2012-07-01 Sun
■ #1161. 英語と日本語における語彙の音節数別割合 [lexicology][statistics][syllable][corpus][japanese]
昨日の記事「#1160. MRC Psychological Database より各種統計を視覚化」 ([2012-06-30-1]) の (3) で,英語語彙を音節数により分別して,それぞれの頻度を出した.それによると,対象となった92767語の語彙全体における1音節語,2音節語,3音節語,4音節語の占める割合は,それぞれ13.46%,35.40%,29.91%,15.26%であり,合わせて94.03%に達する.とりわけ2音節語と3音節語を合わせて65.31%である.9万余という大規模な語彙で調査する限り,英語語彙の3分の2近くは2--3音節語であるということになる.
一方,##348,349,355 の記事では,BNC や COLT のコーパスを用いて,最も頻度の高い数百語から数千語を対象に音節数調査を行なった.調査対象となる語彙の規模は格段に小さく,それに従って音節数別の割合も変わる.1音節語と2音節語が優勢であり,最大の6000語規模の調査でもこの2種類だけで68.7%を占める(「#349. BNC Word Frequency List による音節数の分布調査 (2)」 ([2010-04-11-1]) のグラフを参照).対象とする語彙規模により,優勢な占有率を示す音節数が変動することがわかるが,全般的に,英語語彙においては1--3音節語が主要であることは間違いないだろう.
では,日本語の語彙について,音節数別の割合はどうだろうか.加藤ほか (80) では,林大氏による『日本語アクセント辞典』の見出し語形に基づく拍数の分布の調査結果が要約されている.辞典の見出し語形であるから対称語彙は数万語の規模と思われる.以下のような結果が出た.
| 1拍 | 2拍 | 3拍 | 4拍 | 5拍 | 6拍 | 7拍 | 8拍 | 9拍 | 10拍 | 計 |
| 0.3 | 4.8 | 22.7 | 38.8 | 17.7 | 11.0 | 3.3 | 1.2 | 0.2 | 0.1 | 100 |
割合のピークは4拍語にあり,その前後の3拍語と5拍語を合わせて79.2%,6拍語を加えれば90.2%になる.英語の語彙の主たる構成要素が1--3音節語とすれば,日本語の語彙の主たる構成要素は3--5拍語となる.音節数でみる限り,英単語は相対的に短く,日本語単語は相対的に長いことがよくわかる.
両言語間の際だった差異は,音韻数の差と音節構造の差に起因するといってよいだろう.音韻数については,[2012-02-12-1]の記事「#1021. 英語と日本語の音素の種類と数」で見たとおり,著しい差がある.また,音節構造については,日本語の音節がほぼ「子音+母音」の1形式だけであるのに対して,英語の音節は,[2012-02-14-1]の記事「#1023. 日本語の拍の種類と数」で示唆したとおり,数万形式がある.
日本語の語彙は,2拍語を基本としていると考えられる.和語でも漢語でも2±1拍語が多く,語彙の膨張に従って,その結合が増え,結果として4±1拍語が主流となってきた経緯がある.洋語についても,優勢な4拍語に合わせて「マスコミュニケーション」→「マスコミ」,「ハンガーストライキ」→「ハンスト」,「エンジンストップ」→「エンスト」と省略されることが多い.2拍語を基本とした日本語語彙の成立と,その後の発展については,小松 (48--62) が詳しい.
・ 加藤 彰彦,佐治 圭三,森田 良行 編 『日本語概説』 おうふう,1989年.
・ 小松 秀雄 『日本語の歴史 青信号はなぜアオなのか』 笠間書院,2001年.
[ 固定リンク | 印刷用ページ ]
2012-06-30 Sat
■ #1160. MRC Psychological Database より各種統計を視覚化 [lexicology][statistics][syllable][corpus]
[2012-06-28-1], [2012-06-29-1]と連日紹介してきた MRC Psycholinguistic Database に基づいて,4つの英語語彙統計を図示したい.原データファイルの仕様に示されている統計表をもとにグラフを作成しただけだが,別のコーパスに基づいて類似した調査を行なってきたものもあるので,比較に値するだろう.数値データは,HTMLソースを参照.
(1) 文字数による頻度
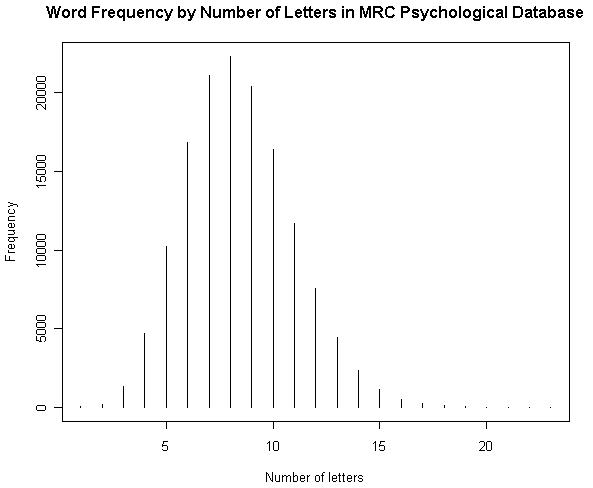
(2) 音素数による頻度
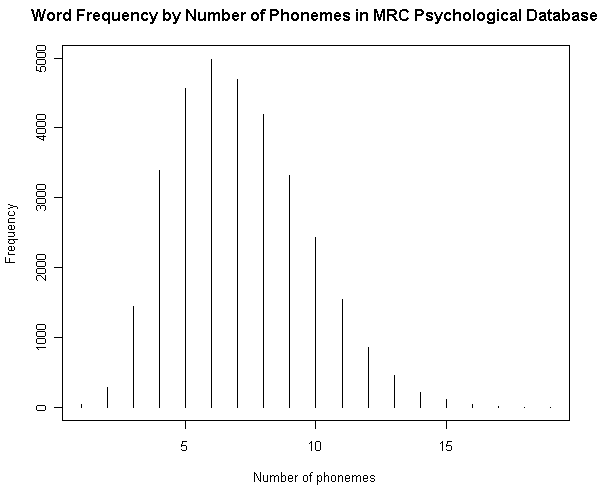
(参考)
・ [2012-02-13-1]: 「#1022. 英語の各音素の生起頻度」
(3) 音節数による頻度
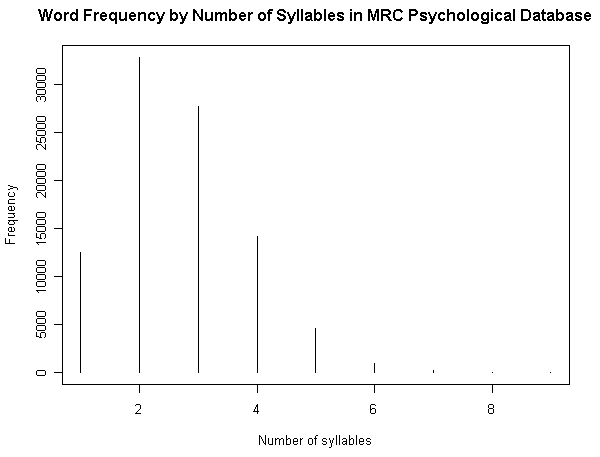
(参考)
・ [2010-04-09-1]: 「#347. 英単語の平均音節数はどのくらいか?」
・ [2010-04-10-1]: 「#348. BNC Word Frequency List による音節数の分布調査」
・ [2010-04-11-1]: 「#349. BNC Word Frequency List による音節数の分布調査 (2)」
・ [2010-04-17-1]: 「#355. COLT Word Frequency List による音節数の分布調査」
(4) 品詞による頻度
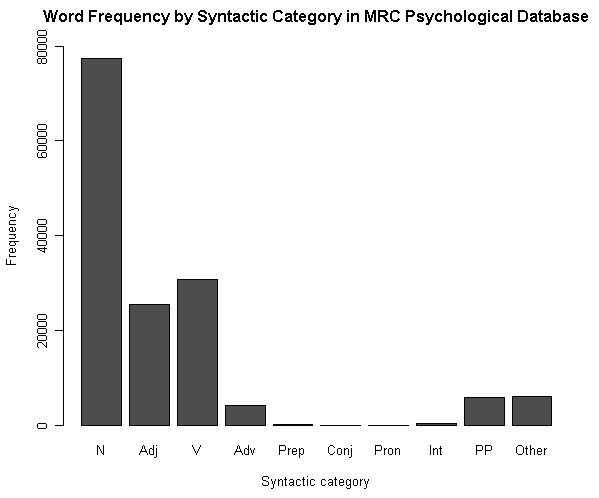
(参考)
・ [2012-06-02-1]: 「#1132. 英単語の品詞別の割合」
・ [2011-02-23-1]: 「#667. COCA 最頻50万語で品詞別の割合は?」
・ [2011-02-22-1]: 「#666. COCA 最頻5000語で品詞別の割合は?」
・ [2011-02-16-1]: 「#660. 中英語のフランス借用語の形容詞比率」
その他,語彙の頻度や,語種別の割合については以下の記事も参照.
