2014-07-18 Fri
■ #1908. 女性を表わす語の意味の悪化 (1) [semantic_change][gender][lexicology][semantics]
「#473. 意味変化の典型的なパターン」 ([2010-08-13-1]) の (3) で示した意味の悪化 (pejoration) は,英語史において例が多い.良い意味,あるいは少なくとも中立的な意味だった語にネガティヴな価値が付される現象である.これまでの記事としては,「#505. silly の意味変化」 ([2010-09-14-1]),「#683. semantic prosody と性悪説」 ([2011-03-11-1] ),「#742. amusing, awful, and artificial」 ([2011-05-09-1]) などで具体例を見てきた.
しかし,英語史における意味の悪化の例としてとりわけよく知られているのは,女性を表わす語彙だろう.英語史を通じて,「女性」を意味する語群は,軒並み侮蔑的な含蓄的意味 (connotation) を獲得していく傾向を示す.「女性」→「性的にだらしない女性」→「娼婦」というのが典型的なパターンである.この話題を正面から扱った Schulz の論文 "The Semantic Derogation of Woman" によると,「女性を表わす語の堕落」がいかに一般的な現象であるかが,これでもかと言わんばかりに示される.3箇所から引用しよう.
Again and again in the history of the language, one finds that a perfectly innocent term designating a girl or woman may begin with totally neutral or even positive connotations, but that gradually it acquires negative implications, at first perhaps only slightly disparaging, but after a period of time becoming abusive and ending as a sexual slur. (82--83)
. . . virtually every originally neutral word for women has at some point in its existence acquired debased connotations or obscene reference, or both. (83)
I have located roughly a thousand words and phrases describing women in sexually derogatory ways. There is nothing approaching this multitude for describing men. Farmer and Henley (1965), for example, have over five hundred terms (in English alone) which are synonyms for prostitute. They have only sixty-five synonyms for whoremonger. (89)
Schulz の論文内には,数多くの例が列挙されている.論文内に現われる99語をアルファベット順に並べてみた.すべてが「性的に堕落した女」「娼婦」にまで意味が悪化したわけではないが,英語史のなかで少なくともある時期に侮蔑的な含意をもって女性を指示し得た単語群である.
abbess, academician, aunt, bag, bat, bawd, beldam, biddy, Biddy, bitch, broad, broadtail, carrion, cat, cleaver, cocktail, courtesan, cousin, cow, crone, dame, daughter, doll, Dolly, dolly, dowager, drab, drap, female, flagger, floozie, frump, game, Gill, girl, governess, guttersnipe, hack, hackney, hag, harlot, harridan, heifer, hussy, jade, jay, Jill, Jude, Jug, Kitty, kitty, lady, laundress, Madam, minx, Miss, Mistress, moonlighter, Mopsy, mother, mutton, natural, needlewoman, niece, nun, nymph, nymphet, omnibus, peach, pig, pinchprick, pirate, plover, Polly, princess, professional, Pug, quean, sister, slattern, slut, sow, spinster, squaw, sweetheart, tail trader, Tart, tickletail, tit, tramp, trollop, trot, twofer, underwear, warhorse, wench, whore, wife, witch
重要なのは,これらに対応する男性を表わす語群は必ずしも意味の悪化を被っていないことだ.spinster (独身女性)に対する bachelor (独身男性),witch (魔女)に対する warlock (男の魔法使い)はネガティヴな含意はないし,どちらかというとポジティヴな評価を付されている.老女性を表わす trot, heifer などは侮蔑的だが,老男性を表わす geezer, codger は少々侮蔑的だとしてもその度合いは小さい.queen (女王)は quean (あばずれ女)と通じ,Byron は "the Queen of queans" などと言葉遊びをしているが,対する king (王)には侮蔑の含意はない.princess と prince も同様に対照的だ.mother, sister, aunt, niece の意味は堕落したことがあったが,対応する father, brother, uncle, nephew にはその気味はない.男性の職業・役割を表わす footman, yeoman, squire は意味の下落を免れるが,abbess, hussy, needlewoman など女性の職業・役割の多くは professional その語が示しているように,容易に「夜の職業」へと転化してゆく.若い男性を表わす語は boy, youth, stripling, lad, fellow, puppy, whelp など中立的だが,doll, girl, nymph は侮蔑的となる.
女性を表わす固有名詞も,しばしば意味の悪化の対象となる.また,男性と女性の両者を指示することができる dog, pig, pirate などの語でも,女性を指示する場合には,ネガティヴな意味が付されるものも少なくない.いやはや,随分と類義語を生み出してきたものである.
・ Schulz, Muriel. "The Semantic Derogation of Woman." Language and Sex: Difference and Dominance. Ed. Barrie Thorne and Nancy Henley. Rowley, MA: Newbury House, 1975. 64--75.
2014-07-06 Sun
■ #1896. 日本語に入った西洋語 [loan_word][borrowing][japanese][lexicology][borrowing][portuguese][spanish][dutch][italian][russian][german][french]
日本語に西洋語が初めて持ち込まれたのは,16世紀半ばである.「#1879. 日本語におけるローマ字の歴史」 ([2014-06-19-1]) でも触れたように,ポルトガル人の渡来が契機だった.キリスト教用語とともに一般的な用語ももたらされたが,前者は後に禁教となったこともあって定着しなかった.後者では,アルヘイトウ(有平糖)(alfeloa) ,カステラ (Castella),カッパ (capa),カボチャ(南瓜,Cambodia),カルサン(軽袗,calsãn),カルタ (carta),コンペイトウ(金平糖,confeitos),サラサ(更紗,saraça),ザボン (zamboa),シャボン (sabão),ジバン(襦袢,gibão),タバコ(煙草,tabaco),チャルメラ (charamela),トタン (tutanaga),パン (pão),ビイドロ (vidro),ビスカット(ビスケット,biscoito),ビロード (veludo),フラスコ (frasco),ブランコ (blanço),ボオロ (bolo),ボタン (botão) などが残った.16世紀末にはスペイン語も入ってきたが,定着したものはメリヤス (medias) ぐらいだった.
近世中期に蘭学が起こると,オランダ語の借用語が流れ込んでくる.自然科学の語彙が多く,後に軍事関係の語彙も入った.まず,医学・薬学では,エーテル (ether),エキス (extract),オブラート (oblaat),カルシウム (calcium),カンフル (kamfer, kampher),コレラ (cholera),ジギタリス (digitalis),スポイト (spuit),ペスト (pest),メス (mes),モルヒネ (morphine).化学・物理・天文では,アルカリ (alkali),アルコール (alcohol),エレキテル (electriciteit),コンパス (kompas),ソーダ (soda),テレスコープ (telescoop),ピント (brandpunt),レンズ (lenz).生活関係では,オルゴール (orgel),ギヤマン (diamant),コーヒ (koffij),コック (kok),コップ(kop; cf. 「#1027. コップとカップ」 ([2012-02-18-1])),ゴム (gom),シロップ (siroop),スコップ (schop),ズック (doek),ソップ(スープ,soep),チョッキ (jak),ビール (bier),ブリキ (blik),ペン (pen),ペンキ (pek), ポンプ (pomp),ホック (hoek),ホップ (hop),ランプ (lamp).軍事関係では,サーベル (sabel),ピストル (pistool),ランドセル (ransel).
明治時代には西洋語のなかでは英語が優勢となってくるが,明治初期にはいまだ「コップ」「ドクトル」などオランダ借用語の使用が幅を利かせていた.しかし,大正中期以降は英語系が大半を占めるようになり,オランダ風の「ソップ」が英語風の「スープ」へ置換されたように,発音も英語風へと統一されてくる.英語以外の西洋語としては,大正から昭和にかけてドイツ語(主に医学,登山,哲学関係),フランス語(主に芸術,服飾,料理関係),イタリア語(主に音楽関係),ロシア語も見られるようになった.それぞれの例を挙げてみよう.
・ ドイツ語:ノイローゼ(Neurose),カルテ(Karte),ガーゼ(Gaze),カプセル(Kapsel),ワクチン(Vakzin),イデオロギー(Ideologie),ゼミナール(Seminar),テーマ(Thema),テーゼ(These),リュックサック(Rucksack),ザイル(Seil),ヒュッテ(Hütte),オブラート (Oblate), クレオソート (Kreosot).
・ フランス語:デッサン(dessin),コンクール(concours),シャンソン(chanson),ロマン(roman),エスプリ(esprit),ジャンル(genre),アトリエ(atelier),クレヨン(crayon),ルージュ(rouge),ネグリジェ(néglige),オムレツ(omelette),コニャック(cognac),シャンパン(champagne),マヨネーズ(mayonnaise)
・ イタリア語:オペラ(opera),ソナタ(sonata),テンポ(tempo),フィナーレ(finale),マカロニ(macaroni),スパゲッティ(spaghetti)
・ ロシア語:ウォッカ(vodka),カンパ(kampaniya),ペチカ(pechka),ノルマ(norma)
今日,西洋語の8割が英語系であり,借用の対象となる英語の変種としては太平洋戦争をはさんで英から米へと切り替わった.
以上,佐藤 (179--80, 185--86) および加藤他 (74) を参照して執筆した.関連して,「#1645. 現代日本語の語種分布」 ([2013-10-28-1]),「#1526. 英語と日本語の語彙史対照表」 ([2013-07-01-1]),「#1067. 初期近代英語と現代日本語の語彙借用」 ([2012-03-29-1]) の記事も参照されたい.
・ 佐藤 武義 編著 『概説 日本語の歴史』 朝倉書店,1995年.
・ 加藤 彰彦,佐治 圭三,森田 良行 編 『日本語概説』 おうふう,1989年.
2014-06-21 Sat
■ #1881. 接尾辞 -ee の起源と発展 (2) [suffix][pde_language_change][lexicology][statistics][oed][productivity][agentive_suffix]
昨日の記事「#1880. 接尾辞 -ee の起源と発展 (1)」 ([2014-06-20-1]) に続き,当該接尾辞の現代英語にかけての質的な変化および量的な発展について,Isozaki に拠りながら考える.
Isozaki は,OED ほかの参考資料に当たり,現代英語から500を超える -ee 語を収集した.そして,これらを初出年代,統語・意味の種別,語幹の語源により分析し,後期近代英語から現代英語にかけての潮流を2点突き止めた.昨日の記事の終わりで述べた,(1) ロマンス系語幹ではなく本来語幹に接続する傾向が生じてきていること,および (2) standee のような動作主(主語)タイプが増えてきていること,の2つである.
(1) については,OED を用いた調査結果をグラフ化すると以下のようになる (Isozaki 7) .
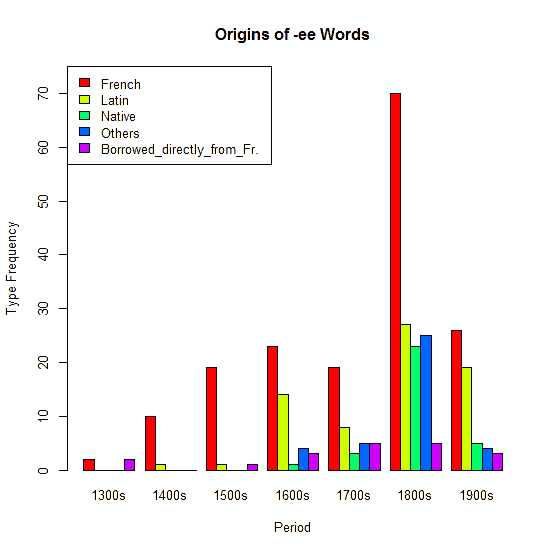
フランス語幹に接続する傾向が一貫して強いことは明らかである.しかし,本来語幹に接続する語例が後期近代より現われてきたことは注目に値する.なお,19世紀の爆発期の後で20世紀が地味に見えるのは,OED の語彙収録の特徴によるところが大きいかもしれない.
次に (2) についてだが,同じく OED を用いて,統語(意味)的な観点から分類した結果は以下の通りである (Isozaki 6) .グラフのなかで,DO は動詞の直接目的語,IO は間接目的語,PO は前置詞目的語,S は主語,Anom. は動詞とは直接に関係しない変則的なものである.
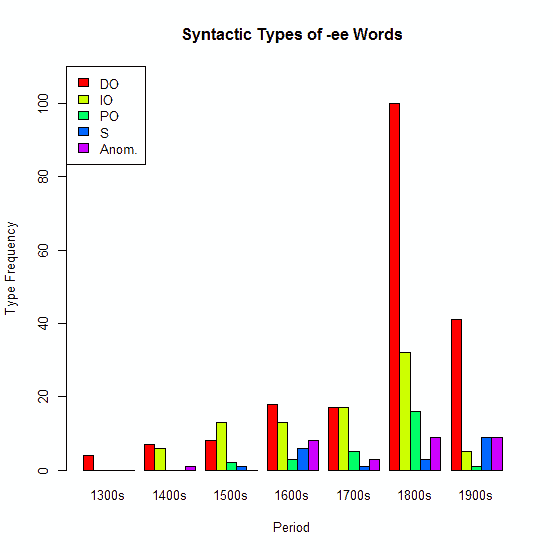
従来型の DO タイプが常に優勢であり続けていることが顕著であり,S タイプの拡張は特に目立たないようにみえる.しかし,OED を離れて,1900--2005年の種々の本や参考図書での出現を考慮に入れると,DO が117例,IO が23例,PO が4例,S が32例,Anom. が18例と,S (主語タイプ)の伸張が示唆される (Isozaki 6) .
-ee 語は臨時語的な使われ方が多いと想像され,使用域の一般化も進んでいるように思われる.今後は語用論的な調査も必要となってくるかもしれない.接辞の生産性 (productivity) という観点からも,アンテナを張っておきたい話題である.
・ Isozaki, Satoko. "520 -ee Words in English." Lexicon 36 (2006): 3--23.
