漱ぎ,流れに枕す」と言ってしまった.これを聞いた親友の王済が「流れは枕にできないし,石では口をすすげない」と言ってからかうと,孫楚は「流れを枕にするのは耳を洗うためであり,石に漱ぐというのは歯を磨くためである」と言って言い逃れたという.この故事を「さすがにうまいこじつけだ」と評し,「流石」の字が当てられたとする説がある.
上の議論では,一般の日本語話者がこの故事を知らない,あるいは普段は特に意識せずに,<流石> = /さすが/ の関係を了解していることを前提とした.故事を意識していれば,<流石> が非常に間接的ながらも何らかの表意機能をもっていると主張できるかもしれないからである.
文字の表語機能については,「#1332. 中英語と近代英語の綴字体系の本質的な差」 ([2012-12-19-1]),「#1386. 近代英語以降に確立してきた標準綴字体系の特徴」 ([2013-02-11-1]),「#1655. 耳で読むのか目で読むのか」 ([2013-11-07-1]),「#1829. 書き言葉テクストの3つの機能」 ([2014-04-30-1]) を参照.
2014-04-19 Sat
■ #1818. 日本語の /r/ [phonetics][consonant][japanese][phoneme][r][l]
「#1618. 英語の /l/ と /r/」 ([2013-10-01-1]) および昨日の記事「#1817. 英語の /l/ と /r/ (2)」 ([2014-04-18-1]) に引き続き,/r/ の話題.今回は日本語の /r/ の音声的実現についてである.
日本語のラ行の子音 /r/ は,典型的には,有声歯茎はじき音 [ɾ] として実現される.特に「あられ」のように,母音に挟まれた環境ではこれが普通である.この音は,BrE の merry や AmE の letter の第2子音として典型的に現れる音でもある.調音音声学的には,この音は有声歯茎閉鎖音 /d/ にかなり近いが,[ɾ] では舌尖と歯茎による閉鎖が弱く,その時間も短いという特徴がある.「ライオン」などの語頭や「アッラー」などの促音の後では接触が強くなり,/d/ にさらに近づくが,閉鎖の開放は弱めである.
意外と知られてないことだが,日本語母語話者の個人によっては,有声側面接近音 [l] に近い子音がラ行子音として用いられている.語頭や撥音の後で現われることが多いが,母音間でも側音に近くなる人もいる.ぴったりの音声標記はないが,有声そり舌破裂音 [ɖ] や 有声歯茎側面はじき音 [ɺ] や(接触が長い場合の)舌尖による有声歯茎側面接近音 [l̺] にも近いので,これらで代用する方法もある.有声歯茎側面はじき音 [ɺ] は,いわば [l] をはじき音化したものだが,タンザニアのチャガ語などで聞かれる子音である.
ほかにも「べらんめえ口調」に典型的とされる有声歯茎ふるえ音 [r] が,日本語 /r/ の自由異音として現れることがある.
以上,斉藤 (91) と佐藤 (43) を参照した.
・ 斉藤 純男 『日本語音声学入門』改訂版 三省堂,2013年.
・ 佐藤 武義(編著) 『展望 現代の日本語』 白帝社,1996年.
2014-03-16 Sun
■ #1784. 沖縄の方言札 [sociolinguistics][language_planning][japanese][linguistic_imperialism][dialect][language_shift][language_death][linguistic_right]
「#1741. 言語政策としての罰札制度 (1)」 ([2014-02-01-1]) の記事で沖縄の方言札を取り上げた後で,井谷著『沖縄の方言札』を読んだ.前の記事で田中による方言札舶来説の疑いに触れたが,これはかなり特異な説のようで,井谷にも一切触れられていない.国内の一部の文化人類学者や沖縄の人々の間では,根拠のはっきりしない「沖縄師範学校発生説」 (170) も取りざたされてきたようだが,井谷はこれを無根拠として切り捨て,むしろ沖縄における自然発生説を強く主張している.
