2012-01-08 Sun
■ #986. COCA の "WORD AND PHRASE . INFO" [coca][corpus][dictionary][synonym][collocation][semantic_prosody][intensifier][web_service]
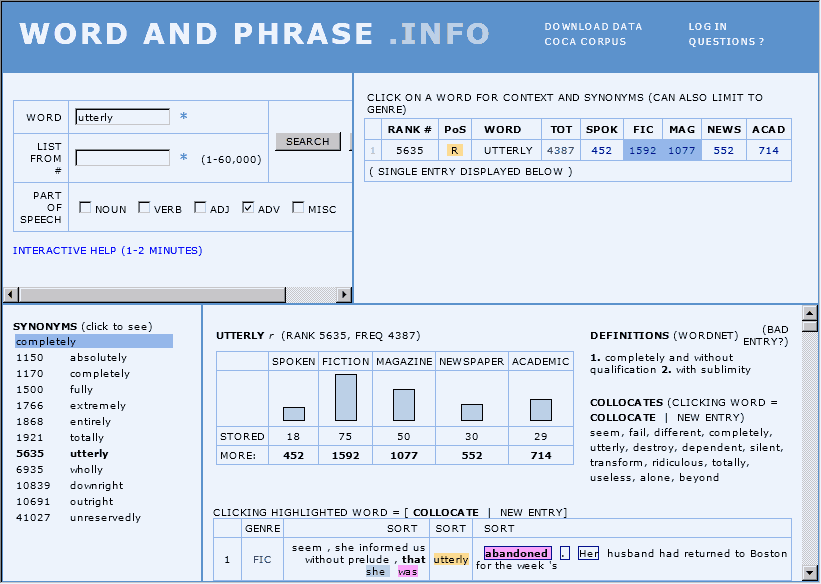
COCA ( Corpus of Contemporary American English ) を運営する Mark Davies 氏が,年末に,COCAベースで語に関する諸情報を一覧できるサービス WORD AND PHRASE . INFO を公開した.語(lemma 頻度で上位60,000語以内に限る)を入力すると,ジャンルごとの生起頻度やそのコンコーダンス・ラインはもとより,WordNet に基づいた定義や類義語群までが画面上に現われる.ほとんどの項目がクリック可能で,さらなる機能へとアクセスできる.インターフェースが直感的で使いやすい.
類義語研究や collocation 研究には相当に役立つ仕様になったのではないか.例えば,semantic_prosody を扱った[2011-03-12-1]の記事「#684. semantic prosody と文法カテゴリー」で,強意語 utterly, absolutely, perfectly, totally, completely, entirely, thoroughly についての研究を紹介したが,WORD AND PHRASE . INFO で utterly を入力すれば,これらの類義語群が左下ウィンドウに一覧される.あとは,各語をクリックしてゆくだけで,頻度や collocation の詳細が得られる.このような当たりをつけるのに効果を発揮しそうだ.
2012-01-04 Wed
■ #982. アメリカ英語の口語に頻出する flat adverb [adverb][adjective][register][corpus][ame_bre][americanisation][colloquialisation][grammar][flat_adverb]
昨日の記事「#981. 副詞と形容詞の近似」 ([2012-01-03-1]) の最後に触れた単純形副詞 (flat adverb) を取り上げる.対応する -ly 形が並存している場合,flat adverb は一般に略式的あるいは口語的であることが多いといわれる.規範的な観点からは,-ly を伴う語形が標準形であり,flat adverb は非難の対象とされるので使用を控えるべしとされるが,LGSWE (Section 7.12.2) によれば,以下のような例は会話コーパスでは普通に見られるという.
The big one went so slow. (CONV)
Well it was hot but it didn't come out quick. (CONV)
They want to make sure it runs smooth first. (CONV†)
特に good や real を副詞として用いる語法は,AmE の口語で広く聞かれる.LGSWE (Section 7.12.2.1) の記述によれば,good を well の意味に用いる例は,AmE の会話で圧倒的によく見られ,一方で書き言葉や BrE では稀である.really の代用としての real については,AmE の会話では really の半分ほどの頻度で使用されているというから,相当な普及度だ.コーパス中の絶対頻度でいえば,これは BrE の会話における really の頻度に匹敵するという.なお,BrE では real のこの用法は皆無ではないが,稀である.両者の例を LGSWE からいくつか挙げよう.
It just worked out good, didn't it? (AmE CONV)
Bruce Jackson, In Excess' trainer said, "He ran good, but he runs good all the time. It was easy." (AmE NEWS)
It would have been real [bad] news. (AmE CONV)
I have a really [good] video with a real [good] soundtrack. (AmE CONV)
例のように,good は動詞と構造をなして述部を作る用法,real は形容詞を強調する用法が普通である.
以上のように,現代英語において flat adverb はアメリカ英語の口語で用いられる傾向が強いことがコーパスから明らかとなっているが,この傾向と関連して[2011-01-12-1]の記事「#625. 現代英語の文法変化に見られる傾向」で触れたアメリカ英語化 (Americanisation) と口語化 (colloquialisation) の潮流を想起せずにいられない.今後,good あるいは real に限らず,英語全体として flat adverb の使用が拡大してゆくという可能性があるということだろうか.合わせて,[2010-03-05-1]の記事「#312. 文法の英米差」の (5) も参照されたい.
・ Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad, and Edward Finegan. Longman Grammar of Spoken and Written English. Harlow: Pearson Education, 1999.
2011-12-09 Fri
■ #956. COCA N-Gram Search [cgi][web_service][coca][corpus][collocation][n-gram]
##953,954,955 の記事で,最近公開された COCA ( Corpus of Contemporary American English ) の n-gram データベースを利用してみた.COCA に現われる 2-grams, 3-grams, 4-grams, 5-grams について,それぞれ最頻約100万の表現を羅列したデータベースで,手元においておけば,工夫次第で COCA のインターフェースだけでは検索しにくい共起表現の検索が可能となる.
ただし,各 n-gram のデータベースは,数十メガバイトの容量のテキストファイルで,直接検索するには重たい.そこで,SQLite データベースへと格納し,SQL 文による検索が可能となるように検索プログラムを組んだ.以下は,検索結果の最初の10行だけを出力する CGI である.
以下,使用法の説明.テーブル名は n-gram の "n" の値に応じて,"two", "three", "four", "five" とした.ちなみに,1-grams のデータベース(事実上,COCA に3回以上現われる語の頻度つきリスト)も付随しており,こちらもテーブル名 "one" としてアクセス可能にした.フィールドは,全テーブルに共通して "freq" (頻度)があてがわれているほか,"n" の値に応じて,"word1" から "word5" までの語形 (case-sensitive) と,"pos1" から "pos5" までの COCA の語類標示タグが設定されている.select 文のみ有効.以下に,典型的な検索式を例として載せておく.
# 1-grams で,前置詞を頻度順に取り出す(ただし,case-sensitive なので再集計が必要)
select * from one where pos1 like "i%" order by freq desc;
# 2-grams で,ハンサムなものを頻度順に取り出す
select * from two where word1 = "handsome" and pos1 = "jj" and pos2 like "nn_" order by freq desc;
# 2-grams で,"absolutely (adj.)" で強調される形容詞を頻度順に取り出す([2011-03-12-1]の記事「#684. semantic prosody と文法カテゴリー」を参照)
select * from two where word1 = "absolutely" and pos2 = "jj" order by freq desc;
# 3-grams で,高頻度の as ... as 表現を取り出す
select * from three where word1 = "as" and word3 = "as" order by freq desc;
# 4-grams で,高頻度の from ... to ... 表現を取り出す
select * from four where word1 = "from" and pos1 = "ii" and word3 = "to" and pos3 = "ii" order by freq desc;
# 5-grams で,死因を探る; "die of" と "die from" の揺れを観察する
select * from five where word1 in ("die", "dies", "died", "dying") and pos1 like "vv%" and word2 in ("of", "from") and pos2 like "i%" order by word3;
n-gram データベースを最大限に使いこなすには,このようにして得られた検索結果をもとにさらに条件を絞り込んだり,複数の検索結果を付き合わせるなどの工夫が必要だろう.
