2018-07-20 Fri
ĒĢ #3371. ―éīüķáÂåąŅļėĪΞŌēņĘŅē―ĪÏąŅļėĪÎļėŨÃĪČĘļËĄĪËĪÉĪÎĪčĪĶĪĘąÆķÁĪōĩÚĪÜĪ·ĪŋĪŦĄĐ [emode][renaissance][printing][speed_of_change][lexicology][grammar][reading][historiography]
ĄĄķáÂåąŅļėīüĪÎŧÏĪÞĪë16ĀĪĩŠĪËĪÏĄĪĪ―ĪÎļåĪÎąŅļėĪÎÎōŧËĪËąÆķÁĪōÍŋĪĻĪëŋôĄđĪΞŌēņĘŅē―ĪŽĀļĪļĪŋĄĨĄÖ#1407. ―éīüķáÂåąŅļėīüĪÎ3ĪÄĪÎĖäÂęĄŨ ([2013-03-04-1]) ĪĮūŌēðĪ·ĪŋĪČĪŠĪęĄĪBaugh and Cable ĄĘĄø156ĄËĪÏ°ĘēžĪÎ5ÅĀĪōĩóĪēĪÆĪĪĪëĄĨ
ĄĄ1. the printing press
ĄĄ2. the rapid spread of popular education
ĄĄ3. the increased communication and means of communication
ĄĄ4. the growth of specialized knowledge
ĄĄ5. the emergence of various forms of self-consciousness about language
ĄĄĪģĪėĪéĪÎÍŨ°øĪÏĄĪĪ·ĪÐĪ·ĪÐÁę―ÅĪĘĪÃĪÆĄĪąŅļėĪÎĘļËĄĪČļėŨÃĪËīÖĀÜÅŠĪĘĪŽĪéĪâąóÂįĪĘąÆķÁĪōĩÚĪÜĪđĪģĪČĪËĪĘĪÃĪŋĄĨBaugh and Cable ĄĘĄø157, pp. 200--01) ĪËĪčĪėĪÐĄĪĪģĪÎąÆķÁÎÏĪÏĩÞŋĘÅŠĪĮĪâĪĒĪęĄĪÆąŧþĪËĘÝžéÅŠĪĮĪâĪĒĪÃĪŋĪČĪĪĪĶĄĨĪÉĪĶĪĪĪĶĪģĪČĪŦĪČĪĪĪĻĪÐĄĪļėŨÃĪËĪÄĪĪĪÆĪÏĩÞŋĘÅŠĪĮĪĒĪęĄĪĘļËĄĪËĪÄĪĪĪÆĪÏĘÝžéÅŠĪĮĪĒĪÃĪŋĪČĪĪĪĶĪģĪČĪĀĄĨ
A radical force is defined as anything that promotes change in language; conservative forces tend to preserve the existing status. Now it is obvious that the printing press, the reading habit, the advances of learning and science, and all forms of communication are favorable to the spread of ideas and stimulating to the growth of the vocabulary, while these same agencies, together with social consciousness . . . work actively toward the promotion and maintenance of a standard, especially in grammar and usage. . . . We shall accordingly be prepared to find that in modern times, changes in grammar have been relatively slight and changes in vocabulary extensive. This is just the reverse of what was true in the Middle English period. Then the changes in grammar were revolutionary, but, apart from the special effects of the Norman Conquest, those in vocabulary were not so great.
ĄĄĪĘĪëĪÛĪÉĄĪķáÂåÅŠĪĘžŌēņūō·ïĪÏĄĪģŦĪŦĪėĪŋÉôĖįĪĮĪĒĪëļėŨÃĪËÂÐĪ·ĪÆĪÏĄĪĪāĪ·ĪíÁýēÃĪōÂĨĪđĪâĪÎĪĀĪíĪĶĪ·ĄĪĘÄĪļĪŋÉôĖįĪĮĪĒĪëĘļËĄĪËÂÐĪ·ĪÆĪÏĩŽČÏÅŠĪĘ°ĩÎÏĪōēÃĪĻĪëĘýļþĪËšîÍŅĪđĪëĪĀĪíĪĶĄĘĄÖķáÂåÅŠĪĘĄŨĪōĄÖļ―ÂåÅŠĪĘĄŨĪČÆÉĪßÂØĪĻĪÆĪâĪ―ĪÎĪÞĪÞÅöĪÆĪÏĪÞĪęĪ―ĪĶĪĘĪÎĪĮĄĪŧäĪŋĪÁĪËĪÏĘŽĪŦĪęĪäĪđĪĪĄËĄĨ
ĄĄĪģĪΰúÍŅĪĮĪŠĪâĪ·ĪíĪĪĪÎĪÏĄĪšĮļåĪËķáÂåąŅļėīüĪōÃæąŅļėīüĪČÂÐČæĪ·ĪÆĪĪĪëĪČĪģĪíĪĀĄĨÃæąŅļėĪĮĪÏĄĪūåĩĪÎĪčĪĶĪĘ―ôūō·ïĪŽĪĘĪŦĪÃĪŋĪŋĪáĪËĄĪĪāĪ·ĪíļėŨÃĪËīØĪ·ĪÆĘÝžéÅŠĪĮĪĒĪęĄĪĘļËĄĪËīØĪ·ĪÆĩÞŋĘÅŠĪĀĪÃĪŋĪČ―ŌĪŲĪéĪėĪÆĪĪĪëĄĨĄÖĨÎĨëĨÞĨóĀŽÉþĪËĪčĪëĨÕĨéĨóĨđļėĪÎÆÃĘĖĪĘąÆķÁĪō―üĪĪĪÆĪÏĄŨĪČĪĪĪĶĪČĪģĪíĪŽąÔĪĪĄĨÃæąŅļėĪÎļėŨÃŧöūðĪČĪ·ĪÆĪÏĄĪĪđĪ°ĪËĨÕĨéĨóĨđļėĪŦĪéĪÎÂįÎĖĪΞÚÍŅļėĪŽŧŨĪĪÉâĪŦĪÓĄĪ·čĪ·ĪÆĄÖĘÝžéÅŠĄŨĪČĪÏĪĪĪĻĪĘĪĪĪÏĪšĪĀĪŽĄĪĪ―ĪėĪÏĪĒĪÞĪęĪËÆÞėĪĘŧöūðĪĮĪĒĪëĪČĪ·ĪÆÏÆĪËÃÖĪĪĪÆĪŠĪąĪÐĄĪģÎĪŦĪËūåĩĪÎīŅŧĄĪÏĪŠĪčĪ―ÅöĪŋĪÃĪÆĪĪĪëĪčĪĶĪËŧŨĪïĪėĪëĄĨBaugh and Cable ĪÏĄĪķņÂÎÅŠĄĶļÄĘĖÅŠĪĘÎōŧËĩ―ŌĄĶĘŽĀÏĪËÄęÉūĪŽĪĒĪëĪŽĄĪĪČĪģĪíĪÉĪíĪģĪËšĢēóĪÎĪčĪĶĪËĀâĖĀĪΰėČĖē―ĪōŧîĪßĪëĨąĄžĨđĪâĪĒĪęĄĪēŋÅŲÆÉĪóĪĮĪâČŊļŦĪŽĪĒĪëĄĨ
ĄĄĄĶ Baugh, Albert C. and Thomas Cable. A History of the English Language. 6th ed. London: Routledge, 2013.
2018-07-17 Tue
ĒĢ #3368. ĄÖĨéĨÆĨóļė·ÏĄŨļėŨÞÚÍŅĪÎŧþÂåĪČ·ÐÏĐ [contact][latin][greek][french][borrowing][lexicology][loan_word]
ĄĄĄÖĨéĨÆĨóļė·ÏĄŨ (Latinate) žÚÍŅļėĪČĪÏĄĪžįĪČĪ·ĪÆĨéĨÆĨóļėĪČĨÕĨéĨóĨđļėĪōĨ―ĄžĨđĪČĪđĪëžÚÍŅļėĪōŧØĪđĄĨīËĪŊēōžáĪ·ĪÆĄĪÂūĪÎĨíĨÞĨóĨđ―ôļėĪŦĪéĪΞÚÍŅļėĪōīÞĪāĪģĪČĪâĪĒĪėĪÐĄĪĨŪĨęĨ·ĨĒļėĪâĨéĨÆĨóļėĪō·ÐÍģĪ·ĪÆąŅļėĪËžčĪęđþĪÞĪėĪëĪģĪČĪŽÂŋĪŦĪÃĪŋĪģĪČĪŦĪéĄĪĨŪĨęĨ·ĨĒžÚÍŅļėĄĘÄūĀÜžÚÍŅĪĩĪėĪŋĪâĪÎĪâĄËĪōīÞĪóĪĮļĀĪïĪėĪëĪģĪČĪâĪĒĪëĄĨąŅļėŧËūåĄĪĨéĨÆĨóļė·ÏĪÎļėŨÞÚÍŅĪŽļŦĪéĪėĪŋŧþÂåĪČ·ÐÏĐĪÏĄĪ°ĘēžĪÎĪčĪĶĪËŋÞžĻĪĮĪĪëĄĘÍÁĀÐĄĪp. 113 ĪÎŋÞĪōŧēūČĪ·ĪŋĄËĄĨ
ĻĢĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĪ
ĻĒ Greek ĻĒ
ĻĶĻĄĻĄĻĄĻĄĻĄĻĄĻĻĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĻĻĄĻĨ
ĻĒ ĻĒ
Ē ĻĒ
ĻĢĻĄĻĄĻĄĻĄĻĄĻĻĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĻĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĪ ĻĒ
ĻĒ Latin ĻĒ Old and Middle French ĻĒ Modern French ĻĒ ĻĒ
ĻĶĻĄĻĄĻĻĻĄĻĄĻŠĻĄĻĄĻĄĻĄĻĄĻĻĻĄĻĄĻĄĻĄĻĄĻĄĻŠĻĄĻĄĻĄĻĄĻĻĻĄĻĄĻĄĻĨ ĻĒ
ĻĒ ĻĒ ĻĒ ĻĒ
ĻĒ ĻĶĻĄĻĄĻĄĻĄĻĄĻĪ ĻĶĻĄĻĄĻĪ ĻĒ
ĻĒ ĻĒ ĻĒ ĻĒ
ĻĢĻĄĻĄĻĄĻŠĻĄĻĻĻĄĻĄĻĄĻĄĻĄĻĄĻĻĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĻĻĄĻĄĻĄĻĄĻĄĻĪĻĒ ĻĒ
ĻĒ ĻĒ ĻĒ ĻĒ ĻĒ ĻĒĻĒ ĻĒ
ĻĒ ĻĒ ĻĒ ĻĒ ĻĒ ĻĒĻĒ ĻĒ
Ē Ē Ē Ē Ē ĒĒ Ē
ĻĢĻĄĻĄĻĄĻĄĻĻĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĻĻĄĻĄĻĄĻĄĻĄĻĄĻĻĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĻĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĪ
ãô?GermanicãôĢąrehistoric OEãôĢ°ld English ãô?Middle Englishãô?Modern Englishãô?
ĻĶĻĄĻĄĻĄĻĄĻŠĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻŠĻĄĻĄĻĄĻĄĻĄĻĄĻŠĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻŠĻĄĻĄĻĄĻĄĻĄĻĄĻĄĻĨ
ĄĄŋÞĪōļŦĪëĪČĄĪžÚÍŅļĩļĀļėĪÎĨėĨŅĄžĨČĨ꥞ĪÏĘŅĪïĪÃĪÆĪĪĪĘĪĪĪâĪÎĪÎĄĪŧþÂåĪËĪčĪÃĪÆ·ÐÏĐĪōīÞĪáĪŋąŅļėĪČĪÎīØĪïĪęĘýĪŽĪ―ĪėĪūĪėÆÃħŊĪĮĪĒĪëĪģĪČĪŽĄĪēþĪáĪÆĪčĪŊĘŽĪŦĪëĄĨąŅļėĪÎļėŨÃĪËĪČĪęĪïĪąķŊĪĪąÆķÁĪōĩÚĪÜĪ·ĪÆĪĪŋļĀļėĪČĪĪĪĻĪÐĄĪūåĩĪÎ "Latinate" languages Īō―üĪąĪÐļÅĨÎĨëĨÉļėĪÎĖūÁ°ĪŽĩóĪŽĪëĪŊĪéĪĪĪĮĪĒĪęĄĪĄÖĨéĨÆĨóļė·ÏĄŨĪÎÂļšßīķĪÎÃøĪ·ĪĩĪŽšÆģÎĮ§ĪĮĪĪëĪĀĪíĪĶĄĨ
ĄĄĨéĨÆĨóļė·ÏĪËļÂĪéĪĘĪĪļėŨÞÚÍŅĪηÐÏĐŋÞĪČĪ·ĪÆĪÏĄĪĄÖ#1930. ·ÏÅýĪČąÆķÁĪōđÍÎļĪËÆþĪėĪŋĀūĨĪĨóĨÉĨ襞ĨíĨÃĨŅļėÂēĪÎīØ·ļŋÞĄŨ ([2014-08-09-1]) ĪâŧēūČĄĨ
ĄĄĄĶ ÍÁĀÐ ÅŊšČĄĄĄÖÂč6ūÏĄĄ·ÁÂÖĘŅē―ĄĶļėŨÃĪÎĘŅÁŦĄŨÉþÉô ĩÁđ°ĄĶŧųĮÏ ―ĪĄĘĘÔĄËĄØÎōŧËļĀļėģØĄŲÄŦÁŌÆüąŅÂÐūČļĀļėģØĨ·Ĩ꥞ĨšĄÎČŊÅļĘÔĄÏ3ĄĄÄŦÁŌ―ņÅđĄĪ2018ĮŊĄĨ106--30ĘĮĄĨ
2018-07-06 Fri
ĒĢ #3357. ÆüËÜļėļėŨÃĪÎŧ°ÁØđ―ÂĪ (2) [japanese][lexicology][lexical_stratification]
ĄĄąŅļėĪČÆüËÜļėĪÎļėŨÃĪËķĶÄĖĪ·ĪÆļŦĪéĪėĪëŧ°ÁØđ―ÂĪĪËīØĪ·ĪÆĄĪĄÖ#2977. ÏĒšÜÂč6ēóĄÖĪĘĪžąŅļėļėŨÃĪË3ÁØđ―ÂĪĪŽĪĒĪëĪÎĪŦĄĐ --- ĨëĨÍĨĩĨóĨđīüĪÎĨéĨÆĨóļėĪŦĪÖĪėĪČĨĪĨóĨŊÔäļėÏĀÁčĄŨĄŨ ([2017-06-21-1]) ĪËÄĨĪÃĪŋĨęĨóĨŊĀčĪÎÂŋĪŊĪÎĩŧöĪĮÏÃÂęĪČĪ·ĪÆĪĪŋĄĨÆüËÜļėļėŨÃĪÎŧ°ÁØđ―ÂĪĪËĪÄĪĪĪÆĄÖ#335. ÆüËÜļėļėŨÃĪÎŧ°ÁØđ―ÂĪĄŨ ([2010-03-28-1]) ĪÎĩŧöĪĮĪĪĪŊĪÄĪŦĪÎÎãĪōĩóĪēĪŋĪŽĄĪšĢēóĪÏĀÐđõ (59) ĪčĪęÎãĪōÉÕĪąÂĪ―ĪĶĄĨ
| ÏÂļė | īÁļė | ģ°Íčļė |
|---|---|---|
| Âæ―ę | ŋßËž | ĨĨÃĨÁĨó |
| ŋÏĘŠ | ĘņÃú | ĨĘĨĪĨÕ |
| ―ÐÁ° | ÂðĮÛ | ĨĮĨęĨÐĨ꥞ |
| ĮãĪĪĘŠ | đØÆþ | Ĩ·ĨįĨÃĨÔĨóĨ° |
| Îđ | ÎđđÔ | ĨČĨéĨŲĨëĄŋĨČĨęĨÃĨŨ |
| ģĪĘÕĄŋÉÍĘÕ | ģĪīß | ĨÓĄžĨÁ |
ĄĄČæĪŲĪÆĪßĪėĪÐĄÖÏÂļėĪĀĪČŋČķáĪĘĨĪĨᥞĨļĄĪīÁļėĪĀĪČļ·ĖĐĪĘĨĪĨᥞĨļĄĪģ°ÍčļėĪĀĪČŋ·ĩŽĪĘĨĪĨᥞĨļĪŽ―ÐĪŧĪëĄŨĄĘĀÐđõĄĪp. 60) ĪČĪĪĪĶĪģĪČĪŽĪčĪŊĘŽĪŦĪëĪĀĪíĪĶĄĨĀÐđõ (62) ĪÏĄĪĪ―ĪėĪūĪėĪÎļėžïĪÎÆÃħĪōžĄĪÎĪčĪĶĪËĪÞĪČĪáĪÆĪĪĪëĄĨ
| ÂÐūÝ | Äđ―ę | Ãŧ―ę | |
|---|---|---|---|
| ÏÂļė | ŋČķáĪĘÆâÍÆ | žŠĪĮĘđĪĪĪÆ°ÕĖĢĪŽĪïĪŦĪëĄĘÏÃĪ·ļĀÍÕļþĪĄËĄĪÆâÍÆĪō°ŨĪ·ĪŊžĻĪŧĪë | ÃęūÝÅŠĪĘÆâÍÆĪōÉ―ĪđĪÎĪŽÉÔÆĀžę |
| īÁļė | ÃęūÝÅŠĪĘÆâÍÆ | ĖÜĪĮļŦĪÆ°ÕĖĢĪŽĪïĪŦĪëĄĘ―ņĪļĀÍÕļþĪĄËĄĪļ·ĖĐĪĘ°ÕĖĢĪōÉ―ĪŧĪë | žŠĪĮĘđĪĪĪŋĪČĪĪË°ÕĖĢĪŽĪïĪŦĪęĪËĪŊĪĪ |
| ģ°Íčļė | ŋ·Ī·ĪĪÆâÍÆ | ģĪģ°ĪΚĮŋ·ĪÎģĩĮ°ĪōžčĪęĪģĪáĪë | ĖÜĪĮļŦĪŋĪČĪĪË°ÕĖĢĪŽĪïĪŦĪęĪËĪŊĪĪ |
ĄĄÏÂļėĪŽÏÃĪ·ļĀÍÕļþĪĄĪīÁļėĪŽ―ņĪļĀÍÕļþĪĪČĪĒĪëĪŽĄĪĪĘĪŦĪËĪÏÎãģ°ĪâĪĒĪëĄĘĀÐđõĄĪp. 74ĄËĄĨÎãĪĻĪÐĄĪĄÖÃįīÖĄŨĪČĄÖĮÚĄĘĪČĪâĪŽĪéĄËĄŨĄĪĄÖīčļĮĄŨĪČĄÖīčĄĘĪŦĪŋĪŊĄËĪĘĄŨĄĪĄÖÉÏËģĄŨĪČĄÖÉÏĪ·ĪĪĄŨĪĘĪÉĄĪÁ°žÔĪÎīÁļėĪÎĪÛĪĶĪŽÁęÂÐÅŠĪËĪĪĪĻĪÐ―ĀĪéĪŦĪŊÏÃĪ·ļĀÍÕÅŠĪĮĄĪļåžÔĪÎÏÂļėĪÏĪāĪ·Īí·øĪŊ―ņĪļĀÍÕÅŠĪËķÁĪŊĪĀĪíĪĶĄĨÆąĪļ·đļþĪÏÆÃĪËīÁļėÉûŧėĪËļŦĪéĪėĪëĪČĪĪĪĶĄĨĄÖÁīÁģĄŨĪČĄÖĪÞĪÃĪŋĪŊĄŨĄĪĄÖÁīÉôĄŨĪČĄÖĪđĪŲĪÆĄŨĄĪĄÖĀäÂÐĄŨĪČĄÖĪŦĪĘĪéĪšĄŨĄĪĄÖÂŋĘŽĄŨĪČĄÖĪŠĪ―ĪéĪŊĄŨĄĪĄÖ°ėČÖĄŨĪČĄÖĪâĪÃĪČĪâĄŨĄĪĄÖÂįÂÎĄŨĪČĄÖĪÛĪÜĄŨĪĘĪÉĪōČæĪŲĪÆĪßĪėĪÐĄĪÁ°žÔĪÎīÁļėĪÎĪÛĪĶĪŽÏÃĪ·ļĀÍÕĪĮĪčĪŊÍŅĪĪĪéĪėĪëĄĨ
ĄĄĪģĪΞïĪÎÎãģ°ĪÏĄĪĪŠĪâĪ·ĪíĪĪĪģĪČĪËąŅļėļėŨÃĪÎŧ°ÁØđ―ÂĪĪËĪÄĪĪĪÆĪâÅöĪÆĪÏĪÞĪëĄĨ°ėČĖÅŠĪËĪÏĄĪąŅļėËÜÍčļėĪÏ―ĀĪéĪŦĪŊĪÆÏÃĪ·ļĀÍÕļþĪĄĪĨÕĨéĨóĨđžÚÍŅļėĪÏ·øĪŊĪÆ―ņĪļĀÍÕļþĪĪČĪĪĪĶÂÐūČĀĪŽģÎĪŦĪËīŅŧĄĪĩĪėĪëĄĘcf. ĄÖ#334. ąŅļėļėŨÃĪÎŧ°ÁØđ―ÂĪĄŨ ([2010-03-27-1])ĄËĄĨĪ·ĪŦĪ·ĄĪĪĘĪŦĪËĪÏ foe ĪČ enemyĄĪdale ĪČ valley ĪÎĪčĪĶĪËĄĪĨÚĨĒĪÎÁ°žÔĄĘąŅļėËÜÍčļėĄËĪÎĪÛĪĶĪŽŧíÅŠĪĘĨÕĨĐĄžĨÞĨęĨÆĨĢĪŽĪĒĪęĄĪļåžÔĄĘĨÕĨéĨóĨđžÚÍŅļėĄËĪÎĪÛĪĶĪŽÆüūïÅŠĪĘķÁĪĪōĪâĪÄÎãĪâĪĒĪëĄĨĪģĪÎĪčĪĶĪĘÎãģ°ŧöūðĪâīÞĪáĪÆĄĪąŅļėĪČÆüËÜļėĪÎļėŨÃĪÎŧ°ÁØđ―ÂĪĪÏŧũĪÆĪĪĪëĪÎĪĮĪĒĪëĄĨ
ĄĄĄĶ ĀÐđõ ·―ĄĄĄØļėŨÃÎÏĪōÃÃĪĻĪëĄŲĄĄļũĘļžŌĄŌļũĘļžŌŋ·―ņĄÓĄĪ2016ĮŊ.
