2017-12-26 Tue
■ #3165. 英製羅語としての conspicuous と external [waseieigo][latin][borrowing][loan_word][derivation][etymology][suffix][adjective][emode][neologism][lexicology][word_formation][shakespeare]
標題と関連する話題は,「#1493. 和製英語ならぬ英製羅語」 ([2013-05-29-1]),「#1927. 英製仏語」 ([2014-08-06-1]),「#2979. Chibanian はラテン語?」 ([2017-06-23-1]) や,waseieigo の各記事で取り上げてきた.
Baugh and Cable (222) で,初期近代期に英語がラテン単語を取り込む際に施した適応 (adaptation) が論じられているが,次のような1文があった.
. . . the Latin ending -us in adjectives was changed to -ous (conspicu-us > conspicuous) or was replaced by -al as in external (L. externus).
これらの英単語は,ある意味では借用された語ともいえるが,ある意味では英語が自ら形成した語ともいえる.「英製羅語」と呼ぶのがふさわしい例ではないだろうか.
OED によれば,conspicuous は,ラテン語 conspicuus に基づき,英語側でやはりラテン語由来の形容詞を作る接尾辞 -ous を付すことによって新たに形成した語である.16世紀半ばに初出している.
1545 T. Raynald tr. E. Roesslin Byrth of Mankynde Hh vij These vaynes doo appeare more conspicuous and notable to the eyes.
実はこの接尾辞を基体(主としてラテン語由来だが,その他の言語の場合もある)に付加して自由に新たな形容詞を作るパターンはロマンス諸語に広く見られたもので,フランス語で -eus を付したものが,14--15世紀を中心として英語にも -ous の形で大量に入ってきた.つまり,まずもって仏製羅語というべきものが作られ,それが英語にも流れ込んできたというわけだ.例として,dangerous, orgulous, adventurous, courageous, grievous, hideous, joyous, riotous, melodious, pompous, rageous, advantageous, gelatinous などが挙げられる(OED の -ous, suffix より).
また,英語でもフランス語に習う形でこのパターンを積極的に利用し,自前で conspicuous のような英製羅語を作るようになってきた.同種の例として,guilous, noyous, beauteous, slumberous, timeous, tyrannous, blusterous, burdenous, murderous, poisonous, thunderous, adiaphorous, leguminous, delirious, felicitous, complicitous, glamorous, pulchritudinous, serendipitous などがある(OED の -ous, suffix より).
標題のもう1つの単語 external も conspicuous とよく似たパターンを示す.この単語は,ラテン語 externus に基づき,英語側でラテン語由来の形容詞を作る接尾辞 -al を付すことによって形成した英製羅語である.初出は Shakespeare.
a1616 Shakespeare Henry VI, Pt. 1 (1623) v. vii. 3 Her vertues graced with externall gifts.
a1616 Shakespeare Antony & Cleopatra (1623) v. ii. 340 If they had swallow'd poyson, 'twould appeare By externall swelling.
反意語の internal も同様の事情かと思いきや,こちらは一応のところ post-classical Latin として internalis が確認されるという.しかし,この語のラテン語としての使用も "14th cent. in a British source" ということなので,やはり英製の匂いはぷんぷんする.英語での初例は,15世紀の Polychronicon.
?a1475 (?a1425) tr. R. Higden Polychron. (Harl. 2261) (1865) I. 53 The begynnenge of the grete see is..at the pyllers of Hercules..; after that hit is diffusede in to sees internalle [a1387 J. Trevisa tr. þe ynnere sees; L. maria interna].
「○製△語」は決して珍しくない.
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 6th ed. London: Routledge, 2013.
2017-12-18 Mon
■ #3157. 華麗なる splendid の同根類義語 [cognate][synonym][lexicology][inkhorn_term][emode][borrowing][loan_word][renaissance][thesaurus][htoed]
「#576. inkhorn term と英語辞書」 ([2010-11-24-1]) の記事で,ルネサンス期のラテン語かぶれの華美を代表する単語の1つとして splendidious を挙げた.この語は現在では廃用となっているが,その意味は現代でも普通に用いられる splendid と同じ「華麗な,豪華な」である.前者はルネサンス華やかなりし15世紀から用いられており,後者も単語としては17世紀前半には初出している(ただし,語義によって初出年代が異なる).この15--17世紀には,語根も意味も同じくする splendid 系の単語がいくつも現われては消えていったのである.HTOED より splendid の項を覗いてみると,次のようにある.
02.04.05.03 (adj.) Splendid
þurhbeorht OE ・ geatolic OE ・ torht OE ・ torhtlic OE ・ wrætlic OE ・ orgulous/orgillous a1400 ・ splendidious 1432/50--1653 ・ splendiferous c1460--1546 ・ splendent 1509-- ・ splendant 1590-- ・ splendorous 1591-- ・ splendidous 1605--1640 ・ transplendent 1622; 1854 ・ florid 1642--1725 ・ splendious 1654 ・ splendid 1815-- ・ splendescent 1848-- ・ nifty 1868-- ・ ducky 1897-- (colloq.) ・ many-splendoured a1907--
歴史的に splendidious, splendiferous, splendent, splendant, splendorous, splendidous, splendious, splendid, splendescent, splendoured の10語が,互いに比較的近接した時期に現われ,大概は後に消えている(ただし,手持ちの英和辞書では,splendiferous, splendent, splendorous は見出しが立てられていた).
基体(ラテン語あるいはフランス語由来)も意味も同じくする類義語 (synonym) がこのように複数あったところで,害こそあれ利はない.それで多くの語が競合し,自滅していったのだろう.
Kay and Allan (15) も,この語群に言及しつつ次のように述べている.
Sometimes there was a degree of experimentation over the form of a new word. In the sixteenth and seventeenth centuries, the OED records the following forms meaning 'splendid': splendant, splendicant, splendidious, splendidous, splendiferous, splendious and splendorous. Splendid itself is first recorded in 1624. Unsurprisingly, most of these forms were short-lived; no language needs quite so many similar words for the same concept.
対応する名詞についても HTOED より抜き出すと,"splendency a1591--1607 ・ splendancy 1591 ・ splendence 1604 ・ splendour 1774-- ・ splendiferousness 1934--" とやはり豊富である.
・ Kay, Christian and Kathryn Allan. English Historical Semantics. Edinburgh: Edinburgh UP, 2015.
2017-12-15 Fri
■ #3154. 英語史上,色彩語が増加してきた理由 [bct][borrowing][lexicology][french][loan_word][sociolinguistics]
「#2103. Basic Color Terms」 ([2015-01-29-1]) および昨日の記事「#3153. 英語史における基本色彩語の発展」 ([2017-12-14-1]) で,基本色彩語 (Basic Colour Terms) の普遍的発展経路の話題に触れた.英語史においても,BCTs の種類は,普遍的発展経路から予想される通りの順序で,古英語から中英語へ,そして中英語から近代英語へと着実に増加してきた.そして,BCTs のみならず non-BCTs も時代とともにその種類を増してきた.これらの色彩語の増加は何がきっかけだったのだろうか.
