2012-10-28 Sun
■ #1280. コーパスの代表性 [corpus][representativeness][variety][idiolect][methodology]
コーパスにとって代表性 (representativeness) が命であることは,コーパスの定義上 ([2010-11-16-1]) あきらかであるし,昨日の記事「#1279. BNC の強みと弱み」 ([2012-10-28-1]) で紹介した Leech もとりわけ主張している点である.McEnery et al. (13) は,代表性について,Leech の定義を参考にしながら "a corpus is thought to be representative of the language variety it is supposed to represent if the findings based on its contents can be generalized to the said language variety" と述べている.
代表性を具体的に考えてみよう.例えば BNC がターゲットとするような,現代イギリス英語という一般的な変種を収録するコーパス (general corpus) の代表性はどのようにすれば得られるのか,その理論化は難しい.話し言葉と書き言葉の割合の問題を考えると,それぞれを50%ずつに割り振ることは,現代イギリス英語の代表性を約束してくれるだろうか.Leech の表現でいえば "impressionistic" とならざるを得ないが,今この瞬間に行なわれている現代イギリス英語の圧倒的な部分が,話し言葉においてではないか.もしそうだとすれば,話し言葉コーパスの割合を,例えば80%ほどに設定するほうがより代表性を確保できるのではないか.母体となる現代イギリス英語の全体像を直接つかむことができない以上,その代表性の議論は行き詰まってしまう.
コーパス(特に一般コーパス)の代表性という場合に,これを balance と sampling という2つの概念に分けて考えることがある.McEnery et al. (13) では,"the representativeness of most corpora is to a great extent determined by two factors: the range of genres included in a corpus (i.e. balance . . .) and how the text chunks for each genre are selected (i.e. sampling . . .)" と説明されている.
balance とは,BNC の用語でいうところの domain や genre という分類の設定に関するものである.例えば,現代イギリス英語のコーパスを標榜しながらも,イギリスの新聞の英語だけを集めたコーパスは,representativeness の点で難がある.現代イギリス英語には書き言葉だけでなく話し言葉もあるし,前者については新聞英語だけでなく文学英語もあれば電子メール英語もあるし,買い物メモ英語もあれば,日記英語もある.これらのあらゆる domain や genre を考慮に入れたいと思うが,果たしていくつの text domain があるのだろうか.新聞英語に限っても,タブロイドもあれば高級紙もある.1つの新聞内でも,社会面,スポーツ面,社説などを区別する必要はないのか,社会面であれば国内記事と国際記事の区別はどうか,等々.理論的にはどこまでも細分化しうる.話し言葉でも同様に細分化を推し進めていけば,個人語 (idiolect) ,さらに個人語における register 別の現われ,などのアトムへと終着してしまう.実際のコーパス作成上は,常識的なレベルで妥協することになるが,「常識的」と "impressionistic" はほぼ同義だろう.
sampling とは代表性を得るための手法である.母体の言語的特徴が再現されるように,質と量の点において考慮を加えながら,コーパス内に各 domain を案配するための理論と実践である.ここには,sampling unit として何を設定するか(典型的には,本,雑誌,新聞などの製品としての単位),そのような単位をリスト化する作業の範囲 (sampling frame) をどこまでに設定するか(特定の年への限定や,ベストセラー本への限定など),標本収集は完全なランダムにするかある程度の体系化を加えた上でのランダムにするか,著作権の問題をどう乗り越えるかなどの,理論的・実践的な問題が含まれる.
代表性に関わるもう1つの概念として,closure あるいは saturation と呼ばれるものもある.McEnery et al. (16) によれば,"Closure/saturation for a particular linguistic feature (e.g. size of lexicon) of a variety of language (e.g. computer manuals) means that the feature appears to be finite or is subject to very limited variation beyond a certain point." と説明されている.平たくいえば,これ以上コーパスの規模を大きくしても,語彙構成の割合は変わらないという規模に到達すれば,そのコーパスは saturated であると考えられる.代表性の指標としては,balance よりも saturation のほうがすぐれているという指摘もあるが,saturation は主として語彙が念頭にあり,他の言語項目への応用は試みられていないのが現状である.
代表性は,定義上コーパスの命であるとはいっても,定義先行というきらいはある.それを確保するための理論もないし,検証法もない.すべてのコーパス編纂者に立ちはだかる頭の痛い問題だろうが,コーパスは次々と編纂されている.理論的な問題は別にして,ひたすら編纂と使用を続けてゆき,ノウハウをため込むべき段階にあるのかもしれない.
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
2012-10-27 Sat
■ #1279. BNC の強みと弱み [bnc][corpus][representativeness]
10月8--11日の4日間にわたり,立教大学英語教育研究所による主催で,Lancaster 大学名誉教授 Geoffrey Leech の公開講演会が開かれた.私は,2日目の "The British National Corpus: Both a Triumph and a Failure" と題する講演のみの参加だったが,聴きに行った.BNC 編者じきじきの作成秘話など,おもしろい話しが何点かあった.
題名にある "triumph" と "failure" について,Leech はそれぞれ次のような項目を列挙していた.
A triumph:
・ It has been claimed that the BNC is the most widely used corpus in the world.
・ It was the first text corpus of its size to be made widely available.
・ It is available from a wide range of different sources.
・ It is widely regarded as a 'standard reference corpus' for the English language.
・ It has been licensed to over 1300 institutions throughout the world, over 1800 users have signed on for access to it through the BNCweb online interface, etc.
A failure:
・ It never reached 100 million words! (98,300,000)
・ The design criteria were never totally achieved.
・ It hardly ever contains complete texts.
・ The spoken materials are poorly transcribed.
・ The metadata are incomplete and can be erroneous.
・ The part-of-speech tagging contains many errors.
・ It is out of date! (dating from the late 20th century)
Leech の言葉の端々には,triumph の各点に示されているように,実績に裏付けされた自信がみなぎっていた.一方,自らのコーパス編集について,こうすればよかった,ああすればよかったという類の後悔ともいえる反省点を多く挙げていたのが印象的である.BNC のタグ付けに用いられたプログラム CLAWS4 の精度が97%ほどある(Hoffmann et al. 43 によると,98--99%)というのは,私は驚くべきことだと思っていたが,コーパス規模が大きいので数パーセントのエラーとはいっても約300万件にのぼるという事実は見落としていた.話しことばコーパスについては,コーパス全体の1割ほどしか含められなかったこと,音声データの transcription の質が悪かったこと,当初採用したデータフォーマット TEI が,話しことばのタグ付けには必ずしも適切でなかったこと,などを挙げていた.
なかでも,企画段階から現在に至るまで一貫してこだわり続けている代表性 (representativeness) について,BNC では完全に目的を果たせなかったことに,後悔をにじませていた.企画段階から,設定する Text Domain のバランスやサイズに関する議論が重ねられてきたことはよく知られている.1ユーザーとしては,限られたリソースのなかで,あれだけの代表性を確保したことは偉業だと評価しているが,Leech にとっては,できる限りのことはやったという自負の反面として,理想が果たせなかったという思いも強いようだ.同時に,穏やかな口調ではあったが,BNC と比較される他のすべての大規模コーパスが,代表性をさほど重視していない点を批判していた.ただし,彼自身が述べているように,コーパスの代表性について独自の理論はもっているが,最終的には "impressionistic" な判断の問題だと考えているようであり,この問題の難しさをにじませていた.いずれにせよ,Leech の代表性への執念の強さに,高度なプロフェッショナリズムを感じた.
なお,[2012-07-05-1]の記事「#1165. 英国でコーパス研究が盛んになった背景」で触れた通り,残念ながらBNCの続編はないだろうということを,Leech は明言していた.
扱う時代は大きく異なるが,初期中英語コーパス The LAEME Corpus の代表性の問題について,[2012-10-10-1], [2012-10-11-1]の記事で考察したので,ご参照を.
・ Hoffmann, Sebastian, Stefan Evert, Nicholas Smith, David Lee, and Ylva Berglund Prytz. Corpus Linguistics with BNCweb : A Practical Guide. Frankfurt am Main: Peter Lang, 2008.
