2013-04-06 Sat
■ #1440. 音節頻度ランキング [syllable][corpus][lexicon][phonetics][frequency][statistics]
「#1424. CELEX2」 ([2013-03-21-1]) で紹介した巨大データベースで何かしてみようと考え,Version 2 で新たに加えられた音節頻度 (English Frequency, Syllables) のサブデータベースにより,現代英語で最も多い音節タイプのランキングを得た.
これは,CELEX2 のもとになっているコーパス全体のうち,7.26%を構成する約130万語の話し言葉サブコーパスから引き出された音節頻度であり,タイプ頻度ではなくトークン頻度によるものである.つまり,話し言葉におけるある単語の頻度が高ければ,その分,その単語に含まれる音節タイプの頻度も高くなるということである.例えば,of を構成する "Ov" (= /ɒv/) と表現される音節は,第4位の頻度である.なお,強勢の有無は考慮せずに頻度を数えている.
以下のリストに挙げる音素表記は,IPA ではなく CELEX 仕様の独特の表記なので,先に対応表を挙げておこう.
では,以下にランキング表でトップ50位までを掲載する.高頻度の単音節語の音節タイプがそのまま上位に反映されていて,あまりおもしろい表ではないが,何かの役に立つときもあるかもしれない.
| Rank | Syllable | Frequency |
|---|---|---|
| 1 | eI | 72971 |
| 2 | Di: | 60967 |
| 3 | tu: | 31446 |
| 4 | Ov | 30108 |
| 5 | In | 29906 |
| 6 | &nd | 28709 |
| 7 | aI | 23822 |
| 8 | lI | 19728 |
| 9 | @ | 19566 |
| 10 | rI | 14356 |
| 11 | ju: | 12598 |
| 12 | dI | 12465 |
| 13 | D&t | 12118 |
| 14 | It | 11504 |
| 15 | wOz | 10834 |
| 16 | fO:r* | 9778 |
| 17 | Iz | 9517 |
| 18 | tI | 9161 |
| 19 | fO | 9042 |
| 20 | Sn, | 8969 |
| 21 | hi: | 8928 |
| 22 | r@n | 8638 |
| 23 | bi: | 8505 |
| 24 | bI | 7936 |
| 25 | nI | 7068 |
| 26 | wID | 7046 |
| 27 | On | 7030 |
| 28 | &z | 6919 |
| 29 | O:l | 6569 |
| 30 | h&d | 6240 |
| 31 | E | 6165 |
| 32 | bl, | 6021 |
| 33 | sI | 5836 |
| 34 | @U | 5824 |
| 35 | t@r* | 5687 |
| 36 | &t | 5652 |
| 37 | hIz | 5564 |
| 38 | bVt | 5416 |
| 39 | mI | 5397 |
| 40 | s@ | 5391 |
| 41 | nOt | 5357 |
| 42 | D@r* | 5339 |
| 43 | I | 5283 |
| 44 | tId | 5259 |
| 45 | DeI | 5162 |
| 46 | IN | 5063 |
| 47 | t@ | 5053 |
| 48 | s@U | 4974 |
| 49 | baI | 4894 |
| 50 | h&v | 4769 |
全ランキング表を見たい方は,タブ区切り形式で Syllable Frequency Rank Table by CELEX2 を参照.ブラウザ上で閲覧したい方は,こちらからどうぞ.全体としては11492の異なる音節タイプが登録されており,頻度が1以上のものは7934タイプある.「#1023. 日本語の拍の種類と数」 ([2012-02-14-1]) の最後で,英語の音節タイプが日本語に比べて驚くほど多種多様であることに触れたが,この数をみれば納得できるだろう.関連して,syllable の各記事を参照.
なお,CELEX2 のマニュアルには以下の但し書きが記されていたので,再掲しておく.
Please note that the English corpus used by CELEX for deriving these frequencies contains only 7.3% spoken material. This means there is a rather tenuous relationship between the full frequency figures, which are based on written forms, and the syllable frequencies, which merely refer to phonemic conversions of these graphemic transcriptions. Of course it could be argued that frequencies of syllables, as lexical sub-units, are less liable to get skewed from differences in medium than full words, but it has to be taken into account that NO FIRM EVIDENCE ABOUT SPOKEN FREQUENCIES can be derived from these data.
2013-03-25 Mon
■ #1428. ye = the [palaeography][spelling][thorn][th][pub][alphabet][graphemics][ppcme2][ppceme][ppcmbe][corpus]
「#13. 英国のパブから ye が消えていくゆゆしき問題」 ([2009-05-11-2]) で,ye や ye が定冠詞 the の代わりに用いられる擬古的な綴字について触れた.
þ (thorn) と y との字形の類似による混同は中英語期から見られたが,この混乱がいわば慣習化したのは þ が衰退してからである.þ が廃れていったのは,「#1329. 英語史における eth, thorn, <th> の盛衰」 ([2012-12-16-1]) や「#1330. 初期中英語における eth, thorn, <th> の盛衰」 ([2012-12-17-1]) で確認したように,Helsinki Corpus の時代区分によるME第4期 (1420--1500) 以降である.それに呼応して,擬古的な定冠詞 ye は近代英語期に入ってから頻度を増してきた.OED を参照すると,ye の使用は中英語から17世紀にかけて,とある.
では,中英語から初期近代英語にかけて,具体的にどの程度 ye が用いられたのだろうか.これを調べるために PPCME2, PPCEME, PPCMBE のPOSファイル群で "ye/D" を検索してみた.MEからは1例のみ,EModEから1259例,LModEから5例が挙がった.各コーパスはおよそ130万語,180万語,100万語からなるが,総語数を考えずとも,傾向は歴然としている.初期近代英語で急激に現われだし,一気に衰微したということである.ただし,PPCEME の1259例のうち975例は,The Journal of George Fox (1673--74) という1作品からである.ほかには10例以上現われるテキストが4つあるのみで,残りは20テキストに少数例ずつ散らばっているにすぎないという分布ではある.隆盛を極めたというよりは,地味な流行といった感じだろうか.
先日,ロンドンを訪れた際に,145 Fleet St の老舗パブ "Ye Olde Cheshire Cheese" と 42 Ludgate Hill の "Ye Olde London" の看板を撮影してきた.残念ながらここでエールを一杯やる機会はなかったけれども,別のパブでは一杯(だけではなく)やりました.


2013-03-21 Thu
■ #1424. CELEX2 [corpus][dictionary][statistics][frequency][lexicology]
英単語の頻度に関連する諸研究(Betty Phillips など)で,CELEX という語彙データベースが使用されているのを見かけることがある.現在取りかかっている研究で,巨大コーパスに基づいた信頼できる語彙頻度統計が必要になったので,郵送料込みで350ドルするこの高価なデータベースを入手してみた.現行版は第2版であり,CELEX2 として購入できる.(なお,予想していなかったが,入手した CD-ROM には,LDC99T42 というデータベースも含まれていた.ここには tagged Brown Corpus, Wall Street Journal, Switchboard tagged など Treebank 系のコーパスが入っている.)
さて,CELEX2 には,英語語彙に関する複数のデータベースが納められている.それぞれのデータベースには,正書法,音韻,音節,形態,統語の各観点から,見出し語 (lemma) あるいは語形 (wordform) ごとに,ソース・コーパス内での頻度等の情報が格納されている.具体的には,次の11のデータベースが利用可能である.
ect (English Corpus Types)
efl (English Frequency, Lemmas)
efs (English Frequency, Syllables)
efw (English Frequency, Wordforms)
eml (English Morphology, Lemmas)
emw (English Morphology, Wordforms)
eol (English Orthography, Lemmas)
eow (English Orthography, Wordforms)
epl (English Phonology, Lemmas)
epw (English Phonology, Wordforms)
esl (English Syntax, Lemmas)
見出し語あるいは語形ごとの token 頻度の取り出しに強いデータベースという認識で購入したが,実際には,含まれている情報の種類は驚くほど豊富で,11のデータベースすべてを合わせたフィールド数はのべ250以上に及ぶ.行数は efl で52,447行,efw で160,595行という巨大さだ.検索用の SQLite DB をこしらえたら,容量にして90MBを超えてしまった.
