2020-03-07 Sat
■ #3967. コーパス利用の注意点 (3) [corpus][methodology][representativeness]
標題については,以下の記事を含む様々な機会に取り上げてきた.
・ 「#307. コーパス利用の注意点」 ([2010-02-28-1])
・ 「#367. コーパス利用の注意点 (2)」 ([2010-04-29-1])
・ 「#428. The Brown family of corpora の利用上の注意」 ([2010-06-29-1])
・ 「#1280. コーパスの代表性」 ([2012-10-28-1])
・ 「#2584. 歴史英語コーパスの代表性」 ([2016-05-24-1])
・ 「#2779. コーパスは英語史研究に使えるけれども」 ([2016-12-05-1])
コーパスを利用した英語(史)研究はますます盛んになってきており,学界でも当然視されるようになったが,だからこそ利用にあたって注意点を確認しておくことは大事である.主旨はおよそ繰り返しとなるが,今回は英語歴史統語論の概説書を著わした Fischer et al. (14) より,4点を指摘しよう.
(i) there can be tension between what is easily retrieved through corpus searches and what is thought to be linguistically most significant; a historical syntactic case in point involves patterns of co-reference of noun phrases . . . ; these have been largely neglected because they involve information status, which is currently not part of any standard annotation scheme;
(ii) when a data search yields large numbers of hits, there may be a temptation to interpret corpus results merely as numbers, which is a severely reductive approach; in cases of grammaticalization, for example, changes in frequency may act as tell-tale signs . . . , but an exclusive quantitative focus will mean that one is ignoring the changes in meaning and context that form the core of the process;
(iii) the substantial amounts of data that can be collected from a corpus can also blind researchers to the dangers of making generalizations about the language as a whole on the basis of a partial view of it; this is a particularly relevant problem for diachronic research, because we only have very incomplete evidence for the state of the language in any historical period . . . ;
(iv) trying to achieve greater representativness by collecting and comparing data from various corpora can also be tricky: principles guiding text inclusion vary widely, there is little standardization in user interfaces, and they can require a significant time investment to learn to operate.
この4点を私の言葉で超訳すれば,次のようになる.
(i) コーパスで遂行しやすい問題が,言語学的には必ずしも意味のある問題ではないかもしれない点に注意すべし
(ii) 量的な観点を重視する研究には役立ちそうだが,質的な観点が見過ごされてしまう危険性がある
(iii) 巨大なコーパスであったとしても,完全に representative であるわけではない(いわゆる歴史言語学における "bad-data problem")
(iv) コーパス編纂者の前提やインターフェース作成者の意図をつかんだ上で,使用法を心して習熟すべし
・ Fischer, Olga, Hendrik De Smet, and Wim van der Wurff. A Brief History of English Syntax. Cambridge: CUP, 2017.
2018-07-21 Sat
■ #3372. 古英語と中英語の資料の制約について数点のメモ [oe][me][philology][manuscript][statistics][representativeness][methodology][evidence]
「#1264. 歴史言語学の限界と,その克服への道」 ([2012-10-12-1]),「#2865. 生き残りやすい言語証拠,消えやすい言語証拠――化石生成学からのヒント」 ([2017-03-01-1]) で取り上げてきたが,歴史言語学には資料の限界という,いかんともしがたい問題がある.質量ともに望むほどのものが残っていてくれないのが現実である.児馬 (29) は,『歴史言語学』のなかの「古英語資料の留意点:量的・質的制約」という節において次のように述べている.
歴史言語学では現存する資料が最重要であることはいうまでもない.現代の言語を研究対象とするのであれば,文字資料・録音資料に加えて,話者の言語直観・内省などの言語心理学的資料も含めて実に豊富な資料を使えるのであるが,歴史言語学ではそうは簡単にならない.古い時代の資料を使うことが多い分野なので,この種の限界は当然のように思えるが,実際は,想像以上に厳しい制約があるのを認識しなければならない.特に扱う資料が古ければ古いほど厳しいものがあり,英語史では,特にOE資料の限界についてはよく認識したうえで,研究を進めていかなくてはならない.
具体的にどれくらいの制約があるのかを垣間見るために,古英語と中英語の資料について児馬が触れている箇所を数点メモしておこう.
・ 古英語期の写本に含まれる語数は約300万語で,文献数は約2000である.部分的にはヴァイキングによる破壊が原因である.この量はノルマン征服以降の約200年間に書かれた中英語の資料よりも少ない.(29)
・ とくに850年以前の資料で残っているものは,4つのテキストと35ほどの法律文書・勅許上などの短い公的文書が大半である.(29)
・ 古英語資料の9割がウェストサクソン方言で書かれた資料である.(31)
・ 自筆資料 (authorial holograph) は非常に珍しく,中英語期でも Ayenbite of Inwit (1340年頃),詩人 Hoccleve (1370?--1450?) の書き物,15世紀ノーフォークの貴族の手による書簡集 Paston Letters やその他の同時期の書簡集ほどである.(34)
英語史における資料の問題は非常に大きい.文献学 (philology) や本文批評 (textual criticism) からのアプローチがこの分野で重要視される所以である.
関連して「#1264. 歴史言語学の限界と,その克服への道」 ([2012-10-12-1]),「#2865. 生き残りやすい言語証拠,消えやすい言語証拠――化石生成学からのヒント」 ([2017-03-01-1]),「#1051. 英語史研究の対象となる資料 (1)」 ([2012-03-13-1]),「#1052. 英語史研究の対象となる資料 (2)」 ([2012-03-14-1]) も参照.
・ 児馬 修 「第2章 英語史概観」服部 義弘・児馬 修(編)『歴史言語学』朝倉日英対照言語学シリーズ[発展編]3 朝倉書店,2018年.22--46頁.
2017-03-01 Wed
■ #2865. 生き残りやすい言語証拠,消えやすい言語証拠――化石生成学からのヒント [philology][writing][manuscript][representativeness][textual_transmission][evidence]
言語の歴史を研究するほぼ唯一の方法は,現存する資料に依拠することである.ところが,現存する資料は質的にも量的にも相当の偏りがあり,コーパス言語学の用語でいえば "representative" でも "balanced" でもない.
まず物理的な条件がある.現在に伝わるためには,長い時間の風雨に耐え得る書写材料や書写道具で記されていることが必要である(「#2457. 書写材料と書写道具 (2)」 ([2016-01-18-1]) を参照).次に,メディアの観点から,話し言葉(的な言葉遣い)は,書き残されて,現在まで伝わる可能性が低いことは明らかだろう.書き手の観点からは,文献にはもっぱら読み書き能力のあるエリート層の言葉遣いや好みの話題が反映され,それ以外の層の言語活動が記録に残さることはほとんどないだろう.さらに,ジャンルや内容という観点から,例えば反体制的な書き物は,歴史の途中で抹殺される可能性が高いだろう.
現存する文献資料は,様々な運命をすり抜けて生き残ってきたという意味で歴史の「偶然性」を体現しているのは確かだが,生き残りやすいものにはいくつかの条件があるという上記の議論を念頭に置くと,ある種の「必然性」をも体現しているとも言える.歴史言語学や文献学において,どのような「条件」や「必然性」があり得るのか,きちんと整理しておくことは重要だろう.
そのための間接的なヒントとして,どのような化石や遺跡が現在まで生き残りやすいかを考察する化石生成学 (taphonomy) という分野の知見を参考にしたい.例えば,人類化石の残りやすさ,残りにくさは,何によって決まると考えられるだろうか.ウッドは「人類化石記録の空白と偏在」と題する節 (73--75) で,次のように述べている.
何十年間も,人類学者は,700?600万年前以降に生存した何千もの人類個体に由来する化石を集めてきた.この数は多いように思えるかもしれないが,大部分は現在に近い年代のものだ.この年代的な偏在のほかにも,人類化石にはさまざまな偏りがある.このような偏りが起こる機序を明らかにし,それを正そうとする学問は「化石生成学」とよばれる.歯や下顎骨あるいは四肢の大きな骨はよく残るが,椎骨,肋骨,骨盤,指の骨などは緻密性が薄く,容易に破損するので残りにくい.つまり,骨の残りやすさは大きさと頑丈さに比例する.椎骨のような軽い骨は雨による川の氾濫で流され,湖に運ばれ,サカナやワニの骨と一緒に化石になる.一方,重い頭骨や大腿骨は洪水で流され,川底の岩の間に引っかかって,ほかの陸生の大型動物の骨と一緒に化石になる.
