2010-10-10 Sun
■ #531. OED の引用データをコーパスとして使えるか [oed][corpus][representativeness]
OED (2nd ed. CD-ROM) を歴史英語コーパスとして用いるという発想は特に電子版が出版されてから広く共有されてきた.実際に多くの研究で OED がコーパスとして活用されている.しかし,そもそもがコーパスとして編まれたわけではない OED 中の用例の集合をコーパスとみなして研究することは,どれくらい妥当なのだろうか.研究の道具について知ることは研究自身と同じくらい重要だと思われるので,このテーマに関連する Hoffmann の論文から要点をまとめてみたい.(私自身が道具としての OED の特徴をよく理解せずに研究に使っていたきらいがあるので,自分のための備忘録というつもりです.田辺春美先生の書かれた論文を参考にしています.)
Hoffmann は OED の用例の集合をコーパスとして用いることができるかという疑問に対して,4つの観点からアプローチしている.各観点と,対応する Hoffmann の結論を要約する.
(1) Selection criteria for the quotations
"a collection of pieces of language that are selected and ordered according to explicit linguistic criteria in order to be used as a sample of the language" (19; cited from Sinclair) という厳密なコーパスの定義に照らせば,OED の用例の集合をコーパスと見なすことはできない.確かに,個々の見出し語下に納められている用例群が,その見出し語に注目した場合の適切なコーパスにならないということは言えるだろう.その語の特殊で低頻度の形態や意味がクローズアップされる傾向があるからである.しかし,特にある見出し語に注目するのでなければ,全体として OED の用例は各時代の英語を代表していると考えられ,コーパスとして活用することは妥当である.
(2) Representativeness and balance of the quotations
OED の用例は実際に何らかの典拠から引いてきた "true quotations" (20) である.編者によって作られた用例もないではないが,数はきわめて少ない.また,典拠のジャンルは多岐にわたり,極端に文学作品に限るなどの偏向がないので,ジャンルに関しては "representative" と言ってよい.ただし,各ジャンルが言語研究にとって適切な割合で分布しているわけではないので,"balanced" とは言えない.例えば Shakespeare が1人で33,000の用例を提供している事例などが挙げられる.OED をコーパスとして見立てる場合には,"balance" の点で注意を要する.
(3) Reliability of the data format
文中の一部が省略されているような用例が,平均して20?25%ほどある.ほとんどの省略では文の構造がいじられていないが,中には不適切な省略で文の構造が変化してしまっている例文もある.節以上の構造を調べるために OED を利用する場合には,注意が必要である.
(4) Quantification of the results
1年当たりの用例数をグラフにプロットすると,17世紀頃に4000例を越える小ピークが,19世紀に10000例を越える大ピークが認められるが,20世紀には激減する.一方で,用例を構成する語の数は時代にかかわらずおおむね13語程度と一定で,20世紀の用例がやや長めなのが目に留まる程度である.用例数が240万例を越える(初版は180万例ほどだった)ことと上記の平均語数から計算して,OED に含まれる用例の総語数は3300?3500万語と推定される.OED をコーパスとして用いる場合には,19世紀の用例数が特に多いことなどに注意して検索結果を解釈すべきだろう.
最後に Hoffmann の結論部を引用する (26) .OED の用例の集合は言語変化の傾向を大雑把に量的に表わすコーパスとして言語変化研究にとって有用である,という常識的な結論だが,具体的な数字が出されていて参考になった.
Although the OED quotations database is not a completely balanced and representative corpus, it can nevertheless provide the linguist with a wealth of useful information. The data it contains chiefly represents naturally occurring language, and the time-span covered is unmatched by any other source of computerized data. Even though over 20 per cent of all its quotations have been shortened, the large majority of these deletions is unlikely to distort the results of many diachronic studies of linguistic features. Given the nature of the data, normalized frequency counts might suggest an inappropriate level of precision, but tendencies in the development over time can nevertheless be expressed in quantitative terms. (26)
・ The Oxford English Dictionary. 2nd ed. CD-ROM. Version 3.1. Oxford: OUP, 2004.
・ Hoffmann, Sebastian. "Using the OED quotations database as a Corpus --- A Linguistic Appraisal." ICAME Journal 28 (April 2004): 17--30. Available online at http://icame.uib.no/ij28/index.html .
・ Tanabe, Harumi. "The Rivalry of give up and its Synonymous Verbs in Modern English." Language Change and Variation from Old English and Late Modern English: A Festschrift for Minoji Akimoto. Ed. Merja Kytö, John Scahill, and Harumi Tanabe. Bern: Peter Lang, 2010. 253--75.
2010-09-27 Mon
■ #518. Singapore English のキーワードを抽出 [text_tool][corpus][flob][ice][singapore_english][keyword]
昨日の記事[2010-09-26-1]で ICE ( International Corpus of English ) からいくつかの英語地域変種コーパスが手に入る旨を紹介したが,そのなかから Singapore English のコーパス ( ICE-SIN ) を少しいじってみた.
[2010-03-10-1]の記事で WordSmith の KeyWords 抽出機能を拙著の英文で試したが,今回は ICE-SIN で同様に試してみるとどうなるだろうかと思った.そこで今回も,1990年代初頭のイギリス英語を対象に編纂された比較可能な FLOB corpus ( see [2010-06-29-1] ) を参照コーパスとし,British English に照らして Singapore English に特徴的な語(=キーワード)を抽出してみた.キーワード性の高い上位20語について,WordSmith に出力された表を掲げよう(上位100語までのリストはこのページのHTMLソースを参照).
| n | word | ice-sin.freq. | ice-sin.lst % | flob.freq. | flob.lst % | keyness |
|---|---|---|---|---|---|---|
| 1 | uh | 8,230 | 0.74 | 8 | 19,246.0 | |
| 2 | you | 18,175 | 1.64 | 7,258 | 0.29 | 17,768.5 |
| 3 | uhm | 3,838 | 0.35 | 0 | 9,021.1 | |
| 4 | ya | 3,580 | 0.32 | 10 | 8,283.9 | |
| 5 | i | 15,166 | 1.37 | 12,230 | 0.49 | 7,051.3 |
| 6 | singapore | 3,041 | 0.27 | 64 | 6,570.0 | |
| 7 | word | 3,490 | 0.32 | 482 | 0.02 | 5,621.8 |
| 8 | know | 4,768 | 0.43 | 1,534 | 0.06 | 5,345.5 |
| 9 | okay | 2,296 | 0.21 | 28 | 5,112.0 | |
| 10 | so | 6,759 | 0.61 | 4,452 | 0.18 | 4,113.8 |
| 11 | lah | 1,747 | 0.16 | 2 | 4,074.4 | |
| 12 | it's | 3,585 | 0.32 | 1,186 | 0.05 | 3,949.9 |
| 13 | your | 3,485 | 0.31 | 1,642 | 0.07 | 2,972.2 |
| 14 | oh | 1,952 | 0.18 | 344 | 0.01 | 2,900.2 |
| 15 | think | 2,761 | 0.25 | 1,208 | 0.05 | 2,501.5 |
| 16 | ah | 1,288 | 0.12 | 142 | 2,204.9 | |
| 17 | we | 5,884 | 0.53 | 5,406 | 0.22 | 2,190.7 |
| 18 | is | 15,022 | 1.36 | 20,588 | 0.83 | 2,027.9 |
| 19 | don't | 2,372 | 0.21 | 1,196 | 0.05 | 1,904.9 |
| 20 | what | 4,635 | 0.42 | 4,072 | 0.16 | 1,865.8 |
上位リストを眺めていたら2つの特徴が浮かんできた.
