2012-10-31 Wed
■ #1283. 共起性の計算法 [corpus][statistics][bnc][collocation][lltest]
[2010-03-04-1]の記事「#311. girl とよく collocate する形容詞は何か」で,語と語の共起 (collocation) を測る計算法 (association measure) にはいくつかの種類があることを見た.コーパス言語学では,Log-Likelihood Test という検定にかかわる計算法が比較的よく使われているが,それぞれの計算法には特徴があるので,なるべく複数の方法を試すのがよい.今回は[2010-03-04-1]の内容と重複する部分もあるが,BNCweb で実装されている7種類の計算法の各々について Hoffmann et al. (149--58) を参照しながら,特徴および利用のヒントを示したい.
各種の計算法は,(a) 共起頻度 (frequency of co-occurrence),(b) 共起有意性 (significance of co-occurrence),(c) エフェクト・サイズ (effect-size) の1つ,あるいは複数の組み合わせに基づいている.(b) は,共起が統計的に有意であるとの確信度を表わす指標であり,共起の強さを表わすものではないことに注意する必要がある.(c) は,観察頻度と期待頻度との比を計算の基本とする指標である.
(1) Rank by frequency
観察される共起頻度そのものを用いる,最も単純で直感的な尺度.他の計算法のような複雑な統計処理はほどこされておらず,指標としては最も粗い.機能語や句読記号などが上位に来ることが多い.通常の共起分析には用いられない.
(2) Log-likelihood
共起有意性を用いる.BNCweb のデフォルトの計算法で,コーパス研究で広く用いられている.機能語や句読記号などの極めて高頻度の語との共起や,逆に極めて低頻度の語(1, 2回など)との共起をはじく傾向がある.しかし,共起頻度の高い組み合わせに高得点を与えるという特徴があり,解釈には注意を要する.
(3) Mutual information (MI)
エフェクト・サイズを用いる.非常によく用いられている計算法だが,利用に当たっては多くの注意を要する.機能語や句読記号などとのありふれた共起を効果的に排除してくれる点はよいが,反面,低頻度の共起表現への偏りが激しい.この偏りの影響を減じるために,BNCweb では "Freq(node, collocate) at least" を10以上に設定することが推奨される.これにより,"conspicuous and intuitively appealing collocations involving words of intermediate frequency" (Hoffmann et al. 154) が浮き彫りとなる.
(4) T-score
共起頻度と共起有意性を考慮する計算法.期待頻度が1以下程度の稀な共起表現については Rank by frequency と似たような振る舞いをし,頻度の高い共起表現については共起有意性を反映した振る舞いをする.また,観察頻度が期待頻度よりも必ず高くなる.Log-likelihood と類似した結果となることが多いが,高頻度へのバイアスは一層強くなる.ノードそのものが1000回を大きく下回る場合に,効果を発揮することがある.
(5) Z-score
共起有意性とエフェクト・サイズを考慮する計算法.高頻度の共起表現にはエフェクト・サイズをより重視するが,低頻度の共起表現にはそこまでエフェクト・サイズに寄りかからない.Log-likelihood と MI の両特徴を兼ね備えたような,バランスの取れた指標である.ただし,MI と同様に,低頻度の共起表現へのバイアスがみられるので,"Freq(node, collocate) at least" を5程度に設定するのがよいとされる.
(6) MI3
共起頻度とエフェクト・サイズを考慮する計算法.MI のもつ低頻度表現への偏重を取り除くべく改善されている.低頻度共起表現にはエフェクト・サイズが,高頻度共起表現には共起頻度が,比較的よく反映される.POS による限定とともに用いると効果的.複数語からなる用語などの取り出しに威力を発揮する.しかし,全体としては高頻度共起表現へのバイアスが強く,一般的な共起分析には向かない.