化石の残り方を左右するもう一つの要因は,捕食動物が死体のどの部分を好むかである.ヒョウはサルの手足を噛むのが好きなので,もし昔の絶滅した捕食動物も同じ習性があったのなら,人類化石の手足も発見されることが少ないはずである.実際,手足の化石はあまり産出しておらず,そのため歯の進化についてはよくわかっているが,手足の進化はよくわかっていない.身体の大きさも,化石が残るかどうかに影響する,身体の大きな種は化石として残りやすいし,同一種内でも身体の大きな個体は残りやすい.もちろん,このような偏りは人類化石にも該当する.
ある環境では,ほかに比べ,骨が化石になりやすく,発見されやすい.したがって,ある年代やある地域に由来する化石が多いからといって,その年代あるいは地域に多くの個体が住んでいたとは限らない.その年代や地域の状況が,ほかに比べて化石化に適していた可能性があるのだ.同様に,ある年代や地域から人類化石が見つからなくても,そこに人類が住んでいなかったことにはならない.「証拠のないのは,存在しない証拠ではない」という格言もある.したがって,昔の種は,最古の化石が発見される年代より前に誕生し,最新の化石が発見される年代より後まで生存していたことになる.つまり,化石種の起源と絶滅の年代は実際に比べて常に控えめになる.
同様の制限は化石発見遺跡の地理的分布にも当てはまる.人類は,化石が発見される遺跡より広範囲で生存していたはずだ.また,過去の環境は現在とは違っていたはずだ.現在では厳しい環境も過去には住みやすかったかもしれないし,逆もあり得る.さらに,骨や歯を化石として保存してくれる環境は決して多くはない.酸性の土壌では,骨も歯もめったに残らない.とくに森林環境では,湿度が高く土壌が酸性なので,化石は残らないと考えられてきた.しかし,最近では,必ずしもそうではないことが明らかになった.とはいえ,考古学者が石器と人骨を一緒に発見したいと願っても,たいてい人骨は溶けてしまい,石器しか発見できないのである.
この問題は,ある語の初出した時期や廃語となった時期を巡る文献学上の問題とも関連するだろう.言語史研究における資料の問題については,「#1051. 英語史研究の対象となる資料 (1)」 ([2012-03-13-1]),「#1052. 英語史研究の対象となる資料 (2)」 ([2012-03-14-1]) を参照されたい.関連して,文字の発生についての考察も参考になる(「#1834. 文字史年表」 ([2014-05-05-1]),「#2389. 文字体系の起源と発達 (1)」([2015-11-11-1]),「#2457. 書写材料と書写道具 (2)」 ([2016-01-18-1]) を参照).
・ バーナード・ウッド(著),馬場 悠男(訳) 『人類の進化――拡散と絶滅の歴史を探る』 丸善出版,2014年.
2016-12-05 Mon
■ #2779. コーパスは英語史研究に使えるけれども [hel_education][corpus][methodology][philology][representativeness]
歴史言語学とコーパス使用とは相性がよいと言われる.例えば英語史で考えれば,歴史的なテキストは有限であるから,すべてを電子的に格納すれば,文字通り網羅的に調査することができる.従来の英語史記述研究も,電子的でこそなかったが,特定のテキスト群を調査対象としてきた点では,同じ「コーパス」研究だったという事情もある.現在では,ますます多くの研究者が電子コーパスとその関連ツールを用いて研究しているし,この潮流は間違いなく一層発展していくだろう.
しかし,注意すべきこともある.英語コーパス言語学の入門書を著わしたリンドクヴィスト (197) が次のように述べている.
1990年以降,歴史言語学者にとってコーパスは非常に重要なツールとなりました.手作業で文献から用例を収集しなければならなかった一昔前よりも,かなり効率よく用例を捜し,傾向を探る手助けになります.とはいえ,歴史言語学では,現代言語のコーパスを使った研究以上に,元の文献に立ち返り,精査する必要があります(ただし古い時代では,その「元の文献」すら必ずしも原本ではなく複写であるかもしれず,さらにはその複写も,複数の写字生がときに自らの方言で改編して残したものの一つにすぎない可能性があります).こうした状況から,この種の歴史的なコーパス言語学は,ここ二,三百年の言語の研究とは性質を異にします.学生が古い時代の英語コーパス研究をしたいならば,英語史の授業との関連で行うのがよいでしょう.
引用に述べられている通り,とりわけ古い時代の言語を対象とする場合には,注意を要する.現代の言語を扱うかのような前提のままでいると,数々の問題にぶつかるからだ.例えば,英語史でいえば,初期近代英語以前では綴字が安定していない.ある単語を検索しようとしても,標準的な綴字がないので,考え得る様々な異綴りで検索してみる必要がある.また,文法的なタグ付けがなされている場合にも,現代英語と古英語・中英語とでは文法範疇も異なっているし,屈折語尾の種類も相違しているので,検索するにあたって事前に古い文法の知識が必須となる.要するに,先に古い言語に習熟していることが求められるのである.
さらに,引用で言及されている通り,「元の文献」の深い理解が不可欠であるにもかかわらず,コーパスを表面的に用いることに慣れてくると,得てして問題の深みに意識が向かなくなりがちだ.換言すれば,本文批評 (textual criticism) や文献学的なアプローチから疎遠になってしまう傾向がある.もちろん,コーパス自体が悪いというわけではなく,研究する者が,このことを意識的に自覚していればよいということではあるのだが,簡単ではない.
もう1つ,電子コーパス時代ならずとも問題になるが,コーパスの代表性 (representativeness) の問題が常にある.古い言語の場合には,現在に伝わるテキストは偶然に生き残ってきたという致し方のない事情があり,代表性の問題はことさらに深い.
古い時代の言語をコーパスで調査するということは,理論的にも実践的にも,一見するほどたやすくないということを理解しておきたい.関連して,以下の記事も参照.
・ 「#568. コーパスの定義と英語コーパス入門」 ([2010-11-16-1])
・ 「#363. 英語コーパス発展の3軸」 ([2010-04-25-1])
・ 「#368. コーパスは研究の可能性を広げた」 ([2010-04-30-1])
・ 「#1165. 英国でコーパス研究が盛んになった背景」 ([2012-07-05-1])
・ 「#307. コーパス利用の注意点」 ([2010-02-28-1])
・ 「#367. コーパス利用の注意点 (2)」 ([2010-04-29-1])
・ 「#1280. コーパスの代表性」 ([2012-10-28-1])
・ 「#2584. 歴史英語コーパスの代表性」 ([2016-05-24-1])
・ ハーンス・リンドクヴィスト(著),渡辺 秀樹・大森 文子・加野 まきみ・小塚 良孝(訳) 『英語コーパスを活用した言語研究』 大修館,2016年.
2016-06-07 Tue
■ #2598. 古ノルド語の影響力と伝播を探る研究において留意すべき中英語コーパスの抱える問題点 [old_norse][loan_word][me_dialect][representativeness][geography][lexical_diffusion][lexicology][methodology][laeme][corpus]
「#1917. numb」 ([2014-07-27-1]) の記事で,中英語における本来語 nimen と古ノルド語借用語 taken の競合について調査した Rynell の研究に触れた.一般に古ノルド語借用語が中英語期中いかにして英語諸方言に浸透していったかを論じる際には,時期の観点と地域方言の観点から考慮される.当然のことながら,言語項の浸透にはある程度の時間がかかるので,初期よりも後期のほうが浸透の度合いは顕著となるだろう.また,古ノルド語の影響は the Danelaw と呼ばれるイングランド北部・東部において最も強烈であり,イングランド南部・西部へは,その衝撃がいくぶん弱まりながら伝播していったと考えるのが自然である.