2011-12-08 Thu
■ #955. 完璧な語呂合わせの2項イディオム [binomial][rhyme][corpus][coca][collocation][euphony][n-gram][suffix][proverb]
[2011-12-06-1], [2011-12-07-1]の記事で,COCA ( Corpus of Contemporary American English ) の 3-gram データベースから取り出した,現代英語における頭韻を踏む2項イディオム (binomial) と脚韻を踏む2項イディオムの例を見てきた.分析するなかで,両リストのなかで重複する2項イディオムが散見されたので,取り出してみた.これぞ,頭韻と脚韻の両方を兼ねそなえた,完璧な語呂合わせとしての共起表現である.(検索結果を収めたテキストファイルはこちら.)整理した50表現を挙げよう.
Saturday and Sunday, personal and professional, himself or herself, quantity and quality, morbidity and mortality, quantitative and qualitative, security and stability, best and brightest, latitude and longitude, sixteenth and seventeenth, whenever and wherever, sensitivity and specificity, watching and waiting, majority and minority, basketball and baseball, fight or flight, ranting and raving, forties and fifties, cooperation and coordination, nature and nurture, pushing and pulling, tossing and turning, twisting and turning, grandchildren and great-grandchildren, skiers and snowboarders, communication and collaboration, cooking and cleaning, psychiatrists and psychologists, biggest and best, development and deployment, slipping and sliding, communication and cooperation, Dungeons and Dragons, heterosexual and homosexual, healthier and happier, grandmother and grandfather, stopping and starting, sixteen or seventeen, hooting and hollering, competence and confidence, stalactites and stalagmites, waxing and waning, positive and productive, reading and rereading, patience and perseverance, bedroom and bathroom, consultation and collaboration, going and getting, grandfather and grandmother, protection and promotion
多くは,頭韻と脚韻が語呂として偶然に一致したと考えるよりは,語幹どうしに語源的な関連があるがゆえに頭韻を踏んでいるのであり,同じ接尾辞を用いているがゆえに脚韻を踏んでいるのだ,と解釈すべきだろう.
単なる語呂遊びというなかれ.上記の例は,音と意味の調和をいやおうなく感じさせ,2項の間に一種の必然性すら呼び起こすかのような,高度に修辞的な表現といえるだろう.fight or flight, nature and nurture, competence and confidence, positive and productive などは,単なる高頻度の共起表現であるという以上に,教訓的,ことわざ的ですらある.
2011-12-07 Wed
■ #954. 脚韻を踏む2項イディオム [binomial][rhyme][corpus][coca][collocation][euphony][n-gram][suffix][compound]
昨日の記事「#953. 頭韻を踏む2項イディオム」 ([2011-12-06-1]) に引き続き,今回は,脚韻を踏む高頻度の binomial を COCA ( Corpus of Contemporary American English ) の n-gram データベースにより拾い出したい.昨日と同様に,3-gram を用い,"A and/but/or B" の形の共起表現で,かつ A と B が脚韻を踏んでいるような例を取りだした.検索結果を納めたテキストファイルはこちら.
検索結果を眺めていて今更ながら気付いたことなのだが,脚韻は頭韻に比べてパターンが見つけやすい.特に顕著なのは,脚韻の多くが,語幹の語尾に依存しているというよりは,接尾辞に依存していることだ.-ing, -ed, -ly, -al, -y, -ion, -er などの屈折接尾辞や派生接尾辞が活躍している.
positive and negative, national and international, internal and external, Friday and Saturday, teaching and learning, gifted and talented, elementary and secondary, hunting and fishing, personal and professional, presence or absence, reliability and validity, coming and going, winners and losers, physical and psychological, formal and informal, directly and indirectly, advantages and disadvantages, rising and falling, physically and mentally, buyers and sellers
また,これも考えてみれば,さもありなんという事例なのだが,複合語の第2要素に同じ形態素を用いることにより韻を踏んでいる例も多い.一種の self-rhyme ではある.
Friday and Saturday, children and grandchildren, Saturday and Sunday, hardware and software, himself or herself, formal and informal, parents and grandparents, direct and indirect, buyers and sellers, mother and grandmother, father and grandfather, Afghanistan and Pakistan, anything and everything, football and basketball, indoor and outdoor, direct or indirect, servicemen and women, likes and dislikes, urban and suburban, indoor and outdoor
接尾辞を多用する屈折や派生,そして right-headed な複合を好む英語においては,脚韻を利用した2項イディオムの形成が容易であり,頻繁であることは,自然に理解できそうだ.逆から見れば,語幹の語頭音を利用する頭韻の2項イディオムの形成は,相対的に難しいということになるのかもしれない.
2011-12-06 Tue
■ #953. 頭韻を踏む2項イディオム [binomial][alliteration][corpus][coca][collocation][euphony][n-gram]
[2011-07-26-1]の記事「#820. 英仏同義語の並列」で,2項イディオム (binomial idiom) を紹介した.and, but, or などの等位接続詞で結ばれる2項からなる表現は現代英語でも顕在であり,よく見られるものには,語呂のよいもの (euphony) が多い.英語において語呂の良さといえば,[2011-11-26-1]の記事「#943. 頭韻の歴史と役割」で取り上げた頭韻 (alliteration) が,典型の1つとして挙げられる.
ところで,11月22日に,大規模オンライン・コーパス COCA ( Corpus of Contemporary American English ) などで知られるコーパス言語学者 Mark Davies が,COCA に基づく n-gram を無償で公開した.2, 3, 4, 5語からなる,それぞれ最頻100万の共起表現 (collocation) を,頻度数とともに列挙したデータベースで,ダウンロードしてオフラインで自由に処理できる.
・ Visit N-GRAMS: from the COCA and COHA corpora of American English. For downloading, directly visit Free lists.
・ Also visit Word frequency lists and dictionary: from the Corpus of Contemporary American English for other COCA-derived n-grams and frequency lists.
ここで,COCA n-gram から現代英語の2項イディオムに見られる頭韻を探して出してみようと思い立った.3-gram データベースを利用し,"A and/but/or B" の形の共起表現を探った.話者の意識していないところでも,頭韻は日常表現のなかに相当活用されているはずだとの予想のもとでの検索だったが,実際に多数の例を拾い出すことができた.検索結果のテキストファイルはこちら.2項の語頭の子音字が一致しているものを取り出しただけなので,それが表わす子音が一致しているとは限らず,注意が必要である.それでも,相当数の生きた日常的な頭韻の例を拾い出すことができた.