2018-06-27 Wed
ĒĢ #3348. ―éīüķáÂåąŅļėīüĪËžÚÍŅ·ÏĪÎĀÜžĄĶīðÂÎĪŽÂįÉýĪËŋÄĨĪ·Īŋ [word_formation][prefix][suffix][neologism][french][latin][loan_word][lexicology][renaissance][emode]
ĄĄWersmer (64, 67) Īä Nevalainen (352, 378, 391) ĪōŧēūČĪ·Īŋ Cowie (610--11) ĪËĪčĪėĪÐĄĪĀÜžĪōÍŅĪĪĪŋŋ·ļė·ÁĀŪĪËĪŠĪĪĪÆĄĪËÜÍč·ÏĪÎĀÜžĪōÍøÍŅĪ·ĪŋĪâĪÎĪČžÚÍŅ·ÏĪÎĪâĪÎĪČČæÎĻĪŽĄĪ―éīüķáÂåąŅļėīüÃæĪËÂįĪĪŊĘŅē―Ī·ĪŋĪČĪĪĪĶĄĨ
The relative frequency of nonnative affixes to native affixes in coined words rises from 20% at the beginning of the Early Modern English period to 70% at the end of it . . . . The proportion of Germanic to French and Latin bases in new coinages falls from about 32% at the beginning of the Early Modern period to some 13% at the end . . . . Together these measures confirm the emergence of non-native affixes as independent English morphemes over the Early modern period. They also seem to contradict claims that the native affixes in Early Modern English are just as, if not more productive, than ever . . . , although it is always less likely that words coined with native affixes would be recorded in a dictionary . . . .
ĄĄĪģĪÎŧþīüĪÎ―éĪáĪËĪÏžÚÍŅ·ÏĪÏ20%ĪĀĪÃĪŋĪŽĄĪ―ŠĪïĪęĪËĪÏ70%ĪËĪÞĪĮÁýēÃĪ·ĪÆĪĪĪëĄĨ°ėĘýĄĪīðÂÎĪËÃíĖÜĪđĪëĪČĄĪžÚÍŅ·ÏĪËÂÐĪđĪëËÜÍč·ÏĪÎČæÎĻĪÏĄĪīüžóĪĮ32%ĪÛĪÉĄĪīüËöĪĮ13%ĪÛĪÉĪËÍîĪÁđþĪóĪĮĪĪĪëĄĨÁīÂÎĪČĪ·ĪÆĄĪ―éīüķáÂåąŅļėīüÃæĪËĄĪžÚÍŅ·ÏĪÎĀÜžĪŠĪčĪÓīðÂÎĪŽĖÜÎĐĪÄĪčĪĶĪËĪĘĪÃĪÆĪĪŋĪģĪČĪÏĩŋĪĪĪĘĪĪĄĨĪŋĪĀĪ·ĄĪ°úÍŅĪΚĮļåĪÎÃĒĪ·―ņĪĪÏ―ÅÍŨĪĮĪÏĪĒĪëĄĨ
ĄĄīØÏĒĪ·ĪÆĄĪĄÖ#1226. ķáÂåąŅļėīüĪËĪŠĪąĪëļėŨÃÁýēÃĪÎĮŊÂåĘĖĘŽÉÛĄŨ ([2012-09-04-1])ĄĪĄÖ#3165. ąŅĀ―ÍåļėĪČĪ·ĪÆĪÎ conspicuous ĪČ externalĄŨ ([2017-12-26-1])ĄĪĄÖ#3166. ąŅĀ―īõÍåļėĪČĪ·ĪÆĪÎēĘģØÍŅļėĄŨ ([2017-12-27-1])ĄĪĄÖ#3258. 17ĀĪĩŠĪËšîĪéĪėĪŋÆ°ŧėĮÉĀļĖūŧė·ēĪÎÄčĪđĪëĖäÂę (1)ĄŨ ([2018-03-29-1])ĄĪĄÖ#3259. 17ĀĪĩŠĪËšîĪéĪėĪŋÆ°ŧėĮÉĀļĖūŧė·ēĪÎÄčĪđĪëĖäÂę (2)ĄŨ ([2018-03-30-1]) ĪōŧēūČĄĨ
ĄĄĄĶ Wersmer, Richard. Statistische Studien zur Entwicklung des englischen Wortschatzes. Bern: Francke, 1976.
ĄĄĄĶ Nevalainen, Terttu. "Early Modern English Lexis and Semantics." 1476--1776. Vol. 3 of The Cambridge History of the English Language. Ed. Roger Lass. Cambridge: CUP, 1999. 332--458.
ĄĄĄĶ Cowie, Claire. "Early Modern English: Morphology." Chapter 38 of English Historical Linguistics: An International Handbook. 2 vols. Ed. Alexander Bergs and Laurel J. Brinton. Berlin: Mouton de Gruyter, 2012. 604--20.
2018-06-21 Thu
ĒĢ #3342. đ֚¥ÖÎōŧËĪŦĪéģØĪÖąŅÃąļėĪÎļėļŧĄŨĪÎĪŠÃÎĪéĪŧ [notice][etymology][lexicology][hel_education][asacul][link]
ĄĄ7·î21ÆüĄĘÅÚĄËĪÎ13:30?16:45ĪËĄĪÄŦÆüĨŦĨëĨÁĨãĄžĨŧĨóĨŋĄžŋ·―ÉķĩžžĪËĪÆÃąČŊĪÎđ֚¥ÖÎōŧËĪŦĪéģØĪÖąŅÃąļėĪÎļėļŧĄŨĪōģŦđÖĪ·ĪÞĪđĄĨÆâÍÆūŌēðĪō°ĘēžĪ˚ƷĮĪ·ĪÞĪđĄĨ
ĄĄąŅļėĪĮĪâÆüËÜļėĪĮĪâĄĪÃąļėĪÎļėļŧĪČĪĪĪĶÏÃÂęĪÏÂŋĪŊĪÎŋÍĪōžæĪĪÄĪąĪÞĪđĄĨ°ėĪÄĪŌĪČĪÄĪÎÃąļėĪËÆČžŦĪÎĩŊļŧĪŽĪĒĪęĄĪ°ėļĀĪĮĪÏļėĪęŋÔĪŊĪŧĪĖÎōŧËĪŽĪĒĪęĄĪļ―šßĪÞĪĮĀļĪÂģĪąĪÆĪĪŋĪŦĪéĪĮĪđĄĨĪÞĪŋĄĪąŅļėĪËĪÄĪĪĪÆĪĪĪĻĪÐĄĪļėļŧĪËĪčĪęąŅÃąļėĪÎļėŨÃĪōÁýĪäĪđĪČĪĪĪĶģØ―ŽËĄĪâĪĒĪęĄĪĪ―ĪΞïĪÎ―ņĀŌĪÏÂŋĪŊ―ÐČĮĪĩĪėĪÆĪĪĪÞĪđĄĨ
ĄĄËÜđÖšÂĪĮĪÏĄĪĪģĪėĪÞĪĮ°ĘūåĪËąŅÃąļėĪÎļėļŧĪōģÚĪ·ĪāĪŋĪáĪËĀ§ČóĪČĪâÉŽÍŨĪČĪĘĪëąŅļėŧËĪËīØĪđĪëÃΞąĪČĘýËĄĪōžĻĪ·ĄĪĪģĪėĪŦĪéĪÎĪßĪĘĪĩĪóĪÎąŅļėģØ―ŽĄĶĀļģčĪËŋ·ĪŋĪĘŧëÅĀĪōÆģÆþĪ·ĪÞĪđĄĨķņÂÎÅŠĪËĪÏĄĪ(1) ąŅļėĪÎÎōŧËĪōĪŋĪÉĪęĪĘĪŽĪéąŅļėļėŨÃĪÎČŊÅļĪōģĩĀâĪ· (ÃąļėÎãĄ§cheese, school, take, people, drama, shampooĄËĄĪ(2) ÃąļėĪËĪŠĪąĪëČŊēŧĄĶÄÖŧúĄĶ°ÕĖĢĪÎĘŅē―ĪΰėČĖÅŠĪĘĨŅĨŋĄžĨóĪËĪÄĪĪĪÆ―ŌĪŲĄĘÃąļėÎãĄ§make, knight, nice, ladyĄËĄĪ(3) ļėļŧžÅĩĪäąŅļėžÅĩĪÎļėļŧÍóĪōÆÉĪßēōĪŊĘýËĄĪōžĻĪ·ĪÞĪđĄĘÃąļėÎãĄ§one, oat, father, theyĄËĄĨĪģĪėĪËĪčĪęĄĪļėļŧĪōÍøÍŅĪ·ĪŋąŅÃąļėÎÏĪÎÁýķŊĪŽēÄĮ―ĪČĪĘĪëĪÐĪŦĪęĪĮĪÏĪĘĪŊĄĪīûÃÎĪÎąŅÃąļėĪÎŋ·ĪŋĪĘÂĶĖĖĪËĩĪĪÅĪĄĪąŅÃąļėĪōģÚĪ·ĪßĪĘĪŽĪéĖĢĪïĪĶĪģĪČĪŽĪĮĪĪëĪčĪĶĪËĪĘĪëĪČģÎŋŪĪ·ĪÞĪđĄĨ
ĄĄąŅÃąļėĪÎļėļŧĪČ°ėļýĪËĪĪĪÃĪÆĪâÁęÅöĪËđĪĪČÏ°ÏĪōīÞĪāĪÎĪĮĪđĪŽĄĪËÜđÖšÂĪĮĪÏĄĪąŅļėĪÎļėŨÃŧËĪäēŧąĪĄĶ°ÕĖĢĘŅē―ĪÎĨŅĨŋĄžĨóĪō°·ĪĶÍýÏĀĘÔĪČĄĪąŅļėļėļŧž―ņĪōÆÉĪßēōĪĪĪÆĨÜĨĨãĨÓĨëĪËĖōÎĐĪÆĪëžÂÁĐĘÔĪČĪōĨÐĨéĨóĨđĪčĪŊĮÛĪ·ĪÆĄĪąŅÃąļėĪÎĖĨÎÏĪō°úĪ―ÐĪđÍ―ÄęĪĮĪđĄĨ"chaque mot a son histoire" (= "every word has its own history") ĪÎŋĀŋņĪōĖĢĪïĪÃĪÆĪŊĪĀĪĩĪĪ (cf. ĄÖ#1273. Ausnahmslose Lautgesetze ĪČ chaque mot a son histoireĄŨ ([2012-10-21-1])) ĄĨ
ĄĄËÜĨÖĨíĨ°ĪĮĪâËÜđÖšÂĪČīØÏĒĪđĪëĩŧöĪōÂŋŋô―ņĪĪĪÆĪĪÞĪ·ĪŋĪŽĄĪĪČĪęĪïĪą°ĘēžĪÎĪâĪÎĪōŧēđÍĪÞĪĮĪËĩóĪēĪÆĪŠĪĪÞĪđĄĨ
ĄĄĄĶ ĄÖ#361. ąŅļėļėļŧūðĘóĪĖĪĪĀĪ·CGIĄĘ°ėģįČĮĄËĄŨ ([2010-04-23-1])
ĄĄĄĶ ĄÖ#485. ļėļŧĪōÃÎĪëĪŋĪáĪÎĨŠĨóĨéĨĪĨóž―ņĄŨ ([2010-08-25-1])
ĄĄĄĶ ĄÖ#600. ąŅļėļėļŧž―ņĪÎ―ņŧïĄŨ ([2010-12-18-1])
ĄĄĄĶ ĄÖ#1765. ÆüËÜĪĮ―žžÂĪ·ĪÆĪĪĪëąŅļėļėļŧģØĪČ Klein ĪÎąŅļėļėļŧžÅĩĄŨ ([2014-02-25-1])
ĄĄĄĶ ĄÖ#2615. ąŅļėļėŨÃĪÎĀĪģĶĀĄŨ ([2016-06-24-1])
ĄĄĄĶ ĄÖ#2966. ąŅļėļėŨÃĪÎĀĪģĶĀ (2)ĄŨ ([2017-06-10-1])
ĄĄĄĶ ĄÖ#466. ļėļŧģØĪÏĩŧ·ÝĪŦēĘģØĪŦĄŨ ([2010-08-06-1])
ĄĄĄĶ ĄÖ#727. ļėļŧģØĪΞŦΧĀĄŨ ([2011-04-24-1])
ĄĄĄĶ ĄÖ#1791. ļėļŧģØĪÏĩŧ·ÝĪŽēĘģØĪŦ (2)ĄŨ ([2014-03-23-1])
ĄĄĄĶ ĄÖ#598. ąŅļėļėļŧģØĪÎÎŽŧË (1)ĄŨ ([2010-12-16-1])
ĄĄĄĶ ĄÖ#599. ąŅļėļėļŧģØĪÎÎŽŧË (2)ĄŨ ([2010-12-17-1])
2018-06-15 Fri
ĒĢ #3336. ÆüËÜļėĪÎļÁĪËÍŅĪĪĪéĪėĪÆĪĪĪëļėžï [japanese][proverb][lexicology][etymology][genre][hel_education]
ĄĄĖÚēž (84--87) ĪŽĄĪÆüËÜļėĪÎļÁĪËÍŅĪĪĪéĪėĪÆĪĪĪëļėŨÃĪōĄÖīÁļėĄŨĄÖÏÂļėĄŨĄÖšŪžïļėĄŋģ°ÍčļėĄŨĪËķčĘŽĪ·ĪÆÄóžĻĪ·ĪÆĪĪĪëĄĨ
| īÁļė | ÏÂļė | šŪžïļėĄŋģ°Íčļė | |
|---|---|---|---|
| ĪÛĪËĪåĪĶÎā | Ī·Ī·ĄĪūÝĄĪĪÆĪóĄĪĪŌĪįĪĶĄĪÂĖĮÏĄĘēŲĘŠąŋĪÓĪÎĮÏĄË | ĪĒĪ·ĪŦĄĪĪĪĪŋĪÁĄĪļĪĄĪĪĶĪĩĪŪĄĪĩíĄĪĮÏĄĪĪŠĪŠĪŦĪߥĪĪĪÄĪÍĄĪĪŊĪÞĄĪĪģĪĶĪâĪęĄĪĪĩĪëĄĪžŊĄĪĪŋĪĖĪĄĪļŨĄĪĮĄĪĪÍĪšĪߥĪÍÓĄĪÆÚĄĪĪāĪļĪĘĄĪĪáĩí | |
| ÄŧÎā | ĪŊĪļĪãĪŊ | ĪĒĪŌĪëĄĪĪĶĄĪĪĶĪ°ĪĪĪđĄĪĪŠĪĶĪāĄĪĪŦĪĩĪĩĪŪĄĪĪŦĪâĄĪĪŦĪéĪđĄĪĪĪļĄĪĪĩĪŪĄĪĪßĪßĪšĪŊĄĪĪđĪšĪáĄĪĪŋĪŦĄĪĪÁĪÉĪęĄĪĪÄĪ°ĪߥĪĪÄĪÐĪáĄĪĪÄĪëĄĪĪČĪÓĄĪĪÏĪČĄĪĪŌĪÐĪęĄĪĪÛĪČĪČĪŪĪđĄĪĪáĪļĪíĄĪŧģÄŧĄĪĪčĪŋĪŦĄĪĪïĪ· | |
| ĪÏÃîÎāĄĶÎūĀļÎā | ĩĩĄĪĪŦĪĻĪëĄĪĪČĪŦĪēĄĪĪØĪÓĄĪĪÞĪāĪ·ĄĪĪïĪË | ||
| ĩûēðÎā | ĪĒĪóĪģĪĶ | ĪĒĪĩĪęĄĪĪĒĪïĪÓĄĪĪĪĪŦĄĪĪĪĪïĪ·ĄĪĩûĄĪĪĶĪĘĪŪĄĪĪĻĪÓĄĪĪŦĪĄĪĪŦĪÄĪŠĄĪĪŦĪËĄĪĪŦĪÞĪđĄĪĪŦĪėĪĪĄĪĪŊĪļĪéĄĪĪŊĪéĪēĄĪĪģĪĪĄĪĪĩĪÐĄĪĪĩĪáĄĪĪĩĪóĪÞĄĪĪ·ĪļĪߥĪĪŋĪģĄĪĪŋĪËĪ·ĄĪĪÉĪļĪįĪĶĄĪĪĘĪÞĪģĄĪĪĘĪÞĪšĄĪĪÏĪžĄĪĪÏĪÞĪ°ĪęĄĪĪÏĪâĄĪĪŌĪéĪáĄĪĪÕĪ°ĄĪĪÕĪĘĄĪĪÞĪ°ĪíĄĪĪÞĪđĄĪĪáĪĀĪŦĄĪĪäĪÄĪáĪĶĪĘĪŪ | |
| ÃîÎā | ĪĒĪÖĄĪĪĒĪęĄĪĪĪĪâĪāĪ·ĄĪĪĶĪļĄĪĪŦĄĪĪŊĪâĄĪĪąĪéĄĪĪ·ĪéĪߥĪĪŧĪߥĪĪŦĪŋĪÄĪāĪęĄĪĪĘĪáĪŊĪļĄĪĪÎĪߥĪĪÏĪĻĄĪĪÏĪÁĄĪĪÛĪŋĪëĄĪĪßĪÎĪāĪ·ĄĪĪāĪŦĪĮ | ||
| ÁÛÁüūåĪÎÆ°ĘŠ | ĪĪęĪóĄĪĪęĪåĪĶ | ĪŠĪËĄĪĪŦĪÃĪŅĄĪĪĖĪĻ | |
| ŋĒĘŠ | īÅÁðĄĪĪ·ĪįĪĶĪÖĄĪĪļĪóĪÁĪįĪĶĪēĄĪĪŧĪóĪĀĪóĄĪĪÜĪŋĪóĄĪĪėĪóĪēÁð | ĪŠĪĩĪŽĪŠĄĪĪĒĪķĪߥĪĪĒĪ·ĄĪĪĒĪäĪáĄĪĪĪĪÐĪéĄĪĪĻĪÎĪĄĪĪŦĪ·ĄĪĪŦĪäĄĪĪąĪäĪĄĪĪģĪąĄĪšųĄĪĪĩĪĩĄĪŋųĄĪĪđĪđĪĄĪÃÝĄĪĪŋĪĮĄĪĪČĪÁĄĪĪÉĪóĪ°ĪęĄĪĖîĩÆĄĪĪÞĪŋĪŋĪÓĄĪūūĄĪĖøĄĪĪäĪÞĪâĪâĄĪĪčĪâĪŪ | |
| ÆŧķņÎā | ģĻĮÏĄĪīĮČÄĄĪķâÁŽĄĪ·õĄĪĪģĪŋĪÄĄĪĪĩĪĪĪģĪíĄĪšâÉÛĄĪž§ĀÐĄĪžÜČŽĄĪŧ°ĖĢĀþĄĪžęÎĒ·õĄĪÄęĩŽĄĪÁ·ĄĪĀþđáĄĪĪūĪĶĪĪóĄĪÂĀļÝĄĪÃãÏŌĄĪĪÁĪįĪĶĪÁĪóĄĪÅīËĪĄĪĪÎĪėĪóĄĪČĄĪČ―ĄĪĪÓĪįĪĶĪÖĄĪĘĐÃÅĄĪĪÕĪČĪóĄĪËĀĄĪĪäĪŦĪóĄĪĪčĪĶĪļĪéĪÃĪŅĄĪĪïĪó | ĪĪĪŦĪęĄĪŧåĄĪĪĶĪđĄĪÂįÆéĄĪĪŠĪąĄĪķĀĄĪĪŦĪŪĄĪĪŦĪīĄĪÅáĄĪĪŦĪĘĪÅĪÁĄĪķâĄĪūâĄĪģøĄĪģųĄĪĪŦĪÞĪÉĄĪŧæĄĪĪŦĪßĪ―ĪęĄĪĪŦĪóĪĘĄĪĪĪÍĄĪĪĪęĄĪĪŊĪĪĄĪÅĢĄĪ·ĄĪķŨĄĪĪģĪÞĄĪĪĩĪŠĄĪĪĩĪŦĪšĪĄĪŧŪĄĪĪķĪëĄĪĪ·ĪáĪĘĪïĄĪ―ûĄĪÎëĄĪËÏĄĪĪđĪęĪģĪŪĄĪŋÅĄĪžęđËĄĪÊĄĪĪŋĪéĪĪĄĪĪŋĪëĄĪūóĄĪĪÄĪÜĄĪĪÆĪģĄĪĪČĀÐĄĪĪÄĪÅĪéĄĪĪĘĪŋĄĪĪĘĪïĄĪĪÎĪߥĪĪÏĪĩĪߥĪČĪĄĪĪÏĪ·ĪīĄĪŋËĄĪēÐÂĮĪÁĀÐĄĪĪŌĪâĄĪÂÞĄĪÉŪĄĪ―ŪĄĪÁĨĄĪĪØĪéĄĪČÁĄĪËíĄĪūĢĄĪĪÞĪĘĪĪĪŋĄĪžŠĪŦĪĄĪĪāĪÁĄĪīãķĀĄĪĖðĄĪĪäĪđĪę | ―ÅČĒĄĪĪđĪęČĄĪĪ―ĪíĪÐĪóĄĪĮïŧŌĖÚĄĪĘÛÅöČĒ |