このように古ノルド語の言語的影響の強さについては,時期と地域方言の間に密接な相互関係があり,その分布は明確であるとされる.実際に「#818. イングランドに残る古ノルド語地名」 ([2011-07-24-1]) や「#1937. 連結形 -son による父称は古ノルド語由来」 ([2014-08-16-1]) に示した語の分布図は,きわめて明確な分布を示す.古英語本来語と古ノルド語借用語が競合するケースでは,一般に上記の分布が確認されることが多いようだ.Rynell (359) 曰く,"The Scn words so far dealt with have this in common that they prevail in the East Midlands, the North, and the North West Midlands, or in one or two of these districts, while their native synonyms hold the field in the South West Midlands and the South."
しかし,事情は一見するほど単純ではないことにも留意する必要がある.Rynell (359--60) は上の文に続けて,次のように但し書きを付け加えている.
This is obviously not tantamount to saying that the native words are wanting in the former parts of the country and, inversely, that the Scn words are all absent from the latter. Instead, the native words are by no means infrequent in the East Midlands, the North, and the North West Midlands, or at least in parts of these districts, and not a few Scn loan-words turn up in the South West Midlands and the South, particularly near the East Midland border in Essex, once the southernmost country of the Danelaw. Moreover, some Scn words seem to have been more generally accepted down there at a surprisingly early stage, in some cases even at the expense of their native equivalents.
加えて注意すべきは,現存する中英語テキストの分布が偏っている点である.言い方をかえれば,中英語コーパスが,時期と地域方言に関して代表性 (representativeness) を欠いているという問題だ.Rynell (358) によれば,
A survey of the entire material above collected, which suffers from the weakness that the texts from the North and the North (and Central) West Midlands are all comparatively late and those from the South West Midlands nearly all early, while the East Midland and Southern texts, particularly the former, represent various periods, shows that in a number of cases the Scn words do prevail in the East Midlands, the North, and the North (and sometimes Central) West Midlands and the South, exclusive of Chaucer's London . . . .
古ノルド語の言語的影響は,中英語の早い時期に北部・東部方言で,遅い時期には南部・西部方言で観察される,ということは概論として述べることはできるものの,それが中英語コーパスの時期・方言の分布と見事に一致している事実を見逃してはならない.つまり,上記の概論的分布は,たまたま現存するテキストの時間・空間的な分布と平行しているために,ことによると不当に強調されているかもしれないのだ.見えやすいものがますます見えやすくなり,見えにくいものが隠れたままにされる構造的な問題が,ここにある.
この問題は,古ノルド語の言語的影響にとどまらず,中英語期に北・東部から南・西部へ伝播した言語変化一般を観察する際にも関与する問題である (see 「#941. 中英語の言語変化はなぜ北から南へ伝播したのか」 ([2011-11-24-1]),「#1843. conservative radicalism」 ([2014-05-14-1])) .
関連して,初期中英語コーパス A Linguistic Atlas of Early Middle English (LAEME) の代表性について「#1262. The LAEME Corpus の代表性 (1)」 ([2012-10-10-1]),「#1263. The LAEME Corpus の代表性 (2)」 ([2012-10-11-1]) も参照.
・ Rynell, Alarik. The Rivalry of Scandinavian and Native Synonyms in Middle English Especially taken and nimen. Lund: Håkan Ohlssons, 1948.
2016-05-24 Tue
■ #2584. 歴史英語コーパスの代表性 [representativeness][corpus][methodology][hc][register]
コーパスの代表性 (representativeness) や均衡 (balance) の問題については,「#1280. コーパスの代表性」 ([2012-10-28-1]) その他の記事で扱ってきた.古い時代の英語のコーパスを扱う場合には,現代英語コーパスに関する諸問題がそのまま当てはまるのは当然のことながら,それに上乗せしてさらに困難な問題が多く立ちはだかる.
まず,歴史英語コーパスという話題以前の問題として,コーパスの元をなす母集合のテキスト集合体そのものが,歴史の偶然により現存しているものに限られるという制約がある.碑文,写本,印刷本,音声資料などに記されて現在まで生き残り,保存されてきたものが,すべてである.また,これらの資料は存在することはわかっていても,現実的にアクセスできるかどうかは別問題である.現実的には,印刷あるいは電子形態で出版されているかどうかにかかっているだろう.それらの資料がテキストの母集合となり,運よく編纂者の選定にかかったその一部が,コーパス(主として電子形態)へと編纂されることになる.こうして成立した歴史英語コーパスは,数々の制約をかいくぐって,ようやく世に出るのであり,この時点で理想的な代表性が達成されている見込みは,残念ながら薄い.
また,歴史英語とひとくくりに言っても,実際には現代英語と同様に様々な lects や registers が区分され,その区分に応じてコーパスが編纂されるケースが多い.確かに,ある意味で汎用コーパスと呼んでもよい Helsinki Corpus のような通時コーパスや,統語情報に特化しているが異なる時代をまたぐ Penn Parsed Corpora of Historical English もあるし,使い方によっては通時コーパスとしても利用できる OED の引用文検索などがある.しかし,通常は,編纂の目的や手間に応じて,より小さな範囲のテキストに絞って編纂されるコーパスが多い.古英語コーパスや中英語コーパスなど時代によって区切ること (chronolects) もあれば ,イギリス英語やアメリカ英語などの方言別 (dialects) の場合もあるし,Chaucer や Shakespeare など特定の作家別 (idiolects) の場合もあろう.社会方言 (sociolects) 別というケースもあり得るし,使用域 (registers) に応じてコーパスを編纂するということもあり得る.使用域といっても,談話の場(ジャンルや主題),媒体(話し言葉か書き言葉か),スタイル(形式性)などに応じて,下位区分することもできる.一方,分類をあまり細かくしてしまうと,上述のように現存するテキストの量が有限であり,たいてい非常に少なかったり分布が偏っているわけだから,代表性や均衡を保つことがなおのこと困難となる.
時代別 (chronolects) の軸を中心にすえて近年の比較的大規模な歴史英語コーパスの編纂状況を概観してみると,各時代の英語の辞書・文法・方言地図のような参考資料の編纂と関連づけて編纂されたものがいくつかあることがわかる.これらは,各時代の基軸コーパスとして位置づけられるといってよいかもしれない.例えば,Dictionary of Old English Corpus (DOEC), A Linguistic Atlas of Early Middle English (LAEME), Middle English Grammar project (MEG) 等である.近代についてはコーパスというよりはテキスト・データベースというべき EEBO (Early English Books Online) も利用可能となってきているし,アメリカ英語については Corpus of Historical American English (COHA) 等の試みもある.
上に挙げた代表的で著名なもののほか,様々な切り口からの歴史英語コーパス編纂の企画が続々と現われている.その逐一については,「#506. CoRD --- 英語歴史コーパスの情報センター」 ([2010-09-15-1]) で紹介した,Helsinki 大学の VARIENG ( Research Unit for Variation, Contacts and Change in English ) プロジェクトより CoRD ( Corpus Resource Database ) を参照されたい.
ハード的にいえば,上述のように,歴史英語コーパスの代表性を巡る問題を根本的に解決するのは困難ではあるが,一方で個別コーパスの編纂は活況を呈しており,諸制約のなかで進歩感はある.今ひとつはソフト的な側面,使用者側のコーパスに対する態度に関する課題もあるように思われる.電子コーパスの時代が到来する以前にも,歴史英語の研究者は,時間を要する手作業ながらも紙媒体による「コーパス」の編纂,使用,分析を常に行なってきたのである.彼らも,私たちが意識しているほどではなかったものの,ある程度はコーパスの代表性や均衡といった問題を考えてきたのであり,解決に至らないとしても,有益な研究を継続し,知見を蓄積してきた.電子コーパス時代となって代表性や均衡の問題が目立って取り上げられるようになったが,確かにその問題自体は大切で,考え続ける必要はあるものの,明らかにしたい言語現象そのものに焦点を当て,コーパスを便利に使いこなしながらその研究を続けてゆくことがより肝要なのではないか.