(7) Dice coefficient
MI3 と同様に,共起頻度とエフェクト・サイズを考慮する計算法.しかし,MI3と異なり,低頻度共起表現には共起頻度が,高頻度共起表現にはエフェクト・サイズがよく反映され,両者の切り替えが急なのが特徴的である.切り替えは,ノードそのものの頻度が共起表現の頻度の10倍ほどの点で起こるとされる.経験的に,Z-score と似たような結果が得られるが,Z-score ほど頻度に基づくバイアスが見られない.
以上のように多種類あって目移りするが,Hoffmann et al. の見解によれば,単一基準の計算法としては Log-likelihood と MI がお勧めで,混合基準の計算法としては Z-score と Dice がお勧めとのことである.
共起性の様々な計算法については,Association measures を参照.
・ Hoffmann, Sebastian, Stefan Evert, Nicholas Smith, David Lee, and Ylva Berglund Prytz. Corpus Linguistics with BNCweb : A Practical Guide. Frankfurt am Main: Peter Lang, 2008.
2012-10-26 Fri
■ #1278. BNC を中心とするコーパス研究関連のリンク集 [corpus][bnc][link][web_service][lltest]
コーパス言語学の勢いが止まらない.分野が分野だけに,関連情報はウェブ上で得られることが多く,便利なようにも思えるが,逆に情報が多すぎて,選択と判断に困る.せめて自分のためだけでも便利なリンク集をまとめておこうと思うのだが,学界のスピードについて行けない.私が最もよく用いる BNC に関連するものを中心に,断片的ではあるが,リンクを張る.リンク集をまとめる労を執るよりは,芋づる式にたどるかキーワード検索のほうが効率的という状況になりつつある・・・.
1. BNC インターフェース
・ BNCweb (要無料登録)
・ BYU-BNC (要無料登録)
・ BNC ( The British National Corpus )
2. BNC のレファレンス・ガイド
・ Quick Reference for Simple Query Syntax (PDF)
・ Reference Guide for the British National Corpus (XML Edition)
・ 上の Reference Guide の目次
* 6.5 Guidelines to the Wordclass Tagging
* The BNC Basic (C5) Tagset
* 9.8 Simplified Wordclass Tags
* 9.7 Contracted forms and multiwords
* 1 Design of the Corpus
* 9.6 Text and genre classification code
3. コーパス関連の総合サイト
・ David Lee による Bookmarks for Corpus-based Linguists
* Corpora, Collections, Data Archives
* Software, Tools, Frequency Lists, etc.
* References, Papers, Journals
* Conferences & Project
4. hellog 内の記事
・ 「#568. コーパスの定義と英語コーパス入門」: [2010-11-16-1]
・ 「#506. CoRD --- 英語歴史コーパスの情報センター」: [2010-09-15-1]
・ 「#308. 現代英語の最頻英単語リスト」: [2010-03-01-1]
・ コーパス関連記事: corpus
・ BNC 関連記事: bnc
・ COCA 関連記事: coca
5. 計算ツール
・ Corpus Frequency Wizard
・ Paul Rayson's Log-likelihood Calculator
・ VassarStats
・ hellog の「#711. Log-Likelihood Tester CGI, Ver. 2」: [2011-04-08-1]
・ Hoffmann, Sebastian, Stefan Evert, Nicholas Smith, David Lee, and Ylva Berglund Prytz. Corpus Linguistics with BNCweb : A Practical Guide. Frankfurt am Main: Peter Lang, 2008.
2011-10-28 Fri
■ #914. BNC による語彙の世代差の調査 [bnc][corpus][statistics][lltest][interjection]
昨日の記事「#913. BNC による語彙の男女差の調査」 ([2011-10-27-1]) で取りあげた Rayson et al. では,話者の性別だけでなく年齢による語彙の変異も調査されている.年齢差といっても,35歳未満か以上かで上下の世代に分けた大雑把な分類だが,結果はいくつかの興味深い示唆を与えてくれる.以下は,χ2 の上位19位までの一覧である (142--43) .