(1) 当然ながら Singapore English としばしば結びつけられる表現が上位に食い込んでいる.例えば,11位の lah は日本語でいう終助詞「ね」「よ」や間投詞のような働きをする pragmatic marker で,Singapore (and Malaysian) English らしい表現として知られている.しかし,やはり局地的な表現だからか手元の英語辞書にはほとんど掲載されておらず,唯一 Macmillan English Dictionary for Advanced Learners, 2nd ed. で次のような説明があった.
adverb INFORMAL
used by people in Malaysia and Singapore for making something they are saying sound more friendly and informal
例文を挙げるには,ICE-SIN から直接拾ってくると早い.会話文ではもちろんのこと,次のような親しい手紙文でも使われている.
Anyway, life is getting colder here. Hottest degree - 16 degrees celcius, coldest so far is 8oc. Brr..rr!! I'm wearing 3 to 4 layers now, like I did in England. So heavy one lah! Get back ache, you know!
ほかには,Singapore が6位に入っていたり,dollar(s), Chinese, Singaporeans, Malay などが上位100語以内に入っている.
(2) lah の頻度の高さとも関係するが,口語性の高い語,会話で頻出すると考えられる語が目立つ.直示性を表わす人称代名詞や副詞,また語調を和らげる語 ( hedge ) が特に多い.広く語用論的な機能をもつ語群としてまとめてよいかもしれない.もっとも話し言葉と結びつけられるキーワードが多いことは予想されたことではある.書き言葉は標準に準拠しやすく,地域変種間の差が少ないのが普通だからである.とりわけ話し言葉に地域変種の差が出やすいということが,今回のキーワード抽出で確かめられたということだろう.
今回のようなキーワード抽出は,もちろん他の地域変種にも応用できる.参照コーパスをイギリス英語以外に動かして相対的に各変種の特徴をみるというのもおもしろそうだ.
2010-09-26 Sun
■ #517. ICE 提供の7種類の地域変種コーパス [corpus][ice]
International Corpus of English @ ICE-corpora.net からは,7種類の英語地域変種コーパスがダウンロードできる.ダウンロードした圧縮ファイルにパスワードがかかっており,別途パスワードを申請(郵送かFAXにより無料)しなければならない.
・ Canada (ICE-CAN): http://ice-corpora.net/ice/icecan.htm
・ East Africa (Kenya & Tanzania) (ICE-EA): http://ice-corpora.net/ice/iceea.htm
・ Hong Kong (ICE-HK): http://ice-corpora.net/ice/icehk.htm
・ India (ICE-IND): http://ice-corpora.net/ice/iceind.htm
・ Jamaica (ICE-JA): http://ice-corpora.net/ice/icejam.htm
・ Philippines (ICE-PHI): http://ice-corpora.net/ice/icephi.htm
・ Singapore (ICE-SIN): http://ice-corpora.net/ice/icesin.htm
ICEでは,他にも相互比較可能な地域変種コーパスが編纂されている最中であり,中にはすでに有料で手に入るものもある.いずれも1990年以降の書き言葉と話し言葉が納められた100万語規模のコーパスである.編纂方式や構成は[2010-06-29-1]の記事で紹介した The Brown family of corpora に準じており,500テキスト×2000語となっている.corpus design や annotation scheme の詳細については,ICEトップページの上部メニューから参照できる.いくつかの地域変種には話し言葉のサンプル音源もあり有用.
この手の英語地域変種コーパスでかつ相互比較可能なものは今のところ他に出ていないだろうから,その目的の研究には重宝するだろう.
ゼミ研究で地域変種を扱っている学生は特に見ておいてください.
2010-09-19 Sun
■ #510. アメリカ英語における whilst の消失 [corpus][coha][ame_bre][ame]
Brigham Young University の Mark Davies により Corpus of Historical American English (COHA) が,最近,公開された.1810--2009年の範囲を覆うアメリカ英語コーパスで,総語数にして4億語を超える大型コーパスだ.公開されてからチョコチョコいじっているが,ワンクリックで10年区切りの頻度が出てグラフまで出してくれるので,この2世紀間のアメリカ英語の通時変化を鳥瞰するのにこれほど便利なツールはない.
特におもしろいのは,現在のイギリス英語とアメリカ英語とで形態や語法が異なっている1対の表現をそれぞれこのコーパスで検索してみることである.かつてはアメリカ英語でももっぱらイギリス的な表現が使われていたのが,時代が下るとともにイギリス色が抜けてゆく(あるいはアメリカ色が強まってゆく)様子がよく分かることだ.このこと自体は容易に予想されることだが,それがあまりに視覚的に明快に示されるので驚いてしまうのだ.例えば,私のゼミ学生で卒業論文のために英米差を調査している学生がいる.特に BrE in the street と AmE on the street の前置詞の差異に注目しているが,COHA でそれぞれをフレーズ検索すると後者が時代とともに増えてきていることが一目瞭然だという.
[2010-09-17-1], [2010-09-18-1]とで接続詞の while と whilst を話題にしたので,今回は COHA を用いて関連する調査をおこなってみたい.現代アメリカ英語では whilst はほとんど使われないが,イギリス英語では文語として現役である.では,かつてのアメリカ英語ではどうだったろうか.かつてはイギリス英語と同様にそれなりに使われていたが,ある時代から徐々に使われなくなり廃語となったという筋書きが予想される.それを COHA で確かめてみた.検索欄に "whilst.[cs]" (従属接続詞としての whilst )と入れて検索すると,たちどころに以下のような年代別頻度数が棒グラフとともに出力される.文字通りワンクリックなので「調査」と呼ぶのも大げさだ.結果としては,whilst は1810年代から2000年代までほぼ漸減を続けている.最も古い1810年代ですら whilst は while に比べれば minor variant にすぎないが,当時は100万語当たり81.27回現れていた.それが1930年代には5.04にまで落ちており,2000年代ではわずか1.59回である.