検索結果上位には,his or her, four or five, six or seven, this or that, Saturday and Sunday など,なるほどとは思わせるが,それほど興味深く感じられない例が少なくない.しかし,イディオム的な性格のもう少し強い,次のような共起表現も次々と挙がり,検索の甲斐があったと満足した.
public and private, rules and regulations, pots and pans, command and control, flora and fauna, free and fair, death and destruction, go and get, safety and security, signs and symptoms, fame and fortune, families and friends, fresh or frozen, peace and prosperity, past and present, quantity and quality, morbidity and mortality, slowly but surely, professional and personal, name and number, facts and figures, pencil and paper, state and society, small but significant, clear and convincing
n-gram については,[2010-12-25-1]の記事「#607. Google Books Ngram Viewer」も参照.
2011-11-13 Sun
■ #930. a large number of people の数の一致 [agreement][number][syntax][bnc][corpus]
現代英語で「a (large) number of + 複数名詞」が主語に立つとき,動詞は複数に一致するのが原則である.完全にこの理解でいたのだが,先日次のような文に出くわした.
A large number of native speakers is perhaps a pre-requisite for a language of wider communication . . . . (Graddol 12)
そこで,数々の辞書や文法書をひっくり返してみた.ほとんどすべての参考書がこの句を複数扱いとしており,統語分析を与えているものについては,number ではなくこの場合で言えば native speakers を主要部 (head) とみなしている.特に,OALD8, LDOCE5, COBUILD English Usage といった典型的な学習者用英英辞書では,複数形の動詞で一致するよう明示的に注記を与えている.また,規範文法のご意見番 Fowler ("number" の項)によると次の通りで,単数一致については明示的な言及はなかった.
. . . as a noun of multitude in the type 'a number of + pl. noun', normally governs a plural verb both in BrE and AmE.
調べたレファレンスのなかで,単数一致について言及していたのは以下のものである.
・ CGEL: "A (large) number of people have applied for the job. [2]" という例文について,"Use of the singular . . . would be considered pedantic in [2] . . . ." (765) と述べている.
・ CALD3: 単数一致を示す例文を "(slightly formal)" というレーベルを与えつつ挙げていた."A large number of invitations has been sent."
・ 『ジーニアス英和大辞典』: 単数一致を「((正式))」としていた."A ? of passengers were [((正式)) was] injured in the accident."
これで,formal or pedantic という register でまれに使用されるらしいということは分かった.では,BNCWeb で確かめてみようと,"a (very)? (large|great|good|small)? number of ((_AV*)? _AJ*)* _NN2 (_VHZ|_VBZ|was_VBD|_VDZ|_VVZ)" として検索し,該当する例のみを手作業で拾い出してみた.全部で25例あったが,1例を除いてすべてが書き言葉からの文例であり,そのうち12例が Academic prose からのものだった.全体として,この表現が academic or pedantic へ強い傾向を示すことは確かなようだ.
・ Graddol, David. The Future of English? The British Council, 1997. Digital version available at http://www.britishcouncil.org/learning-research-futureofenglish.htm.
・ Burchfield, Robert, ed. Fowler's Modern English Usage. Rev. 3rd ed. Oxford: OUP, 1998.
・ Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech, and Jan Svartvik. A Comprehensive Grammar of the English Language. London: Longman, 1985.
2011-10-28 Fri
■ #914. BNC による語彙の世代差の調査 [bnc][corpus][statistics][lltest][interjection]
昨日の記事「#913. BNC による語彙の男女差の調査」 ([2011-10-27-1]) で取りあげた Rayson et al. では,話者の性別だけでなく年齢による語彙の変異も調査されている.年齢差といっても,35歳未満か以上かで上下の世代に分けた大雑把な分類だが,結果はいくつかの興味深い示唆を与えてくれる.以下は,χ2 の上位19位までの一覧である (142--43) .
| Rank | Under 35 | Over 35 | ||
| Word | χ2 | Word | χ2 | |
| 1 | mum | 1409.3 | yes | 2365.0 |
| 2 | fucking | 1184.6 | well | 1059.8 |
| 3 | my | 762.4 | mm | 895.2 |
| 4 | mummy | 755.2 | er | 773.8 |
| 5 | like | 745.2 | they | 682.2 |
| 6 | na as in wanna and gonna | 712.8 | said | 538.3 |
| 7 | goes | 606.6 | says | 443.1 |
| 8 | shit | 410.1 | were | 385.8 |
| 9 | dad | 403.7 | the | 352.2 |
| 10 | daddy | 380.1 | of | 314.6 |
| 11 | me | 371.9 | and | 224.7 |
| 12 | what | 357.3 | to | 211.2 |
| 13 | fuck | 330.1 | mean | 155.0 |
| 14 | wan as in wanna | 320.6 | he | 144.0 |
| 15 | really | 277.0 | but | 139.0 |
| 16 | okay | 257.0 | perhaps | 136.0 |
| 17 | cos | 254.4 | that | 131.3 |
| 18 | just | 251.8 | see | 122.1 |
| 19 | why | 240.0 | had | 118.3 |
予想される通り,若い世代に特徴的なキーワードはくだけた語を多く含んでいる.表外の語も含めてだが,yeah, okay, ah, ow, hi, hey, ha, no, ooh, wow, hello などの間投詞,fucking, shit, fuck, crap, arse, bollocks などのタブー語が目立つ.しかし,若い世代のキーワードとして,一見すると予想しがたい語も挙がる.例えば,please, sorry, pardon, excuse などの丁寧語が若い世代に特徴的だという.
ほかには,若い世代に特徴的な形容詞や副詞がいくつか見られる (ex. weird, massive, horrible, sick, funny, disgusting, brilliant, really, alright, basically) .評価を表わす形容詞・副詞が多く,一種の流行とみなすことができる語群だろう.年齢差を "apparent time" の差と考えれば,そこには "real time" の変化が示唆されることになるので,この語群の通時的な頻度の増加を探るのもおもしろそうだ.
・ Rayson, Paul, Geoffrey Leech, and Mary Hodges. "Social Differentiation in the Use of English Vocabulary: Some Analyses of the Conversational Component of the British National Corpus." International Journal of Corpus Linguistics 2 (1997): 133--52.
2011-10-27 Thu
■ #913. BNC による語彙の男女差の調査 [bnc][corpus][statistics][lltest][interjection][gender_difference]
標題の話題を扱った Rayson et al. の論文を読んだ.BNC の中で,人口統計的な基準で分類された,話し言葉を収録したサブコーパス(総語数4,552,555語)を対象として,語彙の男女差,年齢差,社会的地位による差を明らかにしようとした研究である.これらの要因のなかで,語彙的変異が統計的に最も強く現われたのは性による差だったということなので,本記事ではその結果を紹介したい.
まず,以下に挙げる数値の解釈には前提知識が必要なので,それに触れておく.BNC に収録された話し言葉は志願者に2日間の自然な会話を Walkman に吹き込んでもらった上で,それを書き起こしたものであり,その志願者の内訳は男性73名,女性75名である.会話に登場する志願者以外の話者についても,女性のほうが多い.したがって,当該サブコーパスへの参加率でいえば,全体として女性が男性よりも高くなることは不思議ではない.
しかし,その前提を踏まえた上でも,全体として女性のほうがよく話すということを示唆する数値が出た.使用された word token 数でいえば,男性を1.00とすると女性が1.51,会話の占有率では,男性を1.00とすると女性は1.33だった.男女混合の会話では男性のほうが高い会話占有率を示すとする先行研究があるが,BNC のサブコーパスでは女性同士の会話が多かったということが,上記の結果の背景にあるのかもしれない.いずれにせよ,興味深い数値であることは間違いない.