| Rank | Under 35 | Over 35 | ||
| Word | χ2 | Word | χ2 | |
| 1 | mum | 1409.3 | yes | 2365.0 |
| 2 | fucking | 1184.6 | well | 1059.8 |
| 3 | my | 762.4 | mm | 895.2 |
| 4 | mummy | 755.2 | er | 773.8 |
| 5 | like | 745.2 | they | 682.2 |
| 6 | na as in wanna and gonna | 712.8 | said | 538.3 |
| 7 | goes | 606.6 | says | 443.1 |
| 8 | shit | 410.1 | were | 385.8 |
| 9 | dad | 403.7 | the | 352.2 |
| 10 | daddy | 380.1 | of | 314.6 |
| 11 | me | 371.9 | and | 224.7 |
| 12 | what | 357.3 | to | 211.2 |
| 13 | fuck | 330.1 | mean | 155.0 |
| 14 | wan as in wanna | 320.6 | he | 144.0 |
| 15 | really | 277.0 | but | 139.0 |
| 16 | okay | 257.0 | perhaps | 136.0 |
| 17 | cos | 254.4 | that | 131.3 |
| 18 | just | 251.8 | see | 122.1 |
| 19 | why | 240.0 | had | 118.3 |
予想される通り,若い世代に特徴的なキーワードはくだけた語を多く含んでいる.表外の語も含めてだが,yeah, okay, ah, ow, hi, hey, ha, no, ooh, wow, hello などの間投詞,fucking, shit, fuck, crap, arse, bollocks などのタブー語が目立つ.しかし,若い世代のキーワードとして,一見すると予想しがたい語も挙がる.例えば,please, sorry, pardon, excuse などの丁寧語が若い世代に特徴的だという.
ほかには,若い世代に特徴的な形容詞や副詞がいくつか見られる (ex. weird, massive, horrible, sick, funny, disgusting, brilliant, really, alright, basically) .評価を表わす形容詞・副詞が多く,一種の流行とみなすことができる語群だろう.年齢差を "apparent time" の差と考えれば,そこには "real time" の変化が示唆されることになるので,この語群の通時的な頻度の増加を探るのもおもしろそうだ.
・ Rayson, Paul, Geoffrey Leech, and Mary Hodges. "Social Differentiation in the Use of English Vocabulary: Some Analyses of the Conversational Component of the British National Corpus." International Journal of Corpus Linguistics 2 (1997): 133--52.
2011-10-27 Thu
■ #913. BNC による語彙の男女差の調査 [bnc][corpus][statistics][lltest][interjection][gender_difference]
標題の話題を扱った Rayson et al. の論文を読んだ.BNC の中で,人口統計的な基準で分類された,話し言葉を収録したサブコーパス(総語数4,552,555語)を対象として,語彙の男女差,年齢差,社会的地位による差を明らかにしようとした研究である.これらの要因のなかで,語彙的変異が統計的に最も強く現われたのは性による差だったということなので,本記事ではその結果を紹介したい.
まず,以下に挙げる数値の解釈には前提知識が必要なので,それに触れておく.BNC に収録された話し言葉は志願者に2日間の自然な会話を Walkman に吹き込んでもらった上で,それを書き起こしたものであり,その志願者の内訳は男性73名,女性75名である.会話に登場する志願者以外の話者についても,女性のほうが多い.したがって,当該サブコーパスへの参加率でいえば,全体として女性が男性よりも高くなることは不思議ではない.
しかし,その前提を踏まえた上でも,全体として女性のほうがよく話すということを示唆する数値が出た.使用された word token 数でいえば,男性を1.00とすると女性が1.51,会話の占有率では,男性を1.00とすると女性は1.33だった.男女混合の会話では男性のほうが高い会話占有率を示すとする先行研究があるが,BNC のサブコーパスでは女性同士の会話が多かったということが,上記の結果の背景にあるのかもしれない.いずれにせよ,興味深い数値であることは間違いない.