・ [2010-03-01-1]: 「#308. 現代英語の最頻英単語リスト」
・ [2011-08-20-1]: 「#845. 現代英語の語彙の起源と割合」
・ [2012-01-07-1]: 「#985. 中英語の語彙の起源と割合」
2012-06-29 Fri
■ #1159. MRC Psycholinguistic Database Search [cgi][web_service][lexicology][frequency][statistics]
昨日の記事[2012-06-28-1]で紹介した英語語彙データベース MRC Psycholinguistic Database を,本ブログ上から簡易検索するツールを作成した.実際には検索ツールというよりは,MRC Psycholinguistic Database を用いると,こんなことができるということを示すデモ版にすぎず,出力結果は10行のみに限定してある.本格的な使用には,昨日示したページからデータベースと検索プログラムをダウンロードするか,ウェブ上のインターフェース (Online search (answers limited to 5000 entries) or Online search (limited search capabilities)) よりどうぞ.
以下,使用法の説明.SQL対応で,テーブル名は "mrc2" として固定.フィールドは以下の27項目:ID, NLET, NPHON, NSYL, K_F_FREQ, K_F_NCATS, K_F_NSAMP, T_L_FREQ, BROWN_FREQ, FAM, CONC, IMAG, MEANC, MEANP, AOA, TQ2, WTYPE, PDWTYPE, ALPHSYL, STATUS, VAR, CAP, IRREG, WORD, PHON, DPHON, STRESS.各パラメータが取る値の詳細については,原データファイルの仕様を参照のこと(仕様中に示されている各種統計値はそれ自身が非常に有用).select 文のみ有効.以下に,典型的な検索式を例として載せておく.
# 文字数で語彙を分別
select NLET, count(NLET) from mrc2 group by NLET;
# 音素数で語彙を分別
select NPHON, count(NPHON) from mrc2 group by NPHON;
# 音節数で語彙を分別
select NSYL, count(NSYL) from mrc2 group by NSYL;
# -ed で終わる形容詞を頻度順に
select WORD, K_F_FREQ from mrc2 where WTYPE = 'J' and WORD like '%ed' order by K_F_FREQ desc;
# 2音節の名詞,形容詞,動詞を強勢パターンごとに分別 (「#814. 名前動後ならぬ形前動後」 ([2011-07-20-1]) 及び「#801. 名前動後の起源 (3)」 ([2011-07-07-1]) を参照)
select WTYPE, STRESS, count(*) from mrc2 where NSYL = 2 and WTYPE in ('N', 'J', 'V') group by WTYPE, STRESS;
# <gh> の綴字で終わり,/f/ の発音で終わる語
select distinct WORD, DPHON from mrc2 where WORD like '%gh' and DPHON like '%f';
# 不規則複数形を頻度順に
select WORD, K_F_FREQ from mrc2 where IRREG = 'Z' and TQ2 != 'Q' order by K_F_FREQ desc;
# 馴染み深く,具体的な意味をもつ語
select distinct WORD, FAM from mrc2 where FAM > 600 and CONC > 600;
# イメージしやすい語
select distinct WORD, IMAG from mrc2 order by IMAG desc limit 30;
# 「有意味」な語
select distinct WORD, MEANC, MEANP from mrc2 order by MEANC + MEANP desc limit 30;
# 名前動後など品詞によって強勢パターンの異なる語
select WORD, WTYPE, DPHON from mrc2 where VAR = 'O';
2012-06-28 Thu
■ #1158. MRC Psycholinguistic Database [web_service][lexicology][frequency][statistics]
心理言語学の分野ではよく知られた英語の語彙データベースのようだが,「#1131. 2音節の名詞と動詞に典型的な強勢パターン」 ([2012-06-01-1]) と「#1132. 英単語の品詞別の割合」 ([2012-06-02-1]) で参照した Amano の論文中にて,その存在を知った.MRC Psycholinguistic Database は,150837語からなる巨大な語彙データベースである.各語に言語学的および心理言語学的な26の属性が設定されており,複雑な条件に適合する語のリストを簡単に作り出すことができるのが最大の特徴だ.特定の目的をもった心理言語学の実験に用いる語彙リストを作成するなどの用途に特に便利に使えるが,検索パラメータの組み合わせ方次第では,容易に語彙統計学の研究に利用できそうだ.
パラメータは実に多岐にわたる.文字数,音素数,音節数の指定に始まり,種々のコーパスに基づく頻度の範囲による絞り込みも可能.心理言語学的な指標として,語の familiarity, concreteness, imageability, meaningfulness なども設定されている.品詞などの統語カテゴリーはもちろん,接頭辞,接尾辞,略語,ハイフン形などの形態カテゴリーの指定もできる.発音や強勢パターンの指定にも対応している.組み合わせによって,およそのことができるのではないかと思わせる精緻さである.
全データベースと検索プログラムはこちらからダウンロードできるが,プログラムをコンパイルするなど面倒が多いので,ウェブ上のインターフェースを用いるのが便利である.2つのインターフェースが用意されており,それぞれ機能は限定されているが,通常の用途には十分だろう.
・ Online search (answers limited to 5000 entries): パラメータの細かい指定が可能だが,出力結果は5000語までに限られる.
・ Online search (limited search capabilities): 出力結果の数に制限はないが,言語学的なパラメータの細かい指定(綴字や発音のパターンの直接指定など)はできない.
・ Amano, Shuichi. "Rhythmic Alternation and the Noun-Verb Stress Difference in English Disyllabic Words." 『名古屋造形大学名古屋造形芸術大学短期大学部紀要』 15 (2009): 83--90.
2012-06-18 Mon
■ #1148. 古英語の豊かな語形成力 [oe][lexicology][derivation][compound][compounding][word_formation][productivity][kenning]
古英語の語形成 (word formation) が,派生 (derivation) や複合 (compounding) により,著しく豊かであることは,古英語の文法書や英語史の概説書を通じてよく知られている.Baugh and Cable (64--65) では,印象的な例として,古英語 mōd "mood, heart, mind, spirit; boldness, courage, pride, haughtiness" という1つの語根から,100以上の語が形成されるという事実が紹介されている.100個とまではいかないが,そこで挙げられている語を,意味とともに列挙してみよう.
・ mōdig "spirited, bold, high-minded, arrogant, stiff-necked"
・ mōdiglic "magnanimous"
・ mōdiglīce "boldly; proudly"
・ mōdignes "magnanimity; pride"
・ mōdigian "to bear oneself proudly or exultantly; to be indignant, to rage"
・ gemōdod "disposed; minded"
・ mōdfull "haughty"
・ mōdlēas "spiritless"
・ mōdsefa "mind, thought, understanding"
・ mōdgeþanc "mind, thought, understanding"
・ mōdgeþoht "mind, thought, understanding"
・ mōdgehygd "mind, thought, understanding"
・ mōdgemynd "mind, thought, understanding"
・ mōdhord "mind, thought, understanding"
・ mōdcræft "intelligence"
・ mōdcræftig "intelligent"
・ glædmōdnes "kindness"
・ mōdlufu "affection"
・ unmōd "despondency"
・ mōdcaru "sorrow"
・ mōdlēast "want of courage"
・ mādmōd "folly"
・ ofermōd "pride"
・ ofermōdigung "pride"
・ ofermōdig "proud"
・ hēahmōd "proud; noble"
・ mōdhete "hate"
・ micelmōd "magnanimous"
・ swīþmōd "great of soul"
・ stīþmōd "resolute; obstinate"
・ gūþmōd "warlike"
・ torhtmōd "glorious"
・ mōdlēof "beloved"
Hall の古英語辞書(第2版)で mōdig 周辺をのぞくと,ほかにも関連語のあることがわかる.

確かに古英語の語形成の "resourcefulness" には驚く.複合に関しては,その延長線上に kenning という文飾的技巧のあることを指摘しておこう.
ただし,この "resourcefulness" が古英語の共時的な生産性を表わすものかどうかという点については熟慮を要する.[2011-05-28-1]の記事「#761. 古英語の derivation は死んでいたか」で考察したように,この "resourcefulness" は,古英語以前からの通時的な派生・複合の結果が累々と蓄積され,豊かな語彙ネットワークとして古英語に共時的に現われているということではないか.synchronic productivity と diachronic productivity とを分けて考える必要があるのではないか.
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
・ Hall, John Richard Clark, ed. A Concise Anglo-Saxon Dictionary. 2nd ed. New York: Macmillan, 1916.