Biggam (123--24) によれば,古英語から中英語にかけての増加は,ノルマン征服後のフランス借用語に帰せられるという.BCTs に関していえば,中英語で加えられたbleu は確かにフランス語由来だし,brun は古英語期から使われていたものの Anglo-French の brun により使用が強化されたという事情もあったろう.また,色合,濃淡 ,彩度,明度を混合させた古英語の BCCs 基準と異なり,中英語期にとりわけ色合を重視する BCCs 基準が現われてきたのは,ある産業技術上の進歩に起因するのではないかという指摘もある.
The dominance of hue in certain ME terms, especially in BCTs, was at least encouraged by certain cultural innovations of the later Middle Ages such as banners, livery, and the display of heraldry on coats-of-arms, all of which encouraged the development and use of strong dyes and paints. (125)
近代英語期になると,PURPLE, ORANGE, PINK が BCCs に加わり,近現代的な11種類が出そろうことになったが,この時期にはそれ以外にもおびただしい non-BCTs が出現することになった.これも,近代期の社会や文化の変化と連動しているという.
From EModE onwards, the colour vocabulary of English increased enormously, as a glance at the HTOED colour categories reveals. Travellers to the New World discovered dyes such as logwood and some types of cochineal, while Renaissance artists experimented with pigments to introduce new effects to their paintings. Much later, synthetic dyes were introduced, beginning with so-called 'mauveine', a purple shade, in 1856. In the same century, the development of industrial processes capable of producing identical items which could only be distinguished by their colours encouraged the proliferation of colour terms to identify and market such products. The twentieth century saw the rise of the mass fashion industry with its regular announcements of 'this year's colours'. In periods like the 1960s, colour, especially vivid hues, seemed to dominate the cultural scene. All of these factors motivated the coining of new colour terms. The burgeoning of the interior décor industry, which has a never-ending supply of subtle mixes of hues and tones, also brought colour to the forefront of modern minds, resulting in a torrent of new colour words and phrases. It has been estimated that Modern British English has at least 8,000 colour terms . . . . (126)
英語の色彩語の歴史を通じて,ちょっとした英語外面史が描けそうである.
・ Kay, Christian and Kathryn Allan. English Historical Semantics. Edinburgh: Edinburgh UP, 2015.
・ Biggam, C. P. "English Colour Terms: A Case Study." Chapter 7 of English Historical Semantics. Christian Kay and Kathryn Allan. Edinburgh: Edinburgh UP, 2015. 113--31.
2017-12-14 Thu
■ #3153. 英語史における基本色彩語の発展 [bct][semantic_change][lexicology][terminology]
「#2103. Basic Color Terms」 ([2015-01-29-1]) で取り上げたように,言語における色彩語の発展には,およそ普遍的といえる道筋があると考えられている.英語の色彩語も,歴史を通じてその道筋をたどったことが確認されている.まず,この問題を論じる上で基本的な用語である basic colour terms (BCTs) と basic colour categories (BCCs) の定義を確認しておこう.Christian and Allan の巻末の用語集より引用する (178) .
basic colour categories (BCCs) are the principal divisions of the colour space which underlie the basic colour terms (BCTs) of a particular speech community. A BCC is an abstract concept which operates independently of things described by terms such as green or yellow. BCCs are presented in small capital letters, for example GREEN.
basic colour terms (BCTs) are the words which languages use to name basic colour categories. A BCT, such as green or yellow, is known to all members of a speech community and is used in a wide range of contexts. Other colour words in a language are called non-basic terms, for example sapphire, scarlet or auburn.
Biggam の要約によると,英語の BCCs の発達は以下の通りである.
OE: (1) WHITE/BRIGHT, (2) BLACK/DARK, (3) RED+ (4) YELLOW, (5) GREEN, (6) GREY
ME: (1) WHITE, (2) BLACK, (3) RED+, (4) YELLOW, (5) GREEN, (6) GREY, (7) BLUE, (8) BROWN
ModE: (1) WHITE, (2) BLACK, (3) RED, (4) YELLOW, (5) GREEN, (6) GREY, (7) BLUE, (8) BROWN, (9) PURPLE, (10) ORANGE, (11) PINK
一方,BCTs の発達は以下の通り.
OE: hwit, blæc/(sweart), read, geolu, grene, græg
ME: whit, blak, red yelwe, grene, grei, bleu, broun
ModE: white, black, red, yellow, green, grey, blue, brown, purple, orange, pink
BCTs の種類は,古英語の6から中英語の8を経由して,近代英語の11へと増えてきたことになる.その経路は,[2015-01-29-1]の図で示した「普遍的な」経路とほぼ重なっている.
・ Kay, Christian and Kathryn Allan. English Historical Semantics. Edinburgh: Edinburgh UP, 2015.
・ Biggam, C. P. "English Colour Terms: A Case Study." Chapter 7 of English Historical Semantics. Christian Kay and Kathryn Allan. Edinburgh: Edinburgh UP, 2015. 113--31.
2017-09-20 Wed
■ #3068. 「宗教改革と英語史」のまとめスライド [reformation][renaissance][bible][emode][lexicology][slide][history][link][map][hel_education][asacul]
英語史における宗教改革の意義について,reformation の各記事で考えてきた.現時点での総括として,「宗教改革と英語史」のまとめスライド (HTML) を公開したい.こちらからどうぞ. * *
15枚からなるスライドで,目次は以下の通り.
1. 宗教改革と英語史
2. 要点
3. 宗教改革とは?
4. 歴史的背景
5. イングランドの宗教改革とその特異性
6. ルネサンスとは?
7. イングランドにおける宗教改革とルネサンスの共存
8. 英語文化へのインパクト
9. プロテスタンティズムの拡大と定着
10. 古英語研究の開始
11. 語彙をめぐる問題
12. 一連の聖書翻訳
13. まとめ
14. 参考文献
15. 補遺:「創世記」11:1--9 (「バベルの塔」)の近現代8ヴァージョン+新共同訳
別の「まとめスライド」として,「#3058. 「英語史における黒死病の意義」のまとめスライド」 ([2017-09-10-1]) もご覧ください.
{kind=link}
2017-08-26 Sat
■ #3043. 後期近代英語期の識字率 [literacy][demography][spelling][lexicology]
過去の社会の識字率を得ることは一般に難しいが,後期近代英語期の英語社会について,ある程度分かっていることがある.以下にメモしておこう.
まず,Fairman (265) は,19世紀初期の状況として次の事実を指摘している.
1) In some parts of England 70% of the population could not write . . . . For them English was only sound, and not also marks on paper.
2) Of the one-third to 40% who could write, less than 5% could produce texts near enough to schooled English --- that is, to the type of English taught formally --- to have a chance of being printed.
Simon (160) は,19世紀中の識字率の激増,特に女性の値の増加について触れている.
The nineteenth century witnessed a huge increase in literacy, especially in the second half of the century. In 1850 30 per cent of men and 45 per cent of women were unable to sign their own names; by 1900 that figure had shrunk to just 1 per cent for both sexes.
上のような識字率と関連させて,Tieken-Boon van Ostade (45--46) がこの時代の綴字教育について論じている.貧しさゆえに就学期間が短く,中途半端な綴字教育しか受けられなかった子供たちは,せいぜい単音節語を綴れるにすぎなかっただろう.このことは,本来語はおよそ綴れるが,ほぼ多音節語からなるラテン語やフランス語からの借用語は綴れないことを意味する.文体レベルの高い借用語を自由に扱えないようでは社会的には無教養とみなされるのだから,彼らは書き言葉における「制限コード」 (restricted code) に甘んじざるをえなかったと表現してもよいだろう.