2014-06-09 Mon
■ #1869. 日本語における仏教語彙 [japanese][kanji][loan_word][religion][buddhism][lexicology]
宗教の伝来が受け入れ側の言語に著しい影響を及ぼすことについて,「#296. 外来宗教が英語と日本語に与えた言語的影響」 ([2010-02-17-1]) で取り上げた.その記事では,日英において顕著な類似点があることを指摘した.ユーラシア大陸の両端で,時をほぼ同じくする6世紀という時期に,それぞれ大陸から仏教とキリスト教が伝わった.各々,漢字とローマ字を受容して本格的な文字文化が始まり,その宗教と関連した種々の文物や語彙が流入した.新宗教は乗り物として機能しており,語彙はそれに乗って,日本とイングランドへ到着したのである.
キリスト教が英語に与えた語彙上の影響については,「#32. 古英語期に借用されたラテン語」 ([2009-05-30-1]) や「#1439. 聖書に由来する表現集」 ([2013-04-05-1]) で触れ,日英の語彙史の比較対照は「#1526. 英語と日本語の語彙史対照表」 ([2013-07-01-1]) や「#1049. 英語の多重語と漢字の異なる字音」 ([2012-03-11-1]) で言及した.今回は,日本語における仏教語の受容について取り上げる.以下,『日本語学研究事典』 (407--08) を参照して記す.
6世紀半ばに仏教が伝来すると,以降,多くの仏教語(あるいは仏語)が日本語へ流入した.聖徳太子以後,仏教を振興した上代には「香炉」「蝋燭」「脇息」「高座」「功徳」「供養」などが入り,天台・真言の二宗の栄えた中古には「大徳」「修法」「念誦」「新発意」「持仏」「名号」「数珠」「加持」「精進」「彼岸」「布施」「回向」「出家」,また「道理」「本意」「世界」「世間」「孝養」「懈怠」「道心」「変化」「稀有」「愛敬」「執念」などが見られた.中古から中世にかけては,信仰がいっそう深まり,仏教説話も多く現われ,「諸行無常」「盛者必衰」「煩悩」「衆生」「修行」「三界」「智慧」「過去」,また「発心」「悲願」「勧進」「微塵」「安穏」など300語以上が借用されている.中世から近世にかけては,臨済・曹洞などの禅宗の伝来とともに使用の拡がった「挨拶」「以心伝心」「向上」「到底」「到頭」「端的」「滅却」「毛頭」「行脚」「看経」に加え,「一得一失」「主眼」「自粛」「体得」「打開」「単刀直入」「門外漢」「老婆心」のように日常化したものも多い.また,インドの経論が漢文に音訳された,いわゆる梵語も「閼伽」「伽藍」「娑婆」「卒塔婆」「荼毘」「檀那」のように日本語へ入ってきている.
仏教語はその他多数あるが,以下に『学研 日本語「語源」辞典』に挙げられている仏教語・梵語に由来することばを列挙しよう.借用された時期はまちまちだが,仏教が日本語の語彙や表現に与えてきた影響の甚大さが知られる.
愛敬〔あいきょう〕,挨拶〔あいさつ〕,愛着〔あいちゃく〕,阿吽〔あうん〕,閼伽〔あか〕,悪魔〔あくま〕,阿修羅〔あしゅら〕,痘痕〔あばた〕,尼〔あま〕,行脚〔あんぎゃ〕,安心〔あんしん〕,意識〔いしき〕,以心伝心〔いしんでんしん〕,一大事〔いちだいじ〕,一念発起〔いちねんほっき〕,一蓮托生〔いちれんたくしょう〕,衣鉢〔いはつ〕,因果〔いんが〕,因業〔いんごう〕,引導〔いんどう〕,因縁〔いんねん〕,有為転変〔ういてんぺん〕,有象無象〔うぞうむぞう〕,有頂天〔うちょうてん〕,優曇華〔うどんげ〕,優婆夷・優婆塞〔うばい・うばそく〕,盂蘭盆〔うらぼん〕,雲水〔うんすい〕,会釈〔えしゃく〕,縁起〔えんぎ〕,往生〔おうじょう〕,応用〔おうよう〕,お題目〔おだいもく〕,億劫〔おっくう〕,餓鬼〔がき〕,加持祈祷〔かじきとう〕,呵責〔かしゃく〕,火宅〔かたく〕,我慢〔がまん〕,空念仏〔からねんぶつ〕,伽藍〔がらん〕,迦陵頻伽〔かりょうびんが〕,瓦〔かわら〕,観念〔かんねん〕,甘露〔かんろ〕,伽羅〔きゃら〕,経木〔きょうぎ〕,行住坐臥〔ぎょうじゅうざが〕,苦界〔くがい〕,愚痴〔ぐち〕,功徳〔くどく〕,供養〔くよう〕,庫裏〔くり〕,紅蓮〔ぐれん〕,怪訝〔けげん〕,袈裟〔けさ〕,解脱〔げだつ〕,外道〔げどう〕,玄関〔げんかん〕,香典〔こうでん〕,虚仮〔こけ〕,居士〔こじ〕,後生〔ごしょう〕,乞食〔こつじき〕,御来迎〔ごらいごう〕,御利益〔ごりやく〕,権化〔ごんげ〕,言語道断〔ごんごどうだん〕,金輪際〔こんりんざい〕,散華〔さんげ〕,懺悔〔ざんげ〕,三途の川〔さんずのかわ〕,三昧〔さんまい〕,四苦八苦〔しくはっく〕,獅子身中の虫〔しししんちゅうのむし〕,竹篦返し〔しっぺがえし〕,七宝〔しっぽう〕,慈悲〔じひ〕,娑婆〔しゃば〕,舎利〔しゃり〕,出世〔しゅっせ〕,修羅〔しゅら〕,精進〔しょうじん〕,正念場〔しょうねんば〕,所詮〔しょせん〕,新発意〔しんぼち〕,随喜〔ずいき〕,頭陀袋〔ずだぶくろ〕,世間〔せけん〕,世知〔せち〕,殺生〔せっしょう〕,雪隠〔せっちん〕,刹那〔せつな〕,専念〔せんねん〕,禅問答〔ぜんもんどう〕,相好〔そうごう〕,息災〔そくさい〕,作麼生〔そもさん〕,醍醐味〔だいごみ〕,大衆〔たいしゅう〕,荼毘〔だび〕,他力本願〔たりきほんがん〕,旦那〔だんな〕,断末魔〔だんまつま〕,知恵〔ちえ〕,長広舌〔ちょうこうぜつ〕,長者〔ちょうじゃ〕,爪弾き〔つまはじき〕,道具〔どうぐ〕,堂堂巡り〔どうどうめぐり〕,道楽〔どうらく〕,内緒〔ないしょ〕,南無三〔なむさん〕,奈落〔ならく〕,涅槃〔ねはん〕,拈華微笑〔ねんげみしょう〕,暖簾〔のれん〕,馬鹿〔ばか〕,彼岸〔ひがん〕,比丘・比丘尼〔びく・びくに〕,非業〔ひごう〕,火の車〔ひのくるま〕,不思議〔ふしぎ〕,普請〔ふしん〕,布施〔ふせ〕,分別〔ふんべつ〕,法師〔ほうし〕,坊主〔ぼうず〕,方便〔ほうべん〕,菩提〔ぼだい〕,法螺〔ほら〕,煩悩〔ぼんのう〕,摩訶不思議〔まかふしぎ〕,魔羅〔まら〕,曼荼羅〔まんだら〕,満遍なく〔まんべんなく〕,微塵〔みじん〕,未曾有〔みぞう〕,冥利〔みょうり〕,未来〔みらい〕,無垢〔むく〕,無残〔むざん〕,無常〔むじょう〕,無尽蔵〔むじんぞう〕,冥土〔めいど〕,滅相もない〔めっそうもない〕,滅法〔めっぽう〕,妄想〔もうそう〕,野狐禅〔やこぜん〕,夜叉〔やしゃ〕,唯我独尊〔ゆいがどくそん〕,遊山〔ゆさん〕,律儀〔りちぎ〕,輪廻〔りんね〕,流転〔るてん〕,瑠璃〔るり〕,老婆心〔ろうばしん〕,渡りに船〔わたりにふね〕
上述のとおり,日本では仏教が国民生活に深く浸透したために,仏教語は日本語語彙に広く見られるだけでなく,転義を生じて俗語となったものも多い.英語側でも同様に,「#32. 古英語期に借用されたラテン語」 ([2009-05-30-1]) や「#1439. 聖書に由来する表現集」 ([2013-04-05-1]) の語彙・表現リストに見られるように,当初はキリスト教の専門用語として始まったものの,後に専門的な響きを弱め,使用域 (register) を拡げた語 (ex. candle, master, noon, school, verse) も少なくない.この点でも,日英両言語において宗教伝来と語彙史の関連を比較対照することは意義深い.
・ 『日本語学研究事典』 飛田 良文ほか 編,明治書院,2007年.
2014-04-01 Tue
■ #1800. 様々な反対語 [semantics][markedness][antonymy][lexicology]
反対語 (opposite) には反意語,反義語などの呼び名があるが,用語の不安定さもさることながら,何をもって反対とするかについての理解も様々である.
黒の反対は白か,しかし白の反対は紅(赤)とも考えられるのではないか.だが『赤と黒』という組み合わせもあるし,信号機を思い浮かべれば赤と青(実際の色は緑)という対立も考え得る.また「高い」の反対には「低い」と「安い」の2つがあるが,「低い」の反対には「高い」1つしかない.兄の反対は弟か,あるいは姉か,はたまた妹か.犬に対する猫,タコに対するイカは反対語といえるのか.happy の反対は unhappy か,それとも sad か.長いと短い,生と死,山と海,北と南,夫と妻は,それぞれ同じ基準によって反対語と呼べるのだろうか.
意味論では,反対語にも様々な種類があることが認められている.以下に Hofmann (40--46, 57--60) に拠って,代表的なものをまとめよう.
(1) (gradable) antonym
最も典型的な反対語は,high / low,long / short, old / new, hot / cold のような程度を表わす形容詞の対である.これらの反対語形容詞は,英語でいえば比較級や最上級にできる,very で程度を強められるなどの特徴をもつ.程度を尋ねる疑問や名詞形に使用されるのは,対のうちいずれかであり,そちらが一時的に中立的な意味を担うことになる.例えば,long / short の対に関しては long が無標となり,How long is the train? や the length of the train などと中和した意味で用いられる.日本語でも「どのくらい長いのか」と尋ねるし,名詞は「長さ」という.漢字では「長短」「大小」「寒暖」などと対にして中立的な程度を表わすことができるのがおもしろい.
(2) complementary
on / off,true / false, finite / infinite, mortal / immortal, single / married などの二律背反の対を構成する.(1) の対と異なり,very などで強めることはできず,程度として表現できないデジタルな関係である.一般的に,否定の接頭辞が付加されている場合を除いて,どちらが無標であるかを決めることができない.ただし,対の一方が (1) の性質をもち,他方が (2)の性質をもつケースもある.例えば,open / shut, cooked / raw, invisible / visible は,それぞれのペアのうち前者は gradable である.
他の品詞では,male / female, stop / move などが挙げられる.
(3) antonymous group
black / white / red / blue / green のように,「反対」となりうるものが集まって一連の語群(この場合には色彩語彙)を形成するもの.これらは反対語というよりは,むしろ同じ語群に属するという意味では類義語とも言うべきである.互いに同類でありながらも,その属の内部では固有の地位を占めており互いに差異的であるという点で,見方によっては「反対語」ともされるにすぎない.dog と cat はそれぞれ同類でありながら,同属の内部で相互に異なっているので,antonymous group の一部をなしているといえる.犬と猫は日本語でも英語でも慣用的にペアをなすので対語と見なされるが,同じグループの構成員としては,鼠,豚,狐,鹿を含めた多くの動物を挙げることができる.形容詞の例としては,big / small であれば (1) の例と同様にみえるが,huge / big / small / tiny という4段階制のなかで考えれば (3) を問題にしていることがわかる.つまり,(3) は,(1) や (2) の2項対立とは異なり,複数項対立と言い換えてもよいだろう.north / south / east / west の4項目など,方向に関して内部構造をもっているようなグループもある.
日本語で山の反対は海(あるいは川?)が普通だが,アメリカでは mountain に対しては valley が普通である.このように,グルーピングに文化的影響が見られるものも多い.
(4) reversative
動詞の動作について,逆転関係を表わす.tie (結ぶ)と untie (ほどく),clothe (着せる)と unclothe (脱がせる)など.過去分詞形容詞にして tied / untied, clothed / unclothed の対立へ転化すると,(1) や (2) の例となる.appear / disappear, enable / disable も同様.
(5) converse
husband / wife, parent / child のような相互に逆方向でありながら補い合う関係."X is the (husband) of Y." のとき,"Y is the (wife) of X." が成り立つ.だが,son / father は上の言い換えが必ずしもできないので,見せかけの converse である (ex. "X is the father of Liz") .
性質は異なるが,buy / sell, lend / borrow のように単一の出来事を反対の観点で見るものや,above / below, in front of / behind, north of / south of, right / left のように空間的位置関係を表わすものも,converse といえる.
上記のようにきれいに分類できないような「反対語」もあるはずだが,一応の区分として参考になるだろう.
・ Hofmann, Th. R. Realms of Meaning. Harlow: Longman, 1993.
2014-03-26 Wed
■ #1794. 借用はなぜ起こるか (2) [borrowing][lexicology][loan_word][typology]
「#46. 借用はなぜ起こるか」 ([2009-06-13-1]) の記事で,語彙が他言語から借用される理由を考えた.しかし,この「なぜ」は究極の問いであり,本格的に追究するのであれば,先に他の4W1Hの問いから潰していかなければならない.why の前に,what, who, when, where, how を問う必要があるということだ.そこで borrowing の記事を中心に,本ブログでも様々なアプローチを採ってきた.