2016-03-22 Tue
■ #2521. 初期中英語の113種類の "such" の異綴字 [spelling][eme][laeme][corpus][scribe][me_dialect][representativeness]
昨日の記事「#2520. 後期中英語の134種類の "such" の異綴字」 ([2016-03-21-1]) に続き,今回は初期中英語コーパス LAEME で "such" の異綴字を取り出してみたい (see 「#1262. The LAEME Corpus の代表性 (1)」 ([2012-10-10-1])) .この語は,初期中英語では形容詞,副詞,接続詞として用いられ,形容詞の場合には屈折もするので,全体として様々な形態が現われる.アルファベット順に一覧しよう(かっこ内の数値は文証される頻度).
hsƿucche (1), schilke (1), schuc (3), scli (1), scuche (1), sec (1), secc (1), secche (1), sech (2), seche (1), selk (1), selke (1), shuc (1), shuch (1), siche (1), silc (1), silk (3), sli (1), slic (5), sliik (1), slik (3), slike (1), slk (1), sly (1), soch (5), soche (1), solchere (1), suc (2), sucche (2), such (51), suche (1), suecche (1), suech (1), sueche (1), sueh (1), sug (1), suic (1), suicchne (1), suich (12), suiche (3), suilc (14), suilce (1), suilch (1), suilk (1), suilke (2), sulch (1), sulche (1), sulk (1), sulke (1), suuche (1), suweche (1), suwilk (1), suyc (1), suych (4), suyche (1), svich (2), sƿche (1), sƿic (3), sƿicche (1), sƿich (1), sƿiche (14), sƿichne (1), sƿilc (30), sƿilch (22), sƿilche (1), sƿilcne (1), sƿilk (14), sƿillc (10), sƿillke (2), sƿi~lch (1), sƿlche (1), sƿuc (4), sƿucch (1), sƿucche (4), sƿucches (1), sƿuch (1), sƿuche (1), sƿuchne (1), sƿuilc (1), sƿulc (8), sƿulce (1), sƿulche (9), swch (1), swecche (1), swech (1), sweche (2), swich (5), swiche (1), swics (1), swil (1), swilc (5), swilce (1), swilk (2), swilke (2), swilkee (2), swlc (1), swlch (1), swlche (1), swlchere (1), swlcne (1), swuche (2), swuh (1), swulcere (1), swulch (3), swulchen (1), swulchere (1), swulke (1), swulne (1), zuich (10), zuiche (14), zuichen (3), zuych (10), zuyche (2)
大文字と小文字の区別はつけずに,合計113種類の綴字が文証される.そのなかで頻度にしてトップ5の綴字を抜き出すと,such, sƿilc, sƿilch, sƿilk, sƿiche となり,この5種類だけで全用例369個のうち131個 (35.5%) を占める.
昨日の後期中英語からの134種類と合わせ,重複綴字を減算すると,中英語全体として247種類の異綴字があることになる.使用した方言地図やコーパスも必ずしも網羅的ではないので,これは控えめな数値と思われる.例えば,MED の swich (adj.) に掲げられている異綴字を加えれば,種類はもう少し増えるだろう.
2014-01-30 Thu
■ #1739. AmE-BrE Diachronic Frequency Comparer [corpus][ame_bre][web_service][cgi][frequency][representativeness]
「#1730. AmE-BrE 2006 Frequency Comparer」 ([2014-01-21-1]) で,2006年前後の書き言葉テキストを編纂した英米各変種コーパスを紹介し,それに基づいた頻度比較ツールを作成・公開した.そのツールを作成しながら気づいたのだが,同じ方法で編纂され,規模も同じく100万語程度の the Brown family of corpora (「#428. The Brown family of corpora の利用上の注意」 ([2010-06-29-1]))と連携させれば,直近50年間ほどの通時的な英米間頻度比較が容易に可能となる.
そこで,前の記事で紹介した Professor Paul Baker - Linguistics and English Language at Lancaster University による AmE06 と BrE06 に加えて,書き言葉アメリカ英語を代表する Brown (1961), Frown (1992),書き言葉イギリス英語を代表する LOB (1961), FLOB (1991) より語形頻度表を抽出し,合わせてデータベース化した.利用の仕方は,AmE-BrE 2006 Frequency Comparer とほぼ同じなので,そちらの取説 ([2014-01-21-1]) を参照されたい.ただし,出力される表では,問題の語形が出現するテキストの数や頻度順位は省いており,純粋に約100万語当たりの頻度を表示するにとどめているので,AmE06 と BE06 について前者の情報が必要な場合には,AmE-BrE 2006 Frequency Comparer をどうぞ.
例えば,^movies?$ と入力してみると,伝統的にアメリカ英語的とされてきたこの語の分布が,過去50年ほどの間に,イギリス英語にも浸透してきている様子がわかる.
英米差の通時的な変化を調査したいのであれば,単語だけではなく語句も受けつけ,かつ規模も巨大な「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) のほうが簡便だろう.しかし,今回のツールは,the Brown family of corpora をベースにしているがゆえに,(1) 均衡かつ比較可能であり,(2) 「素性」がわかっている(再現可能性が確保されている)という利点があることは指摘しておきたい.望ましいのは,小型できめ細かなコーパスと,大型で傾向を大づかみにするコーパスとを上手に連携させることだろう.
2014-01-07 Tue
■ #1716. shew と show (3) [spelling][corpus][clmet][representativeness]
「#1415. shew と show (1)」 ([2013-03-12-1]) と「#1416. shew と show (2)」 ([2013-03-13-1]) で扱った問題を,「#1637. CLMET3.0 で between と betwixt の分布を調査」 ([2013-10-20-1]) で紹介した The Corpus of Late Modern English Texts, version 3.0 (CLMET3.0) により再訪したい.具体的には,同タグ付きコーパスを "\bshow(s|n|ed|ing)?_VB" と "\bshew(s|n|ed|ing)?_VB" で検索して,3時代区分ごとに生起頻度数を比べた.以下の結果が出た.
| shew 系列 | show 系列 | 総語数 | |
|---|---|---|---|
| 1710--1780 | 335 | 1,545 | 10,480,431 |
| 1780--1850 | 159 | 3,100 | 11,285,587 |
| 1850--1920 | 92 | 5,118 | 12,620,207 |
前回「#1416. shew と show (2)」 ([2013-03-13-1]) で利用した PPCMBE (Penn Parsed Corpus of Modern British English) は100万語弱のコーパスだが,今回の CLMET3.0 は約3,400万語の巨大コーパスである.ほぼ同じ時代をカバーしているので比較には都合がよい.前回と同様に今回も show が shew を着実に置き換えている様子がうかがえるが,前回と大きく異なるのは,1710--1780年の第1期においてすでに show が圧倒的に勝っていることである.これを信じるならば,後期近代英語期に入るまでに,すでに show は勝敗を決していたということになる.PPCMBE では shew は後期近代英語期中に「優勢→同列→劣勢」と推移したが,CLMET3.0 では「当初から劣勢→もっと劣勢→さらに劣勢」と推移している.2世紀にわたる通時的な視点からは両コーパスともに大雑把には似たような傾向を示すとはいえるものの,18世紀の共時的な分布については両コーパスの示す数値の差は大きすぎるように思われる.ここには「#1280. コーパスの代表性」 ([2012-10-28-1]) という問題が関わってきそうであり,慎重な解釈が求められることになろう.
なお,1つの文脈で shew と show がともに用いられている興味深い例もいくつかあった.3例のみ挙げよう.
・ Why, you have shewn your wit upon the subject, and I mean to show your courage;
・ Mr. Wright, as well as Nadin, professed they were perfectly satisfied of this, and appeared to shew to me all the polite attention that they were capable of showing.
・ Assuredly I did not show him the face which I shewed Folderico.
2012-10-28 Sun
■ #1280. コーパスの代表性 [corpus][representativeness][variety][idiolect][methodology]
コーパスにとって代表性 (representativeness) が命であることは,コーパスの定義上 ([2010-11-16-1]) あきらかであるし,昨日の記事「#1279. BNC の強みと弱み」 ([2012-10-28-1]) で紹介した Leech もとりわけ主張している点である.McEnery et al. (13) は,代表性について,Leech の定義を参考にしながら "a corpus is thought to be representative of the language variety it is supposed to represent if the findings based on its contents can be generalized to the said language variety" と述べている.