識字率,綴字教育,音節数,本来語と借用語,制限コード.これらは言語と社会の接点を示すキーワードである.
・ Fairman, Tony. "Letters of the English Labouring Classes and the English Language, 1800--34." Insights into Late Modern English. 2nd ed. Ed. Marina Dossena and Charles Jones. Bern: Peter Lang, 2007. 265--82.
・ Horobin, Simon. Does Spelling Matter? Oxford: OUP, 2013.
・ Tieken-Boon van Ostade, Ingrid. An Introduction to Late Modern English. Edinburgh: Edinburgh UP, 2009.
2017-08-17 Thu
■ #3034. 2つの世界大戦と語彙革新 (2) [lexicology][history][war]
昨日の記事 ([2017-08-16-1]) で,戦争が語彙に及ぼす影響について取り上げ,2つの世界大戦より具体例を挙げた.戦時に様々な戦争用語が生まれるというのは自然なことであり,疑うべきことではないが,戦争と「著しい」語彙革新とが常に関連づけられるものかどうかは慎重に調べる必要がある.というのは,むしろ2つの世界大戦期には,語彙革新が相対的に少なかったというデータがあるからだ.
Beal (29--34) の A Chronological English Dictionary に基づいた新語の初例登録年代の調査によると,意外なことに,1915--19年と1944--45年に新語導入の谷が現われている.この年代はちょうど両世界大戦に相当し,むしろ語彙革新が激しかったのではないかと予想される時期である.
ここで重要なのは,これらの時期に「戦時新語」が他の時期と比べて多かっただろうことは自明だが,「戦時新語」以外の新語を含めた新語の総数が多かったとは限らないという点だ.研究者も私たちも,この時期に「戦時新語」の例を探し求めたがり,結果としていくつかの例を見出すことになるが,それはその時期の新語総数が多かったということと同義ではない.新語総数としては著しくなかかったという可能性があるし,事実,この調査によればその通りだったのだ.Beal (33) は次のように述べている.
[W]ar does not stimulate lexical innovation: although the loan-words from allies and enemies alike are noticed during and after these conflicts, they are not great in number.
予想に反して戦時には新語が少ないという仮の結論となったが,これが本当だとすると,いったいなぜだろうか.これはこれで興味深い問題となる.
・ Beal, Joan C. English in Modern Times: 1700--1945. Arnold: OUP, 2004.
2017-08-16 Wed
■ #3033. 2つの世界大戦と語彙革新 (1) [lexicology][history][semantic_change][neologism][war]
Baugh and Cable (293--94) によれば,戦争は語彙の革新をもたらすということがわかる.戦争に関わる新語 (neologism) が形成されたり借用されたりするほか,既存の語の意味が戦争仕様に変化することも含め,戦争という歴史的事件は語彙に大きな影響を及ぼすものらしい.例を挙げてみよう.
1914--18年にかけて,第1次世界大戦の直接的な影響により,語彙に革新がもたらされた.air raid (空襲),antiaircraft gun (高射砲),tank (戦車),blimp (小型軟式飛行船),gas mask (ガスマスク),liaison officer (連絡将校)などの語が作られた.借用語としては,フランス語から camouflage (迷彩)が入った.既存の語で語義が変化したものとしては,sector (扇形戦区),barrage (弾幕),dud (不発弾),ace (優秀パイロット)がある.専門用語だったものが一般に用いられるようになったという点では,hand grenade (手榴弾),dugout (防空壕),machine gun (機関銃),periscope (潜望鏡),no man's land (中間地帯),doughboy (米軍歩兵)などがある.その他,blighty (本国送還になるような負傷),slacker (兵役忌避者),trench foot (塹壕足炎),cootie (バイキン),war bride (戦争花嫁)などの軍俗語が挙げられる.
第1次大戦に比べれば第2次世界大戦はさほど語彙革新を巻き起こさなかったとはいえ,少なからぬ新語・新用法が確認される.alert (空襲警報),blackout (報道管制),blitz (電撃攻撃),blockbuster (大型爆弾),dive-bombing (急降下爆撃),evacuate (避難させる),air-raid shelter (防空壕),beachhead (橋頭堡),parachutist (落下傘兵),paratroop (落下傘兵),landing strip (仮設滑走路),crash landing (胴体着陸),roadblock (路上バリケード),jeep (ジープ),fox hole (たこつぼ壕),bulldozer (ブルドーザー),decontamination (放射能浄化),task force (機動部隊),resistance movement (レジスタンス),radar (レーダー)が挙げられる.動詞の例としては,to spearhead (先頭に立つ),to mop up (掃討する),appease (宥和政策を取る)を挙げておこう.借用語としては,ドイツ語から flack (対空射撃),ポルトガル語からcommando (奇襲部隊)がある.語義が流行した語としては,priority (優先事項),tooling up (機会設備),bottleneck (障害),ceiling (最高限度),backlog (残務),stockpile (備蓄),lend-lease (武器貸与).
戦後の用語としては,iron curtain (鉄のカーテン),cold war (冷戦),fellow traveler (シンパ),front organization (みせかけの組織),police state (警察国家)がある.
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 6th ed. London: Routledge, 2013.
2017-07-28 Fri
■ #3014. 英語史におけるギリシア語の真の存在感は19世紀から [greek][compound][compounding][combining_form][lexicology][scientific_name][word_formation][lmode][neologism]
昨日の記事「#3013. 19世紀に非難された新古典主義的複合語」 ([2017-07-27-1]) でも触れたように,19世紀は専門用語の造語のために,古典語に由来する要素が連結形 (combining_form) としておおいに利用された時代である.古典語とはラテン語とギリシア語を指す.前者は英語史を通じて多大な影響を及ぼしてきたものの,後者の存在感は中英語まではほとんど感じられない.ようやく初期近代英語期に入って,直接の語彙借用がなされるようになってきたにすぎず,その後もしばらく特に目立つところもなかった (cf. 「#516. 直接のギリシア語借用は15世紀から」 ([2010-09-25-1]),「#114. 初期近代英語の借用語の起源と割合」 ([2009-08-19-1])) .
しかし,「#2385. OED による,古典語およびロマンス諸語からの借用語彙の統計 (2)」 ([2015-11-07-1]) のグラフや「#2357. OED による,古典語およびロマンス諸語からの借用語彙の統計」 ([2015-10-10-1]) の要約からわかるとおり,19世紀にギリシア語要素が著しく存在感を増した.通時的にみると,ギリシア語由来の英単語の圧倒的過半数が,19世紀以降の導入である.Beal (26) のコメントを参照しよう.
Whilst Greek had been recognized as a language of learning for centuries, it was not until the nineteenth century that large numbers of neologisms were formed from etymologically Greek words and elements. Indeed, Bailey (1996: 144 [= Bailey, R. W. Nineteenth-Century English. Ann Arbor: U of Michigan P, 1996]) points out that 70 per cent of the Greek words in the 80,000-word core vocabulary of English appeared after 1800.
