2015-03-31 Tue
■ #2164. 英語史であまり目立たないドイツ語からの借用 [oed][loan_word][german][lexicology][statistics][lmode][loan_translation][scientific_english]
ヨーロッパの主要な言語のなかで,ドイツ語は英語の借用語ソースとして意外と目立たない.歴史的にある程度の規模でドイツ借用語が現われるのは後期近代英語からであり,それ以前は僅少である.英語もドイツ語もゲルマン語派 (Germanic) に属し共通の起源をもつということが広く知られている割には,両言語間で借用という横の関係は希薄である.
英語にドイツ語の語彙的影響が著しくないことは Jespersen (143) や荒木ほか (258) などの英語史概説書でも触れられている通りだが,ドイツ語借用が少ないとはいってもフランス語やラテン語と比べての話しであって,実際にはある程度の数は主として専門用語として入ってきている.近年においても然りのようだ (Algeo 80; 「#874. 現代英語の新語におけるソース言語の分布」 ([2011-09-18-1])) .「#2162. OED によるフランス語・ラテン語からの借用語の推移」 ([2015-03-29-1]) で紹介した Wordorigins.org の "Where Do English Words Come From?" でも,次のように述べられている.
Other European languages remain steady, contributing 3--4% of new words throughout the centuries. The exception is German, which starting in the eighteenth century begins to increase its contribution to English vocabulary, reaching 3% of new words all by itself, and nosing ahead of French by the twentieth century.
上の同じ記事より入手した OED に基づく語種別統計でドイツ借用語の歴史的推移をグラフ化すると,以下のようになる.
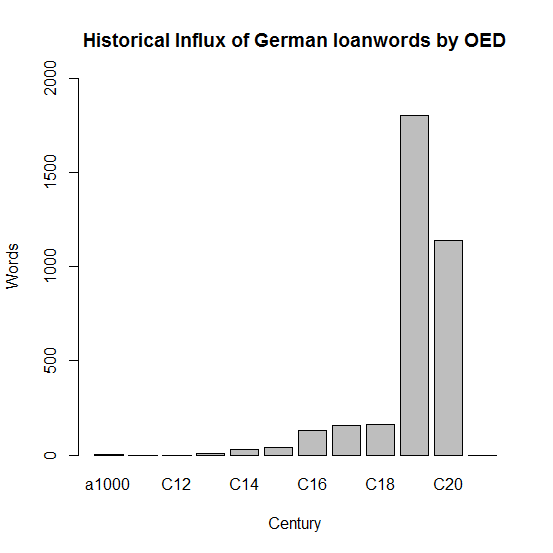
宇賀治 (115--17) によれば,ドイツは16世紀に鉱山術や冶金術に長けていたので,その影響が17--18世紀における英語語彙に反映されている(グラフでの若干の高まりも16世紀からである).17世紀以降は食品名の借用も多い.また,ドイツは19世紀に哲学や医学を含む諸学問で飛躍的な発展を遂げたため,専門的な用語や概念が英語へも流れ込んだ(グラフ上も19世紀にピークを迎える).通常の借用のほか,翻訳借用 (loan_translation) が多いのもドイツ語からの借用の特徴といえるかもしれない.以下,分野別にドイツ借用語(翻訳借用も含む)を列挙しよう.
[鉱山・冶金]
cobalt, gneiss, meerschaum, quartz, zinc
[哲学・文芸批評]
folksong, gestalt, leitmotif, nihilism, objective, subjective, superman, transcendental, zeitgeist
[比較言語学]
ablaut, schwa, strong [weak] (declension), Umlaut
[教育制度]
kindergarten, semester, seminar
[物理学・化学]
aniline, dynamo, ohm, protein, relativity, saccharine, sarin, uranium
[医学・薬学]
aspirin, heroin, pepsin, Roentgen-ray [X-ray]
[食品]
delicatessen, frankfurter, hamburger, lager, noodle, pumpernickel, sauerkraut, schnitzel
ドイツ借用語について紙幅を割いている英語史概説書は多くないが,Carr, Charles T. The German Influence on the English Vocabulary. London: Clarendon, 1934. という研究書があるようである.
関連して,「#150. アメリカ英語へのドイツ語の貢献」 ([2009-09-24-1]),「#756. 世界からの借用語」 ([2011-05-23-1]) も参照されたい.
(後記 2015/09/06(Sun):Begoña Crespo ("Historical Background of Multilingualism and Its Impact." Multilingualism in Later Medieval Britan. Ed. D. A. Trotter. Cambridge: D. S. Brewer, 2000. p. 29.) によれば,すでに中英語期の15世紀にも,高地ドイツ語からの鉱物学に関する用語がある程度入っていたという.)
・ Jespersen, Otto. Growth and Structure of the English Language. 10th ed. Chicago: U of Chicago, 1982.
・ 荒木 一雄,宇賀治 正朋 『英語史IIIA』 英語学大系第10巻,大修館書店,1984年.
・ Algeo, John. "Vocabulary." The Cambridge History of the English Language. Vol. 4. Cambridge: CUP, 1998. 57--91.
2015-03-29 Sun
■ #2162. OED によるフランス語・ラテン語からの借用語の推移 [oed][loan_word][statistics][french][latin][lexicology]
Wordorigins.org の "Where Do English Words Come From?" と題する記事では,OED をソースとした語種比率の通時的推移の調査報告がある.古英語から現代英語への各世紀に,語源別にどれだけの新語が語彙に加えられたかが解説とともにグラフで示されている.本文中にも述べられているように,見出し語の語源に関して OED の語源欄より引き出された情報は,眉に唾をつけて解釈しなければならない.というのは,語源欄にある言語が言及されていたとしても,それが借用元の語源を表すとは限らないからだ.しかし,およその参考になることは確かであり,通時的な概観のために有用であることには相違ない.
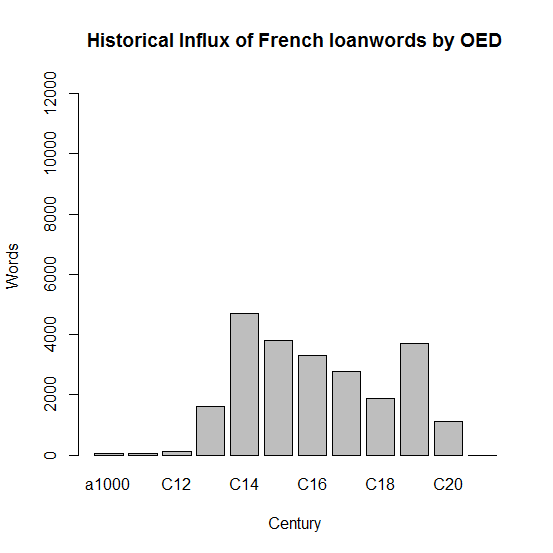
ここでは,CSV形式あるいはEXCEL形式で公開されている世紀別で語源別の数値を拝借し,フランス語とラテン語から英語語彙へ追加された借用語の推移をグラフ化して並べてみた.
 |
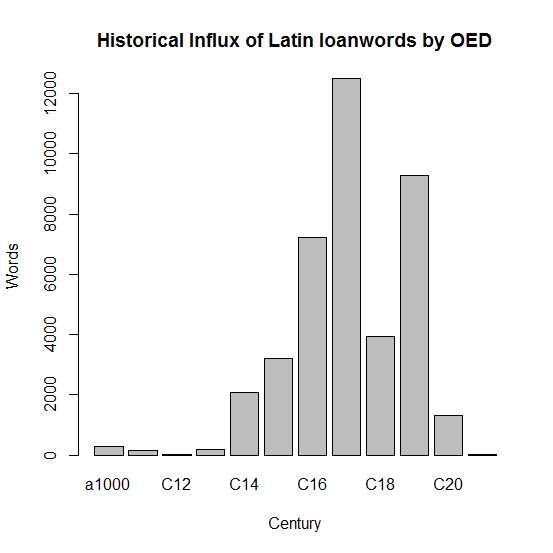 |
得られた傾向は,一般的な概説書で述べられているものと一致する.フランス語のピークは後期中英語,ラテン語のピークは初期近代英語である.比較すると,ラテン語の規模の著しさがよくわかる.フランス語とラテン語からの借用語に関連する統計については,すでに以下のように多くの記事で取り上げてきたので,そちらも参照されたい.
[2009-08-22-1]: #117. フランス借用語の年代別分布
[2009-11-15-1]: #202. 現代英語の基本語彙600語の起源と割合
[2010-06-30-1]: #429. 現代英語の最頻語彙10000語の起源と割合
[2010-12-12-1]: #594. 近代英語以降のフランス借用語の特徴
[2011-02-16-1]: #660. 中英語のフランス借用語の形容詞比率
[2011-08-20-1]: #845. 現代英語の語彙の起源と割合
[2011-09-18-1]: #874. 現代英語の新語におけるソース言語の分布
[2012-08-11-1]: #1202. 現代英語の語彙の起源と割合 (2)
[2012-08-18-1]: #1209. 1250年を境とするフランス借用語の区分
[2012-08-20-1]: #1211. 中英語のラテン借用語の一覧
[2012-09-03-1]: #1225. フランス借用語の分布の特異性
[2012-09-04-1]: #1226. 近代英語期における語彙増加の年代別分布
[2012-11-12-1]: #1295. フランス語とラテン語の2重語
[2014-08-24-1]: #1945. 古英語期以前のラテン語借用の時代別分類
また,OED の利用に際しては,以下の記事も参照されたい.
