2011-04-28 Thu
■ #731. 接尾辞 -dom をもつ名詞の通時的分布 [suffix][oed][corpus][productivity]
[2009-05-18-1]の記事「接尾辞-dom をもつ名詞」では現代英語で使われる -dom 語をいくつか挙げたが,今回は通時的な観点からこの接尾辞を眺めてみたい.Bauer (220) によると,-dom は一度は瀕死の接尾辞とみなされるほどに衰退していたが,現代英語では一定の生産性を取り戻してきているという.
-dom This suffix forms abstract, uncountable nouns from concrete, countable ones. For a long time it was thought that the suffix was moribund or totally non-productive, but Wentworth (1941) showed that it had never completely died out, and it is still productive in contemporary English, though not very much so. Recent examples include Dollardom, fagdom, gangsterdom, girldom (all OEDS). (220)
-dom は原則として名詞の基体に付加して抽象名詞を作るが,freedom のように形容詞の基体に付加する例もある.
OED で通時的分布を調べてみた.[2011-01-05-1]で紹介した「OED の検索結果から語彙を初出世紀ごとに分類する CGI」を利用して世紀ごとに -dom 語を数え上げ,以下のように視覚化した.Sodom などの雑音も多少は混じっており,ざっと見て気付いたものは削除したが,大雑把な数え上げとして理解されたい.数値データはこのページのHTMLソースを参照.
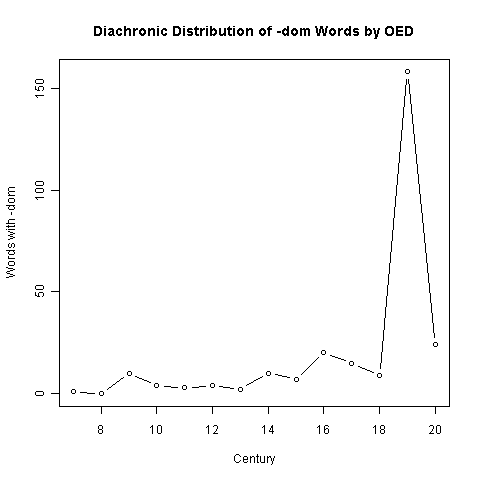
中英語から近代英語にかけてのじわじわとした復活,そして19世紀の爆発は印象的である.20世紀の下火は,現実を反映しているのか,あるいは OED の語彙収集上の事情によるものだろうか.いずれにしても19世紀以降の新 -dom 語彙はすべてが低頻度語で,nonce-word も多い.Frequency Sorter によると,ANC (American National Corpus) で10回以上用いられているものは,fandom, boredom, stardom, fiefdom くらいだ.
接辞の生産性 (productivity) は理論的に計算するのが難しいとされる (Baayen and Lieber) .-dom の19世紀の爆発は20世紀そして21世紀にどの程度続いているのか,直感的に捉えられる接辞の生産性とは客観的にどのように記述されるのか,生産性の問題にコーパスがどのように活用できるのか.-dom に注目するだけでも,様々な問題が持ち上がってくる.
・ Bauer, Laurie. English Word-Formation. Cambridge: CUP, 1983.
・ Baayen, Harald and Rochelle Lieber. "Productivity and English Derivation: A Corpus-Based Study." Linguistics 29 (1991): 801--43.
2011-04-08 Fri
■ #711. Log-Likelihood Tester CGI, Ver. 2 [corpus][bnc][statistics][web_service][cgi][lltest]
以下に,汎用の Log-Likelihood Tester, Ver. 2 を公開.(後に説明するように,入力データのフォーマットに不備がある場合や,モードが適切に選択されていない場合にはサーバーでエラーが生じる可能性があるので注意.)
[2011-03-25-1]の記事で,コーパス研究でよく用いられる対数尤度検定 ( Log-Likelihood Test ) の計算機 Log-Likelihood Tester, Ver. 1 を公開した.Ver. 1 は,コーパスサイズを加味しながら2つのコーパスでのキーワード(群)の出現頻度を比べ,コーパス間の差が有意であるかどうかを検定するものだった.