具体例としては当時の専門用語が多いが,現在までに一般化したものも含まれている.cyclosis (細胞質環流), creosote (防腐用・医療用クレオソート), eclecticism (折衷技法), ideograph (表意文字), phonograph (蓄音機), telephone (電話機)などだ.
なお,これらの単語の多くは,厳密にいえばギリシア語からの借用語というよりもギリシア語に由来する要素による造語とみなすのが適切だろう.「#1694. 科学語彙においてギリシア語要素が繁栄した理由」 ([2013-12-16-1]) も参照されたい.
・ Beal, Joan C. English in Modern Times: 1700--1945. Arnold: OUP, 2004.
2017-07-27 Thu
■ #3013. 19世紀に非難された新古典主義的複合語 [compounding][greek][latin][neo-latin][inkhorn_term][lexicology][combining_form][scientific_name][lmode][word_formation][neologism]
英語の豊かな語彙史について「#756. 世界からの借用語」 ([2011-05-23-1]), 「#1526. 英語と日本語の語彙史対照表」 ([2013-07-01-1]),「#2966. 英語語彙の世界性 (2)」 ([2017-06-10-1]),「#2977. 連載第6回「なぜ英語語彙に3層構造があるのか? --- ルネサンス期のラテン語かぶれとインク壺語論争」」 ([2017-06-21-1]) などで取り上げてきた.しかし,豊かであるがゆえに,歴史上,むやみに借りすぎだ,作りすぎだという批判が繰り返されてきた.
最も有名なのは16世紀後半の「インク壺語」 (inkhorn_term) 論争であり,「#576. inkhorn term と英語辞書」 ([2010-11-24-1]) などで紹介してきた.しかし,ほかにも「#2147. 中英語期のフランス借用語批判」 ([2015-03-14-1]),「#2813. Bokenham の純粋主義」 ([2017-01-08-1]),「#1411. 初期近代英語に入った "oversea language"」 ([2013-03-08-1]) のように,あまり目立たないところで語彙批判は繰り返されてきた.
もう1つ付け加えるべきは,後期近代英語期の造語法の特徴ともいえる新古典主義的複合語 (neo-classical compounds) に向けられた批判である.主にラテン語やギリシア語の連結形 (combining_form) を用いて造語するもので,neo-Latin compounds や neo-Hellenic compounds とも呼ばれる.この造語法は,19世紀に科学用語などの専門用語が大量に必要となった際に利用された方法である (cf. 「#1694. 科学語彙においてギリシア語要素が繁栄した理由」 ([2013-12-16-1])) .
Beal (22--23) は19世紀の新古典主義的複合語への批判と,かつての「インク壺語」の論争がよく似ている点を指摘している.
If we look at comments on language in the nineteenth century, we find a range of opinions remarkably similar to those expressed during the 'inkhorn' controversy of the late sixteenth/early seventeenth centuries. On the one hand, there were complaints about the number of new words coined from Latin and Greek. Richard Grant White writes:
In no way is our language more wronged than by a weak readiness with which many of those who, having neither a hearty love nor a ready mastery of it, or lacking both, fly readily to the Latin tongue or to the Greek for help in naming a new thought or thing, or the partial concealment of an old one . . . By doing so they help to deface the characteristic traits of our mother tongue, and to mar and stunt its kindly growth (1872; 22, cited in Bailey, 1996: 141--2 [= Bailey, R. W. Nineteenth-Century English. Ann Arbor: U of Michigan P, 1996]).
Others objected to the profusion of technical and scientific vocabulary, again mainly from Greek and Latin sources. R. Chenevix Trench wrote (1860: 57--8) that these were 'not, for the most part, except by an abuse of language, words at all, but signs: having been deliberately invented as the nomenclature and, so to speak, the algebraic notation of some special art or science'.
新古典主義的複合語は,数と質の両方の点において(少なくとも一部の論者にとって)批判の対象となっていたことがわかる.
ついでながら,日本語の明治期における「チンプン漢語」批判や現在の「カタカナ語」の氾濫問題も,英語史からの上記のケースとよく似ている.これについては,「#1630. インク壺語,カタカナ語,チンプン漢語」 ([2013-10-13-1]),「#1999. Chuo Online の記事「カタカナ語の氾濫問題を立体的に視る」」 ([2014-10-17-1]),「#2977. 連載第6回「なぜ英語語彙に3層構造があるのか? --- ルネサンス期のラテン語かぶれとインク壺語論争」」 ([2017-06-21-1]) で解説・論評しているので是非ご参照を.
・ Beal, Joan C. English in Modern Times: 1700--1945. Arnold: OUP, 2004.
2017-07-09 Sun
■ #2995. Augustan Age の語彙的保守性 [lexicology][emode][inkhorn_term][purism][loan_word][latin][greek]
17世紀後半から18世紀にかけて語彙の増加が比較的低迷した時期がある.この事実は「#203. 1500--1900年における英語語彙の増加」 ([2009-11-16-1]),「#1226. 近代英語期における語彙増加の年代別分布」 ([2012-09-04-1]) のグラフより,一目瞭然だろう.英国史では,一般に1700年に前後する時代は保守的で渋好みの新古典主義時代(Augustan Age) と称されており,その傾向が言語上に新語彙導入の低迷というかたちで反映していると解釈することができる(関連して,「#2650. 17世紀末の質素好みから18世紀半ばの華美好みへ」 ([2016-07-29-1]),「#2782. 18世紀のフランス借用語への「反感」」 ([2016-12-08-1]) を参照).
この時代の語彙的保守性には歴史的背景がある.1つは,先立つ時代,特に16世紀後半から17世紀前半に,ラテン語やギリシア語といった古典語から大量の語彙が流入したという事実がある.「インク壺用語」 (inkhorn_term) と揶揄されるほどの,鼻につくような外国語の洪水に特徴づけられた時代である.このような大量借用は,確かに部分的には必要だった.科学,宗教,医学,哲学などの媒介言語がラテン語から英語へと急激に切り替わる時代にあって,英語は多くの語彙を確かに必要とした.しかし,短期集中で語彙を借用した結果,早々と英語の「語彙の必要」は満たされ,続く時代にはそれ以上借用するものがなくなってきた.Augustan Age で相対的に語彙借用が減ったのは,先立つ時代の「借用しすぎ」によるところも大きかったと思われる.語彙史も,ピークばかりでは疲れてしまうということか.
もう1つの歴史的背景としては,Augustan Age は,前時代の「借用しすぎ」を差し引いても,やはり保守的な言語観に支配されていた時代だったという事実がある.例えば,Jonathan Swift (1667--1745) や Joseph Addison (1672--1719) は当時を代表する保守派の論客であり,英語の堕落を嘆き,その改善・洗練・固定化を目指すために活発な執筆活動を行なっていた.「#1947. Swift の clipping 批判」([2014-08-26-1]) や「#1948. Addison の clipping 批判」 ([2014-08-27-1]),「#2741. ascertaining, refining, fixing」 ([2016-10-28-1]) に見られるように,時代の雰囲気は,華美を避け,質実剛健を求める保守主義だったのである.
