2013-03-05 Tue
■ #1408. インク壺語論争 [popular_passage][inkhorn_term][loan_word][lexicology][emode][renaissance][latin][greek][purism]
16世紀のインク壺語 (inkhorn term) を巡る問題の一端については,昨日の記事「#1407. 初期近代英語期の3つの問題」 ([2013-03-04-1]) 以前にも,「#478. 初期近代英語期に湯水のように借りられては捨てられたラテン語」 ([2010-08-18-1]) ,「#576. inkhorn term と英語辞書」 ([2010-11-24-1]) ほか inkhorn_term の各記事で触れてきた.インク壺語批判の先鋒としては,[2010-11-24-1]で引用した The Arte of Rhetorique (1553) の著者 Thomas Wilson (1528?--81) が挙げられるが,もう1人挙げるとするならば Sir John Cheke (1514--57) がふさわしい.Cheke は自らがギリシア語学者でありながら,古典語からのむやみやたらな借用を強く非難した.同じくギリシア語学者である Roger Ascham (1515?--68) も似たような態度を示していた点が興味深い.Cheke は Sir Thomas Hoby に宛てた手紙 (1561) のなかで,純粋主義の主張を行なった(Baugh and Cable, pp. 217--18 より引用).
I am of this opinion that our own tung shold be written cleane and pure, unmixt and unmangeled with borowing of other tunges, wherin if we take not heed by tijm, ever borowing and never payeng, she shall be fain to keep her house as bankrupt. For then doth our tung naturallie and praisablie utter her meaning, when she bouroweth no counterfeitness of other tunges to attire her self withall, but useth plainlie her own, with such shift, as nature, craft, experiens and folowing of other excellent doth lead her unto, and if she want at ani tijm (as being unperfight she must) yet let her borow with suche bashfulnes, that it mai appeer, that if either the mould of our own tung could serve us to fascion a woord of our own, or if the old denisoned wordes could content and ease this neede, we wold not boldly venture of unknowen wordes.
Erasmus の Praise of Folly を1549年に英訳した Sir Thomas Chaloner も,インク壺語の衒学たることを揶揄した(Baugh and Cable, p. 218 より引用).
Such men therfore, that in deede are archdoltes, and woulde be taken yet for sages and philosophers, maie I not aptelie calle theim foolelosophers? For as in this behalfe I have thought good to borowe a littell of the Rethoriciens of these daies, who plainely thynke theim selfes demygods, if lyke horsleches thei can shew two tongues, I meane to mingle their writings with words sought out of strange langages, as if it were alonely thyng for theim to poudre theyr bokes with ynkehorne termes, although perchaunce as unaptly applied as a gold rynge in a sowes nose. That and if they want suche farre fetched vocables, than serche they out of some rotten Pamphlet foure or fyve disused woords of antiquitee, therewith to darken the sence unto the reader, to the ende that who so understandeth theim maie repute hym selfe for more cunnyng and litterate: and who so dooeth not, shall so muche the rather yet esteeme it to be some high mattier, because it passeth his learnyng.
"foolelosophers" とは厳しい.
このようにインク壺語批判はあったが,時代の趨勢が変わることはなかった.インク壺語を(擁護したとは言わずとも)穏健に容認した Sir Thomas Elyot (c1490--1546) や Richard Mulcaster (1530?--1611) などの主たる人文主義者たちの示した態度こそが,時代の潮流にマッチしていたのである.
なお,OED によると,ink-horn term という表現の初出は1543年.
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
2013-03-04 Mon
■ #1407. 初期近代英語期の3つの問題 [emode][renaissance][popular_passage][orthoepy][orthography][spelling_reform][standardisation][mulcaster][loan_word][latin][inkhorn_term][lexicology][hart]
初期近代英語期,特に16世紀には英語を巡る大きな問題が3つあった.Baugh and Cable (203) の表現を借りれば,"(1) recognition in the fields where Latin had for centuries been supreme, (2) the establishment of a more uniform orthography, and (3) the enrichment of the vocabulary so that it would be adequate to meet the demands that would be made upon it in its wiser use" である.
(1) 16世紀は,vernacular である英語が,従来ラテン語の占めていた領分へと,その機能と価値を広げていった過程である.世紀半ばまでは,Sir Thomas Elyot (c1490--1546), Roger Ascham (1515?--68), Thomas Wilson (1525?--81) , George Puttenham (1530?--90) に代表される英語の書き手たちは,英語で書くことについてやや "apologetic" だったが,世紀後半になるとそのような詫びも目立たなくなってくる.英語への信頼は,特に Richard Mulcaster (1530?--1611) の "I love Rome, but London better, I favor Italie, but England more, I honor the Latin, but I worship the English." に要約されている.
(2) 綴字標準化の動きは,Sir John Cheke (1514--57), Sir Thomas Smith (1513--77; De Recta et Emendata Linguae Anglicae Scriptione Dialogus [1568]), John Hart (d. 1574; An Orthographie [1569]), William Bullokar (fl. 1586; Book at Large [1582], Bref Grammar for English [1586]) などによる急進的な表音主義的な諸提案を経由して,Richard Mulcaster (The First Part of the Elementarie [1582]), E. Coot (English Schoole-master [1596]), P. Gr. (Paulo Graves?; Grammatica Anglicana [1594]) などによる穏健な慣用路線へと向かい,これが主として次の世紀に印刷家の支持を受けて定着した.
(3) 「#478. 初期近代英語期に湯水のように借りられては捨てられたラテン語」 ([2010-08-18-1]),「#576. inkhorn term と英語辞書」 ([2010-11-24-1]),「#1226. 近代英語期における語彙増加の年代別分布」 ([2012-09-04-1]) などの記事で繰り返し述べてきたように,16世紀は主としてラテン語からおびただしい数の借用語が流入した.ルネサンス期の文人たちの多くが,Sir Thomas Elyot のいうように "augment our Englysshe tongue" を目指したのである.
vernacular としての初期近代英語の抱えた上記3つの問題の背景には,中世から近代への急激な社会変化があった.再び Baugh and Cable (200) を参照すれば,その要因は5つあった.
1. the printing press
2. the rapid spread of popular education
3. the increased communication and means of communication
4. the growth of specialized knowledge
5. the emergence of various forms of self-consciousness about language
まさに,文明開化の音がするようだ.[2012-03-29-1]の記事「#1067. 初期近代英語と現代日本語の語彙借用」も参照.
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
2013-02-25 Mon
■ #1400. relational adjective から qualitative adjective への意味変化の原動力 [push_chain][semantic_change][bleaching][lexicology][adjective][french][loan_word][lexical_stratification]
「#968. 中英語におけるフランス借用語の質的形容詞」 ([2011-12-21-1]) で,日本歴史言語学会第一回大会における輿石氏の研究発表に関連して記事を書いた.先日,同発表に基づいて輿石氏が『歴史言語学』第1号に寄稿した論文の抜き刷りをいただいた.(論文では,本ブログの[2011-12-21-1]の記事を参照いただきました.輿石さん,ありがとうございます.)
輿石氏はこの論文の中で,(1) 英語の語形成は歴史的に Native Agglutination (NA) と Latinate Fusion (LF) とへ二分される,(2) NA 対 LF の語形成上の対立は,RA (関係的・記述的な形容詞)対 QA (質的・評価的な形容詞)の意味上の対立と概ね一致する,(3) 通時的に RA が QA へと推移する傾向が見られる,の3点を主張している.この問題,とりわけ (3) の通時的な問題に関しては,輿石氏の先の研究発表に触発されて,本ブログでも Farsi の論文を参照しながら 「#1099. 記述の形容詞と評価の形容詞」 ([2012-04-30-1]),「#1100. Farsi の形容詞区分の通時的な意味合い」 ([2012-05-01-1]),「#1193. フランス語に脅かされた英語の言語項目」 ([2012-08-02-1]) で少しく議論した.