借用語の「なぜ」に迫る論考としては,Hans Käsmann (Studien zum kirchlichen Wortschatz des Mittelenglischen 1100--1350. Eng Beitrag zum Problem der Sprachmischung. Tübingen, 1961.) に拠った Görlach (149--50) のものがあるので紹介しよう."causes and situations favouring the transfer" として,次のような分類表を掲げている(語例の前の "A11" などは.Görlach のテキスト参照記号).
(A) Gaps in the indigenous lexis
1. The word is taken over together with the new content and the new object: A11 myrre, D31 senep, F21 sabat, synagoge.
2. A well-known content has no word to designate it: D32 plant
3. Existing expressions are insufficient to render specific nuances ('misericordia', see blow).
(B) Previous weakening of the indigenous lexis
4. The content had been experimentally rendered by a number of unsatisfactory expressions: E15 leorningcniht||disciple.
5. The content had been rendered by a word weakened by homonymy, polysemy, or being part of an obsolescent type of word-formation: C24 hilid||covered; C25 hǣlan = heal, save; H11 hǣlend||sauyoure.
6. An expression which is connotationally loaded needs to be replaced by a neutral expression.
(C) Associative relations
7. A word is borrowed after a word of the same family has been adopted: D49 iust (after justice; cf. judge n., v., judgement).
8. The borrowing is supported by a native word of similar form: læccan × catchen; the process was particularly important with adoptions from Scandinavian.
9. 'Corrections': an earlier loanword is adapted in form/replaced by a new loanword: F2 engel||aungel.
(D) Special extralinguistic conditions
10. Borrowing of words needed for rhymes and metre.
11. Adoptions not motivated by necessity but by fashion and prestige.
12. Words left untranslated because the translator was incompetent, lazy or anxious to stay close to his source: H10 euangelise EV.
There remain a large number of uncertain classifications, most of these somehow connected with 11), a category which is very difficult to define.
(A), (B), (C) はまとめて,既存の語彙体系から生じる借用への圧力ということができるだろうか.「#901. 借用の分類」 ([2011-10-15-1]) でみたタイポロジーとも交差する.(D) はおよそ言語外的な要因というべきものである.通常,語の借用を話題にする場合には,言語外的な要因が注目されることも多いが,この分類は相対的にその扱いが弱いのが特徴だ.結局のところ,最後に但し書きで逃げ口上を打っているように,このような分類を立てることに限界があるのだろう.Fischer (105) は,この分類に不満を表明している.
Like all attempts to "explain" language change, this one suffers from the fact that explanations can only be guessed at and that actual, verifiable proof is hard to come by. Any such typology, therefore, will remain tentative.
冒頭で述べたように,まずは借用の4W1Hを着実に理解してゆくところから始める必要がある.
・ Görlach, Manfred. The Linguistic History of English. Basingstoke: Macmillan, 1997.
・ Fischer, Andreas. "Lexical Borrowing and the History of English: A Typology of Typologies." Language Contact in the History of English. 2nd rev. ed. Ed. Dieter Kastovsky and Arthur Mettingers. Frankfurt am Main: Peter Lang, 2003. 97--115.
2014-03-24 Mon
■ #1792. 18--20世紀のフランス借用語 [french][loan_word][lexicology]
「#117. フランス借用語の年代別分布」 ([2009-08-22-1]) で見たとおり,英語史では,ノルマン・コンクェスト以降,フランス借用語の流入が絶えた時期はない.14世紀,16世紀を2つのピークとして近代以降は相対的に流入は少なめだが,現在に至るまでフランス借用語は英語の語彙に着実に貢献してきている.
時代ごとのフランス借用語の特徴や一覧については,「#1210. 中英語のフランス借用語の一覧」 ([2012-08-19-1]),「#1291. フランス借用語の借用時期の差」 ([2012-11-08-1]),「#1209. 1250年を境とするフランス借用語の区分」 ([2012-08-18-1]),「#1411. 初期近代英語に入った "oversea language"」 ([2013-03-08-1]),「#678. 汎ヨーロッパ的な18世紀のフランス借用語」 ([2011-03-06-1]),「#594. 近代英語以降のフランス借用語の特徴」 ([2010-12-12-1]) などで取り上げてきたが,今回は Crystal (460) に掲載されている18--20世紀のフランス借用語の抜粋を示そう.
[18th century loanwords]
bouquet, canteen, clique, connoisseur, coterie, cuisine, debut, espionage, etiquette, glacier, liqueur, migraine, nuance, protégé, roulette, salon, silhouette, souvenir, toupee, vignette
[19th century loanwords]
acrobat, baroque, beige, blouse, bonhomie, café, camaraderie, can-can, chauffeur, chef, chic, cinematography, cliché, communism, croquet, debutant, dossier, en masse, flair, foyer, genre, gourmet, impasse, lingerie, matinée, menu, morgue, mousse, nocturne, parquet, physique, pince-nez, première, raison d'être, renaissance, repertoire, restaurant, risqué, sorbet, soufflé, surveillance, vol-au-vent, volte-face
[20th century loanwords]
art deco, art nouveau, u pair, auteur, blasé, brassiere, chassis, cinéma-vérité, cinematic, coulis, courgette, crime passionnel, détente, disco, fromage frais, fuselage, garage, hangar, limousine, microfiche, montage, nouvelle cuisine, nouvelle vague, questionnaire, tranche, visagiste, voyeurism
借用語の分野としては,18世紀は社会制度・習慣,19世紀は芸術,食物,衣類,20世紀は新芸術,技術が特徴的だろうか.数だけでいえば,後期近代におけるフランス借用語のピークは19世紀にあるとみてよいだろう.
なお,21世紀のフランス借用語について OED を検索したところ,parkour, traceur の2語だけがヒットした.前者は2002年が初出で,"The discipline or activity of moving rapidly and freely over or around the obstacles presented by an (esp. urban) environment by running, jumping, climbing, etc." と定義される.後者は2003年が初出で,"A person who participates in parkour" とのこと.英語にとっては腐れ縁ともいえるフランス語からの借用は,21世紀も続いてゆく・・・.
・ Crystal, David. The Stories of English. London: Penguin, 2005.
2014-03-10 Mon
■ #1778. 借用語研究の to-do list [loan_word][borrowing][semantics][lexicology][typology][methodology]
ゼミの学生の卒業論文研究をみている過程で,Fischer による借用語研究のタイポロジーについての論文を読んだ.英語史を含めた諸言語における借用語彙の研究は,3つの観点からなされてきたという.(1) morpho-etymological (or morphological), (2) lexico-semantic (or semantic), (3) socio-historical (or sociolinguistic) である.
(1) は,「#901. 借用の分類」 ([2011-10-15-1]) で論じたように,model と loan とが形態的にいかなる関係にあるかという観点である.形態的な関係が目に見えるものが importation,見えないもの(すなわち意味のみの借用)が importation である.(2) は,借用の衝撃により,借用側言語の意味体系と語彙体系が再編されたか否かを論じる観点である.(3) は,語の借用がどのような社会言語学的な状況のもとに行われたか,両者の相関関係を明らかにしようとする観点である.この3分類は互いに交わるところもあるし,事実その交わり方の組み合わせこそが追究されなければならないのだが,おおむね明解な分け方だと思う.
Fischer は,このなかで (3) の社会言語学的な観点は最も興味をそそるが,目に見える研究成果は期待できないだろうと悲観的である.この観点を重視した Thomason and Kaufman を参照し,高く評価しながらも,借用語研究には貢献しないだろうと述べている.
Of the three types of typologies discussed here, the third, although the most attractive because of its sociolinguistic orientation, is possibly the least useful for a study of lexical borrowing: lexis is an unreliable indicator of the precise nature of a contact situation, and the socio-historical evidence necessary to reconstruct the latter is often not available. Morphological and semantic typologies on the other hand, though seemingly more traditional, can yield a great deal of new information if an attempt is made to study a whole semantic domain and if such studies are truly comparative, comparing different text types, different source languages or different periods. (110)
Fischer は (1) と (2) の観点こそが,借用語研究において希望のもてる方向であると指南する.一見すると,英語史に限定した場合,この2つの観点,とりわけ (1) の観点からは,相当に研究がなされているのではないかと思われるが,案外とそうでもない.例えば,意味借用 (semantic loan) に代表される substitution 型の借用語については,研究の蓄積がそれほどない.これには,importation に対して substitution は意味を扱うので見えにくいこと,頻度として比較的少ないことが理由として挙げられる.
それにしても,語を借用するときに,ある場合には importation 型で,別の場合には substitution 型で取り込むのはなぜだろうか.背後にどのような選択原理が働いているのだろうか.借用側言語の話者(集団)の心理や,公的・私的な言語政策といった社会言語学的な要因については言及されることがあるが,上記 (1) や (2) の言語学的な観点からのアプローチはほとんどないといってよい.Fischer (100) の問題意識,"why certain types of borrowing seem to be more frequent than others, depending on period, source language, text type, speech community or language policy, to name only the most obvious factors." は的を射ている.私自身も,同様の問題意識を,「#902. 借用されやすい言語項目」 ([2011-10-16-1]),「#903. 借用の多い言語と少ない言語」 ([2011-10-17-1]),「#934. 借用の多い言語と少ない言語 (2)」 ([2011-11-17-1]),「#1619. なぜ deus が借用されず God が保たれたのか」 ([2013-10-02-1]) などで示唆してきた.
英語史におけるラテン借用語を考えてみれば,古英語では importation と並んで substitution も多かった(むしろ後者のほうが多かったとも議論しうる)が,中英語以降は importation が主流である.Fischer (101) で触れられているように,Standard High German と Swiss High German におけるロマンス系借用語では,前者が substitution 寄り,後者は importation 寄りの傾向を示すし,アメリカ英語での substitution 型の fall に対してイギリス英語での importation 型の autumn という興味深い例もある.日本語への西洋語の借用も,明治期には漢語による substitution が主流だったが,後には importation が圧倒的となった.言語によって,時代によって,importation と substitution の比率が変動するが,ここには社会言語学的な要因とは別に何らかの言語学的な要因も働いている可能性があるのだろうか.
Fischer (105) は,このような新しい設問を多数思いつくことができるとし,英語史における設問例として3つを挙げている.
・ How many of all Scandinavian borrowings have replaced native terms, how many have led to semantic differentiation?
・ How does French compare with Scandinavian in this respect?
・ How many borrowings from language x are importations, how many are substitutions, and what semantic domains do they belong to?
HTOED (Historical Thesaurus of the Oxford English Dictionary) が出版された現在,意味の借用である substitution に関する研究も断然しやすくなってきた.英語借用語研究の未来はこれからも明るそうだ.
・ Fischer, Andreas. "Lexical Borrowing and the History of English: A Typology of Typologies." Language Contact in the History of English. 2nd rev. ed. Ed. Dieter Kastovsky and Arthur Mettingers. Frankfurt am Main: Peter Lang, 2003. 97--115.
・ Thomason, Sarah Grey and Terrence Kaufman. Language Contact, Creolization, and Genetic Linguistics. Berkeley: U of California P, 1988.
2014-02-25 Tue
■ #1765. 日本で充実している英語語源学と Klein の英語語源辞典 [etymology][dictionary][lexicology][hebrew]
日本にもたびたび訪れている英語史界の重鎮,ポーランドの Fisiak (8) に,日本の英語語源学が充実している旨,言及がある.
One important area of research in Japan is English etymology. At least two important recent dictionaries should be mentioned: Osamu Fukushima An etymological dictionary of English derivatives, 1992 (in English), and Yoshio Terasawa.(sic) The Kenkyusha dictionary of English etymology, 1997 (in Japanese), I received both of them in 1997. Fushima's (sic) dictionary is unique in its handling solely derivatives. Terasawa's opus magnum is in Japanese but with some explanations it can be used by people who do not read Japanese. . . . The dictionary is a magnificent piece of work. It is the largest etymological dictionary of English. Its scope is unusually wide. In the notes sent to me Professor Terasawa wrote that the dictionary "includes approximately 50.000 words, the majority of which are common words found in general use, new coinages, slang, and such technical terms as seen in science and technology, such components of a word as prefixes, suffixes, linking forms, as well as major place names and common personal names" (private correspondence). It is comprehensive and up-to-date, well-researched and contains a fairly large number of entries thoroughly revised in comparison with earlier etymological dictionaries. Onions' Oxford dictionary of English etymology, 1966 contains 38.000 words with the derivatives and as could be expected many of the etymologies require revisions. From a linguistic point of view Terasawa's dictionary compares favorably with Klein's comprehensive etymological dictionary of the English language, 1966--67.
寺澤,福島による語源辞典を愛用する者として,おおいに歓迎すべき評である.Fisiak は,『英語語源辞典』を Klein の辞典に比較すべき労作であるとしているが,ここで引き合いに出されている Klein の英語語源辞典とはどのようなものか,確認しておこう.Klein については,寺澤自身が『辞書・世界英語・方言』 (80) で次のように評している.
本辞典は,'history of words' と同時に 'history in words' を明らかにすることを目標としている.その副題も "Dealing with the origin of words and their sense development thus illustrating the history of civilization and culture" とあり,巻頭のモットーにも "To know the origin of words is to know the cultural history of mankind" と揚言されている.言い換えれば,単語を,言語の一要素であると同時にそれを用いる人間の一要素,自然・人文・科学の諸分野の発達を写し出す鏡の役目をもつものと捉える.これが本辞書の第一の特色である.第二は,印欧語根に遡る場合,従来の英語辞典であまり取り上げられなかったトカラ語 (Tocharian) の同族語を記載する,第三は750に及ぶセム語 (Semitic) 起源の語について,印欧語に準ずる記述を行なう.第四は人名のほか,神話・伝説上の固有名詞(例:Danaüs.ただし,その語源解には問題あり)を豊富に採録.第五は科学・技術の専門語を重視する,などである
Klein は1日11時間,18年の年月をかけてこの辞典を編んだというから,まさに労作中の労作である.Klein については,荒 (100) も次のように評している.「E. クラインは,初めチェッコスロヴァキアでラビ(ユダヤ教の教師)をしていたが,ナチの強制収容所に捕えられ,その間,父,妻,一人息子,三人姉妹の二人を失った.戦後,カナダに移り,イギリス語の語原辞典の編集を思い立ち,文明と文化に重点をおき,これまで無視されていたセミティック系の諸言語との関係を究明した点では,画期的なもの」である.