2012-06-02 Sat
■ #1132. 英単語の品詞別の割合 [lexicology][corpus][statistics]
昨日の記事で,MRC Psycholinguistic Database (全150837語を含む)を利用した Amano の研究を参照した.Amano では,名詞と動詞の stress typicality の調査の副産物として,同データベースに基づいた語の品詞別割合の表が示されていたので,今回はそれをメモしておきたい.
Amano (86) は,データベースより計10894個の2音節語を抜き出した.複数の品詞の機能をあわせもつ語については,それぞれの品詞のもとで1個として加えた(その他,詳しい作業手順は p. 86 に明記されている).結果として得られた品詞別の個数と割合は以下の通りである.
| POS | FREQ | % |
| noun | 7326 | 57.04% |
| verb | 2501 | 19.47% |
| adjective | 2420 | 18.84% |
| adverb | 291 | 2.27% |
| preposition | 68 | 0.53% |
| conjunction | 21 | 0.16% |
| pronoun | 15 | 0.12% |
| interjection | 37 | 0.29% |
| past participle | 57 | 0.44% |
| others | 108 | 0.84% |
品詞別の割合の算出は,用いるデータベースやコーパスの性質や規模,word form で数えるか lemma で数えるかなどの「語」の定義の問題に左右されるが,複数の調査結果を比較すれば,ある程度は信頼できる値が得られるだろう.本ブログ内でこれまでに紹介した品詞別の割合については,以下を参照.
・ [2011-02-23-1]: 「#667. COCA 最頻50万語で品詞別の割合は?」
・ [2011-02-22-1]: 「#666. COCA 最頻5000語で品詞別の割合は?」
・ [2011-02-16-1]: 「#660. 中英語のフランス借用語の形容詞比率」
・ Amano, Shuichi. "Rhythmic Alternation and the Noun-Verb Stress Difference in English Disyllabic Words." 『名古屋造形大学名古屋造形芸術大学短期大学部紀要』 15 (2009): 83--90.
2012-05-30 Wed
■ #1129. 印欧祖語の分岐は紀元前5800--7800年? [indo-european][archaeology][glottochronology][family_tree][lexicology]
印欧祖語の故郷と時代について,「#637. クルガン文化と印欧祖語」 ([2011-01-24-1]) 及び「#1117. 印欧祖語の故地は Anatolia か?」 ([2012-05-18-1]) の記事で,Gimbutas の唱道する Kurgan expansion hypothesis と Renfrew の唱道する Anatolian farming hypothesis をそれぞれ概観した.印欧祖語の分岐の時期について,前者は紀元前4千年紀,後者は紀元前6000--7500年に遡るとしており,深く対立している.
昨日の記事「#1128. glottochronology」 ([2012-05-29-1]) で触れたように,統計手法を用いた語彙研究を比較言語学へ応用する試みは様々な批判を受けてきた.しかし,語彙統計学者はその批判をエネルギーに替えて,次々と高度な手法を編み出してきた.近年では,Gray and Atkinson が,印欧語族の87言語について2449語を対象に,進化生物学のモデルに基づいて計算した例がある.
統計に当たっては常にそうであるように,何が前提とされているかが重要である.Gray and Atkinson の研究でも非常に多くの条件や情報が前提とされており,議論と結論を正しく評価するためには,そのいちいちの前提が妥当かどうかを確認してゆく必要がある.とりわけ,生物学の手法がそのまま比較言語学に応用できるのかどうか,生物と言語の類似点と相違点は何かという本質的な問題を論じる必要があるだろう([2011-07-13-1]の記事「#807. 言語系統図と生物系統図の類似点と相違点」を参照).以上の問題が山積しており,私には Gray and Atkinson の研究を適切に評価することはできないが,結論が興味深いので,少なくとも紹介するには値する.以下に,Gray and Atkinson の得た,分岐年代入りの印欧語系統樹を再掲しよう (437) .
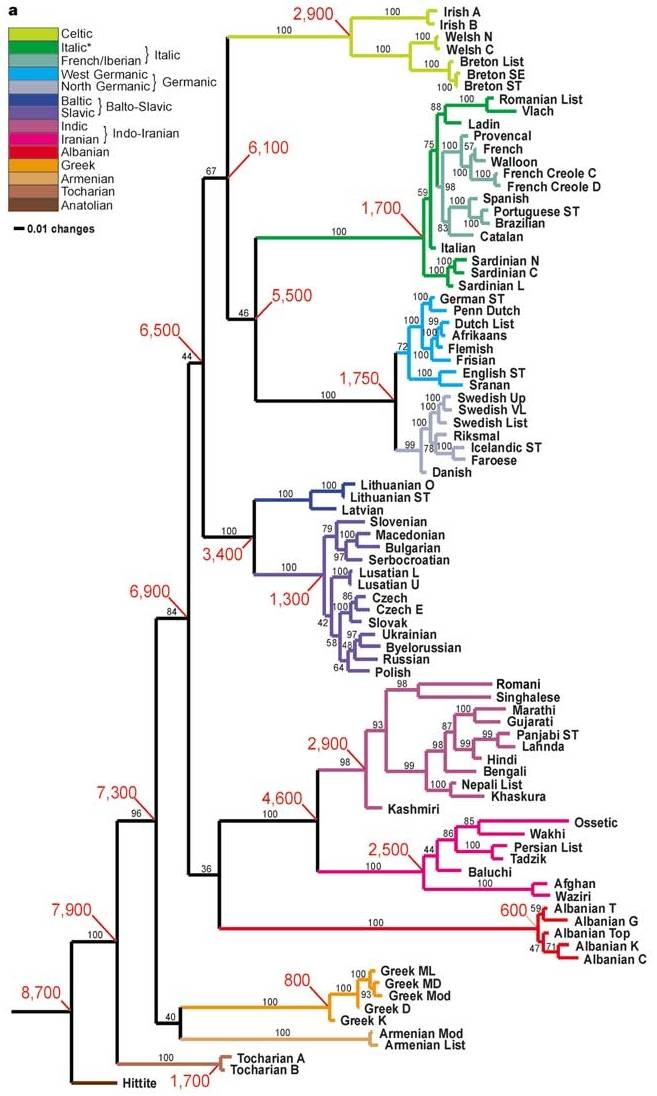
この図によると,印欧祖語が Hittite とその他の語群へ2分割したのは8700BP(=6700BC).Anatolia から農業が伝播し始めた時期に相当すると解釈できる.おもしろいのは,Italic, Celtic, Balto-Slavic そしておそらくは Indo-Iranian も含め,主立った語派が急速に分化してゆく時期が,紀元前5--4千年紀に観察されることだ.これは,時期的には Kurgan expansion hypothesis と符合する.とすると,両仮説は対立するものではなく,むしろ補完するものとも捉えられる (Gray and Atkinson 438) .
先にも述べたように,この結論を正しく評価できる立場にはない.しかし,進化生物学の知見を活かして語彙統計学の新手法を開発するというように,他分野と連係して学際的な難問に挑む試みはエキサイティングである.
・ Gray, Russell D. and Quentin D. Atkinson. "Language-Tree Divergence Times Support the Anatolian Theory of Indo-European Origin." Nature 426 (November 2003): 435--39.
2012-05-29 Tue
■ #1128. glottochronology [glottochronology][history_of_linguistics][family_tree][lexicology]
glottochronology (言語年代学)は,アメリカの言語学者 Morris Swadesh (1909--67) および Robert Lees (1922--65) によって1940年代に開かれた通時言語学の1分野である.その手法は lexicostatistics (語彙統計学)と呼ばれる.
人類言語学の知見によれば,人類文化の基礎的範疇を表わす語彙 (basic vocabulary) は言語間で共有されており,歴史的変化や外部からの影響を最も受けにくい単語群とされる.しかし,長期的にみれば,これらの基礎語彙もいずれ置換されてゆくものである.複数の関連する言語の間で共有されていた基礎的な同根語 (cognate) が,各言語において一定のゆっくりとした速度で非同根語に置換されてゆくこと (a constant rate of loss) を前提とし,それらの言語が互いに分岐した年代や速度を測ろうとするものが,glottochronology である.明らかに考古学の年代測定法にヒントを得ている.
glottochronology は上記のものを含む多くの前提の上に成り立っているが,そのいずれの前提もが激しく批判にさらされてきた.論争とされてきたのは次のような点である.
(1) Swadesh の基礎語彙 (basic vocabulary) 100語(以下に掲載)は,歴史や文化といった社会的な要因による変化を被りにくい語彙として選定されているが,これらは本当に特定の文化に依存しないと言い切れるのか.例えば,sun や moon は,文化によっては宗教的な意味を付されており,その意味において文化語ではないか.