RA から QA への推移という問題について,輿石氏はこれを "a compensatory strategy for semantic strategy for semantic bleaching of QAs" (23) と位置づけ,"a general linguistic change from the marked to the unmarked" (23) ととらえている.結論部に近い次の1段落を引用する.
In my opinion, what underlies the diachronic shift and the synchronic mechanism is a familiar transition from the marked RA to the unmarked QA. The central member of the adjective is what I call the 'evaluative', which can be fundamentally expressed as a certain point in the 'good/bad' scale. Since adjectives on this scale typically undergo 'semantic bleaching' and their meanings easily get watered down, language has to find some way to compensate for the bleaching and ensure the diversity of evaluatives. In my view, the categorial shifts from RAs to QAs are best to be considered one of the compensatory strategies for this semantic bleaching. (34--35)
RA が評価を帯びて QA へと推移してゆく過程は,「#1100. Farsi の形容詞区分の通時的な意味合い」 ([2012-05-01-1]) で述べたように,自然な言語変化として受け入れられる.だが,その背景に,既存の QA の "semantic bleaching" があり,その間隙につけ込む形で本来の RA から派生した QA が割り込むと想定することに関して,私は異なった考えをもっている.意味的漂白につけ込んでの QA 化ということは,意味上の drag chain が生じているということにほかならないが,例えば「#660. 中英語のフランス借用語の形容詞比率」 ([2011-02-16-1]) で挙げたフランス借用語形容詞は,英語本来語形容詞の意味的漂白につけ込んだと考えることができるのだろうか.あるいは,「#1193. フランス語に脅かされた英語の言語項目」 ([2012-08-02-1]) で紹介した -ness と -ity の競合も,前者の漂白の隙を突いた drag chain として説明できるのかどうか.また,上の引用の直後で,日本語のイ形容詞とナ形容詞(形容動詞)の間の類似現象に触れられているが,日本語史では,漢語に基づくナ形容詞が大量に生産されたのは,和語のイ形容詞の不足を補完するためだったとされ(佐藤,p. 121--22),和語のイ形容詞が意味的に漂白した後の間隙を埋めるためだったという議論は聞かない.さらに付け加えれば,現存する本来語の QA は,多くは基本語であり,意味的に漂白しているというよりは,むしろロマンス系の類義語と比べて強い感情をこめて用いられる傾向がある(関連して三層構造の各記事を参照).
意味的漂白につけ込む drag chain を想定するのではなく,ロマンス系の外来勢力が本来語要素を積極的に押しのけたという考え方,つまり push chain の過程を想定することはできないだろうか.もちろん,drag chain と push chain は必ずしも相反するものではなく,両方がともに作用するということもあり得るだろうが.いずれにせよ,結果として様々な評価的な形容詞が累積して,"the diversity of evaluatives" (35) が得られていることは確かだろう.
輿石さん,この問題について(だけではなく),ぜひ一緒に議論しましょう!
・ Koshiishi, Tetsuya. "Two Types of Adjectives and the History of English Word Formation." 『歴史言語学』第1号,2012年,23--38頁.
・ Farsi, A. A. "Classification of Adjectives." Language Learning 18 (1968): 45--60.
・ 佐藤 武義 編著 『概説 日本語の歴史』 朝倉書店,1995年.
2013-02-23 Sat
■ #1398. 2012年の英語流行語大賞 [lexicology][ads][woy]
今年はこの話題を持ち出すのを今まで忘れていた.例年,本ブログでも1月前半に取り上げるはずの話題である.1月4日に,American Dialect Society により 2012年の The Word of the Year が公表された.大賞は Twitter のシンボル hashtag である.「#263. 1990年から2009年までの英語流行語大賞」 ([2010-01-15-1]) で見たように,2009年の WOY が twitter そのものだったことを合わせて考えると,この新メディアの影響力の大きさが改めて実感される.この語は次のように定義される.
Hashtag refers to the practice used on Twitter for marking topics or making commentary by means of a hash symbol (#) followed by a word or phrase.
大賞のほかに様々な部門賞が設けられているが,MOST USEFUL 部門の受賞は接尾辞 -(po)calypse, -(ma)geddon (hyperbolic combining forms for various catastrophes) .MOST CREATIVE 部門からは,gate lice (airline passengers who crowd around a gate waiting to board) .MOST UNNECESSARY 部門と MOST OUTRAGEOUS 部門の2部門を制覇したのは,legitimate rape (type of rape that Missouri Senate candidate Todd Akin claimed rarely results in pregnancy) .MOST EUPHEMISTIC 部門では,self-deportation (policy of encouraging illegal immigrants to return voluntarily to their home) .MOST LIKELY TO SUCCEED 部門からは marriage equality (legal recognition of same-sex marriage) が,LEAST LIKELY TO SUCCEED 部門からは phablet (mid-sized electronic device between a smartphone and a tablet) 及び YOLO (acronym for "You Only Live Once," often used sarcastically or self-deprecatingly) が受賞した.大統領選挙の年の新部門として ELECTION WORDS 部門からは,binders (full of women) (term used by Romney in the second presidential debate to describe the resumes of female job candidates that he consulted as governor of Massachusetts) が選ばれた.
その他,個人的には MOST CREATIVE 部門のノミネートに挙がった alpacalypse (the Mayan apocalypse predicted for Dec. 21, 2012 (alpaca + -lypse)) がおもしろい.各部門のノミネート語句など,詳しくはプレスリリースをどうぞ.また,かつての流行語対象の受賞については,All of the Words of the Year, 1990 to Present 及び,本ブログ内の woy の記事を参照.
2013-01-22 Tue
■ #1366. 英語が非民主的な言語と呼ばれる理由 [lexicology][loan_word][french][latin][renaissance][history][register][sociolinguistics][lexical_stratification]
「#134. 英語が民主的な言語と呼ばれる理由」 ([2009-09-08-1]) で英語(の歴史)の民主的な側面を垣間見たが,バランスのとれた視点を保つために,今回は,やはり歴史的な観点から,英語の非民主的な側面を紹介しよう.
英語は,近代英語初期(英国ルネサンス期)に夥しいラテン借用語の流入を経験した (##114,1067,1226).これによって,英語語彙における三層構造が完成されたが,これについては「#334. 英語語彙の三層構造」 ([2010-03-27-1]) や「#1296. 三層構造の例を追加」 ([2012-11-13-1]) で見たとおりである.語彙に階層が設けられたということは,その使用者や使用域 (register) にも対応する階層がありうることを示唆する.もちろん,語彙の階層とその使用に関わる社会的階層のあいだに必然的な関係があるというわけではないが,歴史的に育まれてきたものとして,そのような相関が存在することは否定できない.上層の語彙は「レベル」の高い話者や使用域と結びつけられ,下層の語彙は「レベル」の低い話者や使用域と結びつけられる傾向ははっきりしている.
この状況について,渡部 (244) は,「英語の中の非民主的性格」と題する節で次のように述べている.
