2014-04-15 Tue
■ #1814. 18--19世紀の be 完了の衰退を CLMET で確認 [perfect][clmet][corpus][syntax][be][auxiliary_verb][aspect][participle][lmode]
「#1653. be 完了の歴史」 ([2013-11-05-1]) で,変移動詞 (mutative verb) は,18世紀末まで,通常 be + 過去分詞というかたちで完了形を作っていたことを見た.英語史では,この be 完了が18世紀末辺りを境に衰退の一途をたどることになったとされている.「#1637. CLMET3.0 で between と betwixt の分布を調査」 ([2013-10-20-1]) で紹介した CLMET3.0 は,1710--1920年をカバーする約3,400万語からなる大型バランスコーパスであり,この種の言語変化を追うには最適なリソースと思われるので,これを用いて be 完了の衰退を確認してみた.
今回は,先の記事でも取り上げた7つの変移動詞 (arrive, become, come, fall, flee, grow; go) に限定し,CLMET3.0 の3つの時代区分 (1710--1780, 1780--1850, 1850--1920) と6つのジャンル分け (Narrative fiction, Narrative non-fiction, Drama, Letters, Treatise, Other) にしたがって,コーパスから用例を拾った.3つの時期のサブコーパスの規模はおよそ同程度だが,ジャンル別のサブコーパスは,[2013-10-20-1]の表で示したように,Narrative fiction に大きく偏っているので,その解釈には注意を要する.以下,(1)--(7) に各動詞に関する推移の積み上げ棒グラフ,(8), (9) に7動詞をひっくるめたジャンル別,動詞別のシェアを示す積み上げ棒グラフを示す.(1)--(6) については,比較のためにY軸の最大値を揃えてある.データファイルと頻度表はソースHTMLを参照されたい.
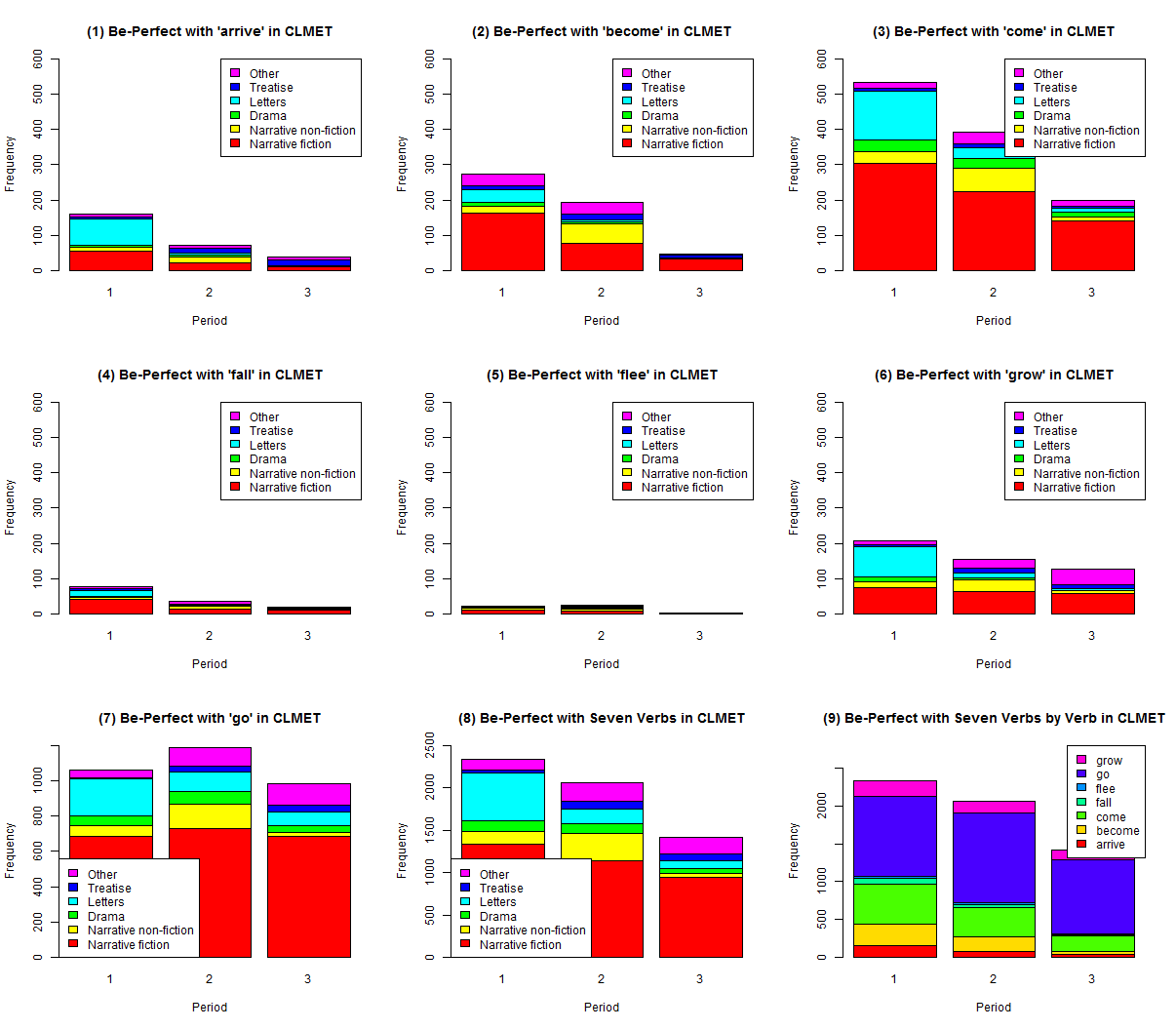
動詞によって衰退のスピードに若干の違いがみられるが,全体として急激に衰退したというよりは,比較的穏やかに,着実に衰退していったという印象を受ける.ただし,(7) の go は(現代英語でも be gone がイディオム化して残っていることから分かるように)後期近代英語期中にはそれほど落ち込んでおらず,しかも用例数が他の動詞よりも大きく上回っているために,(8) や (9) に示されるような be 完了の衰退の全体像を多少なりとも歪めていることには注意する必要がある.
2014-04-09 Wed
■ #1808. ARCHER 検索結果の時代×ジャンル仕分けツール (ARCHER Period-Genre Sorter) [cgi][web_service][corpus][archer][mode]
この2日間の記事「#1806. ARCHER で shew と show」 ([2014-04-07-1]) と「#1807. ARCHER で between と betwixt」 ([2014-04-08-1]) で,ARCHER の Untagged 版 を用いて,語の変異形の頻度が通時的にどのように推移してきたかを調査した.
近代英語の初期から後期を含むコーパスとしては,ほかに CEECS (The Corpus of Early English Correspondence, LC (The Lampeter Corpus of Early Modern English Tracts), CLMET3.0 (The Corpus of Late Modern English Texts, version 3.0), PPCMBE, COHA などがあり,それぞれに特徴があるが,ARCHER は,1600--1999年というまとまった期間をカバーし,英米変種それぞれについてジャンル分けがなされており,比較的大型の歴史コーパスとして価値が高い.しかし,「#1802. ARCHER 3.2」 ([2014-04-03-1]) で紹介した通り,現在ウェブ上で一般公開されている版については,いまだタグ検索などが実装されておらず,可能性を最大限に利用することはできない.しかし,工夫次第でいろいろと活用できる.実装されている Frequency lists や Keywords の機能はアイディア次第で有効に使えそうだし,コーパス全体の単語頻度リスト (TXT)も公開されている.
通時的な言語変化という観点から ARCHER に望む機能は,この2日間の記事で調査したように,ある検索語の頻度が時期を追って(ついでにジャンル別に)どのように推移してきたかを,簡単に確認できるようにすることだ.Restricted query で時期とジャンルを絞り,検索欄に検索語を入力してヒット数を数えてゆくということは手作業でできるが,時間がかかるし面倒だ.「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) や COHA では,この通時的な一覧を可能にする機能が実装されているので,ARCHER でも余計に同様の機能が欲しくなる.そこで,欲しいのならば作ってしまおうということで,簡単なスクリプトを組んだ.ARCHER の検索結果のコンコーダンス・ラインには,テキストを表わすファイル名が付されているが,ファイル名の仕様によれば,末尾3文字がそれぞれジャンル,時期,英米変種のいずれかを表わす記号となっている.そこで,検索結果をコピーして,以下のテキストボックスに貼り付けてやると,適切にファイル名を解析し,時期,ジャンル,変種ごとにヒット数を整理してくれ,グラフ化してくれるというツール (ARCHER Period-Genre Sorter) を作成した.ARCHER での出力結果が数ページにまたがる場合には,少し手数がかかるが,各ページをコピペして累積していけばよい.