[2010-10-10-1] #:531. OED の引用データをコーパスとして使えるか
[2010-10-14-1] #:535. OED の引用データをコーパスとして使えるか (2)
[2010-10-15-1] #:536. OED の引用データをコーパスとして使えるか (3)
[2011-01-05-1] #:618. OED の検索結果から語彙を初出世紀ごとに分類する CGI
[2011-01-29-1] #:642. OED の引用データをコーパスとして使えるか (4)
2015-03-16 Mon
■ #2149. 意味借用 [borrowing][loan_word][loan_translation][semantic_change][lexicology][old_norse][semantic_borrowing][christianity]
本ブログのいくつかの記事で 意味借用,semantic_borrowing, あるいは "semantic loan" という用語を使ってきたが,とりたてて話題にしたことはなかったので,今回いくつか例を挙げておきたい.意味借用はときに翻訳借用 (loan_translation) と混同して用いられることがあるが,2つは異なる過程である.翻訳借用においては新たな語彙項目が生み出されるが,意味借用においては既存の語彙項目に新たな語義が追加されるか,それが古い語義を置き換えるかするのみで,新たな語彙項目は生み出されない.ただし,いずれも借用元言語の形態は反映されないという点で共通点がある.「#901. 借用の分類」 ([2011-10-15-1]) で説明した Haugen の用語に従えば,いずれも importation ではなく substitution の例ということになる.
英語史における意味借用の典型例の1つに,dream がある.古英語 drēam は "joy, music" (喜び,音楽)の意で用いられたが,対応する古ノルド語の draumr が "vision" (夢)の意をもっていたことにより,その影響で中英語までに「夢」の語義を獲得した.もともとのゲルマン語の段階での原義「(叫び声などによる)惑わし」からの意味発展により「(歓楽による)叫び声,騒ぎ;歓楽;喜び」の系列と「幻影;夢」の系列とが共存していたと考えられるが,後者は古英語へは伝わらなかったようだ.だが実際には,古英語期にも,古ノルド語の影響の強い東中部や北部では「夢」の語義も行われていた形跡がある.
ほかによく知られているものとして,bloom がある.古英語 blōma は "ingot of iron" (塊鉄)を意味したが,古ノルド語 blóm "flower, blossom" (花)の影響で,中英語までに新しい語義を獲得した(ただし,これには異説もある).dwell に相当する古英語単語 dwellan, dwelian は "to lead astray" (迷わせる)で用いられたが,古ノルド語 dvelja (ぐずぐずする;とどまる)より発展的な語義「住む」を借用したとされる.また,「#340. 古ノルド語が英語に与えた影響の Jespersen 評」 ([2010-04-02-1]) で触れたように,bread は古英語では brēad "morsel of food" ほどの意味だったが,古ノルド語 brauð "bread" より「パン」の語義を借りてきたようだ (Old Northumbrian に「パン」としての用例がみられる).
古ノルド語からの意味借用の例をいくつか挙げたが,ラテン語からの例としてラテン語 rēs が「集会;こと,もの」の語義をもっていたことから,本来「集会」のみを意味した古英語 þing が「こと,もの」の意味を得たとされる.同様に,古英語の Dryhten "lord" に "the Lord" の語義が追加されたのも,対応するラテン語の dominus の影響だろう(関連して「#1619. なぜ deus が借用されず God が保たれたのか」 ([2013-10-02-1]) を参照).古英語における本来語のキリスト教用語には,対応するラテン語の影響で新たに意味を獲得したものが多い (ex. wītega "prophet", þrōþung "suffering", getimbran "edify", cniht "pupil" 等々 (cf. Strang 368--69) .
ほかには,「新しいもの」の意味でフランス語から英語に入ってきたnovel が,その後スペイン語及びイタリア語の対応語から「物語;小説」の意味を取り入れた例などがある.
英語が意味を貸し出した側となっている例もある.フランス語の realizer (はっきり理解する)と introduir(紹介する)のそれぞれの語義は,英語の対応語からの借用である.また,アメリカで話されるポルトガル語の engenho は「技術」を意味したが,英語 engine から「機関車」の意味を借用した.さらに,日本語「触れる」「払う」はそれぞれ物理的な意味のほかに「(問題などに)言及する」「(注意・敬意などを)払う」の意味をもつが,これは対応する touch, pay が両義をもつことからの影響とされる.
・ Strang, Barbara M. H. A History of English. London: Methuen, 1970.
2015-03-14 Sat
■ #2147. 中英語期のフランス借用語批判 [purism][loan_word][french][inkhorn_term][me][lexicology]
16世紀には,ラテン借用語をはじめとしてロマンス諸語などからの借用語がおびただしく英語へ流入した(「#1410. インク壺語批判と本来語回帰」 ([2013-03-07-1]) や「#1411. 初期近代英語に入った "oversea language"」 ([2013-03-08-1]) を参照).日本語でも明治以降,大量の漢語が作られ,昭和以降は無数のカタカナ語が流入した(「#1617. 日本語における外来語の氾濫」 ([2013-09-30-1]) 及び「#1630. インク壺語,カタカナ語,チンプン漢語」 ([2013-10-13-1]) を参照).これらの時代の各々において,純粋主義 (purism) の立場からの借用語批判が聞かれた.借用語をむやみやたらに使用するのは控えて,本来語をもっと多く使うべし,という議論である.
英語史においてあまり聞かないのは,中英語期に怒濤のように押し寄せたフランス借用語に対する批判である.「#117. フランス借用語の年代別分布」 ([2009-08-22-1]) で見たとおり,英語はノルマン・コンクェスト後の数世紀間で,歴史上初めて数千語という規模での大量語彙借用を経験してきたが,そのフランス借用語への批判はなかったのだろうか.
確かにルネサンス期のインク壺語批判ほどは目立たないが,中英語におけるフランス借用語批判がまったくなかったわけではない.Ranulph Higden (c. 1280--1364) によるラテン語の Polychronicon を1387年に英訳した John of Trevisa (1326--1402) は,ある一節で,古ノルド語とともにフランス語からの借用語の無分別な使用について苦情を呈している.Crystal (186) からの引用を再現しよう.
by commyxstion and mellyng, furst wiþ Danes and afterward wiþ Normans, in menye þe contray longage ys apeyred, and som vseþ strange wlaffyng, chyteryng, harryng, and garryng grisbittyng.
同様に,Richard Rolle of Hampole (1290?--1349.) による Psalter (a1350) でも,"seke no strange Inglis" (見知らぬ英語は使わない)とフランス借用語に対して暗に不快感を示しているし,15世紀に Polychronicon を英訳した Osbern Bokenham (1393?--1447?) も,フランス語が英語を野蛮にしたと非難している (Crystal 186) .しかし,彼らとて,自らの著書のなかで,洗練されたフランス借用語を用いていたことはいうまでもない.
このように中英語期のフランス借用語への純粋主義的な非難はいくつか確認されるが,後世の激しいインク壺語批判に比べれば単発的であり,特に大きな潮流を形成しなかったようだ.英語自体がまだ一国の言語としておぼつかない地位にあって,英語の本来語への思慕や借用語の嫌悪という純粋主義的な態度が世の注目を浴びるには,まだ時代が早かったものと思われる.それでも,この中英語期の早熟な純粋主義的批判は,後世の苛烈な批判の前段階として,確かに英語史上に位置づけられるものではあるだろう.
・ Crystal, David. The Stories of English. London: Penguin, 2005.
2015-01-28 Wed
■ #2102. 英語史における意味の拡大と縮小の例 [semantic_change][semantics][hyponymy][semantic_field][lexicology]
「#473. 意味変化の典型的なパターン」 ([2010-08-13-1]) で意味の一般化 (generalization) と特殊化 (specialization) について触れた.別の言い方をすれば,意味の拡大 (widening) と縮小 (narrowing) である.英語史からの意味の伸縮の例が一覧できると便利だと思っていたところ,Williams にいろいろと挙げられていたので掲載しよう.
まず,縮小の例から (Williams 171--73) .かっこ内に挙げた意味(の推移)は,縮小を起こす前段階のより広い意味である.現在の主要な語義と比較されたい.
accident (an event)
accost (come alongside in a boat > to approach anyone)
addict (someone who devotes himself to anything)
admonish (advise)
affection (the act of being affected > any affection of the mind)
argue (make clear)
arrest (stop)
artillery (any large implement of war)
carp (talk)
censure (judge)
condemn (pass sentence)
corn (any grain)
cunning (knowledge, skill)
damn (pass sentence)
deer (any animal)
denizen (a citizen of a country or city)
deserts (whatever one deserves, good or bad)
disease (discomfort)
doom (judge)
ecstasy (beside oneself with any strong emotion: fear, joy, pain)
effigy (any likeness)
erotic (relating to love)
esteem (put a value on, good or bad)
fame (report, rumor)
fiend (the enemy)
filth (dirt)
fortune (chance)
fowl (any bird)
ghost (spirit)
grumble (murmur, make low sounds)
hound (any dog)
immoral (not customary)
leer (look obliquely out of the side of the eye)
liquor (liquid)
lust (desire in general)
manure (v., hold land > to cultivate land)
meat (food)
molest (trouble or annoy)
odor (anything perceptible to the sense of smell)
orgy (secret observances)
peculiar (belonging to or characteristic of an individual)
pill (any medicinal ball)
praise (from (ap)praise: set a value on, good or bad)
predicament (any situation)
proposition (a statement set forth for discussion)
reek (smoke from burning matter > produce any vapor)
retaliate (repay for anything)
sanctimonious (holy, sacred)
scheme (horoscope > diagram > plan)
seduce (persuade someone to desert his duty)
shroud (an article of clothing)
smirk (smile)
smug (trim neat)
starve (die)
stink (any odor)
stool (a chair)
success (any outcome)
suggestive (that which suggests something)
syndicate (a group of civil authorities > any group of businessmen pursuing a common commercial activity)
thank (from the general word for think)
vice (a flaw)
次に,拡大の例 (Williams 175--77) を挙げる.