I, you, we, this, that, who, what, not, all, many, one, two, big, long, small, woman, man, person, fish, bird, dog, louse, tree, seed, leaf, root, bark, skin, flesh, blood, bone, grease, egg, horn, tail, feather, hair, head, ear, eye, nose, mouth, tooth, tongue, claw, foot, knee, hand, belly, neck, breasts, heart, liver, drink, eat, bite, see, hear, know, sleep, die, kill, swim, fly, walk, come, lie, sit, stand, give, say, sun, moon, star, water, rain, stone, sand, earth, cloud, smoke, fire, ash, burn, path, mountain, red, green, yellow, white, black, night, hot, cold, full, new, good, round, dry, name
(2) 年代測定のための "a constant rate of loss" はすべての言語で同じであると前提できるのか.分岐して1000年たった2言語では86%の基礎語彙がいまだ共有されているといわれるが,分岐の歴史が先に分かっている多くの言語で検証すると,この率が当てはまらないケースもある.もし基礎語彙の分析について少数であったとしても誤りがあれば,この率に基づいて計算される年代は,古く溯れば溯るほど,大きな誤差を伴うことになる.
なお,以下のグラフは,2言語で共有されている基礎語彙のパーセンテージによって,分岐が少なくとも何世紀前にあったかが分かるという,glottochronology の理論的なツールである.例えば,2言語間で7割の基礎語彙が共有されていれば,その分岐の年代は少なくとも約1200年前であり,3割しか共有されていなければ,分岐年代は少なくとも約4000年前である.
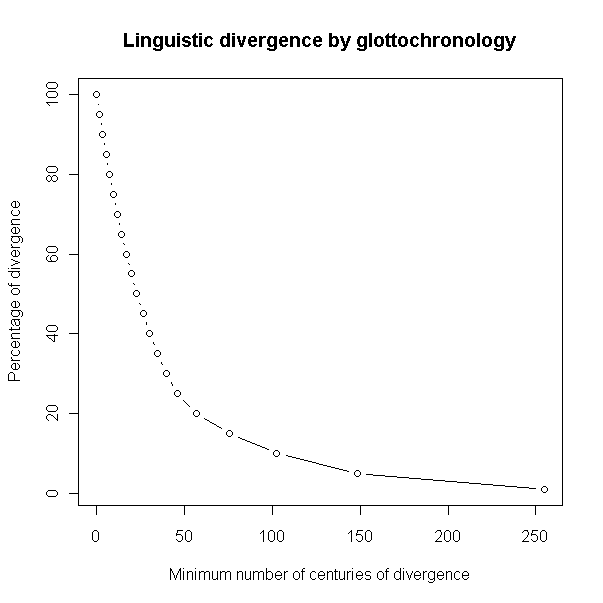
(3) cognate の同定に関わる多くの問題がある.異なる言語からの対応するとおぼしき2つの語が cognates であると言えるためには,音声的,意味的にどのような条件が必要だろうか.2語の関係が cognates ではなく loanwords であるという可能性が常にあるのではないか.これは比較言語学でも共有されている問題だが,時代を遡れば遡るほど,判別は難しい.また,古い言語では,基礎語彙のすべての語が文証されるわけではなく,言語間比較に証拠の穴が生じてしまうことがある.
glottochronology は,言語学史上,興味深い一幕を演出してくれたものの,その理論的妥当性は,現在では,ほとんどの言語学者によって疑われている.
以上,Crystal (333) などを参照して執筆した.
・ Crystal, David. The Cambridge Encyclopedia of Language. 2nd ed. Cambridge: CUP, 1997.
2012-05-04 Fri
■ #1103. GSL による Zipf's law の検証 [lexicology][statistics][frequency][zipfs_law][corpus]
[2012-05-02-1], [2012-05-03-1]の記事で取り上げてきた Zipf's law を検証(というよりは体験)するために,General Service List (GSL) の最頻2000語余りのデータを利用して計算してみた(データファイルはこちら).
![]()
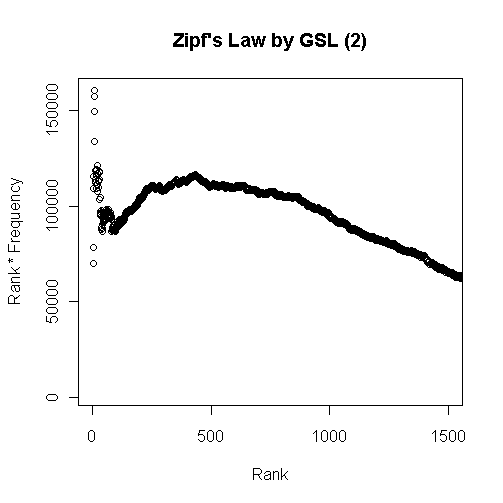
最初のグラフは頻度順位と頻度を掛け合わせたグラフで,頻度順で100位ほどまでの語を対象とした.以下はひたすら漸減してゆくのみなので省略.累積頻度のグラフを作成するまでもなく,最頻の数十語ほどで延べ語数のほとんどを覆ってしまう様子がよくわかる.
次のグラフは,Zipf's law によると定数になるとされる頻度順位と頻度の積を縦軸にとったものである.上位数十語までは「定数」は上下に大きく揺れて安定しないが,以後1000語ぐらいまでは,緩やかな増減はあるものの,落ち着く.その後のグラフ外ではひたすら漸減を続ける.したがって,「定数」を云々できるのは大目に見ても上位1000語ぐらいまでだろう.
これを法則と呼ぶのはあまりに外れていると考えるか,統計的傾向がよく出ているととらえるかは,観察者の見方ひとつである.Zipf's law における「定数」は「およそ定数」と解釈するのが暗黙の了解だが,「およそ」の幅がどの程度であるのかは明示されていない.また,Zipf's law が主張しているのと異なり,グラフの線は頻度をとるコーパスのサイズにも依存するようだ.
2012-05-01 Tue
■ #1100. Farsi の形容詞区分の通時的な意味合い [adjective][loan_word][lexicology][suffix][semantic_change][prediction_of_language_change][register][lexical_stratification]
昨日の記事[2012-04-30-1]で Farsi による「#1099. 記述の形容詞と評価の形容詞」の区分を見た.記述的な Class A,評価的な Class B,両性質を兼ね備えた Class C という区分は,共時的な観点からの区分だが,それぞれのクラスに属する形容詞を対照して眺めていると,通時的な意味合いが浮き上がってくる.Farsi は次の2点を指摘する (56--58) .
(1) Class A から Class C へと所属変更した形容詞がいくつかある.もともとは記述的な "concerning X" ほどの語義を有していた Class A 形容詞が,評価的な "worthy of X" ほどの語義を獲得し,新旧の語義を合わせもつ結果となっている.English, American, Christian, logical, philosophical, scientific などが,このような通時的経過をたどった.
(2) 上記のような例から推測するに,現在 Class A に属する形容詞が,将来,評価的な意味を獲得して Class C へ移行するということがあり得るのではないか.例えば,phonemic は「音素の」という記述的な語義をもつ典型的な Class A 形容詞だが,音素という考え方を軽視する音韻論を批判的に指して *unphonemic と表現すれば,その裏返しとしての *phonemic も評価的な語義を獲得することになり,Class C と認定されることになる.Class A に属するどの形容詞にも,評価的語義を獲得する機会は開かれている.
Class A から Class C への通時的移行,あるいは意味の発展は,使用域 (register) に応じてみられる記述的語義と評価的語義のあいだの揺れという共時的な事実として表出してくる.例えば,mental は標準的な用法では記述的だが,非標準的な用法では評価のこもった「精神のおかしい」という意味を帯びる.aesthetic は通常は記述的にも評価的にも用いられるが,美学の文脈では,もっぱら記述的に用いられるだろう.
Farsi は,Class A から Class C への方向しか取り上げていないが,論理的にはそれ以外の方向の変化もあり得るとは述べている.しかし,非評価的な語が評価的な語義を帯びるという意味変化は,その逆よりも遥かに多いだろうと直感される.客観から主観への方向を主張する文法化 (grammaticalisation) しかり,[2011-03-11-1]の記事「#683. semantic prosody と性悪説」で示唆した人間の批判精神しかり.Hotta (2011) で調査した形容詞接尾辞 -ish の軽蔑的意味の獲得でも,関連する問題を扱った([2009-09-07-1]の記事「#133. 形容詞をつくる接尾辞 -ish の拡大の経路」も参照).Farsi の形容詞の分類は,このように,意味変化の方向の問題,意味変化と使用域の問題などにも示唆を与えてくれる.