| ÎÁÍý | ĪŧĪóĪŲĪĪĄĪĪŋĪŊĪĒĪóĄĪĪÞĪóĪļĪåĪĶ | ĪĒĪšĪČÓĄĪĪĪĪâ―ÁĄĪĪŦĪÐūÆĄĪĪŦĪæĄĪŧÉŋČĄĪąöĪŦĪéĄĪĪŋĪé―ÁĄĪĪÄĪąĘŠĄĪĪÉĪļĪįĪĶ―ÁĄĪĪĘĪÞĪđĄĪžŅĪ·ĪáĄĪÎäžōĄĪÎäČÓĄĪĪÜĪŋĪâĪÁĄĪČÓĄĪĪâĪÁ | īÅÃãĄĪķâĪÄĪÐĄĪÃÄŧŌĄĪÃãÄŌĪąĄĪÅīËĪ―ÁĄĪÆĶÉå―Á |
| ŋĐÉĘĄĶŋĐšā | ĩíÆýĄĪĪģĪ·ĪįĪĶĄĪĪģĪóĪËĪãĪŊĄĪĪģĪóĪÖĄĪĪĩĪČĪĶĄĪĪĩĪóĪ·ĪįĪĶĄĪĪ·ĪįĪĶĪæĄĪÃãĄĪÆĶÉåĄĪĮžÆĶĄĪÆųĄĪĪßĪ― | ĖýĪĒĪēĄĪĪŦĪÄĪŠĪÖĪ·ĄĪĘÆĄĪžōĄĪąöĄĪŋÝĄĪĪŋĪÞĪī | ūÆÆĶÉå |
| ĖîšÚĄĶšîĘŠ | ĪīĪÜĪĶĄĪĪīĪÞĄĪĪđĪĪĪŦĄĪÂįšŽĄĪĪËĪóĪļĪóĄĪĪŌĪįĪĶĪŋĪóĄĪĪÓĪïĄĪĪæĪš | ËãĄĪūŪÆĶĄĪĪĪĪÍĄĪĪĪĪâĄĪĪĶĪÉĄĪĮߥĪąŧĄĪģÁĄĪĩÆĄĪ·ŠĄĪĪ·ĪáĪļĄĪĪ―ĪÐĄĪĪĀĪĪĪĀĪĪĄĪĪŋĪąĪÎĪģĄĪÄđĪĪĪâĄĪĪĘĪ·ĄĪĪĘĪđĄĪĪÍĪŪĄĪĪÏĪđĄĪĪØĪÁĪÞĄĪĪÞĪÄĪŋĪąĄĪĮþĄĪÅíĄĪŧģĪĪĪâĄĪĪïĪéĪÓ | ĪŦĪÜĪÁĪã |
| °áÉþ | ąĻËđŧŌĄĪēžÂĖĄĪĪšĪĪóĄĪĀãÂĖĄĪĪūĪĶĪęĄĪĪÏĪóĪÆĪó | ÂÓĄĪģÞĄĪĪŦĪŋĪÓĪéĄĪĪŦĪßĪ·ĪâĄĪĪŦĪĩĄĪūŪÂĩĄĪ°áĄĪĪŋĪđĪĄĪÂÂÞĄĪąĐŋĨĄĪÆüĪŽĪĩĄĪŋķÂĩĄĪĪßĪÎĄĪĪāĪÄĪĄĘĪŠĪāĪÄĄËĄĪĪïĪéĪļ | ąÛÃæĪÕĪóĪÉĪ·ĄĪĮōĪāĪŊĄĪđâēžÂĖĄĪĪÞĪÁīŽĪĄĪĪŦĪÖĪČĄĪĪļĪåĪÐĪó |
ĄĄĪģĪėĪÏĄÖļÁĪČĪĪĪĶĨÆĨĨđĨČĨŋĨĪĨŨĪËĪŠĪąĪëļėžïĄĘĖūŧėĄËĪÎĘŽÉÛĄŨĪōÉ―ĪïĪđķčĘŽÉ―ĪĮĪĒĪęĄĪžÂšÝĪËēŋĪÎĖōĪËÎĐĪÄĪÎĪŦĪÏĘŽĪŦĪéĪĘĪĪĪâĪÎĪÎĄĪÄŊĪáĪÆĪĪĪÆĪĘĪóĪĀĪŦĪŠĪâĪ·ĪíĪĪĄĨĪĘĪóĪéĪŦĪÎĘýËĄĪĮļėŨÃļĶĩæĪËđŨļĨĪ·Ī―ĪĶĪĘÍ―īķĪŽĪđĪëĄĨĪģĪėĪōąŅļėĪÎļÁĪĮĪâĪäĪÃĪÆĪßĪŋĪéĄĪĪ―ĪėĪĘĪęĪËĪŠĪâĪ·ĪíĪŊĪĘĪëĪŦĪâĪ·ĪėĪĘĪĪĄĨ
ĄĄĪģĪÎķčĘŽÉ―Īō·ĮĪēĪŋļåĪĮĄĪĖÚēž (88) ĪŽžĄĪÎĪčĪĶĪËĨģĨáĨóĨČĪ·ĪÆĪĪĪëĄĨ
ĄĄÆŧķņĄĪ°áÉþĪĘĪÉĪÏĄĪÍÎÉũē―ĄĪĩĄģĢē―ĪŽŋĘĪóĪĀļ―šßĪĮĪÏĄĪĪÛĪČĪóĪÉļŦĪéĪėĪĘĪŊĪĘĪÃĪÆĪ·ĪÞĪÃĪŋĪâĪÎĪŽÂŋĪŊĪĒĪęĪÞĪđĄĨĀļģčĪŽĘØÍøĪËĪĘĪÃĪŋČūĖĖĄĪÆüËÜĪÎÅÁÅýÅŠĪĘĀļģčĪÎÆŧķņĪŽĪ·ĪĀĪĪĪËŧäĪŋĪÁĪÎĪÞĪïĪęĪŦĪéŧŅĪōūÃĪ·ĪÆĪĪĪÞĪđĄĨĪ―Ī·ĪÆĄĪĪŠĪâĪ·ĪíĪĪĪģĪČĪËĄĪŋ·Ī·ĪŊšîĪéĪėĪŋĘØÍøĪĘÆŧķņĪÏĄĪĪÞĪĀĄĪÎōŧËĪŽĀõĪĪĪŧĪĪĪŦĄĪĪģĪČĪïĪķĪÎĪĘĪŦĪËĪÏļŦĪÄĪŦĪęĪÞĪŧĪóĄĨūÍčĄĪĨÆĨėĨÓĪäĨéĨļĨŠĄĪĪŧĪóĪŋĪŊĩĄĄĪĪ―ĪĶĪļĩĄĪĘĪÉĪČĪĪĪÃĪŋĪģĪČĪÐĪōŧČĪÃĪŋĪģĪČĪïĪķĪŽĪĮĪĪëĪŦĪâĪ·ĪėĪÞĪŧĪóĪÍĄĨ
ĄĄÆ°ĘŠĪËĪ·ĪÆĪâĄĪŋĒĘŠĪËĪ·ĪÆĪâĄĪÃîĪËĪ·ĪÆĪâĄĪĪŋĪŊĪĩĪóĪÎĖūÁ°ĪōĄĪĪģĪČĪïĪķĪÎÃæĪËļŦĪëĪģĪČĪŽĪĮĪĪÞĪđĄĨĪģĪÎÃæĪÎēŋžïÎāĪŦĪÏĄĪĪâĪĶĪïĪŋĪ·ĪŋĪÁĪÎĪÞĪïĪęĪĮĪÏļŦĪëĪģĪČĪŽĪĮĪĪÞĪŧĪóĄĨžŦÁģĮËēõĪŽŋĘĪóĪĮĄĪŋđĪäĖîļķĪäūÂĪŽĪĘĪŊĪĘĪęĄĪĀîĪâģĪĪâŧŅĪōĘŅĪĻĪÄĪÄĪĒĪęĪÞĪđĄĨŧäĪŋĪÁĪÎĀļģčĪōĘØÍøĪËĪ·ĄĪĪčĪęđâÅŲĪĘĘļĖĀĪōšîĪęūåĪēĪëĪŋĪáĪËĪÏĄĪĪĪĪŋĪ·ĪŦĪŋĪĘĪĪÂĶĖĖĪâĪĒĪëĪÎĪĮĪđĪŽĄĪĪģĪėĪéĪÎĪģĪČĪïĪķĪōĘđĪŊĪŋĪÓĪËĄĪĪĩĪÓĪ·ĪĪĩĪŧýĪÁĪËĪĘĪęĪÞĪđĪÍĄĨ
ĄĄģÆļĀļėĪÎļÁĪČĪĪĪĶĪÎĪÏĄĪĪĪĪíĪóĪĘĘýĖĖĪŦĪéĨĮĨĢĨđĨŦĨÃĨ·ĨįĨóĪÎÂęšāĪČĪĘĪęĪ―ĪĶĪĀĄĨ
ĄĄĄĶ ĖÚēž ÅŊĀļĄĄĄØĪģĪČĪïĪķĪËĪĶĪ―ĪÏĪĘĪĪĄĐĄŲĄĄĨĒĨęĨđīÛĄĪ1997ĮŊĄĨ
2018-06-08 Fri
ĒĢ #3329. ĪĘĪžļ―ÂåĪÏūĘÎŽĄĘļėĄËĪŽÂŋĪĪĪÎĪŦĄĐ [abbreviation][shortening][acronym][blend][lexicology][word_formation][productivity][sociolinguistics][sobokunagimon]
ĄĄ·ÐļģÅŠĪĘŧöžÂĪČĪ·ĪÆĄĪąŅļėĪĮĪâÆüËÜļėĪĮĪâļ―ÂåĪÏ°ėČĖĪËūĘÎŽĄĘļėĄËĪηÁĀŪĪŠĪčĪÓŧČÍŅĪŽÂŋĪĪĄĨļ―ÂåĪÎĪģĪÎÄŽÎŪĪËĪÄĪĪĪÆĪÏĄĪĄÖ#625. ļ―ÂåąŅļėĪÎĘļËĄĘŅē―ĪËļŦĪéĪėĪë·đļþĄŨ ([2011-01-12-1])ĄĪĄÖ#631. blending ĪÎģČÂįĄŨ ([2011-01-18-1])ĄĪĄÖ#876. ļ―ÂåąŅļėĪËĪŠĪąĪëĪŦĪÐĪóļėĪÎĀļŧšĀĪÏËÜÅöĪËđâĪĪĪŦĄĐĄŨ ([2011-09-20-1])ĄĪĄÖ#878. Algeo ĪČ Bauer ĪÎŋ·ļėĨ―ĄžĨđÄīššĪÎČæģÓĄŨ ([2011-09-22-1])ĄĪĄÖ#879. Algeo ĪÎŋ·ļėĨ―ĄžĨđÄīššĪŦĪéžĻšķĪĩĪėĪëÄĖŧþÅŠ·đļþĄŨ([2011-09-23-1])ĄĪĄÖ#889. acronym ĪÎ20ĀĪĩŠĄŨ ([2011-10-03-1])ĄĪĄÖ#2982. ļ―ÂåÆüËÜļėĪË°îĪėĪëĨĒĨëĨÕĨĄĨŲĨÃĨČÆŽŧúļėĄŨ ([2017-06-26-1]) ĪĘĪÉĪÎĩŧöĪĮŋĻĪėĪÆĪĪŋĄĨļ―ÂåąŅļėĪÎŋ·ļė·ÁĀŪĪČĪ·ĪÆĄĪģÆžïĪÎūĘÎŽ (abbreviation) ĪōīÞĪāÃŧ―Ė (shortening) ĪÏĮËÃÝĪÎĀŠĪĪĪōžĻĪ·ĪÆĪĪĪëĄĨ
ĄĄĪĮĪÏĄĪĪĘĪžļ―ÂåĪÏūĘÎŽĄĘļėĄËĪŽĪģĪÎĪčĪĶĪËÂŋÍŅĪĩĪėĪëĪÎĪĀĪíĪĶĪŦĄĨĪģĪėĪËĪÄĪĪĪÆÂįģØĪΞøķČĪĮĨÖĨėĨđĨČĪ·ĪÆĪßĪŋĪéĄĪĪĪĪíĪĪĪíĪČķ―ĖĢŋžĪĪ°ÕļŦĪŽ―ļĪÞĪÃĪŋĄĨĪÞĪČĪáĪëĪČĄĪ°ĘēžĪÎ3ÅĀĪÛĪÉĪËđĘĪéĪėĪëĄĨ
ĄĄĄĶ ŧþīÖÃŧ―ĖĄĪĨĻĨÍĨëĨŪĄžÃŧ―ĖĪÎÍßĩáĪÎđâĪÞĪęĄĨūðĘóĪÎđâĖĐÅŲē― (densification) ĪηđļþĄĨ
ĄĄĄĶ ūĘÎŽÉ―ļ―ĪōŧČĪÃĪÆĪĪĪëŋÍĪÏĄĪļĩĪÎÉ―ļ―ĪäĪ―ĪÎŧØžĻÂÐūÝĪËĪÄĪĪĪÆĀšÄĖĪ·ĪÆĪĪĪëĪČĪĪĪĶīķģÐĄĪĪđĪĘĪïĪÁĄÖŧČĪĪĪģĪĘĪ·ĪÆĪĪĪëīķĄŨĪŽĪĒĪëĄĨĪ―ĪÎĨâĨÎĪäĖūÁ°ĪōÃÎĪéĪĘĪĪŋÍĪËÂÐĪ·ĪÆÍĨąÛīķĪÎĪčĪĶĪĘĪâĪÎĪŽĪĒĪëĪÎĪĮĪÏĪĘĪĪĪŦĄĨļĩĪÎÉ―ļ―ĪōÃŧĪŊĘøĪđĪČĪĪĪĶÁāšîĪÏĄĪĪ―ĪÎÉ―ļ―Īō―ÏÃÎĪ·ĪÆĪĪĪëĪČĪĪĪĶÁ°ÄóĪÎūåĪËĀŪĪęÎĐĪÄĪŋĪáĄĪļžŋÍīķĪōÉšĪïĪŧĪëĪģĪČĪŽĪĮĪĪëĄĨ
ĄĄĄĶ ūĘÎŽĄĘļėĄËĪōÍŅĪĪĪëÆ°ĩĄĪÏĪĪĪÄĪÎŧþÂåĪËĪâĪĒĪÃĪŋĪÏĪšĪĀĪŽĄĪĪŦĪÄĪÆĪÏļĀļėŧČÍŅĪËĪŠĪąĪëĄÖÂÄÍîĄŨĪČĪĪĪĶÉéĪÎĨėĨÃĨÆĨëĪōÅ―ĪéĪėĪŽĪÁĪĮĄĪŧČÍŅĪŽÍÞĀĐĪĩĪėĪë·đļþĪŽĪĒĪÃĪŋĄĨĪ·ĪŦĪ·ĄĪļ―ÂåĪÏžŌēņÅŠĪĘĮûĪęĪŽīËĪóĪĮĪĪÆĪŠĪęĄĪĪ―ĪÎĪčĪĶĪĘĄÖÂÄÍîĄŨĪŽĪŦĪÄĪÆĪčĪęĪâĩöÍÆĪĩĪėĪëÉũÄŽĪŽĪĒĪëĪŋĪáĄĪĀøšßÅŠĪĘūĘÎŽÍßĩáĪŽļēšßē―Ī·ĪÆĪĪŋĪČĪĪĪĶĪģĪČĪĮĪÏĪĘĪĪĪŦĄĨ
ĄĄ2ÅĀĖÜĪÎĄÖŧČĪĪĪģĪĘĪ·ĪÆĪĪĪëīķĄŨĪÎŧØÅĶĪŽąÔĪĪĪČŧŨĪĶĄĨĪģĪėĪÏĄĪĄÖ#1946. ĩĄĮ―ÅŠĪĘīŅÅĀĪŦĪéĪßĪëÃŧē―ĄŨ ([2014-08-25-1]) ĪĮŋĻĪėĪŋĄÖīķūðÅŠĪĘļúēĖĄŨ ("emotive effects") ĪÎČŊÅļČĮĪČđÍĪĻĪéĪėĪëĪ·ĄĪĄÖ#3075. ÎŽļėĪČ°ÅđæĄŨ ([2017-09-27-1]) ĪĮļĀĩÚĪ·ĪŋĄÖČëÆŋĪÎĖÜÅŠĄŨĪËĪâÄĖĪļĪëĄĨĪđĪĘĪïĪÁĄĪĪģĪÎļŦēōĪÏĄĪĪĒĪëĨâĨÎĪäÉ―ļ―ĪōÃÎĪÃĪÆĪĪĪëĪŦČÝĪŦĪËĪčĪÃĪÆÏÃžÔĄĘ―ļÃÄĄËĪōķčĘĖē―ĪđĪëĪČĪĪĪĶĄĪĪđĪ°ĪėĪÆžŌēņļĀļėģØÅŠĪĘĩĄĮ―ĪÎÂļšßĪōžĻšķĪ·ĪÆĪĪĪëĄĨĪģĪėĪōžŌēņģØÅŠĪËĘŽĀÏĪđĪėĪÐĄĪĄÖŧþÂåĪÎÎŪĪėĪŽÂŪĪđĪŪĪëĪŋĪáĪËĄĪĀĪÂåšđĪËĪčĪëžŌēņĪÎĘŽÃĮĪâ·ãĪ·ĪŊĪĘĪÃĪÆĪĪÆĪŠĪęĄĪĪ―ĪÎÄøÅŲĪōÉ―ĪïĪđŧØÉļĪČĪ·ĪÆūĘÎŽĄĘļėĄËĪÎÂŋÍŅĪŽĮ§ĪáĪéĪėĪëĄŨĪČĪĪĪĶĪģĪČĪĮĪÏĪĘĪĪĪĀĪíĪĶĪŦĄĨ
2018-04-27 Fri
ĒĢ #3287. ĨŋĨŽĨíĨ°ļėļėŨÃĪÎŧ°ÁØđ―ÂĪ [tagalog][lexicology][lexical_stratification]
ĄĄąŅļėļėŨÃĪŠĪčĪÓÆüËÜļėļėŨÃĪÎŧ°ÁØđ―ÂĪĪËĪÄĪĪĪÆĄĪĄÖ#334. ąŅļėļėŨÃĪÎŧ°ÁØđ―ÂĪĄŨ ([2010-03-27-1]) ĪäĄÖ#335. ÆüËÜļėļėŨÃĪÎŧ°ÁØđ―ÂĪĄŨ ([2010-03-28-1]) ĪōŧÏĪáĪČĪ·ĪÆĄĪĄÖ#2977. ÏĒšÜÂč6ēóĄÖĪĘĪžąŅļėļėŨÃĪË3ÁØđ―ÂĪĪŽĪĒĪëĪÎĪŦĄĐ --- ĨëĨÍĨĩĨóĨđīüĪÎĨéĨÆĨóļėĪŦĪÖĪėĪČĨĪĨóĨŊÔäļėÏĀÁčĄŨĄŨ ([2017-06-21-1]) ĪËÄĨĪÃĪŋĨęĨóĨŊĀčĪÎÂŋĪŊĪÎĩŧöĪĮžčĪęūåĪēĪÆĪĪŋĄĨ
ĄĄĨÕĨĢĨęĨÔĨóĪĮšĮĪâđĪŊÏÃĪĩĪėĪëĨŋĨŽĨíĨ°ļėĄĘTagalog; ļøž°ĖūūÎ PilipinoĄËĪËĪâĄĪąŅļėĪäÆüËÜļėĪÎĪâĪÎĪČīËĪŊČæģÓĪĩĪėĪëŧ°ÁØđ―ÂĪĪŽĪĒĪëĪČÃÎĪÃĪŋĄĨĮØ·ĘĪËĪÏĄĪĄÖ#1589. ĨÕĨĢĨęĨÔĨóĪÎąŅļėŧöūðĄŨ ([2013-09-02-1])ĄĪĄÖ#1593. ĨÕĨĢĨęĨÔĨóĪÎąŅļėŧöūð (2)ĄŨ ([2013-09-06-1]) ĪĮūŌēðĪ·ĪŋĄĪķáÂåīüĪÎĨđĨÚĨĪĨóĪäĨĒĨáĨęĨŦĪËĪčĪëŧŲĮÛĪÎÎōŧËĪŽĪĒĪëĄĨļėŨÃĪÎēžÁØĄĪÃæÁØĄĪūåÁØĪōđ―ĀŪĪđĪëĪÎĪÏĄĪĪ―ĪėĪūĪėĨŋĨŽĨíĨ°ļėĄĘËÜÍčļėĄËĄĪĨđĨÚĨĪĨóļėĄĪąŅļėĪÎÃąļė·ēĪĮĪĒĪëĄĨēÏļķ (70) Īō°úÍŅĪ·ĪčĪĶĄĨ
ĄĄĪģĪģĪĮĄĪĨŋĨŽĨíĨ°ļėĪÎŧ°―Åđ―ÂĪĪËŋĻĪėĪëĪŲĪĪĀĪíĪĶĄĨĪ―ĪėĪÏĨŋĨŽĨíĨ°ļėĪÎļėŨÃĪËĪÏŧ°―Åđ―ÂĪĄĘļĩÍčĪÎĨŋĨŽĨíĨ°ļėĪÎļėŨÃĄĪĨđĨÚĨĪĨóļė·ÏĪÎļėŨÃĄĪąŅļė·ÏĪÎļėŨÃĄËĪŽļŦĪéĪėĪëĪģĪČĪĮĪĒĪëĄĨĪĒĪëŧöĘÁĪōžĻĪđĪÎĪËĄĪŧ°žïÎāĪÎÉ―ļ―ËĄĪŽĘÂÎóĪ·ĪÆĪĪĪëūėđįĪŽĪĒĪëĄĨĪŋĪČĪĻĪÐĄĪĪŠķâĪÎÃą°ĖĪĮ50ĨÚĨ―ĪōžĻĪđĪČĪĪËĪÏĄĪlimampung piso ĄĘĨŋĨŽĨíĨ°ļėĄËĄĪsingkwenta pesos ĄĘĨđĨÚĨĪĨóļėĄËĄĪfifty pesos ĄĘąŅļėĄËĪÎĪđĪŲĪÆĪÎÉ―ļ―ĪŽēÄĮ―ĪĮĪĒĪęĄĪŧÔūėĪĮĪÏĄĪĪÉĪÎÉ―ļ―Īâ――ĘŽĪËÍýēōĪĩĪėĪëĄĨĪÉĪėĪōÁŠÂōĪđĪëĪŦĪÏÁęžęĪäūõķ·ĪËĪčĪÃĪÆÄęĪÞĪÃĪÆĪĪĪŊĄĨ
ĄĄĪģĪģĪĮĄĪÆüËÜļėĪÎÂηÏĪōđÍĪĻĪÆĪßĪčĪĶĄĨÆüËÜļėĪÎļėŨÃĪÏĄĪÏÂļėĄ―īÁļėĄ―ģ°ÍčļėĪŦĪéĀŪĪęÎĐĪÃĪÆĪĪĪëĄĨĪŦĪĘĪęķŊ°úĪĘĨĒĨĘĨíĨļĄžĪĮĪĒĪëĪŽĄĪĨÕĨĢĨęĨÔĨóĪĮĪÏĄĪļĩÍčĪÎĨŋĨŽĨíĨ°ļėĄ―ĨđĨÚĨĪĨóļėĄ―ąŅļėĪÎļėŨÃĪÏĄĪÏÂļėĪÎĪčĪĶĪĘĩĄĮ―ĪōēĖĪŋĪ·ĪÆĪĪĪëĄĨĪÄĪÞĪę kumain ĄĘŋĐĪŲĪëĄË uminom ĄĘ°ûĪāĄËĪÎĪčĪĶĪĘīðËÜļėĪĮĪĒĪëĄĨĨđĨÚĨĪĨóļėĪÎļėŨÃĪÏĄĪĨđĨÚĨĪĨóŧþÂåĪËžčĪęÆþĪėĪéĪėĪŋ―ĄķĩĄĪžŌēņÁČŋĨĄĪ˥ΧĄĪÅýžĢĨ·ĨđĨÆĨāĪËīØĪđĪëļėĪŽÂŋĪŊĄĪÆüËÜļėĪÎÃæĪĮĪÎīÁļėĪÎĪčĪĶĪĘÆŊĪĪōĪ·ĪÆĪĪĪëĄĨabogado ĄĘĘÛļîŧÎĄËĄĪmunisipyo ĄĘŧÔĄËĪĘĪÉĪÎļėŨÃĪĮĪĒĪëĄĨąŅļėĪÏļ―ÂåÅŠĪĘĀĐÅŲĄĶģĩĮ°ĪōžĻĪ·ĄĪĀŊÉÜĄĪēĘģØĩŧ―ŅĄĪĨÓĨļĨÍĨđĄĪŧšķČĄĪļäģÚĪËīØÏĒĪđĪëļėŨÃĪŽÂŋĪŊĄĪÆüËÜļėĪËĪŠĪąĪëģ°ÍčļėĪËÁęÅöĪđĪëĄĨÎãĪĻĪÐĄĪmiting ĄĘĨߥžĨÆĨĢĨóĨ°ĄËĄĪweyter ĄĘĨĶĨ§ĨĪĨŋĄžĄËĄĪkabinet ĄĘÆâģÕĄËĪĘĪÉĪĮĪĒĪëĄĨ
ĄĄĪŋĪĀĄĪļĩÍčĪÎĨŋĨŽĨíĨ°ļėĄĪĨđĨÚĨĪĨóļėĄĪąŅļėĪČĪâÆąĪļĨĒĨëĨÕĨĄĨŲĨÃĨČĪōÍŅĪĪĪÆĪĪĪëĪÎĪĮĄĪÆüËÜļėĪČČæĪŲĪėĪÐĄĪÁęļßĪÎĩũÎĨīķĪÏūŊĪĘĪĪĄĨÆüËÜļėĪĮĪÏĄĪĪŌĪéĪŽĪĘĄĘÏÂļėĄËĄĪīÁŧúĄĘīÁļėĄËĄĪĨŦĨŋĨŦĨĘĄĘģ°ÍčļėĄËĪČĄĪĘĖĄđĪÎÉ―ĩËĄĪŽĪĒĪęĄĪļßĪĪĪΰãĪĪĪŽšÝÎĐĪÃĪÆĪĪĪÆĄĪ―ņĪļĀÍÕĪÎūėđįĪÏČÝąþĪĘĪ·ĪËĄĪļßĪĪĪΰãĪĪĪō°ÕžąĪ·ĪÆĪ·ĪÞĪĶĄĨ