Augustan Age の全体的な言語的傾向としては上記の通りだが,個々の年でいえば,例外的に新語彙導入の目立つ年もあった.例えば,1740年代から50年代にかけては,全体として語彙増加が最も低調な時代ではあるが,1753年には Chambers' Cyclopaedia が出版されており,そこに多くの科学用語が含まれていたために,例外的に語彙の生産力が高まった年として記録されている (Beal 21) .具体例を挙げれば,ラテン語およびギリシア語から adarticulation, aeronautics, azalea, ballistics, hydrangea, primula, sphagnum, trifoliate; anthropomorphism, eczema, mnemonic, urology 等が,この年に記録されている.
・ Beal, Joan C. English in Modern Times: 1700--1945. Arnold: OUP, 2004.
2017-07-01 Sat
■ #2987. ヨーロッパでそのまま通用する英語語句 [loan_word][borrowing][lexicology]
英語は歴史を通じて様々な言語から数多くの単語を借用してきた.この事実について,最近では「#2966. 英語語彙の世界性 (2)」 ([2017-06-10-1]) で総括した.しかし,現代世界において,英語は語彙の借り入れ側というよりも,むしろ貸し出し側としての役割のほうが目立っている.近年,日本語にも無数の英単語がカタカナ語として流入しているし,世界の諸言語を見渡しても,英語から何らかの語彙的影響を被っていない言語はほぼ皆無だろう(カタカナ語問題については,「#1999. Chuo Online の記事「カタカナ語の氾濫問題を立体的に視る」」 ([2014-10-17-1]) を参照).
独自の標準語が安定的に確立しているヨーロッパ諸国ですら,英語の語彙的影響は著しい.以下は,ヨーロッパの多くの言語でそのまま通用する英語語句の例である (Crystal 272) .
[ Sport ]
baseball, bobsleigh, clinch, comeback, deuce, football, goalie, jockey, offside, photo-finish, semi-final, volley, walkover
[ Tourism, transport etc. ]
antifreeze, camping, hijack, hitch-hike, jeep, joy-ride, motel, parking, picnic, runway, scooter, sightseeing, stewardess, stop (sign), tanker, taxi
[ Politics, commerce ]
big business, boom, briefing, dollar, good-will, marketing, new deal, senator, sterling, top secret
[ Culture, entertainment ]
cowboy, group, happy ending, heavy metal, hi-fi, jam session, jazz, juke-box, Miss World (etc.), musical, night-club, pimp, ping-pong, pop, rock, showbiz, soul, striptease, top twenty, Western, yeah-yeah-yeah
[ People and behaviour ]
AIDS, angry young man, baby-sitter, boy friend, boy scout, callgirl, cool, cover girl, crack (drugs), crazy, dancing, gangster, hash, hold-up, jogging, mob, OK, pin-up, reporter, sex-appeal, sexy, smart, snob, snow, teenager
[ Consumer society ]
air conditioner, all rights reserved, aspirin, bar, best-seller, bulldozer, camera, chewing gum, Coca Cola, cocktail, coke, drive-in, eye-liner, film, hamburger, hoover, jumper, ketchup, kingsize, Kleenex, layout, Levis, LP, make-up, sandwich, science fiction, Scrabble, self-service, smoking, snackbar, supermarket, tape, thriller, up-to-date, WC, weekend
これらの語句には,ヨーロッパのみならず日本語でもカタカナ語として通用しているものが多い.その意味では,世界的な語彙 (cosmopolitan vocabulary) に接近していると言えるかもしれない.
・ Crystal, David. The English Language. 2nd ed. London: Penguin, 2002.
2017-06-21 Wed
■ #2977. 連載第6回「なぜ英語語彙に3層構造があるのか? --- ルネサンス期のラテン語かぶれとインク壺語論争」 [notice][link][loan_word][borrowing][lexicology][french][latin][lexical_stratification][japanese][inkhorn_term][rensai][sobokunagimon]
昨日付けで,英語史連載企画「現代英語を英語史の視点から考える」の第6回の記事「なぜ英語語彙に3層構造があるのか? --- ルネサンス期のラテン語かぶれとインク壺語論争」が公開されました.
今回の話は,英語語彙を学ぶ際の障壁ともなっている多数の類義語セットが,いかに構造をなしており,なぜそのような構造が存在するのかという素朴な疑問に,歴史的な観点から迫ったものです.背景には,英語が特定の時代の特定の社会的文脈のなかで特定の言語と接触してきた経緯があります.また,英語語彙史をひもといていくと,興味深いことに,日本語語彙史との平行性も見えてきます.対照言語学的な日英語比較においては,両言語の違いが強調される傾向がありますが,対照歴史言語学の観点からみると,こと語彙史に関する限り,両言語はとてもよく似ています.連載記事の後半では,この点を議論しています.
英語語彙(と日本語語彙)の3層構造の話題については,拙著『英語の「なぜ?」に答える はじめての英語史』のの5.1節「なぜ Help me! とは叫ぶが Aid me! とは叫ばないのか?」と5.2節「なぜ Assist me! とはなおさら叫ばないのか?」でも扱っていますが,本ブログでも様々に議論してきたので,そのリンクを以下に張っておきます.合わせてご覧ください.また,同様の話題について「#1999. Chuo Online の記事「カタカナ語の氾濫問題を立体的に視る」」 ([2014-10-17-1]) で紹介した拙論もこちらからご覧ください.
・ 「#334. 英語語彙の三層構造」 ([2010-03-27-1])
・ 「#1296. 三層構造の例を追加」 ([2012-11-13-1])
・ 「#1960. 英語語彙のピラミッド構造」 ([2014-09-08-1])
・ 「#2072. 英語語彙の三層構造の是非」 ([2014-12-29-1])
・ 「#2279. 英語語彙の逆転二層構造」 ([2015-07-24-1])
・ 「#2643. 英語語彙の三層構造の神話?」 ([2016-07-22-1])
・ 「#387. trisociation と triset」 ([2010-05-19-1])
・ 「#1437. 古英語期以前に借用されたラテン語の例」 ([2013-04-03-1])
・ 「#32. 古英語期に借用されたラテン語」 ([2009-05-30-1])
・ 「#1945. 古英語期以前のラテン語借用の時代別分類」 ([2014-08-24-1])
・ 「#120. 意外と多かった中英語期のラテン借用語」 ([2009-08-25-1])
・ 「#1211. 中英語のラテン借用語の一覧」 ([2012-08-20-1])
・ 「#478. 初期近代英語期に湯水のように借りられては捨てられたラテン語」 ([2010-08-18-1])
・ 「#114. 初期近代英語の借用語の起源と割合」 ([2009-08-19-1])
・ 「#1226. 近代英語期における語彙増加の年代別分布」 ([2012-09-04-1])
・ 「#2162. OED によるフランス語・ラテン語からの借用語の推移」 ([2015-03-29-1])
・ 「#2385. OED による,古典語およびロマンス諸語からの借用語彙の統計 (2)」 ([2015-11-07-1])
・ 「#576. inkhorn term と英語辞書」 ([2010-11-24-1])
・ 「#1408. インク壺語論争」 ([2013-03-05-1])
・ 「#1409. 生き残ったインク壺語,消えたインク壺語」 ([2013-03-06-1])
・ 「#1410. インク壺語批判と本来語回帰」 ([2013-03-07-1])
・ 「#1615. インク壺語を統合する試み,2種」 ([2013-09-28-1])
・ 「#609. 難語辞書の17世紀」 ([2010-12-27-1])
・ 「#335. 日本語語彙の三層構造」 ([2010-03-28-1])
・ 「#1630. インク壺語,カタカナ語,チンプン漢語」 ([2013-10-13-1])
・ 「#1629. 和製漢語」 ([2013-10-12-1])
・ 「#1067. 初期近代英語と現代日本語の語彙借用」 ([2012-03-29-1])
・ 「#296. 外来宗教が英語と日本語に与えた言語的影響」 ([2010-02-17-1])
・ 「#1526. 英語と日本語の語彙史対照表」 ([2013-07-01-1])
2017-06-10 Sat
■ #2966. 英語語彙の世界性 (2) [lexicology][loan_word][borrowing][statistics][link]
英語語彙の世界性について,1年ほど前の記事 ([2016-06-24-1]) で様々なリンクを張ったが,その後書き足した記事もあるので,リンク等をアップデートしておきたい.記事を読み進めていけば,英語語彙史の概要が分かる.