次に,より細かく語彙における男女差を見てみよう.男女差の度合いの高いキーワードを抜き出す手法は,原理としては[2010-03-10-1], [2010-09-27-1], [2011-09-24-1]の記事で紹介したのと同じ手法である.男性コーパスと女性コーパスを区別し,それぞれから作られた語彙頻度表を突き合わせて統計的に処理し,カイ二乗値 (χ2) の高い順に並び替えればよい.以下は,上位25位までの一覧である (136--37) .
| Rank | Characteristically male | Characteristically female | ||
| Word | χ2 | Word | χ2 | |
| 1 | fucking | 1233.1 | she | 3109.7 |
| 2 | er | 945.4 | her | 965.4 |
| 3 | the | 698.0 | said | 872.0 |
| 4 | year | 310.3 | n't | 443.9 |
| 5 | aye | 291.8 | I | 357.9 |
| 6 | right | 276.0 | and | 245.3 |
| 7 | hundred | 251.1 | to | 198.6 |
| 8 | fuck | 239.0 | cos | 194.6 |
| 9 | is | 233.3 | oh | 170.2 |
| 10 | of | 203.6 | Christmas | 163.9 |
| 11 | two | 170.3 | thought | 159.7 |
| 12 | three | 168.2 | lovely | 140.3 |
| 13 | a | 151.6 | nice | 134.4 |
| 14 | four | 145.5 | mm | 133.8 |
| 15 | ah | 143.6 | had | 125.9 |
| 16 | no | 140.8 | did | 109.6 |
| 17 | number | 133.9 | going | 109.0 |
| 18 | quid | 124.2 | because | 105.0 |
| 19 | one | 123.6 | him | 99.2 |
| 20 | mate | 120.8 | really | 97.6 |
| 21 | which | 120.5 | school | 96.3 |
| 22 | okay | 119.9 | he | 90.4 |
| 23 | that | 114.2 | think | 88.8 |
| 24 | guy | 108.6 | home | 84.0 |
| 25 | da | 105.3 | me | 83.5 |
必ずしもこの25位までの表からだけでは読み取れないが,Rayson et al. (138--40) によれば以下の点が注目に値するという.
・ "four-letter words",数詞,特定の間投詞は男性に特徴的である (ex. shit, hell, crap; hundred, one, three, two, four; er, yeah, aye, okay, ah, eh, hmm)
・ 女性人称代名詞,1人称代名詞,特定の間投詞は女性に特徴的である (ex. she, her, hers; I, me, my, mine; yes, mm, really) (男性代名詞の使用には特に男女差はない)
・ the や of の使用は男性に多い(男性に一般名詞を用いた名詞句の使用が多いという別の事実と関連するか?)
・ 固有名詞,代名詞,動詞は女性に多い(男性の事実描写 "report" の傾向に対する女性の関係構築 "rapport" の傾向の現われか?)
・ 固有名詞のなかでも,人名は女性の使用が多く,地名は男性の使用が多い.
他のコーパスによる検証が必要だろうが,この結果と解釈に興味深い含蓄があることは確かである.
キーワードの統計処理と関連して,コーパス言語学でカイ二乗検定の代用として広く使用されるようになってきた Log-Likelihood 検定については,自作の Log-Likelihood Tester, Ver. 1 や Log-Likelihood Tester, Ver. 2 を参照.
・ Rayson, Paul, Geoffrey Leech, and Mary Hodges. "Social Differentiation in the Use of English Vocabulary: Some Analyses of the Conversational Component of the British National Corpus." International Journal of Corpus Linguistics 2 (1997): 133--52.
2011-09-24 Sat
■ #880. いかにもイギリス英語,いかにもアメリカ英語の単語 [corpus][ame_bre][ame][bre][flob][frown][text_tool][keyword]
道具が揃っていれば簡単に実行でき,しかも結果がとてもおもしろいコーパスの使い方として,キーワード抽出がある.その原理については[2010-03-10-1]の記事「#317. 拙著で自分マイニング(キーワード編)」で概説し,[2010-09-27-1]の記事「#518. Singapore English のキーワードを抽出」でもキーワード抽出の事例を紹介した.
今回はより身近な疑問として,(1) アメリカ英語に対していかにもイギリス英語的な単語は何か,(2) イギリス英語に対していかにもアメリカ英語的な単語は何か,を FLOB と Frown の2コーパスを用いて取り出してみたい(両コーパスについては[2010-06-29-1]の記事「#428. The Brown family of corpora の利用上の注意」を参照).解析のお供は,以前と同様 WordSmith の KeyWords 抽出機能である.
両変種の語彙頻度表を互いに突き合わせ,それぞれキーワード性 (keyness) の高い順に上位500語を取り出した(全リストはこちらのテキストファイルを参照).ここでは,それぞれから上位50語のみを再掲しよう.すべて小文字で示す.
Q. (1) アメリカ英語に対していかにもイギリス英語的な単語は何か?
A. (1) 以下の通り.
cent, which, labour, uk, towards, london, per, centre, was, british, programme, behaviour, it, be, colour, britain, defence, favour, royal, there, been, round, bbc, thatcher, sir, mp, charter, nhs, realised, scottish, yesterday, lord, favourite, local, council, recognised, theatre, mr, being, fviii, tory, kinnock, mps, thalidomide, whilst, scotland, churches, should, programmes, parliament
Q. (2) イギリス英語に対していかにもアメリカ英語的な単語は何か
A. (2) 以下の通り.
percent, toward, program, programs, clinton, u, bush, labor, s, defense, president, american, states, center, washington, formula, federal, behavior, color, united, black, state, fiber, says, zen, americans, ó, california, congress, zach, san, o, white, presidential, pex, jell, women, treaty, favorite, said, bill, gray, colors, perot, favor, douglass, hershey, quayle, j, n
中には,それだけでは意味不明のものもある.BrE の第1位 cent などは何故かと思うかもしれないが,分かち書きをする per cent の2語目が抜き出された結果である.AmE では対応する percent が第1位である.他にも綴字の英米差はよく反映されており,behaviour, centre, colour, defence, favour, favourite, labour, programme(s) は互いのリストに現われる.
英国の政治を特徴づける MP(s), NHS, Parliament, Royal, Scotland, Tory,対応する米国の Congress, Federal, President, State(s), Washington, White (House) などは,なるほどと頷かせる.両コーパスのテキスト年代である1990年代初頭(と少し以前の時期)を特徴づける Thatcher, Bush, Clinton も含まれている.
文法語としては,BrE の which や whilst ([2010-09-17-1]の記事「#508. Dracula に現れる whilst」を参照)が興味深い.
それにしても,それぞれ鼻につくほどの BrE あるいは AmE である.逆に,各変種の汎用コーパスからこのようにして抽出されたキーワードがどれくらい含まれているかによって,小説なり何なりのテキストがいかに BrE 的か AmE 的か,あるいはより中立な "World Standard English" に近いかということを測ることができるかもしれない.
キーワード抽出による「いかにも」シリーズは今後も続きそう.
2011-09-16 Fri
■ #872. -ick or -ic [suffix][johnson][webster][corpus][google_books][spelling][n-gram]
現代英語の動詞 panic や picnic は,屈折語尾や派生語尾が付加されると,panicking, panicky, picnicked, picnicker などと <k> が挿入される.また,brick, kick, stick などの接尾辞ではない,語根の一部としての /-ɪk/ にも <k> が現われる.しかし,一般に接尾辞としての /-ɪk/ が語末に現われる場合,対応する綴字は -ick ではなく -ic である (ex. public, music, specific, basic, domestic, traffic, democratic, scientific, characteristic, academic) .