ĄĄ°úÍŅĪΚĮļåĪÎÃĘÍîĪĮ―ŌĪŲĪéĪėĪÆĪĪĪëĪģĪČĪÏĄĪąŅļėļėŨÃĪËĪŠĪąĪëŧ°ÁØđ―ÂĪĪËĪÄĪĪĪÆĪâļĀĪĻĪëĄĨąŅļėĪĮĪâĘļŧúžïĪÏūïĪËĨíĄžĨÞĨóĄĶĨĒĨëĨÕĨĄĨŲĨÃĨČĪÎĪßĪĮĪĒĪëĪŦĪéĄĪļŦĪŋĖÜĪĮĪÎļėžïĪÎķčĘĖĪÏÆüËÜļėĪÎūėđįĪËČæĪŲĪÆÃøĪ·ĪŊĪĘĪĪĄĨ
ĄĄąŅļėĄĪÆüËÜļėĄĪĨŋĨŽĨíĨ°ļėĪÎļėŨÃĪÎīÖĪËČæģÓĪĩĪėĪëŧ°ÁØđ―ÂĪĪŽģÎĮ§ĪĩĪėĪëĪČĪÏĪĪĪÃĪÆĪâĄĪĪ―ĪÎĩŽĖÏĄĪĘŽÉÛĄĪĪĒĪęĘýĪÏĪ―ĪėĪūĪėÆČžŦĪÎĪâĪÎĪĀĪíĪĶĄĨĀĪģĶÃæĪÎļĀļėĪōÄīššĪđĪėĪÐĄĪĪģĪÎĪčĪĶĪĘļėŨÃĪÎģŽÁØđ―ÂĪĪÏĪĒĪëÄøÅŲļŦĪéĪėĪëĪâĪÎĪŦĪâĪ·ĪėĪĘĪĪĪŽĄĪÅöĪŋĪęÁ°ĪÎĪčĪĶĪËÂŋĪŊÂļšßĪđĪëĪČĪÏŧŨĪĻĪĘĪĪĄĨČæģÓÅŠÆðÛĪĘÎāŧũÅĀĪĮĪĒĪëĪČÍýēōĪ·ĪÆĪŠĪĪĪÆÂÅÅöĪĀĪíĪĶĄĨ
ĄĄĄĶ ēÏļķ ―ÓūžĄĄĄÖÂč3ūÏĄĄĨÕĨĢĨęĨÔĨóĪÎđņļėĀŊšöĪÎÎōŧËĄĄĄ―ĨŋĨŽĨíĨ°ļėĪŦĪéĨÕĨĢĨęĨÔĨÎļėĪØĄ―ĄŨĄĄēÏļķ―ÓūžĄĘĘÔÃøĄËĄØĀĪģĶĪÎļĀļėĀŊšöĄĄÂūļĀļėžŌēņĪČÆüËÜĄŲĄĄĪŊĪíĪ·ĪŠ―ÐČĮĄĪ2002ĮŊĄĨ65--97ĘĮĄĨ
2018-04-16 Mon
ĒĢ #3276. Churchill ĪÎ We Shall Fight on the Beaches ąéĀâ [popular_passage][lexicology][lexical_stratification]
ĄĄĀčÆüĄĪĄØĨĶĨĢĨóĨđĨČĨóĄĶĨÁĨãĄžĨÁĨëĄŋĨŌĨČĨ饞ĪŦĪéĀĪģĶĪōĩßĪÃĪŋÃËĄŲĄĘļķÂę Darkest HourĄËĪōīŅĪËđÔĪÃĪŋĄĨĨĒĨŦĨĮĨߥžūÞĪĮ Gary Oldman ĪŽžįąéÃËÍĨūÞĪōģÍÆĀĪ·ĄĪÆüËÜŋÍĪÎÄÔ°ėđ°ŧáĪŽĨáĨĪĨŊĨĒĨÃĨŨūÞĪō―éžõūÞĪ·ĪŋĄĨĨĀĨóĨąĨëĨŊĪÎĀïĪĪĪōĀĐĪđĪëĪģĪČĪËĪĘĪëĨĪĨŪĨęĨđšËÁę Winston Churchill ĪÎĄĪÂÐĨÉĨĪĨÄĀïĀþĪÎķėĮšĪōÄÖĪÃĪŋšîÉĘĪĮĪĒĪëĄĨūÜšŲĪÏūĘĪŊĪŽĄĪąĮēčĪĮĪÏĪŦĪÎÍĖūĪĘ We Shall Fight on the Beaches ĪÎąéĀâĪÎĨ·ĄžĨóĪŽšÆļ―ĪĩĪėĪëĄĨ1940ĮŊ6·î4ÆüĪÎēžąĄĪËĪŠĪąĪëąéĀâĪĮĪĒĪëĄĨ°ĘēžĪËĄĪąéĀâĪΚĮļåĪÎÉôĘŽĪōÅūšÜĪ·ĪčĪĶĄĘÅĩĩōĪÏĪģĪÁĪéĄËĄĨąĮēčĪĮĪÏĪĘĪŊËÜĘŠĪÎēŧļŧĪÏĄĪĪģĪÁĪéĪĘĪÉĪŦĪé YouTube ĪĮŧëÄ°ĪĮĪĪëĄĨ
I have, myself, full confidence that if all do their duty, if nothing is neglected, and if the best arrangements are made, as they are being made, we shall prove ourselves once again able to defend our Island home, to ride out the storm of war, and to outlive the menace of tyranny, if necessary for years, if necessary alone. At any rate, that is what we are going to try to do. That is the resolve of His Majesty's Government --- every man of them. That is the will of Parliament and the nation. The British Empire and the French Republic, linked together in their cause and in their need, will defend to the death their native soil, aiding each other like good comrades to the utmost of their strength. Even though large tracts of Europe and many old and famous States have fallen or may fall into the grip of the Gestapo and all the odious apparatus of Nazi rule, we shall not flag or fail. We shall go on to the end, we shall fight in France, we shall fight on the seas and oceans, we shall fight with growing confidence and growing strength in the air, we shall defend our Island, whatever the cost may be, we shall fight on the beaches, we shall fight on the landing grounds, we shall fight in the fields and in the streets, we shall fight in the hills; we shall never surrender, and even if, which I do not for a moment believe, this Island or a large part of it were subjugated and starving, then our Empire beyond the seas, armed and guarded by the British Fleet, would carry on the struggle, until, in God's good time, the New World, with all its power and might, steps forth to the rescue and the liberation of the old.
ĄĄĪģĪÎąéĀâĪōąŅļėļėŨÃĄĘŧËĄËĪÎīŅÅĀĪŦĪéĪßĪëĪČĄĪĨŊĨéĨĪĨÞĨÃĨŊĨđĪÎ we shall fight on the beaches ĪÎĪŊĪĀĪęĪĮÍŅĪĪĪéĪėĪÆĪĪĪëļėŨÃĪŽģĩĪÍąŅļėËÜÍčļėĪĮĪĒĪëĪģĪČĪŽĄĪŧûß·―âĀčĀļĪÎĄØąŅļėĪÎÎōŧËĄŲ (pp. 48--50) ĪĮŋĻĪėĪéĪėĪÆĪĪĪëĄĨĪģĪÎēÕ―ęĪËĨÕĨéĨóĨđļėĪäĨéĨÆĨóļėÍģÍčĪÎļėŨÃĪŽËÉŲĪËŋĨĪęļōĪžĪéĪėĪÆĪĪĪŋĪéĄĪĨĪĨŪĨęĨđđņĖąĪËĪĩĪÛĪÉžõĪąĪĘĪŦĪÃĪŋĪŦĪâĪ·ĪėĪĘĪĪĄĨÎōŧËĪōĘŅĪĻĪŋĪŦĪâĪ·ĪėĪĘĪĪĄĘĄĐĄËËÜÍčļėŧČÍŅĪČĪĪĪĶĪïĪąĪĀĄĨ
ĄĄąŅļėļėŨÃĪΞïÎāĪČģŽÁØĀĪËĪÄĪĪĪÆĪÏĄĪĄÖ#334. ąŅļėļėŨÃĪÎŧ°ÁØđ―ÂĪĄŨ ([2010-03-27-1]) ĪäĄÖ#2977. ÏĒšÜÂč6ēóĄÖĪĘĪžąŅļėļėŨÃĪË3ÁØđ―ÂĪĪŽĪĒĪëĪÎĪŦĄĐ --- ĨëĨÍĨĩĨóĨđīüĪÎĨéĨÆĨóļėĪŦĪÖĪėĪČĨĪĨóĨŊÔäļėÏĀÁčĄŨĄŨ ([2017-06-21-1]) ĪÎĩŧöĪÛĪŦĄĪlexical_stratification ĪÎ―ôĩŧöĪōŧēūČĄĨ
ĄĄĄĶ ŧûß· ―⥥ĄØąŅļėĪÎÎōŧËĄŲĄĄÃæąûļøÏĀŋ·žŌĄŌÃæļøŋ·―ņĄÓĄĪ2008ĮŊ.
2018-04-02 Mon
ĒĢ #3262. ļåīüÃæąŅļėĪÎÉļ―āē―ĪËĪŠĪąĪë "intensive elaboration" [lme][standardisation][latin][french][register][terminology][lexicology][loan_word][lexical_stratification]
ĄĄĄÖ#2742. Haugen ĪÎļĀļėÉļ―āē―ĪÎ4ÃĘģŽĄŨ ([2016-10-29-1]) ĪäĄÖ#2745. Haugen ĪÎļĀļėÉļ―āē―ĪÎ4ÃĘģŽ (2)ĄŨ ([2016-11-01-1]) ĪĮūŌēðĪ·Īŋ Haugen ĪÎļĀļėÉļ―āē― (standardisation) ĪÎĨâĨĮĨëĪĮĪÏĄĪ·Áž° (form) ĪČĩĄĮ― (function) ĪÎÂÐÃÖĪËĪŠĪĪĪÆÉļ―āē―ĪŽĪČĪéĪĻĪéĪėĪÆĪĪĪëĄĨĪ―ĪėĪËĪčĪëĪČĄĪÉļ―āē―ĪČĪÏ "maximal variation in function" ĪŦĪÄ "minimal variation in form" ĪËÆÃħĪÅĪąĪéĪėĪëļ―ūÝĪĮĪĒĪëĄĨÁ°žÔĪÏ codification (of form)ĄĪļåžÔĪÏ elaboration (of function) ĪËÂÐąþĪđĪëĪČđÍĪĻĪéĪėĪëĄĨ
ĄĄĪ·ĪŦĪ·ĄĪ"elaboration" ĪČĪĪĪĶÍŅļėĪÏÃí°ÕĪŽÉŽÍŨĪĮĪĒĪëĄĨHaugen ĪŽÉļ―āē―ĪÎĩÄÏĀĪĮ°ÕŋÞĪ·ĪÆĪĪĪëĪÎĪÏĄĪÍÍĄđĪĘŧČÍŅ°č (register) ĪĮđĪŊÍŅĪĪĪëĪģĪČĪŽĪĮĪĪëĪČĪĪĪĶ°ÕĖĢĪĮĪÎ "elaboration of function" ĪÎĪģĪČĪĀĪŽĄĪ°ėĘý "elaboration of form" ĪČĪĪĪĶĘĖĪÎēáÄøĪâĄĪļåīüÃæąŅļėĪËĪŠĪąĪëÉļ―āē―ĪČŋžĪŊīØÏĒĪđĪëĪŦĪéĪĀĄĨšŪÍðĪōČōĪąĪëĪŋĪáĪËĄĪHaugen ĪŽŧČĪÃĪŋ°ÕĖĢĪĮĪÎ "elaboration of function" Īō "extensive elaboration" ĪČļÆĪÓĄĪ"elaboration of form" ĪÎĪÛĪĶĪō "intensive elaboration" ĪČļÆĪóĪĮĪâĪĪĪĪĪĀĪíĪĶ (Schaefer 209) ĄĨ
ĄĄĪĮĪÏĄĪ"intensive elaboration" ĪĒĪëĪĪĪÏ "elaboration of form" ĪČĪÏēŋĪōŧØĪđĪÎĪŦĄĨSchaefer (209) ĪËĪčĪėĪÐĄĪĪģĪÎēáÄøĪËĪŠĪĪĪÆĪÏ "the range of the native linguistic inventory is increased by new forms adding further 'variability and expressiveness'" ĪĀĪČĪĪĪĶĄĨÃæąŅļėĪÎļåČūĪÞĪĮĪÏĄĪ―ņĪļĀÍÕĪÎÉļ―āļėĪČĪĪĪĻĪÐĄĪąŅļėĪÎēŋĪéĪŦĪÎĘýļĀĪĮĪÏĪĘĪŊĄĪĪāĪ·ĪíĨéĨÆĨóļėĪäĨÕĨéĨóĨđļėĪČĪĪĪĶģ°đņļėĪĀĪÃĪŋĄĨļåīüĪËĪŦĪąĪÆąŅļėĪŽÉüļĒĪ·ĪÆĪŊĪëĪČĄĪąŅļėĪŽĪ―ĪėĪéĪÎģ°đņļėĪËÂåĪïĪÃĪÆÉļ―āļėĪÎÃÏ°ĖĪË―ĒĪŊĪģĪČĪËĪĘĪÃĪŋĪŽĄĪĪ―ĪΚÝĪËĀčĮÚÉļ―āļėĪŋĪëĨéĨÆĨóļėĪäĨÕĨéĨóĨđļėĪŦĪéÂįÎĖĪÎļėŨÃĪōžõĪą·ŅĪĪĪĀĄĨąŅļėĪÏËÜÍčļėŨÃĪâÂŋĪŊĘÝĪÃĪŋĪÞĪÞĪËĄĪĪ―ĪģĪËūåūčĪŧĪ·ĪÆĄĪĨÕĨéĨóĨđļėĪÎļėŨÃĪČĨéĨÆĨóļėĪÎļėŨÃĪōžčĪęÆþĪėĄĪÁīÂÎĪČĪ·ĪÆ―øÎóĪōĪĘĪđŧ°ÁØđ―ÂĪĪÎļėŨÃĪōģÍÆĀĪđĪëĪËŧęĪÃĪŋĄĘĪģĪÎŧöūðĪËĪÄĪĪĪÆĪÏĄĪĄÖ#334. ąŅļėļėŨÃĪÎŧ°ÁØđ―ÂĪĄŨ ([2010-03-27-1]) ĪäĄÖ#2977. ÏĒšÜÂč6ēóĄÖĪĘĪžąŅļėļėŨÃĪË3ÁØđ―ÂĪĪŽĪĒĪëĪÎĪŦĄĐ --- ĨëĨÍĨĩĨóĨđīüĪÎĨéĨÆĨóļėĪŦĪÖĪėĪČĨĪĨóĨŊÔäļėÏĀÁčĄŨĄŨ ([2017-06-21-1]) ĪÎĩŧöĪōŧēūČĄËĄĨžÚÍŅļėŨÃĪŽÂįÎĖĪËÆþĪęđþĪߥĪ―ņĪļĀÍÕūåĄĪąŅļėĪÎļėŨÃĪŽ―øÎóē―ĪĩĪėšÆĘÔĀŪĪĩĪėĪŋĪČĪĘĪėĪÐĄĪĪģĪėĪÏļĀļėÉļ―āē―ĪōÆÃħĪÅĪąĪë "minimal variation in form" ĪČĪĪĪĶĪčĪęĪÏĄĪĪāĪ·Īí "maximal variation in form" ĪØļþĪŦĪÃĪÆĪĪĪëĪčĪĶĪĘ°õūÝĪđĪéÍŋĪĻĪëĄĨĪģĪΞïĪÎ variation ĪĒĪëĪĪĪÏ variability ĪÎÁýēÃĪōŧØĪ·ĪÆĄĪ"intensive elaboration" ĪĒĪëĪĪĪÏ "elaboration of form" ĪČļÆĪÖĪÎĪĮĪĒĪëĄĨ
ĄĄĪÄĪÞĪęĄĪļĀļėÉļ―āē―ĪËĪÏ·Áž°ūåĪÎĘŅ°ÛĪŽūŪĪĩĪŊĪĘĪëÂĶĖĖĪâĪĒĪėĪÐĄĪ°ÛĪĘĪ랥ļĩĪĮĄĪ·Áž°ūåĪÎĘŅ°ÛĪŽÂįĪĪŊĪĘĪëÂĶĖĖĪâĪĒĪęĪĶĪëĪČĪĪĪĶĪģĪČĪĮĪĒĪëĄĨĪģĪΰėļŦĖ·―âĪđĪëĪčĪĶĪĘÉļ―āē―ĪÎĪĒĪęĘýĪōĄĪSchaefer (220) ĪÏžĄĪÎĪčĪĶĪËĪÞĪČĪáĪÆĪĪĪëĄĨ
While such standardizing developments reduced variation, the extensive elaboration to achieve a "maximal variation in function" demanded increased variation, or rather variability. This type of standardization, and hence norm-compliance, aimed at the discourse-traditional norms already available in the literary languages French and Latin. Late Middle English was thus re-established in writing with the help of both Latin and French norms rather than merely substituting for these literary languages.