もう1つ,通時態との関連で議論しておきたいのは,Farsi の分類と借用あるいは語種との関係である.昨日の記事の冒頭でも述べたが,「#334. 英語語彙の三層構造」 ([2010-03-27-1]) やその他の三層構造の記事で見てきたとおり,本来語は評価的で,(Greco-Latin 系)借用語は記述的であるような語のペアが多い.このような共時的な分布を通時的な観点から解釈すると,次のような歴史を仮定することができるのではないか.古英語では,形容詞はほぼ本来語のみであり,意味にしたがって Class A, B, C の3種類があった.中英語以降,フランス語やラテン語から大量の形容詞が借用され([2011-02-16-1]の記事「#660. 中英語のフランス借用語の形容詞比率」),その多くは記述的語義をもっていたため,Class A や Class C に属していた本来語はその圧力に屈して対応する記述的語義を失っていった.つまり,本来語は主として評価的語義をもった Class B に閉じ込められた.一方,借用語も次第に評価的語義を帯びて Class B や Class C へ侵入し,そこでも本来語を脅かした.その結果としての現在,借用語はクラスにかかわらず広く分布しているが,本来語は主要なものが Class B に属しているばかりである.
以上が大雑把な仮説である.「本来語」や「借用語」は,より正確には「本来形態素」や「借用形態素」と呼ぶほうがよいかもしれないし,behavioural や mannerly などの混種語 ( hybrid ) の扱いを仮説内でどのように位置づけるべきかも考える必要がある.昨日掲げた Farsi の形容詞リストがどのように作成されたもので,どの程度網羅的なのかなども検証する必要があろう.
評価的語義の獲得,使用域,本来語と借用語―――このような問題の交差点として,Farsi の形容詞分類をとらえなおすことができるように思われる.英語語彙の三層構造を理解するためにも,そして日本語語彙の三層構造([2010-03-28-1]の記事「#335. 日本語語彙の三層構造」)の理解のためにも,魅力あるテーマとなりそうだ.
・ Farsi, A. A. "Classification of Adjectives." Language Learning 18 (1968): 45--60.
・ Hotta, Ryuichi. "The Suffix -ish and Its Derogatory Connotation: An OED Based Historical Study." Journal of the Faculty of Letters: Language, Literature and Culture 108 (2011): 107--32.
2012-04-30 Mon
■ #1099. 記述の形容詞と評価の形容詞 [adjective][loan_word][lexicology][lexical_stratification]
[2011-12-21-1]の記事「#968. 中英語におけるフランス借用語の質的形容詞」で触れたように,形容詞を意味の上で大きく二分すると,評価を表わす qualitative adjective (QA) と関係を示す relational adjective (RA) とが区別される.QA と RA の意味,形態,統語における特徴の違いにも興味があったが,それ以上に語種(本来語か借用語か)との関係が気になっていた.というのは,「#334. 英語語彙の三層構造」 ([2010-03-27-1]) やその他の三層構造の記事で言及してきた通り,本来語は評価的,主観的で,(Greco-Latin 系)借用語は記述的,客観的であるのが英語語彙の典型とされているからだ.形容詞はその区別がとりわけ表出しやすい語類であるように思われる.
この問題に関連して Farsi の論文を読んでみた.Farsi は,QA や RA という用語こそ使っていないが,"descriptive adjective" として Class A を,"evaluative adjective" として Class B の区分を設けた.さらに,両方の性質(より正確には両方の語義と語法)を兼ね備えた Class C をも設けて,英語の形容詞を鮮やかに分類した.理解しやすく,説得力があり,形容詞に関連する諸問題に示唆を与える卓論と評価したい.Class A, B, C の例を示そう.
| Class A | Class B | Class C |
|---|---|---|
| affective | affectionate | academic |
| appositive | apposite | aesthetic |
| behavioural | mannerly | American |
| bibliographic | bookish | artistic |
| cardiac | hearty | British |
| causal | effectual | Christian |
| ceremonial | ceremonious | cinematic |
| commemorative | memorable | civil |
| conceptual | thoughtful | constitutional |
| connective | coherent | conventional |
| consonantal | consonant | critical |
| continental | continent | demonstrative |
| corrective | correct | diplomatic |
| cultural | cultured | dramatic |
| deductive | seductive | emotional |
| dental | toothsome | English |
| devotional | devout | ethical |
| doctrinal | docile | formal |
| durative | durable | French |
| elective | eligible | grammatical |
| entrepreneurial | enterprising | historical |
| evaluative | valid | human |
| experiential | experienced | legal |
| factual | accurate | literary |
| fiduciary | faithful | logical |
| financial | lucrative | Marxian |
| genealogical | genteel | moral |
| generative | degenerate | musical |
| generic | generous | parliamentary |
| governmental | ruly | philosophical |
| gustatory | tasteful | poetic |
| inflexional | flexible | professional |
| interrogative | inquisitive | rational |
| intonational | tuneful | religious |
| juridical | just | royal |
| legislative | legitimate | sanitary |
| manual | handy | scientific |
| mental | sane | social |
| methodological | methodical | spiritual |
| modal | modish | theatrical |
| morphological | shapely | |
| nutritional | nutritious | |
| observational | observant | |
| olfactory | savoury | |
| optical | sightly | |
| ostensive | ostentatious | |
| palatal | palatable | |
| pecuniary | pecunious | |
| pedagogic | pedantic | |
| penitential | penitent | |
| perceptual | perceptive | |
| pictorial | picturesque | |
| residential | homely | |
| retributive | rewarding | |
| semantic | significant | |
| sensory | sensitive | |
| sociological | sociable | |
| stylistic | stylish | |
| supervisory | watchful | |
| syntactic | orderly | |
| tactile | tactful | |
| temporal | timely | |
| theological | godly | |
| urban | urbane | |
| verbal | verbose | |
| verificatory | veracious | |
| visual | conspicuous | |
| vocalic | equivocal | |
| vocative | provocative | |
| volitional | willing |
Class A と B には,意味的あるいは語源的に関連する語がペアで並んでいる.Class A は記述的,客観的,Class B は評価的,主観的であることがよくわかるだろう.Class C は,Class A, B とは独立した形容詞のリストであり,語法に応じて Class A のように記述的意味を帯びることもあるし,Class B のように評価的意味を帯びることもある.
この区分は意味による区分だが,形態論や統語論にも関与している (51) .否定接辞がつく場合には,典型的に,Class A は non- を,Class B は un-, in-, dis- をとる.Class A は very で修飾されないが,Class B は修飾される.形容詞が等位接続されるときには,Class A の形容詞は Class A あるいは Class C の形容詞としか接続されず,Class B の形容詞は Class B あるいは Class C の形容詞としか接続されない.複数の形容詞が順列に並んで名詞を修飾する all the ten fine old stone houses のような場合,Class A 形容詞は stone の位置に,Class B は fine の位置に置かれる.
上の最後に触れた統語的性質は,2点において興味深い.1つ目は,Class A 形容詞が,stone のような修飾語としての名詞と同列に置かれるということである.これは,Class A 形容詞が Class B 形容詞よりも一歩名詞に近い性質をもっているということを示唆する.2つ目は,Class A と Class B の両方の性質(語義)をもつ Class C の形容詞は,形容詞の順列において2つの異なる位置で生起できるという事実である.a not very Christian Christian priest, Milton's hardly dramatic dramatic poems, the lady novelist's far from historical historical romances, Eliot's not invariably poetic poetic drama, a highly professional professional writer などの例がある (56) .
Class A と B の区分は,このように鮮やかに見える.しかし,Class C のような中間的な形容詞が多数存在することは,この区分が必ずしも画然としていないことを物語る.また,特定の形容詞接尾辞とクラスとが対応している事実はないということにも注意したい.つまり,この区分は overt ではなく covert な区分である (56) .
論文の最後では,この区分に基づいた,形容詞の新しい定義が披露される.
A word which can occupy the position between an article and a noun and the position after a linking verb and which cannot be transposed with the noun it modifies is an adjective if it contains a typical adjective-forming suffix or takes the comparative and superlative suffixes or adds the suffix -ly to form an adverb.
では,この区分のもつ通時的な implication は何か,語種との関係はどうなっているか.この問題は明日の記事で考える.
・ Farsi, A. A. "Classification of Adjectives." Language Learning 18 (1968): 45--60.
2012-03-29 Thu
■ #1067. 初期近代英語と現代日本語の語彙借用 [lexicology][loan_word][borrowing][emode][renaissance][latin][japanese][linguistic_imperialism][lexical_stratification]
英語と日本語の語彙史は,特に借用語の種類,規模,受容された時代という点でしばしば比較される.語彙借用の歴史に似ている点が多く,その顕著な現われとして両言語に共通する三層構造があることは [2010-03-27-1], [2010-03-28-1] の両記事で触れた.
英語語彙の最上層にあたるラテン語,ギリシア語がおびただしく英語に流入したのは,語初期近代英語の時代,英国ルネッサンス (Renaissance) 期のことである(「#114. 初期近代英語の借用語の起源と割合」 ([2009-08-19-1]) , 「#478. 初期近代英語期に湯水のように借りられては捨てられたラテン語」 ([2010-08-18-1]) を参照).思想や科学など文化の多くの側面において新しい知識が爆発的に増えるとともに,それを表現する新しい語彙が必要とされたことが,大量借用の直接の理由である.そこへ,ラテン語,ギリシア語の旺盛な造語力という言語的な特徴と,踏み固められた古典語への憧れという心理的な要素とが相俟って,かつての中英語期のフランス語借用を規模の点でしのぐほどの借用熱が生じた.