人文主義による語彙豊饒化の努力が産んだもう一つの結果は,英語が非民主的な性格を持つようになった,ということであろう.OE時代には王様の言葉も農民の言葉もたいして変りなかったと思われる.上流階級だからと言って特に難かしい単語を使うということは少なかったからである.その状態は Norman Conquest によって,上層はフランス語,下層は英語という社会的二重言語 (social bilingualism) に変ったが,英語が復権すると,英語それ自体の中に,一種の社会的二言語状況を持ち込んだ形になった.その傾向を助長したのは人文主義であって,その点,Purism をその批判勢力と見ることが可能である.事実,聖書をほとんど唯一の読書の対象とする層は,その後近代に至るまでイギリスの民衆的な諸運動とも結びついている.
英語(の歴史)は,ある側面では非民主的だが,別の側面では民主的である.だが,このことは多かれ少なかれどの言語にも言えることだろう.また,言語について言われる「民主性」というのは,「#1318. 言語において保守的とは何か?」 ([2012-12-05-1]) や「#1304. アメリカ英語の「保守性」」 ([2012-11-21-1]) で取り上げた「保守性」と同じように,解釈に注意が必要である.「民主性」も「保守性」も価値観を含んだ表現であり,それ自体の善し悪しのとらえ方は個人によって異なるだろうからだ.それでも,社会言語学的な観点からは,言語の民主性というのはおもしろいテーマだろう.
なお,英語における民主的な潮流といえば,「#625. 現代英語の文法変化に見られる傾向」 ([2011-01-12-1]) や「#1059. 権力重視から仲間意識重視へ推移してきた T/V distinction」 ([2012-03-21-1]) の話題が思い出される.
・ 渡部 昇一 『英語の歴史』 大修館,1983年.
2012-12-18 Tue
■ #1331. 語彙の英米差を整理するための術語 [terminology][ame_bre][lexicology][lexeme]
語彙の英米差には,様々な種類ものがある(例は,[2010-04-19-1]の記事「#357. American English or British English?」を参照).種々の語彙の英米差を区別,整理,言及するのに,一群の術語を導入すると便利だと考えた.以下で説明しよう.
英語には英米の変種が区別されると言われる.各変種をそれぞれ "the British variety of English", "the American variety of English" と呼ぶことにしよう(この短縮形が,それぞれ "British English" であり "American English" である).この2つの変種の間には多くの "lexical variation" (語彙的変異)が観察される.その変異の例の一つひとつを "a (lexical) variable" ((語彙的)変項)と呼ぶことにする.例えば,"a rest of time" (休暇)を意味するのに,典型的にイギリス英語では holiday を用いるが,アメリカ英語では vacation を用いる.このとき,この意味に関する英米変種間の variable は, "the British variant" (イギリス英語版の異形) holiday と,"the American variant" (アメリカ英語版の異形) vacation の2つの異形のあいだの揺れとして記述できる.これを次の1のような記法で表わすことにしよう.
1. ("a time of rest"): BrE holiday ~ AmE vacation
語彙的変項には別種のものもある.pants という語は,イギリス英語では "underpants" (下着)を意味するが,アメリカ英語では "trousers" (ズボン)を意味する.これは次の2のように記述できる.
2. (pants): BrE "underpants" ~ AmE "trousers"
いずれの場合も変項は ( ) で囲むこととし,斜体の文字列は "signifiant" を,引用符でくくった文字列は "signifié" を表わすものとする.あるいは,別の用語を導入すれば,斜体の文字列は "lexeme" (語彙素)を,引用符でくくった文字列は "sememe" (意義素)を表わすものとする.
語彙的変異のなかでも,1のタイプの変項は,同じ sememe に対して異なる lexeme が各変種で対応するので,"a synonymic variable" と呼ぶことができる.一方,2のタイプの変項は,同じ lexeme に対して異なる sememe が各変種で対応するので,"a homonymic variable" と呼ぶことができる.
ほかにも,underground と subway の関係のように,英米変種間でともに "synonymic variables" でもあり "homonymic variables" でもあるような語群があるが,このような語群は "a lexical class (field) of variables" を構成していると表現できるだろう.first floor, second floor, third floor 等々も,階数に関する "a lexical class of variables" と呼んでよい.
以上のように,"variation", "a (lexical) variable", "a variant", "a lexeme", "a sememe", "a synonymic variable", "a homonymic variable", "a lexical class of variables" という用語を導入することで,語彙の英米差の複雑な状況を整理することに役立つのではないか.なお,ここでの lexeme や sememe という術語の用法は,形態論や意味論で用いられる際の定義と厳密には異なっている可能性があるが,前者が問題の variant における signifiant を,後者が signifié を指すものとして前もって了解しておけば,対応語句として便利に使えるだろう.あえて "word" (語)という術語を用いず,"lexeme" などを持ち出したのは,必要であれば,「#22. イディオムと英語史」 ([2009-05-20-1]) で触れたようにイディオムのような単位にも対応させられるからである.
2012-11-13 Tue
■ #1296. 三層構造の例を追加 [lexicology][loan_word][french][latin][greek][lexical_stratification]
英語語彙の三層構造について,「#334. 英語語彙の三層構造」 ([2010-03-27-1]) を始めとする各記事で触れてきた.今回は,様々な典拠から Schmitt and Marsden (89) が集めた,英語(下層あるいは "general"),フランス語(中層あるいは "formal"),ラテン・ギリシア語(上層あるいは "intellectual")の三層構造をなす例を追加して,表の形で示す.
| Old English (general) | French (formal) | Latin or Greek (intellectual) |
|---|---|---|
| ask | question | interrogate |
| book | volume | text |
| fair | beautiful | attractive |
| fast | firm | secure |
| fear | terror | trepidation |
| fire | flame | conflagration |
| foe | enemy | adversary |
| gift | present | donation |
| goodness | virtue | probity |
| hearty | cordial | cardiac |
| help | aid | assistance |
| holy | sacred | consecrated |
| kingly | royal | regal |
| lively | vivacious | animated |
| rise | mount | ascend |
| time | age | epoch |
| word | term | lexeme |
表を眺めてみると,確かに各行に並んだ3種類の語はそれぞれ使用域 (register) が異なっているように思われる.意味の広がり,共起語の選択,使用頻度においても差があるだろう.
さて,このような三層構造を英語語彙の際立った特徴として取り上げることは一般論としては有効だろう.しかし,細かくいえば問題がないわけではない.まず,三層をなす3語1組をほかに集めようとしても難しい.英語語彙の特徴であるからには,例を次々と思いついてもおかしくなさそうだが,意外と難しい.上記の例は,三層構造を例証する選ばれし語群なのだ.
次に,類義語 (synonym) の範囲の曖昧さがある.各行の3種類の語は意味を共有する類義語だが,類義性をどこまで認めるかの判断は解釈者しだいである.例えば,hearty と cordial は「真心の」でつながるとしても,cardiac は別物ではないか.book -- volume -- text もどうか,等々.類義語辞典によっても収録する類義語の種類や数は異なっており,類義性の判断に絶対的な基準を設けることはできない.すると,上記の例は選んで探してきた例である,ということにならないか.
最後に,ゼミ生が類義語辞典から探し当てた例だが,stealthy -- secret -- confidential という三層構造では,本来語の stealthy は予想される general の層に属するとはいえないだろうし,むしろフランス語の secret のほうがずっと general である.三層構造という一般論に対してこのような個々の例外はほかにも多くあるだろうが,あくまで一般的な特徴づけであることを思い出させてくれる点で,このような例外の指摘は価値がある.
(後記 2014/08/20(Wed): Hughes (15) を参照して,以下の3例を追加する.)
| Old English (general) | French (formal) | Latin or Greek (intellectual) |
|---|---|---|
| folk | people | population |
| go | depart | exit |
| guts | entrails | intestines |
| word-hoard | vocabulary | lexicon |
・ Schmitt, Norbert, and Richard Marsden. Why Is English Like That? Ann Arbor, Mich.: U of Michigan P, 2006.
