2016-06-07 Tue
■ #2598. 古ノルド語の影響力と伝播を探る研究において留意すべき中英語コーパスの抱える問題点 [old_norse][loan_word][me_dialect][representativeness][geography][lexical_diffusion][lexicology][methodology][laeme][corpus]
「#1917. numb」 ([2014-07-27-1]) の記事で,中英語における本来語 nimen と古ノルド語借用語 taken の競合について調査した Rynell の研究に触れた.一般に古ノルド語借用語が中英語期中いかにして英語諸方言に浸透していったかを論じる際には,時期の観点と地域方言の観点から考慮される.当然のことながら,言語項の浸透にはある程度の時間がかかるので,初期よりも後期のほうが浸透の度合いは顕著となるだろう.また,古ノルド語の影響は the Danelaw と呼ばれるイングランド北部・東部において最も強烈であり,イングランド南部・西部へは,その衝撃がいくぶん弱まりながら伝播していったと考えるのが自然である.
このように古ノルド語の言語的影響の強さについては,時期と地域方言の間に密接な相互関係があり,その分布は明確であるとされる.実際に「#818. イングランドに残る古ノルド語地名」 ([2011-07-24-1]) や「#1937. 連結形 -son による父称は古ノルド語由来」 ([2014-08-16-1]) に示した語の分布図は,きわめて明確な分布を示す.古英語本来語と古ノルド語借用語が競合するケースでは,一般に上記の分布が確認されることが多いようだ.Rynell (359) 曰く,"The Scn words so far dealt with have this in common that they prevail in the East Midlands, the North, and the North West Midlands, or in one or two of these districts, while their native synonyms hold the field in the South West Midlands and the South."
しかし,事情は一見するほど単純ではないことにも留意する必要がある.Rynell (359--60) は上の文に続けて,次のように但し書きを付け加えている.
This is obviously not tantamount to saying that the native words are wanting in the former parts of the country and, inversely, that the Scn words are all absent from the latter. Instead, the native words are by no means infrequent in the East Midlands, the North, and the North West Midlands, or at least in parts of these districts, and not a few Scn loan-words turn up in the South West Midlands and the South, particularly near the East Midland border in Essex, once the southernmost country of the Danelaw. Moreover, some Scn words seem to have been more generally accepted down there at a surprisingly early stage, in some cases even at the expense of their native equivalents.
加えて注意すべきは,現存する中英語テキストの分布が偏っている点である.言い方をかえれば,中英語コーパスが,時期と地域方言に関して代表性 (representativeness) を欠いているという問題だ.Rynell (358) によれば,
A survey of the entire material above collected, which suffers from the weakness that the texts from the North and the North (and Central) West Midlands are all comparatively late and those from the South West Midlands nearly all early, while the East Midland and Southern texts, particularly the former, represent various periods, shows that in a number of cases the Scn words do prevail in the East Midlands, the North, and the North (and sometimes Central) West Midlands and the South, exclusive of Chaucer's London . . . .
古ノルド語の言語的影響は,中英語の早い時期に北部・東部方言で,遅い時期には南部・西部方言で観察される,ということは概論として述べることはできるものの,それが中英語コーパスの時期・方言の分布と見事に一致している事実を見逃してはならない.つまり,上記の概論的分布は,たまたま現存するテキストの時間・空間的な分布と平行しているために,ことによると不当に強調されているかもしれないのだ.見えやすいものがますます見えやすくなり,見えにくいものが隠れたままにされる構造的な問題が,ここにある.
この問題は,古ノルド語の言語的影響にとどまらず,中英語期に北・東部から南・西部へ伝播した言語変化一般を観察する際にも関与する問題である (see 「#941. 中英語の言語変化はなぜ北から南へ伝播したのか」 ([2011-11-24-1]),「#1843. conservative radicalism」 ([2014-05-14-1])) .
関連して,初期中英語コーパス A Linguistic Atlas of Early Middle English (LAEME) の代表性について「#1262. The LAEME Corpus の代表性 (1)」 ([2012-10-10-1]),「#1263. The LAEME Corpus の代表性 (2)」 ([2012-10-11-1]) も参照.
・ Rynell, Alarik. The Rivalry of Scandinavian and Native Synonyms in Middle English Especially taken and nimen. Lund: Håkan Ohlssons, 1948.
2016-05-24 Tue
■ #2584. 歴史英語コーパスの代表性 [representativeness][corpus][methodology][hc][register]
コーパスの代表性 (representativeness) や均衡 (balance) の問題については,「#1280. コーパスの代表性」 ([2012-10-28-1]) その他の記事で扱ってきた.古い時代の英語のコーパスを扱う場合には,現代英語コーパスに関する諸問題がそのまま当てはまるのは当然のことながら,それに上乗せしてさらに困難な問題が多く立ちはだかる.
まず,歴史英語コーパスという話題以前の問題として,コーパスの元をなす母集合のテキスト集合体そのものが,歴史の偶然により現存しているものに限られるという制約がある.碑文,写本,印刷本,音声資料などに記されて現在まで生き残り,保存されてきたものが,すべてである.また,これらの資料は存在することはわかっていても,現実的にアクセスできるかどうかは別問題である.現実的には,印刷あるいは電子形態で出版されているかどうかにかかっているだろう.それらの資料がテキストの母集合となり,運よく編纂者の選定にかかったその一部が,コーパス(主として電子形態)へと編纂されることになる.こうして成立した歴史英語コーパスは,数々の制約をかいくぐって,ようやく世に出るのであり,この時点で理想的な代表性が達成されている見込みは,残念ながら薄い.
また,歴史英語とひとくくりに言っても,実際には現代英語と同様に様々な lects や registers が区分され,その区分に応じてコーパスが編纂されるケースが多い.確かに,ある意味で汎用コーパスと呼んでもよい Helsinki Corpus のような通時コーパスや,統語情報に特化しているが異なる時代をまたぐ Penn Parsed Corpora of Historical English もあるし,使い方によっては通時コーパスとしても利用できる OED の引用文検索などがある.しかし,通常は,編纂の目的や手間に応じて,より小さな範囲のテキストに絞って編纂されるコーパスが多い.古英語コーパスや中英語コーパスなど時代によって区切ること (chronolects) もあれば ,イギリス英語やアメリカ英語などの方言別 (dialects) の場合もあるし,Chaucer や Shakespeare など特定の作家別 (idiolects) の場合もあろう.社会方言 (sociolects) 別というケースもあり得るし,使用域 (registers) に応じてコーパスを編纂するということもあり得る.使用域といっても,談話の場(ジャンルや主題),媒体(話し言葉か書き言葉か),スタイル(形式性)などに応じて,下位区分することもできる.一方,分類をあまり細かくしてしまうと,上述のように現存するテキストの量が有限であり,たいてい非常に少なかったり分布が偏っているわけだから,代表性や均衡を保つことがなおのこと困難となる.
時代別 (chronolects) の軸を中心にすえて近年の比較的大規模な歴史英語コーパスの編纂状況を概観してみると,各時代の英語の辞書・文法・方言地図のような参考資料の編纂と関連づけて編纂されたものがいくつかあることがわかる.これらは,各時代の基軸コーパスとして位置づけられるといってよいかもしれない.例えば,Dictionary of Old English Corpus (DOEC), A Linguistic Atlas of Early Middle English (LAEME), Middle English Grammar project (MEG) 等である.近代についてはコーパスというよりはテキスト・データベースというべき EEBO (Early English Books Online) も利用可能となってきているし,アメリカ英語については Corpus of Historical American English (COHA) 等の試みもある.
上に挙げた代表的で著名なもののほか,様々な切り口からの歴史英語コーパス編纂の企画が続々と現われている.その逐一については,「#506. CoRD --- 英語歴史コーパスの情報センター」 ([2010-09-15-1]) で紹介した,Helsinki 大学の VARIENG ( Research Unit for Variation, Contacts and Change in English ) プロジェクトより CoRD ( Corpus Resource Database ) を参照されたい.
ハード的にいえば,上述のように,歴史英語コーパスの代表性を巡る問題を根本的に解決するのは困難ではあるが,一方で個別コーパスの編纂は活況を呈しており,諸制約のなかで進歩感はある.今ひとつはソフト的な側面,使用者側のコーパスに対する態度に関する課題もあるように思われる.電子コーパスの時代が到来する以前にも,歴史英語の研究者は,時間を要する手作業ながらも紙媒体による「コーパス」の編纂,使用,分析を常に行なってきたのである.彼らも,私たちが意識しているほどではなかったものの,ある程度はコーパスの代表性や均衡といった問題を考えてきたのであり,解決に至らないとしても,有益な研究を継続し,知見を蓄積してきた.電子コーパス時代となって代表性や均衡の問題が目立って取り上げられるようになったが,確かにその問題自体は大切で,考え続ける必要はあるものの,明らかにしたい言語現象そのものに焦点を当て,コーパスを便利に使いこなしながらその研究を続けてゆくことがより肝要なのではないか.
2016-03-22 Tue
■ #2521. 初期中英語の113種類の "such" の異綴字 [spelling][eme][laeme][corpus][scribe][me_dialect][representativeness]
昨日の記事「#2520. 後期中英語の134種類の "such" の異綴字」 ([2016-03-21-1]) に続き,今回は初期中英語コーパス LAEME で "such" の異綴字を取り出してみたい (see 「#1262. The LAEME Corpus の代表性 (1)」 ([2012-10-10-1])) .この語は,初期中英語では形容詞,副詞,接続詞として用いられ,形容詞の場合には屈折もするので,全体として様々な形態が現われる.アルファベット順に一覧しよう(かっこ内の数値は文証される頻度).
hsƿucche (1), schilke (1), schuc (3), scli (1), scuche (1), sec (1), secc (1), secche (1), sech (2), seche (1), selk (1), selke (1), shuc (1), shuch (1), siche (1), silc (1), silk (3), sli (1), slic (5), sliik (1), slik (3), slike (1), slk (1), sly (1), soch (5), soche (1), solchere (1), suc (2), sucche (2), such (51), suche (1), suecche (1), suech (1), sueche (1), sueh (1), sug (1), suic (1), suicchne (1), suich (12), suiche (3), suilc (14), suilce (1), suilch (1), suilk (1), suilke (2), sulch (1), sulche (1), sulk (1), sulke (1), suuche (1), suweche (1), suwilk (1), suyc (1), suych (4), suyche (1), svich (2), sƿche (1), sƿic (3), sƿicche (1), sƿich (1), sƿiche (14), sƿichne (1), sƿilc (30), sƿilch (22), sƿilche (1), sƿilcne (1), sƿilk (14), sƿillc (10), sƿillke (2), sƿi~lch (1), sƿlche (1), sƿuc (4), sƿucch (1), sƿucche (4), sƿucches (1), sƿuch (1), sƿuche (1), sƿuchne (1), sƿuilc (1), sƿulc (8), sƿulce (1), sƿulche (9), swch (1), swecche (1), swech (1), sweche (2), swich (5), swiche (1), swics (1), swil (1), swilc (5), swilce (1), swilk (2), swilke (2), swilkee (2), swlc (1), swlch (1), swlche (1), swlchere (1), swlcne (1), swuche (2), swuh (1), swulcere (1), swulch (3), swulchen (1), swulchere (1), swulke (1), swulne (1), zuich (10), zuiche (14), zuichen (3), zuych (10), zuyche (2)
大文字と小文字の区別はつけずに,合計113種類の綴字が文証される.そのなかで頻度にしてトップ5の綴字を抜き出すと,such, sƿilc, sƿilch, sƿilk, sƿiche となり,この5種類だけで全用例369個のうち131個 (35.5%) を占める.