allude (mock)
aroma (the smell of spices)
aunt (father's sister)
barn (a store for barley)
bend (bring a bow into tension with a bow string)
bird (young of the family avis)
box (a small container made of boxwood)
butcher (one who slaughters goats)
carry (transport by cart)
chicken (a young hen or rooster)
deplore (weep for)
detest (condemn, curse)
dirt (excrement)
divest (remove one's clothes)
elope (run away from one's husband)
fact (a thing done)
frantic (madness)
frenzy (wild delirium)
gang (a set of tools laid out for use > a group of workmen/slaves)
go (walk)
harvest (reap ripened grain)
holiday (a holy day)
journey (a day > a day's trip or day's work)
magic (the knowledge and skill of the Magi)
manner (the mode of handling something by hand)
mess (a meal set out for a group of four)
mind (memory > thought, purpose, intention)
mystery (divine revealed knowledge)
oil (olive oil)
ordeal (trial by torture)
pen (a feather for writing)
picture (a painted likeness)
picture (a painting or drawing)
plant (a young slip or cutting)
sail (cross water propelled by the wind)
sail (travel on water)
sanctuary (a holy place)
scent (animal odor for tracking)
silly (deserving of pity > frail > simple, ignorant > feeble minded)
slogan (the battle cry of Scottish clans)
start (move suddenly)
stop (fill or plug up > prevent passage by stopping up > prevent the movement of a person)
surly (sir-ly, that behavior which characterizes a "Sir")
uncle (mother's brother)
ここに挙げた事例数からも推測されるように,意味の拡大と縮小の例を比較すると,縮小の例のほうが一般的に多いもののようだ.その理由は定かではないが,時代とともにあらゆるものが分化していく速度のほうが,それら断片を総合しようとする人間の営為よりも勝っているからかもしれない.概念階層 (cf. 「#1962. 概念階層」 ([2014-09-10-1])) の観点からみれば,下位語 (hyponyms) を作り出し,枝を下へ下へ伸ばしていくことは半ば自動的に進むが,新たな上位語 (hypernyms) を作り出す統合の作業には労力が要る.学問も,ひたすら細分化していきこそすれ,総合の機会は少ない・・・.Williams (177) は,次のような見解を述べている.
It is harder to find a pattern for widening than it is for narrowing. It is not entirely certain, but meanings seem to widen somewhat less frequently than they narrow. As a culture becomes more diversified and more complex with more areas of knowledge and activity, those areas require a vocabulary. Because every language has a finite number of words and because speakers are not inclined to coin completely new forms for new concepts, the simplest way to deal with new areas of knowledge is to use the current vocabulary. Borrowing, derivation, compounding, and so on operate here. But perhaps even more frequent is narrowing.
But on the other hand it can also be difficult to talk about the most ordinary activities of daily life as they diversify. Once it becomes possible to drive (drive originally meaning to force an animal along), or ride (ride originally meaning to go on horseback), or walk (originally meaning to travel about in public), then talking about getting some place without specifying how becomes difficult. The word go, originally meaning to walk, generalized so that an English speaker can now say I am going to town this morning without having to specify how he gets there. Carry generalized from transporting specifically in a conveyance of some sort to transporting by bearing up in general: The wind carried the seed, and so on.
上掲の一覧には,広い意味と狭い意味が完全に推移 (shift) しきった例ばかりではなく,古いほうの語義も残存し,新旧が並存している pill や sanctuary などの例も少なくない.
・ Williams, Joseph M. Origins of the English Language: A Social and Linguistic History. New York: Free P, 1975.
2015-01-24 Sat
■ #2098. 2014年の英語流行語大賞 [lexicology][ads][woy][netspeak][punctuation][adjective]
去る1月9日,American Dialect Society による 2014年の The Word of the Year が発表された.プレス・リリース (PDF) はこちら.
2014年の大賞は #blacklivesmatter である.新設されたHASHTAG部門からの大賞受賞で,2009年の受賞語 twitter,2012年の受賞語 hashtag に続き,twitter 周辺のメッセージ性が評価されているということだろう.
The hashtag #blacklivesmatter took on special significance in 2014 after the deaths of Michael Brown in Ferguson, Mo. and Eric Garner in Staten Island, N.Y., and the failure of grand juries to indict police officers in both cases. It became a rallying cry and vehicle for expressing protest, fueled by social media.
The word hashtag itself was the ADS Word of the Year in 2012. Now, two years later, hashtags were recognized with their own special category in the voting, which was also won by #blacklivesmatter.
"While #blacklivesmatter may not fit the traditional definition of a word, it demonstrates how powerfully a hashtag can convey a succinct social message," Zimmer said. "Language scholars are paying attention to the innovative linguistic force of hashtags, and #blacklivesmatter was certainly a forceful example of this in 2014."
MOST LIKELY TO SUCCEED 部門の受賞語 salty とノミネート語 basic はいずれも既存の形容詞だが,新たに生じた語義が注目されているようだ.salty は "exceptionally bitter, angry, or upset" の意味で,basic は "plain, socially awkward, unattractive, uninteresting, ignorant, pathetic, uncool, etc." の意味で新しく用いられているという.いずれも俗語的な響きをもち否定的な評価的意味 (evaluative meaning) を発展させているという点で共通している.関連して,評価的意味とその歴史的発展について「#1099. 記述の形容詞と評価の形容詞」 ([2012-04-30-1]),「#1100. Farsi の形容詞区分の通時的な意味合い」 ([2012-05-01-1]),「#1193. フランス語に脅かされた英語の言語項目」 ([2012-08-02-1]),「#1400. relational adjective から qualitative adjective への意味変化の原動力」 ([2013-02-25-1]) を参照されたい.
2015-01-22 Thu
■ #2096. SUBTLEX-US Word Frequency List [frequency][statistics][corpus][lexicology][zipfs_law][cgi][web_service]
従来の英語学研究において,権威ある語彙頻度表といえばアメリカ英語に関する Kucera and Francis (1967) のものや,イギリス英語に比重を置いたより新しいものとして CELEX (1993) やその2版 (cf. 「#1424. CELEX2」 ([2013-03-21-1])) がよく用いられてきた.しかし,最近,これらを批判し,新しい手法に基づいたアメリカ英語の語彙頻度表が現われた.ベルギー,ヘント大学の実験心理学科の提供する SUBTLEXus である.左のHPから,SUBTLEXus の一群の頻度表のファイルや記述がダウンドーロできる.
SUBTLEXus の基盤にあるコーパスは,8388件の映画の字幕の集成であり,総語数は5100万語に及ぶ.SUBTLEXus の頻度表は,Kucera and Francis や CELEX の頻度表と比べて,いくつかの算出された指標においてすぐれていると主張されている.頻度は,見出し語 (lemma) ごとではなく語形 (word form) ごとに数えられており,例えば名詞であれば単数形と -s 語尾などをもつ複数形は別扱いされる(異なる語形は74,286種類).名詞と動詞など複数の品詞として用いられる語形については,それぞれの品詞ごとの頻度にもアクセスできるし,より優勢な品詞 (Dominant POS) のほうへ合算した頻度へもアクセスできる.データには,ほかに何件の映画に現われているか,小文字として現われているのは何回か,頻度の対数を取った指標,Zipf 指標 (cf. 「#1101. Zipf's law」 ([2012-05-02-1])) なども含まれている.これだけの種類のデータが含まれていると,目的とアイデア次第でおおいに有効に利用できるだろう.話し言葉ベースであることも顕著な特徴だ.
ダウンロードできるいくつかのデータのなかで "a zipped Excel file of SUBTLEX-US with the Zipf values included" をダウンロードし,少しいじってみた.例えば,(1) 全体的に多く現われ,かつ (2) 多くの映画にも現われる語形は,総合的な意味で頻度が高いと考えられるだろう.そこで (1) と (2) に関する対数の指標を掛け合わせて,それを降順に並べて最初の100語を取ると,正真正銘の最頻単語100語が得られるはずだ.省略形の片割れなども含まれているが,以下がそのリストである.
you, I, the, to, s, a, it, t, that, and, of, what, in, me, is, we, this, he, on, for, my, m, your, don, have, do, re, no, be, know, was, not, can, are, all, with, just, get, here, but, there, ll, so, they, like, right, out, go, up, about, she, if, him, got, at, now, come, oh, one, how, well, want, yeah, her, think, good, see, let, did, why, who, as, going, his, will, from, when, back, time, yes, look, d, take, an, where, man, would, them, been, some, or, tell, us, had, were, say, could, gonna, didn, hey
ほかには,最頻10語,25語,50語,100語,250語,500語,1,000語,2,500語,5,000語,10,000語,25,000語,50,000語,100,000語について,Dominant POS ごとに数え上げてみることもたやすい.「#666. COCA 最頻5000語で品詞別の割合は?」 ([2011-02-22-1]),「#667. COCA 最頻50万語で品詞別の割合は?」 ([2011-02-23-1]),「#1132. 英単語の品詞別の割合」 ([2012-06-02-1]) の記事でも,別のコーパスにより似たような調査を行ったが,SUBTLEX-US 版の調査結果は次のグラフにまとめられる.
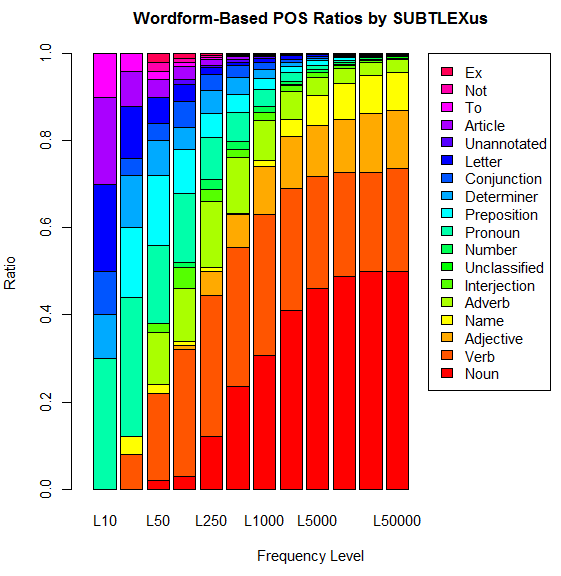
以下はおまけの検索ツール (SUBTLEX-US Word Frequency Extractor) .おまけなので,10例までしか結果が出力されない仕様です.SUBTLEXus の提供する複雑な検索も可能な,SUBTLEXus Online Search もどうぞ.