ひるがえって日本語における洋語の借用史を振り返ってみると,大きな波が3つあった.1つ目は16--17世紀のポルトガル語,スペイン語,オランダ語からの借用,2つ目は幕末から明治期の英独仏伊露の各言語からの借用,3つ目は戦後の主として英語からの借用である.いずれの借用も,当時の日本にとって刺激的だった文化接触の直接の結果である.
英国のルネッサンスと日本の文明開化とは,文化の革新と新知識の増大という点でよく似ており,文化史という観点からは,初期近代英語のラテン語,ギリシア語借用と明治日本の英語借用とを結びつけて考えることができそうだ.しかし,語彙借用の実際を比べてみると,初期近代英語の状況は,明治日本とではなく,むしろ戦後日本の状況に近い.明治期の英語語彙借用は,英語の語形を日本語風にして取り入れる通常の意味での借用もありはしたが,多くは漢熟語による翻訳語という形で受容したのが特徴的である.「#901. 借用の分類」 ([2011-10-15-1]) で示した借用のタイプでいえば,importation ではなく substitution が主であったといえるだろう(関連して,##902,903 も参照).また,翻訳語も含めた英語借用の規模はそれほど大きくもなかった.一方,戦後日本の英語借用の方法は,そのままカタカナ語として受容する importation が主であった.また,借用の規模も前時代に比べて著大である.したがって,借用の方法と規模という観点からは,英国ルネッサンスの状況は戦後日本の状況に近いといえる.
中村 (60--61) は,「文芸復興期に英語が社会的に優勢なロマンス語諸語と接触して,一時的にヌエ的な人間を生み出しながら,結局は,ロマンス語を英語の中に取り込んで英語の一部にし得た」と,初期近代英語の借用事情を価値観を込めて解釈しているが,これを戦後日本の借用事情へ読み替えると「戦後に日本語が社会的に優勢な英語と接触して,一時的にヌエ的な人間を生み出しながら,結局は,英語を日本語の中に取り込んで日本語の一部にし得た」ということになる.仮に文頭の「戦後」を「明治期」に書き換えると主張が弱まるように感じるが,そのように感じられるのは,両時代の借用の方法と規模が異なるからではないだろうか.あるいは,「ヌエ的」という価値のこもった表現に引きずられて,私がそのように感じているだけかもしれないが.
価値観ということでいえば,中村氏の著は,英語帝国主義に抗する立場から書かれた,価値観の強くこもった英語史である.主として近代の外面史を扱っており,言語記述重視の英語史とは一線を画している.反英語帝国主義の強い口調で語られており,上述の「ヌエ的」という表現も著者のお気に入りらしく,おもしろい.展開されている主張には賛否あるだろうが,非英語母語話者が英語史を綴ることの意味について深く考えさせられる一冊である.
・ 中村 敬 『英語はどんな言語か 英語の社会的特性』 三省堂,1989年.
2012-01-11 Wed
■ #989. 2011年の英語流行語大賞 [lexicology][ads][woy]
今年もこの時期が巡ってきた.American Dialect Society による The Word of the Year の公表の時期だ.2011年の大賞は occupy だった.既存の語ではあるが,"verb, noun, and combining form referring to the Occupy protest movement" という用法により新たに生命を吹き込まれた.
2011年9月17日,New York の Zuccotti Park で "Occupy Wall Street" の運動が始まった.これ以降,世界で類似の Occupy movement が多発.民衆が,"We are the 99%" というスローガンを掲げて,経済や社会の不平等を一斉に唱え出した事件である.
occupy は,ノミネートされた語句のなかでは,2011年のかなり後半からの出馬だったが,よほど衝撃が強かったようで,決選投票の末に次点の the 99%, 99 percenters を大差で破った.後者は "those held to be at a financial or political disadvantage to the top moneymakers, the one-percenters" を意味し,これも言ってみれば occupy 関連用語だから,当社会現象の影響の大きさが知れる.
ADS の公表について,詳しくは1月7日付けのADS による公式発表とプレスリリース (PDF)を参照されたい.Wordorigins.org の運営者による,この結果についてのレビューが,こちらのページで読める.
2011年の流行語については,The Daily Telegraph の2011年11月10日の記事でも,occupy が過去1年間でインターネット及び紙面で最も多く使われた英単語だったとする研究を紹介している.
The most commonly used English word on the internet and in print in the past year was "occupy", a study has found. Repeated references to the Occupy Movement, which inspired protests outside St Paul's Cathedral in London and in other major world cities, helped push the word into first place, researchers said.
流行語の公表としては,ほかに Global Language Monitor によるものがある.その記事によると,2011年の Top Word はやはり occupy.Top Phrase は Arab Spring で,Top Name は Steve Jobs とのこと.
過去の ADS による流行語大賞関連の記事については,##623,262,263,245 などを参照.
2012-01-07 Sat
■ #985. 中英語の語彙の起源と割合 [lexicology][loan_word][statistics][me][sggk]
[2011-08-20-1]の記事で「#845. 現代英語の語彙の起源と割合」を総括したが,中英語の語彙の内訳はどうだったのだろうか.これについても様々な研究があるが,従来の統計では,古英語由来の語彙が60--70%,古仏語由来の語彙が22--30%,古ノルド語由来の語彙が8--10%,それ以外が1%未満という数値が出されている (Duggan 238) .
ところが,Norman Hinton が1980年代後半から発表している中英語語彙の大規模な調査の報告によれば,従来の統計とは相当に異なる数値が示されている.Hinton の論文は未入手なので,以下は Hinton の報告そのものではなく,Duggan (238--39) で言及されているその概要に基づくものだが,参考までに要約する.
MED からランダムに取り出した数千語の見出し語とその語源情報に基づいて語種を分類した結果,Germanic 35.06%, Romance 64.54%, Other 0.35% という数値がはじき出された.従来の統計と比べると Germanic と Romance の数値が逆転しているかのようであり,統計の前提や手法によって,これほどまでに結果が左右されるものかと恐ろしくなる.いずれの統計も,眉に唾を付けて解釈しなければならないことは認めつつ,先を続けよう.
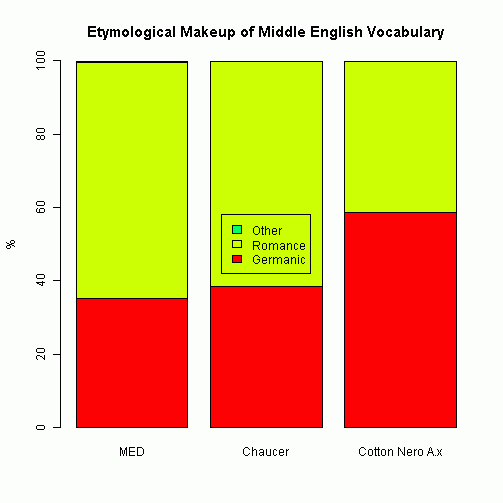
Hinton は,Chaucer や Cotton Nero A.x の言語についても語彙分類を行なっており,中英語の特定の時期における語彙の平均的な内訳と比較することによって,各言語の「年代測定」を試みている.Chaucer の語彙内訳は Germanic 38.5%, Romance 61.2%, Other 0.09% という比率であり,これは1460年の平均的な比率に相当するという.また,Cotton Nero A.x については Germanic 58.7, Romance 41%, Other 0.15% という比率で,1390年の平均的な比率を指すという.これはもちろん理論値であり,絶対年代を指すわけではない.むしろ,Chaucer と Cotton Nero A.x の70年という相対的な差が,それぞれの語彙の使い分けの差,そしておそらくは文体的な差に対応しているかもしれないという可能性がおもしろい.
・ Duggan, H. N. "Meter, Stanza, Vocabulary, Dialect". Chapter 8 of A Companion to the Gawain-Poet. Ed. Derek Brewer and Jonathan Gibson. Cambridge: Brewer, 1997. 221--42.
・ Hinton, Norman "The Language of the Gawain-Poems." Arthurian Interpretations 2 (1987): 83--94.
2011-10-26 Wed
■ #912. 語の定義がなぜ難しいか (3) [morphology][terminology][word_formation][word][dictionary][lexicology][hapax_legomenon][ghost_word]
[2011-10-24-1], [2011-10-25-1]に引き続き,語の定義の難しさを垣間見る記事の第3弾.語を定義する最も単純な方法,語の範囲を限定する最も直感的な方法は,辞書を参照することだろうと思われるかもしれない.辞書の見出し語はすべて「語」のはずであり,大型辞書を参照すれば当該言語の語の目録 (lexicon) を作成することができる,と.しかし,語の範囲を限定する際に,辞書に頼ってはならないいくつかの理由がある.Lieber (13--15) に拠って,列挙しよう.