2012-10-26 Fri
■ #1278. BNC を中心とするコーパス研究関連のリンク集 [corpus][bnc][link][web_service][lltest]
コーパス言語学の勢いが止まらない.分野が分野だけに,関連情報はウェブ上で得られることが多く,便利なようにも思えるが,逆に情報が多すぎて,選択と判断に困る.せめて自分のためだけでも便利なリンク集をまとめておこうと思うのだが,学界のスピードについて行けない.私が最もよく用いる BNC に関連するものを中心に,断片的ではあるが,リンクを張る.リンク集をまとめる労を執るよりは,芋づる式にたどるかキーワード検索のほうが効率的という状況になりつつある・・・.
1. BNC インターフェース
・ BNCweb (要無料登録)
・ BYU-BNC (要無料登録)
・ BNC ( The British National Corpus )
2. BNC のレファレンス・ガイド
・ Quick Reference for Simple Query Syntax (PDF)
・ Reference Guide for the British National Corpus (XML Edition)
・ 上の Reference Guide の目次
* 6.5 Guidelines to the Wordclass Tagging
* The BNC Basic (C5) Tagset
* 9.8 Simplified Wordclass Tags
* 9.7 Contracted forms and multiwords
* 1 Design of the Corpus
* 9.6 Text and genre classification code
3. コーパス関連の総合サイト
・ David Lee による Bookmarks for Corpus-based Linguists
* Corpora, Collections, Data Archives
* Software, Tools, Frequency Lists, etc.
* References, Papers, Journals
* Conferences & Project
4. hellog 内の記事
・ 「#568. コーパスの定義と英語コーパス入門」: [2010-11-16-1]
・ 「#506. CoRD --- 英語歴史コーパスの情報センター」: [2010-09-15-1]
・ 「#308. 現代英語の最頻英単語リスト」: [2010-03-01-1]
・ コーパス関連記事: corpus
・ BNC 関連記事: bnc
・ COCA 関連記事: coca
5. 計算ツール
・ Corpus Frequency Wizard
・ Paul Rayson's Log-likelihood Calculator
・ VassarStats
・ hellog の「#711. Log-Likelihood Tester CGI, Ver. 2」: [2011-04-08-1]
・ Hoffmann, Sebastian, Stefan Evert, Nicholas Smith, David Lee, and Ylva Berglund Prytz. Corpus Linguistics with BNCweb : A Practical Guide. Frankfurt am Main: Peter Lang, 2008.
2012-10-24 Wed
■ #1276. hereby, hereof, thereto, therewith, etc. [compounding][synthesis_to_analysis][adverb][register][corpus][bnc][hc]
標題のような here や there を第1要素とし,前置詞を第2要素とする複合副詞は多数ある.これらは,here を this と,there を it や that と読み替えて,それを前置詞の後ろに回した句と意味的に等しく,標題の語はそれぞれ by this, of this, to that, with that ほどを意味する.現代では非常に形式張った響きがあるが,古英語から初期近代英語にかけてはよく使用され,その種類や頻度はむしろ増えていたほどである.だが,17世紀以降は急激に減ってゆき,現代のような限られた使用域 (register) へと追い込まれた.衰退の理由としては,英語の構造として典型的でないという点,つまり総合から分析への英語の自然な流れに反するという点が指摘されている (Rissanen 127) .文法化した語として,現代まで固定された状態で受け継がれた語は,therefore のみといってよいだろう.
現代英語で確認される使用域の偏りは,すでに中英語にも萌芽が見られる.here-, there- 複合語は,後期中英語ではいまだ普通に使われているが,ジャンルでみると法律文書での使用が際だっている.以下は,Rissanen (127) の Helsinki Corpus による調査結果である(数字は頻度,カッコ内の数字は1万語当たりの頻度を表わす).
| Statutes | Other texts | |
|---|---|---|
| ME4 (1420--1500) | 68 (60) | 621 (31) |
| EModE1 (1500--70) | 77 (65) | 503 (28) |
| EModE2 (1570--1640) | 84 (71) | 461 (26) |
| EModE3 (1640--1710) | 126 (96) | 191 (12) |
初期近代英語のあいだ,一般には問題の複合語の頻度は落ちているが,法律文書においては token 頻度が(そして,Rissanen, p. 128 によれば type 頻度も)増加していることに注意されたい.後の時代でも,法律文書における使用は続き,現代に至る.
現代の分布については,独自に BNCweb で調べてみた.therefore を除く,hereabout, hereabouts, hereafter, hereby, herein, hereinafter, hereof, hereto, heretofore, hereupon, herewith, thereabout, thereabouts, thereafter, thereby, therefrom, therein, thereinafter, thereof, thereon, thereto, theretofore, thereunder, thereupon, therewith の25語について,Written Corpus に絞った上で,CQP syntax にて 「"(hereabout|hereabouts|hereafter|hereby|herein|hereinafter|hereof|hereto|heretofore|hereupon|herewith|thereabout|thereabouts|thereafter|thereby|therefrom|therein|thereinafter|thereof|thereon|thereto|theretofore|thereunder|thereupon|therewith)" %c」と検索した.出現頻度は 68.93 wpm で,散らばり具合は3140テキスト中の1522テキストである.
次に,法律関係の文書を最も多く含んでいると想定されるジャンルとして「W:ac:polit_law_edu」に絞り,同じ検索式で結果を見ると,231.33 wpm で,186テキスト中の153テキストに出現する.なお,「W:admin」に絞ると,コーパスサイズはずっと小さくなるが,頻度は439.85 wpm となり,最頻出ジャンルであることがわかる.いずれにせよ,この種のジャンルで here-, there- 複合語が今なお頻繁に用いられていることは確かめられた.
・ Rissanen, Matti. "Standardisation and the Language of Early Statutes." The Development of Standard English, 1300--1800. Ed. Laura Wright. Cambridge: CUP, 2000. 117--30.
2012-10-12 Fri
■ #1264. 歴史言語学の限界と,その克服への道 [methodology][uniformitarian_principle][writing][history][sociolinguistics][laeme][corpus][representativeness][evidence]
[2012-10-10-1], [2012-10-11-1]の記事で,The LAEME Corpus の代表性について取りあげた.私の評価としては,カバーしている方言と時代という観点からみて代表性は著しく損なわれているものの,現在利用できる初期中英語コーパスとしては体系的に編まれた最大規模のコーパスであり,十分な注意を払ったうえで言語研究に活用すべきツールである.The LAEME Corpus の改善すべき点はもちろんあるし,他のコーパスによる補完も目指されるべきだとは考えるが,言語を歴史的に研究する際に必然的につきまとう限界も考慮した上で評価しないとアンフェアである.
歴史言語学は,言語の過去の状態を観察し,復元するという課題を自らに課している.過去を扱う作業には,現在を扱う作業には見られないある限界がつきまとう.Milroy (45) の指摘する歴史言語学研究の2つの限界 (limitations of historical inquiry) を示そう.
[P]ast states of language are attested in writing, rather than in speech . . . [W]ritten language tends to be message-oriented and is deprived of the social and situational contexts in which speech events occur.
[H]istorical data have been accidentally preserved and are therefore not equally representative of all aspects of the language of past states . . . . Some styles and varieties may therefore be over-represented in the data, while others are under-represented . . . . For some periods of time there may be a great deal of surviving information: for other periods there may be very little or none at all.
乗り越えがたい限界ではあるが,克服の努力あるいは克服にできるだけ近づく努力は,いろいろな方法でなされている.そのなかでも,Smith はその著書の随所で (1) 書き言葉と話し言葉の関係の理解を深めること,(2) 言語の内面史と外面史の対応に注目すること,(3) 現在の知見の過去への応用の可能性を探ること,の重要性を指摘している.
とりわけ (3) については,近年,社会言語学による言語変化の理解が急速に進み,その原理の過去への応用が盛んになされるようになってきた.Labov の論文の標題 "On the Use of the Present to Explain the Past" が,この方法論を直截に物語っている.
これと関連する方法論である uniformitarian_principle (斉一論の原則)を前面に押し出した歴史英語の論文集が,Denison et al. 編集のもとに,今年出版されたことも付け加えておこう.
・ Milroy, James. Linguistic Variation and Change: On the Historical Sociolinguistics of English. Oxford: Blackwell, 1992.