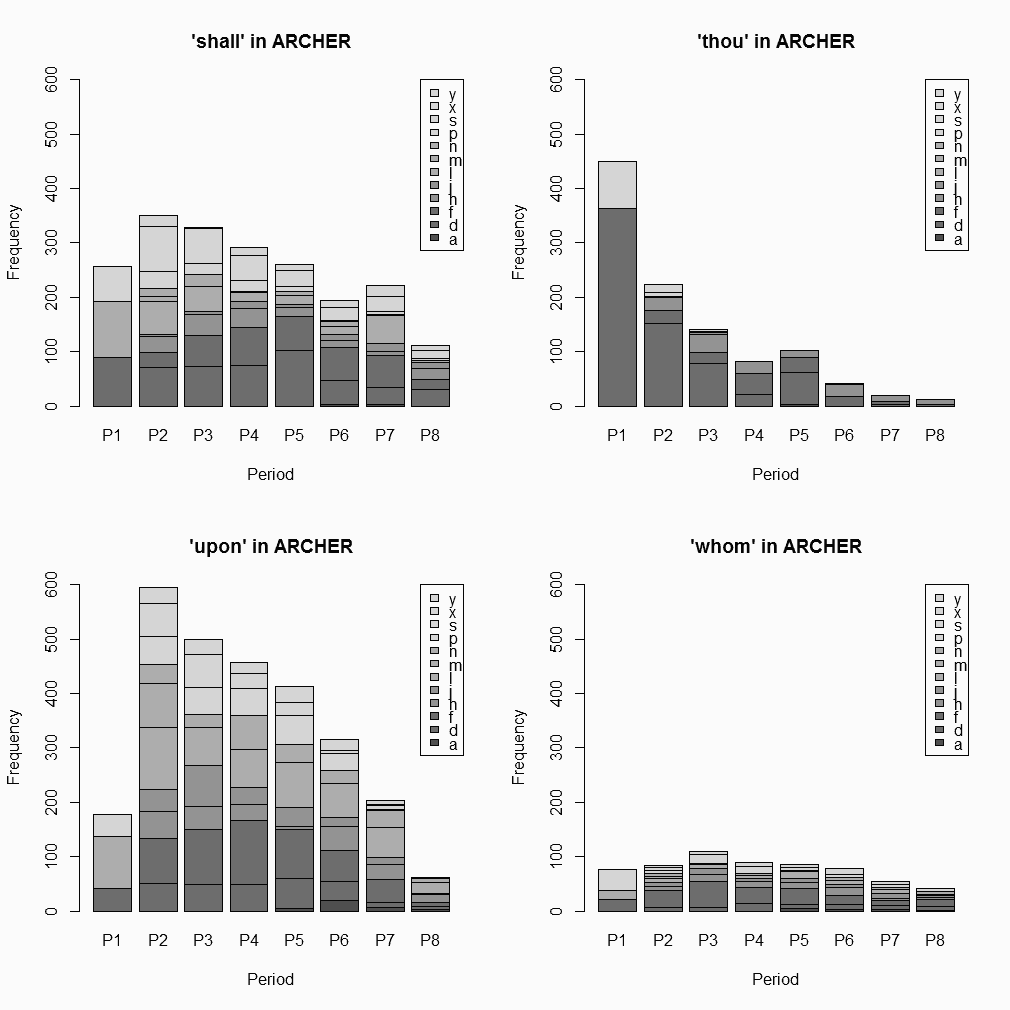
このツールの使用の応用例として,ここ数世紀の間で使用頻度が衰退しただろうと疑われる4語,shall, thou (= thou, thy, thee, thine), upon, whom を取り上げる.今回は,イギリス英語のサブコーパスのみに限定した.以下は,ツールが返した集計表をもとにグラフ化したものである.(ツールがどのように機能するかを確認するために,試しに ARCHER による 'thou' の出力結果のテキストファイル (194KB) の内容を上のテキストボックスにコピペされたい.)
2014-04-08 Tue
■ #1807. ARCHER で between と betwixt [spelling][corpus][archer][mode]
昨日の記事「#1806. ARCHER で shew と show」 ([2014-04-07-1]) に引き続き,[2014-04-03-1]の記事で紹介した「#1802. ARCHER 3.2」を利用して,別の問題に臨む.標記の between と betwixt の後期近代英語における分布について,「#1637. CLMET3.0 で between と betwixt の分布を調査」 ([2013-10-20-1]) で話題にしたが,ARCHER の Untagged 版ではどのような調査結果が出るだろうか.
検索にあたっては,とりわけ17世紀の段階では綴字が完全に定まっていたわけではないため,それぞれの語の異綴字も考慮に入れた.具体的には,between 系列として between, betweene, betwen, betwene, betwn が,betwixt 系列として betwixt, betwext が異綴字として挙がってきた.昨日と同様に,ヒット数を12ジャンルおよび1600--1999年を50年刻みにした8期に分けて数え上げた.以下に,集計結果のグラフのみ示す(データファイルと頻度表はソースHTMLを参照されたい).なお,betwixt and between の形では1例も現れていない.
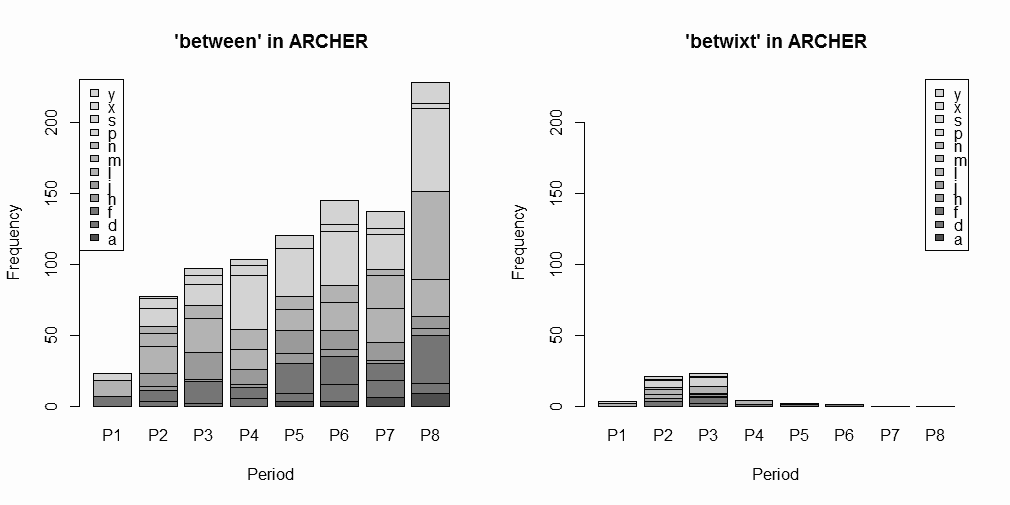
全体として,17--19世紀のどの時期においても between が圧倒していることは,以前の CLMET3.0 による調査結果からも予想されたことである.しかし,P2--P3 (1650--1749) の時期に限ってではあるが,betwixt が20%ほどのシェアを占めていたという事実は注目してよい(P1のサブコーパスは他の各時期のサブコーパスの1/3ほどの規模であることにも注意).CLMET3.0 による調査でも18世紀中までは bewixt が10%ほどのシェアを占めていたという結果が出ているから,大雑把にいって1750年くらいまでは betwix は between の異形としてそれなりの存在感を示していたことが確認できた.
2014-04-07 Mon
■ #1806. ARCHER で shew と show [spelling][corpus][archer][mode]
標記の語を巡る綴字の変異について,「#1415. shew と show (1)」 ([2013-03-12-1]),「#1416. shew と show (2)」 ([2013-03-13-1]),「#1716. shew と show (3)」 ([2014-01-07-1]) で取り上げてきた.今回は,[2014-04-03-1]の記事で紹介した「#1802. ARCHER 3.2」を利用して,近代英語期における両綴字の分布を改めて確認しよう.
ARCHER: A Representative Corpus of Historical English Registers の Untagged 版で,shew 系列 (shew, shews, shewed, shewn, shewing) と show 系列 (show, shows, showed, shown, showing) の語形を検索し,ヒット数を12ジャンルおよび1600--1999年を50年刻みにした8期に分けて数え上げた.データファイルと頻度表はソースHTMLを参照してもらうとして,結果をグラフ化したもののみ示そう.