井谷の用意している論拠は多方面にわたるが,重要な点の1つとして,「少なくとも表面的には一度として「方言札を使え」などというような条例が制定されたり,件の通達が出たりしたことはなかった」 (8) という事実がある.沖縄の方言札は20世紀初頭から戦後の60年代まで沖縄県・奄美諸島で用いられた制度だが,「制度」とはいっても,言語計画や言語政策といった用語が当てはまるほど公的に組織化されたものでは決してなく,あくまで村レベル,学校レベルで行われた習俗に近いという.
もう1つ重要な点は,「「方言札」の母体である間切村内法(「間切」は沖縄独自の行政区分の名称)における「罰札制度」が,極めて古い歴史的基盤の上に成り立つ制度である」 (8) ことだ.井谷は,この2点を主たる論拠に据えて,沖縄の方言札の自然発生説を繰り返し説いてゆく.本書のなかで,著者の主旨が最もよく現れていると考える一節を挙げよう.
先述したように,私は「方言札」を強権的国家主義教育の主張や,植民地主義的同化教育,ましてや「言語帝国主義」の象徴として把握することには批判的な立場に立つものである.ごく単純に言って,それは国家からの一方的な強制でできた札ではないし,それを使用した教育に関しては,確かに強権的な使われ方をして生徒を脅迫したことはその通りであるが,同時に遊び半分に使われる時代・場所もありえた.即ち強権的であることは札の属性とは言い切れないし,権力関係のなかだけで札を捉えることは,その札のもつ歴史的性格と,何故そこまで根強く沖縄社会に根を張りえたのかという土着性をみえなくする.それよりも,私は「方言札」を「他律的 identity の象徴」として捉えるべきだと考える.即ち,自文化を否定し,自分たちの存在を他文化・他言語へ仮託するという近代沖縄社会の在り方の象徴として捉えたい.それは,伊波が指摘したように,昨日今日にできあがったものではなく,大国に挟まれた孤立した小さな島国という地政学的条件に基盤をおくものであり,近代以前の沖縄にとってはある意味では不可避的に強いられた性格であった. (85--86)
井谷は,1940年代に本土の知識人が方言札を「発見」し,大きな論争を巻き起こして以来,方言札は「沖縄言語教育史や戦中の軍国主義教育を論じる際のひとつのアイテムに近い」 (30) ものとして,即ち一種の言説生産装置として機能するようになってしまったことを嘆いている.実際には,日本本土語の教育熱と学習熱の高まりとともに沖縄で自然発生したものにすぎないにもかかわらず,と.
門外漢の私には沖縄の方言札の発生について結論を下すことはできないが,少なくとも井谷の議論は,地政学的に強力な言語に囲まれた弱小な言語やその話者がどのような道をたどり得るのかという一般的な問題について再考する機会を与えてくれる.そこからは,言語の死 (language_death) や言語の自殺 (language suicide),方言の死 (dialect death), 言語交替 (language_shift),言語帝国主義 (linguistic_imperialism),言語権 (linguistic_right) といったキーワードが喚起されてくる.方言札の問題は,それがいかなる仕方で発生したものであれ,自らの用いる言語を選択する権利の問題と直結することは確かだろう.
言語権については,本ブログでは「#278. ニュージーランドにおけるマオリ語の活性化」 ([2010-01-30-1]),「#280. 危機に瀕した言語に関連するサイト」 ([2010-02-01-1]),「#1537. 「母語」にまつわる3つの問題」 ([2013-07-12-1]),「#1657. アメリカの英語公用語化運動」 ([2013-11-09-1]) などで部分的に扱ってきたにすぎない.明日の記事はこの話題に注目してみたい.
・ 井谷 泰彦 『沖縄の方言札 さまよえる沖縄の言葉をめぐる論考』 ボーダーインク,2006年.
・ 田中 克彦 『ことばと国家』 岩波書店,1981年.
2014-03-12 Wed
■ #1780. 言語接触と借用の尺度 [contact][borrowing][sociolinguistics][loan_word][typology][japanese]
2言語間の言語接触においては,一方向あるいは双方向に言語項の借用が生じる.その言語接触と借用の強度は,少数の語彙が借用される程度の小さいなものから,文法範疇などの構造的な要素が借用される程度の大きいものまで様々ありうるが,古今東西の言語接触の事例から,その尺度を類型化することは可能だろうか.