・ Smith, Jeremy J. An Historical Study of English: Function, Form and Change. London: Routledge, 1996.
・ Labov, William. "On the Use of the Present to Explain the Past." Readings in Historical Phonology: Chapters in the Theory of Sound Change. Ed. Philip Baldi and Ronald N. Werth. Philadelphia: U of Pennsylvania P, 1978. 275--312.
・ Denison, David, Ricardo Bermúdez-Otero, Chris McCully, and Emma Moore, eds. Analysing Older English. Cambridge: CUP, 2012.
2012-10-11 Thu
■ #1263. The LAEME Corpus の代表性 (2) [laeme][corpus][representativeness]
昨日の記事[2012-10-10-1]に引き続き,The LAEME Corpus の代表性の話題.今回は,語数,より正確には同コーパスで文法情報が付与されている語 (tagged words) の数により,方言・時代ごとの代表性を考える.まず,表を掲げよう.
Table 2: Dialectal and Diachronic Distribution of Linguistic Evidence by Number of Tagged Words
| C12b | C13a | C13b | C14a | Total | |
|---|---|---|---|---|---|
| N | 0 (0.000%) | 362 (0.062) | 0 (0.000) | 52,883 (9.083) | 53,245 (9.146) |
| NEM | 11,342 (1.948) | 0 (0.000) | 3,980 (0.684) | 2,344 (0.403) | 17,666 (3.034) |
| NWM | 0 (0.000) | 58,332 (10.019) | 16,173 (2.778) | 0 (0.000) | 74,505 (12.797) |
| SEM | 40,082 (6.885) | 26,722 (4.590) | 21,921 (3.765) | 31,408 (5.395) | 120,133 (20.634) |
| SWM | 1,030 (0.177) | 90,400 (15.527) | 106,981 (18.375) | 108 (0.019) | 198,519 (34.098) |
| SW | 1,168 (0.201) | 2,610 (0.448) | 46,032 (7.907) | 30,517 (5.242) | 80,327 (13.797) |
| SE | 0 (0.000) | 4,043 (0.694) | 3,199 (0.549) | 30,561 (5.249) | 37,803 (6.493) |
| Total | 53,622 (9.210) | 182,469 (31.341) | 198,286 (34.058) | 147,821 (25.390) | 582,198 (100.000) |
直感的に理解できるように,この分布をモザイクプロットで表現したのが下図である(印刷用にはこちらのPDFをどうぞ).
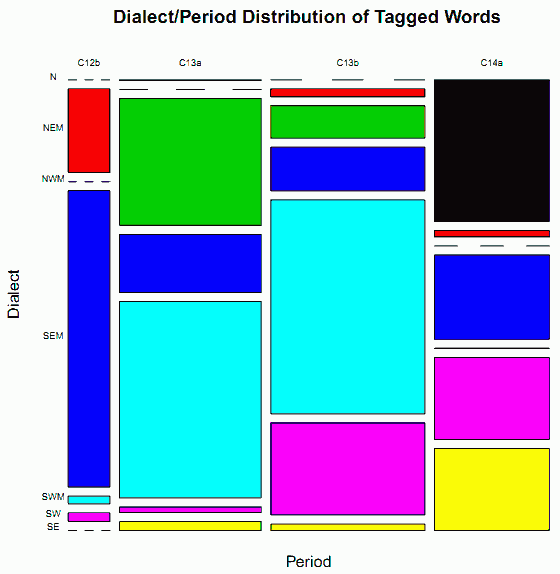
分布の偏りは一目瞭然である.しかし,方言・時代の各スロットを構成するテキストの種類などをより細かく調べると,さらに重要な問題が見えてくる.いくつかのスロットでは,総語数の大部分がほんの一握りのテキストによって占められているのである.例えば,N C14a というスロットは,全体のなかで4番目に収録語数の多いスロットだが,その語数の95.61%は Cursor Mundi という1作品(正確には,それを表わす3種類の異なる書写言語を反映した 3 scribal texts [##296, 297, 298])で占められている.同様に,NEM C13b では #182 のみで80.93%の語数がカバーされている.NWM C13b では #272 のみで93.11%だ.SEM C12b では異なる2人の写字生の手による Trinity Homilies (##1200, 1300) が総語数の84.06%を占め,SEM C13a でも異なる2人の写字生の手による Vices and Virtues (##64, 65) が総語数の93.83%を占める.SW C13b の #1600 は,それだけで69.71%を占める,等々.
これらの例が示唆することは,問題の方言・時代スロットは必ずしもその方言・時代の言語変種を代表しているわけではなく,むしろ特定のテキストに現われる言語変種を代表しているということかもしれなということだ.The LAEME Corpus の使用の際には,なお一層の注意が必要である.
2012-10-10 Wed
■ #1262. The LAEME Corpus の代表性 (1) [laeme][corpus][representativeness]
私の関心の中心は初期中英語期の形態論である.この時代に関心をもつ者にとっては,LAEME (編者によれば,発音は /ˈleɪmiː/ )とそこから派生した The LAEME Corpus (Text Database) の登場は,同時代に関する研究環境を著しく改善し得るツールとして,最大限に歓迎される.LAEME については,本ブログでも laeme の記事で採りあげてきたし,とりわけツールとしての可能性を探り,拡張すべく「#846. HelMapperUK --- hellog 仕様の英国地図作成 CGI」 ([2011-08-21-1]) ,「#856. LAEME text database のデータ点とテキスト規模」 ([2011-08-31-1]) ,「#942. LAEME Index of Sources の検索ツール」 ([2011-11-25-1]) ,「#1057. LAEME Index of Sources の検索ツール Ver. 2」 ([2012-03-19-1]) を公表してきた.
大工にとって道具の手入れが大事なように,研究者にとってツールの研究は大事である.具体的に The LAEME Corpus を使っているうちに,全体として俯瞰するとどのようなコーパスなのか,知りたくなってきた.[2010-11-16-1]の記事「#568. コーパスの定義と英語コーパス入門」で示した通り,コーパスの主たる特徴の1つに representativeness (代表性)がある.これは,コーパス評価のための指標の1つでもある.歴史コーパスにおける代表性の確保の難しさについては,「#531. OED の引用データをコーパスとして使えるか」 ([2010-10-10-1]) や「#1243. 語の頻度を考慮する通時的研究のために」 ([2012-09-21-1]) でも触れてきたが,この点では The LAEME Corpus も苦戦を強いられている.カバーしている方言分布については「#856. LAEME text database のデータ点とテキスト規模」 ([2011-08-31-1]) で採りあげたが,今回は方言区分に加えて時代区分も含めながら The LAEME Corpus のツール分析を試みたい.
まずは,収録されているテキストの数を考える.当該コーパスは "scribal text" という単位でテキストが収録されているが,これを方言と時代にしたがって分別すると,散らばり具合がわかる.なお,方言区分と時代区分はそれ自体が方法論上の大問題なのだが,以下では,恣意的な区分(とはいってもある程度の根拠はあるが)として,方言は7つへ,時代は4つへと分けている.すなわち,方言は N (Northern), NEM (North-East Midland), NWM (North-West Midland), SEM (South-East Midland), SWM (South-West Midland), SW (Southwestern), SE (Southeastern) へ,時代は C12b (12世紀後半),C13a, C13b, C14a へ.中英語の方言区分については「#130. 中英語の方言区分」 ([2009-09-04-1]) も参照.
Table 1: Dialectal and Diachronic Distribution of Linguistic Evidence by Number of Texts
| C12b | C13a | C13b | C14a | Total | |
|---|---|---|---|---|---|
| N | 0 (0.00%) | 1 (0.86) | 0 (0.00) | 7 (6.03) | 8 (6.90) |
| NEM | 1 (0.86) | 0 (0.00) | 5 (4.31) | 2 (1.72) | 8 (6.90) |
| NWM | 0 (0.00) | 9 (7.76) | 5 (4.31) | 0 (0.00) | 14 (12.07) |
| SEM | 4 (3.45) | 7 (6.03) | 14 (12.07) | 7 (6.03) | 32 (27.59) |
| SWM | 2 (1.72) | 13 (11.21) | 17 (14.66) | 1 (0.86) | 33 (28.45) |
| SW | 3 (2.59) | 5 (4.31) | 7 (6.03) | 2 (1.72) | 17 (14.66) |
| SE | 0 (0.00) | 2 (1.72) | 1 (0.86) | 1 (0.86) | 4 (3.45) |
| Total | 10 (8.62) | 37 (31.90) | 49 (42.24) | 20 (17.24) | 116 (100.00) |
上の表を作成するにあたり対象としたのは,The LAEME Corpus に収録されている167個の scribal texts のうち,半世紀という単位で時代の区分がなされている116個のみである.