Log-Likelihood Test は上述の目的で用いることが多いと思い,Ver. 1 ではあえて機能を特化させたのだが,より一般的に複数行,複数列の分割表で与えられるデータに対応する対数尤度検定を行ないたい場合もある.例えば,昨日の記事[2011-04-07-1]で,現代英語における though と although の出現傾向について BNC に基づいた調査を紹介したが,Text Domain ごとの頻度比率は,両語の間で統計的にどの程度一致している,あるいは一致していないとみなすことができるのだろうか.昨日のグラフから,although は学術散文に多く,though は創作散文に多いという傾向が一目瞭然だが,この直感的な「一目瞭然」は統計的にはどのように表現されるのだろうか.
このような場合には,次のような頻度表(値は100万語当たりの出現頻度に標準化済み)を準備し,これをコピーして入力ボックスに貼り付ける."lump mode" にチェックを入れ替え,"Go!" する.(デフォルトは "each-line mode" で,これは Ver. 1 と同等のモード.)
| though | although | |
|---|---|---|
| Natural and pure sciences | 56.3 | 80.13 |
| Applied science | 37.36 | 68.31 |
| World affairs | 45.81 | 68.2 |
| Social science | 48.98 | 63.38 |
| Commerce and finance | 46.18 | 57.21 |
| Arts | 74.07 | 52.93 |
| Leisure | 45.85 | 49.46 |
| Belief and thought | 70.78 | 46.75 |
| Imaginative prose | 80.2 | 26.37 |
結果は,1行だけの表として出力される.though と although を表わす2列の数値の並びが,統計的にどのくらい近似しているかを計算している.結論としては,両語の Text Domain ごとの頻度の並びの差は p < 0.0001 という非常に高いレベルで有意であり,両語の出現傾向は Text Domain によってほぼ確実に異なるといえる.
入力ボックスに入れるデータの書式は,タブ区切りの分割表.表頭と表側はいずれも省略可.サンプルのように表頭と表側の両方を含める場合には,左上のセルは空白にしておく必要あり.
"each-line mode" の機能は Ver. 1 と互換なので,入力形式もそちらの説明を参照.今回の Ver. 2 の "each-line mode" では,出力結果をシンプルにおさえてある(逆に,詳しい内部計算値を得たい場合には Ver. 1 のほうが有用).
Log-Likelihood Test の概要については,[2011-03-24-1]の記事を参照.
2011-04-07 Thu
■ #710. though と although の語法の差 (2) [bnc][corpus][lltest][conjunction][statistics]
昨日の記事[2011-04-06-1]で,though と although の語法の差に触れた.今日も同じ話題で.
4000万語超からなる The Longman Spoken and Written English Corpus (the LSWE Corpus) を駆使した現代英語の文法書,Biber et al. (845--46) では次のようにある.
Both of these subordinators [though and although] occur in all four registers [conversation, fiction, news, and academic prose], although the registers show different preferences of use. Conversation and fiction show a slightly greater use of though (concessive clauses are, however, uncommon in conversation generally). News shows no particular preference. In academic prose, although is about three times as frequent as though. Although seems to have a slightly more formal tone to it, fitting the style of academic prose . . . . The greater use of although by writers of academic prose may also result from an attempt to distinguish this subordinator from the common use of though as a linking adverbial in conversation . . . .
また,同書の p. 842 の表からは,相対的に though が fiction で多く,although は academic prose で多いことが確認される.ジャンルによる差が現われているとの結果だ.
このような先行研究を受けて,今回は BNC ( The British National Corpus ) によりこれを確かめてみる.BNCweb で,{although/CONJ}, {though/CONJ} をそれぞれ検索し,Written/Spoken, Text Domain, Sex of Author/Speaker, Perceived Level of Difficulty など様々なパラメータで出現分布を分析した.主立った結果を以下に示そう(数値データはこのページのHTMLソースを参照).