この問題については,「#902. 借用されやすい言語項目」 ([2011-10-16-1]),「#903. 借用の多い言語と少ない言語」 ([2011-10-17-1]),「#934. 借用の多い言語と少ない言語 (2)」 ([2011-11-17-1]) ほかで部分的に言及してきたが,昨日の記事「#1779. 言語接触の程度と種類を予測する指標」 ([2014-03-11-1]) で引用した Thomason and Kaufman (74--76) による借用尺度 ("BORROWING SCALE") が,現在のところ最も本格的なものだろう.著者たちは言語接触を大きく borrowing と shift-induced interference に分けているが,ここでの尺度はあくまで前者に関するものである.5段階に区別されたレベルの説明を引用する.
(1) Casual contact: lexical borrowing only
Lexicon:
Content words. For cultural and functional (rather than typological) reasons, non-basic vocabulary will be borrowed before basic vocabulary.
(2) Slightly more intense contact: slight structural borrowing
Lexicon:
Function words: conjunctions and various adverbial particles.
Structure:
Minor phonological, syntactic, and lexical semantic features. Phonological borrowing here is likely to be confined to the appearance of new phonemes with new phones, but only in loanwords. Syntactic features borrowed at this stage will probably be restricted to new functions (or functional restrictions) and new orderings that cause little or no typological disruption.
(3) More intense contact: slightly more structural borrowing
Lexicon:
Function words: adpositions (prepositions and postpositions). At this stage derivational affixes may be abstracted from borrowed words and added to native vocabulary; inflectional affixes may enter the borrowing language attached to, and will remain confined to, borrowed vocabulary items. Personal and demonstrative pronouns and low numerals, which belong to the basic vocabulary, are more likely to be borrowed at this stage than in more casual contact situations.
Structure:
Slightly less minor structural features than in category (2). In phonology, borrowing will probably include the phonemicization, even in native vocabulary, of previously allophonic alternations. This is especially true of those that exploit distinctive features already present in the borrowing language, and also easily borrowed prosodic and syllable-structure features, such as stress rules and the addition of syllable-final consonants (in loanwords only). In syntax, a complete change from, say, SOV to SVO syntax will not occur here, but a few aspects of such a switch may be found, as, for example, borrowed postpositions in an otherwise prepositional language (or vice versa).
(4) Strong cultural pressure: moderate structural borrowing
Structure:
Major structural features that cause relatively little typological change. Phonological borrowing at this stage includes introduction of new distinctive features in contrastive sets that are represented in native vocabulary, and perhaps loss of some contrasts; new syllable structure constraints, also in native vocabulary; and a few natural allophonic and automatic morphophonemic rules, such as palatalization or final obstruent devoicing. Fairly extensive word order changes will occur at this stage, as will other syntactic changes that cause little categorial alteration. In morphology, borrowed inflectional affixes and categories (e.g., new cases) will be added to native words, especially if there is a good typological fit in both category and ordering.
(5) Very strong cultural pressure: heavy structural borrowing
Structure:
Major structural features that cause significant typological disruption: added morphophonemic rules; phonetic changes (i.e., subphonemic changes in habits of articulation, including allophonic alternations); loss of phonemic contrasts and of morphophonemic rules; changes in word structure rules (e.g., adding prefixes in a language that was exclusively suf-fixing or a change from flexional toward agglutinative morphology); categorial as well as more extensive ordering changes in morphosyntax (e.g., development of ergative morphosyntax); and added concord rules, including bound pronominal elements.
英語史上の主要な言語接触の事例に当てはめると,古英語以前におけるケルト語,古英語以降のラテン語との接触はレベル1程度,中英語以降のフランス語との接触はレベル2程度,古英語末期からの古ノルド語との接触はせいぜいレベル3程度である.英語は歴史的に言語接触が多く,借用された言語項にあふれているという一般的な英語(史)観は,それ自体として誤っているわけではないが,Thomason and Kaufman のスケールでいえば,たいしたことはない,世界にはもっと激しい接触を経てきた言語が多く存在するのだ,ということになる.通言語的な類型論が,個別言語をみる見方をがらんと変えてみせてくれる好例ではないだろうか.