・ Hughes, G. A History of English Words. Oxford: Blackwell, 2000.
2012-11-11 Sun
■ #1294. 英語語源分析ツールの夢 [etymology][lexicology][statistics][web_service]
英文を投げ込むと,各単語(あるいは形態素)が語源別に色づけされて返ってくるような語源分析ツールがあるとよいなと思っている.しかも,各単語に語源辞書のエントリーへのリンクが張られているような.語彙研究や英語教育にも活かせるだろうし,出力を眺めているだけでもおもしろそうだ.このようなツールを作成するには精度の高い形態素分析プログラムと語源データベースの完備が欠かせないが,完璧を求めてしまうと実現は不可能だろう.
同じことを考える人はいるようだ.例えば,Visualizing English Word Origins はツールを公開こそしていないが,Douglas Harper による Online Etymology Dictionary に基づく自作のツールで,いくつかの短い英文一節を色づけ語源分析している.テキストの分野別に本来語やラテン語の割合が何パーセントであるかなどを示しており,およそ予想通りの結果が出されたとはいえ,実におもしろい.この分析に関して,The Economist に記事があった.
また,今は残念ながらリンク切れとなっているが,かつて http://huco.artsrn.ualberta.ca/~mburden/project/message.php?thread=Shakspere&id=174 に簡易的な語源分析ツールが公開されていた.こちらの紹介記事 にあるとおりで,なかなか有望なツールだった.私も少し利用した記憶があるのだが,どこへ消えてしまったのだろうか.
英語語源関連のオンライン・コンテンツも増えてきた.以下にいくつかをまとめておく.
・ 「#485. 語源を知るためのオンライン辞書」: [2010-08-25-1]
・ Etymology 関連の外部リンク集
・ 「#361. 英語語源情報ぬきだしCGI(一括版)」: [2010-04-23-1]
・ Behind the Name: The Etymology and History of First Names
・ Behind the Name: The Etymology and History of Surnames
・ 語源別語彙統計に関する本ブログ内の記事: lexicology loan_word statistics
・ Etymologic! The Toughest Word Game on the Web: 英語語源クイズ.
2012-09-19 Wed
■ #1241. 語彙的にみれば Anglo-Saxon 語の終わりは13世紀? [periodisation][lexicology][french][loan_word][romance]
英語史の時代区分について,periodisation の記事で扱ってきた.とりわけ,いつ古英語が終わり,中英語が始まったかについては,[2012-06-12-1], [2012-06-13-1]の記事で諸説を見た.中英語の開始時期については,いずれの議論も屈折の衰退という形態的な基準に拠っているが,あえてその伝統的な基準を退け,語彙的な基準を採用すると,様相は一変する.昨日の記事「#1240. ノルマン・コンクェスト後の法律用語の置換」 ([2012-09-18-1]) で取り上げた Lutz の論文では,語彙の観点からの時代区分がやんわりと提案されている.
Lutz は,(1) よく知られているようにフランス語彙の流入のピークは13世紀以降であり([2009-08-22-1]の記事「#117. フランス借用語の年代別分布」,[2012-08-14-1]の記事「#1205. 英語の復権期にフランス借用語が爆発したのはなぜか」を参照),(2) 初期中英語期の英語テキストは古英語テキストの伝統を引き継ぐものが多く,フランス借用語はそれほど顕著に反映しておらず,(3) 他言語に比べ英語ロマンスの出現が遅れた,という事実を示しながら,古英語(あるいは Lutz の呼ぶように Anglo-Saxon)の終わりを,伝統的な区分での初期中英語の終わりに置くことができるのではないかと提案する.
For the lexicon, we need a . . . bipartite periodization distinguishing Anglo-Saxon (comprising Old and Early Middle English) from English (comprising all later stages), which reflects the lexical and cultural facts. . . . During this extended period of time, several generations of inhabitants of post-Conquest England preserved their Anglo-Saxon lexicon and, more generally, seem to have looked back to their Anglo-Saxon cultural heritage when they expressed themselves in their own tongue. . . . / By contrast, the English we are familiar with is basically a creation of the late thirteenth to fifteenth centuries when the French-speaking ruling classes of England gradually switched to the language of those they governed and, in the course of that process, imported their superstratal lexicon in large quantities. (161--62)
Lutz の論考は,結果として,ノルマン・コンクェストとフランス借用語の本格的流入のあいだには時差があるという事実を強調していることになるだろう.
・ Lutz, Angelika. "When did English Begin?" Sounds, Words, Texts and Change. Ed. Teresa Fanego, Belén Méndez-Naya, and Elena Seoane. Amsterdam and Philadelphia: John Benjamins, 2002. 145--71.
2012-09-18 Tue
■ #1240. ノルマン・コンクェスト後の法律用語の置換 [lexicology][norman_conquest][history][loan_word][french][norman_french][me][law_french]
[2012-09-03-1]の記事「#1225. フランス借用語の分布の特異性」で言及した Lutz の論文に,標題の語彙交替を示す表が挙げられていた.古英語で用いられていた本来語の法律用語が,中英語以降(現代英語へ続く)に対応するフランス借用語語により置きかえられたという例である.網羅的ではないが,一瞥するだけで置換の様子がよく分かる表である.以下に再現しよう (149) .
| OE | ModE | |
| dōm | -- | judgment |
| dōmærn †, dōmhūs | -- | court-house |
| dōmlic † | -- | judicial |
| dēma †, dēmere † | -- | judge |
| dēman | -- | to judge |
| fordēman | -- | to condemn |
| fordēmend | -- | accuser |
| betihtlian † | -- | to accuse, charge |
| gebodian †, gemeldian † | -- | to denounce, inform |
| andsacian †, onsecgan † | -- | to renounce, abjure |
| gefriþian † | -- | to afford sanctuary |
| mānswaru †, āþbryce † | -- | perjury |
| mānswara † | -- | perjurer |
| mānswerian † | -- | to perjure oneself |
| (ge)scyld †, scyldignes † | -- | guilt |
| scyldig † | -- | guilty, liable |
| scyldlēas | -- | guiltless |
| āþ | > | oath |
| þēof | > | thief |
| þeofþ | > | theft |
| morþ, morþor + OF murdre | > | murder |
doom や deem など,現代まで残っている本来語はあるが,法律用語としての語義は失っている.また,法律用語として残っている最後の4語についても,フランク語や古ノルド語の同根語がノルマン人の法律用語としてすでに定着していたゆえとも考えられる.
Lutz は,征服者の制度と強く結びついたこれらの語彙が英語へ借用された事実を挙げ,とかくフランス文化への憧れというような借用の原動力に関する議論がなされるが,征服者の「力」を想定せざるを得ないフランス語借用もあるということを主張する.フランス語のもつ宮廷文化,ロマンス,食事,学問といった華やかな連想の影に,生々しい政治的,軍事的な力が隠されてしまっているのではないか,と問題を提起しているかのようだ.
. . . the particularly large share of French in the basic vocabulary of Modern Standard English cannot be attributed to its cultural appeal alone but results from forced linguistic contact exerted by the speakers of the language of a conquering power on that of the conquered population. Ordinary borrowing, guided by the wish to acquire new things and concepts and, together with them, the appropriate foreign terms, could not have led to such an extreme effect on the basic vocabulary of the recipient language.