しかし,Johnson の A Dictionary of the English Language (1755) では,-ic 語はすべて,いまだ -ick として綴られていた.これを現代風の -ic へと改めたのはアメリカの辞書編纂者 Noah Webster だった.彼が The American Dictionary of the English Language (1828) で体現した改革により public の綴字が定着し,そのほかの多くの -ic 語の綴字も定着した.そして,これがアメリカ英語のみならずイギリス英語へも拡大していったのである (Potter 41) .
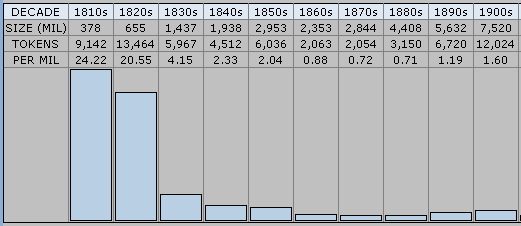
もっとも,Webster 以前に -ic の綴字がなかったわけではない.むしろ,ある程度の市民権を得ていたからこそ,Webster の一押しが効いたという側面がある.[2010-12-25-1]の記事で紹介した Google Books Ngram Viewer による public と publick の頻度の変遷を見れば,この状況が把握できる.AmE の変遷グラフ と BrE の変遷グラフ を確認されたい.同じデータを Mark Davies による Google Books: American English 経由で10年刻みに見ると,publick は1810--29年までは100万語辺りで20回以上現われていたが,1830年代には4.15回へ激減しているのが分かる.
接尾辞 -ic に関連する話題としては,次の記事も参照.
・ [2009-08-02-1]: #97. 借用接尾辞「チック」
・ [2009-08-03-1]: #98. 「リック」や「ニック」ではなく「チック」で切り出した理由
・ [2009-08-10-1]: #105. 日本語に入った「チック」語
・ Potter, Simon. Changing English. London: Deutsch, 1969.
2011-09-12 Mon
■ #868. EDD Online [dialect][web_service][corpus][lmode][lexicography][edd][dictionary]
図書館の reference corner に,古めかしい浩瀚の辞書があるのを日々見ていた.自分ではあまり使うことはないかなと思っていたが,数年前,博士論文研究に関連して eyes (「目」の複数形)に対応する中英語の諸方言形が近代英語や現代英語でどのように発達し,方言分布を変化させてきたかを調べる必要があり,そのときにこの辞書を開いたのが初めてだったように思う(その成果は Hotta (2005) にあり.[2009-12-02-1]の記事「eyes を表す172通りの綴字」も参照).Joseph Wright による6巻ものの辞書 The English Dialect Dictionary (EDD) である.
それ以降もたまに開く機会はあったが,先日参加した学会で,この辞書がオンライン化されたと知った.久しぶりに EDD に触れる良い機会だと思い,早速アクセスしてみることにした.Innsbruck 大学の Prof. Manfred Markus が責任者を務める SPEED (Spoken English in Early Dialects) プロジェクトの成果たる EDD Online の beta-version が公開中である.現時点では完成版ではないとしつつも,すでに検索等の機能は豊富に実装されており(豊富すぎて活用仕切れないほど),学術研究用に使用許可を取得すれば無償でアクセスできる.(使用マニュアルも参照.)
早速,使用許可を得てアクセスしてみた.ただし,調べる題材がない私にとっては,豚に真珠,猫に小判.悲しいかな,見出し語検索に eye を入れてみたりして・・・(←紙で引け!懐かしむな!)(ただし,"structured view" で表示すると,紙版よりずっと見やすいのでそれだけでも有用).Markus 氏が学会でじきじきに宣伝していた通り,様々な検索が可能のようである.見出し語検索や全文検索はもちろんのこと,dialect area 検索では語によっては county レベルで地域を指定できる.usage label 検索では頻度ラベル,意味ラベル(denotation, simile, synonym など),語用ラベル(derogatory, slang など)の条件指定が可能である.etymology 検索の機能も備わっている.これらを組み合わせれば,特定地域と特定の言語からの借用語彙の関係などが見えてくるかもしれない.活用法を考えるに当たっては,まずは EDD がどのような辞書か,EDD Online がどのような機能を実装しているのかを学ばなければ・・・.
EDD そのものについては,VARIENG (Research Unit for Variation, Contacts and Change in English) に掲載されている,Markus 氏による Wright's English Dialect Dictionary computerised: towards a new source of information がよくまとまっている.
(後記 2022/10/21(Fri):EDD や SPEED へのリンクが切れていたのを発見した.EDD は新たにこちらよりどうぞ.)
・ Hotta, Ryuichi. "A Historical Study on 'eyes' in English from a Panchronic Point of View." Studies in Medieval English Language and Literature 20 (2005): 75--100.
・ Wright, Joseph, ed. The English Dialect Dictionary. 6 vols. Henry Frowde, 1898--1905.
2011-08-29 Mon
■ #854. 船や国名を受ける代名詞 she (3) [personal_pronoun][she][gender][personification][political_correctness][corpus][statistics][lexical_diffusion]
標題について[2011-08-27-1], [2011-08-28-1]の記事で話題にしてきたが,現代英語でこの用法の she が《古風》となってきている,あるいは少なくともその register が狭まってきているのはなぜだろうか.
これには,1960年代以降,とりわけアメリカ英語で高まってきた言語の gender 論,男女平等という観点からの political correctness (PC) への関心がかかわっている.この観点から,人間の総称としての man(kind),女性接尾辞 -ess,職業人を表わす複合語要素 -man,一般人称代名詞としての he の使用などが疑問視され,数々の代替表現が提案されてきた.(関連する話題は,[2009-08-20-1]「男の人魚はいないのか?」, [2010-01-27-1]「現代英語の三人称単数共性代名詞」, [2011-04-17-1]「レトリック的トポスとしての語源」などの記事を参照.)
この観点から she の特殊用法を見ると,船や国名を取り立てて女性代名詞で受ける理由はないではないかという議論が生じる.船乗りや国の為政者が主として男性だったという英語国の歴史を反映していることは確かだろうが,現在も旧来の慣習を受け継ぐべき合理性はないという考え方である.
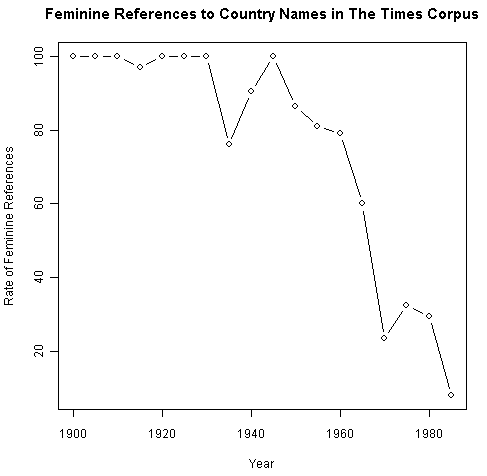
特に国名を受ける she の用法は,形式張った書き言葉という register に限ると,1960年代以降,激減してきていることが実証される.The Times corpus を用いてこれを検証した Bauer (148--49) によると,1930年までは国を指示する she の用法は標準的だった.実際,1900年から1930年の間で,国を指示する it の用例は3例のみだったという.ところが,1935年以降,it の例が断続的に現われだし,1970年にはshe を圧迫して一気に標準となった.she の用例が減少してきた過程は逆S字曲線を描いているかのようであり,語彙拡散 (lexical diffusion) を思わせる.以下のグラフは Bauer (149) のグラフに基づいて概数から再作成したものである.