表を一瞥すればわかるように,テキスト分布の偏りは大きい.方言でいえば SEM と SWM は層が異常に厚く,全体の3分の2ほどをカバーしているが,一方で N, NEM, SE は層が薄い.時代でみると,C13a と C13b だけで7割を越え,C12b と C14a は層が薄い.方言・時代の組み合わせでは,6スロットまでが "0" を示す.歴史コーパス編纂における representative の確保は絶望的とすら思えてくる.少なくとも,The LAEME Corpus を用いて得られる方言や時代についてのデータやそこから得られる結論は,よくよく注意して解釈しなければならないということがいえるだろう.
この表は scribal text の数をもとに作成されているが,各 scribal text の長さはまちまちである.そこで,テキスト数ではなく,語数による分布の具合も調べてみる必要がある.語数に基づく代表性の議論は,明日の記事で.
2012-09-21 Fri
■ #1243. 語の頻度を考慮する通時的研究のために [frequency][corpus][representativeness]
昨日の記事「#1242. -ate 動詞の強勢移行」 ([2012-09-20-1]) や「#1239. Frequency Actuation Hypothesis」 ([2012-09-17-1]) で取り上げた Phillips の研究のように,語の頻度を考慮する言語変化の研究には多大な関心を寄せているが,方法論上の素朴な疑問として,ある語の頻度それ自体が通時的に変わるという事実をどのように考えればよいのかという問題がある.ある特定の語ではなく,語彙の全体あるいは部分集合を考える場合には,1--2世代の時差は大きな問題ではないだろうと直感される.だが,1世紀の時差ではどうか,2世紀ではどうか,と考えると,どこまで直感に頼れるものか,はなはだ心許ない.Phillips (225--26) は,この問題について次のように楽観している.
The words' frequencies are based on present-day English, but the general pattern of relative frequencies probably holds for the English in our data base (1755--1993) as well. For example, I would be very surprised if the 3-syllable verbs with CELEX frequencies over 100 --- concentrate, demonstrate, illustrate, contemplate, compensate, designate, and alternate --- were not also much more common in 1755 than those with frequencies of 0 --- altercate, auscultate, condensate, defalcate, eructate, exculpate, expuergate, extirpate, fecundate, etc.
2世紀余の時差を相手にしていながら,頻度が100回以上の語と0回の語を比べるというのは大雑把にすぎるように思われる.確かに,Phillips は実際の頻度分析でも101回以上,10--100回,1--10回という荒い区分を用いており,大雑把な頻度情報を大雑把なままに用いる慎重さは示している.しかし,もし特に10--100回辺りの中頻度レベルの語をより詳細に調べようとするのであれば,2世紀の間にそれなりに頻度が変化している可能性はある.Phillips ならずとも,頻度を利用した通時的研究に関心をもつ誰もが突き当たるはずの問題だ.
すぐに思いつく単純な解決案は,各時代を代表するできるだけ大きなコーパスを利用して頻度表を作成することである.案としては単純だが,実際に遂行するのは一手間も二手間もかかる.綴字がある程度固定した近代英語であれば,コーパスを用意して頻度表の自動作成ができそうだが,中英語以前では綴字や語形の variation ゆえに lemmatise されていない限りは見出し語単位での頻度表作成は難航しそうだ.また,時代が古くなればなるほど,コーパスに含まれるテキストの representativeness の問題は深刻になる.ただし,荒っぽい頻度表でも,ないよりはあるほうがよい.いずれ作成してみたいと思っている.あるいは,時代によってはすでにあるだろうか?
なお,引用にある CELEX という単語データベースは,現代英語の語や形態に関する量的な研究でよく使われているものである.詳細は,CELEX2 を参照.また,頻度と通時態の関係については,[2012-05-03-1]の記事「#1102. Zipf's law と語の新陳代謝」を参照.
・ Phillips, Betty S. "Word Frequency and Lexical Diffusion in English Stress Shifts." Germanic Linguistics. Ed. Richard Hogg and Linda van Bergen. Amsterdam: John Benjamins, 1998. 223--32.
2012-08-27 Mon
■ #1218. 話し言葉にみられる whom の衰退 [pde_language_change][interrogative][relative_pronoun][corpus][ame][preposition_stranding]
現代英語における whom の衰退については,多くの研究がある.現代英語でもよく知られた言語変化であり,本ブログでも ##622,624,860,301,737 の各記事で触れてきた.かつての卒論学生にもこの話題を扱ったものがある ([2010-12-26-1]) .
最近の研究としては,Iyeiri and Yaguchi がある.これは,Michael Barlow が編纂し,Athelstan より有償で提供されている The Corpus of Spoken Professional American English (CSPAE) に基づいた研究である.CSPAE は,1990年代の専門アメリカ英語の話し言葉コーパスで,(1) White House での記者会見,(2) The University of North Carolina の教授会,(3) 数学テスト委員会の国家会議,(4) 読解テスト委員会の国家会議の,4つの状況が区分されており,全体として200万語から成る.また,CLAWS7 でタグ付けされている.研究の狙いは,whom は形式張った文体,特に書き言葉において使用されるといわれるが,では,形式張った話し言葉という環境でどの程度使われるのだろうかという問いに答えることである.
調査結果に従えば,spoken professional American English においては,whom の衰退は否定できないものの,いまだある程度の頻度では見られる.whom が生起する環境にも明らかな傾向があり,前置詞の直後においては最もよく保たれている(ただし,この環境ですら who の使用例は皆無ではない).一方,前置詞懸垂 (preposition_stranding) にはおいては who が通例である.また,who(m) が前置詞の目的語ではなく動詞の目的語として機能している場合には,より大きな揺れが見られる.
疑問詞としての whom と関係詞としての whom を比べると,前者のほうが衰退が激しい.これを説明するのに,筆者らは Rohdenburg による "Complexity Principle (transparency principle)" を援用している.これは,"[i]n the case of more or less explicit grammatical options the more explicit one(s) will tend to be favored in cognitively more complex environments" (cited in Iyeiri and Yaguchi, p. 185) という原理で,whom の議論に当てはめると,関係詞を含む構文は認知上より複雑であり,より明示的な格標示を要求する,ということになる.
上述のとおり,whom の衰退は現代英語の言語変化として取り上げられることが多い.このような話題について,references に参考資料がまとめられているのはありがたい.また,話し言葉コーパスの使用にも関心がわいた.関連して,The Michigan Corpus of Academic Spoken English というコーパスも参照.
・ Iyeiri, Yoko and Michiko Yaguchi. "Relative and Interrogative Who/Whom in Contemporary Professional American English." Germanic Languages and Linguistic Universals. Ed. John Ole Askedal, Ian Roberts, Tomonori Matsushita, and Hiroshi Hasegawa. Tokyo: Senshu University, 2009. 177--91.
2012-07-05 Thu
■ #1165. 英国でコーパス研究が盛んになった背景 [corpus][history_of_linguistics][methodology]
『英語コーパス研究』第19号に掲載の論文で,1960年代に誕生して以来,コーパス言語学がとりわけ英国で発展してきた経緯が話題とされていた.そこでは,the University of Birmingham, Lancaster University, the University of Nottingham の3大学がコーパス言語学の発展に果たしてきた役割が強調されており,英国におけるコーパス研究の現状と展望までもが要領よく概観され,非常に参考になった.
その論文によると,英国でコーパス研究が盛んになった背景には,次の5点があった (68--69) .
(1) 研究者に,大規模な研究プロジェクトに参加する時間的な余裕があった(ある).
(2) 生成文法以外の言語理論に対して寛容な土壌があった.