昨日の後期中英語からの134種類と合わせ,重複綴字を減算すると,中英語全体として247種類の異綴字があることになる.使用した方言地図やコーパスも必ずしも網羅的ではないので,これは控えめな数値と思われる.例えば,MED の swich (adj.) に掲げられている異綴字を加えれば,種類はもう少し増えるだろう.
2016-03-21 Mon
■ #2520. 後期中英語の134種類の "such" の異綴字 [spelling][lme][lalme][corpus][scribe][me_dialect][frequency]
「#53. 後期中英語期の through の綴りは515通り」 ([2009-06-20-1]),「#219. eyes を表す172通りの綴字」 ([2009-12-02-1]) に引き続き,英語史における著しい綴字の変異について.今回は,異綴字の種類の多さに定評のある(?) "such" を取り上げる.
「#1622. eLALME」 ([2013-10-05-1]) で紹介した,後期中英語の方言地図 LALME の改訂・電子版 eLALME において,Item List 10 が "such" を扱っている.この一覧から異綴字を抜き出すと,不確かな例を除いて少な目に数えても,以下の134種類が挙がる(かっこ内の数値は文証される頻度).
asoche (1), aswyche (1), schch (1), schech (1), scheche (3), schiche (1), schoche (1), scht (1), schuc (1), schuch (3), schuche (4), schut (1), schute (1), sclik (2), sclike (1), sclyk (2), sclyke (2), scoche (1), scwche (1), sech (8), seche (39), sewyche (2), shich (1), shiche (1), shoch (1), shoche (1), shuch (5), shuche (3), shych (1), sic (6), sic- (1), sich (53), siche (101), sick (1), sɩͨh (1), sik (1), sik- (1), sike (2), silk (3), sli (1), slieke (1), slik (10), slike (26), slilk (2), slkyke (1), slyk (13), slyke (26), soch (12), soche (60), souche (3), sowche (2), soyche (1), squike (1), squilk (2), squylk (1), sqwych (1), sqwyche (1), sswiche (1), suc (1), succh (1), sucche (5), such (242), suche (375), suchee (1), sucheȝ (1), suchet (1), sucht (1), suchte (1), suech (4), sueche (6), suhc (1), suhe (1), suich (9), suiche (7), suilk (6), suilk- (1), suilke (3), suilkin (1), sulc (1), sulk (4), sulke (2), sutche (1), suth (1), suuch (1), suuche (1), suuech (1), suueche (1), suych (13), suyche (15), suylk (7), suylke (6), svche (1), sviche (1), swc (1), swch (7), swche (4), swech (19), sweche (48), swelk (4), swhiche (2), swhilke (2), swhych (2), swhyche (1), swic (2), swich (77), swiche (84), swichee (1), swilc (3), swilk (76), swilke (45), swilkes (1), swisɩͨhe (1), swlk (1), swlke (1), swuch (3), swuche (2), swych (56), swyche (65), swyeche (1), swyk (1), swyke (1), swyl (1), swylk (62), swylke (35), swylle (1), syc- (1), sych (23), syche (67), syge (1), syk (4), syk- (1), syke (5), sylk (3), sylke (2)
方言の別を度外視して頻度の統計を取ると,トップ10が suche, such, siche, swiche, swich, swilk, syche, swyche, swylk, soche である.トップの2種類 suche と such は現代英語を見慣れている者にとって,十分常識的にみえるだろう.実際,この2種類だけで617例が文証され,総1867例のほぼ3分の1を占める.また,トップの10種類だけで,ほぼ3分の2を占める.したがって,異綴字がこれだけ多くあるからといって,そのまま完全なる混沌に等しい,ということにはならない.このような事情は,中英語期に多種類の綴字が認められる多くの語について認められ,混沌のなかにもある程度の秩序らしきものがが宿っているといえる.そうだとしても,当時の書き手と読み手にとってはやはり不便な状況だったに違いない.この点については,「#1311. 綴字の標準化はなぜ必要か」 ([2012-11-28-1]),「#1450. 中英語の綴字の多様性はやはり不便である」 ([2013-04-16-1]) で論じた通りである.
初期中英語や近現代の諸方言形を調べれば,もっと異綴字の種類は増すだろう.出典は失念したが,数え方にもよるものの,500種類ほどという数字を見かけたことがある・・・.
2015-10-16 Fri
■ #2363. hapax legomenon [hapax_legomenon][terminology][lexicology][lexicography][word_formation][productivity][bible][zipfs_law][frequency][corpus][shakespeare][chaucer]
昨日の記事「#2362. haplology」 ([2015-10-15-1]) でギリシア語の haplo- (one, single) に触れたが,この語根に関連してもう1つ文献学や辞書学の用語としてしばしば出会う hapax (legomenon) を取り上げよう.ある資料のなかで(タイプ数えではなくトークン数えで)1度しか用いられていない語(句)を指す.ギリシア語の hapax (once) + legomenon (something said) からなる複合語だ.複数形は hapax legomena という.
"nonce word" を hapax legomenon と同義としている辞書もあるが,前者は「臨時語」と訳され「その時限りに用いる語」を指す.nonce-word は新語の臨時的な生産性を念頭に用いられることが多いのに対し,hapax legomenon は文献に現われる回数が1度であることに焦点が当てられているという違いが感じられる.nonce (その場限りの)という語の語源については,「#1306. for the nonce」 ([2012-11-23-1]) を参照.
hapax legomenon は,聖書の注釈との関連で,しばしば言及されてきた歴史がある.OED によると英語における初例は1692年のことで,"J. Dunton Young-students-libr. 242/1 There are many words but once used in Scripture, especially in such a sence, and are called the Apax legomena." とある.
文献学や語源学において,hapax legomenon はしばしば問題となる.その語の語源はおろか,意味すら不明であることが少なくない.語彙論や辞書学では,それを一人前の「語」として認めてよいのか,何かの間違いではないか,辞書に掲載すべきか否か,という頭の痛い問題がある (see 「#912. 語の定義がなぜ難しいか (3)」 ([2011-10-26-1])) .一方で,語形成やその生産性という観点からは,hapax legomenon は重要な考察対象となる.というのは,1度だけ臨時的に出現するためには,話者の生産的な語形成機構が前提とされなければならないからである (see 「#938. 語形成の生産性 (4)」 ([2011-11-21-1])) .
だが,実際のところ halax legomenon は決して少なくない.このことは,ジップの法則に照らせば驚くべきことではないだろう (see 「#1101. Zipf's law」 ([2012-05-02-1]), 「#1103. GSL による Zipf's law の検証」 ([2012-05-04-1])) .英語の例としては,Chaucer の用いたnortelrye (education) や Shakespeare の honorificabilitudinitatibus, また Dickens の sassigassity (audacity?) などが挙げられる.
2015-09-26 Sat
■ #2343. 19世紀における a lot of の爆発 [clmet][corpus][lmode][agreement][3pp][syntax][reanalysis]
「#2333. a lot of」 ([2015-09-16-1]) で,現代英語で極めて頻度の高いこの句限定詞 (phrasal determiner) の歴史が,たかだか200年余であることをみた.19世紀に入るまでは,この句における lot は「一山,一組;集団,一群」ほどの語義で用いられており,その後,ようやく「多数;多量」の語義が生じたということだった.そこで,後期近代英語期における a lot of と lots of の例を確認すべく,CLMET3.0 で例文を拾ってみた.(検索結果のテキストファイルはこちら.)
第1期 (1710--1780) のサブコーパス(10,480,431語)からは4例がヒットしたが,いずれも「多数の?」を意味する句としては用いられていない.a lot of my own drawing では「多数」ではなく「一山」の語義として用いられており,"Annuities for lives have occasionally been granted in two different ways; either upon separate lives, or upon lots of lives" では明らかに「集団」の語義だろう.しかし,最初の例などでは,語義が「多数」へと発展していきそうな雰囲気は感じられる.
第2期 (1780--1850) のサブコーパス(11,285,587語)からは22例が得られた.予想通り,問題の用法で使われているものがちらほらと現われ出す.いくつかの例文を挙げよう.
・ You know when a lot of servants gets together they like to talk about their betters; and some, for a bit of swagger, likes to make it appear as though they knew more than they do, and to throw out hints and things just to astonish the others. (Anne Brontë, The Tenant of Wildfell Hall (1848))
・ There’ll be lots to speak for her! (ibid.)
・ . . . there's a high fender, and an iron safe, and some cards about ships that are going to sail, and an almanack, and some desks and stools, and an inkbottle, and some books, and some boxes, and a lot of cobwebs, . . . (Charles Dickens, Dombey and Son (1844))
・ . . . I ran on through a lot of alleys and back-slums, until I got somewhere in St. Giles's, and here I took a cab. (Punch, Vol. 1 (1841))
a lot of の数の一致が判断できる例文は少なかったが,上の第1の例文が興味深い.主語の a lot of servants に対して gets と受けているが,この動詞の -s 語尾は,後続する some . . . likes から判断しても,複数主語に一致する複数現在の -s と考えるのが妥当だろう(複現の -s については 3pp の各記事を参照).
第3期 (1850--1920) のサブコーパス(12,620,207語)からは,表現の頻度自体が大幅に増え,384例がヒットした.lot(s) が旧来の語義で用いられている例も少々みられるが,基本的には現代英語並と疑われるほど普通に「多数の?」の意味で用いられている.1800年前後に初出し,その後数十年で一気に広まった流行語法であることがわかる.
2015-09-21 Mon
■ #2338. 16世紀,hem, 'em 不在の謎 (2) [personal_pronoun][emode][corpus][eebo][punctuation][apostrophe]
昨日の記事 ([2015-09-20-1]) に引き続いての話題.16世紀に hem, 'em が不在,あるいは非常に低頻度という件について,EEBO (Early English Books Online) のテキストデータベースを利用して,簡易検索してみた.検索結果は,動詞 hem を含め,相当の雑音が混じっており,丁寧に除去する手間は取っていないものの,16世紀からの例は確かに極端に少ないことがわかった.
16世紀前半からの明確な例は,Andrew Boorde, The pryncyples of astronamye (1547) に現われる "doth geue influence to hem the which be borne vnder this signe" の1例のみである.16世紀前半の300万語ほどのサブコーパスのなかで,極めて珍しい.'em に至っては,16世紀後半のサブコーパスも含めても例がない.