代表性を具体的に考えてみよう.例えば BNC がターゲットとするような,現代イギリス英語という一般的な変種を収録するコーパス (general corpus) の代表性はどのようにすれば得られるのか,その理論化は難しい.話し言葉と書き言葉の割合の問題を考えると,それぞれを50%ずつに割り振ることは,現代イギリス英語の代表性を約束してくれるだろうか.Leech の表現でいえば "impressionistic" とならざるを得ないが,今この瞬間に行なわれている現代イギリス英語の圧倒的な部分が,話し言葉においてではないか.もしそうだとすれば,話し言葉コーパスの割合を,例えば80%ほどに設定するほうがより代表性を確保できるのではないか.母体となる現代イギリス英語の全体像を直接つかむことができない以上,その代表性の議論は行き詰まってしまう.
コーパス(特に一般コーパス)の代表性という場合に,これを balance と sampling という2つの概念に分けて考えることがある.McEnery et al. (13) では,"the representativeness of most corpora is to a great extent determined by two factors: the range of genres included in a corpus (i.e. balance . . .) and how the text chunks for each genre are selected (i.e. sampling . . .)" と説明されている.
balance とは,BNC の用語でいうところの domain や genre という分類の設定に関するものである.例えば,現代イギリス英語のコーパスを標榜しながらも,イギリスの新聞の英語だけを集めたコーパスは,representativeness の点で難がある.現代イギリス英語には書き言葉だけでなく話し言葉もあるし,前者については新聞英語だけでなく文学英語もあれば電子メール英語もあるし,買い物メモ英語もあれば,日記英語もある.これらのあらゆる domain や genre を考慮に入れたいと思うが,果たしていくつの text domain があるのだろうか.新聞英語に限っても,タブロイドもあれば高級紙もある.1つの新聞内でも,社会面,スポーツ面,社説などを区別する必要はないのか,社会面であれば国内記事と国際記事の区別はどうか,等々.理論的にはどこまでも細分化しうる.話し言葉でも同様に細分化を推し進めていけば,個人語 (idiolect) ,さらに個人語における register 別の現われ,などのアトムへと終着してしまう.実際のコーパス作成上は,常識的なレベルで妥協することになるが,「常識的」と "impressionistic" はほぼ同義だろう.
sampling とは代表性を得るための手法である.母体の言語的特徴が再現されるように,質と量の点において考慮を加えながら,コーパス内に各 domain を案配するための理論と実践である.ここには,sampling unit として何を設定するか(典型的には,本,雑誌,新聞などの製品としての単位),そのような単位をリスト化する作業の範囲 (sampling frame) をどこまでに設定するか(特定の年への限定や,ベストセラー本への限定など),標本収集は完全なランダムにするかある程度の体系化を加えた上でのランダムにするか,著作権の問題をどう乗り越えるかなどの,理論的・実践的な問題が含まれる.
代表性に関わるもう1つの概念として,closure あるいは saturation と呼ばれるものもある.McEnery et al. (16) によれば,"Closure/saturation for a particular linguistic feature (e.g. size of lexicon) of a variety of language (e.g. computer manuals) means that the feature appears to be finite or is subject to very limited variation beyond a certain point." と説明されている.平たくいえば,これ以上コーパスの規模を大きくしても,語彙構成の割合は変わらないという規模に到達すれば,そのコーパスは saturated であると考えられる.代表性の指標としては,balance よりも saturation のほうがすぐれているという指摘もあるが,saturation は主として語彙が念頭にあり,他の言語項目への応用は試みられていないのが現状である.
代表性は,定義上コーパスの命であるとはいっても,定義先行というきらいはある.それを確保するための理論もないし,検証法もない.すべてのコーパス編纂者に立ちはだかる頭の痛い問題だろうが,コーパスは次々と編纂されている.理論的な問題は別にして,ひたすら編纂と使用を続けてゆき,ノウハウをため込むべき段階にあるのかもしれない.
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
2012-10-27 Sat
■ #1279. BNC の強みと弱み [bnc][corpus][representativeness]
10月8--11日の4日間にわたり,立教大学英語教育研究所による主催で,Lancaster 大学名誉教授 Geoffrey Leech の公開講演会が開かれた.私は,2日目の "The British National Corpus: Both a Triumph and a Failure" と題する講演のみの参加だったが,聴きに行った.BNC 編者じきじきの作成秘話など,おもしろい話しが何点かあった.
題名にある "triumph" と "failure" について,Leech はそれぞれ次のような項目を列挙していた.
A triumph:
・ It has been claimed that the BNC is the most widely used corpus in the world.
・ It was the first text corpus of its size to be made widely available.
・ It is available from a wide range of different sources.
・ It is widely regarded as a 'standard reference corpus' for the English language.
・ It has been licensed to over 1300 institutions throughout the world, over 1800 users have signed on for access to it through the BNCweb online interface, etc.
A failure:
・ It never reached 100 million words! (98,300,000)
・ The design criteria were never totally achieved.
・ It hardly ever contains complete texts.
・ The spoken materials are poorly transcribed.
・ The metadata are incomplete and can be erroneous.
・ The part-of-speech tagging contains many errors.
・ It is out of date! (dating from the late 20th century)
Leech の言葉の端々には,triumph の各点に示されているように,実績に裏付けされた自信がみなぎっていた.一方,自らのコーパス編集について,こうすればよかった,ああすればよかったという類の後悔ともいえる反省点を多く挙げていたのが印象的である.BNC のタグ付けに用いられたプログラム CLAWS4 の精度が97%ほどある(Hoffmann et al. 43 によると,98--99%)というのは,私は驚くべきことだと思っていたが,コーパス規模が大きいので数パーセントのエラーとはいっても約300万件にのぼるという事実は見落としていた.話しことばコーパスについては,コーパス全体の1割ほどしか含められなかったこと,音声データの transcription の質が悪かったこと,当初採用したデータフォーマット TEI が,話しことばのタグ付けには必ずしも適切でなかったこと,などを挙げていた.
なかでも,企画段階から現在に至るまで一貫してこだわり続けている代表性 (representativeness) について,BNC では完全に目的を果たせなかったことに,後悔をにじませていた.企画段階から,設定する Text Domain のバランスやサイズに関する議論が重ねられてきたことはよく知られている.1ユーザーとしては,限られたリソースのなかで,あれだけの代表性を確保したことは偉業だと評価しているが,Leech にとっては,できる限りのことはやったという自負の反面として,理想が果たせなかったという思いも強いようだ.同時に,穏やかな口調ではあったが,BNC と比較される他のすべての大規模コーパスが,代表性をさほど重視していない点を批判していた.ただし,彼自身が述べているように,コーパスの代表性について独自の理論はもっているが,最終的には "impressionistic" な判断の問題だと考えているようであり,この問題の難しさをにじませていた.いずれにせよ,Leech の代表性への執念の強さに,高度なプロフェッショナリズムを感じた.
なお,[2012-07-05-1]の記事「#1165. 英国でコーパス研究が盛んになった背景」で触れた通り,残念ながらBNCの続編はないだろうということを,Leech は明言していた.
扱う時代は大きく異なるが,初期中英語コーパス The LAEME Corpus の代表性の問題について,[2012-10-10-1], [2012-10-11-1]の記事で考察したので,ご参照を.
・ Hoffmann, Sebastian, Stefan Evert, Nicholas Smith, David Lee, and Ylva Berglund Prytz. Corpus Linguistics with BNCweb : A Practical Guide. Frankfurt am Main: Peter Lang, 2008.
2012-10-12 Fri
■ #1264. 歴史言語学の限界と,その克服への道 [methodology][uniformitarian_principle][writing][history][sociolinguistics][laeme][corpus][representativeness][evidence]
[2012-10-10-1], [2012-10-11-1]の記事で,The LAEME Corpus の代表性について取りあげた.私の評価としては,カバーしている方言と時代という観点からみて代表性は著しく損なわれているものの,現在利用できる初期中英語コーパスとしては体系的に編まれた最大規模のコーパスであり,十分な注意を払ったうえで言語研究に活用すべきツールである.The LAEME Corpus の改善すべき点はもちろんあるし,他のコーパスによる補完も目指されるべきだとは考えるが,言語を歴史的に研究する際に必然的につきまとう限界も考慮した上で評価しないとアンフェアである.