ĄĄĄĶ Schaefer Ursula. "Standardization." Chapter 11 of The History of English. Vol. 3. Ed. Laurel J. Brinton and Alexander Bergs. Berlin/Boston: De Gruyter, 2017. 205--23.
2018-03-31 Sat
ĒĢ #3260. ļÅąŅļėĪËĪŠĪąĪëÉļ―āē― [oe][standardisation][orthography][lexicology]
ĄĄļÅąŅļėĪËĪÄĪĪĪÆÉļ―āē― (standardisation) ĪōÏĀĪļĪëšÝĪËžįĪŋĪëÏÃÂęĪČĪĘĪëĪÎĪÏĄĪ(1) ―éīüļÅąŅļėĪÎ "Early West Saxon" ĪĒĪëĪĪĪÏ "Alfredian Old English" ĪÎĀĩ―ņËĄĄĪ(2) ļåīüļÅąŅļėĪÎ "Late West Saxon", "Ælfrician Old English" ĪĒĪëĪĪĪÏ "Standard Old English" ĪÎĀĩ―ņËĄĄĪ(3) "Winchester vocabulary" ĪÎ3ÅĀĪĀĪíĪĶĪŦĄĨĪ―ĪÎĪÛĪŦĪËĪâĄĪ"Mercian literary language" ĪĘĪÉĪâÉļ―āē―ĪČĪĪĪĶđāĖÜĪÎĪâĪČĪĮ°·ĪĪÆĀĪëÏÃÂęĪŦĪâĪ·ĪėĪĘĪĪĄĨ
ĄĄĪģĪėĪéĪÎļÅąŅļėĪÎĄÖÉļ―āļėĄŨĪÏĄĪĄÖ#2745. Haugen ĪÎļĀļėÉļ―āē―ĪÎ4ÃĘģŽ (2)ĄŨ ([2016-11-01-1]) ĪäĄÖ#3209. ļĀļėÉļ―āē―ĪÎ7ĪÄĪÎÂĶĖĖĄŨ ([2018-02-08-1]) ĪĮūŌēðĪ·Īŋ Haugen Īä Milroy and Milroy ĪÎÉļ―āē―ĪÎÍýÏĀÅŠĪĘīð―āĪËūČĪéĪ·ĪÆĪßĪėĪÐĄĪĪĒĪŊĪÞĪĮļÂÄęÅŠĪĘ°ÕĖĢĪĮĪÎĄÖÉļ―āļėĄŨĪËĪđĪŪĪĘĪĪĪČĪÏĪĪĪĻĪëĪĀĪíĪĶĄĨÎãĪĻĪÐ Late West Saxon ĪŽļÅąŅļėĪÎÉļ―āļėĄĘūŊĪĘĪŊĪČĪâĀĩ―ņËĄĪËĪŠĪĪĪÆĄËĪĮĪĒĪëĪČĪĪĪĶŠĪĻĘýĪŽ°ėČĖÅŠĪËĪĘĪÃĪÆĪĪĪëĪŽĄĪĪ―ĪėĪÏ Haugen ĪÎĪĪĪĶ Selection ĪÎÃĘģŽĪō·ÐĪŋÄøÅŲĪËēáĪŪĪšĄĪCodification, Elaboration, Acceptance ĪČĪĪĪĶÂĶĖĖĪËĪÄĪĪĪÆĪÏĪÛĪÜēŋĪâīØĪïĪÃĪÆĪĪĪĘĪĪĄĨļ·ĖĐĪËĪĪĪĶĪÎĪĮĪĒĪėĪÐĄĪĄÖÉļ―āļėĄŨĪĘĪÉĪĮĪÏĪĘĪĪĪČĪĪĪĶĪģĪČĪËĪĘĪëĄĨLate West Saxon ĪËĪÄĪĪĪÆĪÏĄĪĀĩ―ņËĄĪĮĪÏĪĘĪŊĄĪĪāĪ·ĪíķþĀÞ·ÁÂÖÏĀĪËĪŠĪąĪëÉļ―āĄĘē―ĄËĪōÏĀĪļĪëĪÛĪĶĪŽÅŽĀÚĪĮĪÏĪĘĪĪĪŦĪČĪĪĪĶ°ÕļŦĪâĪĒĪë (Kornexl 231) ĄĨ
ĄĄĪ·ĪŦĪ·ĄĪąŅļėŧËÁīÂÎĪÎÎŪĪėĪÎĪĘĪŦĪĮÉļ―āē―ĪōđÍĪĻĪëūåĪĮĪÏĄĪĪäĪÏĪęļÅąŅļėĪÎūõķ·ĪâČæģÓÂÐūÝĪČĪ·ĪÆēĄĪĩĪĻĪÆĪŠĪŊĪÎĪŽĪčĪĪĄĨÎãĪĻĪÐĄĪ―éīüļÅąŅļėĪÎ Early West Saxon ĪČļåīüļÅąŅļėĪÎ Late West Saxon ĪËĪÄĪĪĪÆĪÏĄĪĪ―ĪėĪūĪėĀĩ―ņËĄūåĪÎļÂÄęÅŠĪĘÉļ―āē―ĪōÏĀĪļĪëĪģĪČĪŽĪĮĪĪëĪŽĄĪÎūžÔĪÎīÖĪËĪÏÉŽĪšĪ·ĪâÄĖŧþÅŠĪĘÏĒÂģĀĪÏĪĘĪĪĪČĪĩĪėĪÆĪĪĪëÅĀĪÏ―ÅÍŨĪĮĪĒĪë (Kornexl 230) ĄĨĪÞĪŋĄĪÃæąŅļėļåīüĪŦĪéČŊÃĢĪđĪëÉļ―āļėĪâĄĪĪģĪėĪéĪÎļÅąŅļėĪÎÉļ―āļėĪÎĪĪĪšĪėĪČĪâÏĒÂģĀĪŽĪĘĪĪĄĨĪÄĪÞĪęĄĪąŅļėĪÎÉļ―āē―ĪÏĄĪÎōŧËūåĄĪÆČÎĐĪ·ĪÆēŋÅŲĪŦĀļĪļĪÆĪĪĪëĄĨ
ĄĄļėŨÃĪËīØĪđĪëļÅąŅļėĪÎÉļ―āē―ĪÎŧöÎãĪČĪ·ĪÆĪÏĄĪ"Winchester vocabulary" ĪŽĩóĪēĪéĪėĪëĄĨ10--11ĀĪĩŠĪË "Winchester group/circle" ĪČĖūÉÕĪąĪéĪėĪŋģØĮÉĪŽ Winchester ĪË―ļĪÃĪÆ―ņĪĪĪŋĘļūÏĪÎĪĘĪŦĪËĄĪšöÄęĪĩĪėĪŋĪČĪŠĪÜĪ·Ī°ėÄęĪÎļėŨÃĪŽģÎĮ§ĪĩĪėĪëĄĨĪ―ĪÎģØĮÉĪÎĪĘĪŦĪĮšĮĪâÅĩ·ŋÅŠĪĘÃøžÔĪÏ Ælfric ĪĮĪĒĪęĄĪČāĪÎĨÆĨĨđĨČĪËĪŠĪĪĪÆĪÏ "Winchester vocabulary" ĪΚÎÍŅÎĻĪÏ98.3%ĪËĪâūåĪëĪČĪĪĪĶĄĨĪģĪÎÉļ―āÅŠļėŨÃĪÎĩŊļŧĪŽĪÉĪģĪËĪĒĪëĪÎĪŦĪËĪÄĪĪĪÆĪÏĩÄÏĀĪŽĪĒĪëĪŽĄĪĨéĨÆĨóļėĨÆĨĨđĨČĪŦĪéĪÎļÅąŅļėËÝĖõĪΚÝĪËĖõļėĪČĪ·ĪÆÄęÃåĪ·ĪŋĪâĪÎĪŽÂŋĪĪĪČĪĪĪĶĪģĪČĪŽļĀĪïĪėĪÆĪĪĪëĄĨĪ·ĪŋĪŽĪÃĪÆĄĪĪĒĪë°ÕĖĢĪĮĪÏģ°ĪŦĪéĪΰĩÎÏĪËĪčĪëÉļ―āē―ĪÎŧöÎãĪČĪĪĪĶĪģĪČĪËĪĘĪíĪĶĪŦĄĨ
ĄĄĄĶ Kornexl, Lucia. "Standardization." Chapter 12 of The History of English. Vol. 2. Ed. Laurel J. Brinton and Alexander Bergs. Berlin/Boston: De Gruyter, 2017. 220--35.
2018-03-30 Fri
ĒĢ #3259. 17ĀĪĩŠĪËšîĪéĪėĪŋÆ°ŧėĮÉĀļĖūŧė·ēĪÎÄčĪđĪëĖäÂę (2) [synonym][loan_word][borrowing][renaissance][inkhorn_term][emode][lexicology][word_formation][suffix][affixation][neologism][derivation][statistics]
ĄĄšōÆüĪÎĩŧö ([2018-03-29-1]) ĪÎÂģĘÔĄĨšōÆüžĻĪ·Īŋ Bauer ĪŦĪéĪÎÆ°ŧėĮÉĀļĖūŧėĪÎĨęĨđĨČĪĮĪÏĄĪ-ment Īä -ure ĪÎĀÜČøžĪÎÂļšßĪŽĖÜÎĐĪÃĪÆĪĪĪŋĄĨ17ĀĪĩŠĪÎĖūŧėĪōšîĪëĀÜČøžĪËĪÉĪÎĪčĪĶĪĘžïÎāĪÎĪâĪÎĪŽĪĒĪęĄĪĪ―ĪėĪūĪėĪŽĪĪĪŊĪÄĪÎĖūŧėĪōšîĪÃĪÆĪĪĪŋĪÎĪĀĪíĪĶĪŦĄĨĪģĪėĪËĪÄĪĪĪÆĪâĄĪBauer (185) ĪŽ OED ĪËīðĪÅĪĪĪÆÅý·ŨĪōĪČĪÃĪÆĪĪĪëĄĨ·ëēĖĪÏ°ĘēžĪÎÄĖĪęĄĨ
| Suffix | Number |
| -y | 2 |
| -ery | 8 |
| -ancy | 10 |
| -ency | 10 |
| -ence | 18 |
| -ion | 20 |
| -ance | 49 |
| -al | 56 |
| -ure | 96 |
| -ation | 190 |
| -ment | 258 |
ĄĄĨČĨÃĨŨŋôžïÎāĪÎĀÜČøžĪŽÂįČūĪōĨŦĨÐĄžĪ·ĪÆĪĪĪëĪģĪČĪŦĪéĄĪÉŅÅŲĪÎđâĪĪĄÖÅĩ·ŋÅŠĪĘĄŨĀÜČøžĪŽĪĒĪëĪģĪČĪÏģÎĪŦĪËĪïĪŦĪëĄĨĪ·ĪŦĪ·ĄĪÅĩ·ŋÅŠĪĘĀÜČøžĪŽūŊŋôĪĒĪëĪČĪĪĪĶĪģĪČĪĮĄĪĖäÂęĪŽēō·čĪđĪëĪģĪČĪËĪÏĪĘĪéĪĘĪĪĄĨĪģĪėĪéĪÎÅĩ·ŋÅŠĪĘĀÜČøžĪōīÞĪáĪŋĘĢŋôžïÎāĪÎĀÜČøžĪŽĄĪÆą°ėĪÎīðÂÎĪËĀÜÂģĪ·ÆĀĪŋĪČĪĪĪĶĪģĪČĄĪĪ―Ī·ĪƞšÝĪËĪ―ĪÎĪčĪĶĪËÂĪļėĪĩĪėĘŧÍŅĪĩĪėĪŋĪČĪĪĪĶūõķ·ĪģĪ―ĪŽĄĪĖäÂęĪĀĪÃĪŋĪĮĪĒĪëĄĨ
ĄĄšōÆüĪÎĩŧöĪĮŋĻĪėĪŋĪčĪĶĪËĄĪBauer ĪÏĪģĪÎĖäÂęĪōŋ·ļėĪÎĨËĄžĨšĪËīØĪïĪëĘĢŧĻĪĩĪËĩĒĪ·ĪÆĪĪĪëĪŽĄĪĪ―ĪėĪČīØÏĒĪ·ĪÆĄĪĀļŧšÅŠĪĘĮÉĀļĪËÂÐĪ·ĪÆČóĀļŧšÅŠĪĘĮÉĀļĪØĪΞûÍŨĪâūïĪËÂļšßĪđĪëĪâĪÎĪĀĪČĪĪĪĶžįÄĨĪōÅļģŦĪ·ĪÆĪĪĪëĄĨ
. . . there is a constant application of unproductive morphology in order to solve problems provided by productive morphology, so that the language is continually having new words added to it which are not the forms which would be the predicted ones, as well as a number of predicted forms. That is, the processes of history add irregularities (which are available to turn into regularities if enough of them are coined). History, rather than simplifying matters (or rather than merely simplifying matters), reflects a process of building in extra complications.
ĄĄļĀļėŧČÍŅžÔĪÎŋ·ļėĪØĪÎÍŨĩáĪÏĄĪÉŽĪšĪ·ĪâĀļŧšÅŠĪĘĮÉĀļĪŽÍŋĪĻĪÆĪŊĪėĪëžęÃĘĪČĪ―ĪηëēĖĪĀĪąĪĮĪÏËþĪŋĪĩĪėĪĘĪĪĪÛĪÉĪËĘĢŧĻĪĮĀšĖŊĪĘĪÎĪĀĪíĪĶĄĨĪ―ĪģĪĮĄĪĪĒĪĻĪÆČóĀļŧšÅŠĪĘĮÉĀļĪΞęÃĘĪōÍŅĪĪĪÆĄĪÉÔĩŽÂ§ĪĘĮÉĀļļėĪōšîĪę―ÐĪđĪģĪČĪâĪĒĪëĪÎĪŦĪâĪ·ĪėĪĘĪĪĄĨļ―ÂåĪÎÎōŧËļĀļėģØžÔĪÏĄĪēáĩîĪËĀļĪĪŋļĀļėŧČÍŅžÔĪÎĄĪĪ―ĪÎĪčĪĶĪĘĘĢŧĻĪĮĀšĖŊĪĘÂĪļėŋīÍýĪËĪÉĪģĪÞĪĮĮũĪėĪëĪÎĪĀĪíĪĶĪŦĄĨšĪÆņĪĮĪÏĪĒĪëĪŽĨĻĨĨĩĨĪĨÆĨĢĨóĨ°ĪĘĨÆĄžĨÞĪĮĪĒĪëĄĨ
ĄĄĄĶ Bauer, Laurie. "Competition in English Word Formation." Chapter 8 of The Handbook of the History of English. Ed. Ans van Kemenade and Bettelou Los. Malden, MA: Blackwell, 2006. 177--98.