16世紀後半のサブコーパスでも,hem の例は少々現われるとはいえ,さして状況は変わらない.F. T., The debate betweene Pride and Lowlines (1577) なるテキストにおいて "for they doon hem blame", "For which hem thinketh they should been aboue" などと生起したり,Joseph Hall, Certaine worthye manuscript poems of great antiquitie reserued long in the studie of a Northfolke gentleman (1597) という当時においても古めかしい詩のなかで何度か現われたりする程度である.
一方,17世紀サブコーパスの検索結果一覧をざっと眺めると,hem の頻度が著しく増えたという印象はないが,'em が見られ始め,ある程度拡張している様子である.後者の 'em の出現は,アポストロフィという句読記号自体の拡大が17世紀にかけて進行したことと関係するだろう (see 「#582. apostrophe」 ([2010-11-30-1])) .
hem, 'em の歴史的継続性という議論については,問題の16世紀にもかろうじて用例が文証されるということから,継続性を認めてよいだろうとは考える.口語ではもっと頻繁に用いられていただろうという推測も,おそらく正しいだろう.しかし,なぜ文章の上にほとんど反映されなかったのかという疑問は残るし,17世紀以降に復活してきた際に,すでに共時的には them の省略形と解釈されていた可能性についてどう考えるかという問題も残る.この話題は,いまだ謎といってよい.
2015-09-19 Sat
■ #2336. Text Analyser --- 簡易テキスト統計分析器 [cgi][text_tool][web_service][corpus]
最近では,テキスト分析のための高機能なツールが手軽に入手できるようになった.英語コーパスを分析するプログラムなどでは,使用語数に基づいて様々な統計値が計算され,見やすい形で提示される.そのようなツールを改めて公開する必要もないといえばないが,簡易テキスト統計分析器の CGI を作成してみたので,ここに hellog 版ということで設置しておきたい.テキストボックスに文章を投げ込むだけ.
背後では Perl モジュール Lingua::EN::Fathom を使用しているが,語や文の認識や音節カウントなど,自動では完全解決の難しい問題も多くあるため,結果としての統計値は近似的なものとして理解されたい.今回のバージョンでは,以下の14の統計値を示すことにした.
(1) Number of characters
(2) Number of words (tokens)
(3) Number of types
(4) Type/token ratio
(5) Per cent of complex words
(6) Average syllables per word
(7) Number of sentences
(8) Average words per sentences
(9) Number of text lines
(10) Number of blank lines
(11) Number of paragraphs
(12) Fog index
(13) Flesch reading ease score
(14) Flesch-Kincaid grade level score
多くの統計値の意味は自明と思われるが,いくつかについて注記しておく.(4) Type/token ratio は,語彙の多様性を示す指標である.テキスト内のすべての語が各々1度きり現われる場合には,最大値 1.0 を示す.ただし,テキストの長さに大きく依存するため,この指標単体ではさほど情報量はない.
(5) Per cent of complex words の "complex words" とは,3音節以上の語の割合である.(12), (13), (14) は,テキストの読みやすさの指標であり,いずれも1文あたりの語数 (words_per_sentence) と1語あたりの音節数 (syllables_per_word) に基づいて計算されている.各指標の特徴と解釈の仕方を以下に略述する.
(12) The Fog index
読みやすさを表わす簡便な指標.( words_per_sentence + percent_complex_words ) * 0.4 で求めることができる.指標の数値は学年を表わし,その学年の標準的な生徒であれば,その文章を一度読んで理解できる水準といわれる.目安としては,8 = childish, 10 = acceptable, 12 = ideal, 14 = difficult, 18 = unreadable.
(13) The Flesch reading ease score
206.835 - (1.015 * words_per_sentence) - (84.6 * syllables_per_word) で求められる.最高点は100点で,指標が高ければ高いほど理解しやすいテキストである.60--70点が最適とされる.
(14) Flesch-Kincaid grade level score
(11.8 * syllables_per_word) + (0.39 * words_per_sentence) - 15.59 で求められる.指標は米国の学年を表わし,例えば 8.0 であれば,そのテキストは第8学年の生徒に理解できる水準ということになる.7.0--8.0 が最適値とされる.
2015-09-15 Tue
■ #2332. EEBO のキーワードを抽出 [eebo][lob][corpus][keyword][text_tool][emode]
コーパスからキーワードを拾うという分析を,「#317. 拙著で自分マイニング(キーワード編)」 ([2010-03-10-1]),「#518. Singapore English のキーワードを抽出」 ([2010-09-27-1]),「#880. いかにもイギリス英語,いかにもアメリカ英語の単語」 ([2011-09-24-1]) で紹介してきた.今回は初期近代英語を中心的に扱うテキスト・データベース EEBO (Early English Books Online) より,キーワードを拾ってみたい.
EEBO から個人的に収集した初期近代英語のテキスト集(全11億語以上)に対し,WordSmith の KeyWords 抽出機能を用いた.参照コーパスとしては,現代イギリス英語を代表するものとして LOB コーパスを指定した.本来は参照コーパスのほうがずっと大規模ではなければならないのだが,EEBO が大きすぎるということで,今回は目をつぶっておきたい.狙いは,現代英語と比べて使用頻度の著しく高い初期近代英語の語を拾い出すということである.当時の社会を特徴づける語彙が集まるはずである.
キーワード性を示す指標の高い順に,500語までのリストがたちどころに得られた.いずれも小文字で示す.
[ Top 100 ]
amp, note, god, and, that, hath, them, christ, shall, haue, thou, they, thy, so, all, our, not, their, upon, doth, vnto, of, unto, his, king, yet, or, hee, eacute, vs, ye, him, lord, thee, which, bee, doe, saith, men, onely, but, vpon, be, nor, de, c, gods, by, faith, holy, great, church, your, o, as, selfe, wee, owne, ad, con, est, things, then, such, therefore, himselfe, may, y, to, sin, grace, cause, tis, us, mr, ther, kings, thereof, let, spirit, man, al, vp, yea, any, this, ac, s, pro, ing, com, thus, e, against, forth, re, shew, whom, l, wherein
[ -- 200 ]
loue, ly, selves, scripture, self, law, st, those, thing, cor, sinne, being, glory, euery, death, good, sonne, true, neuer, whereof, iohn, againe, psal, pope, religion, ed, hym, soule, hast, lib, ex, heaven, agrave, whiche, pray, neither, downe, acirc, tion, quod, my, sed, fore, soul, nature, euen, dayes, is, p, apostles, euer, till, feare, chap, ver, rom, vnder, ma, qui, vse, according, giue, power, ouer, mans, egrave, lesse, se, doctrine, ne, ment, meanes, themselues, shal, d, sins, viz, prince, did, vertue, wicked, honour, earth, ut, blessed, princes, ter, apostle, th, persons, que, thinke, same, others, lords, ought, pag, truth, none, kingdome
[ -- 300 ]
tho, si, cap, goe, if, beene, flesh, et, christs, make, fathers, concerning, reason, body, mercy, selues, enemies, bishops, farre, v, bishop, ar, hearts, wil, likewise, other, rome, name, obedience, en, wise, cum, speake, finde, nay, iesus, we, conscience, manner, non, heart, sinnes, it, yt, hauing, saints, generall, mat, contrary, worke, wit, sayd, whereby, covenant, wherefore, gen, passe, poore, lorde, publick, word, mens, suffer, na, heare, mee, ei, heb, divers, christians, therein, theyr, minde, shalt, bloud, shewed, certaine, vers, un, son, amongst, ibid, ca, jesus, betwixt, quae, scriptures, say, divine, thine, rest, countrey, besides, di, heauen, cannot, qu, therfore, godly, sent
[ -- 400 ]
m, moses, these, christian, called, n, vn, false, should, paul, also, discourse, meane, without, booke, whence, shee, emperour, souls, place, thereby, yeares, tyme, lawes, peace, what, dis, behold, foure, citie, giuen, israel, anno, liberty, thence, gospel, cast, ograve, aboue, souldiers, tooke, sa, priests, gaue, fol, maketh, places, pardon, te, warre, saviour, wayes, saint, thinges, will, themselves, kinde, suche, bene, love, salvation, yeare, towne, spirituall, esse, fa, duke, majesty, brethren, laws, alwayes, workes, ab, lest, for, wrath, wordes, soules, done, sunt, angels, vel, ry, liue, ted, ty, looke, repentance, dr, beare, prayer, keepe, faire, ii, parts, helpe, iudge, no, churches, r
[ -- 500 ]
dy, vsed, prophet, outward, ble, ap, spake, sect, armes, notwithstanding, come, h, naturall, maner, crosse, popes, sayth, pa, papists, whatsoever, gospell, iudgement, writ, noble, hoc, par, sacrifice, dye, worship, ons, af, eternal, leaue, ob, euill, am, sacrament, diuers, both, ghost, quam, lye, yee, comming, secondly, how, iustice, sword, daies, father, vi, before, prayers, bodie, whome, councell, nec, though, faithfull, lawe, humane, aut, wel, mi, hir, iii, worthy, isa, easie, ugrave, nowe, lawfull, ere, seene, priest, glorious, serue, commanded, earle, forme, thither, eternall, prophets, turne, iewes, mo, im, halfe, matth, manifest, wilt, are, words, iust, betweene, affections, ocirc, li, ned, creatures
対象としたのは EEBO から収集した平テキストであり,そこには多くの注記やタグも含まれている.それを除去するなどの特別なテキスト処理は施していないので,雑音も相当混じっていることに注意したい.実際,1位の amp はタグの一部であり,2位の note も注記を表わす記号と考えてよいので,いずれも無視すべきだが,ここではキーワード抽出結果をそのまま提示することにした.
現代でも高頻度語ではあるが,初期近代では綴字が異なる hath, haue, doth, hee, vs, bee などが上位に来ることは理解できるだろう.また,現代では古風となっている2人称単数代名詞 thou, thy, thee の顕著なことも理解できる.
おもしろいのは,現在でも現役ではあるが,それほど顕著ではなくなっている語である.例えば,リストの上位にキリスト教的な語が多いことに気づく.200位以内に限ってざっと拾うだけでも,god, christ, gods, faith, holy, church, grace, spirit, loue, scripture, sinne, glory, death, pope, religion, soule, heaven, pray, soul, apostles, vertue, wicked, honour, blessed, apostle などが挙がる.チューダー朝,スチュアート朝ともに,キリスト教に翻弄され続けた時代だったことも関係するだろう.逆にいえば,現代がいかに世俗化したか,ということでもある.
綴字としては,無音の <e> の自由な付加・脱落,<u> と <v> 及び <i> と <j> の混在,shall の顕著な使用,ye の残存などが挙げられるだろう (see 「#373. <u> と <v> の分化 (1)」 ([2010-05-05-1]),「#374. <u> と <v> の分化 (2)」 ([2010-05-06-1]); 「#1650. 文字素としての j の独立」 ([2013-11-02-1])) .また,現在では堅苦しい機能語も多い (ex. upon, vnto, nor, therefore, thereof, whereof) .