・ Bauer, Laurie. Watching English Change: An Introduction to the Study of Linguistic Change in Standard Englishes in the Twentieth Century. Harlow: Longman, 1994.
2011-08-20 Sat
■ #845. 現代英語の語彙の起源と割合 [lexicology][loan_word][statistics][bnc][corpus]
現代英語の語彙における本来語と借用語の比率については,本ブログでも何度か取り上げてきた.いくつかリンクを張っておこう.
・ [2010-12-31-1]: #613. Academic Word List に含まれる本来語の割合
・ [2010-06-30-1]: #429. 現代英語の最頻語彙10000語の起源と割合
・ [2010-05-16-1]: #384. 語彙数とゲルマン語彙比率で古英語と現代英語の語彙を比較する
・ [2010-03-02-1]: #309. 現代英語の基本語彙100語の起源と割合
・ [2009-11-15-1]: #202. 現代英語の基本語彙600語の起源と割合
・ [2009-11-14-1]: #201. 現代英語の借用語の起源と割合 (2)
・ [2009-08-15-1]: #110. 現代英語の借用語の起源と割合
語種の数量的な調査には,数え挙げる際のソースを何にするか,type-count か token-count か,どのくらいの語彙規模を扱うか,語源にまつわる不正確さをどのように処理するか,などの考慮すべき事項が様々あり,研究者によって結果がまちまちとなることがある.しかし,複数の調査を比べれば,およその平均値や全体像が見えてくるのも確かである.
先日参加してきた ICOME7 (The Seventh International Conference on Middle English) で,8月4日,OED3 の主幹語源学者 Philip Durkin 氏が "Some neglected aspects of Middle English lexical borrowing from (Anglo-)French" と題する講演で関連する話題について触れていたので,要点をメモしておく.
Durkin 氏は BNC から最頻1000語のリストを取り出し,語源分析した.その結果,英語本来語が489語,フランス・ラテン語が489語,ノルド語が32語,それ以外の言語が10語という数値が得られた.大規模コーパスの頻度リスト (see [2010-03-01-1]) を利用した語源調査はいつか自分でやろうと思っていたが,Durkin 氏のおかげでその労力を省くことができた(ありがとうございます!).
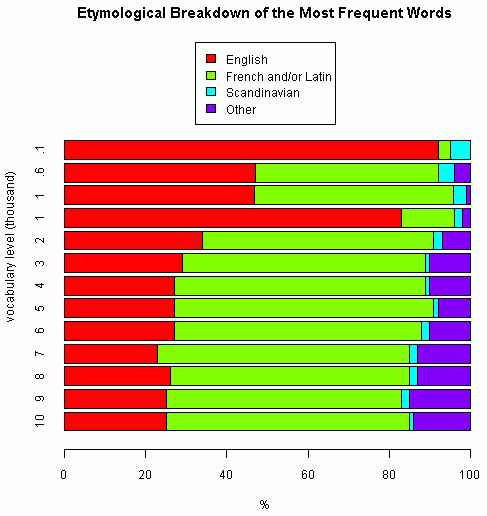
これにより,上記のリンクで示した諸調査と合わせて,type-count に基づく最頻100語,600語,1000語,2000語,3000語,4000語,5000語,6000語,7000語,8000語,9000語,10000語という12段階の語彙規模での語種別比率が得られたことになる.母体となる現代英語語彙の情報ソース,数え方,語種区分はそれぞれ異なっているのかもしれないが,一応の目安として以下で全体像を示したい.語種区分は English, French and/or Latin, Scandinavian, Other として4種類に統一した.
|
|
上から3つ目と4つ目の棒グラフは,同じ最頻1000語レベルでの比較だが,3つ目は上述の Durkin の BNC 調査によるもの,4つ目は[2010-06-30-1]の記事で示した Williams のものである.著しい差異が生じたが,これも調査方法が異なるがゆえだろうか.注意して解釈する必要があるが,この点を除けば全体としてなだらかに推移し,最終的には本来語25%,ラテン・フランス語60%,それ以外が15%という数値におよそ落ち着くようだ.
2011-07-05 Tue
■ #799. 海賊複数の <z> [plural][netspeak][suffix][corpus][z][alphabet]
複数形ウォッチャーとして,気になる複数接尾辞がある.発音は -s の場合と同様だが,綴字が <z> となる「z 複数」である.Crystal (137) が以下のように指摘していた.
New spelling conventions have emerged, such as the replacement of plural -s by -z to refer to pirated versions of software, as in warez, tunez, gamez, serialz, pornz, downloadz, and filez. (137)
それぞれ発音の差異を伴わない完全に綴字上の異形態だが,いかがわしい効果は抜群である.このいかがわしさが何に由来するのかといえば,<z> の文字自体のもつ異様さだろう.[2010-07-17-1]の記事「しぶとく生き残ってきた <z>」で取りあげたように,<z> はきわめて影の薄い文字だが,<s> の明らかに期待されるところで <z> が前景化されるとやけに目立つ.
しかし,「海賊複数」 ( plural of piracy ) とでも呼びたくなるこの <z> 接尾辞(字)の使用は,現在では NetSpeak での隠語としての使用に限定されているようだ.COCA ( Corpus of Contemporary American English ) の検索によると,warez で4例がヒットした( warez 以外の上掲の語はヒットなし).以下はそのうちの1例で,2004年の Houston Chronicle からの記事である.
CW Shredder - www.spyware info.com/merijn/ Developed by the same author as Hijack This!, CW Shredder removes a very common piece of spyware known as the Coolwebsearch Trojan. It takes advantage of a flaw in a key component of Windows - Microsoft's version of the Java Virtual Machine - to install itself via pop-ups often found on porn and illegal software (a.k.a. "warez") sites.
他に BNCweb で "*z_NN2" として検索してみると,BOYZ が多数ヒットした.ただし,これはアメリカの人気グループ Boyz II Men やアメリカ英語 Boyz n the Hood への言及によるもので,海賊複数とは趣が異なる.とはいえ,固有名や商品名(の宣伝)に非標準的な綴字を用いることは商業広告では広く見られる現象であり(例えば Heinz 社の "Heinz Buildz Kidz" ),目立たせる効果を狙っている点では共通性が感じられる.
ちなみに,Kirg(h)iz 「キルギス人」がヒットしたが,これはロシア語の綴字に準じたもので単複同形であるにすぎない(異形として Kirg(h)izes もあり).
・ Crystal, David. The English Language. 2nd ed. London: Penguin, 2002.
2011-06-09 Thu
■ #773. PPCMBE と COHA の比較 [corpus][coha][ppcmbe][lmode][adjective][comparison][inflection][representativeness]
本ブログでも何度か取り上げている2つの歴史英語コーパス PPCMBE ( Penn Parsed Corpus of Modern British English; see [2010-03-03-1]. ) と COHA ( Corpus of Historical American English; see [2010-09-19-1]. ) について,塚本氏が『英語コーパス研究』の最新号に研究ノートを発表している.両者とも2010年に公開された近代英語後期のコーパスだが,それぞれ英米変種であること,また編纂目的が異なることから細かな比較の対象には適さない.しかし,代表性をはじめとするコーパスの一般的な特徴を比べることは意味があるだろう.
PPCMBE は1700--1914年のイギリス英語テキスト約949,000語で構成されており,Parsed Corpora of Historical English の1部をなす.同様に構文解析されたより古い時代の対応するコーパスとの接続を意識した作りである.有料でデータを入手する必要がある.一方,COHA は1810--2009年のアメリカ英語テキスト4億語を収録した巨大コーパスである.こちらは,構文解析はされていない.COHA は無料でオンラインアクセスできるため使いやすいが,インターフェースが固定されているので柔軟なデータ検索ができないという難点がある.