2018-03-29 Thu
ĒĢ #3258. 17ĀĪĩŠĪËšîĪéĪėĪŋÆ°ŧėĮÉĀļĖūŧė·ēĪÎÄčĪđĪëĖäÂę (1) [synonym][lexical_blocking][loan_word][borrowing][renaissance][inkhorn_term][emode][lexicology][word_formation][suffix][affixation][neologism][derivation][cognate]
ĄĄąŅđņĨëĨÍĨĩĨóĨđīüĪÎ17ĀĪĩŠĪËĪÏĄĪĨéĨÆĨóļėĪäĨŪĨęĨ·ĨĒļėĪōÃæŋīĪČĪđĪë―ôļĀļėĪŦĪéÂįÎĖĪÎļėŨÃĪŽžÚÍŅĪĩĪėĪŋĄĨĪģĪηаÞĪËĪÄĪĪĪÆĪÏĄĪĪģĪėĪÞĪĮĄÖ#478. ―éīüķáÂåąŅļėīüĪËÅōŋåĪÎĪčĪĶĪËžÚĪęĪéĪėĪÆĪÏžÎĪÆĪéĪėĪŋĨéĨÆĨóļėĄŨ ([2010-08-18-1])ĄĪĄÖ#114. ―éīüķáÂåąŅļėĪΞÚÍŅļėĪÎĩŊļŧĪČģäđįĄŨ ([2009-08-19-1])ĄĪĄÖ#1226. ķáÂåąŅļėīüĪËĪŠĪąĪëļėŨÃÁýēÃĪÎĮŊÂåĘĖĘŽÉÛĄŨ ([2012-09-04-1]) ĪĘĪÉĪÎĩŧöĪĮÍÍĄđĪĘģŅÅŲĪŦĪéžčĪęūåĪēĪÆĪĪŋĄĨĪģĪÎŧþÂåĪËĪÏĄĪĪ·ĪÐĪ·ĪÐĄÖÆąĪļļėĄŨĪŽ°ÛĪĘĪÃĪŋĀÜČøžĪōČžĪÃĪÆÃÂĀļĪđĪëĪČĪĪĪĶļ―ūÝĪŽļŦĪéĪėĪŋĄĨÎãĪĻĪÐĄĪĪđĪĮĪË1586ĮŊĪË discovery ĪŽąŅļėļėŨÃĪËēÃĪĻĪéĪėĪÆĪĪĪŋĪČĪģĪíĪËĄĪ17ĀĪĩŠĪËĪĘĪÃĪÆÆąĩÁĪÎ discoverance Īä discoverment Īâļ―ĪïĪėĄĪÃŧīüīÖĪČĪÏĪĪĪĻķĨđįĄĶķĶÂļĪ·ĪŋĪÎĪĮĪĒĪëĄĘīØÏĒĪ·ĪÆĄĪĄÖ#3157. ēÚÎïĪĘĪë splendid ĪÎÆąšŽÎāĩÁļėĄŨ ([2017-12-18-1]) ĪâŧēūČĄËĄĨ
ĄĄ°ĘēžĪÏĄĪBauer (186) ĪŽ OED ĪŦĪéžý―ļĪ·ĪŋĄĪ17ĀĪĩŠĪË―é―ÐĪđĪëÆ°ŧėĮÉĀļĖūŧėĪÎÁČĪĮĪĒĪëĄĨ
| abutment | abuttal | |
| bequeathal | bequeathment | |
| bewitchery | bewitchment | |
| commitment | committal | committance |
| composal | compositure | |
| comprisal | comprisement | comprisure |
| concumbence | concumbency | |
| condolement | condolence | |
| conducence | conducency | |
| contrival | contrivance | |
| depositation | depositure | |
| deprival | deprivement | |
| desistance | desistency | |
| discoverance | discoverment | |
| disfiguration | disfigurement | |
| disproval | disprovement | |
| disquietal | disquietment | |
| dissentation | dissentment | |
| disseveration | disseverment | |
| encompassment | encompassure | |
| engraftment | engrafture | |
| exhaustment | exhausture | |
| exposal | exposement | exposure |
| expugnance | expugnancy | |
| expulsation | expulsure | |
| extendment | extendure | |
| impartment | imparture | |
| imposal | imposement | imposure |
| insistence | insisture | |
| interposal | interposure | |
| pretendence | pretendment | |
| promotement | promoval | |
| proposal | proposure | |
| redamancy | redamation | |
| renewal | renewance | |
| reposance | reposure | |
| reserval | reservancy | |
| resistal | resistment | |
| retrieval | retrievement | |
| returnal | returnment | |
| securance | securement | |
| subdual | subduement | |
| supportment | supporture | |
| surchargement | surchargure |
ĄĄĪģĪėĪéĪÎļėĪÎĪĘĪŦĪËĪÏĄĪļ―šßĪĮĪâÉļ―āÅŠĪĘĪâĪÎĪâĪĒĪėĪÐĄĪĪđĪĮĪËĮŅļėĪČĪĘĪÃĪÆĪĪĪëĪâĪÎĪâĪĒĪëĄĨÃŧīüīÖĪ·ĪŦÍŅĪĪĪéĪėĪĘĪŦĪÃĪŋĪâĪÎĪâĪĒĪėĪÐĄĪđĪŊžõĪąÆþĪėĪéĪėĪŋĪâĪÎĪâĪĒĪëĄĨ17ĀĪĩŠĪčĪęÁ°ĪŦļåĪËšîĪéĪėĪŋÆąĩÁĪÎĮÉĀļĖūŧėĪČķĨđįĪ·ĪŋĪâĪÎĪâĪĒĪėĪÐĄĪĪ―ĪĶĪĮĪĘĪĪĪâĪÎĪâĪĒĪëĄĨĪģĪÎŧþÂåĪÎļåĄĪļ―ÂåĪËŧęĪëĪÞĪĮĪËĄĪĪģĪėĪéĪÎ2―ÅļėĪä3―ÅļėĪÎĘÂÂļūõķ·ĪŽĀ°ÍýĪĩĪėĪÆĪĪĪÃĪŋĨąĄžĨđĪâĪĒĪėĪÐĄĪĪ―ĪĶĪĮĪĘĪĪĨąĄžĨđĪâĪĒĪëĄĨĀ°ÍýĪÎĪĩĪėĘýĪŽ lexical_blocking ĪÎļķÍýĪËĪčĪęĀâĖĀĪĮĪĪëĪâĪÎĪâĪĒĪėĪÐĄĪĪ―ĪĶĪĮĪĘĪĪĪâĪÎĪâĪĒĪëĄĨĪÄĪÞĪęĄĪĪģĪėĪéĪÎÁČĪËĪÄĪĪĪÆ°ėČĖē―Ī·ĪÆļĀĪĻĪëĪģĪČĪÏĪĒĪÞĪęĪĘĪĪĪÎĪĮĪĒĪëĄĨ
ĄĄ17ĀĪĩŠĪËļÂĪéĪĘĪĪĪČĪÏĪĪĪĻĄĪĪČĪęĪïĪąĪģĪÎĀĪĩŠĪËĄĪļßĪĪĪË°ÕĖĢĪō°ãĪĻĪĘĪĪĮÉĀļĖūŧėĪŽĘĢŋôšîĪéĪėĄĪķĨđįĄĶķĶÂļĪ·ĪŋĪČĪĪĪĶŧöžÂĪÏēŋĪōĘŠļėĪëĪÎĪĀĪíĪĶĪŦĄĨĨéĨÆĨóļėĪäĨŪĨęĨ·ĨĒļėĪŦĪéÅōŋåĪÎĪčĪĶĪËļėĪōžÚÍŅĪ·Īŋ·ëēĖĪČĪâĪĪĪĻĪëĪ·ĄĪĪ―ĪėĪéĪŦĪéÃę―ÐĪ·ĪŋĖūŧėĮÉĀļĀÜČøžĪōÍøÍŅĪ·ĪÆĖĩĘýŋËĪËÍÍĄđĪĘĮÉĀļĖūŧėĪōÂĪļėĪ·ĪÆĪĪĪÃĪŋ·ëēĖĪČĪâĪĪĪĻĪëĄĨĪ·ĪŦĪ·ĄĪBauer (197) ĪÏžŌēņļĀļėģØÅŠĪĘīŅÅĀĪŦĪéĄĪžĄĪÎĪčĪĶĪËžĻšķĪ·ĪÆĪĪĪëĄĨ
Individual ad hoc decisions on relevant forms may or may not be picked up widely in the community. . . . [I]t is clear from the history which the OED presents that the need of the individual for a particular word is not always matched by the need of the community for the same word, with the result that multiple coinages are possible.
ĄĄĪĪĪšĪėĪËĪŧĪčĄĪĪģĪÎÎōŧËÅŠŧöūðĪŽĄĪļ―ÂåąŅļėĪÎÆ°ŧėĮÉĀļĖūŧėĪηÁÂÖĪËūŊĪĘĪŦĪéĪĖÉÔÅý°ėĪČšŪÍðĪōĪâĪŋĪéĪ·ÂģĪąĪÆĪĪĪëĪģĪČĪÏŧöžÂĪĮĪĒĪëĄĨšĢļåĄĪĀ°ÍýĪĩĪėĪÆĪæĪŊĪČĪ·ĪÆĪâĄĪĪŠĪ―ĪéĪŊĪ―ĪėĪËĪÏŋôĀĪĩŠĪČĪĪĪĶÄđĪĪŧþīÖĪŽĪŦĪŦĪëĪģĪČĪĀĪíĪĶĄĨ
ĄĄĄĶ Bauer, Laurie. "Competition in English Word Formation." Chapter 8 of The Handbook of the History of English. Ed. Ans van Kemenade and Bettelou Los. Malden, MA: Blackwell, 2006. 177--98.
2018-02-23 Fri
ĒĢ #3224. Thomas Harman, A Caveat or Warening for Common Cursetors (1567) [dictionary][slang][lexicology][lexicography][renaissance][register]
ĄĄšōÆüĪÎĩŧöĄÖ#3223. George Andrews, A Dictionary of the Slang and Cant language (1809)ĄŨ ([2018-02-22-1]) ĪĮĄĪąŅļėŧËūå―éĪÎÂŊļėĄĶąĢļėĪÎÍŅļė―ļĄĪThomas Harman ĪÎ A Caveat or Warening for Common Cursetors (1567) ĪËļĀĩÚĪ·ĪŋĄĨąŅļėŧËūå―éĪÎąŅąŅž―ņĄĪRobert Cawdrey ĪÎ A Table Alphabeticall ĪË30ĮŊ°ĘūåĪâĀčķîĪąĪÆ―ÐČĮĪĩĪėĪŋĪČĪĪĪĶĪÎĪÏķÃĪŊĪŲĪĪģĪČĪËŧŨĪïĪėĪëĪŦĪâĪ·ĪėĪĘĪĪĄĨÉáÄĖĪÎąŅąŅž―ņĪčĪęĪâĄĪÎĒĀĪģĶĪÎÍŅļė―ļĪÎĪÛĪĶĪŽÁáĪĪĪČĪĪĪĶĪÎĪÏĄĪēŋĪĀĪŦĪŠĪâĪ·ĪíĪĪĄĨ
ĄĄĪ·ĪŦĪ·ĄĪĨëĨÍĨĩĨóĨđīü°ĘÁ°ĪÎĨĪĨóĨ°ĨéĨóĨÉĪËĪŠĪąĪëž―ņĘÔŧžĪηаÞĪōŋķĪęĘÖĪÃĪÆĪßĪëĪČĄĪĪāĪ·ĪíĪģĪÎÎŪĪėĪÏžŦÁģĪĮĪĒĪëĄĨĪÞĪšĄĪĪĒĪëļĀļėĪËĪÄĪĪĪÆšĮ―éĪËšîĪéĪėĪëž―ņĄĶÍŅļė―ļĪÏĄĪĪÛĪÜīÖ°ãĪĪĪĘĪŊģ°đņļėž―ņĄĪĪÄĪÞĪę bilingual dictionaries/glossaries ĪĮĪĒĪëĄĨžÂšÝĄĪÍåąŅž―ņĄĪĘĐąŅž―ņĄĪ°ËąŅž―ņĪĘĪÉĪŽąŅļėŧËūåĄĪĀčĪËļ―ĪïĪėĪÆĪĪĪëĄĨĪģĪÎĪģĪČĪÏĄĪđÍĪĻĪÆĪßĪėĪÐÅöÁģĪĮĪĒĪëĄĨēŋĪČĪĪĪÃĪÆĪâĄĪÍýēōĪĮĪĪĘĪĪļĀļėĪÎÃąļėĪōĘėļėĪÎÃąļėĪĮķĩĪĻĪÆĪŊĪėĪëĪÎĪŽĄĪž―ņĪÎÂč1ĪÎĖōģäĪĮĪĒĪëĄĨĪđĪĮĪËĪčĪŊÃÎĪÃĪÆĪĪĪëĘėļėĪÎÃąļėĪōĘėļėĪĮļĀĪĪīđĪĻĪŋĪęĀâĖĀĪ·ĪŋĪęĪđĪë monolingual dictionaries/glossaries ĪÏĄĪļ―ÂåĪĮĪģĪ―ēÁÃÍĪĒĪëĪâĪÎĪČÎŧēōĪĩĪėĪÆĪĪĪëĪŽĄĪķáÂå―éīüĪËĪĒĪÃĪÆĪÏĄĪĪĪĪÞĪĀĪ―ĪΰÕĩÁĪÏŋÍĄđĪËĨÔĨóĪČĪģĪĘĪŦĪÃĪŋĪíĪĶĄĨ
ĄĄĪ―Ī·ĪÆĄĪģ°đņļėž―ņĪË―āĪšĪëĪâĪÎĪČĪ·ĪÆĄĪžĄĪËÎĒĀĪģĶĪÎÂŊļėĄĶąĢļė (canting language) ĪÎÍŅļė―ļĪŽĘÔĪÞĪėĪëĪģĪČĪËĪĘĪÃĪŋĄĨÁąÎÉĪĘ°ėČĖŧÔĖąĪËĪČĪÃĪÆĄĪcanting language ĪÏģ°đņļėĪâÆąÁģĪĮĪĒĪëĄĨĪ·ĪŋĪŽĪÃĪÆĄĪA Caviat ĪâĪĒĪëžïĪÎ bilingual glossary ĪĀĪÃĪŋĪČļĀĪÃĪÆĪčĪĪĪÎĪĮĪĒĪëĄĨ
ĄĄÂģĪąĪÆĄĪ1604ĮŊĪËąŅļėŧËūå―éĪÎĄÖÉáÄĖĪÎąŅąŅž―ņĄŨĪČĀčĪÛĪÉļĀĩÚĪ·Īŋ A Table Alphabeticall ĪŽ―ÐČĮĪĩĪėĪŋĪŽĄĪžÂšÝĪËĪÏĄÖÉáÄĖĄŨĪÎąŅÃąļėĪō―ļĪáĪŋĪâĪÎĪĮĪÏĪĘĪŊĄĪžįĪČĪ·ĪÆĨéĨÆĨóžÚÍŅļėĪĘĪÉĪŦĪéĪĘĪëĄÖÆņļėĄŨĪō―ļĪáĪŋĪâĪÎĪĀĪÃĪŋĄĨĪģĪėĪâļŦĘýĪËĪčĪÃĪÆĪÏ bilingual dictionary ĪČĪâļĀĪĻĪëĪâĪÎĪĮĪĒĪëĄĨĪ―ĪÎļåĄĪ17ĀĪĩŠĪōÄĖĪļĪÆąŅļėĪËīØĪđĪëž―ņĪŽĪŋĪŊĪĩĪó―ÐČĮĪĩĪėĪŋĪŽĄĪĪĪĪšĪėĪâÆņļėž―ņĪĮĪĒĪęĄĪbilingual dictionaries ĪΰčĪō―ÐĪÆĪÏĪĪĪĘĪŦĪÃĪŋĪČĪâđÍĪĻĪéĪėĪëĄĘcf. ĄÖ#609. Æņļėž―ņĪÎ17ĀĪĩŠĄŨ ([2010-12-27-1])ĄËĄĨ
ĄĄūåĩĪηаÞĪōīŠ°ÆĪđĪëĪČĄĪĪĪĪŋĪšĪéĪÝĪĪļŦĘýĪōĪ·ĪÆĄĪąŅļėŧËūå―éĪÎąŅąŅž―ņĄĶÍŅļė―ļĪÏ A Caviat ĪĮĪĒĪëĪČĀëļĀĪđĪëĪģĪČĪâĪĮĪĪëĪŦĪâĪ·ĪėĪĘĪĪĪÎĪĀĄĨĪģĪÎÅĀĪËĪÄĪĪĪÆĄĪBlank (231) Īō°úÍŅĪ·ĪŋĪĪĄĨ
In fact the original English-English dictionaries, long preceding those produced in the seventeenth century, were glossaries of the canting language. As Thomas Harman and his followers often noted, cant was otherwise known in the period as 'pedlar's French', a term which again reinforced notions of its 'foreign' nature. Harman's popular pamphlet A Caveat or Warening for Common Cursetors (1567) describes the underworld language as a 'leud, lousey language of these lewtering Luskes and lasy Lorrels . . . a vnknowen toung onely, but to these bold, beastly, bawdy Beggers, and vaine Vacabondes'. As a measure of social precaution, he included a glossary intended to expose the 'vnknowen toung', thereby translating the 'leud, lousey' language into 'common' English:
Nab, a pratling chete, quaromes, a head. a tounge. a body. Nabchet, Crashing chetes, prat, a hat or cap. teeth. a buttocke.
and so on through a list that includes 120 terms.
ĄĄĄĶ Blank, Paula. "The Babel of Renaissance English." Chapter 8 of The Oxford History of English. Ed. Lynda Mugglestone. Oxford: OUP, 2006. 212--39.
2018-02-22 Thu
ĒĢ #3223. George Andrews, A Dictionary of the Slang and Cant language (1809) [lexicology][lexicography][slang][register]
ĄĄ19ĀĪĩŠÁ°ČūĪËĪÏŋô――ĪÎÂŊļėž―ņĪŽĘÔŧžĪĩĪėĪŋĪŽĄĪĪ―ĪÎĖÜÅŠĪÎ1ĪÄĪËĄĪĨÏĨĪĨŦĨëĨÁĨãĄžĪĘļėŨÃĪ·ĪŦžýÏŋĪ·ĪĘĪŦĪÃĪŋ Johnson ĪΞ―ņĪōĘäī°ĪđĪëĪČĪĪĪĶÁĀĪĪĪŽĪĒĪÃĪŋĪíĪĶĄĨĪ·ĪŦĪ·ĄĪšĢēóžčĪęūåĪēĪë George Andrews ĪËĪčĪë A Dictionary of the Slang and Cant language (1809) ĪËĪÏĄĪĪâĪÃĪČĄÖ·žĖØÅŠĄŨĪĘĖōģäĪŽĪĒĪÃĪŋĄĨĪ―ĪėĪÏĄĪÅĨËĀĪÎÂŊļėĄĶąĢļėĪōĀĪĪËđĪŊÃÎĪéĪ·ĪáĪëĪģĪČĪËĪčĪęĄĪČČšáÍÞŧßĪōÁĀĪĶĪČĪĪĪĶĪâĪÎĪĀĪÃĪŋĄĨĪĒĪëžïĪΞŌēņĀĩĩÁĪōĖÜŧØĪ·Īŋ―ņĪČĪĪĪÃĪÆĪčĪĪĪŦĪâĪ·ĪėĪĘĪĪĄĨCrystal (68) ĪËĪčĪëĪČĄĪĪģĪΞ―ņĪÎĮäĪęĘļķįĪČĪ·ĪÆĄĪžĄĪÎĪčĪĶĪĘĀëÅÁĪŽ―ņĪŦĪėĪÆĪĪĪŋĪČĪĪĪĶĄĨ
One great misfortune to which the Public are liable, is, that Thieves have a Language of their own; by which means they associate together in the streets, without fear of being over-heard or understood.
The principal end I had in view in publishing this DICTIONARY, was, to expose the Cant Terms of their Language, in order to the more easy detection of their crimes; and I flatter myself, by the perusal of this Work, the Public will become acquainted with their mysterious Phrases; and be better able to frustrate their designs.
ĄĄCrystal (68) Ī˚ƷĮĪĩĪėĪÆĪĪĪëĄĪĪĪĪŊĪÄĪŦĪÎļŦ―ÐĪ·ļėĪČÄęĩÁĪō°ĘēžĪËĩóĪēĪčĪĶĄĨ19ĀĪĩŠ―éÆŽĪÎÅĨËĀĪÎąĢļėĪĀĪŽĄĪĪŠĪ―ĪéĪŊļ―šßĪÎÅĨËĀĪËĪÏÄĖĪļĪĘĪĪĪÎĪĀĪíĪĶĪĘĪĒĄĶĄĶĄĶĄĨ
| Adam Tylers | pickpockets' accomplices |
| badgers | hawkers |
| bullies, bully-huffs, bully-rooks | hired ruffians |
| bloods | roisterers |
| buffers | horse killers (for the skins) |
| beau-traps | well-dressed sharpers |
| cloak-twitchers | cloak-snatchers (from off people's shoulders) |
| clapperdogeons (also spelled clapperdudgeon) | beggars |
| coiners | counterfeiters |
| cadgers | beggars |
| duffers | hawkers |
| divers | pickpockets |
| dragsmen | vehicle thieves |
| filers | coin-filers |
| fencers | receivers of stolen goods |
| footpads | highwaymen who rob on foot |
| gammoners | pickpockets' accomplices |
| ginglers (also jinglers) | horse-dealers |
| kencrackers | housebreakers |
| knackers | tricksters |
| lully-priggers | linen-thieves |
| millers | housebreakers |
| priggers | thieves |
| rum-padders | highwaymen |
| strollers | pedlars |
| sweeteners | cheats, decoys |
| spicers | footpads |
| smashers | counterfeiters |
| swadlers (also swadders) | pedlars |
| whidlers (also whiddlers) | informers |
| water-pads | robbers of ships |
ĄĄĪĘĪŠĄĪąŅļėŧËūåĪÎÂŊļėĄĶąĢļėž―ņĪÎÁöĪęĪÏĄĪ1567ĮŊĪÎ Thomas Harman ĪËĪčĪëÍŅļė―ļ A Caveat or Warening for Common Cursetors ĪČĪĩĪėĪëĄĨÄĖūïĪÎąŅļėž―ņĪÎÓåĖðĪŽ Robert Cawdrey ĪËĪčĪë1604ĮŊĪÎĄÖ#603. šĮ―éĪÎąŅąŅž―ņ A Table Alphabeticall (1)ĄŨ ([2010-12-21-1]) ĪĮĪĒĪëĪģĪČĪōđÍĪĻĪëĪČĄĪž―ņĘÔŧžķČĪËĪŠĪĪĪÆĪâ°ÅđõĀĪģĶĪÏĀčŋĘÅŠĄĘĄĐĄËĪĀĪÃĪŋĪÎĪŦĪČīķĪļÆþĪ랥ÂčĪĮĪĒĪëĄĨ
ĄĄslang, cant, argot, jargon ĪĘĪÉĪÎÍŅļėĪËĪÄĪĪĪÆĪÏĄÖ#2410. slang, cant, argot, jargon, antilanguageĄŨ ([2015-12-02-1]) ĪōŧēūČĄĨĪÞĪŋĄĪąĢļėĪÎĀžÁĪËĪÄĪĪĪÆĪÏĄÖ#2166. argot ĄĘąĢļėĄËĪÎÂūΧĀĄŨ ([2015-04-02-1])ĄĪĄÖ#3076. ąĢļėĄĪĨŋĨÖĄžĄĪ°ÅđæĄŨ ([2017-09-28-1]) ĪâĪÉĪĶĪūĄĨ
ĄĄĄĶ Crystal, David. Evolving English: One Language, Many Voices. London: The British Library, 2010.