次に,より細かく語彙における男女差を見てみよう.男女差の度合いの高いキーワードを抜き出す手法は,原理としては[2010-03-10-1], [2010-09-27-1], [2011-09-24-1]の記事で紹介したのと同じ手法である.男性コーパスと女性コーパスを区別し,それぞれから作られた語彙頻度表を突き合わせて統計的に処理し,カイ二乗値 (χ2) の高い順に並び替えればよい.以下は,上位25位までの一覧である (136--37) .
| Rank | Characteristically male | Characteristically female | ||
| Word | χ2 | Word | χ2 | |
| 1 | fucking | 1233.1 | she | 3109.7 |
| 2 | er | 945.4 | her | 965.4 |
| 3 | the | 698.0 | said | 872.0 |
| 4 | year | 310.3 | n't | 443.9 |
| 5 | aye | 291.8 | I | 357.9 |
| 6 | right | 276.0 | and | 245.3 |
| 7 | hundred | 251.1 | to | 198.6 |
| 8 | fuck | 239.0 | cos | 194.6 |
| 9 | is | 233.3 | oh | 170.2 |
| 10 | of | 203.6 | Christmas | 163.9 |
| 11 | two | 170.3 | thought | 159.7 |
| 12 | three | 168.2 | lovely | 140.3 |
| 13 | a | 151.6 | nice | 134.4 |
| 14 | four | 145.5 | mm | 133.8 |
| 15 | ah | 143.6 | had | 125.9 |
| 16 | no | 140.8 | did | 109.6 |
| 17 | number | 133.9 | going | 109.0 |
| 18 | quid | 124.2 | because | 105.0 |
| 19 | one | 123.6 | him | 99.2 |
| 20 | mate | 120.8 | really | 97.6 |
| 21 | which | 120.5 | school | 96.3 |
| 22 | okay | 119.9 | he | 90.4 |
| 23 | that | 114.2 | think | 88.8 |
| 24 | guy | 108.6 | home | 84.0 |
| 25 | da | 105.3 | me | 83.5 |
必ずしもこの25位までの表からだけでは読み取れないが,Rayson et al. (138--40) によれば以下の点が注目に値するという.
・ "four-letter words",数詞,特定の間投詞は男性に特徴的である (ex. shit, hell, crap; hundred, one, three, two, four; er, yeah, aye, okay, ah, eh, hmm)
・ 女性人称代名詞,1人称代名詞,特定の間投詞は女性に特徴的である (ex. she, her, hers; I, me, my, mine; yes, mm, really) (男性代名詞の使用には特に男女差はない)
・ the や of の使用は男性に多い(男性に一般名詞を用いた名詞句の使用が多いという別の事実と関連するか?)
・ 固有名詞,代名詞,動詞は女性に多い(男性の事実描写 "report" の傾向に対する女性の関係構築 "rapport" の傾向の現われか?)
・ 固有名詞のなかでも,人名は女性の使用が多く,地名は男性の使用が多い.
他のコーパスによる検証が必要だろうが,この結果と解釈に興味深い含蓄があることは確かである.
キーワードの統計処理と関連して,コーパス言語学でカイ二乗検定の代用として広く使用されるようになってきた Log-Likelihood 検定については,自作の Log-Likelihood Tester, Ver. 1 や Log-Likelihood Tester, Ver. 2 を参照.
・ Rayson, Paul, Geoffrey Leech, and Mary Hodges. "Social Differentiation in the Use of English Vocabulary: Some Analyses of the Conversational Component of the British National Corpus." International Journal of Corpus Linguistics 2 (1997): 133--52.
2011-04-08 Fri
■ #711. Log-Likelihood Tester CGI, Ver. 2 [corpus][bnc][statistics][web_service][cgi][lltest]
以下に,汎用の Log-Likelihood Tester, Ver. 2 を公開.(後に説明するように,入力データのフォーマットに不備がある場合や,モードが適切に選択されていない場合にはサーバーでエラーが生じる可能性があるので注意.)