コーパスの規模とも関係するが,PPCMBE は代表性 (representativeness) の点で難がある.PPCMBE のコーパステキストを18ジャンルへ細かく分類し,テキスト年代を10年刻みでとると,サイズがゼロとなるマス目が多く現われる.これは,区分を細かくしすぎると有意義な分析結果が出ないということであり,使用に際して注意を要する.
一方,COHA のコーパステキストは Fiction, Popular Magazines, Newspapers, Non-Fiction Books の4ジャンルへ大雑把に区分されている.細かいジャンル分けの研究には利用できないが,10年刻みでも各マス目に適切なサイズのテキストが配されており,代表性はよく確保されている.ただし,Fiction の構成比率がどの時代も約50%を占めており,Fiction の言語の特徴(特に語彙)がコーパス全体の言語の特徴に影響を与えていると考えられ,分析の際にはこの点に注意を要する.
塚本氏は,両コーパスの以上の特徴を,後期近代英語における形容詞の比較級・最上級の問題によって示している.CONCE (Corpus of Nineteenth-Century English) を用いた Kytö and Romaine の先行研究によれば,19世紀の間,比較級の迂言形に対する屈折形の割合は,30年刻みで世紀初頭の57.1%から世紀末の67.8%へと増加しているという.同様の調査を COHA と PPCMBE で10年刻みに施したところ,前者では1810年の64.7%から1910年の74.3%へ着実に増加していることが確かめられたが,後者では1810年の79.4%から1910年の78.0%まで増減の揺れが激しかったという(塚本,p. 56).しかし,CONCEと同様の30年刻みで分析し直すと,PPCMBE でも有意な変化をほぼ観察できるほどの結果がでるという.
コーパスはそれぞれ独自の特徴をもっている.よく把握して利用する必要があることを確認した.関連して,[2010-06-04-1]の記事「流れに逆らっている比較級形成の歴史」を参照.
・ 塚本 聡 「2つの指摘コーパス---その代表性と類似性」『英語コーパス研究』第18号,英語コーパス学会,2011年,49--59頁.
・ Kytö, M. and S. Romaine. "Adjective Comparison in Nineteenth-Century English." Nineteenth-Century English: Stability and Change. Ed. M. Kytö, M. Rydén, and E. Smitterberg. Cambridge: CUP, 2006. 194--214.
2011-06-07 Tue
■ #771. 名詞の単数形と複数形の頻度 [corpus][statistics][plural][countability]
Biber et al. (Section 4.5.6 [pp. 291--22]) に,一般名詞の単数形と複数形の頻度に関する記述がある.現代英語における大雑把な分布ではあるが,LSWE Corpus の500万語サブコーパスを用いた信頼できる数値なので参考までにメモしておく.まず,各サブコーパスで100万語当たりの生起数に換算してのグラフの再現から(数値データは与えられていなかったのでグラフから概数を読み取っての再現).
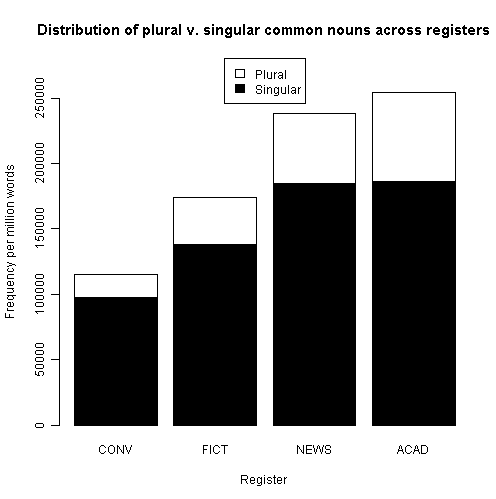
(1) conversation transcription (CONV), fiction text (FICT), newspaper text (NEWS), academic text (ACAD) の4サブコーパス間の差が激しい.
- 原則として複数形をとらない不可算名詞も含めているとはいえ,すべてのサブコーパスで単数形が複数形よりも頻度が高い.
- 会話では単数形の頻度が比較的高い.
- 書き言葉では話し言葉よりも複数形の頻度が3--4倍も高い.
(2) 個々の名詞でみると,多くの名詞が単数形あるいは複数形のいずれかへの強い偏りを示す.
(3) 例えば,次の名詞は75%以上の割合で単数形をとる.ex. car, god, government, grandmother, head, house, theory.
(4) 例えば,次の名詞は75%以上の割合で複数形をとる.ex. grandchildren, parents, socks, circumstances, eyebrows, onlookers, employees, perks.
(1) に関して,単数形が圧倒的に多いこと自体はまったく不思議ではない.上述のように不可算名詞は原則として単数形しかあり得ない.また,ほとんどの可算名詞では単数形が lemma そのものであるし無標の形態でもある.ほかには,数の概念が中立化される場合,例えば hand in hand, from time to time などの慣用表現においては,単数形が用いられるのが普通である.
(2)--(4) に関して,名詞によって単数形か複数形への偏りを示すというのも驚くに当たらない.それぞれの語群を眺めれば,そこに "the communicative needs of the language user" (291) が反映されていることがはっきりと分かるだろう.名詞全体をならせば,「コミュニケーション上の必要性」が単数形に偏りそうだということも直感される.
では,会話で単数形の使用が多いというのは,どういうわけだろうか.Biber et al. (291--92) は次のように述べている.
In general, the high frequency of singular nouns in conversation probably follows from the concern of speakers with individuals: a person, a thing, an event. Writers of academic prose, on the other hand, are more preoccupied with generalizations that are valid more widely (for people, things, events, etc.). This same tendency applies not only to nouns, but also to determiners and pronouns (4.4.3.1, 4.12.1, 4.14.1, 4.15.2.1).
コーパス全体としては,複数形は一般名詞の2割程度しか占めないことになる.複数形の研究を専門とする(つまり複数形の例をなるべく多く集めなければならない)私にとっては,なかなか厳しい数値だなあ・・・.
・ Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad, and Edward Finegan. Longman Grammar of Spoken and Written English. Harlow: Pearson Education, 1999.
2011-05-24 Tue
■ #757. decline + 蜍募錐隧杣syntax] [gerund][bnc][corpus]
1796年9月19日,アメリカ合衆国の初代大統領 George Washington (1732--99) が大統領職を去るに当たって farewell address 「お別れのスピーチ」を読んだ.渡辺昇一先生の『英文法を知ってますか』 (252--53) によると,その語り出しの部分が英語精読力の試金石になるというので,院生と精読する機会をもった.以下の英文である.
FRIENDS AND FELLOW-CITIZENS. The period for a new election of a citizen, to administer the executive government of the United States, being not far distant, and the time actually arrived, when your thoughts must be employed in designating the person who is to be clothed with that important trust, it appears to me proper, especially as it may conduce to a more distinct expression of the public voice, that I should now apprise you of the resolution I have formed, to decline being considered among the number of those out of whom a choice is to be made.
確かに読み応えのある英文である.注を付すべき英文法のポイントはたくさんあるが,最後のほうに decline に不定詞でなく動名詞が後続する点を指摘してくれた学生がいた.私は見逃していたので余計に関心をもったのだが,decline の用法を学習者用英英辞書で調べると,動名詞が後続する構文は触れられていない.しかし,大きな英和辞書では,一般的ではないとしながらも,動名詞が後続し得ると記述されている.また,OED で調べると decline, v. の語義 13b に挙げられている17世紀末以降からの数例で,動名詞の後続する構文が確認される.したがって,Washington がここで動名詞を使用しているのは歴史的にあり得ない構文ではなかったということになる.