1 数でみる英語語彙
1.1 語彙の規模の大きさ (#898)
1.2 語彙の種類の豊富さ (##756,309,202,429,845,1202,110,201,384)
1.3 英語語彙史の概略 (##37,1526,126,45)
2 語彙借用とは?
2.1 なぜ語彙を借用するのか? (##46,1794)
2.2 借用の5W1H:いつ,どこで,何を,誰から,どのように,なぜ借りたのか? (#37)
3 英語の語彙借用の歴史 (#1526)
3.1 大陸時代 (--449)
3.1.1 ラテン語 (#1437)
3.2 古英語期 (449--1100)
3.2.1 ケルト語 (##1216,2443)
3.2.2 ラテン語 (#32)
3.2.3 古ノルド語 (##2625,2693,340,818)
3.2.4 古英語本来語のその後 (##450,2556,648)
3.3 中英語期 (1100--1500)
3.3.1 フランス語 (##117,1210)
3.3.2 ラテン語 (##120,1211)
3.3.3 中英語の語彙の起源と割合 (#985)
3.4 初期近代英語期 (1500--1700)
3.4.1 ラテン語 (##478,114,1226)
3.4.2 ギリシア語 (#516)
3.4.3 ロマンス諸語 (##2385,2162,1411,1638)
3.5 後期近代英語期 (1700--1900) と現代英語期 (1900--)
3.5.1 語彙の爆発 (##203,616)
3.5.2 世界の諸言語 (##874,2165,2164)
4 現代の英語語彙にみられる歴史の遺産
4.1 フランス語とラテン語からの借用語 (#2162)
4.2 動物と肉を表わす単語 (##331,754)
4.3 語彙の3層構造 (##334,1296,335,1960)
4.4 日英語の語彙の共通点 (##1645,296,1630,1067)
5 現在そして未来の英語語彙
5.1 借用以外の新語の源泉 (##873,874,875)
5.2 語彙は時代を映し出す (##625,631,876,889)
英語語彙史を大づかみする上で最重要となる3点を指摘しておきたい.
(1) 英語語彙史は,英語と他言語の交流の歴史と連動している
(2) 語彙借用の動機づけは「必要性」のみではない
(3) 語彙借用により類義語が積み上げられていき,結果として3層構造が生じた
2017-05-20 Sat
■ #2945. 間違えやすい同音異綴語のペア [homonymy][homophony][lexicology]
現代英語には,多くの同音異綴(語) (homophony) のペアがある.異なる語であるとはいえ意味も互いに似ているものが多く,しばしば学習しにくい.以下は,Crystal (81) より持ってきたものだが,いずれも(ほぼ)同音異綴語を含む例文である.各組において,どちらが文脈上・文法上適切な語か指摘できるだろうか.解答はソースHTMLを参照.
(1a) Did they all accept/except?
(1b) Everyone accept/except John left?
(2a) Did we prophecy/prophesy the right result?
(2b) It was a rotten prophecy/prophesy.
(3a) Has he made any allusions/illusions to the problem?
(3b) He's under no allusions/illusions about its difficulty
(4a) I want to amend/emend what I wrote.
(4b) I want to amend/emend my ways.
(5a) She was born/borne through the crowds.
(5b) She was born/borne in 1568.
(6a) That will complement/compliment your shirt nicely.
(6b) Thank you for your complement/compliment.
(7a) Someone's complained to the council/counsel.
(7b) You should take some council/counsel about that.
(8a) You need a new licence/license for that hamster.
(8b) I'll licence/license it next week.
(9a) Look at that fantastic lightning/lightening.
(9b) I think the sky's lightning/lightening now.
(10a) I need some more stationary/stationery.
(10b) That car's stationary/stationery.
(11a) I'm the principle/principal speaker.
(11b) I'm going to stick to my principles/principals.
(12a) I'm going to do some sowing/sewing in the sitting room.
(12b) I'm going to do some sowing/sewing in the long field.
関連して,「#286. homonymy, homophony, homography, polysemy」 ([2010-02-07-1]),「#2097. 表語文字,同音異綴,綴字発音」 ([2015-01-23-1]),「#2432. Bolinger の視覚的形態素」 ([2015-12-24-1]) を参照.
・ Crystal, David. The English Language. 2nd ed. London: Penguin, 2002.
2017-03-12 Sun
■ #2876. 英語語彙の頻度分布に関する格差上位1%のシェア [lexicology][statistics][frequency][corpus]
昨日の記事「#2875. 英語語彙の頻度分布の格差をジニ係数とローレンツ曲線でみる」 ([2017-03-11-1]) に引き続き,英語語彙頻度の格差について考えてみたい.昨日扱ったジニ係数よりも直感的に格差を認識できる指標として,格差上位1%のシェアというものがある.経済学でいえば,トマス・ピケティも愛用している「トップ富裕層の所得シェア」である.大金持ちがどのくらい金持ちか,という指標と理解すればよい.英語語彙について言えば,生起頻度でトップ1%に入るそれほど多くない語によって,全体のどのくらいのシェアが占められているかを示す指標となる.
昨日と同じように,総頻度数が81.5万ほどの比較的小規模な GSL の語彙頻度表と,1850万ほどの巨大コーパス「#1424. CELEX2」 ([2013-03-21-1]) に基づく語彙頻度表で計算してみた.トップ1%とトップ0.1%での値は,以下の通り.
| GSL | CELEX2 | |
|---|---|---|
| 1% | 47.05% | 69.36% |
| 0.1% | 14.60% | 43.57% |
実際,ここまで高い値になるとは予想していなかった.英語学習という観点からみると,極端な話し,高頻度語のトップ1%を暗記すれば,5?7割ほどの語が認識できることになる.それでテキストを理解できるかというと,それはまったく別問題ではあるが,語彙学習の効率について再考させられる.
参考までに,2000年の時点での日米の所得シェアを見てみると,アメリカではトップ0.1%の富裕層が所得全体の7%ほど,日本では2%ほどである(吉川,p. 226).近年,両国ともに格差は開いてきているようだが,さすがに語彙の世界ほどの格差に至ることはないだろう.語彙の社会は,あらためて不平等な社会である.