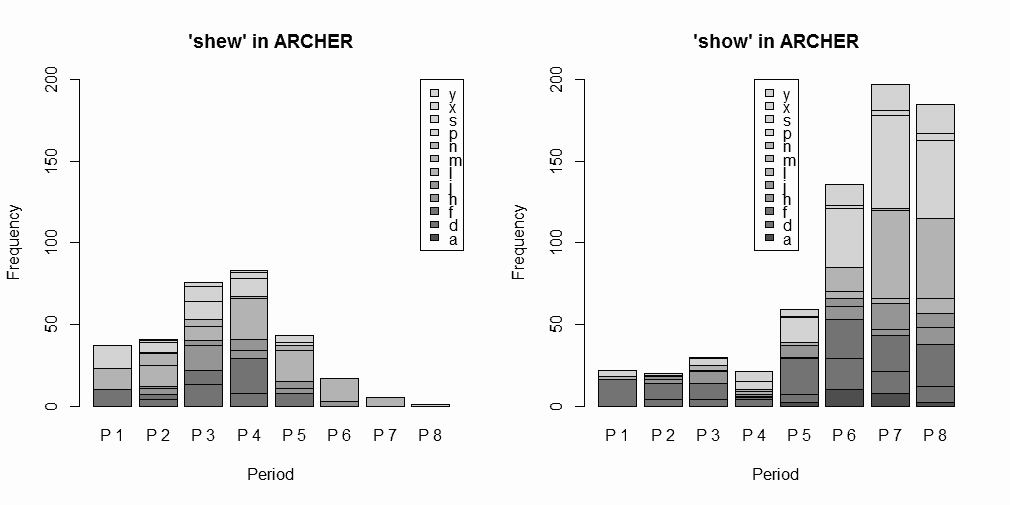
ジャンルの考慮はおいておくとして,通時的な推移に注目しよう.P1 (1600--49) から P4 (1750--99) まで,つまり17--18世紀には,絶対頻度で shew のほうが show より優勢だが,P5 (1800--49) に両者がおよそ肩を並べ,P6 以降には show が一気に shew を駆逐してゆく過程が見てとれる.この推移の概要は,過去の記事で調査した Helsinki Corpus および PPCMBE の結果とは符合するが,CLMET3.0 の結果とは少々異なる.CLMET3.0 では,[2014-01-07-1]の記事で見たように,18世紀中から絶対頻度で show が shew を圧倒的に上回っていたのである.このコーパス間の違いが,各コーパスの代表性の違いによるものなのか,それともジャンル分け等が関与しているのか,あるいは複数の語形を一括して数えたことに由来するものなのか,詳しくは調査していない(P1のサブコーパスについては,他の各時期のサブコーパスの1/3ほどの規模であることに注意).しかし,両系列の相対的な盛衰ではなく,shew 系列の衰退という観点で考えるのであれば,いずれのコーパスを参照しても,それは19世紀前半の出来事とみなしてよいだろう.
2014-04-03 Thu
■ #1802. ARCHER 3.2 [corpus][archer][mode][frequency]
昨年末のことになるが,近代英米語コーパス ARCHER: A Representative Corpus of Historical English Registers の Untagged 版が公開された.詳細は,公式の Documentation,あるいは VARIENG によるコーパスの解説からどうぞ.英語史研究会のオンライン会報より,三浦あゆみさんの記事「ARCHERの新版公開」も参考になる.
ARCHER は,1990年代初頭より Biber and Finegan が編纂してきたもので,現在では14の大学が合同で管理している.2013年に公開されたこの3.2版は Manchester 大学 ( David Denison and Nuria Yáñez-Bouza) による提供である.コーパスの内容と用途を端的に表現すれば,"a multi-genre historical corpus of British and American English covering the period 1600--1999. The corpus has been designed as a tool for the analysis of language change and variation in a range of written and speech-based registers of English." ということである.
コーパスの規模は1,710ファイル,3,298,080語からなり,語数での英米比は6:4ほど.また,時期として8期,内容により12種類にジャンル分けされている (a = advertising, d = drama, f = fiction, h = sermons, j = journals, l = legal, m = medicine, n = news, p = early prose, s = science, x = letters, y = diaries) .ファイル数と語数の内訳は以下の通り.
| BRITISH | a | d | f | h | j | l | m | n | p | s | x | y | TOTAL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1600--49 | files | 0 | 10 | 0 | 0 | 0 | 10 | 0 | 0 | 10 | 0 | 0 | 0 | 30 |
| words | 0 | 32,342 | 0 | 0 | 0 | 21,026 | 0 | 0 | 32,741 | 0 | 0 | 0 | 86,109 | |
| 1650--99 | files | 0 | 10 | 11 | 10 | 10 | 10 | 21 | 10 | 0 | 10 | 75 | 10 | 177 |
| words | 0 | 30,328 | 41,667 | 21,818 | 21,186 | 20,466 | 23,811 | 22,304 | 0 | 21,427 | 38,767 | 20,488 | 262,262 | |
| 1700--49 | files | 0 | 10 | 11 | 10 | 11 | 10 | 14 | 10 | 0 | 10 | 77 | 10 | 173 |
| words | 0 | 27,862 | 44,057 | 21,511 | 23,265 | 21,315 | 22,066 | 21,612 | 0 | 20,812 | 33,896 | 20,495 | 256,891 | |
| 1750--99 | files | 10 | 10 | 10 | 10 | 10 | 10 | 20 | 10 | 0 | 10 | 70 | 11 | 181 |
| words | 25,386 | 27,484 | 45,198 | 21,752 | 21,284 | 20,367 | 21,002 | 23,172 | 0 | 20,599 | 29,589 | 23,043 | 278,876 | |
| 1800--49 | files | 10 | 10 | 10 | 10 | 11 | 10 | 10 | 10 | 0 | 10 | 25 | 10 | 126 |
| words | 30,804 | 31,211 | 45,107 | 21,777 | 23,249 | 20,531 | 20,286 | 22,951 | 0 | 21,015 | 12,671 | 20,883 | 270,485 | |
| 1850--99 | files | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 0 | 10 | 26 | 10 | 126 |
| words | 30,684 | 34,856 | 43,427 | 21,322 | 21,243 | 20,757 | 22,265 | 23,072 | 0 | 21,810 | 10,819 | 21,789 | 272,044 | |
| 1900--49 | files | 10 | 11 | 10 | 10 | 10 | 10 | 10 | 10 | 0 | 10 | 29 | 10 | 130 |
| words | 26,717 | 31,391 | 45,408 | 21,123 | 22,208 | 21,160 | 20,213 | 21,977 | 0 | 21,664 | 12,529 | 22,424 | 266,814 | |
| 1950--99 | files | 10 | 11 | 10 | 10 | 10 | 10 | 13 | 10 | 0 | 10 | 28 | 10 | 132 |
| words | 23,437 | 32,200 | 45,109 | 21,093 | 22,723 | 20,721 | 20,994 | 22,935 | 0 | 21,385 | 11,361 | 22,060 | 264,018 | |
| TOTAL | files | 50 | 82 | 72 | 70 | 72 | 80 | 98 | 70 | 10 | 70 | 330 | 71 | 1,075 |
| words | 137,028 | 247,674 | 309,973 | 150,396 | 155,158 | 166,343 | 150,637 | 158,023 | 32,741 | 148,712 | 149,632 | 151,182 | 1,957,499 | |
| AMERICAN | a | d | f | h | j | l | m | n | p | s | x | y | TOTAL | |
| 1750--99 | files | 3 | 10 | 10 | 10 | 10 | 12 | 9 | 10 | 0 | 10 | 58 | 10 | 152 |
| words | 9,214 | 29,980 | 38,980 | 21,271 | 21,896 | 41,177 | 23,541 | 22,265 | 0 | 20,668 | 27,860 | 21,315 | 278,167 | |
| 1800--49 | files | 1 | 10 | 10 | 0 | 10 | 12 | 0 | 10 | 0 | 10 | 10 | 10 | 83 |
| words | 2,822 | 40,568 | 44,676 | 0 | 21,476 | 33,409 | 0 | 37,107 | 0 | 20,904 | 20,739 | 20,695 | 242,396 | |
| 1850--99 | files | 8 | 10 | 11 | 10 | 10 | 10 | 10 | 10 | 0 | 10 | 28 | 11 | 128 |
| words | 24,480 | 32,721 | 44,394 | 21,056 | 22,436 | 28,506 | 20,547 | 21,994 | 0 | 21,311 | 11,361 | 23,419 | 272,225 | |
| 1900--49 | files | 10 | 10 | 10 | 0 | 10 | 11 | 0 | 15 | 0 | 10 | 52 | 10 | 138 |
| words | 30,460 | 52,514 | 53,430 | 0 | 21,661 | 21,607 | 0 | 22,802 | 0 | 20,984 | 25,021 | 20,731 | 269,210 | |
| 1950--99 | files | 10 | 10 | 10 | 10 | 10 | 12 | 10 | 10 | 0 | 12 | 30 | 10 | 134 |
| words | 29,563 | 31,037 | 44,382 | 21,051 | 22,109 | 25,517 | 22,617 | 23,069 | 0 | 25,623 | 11,961 | 21,654 | 278,583 | |
| TOTAL | files | 32 | 50 | 51 | 30 | 50 | 57 | 29 | 55 | 0 | 52 | 178 | 51 | 635 |
| words | 96,539 | 186,820 | 225,862 | 63,378 | 109,578 | 150,216 | 66,705 | 127,237 | 0 | 109,490 | 96,942 | 107,814 | 1,340,581 | |
Documentation のページより,完全単語リストをダウンロード可能.タグ付きの検索が可能な版もいずれ公開されるということなので,期待したい.「#1752. interpretor → interpreter (2)」 ([2014-02-12-1]) の記事で少し使ってみたので,そちらも参照を.