まず,Written/Spoken の差については,予想されるとおり,両語とも Written への偏りが激しい(差異係数は though で 0.66344 ,although で 0.49770 で,明らかに書き言葉に偏る).Log-Likelihood Test では,p < 0.0001 のレベルで書き言葉と話し言葉の有意差が明確に示された.
書き手,話し手の性による差も興味深い.書き言葉と話し言葉の両方で,although は有意差をもって男性の使用に偏っている.though については,性差は although ほど顕著ではない(ただし書き言葉では p < 0.05 で有意差あり).
次に,Text Domain 別に頻度をみる.9種類の Text Domain を区別した ( Natural and pure sciences, Applied science, World affairs, Social science, Commerce and finance, Arts, Leisure, Belief and thought, Imaginative prose ) .100万語当たりの出現回数に標準化した値で,両語の Text Domain 別頻度をグラフ化したのが以下の図だ.
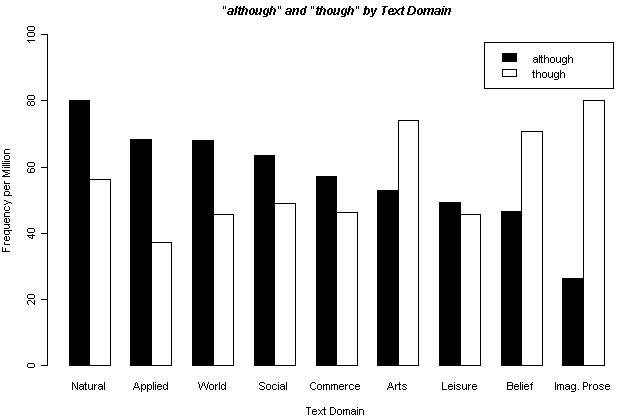
Text Domain によって両語の出現頻度に対照的な傾向が見られることがわかる.相対的に sciences ( = academic prose ) に although が目立ち,Imag(inative) Prose ( = fiction ) に though が多い.Log-Likelihood Test では,Text Domain による出現傾向の差は p < 0.0001 で有意である.
直感的にも先行研究の結果からも予想され得たことではあるが,although は男性の書き手により学術散文で顕著に用いられるという図式が現われた.
・ Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad, and Edward Finegan. Longman Grammar of Spoken and Written English. Harlow: Pearson Education, 1999.
2011-04-05 Tue
■ #708. Frequency Sorter CGI [corpus][bnc][statistics][web_service][cgi][lexicology][plural]
何らかの基準で集めた英単語のリストを,一般的な頻度の順に並び替えたいことがある.例えば,[2011-03-22-1]で論じたように,頻度と不規則な振る舞いとの関係を調べたいときに,注目する語(群)の一般的な頻度を知る必要がある.この目的には,[2010-03-01-1]で紹介したような大規模な汎用コーパスに基づく頻度表が有用である.BNC lemma-pos list (122KB) や ANC word-tagset list (7.2MB) などで問題の語を一つひとつ検索し,頻度数や頻度順位を調べてゆけばよいが,語数が多い場合には面倒だ.そこで,上記2つの頻度表から,入力した語(群)の頻度と順位を取り出す CGI を作成した.
改行でもスペースでもカンマでもよいのだが,区切られた単語リストを以下のボックスに入力し,"Frequency Sort Go!" をクリックする.出力結果を頻度順位の高い順にソートする場合には,"sort by rank?" をオンにする(デフォルトでオン.オフにすると,入力順に出力される).例えば,現代標準英語に残る純粋に i-mutation を示す複数形は以下の7語のみである(複合語,二重複数,[2011-04-01-1]で話題にした sister(e)n は除く).これをコピーしてボックスに入力する.
foot, goose, louse, man, mouse, tooth, woman
まず,BNC lemma-pos list による出力だが,この頻度表は約1億語の BNC 全体から,頻度にして800回以上現われる,上位6318位までの見出し語 ( lemma ) を収録している.したがって,それよりも頻度の下回る goose, louse については空欄となっている.頻度と不規則性の相関関係を考える際に参考になるだろう.