(1) 辞書は,編集者によってある方針に基づいて編まれている.編集者の想定する語の定義によっては収録語彙の範囲に差が生じる可能性があり,実際に,語に対する考え方は辞書間で異なっていることが普通である.差別用語や専門用語を掲載するかどうか,俗語や古語はどうか,新語はどの程度社会に浸透していれば収録可とみなせるか,接辞は語に含まれるか,派生語や複合語はどこまで納めるか,等々の決定において,各辞書編集者は独自の方針をもっている.世界最大の英語辞書 OED であっても,事情は変わらない.また,参照者においてもどの辞書を選ぶかという決定は恣意的である.辞書に語の定義を委ねることは,問題を一段階さかのぼらせたにすぎず,問題の解決になっていない.
(2) 辞書には,一度しか文証されない語(臨時語,nonce word, hapax legomenon)が収録されている場合がある.例えば,OED では umbershoot という語が見出し語として挙げられており,James Joyce の Ulysses からの唯一の例が引かれているが,定義欄に "a word of obscure meaning" とある.果たして,これを実際的な意味において語とみなしてよいのだろうか.文豪 Joyce だから許されるのか,一般の話者の発する臨時語はどうなのか.
(3) 誤植,勘違い,民間語源などにより,間違えて辞書に忍び込んでしまった幽霊語 (ghost word) なる語がある.OED には,ambassady なる hapax legomenon が収録されているが,これは ambassade の単純な綴り間違い,あるいは誤植ではないかと考えられている.辞書を盲信すると,実在しないかもしれない語を語としてみなす誤りが生じうる.特殊で意図的な幽霊語として,"mountweazel" 語と呼ばれるものがある.これは,辞書編纂者が他の辞書編纂者による辞書の著作権侵害を見破るために,意図的に密かに挿入した幽霊語であり,実在の語ではない.このような mountweazel 語の存在は,辞書を絶対的な語彙目録として用いることの危険を物語っている.
辞書やその他の権威は,"Is xyz a word?" という問いに必ずしも正しい答えを与えてくれるとは限らないことが分かるだろう.
・ Lieber, Rochelle. Introducing Morphology. Cambridge: CUP, 2010.
2011-09-23 Fri
■ #879. Algeo の新語ソース調査から示唆される通時的傾向 [pde][word_formation][loan_word][statistics][lexicology][neologism]
連日の話題となっているが,Algeo と Bauer を比べているうちに俄然おもしろくなってきた新語ソース調査について (##873,874,875,876,877,878,879) .Algeo の詳細な区分 は,1963--72年の新語サンプル5000語に基づいたあくまで共時的な調査結果だが,いくつかの点で通時的な傾向を示唆しているように思える.Algeo 自身が言及あるいは議論している点について,以下に要約する.
(1) 新語の約3分の2 (63.9%) が,既存要素の合成,つまり複合 (compounding) と接辞添加 (affixation) により生じている.複合と接辞添加は特に古英語において新語形成の主要な手段だったと言及されることが多いが,現在英語においてもお得意の語形成であるという事実は変わっていない.
(2) 合成のなかでは,接辞添加 (34.1%) のほうが複合 (29.8%) よりも多い.前者のなかでは,接頭辞のほうが接尾辞より種類が多いものの,接尾辞は統語機能をそなえているために出現頻度が高く,より重要である.この意味で,英語は "a suffixing language" (272) である.
(3) 短縮 (shortening) は,客観的な証拠はないものの,"I suspect that the number of shortenings in English has increased greatly during the last two or three centuries" (271) .その理由としては,識字率向上の結果として生じた書き言葉の優勢を指摘している."Of the various kinds of shortening, the largest subgroup is that in which the shortening is based on the written form (acronyms, alphabetisms, and the like); this preeminence of the written language is clearly one of the consequences of increasing literacy" (272) .
(4) 英語において借用 (borrowing) は14世紀をピークとして衰退してきており,現在ではむしろ他言語へ単語を貸し出すソース言語としての役割が大きくなってきている.
もう1つ,詳細な区分では数値として表われていないが興味深い事実として,以下の点を指摘している.
. . . of the whole sample of new words, 76.7 percent are nouns, 15.2 percent adjectives, 7.8 percent verbs, and .3 percent other parts of speech. It seems that there are far more new things than new events to talk about. Whatever the case may be syntactically, in its lexicon, English is a nominalizing language. (272)
新語に名詞が多いという事実は驚くに当たらないかもしれない(英語語彙の品詞別割合については[2011-02-22-1], [2011-02-23-1]の記事を参照).英語が本当に "a nominalizing language" かどうかを検証するには,語彙全体における名詞の割合について通言語的に調査する必要があるだろう.それでも,Algeo のこの指摘は,Potter のいう現代英語の "noun disease" (100--05) という問題と関係しているかもしれないと考えると,興味をそそられる( "noun disease" については,[2011-09-04-1]の記事「#860. 現代英語の変化と変異の一覧」の1項目として挙げた).
最後に,影が薄くなってきている新語ソースとしての借用について,借用元言語として日本語がフランス語に次いで第2位であるという事実が注意をひく.日本語からの借用については,以下の記事を参照.
・ #45. 英語語彙にまつわる数値: [2009-06-12-1]
・ #142. 英語に借用された日本語の分布: [2009-09-16-1]
・ #126. 7言語による英語への影響の比較: [2009-08-31-1]
・ Algeo, John. "Where Do the New Words Come From?" American Speech 55 (1980): 264--77.
・ Potter, Simon. Changing English. London: Deutsch, 1969.
2011-09-22 Thu
■ #878. Algeo と Bauer の新語ソース調査の比較 [pde][word_formation][loan_word][statistics][lexicology][neologism]
今日も,現代英語の新語ソースに関する最近の一連の話題 (##873,874,875,876,877,878) の続き.[2011-09-19-1]の記事「#875. Bauer による現代英語の新語のソースのまとめ」で Bauer の調査結果をグラフ化したが,それに Algeo の調査結果を追加したものを作成した(原データと表はHTMLソースを参照).各項目で4本目の棒が,Algeo による Barnhart の新語辞書に基づく1963--1974年の数値を反映している.棒グラフとしては隣り合っているが,Algeo の調査対象年代は Bauer の第3期に包含されることに注意されたい.
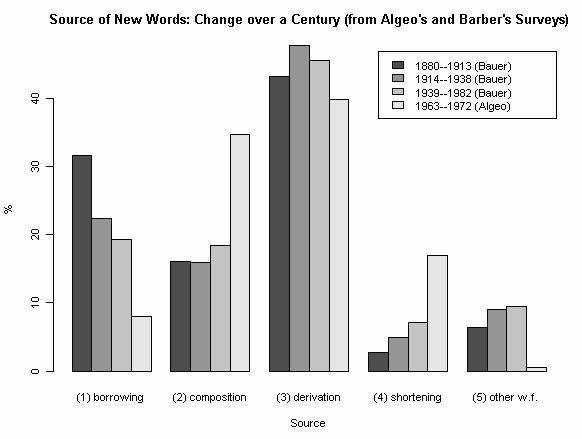
昨日の記事[2011-09-21-1]でも述べた通り,Bauer と Algeo の調査では前提がいくつか異なっている.特に Bauer では品詞転換が考慮に入れられていないので,比較条件を揃えるために,Algeo のデータから "Shifts" として区分されている数値を除いてあることにも注意されたい( "Shifts" は調査語彙全体の14.2%を占める小さくはない数値である.こちらの詳細区分を参照).また,Algeo の "Blends" は,今回のグラフ作成では "shortening" の一種として扱った.
Algeo の数値は Bauer の第3期の数値と開きこそあるが,新語ソースの傾向としてはおもしろいほどに一致している.Bauer の示唆する通時的な傾向が,Algeo によって著しく強調されて示されていると言ったらよいだろうか.比較基準の差異という問題は常について回るだろうが,互いに支持する結果となったのが興味深い.
・ Algeo, John. "Where Do the New Words Come From?" American Speech 55 (1980): 264--77.
・ Bauer, Laurie. Watching English Change: An Introduction to the Study of Linguistic Change in Standard Englishes in the Twentieth Century. Harlow: Longman, 1994.
2011-09-21 Wed
■ #877. Algeo の現代英語の新語ソース調査 [pde][word_formation][loan_word][statistics][lexicology][neologism]
[2011-09-17-1], [2011-09-18-1], [2011-09-19-1]の記事で,Bauer (35, 38) による1880--1982年の約1世紀のあいだの新語ソースの変遷について触れてきた.現代英語の新語ソースの内訳が通時的にいかに変化してきたかに関する研究は他にあまり見たことがないが,共時的な内訳の調査であれば昨日の記事「#876. 現代英語におけるかばん語の生産性は本当に高いか?」 ([2011-09-20-1]) で触れた Algeo がある.