CELEX2 のソースは,辞書情報については Oxford Advanced Learner's Dictionary (1974) 及び Longman Dictionary of Contemporary English (1978) であり,頻度情報については 1790万語からなる COBUILD/Birmingham corpus である.このコーパスの構成は,1660万語 (92.74%) が書き言葉コーパス,130万語 (7.26%) が話し言葉コーパスで,前者を構成する284テキストのうち44テキスト (15.49%) がアメリカ英語である.しかし,これらのアメリカ英語はほとんどがイギリス英語の綴字に直されていることに注意したい.
CELEX2 における "lemma" の定義は,以下の5点に依存する.
(1) orthography of the wordforms: peek vs peak
(2) syntactic class: meet (adj.) vs meet (adv.)
(3) inflectional paradigm: water (v.) vs water (n.)
(4) morphological structure: rubber (someone or something that rubs) vs rubber (the elastic substance)
(5) pronunciation of the wordforms: recount [ˈriː-kaʊnt] vs recount [rɪ-ˈkaʊnt]
したがって,通常異なる lexeme として扱われる bank (土手)と bank (銀行)などは,CELEX2 では同一の lemma として扱われているので注意が必要である.
このように CELEX2 は非常に強力な語彙頻度データベースだが,その他にも語彙頻度研究に資するデータベースやツールは存在する.本ブログで触れたものとしては,frequency statistics lexicology の各記事や,特に以下の記事が参考になるだろう.
・ 「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1])
・ 「#607. Google Books Ngram Viewer」 ([2010-12-25-1])
・ 「#708. Frequency Sorter CGI」 ([2011-04-05-1])
・ 「#1159. MRC Psycholinguistic Database Search」 ([2012-06-29-1])
・ Baayen R. H., R. Piepenbrock and L. Gulikers. CELEX2. CD-ROM. Philadelphia: Linguistic Data Consortium, 1996.
2013-03-20 Wed
■ #1423. 初期近代英語の3複現の -s (2) [verb][conjugation][emode][corpus][ppceme][ppcbme][number][agreement][analogy][3pp]
「#1413. 初期近代英語の3複現の -s」 ([2013-03-10-1]) の記事の続き.前の記事では,PPCEME による検索で,3複現の -s の例を50件ほど取り出すことができたと述べたが,文脈を見ながら手作業で整理したところ,全52例が確認された(データのテキストファイルはこちら).
PPCEME では,E1 (1500--1569), E2 (1570--1639), E3 (1640--1710) の3期が区分されているが,その区分ごとに3複現の -s の生起数を示すと以下のようになる(各期のコーパスの総語数も示した).
| Period | Tokens | Wordcount |
|---|---|---|
| E1 (1500--1569) | 13 | 567,795 |
| E2 (1570--1639) | 18 | 628,463 |
| E3 (1640--1710) | 21 | 541,595 |
| Total | 52 | 1,737,853 |
Queen Elizabeth I's Boethius (E2), Thomas Middleton's A chaste maid in Cheapside (E2), Celia Fiennes's journeys (E3) などの特定のテキストに数回以上生起するとはいえ,全体として少ない生起数ながらも,およそむらなく分布しているとは言えるかもしれない.例文を眺めてみると,以下のように主語と動詞の倒置がみられるものがいくつかあり,現代英語の「there is + 複数名詞」のような構文を想起させる.
・ and after them comys mo harolds,
・ Here comes our Gossips now,
・ Now in goes the long Fingers that are wash't Some thrice a day in Vrin,
さて,Lass (166) に3複現の -s について関連する言及を見つけたので,紹介しておこう.Lass は,3複現の -s の起源について,単数に比べれば時代は遅れたものの,北部方言からの伝播だと考えているようだ.
The {-s} plural appears considerably later than the {-s} singular, and if it too is northern (as seems likely), it represents a later diffusion. The earliest example cited by Wyld ([History of Modern Colloquial English] 346) is from the State Papers of Henry VIII (1515): 'the noble folk of the land shotes at hym'. It is common throughout the sixteenth and seventeenth centuries as a minority alternant of zero, and persists sporadically into the eighteenth century.
16,17世紀を通じて行なわれていたということは,上記の PPCEME からの例で確かに認められた.なお,後期近代英語をカバーする PPCMBE で18世紀以降の状況を調べてみると,こちらの6例が挙がった.しかし,実体の数と観念の上で焦点化される数との不一致の例と読めるものも含まれており([2012-06-14-1]の記事「#1144. 現代英語における数の不一致の例」を参照),後期近代英語では3複現の -s は皆無に近いと考えてよさそうだ.
・ Lass, Roger. "Phonology and Morphology." 1476--1776. Vol. 3 of The Cambridge History of the English Language. Ed. Roger Lass. Cambridge: CUP, 1999. 56--186.
2013-03-14 Thu
■ #1417. 群属格の発達 [genitive][clitic][synthesis_to_analysis][metanalysis][corpus][ppcme2][syntax]
近代英語以降の apostrophe s は,名詞につく屈折接尾辞とみなすよりは,名詞句につく前接語 (enclitic) とみなすほうが正確である.というのは,the king of England's daughter のような群属格 (group genitive) としての用法が広く認められるからである.apostrophe s は,語に接続する純粋に形態的な単位というよりは,語群に接続する統語的な単位,すなわち接語 (clitic) とみなす必要がある.
しかし,apostrophe s の起源と考えられる -es 語尾は,中英語以前には,確かに名詞につく屈折語尾だった.それが名詞句へ前接し,群属格を作る用法を得たのはなぜか.その契機は何だったのか.英語史でも盛んに議論されてきた問題である.
一つの見方 (Janda) によれば,群属格への発展の途中段階で「#819. his 属格」 ([2011-07-25-1]) が媒介として作用したのではないかという.この説を単純化して示せば,(1) 属格語尾 -es と人称代名詞の男性単数属格 his とが無強勢で同音となる事実と,(2) 直前の名詞句を受ける代名詞としての his 属格の特性との2点が相俟って,次のような比例式が可能となったのではないかという.
king his doughter : king of England his doughter = kinges doughter : X
X = king of Englandes doughter
しかし,Allen はこの説に同意しない.PPCME2 やその他の中英語テキストを走査し,関与するあらゆる例を検討した結果,his 属格が媒介となって群属格が生じたとする見解には,証拠上,数々の無理があるとする.Allen は,とりわけ,"attached genitive" (歴史的な -es 属格)と "separated genitive" (his 属格)との間に,統語環境に応じての分布上の差がないことを根拠に,中英語の his 属格は "just an orthographical variant of the inflection" (118) であると結論する.
では,群属格の発達が his 属格を媒介としたものではなかったとすると,他にどのような契機がありえたのだろうか.Allen はその答えとして,"the gradual extension of the ending -es to all classes of nouns, making what used to be an inflection indistinguishable from a clitic" (120) を提案している.14世紀末までに属格語尾が一律に -(e)s を取り得るようになり,これがもはや屈折語尾としてではなく無変化の前接語と捉えられるに至ったのではないかという.また,最初期の群属格の例は,The grete god of Loves name (Chaucer, HF 1489) や þe kyng of Frances men (Trevisa's Polychronicon, VIII, 349.380) に見られるような,出自を示す of 句を伴った定型句であり,複合名詞とすら解釈できるような表現である.これが一塊と解され,その直後に所有を示す -(e)s がつくというのはまったく不思議ではない.
さらに Allen は,16世紀後半から現われる his 属格と平行的な her 属格や their 属格については,すでに-(e)s による群属格が確立した後の異分析 (metanalysis) の結果であり,周辺的な表現にすぎないと見ている.この異分析を,"spelling pronunciation" ならぬ "spelling syntax" (124) と言及しているのが興味深い.
Allen の結論部を引用しよう (124) .