次に,ANC word-tagset list による出力が続くが,この頻度表は BNC のものよりも規模が大きく,かつきめ細かい.合計22,164,985語を有する ANC (American National Corpus) から,Penn Treebank Tagset によってクラス付与された単位で語形が列挙されたリストである.タグセットが細かいので読みにくいし,自動タグ付与に起因するエラーも少なからず含まれているが,BNC のものよりも低頻度の語(形)を収録しているので,goose や louse の頻度情報も現われる.こちらの頻度表では WORD FORM ごとの頻度も確認できるため,直接 geese や lice の頻度も確かめられる.
当初 Frequency Sorter の用途として想定していたのは,上記の不規則複数形を示す語群などの頻度と順位の一括調査だったが,他にも用途はあるかもしれない.以下に,思いつきをメモ.
・ 1単語から使えるので,like のような多品詞語を入力して,品詞(あるいはタグ付与されたクラス)ごとの頻度を取り出せる.
・ ヒット数だけを確認したい場合には,いちいちコーパスを立ち上げる必要がない.
・ 論文やプレゼンで,ある目的で集めた数百語の単語リストの中から典型的な例,分かりやすい例を10個ほど示したいときなど,頻度の高い10個を選べばよい.例えば,[2011-03-29-1]で列挙した sur- を接頭辞にもつ単語リストのうち,例示に最もふさわしい10個を選ぶなどの目的に.頻度に基づいた順番のほうが,ランダム順やアルファベット順よりも親切なことが多いだろう(今後,本ブログ執筆に活用する予定).
・ 英米それぞれの代表的なコーパスに基づく頻度表を利用しているので,綴字や形態などの頻度の英米差を確認するのに使える.
・ (実際には lemmatisation が必要だが)適当な英文を放り込んでみて,妙に頻度の低い語が含まれていないかを調べる.頻度のツールなので,その他,教育・学習目的にいろいろと使えるかもしれない.
2011-04-01 Fri
■ #704. brethren and sister(e)n [plural][analogy][ame][i-mutation][relationship_noun][corpus][coca][coha]
昨日の記事[2011-03-31-1]で,古英語の親族名詞の屈折表を見た.brethren の起源についても言及したが,これと関連して親族名詞お得意の類推 ( analogy ) の例をもう一つ挙げよう.brethren との類推で sister(e)n という複数形がある.MED の記述にあるように,中英語では -(e)n 形はごく普通であり,-s 形が一般化するのは brother の場合と同じく近代期以降である.この辺りの話題は私の専門領域なので,詳細なデータをもっている.初期中英語でもイングランドの北部や東部では -s が優勢だが,南部や西部ではこの時期の sister の複数形は原則として -n あるいは母音の語尾が圧倒していることは間違いない ( Hotta, p. 256 ) .
さて,sister(e)n は現代英語に生き残っているが,brethren と異なり,通常辞書には記載されていない.BNC ( The British National Corpus ) でもヒットしなかった.しかし,COCA ( Corpus of Contemporary American English ), COHA ( Corpus of Historical American English ) ではそれぞれ4例,15例(19世紀後半以降の例)がヒットし,もっぱらアメリカ英語で聞かれることが分かる.COCA からの例を1つ挙げる.政治討論会番組 "CNN Crossfire" からの用例である(赤字は引用者).
Well, you know, I hate to correct you, but you made the same mistake many of your liberal brethren and sisteren, have said in analyzing this dissent by Judge Stevens.
COCA, COHA 両コーパスからの計19例のうち16例までが brethren and sister(e)n として現われ,主にフィクションで用いられ,dear や my が先行する呼びかけの使い方が多い.brethren と同様に宗教的,組合的な文脈で現われているようだが,限定された語義としてのほか,文体的な効果もあるのかもしれない.関連して,OED の sister の語義5を引用しておこう."In the vocative, as a mode of address, chiefly in transferred senses. Also colloq. as a mode of address to an unrelated woman, esp. one whose name is not known."
もっぱらアメリカ英語で用いられることについては,Mencken (502) が触れている.