この労作と比肩するものとして日本の英語語源辞典が紹介されているということは,素直に賞賛と受け取ってよいだろう.ただし,Klein の辞典の利用には注意が必要である.英語史内での語史記述が不十分であること,編者の経歴からセム語(特にヘブライ語)の記述は期待されそうだが必ずしも正確ではないことなどは,気にとめておく必要がある.
関連して,「#600. 英語語源辞書の書誌」 ([2010-12-18-1]) も参照.
・ Fisiak, Jacek. "Discovering English Historical Linguistics in Japan." Phrases of the History of English: Selection Papers Read at SHELL 2012. Ed. Michio Hosaka, Michiko Ogura, Hironori Suzuki, and Akinobu Tani. Frankfurt am Main: Peter Lang, 2013.
・ 寺澤 芳雄 (編集主幹) 『英語語源辞典』 研究社,1997年.
・ 福島 治 編 『英語派生語語源辞典』 日本図書ライブ,1992年.
・ Klein, Ernest. A Comprehensive Etymological Dictionary of the English Language, Dealing with the Origin of Words and Their Sense Development, Thus Illustrating the History of Civilization and Culture. 2 vols. Amsterdam/London/New York: Elsevier, 1966--67. Unabridged, one-volume ed. 1971.
・ 寺澤 芳雄(編) 『辞書・世界英語・方言』 研究社英語学文献解題 第8巻.研究社.2006年.
・ 荒 正人 『ヴァイキング 世界史を変えた海の戦士』 中央公論新社〈中公新書〉,1968年.
2014-02-04 Tue
■ #1744. 2013年の英語流行語大賞 [lexicology][ads][woy][register][rhetoric][punctuation]
一月前のことになるが,1月3日,American Dialect Society による 2013年の The Word of the Year が発表された.プレス・リリース (PDF) はこちら.
2013年の大賞は because である.古い語だが,新しい語法が発達してきたゆえの受賞という.
This past year, the very old word because exploded with new grammatical possibilities in informal online use. . . . No longer does because have to be followed by of or a full clause. Now one often sees tersely worded rationales like 'because science' or 'because reasons.' You might not go to a party 'because tired.' As one supporter put it, because should be Word of the Year 'because useful!'
この新用法は,現在は "in informal online use" という register に限定されているが,上記の通り便利であるにはちがいないので,今後 register を拡げてゆく可能性がある.MOST USEFUL 部門でも受賞している.
新用法は because が節ではなく語や句を従えることができるようになったというものだが,これには2種類が区別されるように思われる.1つは,"because tired" や "because useful" のように,統語的要素が省略されていると考えられるもの.ここでは,それぞれ "because (I am) tired" や "because (it is) useful" のように主語+ be 動詞が省略されていると解釈できる.発話されている状況などの語用論的な情報を参照せずとも,統語的に「復元」できるタイプだ.統語的に論じられるべき用法といえるだろう.
もう1つは,"because science" や "because reasons" のタイプだ.これは "because of science" や "because of reasons" とも異なるし,一意に統語的に節へ「復元」できるわけでもない.むしろ,1語により節に相当する意味を想像させ,含蓄や余韻を与える修辞的な効果を出している.こちらは,統語的というよりは修辞的に論じられるべき用法といえる.
さて,受賞した because のほかにも,ノミネート語句や他部門での受賞語句があり,眺めてみるとおもしろい.例えば slash は,"used as a coordinating conjunction to mean 'and/or' (e.g., 'come and visit slash stay') or 'so' ('I love that place, slash can we go there?')" と説明されており,確かに便利な語である.書き言葉に属する句読記号 (punctuation) の1つを表す語が,話し言葉で接続詞として用いられているというのがおもしろい.「以上終わり」を意味する間投詞としての Period. に類する特異な例である.
2014-01-20 Mon
■ #1729. glottochronology 再訪 [glottochronology][lexicology][family_tree][pidgin][punctuated_equilibrium][speed_of_change]
「#1128. glottochronology」 ([2012-05-29-1]) で,アメリカの言語学者・人類学者 Swadesh (1909--67) の提唱した言語年代学をみた.その理論的支柱となるのは,"the fundamental everyday vocabulary of any language---as against the specialized or 'cultural' vocabulary---changes at a relatively constant rate" (452) というものだ.Swadesh は複数の言語の調査に基づき,その一定速度は約86%であるとみている.この考え方には様々な批判が提出されているが,仮に受け入れるとしても,なぜ一定速度というものありうるのかという大きな問題が残る.基本語彙が一定の速度で置換されてゆくことに関する原理的説明の問題だ.これについて,Swadesh 自身は,次のように述べている.
Why does the fundamental vocabulary change at a constant rate? . . . . / A language is a highly complex system of symbols serving a vital communicative function in society. The symbols are subject to change by the influence of many circumstances, yet they cannot change too fast without destroying the intelligibility of language. If the factors leading to change are great enough, they will keep the rate of change up to the maximum permitted by the communicative function of language. We have, as it were, a powerful motor kept in check by a speed regulating mechanism. . . . / While it is subject to manifold impulses toward change, language still must maintain a considerable amount of uniformity. If it is to be mutually intelligible among the members of the community, there must be a large element of agreement in its details among the individuals who make up the community. As between the oldest and the youngest generations, there are often difference of vocabulary and usage but these are never so great as to make it impossible for the two groups to understand each other. This is the circumstance which sets a maximum limit on the speed of change in language. / Acquisition of additional vocabulary may proceed at a faster rate than the replacement of old words. Replacement in culture vocabulary usually goes with the introduction of new cultural traits replacing the old ones, a process which at times may be completed in a few generations. Replacement of fundamental vocabulary must be slower because the concepts (e.g., body parts) do not change fundamentally. Change can come about by the introduction of partial synonyms which only rarely, and even then for the most part gradually, expand their area and frequency of usage to the point of replacing the earlier word. (459--60)
これは基礎語彙の置換速度のとる値に限界があることに関しての原理的説明にはなっているが,なぜ86%前後というほぼ一定の値をとるのかという問いには答えていないように思われる.早い場合も遅い場合もあるが,ならせばそのくらいになるという経験的な記述にとどまるということだろうか.
また,glottochronology が前提としているのは,印欧語族の系統樹に示されるような,諸言語の時間的な連続性である.しかし,強度の言語接触の過程としてのピジン化 (pidginisation) の事例などを考慮すると,上記の計算はまるで通用しないだろう.系統樹モデルでうまく扱えるような言語については基礎語彙の置換の一定速度を論じることができるかもしれないが,世代間の断絶を示す言語状況に同じ議論を適用することはできないのではないか.そして,後者の言語状況は,ピジン語の研究や「#1397. 断続平衡モデル」 ([2013-02-22-1]) が示唆するように,人類言語の歴史においては,これまで想定されていたよりもずっと普通のことであった可能性が高い.
ただし,glottochronology は,系統樹モデルでうまく扱えるような言語に関する限りにおいては,少なくとも記述統計的に興味深い学説でありうると思う.このような限定つきで評価する価値はあるのではないか.
・ Swadesh, Morris. "Lexico-Statistic Dating of Prehistoric Ethnic Contacts: With Special Reference to North American Indians and Eskimos." Proceedings of the American Philosophical Society 96 (1952): 452--63.
2014-01-15 Wed
■ #1724. Skeat による2重語一覧 [doublet][etymology][lexicology]
昨日の記事「#1723. シップリーによる2重語一覧」 ([2014-01-14-1]) に引き続き,今度は Skeat の語源辞典 (748--51) に掲載されている2重語 (doublet) を一覧しよう.その前に,Skeat (748) の2重語の定義を掲げよう.
Doublets are words which, though apparently differing in form, are nevertheless, from an etymological point of view, one and the same, or only differ in some unimportant suffix. Thus aggrieve is from L. aggrauāre; whilst aggravate, though really from the pp. aggrauātus, is nevertheless used as a verb, precisely as aggrieve is used, though the senses of the words have been differentiated.
では,以下に645組の2重語一覧を掲げる.(なお,本ブログ右欄に「今日の doublet」コーナーを設けてみました.)
| abbreviate | abridge |
| abet | bet |
| acajou | cashew |
| adamant | diamond |
| adventure | venture |
| advocate | avouch, avow |
| aggrieve | aggravate |
| ait | eyot |
| alarm | alarum |
| allocate | allow |
| ameer | emir, omrah |
| amiable | amicable |
| an | one |
| ancient | ensign |
| announce | annunciate |
| ant | emmet |
| anthem | antiphon |
| antic | antique |
| appal | pall |
| appeal (sb) | peal |
| appear | peer |
| appraise | appreciate |
| apprentice | prentice |
| aptitude | attitude |
| arc | arch |
| army | armada |
| arrack | rack, raki |
| asphodel | daffodil |
| assay | essay |
| assemble | assimilate |
| assess | assize (vb) |
| assoil | absolve |
| attach | attack |
| attire | tire, tire |
| bale | ball |
| balm | balsam |
| band | bond |
| banjo | mandoline |
| barb | bard |
| base | basis |
| bashaw | pasha |
| baton | batten |
| bawd | bold |
| beadle | bedell |
| beaker | pitcher |
| beef | cow |
| beldam | belladonna |
| bench | bank, bank |
| benison | benediction |
| blame | blaspheme |
| boil | bile |
| boss | botch |
| bough | bow |
| bound | bourn |
| bower | byre |
| bowl | bull |
| box | pyx, bush |
| brave | bravo |
| breve | brief |
| brother | friar |
| brown | bruin |
| buff | buffalo |
| cadence | chance |
| caitiff | captive |
| caldron, cauldron | chaldron |
| caliber | caliver |
| calumny | challenge |
| camera | chamber |
| cancer | canker |
| cannon | canon |
| caravan | van |
| card | chart, carte |
| case | chase, cash |
| cask | casque |
| castigate | chasten |
| catch | chase |
| cattle | chattels, capital |
| cavalier | chevalier |
| cavalry | chivalry |
| cess | assess |
| chaise | chair |
| chalk | calx |
| champaign | campaign |
| channel | canal, kennel |
| chant | cant |
| chapiter | capital |
| charge | cark, cargo |
| chateau | castle |
| cheat | escheat |
| check (sb) | shah |
| chicory | succory |
| chief | cape |
| chieftain | captain |
| chirurgeon | surgeon |
| choir | chorus, quire |
| choler | cholera |
| chord | cord |
| chuck | shock, shog |
| church | kirk |
| cipher | zero |
| cist | chest |
| cithern | guitar, gittern, kit |
| cive | chive |
| clause | close (sb) |
| climate | clime |
| coffer | coffin |
| coin | coign, quoin |
| cole | kail |
| collect | cull, coil (vb) |
| collocate | couch |
| comfit | confect |
| commend | command |
| commodore | commander |
| complacent | complaisant |
| complete (vb) | comply |
| compost | composite |
| comprehend | comprise |
| compute | count |
| conduct (sb) | conduit |
| confound | confuse |
| construe | construct |
| convey | convoy |
| cool | gelid |
| corn | grain |
| corn | horn |
| coronation | carnation |
| corral | kraal |
| corsair | hussar |
| costume | custom |
| cot | cote |
| couple (vb) | copulate |
| coy | quiet, quit, quite |
| coy | cage |
| crape | crisp |
| cream | chrism |
| crease | crest |
| crevice | crevasse |
| crib | cratch |
| crimson | carmine |
| crop | coup |
| crowd | rote |
| crypt | grot |
| cud | quid |
| cue | queue |
| curari | wourali |
| curricle | curriculum |
| curtle-axe | cutlass |
| cycle | wheel |
| dace | dart, dare |
| dainty | dignity |
| dame | dam, donna, duenna |
| dan | don, domino |
| dauphin | dolphin |
| deck | thatch |
| defence | fence |
| defend | fend |
| delay | dilate |
| dell | dale |
| demesne | domain |
| dent | dint |
| deploy | display, splay |
| depot | deposit (sb) |
| descry | describe |
| desiderate | desire (vb) |
| despite | spite |
| deuce | two |
| devilish | diabolic |
| die | dado |
| direct (vb) | dress |
| dish | disc, desk, daïs |
| disport | sport |
| distain | stain |
| ditch | dike |
| ditto | dictum |
| diurnal | journal |
| doge | duke |
| doit | thwaite |
| dole | deal (sb) |
| dominion | dungeon |
| doom | -dom (suffix) |
| dragon | dragoon |
| dropsy | hydropsy |