しかし,Washington があえて稀な構文を用いたのはなぜか.style や formality の問題なのか,あるいは decline の取り得る構文の種類の相対頻度が当時から現在までの期間に通時的に変化してきたということなのか.精読を目指すからには,この点が気になった.本格的には通時コーパスなどで調べる必要があるが,まずは BNCweb でどのくらいヒットするか調べてみた.
不定詞が後続する構文を取り出すのに,"{decline/V} (_{ADV})* _TO0" で検索すると,769例がヒット.一方,動名詞が後続する構文は "{decline/V} (_{ADV})* _VVG" で取り出し,ヒットした9例のうち実際には3例のみ該当する例であることが判明した.コンコーダンスラインを示す.
- FTT 821: . . . but with proper delicacy to this subject they decline making application at Present and till it is ascertained how cattle markets may go in June next . . .
- FTT 839: The Presses of this meeting, as being part owner of the Steam Boat, declines allowing the assessment for the Steam Boat to be charged for this year.
- HW8 831: Dosh and Freddie didn't take much persuading but Chase thankfully declined saying that parties didn't like him.
FTT なる典拠(An Islay Notebook という non-academic prose and biography)から2例が例証されるというのは,書き手の癖の問題なのだろうか.Washington の動名詞の使用例については判断を下せないままだが,現在までに古風あるいは格式張った使い方に限定されてきた可能性,通時的に頻度が減ってきた可能性はありそうだ.
・ 渡辺 昇一 『英文法を知ってますか』 文藝春秋〈文春新書〉,2003年.
2011-05-05 Thu
■ #738. inclusive superlative [superlative][contamination][syntax][corpus][ppceme]
昨日の記事「構文の contamination」 ([2011-05-04-1]) で最後に取り上げた "inclusive superlative" について,BNCweb でどのくらいヒットするか試してみた."(most _AJ0 | _AJS) (_{N})* of (any)? other" で検索すると,以下の7例を取り出すことができた(赤字は引用者).
- Chang's speed was the best of any other player.
- Perhaps the most notable of other attempts to describe parents in this fashion was undertaken by Earl S. Schaefer.
- This percentage is the largest of any other constituency in England.
- But centuries of migration, conquest, occupation, intermarriage, trade and cultural exchange - not to mention the tendency of artists to copy or reinterpret the most successful facets of other artists' work - have eroded much of this exclusivity.
- Commander Keen has the largest fan club of any other shareware game available.
- 'In proportion to the kiwi's size the egg is the largest of any other bird.
- I say in particular our union because everyone here knows we probably have the largest and best training programme of any other union in Britain today.
初期近代英語にも見られたということなので,The Penn-Helsinki Parsed Corpus of Early Modern English (PPCEME) でざっと調べてみると,John Fryer (b. c1650, d. 1733) なる人物の東洋旅行記に次の1例があった.
They yet retain a Warlike Disposition, being still accounted the best Gunners here of any other places in Persia;
この妙な構文の起源と歴史を探るには,混交のもととなっている2つの構文 comparative + than any other と superlative + of all の頻度や文脈をまず洗い出す必要があるだろう.
2011-05-04 Wed
■ #737. 構文の contamination [blend][contamination][syntax][superlative][bnc][corpus]
[2011-01-17-1]で blend 「混成語」を話題にした際に少々触れたが,類似した過程に contamination 「混交」がある.両者は意識的か否かという観点か区別されることがあるが,特に区別せず同様に用いられることもある.通常は語形成上の過程として捉えられるが,[2011-01-17-1]の記事で触れたように構文のレベルででも起こりうる.例えば,前の記事では,"Why did you do that for?" や "different than" を挙げた.
Graddol を講読中に構文の contamination に出会った(赤字は引用者).
English is remarkable for its diversity, its propensity to change and be changed. This has resulted in both a variety of forms of English, but also a diversity of cultural contexts within which English is used in daily life. (5)
ここでは,both . . . and . . . と not only . . . but also . . . の構文が混交している.BNCweb より検索キーワード "both +** but also" で類例を探してみると,6例ほどが見つかった(赤字は引用者).
- Ion Pacepa, Ceausescu's chief intelligence officer who defected in 1978, takes particular pleasure in his memoirs in exposing Stefan Andrei as both corrupt but also as well aware of the absurdity of the Ceausescus' pretensions, especially Elena's academic titles.
- Their economy and population were both suffering, but also they were becoming wary of the Dzhungars' increasing strength.
- In fitting statistical models to study relationships, it is important to take account of such hierarchies, both for technical reasons but also because influential factors can be present at any or all levels of aggregation.
- The changes that have been introduced into South Africa [pause] forced upon the white minority government by both international pressure but also by the magnificent work at the A N C in Cosatu [pause] must be supported as well but we cannot treat South Africa as anything but a pariah [pause] a, a, a national pariah [pause] until we see one person one vote, and a black majority government in South Africa.
- 'Committees' means both actual committees but also individuals or organisers listed as committees.
- I mean that can be both pleasurable, but also make somebody feel uncomfortable.
contamination は,共時的には話者の発話時に生じる2つの関連構文の混交として解釈されるが,これが共同体に広がってある程度の認知度を得ると,新しい構文として独立し定着することがある.そのような場合には,contamination は通時的な観点からアプローチすることができるだろう.以下は現代英語に見られる構文の contamination の例だが,これらがいつ頃に現われ,現在までにどの程度の認知度を得てきたかという問題は,英語史の問題である.
(1) these kinds of things: these things と this kind of things の混交.
(2) different than: different from と other than の混交.
(3) different to: different from と opposed to の混交.similar to との類推とも考えられる.
(4) cannot help but do: cannot help doing と cannot but do の混交.
(5) It is no good for us complaining about it.: It is no good for us to complain about it. と It is no good we complaining about it. の混交.
(6) no sooner . . . when: no sooner . . . than と scarcely . . . when の混交.
(7) I am friends with him.: I am friendly with him. と He and I are friends. の混交.
(8) a man whom she thought was a murderer: a man who she thought was a murderer と a man whom she thought to be a murderer の混交.
(9) the cleverest of all the other boys: cleverer than the other boys と the cleverest of all the boys の混交.
調べてみるといろいろとあるようだが,(9) のような例は少なくないようで,石橋 (127) は次のようにコメントしている.研究材料としておもしろそうだ.
Sunday's action was the most brilliant and fruitful of any fought up to that date by the fighters of the Royal Air Force. [the most . . . of (all) + (more . . . than) any]---W. Churchill / This is the greatest error of all the rest. [the greatest . . . of (all) + (a greater . . . than) all the rest]---Sh., Mids. N. D. v. i. 250. 最後の例のように,最上級に修飾される名詞を,意味上はそれを含まないはずの「その他」の中に包括させた混交表現を,とくに包括最上級 (Inclusive superlative) と呼ぶことがある.その例は近代初期の英語にときどき見いだされる.
・ Graddol, David. The Future of English? The British Council, 1997. Digital version available at http://www.britishcouncil.org/learning-research-futureofenglish.htm.
・ 石橋 幸太郎 編 『現代英語学辞典』 成美堂,1973年.
Powered by WinChalow1.0rc4 based on chalow