2015-09-07 Mon
■ #2324. n-gram [corpus][information_theory][coca][bnc][google_books][statistics][n-gram][collocation][frequency][link]
情報理論や自然言語処理の分野で用いられる n-gram という分析手法がある.コーパス言語学でもすでにお馴染みの概念であり,共起表現 (collocation) の研究などでは当たり前のように用いられるようになった.種々のコーパスのインターフェースにおいても採用されており,「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) では名前に含まれているほどだし,本ブログでも COCA (Corpus of Contemporary American English) の N-gram データベースを用いて「#956. COCA N-Gram Search」 ([2011-12-09-1]) を実装してきた(その応用は,「#953. 頭韻を踏む2項イディオム」 ([2011-12-06-1]),「#954. 脚韻を踏む2項イディオム」 ([2011-12-07-1]),「#955. 完璧な語呂合わせの2項イディオム」 ([2011-12-08-1]) を参照).BNC では,Explore Words and Phrases from the BNC が利用できる.
コンピュータを用いた分析手法というと難しそうに聞こえるが,n-gram の考え方は至って単純である.文字レベルの 2-gram (bigram) を考えてみよう.最長の英単語といわれる pneumonoultramicroscopicsilicovolcanoconiosis (「#63. 塵肺症は英語で最も重い病気?」 ([2009-06-30-1])) を例にとる.まず,先頭の2文字1組の pn を取り出す.次に,2文字目に進んで同じように ne を取り出す.3文字目に進んで eu を,4文字目に進んで um を得る.同じように,1文字ずつ右にずらしながら,最後の is まで2文字1組を次々と拾っていく.これで44組の2文字を得たことになる.この組のなかで,ic と co という組み合わせは各々3回起こり,os, si, no, on の組み合わせは各々2回現われ,それ以外の組み合わせはいずれも1度きりである.したがって,この単語において最高頻度の2文字1組は ic と co となる.
n-gram の単位は,このように文字である必要はなく,音素でもよいし,より大きな単位である形態素や語でもよく,さらに大きな句などのより大きな単位でもよい.英語コーパス言語学では,語という単位で考えるのが普通だろう.Martin Luther King, Jr. の I Have a Dream の演説のテキストで語単位の 4-gram を取ると,最も多い4語の組み合わせは,予想通り "I have a dream" の8回だが,"will be able to" も同じく8回現われる."Let freedom ring from" も7回とよく現われる,等々の分析が可能となる.ここでは4語という「窓」を設定したので 4-gram と呼ばれるが,隣接するいくつの文字を考慮するかにより 1-gram (unigram), 2-gram (bigram), 3-gram (trigram),そして 5-gram 以上ももちろん考えることができる(1-gram の場合,得られるリストは,事実上各語の生起頻度表である).
巨大コーパスから得られた 2-gram や 3-gram の一覧は,それ自体が共起表現の研究などでは基本データとなるため,ウェブ上でもいろいろと公開されている.日本語では「N-gram コーパス - 日本語ウェブコーパス 2010」があるし,現代英語では COCA の n-gram データベース がある.また,Bigram Plus では,歴史英語コーパスを含めた各種英語コーパスから N-Gram Search を行なえる機能を提供している.ほかにも任意のテキストやコーパスを対象に n-gram を取る各種のツールやソフトも,ウェブ上で入手可能だ.
n-gram 分析の言語分野への応用範囲は広い.次に来る語(音,文字)は何か,という予測可能性とも関係が深いため,機械による音声認識,統語分析,言語判定,自動翻訳,スペルチェック,剽窃探知,全文検索用インデックスの作成などに活用される.もちろん,共起表現の研究では,基本にして不可欠の手段となっている.一方,n-gram はもっぱら言語として表面化されたテキストを対象とし,深層にある構造にまったく触れることがないため,生成文法のような言語理論の方面からは批判があるようだ.詳しくは,n-gram in Wikipedia を参照.
n-gram は工夫次第で,まだまだ使い道がありそうだ.歴史英語テキストにも,応用していきたい.
(後記 2015/09/12(Sat): Sketch Engine より N-grams も参照.)
2015-05-22 Fri
■ #2216. 研究社Webマガジンの記事「コーパスで探る英語の英米差 ―― 実践編 ――」 [link][corpus][bnc][coca][ame_bre][sociolinguistics][language_change][gender_difference][link]
一ヶ月前の「#2186. 研究社Webマガジンの記事「コーパスで探る英語の英米差 ―― 基礎編 ――」」 ([2015-04-22-1]) に引き続き,5月20日付で「実践編」が公開されました.研究社WEBマガジン Lingua リンガより,こちらをご覧ください. *
今回は,複数のコーパスを用いることの利点やおもしろさを押し出しました.また,英語の英米差という一見すると静的な話題にも,動的あるいは通時的に迫ることにより,新たな見方が得られる点も強調しました.
記事のなかでも触れましたが,実際には今回の「実践編」で述べた結論に至るには,もっと詳しく調査しなければなりません.しかし,コーパスを用いて,例えばこのような言語変化の徴候をとらえることができるかもしれないという可能性を感じ取ってもらえれば,という気持ちで執筆しました.基礎編,実践編で私の執筆担当は完結ですが,来月以降も引き続き研究社WEBマガジン Lingua リンガの記事にご注目ください.バックナンバーも非常に有用です.以下,改めて研究社WEBマガジン Lingua リンガの各記事へのリンク(最新版)を張っておきます.
1. なぜコーパスか? (赤須 薫)
2. 英語コーパス体験ツアー ― BNCweb を検索してみる ―(前編) (石井 康毅)
3. 英語コーパス体験ツアー ― BNCweb を検索してみる ―(後編) (石井 康毅)
4. Google をコーパスに見立てる (仁科 恭徳)
5. 言語統計の基礎(前編) ― 頻度差の検定 ― (小林 雄一郎 )
6. 言語統計の基礎(後編) ― 共起尺度 ― (小林 雄一郎)
7. コーパスを活用した古くて新しい学問領域:フレイジオロジー ― 理論編 ― (井上 亜依)
8. コーパスを活用した古くて新しい学問領域:フレイジオロジー ― 実践編 ― (井上 亜依)
9. 学習者コーパスとは何か? (鎌倉 義士)
10. 学習者コーパスで何ができるのか? (鎌倉 義士)
11. パラレルコーパスの可能性 (仁科 恭徳)
12. 日本語コーパスに見られる慣用句の用法 (石田 プリシラ)
13. 日本語コーパスに見られる慣用句の変化可能性 (石田 プリシラ)
14. COCA を使ったコロケーションの検索 (内田 諭)
15. COCA を使った類義語の検証 (内田 諭)
16. コーパスで話し言葉を探る ― 基礎編 ― (青木 理香)
17. コーパスで話し言葉を探る ― 実践編 ― (青木 理香)
18. 学習者の話し言葉コーパスを使った語用論分析 (1)談話標識 well, I mean, kind of, like の使い方 (三浦 愛香)
19. 学習者の話し言葉コーパスを使った語用論分析 (2)買い物での要求の表現 (三浦 愛香)
20. 認知言語学を用いてコーパスから意味を探る― 入門編 ― (大谷 直輝)
21. 認知言語学を用いてコーパスから意味を探る― 前置詞・句動詞編 ― (大谷 直輝)
22. コーパスで探る英語の英米差 ―― 基礎編 ―― (堀田 隆一)
23. コーパスで探る英語の英米差 ―― 実践編 ―― (堀田 隆一)
なお,今回の実践編で注目した gorgeous に関しては,本ブログでも以下の記事で扱ってきましたのでご参照ください.
・ 「#476. That's gorgeous!」 ([2010-08-16-1])
・ 「#477. That's gorgeous! (2)」 ([2010-08-17-1])
・ 「#607. Google Books Ngram Viewer」 ([2010-12-25-1])
また,英語(言語)の男女差についても gender_difference の各記事で扱ってきました.特に言語の男女差とコーパス利用を絡めた記事として,「#913. BNC による語彙の男女差の調査」 ([2011-10-27-1]) をご覧ください.
2015-04-22 Wed
■ #2186. 研究社Webマガジンの記事「コーパスで探る英語の英米差 ―― 基礎編 ――」 [link][corpus][brown][ame_bre]
4月20日付けで,研究社WEBマガジン Lingua リンガのリレー連載 実践で学ぶコーパス活用術に,私の執筆した「コーパスで探る英語の英米差 ―― 基礎編 ――」の記事が掲載されました.今日は,このリレー連載と私の記事について紹介します. *
連載「実践で学ぶコーパス活用術」はコーパス利用初心者向けのオムニバス記事で,毎月様々な言語学研究者が登場し,易しくかつ実践的にコーパス活用の方法を解説してゆくシリーズです.すでに20の記事が掲載されており,コーパスの基本から始まり,各種のコーパスの紹介,利用のコツ,事例研究,言語統計入門に至るまで,コーパスに関連する様々な視点が丁寧に解説されています.以下に,各記事へのリンクを張っておきます.
1. なぜコーパスか? (赤須 薫)
2. 英語コーパス体験ツアー ― BNCweb を検索してみる ―(前編) (石井 康毅)
3. 英語コーパス体験ツアー ― BNCweb を検索してみる ―(後編) (石井 康毅)
4. Google をコーパスに見立てる (仁科 恭徳)
5. 言語統計の基礎(前編) ― 頻度差の検定 ― (小林 雄一郎 )
6. 言語統計の基礎(後編) ― 共起尺度 ― (小林 雄一郎)
7. コーパスを活用した古くて新しい学問領域:フレイジオロジー ― 理論編 ― (井上 亜依)
8. コーパスを活用した古くて新しい学問領域:フレイジオロジー ― 実践編 ― (井上 亜依)
9. 学習者コーパスとは何か? (鎌倉 義士)
10. 学習者コーパスで何ができるのか? (鎌倉 義士)
11. パラレルコーパスの可能性 (仁科 恭徳)
12. 日本語コーパスに見られる慣用句の用法 (石田 プリシラ)
13. 日本語コーパスに見られる慣用句の変化可能性 (石田 プリシラ)
14. COCA を使ったコロケーションの検索 (内田 諭)
15. COCA を使った類義語の検証 (内田 諭)
16. コーパスで話し言葉を探る ― 基礎編 ― (青木 理香)
17. コーパスで話し言葉を探る ― 実践編 ― (青木 理香)
18. 学習者の話し言葉コーパスを使った語用論分析 (1)談話標識 well, I mean, kind of, like の使い方 (三浦 愛香)
19. 学習者の話し言葉コーパスを使った語用論分析 (2)買い物での要求の表現 (三浦 愛香)
20. 認知言語学を用いてコーパスから意味を探る― 入門編 ― (大谷 直輝)(←2015/05/18(Mon)にリンクを追加)
21. 認知言語学を用いてコーパスから意味を探る― 前置詞・句動詞編 ― (大谷 直輝)(←2015/05/18(Mon)にリンクを追加)
22. コーパスで探る英語の英米差 ―― 基礎編 ―― (堀田 隆一)
23. コーパスで探る英語の英米差 ―― 実践編 ―― (堀田 隆一)(←2015/05/21(Thu)にリンクを追加)
今回私の書いた記事は,コーパスを用いて英語の英米差について考えようという趣旨で,みかけは現代イギリス英語と現代アメリカ英語の共時的比較ですが,2変種を比較対照するに当たっては歴史的な背景や通時的な視点も欠かせないということを強調しています.今回は「基礎編」と銘打って,英語の英米差を論じるに当たっての準備事項を説明し,英米差の調査に利用できるコーパスを紹介しています.