(3) 出版社が,コーパス研究の実用的な応用(特に辞書編纂)に関心を寄せた.
(4) 1990年代には,the Bank of English, the British National Corpus, the London-Lund Corpus を含む,多くの巨大で良質なコーパスにアクセスできた.
(5) 技術者との連係により,コーパスを分析するツールが手に入った(ex. Micro-Concord, WordSmith, AntConc, BNCweb).
現状について.Birmingham では,John Sinclair の強力な指導力のもとに培われた伝統が継続している.collocation, meaning unit, semantic preference, semantic prosody, discourse analysis, pattern grammar, expressions of evaluation, modal-like expressions などをキーワードとするコーパス研究が盛んに進められている.
Lancaster では,Geoffrey Leech, Tony McEnery, Andrew Wilson などによるコーパスの開発と研究が進められてきた.The Brown Family of Corpora の作成に関わったほか,タグ付けプログラム CLAWS や BNCweb の開発,UCREL (University Centre for Computer Corpus Research in Language) の設立など,技術的,運営的な側面でも一日の長がある.現在では,量的な研究を主体としながら,英語以外の言語へと関心を広げつつある.一方で,資金難により BNC のような巨大プロジェクトの続編は期待できないようだ.
Nottingham では,Ronald Carter, Michael McCarthy が話し言葉への関心から,1990年代初頭に CUP と共同して,CANCODE (the Cambridge and Nottingham Corpus of Discourse in English) を編纂した.その後も,続々と様々なコーパスをリリースしてきた.Nottingham におけるコーパス研究の特徴としては,話し言葉と書き言葉における語彙文法の差異,multimodal corpus 編纂などの技術的な革新,言語教育への応用が挙げられる.
1960年代に産声を上げた近代コーパス言語学が,1970--1980年代の発展の結果,1990年代に主流をなす分野として確立し,21世紀に入り「黄金時代」に至っている.
・ Anthony, Laurence, Yasunori Nishina, Kaoru Takahashi, and Michael Handford. "Current Trends in Corpus Linguistics: Voices from Britain." 『英語コーパス研究』第19号,英語コーパス学会,2012年,67--92頁.
2012-07-01 Sun
■ #1161. 英語と日本語における語彙の音節数別割合 [lexicology][statistics][syllable][corpus][japanese]
昨日の記事「#1160. MRC Psychological Database より各種統計を視覚化」 ([2012-06-30-1]) の (3) で,英語語彙を音節数により分別して,それぞれの頻度を出した.それによると,対象となった92767語の語彙全体における1音節語,2音節語,3音節語,4音節語の占める割合は,それぞれ13.46%,35.40%,29.91%,15.26%であり,合わせて94.03%に達する.とりわけ2音節語と3音節語を合わせて65.31%である.9万余という大規模な語彙で調査する限り,英語語彙の3分の2近くは2--3音節語であるということになる.
一方,##348,349,355 の記事では,BNC や COLT のコーパスを用いて,最も頻度の高い数百語から数千語を対象に音節数調査を行なった.調査対象となる語彙の規模は格段に小さく,それに従って音節数別の割合も変わる.1音節語と2音節語が優勢であり,最大の6000語規模の調査でもこの2種類だけで68.7%を占める(「#349. BNC Word Frequency List による音節数の分布調査 (2)」 ([2010-04-11-1]) のグラフを参照).対象とする語彙規模により,優勢な占有率を示す音節数が変動することがわかるが,全般的に,英語語彙においては1--3音節語が主要であることは間違いないだろう.
では,日本語の語彙について,音節数別の割合はどうだろうか.加藤ほか (80) では,林大氏による『日本語アクセント辞典』の見出し語形に基づく拍数の分布の調査結果が要約されている.辞典の見出し語形であるから対称語彙は数万語の規模と思われる.以下のような結果が出た.
| 1拍 | 2拍 | 3拍 | 4拍 | 5拍 | 6拍 | 7拍 | 8拍 | 9拍 | 10拍 | 計 |
| 0.3 | 4.8 | 22.7 | 38.8 | 17.7 | 11.0 | 3.3 | 1.2 | 0.2 | 0.1 | 100 |
割合のピークは4拍語にあり,その前後の3拍語と5拍語を合わせて79.2%,6拍語を加えれば90.2%になる.英語の語彙の主たる構成要素が1--3音節語とすれば,日本語の語彙の主たる構成要素は3--5拍語となる.音節数でみる限り,英単語は相対的に短く,日本語単語は相対的に長いことがよくわかる.
両言語間の際だった差異は,音韻数の差と音節構造の差に起因するといってよいだろう.音韻数については,[2012-02-12-1]の記事「#1021. 英語と日本語の音素の種類と数」で見たとおり,著しい差がある.また,音節構造については,日本語の音節がほぼ「子音+母音」の1形式だけであるのに対して,英語の音節は,[2012-02-14-1]の記事「#1023. 日本語の拍の種類と数」で示唆したとおり,数万形式がある.
日本語の語彙は,2拍語を基本としていると考えられる.和語でも漢語でも2±1拍語が多く,語彙の膨張に従って,その結合が増え,結果として4±1拍語が主流となってきた経緯がある.洋語についても,優勢な4拍語に合わせて「マスコミュニケーション」→「マスコミ」,「ハンガーストライキ」→「ハンスト」,「エンジンストップ」→「エンスト」と省略されることが多い.2拍語を基本とした日本語語彙の成立と,その後の発展については,小松 (48--62) が詳しい.
・ 加藤 彰彦,佐治 圭三,森田 良行 編 『日本語概説』 おうふう,1989年.
・ 小松 秀雄 『日本語の歴史 青信号はなぜアオなのか』 笠間書院,2001年.
[ 固定リンク | 印刷用ページ ]
2012-06-30 Sat
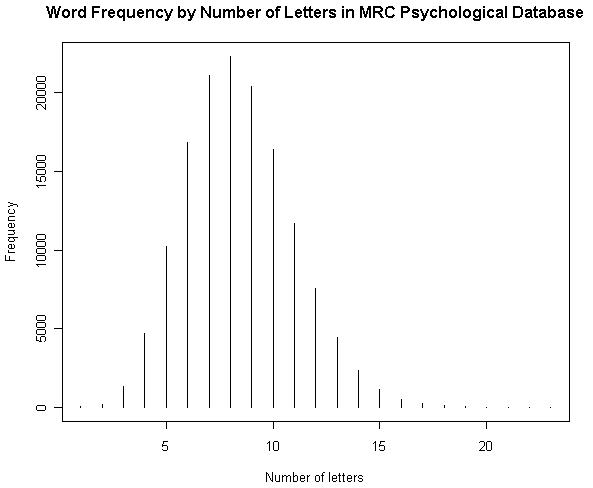
■ #1160. MRC Psychological Database より各種統計を視覚化 [lexicology][statistics][syllable][corpus]
[2012-06-28-1], [2012-06-29-1]と連日紹介してきた MRC Psycholinguistic Database に基づいて,4つの英語語彙統計を図示したい.原データファイルの仕様に示されている統計表をもとにグラフを作成しただけだが,別のコーパスに基づいて類似した調査を行なってきたものもあるので,比較に値するだろう.数値データは,HTMLソースを参照.