日本語についても,歴史時代に限定すれば中国語(漢字)からの重要な影響があったものの,BORROWING SCALE でいえば,やはり軽度だろう.しかし,先史時代を含めれば諸言語からの重度の接触があったかもしれないし,場合によっては borrowing とは別次元の言語接触であり,上記のスケールの管轄外にあるとみなされる shift-induced interference が関与していた可能性もある.
・ Thomason, Sarah Grey and Terrence Kaufman. Language Contact, Creolization, and Genetic Linguistics. Berkeley: U of California P, 1988.
2014-02-21 Fri
■ #1761. 屈折形態論と派生形態論の枠を取っ払う「高さ」と「高み」 [suffix][japanese][morphology][derivation][productivity][neurolinguistics]
日本語の名詞形成接尾辞「さ」と「み」について,Hagiwara et al. の論文を読んだ.いずれも形容詞の語幹に接続して名詞化する機能をもっているが,「さ」は著しく生産的である一方で,「み」は基体を選ぶということが知られている.「温かい」「甘い」「明るい」「痛い」「重い」「高い」「強い」「苦い」「深い」「丸い」「柔らかい」などはいずれの接尾辞も取ることができるが,「冷たい」「固い」「安い」などは「み」を排除するし,複合形容詞「子供らしい」「奥深い」なども同様だ.実際,「み」の接続できるものは30語ほどに限られ,生産性が極めて限定されている.意味上も,「さ」名詞は無標で予測可能性が高いが,「み」名詞は有標で予測可能性が低い.例えば,「高さ」は抽象的な性質名詞だが,「高み」は「高いところ」ほどのより具体的な意味をもつ名詞である.
この「さ」と「み」の形態的・意味的な性質の違いは,英語の -ness と -ity の違いとおよそ平行している.英語の2つの名詞形成接尾辞については「#935. 語形成の生産性 (1)」 ([2011-11-18-1]) で取り上げたので,そちらを参照していただきたいが,日本語と英語のケースとでの差異は,英語の非生産的な接尾辞 -ity は基体の音韻形態を変化させ得る (ex. válid vs valídity) のに対して,日本語の非生産的な接尾辞「み」は基体の音韻形態を保つということだ.しかし,全体としては,日英語4接尾辞のあいだの平行性には注目すべきだろう.
Hagiwara et al. の議論の要点はこうである.英語の規則動詞の活用形は規則により生成されるが,不規則動詞の活用形は記憶から直接引き出される.それと同じように,日本語の「さ」名詞は規則により生成されるが,「み」名詞は記憶から直接引き出されているのではないか.この際に,英語の動詞の例は屈折形態論 (inflectional morphology) に属する話題であり,日本語の「さ」「み」の例は派生形態論 (derivational morphology) に属する話題ではあるが,これは同じ原理が両形態論をまたいで働いている証拠ではないか,と.従来,屈折形態論と派生形態論は峻別すべき2つの部門と考えられてきたが,生産性の極めて高い派生の過程は,むしろ屈折に近い振る舞いをすると考えられるのではないか,というのが Hagiwara et al. の提案である.以上の議論が,失語症患者のテストや神経言語学 (neurolinguistics) の観点からなされている.結論部を引用しよう.
Our investigation of the Japanese nominal suffixes -sa annd -mi led us to the conclusion that the affixation of these two suffixes involves two different mental mechanisms, and that the two mechanisms are supported by different neurological substrates. The results of our study constitute a new piece of evidence for the dual-mechanism model of morphology, where default rule application and associative memory are supposed to operate as mutually independent mechanisms. Furthermore, we have demonstrated that the dual-mechanism model is valid for morphological processes in general, and is not limited to inflectional ones. This, in turn, shows that some derivational processes can involve default rules or computation, much like those in inflection or syntactic operations. From the neurolinguistic point of view, our study has contributed to the clarification of the localization of linguistic functions, namely, the Broca's area functions as the rule-governed grammatical computational system whereas the left-middle and inferior temporal areas subserve the unproductive/semiproductive memory-based lexical-semantic processing system. (758)
屈折形態論と派生形態論の枠を部分的に取っ払うというという,この神経言語学上の提案は,例えば「#456. 比較の -er, -est は屈折か否か」 ([2010-07-27-1]) のような問題にも新たな光を投げかけることになるかもしれない.