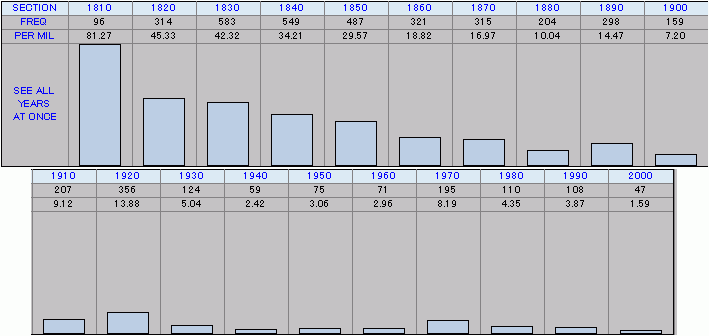
[2010-09-18-1]で出見たように Dracula (1897年) で while が14回しか現れないのに対して whilst が95回というのは,時代や文体によるところが大きいとしても,激しくイギリス的であることは間違いないようだ.
2010-09-18 Sat
■ #509. Dracula に現れる whilst (2) [corpus][lob][brown][bnc][oanc][coca][lmode][conjunction]
昨日の記事[2010-09-17-1]の続編.Dracula に現れる同時性・対立を表す接続詞の3異形態 while, whilst, whiles の頻度を,20世紀後半以降の英米変種における頻度と比べることによって,この60?110年くらいの間に起こった言語変化の一端を垣間見たい.用いたコーパスは以下の通り.
(1) Dracula ( Gutenberg 版テキスト ): 1897年,イギリス英語.
(2) LOB Corpus ( see also [2010-06-29-1] ): 1961年,イギリス英語.
(3) BNC ( The British National Corpus ): late twentieth century,イギリス英語.
(4) Brown Corpus ( see also [2010-06-29-1] ): 1961年,アメリカ英語.
(5) OANC (Open American National Corpus): 1990年以降,アメリカ英語.
(6) Corpus of Contemporary American English (BYU-COCA): 1990--2010年,アメリカ英語.
各コーパスにおける接続詞としての while, whilst, whiles の度数と3者間の相対比率は以下の通り.
| while | whilst | whiles | |
| (1) Dracula | 14 (12.61%) | 95 (85.59%) | 2 (1.80%) |
| (2) LOB | 517 (88.68%) | 66 (11.32%) | 0 (0.00%) |
| (3) BNC | 48,761 (89.41%) | 5,773 (10.59%) | 0 (0.00%) |
| (4) Brown | 592 (100.00%) | 0 (0.00%) | 0 (0.00%) |
| (5) OANC | 7,893 (100.00%) | 0 (0.00%) | 0 (0.00%) |
| (6) COCA | 246,207 (99.82%) | 447 (0.18%) | 0 (0.00%) |
Dracula の whilst の比率が異常に高い.はたして同時代のイギリス英語の文語の特徴なのだろうか.この表だけ眺めると,20世紀前半にイギリス英語で whilst が激減し,同世紀後半以降は10%程度で安定したと読める.アメリカ英語では20世紀後半では whilst はほぼ無に等しく,問題にならない.whiles に至っては,関心の発端であった Dracula での2例のみ(他に副詞としては1例あった)で,あとはどこを探しても見つからなかった.しかも,その Dracula の2例というのはいずれも訛りの強い英語を話すオランダ人医師 Van Helsing の口から発せられているもので,同時代イギリス英語でどの程度 spontaneous form であったかは分からない.
今回の調査はもとより体系的な調査ではない.ジャンルの区別や作家の文体を意識していないし,比較する時代の間隔はたまたま入手可能なコーパスに依存したにすぎない.英米変種での比較というのも思いつきである.しかし,興味深い問いが新たに生まれたので,今後は追跡調査をしてみたい.
・ Dracula と同時代の他のイギリス文語では各異形の頻度はどうなのか
・ 20世紀前半に whilst が激減したように見えるのは本当なのか,本当だとしたらその背景に何があるのか
・ アメリカ英語のより古い段階では whilst はもっと頻度が高かったと考えてよいのか
・ whiles はいつ頃まで普通に見られたのか,あるいはそもそも普通に見られる形態ではなかったのか
・ the while や the whilst などの複合形については頻度はどうだったのか
2010-09-15 Wed
■ #506. CoRD --- 英語歴史コーパスの情報センター [corpus][link]
Helsinki 大学の VARIENG ( Research Unit for Variation, Contacts and Change in English ) プロジェクトに関わる電子サービスの一環として,英語歴史コーパス(と英語変種コーパス)の情報をとりまとめる CoRD ( Corpus Resource Database ) なるサービスがある.すでに51件のコーパス情報が登録されており,今後も増え続けるだろう.種々のコーパスが様々な形態で公開され,そろそろ本格的な整理の必要が感じられるようになってきたので,CoRD のようなハブが出てくると重宝する.今後の登録コーパスの増加に期待したい.
・ List of Corpora: まずはこちらの一覧を.
・ Corpus Finder: 登録されている全コーパスの情報が表形式のデータベースになっている."Corpus", "Start", "End", "Periods", "Word Count", "Text Samples", "Spoken/Written", "Annotation", "Format", "Availability" の各列でソートやフィルターが可能.(こういうデータベースがあると便利だろうなと思っていた!)
各コーパスのリンク先には,概要説明から入手情報までの情報がよくまとまっている.特に "Basic structure of the corpus" は図表付きのものが多く有用."Reference lines and copyright" なども,ちょっとしたことなのだが論文を書くときなどにコピーできて便利.覚えておいて損はない HP だろう.
CoRD の他にも,英語コーパス言語学に関連する重要な HP をいくつか掲載しておきたい.個々のコーパスの関連ページはしばしばリンク切れになっているので,複数のハブを押さえておく必要がある.
・ コーパス言語学関係のリンク集: 家入葉子先生のサイトより.
・ 英語史関係のコーパス・電子テキスト: 同上.
・ 英語史関係のコーパス: 三浦あゆみさんの A Gateway to Studying HEL より.
・ JAECS 英語コーパス学会のリンク集: 『英語コーパス言語学:第二版』(東京:研究社, 2005)に掲載されているものをまとめたリンク集.
・ コーパス関連サイト: 『実践コーパス言語学』の著者の一人,須賀廣氏のリンク集.
・ ICAME Corpus Manuals: ICAME コーパスのマニュアルがまとまっている.
2010-09-02 Thu
■ #493. It's raining cats and dogs. [idiom][corpus][etymology]
『実践コーパス言語学』の冒頭に標題の慣用表現に関する論考がある ( pp. 1--8 ) .この表現は「雨が土砂降りに降る」を意味する慣用表現で,新奇な連想を誘うためか日本の英語教育でもしばしば取り上げられる.しかし,この有名な慣用表現が実は自然な英語表現とみなすことはできないのではないかという問題提起がなされている.
その根拠の1つは,1億語を誇る BNC ( The British National Corpus ) ですら例がわずかしか挙がらないという事実である.実際に検索してみると以下の3例しか挙がらず(いずれも書き言葉のサブコーパスから),しかも3つめの例は構文の説明という文脈で現れており,自然な例とは考えられない.
1. It was raining cats and dogs and the teachers were running in and out helping us get our stuff in and just couldn't do enough for us.