A closer examination of the relationship between case-marking syncretism and the rise of the 'group genitive' than has previously been carried out provides evidence that the increase in syncretism led to the reanalysis of -es as a clitic. There is evidence that this change of status from inflection to clitic was not accomplished all at once; inflectional genitives coexisted with the clitic genitive in late ME and the clitic seems to have attached to conjoined nouns and appositives before it attached to NPs which did not end in a possessor noun. The evidence strongly suggests that the separated genitive of ME did not serve as the model for the introduction of the group genitive, and I have suggested that the separated genitive was an orthographic variant of the inflectional genitive, but that after the group genitive was firmly established there were attempts to treat it as a genitive pronoun.
Allen は Appendix I にて,Mustanoja (160) 等がhis 属格として挙げている古英語や中英語からの例([2011-07-25-1]で挙げた例)の多くが疑わしい例であると論じている.
なお,群属格については,Baugh and Cable (241) にも簡単な言及がある.
・ Janda , Richard. "On the Decline of Declensional Systems: The Overall Loss of OE Nominal Case Inflections and the ME Reanalysis of -es as his." Papers from the Fourth International Conference on Historical Linguistics. Ed. Elizabeth C. Traugott, Rebecca Labrum, and Susan Shepherd. Amsterdam: John Benjamins, 243--52.
・ Allen, Cynthia L. "The Origins of the 'Group Genitive' in English." Transactions of the Philological Society 95 (1997): 111--31.
・ Mustanoja, T. F. A Middle English Syntax. Helsinki: Société Néophilologique, 1960.
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
2013-03-13 Wed
■ #1416. shew と show (2) [spelling][corpus][ppcmbe][johnson][pronunciation_spelling]
昨日の記事「#1414. shew と show (1)」 ([2013-03-12-1]) の続編.昨日は Helsinki Corpus を用いて初期近代英語期までの shew と show の分布を調査したが,今回は後期近代英語期における分布を PPCMBE (Penn Parsed Corpus of Modern British English; see [2010-03-03-1]) によって簡単に調査した.
PPCMBE は,1700年から1914年までの総語数948,895語のコーパスである.これを約70年ずつの3期に分け,見出し語化された pos ファイル群を対象に検索することで shew 系列と show 系列の token 数を数え上げた.結果は以下の通り.
| shew 系列 | show 系列 | 総語数 | |
|---|---|---|---|
| 1700--1769 | 80 | 25 | 298,764 |
| 1770--1839 | 79 | 86 | 368,804 |
| 1840--1914 | 17 | 162 | 281,327 |
大雑把な数え上げではあるが,第1期と第3期は明らかに分布に有意差が出る.1800年前後を境に形勢が逆転し,show が優勢になってきたことがわかるだろう.なぜ形勢が逆転したかという理由については,Johnson の Dictionary (1755) の記述が参考になる."To SHOW" の見出しのもとに次のようにあるので,引用しておこう.
This word is frequently written shew; but since it is always pronounced and often written show, which is favoured likewise by the Dutch schowen, I have adjusted the orthography to the pronunciation.
つまり,spelling_pronunciation ならぬ pronunciation_spelling の例ということになるのだろうか.show ほどの高頻度語でこのような一種の理性的な過程が作用したというのは不思議にも思えるが,中英語期以来,劣勢とはいえ show 系列が一応は行なわれていたという事実が背景にあったことは,確かに効いているだろう.
2013-03-12 Tue
■ #1415. shew と show (1) [spelling][phonetics][corpus][hc][diphthong]
動詞 show には古い異綴り shew がある.法律文書,聖書,詩などには見られるものの,現在では一般的にはあまりお目にかからない.しかし,shew は18世紀まで優勢な綴字であり,19世紀前半まで現役として活躍していたし,20世紀前半ですら目にすることがあった.OED "show, v." の語源欄の記述を参照しよう.
The spelling shew, prevalent in the 18th cent. and not uncommon in the first half of the 19th cent., is now obsolete exc. in legal documents. It represents the obsolete pronunciation (indicated by rhymes like view, true down to c1700) normally descending from the Old English scéaw- with falling diphthong. The present pronunciation, to which the present spelling corresponds, represents an Old English (? dialectal) sceāw- with a rising diphthong.
この異綴りの由来は,古英語 scéawian (to look) の形態に由来する.語幹の2重母音が長母音へと滑化 (smoothing) する際に,もともと下降調2重母音であれば最初の母音が伸びて ē となり,上昇調2重母音であれば最後の母音が伸び,結果として ō となった.shew に連なる前者の系列では,規則的な音発達により,/ʃjuː/ が出力されるはずだが,show に連なる後者の系列の発音 /ʃoʊ/ に置換されることになった.近代後半までに綴字としては shew が優勢でありながら,発音としては show が一般化していたとことになる.なお,sew /soʊ/ も,これと平行的な発達の結果である.
OED や語源辞書では,近代までは shew 系列が優勢だったということだが,劣勢だった show 系列の萌芽は中英語から確認される (cf. MED "sheuen (v.(1))") .Helsinki Corpus により,中英語から近代英語までの shew vs show の通時的な分布を概観してみよう.(データファイルは "shew" and "show" in Helsinki Corpus を参照.)
| shew 系列 | show 系列 | |
|---|---|---|
| M1 | 12 | 0 |
| M2 | 36 | 2 |
| M3 | 185 | 0 |
| M4 | 207 | 7 |
| E1 | 198 | 13 |
| E2 | 113 | 15 |
| E3 | 71 | 4 |
確かに初期近代英語期までの通時的な傾向は明白である.だが,後期近代英語期以降の show の逆転劇については未調査なので,明日の記事で探ってみる.
2013-03-10 Sun
■ #1413. 初期近代英語の3複現の -s [verb][conjugation][emode][corpus][ppceme][number][agreement][analogy][3pp]
標記について Baugh and Cable (247) に触れられており,目を惹いた.3単現ならぬ3複現における -s は,中英語では珍しくない.中英語の北部方言では,「#790. 中英語方言における動詞屈折語尾の分布」 ([2011-06-26-1]) の下の地図で示したように,直説法3人称複数では -es が基本だった.しかし,初期近代英語の標準変種において3複現の -s が散見されるというのは不思議である.というのは,この時期の文学や公文書に反映される標準変種では,中英語の East Midland 方言の -e(n) が消失した結果としてのゼロ語尾が予想されるし,実際に分布として圧倒的だからだ.しかし,3複現の -s は確かに Shakespeare でも散見される.
この問題について,Baugh and Cable (247) は次のように指摘している.
Their occurrence is also often attributed to the influence of the Northern dialect, but this explanation has been quite justly questioned, and it is suggested that they are due to analogy with the singular. While we are in some danger here of explaining ignotum per ignotius, we must admit that no better way of accounting for this peculiarity has been offered. And when we remember that a certain number of Southern plurals in -eth continued apparently in colloquial use, the alternation of -s with this -eth would be quite like the alternation of these endings in the singular. Only they were much less common. Plural forms in -s are occasionally found as late as the eighteenth century.
ここで,3複現の -s が北部方言からの影響ではないとする Baugh and Cable の見解は,Wyld, History of Modern Colloquial English, p. 340 の言及に負っている.むしろ,この時期の3単現の -s 対 -th の交替が,複数にも類推的に飛び火した結果だろうと考えている.なお,Görlach (89) は,方言からきたものか単数からきたものか決めかねている.
この問題を考察するにあたって,何はともあれ,初期近代英語において3複現の -s なり -th なりが具体的にどのくらいの頻度で現われるのかを確認しておく必要がある.そこで,The Penn-Helsinki Parsed Corpus of Early Modern English (PPCEME) によりざっと検索してみた.約180万語という規模のコーパスだが,3複現の -s の例は50件ほど,3複現の -th の例は60件ほどが挙がった(結果テキストファイルは左をクリック).年代や文脈などの詳細な分析はしていないが,典型的な例を少し挙げておく.
・ and all your children prayes you for your daly blessing.
・ but the carving and battlements and towers looks well;
・ then go to the pot where your earning bagges hangs,
・ as our ioyes growes, We must remember still from whence it flowes,
・ Ther growes smale Raysons that we call reysons of Corans,
・ now here followeth the three Tables,
・ And yf there be no God, from whence cometh good thynges?
・ First I wold shewe that the instruccyons of this holy gospell perteyneth to the vniuersal chirche of chryst.