2014-12-29 Mon
■ #2072. 英語語彙の三層構造の是非 [lexicology][loan_word][latin][french][register][synonym][romancisation][lexical_stratification]
英語語彙の三層構造について「#334. 英語語彙の三層構造」 ([2010-03-27-1]),「#335. 日本語語彙の三層構造」 ([2010-03-28-1]),「#1296. 三層構造の例を追加」 ([2012-11-13-1]),「#1960. 英語語彙のピラミッド構造」 ([2014-09-08-1]) など,多くの記事で言及してきた.「#1366. 英語が非民主的な言語と呼ばれる理由」 ([2013-01-22-1]) でみたように,語彙の三層構造ゆえに英語は非民主的な言語であるとすら言われることがあるが,英語語彙のこの特徴は見方によっては是とも非となる類いのものである.
Jespersen (121--39) がその是と非の要点を列挙している.まず,長所から.
(1) 英仏羅語に由来する類義語が多いことにより,意味の "subtle shades" が表せるようになった.
(2) 文体的・修辞的な表現の選択が可能になった.
(3) 借用語には長い単語が多いので,それを使う話者は考慮のための時間を確保することができる.
(4) ラテン借用語により国際性が担保される.
まず (1) と (2) は関連しており,表現力の大きさという観点からは確かに是とすべき項目だろう.日本語語彙の三層構造と比較すれば,表現者にとってのメリットは実感されよう.しかし,聞き手や学習者にとっては厄介な特徴ともいえ,その是非はあくまで相対的なものであるということも忘れてはならない.(3) はおもしろい指摘である.非母語話者として英語を話す際には,ミリ秒単位(?)のごく僅かな時間稼ぎですら役に立つことがある.長い単語で時間稼ぎというのは,状況にもよるが,戦略としては確かにあるのではないか.(4) はラテン借用語だけではなくギリシア借用語についても言えるだろう.関連して「#512. 学名」 ([2010-09-21-1]) や「#1694. 科学語彙においてギリシア語要素が繁栄した理由」 ([2013-12-16-1]) も参照されたい.
次に,Jespersen が挙げている短所を列挙する.
(5) 不必要,不適切なラテン借用語の使用により,意味の焦点がぼやけることがある.
(6) 発音,綴字,派生語などについて記憶の負担が増える.例えば,「#859. gaseous の発音」 ([2011-09-03-1]) の各種のヴァリエーションの問題や「#573. 名詞と形容詞の対応関係が複雑である3つの事情」 ([2010-11-21-1]) でみた labyrinth の派生形容詞の問題などは厄介である.
(7) 科学の日常化により,関連語彙には国際性よりも本来語要素による分かりやすさが求められるようになってきている.例えば insomnia よりも sleeplessness のほうが分かりやすく有用であるといえる.
(8) 非本来語由来の要素の導入により,派生語間の強勢位置の問題が生じた (ex. Cánada vs Canádian) .
(9) ラテン語の複数形 (ex. phenomena, nuclei) が英語へもそのまま持ち越されるなどし,形態論的な統一性が崩れた.
(10) 語彙が非民主的になった.
是と非とはコインの表裏の関係にあり,絶対的な判断は下しにくいことがわかるだろう.結局のところ,英語の語彙構造それ自体が問題というよりは,それを使用者がいかに使うかという問題なのだろう.現代英語の語彙構造は,各時代の言語接触などが生み出してきた様々な語彙資源の歴史的堆積物にすぎず,それ自体に良いも悪いもない.したがって,そこに民主的あるいは非民主的というような評価を加えるということは,評価者が英語語彙を見る自らの立ち位置を表明しているということである.Jespersen (139) は次の総評をくだしている.
While the composite character of the language gives variety and to some extent precision to the style of the greatest masters, on the other hand it encourages an inflated turgidity of style. . . . [W]e shall probably be near the truth if we recognize in the latest influence from the classical languages 'something between a hindrance and a help'.
日本語において明治期に大量に生産された(チンプン)漢語や20世紀にもたらされた夥しいカタカナ語にも,似たような評価を加えることができそうだ(「#1999. Chuo Online の記事「カタカナ語の氾濫問題を立体的に視る」」 ([2014-10-17-1]) とそこに張ったリンク先を参照).
英語という言語の民主性・非民主性という問題については「#134. 英語が民主的な言語と呼ばれる理由」 ([2009-09-08-1]),「#1366. 英語が非民主的な言語と呼ばれる理由」 ([2013-01-22-1]),「#1845. 英語が非民主的な言語と呼ばれる理由 (2)」 ([2014-05-16-1]) で取り上げたので,そちらも参照されたい.また,英語語彙のロマンス化 (romancisation) に関する評価については「#153. Cosmopolitan Vocabulary は Asset か?」 ([2009-09-27-1]) や「#395. 英語のロマンス語化についての評」 ([2010-05-27-1]) を参照.
・ Jespersen, Otto. Growth and Structure of the English Language. 10th ed. Chicago: U of Chicago, 1982.
2014-10-17 Fri
■ #1999. Chuo Online の記事「カタカナ語の氾濫問題を立体的に視る」 [japanese][katakana][kanji][lexicology][lexicography][inkhorn_term][loan_word][waseieigo][link]
ヨミウリ・オンライン(読売新聞)内に,中央大学が発信するニュースサイト Chuo Online がある.そのなかの 教育×Chuo Online へ寄稿した「カタカナ語の氾濫問題を立体的に視る」と題する私の記事が,昨日(2014年10月16日)付で公開されたので,関心のある方はご参照ください.ちょうど今期の英語史概説の授業で,この問題の英語版ともいえる初期近代英語期のインク壺語 (inkhorn_term) を巡る論争について取り上げる矢先だったので,とてもタイムリー.数週間後に記事の英語版も公開される予定. *
上の投稿記事に関連する内容は本ブログでも何度か取り上げてきたものなので,関係する外部リンクと合わせて,この機会にリンクを張っておきたい.
・ 文化庁による平成25年度「国語に関する世論調査」
・ 「#32. 古英語期に借用されたラテン語」 ([2009-05-30-1])
・ 「#296. 外来宗教が英語と日本語に与えた言語的影響」 ([2010-02-17-1])
・ 「#478. 初期近代英語期に湯水のように借りられては捨てられたラテン語」 ([2010-08-18-1])
・ 「#576. inkhorn term と英語辞書」 ([2010-11-24-1])
・ 「#609. 難語辞書の17世紀」 ([2010-12-27-1])
・ 「#845. 現代英語の語彙の起源と割合」 ([2011-08-20-1])
・ 「#1067. 初期近代英語と現代日本語の語彙借用」 ([2012-03-29-1])
・ 「#1202. 現代英語の語彙の起源と割合 (2)」 ([2012-08-11-1])
・ 「#1408. インク壺語論争」 ([2013-03-05-1])
・ 「#1410. インク壺語批判と本来語回帰」 ([2013-03-07-1])
・ 「#1411. 初期近代英語に入った "oversea language"」 ([2013-03-08-1])
・ 「#1493. 和製英語ならぬ英製羅語」 ([2013-05-29-1])
・ 「#1526. 英語と日本語の語彙史対照表」 ([2013-07-01-1])
・ 「#1606. 英語言語帝国主義,言語差別,英語覇権」 ([2013-09-19-1])
・ 「#1615. インク壺語を統合する試み,2種」 ([2013-09-28-1])
・ 「#1616. カタカナ語を統合する試み,2種」 ([2013-09-29-1])
・ 「#1617. 日本語における外来語の氾濫」 ([2013-09-30-1])
・ 「#1624. 和製英語の一覧」 ([2013-10-07-1])
・ 「#1629. 和製漢語」 ([2013-10-12-1])
・ 「#1630. インク壺語,カタカナ語,チンプン漢語」 ([2013-10-13-1])
・ 「#1645. 現代日本語の語種分布」 ([2013-10-28-1]) とそこに張ったリンク集
・ 「#1869. 日本語における仏教語彙」 ([2014-06-09-1])
・ 「#1896. 日本語に入った西洋語」 ([2014-07-06-1])
・ 「#1927. 英製仏語」 ([2014-08-06-1])
(後記 2014/10/30(Thu):英語版の記事はこちら. *)
2014-10-13 Mon
■ #1995. Mulcaster の語彙リスト "generall table" における語源的綴字 [mulcaster][lexicography][lexicology][cawdrey][emode][dictionary][spelling_reform][etymological_respelling][final_e]
昨日の記事「#1994. John Hart による語源的綴字への批判」 ([2014-10-12-1]) や「#1939. 16世紀の正書法をめぐる議論」 ([2014-08-18-1]),「#1940. 16世紀の綴字論者の系譜」 ([2014-08-19-1]),「#1943. Holofernes --- 語源的綴字の礼賛者」 ([2014-08-22-1]) で Richard Mulcaster の名前を挙げた.「#441. Richard Mulcaster」 ([2010-07-12-1]) ほか mulcaster の各記事でも話題にしてきたこの初期近代英語期の重要人物は,辞書編纂史の観点からも,特筆に値する.
英語史上最初の英英辞書は,「#603. 最初の英英辞書 A Table Alphabeticall (1)」 ([2010-12-21-1]),「#604. 最初の英英辞書 A Table Alphabeticall (2)」 ([2010-12-22-1]),「#726. 現代でも使えるかもしれない教育的な Cawdrey の辞書」 ([2011-04-23-1]),「#1609. Cawdrey の辞書をデータベース化」 ([2013-09-22-1]) で取り上げたように,Robert Cawdrey (1537/38--1604) の A Table Alphabeticall (1604) と言われている.しかし,それに先だって Mulcaster が The First Part of the Elementarie (1582) において約8000語の語彙リスト "generall table" を掲げていたことは銘記しておく必要がある.Mulcaster は,教育的な見地から英語辞書の編纂の必要性を訴え,いわば試作としてとしてこの "generall table" を世に出した.Cawdrey は Mulcaster に刺激を受けたものと思われ,その多くの語彙を自らの辞書に採録している.Mulcaster の英英辞書の出版を希求する切実な思いは,次の一節に示されている.