(1) 文字数による頻度
(2) 音素数による頻度
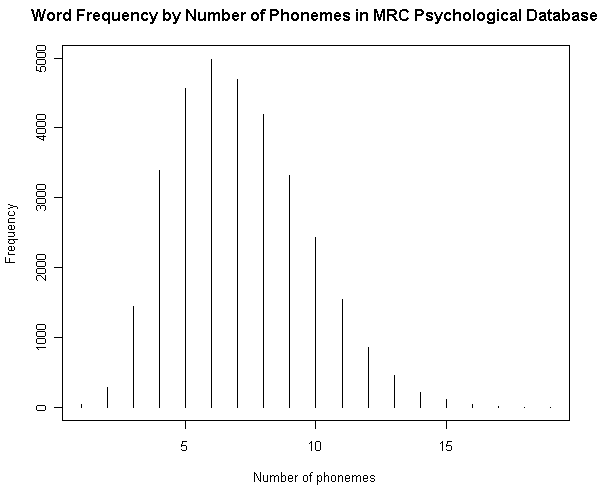
(参考)
・ [2012-02-13-1]: 「#1022. 英語の各音素の生起頻度」
(3) 音節数による頻度
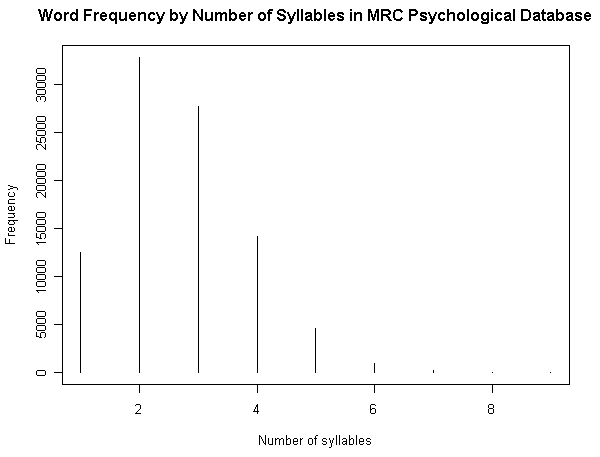
(参考)
・ [2010-04-09-1]: 「#347. 英単語の平均音節数はどのくらいか?」
・ [2010-04-10-1]: 「#348. BNC Word Frequency List による音節数の分布調査」
・ [2010-04-11-1]: 「#349. BNC Word Frequency List による音節数の分布調査 (2)」
・ [2010-04-17-1]: 「#355. COLT Word Frequency List による音節数の分布調査」
(4) 品詞による頻度
(参考)
・ [2012-06-02-1]: 「#1132. 英単語の品詞別の割合」
・ [2011-02-23-1]: 「#667. COCA 最頻50万語で品詞別の割合は?」
・ [2011-02-22-1]: 「#666. COCA 最頻5000語で品詞別の割合は?」
・ [2011-02-16-1]: 「#660. 中英語のフランス借用語の形容詞比率」
その他,語彙の頻度や,語種別の割合については以下の記事も参照.
・ [2010-03-01-1]: 「#308. 現代英語の最頻英単語リスト」
・ [2011-08-20-1]: 「#845. 現代英語の語彙の起源と割合」
・ [2012-01-07-1]: 「#985. 中英語の語彙の起源と割合」
2012-06-02 Sat
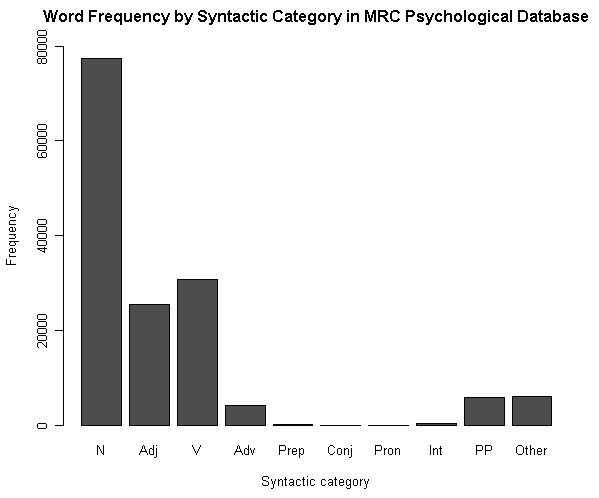
■ #1132. 英単語の品詞別の割合 [lexicology][corpus][statistics]
昨日の記事で,MRC Psycholinguistic Database (全150837語を含む)を利用した Amano の研究を参照した.Amano では,名詞と動詞の stress typicality の調査の副産物として,同データベースに基づいた語の品詞別割合の表が示されていたので,今回はそれをメモしておきたい.
Amano (86) は,データベースより計10894個の2音節語を抜き出した.複数の品詞の機能をあわせもつ語については,それぞれの品詞のもとで1個として加えた(その他,詳しい作業手順は p. 86 に明記されている).結果として得られた品詞別の個数と割合は以下の通りである.
| POS | FREQ | % |
| noun | 7326 | 57.04% |
| verb | 2501 | 19.47% |
| adjective | 2420 | 18.84% |
| adverb | 291 | 2.27% |
| preposition | 68 | 0.53% |
| conjunction | 21 | 0.16% |
| pronoun | 15 | 0.12% |
| interjection | 37 | 0.29% |
| past participle | 57 | 0.44% |
| others | 108 | 0.84% |
品詞別の割合の算出は,用いるデータベースやコーパスの性質や規模,word form で数えるか lemma で数えるかなどの「語」の定義の問題に左右されるが,複数の調査結果を比較すれば,ある程度は信頼できる値が得られるだろう.本ブログ内でこれまでに紹介した品詞別の割合については,以下を参照.
・ [2011-02-23-1]: 「#667. COCA 最頻50万語で品詞別の割合は?」
・ [2011-02-22-1]: 「#666. COCA 最頻5000語で品詞別の割合は?」
・ [2011-02-16-1]: 「#660. 中英語のフランス借用語の形容詞比率」
・ Amano, Shuichi. "Rhythmic Alternation and the Noun-Verb Stress Difference in English Disyllabic Words." 『名古屋造形大学名古屋造形芸術大学短期大学部紀要』 15 (2009): 83--90.
2012-05-06 Sun
■ #1105. 美女の形容としての grey eyes (2) [romance][adjective][collocation][bnc][corpus]
昨日の記事[2012-05-05-1]に引き続き grey eyes の話題.昨日は,中英語ロマンスの grey eyes について考えたが,この共起表現は現代にも続いている.BNCWeb で,"(grey|gray) {eye/N}" として検索すると,287例がヒットした.grey eyes がさらに別の形容詞に先行されている例をみると,clear, dark, deep, pale が比較的多い.beautiful や bright の例もわずかながらあった.
このような例から判断すると,grey 自体は輝きの有無を表わす意味を担当していないように思われる.もし担当しているとすれば,むしろ pale 寄りの「薄い,輝きのない」という解釈に引き寄せられるだろう.英英辞書で確認する限り,現代英語の grey の一般的な語感は,日本語のそれとよく似て,negative だからだ.老年,陰気,病気,憂鬱,退屈,悪天候のイメージだ.したがって,現代英語の grey eyes は,negative なニュアンスを特に含意しない読みを求めるとするならば,純粋に色としての「灰色」あるいは「青みのいくぶん混じった灰色」を表わすものと考えられる.あるいは,grey eyes は,意味の薄まった共起表現の伝統として用いられているにすぎないという可能性もあるかもしれない.
すると,ますます中英語の美女の典型的な描写としての grey eyes がわからない.もし,MED や Silverstein が述べている通り,中英語の grey が輝きを表わしたのだとすれば,現代英語の輝きのない grey は180度の意味変化を経たことになる.
色は gradation を描くものであり,かつて覆っていた範囲や意味を推定して復元することは,なかなか難しい.英語のみならず日本語においても,色彩語を巡る議論は厄介である.
なお,中世の美女の典型的な描写を示しておこう.Brewer (258) は,Matthew of Vandôme による Helen of Troy の描写が,以下の要約の通り,1つの型であるとしている.
. . . her hair is golden, forehead white as paper, eyebrows black and thin. The space between the eyes (in contrast to the Greek ideal) is white and clear, a 'milky way'; the face is a shining star; the eyes are like stars. She has a little smile, a nose neither too big nor too small. Her face is rosy, her colouring white and red, like rose and snow. Teeth are like ivory, lips are small, slightly swelling, honeyed. Her mouth smells like a rose, her neck is smooth, shoulders radiant, well-spaced (dispatiati), breasts small, and figure incomparable.
こんな女性,いるんでしょうか,ぜひ会ってみたい・・・.
・ Silverstein, Theodore, ed. Sir Gawain and the Green Knight. Chicago: U of Chicago P, 1983.
・ Brewer, D. S. "The Ideal of Feminine Beauty in Medieval Literature, Especially 'Harley Lyrics', Chaucer, and Some Elizabethans." The Modern Language Review 50 (1955): 257--69.