・ Hagiwara, Hiroko, Yoko Sugioka, Takane Ito, Mitsuru Kawamura, and Jun ichi Shiota. "Neurolinguistic Evidence for Rule-Based Nominal Suffixation." Language 75 (1999): 739--63.
2014-02-06 Thu
■ #1746. 看板表記のローマ字 [language_planning][japanese][writing][grammatology][linguistic_landscape]
社会言語学の概念で,言語環境あるいは言語景観というものがある.「#1612. 道路案内標識,ローマ字から英語表記へ」 ([2013-09-25-1]) および「#1613. 道路案内標識の英語表記化と「言語環境」」 ([2013-09-26-1]) で話題にしたように,街にある標識や看板などの文字の使い方は,街の印象を決定すると同時に,諸々の言語の重要性やその象徴的な威信を反映していると考えられる.このような観点から,日本でも街の看板表記のフィールドワークが行われるようになってきた.
2001--02年にかけて染谷が小田急線沿線の駅周辺で行った店名看板調査も,そのような試みの1つである.日常生活の匂いがする商店街をターゲットに,計千件の看板の文字種を調査した.漢字・ひらがな・カタカナ・ローマ字のうち,どの文字種(の組み合わせ)が看板に用いられているかを示したのが以下の表である(染谷,p. 224 より).
| 組み合わせ | 看板数(件) |
|---|---|
| 漢字 | 197 |
| ひらがな | 21 |
| カタカナ | 49 |
| ローマ字 | 109 |
| 1種合計 | 376 |
| 漢字+ひらがな | 220 |
| 漢字+カタカナ | 130 |
| 漢字+ローマ字 | 30 |
| ひらがな+カタカナ | 10 |
| ひらがな+ローマ字 | 10 |
| カタカナ+ローマ字 | 42 |
| 2種合計 | 442 |
| 漢+ひら+カタ | 77 |
| 漢+ひら+ロマ | 27 |
| 漢+カタ+ロマ | 44 |
| ひら+カタ+ロマ | 9 |
| 3種合計 | 157 |
| 漢+ひら+カタ+ロマ | 24 |
| 4種合計 | 24 |
概ね直感と合う結果と思われる,漢字のみ,あるいは漢字+ひらがなで表記される看板が最も多い.現代日本語の最も一般的な表記の状況を反映しているといってよいだろう.しかし,思いのほか多かったのがローマ字単独表記である.他の文字種との組み合わせも足し合わせると,ローマ字の存在感は決して小さくない.BAR, CAFE, CLEANING, COSMETIC, HAIRCUT, PUB など店の業種や扱っている商品によってローマ字使用が多いケースがあることは容易に理解できるが,WADAYA, LaLaLa, ASTORIA, Sis., FRAIS, Pappa Duduu など業種が想像できないようなものも多かったという.
染谷 (239) は,看板におけるローマ字表記について次のような可能性を指摘している.
むしろ最近気になるのは,ローマ字表記の縦書き看板である.たとえば,JRの駅の柱には駅名が「Shinjuku」のように横書きで九〇度回転した状態で表示してある.日常こういう表記に慣れていたが,今回の最終で「HOTEL」,「英会話NOVA」,「ZOO」(店名)のようなローマ字の縦書き看板は多くはないが確実に見られる.首を横にしないで見られるローマ字の縦書き看板は今後増える可能性があるかもしれない.とすれば,一般の表記にも影響する可能性がある.縦書きの文章に縦書きのローマ字表記が出てくる時代がくるのだろうか.
染谷 (243) は続けて,危惧をも表明している.