[2011-03-25-1]の記事で,コーパス研究でよく用いられる対数尤度検定 ( Log-Likelihood Test ) の計算機 Log-Likelihood Tester, Ver. 1 を公開した.Ver. 1 は,コーパスサイズを加味しながら2つのコーパスでのキーワード(群)の出現頻度を比べ,コーパス間の差が有意であるかどうかを検定するものだった.
Log-Likelihood Test は上述の目的で用いることが多いと思い,Ver. 1 ではあえて機能を特化させたのだが,より一般的に複数行,複数列の分割表で与えられるデータに対応する対数尤度検定を行ないたい場合もある.例えば,昨日の記事[2011-04-07-1]で,現代英語における though と although の出現傾向について BNC に基づいた調査を紹介したが,Text Domain ごとの頻度比率は,両語の間で統計的にどの程度一致している,あるいは一致していないとみなすことができるのだろうか.昨日のグラフから,although は学術散文に多く,though は創作散文に多いという傾向が一目瞭然だが,この直感的な「一目瞭然」は統計的にはどのように表現されるのだろうか.
このような場合には,次のような頻度表(値は100万語当たりの出現頻度に標準化済み)を準備し,これをコピーして入力ボックスに貼り付ける."lump mode" にチェックを入れ替え,"Go!" する.(デフォルトは "each-line mode" で,これは Ver. 1 と同等のモード.)
| though | although | |
|---|---|---|
| Natural and pure sciences | 56.3 | 80.13 |
| Applied science | 37.36 | 68.31 |
| World affairs | 45.81 | 68.2 |
| Social science | 48.98 | 63.38 |
| Commerce and finance | 46.18 | 57.21 |
| Arts | 74.07 | 52.93 |
| Leisure | 45.85 | 49.46 |
| Belief and thought | 70.78 | 46.75 |
| Imaginative prose | 80.2 | 26.37 |
結果は,1行だけの表として出力される.though と although を表わす2列の数値の並びが,統計的にどのくらい近似しているかを計算している.結論としては,両語の Text Domain ごとの頻度の並びの差は p < 0.0001 という非常に高いレベルで有意であり,両語の出現傾向は Text Domain によってほぼ確実に異なるといえる.
入力ボックスに入れるデータの書式は,タブ区切りの分割表.表頭と表側はいずれも省略可.サンプルのように表頭と表側の両方を含める場合には,左上のセルは空白にしておく必要あり.
"each-line mode" の機能は Ver. 1 と互換なので,入力形式もそちらの説明を参照.今回の Ver. 2 の "each-line mode" では,出力結果をシンプルにおさえてある(逆に,詳しい内部計算値を得たい場合には Ver. 1 のほうが有用).
Log-Likelihood Test の概要については,[2011-03-24-1]の記事を参照.
2011-04-07 Thu
■ #710. though と although の語法の差 (2) [bnc][corpus][lltest][conjunction][statistics]
昨日の記事[2011-04-06-1]で,though と although の語法の差に触れた.今日も同じ話題で.
4000万語超からなる The Longman Spoken and Written English Corpus (the LSWE Corpus) を駆使した現代英語の文法書,Biber et al. (845--46) では次のようにある.
Both of these subordinators [though and although] occur in all four registers [conversation, fiction, news, and academic prose], although the registers show different preferences of use. Conversation and fiction show a slightly greater use of though (concessive clauses are, however, uncommon in conversation generally). News shows no particular preference. In academic prose, although is about three times as frequent as though. Although seems to have a slightly more formal tone to it, fitting the style of academic prose . . . . The greater use of although by writers of academic prose may also result from an attempt to distinguish this subordinator from the common use of though as a linking adverbial in conversation . . . .
また,同書の p. 842 の表からは,相対的に though が fiction で多く,although は academic prose で多いことが確認される.ジャンルによる差が現われているとの結果だ.