2012-05-04 Fri
■ #1103. GSL による Zipf's law の検証 [lexicology][statistics][frequency][zipfs_law][corpus]
[2012-05-02-1], [2012-05-03-1]の記事で取り上げてきた Zipf's law を検証(というよりは体験)するために,General Service List (GSL) の最頻2000語余りのデータを利用して計算してみた(データファイルはこちら).
![]()
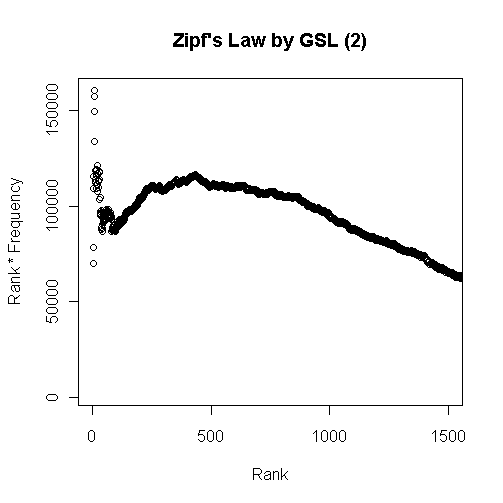
最初のグラフは頻度順位と頻度を掛け合わせたグラフで,頻度順で100位ほどまでの語を対象とした.以下はひたすら漸減してゆくのみなので省略.累積頻度のグラフを作成するまでもなく,最頻の数十語ほどで延べ語数のほとんどを覆ってしまう様子がよくわかる.
次のグラフは,Zipf's law によると定数になるとされる頻度順位と頻度の積を縦軸にとったものである.上位数十語までは「定数」は上下に大きく揺れて安定しないが,以後1000語ぐらいまでは,緩やかな増減はあるものの,落ち着く.その後のグラフ外ではひたすら漸減を続ける.したがって,「定数」を云々できるのは大目に見ても上位1000語ぐらいまでだろう.
これを法則と呼ぶのはあまりに外れていると考えるか,統計的傾向がよく出ているととらえるかは,観察者の見方ひとつである.Zipf's law における「定数」は「およそ定数」と解釈するのが暗黙の了解だが,「およそ」の幅がどの程度であるのかは明示されていない.また,Zipf's law が主張しているのと異なり,グラフの線は頻度をとるコーパスのサイズにも依存するようだ.
2012-04-29 Sun
■ #1098. 情報理論が言語学に与えてくれる示唆を2点 [information_theory][redundancy][corpus]
##1089,1090,1091 の記事で,言語学が情報理論 (information theory) から得られる知見について,特に言語の余剰性 (redundancy) に注目しながら紹介した.今回は,Jakobson による "Linguistics and Communication Theory" と題する論文にしたがって,情報理論が言語学に与えてくれるヒントを考えてみたい.
Jakobson は,彼の提示した二進法的な音素の示差的特徴 (distinctive feature) と,情報理論における基本単位である "digit" あるいは "bit" との親和性に気づき,(構造)言語学と情報理論の接点に注目した.Jakobson は両分野の共通点と相違点を洗い出し,言語学が情報言語から学べることは何か,両者の間で同一視してはいけないことは何かということを論じている.その中で特に2点が私の関心に引っかかったので,紹介したい.
(1) 情報理論は,もっぱら物理的な情報伝達の効率や情報体系の仕組み (code) に関心があり,その発信者,受信者,文脈,意味は考慮しない.言語体系も code ではあるが,それは言語行動が必要とする諸側面の1つにすぎず,code のみに注目する態度は避けるべきである.code が1側面にすぎないことは「#1070. Jakobson による言語行動に不可欠な6つの構成要素」 ([2012-04-01-1]) で見たとおりである.
There is a similar danger when interpreting human inter-communication in terms of physical information. Attempts to construct a model of language without any relation either to the speaker or to the hearer and thus to hypostasize a code detached from actual communication threaten to make a scholastic fiction from language. (250)
(2) 言語学が (1) の注意点を意識した上で,情報理論の手法を用いて言語体系の効率を測ろうとするとき,二項対立の体系としての理論的な効率と,言語項目の頻度を考慮した実際上の効率との両方を視野に入れておかなければならない.前者は type 的,langue 的な意味での効率,後者は token 的,parole 的な意味での効率といえばわかりやすいだろうか.Jakobson は,音素の示唆的特徴だけでなく形態カテゴリーも二項対立で記述でき,最終的には統語をも "bit" によって記述できると考えており,それにより言語Aと言語Bの文法情報の効率なども比較できるだろうとしているが,これは抽象化された言語体系としての code の効率のことを指している.一方で,言語使用の実際における情報伝達の効率を測ろうとすれば,言語項目の出現頻度を加味した情報の重みづけという作業が必要である.理論と実際のバランスが肝要ということである.
The amount of grammatical information which is potentially contained in the paradigms of a given language (statistics of the code) must be further confronted with a similar amount in the tokens, in the actual occurrences of the various grammatical forms within a corpus of messages. Any attempt to ignore this duality and to confine linguistic analysis and calculation only to the code or only to the corpus impoverishes the research. The crucial question of relationship between the patterning of the constituents of the verbal code and their relative frequency both in the code and in its use cannot be passed over. (251)
(2) の教訓を現代の言語研究に引きつけて解釈すると,構造言語学とコーパス言語学の連携というような課題につながってくるのではないか.コーパスによって得られた統計値をもとに各言語項目に重みづけを行ない,それを対立の集合として記述された言語体系のパラメータとして含めてやる.そうすることによって,Martinet の主張する言語の経済性の原理 ([2012-03-24-1], [2012-04-21-1]) なども検証可能となるのではないか.
・ Jakobson, Roman. "Linguistics and Communication Theory." Structure of Language and Its Mathematical Aspects. Providence: American Mathematical Society, 1961. 245--52.
2012-03-30 Fri
■ #1068. choose between war or peace [conjunction][corpus][bnc][preposition]
ある英文を読んでいて,the choice is between rhyme or prose という句に出くわした.between には等位接続詞 and が期待されるところだが,choice の語感に引きずられて or が使用されているものらしい.ジーニアス大辞典では,この用法について以下のように触れられている.
1(3) between 1980 to 1990 や choose between war or peace のように and の代りに to や or を用いるのは((まれ)).to は from A to Bの類推.or はchoose, decide などの動詞と連語するときに多く用いられる.これは choice [decision] A or B の類推と考えられる(→2).
2[区別・選択・分配] …の間に[で];…のどちらかを?choose ? peace and war 平和か戦争かのいずれかを選ぶ《◆and の代りに or を用いることがある; →1 [語法](3)》
OED では,"between" 18 が区別・選択・分配の用法を説明しているが,or を使用する例文は挙げられていない.同じく,MED では bitwene 7 がこの用法に対応するが,やはり or の例文はない."between A or B" の例がいつ現われたのかという問いに答えるには,より詳しく辞書や歴史コーパスを調べる必要がありそうだ.
現代英語について,BNCWeb で動詞句 "{choose/V} between_PRP + or_CJC" として検索し,該当する例文を選り分けたところ,ほんの8例ではあるが用例が得られた.いずれも Written books and periodicals からの例である.比較的わかりやすい4例を挙げよう.
・ . . . in 1627 Emperor Ferdinand ordered all his Bohemian subjects to choose between Catholicism or exile.
・ The main characters are all glorified psychopaths, with little to choose between hero or villain in terms of basic humanity.
・ . . . Mapleton, already out of breath, had to choose between talking or using his energy to keep up.
・ It is for you to choose between clinical or disciplinary action.
同様に,名詞句 "{choice/N} between_PRP + or_CJC" の検索結果も参照されたい.
"between A or B" はあまりに稀な構造だからか,特に規範文法で攻撃されている風でもなさそうだ.先行する語が区別,選択,決定,判定を意味する場合には or の語感は非常によく理解できるし,or の使用によって多義である between の語義が限定されるのだから,このような語法はむしろ推奨されるべきと考える.