関連して,「#1209. 1250年を境とするフランス借用語の区分」 ([2012-08-18-1]) や「#1210. 中英語のフランス借用語の一覧」 ([2012-08-19-1]) を参照.また,法律におけるフランス語について,「#336. Law French」 ([2010-03-29-1]) と「#433. Law French と英国王の大紋章」 ([2010-07-04-1]) も参照.
・ Lutz, Angelika. "When did English Begin?" Sounds, Words, Texts and Change. Ed. Teresa Fanego, Belén Méndez-Naya, and Elena Seoane. Amsterdam and Philadelphia: John Benjamins, 2002. 145--71.
2012-09-04 Tue
■ #1226. 近代英語期における語彙増加の年代別分布 [loan_word][lexicology][statistics][emode][renaissance][inkhorn_term][latin]
英語史における借用語の最たる話題として,中英語期におけるフランス語彙の著しい流入が挙げられる.この話題に関しては,語彙統計の観点からだけでも,「#117. フランス借用語の年代別分布」 ([2009-08-22-1]) を始めとして,french loan_word statistics のいくつかの記事で取り上げてきた.しかし,語彙統計ということでいえば,近代英語期のラテン借用語を核とする語彙増加のほうが記録的である.
[2009-08-19-1]の記事「#114. 初期近代英語の借用語の起源と割合」で言及したが,Görlach は初期近代英語の語彙の著しい増大を次のように評価し,説明している.
The EModE period (especially 1530--1660) exhibits the fastest growth of the vocabulary in the history of the English language, in absolute figures as well as in proportion to the total. (136)
. . . the general tendencies of development are quite obvious: an extremely rapid increase in new words especially between 1570 and 1630 was followed by a low during the Restoration and Augustan periods (in particular 1680--1780). The sixteenth-century increase was caused by two factors: the objective need to express new ideas in English (mainly in fields that had been reserved to, or dominated by, Latin) and, especially from 1570, the subjective desire to enrich the rhetorical potential of the vernacular. / Since there were no dictionaries or academics to curb the number of new words, an atmosphere favouring linguistic experiments led to redundant production, often on the basis of competing derivation patterns. This proliferation was not cut back until the late seventeenth/eighteenth centuries, as a consequence of natural selection or a s a result of grammarians' or lexicographers' prescriptivism. (137--38)
Görlach は,A Chronological English Dictionary に基づいて,次のような語彙統計も与えている (137) .これを図示してみよう.
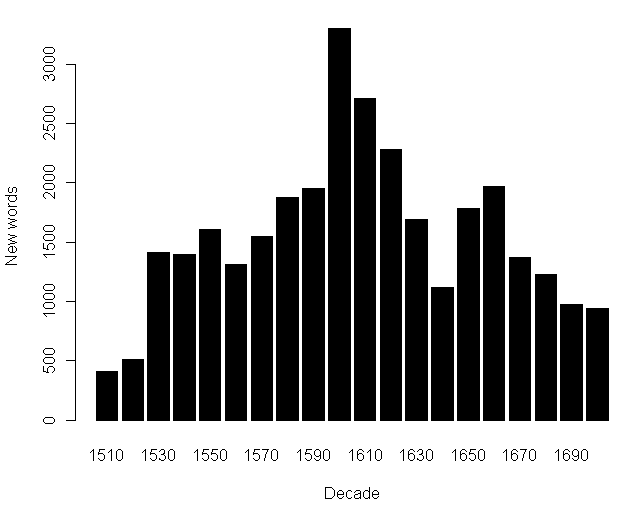
| Decade | 1510 | 1520 | 1530 | 1540 | 1550 | 1560 | 1570 | 1580 | 1590 | 1600 | 1610 | 1620 | 1630 | 1640 | 1650 | 1660 | 1670 | 1680 | 1690 | 1700 |
| New words | 409 | 508 | 1415 | 1400 | 1609 | 1310 | 1548 | 1876 | 1951 | 3300 | 2710 | 2281 | 1688 | 1122 | 1786 | 1973 | 1370 | 1228 | 974 | 943 |
近代英語期のラテン借用について関連する話題は,「#203. 1500--1900年における英語語彙の増加」 ([2009-11-16-1]) や emode loan_word lexicology の各記事を参照.
・ Görlach, Manfred. Introduction to Early Modern English. Cambridge: CUP, 1991.
・ Finkenstaedt, T., E. Leisi, and D. Wolff, eds. A Chronological English Dictionary. Heidelberg: Winter, 1970.
2012-09-03 Mon
■ #1225. フランス借用語の分布の特異性 [lexicology][statistics][loan_word][french][lexical_stratification]
「#845. 現代英語の語彙の起源と割合」 ([2011-08-20-1]) や「#1202. 現代英語の語彙の起源と割合 (2)」 ([2012-08-11-1]) でたびたび扱ってきた話題だが,もう1つ似たような統計を Brinton and Arnovick (298) に見つけた.Manfred Scheler に基づいた Angelika Lutz の統計から引用しているものである.General Service List (GSL; [2010-03-01-1]の記事「#308. 現代英語の最頻英単語リスト」ほか,##309,612,1103 を参照),Advanced Learners' Dictionary (ALD), Shorter Oxford English Dictionary (SOED) の3種の語彙リストを語源別に分類し,それぞれの割合を出している.表からグラフを作成してみた.
| SOED (80,096 words) | ALD (27,241 words) | GSL (3,984 words) | |
|---|---|---|---|
| West Germanic | 22.20% | 27.43% | 47.08% |
| French | 28.37% | 35.89% | 38.00% |
| Latin | 28.29% | 22.05% | 9.59% |
| Greek | 5.32% | 1.59% | 0.25% |
| Other Romance | 1.86% | 1.60% | 0.20% |
| Celtic | 0.34% | 0.25% | --- |
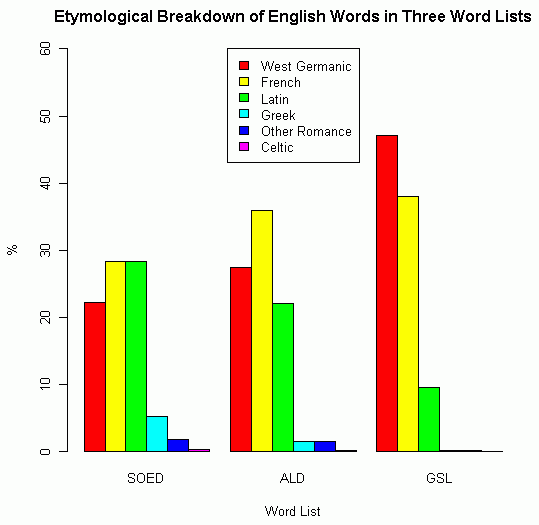
この統計のおもしろい点は,左列から右列に向かって対象語彙が小さくなるように並べられていることだ.別の言い方をすれば,語彙の難易度が右列に向かって下がっている.語彙が基本的であればあるほど,本来語の割合が高いことは上記の過去記事でも触れてきたが,意外なことにフランス借用語についても同様の傾向が見られるという.確かに,左列から右列に向かって割合が増えているのは,赤 (West Germanic) と黄色 (French) のみである.それ以外の語種は,むしろ割合が減っている.
このことから示唆されるのは,フランス借用は,ラテン借用のように文化的で専門的であるばかりではなく,征服者が被征服者に強要した言語接触の結果として,ある程度は基本的でもあるということだ.実際,英語語彙の三層構造 ([2010-03-27-1]) においてフランス語は中層を担っているが,覆う範囲は3層のなかで最も広く,下層へも(そして上層へも)大きくはみ出している.フランス借用語の分布の特異性は,フランス語との接触の歴史の特徴と関連していると考えられる.