2. What must you be careful of when it's raining cats and dogs?
3. Fig 4.5 shows the structure of the compound tree for the compounds 'rain cats and dogs', 'tennis ball' and 'tennis court'.
Collins COBUILD Resource Pack から The Bank of English に基づく500万語のコーパス Wordbank で検索しても,3例しか見つからなかった.いずれもやはりイギリス英語の書き言葉からだ.
1. You mean she wasn't wearing a coat, even though it was raining cats and dogs?" said Cicero, gently puzzled.
2. It was the longest section in terms of distance, over 38 miles, and it rained cats and dogs all day long.
3. "Well if you just hold on for a wee while sir, it looks like it'll be raining cats and dogs soon and that'll put it out."
一方,Corpus of Contemporary American English (BYU-COCA) では23例が見つかった.今度は話し言葉でも使われている.
EFL 辞書で調べてみると,記載や例文のあることは多いが,辞書によって spoken, informal, old-fashioned など別々のレーベルが貼られており使用域が一定しない.こう見てくると,習ったことはあるにせよ自信をもって使うには躊躇せざるをえない表現という印象が強まってきた.
この慣用表現の起源には諸説ある.(1) 犬と猫が互いに仲が悪いことから激しくいがみ合うというイメージが醸成され,それが激しい降雨と結びつけられた.(2) 昔は排水が劣悪で土砂降りのあとに野良犬や野良猫が死体となって浮いていたことから.(3) ギリシア語の καταδουπεω ( catadūpeō ) "to fall with a heavy sound" と結びつけられた.(4) 北欧神話で魔女が猫の姿をして嵐に乗って現れ,嵐の神 Odin が犬を連れていたことから.
(1) の「激しさ」に引っかける説は,次のような表現があることから支持されるかもしれない.
1. fight like cat(s) and dog(s) 「猛烈にいがみ合う」
2. Cats and dogs have different natures. 「犬と猫は性質[本性]が違う.」
3. They agree like cats and dogs. 「(皮肉に)犬猿の仲だ.」
It's raining cats and dogs の variation としては,次のようなものがあるようなので参考までに.
1. It poured cats and dogs.
2. It's pelting cats and dogs.
3. rain pitchforks [buckets, chicken coops, darning needles, hammer handles,(英話)stair-rods,(英俗)trams and omnibuses] (『ランダムハウス英語辞典』より)
4. It's raining pigs and horses. (オーストラリア語法)
OED によると初例は1738年の Swift の文章である.ただし,a1652年として It shall raine . . Dogs and Polecats. なる関連表現がある.
・ 鷹家 秀史,須賀 廣 『実践コーパス言語学』 桐原ユニ,1998年.
2010-09-01 Wed
■ #492. 近代英語期の強変化動詞過去形の揺れ [emode][verb][conjugation][variation][corpus][ppceme]
近代英語期には,動詞の過去形や過去分詞形に数々の異形態があったことが知られている.特に母音の変化 ( ablaut, or vowel gradation ) によって過去形,過去分詞形を作った古英語の強変化動詞に由来する動詞は,-ed への規則化の傾向とも相俟って変異の種類が多かった.
現代英語でも過去形や過去分詞形に変異のある動詞はないわけではない.例えば bid -- bid / bade / bad -- bid / bidden, prove -- proved -- proved / proven, show -- showed -- shown / showed, sow -- sowed / sown -- sown / sowed などがある.しかし,近代英語期の異形態間の揺れは現代英語の比ではない.18世紀の著名な規範文法家 Robert Lowth (1710-87) ですら揺れを許容しているほどだから,それだけ収拾がつかなかったということだろう ( Nevalainen, pp. 93--94 ) .
今回はこの問題に関して,[2010-03-03-1]で紹介した PPCEME ( Penn-Helsinki Parsed Corpus of Early Modern English, second edition ) により,主要な動詞(とその派生・複合動詞)の過去形について異形態をざっと検索してみた.単に異綴りと考えられるものもあるが,明らかに語幹母音の音価の異なるものもあり,揺れの激しさが分かるだろう.カッコ内は頻度.
・ awake : awaked (1), awoke (3)
・ bear : bar (6), bare (133), barest (2), beare (1), bore (24)
・ begin : be-gane (12), be-gayne (1), began (281), began'st (1), begane (13), begann (1), beganne (27), begannyst (1), begayn (1), begayne (1), begon (1), begun (10)
・ break : brak (6), brake (60), brakest (2), break (2), broake (7), brok (4), broke (49), brokest (1)
・ come : bacame (1), becam (5), became (79), become (1), cam (475), came (2170), camest (11), camst (4), com (27), come (55), comst (1), ouercame (4), ouercome (2), over-cam (1), overcame (2), overcome (1)
・ drink : drancke (3), dranckt (1), drank (19), dranke (21), dronke (3), drunk (1), drunke (2)
・ eat : ate (15), eat (11), eate (12), ete (2)
・ fall : befel (1), befell (6), fel (15), fele (1), fell (306), felle (4), ffell (1)
・ find : fande (4), ffond (1), ffonde (1), ffound (1), find (1), fond (2), fonde (2), found (344), founde (63)
・ get : begat (67), begate (60), begot (3), begott (2), forgat (3), forgate (2), forgot (8), forgote (1), forgott (2), gat (10), gate (15), gatt (4), gatte (1), got (101), gote (23), gott (23)
・ give : forgaue (2), gaue (261), gauest (9), gave (364), gavest (12), gayff (4), gayffe (2), geve (1), misgaue (1)
・ help : help'd (2), help't (1), helped (5), helpt (1), holp (1), holpe (1)
・ know : knew (419), knewe (88), knewest (3), knewyst (1), know (1), knowe (1), knowethe (1), knue (1), knwe (1)
・ ring : rang'd (1), rong (1), rung (1), runge (1)
・ run : ran (77), rane (7), rann (3), ranne (38), run (12), rune (1), runn (1)
・ see : saw (627), saw (1), sawe (237), sawest (14), sawiste (1), see (5)
・ sing : sang (7), sange (5), song (11), songe (3), sung (13)
・ sink : sanke (1), sunke (1)
・ speak : bespake (2), spak (2), spake (318), spoak (1), spoake (8), spock (1), spoke (61), spokest (2)
・ spring : sprang (1), sprange (5), spronge (1), sprung (3), sprunge (1)
・ swear : sware (55), swoare (1), swore (56)
・ take : betoke (1), betook (4), betooke (4), mistook (1), mistooke (2), ouer-tooke (1), ouertoke (2), ouertooke (3), overtook (2), overtooke (2), take (1), taked (3), tok (2), toke (333), tokened (1), tokest (2), took (296), tooke (333), tooke (1), undertook (8), undertooke (2), vnd=er=tooke (1), vndertooke (2)
・ write : wrat (1), wrate (7), wret (32), wrett (49), writ (19), write (2), writt (8), writte (1), wrot (21), wrote (106), wrote (1), wrott (7), wrotte (3), wryt (1), wryte (1), wrytt (2)
近代英語期の強変化動詞の過去形,過去分詞形の揺れは様々に研究されているが,Nevalainen の References から以下の2件の研究を見つけたのでメモしておく.