・ 吉川 洋 『人口と日本経済』 中央公論新社〈中公新書〉,2016年.
[ 固定リンク | 印刷用ページ ]
2017-03-11 Sat
■ #2875. 英語語彙の頻度分布の格差をジニ係数とローレンツ曲線でみる [lexicology][statistics][frequency][zipfs_law][corpus]
「#1103. GSL による Zipf's law の検証」 ([2012-05-04-1]) で,General Service List (GSL) の最頻2000語余りの語彙頻度表を用いて,zipfs_law が成立する様子を実演した.頻度順位の高い少数の語がただの高頻度語ではなく超高頻度語であること,一方でそれ以外の大多数の語がおしなべて低頻度語であるということが確認された.このことは,英語(そして,おそらくあらゆる言語)の語彙の頻度分布がきわめて不平等・不均衡であり,大きなばらつきと格差に特徴づけられていることを示すものである.
このような分布の格差を示す代表的な指標に,イタリアの経済学者ジニが所得や資産の分布の不平等を計測する指標として1936年に考案したジニ係数 (Gini's coefficient) がある.考え方は次の通りだ.X軸に沿って左から右へ最も頻度の低い語から高い語へと順に並べ,その累積頻度のシェアをY軸方向に取っていく.この点をつなげると,何らかの形の右肩上がりの曲線となる.これをローレンツ曲線 (Lorenz curve) という.すべての語が同頻度で現われるときにはローレンツ曲線は45度の右肩上がりの直線となり「完全平等」を示す.逆に,極端な例として,1つの語のみが生起頻度のすべてを占有し,他のすべての語が頻度ゼロの場合に「完全不平等」となり,ローレンツ曲線は左右逆L字型となる.普通は,ローレンツ曲線は,45度の右肩上がりの線の下部に,三日月形の弧として描かれる.ジニ係数は,三日月の面積と,45度の右肩上がりの線を直角の対辺とする直角二等辺三角形の比率として表現される.したがって,値0が完全平等,値1が完全不平等ということになる.
さて,GSL のデータファイルで計算した結果,ジニ係数は0.812と出た.ローレンツ曲線を描くと,以下のようになる.
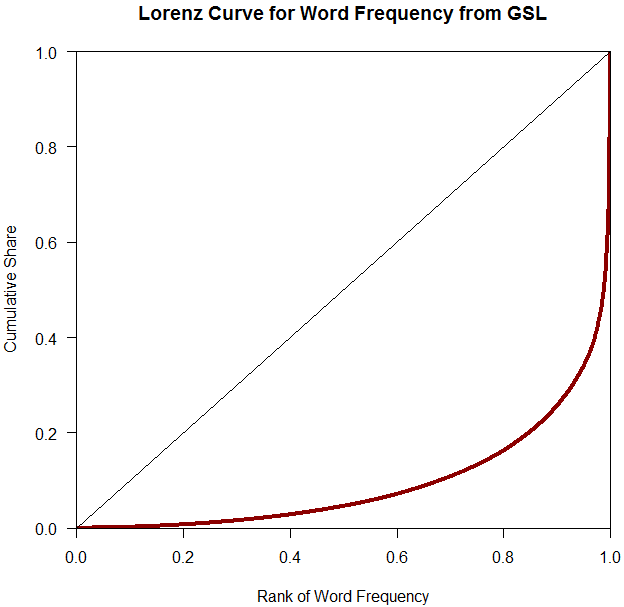
明らかに不平等な分布といえる.ちなみに,GSL よりも巨大なコーパスの語彙頻度表を使うと,さらにジニ係数は上がる(例えば,1790万語からなるコーパス「#1424. CELEX2」 ([2013-03-21-1]) に基づいた計算では,0.950 というすさまじい値が出た!).
参考までに,吉川 (122) に拠って2010年の諸国の所得格差を示すジニ係数をいくつか挙げると,日本が 0.336,アメリカが 0.380,チリが 0.510,アイスランドが 0.246 である.語彙の社会が極めて不平等な社会であることが分かるだろう.
・ 吉川 洋 『人口と日本経済』 中央公論新社〈中公新書〉,2016年.
2017-02-06 Mon
■ #2842. 固有名詞から生まれた語 [eponym][toponym][onomastics][etymology][metonymy][semantic_change][lexicology]
シップリー (722--39) に「固有名詞から生まれた言葉」の一覧がある.以下では,その一覧を参照用に再現する.各表現の故事来歴について詳しくは直接シップリーに,あるいは各種の辞書に当たっていただきたい.とりあえず,このような表現がたくさんあるものだということを示しておきたい.
Adonis
agaric
agate
Alexandrine
Alice blue
America
ammonia
ampere
Ananias
Annie Oakley
aphrodisiac
areopagus
argosy
Argus-eyed
arras
artesian well
astrachan
Atlantic
atlas
babbitt
bacchanals
bakelite
barlett (pear)
battology
bayonet
begonia
bellarmine
bergamask
bison
blanket
bloomers
bobby
bohemian
bowdlerize
bowie
boycott
braille
brie
Brithg's disease
bronze
brougham
Brownian movement
brummagem
bunsen (burner)
Casarean
camembert
cantaloup
cardigan
caryatid
Cassandra
cereal
chalcedony
cherrystone clams
Chippendale
coach
Colombia, Columbia
cologne
colophony
colt
copper
coulomb
cravat
cupidity
currant
daguerreotype
dauphin
derby
diesel (engine)
diddle
doily
dollar
dumdum bullet
Duncan Phyfe
Dundreary (whiskers)
echo
epicurean
ermine
erotic
euhemerism
euphuism
Fabian
Fahrenheit
faience
Fallopian
farad
Ferris (wheel)
fez
forsythia
frankfurter
frieze
galvanize
gamboges
gardenia
gargantuan
gasconade
gauss
gavotte
gibus
Gilbertian
gladstone (bag)
Gobelin
gongorism
Gordian knot
gothite
greengage
Gregorian (calendar/chant)
guillotine
hamburger
havelock
Heaviside layer
hector
helot
henry
hermetically
hiddenite
Hitlerism
Hobson's choice
hyacinth
indigo
iridium
iris
jacinth
Jack Ketch
Jack Tar
jeremiad
jobation
Jonah
joule
jovial
Julian calendear
laconic
lambert
landau
Laputan, Laputian
lavalier
lazar
leather-stocking
Leninism
Leyden jar
lilliputian
limousine
loganberry
Lothario
lyceum
lynch
macadamize
machiavellian
machinaw
mackintosh
magnet
magnolia
malapropism
Malpighian tubes
manil(l)a
mansard roof
marcel
martinet
Marxist
maudlin
mausoleum
maxim (gun)
mayonnaise
mazurka
McIntosh (apple)
Melba toast
Mendelian
mentor
Mercator projection
mercerize
mercurial
meringue
mesmerism
mho
milliner
mnemonic
morphine
morris chair
morris dance
Morse code
negus
nicotine
Nestor
Occam's razor
odyssey
ogre
ohm
Olympian
panama (hat)
panic
parchment
Parthian glance, Parthian shot
pasteurize
peach
peeler
peony
percheron
philippic
pinchbeck
Platonic
Plimsoll line [mark]
poinsettia
polka
polonaise
pompadour
praline
Prince Albert
procrustean
protean
prussic (acid)
Ptolemaic system
Pullman
pyrrhic victory
pyrrhonism
quisling
quixotic
raglan
rhinestone
rodomontade
Roentgen ray
roquefort
Rosetta Stone
Rosicrucian
Salic (law)
Sally Lunn
Samaritan
sandwich
sardine
sardonic
sardonyx
satire
saxophone
scrooge
Seidlitz
sequoia
shanghai
Sheraton
shrapnel
silhouette
simony
sisyphean
socratic
solecism
spaniel
Spencer
spinach
spruce
Stalinism
stentorian
Steve Brodie
sybarite
tabasco
tangerine
tarantella
tarantula
thrasonical
timothy
titanic
tobacco
Trotskyte
trudgen
Vandyke
vaudeville
venery
Victoria
volcano
volt
vulcanize
watt
Wedgwood ware
Wellington (boot)
Winchester rifle
wulfenite
Xant(h)ippe
Zeppelin
場所や人の名前をもとに,その来歴や何らかの特徴を反映した普通名詞が生まれるのは,主に metonymy の作用と考えられる.また,本来は固有の指示対象をもっていたものが,一般的に用いられるようになったという点で,意味の拡大の事例ともいえるだろう.