Algeo の調査は1963年以降の新語を収録した Barnhart の辞書から無作為抽出した1000語に基づくもので,時期区分で言えば Bauer の第3期(1939--82年)のおよそ後半に相当する時期の新語に関する調査ということになる.新語ソースの分類が Bauer に比べてずっと細かいのが特徴で,分類ラベルを眺めるだけでも形態論や語彙論の概要がつかめてしまいそうな細かさだ.また,Bauer は 品詞転換 (conversion) を調査対象に含めていないが,Algeo は "Shifts" の1部として含めている.ただし,この "Shifts" には意味変化の例も含まれており,新語の定義の問題(新語形のことなのか,あるいは新語義も含むのか)を考えさせられる.
Algeo の論文の Appendix (273--76) に掲載されている,詳細な新語ソース区分とその内訳の数値をこちらのページに転載したので,参照されたい.
上記のように Bauer と Algeo では調査対象とした辞書,時代,新語ソース区分,前提としている新語の定義が一致していないので直接比較はできないものの,両者の与える数値はいずれにせよ概数であるから,合わせて現代英語の新語ソースに関する傾向を示唆するものとして大いに参考になるだろう.
現代英語の新語については,[2011-01-16-1]の記事「#629. 英語の新語サイト Word Spy」を参照.
・ Bauer, Laurie. Watching English Change: An Introduction to the Study of Linguistic Change in Standard Englishes in the Twentieth Century. Harlow: Longman, 1994.
・ Algeo, John. "Where Do the New Words Come From?" American Speech 55 (1980): 264--77.
・ Barnhart, Clarence L., Sol Steinmetz, and Robert K. Barnhart, eds. The Barnhart Dictionary of New English since 1963. Bronxville, N.Y.: Barnhart, 1973.
2011-09-20 Tue
■ #876. 現代英語におけるかばん語の生産性は本当に高いか? [blend][productivity][pde][pde_language_change][word_formation][statistics][lexicology]
[2011-01-18-1]の記事「#631. blending の拡大」で,現代英語においてかばん語が増加している件について取り上げた.かばん語は,現代英語の傾向の1つとして Leech et al. が指摘している "densification" (50) の現われと考えられそうである([2011-01-12-1]の記事「現代英語の文法変化に見られる傾向」を参照).多数のかばん語の例を示されれば,確かにさもありなんと直感されるところではある.しかし,[2011-09-17-1]の記事「#873. 現代英語の新語における複合と派生のバランス」で触れたとおり,Bauer の新語調査によれば,新語におけるかばん語の割合は1880--1982年の期間で p < 0.05 のレベルでも有意な増加を示していない(ただし絶対数は増加している).複数の観察者が指摘しており,私たちの直感にも適うかばん語の増加傾向と,客観的な統計値とのあいだに差があるのはどういうことだろうか.
1つには,Bauer の調査対象期間が1982年で終わっているということがあるだろう.当時の客観的状況と2011年の時点で私たちの抱いている直感とが食い違っていても不思議はない.この30年ほどの間に blending が激増したという可能性も考えられる.
もう1つ,直感と数値のギャップを説明し得る要因がある.この点に関して,Algeo の調査を紹介したい.多くの語彙研究が OED 系の辞書を利用しているが,Algeo はそれとは別系列の辞書を利用して独立した新語調査を行なった.彼の採った方法は,1963年以降の新語を収録した Barnhart の辞書から1000語を無作為抽出し,それをソースや語形成ごとに振り分けるというものである.その調査によると,かばん語は調査した新語語彙全体の4.8%を占めるにすぎず,他の主要な語形成のなかでは目立たないカテゴリーであるという結果となった.しかし,Algeo (271) はこの数値は過小評価だろうと述べている.
Last in numerical importance as a source of new words is blending. Less than a twentieth of our new words have been formed in that way (4.8 percent); however, blending is more popular than that statistic suggests. Its principal areas of use are popular journalism and advertising. Time magazine and Madison Avenue dearly love a blend. Most of the popular coinages are nonce forms that were unreported in the Barnhart dictionary and consequently are not included in these statistics. But every new word begins as a nonce form, so a source that is prolific of nonce forms today may be expected to increase its contribution to the general vocabulary tomorrow. Blending may look like a long shot, but the smart money will keep an eye on it.
"nonce-form" あるいは "nonce-word" (臨時語)に blending が多用されるというのは客観的に確かめにくいが,直感には適う.形態の生産性 (productivity) とは何を指すかという問題は,[2011-04-28-1], [2011-04-29-1], [2011-05-28-1]の記事でも触れてきたように,明確な解答を与えるのが難しい問題である.この問いは,何を(辞書に掲載するに値する)語とみなすかというもう1つの難問にも関係してくる([2011-03-28-1]の記事「#700. 語,形態素,接辞,語根,語幹,複合語,基体」を参照).blending の真の生産性は辞書や辞書に基づいた統計値には現われにくいが,言語使用の現場において活躍している語形成であることは恐らく間違いない.問題は,この主観的評価を,いかにして客観的に支持し得るかという方法の問題なのではないか.
・ Leech, Geoffrey, Marianne Hundt, Christian Mair, and Nicholas Smith. Change in Contemporary English: A Grammatical Study. Cambridge: CUP, 2009.
・ Bauer, Laurie. Watching English Change: An Introduction to the Study of Linguistic Change in Standard Englishes in the Twentieth Century. Harlow: Longman, 1994.
・ Algeo, John. "Where Do the New Words Come From?" American Speech 55 (1980): 264--77.
・ Barnhart, Clarence L., Sol Steinmetz, and Robert K. Barnhart, eds. The Barnhart Dictionary of New English since 1963. Bronxville, N.Y.: Barnhart, 1973.
2011-09-19 Mon
■ #875. Bauer による現代英語の新語のソースのまとめ [loan_word][word_formation][lexicology][pde][pde_language_change][statistics][lexicology]
過去2日の記事[2011-09-17-1], [2011-09-18-1]で,Bauer の調査結果に基づいて新語のソースを概観した.類似した調査はそれほど多くないようなので,Bauer のデータ (35, 38) は貴重だと思い,もう少し分析してみた.(データは整理してHTMLソースに載せておいた.)
新語のソースを大きく2分すると,借用 (borrowing) と語形成 (word formation) のカテゴリーが得られる.借用は借用元言語によって数種類に下位区分され,語形成も主として形態論の観点から数種類に下位区分される.あまり細かく区分しても大きな傾向が見にくくなるので,借用は借用元言語を区別せず,語形成は4種類に大別し,(1) borrowing, (2) composition, (3) derivation, (4) shortening, (5) other word formations の5区分で集計しなおした.以下のグラフでは,ソースごとの3期にわたる割合の変化がつかみやすいように百分率で表示してある.例えば,第1期1880--1913年を示す黒棒の数値を足し合わせると100%となる,という読み方である.
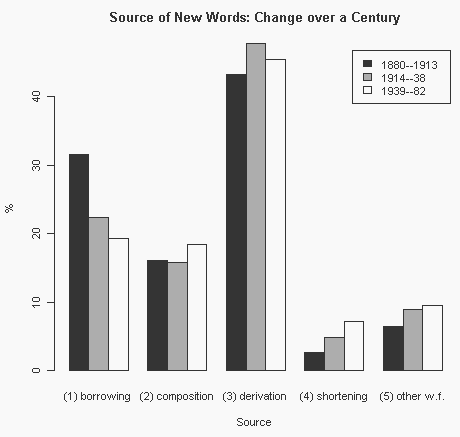
全体として,対象となった約100年間の通時的変化は p < 0.0001 のレベルで有意差が出た.そのなかでも借用の激減が最も顕著な変化である(同じく p < 0.0001 のレベルで有意).一方,各時期で合わせて6割ほどを示す composition と derivation の主要2カテゴリーは,時期によってそれほど変化していない( p < 0.05 レベルで有意差なし).また,全体での割合からすると目立たない shortening や他の語形成が順調に増加していることも見逃してはならない(shortening については,p < 0.001 のレベルで有意).カテゴリーの区別の仕方によって傾向の見え方も変化するので,同じデータを様々な角度から眺めることが必要だろう.
この3日間の記事のグラフをまとめてみられるように,3記事を「##873,874,875」で連結したので比較までに.
・ Bauer, Laurie. Watching English Change: An Introduction to the Study of Linguistic Change in Standard Englishes in the Twentieth Century. Harlow: Longman, 1994.
Powered by WinChalow1.0rc4 based on chalow