・ and so the armes goith a sundre to the by crekes.
・ And to this agreith the wordes of the Prophetes, as it is written.
・ Also high browes and thicke betokeneth hardnes:
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
・ Görlach, Manfred. Introduction to Early Modern English. Cambridge: CUP, 1991.
2013-02-24 Sun
■ #1399. 初期中英語における between の異形態の分布 [laeme][corpus][preposition][me_dialect][methodology]
「#1389. between の語源」 ([2013-02-14-1]),「#1393. between の歴史的異形態の豊富さ」([2013-02-18-1]),「#1394. between の異形態の分布の通時的変化」 ([2013-02-19-1]) に続いて,今回は LAEME を用いて通時的変化および方言別分布を調査した結果を報告する.
Helsinki Corpus による通時的調査 ([2013-02-19-1]) の場合と同様に,多数の異形態をまとめるに当たって,語尾以外における母音の違いは無視し,第2音節以降の子音(と,もしあれば語尾の母音も)の種類と組み合わせに注目した.lexel に "between" を指定して取り出した例をもとに,241個のトークンを半世紀ごと,方言別に整理した(区分は[2012-10-10-1]の記事「#1262. The LAEME Corpus の代表性 (1)」で採用したものと同じ).原データはこちらを参照.以下,最初に年代別,次に方言別の集計結果を掲げる.
| PERIOD | nn | n | ne | x | xe | xn | xte | hn | he | tn | tx | txn | txe | ths | s | e | yn | zn | Sum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C12b | 18 | 1 | 2 | 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 28 |
| C13a | 23 | 4 | 19 | 6 | 4 | 4 | 0 | 9 | 14 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 85 |
| C13b | 20 | 3 | 23 | 2 | 1 | 3 | 4 | 1 | 0 | 0 | 0 | 1 | 0 | 2 | 1 | 1 | 1 | 1 | 64 |
| C14a | 5 | 13 | 28 | 9 | 2 | 2 | 0 | 0 | 0 | 3 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 64 |
| Sum | 66 | 21 | 72 | 24 | 7 | 9 | 4 | 10 | 14 | 3 | 2 | 1 | 1 | 2 | 1 | 2 | 1 | 1 | 241 |
| DIALECT | nn | n | ne | x | xe | xn | xte | hn | he | tn | tx | txn | txe | ths | s | e | yn | zn | Sum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N | 0 | 0 | 1 | 9 | 2 | 2 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 15 |
| NEM | 14 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 14 |
| NWM | 7 | 0 | 6 | 0 | 0 | 0 | 0 | 8 | 14 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 37 |
| SEM | 14 | 20 | 9 | 5 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 52 |
| SWM | 31 | 1 | 26 | 7 | 5 | 7 | 0 | 2 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 84 |
| SW | 0 | 0 | 16 | 3 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 24 |
| SE | 0 | 0 | 14 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 15 |
| Sum | 66 | 21 | 72 | 24 | 7 | 9 | 4 | 10 | 14 | 3 | 2 | 1 | 1 | 2 | 1 | 2 | 1 | 1 | 241 |
現代英語の between に連なる,n を含む最も普通のタイプが左3列に示されているが,bitweonen などの "nn" タイプは時代とともに "n" タイプや "ne" タイプに置換されてゆく様子がうかがえる.Mustanoja (369) は,"nn" タイプについて "The -en forms occur mainly in the more southern parts of the country" と記述しているが,実際には NEM や NWM にも現われている.つまり,"nn" タイプの分布は,方言の問題である以上に時代の問題である可能性がある.語尾の n の脱落がより北部で,かつ,より遅い時代に見られることは,予想できることだろう.
n 系列には遠く及ばないが,bituix や bitƿixen などの x 系列の使用がこの時期に稀でないことは,Helsinki Corpus の調査結果と符合している.x 系列は N, SEM, SWM, SW に分布しており,間に挟まれた NEM, NWM には文証されない.この分布は妙だが,全体として例が十分に多くないために,North Midlands の現存テキストに現われる機会がなかったということかもしれない.近代英語期にかけて成長する t を付加した xte タイプは,初期中英語では C13b SW に bitwixte などの形態でわずかに現われるにとどまっている.
bituhen や bituhe などの h 系列は,Helsinki Corpus によれば,古英語後期より一気に衰退したとのことだったが,LAEME によれば,初期中英語では C13a NWM に集中する形で生き残っていたようだ.しかし,その時までに衰退傾向は決定づけられていたと言えるだろう.
今回の調査で感覚を得たが,(初期)中英語期に開始した,あるいは進行していると疑われる変化について調べるには,Helsinki Corpus で通時的変化を大づかみにした上で,LAEME を用いて,より細かい時代区分と方言の別を考慮して掘り下げてゆくのがよさそうだ.
2013-02-19 Tue
■ #1394. between の異形態の分布の通時的変化 [hc][corpus][preposition]
「#1389. between の語源」 ([2013-02-14-1]) 及び昨日の記事「#1393. between の歴史的異形態の豊富さ」([2013-02-18-1]) に引き続いての話題.between の歴史的な異形態の分布を,Helsinki Corpus でざっと調査してみた.調査の結果,全コーパスより between の形態として 97 types, 793 tokens が確認された.以下はその97種類の異形態,異綴りである.
be-twen, be-twene, be-twix, be-twyen, be-twyn, be-twyx, be-twyxe, betuen, betuene, betuh, betuih, betuixt, betun, betux, betuyx, betwe, between, betweene, betwen, betwenan, betwene, betweoh, betweohn, betweon, betweonan, betweonen, betweonon, betweonum, betweox, betweoxan, betwex, betwi, betwih, betwihn, betwinan, betwinum, betwioh, betwion, betwix, betwixe, betwixt, betwixte, betwixts, betwne, betwoex, betwonen, betwuh, betwux, betwuxn, betwyh, betwyn, betwynan, betwyne, betwyx, betwyxe, betwyxen, betwyxte, bi-tuine, bi-twen, bi-twene, bi-twenen, bi-tweohnen, bi-tweone, bi-tweonen, bi-twexst, bi-twext, bi-twihan, bi-twixst, bituen, bituene, bituhe, bituhen, bituhhe, bituhhen, bituien, bituih, bituin, bituix, bitunon, bitweies, bitwen, bitwene, bitwenen, bitwenenn, bitweon, bitweone, bitweonen, bitweonon, bitweonum, bitwex, bitwexe, bitwien, bitwih, bitwix, bitwixe, bitwixen, bitwyxe
全793例の形態を一定の基準でまとめて集計するのは容易ではないが,今回は語尾以外における母音の違いは無視することにし,第2音節以降の子音(と,もしあれば語尾の母音も)の種類と組み合わせによって集計した.例えば,"nm", "nn", "x", "xt" というタイプは,それぞれ betweonum, betweonan, betwyx, betwixt などの形態を代表する.以下の表は,Helsinki Corpus における時代区分を参照し,例の挙がらなかった O1 (古英語第1期)の時期を除く10期における通時的変化を要約したものである.
| nm | nn | n | ne | x | xe | xn | xt | xte | xst | xts | h | hn | hnn | he | s | e | i | Sum | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| O2 | 14 | 1 | 0 | 0 | 13 | 0 | 1 | 0 | 0 | 0 | 0 | 31 | 4 | 0 | 0 | 0 | 0 | 0 | 64 |
| O3 | 5 | 22 | 16 | 0 | 56 | 0 | 0 | 0 | 0 | 0 | 0 | 48 | 0 | 0 | 0 | 0 | 0 | 0 | 147 |
| O4 | 1 | 15 | 3 | 0 | 22 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 44 |
| M1 | 0 | 28 | 4 | 8 | 13 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 4 | 1 | 9 | 0 | 0 | 0 | 68 |
| M2 | 0 | 1 | 5 | 32 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 42 |
| M3 | 0 | 0 | 4 | 31 | 24 | 18 | 0 | 1 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 83 |
| M4 | 0 | 0 | 4 | 11 | 25 | 6 | 2 | 1 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 56 |
| E1 | 0 | 0 | 12 | 66 | 2 | 0 | 0 | 25 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 108 |
| E2 | 0 | 0 | 23 | 44 | 0 | 0 | 0 | 31 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 104 |
| E3 | 0 | 0 | 54 | 8 | 0 | 0 | 0 | 14 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 77 |
| Sum | 20 | 67 | 125 | 200 | 156 | 25 | 5 | 72 | 15 | 4 | 1 | 82 | 8 | 1 | 9 | 1 | 1 | 1 | 793 |
現代の between に連なる n をもつ形態は,古英語から近代英語に至るまで一貫して主流派であることがわかる.betwix などの x 系列も,古英語から中英語まで n 系列に匹敵するほど頻用されているが,近代英語で xt 系列が出現するに及び,古くからの x 系列は影を潜めてゆく.h 系列は,古英語では盛んだったが,古英語末期から一気に衰退してゆく.