| due | debt |
| dune | down |
| eatable | edible |
| éclat | slate |
| elf | oaf, ouphe |
| élite | elect |
| emerald | smaragdus |
| emerods | hemorrhoids |
| employ | imply, implicate |
| endow | endue, indue |
| engine | gin |
| entire | integer |
| envious | invidious |
| escape | scape |
| eschew | shy (vb) |
| escutcheon | scutcheon |
| especial | special |
| espy | spy |
| esquire | squire |
| establish | stablish |
| estate | state, status |
| estimate | esteem |
| estop | stop |
| estreat | extract |
| etiquette | ticket |
| example | ensample, sample |
| exemplar | sampler |
| extraneous | strange |
| fabric | forge (sb) |
| fact | feat |
| faculty | facility |
| fan | van |
| fancy | fantasy, phantasy |
| fashion | faction |
| fat | vat |
| fauteuil | faldstool |
| fealty | fidelity |
| feeble | foible |
| fell | pell |
| fester (sb) | fistula |
| feud | fief, fee |
| feverfew | febrifuge |
| fiddle | viol |
| fife | pipe, peep |
| finch | spink |
| finite | fine |
| fitch | vetch |
| flag | flake, flaw |
| flower | flour |
| flush | flux |
| foam | spume |
| font | fount |
| force | farce |
| foremost | prime |
| foster | forester |
| fragile | frail |
| fray | affray |
| fro | from |
| frounce | flounce |
| fungus | sponge |
| furl | fardel |
| gabble | jabber |
| gad | ged |
| gaffer | grandfather |
| gage | wage |
| gambado | gambol |
| game | gammon |
| gaol | jail |
| garth | yard |
| gear | garb |
| genteel | gentle, gentile |
| genus | kin |
| germ | germen |
| gig | jig |
| gin | juniper |
| gird | gride |
| girdle | girth |
| glamour | gramarye |
| grain | corn |
| granary | garner |
| grece, grise | grade |
| guarantee (sb) | warranty |
| guard | ward |
| guardian | warden |
| guest | host |
| guile | wile |
| guise | wise |
| gullet | gully |
| gust | gusto |
| guy | guide (sb) |
| gypsy | Egyptian |
| hackbut | arquebus |
| hale | whole |
| hamper | hanaper |
| harangue | ring, rank, rink |
| hash (vb) | hatch |
| hatchment | achievement |
| hautboy | oboe |
| heap | hope |
| heckle | hackle, hatchel |
| hemi- | semi- |
| hent | hint |
| history | story |
| hock | hough |
| hoop | whoop |
| hospital | hostel, hotel, spital, spittle |
| hub | hob |
| human | humane |
| hyacinth | jacinth |
| hydra | otter |
| hyper- | super- |
| hypo- | sub- |
| illumine | limn |
| inapt | inept |
| inch | ounce |
| indite | indict |
| influence | influenza |
| innocuous | innoxious |
| invite | vie |
| invoke | invocate |
| iota | jot |
| isolate | insulate |
| jaggery | sugar |
| jealous | zealous |
| jinn | genie |
| joint | junta, junto |
| jointure | juncture |
| jut | jet |
| jutty | jetty |
| ketch | catch |
| label | lapel, lappet |
| lac | lake |
| lace | lasso |
| lair | leaguer |
| lake | loch, lough |
| lateen | Latin |
| launch, lanch | lance (vb) |
| leal | loyal, legal |
| lection | lesson |
| lib | glib |
| lieu | locus |
| limb | limbo |
| limbeck | alembic |
| lineal | linear |
| liquor | liqueur |
| list | lust |
| load | lode |
| lobby | lodge |
| locust | lobster |
| lone | alone |
| losel | lorel |
| lurch | lurk |
| madam | madonna |
| major | mayor |
| male | masculine |
| malediction | malison |
| mandate | maundy |
| mangle | mangonel |
| manœuvre | manure |
| march | mark, marque |
| margin | margent, marge |
| marish | morass |
| maul | mall |
| mauve | mallow |
| maxim | maximum |
| mazer | mazzard |
| mean | mesne, mizen |
| memory | memoir |
| mentor | monitor |
| metal | mettle |
| milt | milk |
| minim | minimum |
| minster | monastery |
| mint | money |
| mister | master |
| mob | mobile, movable |
| mode | mood |
| mohair | moire |
| moment | momentum, movement |
| monster | muster |
| morrow | morn |
| moslem | mussulman |
| mould | module |
| munnion | mullion |
| musket | mosquito |
| naive | native |
| naked | nude |
| name | noun |
| natron | nitre |
| naught, nought | not |
| nausea | noise |
| neat | net |
| nias | eyas |
| noyau | newel |
| obedience | obeisance |
| octave | utas |
| of | off |
| onion | union |
| oration | orison |
| ordinance | ordnance |
| orpiment | orpine |
| osprey | ossifrage |
| otto | attar |
| ouch | nouch |
| outer | utter |
| overplus | surplus |
| paddle | spatula |
| paddock | park |
| pain (vb) | pine |
| paladin | palatine |
| pale | pallid, fallow |
| palette | pallet |
| paper | papyrus |
| parade | parry |
| paradise | parvis |
| paralysis | palsy |
| parole | parable, parle, palaver |
| parson | person |
| pass | pace |
| pastel | pastille |
| pasty | patty |
| pate | plate |
| patron | pattern |
| pause | pose |
| pawn | pane, vane |
| paynim | paganism |
| peer | appear |
| peise | poise |
| pelisse | pilch |
| pellitory | paritory |
| penance | penitence |
| peregrine | pilgrim |
| peruke | periwig, wig |
| pewter | spelter |
| phantasm | phantom |
| piazza | place |
| pick | peck, pitch (vb) |
| picket | piquet |
| piety | pity |
| pigment | pimento |
| pike | peak, pick (sb), pique (sb), spike |
| pippin | pip |
| pistil | pestle |
| pistol | pistole |
| plaintiff | plaintive |
| plait | pleat, plight |
| plan | plain, plane, llano |
| plateau | platter |
| plum | prune |
| poignant | pungent |
| point | punt |
| poison | potion |
| poke | pouch |
| pole | pale, pawl |
| pomade, pommade | pomatum |
| pomp | pump |
| poor | pauper |
| pope | papa |
| porch | portico |
| posy | poesy |
| potent | puissant |
| poult | pullet |
| pounce | punch |
| pounce | pumice |
| pound | pond |
| pound | pun (vb) |
| power | posse |
| praise | price |
| preach | predicate |
| premier | primero |
| priest | presbyter |
| private | privy |
| probe (sb) | proof |
| proctor | procurator |
| prolong | purloin |
| prosecute | pursue |
| provide | purvey |
| provident | prudent |
| punch | punish |
| puny | puisne |
| purl | profile |
| purpose | propose |
| purview | proviso |
| quartern | quadroon |
| queen | quean |
| raceme | raisin |
| rack | wrack, wreck |
| radix | radish, race, root, wort |
| raid | road |
| rail | rally |
| raise | rear |
| ramp | romp |
| ransom | redemption |
| rapine | ravine, raven |
| rase | raze |
| ratio | ration, reason |
| ray | radius |
| rayah | ryot |
| rear-ward | rear-guard |
| reave | rob |
| reconnaissance | recognisance |
| regal | royal, real |
| relic | relique |
| renegade | runagate |
| renew | renovate |
| reprieve | reprove |
| residue | residuum |
| respect | respite |
| revenge | revindicate |
| reward | regard |
| rhomb, rhombus | rumb |
| ridge | rig |
| rod | rood |
| rondeau | roundel |
| rote | route, rout, rut |
| round | rotund |
| rouse | row |
| rover | robber |
| sack | sac |
| sacristan | sexton |
| saw | saga |
| saxifrage | sassafras |
| scabby | shabby |
| scale | shale |
| scandal | slander |
| scar, scaur | share |
| scarf | scrip, scrap |
| scatter | shatter |
| school | shoal, scull |
| scot(free) | shot |
| screen | shriek |
| screed | shred |
| screw | shrew |
| scur | scour |
| scuttle | skillet |
| sect, sept, set | suite, suit |
| sennet | signet |
| separate | sever |
| sequin | sicca |
| sergeant, serjeant | servant |
| settle | sell, saddle |
| shammy | chamois |
| shark | search |
| shawm, shalm | haulm |
| sheave | shive |
| shed | shade |
| shirt | skirt |
| shrub | sherbet, syrup |
| shuffle | scuffle |
| sicker, siker | secure, sure |
| sine | sinus |
| sir, sire | senior, seignior, señor, signor |
| size, size | assise |
| skewer | shiver |
| skiff | ship |
| skirmish | scrimmage, scaramouch |
| slabber | slaver |
| sleight | sloid |
| sleuth | slot |
| slobber | slubber |
| sloop | shallop |
| snivel | snuffle |
| snub | snuff |
| soil | sole, sole |
| soprano | sovereign |
| sough | surf |
| soup | sup |
| souse | sauce |
| spade | spade |
| species | spice |
| spell | spill |
| spend | dispend |
| spirit | sprite, spright |
| spoor | spur |
| spray | sprig, asparagus |
| sprit | sprout (sb) |
| sprout (vb) | spout |
| spry | spark |
| squall | squeal |
| squinancy | quinsy |
| squire | square |
| stank | tank |
| stave | staff |
| steer | Taurus |
| still | distil |
| stock | tuck |
| stove | stew (sb) |
| strait | strict |
| strap | strop |
| stress | distress |
| superficies | surface |
| supersede | surcease |
| suppliant | supplicant |
| sweep | swoop |
| tabor | tambour |
| tache | tack |
| taint | attaint |
| tamper | temper |
| tarpauling | tar |
| task | tax |
| taunt | tempt, tent |
| tawny | tenny |
| tease | tose |
| tee | taw |
| teind | tithe, tenth |
| tend | tender |
| tense | toise |
| tercel | tassel |
| thread | thrid |
| thrill, thirl | drill |
| tine | tooth |
| tippet | tape |
| tit | teat |
| title | tittle |
| to | too |
| ton | tun |
| tone | tune |
| tour | turn |
| tow | tug |
| town | down |
| track | trick |
| tract | trait |
| tradition | treason |
| travail | travel |
| treble | triple |
| trifle | truffle |
| tripod | trivet |
| triumph | trump |
| troth | truth |
| tuck | tug |
| tuck | touch |
| tulip | turban |
| tweak | twitch |
| umbel | umbrella |
| unity | unit |
| ure | opera |
| vade | fade |
| vair | various |
| valet | varlet |
| vantage | advantage |
| vast | waste |
| vaward | vanguard |
| veal | wether |
| veldt | field |
| veneer | furnish |
| venew, veney | venue |
| verb | word |
| vermeil | vermillion |
| vertex | vortex |
| vervain | verbena |
| viaticum | voyage |
| viper | wyvern, wivern |
| visor | vizard |
| vizier, visier | alguazil |
| vocal | vowel |
| wain | wagon, waggon |
| wale | weal |
| wattle | wallet |
| weet | wit |
| whirl | warble |
| wight | whit |
| wold | weald |
| yelp | yap |
・ Skeat, Walter William, ed. An Etymological Dictionary of the English Language. 4th ed. Oxford: Clarendon, 1910. 1st ed. 1879--82. 2nd ed. 1883.
2014-01-14 Tue
■ #1723. シップリーによる2重語一覧 [doublet][etymology][lexicology]
本ブログでは2重語 (doublet) に関する記事を多く書いてきたが,一覧を作っておくと便利である.シップリーの語源辞典の巻末に,2重語(と3重語以上の多重語)のリストが載っていたので,以下に転載する.その前に,シップリー (708) による2重語の定義と説明を示しておこう.
二重語とは,同じ語源の言葉が異なった経路を経て英語になった一組の言葉(あるいはその組の一語)を意味する.下記はその例に数えられるもので,それらの語源や経路をたどろうと思えば,すべて OED (『オックスフォード英語大辞典』)で見ることができ,これらの二重語から,英語の豊かさと,言葉についてのさまざまな興味ある話しを読み取ることができる.二重語には,語源は同じでありながら,その意味は互いに大いに異なるものがある.
では,以下に126組の2重語一覧を掲げる.