It were a thing verie praiseworthie in my opinion, and no lesse profitable then praise worthie, if som one well learned and as laborious a man, wold gather all the words which we vse in our English tung, whether naturall or incorporate, out of all professions, as well learned as not, into one dictionarie, and besides the right writing, which is incident to the Alphabete, wold open vnto vs therein, both their naturall force, and their proper vse . . . .
上の引用の最後の方にあるように,辞書編纂史上重要なこの "generall table" は,語彙リストである以上に,「正しい」綴字の指南書となることも目指していた.当時の綴字改革ブームのなかにあって Mulcaster は伝統主義の穏健派を代表していたが,穏健派ながらも final e 等のいくつかの規則は提示しており,その効果を具体的な単語の綴字の列挙によって示そうとしたのである.
For the words, which concern the substance thereof: I haue gathered togither so manie of them both enfranchised and naturall, as maie easilie direct our generall writing, either bycause theie be the verie most of those words which we commonlie vse, or bycause all other, whether not here expressed or not yet inuented, will conform themselues, to the presidencie of these.
「#1387. 語源的綴字の採用は17世紀」 ([2013-02-12-1]) で,Mulcaster は <doubt> のような語源的綴字には否定的だったと述べたが,それを "generall table" を参照して確認してみよう.EEBO (Early English Books Online) のデジタル版 The first part of the elementarie により,いくつかの典型的な語源的綴字を表わす語を参照したところ,auance., auantage., auentur., autentik., autor., autoritie., colerak., delite, det, dout, imprenable, indite, perfit, receit, rime, soueranitie, verdit, vitail など多数の語において,「余分な」文字は挿入されていない.確かに Mulcaster は語源的綴字を受け入れていないように見える.しかし,他の語例を参照すると,「余分な」文字の挿入されている aduise., language, psalm, realm, salmon, saluation, scholer, school, soldyer, throne なども確認される.
語によって扱いが異なるというのはある意味で折衷派の Mulcaster らしい振る舞いともいえるが,Mulcaster の扱い方の問題というよりも,当時の各語各綴字の定着度に依存する問題である可能性がある.つまり,すでに語源的綴字がある程度定着していればそれがそのまま採用となったということかもしれないし,まだ定着していなければ採用されなかったということかもしれない.Mulcaster の選択を正確に評価するためには,各語における語源的綴字の挿入の時期や,その拡散と定着の時期を調査する必要があるだろう.
"generall table" のサンプル画像が British Library の Mulcaster's Elementarie より閲覧できるので,要参照. *
2014-09-15 Mon
■ #1967. 料理に関するフランス借用語 [loan_word][french][lexicology][norman_conquest][semantic_field][recipe]
昨日の記事「#1966. 段々おいしくなってきた英語の飲食物メニュー」 ([2014-09-14-1]) で,英語の料理や飲食物に関する語彙には,歴史的にフランス借用語が幅を利かせてきたことを確認した.その背景にあるのは,疑いなく1066年のノルマン・コンクェエストである.それ以降,「#331. 動物とその肉を表す英単語」 ([2010-03-24-1]) で典型的に知られているように,アングロサクソン系の大多数の庶民は家畜の世話に追われ,フランス系の上流階級はフランスの料理に舌鼓を打った.イングランドにおいてフランス料理は,単においしいだけでなく,権威や洗練の象徴として社会的な含意をもっていた.
動物とその肉料理に関する sheep / mutton; ox / beef; pig / pork, bacon, gammon; calf / veal; boar / brawn; fowl / poultry の英仏語彙の対立はよく知られているが,ほかにもフランス借用語が料理に関する意味場を広く占めている証拠はたくさんある.昨日の記事で引用した Hughes は,"The sociology of food" (117--20) と題する節で,興味深い事例を列挙している.
まず,動物の可食部位で上質な部位と下等な部位とで呼び名が異なるという事実がある.haunch, joint, cutlet はフランス語だが,brains, tongue, shank は英語だ.ある程度豪華な食事を表わす dinner, supper, banquet はフランス語だが,質素な breakfast は英語だ(なお,lunch は16世紀末に初出し,昼食の意では19世紀から).火を通す調理法は「#1962. 概念階層」 ([2014-09-10-1]) の COOK の配下に挙げた boil, broil, roast, grill, fry など多くの動詞がフランス語だ.スープ,デザート,調味料など風味の素材も然り (ex. soup, potage, sauce, dessert, mustard, cream, ginger, liquorice, flan, pasty, claret, biscuit) .アングロ・サクソンの食文化のひもじさが悲しいほどだ.
中世のご馳走を用意する係の名前にもフランス語が目立つ.steward (給仕長)こそ英語だが(sty + ward で「豚小屋世話人」というのが皮肉),marshal (接待係),sewer (配膳方),pantler (食料貯蔵室管理人),butler (執事)はフランス語である.下働きの scullion (皿洗い男),blackguard (召使い),pot-boy (ボーイ)はいずれも英語である.
最後に,15世紀のレシピの英文を覗いてみよう.Hughes (118) からの再引用だが,イタリック体の語がフランス借用語である.いかに料理の意味場がフランス語かぶれしているかが分かるだろう.
Oystres in grauey
Take almondes, and blanche hem, and grinde hem and drawe þorgh a streynour with wyne, and with goode fressh broth into gode mylke, and sette hit on þe fire and lete boyle; and cast therto Maces, clowes, Sugur, pouder of Ginger, and faire parboyled oynons mynced; And þen take faire oystres, and parboile hem togidre in faire water; And then caste hem ther-to, And let hem boyle togidre til þey ben ynowe; and serve hem forth for gode potage.
いかにもフランス語かぶれしている.しかし,かぶれていなかったら,今でさえ評価されることの少ないイングランドの食事情は,さらに貧しいものとなったに違いない.人たるもの,食の分野において purism の議論はあり得ない.
・ Hughes, G. A History of English Words. Oxford: Blackwell, 2000.
2014-09-14 Sun
■ #1966. 段々おいしくなってきた英語の飲食物メニュー [loan_word][french][history][lexicology]
Hughes (119) に,眺めているだけでおいしくなってくる英語の "A historical menu" が掲載されている.古英語期から現代英語期までに次々と英語へ入ってきた飲食物を表わす借用語が,時代順に並んでいる.Hughes は現代から古英語へと遡るように一覧を提示しており,昔の食べ物は素朴だったなあという感慨を得るにはよいのだが,下から読んだほうが圧倒的に食欲が増すので,そのように読むことをお勧めしたい.
| Food | Drink | |
|---|---|---|
| pesto, salsa, sushi | ||
| tacos, quiche, schwarma | ||
| pizza, osso bucco | Chardonnay | |
| 1900 | paella, tuna, goulash | |
| hamburger, mousse, borscht | Coca Cola | |
| grapefruit, éclair, chips | soda water | |
| bouillabaisse, mayonnaise | ||
| ravioli, crêpes, consommé | riesling | |
| 1800 | spaghetti, soufflé, bechamel | tequila |
| ice cream | ||
| kipper, chowder | ||
| sandwich, jam | seltzer | |
| meringue, hors d'oeuvre, welsh rabbit | whisky | |
| 1700 | avocado, pâté | gin |
| muffin | port | |
| vanilla, mincemeat, pasta | champagne | |
| salmagundi | brandy | |
| yoghurt, kedgeree | sherbet | |
| 1600 | omelette, litchi, tomato, curry, chocolate | tea, sherry |
| banana, macaroni, caviar, pilav | coffee | |
| anchovy, maize | ||
| potato, turkey | ||
| artichoke, scone | sillabub | |
| 1500 | marchpane (marzipan) | |
| whiting, offal, melon | ||
| pineapple, mushroom | ||
| salmon, partridge | ||
| Middle English | venison, pheasant | muscatel |
| crisp, cream, bacon | rhenish (rhine wine) | |
| biscuit, oyster | claret | |
| toast, pastry, jelly | ||
| ham, veal, mustard | ||
| beef, mutton, brawn | ||
| sauce, potage | ||
| broth, herring | ||
| meat, cheese | ale | |
| Old English | cucumber, mussel | beer |
| butter, fish | wine | |
| bread | water |
予想通りフランス借用語が多いものの,全体的にはバラエティ豊かで多国籍風である.
料理の分野におけるフランス語については,ほかにも「#61. porridge は愛情をこめて煮込むべし」 ([2009-06-28-1]),「#331. 動物とその肉を表す英単語」 ([2010-03-24-1]),「#332. 「動物とその肉を表す英単語」の神話」 ([2010-03-25-1]),「#1583. swine vs pork の社会言語学的意義」 ([2013-08-27-1]),「#1603. 「動物とその肉を表す英単語」を最初に指摘した人」 ([2013-09-16-1]),「#678. 汎ヨーロッパ的な18世紀のフランス借用語」 ([2011-03-06-1]),「#1792. 18--20世紀のフランス借用語」 ([2014-03-24-1]),「#1667. フランス語の影響による形容詞の後置修飾 (1)」 ([2013-11-19-1]),「#1210. 中英語のフランス借用語の一覧」 ([2012-08-19-1]) を参照.
・ Hughes, G. A History of English Words. Oxford: Blackwell, 2000.