2012-03-03 Sat
■ #1041. COCA の "ANALYZE TEXT" [coca][corpus][web_service][academic_word_list][text_tool]
COCA ( Corpus of Contemporary American English ) を運営する Mark Davies 氏が,[2012-01-08-1]の記事「#986. COCA の "WORD AND PHRASE . INFO"」で紹介した機能 (Frequency List) に加え,英文を投げ込むとCOCAベースで各語に関する諸情報を色づけして返してくれるサービス WORD AND PHRASE . INFO, ANALYZE TEXT を公開した.
適当な英文を投げ込むと,各単語が頻度レベルによって色分けされた状態で返される.上位500語までの超高頻度語は青,3,000語までの高頻度語は緑,それ以下の頻度の語は黄色で示されるほか,academic word が赤字として返される.文章内でのそれぞれの割合も示され,その語彙リストを出すことも容易だ.各語はクリッカブルで,クリックすると用例のサンプルが KWIC で右下ペインに表示される.また,左下ペインには類義語が現われる.以下は,昨日の記事「#1040. 通時的変化と共時的変異」 ([2012-03-02-1]) に引用した英文を投げ込んでのスクリーンショット.
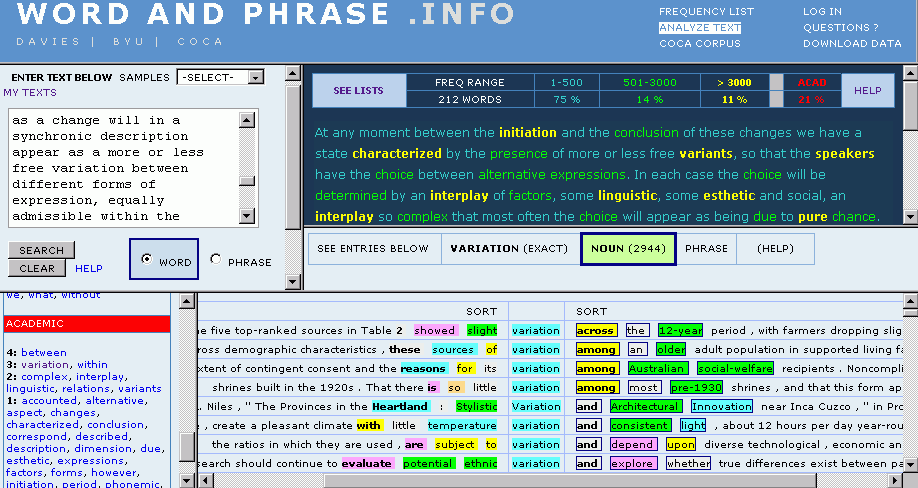
英文を書くときには collocation や synonym を調べながら書くことが多いので,使い方次第では英作文学習に威力を発揮しそうだ.ある文章の academic 度を判定するのにも使える.Academic Word List に含まれる語彙の含有度ということでいえば,[2010-12-30-1]の記事「#612. Academic Word List」で挙げた The AWL Highlighter も類似ツールだ.
2012-02-26 Sun
■ #1035. 列挙された人称代名詞の順序 [personal_pronoun][corpus][bnc][honorific]
昨日の記事「#1034. 英語における敬意を示す言語的手段」 ([2012-02-25-1]) の (4) で,英語では,1人称と他人称が並列される場合に,「倫理的敬意」から1人称が後置されることに触れた.謙譲的な語法といってよいだろう.2人称→3人称→1人称という順序が普通であり,"you and I", "she and I", "you, he, and I" などとなる.このことを初めて学んだとき,これはまさしく尊敬と謙譲の精神の現われであり,日本語に匹敵する敬意と配慮だ,などと感心したものである.Quirk et al. (Section 13.56, Note [a]) には次のようにある.
When one of the conjoins is a personal pronoun, it is considered polite to follow the order of placing 2nd person pronouns first, and (more importantly) 1st person pronouns last: Jill and I (not I and Jill); you and Jill, (not Jill and you), you, Jill, or me (not me, you, or Jill), etc.
同趣旨の記述は,Huddleston and Pullum (1288), Biber et al. (338) にもある.
ところが,英語の人称代名詞の順序を politeness として本当に賛美してよいのかどうか疑わしくなる記述に出くわした.細江 (191) によると,複数では1人称→2人称→3人称の順序が慣例だという.つまり,"we and you", "we and they", "we, you, and they" などとなる.これでは,敬譲にはならないだろう.
ただし,複数主格形について BNCWeb で調べたところ,そもそも用例が少なく,確かめようがないというのが実際のところだ.3つの人称の並列される例などは皆無だった.
・ we and you (0), you and we (0);
・ we and they (11), they and we (7)
・ you and they (11), they and you (6)
・ we, you, and they (0), we, they, and you (0)
・ you, we, and they (0), you, they and we (0)
・ they, we, and you (0), they, you, and we (0)
複数については,例文を豊富に挙げるのを身上とする細江にも例文が挙がっていないことからすると,何らかの規範文法書から取ってきたものなのだろうか.先の3種の大型英文法書にも言及がない.
単数についても,先に示した順序はあくまで慣例であり,場合によってはこの慣例から外れる場合もある.例えば,悪いことをしたときには,1人称を先に出すのがよいとされる (ex. I and Bob were arrested for speeding.) .また,自分の身分のほうが明らかに上の場合には,I and my children や I and my dog も当然ありうる.慣用はあるとしても,最終的にはケースバイケースだろう.
・ Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech, and Jan Svartvik. A Comprehensive Grammar of the English Language. London: Longman, 1985.
・ Huddleston, Rodney and Geoffrey K. Pullum. The Cambridge Grammar of the English Language. Cambridge: CUP, 2002.
・ Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad, and Edward Finegan. Longman Grammar of Spoken and Written English. Harlow: Pearson Education, 1999.
・ 細江 逸記 『英文法汎論』3版 泰文堂,1926年.
2012-01-09 Mon
■ #987. Don't drink more pints of beer than you can help. (1) [negative][comparison][idiom][syntax][corpus][bnc]
cannot help doing は,「?することが避けられない」を原義とし,「?せずにはいられない,?するのは仕方がない」を意味する慣用表現である.cannot but do としても同義.日本人には比較的使いやすい表現だが,標題のように比較の文において than 節のなかで現われる同構文には注意が必要である.
先に類例を挙げておこう.BNCWeb により "(more (_AJ0 | _AV0)? | _AJC) * than * (can|could) (_XX0)? help" で検索すると,関連する例が8件ヒットした.ほぼ同じ表現は削除して,整理した6例を示そう.
・ . . . the Commander struck out for the shore in a strong breaststroke that did not disturb the phosphorescence more than he could help . . . .
・ I'm not putting money in the pocket of the bloody Hamiltons more than I can help.
・ "Don't be more stupid than you can help, Greg!"
・ Resolutely, and determined to think no more than she could help about it . . . .
・ And I won't spend more than I can help.
・ "We'll do our best; we won't get in your way more than we can help."
さて,この構文の問題は,意図されている意味と統語上の論理が食い違っている点にある.例えば,毎日どうしてもビール3杯は飲まずにいられない人に対してこの命令文を発すると「3杯までは許す,だが4杯は飲むな」という趣旨となるだろう(ここでは話しをわかりやすくするために杯数は自然数とする).少なくとも,それが発話者の意図であると考えられる.しかし,論理的に考えると,you can help と肯定であるから,この量は,何とか飲まずにこらえられるぎりぎりの量,4杯を指すはずだ.これより多くは飲むなということだから,「4杯までは許す,だが5杯は飲むな」となってしまう.つまり,発話者の意図と統語上の意味とが食い違ってしまう.あくまで論理的にいうのであれば,*Don't drink more pints of beer than you cannot help. となるはずだが,この種の構文は BNCWeb でも文証されない.
理屈で言えば上記のようになるが,後者の意図で当該の文を発する機会はほとんどないと想像され,語用的に混乱が生じることはないだろう.また,[2011-12-03-1]の記事「#950. Be it never so humble, there's no place like home. (3)」で見たように,肯定でも否定でも意味が変わらないという,にわかには信じられないような統語構造が確かに存在する.とすると,標題の統語構造が許容される語用論的,統語意味論的な余地はあるということになる.
ちなみに,標記の文は今年の私の標語の1つである.ただし,その論理については……できるだけ広く解釈しておきたい.
Powered by WinChalow1.0rc4 based on chalow