ただし,この統計には不明な点もあり,解釈には注意を要する.本来語は West Germanic という広いくくりのなかに含まれると思われるが,ある程度の数のある北欧語系借用語はどこに納まっているのだろうか.また,上の議論では,特にラテン借用語の割合に対するフランス借用語の割合が鍵を握っているが,[2011-02-09-1]や[2011-08-23-1]でみたように,フランス借用語とラテン借用語の区別は難しい.語源判定の不確かさをここではどう処理しているのか,判定ミスによって数値はどのくらい変動するのだろうか.直接 Lutz に当たってみる必要がある.
(後記 2012/09/04(Tue): Lutz (147) を参照したところ,上記の北欧語系借用語に関する疑問について,"Other sources of lexical influence have been left out of account here." とあった.詳細は Scheler を参照せよとのことである.)
・ Brinton, Laurel J. and Leslie K. Arnovick. The English Language: A Linguistic History. Oxford: OUP, 2006.
・ Lutz, Angelika. "When did English Begin?" Sounds, Words, Texts and Change. Ed. Teresa Fanego, Belén Méndez-Naya, and Elena Seoane. Amsterdam and Philadelphia: John Benjamins, 2002. 145--71.
2012-08-30 Thu
■ #1221. 季節語の歴史 [semantic_change][lexicology][metonymy][calendar][onomasiology]
Fischer が英語の季節語に関する興味深い論文を書いている.要約すると次のようになる.
ゲルマン文化において,1年は夏と冬の2季に区分されていた.しかし,四季を区分する南欧文化との接触により,早くから春と秋の概念も入ってきてはいた.古英語では,sumer と winter の伝統的な2季区分に加えて,狭義に春の特定の1期間を表わす lencten が 広義に「春」として用いられ,狭義に秋の特定の1期間を表わす hærfest が広義に「秋」として用いられる例があり,現代のように四季の概念も語も揃っていた.ただし,lencten と hærfest のそれぞれの語には相変わらず狭義も併存していたため,専ら広義に季節を表わす現代英語の spring や autumn, fall と比べると,季節名称としての存在感はやや希薄だった.
中英語になると,古英語 lencten に対応する語は狭義へと退行する.14--15世紀には広義の「春」を失い,「春」の意味の場を巡る語彙の競合が始まる.「春」の意味の場は不安定となり,かつてのゲルマン的2季区分の記憶ゆえか,sumer が「春」をも含む超広義を発達させる.こうして,13世紀後半には,春の到来を告げる表現 Sumer is icumen in が現われた.
近代英語に入ると,「春」を巡る競合を制して,spring が台頭してくる.これは,植物が芽吹くイメージに重ね合わせた比喩として,生き生きとした表現に感じられたためかもしれない.spring of the leaf のような metonymy 表現もあれば,spring of the year のような metaphor もあった.同様に,古英語以降長らく「秋」を担当していた hervest も,18世紀の終わりまでには,やはり植物に比喩を取った fall や,フランス借用語の autumn などの類義語に徐々に地位を明け渡した.最終的に,同じように植物に比喩をとった spring と fall が生き残ったのは偶然ではないだろう.
Fischer は,以上の結論を得るために,古英語から近代英語にかけての「春」「秋」語彙を詳細に調査し,季節語の多義の消長を示す semasiological diagram と,季節に対応する類義語の消長を示す onomasiological diagram を描いた.結論の一環として,spring の存在は drag-chain によって,harvest の消失は push-chain によって説明されるとしている点も興味深い (86) .
・ Fischer, Andreas. "'Sumer is icumen in': The Seasons of the Year in Middle English and Early Modern English". Studies in Early Modern English. Ed. Dieter Kastovsky. Mouton de Gruyter, 1994. 79--95.
2012-08-20 Mon
■ #1211. 中英語のラテン借用語の一覧 [latin][loan_word][lexicology][me][wycliffe][bible][statistics]
昨日の記事「#1210. 中英語のフランス借用語の一覧」 ([2012-08-19-1]) に続いて,今回は中英語に借用されたラテン語の一覧を掲げたい.「#120. 意外と多かった中英語期のラテン借用語」 ([2009-08-25-1]) でも57語からなる簡単な一覧を示したが,Baugh and Cable (185) を参照して,もう少し長い123語の一覧とした.むろん網羅的ではなくサンプルにすぎない.
中英語期には,ラテン語は14--15世紀を中心に千数百語ほどが借用されたといわれる.教会関係者や学者を通じて,話し言葉から入ったものもあるが,主として文献から入ったものである.ラテン語から英語への翻訳に際して原語を用いたという背景があり,Wycliffe とその周辺による聖書翻訳が典型例だが,Bartholomew Anglicus による De Proprietatibus Rerum を Trevisa が英訳した際にも数百語のラテン語が入ったという事例がある (Baugh and Cable 184) .
abject, actor, adjacent, adoption, allegory, ambitious, ceremony, client, comet, conflict, conspiracy, contempt, conviction, custody, depression, desk, dial, diaphragm, digit, distract, equal, equator, equivalent, exclude, executor, explanation, formal, frustrate, genius, gesture, gloria, hepatic, history, homicide, immune, impediment, implement, implication, incarnate, include, incredible, incubus, incumbent, index, individual, infancy, inferior, infinite, innate, innumerable, intellect, intercept, interrupt, item, juniper, lapidary, lector, legal, legitimate, library, limbo, lucrative, lunatic, magnify, malefactor, mechanical, mediator, minor, missal, moderate, necessary, nervous, notary, ornate, picture, polite, popular, prevent, private, project, promote, prosecute, prosody, pulpit, quiet, rational, recipe, reject, remit, reprehend, requiem, rosary, saliva, scribe, script, scripture, scrutiny, secular, solar, solitary, spacious, stupor, subdivide, subjugate, submit, subordinate, subscribe, substitute, summary, superabundance, supplicate, suppress, temperate, temporal, testify, testimony, tincture, tract, tradition, tributary, ulcer, zenith, zephyr
なお,赤字で示した語は,現代英語の頻度順位で1000位以内に入る高頻度語である(Frequency Sorter より).ラテン借用語に意外と身近な側面があることがわかるだろう.
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
2012-08-19 Sun
■ #1210. 中英語のフランス借用語の一覧 [french][loan_word][lexicology][me][web_service][cgi]
中英語にフランス語から借用された単語リストはどの英語史概説書にも掲載されているが,本ブログでも簡便に参照できるように一覧化ツールを作ってみた.
フランス借用語の簡易データベースを,Baugh and Cable (169--74, 177) に基づいて作成し,意味その他の基準で9個のカテゴリーに分けた (Miscellany; Fashion, Meals, and Social Life; Art, Learning, Medicine; Government and Administration; Law; Army and Navy; Christian Church; 15th-Century Literary Words; Phrases) .954個の語句からなるデータを納めたテキストファイルはこちら.ここから,カテゴリーごとに10語句をランダムに取り出したのが,以下のリストである.このリストに飽き足りなければ,
をクリックすれば,次々にランダムな一覧が生成される.「こんな語句もフランス語だったとは」と驚かせるプレゼン用途にどうぞ.