Sisteren or sistern, now confined to the Christians, white and black, of the Get-Right-with-God country, was common in Middle English and is just as respectable, etymologically speaking, as brethren.
sister(e)n という複数形に関する歴史的な問題は,近現代アメリカ英語での使用を,中英語期以来の継続としてとらえるべきか,あるいはアメリカ英語で改めてもたらされた刷新としてとらえるべきか,である.OED によると,sister(e)n は一般的な文章語としては16世紀半ばに廃れたとある.初期近代英語期の例やイギリス英語を含めた諸方言の例を調査しないと分からないが,(1) brethren との類推は時代を問わずありそうであること,(2) brethren と脚韻を踏むので呼びかけなど口語で特に好まれそうであること,この2点からアメリカ英語での再形成と考えるのが妥当ではないだろうか.中英語で非語源的な sister(e)n が作り出されたくらいだから,近代英語で改めて作られたとしても不思議はない.
sister(e)n は通常の辞書には載っていないくらいのレアな複数形だが,brethren, children, oxen (but see [2010-08-22-1]) と同じ,現代に残る少数派 -en 複数の仲間に入れてあげたい気がする.
・ Hotta, Ryuichi. The Development of the Nominal Plural Forms in Early Middle English. Hituzi Linguistics in English 10. Tokyo: Hituzi Syobo, 2009.
・ Mencken, H. L. The American Language. Abridged ed. New York: Knopf, 1963.
2011-03-25 Fri
■ #697. Log-Likelihood Tester CGI [corpus][bnc][statistics][web_service][cgi][lltest][sociolinguistics]
昨日の記事[2011-03-24-1]で Log-Likelihood Test を話題にした.計算には Rayson 氏の Log-likelihood calculator を利用すればよいと述べたが,実際の検定の際に作業をもう少し自動化したいと思ったので CGI を自作してみた.細かい不備はあると思うが,とりあえず公開.
上のテキストボックスに入力すべきデータは,タブ区切りの表の形式.1行目(省略可)はコーパス名,2行目以降はキーワードと観察頻度数(ヒット数),最終行は各コーパスのサイズ(語数)."#" で始まる行はコメント行として無視される.1列目のキーワード列は省略可.
以下のテキストが入力サンプル.[2010-09-11-1]の記事で取り上げたテレビ広告で頻用される形容詞(比較級と最上級を含む)トップ20の頻度を,BNCweb の話し言葉サブコーパスから話者の性別に整理した表である.このままコピーして入力ボックスに貼り付けると,出力結果が確認できる.
BNC_Male_Speakers BNC_Female_Speakers new 149 91 good 408 310 free 173 75 fresh 84 118 delicious 12 34 full 210 107 sure 532 328 clean 197 223 wonderful 270 258 special 177 82 crisp 10 16 fine 347 215 big 470 415 great 203 96 real 163 80 easy 326 157 bright 113 110 extra 347 203 safe 182 92 rich 120 45 #-------- corpus_size 4949938 3290569
男女間で有意差の特に大きいのは,対応行が赤で塗りつぶされた fresh, delicious, clean, wonderful, big で,いずれも期待度数に基づいて計算された Diff_Co ( "Difference Coefficient" 「差異係数」 ) がマイナスであることから,女性に特徴的な形容詞ということになる.big は意外な気がしたが,おもしろい結果である.一方,男性に偏って有意差を示すのは黄色で示した easy や rich である.この結果はいろいろと読み込むことができそうだし,より詳細に調べることもできる.広告の形容詞という観点からは,話者ではなく聞き手の性別,年齢,社会階級などを軸に調査してもおもしろそうだ.いろいろと応用できる.
2011-03-24 Thu
■ #696. Log-Likelihood Test [corpus][bnc][statistics][lltest]
[2010-03-04-1]の記事で触れたが,コーパス言語学では各種の統計手法が用いられる.いくつかある手法のなかでも,ある表現のコーパス間の頻度を比較したり,collocation の度合いを測るのに広く用いられているのが Log-Likelihood Test ( LL Test, G Test, G2 Test などとも)呼ばれる検定である.コーパスサイズを考慮に入れた検定なのでサイズの異なるコーパス間での比較が可能であり,同じ目的で以前によく用いられていたカイ2乗検定 ( Chi-Squared Test ) よりもいくつかの点ですぐれた手法と評価されており,最近のコーパス研究では広く用いられている.(例えば,カイ2乗検定は期待頻度が5回より少ないとき,高頻度語を扱うとき,コーパスサイズが大きいものと小さいものを比較するときに信頼性が低くなるが,Log-Likelihood Test はこれらの影響を受けにくい [ Rayson and Garside 2 ] .)