このような先行研究を受けて,今回は BNC ( The British National Corpus ) によりこれを確かめてみる.BNCweb で,{although/CONJ}, {though/CONJ} をそれぞれ検索し,Written/Spoken, Text Domain, Sex of Author/Speaker, Perceived Level of Difficulty など様々なパラメータで出現分布を分析した.主立った結果を以下に示そう(数値データはこのページのHTMLソースを参照).
まず,Written/Spoken の差については,予想されるとおり,両語とも Written への偏りが激しい(差異係数は though で 0.66344 ,although で 0.49770 で,明らかに書き言葉に偏る).Log-Likelihood Test では,p < 0.0001 のレベルで書き言葉と話し言葉の有意差が明確に示された.
書き手,話し手の性による差も興味深い.書き言葉と話し言葉の両方で,although は有意差をもって男性の使用に偏っている.though については,性差は although ほど顕著ではない(ただし書き言葉では p < 0.05 で有意差あり).
次に,Text Domain 別に頻度をみる.9種類の Text Domain を区別した ( Natural and pure sciences, Applied science, World affairs, Social science, Commerce and finance, Arts, Leisure, Belief and thought, Imaginative prose ) .100万語当たりの出現回数に標準化した値で,両語の Text Domain 別頻度をグラフ化したのが以下の図だ.
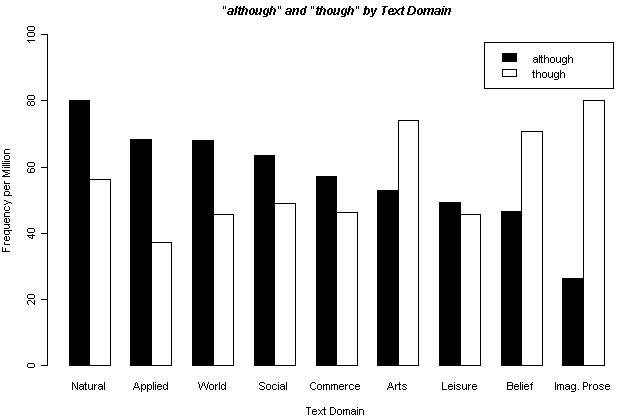
Text Domain によって両語の出現頻度に対照的な傾向が見られることがわかる.相対的に sciences ( = academic prose ) に although が目立ち,Imag(inative) Prose ( = fiction ) に though が多い.Log-Likelihood Test では,Text Domain による出現傾向の差は p < 0.0001 で有意である.
直感的にも先行研究の結果からも予想され得たことではあるが,although は男性の書き手により学術散文で顕著に用いられるという図式が現われた.
・ Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad, and Edward Finegan. Longman Grammar of Spoken and Written English. Harlow: Pearson Education, 1999.
2011-03-25 Fri
■ #697. Log-Likelihood Tester CGI [corpus][bnc][statistics][web_service][cgi][lltest][sociolinguistics]
昨日の記事[2011-03-24-1]で Log-Likelihood Test を話題にした.計算には Rayson 氏の Log-likelihood calculator を利用すればよいと述べたが,実際の検定の際に作業をもう少し自動化したいと思ったので CGI を自作してみた.細かい不備はあると思うが,とりあえず公開.
上のテキストボックスに入力すべきデータは,タブ区切りの表の形式.1行目(省略可)はコーパス名,2行目以降はキーワードと観察頻度数(ヒット数),最終行は各コーパスのサイズ(語数)."#" で始まる行はコメント行として無視される.1列目のキーワード列は省略可.
以下のテキストが入力サンプル.[2010-09-11-1]の記事で取り上げたテレビ広告で頻用される形容詞(比較級と最上級を含む)トップ20の頻度を,BNCweb の話し言葉サブコーパスから話者の性別に整理した表である.このままコピーして入力ボックスに貼り付けると,出力結果が確認できる.