2018-02-16 Fri
ĒĢ #3217. ĨÉĄžĨĨóĨđĪČļĀļėĘŅē―ÏĀ (3) [evolution][biology][language_change][semantic_change][bleaching][meme][lexicology]
ĄĄĪģĪÎ2ÆüīÖĪÎĩŧö ([2018-02-14-1], [2018-02-15-1]) ĪËÂģĪĄĪĨÉĄžĨĨóĨđĪÎĄØĖÕĖÜĪÎŧþ·ŨŋĶŋÍĄŲĪčĪęĄĪĀļĘŠŋĘē―ĪČļĀļėĘŅē―ĪÎÎāŧũÅĀĪäÁę°ãÅĀĪËĪÄĪĪĪÆđÍĪĻĪëĄĨÆąÃøĪËĪÏĄĪŧþīÖĪČĪČĪâĪËķŊ°ÕļėĪŦĪéķŊ°ÕĪŽžšĪïĪėĪÆĪĪĪĄĪĪ―ĪėĪōËäĪáđįĪïĪŧĪëŋ·ĪŋĪĘķŊ°ÕļėĪŽĀļĪÞĪėĪëļ―ūÝĄĪĪđĪĘĪïĪÁĄÖķŊ°ÕÄþļšĪÎ˥§ĄŨĪČļÆĪÖĪŲĪÏÃÂęĪōžčĪęĪĒĪēĪÆĪĪĪëēÕ―ęĪŽĪĒĪë (349--50) ĄĨĄÖēÖ·ÁĖōžÔĄŨĪō°ÕĖĢĪđĪëąŅÃąļė star ĪËĪÞĪÄĪïĪëķŊ°ÕÄþļšĪËŋĻĪėĪÆĪĪĪëĄĨ
ĄĖļĀļėĪËĪÏĄÍ―ãŋčĪËÃęūÝÅŠĪĮēÁÃÍīŅĪËĮûĪéĪėĪĘĪĪ°ÕĖĢĪĒĪĪĪĮÁ°ŋĘÅŠĪĘĄĪŋĘē―ĪÎĪčĪĶĪĘ·đļþĪōÃĩĪęÅöĪÆĪëĪģĪČĪŽĪĮĪĪëĄĨĪ―Ī·ĪÆĄĪ°ÕĖĢĪÎĨĻĨđĨŦĨėĄžĨ·ĨįĨóĪČĪĪĪĶĪŦĪŋĪÁĪĮĄĘĪĒĪëĪĪĪÏĘĖĪÎģŅÅŲĪŦĪéĪ―ĪėĪōļŦĪėĪÐĄĪÂāē―ĪČĪĪĪĶĪģĪČĪËĪĘĪëĄËĀĩĪÎĨÕĨĢĄžĨÉĨÐĨÃĨŊĪÎūÚĩōĪŽļŦĪĪĪĀĪĩĪėĪĩĪĻĪđĪëĪĀĪíĪĶĄĨĪŋĪČĪĻĪÐĄĪĄÖĨđĨŋĄžĄŨĪČĪĪĪĶÃąļėĪÏĄĪĪÞĪÃĪŋĪŊÎāĪÞĪėĪĘĖūĀžĪōÆĀĪŋąĮēčĮÐÍĨĪō°ÕĖĢĪđĪëĪâĪÎĪČĪ·ĪÆŧČĪïĪėĪÆĪĪĪŋĄĨĪ―ĪėĪŦĪéĪ―ĪÎÃąļėĪÏĄĪĪĒĪëąĮēčĪĮžįÍŨÅÐūėŋÍĘŠĪΰėŋÍĪōąéĪļĪëĪŊĪĪĪéĪĪĪÎÉáÄĖĪÎĮÐÍĨĪō°ÕĖĢĪđĪëĪčĪĶĪËÂāē―Ī·ĪŋĄĨĪ·ĪŋĪŽĪÃĪÆĄĪÎāĪÞĪėĪĘĖūĀžĪČĪĪĪĶĪâĪČĪΰÕĖĢĪōžčĪęĖáĪđĪŋĪáĪËĄĪĪ―ĪÎÃąļėĪÏĄÖĨđĄžĨŅĄžĨđĨŋĄžĄŨĪËĨĻĨđĨŦĨėĄžĨČĪ·ĪĘĪąĪėĪÐĪĘĪéĪĘĪŦĪÃĪŋĄĨĪ―ĪÎĪĶĪÁąĮēčĨđĨŋĨļĨŠĪÎĀëÅÁĪŽĄÖĨđĄžĨŅĄžĨđĨŋĄžĄŨĪČĪĪĪĶÃąļėĪōĪßĪóĪĘĪÎĘđĪĪĪŋĪģĪČĪâĪĘĪĪĪčĪĶĪĘĮÐÍĨĪËĪÞĪĮŧČĪĪĪĀĪ·ĪŋĪÎĪĮĄĪĄÖĨáĨŽĨđĨŋĄžĄŨĪØĪÎĪĩĪéĪĘĪëĨĻĨđĨŦĨėĄžĨ·ĨįĨóĪŽĪĒĪÃĪŋĄĨĪĩĪÆĪĪĪÞĪĮĪÏĄĪÂŋĪŊĪÎĮä―ÐĪ·ÃæĪÎĄÖĨáĨŽĨđĨŋĄžĄŨĪŽĪĪĪëĪŽĄĪūŊĪĘĪŊĪČĪâŧäĪŽĪģĪėĪÞĪĮĘđĪĪĪŋĪģĪČĪâĪĘĪĪŋÍĘŠĪĘĪÎĪĮĄĪĪŋĪÖĪóĪ―ĪíĪ―Ī힥ĪÎĨĻĨđĨŦĨėĄžĨ·ĨįĨóĪŽĪĒĪëĪĀĪíĪĶĄĨĪïĪėĪïĪėĪÏĪâĪĶĪļĪĄÖĨÏĨĪĨŅĄžĨđĨŋĄžĄŨĪÎą―ĪōĘđĪŊĪģĪČĪËĪĘĪëĪÎĪĀĪíĪĶĪŦĄĐĄĄĪ―ĪėĪČŧũĪŋĪčĪĶĪĘĀĩĪÎĨÕĨĢĄžĨÉĨÐĨÃĨŊĪÏĄĪĄÖĨ·Ĩ§ĨÕĄŨĪČĪĪĪĶÃąļėĪÎēÁÃÍĪōĪŠĪČĪ·ĪáĪÆĪ·ĪÞĪÃĪŋĄĨĪāĪíĪóĄĪĪģĪÎÃąļėĪÏĨÕĨéĨóĨđļėĪÎĨ·Ĩ§ĨÕĄĶĨÉĄĶĨĨåĨĪĨļĄžĨĖĪŦĪéÍčĪÆĪŠĪęĄĪŋßËžĪÎĨÁĄžĨÕĪĒĪëĪĪĪÏÄđĪō°ÕĖĢĪ·ĪÆĪĪĪëĄĨĪģĪėĪÏĨŠĨÃĨŊĨđĨÕĨĐĄžĨÉžÅĩĪËšÜĪÃĪÆĪĪĪë°ÕĖĢĪĮĪĒĪëĄĨĪÄĪÞĪęÄęĩÁūåĪÏŋßËžĪĒĪŋĪę°ėŋÍĪÎĨ·Ĩ§ĨÕĪ·ĪŦĪĪĪĘĪĪĪÏĪšĪĀĄĨĪČĪģĪíĪŽĄĪĪŠĪ―ĪéĪŊÂÐĖĖĪōĘÝĪÄĪŋĪáĪĀĪíĪĶĄĪÄĖūïĪÎĄĘÃËĪÎĄËĨģĨÃĨŊĪŽĄĪĪĪĪäĪŦĪąĪĀĪ·ĪÎĨÏĨóĨÐĄžĨŽĄžČÖĪĮĪĩĪĻĪâĪŽĄĪžŦĘŽĪŋĪÁĪÎĪģĪČĪōĄÖĨ·Ĩ§ĨÕĄŨĪČļÆĪÓ―ÐĪ·ĪŋĄĨĪ―ĪηëēĖĄĪĪĪĪÞĪĮĪÏĄÖĨ·Ĩ§ĨÕÄđĄŨĪĘĪëÆąĩÁČŋÉüÅŠĪĘļĀĪĪĪÞĪïĪ·ĪŽĪ·ĪÐĪ·ĪÐĘđĪŦĪėĪëĪčĪĶĪËĪĘĪÃĪÆĪĪĪëĄĨ
ĄĄĨÉĄžĨĨóĨđĪÏĄĪĪģĪģĪĮĄÖĨđĨŋĄžĄŨĪäĄÖĨ·Ĩ§ĨÕĄŨĪÎĪâĪČĪâĪČĪΰÕĖĢĪōĨߥžĨā (meme) ĪČĪ·ĪÆĪČĪéĪĻĪÆĪĪĪëĪÎĪŦĪâĪ·ĪėĪĘĪĪĄĘīØÏĒĪ·ĪÆĄĪĄÖ#3188. ĨߥžĨāĪČĪ·ĪÆĪÎļĀļė (1)ĄŨ ([2018-01-18-1])ĄĪĄÖ#3189. ĨߥžĨāĪČĪ·ĪÆĪÎļĀļė (2)ĄŨ ([2018-01-19-1])ĄËĄĨĪĪĪšĪėĪËĪŧĪčĄĪĘŅē―ĪÎĘýļþĀĪËēÁÃÍīŅĪōīÞĪáĪĘĪĪĪČĪĪĪĶÅĀĪĮĄĪĨÉĄžĨĨóĨđĪÏÅ°ÆŽÅ°ČøĨĀĄžĨĶĨĢĨËĨđĨČĪĮĪĒĪëĄĨ
ĄĄķŊ°ÕĪÎÄþļšĪËīØĪđĪëÏÃÂęĪČĪ·ĪÆĪÏĄĪĄÖ#992. ķŊ°ÕļėĪČĄÖļÂģĶļúÍŅÄþļšĪÎ˥§ĄŨĄŨ ([2012-01-14-1]) ĪäĄÖ#1219. ķŊ°ÕļėĪÏĪĘĪžžïÎāĪŽËÉŲĪŦĄŨ ([2012-08-28-1])ĄĪĄÖ#2190. ļķĩÁĪΞåĪÞĪÃĪŋķŊ°ÕļėĄŨ ([2015-04-26-1]) ĪĘĪÉĪōŧēūČĪĩĪėĪŋĪĪĄĨ
ĄĄĄĶ ĨÉĄžĨĨóĨđĄĪĨęĨÁĨãĄžĨÉĄĘÃøĄËĄĪÃæÅč đŊÍĩĄĶąóÆĢ ūīĄĶąóÆĢ ÃÎÆóĄĶÉĨÅÄ ÅØĄĘĖõĄËĄĪÆüđâ ÉŌÎīĄĘīÆ―ĪĄËĄĄĄØĖÕĖÜĪÎŧþ·ŨŋĶŋÍĄĄžŦÁģÅņÂÁĪÏķöÁģĪŦĄĐĄŲĄĄÁáĀî―ņËžĄĪ2004ĮŊĄĨ
2018-01-10 Wed
ĒĢ #3180. ―ųĄđĪËđâÉŅÅŲļėĪÎÃįīÖÆþĪęĪōēĖĪŋĪ·ĪÆĪĪŋĨÕĨéĨóĨđĄĶĨéĨÆĨóžÚÍŅļė [french][latin][loan_word][borrowing][frequency][statistics][lexicology][hc][bnc]
ĄĄąŅļėŧËĪĮĪÏĄĪÃæąŅļėĪŦĪé―éīüķáÂåąŅļėĪËĪŦĪąĪÆĄĪĨÕĨéĨóĨđļėĪČĨéĨÆĨóļėĪŦĪéÂįÎĖĪÎļėŨÞÚÍŅĪŽĪĘĪĩĪėĪŋĄĨĪ―ĪėĪéĪÎĪĶĪÁļ―šßūïÍŅĪĩĪėĪëĪâĪÎĪËĪÄĪĪĪÆĪÏĄĪĪŠĪ―ĪéĪŊžÚÍŅŧþÅĀĪŦĪéĨđĨŋĄžĨČĪ·ĪÆŧþīÖĪČĪČĪâĪËŧČÍŅÉŅÅŲĪŽÁýĪ·ĪÆĪĪŋĪâĪÎĪČÁÛÁüĪĩĪėĪëĄĨĪČĪĪĪĶĪÎĪÏĄĪžÚÍŅĪĩĪėĪŋÅö―éĪŦĪéđâÉŅÅŲĪĮÍŅĪĪĪéĪėĪŋĪČĪÏđÍĪĻĪËĪŊĪŊĄĪ―ųĄđĪËąŅļėĪËÆąē―Ī·ĄĪÆüūïē―Ī·ĪÆĪĪŋĪČĪČĪéĪĻĪëĪÎĪŽžŦÁģĪĀĪŦĪéĪĀĄĨ
ĄĄĪģĪÎēūĀâĪōžÂūÚĪđĪëĪÎĪËĪĪĪŊĪÄĪŦĪÎĘýËĄĪŽĪĒĪęĪ―ĪĶĪĀĪŽĄĪDurkin ĪŽĪĒĪëĪäĪęĘýĪĮÄīššĪōđÔĪĘĪÃĪÆĪĪĪëĄĨÃæąŅļėĄĪ―éīüķáÂåąŅļėĄĪļ―ÂåąŅļėĪÎĪ―ĪėĪūĪėĪËĪŠĪĪĪÆĨģĄžĨŅĨđĪËīðĪÅĪŊšĮđâÉŅÅŲļėĨęĨđĨČĪōšîĪęĄĪĪ―ĪÎĪĘĪŦĪËĨÕĨéĨóĨđĄĶĨéĨÆĨóžÚÍŅļėĪŽĪÉĪÎĪŊĪéĪĪĪÎģäđįĪĮīÞĪÞĪėĪÆĪĪĪëĪŦĪōÄīĪŲĄĪĪ―ĪÎģäđįĪÎÄĖŧþÅŠŋä°ÜĪōČæģÓĪđĪëĪČĪĪĪĶžęËĄĪĀĄĨļÅĪĪŧþÂåĪÎĨģĄžĨŅĨđĪĮĪÏÄÖŧúĪÎĘŅ°ÛĪČĪĪĪĶĖäÂęĪŽīØĪïĪëĪŋĪáĄĪļ·ĖĐĪËÄīššĪ·ĪčĪĶĪČĪđĪėĪÐÃą―ãĪËĪÏĪĪĪŦĪĘĪĪĪŽĄĪDurkin ĪÏĪČĪęĪĒĪĻĪšĪÎĘØËĄĪČĪ·ĪÆĄĪÃæąŅļėĪČ―éīüķáÂåąŅļėĪËĪÄĪĪĪÆĪÏ Helsinki Corpus ĪÎ 1150--1500ĮŊĪČ1500--1710ĮŊĪÎĨŧĨŊĨ·ĨįĨóĪōÍŅĪĪĪÆĄĪļ―ÂåąŅļėĪËĪÄĪĪĪÆĪÏ BNC ĪōÍŅĪĪĪÆ°ÛÄÖŧúĨŲĄžĨđĪĮÄīššĪ·ĪŋĄĨĪ―ĪėĪūĪėÉŅÅŲĨéĨóĨĨóĨ°ĪËĪ·ĪÆ900--1000°ĖĪÛĪÉĪÞĪĮĪÎÃąļėĄĘÄÖŧúĄËĨęĨđĨČĪōšîĪęĄĪĪ―ĪÎĪĘĪŦĪĮĨÕĨéĨóĨđĄĶĨéĨÆĨóļėžÚÍŅļėĪŽĀęĪáĪëģäđįĪōĪÏĪļĪ―ÐĪ·ĪŋĄĨ
ĄĄ·ëēĖĪÏĄĪÃæąŅļėĨŧĨŊĨ·ĨįĨóĪĮĪÏ7%ĪÛĪÉĪĀĪÃĪŋĪâĪÎĪŽĄĪ―éīüķáÂåąŅļėĨŧĨŊĨ·ĨįĨóĪĮĪÏ19%ĪÞĪĮūåūšĪ·ĄĪĪĩĪéĪËļ―ÂåąŅļėĨŧĨŊĨ·ĨįĨóĪĮĪÏ38%ĪÞĪĮĪËŧęĪÃĪÆĪĪĪëĄĨÁÆĪĪÄīššĪĮĪĒĪëĪģĪČĪÏĮ§ĪáĪÄĪÄĪâĄĪĨÕĨéĨóĨđĄĶĨéĨÆĨóžÚÍŅļėĪĮļ―šßÉŅÍŅĪĩĪėĪÆĪĪĪëĪâĪÎĪÎÂŋĪŊĪËĪÄĪĪĪÆĪÏĄĪÎōŧËĪÎĪĘĪŦĪĮ―ųĄđĪËÉŅÅŲĪōūåĪēĪÆĪĪŋ·ëēĖĪČĪ·ĪÆĄĪļ―šßĪÎÆüūïÅŠĪĘĀģĘĪōžĻĪđĪģĪČĪŽĪčĪŊĪïĪŦĪÃĪŋĄĨ
ĄĄĪĩĪéĪËĪŠĪâĪ·ĪíĪĪĪģĪČĪËĄĪ―éīüķáÂåąŅļėĪÎĨŧĨŊĨ·ĨįĨóĄĘ1500--1710ĮŊĄËĪËīØĪđĪëŋôÃÍĪËĪÄĪĪĪÆĄĪđâÉŅÅŲļėĨęĨđĨČĪËīÞĪÞĪėĪëĨÕĨéĨóĨđĄĶĨéĨÆĨóžÚÍŅļėĪÎĪđĪŲĪÆĪŽ1500ĮŊĪčĪęÁ°ĪËžÚÍŅĪĩĪėĪŋĪâĪÎĪĮĪĒĪęĄĪĪ·ĪŦĪâĪ―ĪÎ2/3ĪÛĪÉĪÏģΞÂĪËĨÕĨéĨóĨđžÚÍŅļėĪĮĪĒĪëĪČĪĪĪĶŧöžÂĪŽģÎĮ§ĪĩĪėĪë (Durkin 338--39) ĄĨ
ĄĄĪÞĪŋĄĪÃæąŅļėĪČ―éīüķáÂåąŅļėĪÎđâÉŅÅŲļėĨęĨđĨČĪËīÞĪÞĪėĪëĨÕĨéĨóĨđĄĶĨéĨÆĨóžÚÍŅļėĪÎÂŋĪŊĪŽĄĪļ―ÂåąŅļėĪÎđâÉŅÅŲļėĨęĨđĨČĪËĪâšÆļ―ĪĩĪėĪÆĪĪĪëŧöžÂĪËĪâŋĻĪėĪÆĪŠĪģĪĶĄĨļÅĪĪ2īüĪËĪÏļ―ĪïĪėĪëĪŽļ―ÂåīüĪŦĪéĪÏÏģĪėĪÆĪĪĪëļė·ēĪōÄŊĪáĪëĪČĄĪĪĘĪóĪČĪâŧþÂåĪÎĘŅē―ĪōīķĪļĪĩĪŧĪÆĪŊĪėĪëĄĨÎãĪĻĪÐĄĪhonour, justice, manner, noble, parliament, pray, prince, realm, religion, supper, treason, usury, virtue ĪĮĪĒĪë (Durkin 340) ĄĨ
ĄĄŧþÂåĪËĪčĪÃĪÆšĮÉŅļėĨęĨđĨČĪäĨĄžĨïĄžĨÉĪŽ°ÛĪĘĪëĪģĪČĪÏÅöÁģĪČĪĪĪĻĪÐÅöÁģĪĀĪŽĄĪÎōŧËąŅļėĨģĄžĨŅĨđĪōÍŅĪĪĪÆÍÍĄđĪĘŧþÂåĪōČæģÓĪ·ĪÆĪßĪëĪČĪŠĪâĪ·ĪíĪ―ĪĶĪĀĄĨÎãĪĻĪÐĄĪ―éīüķáÂåąŅļėĨģĄžĨŅĨđĪËīðĪÅĪŊĨĄžĨïĄžĨÉĄĶĨęĨđĨČĪËĪÄĪĪĪÆĄÖ#2332. EEBO ĪÎĨĄžĨïĄžĨÉĪōÃę―ÐĄŨ ([2015-09-15-1]) ĪōŧēūČĄĨĪÞĪŋĄĪÉŅÅŲĪČÎōŧËĪÎĖäÂęĪËĪÄĪĪĪÆĪÏĄÖ#1243. ļėĪÎÉŅÅŲĪōđÍÎļĪđĪëÄĖŧþÅŠļĶĩæĪÎĪŋĪáĪËĄŨ ([2012-09-21-1]) ĪâŧēūČĪĩĪėĪŋĪĪĄĨ
ĄĄĄĶ Durkin, Philip. Borrowed Words: A History of Loanwords in English. Oxford: OUP, 2014.