以下,今回のリレー連載の記事と合わせて読むと有用と思われる本ブログ内の記事にリンクを張ります.ほかにもコーパス利用については corpus の記事,英語の英米差については ame_bre の記事もご参照ください.
・ 「#1730. AmE-BrE 2006 Frequency Comparer」 ([2014-01-21-1])
・ 「#1739. AmE-BrE Diachronic Frequency Comparer」 ([2014-01-30-1])
・ 「#1743. ICE Frequency Comparer」 ([2014-02-03-1])
・ 「#428. The Brown family of corpora の利用上の注意」 ([2010-06-29-1])
・ 「#607. Google Books Ngram Viewer」 ([2010-12-25-1])
・ 「#517. ICE 提供の7種類の地域変種コーパス」 ([2010-09-26-1])
・ 「#1278. BNC を中心とするコーパス研究関連のリンク集」 ([2012-10-26-1])
・ 「#307. コーパス利用の注意点」 ([2010-02-28-1])
・ 「#367. コーパス利用の注意点 (2)」 ([2010-04-29-1])
・ 「#368. コーパスは研究の可能性を広げた」 ([2010-04-30-1])
・ 「#240. 綴字の英米差は大きいか小さいか?」 ([2009-12-23-1])
・ 「#244. 綴字の英米差のリスト」 ([2009-12-27-1])
・ 「#312. 文法の英米差」 ([2010-03-05-1])
・ 「#315. イギリス英語はアメリカ英語に比べて保守的か」 ([2010-03-08-1])
・ 「#357. American English or British English?」 ([2010-04-19-1])
・ 「#627. 2変種間の通時比較によって得られる言語的差異の類型論」 ([2011-01-14-1])
・ 「#628. 2変種間の通時比較によって得られる言語的差異の類型論 (2)」 ([2011-01-15-1])
・ 「#677. 現代英語における法助動詞の衰退」 ([2011-03-05-1])
・ 「#880. いかにもイギリス英語,いかにもアメリカ英語の単語」 ([2011-09-24-1])
・ 「#1010. 英語の英米差について Martinet からの一言」 ([2012-02-01-1])
・ 「#1221. 季節語の歴史」 ([2012-08-30-1])
・ 「#1304. アメリカ英語の「保守性」」 ([2012-11-21-1])
・ 「#1331. 語彙の英米差を整理するための術語」 ([2012-12-18-1])
・ 「#1343. 英語の英米差を整理(主として発音と語彙)」 ([2012-12-30-1])
今回のリレー連載記事は「基礎編」でしたが,来月号は「実践編」を掲載する予定です.
2015-01-22 Thu
■ #2096. SUBTLEX-US Word Frequency List [frequency][statistics][corpus][lexicology][zipfs_law][cgi][web_service]
従来の英語学研究において,権威ある語彙頻度表といえばアメリカ英語に関する Kucera and Francis (1967) のものや,イギリス英語に比重を置いたより新しいものとして CELEX (1993) やその2版 (cf. 「#1424. CELEX2」 ([2013-03-21-1])) がよく用いられてきた.しかし,最近,これらを批判し,新しい手法に基づいたアメリカ英語の語彙頻度表が現われた.ベルギー,ヘント大学の実験心理学科の提供する SUBTLEXus である.左のHPから,SUBTLEXus の一群の頻度表のファイルや記述がダウンドーロできる.
SUBTLEXus の基盤にあるコーパスは,8388件の映画の字幕の集成であり,総語数は5100万語に及ぶ.SUBTLEXus の頻度表は,Kucera and Francis や CELEX の頻度表と比べて,いくつかの算出された指標においてすぐれていると主張されている.頻度は,見出し語 (lemma) ごとではなく語形 (word form) ごとに数えられており,例えば名詞であれば単数形と -s 語尾などをもつ複数形は別扱いされる(異なる語形は74,286種類).名詞と動詞など複数の品詞として用いられる語形については,それぞれの品詞ごとの頻度にもアクセスできるし,より優勢な品詞 (Dominant POS) のほうへ合算した頻度へもアクセスできる.データには,ほかに何件の映画に現われているか,小文字として現われているのは何回か,頻度の対数を取った指標,Zipf 指標 (cf. 「#1101. Zipf's law」 ([2012-05-02-1])) なども含まれている.これだけの種類のデータが含まれていると,目的とアイデア次第でおおいに有効に利用できるだろう.話し言葉ベースであることも顕著な特徴だ.
ダウンロードできるいくつかのデータのなかで "a zipped Excel file of SUBTLEX-US with the Zipf values included" をダウンロードし,少しいじってみた.例えば,(1) 全体的に多く現われ,かつ (2) 多くの映画にも現われる語形は,総合的な意味で頻度が高いと考えられるだろう.そこで (1) と (2) に関する対数の指標を掛け合わせて,それを降順に並べて最初の100語を取ると,正真正銘の最頻単語100語が得られるはずだ.省略形の片割れなども含まれているが,以下がそのリストである.
you, I, the, to, s, a, it, t, that, and, of, what, in, me, is, we, this, he, on, for, my, m, your, don, have, do, re, no, be, know, was, not, can, are, all, with, just, get, here, but, there, ll, so, they, like, right, out, go, up, about, she, if, him, got, at, now, come, oh, one, how, well, want, yeah, her, think, good, see, let, did, why, who, as, going, his, will, from, when, back, time, yes, look, d, take, an, where, man, would, them, been, some, or, tell, us, had, were, say, could, gonna, didn, hey
ほかには,最頻10語,25語,50語,100語,250語,500語,1,000語,2,500語,5,000語,10,000語,25,000語,50,000語,100,000語について,Dominant POS ごとに数え上げてみることもたやすい.「#666. COCA 最頻5000語で品詞別の割合は?」 ([2011-02-22-1]),「#667. COCA 最頻50万語で品詞別の割合は?」 ([2011-02-23-1]),「#1132. 英単語の品詞別の割合」 ([2012-06-02-1]) の記事でも,別のコーパスにより似たような調査を行ったが,SUBTLEX-US 版の調査結果は次のグラフにまとめられる.
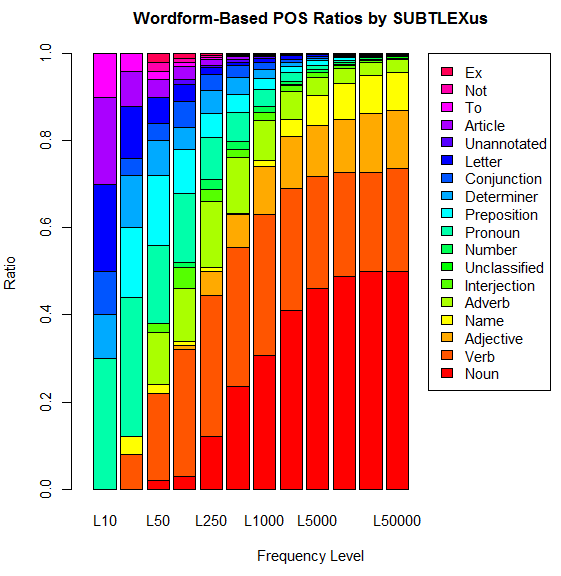
以下はおまけの検索ツール (SUBTLEX-US Word Frequency Extractor) .おまけなので,10例までしか結果が出力されない仕様です.SUBTLEXus の提供する複雑な検索も可能な,SUBTLEXus Online Search もどうぞ.
2014-12-28 Sun
■ #2071. <dispatch> vs <despatch> [spelling][johnson][corpus][clmet]
標記の語の綴字は,前者の <dispatch> が標準的とされるが,特にイギリス英語では後者の <despatch> も用いられる.辞書では両方記載されているのが普通で,後者が特に非標準的であるという記述はない.しかし,規範家のなかには後者を語源的な観点から非難する向きもあるようだ.この問題について Horobin (230--31) は次のように述べている.
The preference for dispatch over despatch is similarly debatable, given that despatch is recorded as an alternative spelling for dispatch by the OED. The spelling dispatch is certainly to be preferred on etymological grounds, since its prefix derives from Latin dis-; the despatch spelling first appeared by mistake in Johnson's Dictionary. However, since the nineteenth century despatch has been in regular usage and continues to be widely employed today. Given this, why should despatch not be used in The Guardian? In fact, a search of this newspaper's online publication shows that occurrences of despatch do sneak into the paper: while dispatch is clearly the more frequent spelling (almost 14,000 occurrences when I carried out the search), there were almost 2,000 instances of the proscribed spelling despatch.
引用にあるとおり,事の発端は Johnson の辞書の記述らしい.確かに Johnson は見出し語として <despatch> を掲げており,語源欄ではフランス語 depescher を参照している.しかし,この接頭辞の母音はロマンス諸語では <i> か <e> かで揺れていたのであり,Johnson の <e> の採用を語源に照らして "mistake" と呼べるかどうかは疑問である.もともとラテン語ではこの語は文証されていないし,イタリア語では dispaccio,フランス語では despeechier などの綴字が行われていた.英語の綴字を決める際にどの語源形が参照されたかの問題であり,正誤の問題ではない.また,Johnson は辞書以外の自らの著作においては一貫して <dispatch> を用いており,いわば二重基準の綴り手だったことを注記しておきたい.
<despatch> の拡大の背景に Johnson の辞書があったということは,実証することは難しいものの,十分にありそうだ.後期近代英語コーパス CLMET3.0 で70年ごとに区切った3期における両系統の綴字の生起頻度を取ってみると,次のように出た.
| Period (subcorpus size) | <dispatch> etc. | <despatch> etc. |
|---|---|---|
| 1710--1780 (10,480,431 words) | 403 | 354 |
| 1780--1850 (11,285,587) | 145 | 267 |
| 1850--1920 (12,620,207) | 67 | 263 |
この調査結果が示唆するのは,当初は <dispatch> が比較的優勢だったものの,時代が下るにつれ相対的に <despatch> が目立ってくるという流れだ.すでに18世紀中に両綴字は肉薄していたようだが,同世紀半ばの Johnson の辞書が契機となって <despatch> がさらに勢いを得たという可能性は十分にありそうだ.