・ Nevalainen, Terttu. An Introduction to Early Modern English. Edinburgh: Edinburgh UP, 2006.
・ Gustafsson, Larisa O. Preterite and Past Participle Forms in English, 1680--1790. Studia Anglistica Upsaliensia 120. Uppsala: Uppsala U, 2002.
・ Lass, Roger. "Proliferation and Option-Cutting: The Strong Verb in the Fifteenth to Eighteenth Centuries." Towards a Standard English, 1600--1800. Ed. Dieter Stein and Ingrid Tieken-Boon van Ostade. Berlin and New York: Mouton de Gruyter, 1993. 81--113.
2010-08-17 Tue
■ #477. That's gorgeous! (2) [coca][corpus][ame][semantic_change][americanisation]
昨日の記事[2010-08-16-1]で触れた gorgeous の話題の続編.昨日は「素敵な」の語義の拡大をイギリス英語を代表する BNC で見たが,アメリカ英語ではどうだろうかと思い,Corpus of Contemporary American English (COCA) にて調べてみることにした.というのは,『ビジネス技術実用英語大辞典第4版』に "My son is an extremely gorgeous baby." における gorgeous の使い方はアメリカ英語だという説明書きがあったからである.イギリス英語での用法はアメリカ語法 ( Americanism ) の波及という可能性があるということだろうか.
まずは,COCA で話し言葉サブコーパスに限定して調べてみると,興味深いことにこの20年間で確実に gorgeous の使用が増えている.

次に,話し言葉に限らず書き言葉も含めて調べると,やはりこの20年間で劇的に増えている.fiction, magazine, newspaper という書き言葉のジャンルでもかなりの頻度を示していることが,gorgeous の全体的な勢いを物語っている.

話し言葉に限っても限らなくても,ここ15年前後で gorgeous の頻度が倍増したことになる.今回の検索結果は,本来の語義「華麗な,豪華な」と新しい語義「素敵な」とを区別していないが,KWIC ( Keyword in Context ) をざっと眺めてみた限り,後者の語義のほうが多いようである.語義や語法の拡大というのは火がつくときには一気に火がつくのだなということが実感できる例だ.
今回の単純な調査だけでは,イギリス英語での使用増加が Americanisation によるものかどうかは判断できなかったが,少なくとも英米変種で今をときめく口語的形容詞といってよさそうだ.
2010-08-16 Mon
■ #476. That's gorgeous! [bnc][corpus][bre][semantic_change][etymology][gender_difference]
フィギュアスケートの実況などで女性コメンテーターが Gorgeous! と感嘆するのを聞くことがある.また,イギリス留学中にまだ赤ん坊だった私の娘の髪型を指して,お世話になっていたイギリス人女性が Gorgeous! と口にしていたのを覚えている.「ゴージャス」は日本語にも借用されており「華麗な,豪華な」という意味で定着しているが,日本語では賞賛を表わす叫びとしては用いないと思うので,上記の英語表現を聞くと用法が違うのだなと気づく.OALD7 によると,形容詞 gorgeous の第1語義は以下の通りである.現在では「素敵な」の語義が主要な使い方になっているようだ.
1. (informal) very beautiful and attractive; giving pleasure and enjoyment
形容詞 gorgeous はフランス語の gorgias "fine, elegant" からの借用で,一説によると語幹の gorge が "bosom, throat" であることから "ruff for the neck" 「首を飾るのにふさわしいひだ襟」と関連づけられるのではないかとされている.別の説ではギリシャの修辞家で贅沢品を好んだという Gorgias (c483--376BC) に由来するともされ,真の語源は詳らかでない.OED によるとこの語は15世紀終わりから用いられており「華麗な,豪華な」という語義が基本だったが,賞賛を表わす口語表現としての用法が19世紀後半から現れ出す.ただし,口語表現としての用法が一般化したのは20世紀に入ってからであり,とりわけポピュラーになったのは20世紀も後半から21世紀にかけてのことではないかと疑われる.
そう考える根拠の1つは,20世紀前半の辞書をいろいろと調べたわけではないが,例えば Webster's Revised Unabridged Dictionary (1913 + 1828) で調べる限り,gorgeous のエントリーに口語的な表現に対応する語義が与えられていない.
もう1つの根拠は,BNCWeb で gorgeous の頻度の統計を取ってみた結果である.いくつか興味深い結果が出た.まず明らかなのは,"informal" というレーベルから当然予想されるとおり,この語は書き言葉よりも話し言葉で頻度が顕著に高いことである.100万語中の出現頻度は,書き言葉で4.8回に対して話し言葉で17.39回である.話し言葉に限定して分布を調べたところ,特に会話文で頻度の高いことが分かった.
そして,何よりもおもしろいのは使用者の性別と年齢の分布である.gorgeous は100万語中,男性には8.89回しか用いられていないが,女性には34.64回も使われている.複数の英和辞書,英英辞書を引き比べて「主に女性語・略式」としてレーベルが貼られているのは『ジーニアス英和大辞典』だけだったが,これほど男女差が明らかであれば他の辞書でも「女性語」のレーベルが欲しいところだ.また,使用者の年齢としては24歳以下が圧倒的である.BNC が代表する20世紀後半のイギリス英語の話し言葉に関する限り,gorgeous は若年層の女性にとりわけポピュラーな表現ということが分かる.一般にはあまりこの語を用いない男性も,若年層に限っては使用頻度が比較的高いという結果も出た.全体として,gorgeous の使用はここ1?2世代の間に使用が拡大していると考えられそうである.
より細かく調査する必要はあるが,以上の情報から判断する限り gorgeous の用法がまさに目の前で変化しているということになる.口語的な賞賛の表現は19世紀末から徐々に発達してきたが,ここ数十年で若年層女子の使用によってブレイクし,それが若年層男性にも拡がりつつある.今後は他の年齢層にも及んできてますますポピュラーになるかもしれないし,一時の流行表現としてしぼんでいくかもしれない.
今後,この用法の行方を見守っていきたい.私も機会があったら(性別・年齢不相応気味に) That's gorgeous! と叫んでみることにしよう.
2010-08-15 Sun
■ #475. That's a whole nother story. [metanalysis][corpus][ame]
現代英語の口語で,標題のような表現がある.「そりゃまったく別の話だよ」という意味で,LDOCE5 によると nother, 'nother の見出しのもとに次のような記述がある.
a whole nother ... used humorously when emphasizing that something is completely different from what you have been talking about. It is a changed form of 'another whole':
- Texas is a whole nother country.
- That窶冱 a whole 'nother ball game.
another ( a(n) + other ) を分解して強調の whole を挟み込む際に,a whole other ではなく a whole nother と異分析 ( metanalysis ) して挟み込んだために生じた表現である(異分析の類例は[2009-05-03-1]を参照).Corpus of Contemporary American English (COCA) では結構な数の例が挙がったが,British National Corpus (BNC) では例がなかった.Merriam-Webster's Advanced Learner's English Dictionary では "US informal" のレーベルが付されていたし,アメリカ英語に多い表現といってよさそうだ.