BNC_Male_Speakers BNC_Female_Speakers new 149 91 good 408 310 free 173 75 fresh 84 118 delicious 12 34 full 210 107 sure 532 328 clean 197 223 wonderful 270 258 special 177 82 crisp 10 16 fine 347 215 big 470 415 great 203 96 real 163 80 easy 326 157 bright 113 110 extra 347 203 safe 182 92 rich 120 45 #-------- corpus_size 4949938 3290569
男女間で有意差の特に大きいのは,対応行が赤で塗りつぶされた fresh, delicious, clean, wonderful, big で,いずれも期待度数に基づいて計算された Diff_Co ( "Difference Coefficient" 「差異係数」 ) がマイナスであることから,女性に特徴的な形容詞ということになる.big は意外な気がしたが,おもしろい結果である.一方,男性に偏って有意差を示すのは黄色で示した easy や rich である.この結果はいろいろと読み込むことができそうだし,より詳細に調べることもできる.広告の形容詞という観点からは,話者ではなく聞き手の性別,年齢,社会階級などを軸に調査してもおもしろそうだ.いろいろと応用できる.
2011-03-24 Thu
■ #696. Log-Likelihood Test [corpus][bnc][statistics][lltest]
[2010-03-04-1]の記事で触れたが,コーパス言語学では各種の統計手法が用いられる.いくつかある手法のなかでも,ある表現のコーパス間の頻度を比較したり,collocation の度合いを測るのに広く用いられているのが Log-Likelihood Test ( LL Test, G Test, G2 Test などとも)呼ばれる検定である.コーパスサイズを考慮に入れた検定なのでサイズの異なるコーパス間での比較が可能であり,同じ目的で以前によく用いられていたカイ2乗検定 ( Chi-Squared Test ) よりもいくつかの点ですぐれた手法と評価されており,最近のコーパス研究では広く用いられている.(例えば,カイ2乗検定は期待頻度が5回より少ないとき,高頻度語を扱うとき,コーパスサイズが大きいものと小さいものを比較するときに信頼性が低くなるが,Log-Likelihood Test はこれらの影響を受けにくい [ Rayson and Garside 2 ] .)
Log-Likelihood Test の基本的な考え方は,コーパスサイズをもとにある表現の期待される出現頻度(期待頻度)を割り出し,その値と実際に出現する頻度(観察頻度)の差が単純な誤差と考えられるほどに近似しているかどうかを判定するというものである.例として,次のようなケース・スタディを試す.BNC ( The British National Corpus ) から話し言葉サブコーパスと書き言葉サブコーパスを区別し,両サブコーパス間で f*ck という four-letter word の頻度を比較する.BNCweb よりこのキーワードを検索すると,次のような結果が得られた.
| Category | No. of words | No. of hits | Dispersion (over files) | Frequency per million words |
|---|---|---|---|---|
| Spoken | 10,409,858 | 579 | 63/908 | 55.62 |
| Written | 87,903,571 | 743 | 172/3,140 | 8.45 |
| total | 98,313,429 | 1,322 | 235/4,048 | 13.45 |
統計処理をほどこすまでもなく最右列 "Frequency per million words" を見れば,f*ck が圧倒的に話し言葉で多く用いられることが分かるが,今回はこれを統計的に裏付ける.まず,帰無仮説として「話し言葉サブコーパスと書き言葉サブコーパスの間での f*ck の頻度差は誤差の範囲内であり,この語に関して両者に意味のある差はない」を設定する.その対立仮説は「話し言葉サブコーパスと書き言葉サブコーパスの間での f*ck の頻度差は誤差の範囲内でなく,この語に関して両者の差は意味がある」となる.帰無仮説が支持されるかどうかを決めるのが,検定の目的である.
| Corpus 1 | Corpus 2 | Total | |
|---|---|---|---|
| Frequency of word | a | b | a+b |
| Frequency of other words | c-a | d-b | c+d-a-b |
| Total | c | d | c+d |
Log-Likelihood Test に用いる Log-Likelihood ratio 「対数尤度比」は,上の表の要領で各サブコーパスの総語数 ( c, d ) と,各サブコーパスでの f*ck の頻度数 ( a, b ) を分割表にまとめた上で,それぞれの期待頻度 E1 と E2 を下の (1) の式で求め,その値を (2) の式に代入して求める.