歴史言語学は,言語の過去の状態を観察し,復元するという課題を自らに課している.過去を扱う作業には,現在を扱う作業には見られないある限界がつきまとう.Milroy (45) の指摘する歴史言語学研究の2つの限界 (limitations of historical inquiry) を示そう.
[P]ast states of language are attested in writing, rather than in speech . . . [W]ritten language tends to be message-oriented and is deprived of the social and situational contexts in which speech events occur.
[H]istorical data have been accidentally preserved and are therefore not equally representative of all aspects of the language of past states . . . . Some styles and varieties may therefore be over-represented in the data, while others are under-represented . . . . For some periods of time there may be a great deal of surviving information: for other periods there may be very little or none at all.
乗り越えがたい限界ではあるが,克服の努力あるいは克服にできるだけ近づく努力は,いろいろな方法でなされている.そのなかでも,Smith はその著書の随所で (1) 書き言葉と話し言葉の関係の理解を深めること,(2) 言語の内面史と外面史の対応に注目すること,(3) 現在の知見の過去への応用の可能性を探ること,の重要性を指摘している.
とりわけ (3) については,近年,社会言語学による言語変化の理解が急速に進み,その原理の過去への応用が盛んになされるようになってきた.Labov の論文の標題 "On the Use of the Present to Explain the Past" が,この方法論を直截に物語っている.
これと関連する方法論である uniformitarian_principle (斉一論の原則)を前面に押し出した歴史英語の論文集が,Denison et al. 編集のもとに,今年出版されたことも付け加えておこう.
・ Milroy, James. Linguistic Variation and Change: On the Historical Sociolinguistics of English. Oxford: Blackwell, 1992.
・ Smith, Jeremy J. An Historical Study of English: Function, Form and Change. London: Routledge, 1996.
・ Labov, William. "On the Use of the Present to Explain the Past." Readings in Historical Phonology: Chapters in the Theory of Sound Change. Ed. Philip Baldi and Ronald N. Werth. Philadelphia: U of Pennsylvania P, 1978. 275--312.
・ Denison, David, Ricardo Bermúdez-Otero, Chris McCully, and Emma Moore, eds. Analysing Older English. Cambridge: CUP, 2012.
2012-10-11 Thu
■ #1263. The LAEME Corpus の代表性 (2) [laeme][corpus][representativeness]
昨日の記事[2012-10-10-1]に引き続き,The LAEME Corpus の代表性の話題.今回は,語数,より正確には同コーパスで文法情報が付与されている語 (tagged words) の数により,方言・時代ごとの代表性を考える.まず,表を掲げよう.
Table 2: Dialectal and Diachronic Distribution of Linguistic Evidence by Number of Tagged Words
| C12b | C13a | C13b | C14a | Total | |
|---|---|---|---|---|---|
| N | 0 (0.000%) | 362 (0.062) | 0 (0.000) | 52,883 (9.083) | 53,245 (9.146) |
| NEM | 11,342 (1.948) | 0 (0.000) | 3,980 (0.684) | 2,344 (0.403) | 17,666 (3.034) |
| NWM | 0 (0.000) | 58,332 (10.019) | 16,173 (2.778) | 0 (0.000) | 74,505 (12.797) |
| SEM | 40,082 (6.885) | 26,722 (4.590) | 21,921 (3.765) | 31,408 (5.395) | 120,133 (20.634) |
| SWM | 1,030 (0.177) | 90,400 (15.527) | 106,981 (18.375) | 108 (0.019) | 198,519 (34.098) |
| SW | 1,168 (0.201) | 2,610 (0.448) | 46,032 (7.907) | 30,517 (5.242) | 80,327 (13.797) |
| SE | 0 (0.000) | 4,043 (0.694) | 3,199 (0.549) | 30,561 (5.249) | 37,803 (6.493) |
| Total | 53,622 (9.210) | 182,469 (31.341) | 198,286 (34.058) | 147,821 (25.390) | 582,198 (100.000) |
直感的に理解できるように,この分布をモザイクプロットで表現したのが下図である(印刷用にはこちらのPDFをどうぞ).
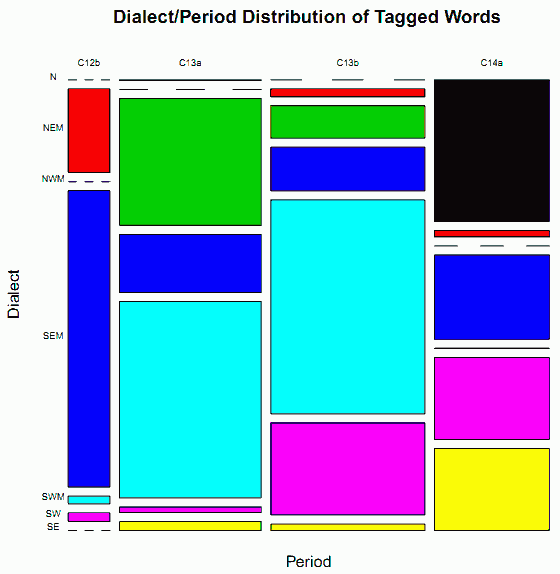
分布の偏りは一目瞭然である.しかし,方言・時代の各スロットを構成するテキストの種類などをより細かく調べると,さらに重要な問題が見えてくる.いくつかのスロットでは,総語数の大部分がほんの一握りのテキストによって占められているのである.例えば,N C14a というスロットは,全体のなかで4番目に収録語数の多いスロットだが,その語数の95.61%は Cursor Mundi という1作品(正確には,それを表わす3種類の異なる書写言語を反映した 3 scribal texts [##296, 297, 298])で占められている.同様に,NEM C13b では #182 のみで80.93%の語数がカバーされている.NWM C13b では #272 のみで93.11%だ.SEM C12b では異なる2人の写字生の手による Trinity Homilies (##1200, 1300) が総語数の84.06%を占め,SEM C13a でも異なる2人の写字生の手による Vices and Virtues (##64, 65) が総語数の93.83%を占める.SW C13b の #1600 は,それだけで69.71%を占める,等々.
これらの例が示唆することは,問題の方言・時代スロットは必ずしもその方言・時代の言語変種を代表しているわけではなく,むしろ特定のテキストに現われる言語変種を代表しているということかもしれなということだ.The LAEME Corpus の使用の際には,なお一層の注意が必要である.
2012-10-10 Wed
■ #1262. The LAEME Corpus の代表性 (1) [laeme][corpus][representativeness]
私の関心の中心は初期中英語期の形態論である.この時代に関心をもつ者にとっては,LAEME (編者によれば,発音は /ˈleɪmiː/ )とそこから派生した The LAEME Corpus (Text Database) の登場は,同時代に関する研究環境を著しく改善し得るツールとして,最大限に歓迎される.LAEME については,本ブログでも laeme の記事で採りあげてきたし,とりわけツールとしての可能性を探り,拡張すべく「#846. HelMapperUK --- hellog 仕様の英国地図作成 CGI」 ([2011-08-21-1]) ,「#856. LAEME text database のデータ点とテキスト規模」 ([2011-08-31-1]) ,「#942. LAEME Index of Sources の検索ツール」 ([2011-11-25-1]) ,「#1057. LAEME Index of Sources の検索ツール Ver. 2」 ([2012-03-19-1]) を公表してきた.
大工にとって道具の手入れが大事なように,研究者にとってツールの研究は大事である.具体的に The LAEME Corpus を使っているうちに,全体として俯瞰するとどのようなコーパスなのか,知りたくなってきた.[2010-11-16-1]の記事「#568. コーパスの定義と英語コーパス入門」で示した通り,コーパスの主たる特徴の1つに representativeness (代表性)がある.これは,コーパス評価のための指標の1つでもある.歴史コーパスにおける代表性の確保の難しさについては,「#531. OED の引用データをコーパスとして使えるか」 ([2010-10-10-1]) や「#1243. 語の頻度を考慮する通時的研究のために」 ([2012-09-21-1]) でも触れてきたが,この点では The LAEME Corpus も苦戦を強いられている.カバーしている方言分布については「#856. LAEME text database のデータ点とテキスト規模」 ([2011-08-31-1]) で採りあげたが,今回は方言区分に加えて時代区分も含めながら The LAEME Corpus のツール分析を試みたい.