外国語表記を主体としたローマ字だけの店名看板も少なからず見え,日常と関わりの深いところでこのような表記を目にしていると,自ずから日本人の文字生活にも影響を与えるのではないかという危惧がある.特に,一部に見える縦書きローマ字が進出してくれば,綴り字が複雑でない英単語などが漢字仮名交じり文に入り込む可能性も十分考えられ得るのではないか.
通常,言語環境は一般の言語使用の影響を受けていると考えられるが,逆に言語環境が一般の言語使用に影響を及ぼすという方向も十分にありうると思われる.言語環境は,言語使用を反映すると同時に,それに影響を及ぼしもするのだ.2020年の東京オリンピックをにらんで,東京(そして日本全国)にローマ字の標識や看板の増えてくる可能性が高いが,そのような言語環境の変化は,徐々に一般の日本語使用にも影響を及ぼさずにはおかないだろう
・ 染谷 裕子 「看板の文字表記」『現代日本語講座 第6巻 文字・表記』(飛田 良文,佐藤 武義(編)) 明治書院,2002年,221--43頁.
2013-10-28 Mon
■ #1645. 現代日本語の語種分布 [japanese][lexicology][statistics][etymology][loan_word][lexical_stratification]
英語語彙の語種別の割合について,これまで多くの記事で各種統計を示してきた.
・ [2012-09-03-1]: 「#1225. フランス借用語の分布の特異性」
・ [2012-08-11-1]: 「#1202. 現代英語の語彙の起源と割合 (2)」
・ [2012-01-07-1]: 「#985. 中英語の語彙の起源と割合」
・ [2011-09-18-1]: 「#874. 現代英語の新語におけるソース言語の分布」
・ [2011-08-20-1]: 「#845. 現代英語の語彙の起源と割合」
・ [2010-12-31-1]: 「#613. Academic Word List に含まれる本来語の割合」
・ [2010-06-30-1]: 「#429. 現代英語の最頻語彙10000語の起源と割合」
・ [2010-05-16-1]: 「#384. 語彙数とゲルマン語彙比率で古英語と現代英語の語彙を比較する」
・ [2010-03-02-1]: 「#309. 現代英語の基本語彙100語の起源と割合」
・ [2009-11-15-1]: 「#202. 現代英語の基本語彙600語の起源と割合」
・ [2009-11-14-1]: 「#201. 現代英語の借用語の起源と割合 (2)」
・ [2009-08-19-1]: 「#114. 初期近代英語の借用語の起源と割合」
・ [2009-08-15-1]: 「#110. 現代英語の借用語の起源と割合」
「#334. 英語語彙の三層構造」 ([2010-03-27-1]),「#335. 日本語語彙の三層構造」 ([2010-03-28-1]),「#1526. 英語と日本語の語彙史対照表」 ([2013-07-01-1]) で見たように,英語と日本語の語彙は比較される歴史をたどってきており,結果として現代の共時的な語彙構成にも共通点が見られる.今回は,現代英語との比較のために,現代日本語の語種別の割合をみよう.一般的にこの種の語彙統計を得るのは難しいが,『日本語百科大事典』 (420--21) に拠りながら3種の調査結果の概観を示す.
(1) 明治から昭和にかけての3種の国語辞典『言海』(明治22年;1889年),『例解国語辞典』(昭和31年;1956年),『例解国語辞典』(昭和44年;1969年)の収録語を語種別に数えた研究がある.総語数は,『言海』39,103,『例解国語辞典』40,393,『角川国語辞典』60,218 である.以下に割合を示す表と図を示そう.