中英語に関しては,方言による分布の差も調査する必要があるだろう.
2013-01-12 Sat
■ #1356. 20世紀イギリス英語での government の数の一致 [bre][number][agreement][noun][syntax][corpus]
昨日の記事「#1355. 20世紀イギリス英語で集合名詞の単数一致は増加したか?」 ([2013-01-11-1]) で取り上げた,Bauer の集合名詞の数の一致に関する調査について,紹介を続ける.The Times の社説のコーパスによる通時的な調査を通じて,Bauer は群を抜いて最頻の集合名詞である government が,20世紀の間に,数の一致に関して興味深い分布を示すことを発見した (Bauer 64--65) .
20世紀の前期には,government は複数一致が多いものの,従来から指摘されているとおり,とらえ方に応じて単複のあいだで変異を示していた.ところが,中期になると,単複一致の違いが指示対象の違いに対応するようになった.複数として用いられるときには英国政府を指し,単数として用いられるときには他国政府を指すという傾向が現われてくるというのだ.文法の問題というよりも,意味(指示対象)の問題へと移行したかのようだ.以下に,Bauer (64) の "Concord with government by meaning from The Times corpus, 1930--65" のデータを再掲しよう.
| Year | British government | Non-British government | ||
|---|---|---|---|---|
| Singular | Plural | Singular | Plural | |
| 1930 | 3 | 15 | 12 | 3 |
| 1935 | 2 | 13 | 1 | 12 |
| 1940 | 2 | 14 | 4 | 2 |
| 1945 | 2 | 7 | 2 | 2 |
| 1950 | 1 | 26 | 26 | 0 |
| 1955 | 2 | 2 | 8 | 0 |
| 1960 | 0 | 23 | 8 | 0 |
| 1965 | 1 | 13 | 4 | 1 |
| Total | 13 | 113 | 65 | 18 |
1965年までにこの傾向が確立したが,その後,世紀の後期にかけて,今度は指示対象にかかわらず単数一致が増えてくる.government に関する限り,世紀の前期は notional variation,中期は semantic distinction,後期は grammatical preference for the singular と振る舞いを変化させてきたということになる.
問うべきは,上記の20世紀中期の使い分けの傾向は社説以外のテキストタイプでも同様に見られるのだろうか,という問題だ.社説に government が高頻度で現われることは予想されたことだが,それだけに社説の言語において特殊な用法が発達したと疑うこともできるかもしれない.コーパスを広げて確認する必要があるだろう.
・ Bauer, Laurie. Watching English Change: An Introduction to the Study of Linguistic Change in Standard Englishes in the Twentieth Century. Harlow: Longman, 1994.
2013-01-11 Fri
■ #1355. 20世紀イギリス英語で集合名詞の単数一致は増加したか? [bre][number][agreement][noun][syntax][corpus][americanisation]
主語と動詞の数の一致については,「#930. a large number of people の数の一致」 ([2011-11-13-1]) ,「#1144. 現代英語における数の不一致の例」 ([2012-06-14-1]) ,「#1334. 中英語における名詞と動詞の数の不一致」 ([2012-12-21-1]) の記事で扱ってきた.一般に,現代英語において government や team などの集合名詞の数の一致は,アメリカ英語ではもっぱら単数で一致するが,イギリス英語ではとらえ方に応じて単数でも複数でも一致するとされる.この一般化は概して有効だが,数の一致に関して変異を示すイギリス英語についてみると,20世紀を通じて単数一致の傾向が強まってきているのではないかという指摘がある.Bauer (61--66) の The Times の社説を対象としたコーパス研究を紹介しよう.
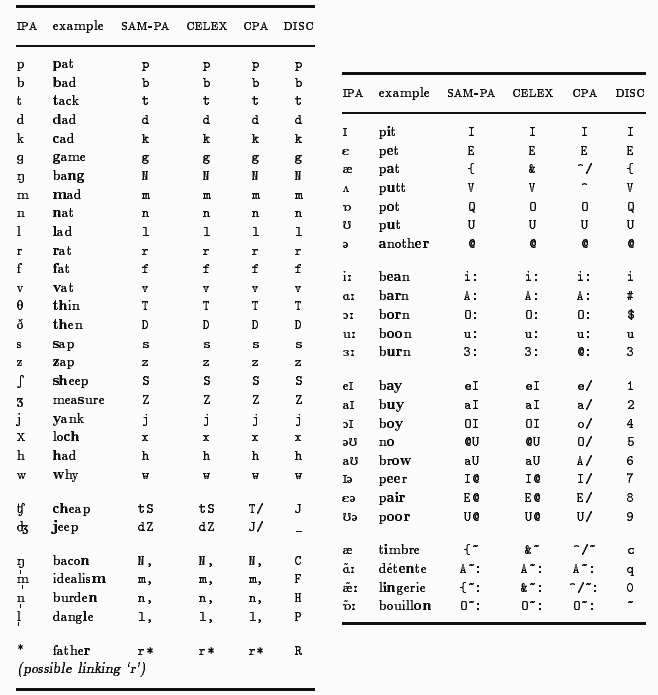
Bauer は,1900--1985年の The Times corpus の社説からなるコーパスを対象に,集合名詞が単数で一致する比率を求めた.Bauer は,本調査は The Times 紙の社説という非常に形式張った文体における調査であり,これが必ずしもイギリス英語全体を代表しているとはいえないと断わった上で,興味深いグラフを与えている.以下は,Bauer (63) のグラフから目検討で数値を読み出し,再作成したものである.
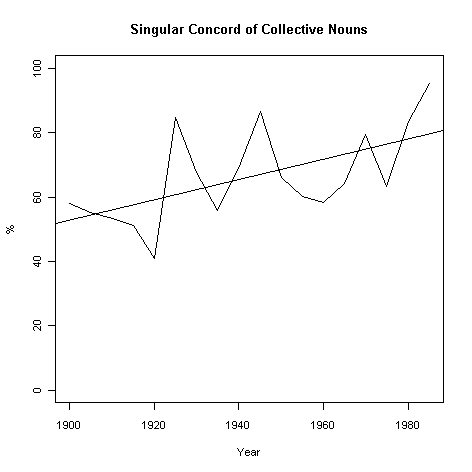
回帰直線としてならせば,毎年0.3178%の割合での微増となっている.数値が安定しないことやコーパスの偏りなどの理由によりこの結果がどこまで信頼できるのかが問題となるが,Bauer は細かい情報を与えておらず,判断できないのが現状である.
Bauer はさらに,コーパス内で最も頻度の高い集合名詞 government が特殊な振る舞いをすることに注目し,この語を除いた集合名詞について,単数一致の割合を再計算した.上のグラフと同じ要領で,Bauer (66) のグラフに基づいて下のグラフを再作成した.ならすと毎年0.1877%の割合での微増である.
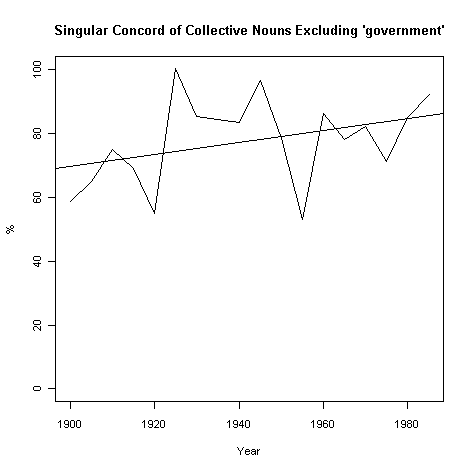
この結果は多くの点で仮の結果にとどまらざるを得ないように思われるが,少なくともさらに調査を進めてゆくためのスタート地点にはなるだろう.