まずは,収録されているテキストの数を考える.当該コーパスは "scribal text" という単位でテキストが収録されているが,これを方言と時代にしたがって分別すると,散らばり具合がわかる.なお,方言区分と時代区分はそれ自体が方法論上の大問題なのだが,以下では,恣意的な区分(とはいってもある程度の根拠はあるが)として,方言は7つへ,時代は4つへと分けている.すなわち,方言は N (Northern), NEM (North-East Midland), NWM (North-West Midland), SEM (South-East Midland), SWM (South-West Midland), SW (Southwestern), SE (Southeastern) へ,時代は C12b (12世紀後半),C13a, C13b, C14a へ.中英語の方言区分については「#130. 中英語の方言区分」 ([2009-09-04-1]) も参照.
Table 1: Dialectal and Diachronic Distribution of Linguistic Evidence by Number of Texts
| C12b | C13a | C13b | C14a | Total | |
|---|---|---|---|---|---|
| N | 0 (0.00%) | 1 (0.86) | 0 (0.00) | 7 (6.03) | 8 (6.90) |
| NEM | 1 (0.86) | 0 (0.00) | 5 (4.31) | 2 (1.72) | 8 (6.90) |
| NWM | 0 (0.00) | 9 (7.76) | 5 (4.31) | 0 (0.00) | 14 (12.07) |
| SEM | 4 (3.45) | 7 (6.03) | 14 (12.07) | 7 (6.03) | 32 (27.59) |
| SWM | 2 (1.72) | 13 (11.21) | 17 (14.66) | 1 (0.86) | 33 (28.45) |
| SW | 3 (2.59) | 5 (4.31) | 7 (6.03) | 2 (1.72) | 17 (14.66) |
| SE | 0 (0.00) | 2 (1.72) | 1 (0.86) | 1 (0.86) | 4 (3.45) |
| Total | 10 (8.62) | 37 (31.90) | 49 (42.24) | 20 (17.24) | 116 (100.00) |
上の表を作成するにあたり対象としたのは,The LAEME Corpus に収録されている167個の scribal texts のうち,半世紀という単位で時代の区分がなされている116個のみである.
表を一瞥すればわかるように,テキスト分布の偏りは大きい.方言でいえば SEM と SWM は層が異常に厚く,全体の3分の2ほどをカバーしているが,一方で N, NEM, SE は層が薄い.時代でみると,C13a と C13b だけで7割を越え,C12b と C14a は層が薄い.方言・時代の組み合わせでは,6スロットまでが "0" を示す.歴史コーパス編纂における representative の確保は絶望的とすら思えてくる.少なくとも,The LAEME Corpus を用いて得られる方言や時代についてのデータやそこから得られる結論は,よくよく注意して解釈しなければならないということがいえるだろう.
この表は scribal text の数をもとに作成されているが,各 scribal text の長さはまちまちである.そこで,テキスト数ではなく,語数による分布の具合も調べてみる必要がある.語数に基づく代表性の議論は,明日の記事で.
2012-09-21 Fri
■ #1243. 語の頻度を考慮する通時的研究のために [frequency][corpus][representativeness]
昨日の記事「#1242. -ate 動詞の強勢移行」 ([2012-09-20-1]) や「#1239. Frequency Actuation Hypothesis」 ([2012-09-17-1]) で取り上げた Phillips の研究のように,語の頻度を考慮する言語変化の研究には多大な関心を寄せているが,方法論上の素朴な疑問として,ある語の頻度それ自体が通時的に変わるという事実をどのように考えればよいのかという問題がある.ある特定の語ではなく,語彙の全体あるいは部分集合を考える場合には,1--2世代の時差は大きな問題ではないだろうと直感される.だが,1世紀の時差ではどうか,2世紀ではどうか,と考えると,どこまで直感に頼れるものか,はなはだ心許ない.Phillips (225--26) は,この問題について次のように楽観している.
The words' frequencies are based on present-day English, but the general pattern of relative frequencies probably holds for the English in our data base (1755--1993) as well. For example, I would be very surprised if the 3-syllable verbs with CELEX frequencies over 100 --- concentrate, demonstrate, illustrate, contemplate, compensate, designate, and alternate --- were not also much more common in 1755 than those with frequencies of 0 --- altercate, auscultate, condensate, defalcate, eructate, exculpate, expuergate, extirpate, fecundate, etc.
2世紀余の時差を相手にしていながら,頻度が100回以上の語と0回の語を比べるというのは大雑把にすぎるように思われる.確かに,Phillips は実際の頻度分析でも101回以上,10--100回,1--10回という荒い区分を用いており,大雑把な頻度情報を大雑把なままに用いる慎重さは示している.しかし,もし特に10--100回辺りの中頻度レベルの語をより詳細に調べようとするのであれば,2世紀の間にそれなりに頻度が変化している可能性はある.Phillips ならずとも,頻度を利用した通時的研究に関心をもつ誰もが突き当たるはずの問題だ.
すぐに思いつく単純な解決案は,各時代を代表するできるだけ大きなコーパスを利用して頻度表を作成することである.案としては単純だが,実際に遂行するのは一手間も二手間もかかる.綴字がある程度固定した近代英語であれば,コーパスを用意して頻度表の自動作成ができそうだが,中英語以前では綴字や語形の variation ゆえに lemmatise されていない限りは見出し語単位での頻度表作成は難航しそうだ.また,時代が古くなればなるほど,コーパスに含まれるテキストの representativeness の問題は深刻になる.ただし,荒っぽい頻度表でも,ないよりはあるほうがよい.いずれ作成してみたいと思っている.あるいは,時代によってはすでにあるだろうか?
なお,引用にある CELEX という単語データベースは,現代英語の語や形態に関する量的な研究でよく使われているものである.詳細は,CELEX2 を参照.また,頻度と通時態の関係については,[2012-05-03-1]の記事「#1102. Zipf's law と語の新陳代謝」を参照.
・ Phillips, Betty S. "Word Frequency and Lexical Diffusion in English Stress Shifts." Germanic Linguistics. Ed. Richard Hogg and Linda van Bergen. Amsterdam: John Benjamins, 1998. 223--32.
2011-06-09 Thu
■ #773. PPCMBE と COHA の比較 [corpus][coha][ppcmbe][lmode][adjective][comparison][inflection][representativeness]
本ブログでも何度か取り上げている2つの歴史英語コーパス PPCMBE ( Penn Parsed Corpus of Modern British English; see [2010-03-03-1]. ) と COHA ( Corpus of Historical American English; see [2010-09-19-1]. ) について,塚本氏が『英語コーパス研究』の最新号に研究ノートを発表している.両者とも2010年に公開された近代英語後期のコーパスだが,それぞれ英米変種であること,また編纂目的が異なることから細かな比較の対象には適さない.しかし,代表性をはじめとするコーパスの一般的な特徴を比べることは意味があるだろう.
PPCMBE は1700--1914年のイギリス英語テキスト約949,000語で構成されており,Parsed Corpora of Historical English の1部をなす.同様に構文解析されたより古い時代の対応するコーパスとの接続を意識した作りである.有料でデータを入手する必要がある.一方,COHA は1810--2009年のアメリカ英語テキスト4億語を収録した巨大コーパスである.こちらは,構文解析はされていない.COHA は無料でオンラインアクセスできるため使いやすいが,インターフェースが固定されているので柔軟なデータ検索ができないという難点がある.
コーパスの規模とも関係するが,PPCMBE は代表性 (representativeness) の点で難がある.PPCMBE のコーパステキストを18ジャンルへ細かく分類し,テキスト年代を10年刻みでとると,サイズがゼロとなるマス目が多く現われる.これは,区分を細かくしすぎると有意義な分析結果が出ないということであり,使用に際して注意を要する.