(1) E1 = c*(a+b)/(c+d); E2 = d*(a+b)/(c+d)
(2) LL = 2*((a*log(a/E1))+(b*log(b/E2)))
f*ck の数値で計算すると,以下のようになる.
E1 = 10409858*(579+743)/(10409858+87903571) = 139.979170861796
E2 = 87903571*(579+743)/(10409858+87903571) = 1182.0208291382
LL = 2*((579*log(579/139.979170861796))+(743*log(743/1182.0208291382))) = 954.2115
Log-likelihood ratio として 954.2115 という値が算出される.次にこの値を,適切な有意水準(通常は 5%, 1%, 0.1%)に対応するカイ二乗値と比較する.2 * 2 の分割表に対する計算では自由度1のカイ二乗値を用いることになっており,その値は有意水準 5%, 1%, 0.1% の順にそれぞれ 3.84, 6.63, 10.83 である.954.2115 の Log-Likelihood ratio は有意水準 0.1% に対応する 10.83 よりもずっと高いので,0.1% の有意水準で帰無仮説は棄却される.言い換えれば,統計的には帰無仮説が真である確率は 0.1% にも満たず,まず偽と考えてよいということである.このようにして対立仮説「話し言葉サブコーパスと書き言葉サブコーパスの間での f*ck の頻度差は誤差の範囲内でなく,この語に関して両者の差は意味がある」が採択されることになる.
Log-Likelihood Test は以上のように進められるが,この検定を行なうにあたっての前提条件を知っておく必要がある.一般には,計算される期待頻度が 5 を下回るセルが1つでもある場合には,検定の精度は落ちるとされる.これは the Cochran rule と呼ばれているが,よりきめ細かなルールを提起した Rayson, Berridge, and Francis (8) によれば,期待頻度が満たすべき最低値は有意水準 5% で13 回,1% で 11 回,0.1% で 8 回だという.有意水準を 0.01% に設定すれば期待頻度 1 回にも耐える精度を得られるので,Rayson et al. はコーパス言語学で慣習的に用いられている3つの水準に加えて,0.01% の水準(対応するカイ二乗値は 15.13 )までの検定を推奨している.
統計には詳しくないが,ある表現の 2(サブ)コーパス間での頻度比較というシーンで簡単に用いることができる検定として,Log-Likelihood Test の応用範囲は広そうだ.計算自体は Rayson 氏の Log-likelihood calculator などに任せればよい(本記事はこのページの記述とリンク先の論文を参考にした).
BNC を用いた f*ck 関連語の分布の研究は,McEnery et al. (264--86) のケース・スタディに詳しい.
関連して,検定は行なわなかったが,かつて本ブログで扱った gorgeous の調査 ([2010-08-16-1], [2010-08-17-1],[2010-12-25-1]) なども参照.
・ Rayson, P., D. Berridge , and B. Francis. "Extending the Cochran Rule for the Comparison of Word Frequencies between Corpora." Le poids des mots: Proceedings of the 7th International Conference on Statistical Analysis of Textual Data (JADT 2004), Louvain-la-Neuve, Belgium, March 10-12, 2004. Ed. Purnelle G., Fairon C., and Dister A. Louvain: Presses universitaires de Louvain, 2004. 926--36. Available online at http://www.comp.lancs.ac.uk/computing/users/paul/publications/rbf04_jadt.pdf .
・ Rayson, P. and R. Garside. "Comparing Corpora Using Frequency Profiling". Proceedings of the Workshop on Comparing Corpora, Held in Conjunction with the 38th Annual Meeting of the Association for Computational Linguistics (ACL 2000), 1-8 October 2000, Hong Kong. 2000. 1--6. Available online at http://www.comp.lancs.ac.uk/computing/users/paul/phd/phd2003.pdf .
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
Powered by WinChalow1.0rc4 based on chalow