2014-09-13 Sat
■ #1965. 普遍的な語彙素 [lexicology][glottochronology][semantics][lexeme][componential_analysis]
先日の「#1961. 基本レベル範疇」 ([2014-09-09-1]) の記事で,基本語彙あるいは基礎語彙の話題を取り上げたときに,Swadesh の提案した基礎語彙に言及した.これは「#1128. glottochronology」 ([2012-05-29-1]) で挙げた100語からなる basic vocabulary のことであり,通言語的に普遍的な基礎語彙であると唱えられている.批判も多いが,比較言語学や歴史言語学では core vocabulary に関する影響力のある提案の1つと認識されている.
core vocabulary を同定するもう1つの試みとして,Wierzbicka や Goddard の提案がある.Swadesh の提案が比較言語学を基盤としているのに対し,Wierzbicka らの提案は意味論を基盤としている.意味論には,ちょうど音韻論において普遍的な弁別素性が仮定されるのと同様に,普遍的な意味の原子要素 (semantic primes) があるはずだと考え,それを同定しようとする伝統がある.これは,意味の成分分析 (componential_analysis) の伝統の延長線上にある.決して成功しているとはいえないが,意味のプリミティヴを追求するというこの魅力的な計画には,これまでも多くの研究者が参加してきた.Goddard もこの計画に魅せられた1人であり,使命感をもって次のように述べている(Cliff Goddard ("Lexico-Semantic Universals: A Critical overview." Linguistic Typology 5.1 (2001): 1--65. p. 3) から引用した Saeed (78) より).
Natural Semantic Metalanguage
. . . a 'meaning' of an expression will be regarded as a paraphrase, framed in semantically simpler terms than the original expression, which is substitutable without change of meaning into all contexts in which the original expression can be used . . . The postulate implies the existence, in all languages, of a finite set of indefinable expressions (words, bound morphemes, phrasemes). The meanings of these indefinable expressions, which represent the terminal elements of language-internal semantic analysis, are known as 'semantic primes'.
具体的には,Wierzbicka と Goddard により,次の60語が "universal semantic primes" として提案されている(Saeed 79).諸言語の語彙を比較調査した上でより抜かれた精鋭の語彙素だといわれる.
| Substantives: | I, you, someone/person, something, body |
| Determiners: | this, the same, other |
| Quantifiers: | one, two, some, all, many/much |
| Evaluators: | good, bad |
| Descriptors: | big, small |
| Mental predicates: | think, know, want, feel, see, hear |
| Speech: | say, word, true |
| Actions, events, movement: | do, happen, move, touch |
| Existence and possession: | is, have |
| Life and death: | live, die |
| Time: | when/time, now, before, after, a long time, a short time, for some time, moment |
| Space: | where/place, here, above, below |
| 'Logical' concepts: | not, maybe, can, because, if |
| Intensifier, augmentor: | very, more |
| Taxonomy: | kind (of), part (of) |
| Similarity: | like |
意味の原子要素を同定するということは一種のメタ言語,論理的な言語をもつことにつながるが,Wierzbicka や Goddard はそれをあえて自然言語の語彙素に対応させて示そうとした.できあがった語彙リストは,したがって,基礎語彙のリストというよりは,普遍的な意味の原子要素を反映する語彙素のリストとして提案されたのである.
・ Saeed, John I. Semantics. 3rd ed. Malden, MA: Wiley-Blackwell, 2009.
2014-09-10 Wed
■ #1962. 概念階層 [lexicology][semantics][hyponymy][terminology][semantic_field][cognitive_linguistics]
昨日の記事「#1961. 基本レベル範疇」 ([2014-09-09-1]) で,概念階層 (conceptual hierarchy) あるいは包摂関係 (hyponymy) という術語を出した.後者の包摂関係は語彙的な関係を念頭においた見方であり,「家具」と「いす」の例で考えれば,「家具」は「いす」の上位語 (hypernym) であるといわれ,「いす」は「家具」の下位語 (hyponym) であるといわれる.一方,前者の概念階層は概念間の関係を念頭においた見方であり,上位と下位の関係が幾重にも広がり,巨大なネットワークが展開されているととらえる.
概念階層を理解するは,具体的にある意味場 (semantic_field) を取り上げ,関係を図示してみるのがよい.生物学における界 (kingdom),門 (phylum or division),綱 (class),目 (order),科 (family),属 (genus),種 (species) の分類図はよく知られた概念階層であるし,比較言語学の系統図 (family_tree) もその一種である.以下では中野 (17) に挙げられている日本語「家具」の意味場における概念階層と,英語 COOK(動詞)の意味場における概念階層を示す.
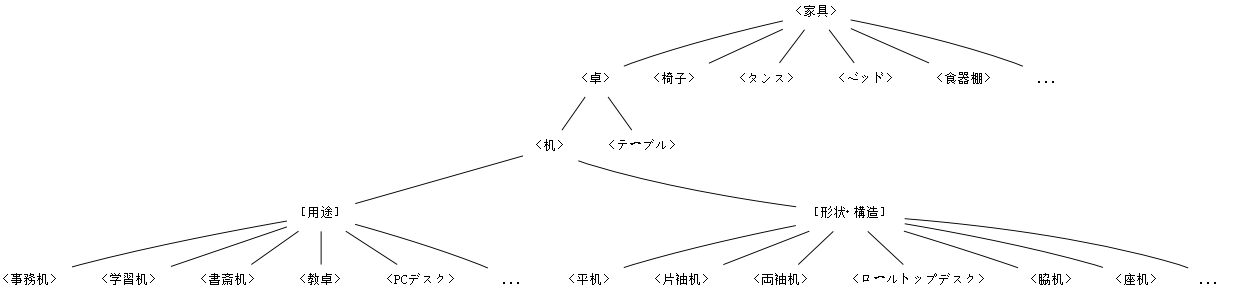
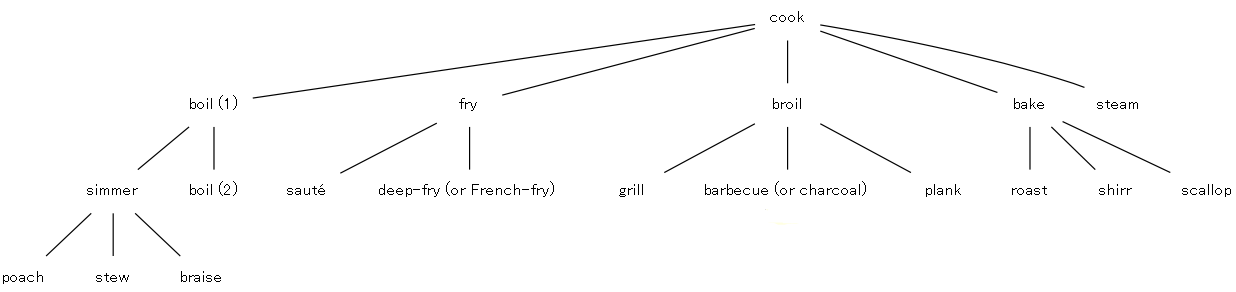
「家具」について[用途]と[形状・構造]というノードがあるが,これはそれ以下の分類が視点に基づいたものであることを示す.意味場に応じてあり得る視点も変わるだろうし,個人によっても異なる可能性があるので,上の図は1つのモデルと考えたい.
すぐに気づくように,概念階層は語彙学習にも役立つ.上記の COOK は動詞の例だが,FURNITURE, FRUIT, VEHICLE, WEAPON, VEGETABLE, TOOL, BIRD, SPORT, TOY, CLOTHING などの名詞の概念階層を描いてみると勉強になりそうだ.
・ 中野 弘三(編)『意味論』 朝倉書店,2012年.
2014-09-09 Tue
■ #1961. 基本レベル範疇 [lexicology][semantics][cognitive_linguistics][prototype][glottochronology][basic_english][hyponymy][terminology][semantic_field]
昨日の記事「#1960. 英語語彙のピラミッド構造」 ([2014-09-08-1]) の最後で,「語彙階層は,基本性,日常性,文体的威信の低さ,頻度,意味・用法の広さといった諸相と相関関係にある」と述べた.言語学では,しばしば「基本的な語彙」が話題になるが,何をもって基本的とするかについては様々な立場がある.直感的には,基本的な語彙とは,日常的に用いられ,高頻度で,子供にも早期に習得される語彙であると済ませることもできそうだし,確かにそれで大きく外れていないと思う.しかし,どこまでを基本語彙と認めるかという問題や,個別言語ごとに異なるものなのか,あるいは通言語的にある程度は普遍的なものなのかという問題もあり,易しいようで難しいテーマである.例えば,言語学史的には「#1128. glottochronology」 ([2012-05-29-1]) を提唱した Swadesh の綴字した基礎語彙に対して,猛烈な批判が加えられたという事例もあったし,実用的な目的で唱えられた Basic English (cf. 「#960. Basic English」 ([2011-12-13-1]),「#1705. Basic English で書かれたお話し」 ([2013-12-27-1])) とその基本語彙についても,疑念の目が向けられたことがあった.
基本的な語彙ということでもう1つ想起されるのは,認知意味論でしばしば取り上げられる基本レベル範疇 (Basic Level Category) である.語彙的な関係の1つに,概念階層 (conceptual hierarchy) あるいは包摂関係 (hyponymy) というものがある.例えば,「家具」という意味場 (semantic_field) を考えてみる.「家具」という包括的なカテゴリーの下に「いす」や「机」のカテゴリーがあり,それぞれの下に「肘掛けいす」「デッキチェア」や「勉強机」「パソコンデスク」などがある.さらに上にも下にも,そして横にもこのような語彙関係が広がっており,「家具」の意味場に巨大な語彙ネットワークが展開しているというのが,意味論や語彙論の考え方だ.ここで「家具」「いす」「肘掛けいす」という3段階の包摂関係について注目すると,最も普通のレベルは真ん中の「いす」と考えられる.「ちょっと疲れたから,いすに座りたいな」は普通だが,「家具に座りたいな」は抽象的で粗すぎるし,「肘掛けいすに座りたいな」は通常の文脈では不自然に細かすぎる.「いす」というレベルが,抽象的すぎず一般的すぎず,ちょうどよいレベルという感覚がある.ここでは,「いす」が Basic Level Category を形成しているといわれる.