さて,古い英語をみてみると,a whole nother のように間に形容詞が挟まっているタイプの nother の例こそいまだ見つけていないが,a + nother と異分析している例は早くも1300年頃から現れている.ane nothir sentence や an nother maner などの例を見ると,nother がすでに独立した語として認識されていたことが分かる.ただ,現代英語(米語?)の a whole nother という句が歴史的な異分析の例とどのような関係にあるのか,現段階の調査では不明である.
2010-08-02 Mon
■ #462. BNC から取り出した発音されない語頭の <h> [corpus][bnc][oanc][ame][bre][h][spelling_pronunciation]
昨日の記事[2010-08-01-1]の OANC からの結果に飽き足りずに,語頭を <h> と綴るが /h/ で発音されない単語をより多く探すべく,BNC でも同じことをやってみた.そちらのほうがおもしろい結果が出たので,結果報告する( OANC の面目丸つぶれ?).
216種類の語が得られたが,固有名詞や頭字語が多く,一覧してもあまりおもしろくない(見たい方はHTMLソースを参照).また,品詞のタグ付けに誤りがある例もあったので,今回はあくまで概要を知るための初期調査として理解されたい.一般名詞や形容詞に絞った117例をアルファベット順に示す.
habitual, habituated, habitué, haemoglobin, half, half-hour, hallucination, hallucinatory, hallucinogenic, handful, haphazardly, happy, haute-couture, hazard, heap, heartening, hedonistic, heir, heir-apparent, heiress, heirloom, hell, heparin, hepatic, heraldic, herbaceous, herbalist, hereditary, heretical, hermaphrodite, heroic, heterogenous, heterologous, heuristic, hexadecimal, hexagonal, hi, hiatus, hibiscus, hide, hierarchical, hierarchically, hierarchy, high, higher, hilarious, historian, historic, historically, historically-created, historically-evolved, historicist, historiographical, history, histrionic, hitherto, hockey, hole, holiday, holistic, holoenzyme, holy, home-grown, homogeneous, homologous, hon., honest, honest-to-god, honest-to-goodness, honestly, honesty, honorable, honorarium, honorary, honour, honour-able, honourable, honourably, honoured, honouring, hopeful, horchata, horizon, horizontal, horrendous, horrific, horror, hors-d'oeuvre, horse, hospital, host/target, hotel, hotel-keeper, hour's-worth, hour-an-a-half, hour-and-a-half, hour-glass, hour-long, hourglass, hourglass-shaped, hourly, hours, howitzer, human, humanities, humble, hundred, hydraulic, hydraulically, hydroxyapatite, hydroxyl, hypnotic, hypostasised, hypothesis, hypothetical, hysterical, hysterically
history, honest, honour, hour の関連語はやはり多い.おもしろいところを取りあげると,habitual, hallucination, hepatic, hereditary, heretical, heroic, hierarchical, hilarious, homogeneous, horizon, horrendous, horrific, hypothetical, hysterical あたりだろうか.いずれも第1音節に主強勢がおかれないので語頭の /h/ が特に弱まりやすい.ただ,第1音節に主強勢が落ちる例も少なくないことは確かである.
昨日の OANC での結果として出た herb や homage が BNC では出なかった.いずれの語も /h/ のない発音はアメリカ英語発音のみであるという辞書の記述と一致しているようだ.
それにしても,BNC と OANC の収録語数に差があるとはいえ,イギリス英語からの例の種類の豊富さは際立っている.確かにイギリス英語には h-dropping で名高い Cockney などの方言もあるし,/h/ の不安定さは著しいのではないかと予想はしていた.また,アメリカ英語では綴り字発音 ( spelling-pronunciation ) の傾向が強いことも一般論としては分かっていた.今回の BNC と OANC での初期調査の結果は予想と一致するものだったが,より詳しく調べていくと結構おもしろいテーマに発展してゆくかもしれない.
2010-08-01 Sun
■ #461. OANC から取り出した発音されない語頭の <h> [corpus][oanc][ame][h][article]
昨日の記事[2010-07-31-1]で OANC (Open American National Corpus) を導入したことを報告したので,今日はそれを実際にいじってみた報告をしよう.
お題は一昨日の記事[2010-07-30-1]で語頭の h を話題にしたので,それに引っかけて,語頭に <h> の綴字をもつが直前の不定冠詞に an を取る語を取り出してみた.[2009-11-27-1]でも触れたように,heir, honest, honour, hour のような語が /h/ をもたないことでよく知られているが,他にどのような語があるだろうか.今回はフラットな単純検索で,話し言葉と書き言葉を区別するとか,その他の細かい処理は行なっていない.以下に結果を頻度とともに一覧.
| word | freq. |
|---|---|
| heir | 1 |
| Henri | 1 |
| herb | 2 |
| hereditary | 3 |
| Hermes | 1 |
| historian | 1 |
| historic | 6 |
| historical | 1 |
| HMO | 10 |
| homage | 4 |
| hommage | 5 |
| honest | 24 |
| honor | 5 |
| honorable | 14 |
| honorarium | 1 |
| honorary | 13 |
| honored | 1 |
| honorific | 3 |
| hour | 135 |
| hourglass | 1 |
| hourlong | 3 |
| hourly | 1 |
| hours-long | 1 |
history, honor, hour の派生語や複合語は理解できる.また,Henri, Hermes, hommage はフランス語として,HMO (Health Maintenance Organization) はアルファベット読みとして納得.だが,herb や homage は発見だった.いずれの単語も,/h/ のない発音はアメリカ英語特有だという.
OANC でなくともよいといえばよい例題だったが,結果らしいことは一応出た.
2010-07-31 Sat
■ #460. OANC ( Open American National Corpus ) [corpus][oanc][ame]
BNC ( The British National Corpus ) のアメリカ英語版で ANC ( American National Corpus ) の作成プロジェクトが進行中である.1990年以降のアメリカ英語の multi-genre corpus で,完成時には BNC に匹敵する1億語以上のコーパスとなる予定とのこと.現時点では2200万語規模のものが Second Release として有料にて入手可能.
一方で,フリーで利用できる約1500万語のサブコーパス OANC (Open ANC) も公開されており,話し言葉が300万語強,書き言葉が1100万語強という構成だ.こちらは316MBほどでダウンロード可能.展開するとデータだけでも5GBほどある.データ変換ツールとして Java で動くプログラムが ANC Software からダウンロードできる.
ANC のエンコード方式はこちらに説明があるとおり,XCES Markup for Standoff Annotation という方式に従っており,テキスト本体と各種 annotation が別々のファイルに収められているのが特徴である.XCESをサポートしていないコンコーダンサーで OANC を扱うには,例えば Xaira 形式や WordSmith 形式などへデータを変換しなければならない.前者にはこちらの解説のとおりに Xaira 付属のインデクサーを用いる.後者は ANCTool のディレクトリで "java -jar ANCTool-xxxx.jar" と走らせれば,あとはGUIウィザードになっているので指示に従えばよい.データの量がものすごいので,時間がかかった.