| abbreviate (略記する) | abridge (短縮する) | |||
| acute (先の尖った) | cute (かわいい) | ague (激しい熱,【病理】悪寒) | ||
| adamant (剛直な) | diamond (ダイアモンド) | |||
| adjutant (助手の) | aid (手伝う) | |||
| aggravate (さらに悪化させる) | aggrieve (悲しませる) | |||
| aim (狙いを定める) | esteem (尊重する) | estimate (評価する) | ||
| allocate (割り当てる) | allow (置く) | |||
| alloy (合金) | ally (同盟する) | |||
| an (一つの:不定冠詞) | one (一つの) | |||
| antic (こっけいなしぐさ) | antique (古臭い) | |||
| appreciate (高く評価する) | appraise (値段をつける) | apprize (尊重する) | ||
| aptitude (適正) | attitude (態度) | |||
| army (軍隊) | armada (艦隊) | |||
| asphodel (《詩語》スイセン) | daffodil (ラッパスイセン) | |||
| assemble (集合させる) | assimilate (消化吸収する) | |||
| astound (仰天させる) | astonish (驚かす) | stun (呆然とさせる) | ||
| attach (貼り付ける) | attack (攻撃する) | |||
| band (バンド) | bond (きずな) | |||
| banjo (バンジョー) | mandolin (マンドリン) | |||
| bark (バーク船) | barge (平底荷船) | |||
| beaker (ビーカー) | pitcher (ピッチャー) | |||
| beam (梁) | boom (【海事】帆桁) | |||
| belly (腹部) | bellows (ふいご) | |||
| benison (祝福の祈り) | benediction (祝福) | |||
| blame (非難する) | blaspheme (冒瀆する) | |||
| block (大きな塊) | plug (栓) | |||
| book (本) | buck(wheat) (ソバ) | beech (ブナ) | ||
| boulevard (広い並木道) | bulwark (堡塁) | |||
| brother (兄弟) | friar (托鉢修道士) | |||
| cadet (仕官候補生) | cad (育ちの悪い男) | |||
| cadence (拍子) | chance (偶然) | |||
| cage (鳥かご) | cave (洞窟) | |||
| calumny (誹謗) | challenge (挑戦) | |||
| cancel (取り消す) | chancel (《教会堂の》内陣) | |||
| cant (偽善的な説教) | chant (詠唱) | |||
| captain (首領) | chieftain (《山賊などの》かしら) | |||
| cavalry (騎兵隊) | chivalry (騎士道) | |||
| cell (《大組織の》基本組織) | hall (ホール) | |||
| charge (負担させる,請求する) | cargo (船荷) | |||
| chariot (《馬で引く》二輪戦車) | cart (荷馬車) | |||
| chattel (【法律】動産) | cattle (畜牛) | capital (資本) | ||
| check (阻止する,【チェス】王手) | shah (イラン国王) | |||
| costume (服装) | custom (慣習) | |||
| crate (わく箱) | hurdle (ハードル) | |||
| daft (ばかな) | deft (器用な) | |||
| dainty (上品な) | dignity (威厳) | |||
| danger (危険) | dominion (支配権) | |||
| dauphin (【歴史】《フランスの》王太子) | dolphin (イルカ) | |||
| deck (デッキ) | thatch (わら葺き屋根) | |||
| defeat (負かす) | defect (欠陥) | |||
| depot (停車場) | deposit (預金) | |||
| devilish (悪魔のような) | diabolical (邪悪な) | |||
| diaper (多彩に小柄模様にする) | jasper (碧玉) | |||
| disc (レコード) | discus (円盤) | dish (皿) | dais (演壇) | desk (机) |
| ditto (同上) | dictum (公式見解,金言) | |||
| employ (雇う) | imply (暗に意味する) | implicate (暗に示す) | ||
| ensign (軍旗) | insignia (記章) | |||
| etiquette (エチケット) | ticket (切符) | |||
| extraneous (外部からの) | strange (奇妙な) | |||
| fabric (織物) | forge (鍛冶場) | |||
| fact (事実) | feat (偉業) | |||
| faculty (才能) | facility (容易さ) | |||
| fashion (ファッション) | faction (派閥) | |||
| feeble (弱い) | foible (《愛嬌のある》弱点) | |||
| flame (炎) | phlegm (痰) | |||
| flask (フラスコ) | fiasco (完全な失敗) | |||
| flour (小麦粉) | flower (花) | |||
| fungus (菌類) | sponge (海綿) | |||
| genteel (上品ぶった) | gentle (優しい) | gentile (異教徒の) | jaunty (陽気な) | |
| glamour (魅惑的な) | grammar (文法) | |||
| guarantee (保証) | warranty (保証,権限) | |||
| hale (健全な) | whole (全体の) | |||
| inch (インチ) | ounce (オンス) | |||
| isolation (孤立) | insulation (隔離) | |||
| jay (カケス) | gay (同性愛の,快活な) | |||
| kennel (溝) | channel (海峡) | canal (運河) | ||
| kin (血縁) | genus (《分類上の》属) | |||
| lace (締めひも) | lasso (投げ輪) | |||
| listen (聴く) | lurk (待ち伏せする) | |||
| lobby (ロビー) | lodge (山小屋) | |||
| locust (バッタ) | lobster (カキ) | |||
| maneuver (作戦行動) | manure (肥料をやる;肥料) | |||
| monetary (通貨の) | monitory (警告の) | |||
| monster (怪物) | muster (召集する) | |||
| musket (マスケット銃) | mosquito (蚊) | |||
| naive (単純な) | native (生まれた時からの) | |||
| onion (タマネギ) | union (結合) | |||
| paddock (小放牧地) | park (公園) | |||
| parable (寓話) | parabola (放物線) | parole (執行猶予) | parley (討議) | palaver (商談) |
| parson (教区牧師) | person (人) | |||
| particle (分子) | parcel (小包) | |||
| patron (後援者) | pattern (模様) | |||
| piazza (《イタリア都市の》広小路) | place (場) | plaza ((スペイン都市などの)広場) | ||
| poignant (痛切な) | pungent (辛らつな) | |||
| poison (毒薬) | potion (《毒液の》一服) | |||
| poor (貧しい) | pauper (乞食) | |||
| pope (ローマ教皇) | papa (パパ) | |||
| praise (ほめる) | price (価格) | |||
| quiet (静かな) | quit (やめる) | quite (すっかり) | coy (内気な) | |
| raid (襲撃) | road (道路) | |||
| ransom (身代金) | redemption (買い戻し) | |||
| ratio (比率) | ration (割り当て) | reason (理由) | ||
| respect (尊敬する) | respite (《仕事などの》小休止) | |||
| restrain (抑制する) | restrict (制限する) | |||
| rover (放浪者) | robber (泥棒) | |||
| saliva (唾液) | slime (ねば土,ぬめり) | |||
| scandal (恥辱) | slander (中傷) | |||
| scourge (むち,天罰) | excoriate (皮をはぐ) | |||
| scout (斥候) | auscultate (聴診する) | |||
| secure (安全な) | sure (自信を持って) | |||
| sergeant (軍曹) | servant (使用人) | |||
| sovereign (主権者) | soprano (ソプラノ) | |||
| stack (干し草の山) | stake (杭) | steak (ステーキ) | stock (蓄え) | |
| supervisor (管理者) | surveyor (測量者) | |||
| tamper (干渉する) | temper (気性) | |||
| triumph (勝利) | trump (トランプ) | |||
| tulip (チューリップ) | turban (ターバン) | |||
| two (2の) | deuce (ジュース) | |||
| utter (口に出す) | outer (外側の) | |||
| valet (近侍) | varlet (従者) | |||
| vast (広大な) | waste (荒廃させる) | |||
| veneer (ベニア) | furnish (家具を設備する) | |||
| verb (動詞) | word (言葉) | |||
| whirl (旋回する) | warble (さえずる) | |||
| yelp (かん高い声を上げる) | yap (キャンキャン吠え立てる) | |||
| zero (ゼロ) | cipher (暗号) |
・ ジョーゼフ T. シップリー 著,梅田 修・眞方 忠道・穴吹 章子 訳 『シップリー英語語源辞典』 大修館,2009年.
2013-12-16 Mon
■ #1694. 科学語彙においてギリシア語要素が繁栄した理由 [greek][compounding][scientific_name][lexicology][combining_form][scientific_name][scientific_english]
科学語彙 (ISV = International Scientific Vocabulary) には,ギリシア語の要素を複合させたものが多い.しばしば neo-Hellenic compounds と呼ばれるが,これらの語彙は主として近代の産物である(ラテン語の場合には neo-Latin compounds とも呼ばれ,合わせて neo-classical compounds と呼ばれることもある).学名においても,「#511. Myrmecophaga tridactyla」 ([2010-09-20-1]) や「#512. 学名」 ([2010-09-21-1]) でみたように,ギリシア語要素が特権的に利用されているし,「#552. combining form」 ([2010-10-31-1]) の供給源としても同言語の役割は大きい.また,eco-, micro-, tele-, -ology などのギリシア語に由来する接辞は生産力が著しく高く,ISV の枠をはみ出して,一般語彙の形成にも及んでいる.
ISV においてギリシア語が繁栄した背景には,近代科学が発展した西洋において,ラテン語と並んでギリシア語が長い間権威ある言語とみなされてきた伝統がある.ヨーロッパにおいて,ギリシア語の威信が語派を超越して広がっていたというのは,近代科学の発展にとっては幸運なことだった.英語もフランス語もドイツ語も,ISV のためには等しくギリシア語を利用するという慣習が確立しやすかった.ルネサンス以降,尊ぶべき知識の源泉はギリシア語(及びラテン語)にあり,と共通して考えられるようになったことで,その後の科学(語彙)の発展と拡大にとって,好条件が整ったのである.
Potter (86) は,知識の源泉としてのギリシア語という考え方が,ゲルマン諸語やロマンス諸語のみならず,スラヴ系のロシア語にも当てはまったことは,とりわけ幸運なことであったと述べている.
In the ever expanding world of science and invention most of these new words are either taken direct from Greek or compounded of Greek elements. This applies not only to English but also to the other three widely disseminated languages --- French, Spanish and Portuguese. Moreover, and in some ways more important still, this also applies to Russian. The modified Cyrillic 33-letter alphabet of modern Russian is based upon the 22-letter alphabet of Greek which is the same today as it was in the time of Plato and Aristotle. Ties between Kiev, Byzantium and Athens have been close throughout the ages. / It is indeed most fortunate that the scientists of the two leading powers --- the United States and the Soviet Union --- both go to Greek for their technical terms. Scientists now have at their disposal a copious store of neo-Hellenic components. They have come to regard the Greek language as a kind of quarry from which they can mine blocks to be shaped at need to make new words or to adapt forms already in use. (86)
ロシア語は,文字体系を含む言語文化の歴史を通じて,ギリシア語との密な接触を保ってきた.西ヨーロッパ諸語文化とロシア語文化との間には歴史的に直接の接点は多くなく,したがって,ともすれば世界の ISV も2つ(以上)の系列に分かれてしまっていたかもしれない.もしそうなっていたら,近代科学の発展の速度はもっと遅くなっていただろう.しかし,ヨーロッパの東西で共通して威信ありと認められていたギリシア語が科学語彙形成の基礎とされたことで,幸運にも ISV は1系列に収まっているのである.
日本語母語話者にとって,ISV の基盤にギリシア語があるからといって,それを学ぶ上で特にメリットがあるわけではない.しかし,ISV が1系列でまとまっていることによって科学の発展が最大限に促され,その恩恵を世界市民として最大限に享受していると考えれば,やはりギリシア語の働きは大きいと評価できるだろう.
・ Potter, Simon. Changing English. London: Deutsch, 1969.
2013-12-11 Wed
■ #1689. 南西太平洋地域のピジン語とクレオール語の語彙 [pidgin][creole][map][reduplication][lexicology][etymology][tok_pisin]
昨日の記事「#1688. Tok Pisin」 ([2013-12-10-1]) を受けて,南西太平洋地域のピジン語とクレオール語の話題.関連諸言語の分布図を,Gramley (220) の地図を参考に示してみた.
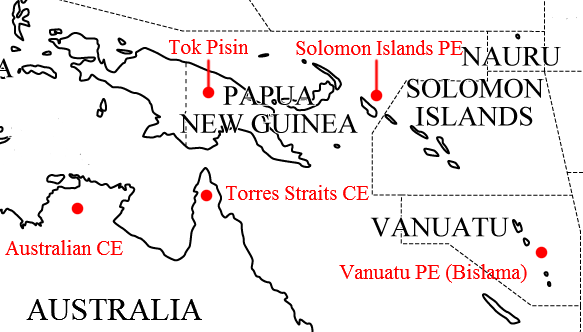
ここに挙げられているピジン語やクレオール語は歴史的に関連が深く,言語的にも近い.いずれも英語を上層言語 (superstrate language) 及び語彙供給言語 (lexifier) とする混成語で,実際にいずれも語彙の8割前後は英語ベースである.Mühlhäusler を参照した Gramley (220) の表によると,ヴァヌアツの Bislama (「#1536. 国語でありながら学校での使用が禁止されている Bislama」 ([2013-07-11-1]) を参照), パプアニューギニアの Tok Pisin, ソロモン諸島の Solomon Pijin の3ピジン語でみると,語種分布は以下の通りである.
| English | Indigenous | Others | |
|---|---|---|---|
| Bislama | 90% | 5 | 3 (French) |
| Tok Pisin | 77 | 16 | 7 (German etc.) |
| Solomon Pijin | 89 | 6 | 5 |
一般にピジン語やクレオール語の語彙は,上層言語を基準とすると,迂言,翻訳借用 (loan_translation),意味変化,加重 (reduplication),異分析などの例に満ちている.以下に,Gramley (220--22) に拠って Tok Pisin からの例を示そう.hair という代わりに gras bilong hed (grass that belongs to the head),beard という代わりに gras bilong fes (grass that belongs to the face) といった風である.現在形と過去形の区別はなく,例えば stei (stay) は文脈次第で現在・過去いずれの意味にもなりうる.tudir (too dear) は,「高価な」を表わす1語として分析され,同様に lego (let go) は「行かせる」, sekan (shake hands) は「和解する」として語彙化している.英語 arse (尻)に起源をもつ, as は文体的に中立な「後部;尻」であり,さらに意味変化を起こして「起源;原因」の意でも用いられる.that's all に起源をもつ tasol は,一般的に but の意味の接続詞として発達した.加重の例については,「#65. 英語における reduplication」 ([2009-07-02-1]) を参照されたい.
現地の文化が語彙に反映されることもある.とりわけ親族名称 (kinship terms) では,mama (mother), papa (father) までは標準英語と同じだが,父系のおじとおばはそれぞれ smalpapa, smalmama だが,母系のおじとおばはともに kandare という1語で表わす.祖父母と孫は性別の区別もなく,一緒くたに tumbuna と表現する.兄弟姉妹も,同性であれば brata,異性であれば susa を用いるという点で,標準英語と異なる.
・ Gramley, Stephan. The History of English: An Introduction. Abingdon: Routledge, 2012.
2013-10-28 Mon
■ #1645. 現代日本語の語種分布 [japanese][lexicology][statistics][etymology][loan_word][lexical_stratification]
英語語彙の語種別の割合について,これまで多くの記事で各種統計を示してきた.
・ [2012-09-03-1]: 「#1225. フランス借用語の分布の特異性」
・ [2012-08-11-1]: 「#1202. 現代英語の語彙の起源と割合 (2)」
・ [2012-01-07-1]: 「#985. 中英語の語彙の起源と割合」
・ [2011-09-18-1]: 「#874. 現代英語の新語におけるソース言語の分布」
・ [2011-08-20-1]: 「#845. 現代英語の語彙の起源と割合」
・ [2010-12-31-1]: 「#613. Academic Word List に含まれる本来語の割合」
・ [2010-06-30-1]: 「#429. 現代英語の最頻語彙10000語の起源と割合」
・ [2010-05-16-1]: 「#384. 語彙数とゲルマン語彙比率で古英語と現代英語の語彙を比較する」
・ [2010-03-02-1]: 「#309. 現代英語の基本語彙100語の起源と割合」
・ [2009-11-15-1]: 「#202. 現代英語の基本語彙600語の起源と割合」
・ [2009-11-14-1]: 「#201. 現代英語の借用語の起源と割合 (2)」
・ [2009-08-19-1]: 「#114. 初期近代英語の借用語の起源と割合」
・ [2009-08-15-1]: 「#110. 現代英語の借用語の起源と割合」
「#334. 英語語彙の三層構造」 ([2010-03-27-1]),「#335. 日本語語彙の三層構造」 ([2010-03-28-1]),「#1526. 英語と日本語の語彙史対照表」 ([2013-07-01-1]) で見たように,英語と日本語の語彙は比較される歴史をたどってきており,結果として現代の共時的な語彙構成にも共通点が見られる.今回は,現代英語との比較のために,現代日本語の語種別の割合をみよう.一般的にこの種の語彙統計を得るのは難しいが,『日本語百科大事典』 (420--21) に拠りながら3種の調査結果の概観を示す.