- Miscellany
- Fashion, Meals, and Social Life
- Art, Learning, Medicine
- Government and Administration
- Law
- Army and Navy
- Christian Church
- 15th-Century Literary Words
- Phrases
please, curious, scandal, approach, faggot, push, fierce, double, purify, carpenter
train, pullet, mustard, sugar, enamel, mackerel, sole, fashion, jollity, russet
pulse, color, cloister, pen, pillar, ceiling, base, lattice, cellar, sulphur
rebel, retinue, reign, duchess, allegiance, treaty, nobility, court, tax, statute
mainpernor, arson, judge, property, culpable, amerce, convict, bounds, innocent, legacy
arm, array, arms, soldier, chieftain, portcullis, havoc, brandish, stratagem, combat
incense, faith, abbey, passion, immortality, cardinal, friar, legate, virtue, convent
ingenious, appellation, destitution, harangue, prolongation, furtive, sumptuous, combustion, diversify, representation
according to, to hold one's peace, without fail, in vain, on the point of, subject to, to make believe, by heart, at large, to draw near
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
2012-08-18 Sat
■ #1209. 1250年を境とするフランス借用語の区分 [french][loan_word][me][norman_french][lexicology][statistics][bilingualism]
英語におけるフランス借用語の話題は,french loan_word などの多くの記事で扱ってきた.特に中英語期にフランス借用語が大量に借用された経緯とその借用の速度について,「#117. フランス借用語の年代別分布」 ([2009-08-22-1]) 及び「#1205. 英語の復権期にフランス借用語が爆発したのはなぜか」 ([2012-08-14-1]) で記述した.借用の速度でみると,13世紀の著しい伸びがフランス語借用史の1つの転換点となっているが,この前後ではフランス語借用について何がどう異なっているのだろうか.Baugh and Cable (168--69) により,それぞれの時代の特徴を概説しよう.
ノルマン・コンクェストから1250年までのフランス借用語は,(1) およそ900語と数が少なく,(2) Anglo-Norman の音韻特徴を示す傾向が強く,(3) 下流階級の人々が貴族階級との接触を通じて知るようになった語彙,とりわけ位階,文学,教会に関連する語彙が多い.例としては,baron, noble, dame, servant, messenger, feast, minstrel, juggler, largess; story, rime, lay, douzepers など.
一方,1250年以降のフランス借用語の特徴は次の通り.(1) 1250--1400年に爆発期を迎え,この1世紀半のあいだに英語史における全フランス借用語の4割が流入した.なお,中英語期に限れば1万語を超える語が英語に流れ込み,そのうちの75%が現在にまで残る (Baugh and Cable 178) .(2) フランス語に多少なりとも慣れ親しんだ上流階級が母語を英語へ切り替える (language shift) 際に持ち込んだとおぼしき種類の語彙が多い.彼らは,英語本来語の語彙では満足に表現できない概念に対してフランス語を用いたこともあったろうし,英語の習熟度が低いためにフランス語で代用するということもあったろうし,慣れ親しんだフランス語による用語を使い続けたということもあったろう.(3) 具体的には政治・行政,教会,法律,軍事,流行,食物,社会生活,芸術,学問,医学の分野の語彙が多いが,このような区分に馴染まないほどに一般的で卑近な語彙も多く借用されている.
要約すれば,1250年を境とする前後の時代は,誰がどのような動機でフランス語を借用したかという点において対照的であるということだ.Baugh and Cable (169) は,鮮やかに要約している.
In general we may say that in the earlier Middle English period the French words introduced into English were such as people speaking one language often learn from those speaking another; in the century and a half following 1250, when all classes were speaking or learning to speak English, they were also such words as people who had been accustomed to speak French would carry over with them into the language of their adoption. Only in this way can we understand the nature and extent of the French importations in this period.
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
2012-08-11 Sat
■ #1202. 現代英語の語彙の起源と割合 (2) [lexicology][loan_word][statistics][old_norse]
[2011-08-20-1]の記事「#845. 現代英語の語彙の起源と割合」で,現代英語の最頻語を借用元言語別に分別した統計値を紹介した.このような語彙統計は,何を資料に使ったか,どのような方法で調査したかなどによって結果が変動しがちであるため,複数の調査結果を照らし合わせて評価するのがよい.Schmitt and Marsden (82) は,Bird による調査結果の統計値を与えている.これをグラフ化してみた.(数値データは,HTMLソースを参照.)
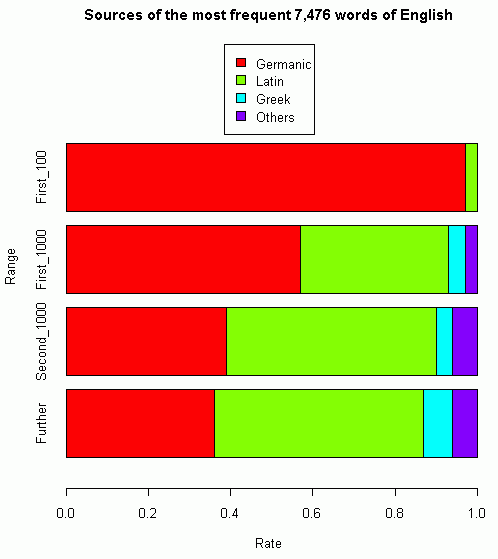
続けて Schmitt and Marsden (83) は,英語本来語のみで構成された印象深い1節を紹介している.
But with all its manifold new words from other tongues, English could never have become anything but English. And as such it has sent out to the world, among many other things, some of the best books the world has ever known. It is not unlikely, in the light of writings by Englishmen in earlier times, that this would have been so even if we had never taken any words from outside the word hoard that has come down to us from those times. It is true that what we have borrowed has brought greater wealth to our word stock, but the true Englishness of our mother tongue has in no way been lessened by such loans, as those who speak and write it lovingly will always keep in mind.
[2010-04-20-1]の記事「#358. アイスランド語と英語の関係」のなかで,"Though they are both weak fellows, she gives them gifts." という北欧単語のみで構成された英文(ただし語源について北欧系かどうか疑わしい語も含まれている)を提示したが,これはさすがに不自然で,強引な文だ.しかし,英語本来語で構成された上の文章は十分に自然だ.
フランス借用語のみで構成された文章は可能だろうか.可能だとしても,どのくらい自然だろうか.
・ Schmitt, Norbert, and Richard Marsden. Why Is English Like That? Ann Arbor, Mich.: U of Michigan P, 2006.
2012-08-02 Thu
■ #1193. フランス語に脅かされた英語の言語項目 [me][french][loan_word][suffix][adjective][grammaticalisation][semantic_change][lexicology][french_influence_on_grammar]
中英語期に,フランス語の影響で,英語の本来的な言語要素が脅かされたり,置き換えられたり,変化を余儀なくされた例は枚挙にいとまがない.語のレベルではもっとも顕著であり,フランス借用語の流入ゆえに古英語語彙の多くが廃用へと追い込まれた.人名についても同じことが言えるし,綴字習慣の多くの部分についても然り,語の意味においてもそうだ ([2009-09-01-1]の記事「#127. deer, beast, and animal」などを参照).
あまり目立たないところでは,接尾辞についても同じことが言えるという指摘がある.米倉先生の論文 (238) によれば,初期中英語では,本来語要素である名詞を派生する接尾辞 -ness は "action of A", "quality of A", "thing that is A", "place of being A" などの広い意味をもっており,対応するフランス語要素である -ity は "quality of being A" のみだった.ところが,後期中英語になると,-ness は "quality of being A" のみへと意味を限定し,逆に -ity は "quality of being A" と "aggregate of being A" の意味を合わせもつようになった.つまり,意味の広がりという観点からすると,-ness と -ity の立場が逆転したことになる.ただし,対象語の意味を詳しく検討した米倉先生は,必ずしもこの概説は当たっておらず,中英語期中は両接尾辞ともに多義であったのではないかとも述べている.とはいえ,-ness が,近代英語期以降に意味を単純化し,固有の意味を失いながら,ついには名詞を派生するという形態的役割をもつのみとなった事実(=文法化 "grammaticalisation")をみれば,少なくとも意味の範囲という点では,数世紀にわたって,いかにフランス語要素 -ity に脅かされてきたかが知れよう.