2014-03-05 Wed
■ #1773. ich, everich, -lich から語尾の ch が消えた時期 [me][corpus][hc][phonetics][personal_pronoun][consonant][-ly]
「#1198. ic → I」 ([2012-08-07-1]) の記事で,古英語から中英語にかけて用いられた1人称単数代名詞の主格 ich が,語末の子音を消失させて近代英語の I へと発展した経緯について論じた.そこでは,純粋な音韻変化というよりは,機能語に見られる強形と弱形の競合が関わっているのではないかと提案した.
しかし,音韻的な要因が皆無というわけではなさそうだ.Schlüter によれば,後続する語頭の音に種類によって,従来の長形 ich か刷新的な短形 i かのいずれかが選ばれやすいという事実が,確かにある.
Schlüter は,Helsinki Corpus を用いて中英語期内で時代ごとに,そして後続音の種類別に,ich, everich, -lich それぞれの変異形の分布を調査した.以下に,Schlüter (224, 227, 226) に掲載されている,各々の分布表を示そう.
| I | 1150--1250 (ME I) | 1250--1350 (ME II) | 1350--1420 (ME III) | 1420--1500 (ME IV) | |||||
|---|---|---|---|---|---|---|---|---|---|
| tokens | % | tokens | % | tokens | % | tokens | % | ||
| before V | ich | 169 | 100 | 121 | 95 | 4 | 3 | 0 | 0 |
| I | 0 | 0 | 6 | 5 | 135 | 97 | 253 | 100 | |
| before <h> | ich | 171 | 100 | 105 | 97 | 3 | 2 | 0 | 0 |
| I | 0 | 0 | 3 | 3 | 156 | 98 | 316 | 100 | |
| before C | ich | 513 | 94 | 363 | 42 | 0 | 0 | 0 | 0 |
| I | 33 | 6 | 494 | 58 | 1106 | 100 | 2043 | 100 | |
| EVERY | 1150--1250 (ME I) | 1250--1350 (ME II) | 1350--1420 (ME III) | 1420--1500 (ME IV) | |||||
| tokens | % | tokens | % | tokens | % | tokens | % | ||
| before V | everich | - | 6 | 86 | 7 | 64 | 9 | 39 | |
| everiche | - | 1 | 14 | 0 | 0 | 0 | 0 | ||
| every | - | 0 | 0 | 4 | 36 | 14 | 61 | ||
| before <h> | everich | - | 0 | 0 | 1 | 20 | - | ||
| everiche | - | 1 | 100 | 1 | 20 | - | |||
| every | - | 0 | 0 | 3 | 60 | - | |||
| before C | everich | - | 6 | 29 | 2 | 2 | 0 | 0 | |
| everiche | - | 10 | 48 | 2 | 2 | 0 | 0 | ||
| every | - | 5 | 24 | 105 | 96 | 138 | 100 | ||
| -LY | 1150--1250 (ME I) | 1250--1350 (ME II) | 1350--1420 (ME III) | 1420--1500 (ME IV) | |||||
| tokens | % | tokens | % | tokens | % | tokens | % | ||
| before V | -lich | 23 | 12 | 8 | 12 | 12 | 4 | 1 | 0 |
| -liche | 162 | 87 | 51 | 77 | 23 | 8 | 21 | 5 | |
| -ly | 1 | 1 | 7 | 11 | 251 | 88 | 421 | 95 | |
| before <h> | -lich | 13 | 18 | 7 | 21 | 1 | 2 | 0 | 0 |
| -liche | 59 | 82 | 24 | 73 | 8 | 14 | 0 | 0 | |
| -ly | 0 | 0 | 2 | 6 | 49 | 84 | 76 | 100 | |
| before C | -lich | 70 | 13 | 18 | 15 | 18 | 2 | 2 | 0 |
| -liche | 468 | 85 | 93 | 77 | 39 | 5 | 23 | 2 | |
| -ly | 11 | 2 | 10 | 8 | 788 | 93 | 947 | 97 | |
3つの表で,とりわけ子音の前位置 (before C) で ch の脱落した短形のパーセンテージを通時的に追ってもらいたい.短形の拡大の速度に多少の違いはあるが,ME II と ME III の境である1350年の前後で,明らかな拡大が観察される.14世紀半ばに,ich → I, everich → every, -lich → -ly の変化が著しく生じたことが読み取れる.
もう少し細かくいえば,問題の3項目を比べる限り,ich, everich, -lich の順で,語尾の ch が,とりわけ子音の前位置において脱落していったことがわかる.この変化に関して重要なのは,音節境界における音韻的な要因は確かに作用しているものの,そこに語彙的な要因がかぶさるように作用しているらしいことである.Schlüter (228) の調査のまとめ部分を引用しよう.
. . . the affricate [ʧ] in final position has turned out to constitute another weak segment whose disappearance is codetermined by syllable structure constraints militating against the adjacency of two Cs or Vs across word boundaries. . . . [T]he three studies have shown that the demise of final [ʧ] proceeds at different speeds depending on the item concerned: it is given up fastest in the personal pronoun, not much later in the quantifier, and most hesitantly in the suffix. In other words, the phonetic erosion is overshadowed by lexical distinctions. Relics of the obsolescent long variants are typically found in high-frequency collocations like ich am or everichone, where the affricate is protected from erosion by the ideal phonotactic constellation it ensures.
関連して,「#40. 接尾辞 -ly は副詞語尾か?」 ([2009-06-07-1]) 及び「#832. every と each」 ([2011-08-07-1]) も参照.
・ Schlüter, Julia. "Weak Segments and Syllable Structure in ME." Phonological Weakness in English: From Old to Present-Day English. Ed. Donka Minkova. Basingstoke: Palgrave Macmillan, 2009. 199--236.
2014-02-12 Wed
■ #1752. interpretor → interpreter (2) [spelling][suffix][corpus][emode][hc][ppcme2][ppceme][archer][lc]
標記の件については「#1740. interpretor → interpreter」 ([2014-01-31-1]) と「#1748. -er or -or」 ([2014-02-08-1]) で触れてきたが,問題の出発点である,16世紀に interpretor が interpreter へ置換されたという言及について,事実かどうかを確認しておく必要がある.この言及は『英語語源辞典』でなされており,おそらく OED の "In 16th cent. conformed to agent-nouns in -er, like speak-er" に依拠しているものと思われるが,手近にある16世紀前後の時代のいくつかのコーパスを検索し,詳細を調べてみた.
まずは,MED で中英語の綴字事情をのぞいてみよう.初例の Wycliffite Bible, Early Version (a1382) を含め,33例までが -our あるいは -or を含み,-er を示すものは Reginald Pecock による Book of Faith (c1456) より2例のみである.初出以来,中英語期中の一般的な綴字は,-o(u)r だったといっていいだろう.
同じ中英語の状況を,PPCME2 でみてみると,Period M4 (1420--1500) から Interpretours が1例のみ挙った.
次に,初期近代英語期 (1418--1680) の約45万語からなる書簡コーパスのサンプル CEECS (The Corpus of Early English Correspondence でも検索してみたが,2期に区分されたコーパスの第2期分 (1580--1680) から interpreter と interpretor がそれぞれ1例ずつあがったにすぎない.
続いて,MEMEM (Michigan Early Modern English Materials) を試す.このオンラインコーパスは,こちらのページに説明のあるとおり,初期近代英語辞書の編纂のために集められた,主として法助動詞のための例文データベースだが,簡便なコーパスとして利用できる.いくつかの綴字で検索したところ,interpretour が2例,いずれも1535?の Thomas Elyot による The Education or Bringing up of Children より得られた.一方,現代的な interpreter(s) の綴字は,9の異なるテキスト(3つは16世紀,6つは17世紀)から計16例確認された.確かに,16世紀からじわじわと -er 形が伸びてきているようだ.