(1) 明治から昭和にかけての3種の国語辞典『言海』(明治22年;1889年),『例解国語辞典』(昭和31年;1956年),『例解国語辞典』(昭和44年;1969年)の収録語を語種別に数えた研究がある.総語数は,『言海』39,103,『例解国語辞典』40,393,『角川国語辞典』60,218 である.以下に割合を示す表と図を示そう.
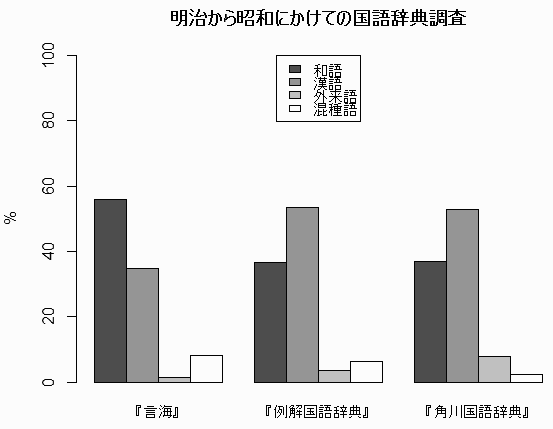
| 和語 | 漢語 | 外来語 | 混種語 | |
|---|---|---|---|---|
| 『言海』 | 55.8% | 34.7 | 1.4 | 8.1 |
| 『例解国語辞典』 | 36.6 | 53.6 | 3.5 | 6.2 |
| 『角川国語辞典』 | 37.1 | 52.9 | 7.8 | 2.2 |
時代が進むにつれて,和語に対する漢語と外来語の割合が高まってきているのがわかる.昭和では,1/2強が漢語,1/3強が和語という割合だ.
(2) 現代の書きことばについては,国立国語研究所の『現代雑誌九十種の用語用字』調査のデータがよく参照される.昭和31年(1956年)の雑誌から,助詞,助動詞,固有名詞を除いて語彙を収集したものである.得られた語彙は,異なり語数で30,331,延べ語数で411,972.21世紀の現在から見ると古いデータではあるが,質において比肩する新しい調査は行われていない.
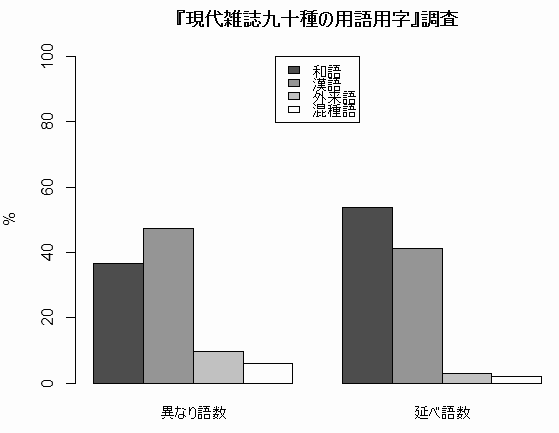
| 和語 | 漢語 | 外来語 | 混種語 | |
|---|---|---|---|---|
| 異なり語数 | 36.7% | 47.5 | 9.8 | 6.0 |
| 延べ語数 | 53.9 | 41.3 | 2.9 | 1.9 |
異なり語数と延べ語数では数値がかなり異なっており,特に和語と漢語の順位が入れ替わっているのが注目に値する.
(3) 現代の話しことばの調査としては,知識層を対象としたものがある.日本語教育および語学関係の研究者7人とその話し相手の会話を延べ42時間分録音し,分析したものである.異なり語数は4,617で,延べ語数は64,023.
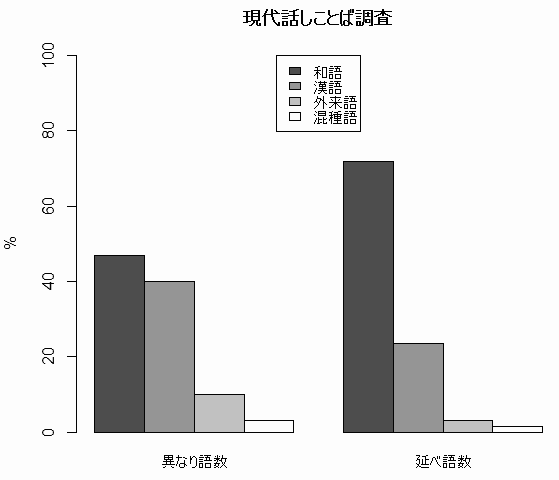
| 和語 | 漢語 | 外来語 | 混種語 | |
|---|---|---|---|---|
| 異なり語数 | 46.9% | 40.0 | 10.1 | 3.0 |
| 延べ語数 | 71.8 | 23.6 | 3.2 | 1.4 |
話しことばでは,書きことばと異なり,異なり語数と延べ語数の間で和漢語の順位入れ替えはない.いずれの数え方でも和語の割合が最も多いが,とりわけ延べ語数では和語が圧倒している.
この話しことばの調査では,公的な場面や私的な場面など場面別に分析がなされたが,全体的な傾向として,和語は (1) 私的な場面でのほうが多い,(2) 延べ語数でのほうが多い,(3) 使用頻度の高い語ほど多い,(4) 話し言葉でのほうが多い,という結果が出た.私的な話しことばで高頻度に用いられる語は,和語である確率が最も高いということになる.この結果は直感と一致するだろう.
英語においても本来語は「私的な場面の話しことばで高頻度に用いられる」確率が高いと想像されるが,これについては統計は見たことはなく,今後,実証してゆく必要があるかもしれない.
・ 『日本語百科大事典』 金田一 春彦ほか 編,大修館,1988年.
2013-10-21 Mon
■ #1638. フランス語とラテン語からの大量語彙借用のタイミングの共通点 [french][latin][renaissance][lexicology][loan_word][borrowing][reestablishment_of_english][language_shift]
フランス語借用の爆発期は「#117. フランス借用語の年代別分布」 ([2009-08-22-1]) で見たように14世紀である.このタイミングについては,「#1205. 英語の復権期にフランス借用語が爆発したのはなぜか」 ([2012-08-14-1]) や「#1209. 1250年を境とするフランス借用語の区分」 ([2012-08-18-1]) の記事で話題にしたように,イングランドにおいて英語が復権してきた時期と重なる.それまでフランス語が担ってきた社会的な機能を英語が肩代わりすることになり,突如として大量の語彙が必要となったからとされる.フランス語を話していたイングランドの王侯貴族にとっては,英語への言語交替 (language shift) が起こっていた時期ともいえる(「#1540. 中英語期における言語交替」 ([2013-07-15-1]) を参照).
一方,ラテン語借用の爆発期は,「#478. 初期近代英語期に湯水のように借りられては捨てられたラテン語」 ([2010-08-18-1]) や「#1226. 近代英語期における語彙増加の年代別分布」 ([2012-09-04-1]) で見たように,16世紀後半を中心とする時期である.このタイミングは,それまでラテン語が担ってきた社会的な機能,とりわけ高尚な書き物の言語にふさわしいとされてきた地位を,英語が徐々に肩代わりし始めた時期と重なる.ルネサンスによる新知識の爆発のために突如として大量の語彙が必要になり,英語は追いつけ,追い越せの目標であるラテン語からそのまま語彙を借用したのだった.このようにラテン語熱がいやましに高まったが,裏を返せば,そのときまでに人々の一般的なラテン語使用が相当落ち込んでいたことを示唆する.イングランド知識人の間に,ある意味でラテン語から英語への言語交替が起こっていたとも考えられる.
つまり,フランス語とラテン語からの大量語彙借用の最盛期は異なってはいるものの,共通項として「英語への言語交替」がくくりだせるように思える.ここでの「言語交替」は文字通りの母語の乗り換えではなく,それまで相手言語がもっていた社会言語学的な機能を,英語が肩代わりするようになったというほどの意味で用いている.この点を指摘した Fennell (148) の洞察の鋭さを評価したい.
As is often the case when use of a language ceases (as French did at the end of the Middle English period), the demise of Latin coincides with the borrowing of huge numbers of Latin words into English in order to fill perceived gaps in the language.
・ Fennell, Barbara A. A History of English: A Sociolinguistic Approach. Malden, MA: Blackwell, 2001.
2013-10-13 Sun
■ #1630. インク壺語,カタカナ語,チンプン漢語 [japanese][kanji][katakana][waseieigo][lexicology][emode]
初期近代英語期,主としてラテン語に由来するインク壺語 (inkhorn_term) と呼ばれる学者語が大量に借用されたとき,外来語の氾濫に対する大議論が巻き起こったことは,「#1408. インク壺語論争」 ([2013-03-05-1]) や「#1410. インク壺語批判と本来語回帰」 ([2013-03-07-1]) などの記事で触れた.Bragg (116) の評価によれば,"This controversy was the first and probably the greatest formal dispute about the English language." ということだった.
現代日本語において似たような問題が,カタカナ語の氾濫という形で生じている.インク壺語とカタカナ語の問題の類似点については,「#1615. インク壺語を統合する試み,2種」 ([2013-09-28-1]) と「#1616. カタカナ語を統合する試み,2種」 ([2013-09-29-1]) で取り上げたが,借用語彙の受容を巡る議論は,およそ似たような性質を帯びるものらしい.そこへもう1つ新語彙の受容を巡る問題を加えるとすれば,近代期の日本の新漢語問題が思い浮かぶ.昨日の記事「#1629. 和製漢語」 ([2013-10-12-1]) でも話題にした,和製漢語を種とする新漢語の大量生産である.
幕末以降,特に明治初期以来,英語をはじめとする大量の西洋語を受け入れるのに,それを漢訳して受容した.当時の知識人に漢学の素養があったからである.漢訳に当たっては,古来の漢語を利用したり,W. Lobscheid の『英華字典』を参照したり(例えば,文学,教育,内閣,国会,階級,伝記など)して対処したものもあったが,和製漢語を作り出す場合が多かった.この大量の新漢語は「漢語の氾濫」問題を惹起し,一般庶民にまで影響を及ぼすことになった.
例えば,『日本語百科大事典』 (453--54) によれば,『都鄙新聞』第1号(慶應4・明治1)に「此は頃鴨東ノの芸妓,少女ニ至ルマデ,専ラ漢語ヲツカフコトヲ好ミ,霖雨ニ盆地ノ金魚ガ脱走シ,火鉢ガ因循シテヰルナド,何ノワキマヘモナクイヒ合フコトコレナリ」という皮肉が聞かれたし,『漢語字類』(明治2)には「方今奎運盛ニ開ケ,文化日ニ新タナリ.上ミハ朝廷ノ政令,方伯ノ啓奏ヨリ,下モ市井閭閻ノ言談論議ニ至ルマデ,皆多ク雑ユルニ漢語ヲ以テス」とある.『我楽多珍報』(明治14. 9. 30)では「生意気な猫ハ漢語で無心いひ」とまである.このように新漢語が流行していたようだが,庶民がどの程度理解していたかは疑問で,「チンプン漢語」とまで呼ばれていたほどである."inkhorn terms" や「カタカナ語」という呼称と比較されよう.そして,漢語を統合する試みの1つとして,漢語字引が次々と出版されたことも,他の2例と驚くほどよく似ている.
現代日本語のカタカナ語問題を議論するのに,16世紀後半のイングランドや19世紀後半の日本の言語事情を参照することは,意味のあることだろう.
・ Bragg, Melvyn. The Adventure of English. New York: Arcade, 2003.
・ 『日本語百科大事典』 金田一 春彦ほか 編,大修館,1988年.
2013-10-12 Sat
■ #1629. 和製漢語 [japanese][kanji][waseieigo][lexicology]
「#1624. 和製英語の一覧」 ([2013-10-07-1]) で和製英語の一覧を掲げたが,今回は和製漢語の例を列挙したい.英単語の借用に慣れた日本語が大正期に和製英語を作り出し始めたように,それにもまして長らく日本語になじんできた漢語がモデルとなって,数々の和製漢語が生み出されてきたことは,まったく自然なことである.和製英語の場合と同様に,ある漢語が和製であるか否かを定めるには日本語および中国語の双方における文献学的な考証が必要となり,たやすい問題ではないが,現代中国の専門家によれば,次の漢語は和製漢語である可能性が高いという(以下の例はすべて『日本語百科大事典』 pp. 1029--30 より).
備品,参看,参照,成因,寵児,単純,等外,敵視,読本,番号,方針,風位,服務,復式,副食,公立,公判,公認,公営,国立,集中,集結,記号,尖兵,堅持,簡単,金額,巨匠,巨星,克服,労作,落選,明確,内勤,農作物,権限,権益,人選,肉弾,実績,実権,私立,訴権,台車,特長,外勤,校訓,興信所,学会,学歴,訓話,訓令,銀翼,印鑑,原動力,原意,原作,陣容,支部,重点,手動,組成,座談
日本の文物を表す漢語も,和製と考えてよいだろう.例としては,和服,和文,人力車,浄瑠璃,能楽,三味線,茶道,弓道,柔道などがある.
また,以下の漢語も和製漢語の可能性をもつが,近代日本と中国の間での移入・移出の関係は複雑であり,一応のリストとして理解しておきたい.これらの多くは,近代期に,英語などを取り入れる際に漢訳して取り入れたことに由来する.