20世紀の調査はしていないが,おそらく,いかにもラテン語風の接頭辞を示す <dispatch> の綴字を標準的とする規範意識が働き始め,<despatch> の肩身が狭くなってきたという顛末ではないだろうか.
・ Horobin, Simon. Does Spelling Matter? Oxford: OUP, 2013.
2014-12-02 Tue
■ #2045. なぜ mayn't が使われないのか? (2) [auxiliary_verb][negative][clitic][corpus][emode][lmode][eebo][clmet][sobokunagimon]
昨日の記事「#2044. なぜ mayn't が使われないのか? (1)」 ([2014-12-01-1]) に引き続き,標記の問題.今回は歴史的な事実を提示する.OED によると,短縮形 mayn't は16世紀から例がみられるというが,引用例として最も早いものは17世紀の Milton からのものだ.
1631 Milton On Univ. Carrier ii. 18 If I mayn't carry, sure I'll ne'er be fetched.
OED に基づくと,注目すべき時代は初期近代英語以後ということになる.そこで EEBO (Early English Books Online) ベースで個人的に作っている巨大テキスト・データベースにて然るべき検索を行ったところ,次のような結果が出た(mai や nat などの異形も含めて検索した).各時期のサブコーパスの規模が異なるので,100万語当たりの頻度 (wpm) で比較されたい.
| Period (subcorpus size) | mayn't | may not |
|---|---|---|
| 1451--1500 (244,602 words) | 0 wpm (0 times) | 474.24 wpm (116 times) |
| 1501--1550 (328,7691 words) | 0 (0) | 133.22 (438) |
| 1551--1600 (13,166,673 words) | 0 (0) | 107.01 (1,409) |
| 1601--1650 (48,784,537 words) | 0.020 (1) | 131.85 (6,432) |
| 1651--1700 (83,777,910 words) | 1.03 (86) | 131.54 (11,020) |
| 1701--1750 (90,945 words) | 0 (0) | 109.96 (10) |
短縮形 mayn't は非短縮形 may not に比べて,常に圧倒的少数派であったことは疑うべくもない.短縮形の16世紀からの例は見つからなかったが,17世紀に少しずつ現われ出す様子はつかむことができた.18世紀からの例がないのは,サブコーパスの規模が小さいからかもしれない.「#1948. Addison の clipping 批判」 ([2014-08-27-1]) で見たように,Addison が18世紀初頭に mayn't を含む短縮形を非難していたほどだから,口語ではよく行われていたのだろう.
続いて後期近代英語のコーパス CLMET3.0 で同様に調べてみた.18--19世紀中にも,mayn't は相対的に少ないながらも確かに使用されており,19世紀後半には頻度もやや高まっているようだ.mayn't と may not の間で揺れを示すテキストも少なくない.
| Period (subcorpus size) | mayn't | may not |
|---|---|---|
| 1710--1780 (10,480,431 words) | 33 | 859 |
| 1780--1850 (11,285,587) | 21 | 703 |
| 1850--1920 (12,620,207) | 68 | 601 |
19世紀後半に mayn't の使用が増えている様子は,近現代アメリカ英語コーパス COHA でも確認できる.

20世紀に入ってからの状況は未調査だが,「#677. 現代英語における法助動詞の衰退」 ([2011-03-05-1]) から示唆されるように,may 自体が徐々に衰退の運命をたどることになったわけだから,mayn't の運命も推して知るべしだろう.昨日の記事で触れたように特に現代アメリカ英語では shan't も shall とともに衰退したてきたことと考え合わせると,否定短縮形の衰退は助動詞本体(肯定形)の衰退と関連づけて理解する必要があるように思われる.may 自体が古く堅苦しい助動詞となれば,インフォーマルな響きをもつ否定接辞を付加した mayn't のぎこちなさは,それだけ著しく感じられるだろう.この辺りに,mayn't の不使用の1つの理由があるのではないか.もう1つ思いつきだが,mayn't の不使用は,非標準的で社会的に低い価値を与えられている ain't と押韻することと関連するかもしれない.いずれも仮説段階の提案にすぎないが,参考までに.
[ 固定リンク | 印刷用ページ ]
2014-12-01 Mon
■ #2044. なぜ mayn't が使われないのか? (1) [auxiliary_verb][negative][tag_question][bnc][corpus][sobokunagimon]
なぜ may not の短縮形 mayn't が現代英語では一般的に用いられないのかという質問をいただいた.確かに不思議だと思っていたのだが,これまで扱わずにきたので少し考えてみたい.
法助動詞が否定辞を伴う形には,たいてい対応する短縮形がある.can't, couldn't, won't, wouldn't, shouldn't, mightn't, mustn't, needn't, use(d)n't, oughtn't 等々だ.しかし,mayn't はあまりお目にかからない.実際のところ大きな辞書には記載があるのだが,レーベルとしては口語的であるとか古風であるとか,特殊な用法とされている.OED でも mayn't は "(colloq., now rare)" や "rare in all varieties of English" とあり,標準英語をターゲットとする英語教育において教えられていないのも無理からぬことである.Quirk et al. (122) でも,mayn't が shan't とともに用いられなくなってきていることが述べられている.
Every auxiliary except the am form of BE has a contracted negative form . . ., but two of these, mayn't and shan't, are now virtually nonexistent in AmE, while in BrE shan't is becoming rare and mayn't even more so.
また Quirk et al. (811--12) は,付加疑問において mayn't I? などの形が使いにくい現状のぎこちなさにも言い及んでいる.mightn't I? や can't I? で代用する話者もいるようだが,スマートではない.may I not? は常に可能だが,堅苦しすぎて多くの文脈にはふさわしくない.
The negative tag question following a positive statement with modal auxiliary may poses a problem because the abbreviated form mayn't is rare (virtually not found in AmE). There is no obvious solution for the tag question, though some speakers will substitute mightn't or can't or --- when the reference is future --- won't:
?I may inspect the books, | mightn't I?
| can't I?
?They may be here next week, | mightn't they?
| won't they?
The abbreviated form is fully acceptable, but limited to formal usage:
I may inspect the books, may I not?
They may be here next week, may they not?
さて,BNC で mayn't を検索すると7例のみヒットした.話し言葉サブコーパスからは2例のみだが,書き言葉サブコーパスからの5例も口語的な文脈において生起している.7例中3例が mayn't you?, mayn't it?, mayn't there といった付加疑問のなかで現われており,一応は使用されていることがわかるが,1億語規模のコーパスでこれだけの例数ということは,やはり事実上の不使用といってよいだろう.
can't や mightn't との平行性を断ち切り,かつ付加疑問におけるそのぎこちなさを甘受してまでも mayn't の使用は避けるというこの状況は,いったいどのように理解すればよいのだろうか.歴史的に何か解明できるのだろうか.歴史的な事情について,明日の記事で考察したい.
・ Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech, and Jan Svartvik. A Comprehensive Grammar of the English Language. London: Longman, 1985.
2014-11-05 Wed
■ #2018. <nacio(u)n> → <nation> の綴字変化 [spelling][latin][etymological_respelling][corpus][hc][eebo]
近現代英語で <nation> と綴られる語は,中英語では主として <nacio(u)n> と綴られていた.<nacio(u)> → <nation> の変化は,具体的にはなぜ,いつ,どのように生じたのだろうか.ここでは母音字 <ou> → <o> の変化と,子音字 <c> → <t> の変化を分けて考える必要がある.
まず母音字の変化について考えよう.中尾 (331) によると,俗ラテン語において /o/ + 鼻音で終わる閉音節は,対応する Norman French の形態では鼻母音化した短母音 /ʊ/ あるいは長母音 /uː/ を示した.この音をもつ語が中英語へ借用されると,round, troumpe, count, nombre, countrefeten, countour, cuntree, counseil, commissioun, condicioun, nacioun, resoun, sesoun, religioun などと綴られた.-<sioun> や -<tioun> の発音は,対応する現代の -<sion> や -<tion> の発音 /ʃ(ə)n/ とは異なり,いまだ同化も弱化もしておらず,完全な音価 /siuːn/ を保っていたと考えられる.後期中英語から初期近代英語にかけてこの音節に強勢が落ちなくなってくると,同化や弱化が始まり,現在の /ʃ(ə)n/ に近づいていったろう.この過程で長母音を示唆する綴字 -<ioun> はふさわしくないと感じられ,1文字を落として -<ion> とするのが一般化したと想像される.
しかし,<ou> → <o> の変化が単に発音と綴字を一致させるべく生じたものであるという説明が妥当かどうかは検証の余地がある.そこには多少なりとも語源的綴字 (etymological_respelling) の作用があったのではないか.というのは,ME nacioun が後に nation へ変化したとき,変化したのは問題の母音字だけではなく,先行する子音字の <c> から <t> への変化もろともだったからである.Upward and Davidson (97) によると,
The letter C with the value /s/ before E and I in OFr had two main sources. One was Lat C: Lat certanus > certain. The other was Lat T, which before unstressed E, I acquired the same value, /ts/, as C had in LLat. Medieval Lat commonly alternated T and C in such cases: nacionem or nationem, whence the widespread use of forms such as nacion in OFr and ME. The C adopted in LLat, OFr and ME for classical Lat T has sometimes survived into ModE: Lat spatium > space; platea > place. Elsewhere, a later preference for classical Lat etymology has led to the restoration of T in place of C, as in the -TION endings: ModE nation.
つまり,<nacio(u)n> → <nation> における母音字の変化も子音字の変化も,古典ラテン語の綴字に一致させるべく生じたものではないか.
この綴字変化がいつ,どのように生じたかについて,歴史コーパスを用いて調査してみた.まずは Helsinki Corpus に当たって,次の結果を得た(以下の検索では,いずれも複数語尾のついた綴字なども一緒に拾ってある).件数は少ないものの,16世紀が変化の時期だったことがうかがわれる.
| <nacion> (<nacioon>) | <nation> | |
|---|---|---|
| M2 (1250--1350) | 0 (1) | 0 |
| M3 (1350--1420) | 7 (1) | 0 |
| M4 (1420--1500) | 2 (0) | 0 |
| E1 (1500--1569) | 2 (0) | 2 |
| E2 (1570--1639) | 0 (0) | 13 |
| E3 (1640--1710) | 0 (0) | 14 |
前回と同様,初期近代英語期 (1418--1680) の約45万語からなる書簡コーパスのサンプル CEECS (The Corpus of Early English Correspondence でも検索してみたが,大雑把な年代区分で仕分けした限り,明確な結果の解釈は難しい.
| <nacion> | <nation> | |
|---|---|---|
| CEECS1 (1418--1638) | 2 | 12 |
| CEECS2 (1580--1680) | 1 | 27 |
有用な結果を得ることができたのは,EEBO (Early English Books Online) からのテキストを蓄積して個人的に作っている巨大なデータベースの検索によってである.半世紀ごとに区分した各サブコーパスの規模はそれぞれ異なるので,通時的な数値の単純比較はできないが,それぞれの時代における異綴字の相対的な分布は一目瞭然だろう.
| <nacion> | <nacioun> | <nation> | <natioun> | |
|---|---|---|---|---|
| 1451--1500 (123,537 words) | 4 | 0 | 0 | 0 |
| 1501--1550 (1,825,565 words) | 90 | 0 | 82 | 0 |
| 1551--1600 (6,648,588 words) | 64 | 0 | 947 | 13 |
| 1601--1650 (21,296,378 words) | 18 | 0 | 6,451 | 0 |
| 1651--1700 (38,545,254 words) | 11 | 0 | 22,350 | 1 |
| 1701--1750 (33,741 words) | 0 | 0 | 12 | 0 |
母音字については,初期近代英語期の入り口までにすでに <-ioun> 形はほぼ廃れていたようである.そして,子音字については,16世紀中に一気に <t> が <c> を置き換えていった様子がわかる.少なくともこの子音字の変化のタイミングについては,一般に語源的綴字の最盛期といわれる16世紀に一致していることは指摘しておいてよいだろう.一方,母音字の変化については,語源的綴字による説明を排除するわけではないが,生じた時期が相対的に早かったことから,先述のとおり発音と綴字を一致させようという動機づけに基づいていた可能性が高いのではないか.