LC (The Lampeter Corpus of Early Modern English Tracts) は,1640--1740年の大衆向け出版物から成る約119万語のコーパスだが,得られた7例はいずれも -er の綴字だった.
同様の結果が,約330万語の近現代英語コーパス ARCHER 3.2 (A Representative Corpus of Historical English Registers) (1600--1999) でも認められた.1672年の例を最初として,13例がいずれも -er である.
最後に,中英語から近代英語にかけて通時的にみてみよう.HC (Helsinki Corpus) によると,E1 (1500--70) の Henry Machyn's Diary より,"he becam an interpretour betwen the constable and certein English pioners;" が1例のみ見られた.HC を拡大させた PPCEME によると,上記の例を含む計17例の時代別分布は以下の通り.
| -o(u)r | -er(s) | |
|---|---|---|
| E1 (1500--1569) | 2 | 1 |
| E2 (1570--1639) | 3 | 5 |
| E3 (1640--1710) | 0 | 6 |
以上を総合すると,確かに16世紀に,おそらくは同世紀の後半に,現代的な -er が優勢になってきたものと思われる.なお,OED では,1840年の例を最後に -or は姿を消している.
2014-02-03 Mon
■ #1743. ICE Frequency Comparer [corpus][web_service][cgi][frequency][new_englishes][variety][ice]
「#1730. AmE-BrE 2006 Frequency Comparer」 ([2014-01-21-1]), 「#1739. AmE-BrE Diachronic Frequency Comparer」 ([2014-01-30-1]) で,the Brown family of corpora ([2010-06-29-1]の記事「#428. The Brown family of corpora の利用上の注意」を参照)を利用した,変種間あるいは通時的な頻度比較ツールを作った.Brown family といえば,似たような設計で編まれた ICE (International Corpus of English) も想起される([2010-09-26-1]の記事「#517. ICE 提供の7種類の地域変種コーパス」を参照).1990年以降の書き言葉と話し言葉が納められた100万語規模のコーパス群で,互いに比較可能となるように作られている.
そこで,手元にある ICE シリーズのうち,Canada, Jamaica, India, Singapore, the Philippines, Hong Kong の英語変種コーパス計6種を対象に,前と同じように頻度表を作り,データベース化し,頻度比較が可能となるツールを作成した.使い方については,「#1730. AmE-BrE 2006 Frequency Comparer」 ([2014-01-21-1]) を参照されたい.
どんな使い道があるかは,アイデア次第だが.例えば,"^snow(s|ed|ing)?$", "^Japan(ese)?$", "^bananas?$", "^Asia(n?)s?$" などで検索してみるとおもしろいかもしれない.
2014-01-30 Thu
■ #1739. AmE-BrE Diachronic Frequency Comparer [corpus][ame_bre][web_service][cgi][frequency][representativeness]
「#1730. AmE-BrE 2006 Frequency Comparer」 ([2014-01-21-1]) で,2006年前後の書き言葉テキストを編纂した英米各変種コーパスを紹介し,それに基づいた頻度比較ツールを作成・公開した.そのツールを作成しながら気づいたのだが,同じ方法で編纂され,規模も同じく100万語程度の the Brown family of corpora (「#428. The Brown family of corpora の利用上の注意」 ([2010-06-29-1]))と連携させれば,直近50年間ほどの通時的な英米間頻度比較が容易に可能となる.
そこで,前の記事で紹介した Professor Paul Baker - Linguistics and English Language at Lancaster University による AmE06 と BrE06 に加えて,書き言葉アメリカ英語を代表する Brown (1961), Frown (1992),書き言葉イギリス英語を代表する LOB (1961), FLOB (1991) より語形頻度表を抽出し,合わせてデータベース化した.利用の仕方は,AmE-BrE 2006 Frequency Comparer とほぼ同じなので,そちらの取説 ([2014-01-21-1]) を参照されたい.ただし,出力される表では,問題の語形が出現するテキストの数や頻度順位は省いており,純粋に約100万語当たりの頻度を表示するにとどめているので,AmE06 と BE06 について前者の情報が必要な場合には,AmE-BrE 2006 Frequency Comparer をどうぞ.
例えば,^movies?$ と入力してみると,伝統的にアメリカ英語的とされてきたこの語の分布が,過去50年ほどの間に,イギリス英語にも浸透してきている様子がわかる.
英米差の通時的な変化を調査したいのであれば,単語だけではなく語句も受けつけ,かつ規模も巨大な「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) のほうが簡便だろう.しかし,今回のツールは,the Brown family of corpora をベースにしているがゆえに,(1) 均衡かつ比較可能であり,(2) 「素性」がわかっている(再現可能性が確保されている)という利点があることは指摘しておきたい.望ましいのは,小型できめ細かなコーパスと,大型で傾向を大づかみにするコーパスとを上手に連携させることだろう.
2014-01-21 Tue
■ #1730. AmE-BrE 2006 Frequency Comparer [corpus][ame_bre][web_service][cgi][frequency][spelling]
先日,Professor Paul Baker - Linguistics and English Language at Lancaster University というページを教えてもらった.Baker 氏の編纂した現代英語・米語コーパス BE06 と AmE06 の情報と,そこから抽出した単語リストが得られる.当該のコーパス自体は,ユーザIDを請求すれば,ランカスター大学の CQP (Corpus Query Processor) system よりアクセスできる.
BE06 と AmE06 は,2006年前後に出版されたイギリス変種とアメリカ変種の書き言葉均衡コーパスである.編纂方式や構成は「#428. The Brown family of corpora の利用上の注意」 ([2010-06-29-1]) で紹介した The Brown family に準じており,500テキスト×2000語の計100万語ほどの規模だ.
さて,上のページからダウンロードできる BE06 Wordlist in WordSmith 5 format と AmE06 Wordlist in WordSmith 5 format より(見出し語ではなく)語形による頻度表を抽出し,それぞれをデータベース化して,英米変種の語の頻度を比較してくれる AmE-BrE Frequency 2006 Comparer なるツールを作成してみた.
入力するのは原則としてPerl5相当の正規表現だが,カンマ,タブ,改行などで区切った(非正規表現の)単語リストも受け付ける.1つの語形のみを入力したい場合には ^ と $ で挟んで ^loves$ のようにするか,あるいは "nothing (non-regex mode only)" のラジオボックスをオンにする.
出力形式は,デフォルトではアメリカ英語コーパスにおける頻度の高い順でソートされるようになっている ("by AmE freq") が,イギリス英語コーパスの頻度順 ("by BrE freq"),語形のアルファベット順 ("alphabetically") も可能.単語リストで入力した場合に,入力したそのままの順序で出力したいときには,"nothing (non-regex mode only)" をオンにする.
いずれも100万語規模の(今となっては)小さめのコーパスなので,語形によっては十分な頻度が得られないこともあるが,簡便に英米差をチェックしたいときには便利だろう.出力結果の WORD, AME_2006, BRE_2006 の3列を切り出して,最後の行にコーパスサイズとして "total\t1000000\t1000000" と補ったうえで,Log-Likelihood Tester, Ver. 1 に放り込めば,英米差を統計的に検定することができる.
例として,「#244. 綴字の英米差のリスト」 ([2009-12-27-1]) のうち,とりわけよく知られている類の米英綴字のペアを抜き出したリストを挙げよう.以下をコピーして,上のテキストボックスに放り込み,"nothing (non-regex mode only)" を選択して実行すると,数値として米英差が実感できる.
acknowledgment, acknowledgement, aging, ageing, aluminum, aluminium, analyze, analyse, apologize, apologise, armor, armour, behavior, behaviour, center, centre, civilization, civilisation, color, colour, defense, defence, disk, disc, endeavor, endeavour, favor, favour, favorite, favourite, fiber, fibre, flavor, flavour, fulfill, fulfil, gray, grey, harbor, harbour, honor, honour, humor, humour, inquiry, enquiry, judgment, judgement, labor, labour, license, licence, liter, litre, marvelous, marvellous, mold, mould, mom, mum, neighbor, neighbour, neighborhood, neighbourhood, odor, odour, organize, organise, pajamas, pyjamas, parlor, parlour, program, programme, realize, realise, recognize, recognise, skeptic, sceptic, specter, spectre, sulfur, sulphur, theater, theatre, traveler, traveller, tumor, tumour
これまでは,語彙や綴字に関する英米差のコーパスによる比較は,「#708. Frequency Sorter CGI」 ([2011-04-05-1]) を用いたり,「BNC Frequency Extractor」 ([2012-12-08-1]) と「#1322. ANC Frequency Extractor」 ([2012-12-09-1]) を組み合わせたり,the Brown Family corpora を併用するなど,各変種コーパスの個別比較により対処してきたが,今回のツールにより多少便利な環境ができた.