なお,Bauer は1930年代にこの傾向に拍車がかかったという事実を根拠に,アメリカ英語が影響を与えたと考えることはできないだろうとしている([2011-08-26-1]の記事「#851. イギリス英語に対するアメリカ英語の影響は第2次世界大戦から」を参照).
government の数の一致に関するおもしろい振る舞いについては,明日の記事で紹介する.
・ Bauer, Laurie. Watching English Change: An Introduction to the Study of Linguistic Change in Standard Englishes in the Twentieth Century. Harlow: Longman, 1994.
2013-01-02 Wed
■ #1346. 付加疑問はどのくらいよく使われるか? [interrogative][tag_question][ame_bre][corpus][frequency][statistics]
現代英語の会話では,付加疑問がよく使われる.だが,具体的にどのくらいよく使われるのだろうか.そもそも一般的に疑問文はどのくらいの頻度で生起するのか.そのなかで,付加疑問はどれくらいの割合を占めるのか.このような疑問を抱いたら,まず当たるべきは Biber et al. の LGSWE である.
最初の問題については,p. 211 に解答が与えられている.疑問符の数による粗い調査だが,CONV(ERSATION) では40語に1つ疑問符が含まれているという.会話コーパスでは,転写上,疑問符が控えめに反映されている可能性が高く,実際には数値以上の頻度で疑問文が生起しているはずである.テキストタイプでいえば,次に大きく差を開けられて FICT(ION) が続き,NEWS と ACAD(EMIC) では疑問文の頻度は限りなく低い.
次に,各サブコーパスにおいて,疑問文全体における付加疑問の生起する割合はどのくらいか.p. 212 に掲載されている統計結果を以下のようにまとめた.各列を縦に足すと100%となる表である.
| (* = 5%; ~ = less than 2.5%) | CONV | FICT | NEWS | ACAD | |
|---|---|---|---|---|---|
| independent clause | wh-question | **** | ******* | ********* | ********** |
| yes/no-question | ***** | ***** | ******* | ******* | |
| alternative question | ~ | ~ | ~ | ~ | |
| declarative question | ** | * | ~ | ~ | |
| fragments | wh-question | * | ** | ** | * |
| other | *** | *** | * | * | |
| tag | positive | * | ~ | ~ | ~ |
| negative | **** | * | ~ | ~ | |
CONV において付加疑問の生起比率が高いことは当然のように予測されたが,同サブコーパスの疑問表現全体のなかで25%を占めるということは発見だった.そのなかでも,肯定の is it? よりも否定の isn't it? のタイプのほうがずっと多い.また,FICT が CONV におよそ準ずる分布を示すのは,フィクション内の会話部分の貢献だろう.一方,NEWS と ACAD で付加疑問の比率が低いのは,この表現と対話との結びつきを強く示唆するものである.また,この2つのサブコーパスでは,完全な独立節での疑問文,特に wh-question が相対的に多いのが注意を引く.
付加疑問の生起比率に関心をもったのは,実は,Schmitt and Marsden (192) に次のような記述を見つけたからだった.
Tag questions (i.e., regular questioning expressions tagged onto a sentence) exist in both American and British English, with British speakers perhaps using them more than Americans: "That's not very nice, is it?" Peremptory and aggressive tags tend to be used more in British English than in American English: "Well, I don't know, do I?" (192)
残念ながら,Biber et al. では付加疑問の頻度の英米差を確かめることはできない.別途,英米のコーパスで調べる必要があるだろう.
・ Schmitt, Norbert, and Richard Marsden. Why Is English Like That? Ann Arbor, Mich.: U of Michigan P, 2006.
・ Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad, and Edward Finegan. Longman Grammar of Spoken and Written English. Harlow: Pearson Education, 1999.
2012-12-12 Wed
■ #1325. 会話で否定形が多い理由 [corpus][negative][frequency]
Cheshire (115) を読んでいて,現代英語に関する記述として,会話において否定形が多く使われるという言及に遭遇した.直感的には確かにそのように思われるが,客観的な裏付けはあるのだろうかと,LGSWE に当たってみた.すると,関連する記述が pp. 159--60 に見つかった.
否定形にも様々な種類があるが,4つの使用域のそれぞれについて,コーパスを用いて "Distribution of not/n't v. other negative forms" を調査した結果が示されていた.100万語当たりの生起数を,グラフと表で示そう.
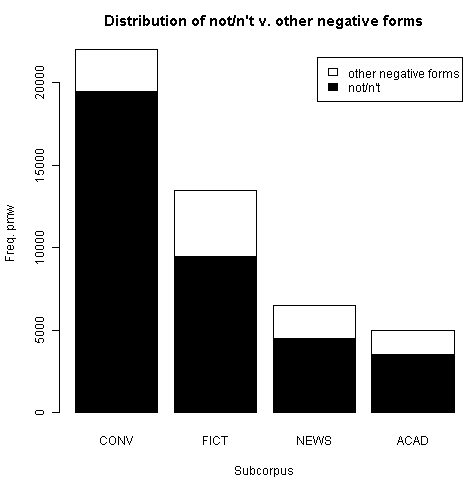
| not/n't | other negative forms | |
|---|---|---|
| CONV | 19500 | 2500 |
| FICT | 9500 | 4000 |
| NEWS | 4500 | 2000 |
| ACAD | 3500 | 1500 |
会話で否定形が頻出する理由として,LGSWE は以下を挙げている.
(1) 会話では他のレジスターよりも動詞が多い.否定は動詞と最も強く結びつくので,会話で否定が多いのは当然予想される.
(2) 会話では他のレジスターよりも節が短く,多い.その分,否定の節も多くなることは当然予想される.
(3) 会話では表現の反復が多い.否定形の反復もそれに含まれる.
(4) 多重否定や付加疑問など,話しことばに典型的な否定構文というものがある.
(5) not と強く共起する動詞があり,それらはとりわけ会話において頻度が高い.例えば,forget, know, mind, remember, think, want, worry などの心理動詞など.
(6) 会話には相手がおり,意見の一致や不一致に関わる表現が多くなる.会話では,not のみならず no や他の否定辞も頻出する.
CONV の次に FICT に否定形が多いのは,おそらくフィクションにおける対話部分が貢献しているからだろう.また,(1) については,会話には全体として動詞が多く生起するという事情も関与しているだろう.
・ Cheshire, Jenny. "Double Negatives are Illogical." Language Myths. Ed. Laurie Bauer and Peter Trudgill. London: Penguin, 1998. 113--22.
・ Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad, and Edward Finegan. Longman Grammar of Spoken and Written English. Harlow: Pearson Education, 1999.
[ 固定リンク | 印刷用ページ ]
2012-12-10 Mon
■ #1323. Helsinki Corpus の COCOA 検索 [cgi][web_service][hc][corpus]
Helsinki Corpus (The Diachronic Part of the Helsinki Corpus of English Texts) は1991年に公開されて以来,英語歴史コーパスの元祖として重用されてきた.HC の役割は現在でも薄れておらず,本ブログでも「#381. oft と often の分布の通時的変化」 ([2010-05-13-1]) を始め,hc の各記事で言及してきた.
HC を本格的に使いこなすには,こちらのマニュアルを熟読する必要がある.とりわけ時代別サブコーパスの語数は押さえておく必要があるし,COCOA Format による参照コードの理解も重要だ.COCOA Format は,HC のソーステキスト内にそのテキストに関する種々の情報を付与するための形式である.各テキストについて,その年代,方言,著者の性別,韻文か散文かなどの情報が,この形式により付与されている.使用者は,この情報を利用することにより,特定の条件を満たすテキストを選び出すことができるというわけだ.