一方,COHA のコーパステキストは Fiction, Popular Magazines, Newspapers, Non-Fiction Books の4ジャンルへ大雑把に区分されている.細かいジャンル分けの研究には利用できないが,10年刻みでも各マス目に適切なサイズのテキストが配されており,代表性はよく確保されている.ただし,Fiction の構成比率がどの時代も約50%を占めており,Fiction の言語の特徴(特に語彙)がコーパス全体の言語の特徴に影響を与えていると考えられ,分析の際にはこの点に注意を要する.
塚本氏は,両コーパスの以上の特徴を,後期近代英語における形容詞の比較級・最上級の問題によって示している.CONCE (Corpus of Nineteenth-Century English) を用いた Kytö and Romaine の先行研究によれば,19世紀の間,比較級の迂言形に対する屈折形の割合は,30年刻みで世紀初頭の57.1%から世紀末の67.8%へと増加しているという.同様の調査を COHA と PPCMBE で10年刻みに施したところ,前者では1810年の64.7%から1910年の74.3%へ着実に増加していることが確かめられたが,後者では1810年の79.4%から1910年の78.0%まで増減の揺れが激しかったという(塚本,p. 56).しかし,CONCEと同様の30年刻みで分析し直すと,PPCMBE でも有意な変化をほぼ観察できるほどの結果がでるという.
コーパスはそれぞれ独自の特徴をもっている.よく把握して利用する必要があることを確認した.関連して,[2010-06-04-1]の記事「流れに逆らっている比較級形成の歴史」を参照.
・ 塚本 聡 「2つの指摘コーパス---その代表性と類似性」『英語コーパス研究』第18号,英語コーパス学会,2011年,49--59頁.
・ Kytö, M. and S. Romaine. "Adjective Comparison in Nineteenth-Century English." Nineteenth-Century English: Stability and Change. Ed. M. Kytö, M. Rydén, and E. Smitterberg. Cambridge: CUP, 2006. 194--214.
2010-11-16 Tue
■ #568. コーパスの定義と英語コーパス入門 [corpus][link][representativeness]
言語研究における corpus 「コーパス」は様々に定義されているが,McEnery et al. の定義が簡潔である.
. . . a corpus is a collection of (1) machine-readable (2) authentic texts (including transcripts of spoken data) which is (3) sampled to be (4) representative of a particular language or language variety.
(1) と (2) についてはおよそ研究者間にコンセンサスがあるが,(3) と (4) については何をもって "sampled" あるいは "representative" とみなすかについて様々な意見がある.しかし,大筋においてこの定義を受け入れることができるだろう.
手軽に英語コーパスを試すには,オンラインのものが便利である.以下は,(登録の必要なものもあるが)オンラインで簡便に利用できる英語コーパス.
・ British National Corpus (いくつかのインターフェースが提供されている)
* BNC ( The British National Corpus )
* BNCweb (要無料登録)
* BYU-BNC (要無料登録)
・ BYU Corpora ( Brigham Young University, Mark Davies 提供のその他のオンラインコーパス群)
* COCA ( Corpus of Contemporary American English ) (要無料登録)
* COHA ( Corpus of Historical American English ) (要無料登録)
* TIME Magazine Corpus of American English (要無料登録)
・ Cobuild Concordance and Collocations Sampler
その他,本ブログではコーパス関係の記事をいろいろと掲載しているので,参考にされたい.
・ hellog 内のコーパス情報の集約記事: [2010-09-15-1]
・ hellog 内のコーパス関連記事: corpus
・ hellog 内の BNC 関連記事: bnc
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
2010-10-10 Sun
■ #531. OED の引用データをコーパスとして使えるか [oed][corpus][representativeness]
OED (2nd ed. CD-ROM) を歴史英語コーパスとして用いるという発想は特に電子版が出版されてから広く共有されてきた.実際に多くの研究で OED がコーパスとして活用されている.しかし,そもそもがコーパスとして編まれたわけではない OED 中の用例の集合をコーパスとみなして研究することは,どれくらい妥当なのだろうか.研究の道具について知ることは研究自身と同じくらい重要だと思われるので,このテーマに関連する Hoffmann の論文から要点をまとめてみたい.(私自身が道具としての OED の特徴をよく理解せずに研究に使っていたきらいがあるので,自分のための備忘録というつもりです.田辺春美先生の書かれた論文を参考にしています.)
Hoffmann は OED の用例の集合をコーパスとして用いることができるかという疑問に対して,4つの観点からアプローチしている.各観点と,対応する Hoffmann の結論を要約する.
(1) Selection criteria for the quotations
"a collection of pieces of language that are selected and ordered according to explicit linguistic criteria in order to be used as a sample of the language" (19; cited from Sinclair) という厳密なコーパスの定義に照らせば,OED の用例の集合をコーパスと見なすことはできない.確かに,個々の見出し語下に納められている用例群が,その見出し語に注目した場合の適切なコーパスにならないということは言えるだろう.その語の特殊で低頻度の形態や意味がクローズアップされる傾向があるからである.しかし,特にある見出し語に注目するのでなければ,全体として OED の用例は各時代の英語を代表していると考えられ,コーパスとして活用することは妥当である.
(2) Representativeness and balance of the quotations
OED の用例は実際に何らかの典拠から引いてきた "true quotations" (20) である.編者によって作られた用例もないではないが,数はきわめて少ない.また,典拠のジャンルは多岐にわたり,極端に文学作品に限るなどの偏向がないので,ジャンルに関しては "representative" と言ってよい.ただし,各ジャンルが言語研究にとって適切な割合で分布しているわけではないので,"balanced" とは言えない.例えば Shakespeare が1人で33,000の用例を提供している事例などが挙げられる.OED をコーパスとして見立てる場合には,"balance" の点で注意を要する.
(3) Reliability of the data format
文中の一部が省略されているような用例が,平均して20?25%ほどある.ほとんどの省略では文の構造がいじられていないが,中には不適切な省略で文の構造が変化してしまっている例文もある.節以上の構造を調べるために OED を利用する場合には,注意が必要である.
(4) Quantification of the results
1年当たりの用例数をグラフにプロットすると,17世紀頃に4000例を越える小ピークが,19世紀に10000例を越える大ピークが認められるが,20世紀には激減する.一方で,用例を構成する語の数は時代にかかわらずおおむね13語程度と一定で,20世紀の用例がやや長めなのが目に留まる程度である.用例数が240万例を越える(初版は180万例ほどだった)ことと上記の平均語数から計算して,OED に含まれる用例の総語数は3300?3500万語と推定される.OED をコーパスとして用いる場合には,19世紀の用例数が特に多いことなどに注意して検索結果を解釈すべきだろう.
最後に Hoffmann の結論部を引用する (26) .OED の用例の集合は言語変化の傾向を大雑把に量的に表わすコーパスとして言語変化研究にとって有用である,という常識的な結論だが,具体的な数字が出されていて参考になった.
Although the OED quotations database is not a completely balanced and representative corpus, it can nevertheless provide the linguist with a wealth of useful information. The data it contains chiefly represents naturally occurring language, and the time-span covered is unmatched by any other source of computerized data. Even though over 20 per cent of all its quotations have been shortened, the large majority of these deletions is unlikely to distort the results of many diachronic studies of linguistic features. Given the nature of the data, normalized frequency counts might suggest an inappropriate level of precision, but tendencies in the development over time can nevertheless be expressed in quantitative terms. (26)
・ The Oxford English Dictionary. 2nd ed. CD-ROM. Version 3.1. Oxford: OUP, 2004.
・ Hoffmann, Sebastian. "Using the OED quotations database as a Corpus --- A Linguistic Appraisal." ICAME Journal 28 (April 2004): 17--30. Available online at http://icame.uib.no/ij28/index.html .
・ Tanabe, Harumi. "The Rivalry of give up and its Synonymous Verbs in Modern English." Language Change and Variation from Old English and Late Modern English: A Festschrift for Minoji Akimoto. Ed. Merja Kytö, John Scahill, and Harumi Tanabe. Bern: Peter Lang, 2010. 253--75.
Powered by WinChalow1.0rc4 based on chalow