2014-01-07 Tue
■ #1716. shew と show (3) [spelling][corpus][clmet][representativeness]
「#1415. shew と show (1)」 ([2013-03-12-1]) と「#1416. shew と show (2)」 ([2013-03-13-1]) で扱った問題を,「#1637. CLMET3.0 で between と betwixt の分布を調査」 ([2013-10-20-1]) で紹介した The Corpus of Late Modern English Texts, version 3.0 (CLMET3.0) により再訪したい.具体的には,同タグ付きコーパスを "\bshow(s|n|ed|ing)?_VB" と "\bshew(s|n|ed|ing)?_VB" で検索して,3時代区分ごとに生起頻度数を比べた.以下の結果が出た.
| shew 系列 | show 系列 | 総語数 | |
|---|---|---|---|
| 1710--1780 | 335 | 1,545 | 10,480,431 |
| 1780--1850 | 159 | 3,100 | 11,285,587 |
| 1850--1920 | 92 | 5,118 | 12,620,207 |
前回「#1416. shew と show (2)」 ([2013-03-13-1]) で利用した PPCMBE (Penn Parsed Corpus of Modern British English) は100万語弱のコーパスだが,今回の CLMET3.0 は約3,400万語の巨大コーパスである.ほぼ同じ時代をカバーしているので比較には都合がよい.前回と同様に今回も show が shew を着実に置き換えている様子がうかがえるが,前回と大きく異なるのは,1710--1780年の第1期においてすでに show が圧倒的に勝っていることである.これを信じるならば,後期近代英語期に入るまでに,すでに show は勝敗を決していたということになる.PPCMBE では shew は後期近代英語期中に「優勢→同列→劣勢」と推移したが,CLMET3.0 では「当初から劣勢→もっと劣勢→さらに劣勢」と推移している.2世紀にわたる通時的な視点からは両コーパスともに大雑把には似たような傾向を示すとはいえるものの,18世紀の共時的な分布については両コーパスの示す数値の差は大きすぎるように思われる.ここには「#1280. コーパスの代表性」 ([2012-10-28-1]) という問題が関わってきそうであり,慎重な解釈が求められることになろう.
なお,1つの文脈で shew と show がともに用いられている興味深い例もいくつかあった.3例のみ挙げよう.
・ Why, you have shewn your wit upon the subject, and I mean to show your courage;
・ Mr. Wright, as well as Nadin, professed they were perfectly satisfied of this, and appeared to shew to me all the polite attention that they were capable of showing.
・ Assuredly I did not show him the face which I shewed Folderico.
2014-01-03 Fri
■ #1712. as regards [preposition][conjunction][impersonal_verb][corpus][clmet]
標題の熟語は,形式張った文体で「?に関しては,?について(いうと)」の意味で用いられる.典型的には "As regards the result, you need not worry so much." のように新しい主題を導くのに用いられる.機能的には前置詞といってよいだろう.
この複合前置詞は,歴史的には「#1201. 後期中英語から初期近代英語にかけての前置詞の爆発」 ([2012-08-10-1]) で示唆したように,近代英語で発達してきた.だが,細かくいえば as regards は初期近代英語ではなく後期近代英語での発達と考えられる.OED の regard, v. によると,語義 8b にこの用法が記述されており,初例としては1797年の "A distinction is made, as regards moral rectitude, in the minds of many individuals." という例文が挙げられている.
b. as regards, as regarded (now rare), †as regarding: with respect or reference to
一方,同じ動詞の現在分詞から発展した regarding, prep. も同様に用いられるが,こちらの初例としては1779年から " The servant was called, and examined regarding the import of the answer he had brought from Madame la Comtesse." の例文が挙げられている.ただし,名詞句に後続する regarding については17世紀より例があり,これが現在分詞なのか前置詞なのかを決定することは難しい.
初出年代の細かな問題はあるにせよ,as regards も regarding も後期近代英語期になって根付いた動詞由来の前置詞であると解釈することに大きな異論はないだろう.OED に記載のある †as regarding も含めて,動詞 regard から派生した前置詞の複数の異形が18世紀後半辺りに活躍しだしたと考えられる.
それを確かめるべく,「#1637. CLMET3.0 で between と betwixt の分布を調査」 ([2013-10-20-1]) で紹介した The Corpus of Late Modern English Texts, version 3.0 (CLMET3.0) により,as regards を検索してみた(as regarding は2例ほどヒット).70年間ごとに区切った頻度をまとめると以下のようになった.
| Decade | Frequency | Corpus size |
|---|---|---|
| 1710--1780 | 5 (5) | 10,480,431 words |
| 1780--1850 | 70 (18) | 11,285,587 |
| 1850--1920 | 347 (6) | 12,620,207 |
OED が示唆するよりも少し早く,18世紀半ばからの例が確認される.しかし,例文を眺めてみると,おもしろいことに第1期からの例はいずれも so [as] far as regards . . . という形で現れている(上の表でかっこ内に示した頻度は,(in) so [as] far as regards . . . の形で現れる内数)."so far as regards the present subject", "as far as regards your knowledge", "so far as regards our present purpose" の如くである.第2期にも同種の例が多いことを考えると,as regards は as far as regards の省略形として発展・定着してきたとも考えられるかもしれない.
なお,現在 as regards は複合前置詞としてとらえられており,統語的に分析する意味はないだろうが,歴史的な関心からあえて統語的に分析すれば,as は従属接続詞であり,主語を取らない非人称構文を導いているということになる.regards に後続する名詞句はあくまで動詞の目的語と分析される.
[ 固定リンク | 印刷用ページ ]
2013-11-21 Thu
■ #1669. longest が lengest を置き換えたのはいつか? [hc][corpus][adjective][comparison][i-mutation][analogy]
「#1649. longer が leng(er) を置き換えたのはいつか?」 ([2013-11-01-1]) で,歴史的な i-mutation 形の比較級 leng(er) が,いつ類推形 longer に置換されたのかをコーパスによって調査した.今回は,同じ過程を経たと想定される最上級について同様の調査を施した結果を報告する.歴史的な i-mutation 形の最上級 lengest は,英語史のどの段階で類推形 longest に置換されたのだろうか.
Helsinki Corpus で,語幹母音のヴァリエーションを念頭に置きつつ,両形を検索した.結果を通時的に整理すると以下のようになる.
| LONGEST | LENGEST | |
|---|---|---|
| O1 | 0 | 0 |
| O2 | 0 | 2 |
| O3 | 0 | 13 |
| O4 | 0 | 3 |
| M1 | 0 | 1 |
| M2 | 0 | 0 |
| M3 | 0 | 1 |
| M4 | 0 | 1 |
| E1 | 3 | 0 |
| E2 | 4 | 0 |
| E3 | 2 | 0 |
比較級よりも例がずっと少ないが,傾向ははっきりしている.比較級の場合と同様に,E1 (1500--1570) が転換期となっている.もちろん,この少数の例のみで結論を急ぐことはできない.例えば,lōng (adj. (1)) の用例を参照すれば,後期中英語の15世紀の Higden's Polychronicon 訳において,"In Armeny..Ytaly and other regiones..the longeste day other ny3hte is but oonly of xv houres equinoccialle." として longest が確かに文証される.それでも,比較級のケースと通時的な分布が似ているということは,今回の結果を評価する上で,重要な点となるだろう.
前回と同様,初期近代英語期 (1418--1680) の約45万語からなる書簡コーパスのサンプル CEECS (The Corpus of Early English Correspondence でも検索してみたが,2期に区分されたコーパスの第1期分 (1418--1638) から longest が1例ヒットしたのみだったので,ここから意味ある見解を引き出すことはできかった.
[ 固定リンク | 印刷用ページ ]
2013-11-01 Fri
■ #1649. longer が leng(er) を置き換えたのはいつか? [hc][corpus][adjective][comparison][i-mutation][analogy]
現代英語の形容詞・副詞 long の比較級の形態は規則的な longer だが,古英語から中英語にかけては lenger (副詞としては leng も)のように語幹に前母音をもつ諸形態が用いられていた.ゲルマン祖語の比較級を表わす形態素 *-iþo が契機となって直前の語幹母音に i-mutation が生じ,本来の語幹の後母音が前母音へと変化した.その効果は,古英語 leng(ra) や中英語の leng(er) に現れている.