・ 中尾 俊夫 『音韻史』 英語学大系第11巻,大修館書店,1985年.
2014-10-09 Thu
■ #1991. 歴史語用論の発展の背景にある言語学の "paradigm shift" [historical_pragmatics][pragmatics][history_of_linguistics][corpus]
「#545. 歴史語用論」 ([2010-10-24-1]) で紹介したように,近年,歴史語用論 (historical_pragmatics) が勢いを増している.ここ数年の国際学会の発表や出版物のタイトルを見ていても,その影響力が増してきていることは疑いえない.2013年に英語歴史語用論の入門書を著わした Jucker and Taavitsainen は,この勢いを言語学の "paradigm shift" によるものと位置づけている.その "paradigm shift" は,以下の6点に要約される (5--9) .
(1) From core areas to sociolinguistics and pragmatics
(2) From homogeneity to heterogeneity
(3) From internalised to externalised language
(4) From introspection to empirical investigation
(5) Renewed interest in diachrony
(6) From stable to discursive features
逆にいえば,この6つの潮流の行き着く先を眺めると,そこに歴史語用論や歴史社会言語学があるといった風の箇条書きである.歴史語用論学者の手前味噌という気味もないではないが,ここ四半世紀の言語学の潮流をよく言い表しているとは思う.この6点を強引に手短にまとめれば,近年の言語学では「外部化された言語実体の多様性,通時的な振る舞い,あるいは談話に対する社会的・語用的な関心が高まってきており,経験主義的な研究方法が重視されるようになってきた」ということになるだろう.さらに私的に短縮していえば「言語の揺らぎへの関心の高まり」である.
上の6つの潮流は互いに密接に関係し合っており,その扇の要に位置している部品として(特に歴史的な)電子コーパスを指摘しておくことは重要だろう.コーパスを歴史語用論の研究に応用することは必ずしも容易ではないが,事例研究は着実に増えてきているし,その方法論も開発されてきている.
この分野の発展には,おおいに期待したいところである.というのは,"English historical sociopragmatic" なる分野の興隆は,伝統的に日本の中世英語研究が目指してきた "English philology" の再発展へとつながるはずだからだ.一皮むけた英語文献学を見るべく,英語歴史語用論も学んでいく必要がある.
・ Jucker, Andreas H. and Irma Taavitsainen. English Historical Pragmatics. Edinburgh: Edinburgh UP, 2013.
2014-10-01 Wed
■ #1983. -ick or -ic (3) [suffix][corpus][spelling][emode][eebo][johnson]
昨日の記事「#1982. -ick or -ic (2)」 ([2014-09-30-1]) に引き続き,初期近代英語での -ic(k) 語の異綴りの分布(推移)を調査する.使用するコーパスは市販のものではなく,個人的に EEBO (Early English Books Online) からダウンロードして蓄積した巨大テキスト集である.まだコーパス風に整備しておらず,代表性も均衡も保たれていない単なるテキストの集合という体なので,調査結果は仮のものとして解釈しておきたい.時代区分は16世紀と17世紀に大雑把に分け,それぞれコーパスサイズは923,115語,9,637,954語である(コーパスサイズに10倍以上の開きがある不均衡な実態に注意).以下では,100万語当たりの頻度 (wpm) で示してある.
| Spelling pair | Period 1 (1501--1600) (in wpm) | Period 2 (1601--1700) (in wpm) |
|---|---|---|
| angelick / angelic | 0.00 / 0.00 | 1.45 / 0.21 |
| antick / antic | 0.00 / 0.00 | 2.49 / 0.10 |
| apoplectick / apoplectic | 0.00 / 0.00 | 0.21 / 0.00 |
| aquatick / aquatic | 0.00 / 0.00 | 0.10 / 0.00 |
| arabick / arabic | 0.00 / 0.00 | 0.52 / 0.10 |
| archbishoprick / archbishopric | 0.00 / 0.00 | 0.10 / 0.00 |
| arctick / arctic | 0.00 / 0.00 | 0.42 / 0.00 |
| arithmetick / arithmetic | 0.00 / 0.00 | 3.22 / 0.31 |
| aromatick / aromatic | 0.00 / 0.00 | 0.83 / 0.10 |
| asiatick / asiatic | 0.00 / 0.00 | 0.31 / 0.00 |
| attick / attic | 0.00 / 0.00 | 0.31 / 0.21 |
| authentick / authentic | 0.00 / 0.00 | 3.94 / 0.42 |
| balsamick / balsamic | 0.00 / 0.00 | 0.73 / 0.10 |
| baltick / baltic | 0.00 / 0.00 | 0.93 / 0.00 |
| bishoprick / bishopric | 1.08 / 0.00 | 4.25 / 0.00 |
| bombastick / bombastic | 0.00 / 0.00 | 0.10 / 0.00 |
| catholick / catholic | 5.42 / 0.00 | 38.39 / 1.97 |
| caustick / caustic | 0.00 / 0.00 | 0.21 / 0.00 |
| characteristick / characteristic | 0.00 / 0.00 | 0.21 / 0.10 |
| cholick / cholic | 0.00 / 0.00 | 0.93 / 0.00 |
| comick / comic | 1.08 / 0.00 | 1.45 / 0.10 |
| critick / critic | 0.00 / 0.00 | 1.76 / 1.87 |
| despotick / despotic | 0.00 / 0.00 | 0.62 / 0.21 |
| domestick / domestic | 0.00 / 0.00 | 8.09 / 0.21 |
| dominick / dominic | 1.08 / 0.00 | 0.62 / 0.42 |
| dramatick / dramatic | 0.00 / 0.00 | 0.83 / 0.10 |
| emetick / emetic | 0.00 / 0.00 | 0.31 / 0.00 |
| epick / epic | 0.00 / 0.00 | 0.21 / 0.10 |
| ethick / ethic | 0.00 / 0.00 | 0.00 / 0.10 |
| exotick / exotic | 0.00 / 0.00 | 0.73 / 0.10 |
| fabrick / fabric | 0.00 / 0.00 | 8.72 / 0.31 |
| fantastick / fantastic | 1.08 / 0.00 | 3.42 / 0.10 |
| frantick / frantic | 1.08 / 0.00 | 3.94 / 0.00 |
| frolick / frolic | 1.08 / 0.00 | 3.32 / 0.00 |
| gallick / gallic | 0.00 / 0.00 | 3.32 / 0.52 |
| garlick / garlic | 0.00 / 0.00 | 2.28 / 0.00 |
| heretick / heretic | 2.17 / 0.00 | 6.02 / 0.00 |
| heroick / heroic | 0.00 / 0.00 | 16.91 / 1.35 |
| hieroglyphick / hieroglyphic | 0.00 / 0.00 | 0.31 / 0.00 |
| lethargick / lethargic | 0.00 / 0.00 | 0.52 / 0.10 |
| logick / logic | 0.00 / 0.00 | 7.06 / 1.04 |
| lunatick / lunatic | 0.00 / 0.00 | 1.66 / 0.00 |
| lyrick / lyric | 0.00 / 0.00 | 0.42 / 0.10 |
| magick / magic | 2.17 / 0.00 | 3.32 / 0.10 |
| majestick / majestic | 0.00 / 0.00 | 4.88 / 0.42 |
| mechanick / mechanic | 0.00 / 0.00 | 4.15 / 0.00 |
| metallick / metallic | 0.00 / 0.00 | 0.21 / 0.00 |
| metaphysick / metaphysic | 0.00 / 0.00 | 0.10 / 0.21 |
| mimick / mimic | 0.00 / 0.00 | 0.42 / 0.00 |
| musick / music | 7.58 / 627.22 | 40.98 / 251.40 |
| mystick / mystic | 0.00 / 0.00 | 1.45 / 0.10 |
| panegyrick / panegyric | 0.00 / 0.00 | 4.46 / 0.10 |
| panick / panic | 0.00 / 0.00 | 1.35 / 0.10 |
| paralytick / paralytic | 0.00 / 0.00 | 0.10 / 0.00 |
| pedantick / pedantic | 0.00 / 0.00 | 0.93 / 0.00 |
| philosophick / philosophic | 0.00 / 0.00 | 0.00 / 0.21 |
| physick / physic | 1.08 / 0.00 | 27.39 / 1.56 |
| plastick / plastic | 0.00 / 0.00 | 0.21 / 0.00 |
| platonick / platonic | 0.00 / 0.00 | 0.93 / 0.00 |
| politick / politic | 0.00 / 0.00 | 15.98 / 1.14 |
| prognostick / prognostic | 0.00 / 0.00 | 0.52 / 0.00 |
| publick / public | 5.42 / 3.25 | 237.39 / 5.71 |
| relick / relic | 0.00 / 0.00 | 0.52 / 0.00 |
| republick / republic | 0.00 / 0.00 | 3.01 / 0.31 |
| rhetorick / rhetoric | 0.00 / 0.00 | 5.71 / 0.21 |
| rheumatick / rheumatic | 0.00 / 0.00 | 0.21 / 0.00 |
| romantick / romantic | 0.00 / 0.00 | 0.83 / 0.00 |
| rustick / rustic | 0.00 / 0.00 | 1.66 / 0.00 |
| sceptick / sceptic | 0.00 / 0.00 | 0.10 / 0.10 |
| scholastick / scholastic | 0.00 / 0.00 | 0.31 / 0.42 |
| stoick / stoic | 0.00 / 0.00 | 0.93 / 0.00 |
| sympathetick / sympathetic | 0.00 / 0.00 | 0.21 / 0.00 |
| topick / topic | 0.00 / 0.00 | 1.45 / 0.00 |
| traffick / traffic | 3.25 / 0.00 | 8.61 / 0.42 |
| tragick / tragic | 3.25 / 0.00 | 2.91 / 0.00 |
| tropick / tropic | 0.00 / 0.00 | 1.04 / 0.00 |
全体として眺めると,初期近代英語では -ick のほうが -ic よりも優勢である.-ic が例外的に優勢なのは,16世紀からの music と,17世紀の critic, scholastic くらいである.昨日の結果と合わせて推測すると,1700年以降,おそらく18世紀前半の間に,-ick から -ic への形勢の逆転が比較的急速に進行していたのではないか.個々の語において逆転のスピードは多少異なるようだが,一般的な傾向はつかむことができた.18世紀半ばに -ick を選んだ Johnson は,やはり保守的だったようだ.