HC の COCOA 情報を利用した条件の絞り込みを簡便にするために,まず表形式にまとめ,それをデータベース化 (SQLite) した.
以下,使用法の説明.SQL対応で,テーブル名は "hccocoa" として固定.select 文のみ有効.フィールドは26項目:"ID", "A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "K", "M", "N", "O", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z".各パラメータの意味は,以下の通り.また,各パラメータの取りうる値の詳細については,マニュアルを参照(あるいは,"select distinct C from hccocoa order by C" などと検索しても調べられる).
A = "author"
B = "name of text file"
C = "part of corpus"
D = "dialect"
E = "participant relationship"
F = "foreign original"
G = "relationship to foreign original"
H = "social rank of author"
I = "setting"
J = "interaction"
K = "contemporaneity"
M = "date of manuscript"
N = "name of text"
O = "date of original"
P = "page"
Q = "text identifier"
R = "record"
S = "sample"
T = "text type"
U = "audience description"
V = "verse" or "prose"
W = "relationship to spoken language"
X = "sex of author"
Y = "age of author"
Z = "prototypical text category"
典型的な検索式を例として挙げておく.
# 表全体を再現[ 固定リンク | 印刷用ページ ]
select * from hccocoa
# 時代区分別のテキスト数
select C, count(*) from hccocoa group by C
# テキストタイプ別のテキスト数
select T, count(*) from hccocoa group by T
# ME に時代区分されているテキストの各種情報を一覧
select B, C, D, V from hccocoa where C like 'M%' order by C
2012-12-09 Sun
■ #1322. ANC Frequency Extractor [cgi][web_service][frequency][corpus][anc]
昨日の記事「#1321. BNC Frequency Extractor」 ([2012-12-08-1]) に引き続き,ANC (American National Corpus) に基づく頻度表がANC Second Release Frequency Data のページに公開されていたので,"ANC Frequency Extractor" を作成した.
仕様は,"BNC Frequency Extractor" と少々異なる.データベースは SQLite で,select 文のみ有効というのは同様.テーブルは "anc" (コーパス全体),"written" (書き言葉コーパス),"spoken" (話し言葉コーパス) ,"token" (語形ごとの頻度と生起率)の4種類.フィールドは,"anc", "written", "spoken" の各テーブルについては,"word", "lemma", "pos", "freq" の4つ,"token" のテーブルについては,"word", "freq", "ratio" の3つである.POS-tag については,Penn Treebank Tagset を参照.
以下に,検索式をいくつか挙げておこう.
# 書き言葉テキストで,英米差があるとされる "diarrhoea" vs. "diarrhea" の綴字の生起頻度を確認
select * from written where word like "diarrh%"
# 書き言葉テキストで,英米差があるとされる "judgement" vs. "judgment" の綴字の生起頻度を確認.(その他,[2009-12-27-1]の記事「#244. 綴字の英米差のリスト」の綴字を放り込んでゆくとおもしろい.)
select * from written where word like "judg%ment%"
# -ly で終わらない副詞を探す(flat adverb かもしれない例を探す)
select * from anc where lemma not like "%ly" and pos like "RB%"
# -s で終わる副詞を探す(adverbial genitive の名残かもしれない例を探す)
select * from anc where pos like "RB%" and word like "%s"
# 単数名詞と複数名詞の token 数の比較を written subcorpus と spoken subcorpus で([2011-06-07-1]の記事「#771. 名詞の単数形と複数形の頻度」を参照)
select pos, sum(freq) from written where pos in ("NN", "NNS") group by pos
select pos, sum(freq) from spoken where pos in ("NN", "NNS") group by pos
select pos, sum(freq) from anc where pos in ("NN", "NNS") group by pos
ANC は有料だが,そこから抜粋された OANC (Open American National Corpus) は無料.ANC 及び OANC については,「#708. Frequency Sorter CGI」 ([2011-04-05-1]) や「#509. Dracula に現れる whilst (2)」 ([2010-09-18-1]) を参照.
"BNC Frequency Extractor" と "ANC Frequency Extractor" を組み合わせて使えば,語彙の英米差について頻度の観点から簡単に調査できる.
2012-12-08 Sat
■ #1321. BNC Frequency Extractor [cgi][web_service][frequency][corpus][bnc]
Adam Kilgarriff が公開している BNC database and word frequency lists から,見出し語化されていない頻度表 (unlemmatised lists) をダウンロードし,検索できるようにデータベースをこしらえた.
仕様の説明.データベースには SQLite を用いており,SQL対応.select 文のみ有効.テーブルは "bnc" (コーパス全体),"written" (書き言葉コーパス),"demog" ('demographic' spoken material) ,"cg" ('context-governed' spoken material) ,"variances" (計算された分散その他の値を含む)の5種類.variances を除く4テーブルについては,フィールドは "freq" (頻度), "word" (語形), "pos" (品詞;BNC CLAWS POS-tags の一覧を参照), "files" (その語形が生起しているテキスト数)の4つ.variances のテーブルについては,上記4フィールドに加えて,"mean" (= freq / files) ,"variance" (分散),"variance_to_mean" (= variance / mean) の3つが設定されている.variances の計算基準となっているサブコーパスは,5000語以上を含む書き言葉テキストということで,全体としては約1千万語(BNC全体の約1割)である.具体的には,"select * from bnc limit 10" や "select * from variances limit 10" などとすれば,データの格納のされ方を確かめることができる.
以下に,典型的な検索式を挙げておこう.
# 書き言葉テキストで,英米差があるとされる "diarrhoea" vs. "diarrhea" の綴字の生起頻度を確認
select * from written where word like "diarrh%"
# s で始まる語形を分散の高い順に
select * from variances where word like "s%" order by variance desc limit 100
# 母音変異の複数形を示す語の単数形の頻度(cf. 「#708. Frequency Sorter CGI」([2011-04-05-1]) の例では lemma 検索だった)
select * from bnc where word in ("foot", "goose", "louse", "man", "mouse", "tooth", "woman") and pos = "nn1" order by freq desc
# 母音変異の複数形の頻度
select * from bnc where word in ("feet", "geese", "lice", "men", "mice", "teeth", "women") and pos = "nn2"
# POSでまとめて頻度の高い順に(話し言葉 'demog')
select pos, sum(freq) from demog group by pos order by sum(freq) desc
# 最も広く多く使われる名詞
select * from variances where pos like "n%" order by variance desc limit 100
# 最も広く多く使われる形容詞
select * from variances where pos like "aj%" order by variance desc limit 100
なお,見出し語化されている頻度表 (lemmatised list) については,頻度にして800回以上現われる,上位6318位までの見出し語のみに限定されており,その検索ツールは「#708. Frequency Sorter CGI」 ([2011-04-05-1]) として実装してある.関連して,「#956. COCA N-Gram Search」 ([2011-12-09-1]) も参照.
2012-11-24 Sat
■ #1307. most と mest [analogy][superlative][vowel][me_dialect][corpus][hc][ppcme2][comparison]
中英語には,最上級 most が mest という前舌母音字を伴って現われることが少なくない.近代英語以降,後者は廃れていったが,両形の起源と分岐はどこにあるのだろうか.
most は Proto-Germanic *maistaz に遡ることができ,ゲルマン諸語では Du. meest, G meist, ON mestr, Goth. maists などで文証される.音韻規則に従えば,古英語形は māst となるはずであり,実際にこの形態は Northumbrian 方言で確認されるものの,南部方言では確認されない.南部では,前舌母音を伴う West-Saxon mǣst や Kentish mēst が用いられた.OED によれば,前舌母音形は,lǣst "least" との類推とされる.この前舌母音の系統が,主として mest(e) という形態で中英語の南部方言へも継承され,そこでは15世紀まで使われた.
一方,北部方言に起源をもつ形態は,中英語では後舌母音の系統を発達させ,主として most(e) という形態が多用された.じきに中部,南部でも一般化したが,北部方言形の南下というこの時期の一般的な趨勢に加え,比較級 mo, more の母音との類推も一役買ったのではないかと想像される.