では,この Basic Level Category は何によって決まるのだろうか.Taylor (52) は,プロトタイプ理論の権威 Rosch に依拠しながら,次のような機能主義的な説明を支持している.
Rosch argues that it is the basic level categories that most fully exploit the real-world correlation of attributes. Basic level terms cut up reality into maximally informative categories. The basic level, therefore, is the level in a categorization hierarchy at which the 'best' categories can emerge. More precisely, Rosch hypothesizes that basic level categories both
(a) maximize the number of attributes shared by members of the category;
and
(b) minimize the number of attributes shared with members of other categories.
「いす」は,その配下の様々な種類のいす,例えば「肘掛けいす」や「デッキチェア」と多くの共通の特性をもつ点で (a) にかなう.また,「いす」は,「机」や様々な種類の机,例えば「勉強机」や「パソコンデスク」と共有する特性は少ないので,(b) にかなう.これは「いす」を中心にして考えた場合だが,同じように「家具」あるいは「肘掛けいす」を中心に考えて (a) と (b) にかなうかどうかを検査してみると,いずれも「いす」ほどには両条件を満たさない.
Basic Level Category の語彙は,認知的に重要と考えられている.また,日常的に最もよく使われ,子供によって最初に習得され,大人も最も速く反応することが知られている.ある種の基本性を備えた語彙といえるだろう.
基本語彙の別の見方については,「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1]),「#1874. 高頻度語の語義の保守性」 ([2014-06-14-1]),「#1101. Zipf's law」 ([2012-05-02-1]) の記事も参照されたい.
・ Taylor, John R. Linguistic Categorization. 3rd ed. Oxford: OUP, 2003.
2014-09-08 Mon
■ #1960. 英語語彙のピラミッド構造 [register][lexicology][loan_word][latin][french][greek][semantics][polysemy][lexical_stratification]
英語語彙に特徴的な三層構造について,「#334. 英語語彙の三層構造」 ([2010-03-27-1]),「#335. 日本語語彙の三層構造」 ([2010-03-28-1]),「#1296. 三層構造の例を追加」 ([2012-11-13-1]) などの記事でみてきた.三層構造という表現が喚起するのは,上下関係と階層のあるビルのような建物のイメージかもしれないが,ビルというよりは,裾野が広く頂点が狭いピラミッドのような形を想像するほうが妥当である.つまり,下から,裾野の広い低階層の本来語彙,やや狭まった中階層のフランス語彙,そして著しく狭い高階層のラテン・ギリシア語彙というイメージだ.
ピラミッドの比喩が適切なのは,1つには,高階層のラテン・ギリシア語彙のもつ特権的な地位と威信がよく示されているからだ.社会言語学的,文体的に他を圧倒するポジションについていることは,ビル型よりもピラミッド型のほうがよく表現できる.
2つ目として,それぞれの語彙の頻度が,ピラミッドにおける各階層の面積として表現できるからである.昨日の記事「#1959. 英文学史と日本文学史における主要な著書・著者の用いた語彙における本来語の割合」 ([2014-09-07-1]) でみたように,話し言葉のみならず書き言葉においても,本来語彙の頻度は他を圧倒している(なお,この分布は,「#1645. 現代日本語の語種分布」 ([2013-10-28-1]) でみたように,現代日本語においても同様だった).対照的に,高階層の語彙は頻度が低い.個々の語については反例もあるだろうが,全体的な傾向としては,各階層の頻度と面積とは対応する.もっとも,各階層の語彙量(異なり語数)ということでいえば,必ずしもそれがピラミッドの面積に対応するわけでない.最頻100語(cf. 「#309. 現代英語の基本語彙100語の起源と割合」 ([2010-03-02-1]) と最頻600語(cf. 「#202. 現代英語の基本語彙600語の起源と割合」 ([2009-11-15-1]))で見る限り,語彙量と面積はおよそ対応しているが,10000語というレベルで調査すると,「#429. 現代英語の最頻語彙10000語の起源と割合」 ([2010-06-30-1]) でみたように,上で前提としてきた3階層の上下関係は崩れる.
ピラミッドの比喩が有効と考えられる3つ目の理由は,ピラミッドにおける各階層の面積が,頻度のみならず,構成語のもつ意味と用法の広さにも対応しているからだ.本来語は相対的に卑近であり頻度も高いが,そればかりでなく,多義であり,用法が多岐にわたる.基本的な語義が同じ「与える」でも,本来語 give は派生的な語義も多く極めて多義だが,ラテン借用語 donate は語義が限定されている.また,give は文型として SVOiOd も SVOd to Oi も取ることができる(すなわち dative shift が可能だ)が,donate は後者の文型しか許容しない.ほかには「#112. フランス・ラテン借用語と仮定法現在」 ([2009-08-17-1]) で示唆したように,語彙階層が統語的な振る舞いに関与していると疑われるケースがある.
この第3の観点から,Hughes (43) は,次のようなピラミッド構造を描いた.
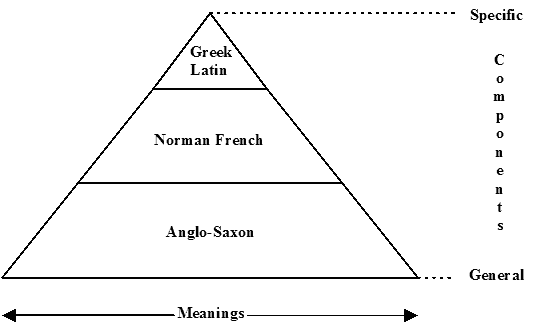
上記の3点のほかにも,各階層の面積と語の理解しやすさ (comprehensibility) が関係しているという見方もある.結局のところ,語彙階層は,基本性,日常性,文体的威信の低さ,頻度,意味・用法の広さといった諸相と相関関係にあるということだろう.ピラミッドの比喩は巧みである.
・ Hughes, G. A History of English Words. Oxford: Blackwell, 2000.
2014-09-07 Sun
■ #1959. 英文学史と日本文学史における主要な著書・著者の用いた語彙における本来語の割合 [statistics][lexicology][literature][style][japanese]
標題について,Hughes (42) は,Frederic T. Wood (An Outline History of the English Language. London: Heinemann, 1959. p.47) を参照して,数値を挙げている.以下にグラフ化して示そう.
King James Bible (1611) (94%): ********************************************************************************
Shakespeare (1564--1616) (90%): ****************************************************************************
Spenser (c1552--99) (86%): *************************************************************************
Milton (1608--74) (81%): ********************************************************************
Addison (1672--1719) (82%): *********************************************************************
Swift (1667--1745) (75%): ***************************************************************
Pope (1688--1744) (80%): ********************************************************************
Johnson (1709--84) (72%): *************************************************************
Hume (1711--76) (73%): **************************************************************
Gibbon (1737--94) (70%): ***********************************************************
Macaulay (1881--1958) (75%): ***************************************************************
Tennyson (1850--92) (77%): *****************************************************************
最高値を示す The King James Version が94%,最低値を示す Gibbon が70%だが,いずれにせよ相当に高い割合で本来語が用いられていることがわかる.話し言葉において本来語が高いことは容易に予想されるが,上記のような書き言葉において,しかも概して荘厳な文体が好まれた近代英語期に,ここまで本来語比率が高いという事実は注目に値する.特に Milton, Johnson, Gibbon などは難解な語彙を多く用いているという印象が強いが,英語史を通じて中核的であり続けた本来語彙の底力が際立っている.一方,最高値と最低値の間の20%ほどの幅は,それぞれの著者の時代や文体の相対的な差異を浮き彫りにしてくれることも確かである.
日本語の古典文学についても同様の調査を見てみよう.宮島達夫著『古典対称語い表』に基づいた加藤ほか (68, 73) に挙げられている数値を表にまとめて示す.
| 和語 | 漢語 | 混種語 | 語彙量(異なり語数) | |
|---|---|---|---|---|
| 万葉集(8世紀後半) | 99.6% | 0.3% | 0.1% | 6,505 |
| 竹取物語(9世紀末?10世紀初め) | 91.7% | 6.7% | 1.6% | 1,311 |
| 伊勢物語(10世紀初め?中ごろ) | 93.8% | 5.3% | 1.0% | 1,692 |
| 古今集(905年) | 99.9% | 0.1% | 0.1% | 1,994 |
| 土佐日記(935年) | 94.1% | 4.5% | 1.4% | 984 |
| 枕草子(1001年ごろ) | 84.1% | 12.2% | 3.6% | 5,247 |
| 源氏物語(11世紀初め) | 87.1% | 8.8% | 4.0% | 11,423 |
| 大鏡(12世紀初めごろ) | 67.6% | 27.6% | 4.8% | 4,819 |
| 方丈記(1212年) | 78.0% | 20.1% | 1.8% | 1,148 |
| 徒然草(1331年頃) | 68.6% | 28.1% | 3.3% | 4,242 |
和語についても,英文学史の場合と同様にグラフ化してみよう.日英語の間で通じるところが多いことに気づくだろう.
万葉集(8世紀後半) (99%): *******************************************************************************
竹取物語(9世紀末?10世紀初め) (91%): *************************************************************************
伊勢物語(10世紀初め?中ごろ) (93%): ***************************************************************************
古今集(905年) (99%): ********************************************************************************
土佐日記(935年) (94%): ***************************************************************************
枕草子(1001年ごろ) (84%): *******************************************************************
源氏物語(11世紀初め) (87%): *********************************************************************
大鏡(12世紀初めごろ) (67%): ******************************************************
方丈記(1212年) (78%): **************************************************************
徒然草(1331年頃) (68%): ******************************************************
関連して,「#1645. 現代日本語の語種分布」 ([2013-10-28-1]) とそこに張られているリンク,および「#1526. 英語と日本語の語彙史対照表」 ([2013-07-01-1]) を参照されたい.