2018-01-09 Tue
ĒĢ #3179. ĄÖŋ·ļÅÅĩžįĩÁÅŠĘĢđįļėĄŨĪŦĄÖąŅĀ―ÍåļėĄŨĪŦ [neo-latin][latin][greek][word_formation][lexicology][loan_word][compounding][derivation][lmode][scientific_english][scientific_name][neologism][waseieigo][terminology][register]
ĄĄŋ·ļÅÅĩžįĩÁÅŠĘĢđįļė (neoclassical compounds) ĪČĪÏĄĪaerobiosis, biomorphism, cryogen, nematocide, ophthalmopathy, plasmocyte, proctoscope, rheophyte, technocracy ĪÎĪčĪĶĪĘļėĄĘĪ·ĪÐĪ·ĪÐēĘģØÍŅļėĄËĪōŧØĪđĄĨDurkin (346--37) ĪËĪčĪėĪÐĄĪĪģĪÎÎāĪĪĪÎļėŨÃĪÏÁáĪŊĪÏ1600ĮŊÁ°ļåĪŦĪéģÎĮ§ĪĩĪėĄĪÎãĪĻĪÐ polycracy (1581), pantometer (1597), multinomial (1608) ĪŽĪßĪéĪėĪëĄĨĪ·ĪŦĪ·ĄĪĮúČŊÅŠĪËÎĖŧšĪĩĪėĪëĪčĪĶĪËĪĘĪÃĪŋĪÎĪÏĄĪēĘģØĪŽĩÞÂŪĪËČŊÅļĪ·ĪŋļåīüķáÂåąŅļėīüĄĪĪČĪęĪïĪą19ĀĪĩŠĪËĪĘĪÃĪÆĪŦĪéĪÎĪģĪČĪĮĪĒĪëĄĘĄÖ#616. ķáÂåąŅļėīüĪÎēĘģØļėŨÃĪÎĮúČŊĄŨ ([2011-01-03-1])ĄĪĄÖ#3013. 19ĀĪĩŠĪËČóÆņĪĩĪėĪŋŋ·ļÅÅĩžįĩÁÅŠĘĢđįļėĄŨ ([2017-07-27-1])ĄĪĄÖ#3014. ąŅļėŧËĪËĪŠĪąĪëĨŪĨęĨ·ĨĒļėĪÎŋŋĪÎÂļšßīķĪÏ19ĀĪĩŠĪŦĪéĄŨ ([2017-07-28-1])ĄĪĄÖ#3166. ąŅĀ―īõÍåļėĪČĪ·ĪÆĪÎēĘģØÍŅļėĄŨ ([2017-12-27-1]) ĪōŧēūČĄËĄĨ
ĄĄŋ·ļÅÅĩžįĩÁÅŠĘĢđįļėĪËĪÄĪĪĪÆķŊÄīĪ·ĪÆĪŠĪŊĪŲĪĪÏĄĪĪ―ĪėĪŽžÚÍŅļėĪĮĪÏĪĘĪŊĄĪĪĒĪŊĪÞĪĮąŅļėĄĘĪōŧÏĪáĪČĪđĪëĨ襞ĨíĨÃĨŅĪÎ―ôļĀļėĄËĪËĪŠĪĪĪÆ·ÁĀŪĪĩĪėĪŋļėĪĮĪĒĪëĪČĪĪĪĶÅĀĪĀĄĨģÎĪŦĪËĨéĨÆĨóļėĪäĨŪĨęĨ·ĨĒļėĪĘĪÉĪÎļÅÅĩļėĪōĨâĨĮĨëĪČĪ·ĪÆĪÏĪĪĪëĪŽĄĪ·čĪ·ĪÆĪ―ĪģĪŦĪéžÚÍŅĪĩĪėĪŋĪïĪąĪĮĪÏĪĘĪĪĄĨĪ―ĪΰÕĖĢĪĮĪÏąŅÃąļėĪÝĪĪÂΚÛĪōĪ·ĪÆĪĪĪĘĪŽĪéĪâąŅÃąļėĪĮĪÏĪĘĪĪĄÖÏÂĀ―ąŅļėĄŨĪČČæģÓĪđĪëĪģĪČĪŽĪĮĪĪëĄĨŋ·ļÅÅĩžįĩÁÅŠĘĢđįļėĪÎÉņÂæĪÏąŅļėĪĮĪĒĪëĪŦĪéĄĪĪÄĪÞĪęĄÖąŅĀ―ÍåļėĄŨĪČĪĪĪÃĪÆĪčĪĪĄĨĪ·ĪŦĪ·ĄĪąŅĀ―ÍåļėĪČÏÂĀ―ąŅļėĪČĪÎĪĪïĪĀĪÃĪŋÁę°ãÅĀĪÏĄĪÁ°žÔĪŽžįĪČĪ·ĪÆđņšÝÅŠĪĮēĘģØÅŠĪĘĘļĖŪĪĮÍŅĪĪĪéĪėĪëĪŽĄĪļåžÔĪÏĪ―ĪĶĪĮĪÏĪĘĪĪĪČĪĪĪĶŧöžÂĪËĪĒĪëĄĨĪđĪĘĪïĪÁĄĪÎūžÔĪÎĪĒĪĪĪĀĪËĪÏŧČÍŅ°čĪËĪŠĪĪĪÆÃøĪ·ĪĪĘÐļþĪŽĪßĪéĪėĪëĄĨDurkin ĪÏĄĪŋ·ļÅÅĩžįĩÁÅŠĘĢđįļėĪËĪÄĪĪĪÆžĄĪÎĪčĪĶĪË―ŌĪŲĪÆĪĪĪëĄĨ
. . . these formations typically belong to the international language of science and move freely, often with little or no morphological adaptation, between English, French, German, and other languages of scientific discourse. They are often treated in very different ways in different traditions of lexicography and lexicology; however, those terms that are coined in modern vernacular languages are certainly not loanwords from Latin or Greek, even though they may be formed from elements that originated in such loanwords. (347)
. . . Latin words and word elements have become ubiquitous in modern technical discourse, but frequently in new compound or derivative formations or with new meanings that have seldom if ever been employed in contextual use in actual Latin sentences. (349)
ĄĄĪģĪėĪéĪÎÂĪļėĪōŧØĪ·ĪÆĄÖŋ·ļÅÅĩžįĩÁÅŠĘĢđįļėĄŨĪČļÆĪÖĪŦĄÖąŅĀ―ÍåļėĄŨĪČļÆĪÖĪŦĪÏĄĪĪŋĪĪĪ·ĪŋĖäÂęĪĮĪÏĪĘĪĪĄĨĪ·ĪŦĪ·ĄĪÏÂĀ―ąŅļėĪÎūėđįĪËĪÏĄÖąŅļėžįĩÁÅŠĘĢđįļėĄŨĪČļÆĪÐĪĘĪĪĪÎĪÏĪĘĪžĪĀĪíĪĶĪŦĄĨĪģĪΰãĪĪĪÏēŋĪËĩŊ°øĪđĪëĪÎĪĀĪíĪĶĪŦĄĨ
ĄĄĄĶ Durkin, Philip. Borrowed Words: A History of Loanwords in English. Oxford: OUP, 2014.
2018-01-04 Thu
ĒĢ #3174. đâÉŅÅŲļėĪÏĨđĨÚĨęĨóĨ°ĪŽÃŧĪĪ (2) [frequency][spelling][orthography][zipfs_law][statistics][lexicology][corpus]
ĄĄšōÆüĪÎĩŧö ([2018-01-03-1]) ĪČÆąĪļÉŅÅŲĪČĨđĨÚĨęĨóĨ°ĪÎÄđĪĩĪËīØĪđĪëĨĮĄžĨŋĪōĄĪĪâĪĶūŊĪ·ĘŽĀÏĪ·ĪÆĪßĪŋĄĨ°ĘēžĪÏĄĪÉŅÅŲĨéĨóĨĨóĨ°ĪÎĨČĨÃĨŨ100ļėĄĪ200ļėĄĪ500ļėĄĪ1000ļėĄĪ2000ļėĄĪ5000ļėĄĪ10000ļėĄĪ20000ļėĄĪ50000ļėĪËĪÄĪĪĪÆĄĪĪ―ĪėĪūĪėšĮÄãÃÍĄĪÂč1ŧÍĘŽ°ĖŋôĄĪÃæąûÃÍĄĪĘŋķŅÃÍĄĪÂč3ŧÍĘŽ°ĖŋôĄĪšĮÂįÃÍĪōžĻĪ·ĪŋÉ―ĪĮĪĒĪëĄĨąŅļėĪÎĀĩ―ņËĄĪōÏĀĪļĪëūåĪĮĪÎīðÁÃĨĮĄžĨŋĪČĪ·ĪÆĪÉĪĶĪūĄĨ
| Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max. | |
|---|---|---|---|---|---|---|
| Top_100 | 1.0 | 2.0 | 3.0 | 3.1 | 4.0 | 5.0 |
| Top_200 | 1.00 | 3.00 | 4.00 | 3.77 | 4.00 | 10.00 |
| Top_500 | 1.000 | 4.000 | 4.000 | 4.498 | 5.000 | 10.000 |
| Top_1K | 1.000 | 4.000 | 5.000 | 4.968 | 6.000 | 15.000 |
| Top_2K | 1.000 | 4.000 | 5.000 | 5.406 | 7.000 | 15.000 |
| Top_5K | 1.000 | 5.000 | 6.000 | 6.014 | 7.000 | 16.000 |
| Top_10K | 1.000 | 5.000 | 6.000 | 6.488 | 8.000 | 16.000 |
| Top_20K | 1.000 | 5.000 | 7.000 | 6.954 | 8.000 | 17.000 |
| Top_50K | 1.000 | 6.000 | 7.000 | 7.622 | 9.000 | 20.000 |
ĄĄĪģĪėĪōĪâĪČĪËŧëģÐē―Ī·ĪŋĪÎĪŽĄĪ°ĘēžĪÎČĒĪŌĪēŋÞĄĨ
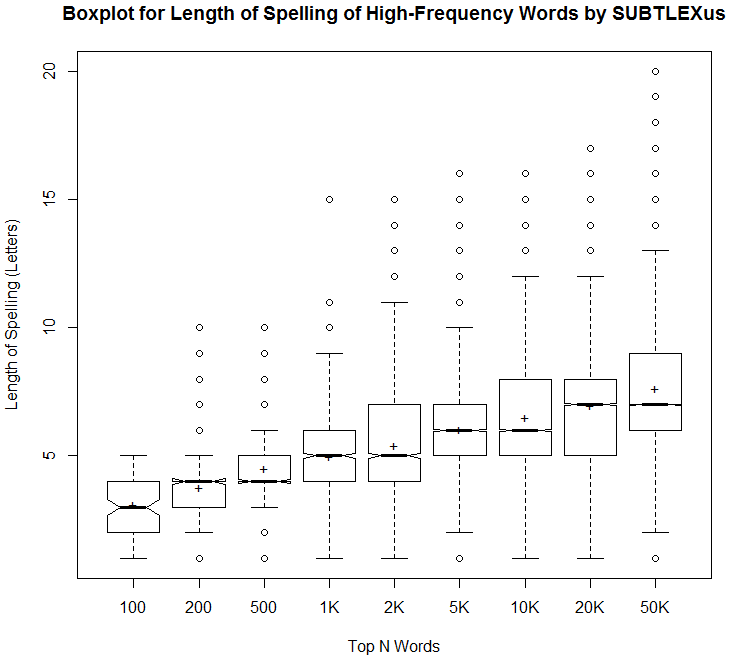
ĄĄÅöÁģÍ―ÁÛĪĩĪėĪŋĪģĪČĪĀĪŽĄĪļėŋôĪŽÁýĪĻĪëĪËĪ·ĪŋĪŽĪÃĪÆĨđĨÚĨęĨóĨ°ĪÎĘŋķŅĪÎÄđĪĩĪÏ―ųĄđĪËÂįĪĪŊĪĘĪÃĪÆĪĪĪĄĪĨÐĨéĨÄĨĪâđĪŽĪÃĪÆĪĪĪŊĄĨĪ·ĪŦĪ·ĄĪĨČĨÃĨŨŋôËüļėĪĮĪßĪÆĪâĘŋķŅĪ·ĪÆ7ĘļŧúÄøÅŲĪČĪĘĪÃĪÆĪŠĪęĄĪĪĩĪÛĪÉÄđĪŊĪĘĪĪĪÎĪĀĪĘĪČĪĪĪĶ°õūÝĪōžõĪąĪŋĄĨ
[ ļĮÄęĨęĨóĨŊ | °õšþÍŅĨÚĄžĨļ ]
2018-01-03 Wed
ĒĢ #3173. đâÉŅÅŲļėĪÏĨđĨÚĨęĨóĨ°ĪŽÃŧĪĪ (1) [frequency][spelling][orthography][zipfs_law][statistics][lexicology][corpus][three-letter_rule]
ĄĄÉļÂęĪÏÆÃĪËĖÜŋ·Ī·ĪĪŧØÅĶĪĮĪÏĪĘĪŊĄĪąŅļėĪōÆÉĪß―ņĪĪđĪëžÔĪËĪÏÄūīķĪĩĪėĪÆĪĪĪëĪģĪČĪĀĪČŧŨĪïĪėĪëĄĨĄÖ#1091. ļĀļėĪÎÍūūęĀĄĪÉŅÅŲĄĪČņÍŅĄŨ ([2012-04-22-1]) ĪäĄÖ#1102. Zipf's law ĪČļėĪÎŋ·ÄÄÂåžÕĄŨ ([2012-05-03-1]) ĪĮĪâŧØÅĶĪ·ĪŋĪčĪĶĪËĄĪĪčĪŊÆÉĪß―ņĪĪđĪëÃąļėĪÎĨđĨÚĨęĨóĨ°ĪÏÃŧĪĪĪÛĪĶĪŽļúÎĻĪŽĪčĪĪĪČđÍĪĻĪéĪėĪëĪŦĪéĪĀĄĨĩÕĪËĄĪĖĮÂŋĪËÆÉĪß―ņĪĪ·ĪĘĪĪÃąļėĪĮĪĒĪėĪÐūŊĄđÄđĪŊĪÆĪâēæËýĪĮĪĪëĄĨÃąļėĪÎĨđĨÚĨęĨóĨ°ĪËļÂĪéĪšĄĪÃąļėĪÎēŧ·ÁĪËĪÄĪĪĪÆĪâÆąÍÍĪÎļķÍýĪŽšîÍŅĪ·ĪÆĪĪĪëĪČŧŨĪïĪėĪëĄĨ
ĄĄĪÞĪŋĄĪąŅļėĪÎĀĩ―ņËĄĪËĪÏÆâÍÆļėĪÏ3Ęļŧú°ĘūåĪĮÄÖĪéĪėĪĘĪąĪėĪÐĪĘĪéĪĘĪĪĪČĪĪĪĶĄÖ#2235. 3ĘļŧúĩŽÂ§ĄŨ ([2015-06-10-1]) ĪŽĪĒĪëĄĨĪģĪėĪÏĩĄĮ―ļėĪČĪĪĪĶÉŅÅŲĪÎĪĪïĪáĪÆđâĪĪļėÎāĪËĪÄĪĪĪÆĪÏÅŽÍŅĪĩĪėĪĘĪĪĄĨĪ·ĪŋĪŽĪÃĪÆĄĪĪģĪÎĩŽÂ§ĪÏūåĩĪÎļúÎĻĪÎĖäÂęĪČĪâīØĪïĪëžÂÍŅÅŠĪĘÂĶĖĖĪōĪâĪÄĪČĪĪĪĻĪëĄĨ
ĄĄđâÉŅÅŲļėĪĮĪĒĪėĪÐĪĒĪëĪÛĪÉĄĪĪ―ĪÎĨđĨÚĨęĨóĨ°ĪŽĘŋķŅÅŠĪËÃŧĪĪĪģĪČĪōžĻĪđĘýËĄĪÎ1ĪÄĪËĄĪÉŅÅŲĨéĨóĨĨóĨ°ĪÎĨČĨÃĨŨ100ļėĄĪ1000ļėĄĪ10000ļėĪĘĪÉĪÎĨęĨđĨČĪËīðĪÅĪĄĪĘļŧúŋôĘĖĪËÃąļėĪōŋôĪĻūåĪēĪëĪČĪĪĪĶĪäĪęĘýĪŽĪĒĪëĄĨĄÖ#2096. SUBTLEX-US Word Frequency ListĄŨ ([2015-01-22-1]) ĪŦĪé°úĪ―ÐĪ·ĪŋÉŅÅŲĨéĨóĨĨóĨ°ĪōÍøÍŅĪ·ĪÆĄĪĨČĨÃĨŨ100ļėĄĪ200ļėĄĪ500ļėĄĪ1000ļėĄĪ2000ļėĄĪ5000ļėĄĪ10000ļėĄĪ20000ļėĄĪ50000ļėĪËĪÄĪĪĪÆÄīššĪ·ĪŋĄĨĨČĨÃĨŨ100ļėĪÎĨęĨđĨČĪËĪÄĪĪĪÆĪÏĀčĪÎĩŧöĪĮĨęĨđĨČĪō·ĮšÜĪ·ĪÆĪĪĪëÄĖĪęĪĮĪĒĪęĄĪĪĘĪŦĪËĪÏ s, ll ĪĘĪÉĨģĄžĨŅĨđĪÎŧÅÍÍĪËÍģÍčĪđĪëĪČĪŠĪÜĪ·ĪēøĪ·ĪĪĄÖļėĄŨĪâĪĒĪëĪŽĄĪ·ëēĖĪÎÂįĀŠĪËĪÏąÆķÁĪōĩÚĪÜĪĩĪĘĪĪĪĀĪíĪĶĄĨ
ĄĄ°ĘēžĪËĨ°ĨéĨÕĪĮĀ°ÍýĪ·ĪŋÄĖĪęĄĪ·ëēĖĪÏĖĀĮōĪĮĪĒĪëĄĘŋôÃÍĨĮĄžĨŋĪÏĨ―ĄžĨđHTMLĪōŧēūČĄËĄĨĨČĨÃĨŨ100ļėĪÎÄķđâÉŅÅŲļė·ēĪĮĪÏ62.00%ĪÞĪĮĪŽ3Ęļŧú°ĘēžĪÎĨđĨÚĨęĨóĨ°ĪĮĪĒĪëĄĨ3Ęļŧú°ĘēžĪÎģäđįĄĘēžĪŦĪé3ĪÄĘŽĪÎĨŠĨėĨóĨļĪÎÂÓĪÞĪĮĄËĪČĪĪĪĶĪģĪČĪĮČæĪŲĪÆĪĪĪŊĪČĄĪĨČĨÃĨŨ200ļėĪŦĪé50000ļėĪÎÄīšš·ëēĖĪÞĪĮĄĪ―įĪË41.50%, 24.60%, 17.00%, 12.65%, 8.06%, 6.01%, 4.55%, 3.20%ĪČĖÜļšĪęĪ·ĪÆĪĪĪŊĄĨ
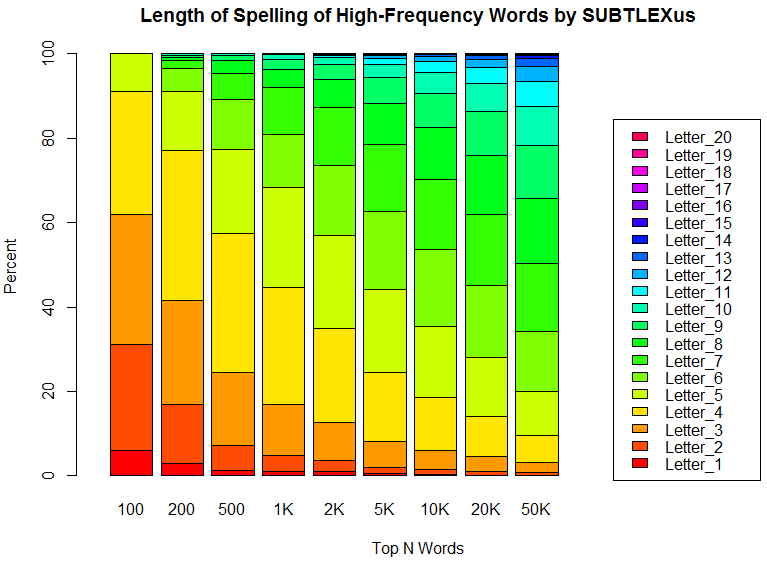
Powered by WinChalow1.0rc4 based on chalow