結果的に,近代英語以降にはゲルマン祖語からの規則的な発達形 most が標準的となってゆき,古英語から中英語にかけて用いられた mest は標準からは失われていった.「一番先の」を意味する中英語 formest (cf. 比較級 former) が,15世紀に foremost として再分析された背景には,上述の most による mest の置換が関与しているかもしれない.もっとも,古英語より,最上級語尾の -est 自体が -ost とよく混同されたのであり,最上級に関わる形態論において,両母音の交替は常にあり得たことなのかもしれない.
なお,PPCME2 でざっと後舌母音系統 (ex. most) と前舌母音系統 (ex. mest) の分布を調べてみると,前者が354例,後者が168例ヒットした.Helsinki Corpus でも簡単に調査したが,中英語でも現代標準英語と同様に most 系統が主流だったことは間違いないようだ.
2012-11-22 Thu
■ #1305. 統語タグのついた Google Books Ngram Corpus [corpus][google_books][ame_bre]
[2010-12-25-1]の記事「#607. Google Books Ngram Viewer」で紹介した Google 提供のコーパスツールに,統語タグが付けられた.インターフェースである Google Books Ngram Viewer の見かけは変わらないが,検索欄へ統語標識つきの検索式を入力できるようになった.その紹介と利用法は,Syntactic Annotations for the Google Books Ngram Corpus で参照できる.
現在,Google Books Ngram Corpus は English, Spanish, French, German, Russian, Italian, Chinese, Hebrew の8言語のコーパスを含むが,英語コーパスに関する限り,4,541,627冊分,468,491,999,492 tokens からなる超巨大テキスト・データベースとなっている.データセットはこちらから入手可能.
実装された統語タグは,具体的にいえば,品詞 (POS) と修飾関係 (head-modifier) である.標識付けは統計学的に自動で行なわれている.品詞は以下の12種類が区別される.
NOUN (nouns), VERB (verbs), ADJ (adjectives), ADV (adverbs), PRON (pronouns), DET (determiners and articles), ADP (prepositions and postpositions), NUM (numerals), CONJ (conjunctions), PRT (particles), '.' (punctuation marks), X (a catch-all for other categories such as abbreviations or foreign words)
入力式としては,例えば "burnt" のように語形を入れることもできるし,"burnt_VERB" のように品詞を指定して入れることもできる.さらに 3-grams 以内の統語連鎖であれば "_ADJ_" のような一括指定も利用できる.以上のパターンを合わせて,"the _ADJ_ girl_NOUN" なども可能だ.修飾関係の指定では,"hair=>black", "read=>book" などと入力でき,冠詞やその他のノイズとなる要素をはじくことが可能となっている.
名詞と動詞の用法を共有している語について,品詞別に頻度変化をみたい場合を考えよう.travel は名詞でも動詞でもあるが,英語コーパス全体を対象とした検索によれば,20世紀に入って名詞用法が動詞用法を追い抜いたことがわかる.ただし,対象コーパスをアメリカ英語とイギリス英語に切り替えて比較すると,後者で名詞が動詞を頻度の上で追い抜くのは1960年代とずっと遅い.
ほかに,have a look 及び take a look という表現の拡大を調べようとする場合に,不定冠詞の後に形容詞などが挿入される可能性も考慮し,"have>=look, take>=look" などと検索してみた.アメリカ英語では take を用いた表現が1970年に追い抜いているが,イギリス英語では20世紀中に徐々に拡大こそしているが,いまだ have を用いた表現に追いついていない.
2012-10-31 Wed
■ #1283. 共起性の計算法 [corpus][statistics][bnc][collocation][lltest]
[2010-03-04-1]の記事「#311. girl とよく collocate する形容詞は何か」で,語と語の共起 (collocation) を測る計算法 (association measure) にはいくつかの種類があることを見た.コーパス言語学では,Log-Likelihood Test という検定にかかわる計算法が比較的よく使われているが,それぞれの計算法には特徴があるので,なるべく複数の方法を試すのがよい.今回は[2010-03-04-1]の内容と重複する部分もあるが,BNCweb で実装されている7種類の計算法の各々について Hoffmann et al. (149--58) を参照しながら,特徴および利用のヒントを示したい.
各種の計算法は,(a) 共起頻度 (frequency of co-occurrence),(b) 共起有意性 (significance of co-occurrence),(c) エフェクト・サイズ (effect-size) の1つ,あるいは複数の組み合わせに基づいている.(b) は,共起が統計的に有意であるとの確信度を表わす指標であり,共起の強さを表わすものではないことに注意する必要がある.(c) は,観察頻度と期待頻度との比を計算の基本とする指標である.
(1) Rank by frequency
観察される共起頻度そのものを用いる,最も単純で直感的な尺度.他の計算法のような複雑な統計処理はほどこされておらず,指標としては最も粗い.機能語や句読記号などが上位に来ることが多い.通常の共起分析には用いられない.
(2) Log-likelihood
共起有意性を用いる.BNCweb のデフォルトの計算法で,コーパス研究で広く用いられている.機能語や句読記号などの極めて高頻度の語との共起や,逆に極めて低頻度の語(1, 2回など)との共起をはじく傾向がある.しかし,共起頻度の高い組み合わせに高得点を与えるという特徴があり,解釈には注意を要する.
(3) Mutual information (MI)
エフェクト・サイズを用いる.非常によく用いられている計算法だが,利用に当たっては多くの注意を要する.機能語や句読記号などとのありふれた共起を効果的に排除してくれる点はよいが,反面,低頻度の共起表現への偏りが激しい.この偏りの影響を減じるために,BNCweb では "Freq(node, collocate) at least" を10以上に設定することが推奨される.これにより,"conspicuous and intuitively appealing collocations involving words of intermediate frequency" (Hoffmann et al. 154) が浮き彫りとなる.
(4) T-score
共起頻度と共起有意性を考慮する計算法.期待頻度が1以下程度の稀な共起表現については Rank by frequency と似たような振る舞いをし,頻度の高い共起表現については共起有意性を反映した振る舞いをする.また,観察頻度が期待頻度よりも必ず高くなる.Log-likelihood と類似した結果となることが多いが,高頻度へのバイアスは一層強くなる.ノードそのものが1000回を大きく下回る場合に,効果を発揮することがある.
(5) Z-score
共起有意性とエフェクト・サイズを考慮する計算法.高頻度の共起表現にはエフェクト・サイズをより重視するが,低頻度の共起表現にはそこまでエフェクト・サイズに寄りかからない.Log-likelihood と MI の両特徴を兼ね備えたような,バランスの取れた指標である.ただし,MI と同様に,低頻度の共起表現へのバイアスがみられるので,"Freq(node, collocate) at least" を5程度に設定するのがよいとされる.
(6) MI3
共起頻度とエフェクト・サイズを考慮する計算法.MI のもつ低頻度表現への偏重を取り除くべく改善されている.低頻度共起表現にはエフェクト・サイズが,高頻度共起表現には共起頻度が,比較的よく反映される.POS による限定とともに用いると効果的.複数語からなる用語などの取り出しに威力を発揮する.しかし,全体としては高頻度共起表現へのバイアスが強く,一般的な共起分析には向かない.
(7) Dice coefficient
MI3 と同様に,共起頻度とエフェクト・サイズを考慮する計算法.しかし,MI3と異なり,低頻度共起表現には共起頻度が,高頻度共起表現にはエフェクト・サイズがよく反映され,両者の切り替えが急なのが特徴的である.切り替えは,ノードそのものの頻度が共起表現の頻度の10倍ほどの点で起こるとされる.経験的に,Z-score と似たような結果が得られるが,Z-score ほど頻度に基づくバイアスが見られない.
以上のように多種類あって目移りするが,Hoffmann et al. の見解によれば,単一基準の計算法としては Log-likelihood と MI がお勧めで,混合基準の計算法としては Z-score と Dice がお勧めとのことである.
共起性の様々な計算法については,Association measures を参照.
・ Hoffmann, Sebastian, Stefan Evert, Nicholas Smith, David Lee, and Ylva Berglund Prytz. Corpus Linguistics with BNCweb : A Practical Guide. Frankfurt am Main: Peter Lang, 2008.
Powered by WinChalow1.0rc4 based on chalow