ところが,原級は古英語でも中英語でも lang, long などと常に後母音を示していたので,やがて類推作用 (analogy) により比較級も原級に -er を付けるだけの規則的な形態を取るようになった.かつての i-mutation という音韻変化の効果が,類推という形態変化の効果により打ち消されたといえる.
さて,類推により longer につらなる形態が現れたのがいつ頃のことかが気になったので,調べてみた.OED では longer として見出しは立っていないので,long の項で例文を探してみると,a1533 に longer が現れている.MED でも同じ事情だったので lōng (adj. (1)) の例文を探すと,a1400 (a1325) に langer が初出する.しかし,例文検索から得られる初出年の情報だけでは心許ない.
一方,leng(er) の最終使用年代を調べるという逆方向の調べ方もしてみた.OED によると,副詞 leng の最終は Chaucer で c1386,形容詞・副詞の lenger は,副詞の用法としての Spenser の1590年が最終例だった.以上を総合すると,14--15世紀頃に longer が現れ,16世紀には歴史的な leng(er) を置き換えたという筋書きになりそうだ.
だが,先に述べたように longer の見出しが立っていない以上,OED の例文に頼るのみで新旧形態の交代過程を結論づけるわけにはいかない.このような目的には,補助的に歴史コーパスが有用である.Helsinki Corpus により,ざっと新旧それぞれの異形態を拾い上げてみた.古英語では第2音節の r は原級の屈折形であることを考慮し,また取りこぼしや雑音混入の可能性にも気をつけたが,完璧ではないかもしれないことを断りつつ,以下に数字を示す.
| LONGER | LENG(ER) | |
|---|---|---|
| O1 | 0 | 1 |
| O2 | 0 | 14 |
| O3 | 0 | 45 |
| O4 | 0 | 7 |
| M1 | 0 | 14 |
| M2 | 0 | 21 |
| M3 | 11 | 26 |
| M4 | 3 | 25 |
| E1 | 11 | 6 |
| E2 | 19 | 0 |
| E3 | 46 | 0 |
M3 (1350--1420) に longer が現れ,E1 (1500--1570) を最後に lenger が姿を消したことがわかる.1500年頃を境に新旧形態の立場が比較的急速に入れ替わったように見えるが,Helsinki Corpus も小規模なコーパスといわざるを得ないので,あくまで近似的な結論ととらえておく必要がある.だが,全体としてこの結果は OED からの証拠が示唆するところとおよそ同じであり,歴史辞書と歴史コーパスが互いに補完し合って結論を強めているといってよいだろう.
さらに,手元にあった初期近代英語期 (1418--1680) の約45万語からなる書簡コーパスのサンプル CEECS (The Corpus of Early English Correspondence でも同様の検索を施した.約24万6千語を含む第1期分 (1418--1638) と約20万4千語を含む第2期分 (1580--1680) を区別して調べたところ,以下の通りとなり,やはりおよそ16世紀後半には古い lenger が廃れたといえそうだ.
| LONGER | LENG(ER) | |
|---|---|---|
| CEECS1 | 31 | 6 |
| CEECS2 | 37 | 0 |
2013-10-20 Sun
■ #1637. CLMET3.0 で between と betwixt の分布を調査 [corpus][lmode][preposition][clmet]
今年3月に Leuven 大学の Hendrik De Smet により The Corpus of Late Modern English Texts, version 3.0 (CLMET3.0) が公開された.編者にメールで使用許可をもらえば無償でダウンロードし利用できる.1710--1920年のイギリス英語コーパスで,約3,400万語からなるジャンルを整理したバランスコーパスである(先行版 CLMETEV の1500万語から大幅に拡大).プレーンテキストとタグ付きテキストで配布されており,70年間で分けた3つの時代区分ごとにヒット数を数える Perl スクリプトが付属しており,とりあえず使うのに便利である.コーパスの構成は以下の通り.
| Sub-period | Number of authors | Number of texts | Number of words |
|---|---|---|---|
| 1710--1780 | 51 | 88 | 10,480,431 |
| 1780--1850 | 70 | 99 | 11,285,587 |
| 1850--1920 | 91 | 146 | 12,620,207 |
| TOTAL | 212 | 333 | 34,386,225 |
| Genre | 1710--1780 | 1780--1850 | 1850--1920 |
|---|---|---|---|
| Narrative fiction | 4,642,670 words | 4,830,718 | 6,311,301 |
| Narrative non-fiction | 1,863,855 | 1,940,245 | 958,410 |
| Drama | 407,885 | 347,493 | 607,401 |
| Letters | 1,016,745 | 714,343 | 479,724 |
| Treatise | 1,114,521 | 1,692,992 | 1,782,124 |
| Other | 1,434,755 | 1,759,796 | 2,481,247 |
現在関心をもっている between と betwixt の揺れについて,後期近代英語でそれぞれがどのような分布を示すか,CLMET3.0 で軽く調査してみた.付属の検索ツールで検索した結果は,以下の通り.
| Sub-period | between | betwixt |
|---|---|---|
| 1710--1780 | 4,869 words (464.58 wpm) | 657 (62.69 wpm) |
| 1780--1850 | 5,457 (483.54 wpm) | 109 (9.66 wpm) |
| 1850--1920 | 7,672 (607.91 wpm) | 51 (4.04 wpm) |
18世紀中は,between (88.11%) と並んで betwixt (11.89%) が,まだある程度の比率で使われていた.しかし,19世紀以降に激減し,現代英語における影の薄い変異形となったことがわかる.
なお,De Smet は同じサイトで The Corpus of English Novels (CEN) も公開している.こちらは1882--1922年という1世代の間に書かれた英米の小説を集めたもので,短期間の言語変化調査や作家間の語法比較を念頭に置いたコーパスだという.全体で2,600万語からなる(内訳はソースHTMLを参照).こちらで調べると,between が9,905例 (98.86%),betwixt が114例 (1.14%) であり,確かに後者はすでに影が薄い.
2013-10-09 Wed
■ #1626. 現代日本語書き言葉均衡コーパス BCCWJ の各種インターフェース [web_service][corpus][link][japanese]
「#1567. 英語と日本語のオンラインコーパスをいくつか紹介」 ([2013-08-11-1]) で,現代日本語のコーパスとしてKOTONOHA 「現代日本語書き言葉均衡コーパス」に言及した.この『現代日本語書き言葉均衡コーパス』 (BCCWJ: Balanced Corpus of Contemporary Written Japanese) は,大学共同利用機関法人人間文化研究機構国立国語研究所と文部科学省科学研究費特定領域研究「日本語コーパス」プロジェクトが共同で開発した本格的なコーパスである.
コーパスの内容については,同サイトに「2012年3月現在,検索対象となっているのは,以下の11種のデータ,合計約1億500万語です」とある.サンプルは,1976--2008年にかけての文書で,その11のジャンルは書籍,雑誌,新聞,白書,教科書,広報紙,Yahoo!知恵袋,Yahoo!ブログ,韻文,法律,国会会議録にわたる.各テキストからは2種類のサンプルが取られており,「ひとつは長さを1000字に固定したサンプル (固定長サンプル),もうひとつは,節や章など文章の意味上のまとまりに対応した単位の全体です (可変長サンプル).これまでの調査によれば,可変長サンプルの平均長は新聞で約1000字,書籍で4000字弱です.」とある.
BCCWJ を利用する方法やインターフェースはいくつかあるが,もっとも簡便なものが,上にもリンクを張った少納言である.登録不要で,表層の文字列によるコーパスの全文検索ができる.出力は無作為の500件と制限があるが,お手軽に試すことができる.
一方,利用申請が必要な中納言では,同コーパスに対して,短単位・長単位・文字列の3つの方法により,形態論的な複雑な検索をかけることができる.
また別のインターフェーとして,NINJAL-LWP for BCCWJ (NLB) がある.現行の1.20版では,BBCWJ のほとんどのデータを対象として,検索をかけることができる.検索ページはこちら.
関連して,NLB と同じインターフェースで利用できるもう1つの日本語コーパスを紹介する.筑波大学がウェブサイトからテキストを収集して編纂した11億語からなる筑波ウェブコーパス (Tsukuba Web Corpus: TWC) へのインターフェース,NINJAL-LWP for TWC (NLT)である.検索ページはこちら.
2013-10-04 Fri
■ #1621. The Middle English Grammar Corpus (MEG-C) [corpus][preposition][me_dialect]
ノルウェーの Stavanger 大学で,Merja Stenroos 氏が中心となって The Middle English Scribal Texts Programme (MEST) が進行中である.Glasgow 大学と Helsinki 大学の協力のもとに,中英語のテキストのコーパス化が進んでいる.このプログラムは具体的には2つのプロジェクトからなり,1つは1998年に Glasgow 大学が立ち上げた Middle English Grammar Project の延長線上にある The Middle English Grammar Corpus (MEG-C) の編纂で,もう1つは2012年に開始された Language and Geography in Middle English Local Documents (MELD) である.