・ Hughes, G. A History of English Words. Oxford: Blackwell, 2000.
・ 加藤 彰彦,佐治 圭三,森田 良行 編 『日本語概説』 おうふう,1989年.
2014-09-06 Sat
■ #1958. Hughes の語彙星雲 [register][semantics][lexicology][purism][semantic_field]
使用域 (register) による語彙と意味の広がりについて,「#611. Murray の語彙星雲」 ([2010-12-29-1]) で見た.そこで図示したように,COMMON (meaning) を中心に,LITERARY, FOREIGN, SCIENTIFIC, TECHNICAL, COLLOQUIAL, SLANG, DIALECTAL へと放射状に語彙と意味が広がっているというのが,Murray の捉え方だ.この図を具体的な語と意味で埋めてみよう.以下の図 (Hughes 5) では,「妊娠した」 (PREGNANT) という意味の場を巡って,種々の語句が然るべき位置を占めていることが示されている.
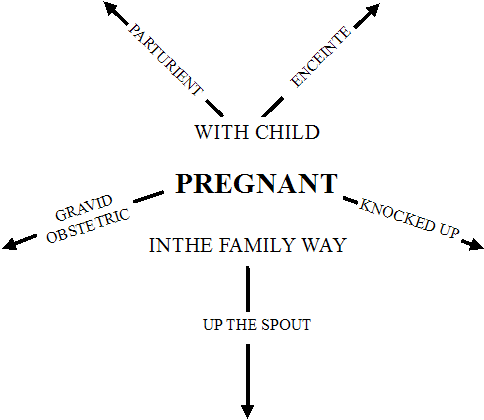
平面的に描かれがちな意味の場に使用域という次元を加え,語彙的な関係を立体的に描くことを可能とした点で,「語彙星雲」との見方は鋭い洞察だった.しかし,Hughes は語彙星雲のあり方も通時的な変化を免れることはないとし,現代英語の語彙星雲を形作るガス(使用域)は,ますます多岐に及んできていると論じた.Murray から100年たった今,別の図式が必要だと.そして,Murray の語彙星雲を次のように改良し,提示した (372) .

新しいラベルが加えられたり位置が変化したりしているが,Hughes (370--71) によれば,これは現代英語の語彙の特性を反映したものであるという.例えば,現代は借用語に対する純粋主義 (purism) が以前よりも弱まり,他言語から語彙が流入しやすくなってきたという点で,FOREIGN とは区別されるべき,取り込まれた外来要素を示すラベル EXOTIC が必要だろう(ただし,現代英語で全体的に語彙借用が減ってきていることについて,「#879. Algeo の新語ソース調査から示唆される通時的傾向」([2011-09-23-1]) を参照).また,SCIENTIFIC と TECHNICAL の語彙の増大や役割の変化に伴って,両者の位置関係についても再考が必要かもしれない.上記4ラベルが ARCHAIC とともに中心から離れた周辺に位置しているのは,これらの語彙の不透明さを反映している.さらに,現代はLITERARY というラベルの守備範囲が曖昧になってきていることから,そのラベルはなしとし,部分的に FORMAL, ARCHAIC, 場合によっては COLLOQUIAL, SLANG, OBSCENITY その他のラベルで補うのが妥当かもしれない.
この図に反映されていないものとして,他変種からの語彙がある.例えば,イギリス英語の語彙を念頭におくとき,そのなかに多く入り込んでくるようになったアメリカ英語の語彙 (americanism) やその他の変種の語彙はどのように位置づけられるだろうか.FOREIGN や EXOTIC とも違うし,伝統的な地域方言が念頭にある DIALECT とも異なる.
語彙構造も意味構造も時代とともに変化する.現代英語もその例に漏れない.現代英語でも,使用域として貼り付けるラベル,そして語彙星雲の図式が,再考を迫られている.
・Hughes, G. A History of English Words. Oxford: Blackwell, 2000.
2014-09-04 Thu
■ #1956. Hughes の英語史略年表 [timeline][lexicology][lexicography][register][slang][hel][historiography]
Hughes (xvii--viii) は,著書 A History of English Words で,語彙史と辞書史を念頭に置いた,外面史を重視した英語史年表を与えている.略年表ではあるが,とりわけ語彙史,辞書との関連が前面に押し出されている点で,著者の狙いが透けて見える年表である.
| 410 | Departure of the Roman legions |
| c.449 | The Invasion of the Angles, Saxons, Jutes and Frisians |
| 597 | The Coming of Christianity |
| 731 | Bede's Ecclesiastical History of the English People |
| 787 | The first recorded Scandinavian raids |
| 871--99 | Alfred King of Wessex |
| 900--1000 | Approximate date of Anglo-Saxon poetry collections |
| 1016--42 | Canute King of England, Scotland and Denmark |
| 1066 | The Norman Conquest |
| c.1150 | Earliest Middle English texts |
| 1204 | Loss of Calais |
| 1362 | English restored as language of Parliament and the law |
| 1370--1400 | The works of Chaucer, Langland and the Gawain poet |
| 1384 | Wycliffite translation of the Bible |
| 1476 | Caxton sets up his press at Westminster |
| 1525 | Tyndale's translation of the Bible |
| 1549 | The Book of Common Prayer |
| 1552 | Early canting dictionaries |
| 1584 | Roanoke settlement of America (abortive) |
| 1590--16610 | Shakespeare's main creative period |
| 1603 | Act of Union between England and Scotland |
| 1604 | Robert Cawdrey's Table Alphabeticall |
| 1607 | Jamestown settlement in America |
| 1609 | English settlement of Jamaica |
| 1611 | Authorized Version of the Bible |
| 1619 | First Arrival of slaves in America |
| 1620 | Arrival of Pilgrim fathers in America |
| 1623 | Shakespeare's First Folio published |
| 1649--60 | Puritan Commonwealth: closure of the theatres |
| 1660 | Restoration of the monarchy |
| 1667 | Milton's Paradise Lost |
| 1721 | Nathaniel Bailey's Universal Etymological English Dictionary |
| 1755 | Samuel Johnson's Dictionary of the English Language |
| 1762--94 | Grammars published by Lowth, Murray, etc. |
| 1765 | Beginning of the English Raj in India |
| 1776 | Declaration of American Independence |
| 1788 | Establishment of the first penal colony in Australia |
| 1828 | Noah Webster's American Dictionary of the English Language |
| 1884--1928 | Publication of the Oxford English Dictionary |
| 1903 | Daily Mirror published as the first tabloid |
| 1922 | Establishment of the BBC |
| 1947 | Independence of India |
| 1957--72 | Independence of various African, Asian and Caribbean states |
| 1961 | Third edition of Webster's Dictionary |
| 1968 | Abolition of the post of Lord Chancellor |
| 1989 | Second edition of the Oxford English Dictionary |
著書を読んだ後に振り返ると,著者の英語史記述に対する姿勢,英語史観がよくわかる.年表というのは1つの歴史観の表現であるなと,つくづく思う.これまで timeline の各記事で,英語史という同一対象に対して異なる年表を飽きもせずに掲げてきたのは,その作者の英語史観を探りたいがためだった.いろいろな年表を眺めてみてください.
・Hughes, G. A History of English Words. Oxford: Blackwell, 2000.
2014-07-19 Sat
■ #1909. 女性を表わす語の意味の悪化 (2) [semantic_change][gender][lexicology][semantics][euphemism][taboo][sapir-whorf_hypothesis]
昨日の記事「#1908. 女性を表わす語の意味の悪化 (1)」 ([2014-07-18-1]) で,英語史を通じて見られる semantic pejoration の一大語群を見た.英語史的には,女性を表わす語の意味の悪化は明らかな傾向であり,その背後には何らかの動機づけがあると考えられる.では,どのような動機づけがあるのだろうか.
1つは,とりわけ「売春婦」を指示する婉曲的な語句 (euphemism) の需要が常に存在したという事情がある.売春婦を意味する語は一種の taboo であり,間接的にやんわりとその指示対象を指示することのできる別の語を常に要求する.ある語に一度ネガティヴな含意がまとわりついてしまうと,それを取り払うのは難しいため,話者は手垢のついていない別の語を用いて指示することを選ぶのである.その方法は,「#469. euphemism の作り方」 ([2010-08-09-1]) でみたように様々あるが,既存の語を取り上げて,その意味を転換(下落)させてしまうというのが簡便なやり方の1つである.日本語の「風俗」「夜鷹」もこの類いである.関連して,女性の下着を表わす語の euphemism について「#908. bra, panties, nightie」 ([2011-10-22-1]) を参照されたい.
しかし,Schulz の主張によれば,最大の動機づけは,男性による女性への偏見,要するに女性蔑視の観念であるという.では,なぜ男性が女性を蔑視するかというと,それは男性が女性を恐れているからだという.恐怖の対象である女性の価値を社会的に(そして言語的にも)下げることによって,男性は恐怖から逃れようとしているのだ,と.さらに,なぜ男性は女性を恐れているのかといえば,根源は男性の "fear of sexual inadequacy" にある,と続く.Schulz (89) は複数の論者に依拠しながら,次のように述べる.
A woman knows the truth about his potency; he cannot lie to her. Yet her own performance remains a secret, a mystery to him. Thus, man's fear of woman is basically sexual, which is perhaps the reason why so many of the derogatory terms for women take on sexual connotations.
うーむ,これは恐ろしい.純粋に歴史言語学的な関心からこの意味変化の話題を取り上げたのだが,こんな議論になってくるとは.最初に予想していたよりもずっと学際的なトピックになり得るらしい.認識の言語への反映という観点からは,サピア=ウォーフの仮説 (sapir-whorf_hypothesis) にも関わってきそうだ.
・ Schulz, Muriel. "The Semantic Derogation of Woman." Language and Sex: Difference and Dominance. Ed. Barrie Thorne and Nancy Henley. Rowley, MA: Newbury House, 1975. 64--75.
Powered by WinChalow1.0rc4 based on chalow