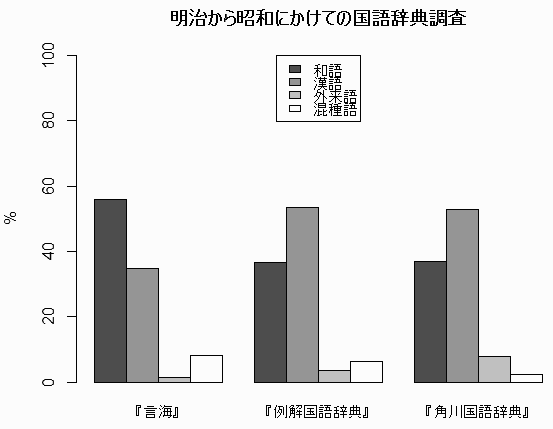
| 和語 | 漢語 | 外来語 | 混種語 | |
|---|---|---|---|---|
| 『言海』 | 55.8% | 34.7 | 1.4 | 8.1 |
| 『例解国語辞典』 | 36.6 | 53.6 | 3.5 | 6.2 |
| 『角川国語辞典』 | 37.1 | 52.9 | 7.8 | 2.2 |
時代が進むにつれて,和語に対する漢語と外来語の割合が高まってきているのがわかる.昭和では,1/2強が漢語,1/3強が和語という割合だ.
(2) 現代の書きことばについては,国立国語研究所の『現代雑誌九十種の用語用字』調査のデータがよく参照される.昭和31年(1956年)の雑誌から,助詞,助動詞,固有名詞を除いて語彙を収集したものである.得られた語彙は,異なり語数で30,331,延べ語数で411,972.21世紀の現在から見ると古いデータではあるが,質において比肩する新しい調査は行われていない.
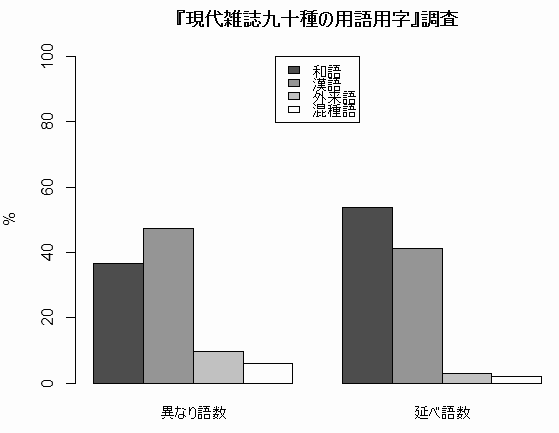
| 和語 | 漢語 | 外来語 | 混種語 | |
|---|---|---|---|---|
| 異なり語数 | 36.7% | 47.5 | 9.8 | 6.0 |
| 延べ語数 | 53.9 | 41.3 | 2.9 | 1.9 |
異なり語数と延べ語数では数値がかなり異なっており,特に和語と漢語の順位が入れ替わっているのが注目に値する.
(3) 現代の話しことばの調査としては,知識層を対象としたものがある.日本語教育および語学関係の研究者7人とその話し相手の会話を延べ42時間分録音し,分析したものである.異なり語数は4,617で,延べ語数は64,023.
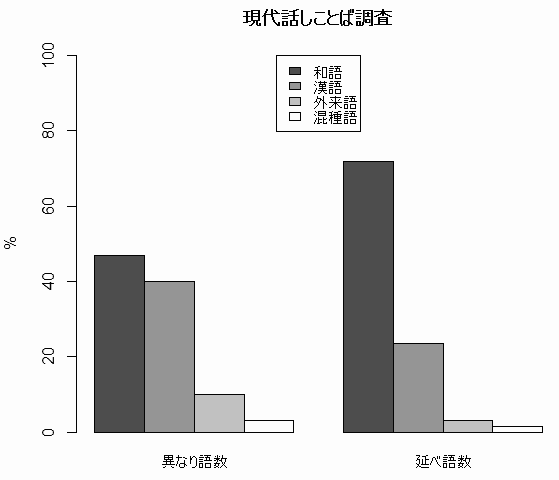
| 和語 | 漢語 | 外来語 | 混種語 | |
|---|---|---|---|---|
| 異なり語数 | 46.9% | 40.0 | 10.1 | 3.0 |
| 延べ語数 | 71.8 | 23.6 | 3.2 | 1.4 |
話しことばでは,書きことばと異なり,異なり語数と延べ語数の間で和漢語の順位入れ替えはない.いずれの数え方でも和語の割合が最も多いが,とりわけ延べ語数では和語が圧倒している.