暗示,白金,半径,飽和,保険,悲劇,背景,本質,比重,必要,標語,表決,波長,不動産,財閥,挿話,成分,乗客,抽象,出版,触媒,大気,代議士,単元,蛋白質,道具,登記,低調,抵抗,地質,電波,電車,電話,電流,電子,動産,独占,隊商,対象,対照,法人,反動,反感,反射,反応,範疇,方程式,方式,雰囲気,否定,附着,複製,改編,改訂,概括,概略,概念,感性,幹部,幹線,高潮,高炉,歌劇,工業,公報,公称,公民,公僕,公訴,共産主義,共鳴,関係,観測,観念,光年,光線,広告,広義,帰納,国際,国庫,国税,寒帯,寒流,航空母艦,号外,化膿,化石,化学,化粧品,画廊,幻灯,幻想曲,回収,会話,会社,会談,活躍,火成岩,積極,基調,基準,集団,計画,技師,仮定,尖端,間接,建築,鑑定,講壇,交際,交響楽,膠着語,脚本,教科書,教養,酵素,接吻,結核,解放,解剖,介入,金剛石,金婚式,金牌,金融,緊張,進度,進化,進化論,進展,経験,景気,警察,警官,浄化,静脈,競技,就任,巨頭,決算,絶対,看護婦,看守,抗議,科学,可決,客観,客体,肯定,空間,会計,拡散,類型,冷蔵,冷蔵庫,理論,理念,理想,理智,力学,立憲,例会,了解,領海,領空,領主,領土,論理学,漫画,盲従,媒質,美感,密度,免許,民法,敏感,命題,黙示,母体,母校,目標,目的,内容,内在,能動,能率,擬人法,年度,暖流,派遣,判決,陪審,配給,批評,平面,評価,企業,気分,気体,気質,汽船,汽笛,契機,前線,強制,軽工業,清教徒,清算,情報,権威,熱帯,人格,人権,任命,溶体,入場券,入超,商法,商業,社交,審判,昇華,生理学,生態学,失恋,施工,施行,時間,実感,実業,使徒,士官,世界観,市場,市長,事態,手工業,受難,水素,思潮,死角,素材,素描,速度,速記,随員,索引,談判,探険,特権,体育,鉄血,統計,投影,投資,図案,外在,温床,温度,文庫,文学,無産者,物質,喜劇,系列,係数,細胞,狭義,繊維,現実,現象,現役,憲兵,相対,想像,象徴,消防,消費,消極,小夜曲,効果,協定,協会,心理学,信号,信託,性能,序幕,序曲,宣戦,旋盤,学位,血栓,血吸虫,巡洋艦,圧延,亜鉛,演出,演奏,燕尾服,陽極,要素,業務,液体,議会,議員,議院,意訳,因子,陰極,銀行,銀婚式,栄養,影像,優生学,油槽車,遊離,予後,元素,園芸,原理,原則,原子,原罪,遠足,運動,運動場,雑誌,債権,債務,展覧会,戦線,哲学,証券,政策,政党,支線,直観,直接,直径,直流,止揚,指標,指導,指数,制裁,制限,制約,質量,終点,仲裁,重工業,主筆,主観,資料,紫外線,宗教,総合,総動員,総理,作品
和製英語にせよ和製漢語にせよ,相手の言語からの直接の語彙借用に十分なじんでくると,今度はそれをモデルとして自家製の語彙を生み出そうとしてきた点が似ている.相手の言語に呑まれていると考えれば語彙借用反対論となるし,相手の言語を手なずけていると考えれば賛成論となる.私は,和製○語の存在は日本語が借用元言語の手なずけに成功し,高次に進んだ借用段階にあることを示すものとして解釈している.
・ 『日本語百科大事典』 金田一 春彦ほか 編,大修館,1988年.
2013-10-07 Mon
■ #1624. 和製英語の一覧 [waseieigo][japanese][katakana][borrowing][semantic_change][word_formation][lexicology][false_friend]
9月21--22日に,大連大学日本言語文化学院で開かれた第五回『中・日・韓日本言語文化研究国際フォーラム』に参加し,中央大学の同僚とチームを組んで「言語使用の前景と背景---言語研究と文学研究について」と題するパネルディスカッションを行った.私は「和製英語の自然さ・不自然さ」という題目で少し話しをした.専門外ではあるが,日本語学において和製英語や外来語の研究は,英語の研究者によるものが少なくないということなので,私もその立場からわずかばかり参与させていただいた,という次第である.
この発表のために,記事末に挙げたような参考図書等から和製英語といわれている表現を収集した.結果として231個が集まった.各々が本当に和製英語か否かという問題については,「#1492. 「ゴールデンウィーク」は和製英語か?」 ([2013-05-28-1]) で触れたように,本来,詳細な文献学的調査が必要だが,今回はそこまでは掘り下げていない.また,和製英語の厳密な定義が難しいという事情もある.したがって,以下の個々の例については疑問が呈されるかもしれないが,上記のような但し書きをつけたうえで,集めたものを一覧として公開しておくことは役に立つだろう.
和製英語の分類については,まだ仮のものにすぎないが,以下のように (1) 記号的和製英語,(2) 意味的和製英語,(3) 形態的和製英語に3分類してみた.分類の精緻化は今後の課題としたい.

(1) 記号的和製英語
アイスキャンディー (popsicle),アイドリングストップ (shutting off the engines),アウトコース (outside),アパート (apartment, apartmenthouse),アフターケア/アフターサービス (after-sales service, after-the-sale service),アフレコ (post recording),アメリカン(コーヒー) ((regular) coffee),イメージアップ (improve one's image),イメージチェンジ (change one's image),ウェストバッグ (fanny bag, bum bag),エステ (beauty salon, beauty spa, beauty-treatment clinic),エッチ (dirty-minded, sex-mad, have a one-track mind, indecent, salacious, pervert, abnormal),オーエル(オフィスレディ) (office worker),オーダーメード (custom-made, made-to-order),オートバイ (motorbike, motorcycle),オービー (alumnus, alumna, graduate),オーブントースター (toaster oven),オープンカー (convertible),オールバック (combed (straight) back, combed towards the back),カフスボタン (cuff links),ガード (overpass),ガードマン ((security) guard, watchman),ガソリンスタンド (gas station),ガッツポーズ (victory pose),キッチンペーパー (paper towel),キャッチコピー (slogan),キャッチホン (call-waiting),キャッチボール (play catch),クーラー (air conditioner),グラビア (glamour photos, cheesecake, Page Threes),グレードアップ (upgrade),ゲームセンター (amusement arcade),コインランドリー (launderette),コストダウン (lower costs, reduce costs),コンセント (outlet, outlet box, receptacle, wall outlet, wall socket),コンビニ (drugstore, grocery),ゴールデンアワー (prime time),ゴールデンウィーク (holidays in May),サイドビジネス (side job),サラリーマン (company employee),シーズンオフ (off-season),シーチキン (canned tuna),シェイプアップ (become thin, lose weight),システムキッチン (organized kitchen),シティホテル (big hotel),シャーペン (mechanical pencil, automatic pencil),シャッターチャンス (the right moment on film),シルバーウィーク (holidays in November),シルバーシート (priority seat),ジージャン (denim jacket, jeans jacket),ジーパン (jeans),ジェットコースター (roller coaster),ジューサー (blender),スーパー (supermarket),スキンシップ (touching, bonding, physical contact),スクールカラー (the traditional feature of a school),スケールメリット (economies of scale),スタメン (starting lineup),スタンドプレー (grandstand play),スピードダウン (slow down),スリーサイズ ((bust-waist-hip) measurement),ゼネコン (big construction company, large construction company),ソーラーシステム (solar power),ソフト (software),ソフトクリーム (soft-serve ice cream, ice cream cone, swirl ice-cream cone),ターミナルホテル (station hotel),タイムサービス (blue-light special, limited time offer (special)),タイムリーヒット (RBI hit),タッチアウト (tagged and out),ダイニングキッチン (kitchenette),ダンプカー (dump truck),チアガール (cheerleader a),チャンスメーカー (table setters),テーブルスピーチ (speech at a party),テレビゲーム (video game),テンキー (numeric keypad),デコレーションケーキ (birthday cake, decorated cake),デッドボール (hit by (a) pitch),デリバリーヘルス (massage parlor),トレーニングパンツ(トレパン) (sweat pants),ドクターストップ (doctor's orders),ドライブイン (rest area, rest stop),ナイター (night game),ニューハーフ (drag queen, transvestite),ネイティヴチェッカー (proof reader, native-speaking proof reader),ネットショッピング (on-line shopping),ノーカット (uncut (movie)),ノースリーブ (sleeveless dress),ノータイ(ノーネクタイ) (without a tie),ノートパソコン (laptop),ノンステップバス (bus without steps),ノンセクション (trivia),ハートフル (heartwarming),ハーフ (someone of mixed race),ハイソックス (knee socks),ハイティーン (late teens),ハイテンション (excitable, overexcited, carried away),ハローワーク (Job Centre),バックミラー (rearview mirror),バトンガール (baton twirler),バトンタッチ (baton pass, hand over),パタンナー (pattern maker),パトカー (police car),パネラー (panelist),パンチパーマ (tight-perm, short-perm),ビーチパラソル (beach umbrella),ビジネスホテル (economy hotel, budget hotel),フィールドアスレチック (obstacle course),フォアボール (base on balls, walk),フライドポテト (French fries, chips),フライング (false start),フリーサイズ (one-size-fits-all),フリーダイヤル (toll-free number),フロントガラス (windshield),ブックカバー (book jacket, dust jacket),プレーガイド (booking office),ヘアヌード (full-frontal nudity (photo)),ヘディングシュート (header),ヘルスメーター (bathroom scale),ベースアップ (raise of the wage base),ベッドタウン (bedroom suburb),ベビーサークル (playpen),ペーパーカンパニー (shell company),ペーパードライバー (person with a driving licence but no practice, driver in name only),ペアルック (dressed in matching outfits),ペットボトル (plastic bottle),ホーム (platform),ホットカーペット (electric carpet),ホットケーキ (pancake),ボディチェック (frisk, security check, body search),マイカー (one's own car),マイナスイメージ (negative image),マイペース (go one's own way),マカロニウェスタン (spaghetti Western),マグカップ (mug),マザコン (mummy's boy),マンツーマン (one-on-one (one-to-one) lesson, private lesson),ミシン (sewing machine),ミニコミ (free paper),ミルクティー (tea with milk),メタボ (big, overweight, fat),モーニングコール (wake-up call),モーニングサービス (breakfast special),ライブハウス (club with live music, live music club),ラブホテル (hot-pillow hotel, no-tell motel),ランニングシャツ (undershirt),ランニングホームラン (inside-the-park home run),リクルートスーツ (suit for an interview),リサイルクルショップ (secondhand shop, recycled-goods shop),リップクリーム (lip balm, chapstick),リフティング (keepy-uppy),ルーズソックス (loose-fitting socks),ローティーン (early teens),ロスタイム (additional time, injury time, stoppage time),ワイシャツ (business shirt),ワイドショー (talk and variety (TV) show, tabloid show, TV magazine show),ワンパターン (predictable, routine)
(2) 意味的和製英語
アイドル (pop idol),アットホーム (cozy, homey),アバウト (irresponsible),(イベント)コンパニオン (booth girl, promotional model, trade show model),カンニング (cheating),クラクション (car horn),クレーム (complaint),サイン (autograph, signature),シール (sticker),スタンド (grandstand),スナック (bar, pub),スマート (slender, slim),センス(服装) (good dress sense, well-dressed, stylish),ソープ(風俗) (bordello, house of ill repute, whorehouse, knocking shop),タレント (celebrity, entertainer, TV personality),ダッチワイフ (blow-up doll),チャック (zipper, zip-fastener),トランプ ((playing) cards),ドライ (businesslike),ドライバー(工具) (screwdriver),ナイーブ (uncorrupted, unspoiled),ネック (weak link, dead wood, disadvantage, burden),ハンドル ((steering) wheel),バーコード(髪型) (Bobby Charlton),バイキング (buffet),パワーアップ (build),ファイト (Go for it, Do your best),フロント (front desk, reception),ブーム (fad),プリント (handout, printout),プロデューサー (coordinator),マジック (felt tip pen, marker pen),マンション (condominium, apartment),メリット/デメリット (pros and cons, advantages and disadvantages),モニター (test user, product tester),ヤンキー (good-for-nothings, layabouts, hooligans, thugs),リフォーム (alteration, refurbish, renovate),リベンジ (rematch),ルーズ (lax, careless, negligent, irresponsible)
(3) 形態的和製英語
アイロン (flat iron),アクセル (accelerator),アプリ (application),アポ/アポイント (appointment),ウイルス (virus),エンスト (engine stall),オンザロック (on the rocks),カレーライス (curry and rice, curry with rice),コーンビーフ (corned beef),コネ (connection),サンオイル (suntan oil),スモークハム (smoked ham),セクハラ (sexual harassment),セットローション (setting lotion),デパート (department store),トイレ (bathroom, restroom),ドンマイ (Don't worry about it, Never mind),ニス (varnish),ネーブル (navel orange),ノート (notebook),ノンプロ (nonprofessional),パーマ (permanent),パソコン (personal computer),パンク (flat tyre, puncture),ビタミン (vitamin),ビル (building),ファンタジック (fantastic),プリン (pudding, custard pudding),プロレスラー (professional wrestler),マイク (microphone),マスコミ (mass communication, mass media, the media),マニア (maniac, fan),リストアップ (list),リストラ (restructuring, corporate downsizing),レジ (cash register)
・ スティーブン・ウォルシュ 『恥ずかしい和製英語』 草思社,2005年.
・ 桐生 りか 『カタカナ語・外来語事典』 汐文社,2006年.
・ 『新版日本語教育事典』 日本語教育学会 編,大修館書店,2005年.
・ デイビッド・セイン 『日本人がつい間違えるNGカタカナ英語』 主婦と生活社,2012年.
・ 『日本語学研究事典』 飛田 良文ほか 編,明治書院,2007年.
・ 『日本語百科大事典』 金田一 春彦ほか 編,大修館,1988年.
・ 村石 利夫 『カタカナ語おもしろ辞典』 さ・え・ら書房,1990年.
・ 山口 理 『国語おもしろ発見クラブ 外来語・和製英語』 2012年.
Powered by WinChalow1.0rc4 based on chalow