[ 固定リンク | 印刷用ページ ]
2014-09-30 Tue
■ #1982. -ick or -ic (2) [suffix][johnson][webster][corpus][spelling][clmet][lmode]
「#872. -ick or -ic」 ([2011-09-16-1]) の記事で,<public> と <publick> の綴字の分布の通時的変化について,Google Books Ngram Viewer と Google Books: American English を用いて簡易調査した.-ic と -ick の歴史上の変異については,Johnson の A Dictionary of the English Language (1755) では前者が好まれていたが,Webster の The American Dictionary of the English Language (1828) では後者へと舵を切っていたと一般論を述べた.しかし,この一般論は少々訂正が必要のようだ.
「#1637. CLMET3.0 で between と betwixt の分布を調査」 ([2013-10-20-1]) で紹介した CLMET3.0 を用いて,後期近代英語の主たる -ic(k) 語の綴字を調査してみた.1710--1920年の期間を3期に分けて,それぞれの綴字で頻度をとっただけだが,結果を以下に掲げよう.
| Spelling pair | Period 1 (1710--1780) | Period 2 (1780--1850) | Period 3 (1850--1920) |
|---|---|---|---|
| angelick / angelic | 6 / 50 | 0 / 68 | 0 / 50 |
| antick / antic | 4 / 10 | 1 / 6 | 0 / 3 |
| apoplectick / apoplectic | 0 / 10 | 1 / 19 | 0 / 14 |
| aquatick / aquatic | 1 / 2 | 0 / 35 | 0 / 56 |
| arabick / arabic | 2 / 101 | 0 / 45 | 0 / 115 |
| archbishoprick / archbishopric | 4 / 7 | 2 / 2 | 0 / 8 |
| arctick / arctic | 1 / 5 | 0 / 20 | 0 / 93 |
| arithmetick / arithmetic | 9 / 32 | 0 / 77 | 0 / 98 |
| aromatick / aromatic | 4 / 14 | 0 / 29 | 0 / 36 |
| asiatick / asiatic | 1 / 101 | 0 / 48 | 0 / 76 |
| attick / attic | 1 / 32 | 0 / 34 | 0 / 71 |
| authentick / authentic | 4 / 160 | 0 / 79 | 0 / 68 |
| balsamick / balsamic | 1 / 1 | 0 / 5 | 0 / 1 |
| baltick / baltic | 4 / 50 | 0 / 33 | 0 / 43 |
| bishoprick / bishopric | 3 / 28 | 2 / 9 | 0 / 19 |
| bombastick / bombastic | 1 / 2 | 0 / 3 | 0 / 4 |
| cathartick / cathartic | 0 / 1 | 1 / 0 | 0 / 0 |
| catholick / catholic | 7 / 291 | 0 / 342 | 0 / 296 |
| caustick / caustic | 1 / 2 | 0 / 11 | 0 / 20 |
| characteristick / characteristic | 8 / 92 | 0 / 354 | 0 / 687 |
| cholick / cholic | 1 / 13 | 0 / 2 | 0 / 1 |
| comick / comic | 1 / 68 | 0 / 67 | 0 / 165 |
| coptick / coptic | 1 / 11 | 0 / 3 | 0 / 35 |
| critick / critic | 12 / 153 | 0 / 168 | 0 / 155 |
| despotick / despotic | 9 / 66 | 0 / 51 | 0 / 65 |
| dialectick / dialectic | 1 / 0 | 0 / 0 | 0 / 6 |
| didactick / didactic | 0 / 10 | 1 / 20 | 0 / 23 |
| domestick / domestic | 46 / 733 | 0 / 736 | 0 / 488 |
| dominick / dominic | 4 / 11 | 0 / 14 | 1 / 3 |
| dramatick / dramatic | 8 / 214 | 0 / 206 | 0 / 216 |
| elliptick / elliptic | 1 / 1 | 0 / 8 | 0 / 2 |
| emetick / emetic | 4 / 5 | 0 / 7 | 0 / 5 |
| epick / epic | 1 / 68 | 0 / 83 | 1 / 38 |
| ethick / ethic | 1 / 6 | 0 / 0 | 0 / 3 |
| exotick / exotic | 2 / 7 | 0 / 20 | 0 / 38 |
| fabrick / fabric | 15 / 116 | 1 / 84 | 0 / 111 |
| fantastick / fantastic | 9 / 45 | 0 / 157 | 0 / 198 |
| frantick / frantic | 5 / 88 | 2 / 163 | 0 / 124 |
| frolick / frolic | 19 / 44 | 0 / 46 | 0 / 32 |
| gaelick / gaelic | 1 / 1 | 0 / 30 | 0 / 64 |
| gallick / gallic | 1 / 75 | 0 / 11 | 0 / 10 |
| gothick / gothic | 2 / 498 | 0 / 131 | 0 / 66 |
| heretick / heretic | 2 / 31 | 0 / 37 | 0 / 24 |
| heroick / heroic | 17 / 201 | 2 / 224 | 0 / 211 |
| hieroglyphick / hieroglyphic | 2 / 4 | 0 / 7 | 0 / 8 |
| hysterick / hysteric | 1 / 9 | 0 / 10 | 0 / 6 |
| laconick / laconic | 2 / 13 | 0 / 14 | 0 / 7 |
| lethargick / lethargic | 1 / 12 | 0 / 8 | 0 / 14 |
| logick / logic | 4 / 62 | 0 / 361 | 0 / 367 |
| lunatick / lunatic | 2 / 32 | 0 / 34 | 0 / 77 |
| lyrick / lyric | 3 / 15 | 0 / 26 | 0 / 37 |
| magick / magic | 9 / 110 | 0 / 296 | 0 / 292 |
| majestick / majestic | 4 / 73 | 0 / 149 | 1 / 115 |
| mechanick / mechanic | 6 / 79 | 0 / 47 | 0 / 58 |
| metallick / metallic | 1 / 9 | 0 / 79 | 0 / 137 |
| metaphysick / metaphysic | 1 / 2 | 0 / 11 | 0 / 9 |
| mimick / mimic | 2 / 25 | 1 / 46 | 0 / 23 |
| musick / music | 87 / 549 | 3 / 1220 | 3 / 1684 |
| mystick / mystic | 1 / 39 | 0 / 92 | 0 / 167 |
| obstetrick / obstetric | 1 / 2 | 0 / 1 | 0 / 0 |
| panegyrick / panegyric | 19 / 121 | 0 / 43 | 0 / 16 |
| panick / panic | 14 / 58 | 1 / 90 | 0 / 314 |
| paralytick / paralytic | 1 / 15 | 0 / 41 | 0 / 14 |
| pedantick / pedantic | 3 / 31 | 0 / 28 | 0 / 29 |
| philippick / philippic | 2 / 2 | 0 / 3 | 0 / 2 |
| philosophick / philosophic | 1 / 140 | 0 / 80 | 0 / 155 |
| physick / physic | 35 / 157 | 4 / 51 | 3 / 38 |
| plastick / plastic | 1 / 4 | 0 / 19 | 0 / 32 |
| platonick / platonic | 5 / 48 | 0 / 30 | 0 / 22 |
| politick / politic | 8 / 40 | 2 / 37 | 0 / 51 |
| prognostick / prognostic | 2 / 18 | 0 / 5 | 0 / 1 |
| publick / public | 767 / 3350 | 1 / 3171 | 2 / 2606 |
| relick / relic | 1 / 26 | 4 / 56 | 0 / 65 |
| republick / republic | 12 / 515 | 0 / 185 | 0 / 171 |
| rhetorick / rhetoric | 26 / 109 | 2 / 40 | 0 / 65 |
| rheumatick / rheumatic | 1 / 7 | 0 / 33 | 0 / 30 |
| romantick / romantic | 32 / 191 | 0 / 346 | 0 / 322 |
| rustick / rustic | 3 / 102 | 0 / 157 | 0 / 80 |
| sarcastick / sarcastic | 1 / 37 | 0 / 66 | 0 / 60 |
| sceptick / sceptic | 3 / 26 | 0 / 19 | 0 / 26 |
| scholastick / scholastic | 2 / 24 | 0 / 42 | 0 / 46 |
| sciatick / sciatic | 1 / 1 | 0 / 1 | 0 / 3 |
| scientifick / scientific | 2 / 16 | 0 / 451 | 0 / 814 |
| stoick / stoic | 5 / 34 | 1 / 15 | 0 / 26 |
| sympathetick / sympathetic | 3 / 26 | 0 / 70 | 0 / 248 |
| systematick / systematic | 1 / 13 | 0 / 64 | 0 / 104 |
| topick / topic | 12 / 128 | 0 / 177 | 0 / 176 |
| traffick / traffic | 80 / 67 | 1 / 164 | 0 / 203 |
| tragick / tragic | 4 / 65 | 0 / 65 | 0 / 209 |
| tropick / tropic | 12 / 37 | 0 / 7 | 0 / 23 |
第2期以降 (1780--1920) は,すべての語において事実上 -ic のみとなったとみてよいが,18世紀の大半を含む第1期 (1710--1780) については,ここかしこに保守的な -ick が散見される.語によっては <critick>, <frolick>, <heroick>, <musick>, <panegyrick>, <panick>, <physick>, <publick>, <rhetorick>, <romantick>, <tropick> など そこそこの頻度を示すものもあるし,<traffick> ではむしろ -ic 形よりも優勢だ(なお,屈折語尾としての -ic(k) ではないが,garlick/garlic は,第1期 17 / 7, 第2期 1 / 8, 第3期 0 / 11 を数え,最初期に -ick が優勢だったもう1つの例である).しかし,全体として -ick 形は散見されるにすぎず,すでに18世紀より -ic 形が幅を利かせていたことがわかる.つまり,18世紀半ばの Johnson の辞書では,すでに影の薄くなっていた保守的な -ic が,半ば意識的に採用されたという解釈が成り立ちそうだ.Webster の時代ではなく,Johnson の時代にすでに -ic 形は事実上の市民権を得ていたと考えられる.
しかし,CLMET で得られた後期近代英語の趨勢を歴史の中に適切に位置づけて解釈するためには,先行する初期近代英語における異綴字の分布(変化)も押えておく必要があるだろう.それについては明日の記事で.
Powered by WinChalow1.0rc4 based on chalow