この話しことばの調査では,公的な場面や私的な場面など場面別に分析がなされたが,全体的な傾向として,和語は (1) 私的な場面でのほうが多い,(2) 延べ語数でのほうが多い,(3) 使用頻度の高い語ほど多い,(4) 話し言葉でのほうが多い,という結果が出た.私的な話しことばで高頻度に用いられる語は,和語である確率が最も高いということになる.この結果は直感と一致するだろう.
英語においても本来語は「私的な場面の話しことばで高頻度に用いられる」確率が高いと想像されるが,これについては統計は見たことはなく,今後,実証してゆく必要があるかもしれない.
・ 『日本語百科大事典』 金田一 春彦ほか 編,大修館,1988年.
2013-10-13 Sun
■ #1630. インク壺語,カタカナ語,チンプン漢語 [japanese][kanji][katakana][waseieigo][lexicology][emode]
初期近代英語期,主としてラテン語に由来するインク壺語 (inkhorn_term) と呼ばれる学者語が大量に借用されたとき,外来語の氾濫に対する大議論が巻き起こったことは,「#1408. インク壺語論争」 ([2013-03-05-1]) や「#1410. インク壺語批判と本来語回帰」 ([2013-03-07-1]) などの記事で触れた.Bragg (116) の評価によれば,"This controversy was the first and probably the greatest formal dispute about the English language." ということだった.
現代日本語において似たような問題が,カタカナ語の氾濫という形で生じている.インク壺語とカタカナ語の問題の類似点については,「#1615. インク壺語を統合する試み,2種」 ([2013-09-28-1]) と「#1616. カタカナ語を統合する試み,2種」 ([2013-09-29-1]) で取り上げたが,借用語彙の受容を巡る議論は,およそ似たような性質を帯びるものらしい.そこへもう1つ新語彙の受容を巡る問題を加えるとすれば,近代期の日本の新漢語問題が思い浮かぶ.昨日の記事「#1629. 和製漢語」 ([2013-10-12-1]) でも話題にした,和製漢語を種とする新漢語の大量生産である.
幕末以降,特に明治初期以来,英語をはじめとする大量の西洋語を受け入れるのに,それを漢訳して受容した.当時の知識人に漢学の素養があったからである.漢訳に当たっては,古来の漢語を利用したり,W. Lobscheid の『英華字典』を参照したり(例えば,文学,教育,内閣,国会,階級,伝記など)して対処したものもあったが,和製漢語を作り出す場合が多かった.この大量の新漢語は「漢語の氾濫」問題を惹起し,一般庶民にまで影響を及ぼすことになった.
例えば,『日本語百科大事典』 (453--54) によれば,『都鄙新聞』第1号(慶應4・明治1)に「此は頃鴨東ノの芸妓,少女ニ至ルマデ,専ラ漢語ヲツカフコトヲ好ミ,霖雨ニ盆地ノ金魚ガ脱走シ,火鉢ガ因循シテヰルナド,何ノワキマヘモナクイヒ合フコトコレナリ」という皮肉が聞かれたし,『漢語字類』(明治2)には「方今奎運盛ニ開ケ,文化日ニ新タナリ.上ミハ朝廷ノ政令,方伯ノ啓奏ヨリ,下モ市井閭閻ノ言談論議ニ至ルマデ,皆多ク雑ユルニ漢語ヲ以テス」とある.『我楽多珍報』(明治14. 9. 30)では「生意気な猫ハ漢語で無心いひ」とまである.このように新漢語が流行していたようだが,庶民がどの程度理解していたかは疑問で,「チンプン漢語」とまで呼ばれていたほどである."inkhorn terms" や「カタカナ語」という呼称と比較されよう.そして,漢語を統合する試みの1つとして,漢語字引が次々と出版されたことも,他の2例と驚くほどよく似ている.
現代日本語のカタカナ語問題を議論するのに,16世紀後半のイングランドや19世紀後半の日本の言語事情を参照することは,意味のあることだろう.
・ Bragg, Melvyn. The Adventure of English. New York: Arcade, 2003.
・ 『日本語百科大事典』 金田一 春彦ほか 編,大修館,1988年.
Powered by WinChalow1.0rc4 based on chalow