現代アメリカ英語の他のコーパスとしては,Mark Davies 提供のウェブ上で利用できる Corpus of Contemporary American English (COCA) などがある.こちらは1990--2009年の4億語強のコーパスだ.Mark Davies によるその他のオンライン・コーパスも要参照.
2010-06-29 Tue
■ #428. The Brown family of corpora の利用上の注意 [corpus][ame_bre][brown]
[2010-04-25-1]の記事で述べたとおり,近代の英語コーパスの走りとして Brown Corpus の果たしてきた役割は甚大である.Brown Corpus のコーパス・デザインに沿った類似コーパスが続々と誕生し,現在も ICE ( International Corpus of English ) のプロジェクトが進行中である.その中でも特に "the Brown family of corpora" と呼ばれる中核となる4つの関連コーパスがある.1960年代初頭のアメリカ英語(書き言葉)を代表する Brown Corpus,そのイギリス英語版の LOB Corpus,さらに30年時間をおいて1990年代初頭のアメリカ英語(書き言葉)を代表する Frown Corpus,そのイギリス英語版の FLOB Corpus である(各コーパスの概要は ICAME の HP を参照).この4つを駆使すると各時期の英米変種の異同だけでなく,各変種で30年の間に起こった言語変化を調べることができる.二つの観点をクロスさせれば,言語変化の英米差を比較することもできる.Leech and Smith (186) より,the Brown family of corpora の相関図を示す.
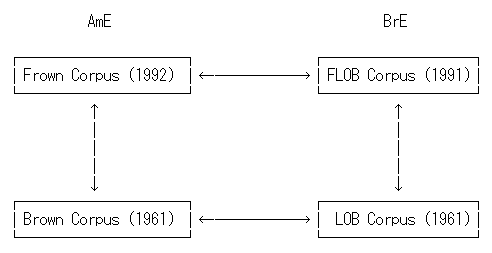
近年は数億語規模の巨大コーパスが林立するなかで,the Brown family のコーパスはそれぞれ約100万語とサイズとしては小型だが "comparable" であるところが最大の売りだろう.テーマによっては今後も十分に有用であり続けるだろうと思われるし,4コーパスを駆使した Leech and Smith の研究などを見ていると,まだまだいろいろな研究ができそうである ( see [2010-06-25-1], [2010-06-26-1] ) .そこで,the Brown family を利用する際の注意事項について,Leech and Smith (186--87) が述べているものを引用して学習しておきたい.以下は「危険な前提」とされているものである.
(a) that the size and composition of the corpora are sufficiently closely matched to validate the basic principle of the comparison: that we are comparing like with like despite different provenances;
(b) that the statistically significant results of the comparisons can be attributed to linguistic differences rather than other factors such as shifts in genre characteristics;
(c) that the grammatical categories are defined and used consistently and in a way that other linguists will find useful;
(d) that the extraction of classified data from the corpus has been acceptably, if not totally, free from error.
The Brown family of corpora は意図的に "comparable" となるように作られてはいるが "perfectly comparable" ではないし,そこから引き出される統計的な結論も絶対ではない.コーパス言語学で言われる一般的な注意点と同じだが,自分でコーパスを用いた研究をしていると,とかく忘れやすい.危険を伴う物品の「利用上の注意」は繰り返し喚起しておく必要があるだろう.毎回の調査結果の末尾に,呪文のように繰り返すくらいの態度が必要なのかもしれない.
コーパス利用の可能性とその他の注意点については,それぞれ[2010-04-30-1]と[2010-02-28-1], [2010-04-29-1]の記事も要参照.
・ Leech, Geoffrey and Nicholas Smith. "Recent Grammatical Change in Written English 1961--1992: Some Preliminary Findings of a Comparison of American with British English." The Changing Face of Corpus Linguistics. Ed. Antoinette Renouf and Andrew Kehoe. Amsterdam and New York: Rodopi, 2006. 185--204.
2010-06-25 Fri
■ #424. 現代アメリカ英語における wh- 関係代名詞の激減 [relative_pronoun][syntax][ame][corpus]
現代英語に起きている文法上の変化として wh- 関係代名詞が減少し,that や zero 関係代名詞が増加しているという例が挙げられる.wh- 関係詞は比較的 formal な響きを有しており,話し言葉よりも書き言葉に現れることが多いとされるが,その書き言葉においても頻度が目に見えて落ちているという.
Leech and Smith (195--96) は the Brown family of corpora を用いて英米各変種における1961年と1991/1992年の間に起こったいくつかの言語変化を調査した.調査によると,AmE では30年ほどの間に関係詞 which が34.9%減少した.それに対して,that は48.3%増加し,zero も23.1%増加した.同様に,BrE でも which は9.5%減少し,that が9%増加,zero が17.1%増加した.いずれの関係詞も,AmE のほうが BrE よりも振れ幅が大きい,つまり増減が激しいということになる.特に AmE での which の減少率が著しい.
これには,私自身も思い当たる経験がある.ちょうど1991/1992年辺りに中学・高校の学校英文法をたたきこまれた私は,関係詞 which の使用についてはドリル練習を通じて精通していた.ところが,後に英語論文を書く立場になって自信をもって which を連発したところ,アメリカ英語母語話者のネイティブチェックでことごとく which でなく that にせよと朱を入れられてしまった経験がある.それが一種のトラウマになったようで,最近は関係詞 which の使用にはかなり慎重である.自分の中で Americanisation が起こりつつあるということだろうか.
アメリカ英語では which は非限定用法にしか使われなくなりつつあるというが,ワープロソフトの校正機能もこうした傾向を助長している節がある.かつてのあのドリル練習は何だったのだろうかと改めて思わせる言語変化である.ドリルに励んでいたあの1991年の時点でもすでに限定用法としての which の衰退は方向づけられていたのに・・・.
・ Leech, Geoffrey and Nicholas Smith. "Recent Grammatical Change in Written English 1961--1992: Some Preliminary Findings of a Comparison of American with British English." The Changing Face of Corpus Linguistics. Ed. Antoinette Renouf and Andrew Kehoe. Amsterdam and New York: Rodopi, 2006. 185--204.