今回は,前者のプロジェクト MEG-C について紹介したい.このコーパスは,後期中英語の方言地図 LALME のソースとなったテキストを電子化するという目的で編纂されている.姉妹版である初期中英語の方言地図 LAEME が最初からコーパス付きでオンライン公開されたのと対照的に,LALME では,編纂された時代が時代だけに,方言地図が紙媒体で公表されたにすぎなかった.2013年に LALME が改訂・電子化され eLALME としてアクセスできるようになったが,方言地図作成のもととなった資料自体は電子化されていなかった.現在,そのコーパスファイル群がMEG-C files から自由にダウンロードできるようになっている.
MEG-C は,実際には LALME の参照した1350--1500年のソーステキストのみならず,より早い時期のテキストをも含むコーパスとして成長している.長いテキストについては3000語のサンプルを取って収容しているが,現行の2011.1版では,目標とするテキストの半分ほどがカバーされているという.写本やファクシミリから転写しているというから,LAEME のコーパスに勝るとも劣らぬ大変な労力である.ありがたく利用させていただきたい.
早速,MEG-C にちょっとした検索をかけてみた.「#1394. between の異形態の分布の通時的変化」 ([2013-02-19-1]) で見た between の歴史的異形の分布のなかで,とりわけ語尾において x をもつ betwix(t) タイプが,後期中英語でどれくらい使用されていたかに関心があった.そこで検索してみると,104例が -x で終わるタイプ,14例が -xe で終わるタイプ,2例が -xt で終わるタイプという結果が出た.この頻度の傾向は,Helsinki Corpus による M3--M4期からの証拠とほぼ符合する.互いのコーパスの信頼度を測ることができたといえるだろう.
中英語の方言研究も,ますますツールが充実してきた感がある.
・ Stenroos, Merja, Martti Mäkinen, Simon Horobin, and Jeremy Smith. The Middle English Grammar Corpus, version 2011. 1. U of Stavanger, 2011. Online at http://www.uis.no/research/culture/the_middle_english_grammar_project/. Accessed : 4 October 2013.
2013-08-11 Sun
■ #1567. 英語と日本語のオンラインコーパスをいくつか紹介 [web_service][corpus][efl][link][japanese]
ウェブ上で用いることのできるコーパスをいくつか紹介したい.
まず,「#1441. JACET 8000 等のベース辞書による語彙レベル分析ツール」 ([2013-04-07-1]) で取り上げた染谷泰正氏は,Business Letter Corpus のオンライン・コンコーダンサーをこちらで公開している.27種のコーパスからの検索が選択可能となっているが,メインは100万語超からなる Business Letter Corpus (BLC2000) とそれにタグ付けした POS-tagged BLC の2つだ.これは1970年代以降の英米その他の出版物から収集したデータである.
Instructions for the First-Time User でまとめられているように,種々のコーパスのなかには,167万語を超える State of the Union Address (1790--2006) などデータをダウンロードできるものもあり,有用である.英作文の学習・教育や,独自データベースのコンコーダンサー作成のために参考になる.
なお,同サイトでは,上述の各種コーパスから N-Gram Search を行なえる Bigram Plus の機能も提供している.N-Gram の検索には,本ブログより「#956. COCA N-Gram Search」 ([2011-12-09-1]) も参照.
次は,英国のリーズ大学 (University of Leeds) が作成した大規模な Leeds collection of Internet corpora.英語を始め,フランス語,日本語などの様々な言語のコーパスをオンラインで検索できる.
日本語のコーパスの情報については詳しくないが,KOTONOHA 「現代日本語書き言葉均衡コーパス」は充実しているようだ.ほかの日本語コーパスの情報源としては,コーパス日本語学のための情報館 --- コーパス紹介が有用.
2013-07-30 Tue
■ #1555. unbeknownst [phonetics][corpus][-st]
昨日の記事「#1554. against の -st 語尾」 ([2013-07-29-1]) に引き続き,非語源的 -st 語の話題.標題の形式張った表現がある.主として文頭などに置かれ,文修飾として「?に知られないで」の意味で用いられる.BrE では unbeknown to が多く用いられるが,AmE では古めかしく見える unbeknownst to がより一般的である.unbeknow(e)ns のように -t が落ちた非標準的な形態も見られる.例文を挙げよう.
・ Unbeknownst to his parents, he and his girlfriend had gotten married.
・ Unbeknownst to her father, she began taking dancing lessons.
・ Unbeknownst to the students, the teacher had entered the room.
・ A person may overhear others unbeknownst to them.
中英語にあった動詞 beknown (recognise, acknowledge) の否定過去分詞形 unbeknown がもとになっている(MED の biknouen (v) を参照).OED によると,否定の接頭辞 un- のついた unbeknown は1636年に初出しているが,さらに語尾に -st を付加した unbeknownst の初出は1854年である.後者はもともと口語的,方言的な響きがあったようだが,20世紀にかけて広く使われるようになった.実際に,COCA (Corpus of Contemporary American English) や Google Books Ngram Viewer で調べてみると,英米変種ともに20世紀後半からの伸び率が著しい.
さて,unbeknownst の -st の語尾音添加 (paragoge) が説明を要する問題である.OED では不明とされており,各種の語源辞典では against, amongst などの -st 語尾からの類推だろうかと自信なさげに述べられている程度である.これらの語と unbeknownst to との類似点は, 前置詞的に機能しているということと,-st の直前の音が鼻音であることぐらいだろうか.-st(t)- という子音連続の観点からは,next to, thanks to などの表現とも関連してくるかもしれない.また,ほかの非語源的な -st 語 (against, amidst, amongst, betwixt, whilst) を並べてみると,およそ「間,中,最中」という共通の意味がくくり出されるように思われるが,unbeknownst も「知られない間に」と解釈することはできる.
非語源的 -st 語に関する記事へのリンクを昨日の記事[2013-07-29-1]の末尾にまとめておいたので,要参照.
(後記 2014/02/24(Mon):Merriam-Webster の辞書の記述を参照.)
2013-05-13 Mon
■ #1477. The Salamanca Corpus --- 近代英語方言コーパス [corpus][emode][dialect][dialectology][caxton][popular_passage]
英語史では,中英語の方言研究は盛んだが,近代英語期の方言研究はほとんど進んでいない.「#1430. 英語史が近代英語期で止まってしまったかのように見える理由 (2)」 ([2013-03-27-1]) でも触れた通り,近代英語期は英語が標準化,規範化していった時期であり,現代世界に甚大な影響を及ぼしている標準英語という視点に立って英語史を研究しようとすると,どうしても標準変種の歴史を追うことに専心してしまうからかもしれない.その結果か,あるいは原因か,近代英語方言テキストの収集や整理もほとんど進んでいない状況である.近代英語の方言状況を知る最大の情報源は,いまだ「#869. Wright's English Dialect Dictionary」 ([2011-09-13-1]) であり,「#868. EDD Online」 ([2011-09-12-1]) で紹介した通り,そのオンライン版が利用できるようになったとはいえ,まだまだである.
2011年より,University of Salamanca がこの分野の進展を促そうと,近代英語期 (c.1500--c.1950) の方言テキストの収集とデジタル化を進めている.The Salamanca Corpus: Digital Archive of English Dialect Texts は,少しずつ登録テキストが増えてきており,今後,貴重な情報源となってゆくかもしれない.
コーパスというよりは電子テキスト集という体裁だが,その構成は以下の通りである.まず,内容別に DIALECT LITERATURE と LITERARY DIALECTS が区別される.前者は方言で書かれたテキスト,後者は方言について言及のあるテキストである.次に,テキストの年代により1500--1700年, 1700--1800年, 1800--1950年へと大きく3区分され,さらに州別の整理,ジャンル別の仕分けがなされている.
コーパスに収録されている最も早い例は,LITERARY DIALECTS -> 1500--1700年 -> The Northern Counties -> Prose と追っていったところに見つけた William Caxton による Eneydos の "Prologue"(1490年)だろう.テキストは221語にすぎないが,こちらのページ経由で手に入る.[2010-03-30-1]の記事「#337. egges or eyren」で引用した,卵をめぐる方言差をめぐる話しを含む部分である.やや小さいが,刊本画像も閲覧できる.Caxton の言語観を知るためには,[2010-03-30-1]の記事で引用した前後の文脈も重要なので,ぜひ一読を.
{kind=link}
Powered by WinChalow1.0rc4 based on chalow