接尾辞における英語とフランス語の対決および逆転現象という議論を読みながら考えていたのは,[2012-05-01-1]の記事「#1100. Farsi の形容詞区分の通時的な意味合い」で述べた,形容詞の意味範囲の語種による差についての仮説である.その仮説を繰り返そう.
古英語では,形容詞はほぼ本来語のみであり,意味にしたがって Class A, B, C の3種類があった.中英語以降,フランス語やラテン語から大量の形容詞が借用され([2011-02-16-1]の記事「#660. 中英語のフランス借用語の形容詞比率」),その多くは記述的語義をもっていたため,Class A や Class C に属していた本来語はその圧力に屈して対応する記述的語義を失っていった.つまり,本来語は主として評価的語義をもった Class B に閉じ込められた.一方,借用語も次第に評価的語義を帯びて Class B や Class C へ侵入し,そこでも本来語を脅かした.その結果としての現在,借用語はクラスにかかわらず広く分布しているが,本来語は主要なものが Class B に属しているばかりである.
-ness と -ity の意味範囲の対立や deer, beast, animal の意味の場を巡る競合は,特定の語や接尾辞の意味に関する単発的な問題だが,より大きな語彙や語種というレベルでも,英仏語勢力の大規模な逆転現象が起こっているのではないか.
・ 米倉 綽 「後期中英語における接尾辞の生産性―-ityと-nessの場合―」『ことばが語るもの―文学と言語学の試み―』米倉 綽 編,英宝社,2012年,213--48頁.
2012-07-15 Sun
■ #1175. ロマンス系動詞借用以前の副詞の役割 [romancisation][lexicology][latin][french][adverb][synonym][japanese][onomatopoeia][lexical_stratification]
英語語彙の三層構造について,「#334. 英語語彙の三層構造」 ([2010-03-27-1]) を始めとする記事で取り上げてきた.本来語とロマンス系借用語との差は,意味や語法上の微妙な差として現われることが多い.例えば,本来語動詞 beat が "to defeat, to win against sb" であるのに対して,フランス語動詞 vanquish は "to defeat sb completely" である.また,本来語動詞 wet が "to make sth wet" であるのに対して,フランス語形容詞から派生した動詞 moisten は "to make sth slightly wet" である.動詞についていえば,類義語間の差異は,多くの場合,迂言的に言い換えた場合の副詞(相当語句)の差異や有無であることが多い.
このことを逆からみれば,ロマンス系動詞が借用される以前の時代(古英語や初期中英語)には,類義語は貧弱であり,表現力を求めるのであれば,副詞(相当語句)により迂言的に表現せざるを得なかったということになる.特に文学の文体における副詞の役割は大きかったに違いない.Donner (2) は,次のように指摘している.
In a period of the language antecedent to the influx of Latin verbs that allow modern authors so readily both to designate an act and to characterize its quality within a single word, modal qualifiers are likely to play rather a more important role than they currently do in literary rhetoric, which largely avoids them . . . .
中英語期以降,法 (mood) を含意する副詞の役割が大きくなっていることは,Killie (127) などの言及している "adverbialization process" として認められるが,それ以前の時代にも,それとは異なる意味においてではあるが,上記の動詞語彙の貧弱さとの関連において,副詞の役割は重要だったと考えられる.
ここで思い出すのは,日本語における動詞の貧弱さと擬音語様態副詞の豊富さだ.和語の動詞は比較的少なく,多くは漢語に補助動詞「する」を付加した派生的な動詞である.漢語が借用される以前の日本語では,先述の諸期中英語以前の状況と同様に,表現力を求めるかぎり,副詞的な役割をもつ語に依存せざるを得なかった.日本語の場合,副詞的な役割をもつ語として,擬音語が異常に発達していたことは広く知られている.現代の「ゴロゴロ」「スヤスヤ」「ジリジリ」「プンプン」「シトシト」「ベロンベロン」等々.漢語の動詞が大量生産された後もこれらの擬音語は遺産として引き継がれ,拡大すらしたが,動詞の表現力を補う副詞としての役割は,相対的に減じているのかもしれない.同様に,英語の副詞はロマンス系動詞の大量借用後も遺産として引き継がれ,拡大すらしたが,動詞の表現力を補う副詞としての役割は,相対的に減じてきたのではないか.
ただし,これは,Donner も触れているとおり,"literary rhetoric" というレジスターにおいてのみ有効な議論かもしれない.いや,それすらも危うい.英語の副詞や日本語の擬音語の多用は幼稚な印象を与えかねない一方で,時にこれらの表現は驚くほど印象的な修辞を生み出すこともあるからだ.しかし,この問題は,英語史にとっても,日英語の比較にとっても,エキサイティングなテーマとなるに違いない.
・ Killie, Kristin. "The Spread of -ly to Present Participles." Advances in English Historical Linguistics. Ed. Jacek Fisiak and Marcin Krygier. Mouton de Gruyter: Berlin and New York: 1998. 119--34.
・ Donner, Morton. "Adverb Form in Middle English." English Studies 72 (1991): 1--11.
2012-07-03 Tue
■ #1163. オンライン語彙データベース DICT.ORG [web_service][dictionary][lexicology][link]
The DICT Development Group による DICT.ORG は,ウェブ上の様々な語彙データベースや辞書を利用するための統一的な仕様を提供するサービスである.登録されている語彙データベースを利用するインターフェースはこちら.
辞書というよりは語彙データベースと呼ぶ方が適切なのは,ある語の定義や発音などを与えてくれるというよりは,ある条件(主として綴字上の条件)を満たす語の一覧を作成するのが得意だからだ.ある特定の目的で行なわれる語彙研究のために,単語リストを準備するのに役立つ.
DICT.ORG で利用できる辞書はオンライン上で公開されている無料のものが多いが,語彙データベースとしての使用を前提とすれば,機能的には十分である.条件指定の方法("strategy" と呼ばれる;以下参照)は,電子辞書などでお馴染みの,綴字の完全一致,前方一致,後方一致,部分一致のほか,正規表現も完全にサポートしており,近似した綴字の語を取り出す Levenshtein distance 検索や Soundex algorithm 検索も実装されている.
Strategy Description
--------- -----------
first : Match the first word within headwords
exact : Match headwords exactly
re : POSIX 1003.2 (modern) regular expressions
last : Match the last word within headwords
nprefix : Match prefixes (skip, count)
soundex : Match using SOUNDEX algorithm
lev : Match headwords within Levenshtein distance one
word : Match separate words within headwords
suffix : Match suffixes
regexp : Old (basic) regular expressions
substring : Match substring occurring anywhere in a headword
prefix : Match prefixes
出力が非常にシンプルであり,まさに語の一覧という体裁なので,この一覧を拾い上げて,別の語彙ツールに投げ込むという使い方もできる.語彙研究に役立つツールを開発するためのベースとして利用できるのではないか.ウェブ上のインターフェースのほか,ローカルからは,Perl で書かれた dict というクライアントなどを経由して利用できる.
DICT.ORG からは,英語の語彙データベースや辞書への役立つリンクが張られていて便利.特に Dictionary Database Site や Other Database Information や Linguistic Data Resources on the Internet: Dictionaries, Lexica, and Lexical Resources の情報が有用.
Powered by WinChalow1.0rc4 based on chalow