2010-05-13 Thu
■ #381. oft と often の分布の通時的変化 [corpus][hc]
過去二日の記事[2010-05-11-1], [2010-05-12-1]で,often という語の歴史をみた.OED によると oft に代わって often が一般化するのは16世紀以降ということだが,頻度の高い語なので Helsinki Corpus ( The Diachronic Part of the Helsinki Corpus of English Texts ) で確かめられそうだと思い,時代区分( COCOA の <C で表される part of corpus )のみをキーにしておおまかに頻度を数えてみた.時代区分の略号などはこちらのマニュアルから.
| WORD | PERIOD | oft | often |
| REGEX | /\bofte?\b/ | /\boft[ei]n\b/ | |
| OE | O1 | 0 | 0 |
| O2 | 72 | 0 | |
| OX/2 | 4 | 0 | |
| O3 | 45 | 0 | |
| O2/3 | 32 | 0 | |
| OX/3 | 106 | 0 | |
| O4 | 9 | 0 | |
| O2/4 | 8 | 0 | |
| O3/4 | 37 | 0 | |
| OX/4 | 2 | 0 | |
| ME | M1 | 67 | 0 |
| MX/1 | 20 | 0 | |
| M2 | 60 | 4 | |
| MX/2 | 9 | 1 | |
| M3 | 63 | 4 | |
| M2/3 | 15 | 0 | |
| M4 | 15 | 7 | |
| M2/4 | 3 | 0 | |
| M3/4 | 17 | 1 | |
| MX/4 | 20 | 0 | |
| EModE | E1 | 14 | 28 |
| E2 | 14 | 33 | |
| E3 | 9 | 78 |
なるほど,確かに近代英語期に入る16世紀に一気に often が広まっている.その後 oft が静かにおもむろに消えてゆく様も確認できた.この交代劇の妙にスピーディなのが気になるところである.
2010-04-30 Fri
■ #368. コーパスは研究の可能性を広げた [corpus]
昨日の記事[2010-04-29-1]では敢えてコーパスの負の側面を見たが,それは近年のコーパスが大いに英語学に貢献してきた状況へのリアクションからであり,コーパス英語学の正の側面を指摘しない限り,評価は完成しない.そこで,特に英語史研究の視点から,コーパス英語学の発展がいかに多大な好影響を与えてきたかを,家入先生による指摘ポイントを含めつつ,何点か列挙したい.
・ 散文と韻文などテキストの形式やジャンルをまたいでの比較が可能になった
・ コーパスの巨大化により,低頻度事項でも例数を集められるようになり,研究可能なテーマが広がった
・ 現代英語の研究者に通時的研究の契機を与えることとなり,英語史研究の裾野が広がった
・ コーパスでは校訂やその他の annotation がタグにより明示されるので,研究者間で共通の前提に立った議論が成り立ちやすい
・ 研究テーマについて,コーパス研究で結論の見当をつけ,次に詳細研究に進むという研究手法が可能になった
・ 定説を含めた従来の仮説をコーパスによって検証するという基盤的な研究ジャンルが開かれた
英語史研究の視点からと述べたが,他分野でも似たようなポイントは挙げられるだろう.
・ 家入 葉子 「<特集:コーパス言語学の現在>英語史研究とコーパス」 『英語青年』 2004年2月号,15-17頁.
2010-04-29 Thu
■ #367. コーパス利用の注意点 (2) [corpus]
[2010-02-28-1]の第二弾.重複することもあるが,改めてコーパス利用研究の注意点や弱点を備忘録として書き留めておきたい.いずれもコーパスやコーパス研究それ自身が悪いわけではなく,コーパス(研究)に依存しすぎると問題が生じると考えられるポイントである.
・ コーパスで研究できないことは研究しなくなる
・ コーパスで都合のよい結果が出ればそれを採用し,都合の悪い結果が出れば見て見ぬふりをする,というアドホックな態度に陥りがちになる
・ コーパスの扱いそのものが目的となってしまう傾向がある
・ コーパス研究はとりあえず数値として明確な結果が出るのでそれで満足してしまい,次の段階へ進まなくなる可能性がある
・ user-friendly なコーパス解析ツールの登場により分析の過程が black box 化されることが多く,行っている作業に無自覚・無責任になる傾向がある
最初の点について付言すると,コーパス研究が可能あるいはふさわしいテーマについては,当然,一つの方法論としてコーパス利用が検討されるべきである.頻度を数え上げるタイプの研究課題がコーパス研究に向いているというのは言わずもがなだが,それ以外にどのようなタイプの研究がコーパスに向いているのか,きちんと考えてみる必要があるだろう.例えば,文献学ではほんの一例の存在が意味をもつことが少なくないので,頻度検索ならぬ有無検索にもコーパスは力を発揮しそうだ.
2010-04-25 Sun
■ #363. 英語コーパス発展の3軸 [corpus]
『英語コーパスの初歩』によると,英語コーパスの発展は (1) 大規模化,(2) 種類の拡大,(3) 品詞標識の付与,という3軸で進んできたという.以下はその詳細.
(1) 大規模化.近代英語コーパスの祖である Brown Corpus ( The Standard Corpus of Present-Day Edited American English ) の公開されたのが1964年.約100万語からなるコーパスで,後の多くの英語コーパスがそのコーパスデザインにならった.しかし,1990年代以降は約1億語の BNC ( The British National Corpus ) や5億語を越える巨大規模の The Bank of English などが現れている.
(2) 種類の拡大.コーパスの種類の拡大は,コーパスを用いて研究できる領域や切り口の選択肢が増えてきたことを意味する.Brown Corpus の正式名称が示唆するとおり,最初期のコーパスは「現代の」「書き言葉の」「英米変種の」「標準的な」英語を対象としていた.しかし,その後「歴史的な」「話し言葉も含めた」「英米変種以外の」「非母語話者や学習者の変種も含めた」英語を視野に入れたコーパスが続々と現れた.今後も,英語学・英文学の様々な領域と切り口を反映した種々のコーパスが編纂されてゆくことだろう.
(3) 品詞標識の付与.より一般的には,annotation の種類や方法が増えてきたといえる.初期の平テキストのコーパスから,まずは品詞標識付け ( POS-Tagging ) が試みられ,続いて統語形態標識,構文解析,意味標識,音調標識なども付与されるようになってきている.これも,コーパス利用が英語学の種々の領域や理論に開かれてきたことと関連する.標識をテキストに埋め込むか,別ファイルとして提供するかという問題や,林立する annotation scheme の存在など,annotation をめぐる混乱はあるが,裏を返せば発展がそれほど著しいということだろう.
上記のコーパス発展の3軸すべての前提として,コンピュータ技術の進歩,とりわけテキスト処理技術の進展があることは間違いない.コーパス分析・開発ソフトウェアの開発,そのマニュアルや教材の出版,研究者によるコーパス使用の試行錯誤もコーパス英語学の発展を後押ししている.テキスト処理技術が今後も発展を続けるのと平行して,コーパス英語学もますます勢いを増してゆくものと思われる.このように技術の進歩にともなってコーパス英語学自体が発展してゆくことは,それ自体としてよいことである.しかし,それだけでは物足りない.やはり研究の切り口を新しく開発することで,コーパス研究を発展させてゆくのが理想なのだろうと思う.
昨日英語コーパス学会の第35回大会に参加しての所感.
・ 大門 正幸,柳 朋宏 著 『英語コーパスの初歩』 英潮社,2006年.5--6頁.
Powered by WinChalow1.0rc4 based on chalow