シップリーの語源に関するリストとしては,ほかに「#1723. シップリーによる2重語一覧」 ([2014-01-14-1]) でも話題にしたので参照を.
・ ジョーゼフ T. シップリー 著,梅田 修・眞方 忠道・穴吹 章子 訳 『シップリー英語語源辞典』 大修館,2009年.
2017-01-06 Fri
■ #2811. 部分語と全体語 [hyponymy][meronymy][lexicology][semantics][semantic_field][terminology]
「#1962. 概念階層」 ([2014-09-10-1]) や「#1961. 基本レベル範疇」 ([2014-09-09-1]) でみた概念階層 (conceptual hierarchy) あるいは包摂関係 (hyponymy) においては,例えば「家具」という上位語 (hypernym) の配下に「机」という下位語 (hyponym) があり,さらにその「机」が上位語となって,その下に「勉強机」や「作業机」という下位語が位置づけられる.ここでは,包摂という関係に基づいて,全体が階層構造をなしているのが特徴的である.
このような hyponymy と類似しているが区別すべき語彙的関係として,meronymy (部分と全体の関係)と呼ばれるものがある.例えば,「車輪」と「自転車」は部分と全体の関係にあり,「車輪」は「自転車」の meronym (部分語),「自転車」は「車輪」の holonym (全体語)と称される.meronymy においても hyponymy の場合と同様に,その関係は相対的なものであり,例えば「車輪」は「自転車」にとっては meronym だが,車輪を構成する「輻(スポーク)」にとっては holonym である.Cruse (105--06) からの meronymy の説明を示そう.
meronymy This is the 'part-whole' relation, exemplified by finger: hand, nose: face, spoke: wheel, blade: knife, harddisk: computer, page: book, and so on. The word referring to the part is called the 'meronym' and the word referring to the whole is called the 'holonym'. The names of sister parts of the same whole is called 'co-meronyms'. Notice that this is a relational notion: a word may be a meronym in relation to a second word, but a holonym in relation to a third. Thus finger is a meronym of hand, but a holonym of knuckle and fingernail. (Meronymy must not be confused with by hyponymy, although some of their properties are similar: for instance, both involve a type of 'inclusion', co-meronyms and co-taxonyms have a mutually exclusive relation, and both are important in lexical hierarchies. However, they are distinct: a dog is a kind of animal, but not a part of an animal; a finger is a part of a hand, but not a kind of hand.
meronymy と hyponymy は,いずれも「包摂」と「階層構造」を示す点で共通しているが,上の説明の最後にあるように,前者は part,後者は kind に対応するものであるという差異が確認される.また,meronymy では,部分と全体が互いにどのくらい必須であるかについて,hyponymy の場合よりも基準が明確でないことが多い.「顔」と「目」の関係はほぼ必須と考えられるが,「シャツ」と「襟」,「家」と「地下室」はどうだろうか.
さらに,hyponymy と meronymy は移行性 (transitivity) の点でも異なる振る舞いを示す.hyponymy では移行性が確保されているが,meronymy では必ずしもそうではない.例えば,「手」と「指」と「爪」は互いに meronymy の関係にあり,「手には指がある」と言えるだけでなく,「手には爪がある」とも言えるので,この関係は transitive とみなせる.しかし,「部屋」と「窓」と「窓ガラス」は互いに meronymy の関係にあるが,「部屋に窓がある」とは言えても「部屋に窓ガラスがある」とは言えないので,transitive ではない.
・ Cruse, Alan. A Glossary of Semantics and Pragmatics. Edinburgh: Edinburgh UP, 2006.
2016-12-23 Fri
■ #2797. floccinaucinihilipilification [spelling][word_formation][latin][neo-latin][lexicology][phonaesthesia][sound_symbolism]
最長の英単語について,「#63. 塵肺症は英語で最も重い病気?」 ([2009-06-30-1]),「#391. antidisestablishmentarianism 「反国教会廃止主義」」 ([2010-05-23-1]),「#392. antidisestablishmentarianism にみる英語のロマンス語化」 ([2010-05-24-1]) の記事で論じてきた.もう1つ,おどけた表現として用いられる標題の単語 floccinaucinihilipilification を知った.『ランダムハウス英語辞典』では「英語で最も長い単語の例として引き合いに出される」とある.
OED の定義によると,"humorous. The action or habit of estimating as worthless." とある.「無価値とみなすこと,軽視癖」の意である.
語源・形態的に解説すると,ラテン語 floccus は「羊毛のふさ」,naucum は「取るに足りないもの」,nihil は「無」,pilus は「一本の毛」を意味し,これらの「つまらないもの」の束に,他動詞を作る facere を付加して,それをさらに名詞化した語である.ラテン語の語形成規則に則って正しく作られている語だが,あくまで英語の内部での造語であるという点では,一種の英製羅語である(関連して「#1493. 和製英語ならぬ英製羅語」 ([2013-05-29-1]) も参照).
OED によると,初出は1741年.以下に,2つほど例文を引用しよう.
1741 W. Shenstone Let. xxii, in Wks. (1777) III. 49, I loved him for nothing so much as his flocci-nauci-nihili-pili-fication of money.
1829 Scott Jrnl. 18 Mar. (1946) 39 They must be taken with an air of contempt, a floccipaucinihilipilification [sic, here and in two other places] of all that can gratify the outward man.
なお,発音は /ˌflɒksɪnɔːsɪˌnɪhɪlɪˌpɪlɪfɪˈkeɪʃən/ となっている.12音節,27音素からなる長大な1単語である.12の母音音素のうち,8個までが前舌後母音 /ɪ/ であるということは,「#242. phonaesthesia と 遠近大小」 ([2009-12-25-1]) で論じた phonaesthesia を思い起こさせる.小さいもの,すなわち無価値なものは,音象徴の観点からは前舌後母音と相性がよい,ということかもしれない.
Powered by WinChalow1.0rc4 based on chalow