Log-Likelihood Test の基本的な考え方は,コーパスサイズをもとにある表現の期待される出現頻度(期待頻度)を割り出し,その値と実際に出現する頻度(観察頻度)の差が単純な誤差と考えられるほどに近似しているかどうかを判定するというものである.例として,次のようなケース・スタディを試す.BNC ( The British National Corpus ) から話し言葉サブコーパスと書き言葉サブコーパスを区別し,両サブコーパス間で f*ck という four-letter word の頻度を比較する.BNCweb よりこのキーワードを検索すると,次のような結果が得られた.
| Category | No. of words | No. of hits | Dispersion (over files) | Frequency per million words |
|---|---|---|---|---|
| Spoken | 10,409,858 | 579 | 63/908 | 55.62 |
| Written | 87,903,571 | 743 | 172/3,140 | 8.45 |
| total | 98,313,429 | 1,322 | 235/4,048 | 13.45 |
統計処理をほどこすまでもなく最右列 "Frequency per million words" を見れば,f*ck が圧倒的に話し言葉で多く用いられることが分かるが,今回はこれを統計的に裏付ける.まず,帰無仮説として「話し言葉サブコーパスと書き言葉サブコーパスの間での f*ck の頻度差は誤差の範囲内であり,この語に関して両者に意味のある差はない」を設定する.その対立仮説は「話し言葉サブコーパスと書き言葉サブコーパスの間での f*ck の頻度差は誤差の範囲内でなく,この語に関して両者の差は意味がある」となる.帰無仮説が支持されるかどうかを決めるのが,検定の目的である.
| Corpus 1 | Corpus 2 | Total | |
|---|---|---|---|
| Frequency of word | a | b | a+b |
| Frequency of other words | c-a | d-b | c+d-a-b |
| Total | c | d | c+d |
Log-Likelihood Test に用いる Log-Likelihood ratio 「対数尤度比」は,上の表の要領で各サブコーパスの総語数 ( c, d ) と,各サブコーパスでの f*ck の頻度数 ( a, b ) を分割表にまとめた上で,それぞれの期待頻度 E1 と E2 を下の (1) の式で求め,その値を (2) の式に代入して求める.
(1) E1 = c*(a+b)/(c+d); E2 = d*(a+b)/(c+d)
(2) LL = 2*((a*log(a/E1))+(b*log(b/E2)))
f*ck の数値で計算すると,以下のようになる.
E1 = 10409858*(579+743)/(10409858+87903571) = 139.979170861796
E2 = 87903571*(579+743)/(10409858+87903571) = 1182.0208291382
LL = 2*((579*log(579/139.979170861796))+(743*log(743/1182.0208291382))) = 954.2115
Log-likelihood ratio として 954.2115 という値が算出される.次にこの値を,適切な有意水準(通常は 5%, 1%, 0.1%)に対応するカイ二乗値と比較する.2 * 2 の分割表に対する計算では自由度1のカイ二乗値を用いることになっており,その値は有意水準 5%, 1%, 0.1% の順にそれぞれ 3.84, 6.63, 10.83 である.954.2115 の Log-Likelihood ratio は有意水準 0.1% に対応する 10.83 よりもずっと高いので,0.1% の有意水準で帰無仮説は棄却される.言い換えれば,統計的には帰無仮説が真である確率は 0.1% にも満たず,まず偽と考えてよいということである.このようにして対立仮説「話し言葉サブコーパスと書き言葉サブコーパスの間での f*ck の頻度差は誤差の範囲内でなく,この語に関して両者の差は意味がある」が採択されることになる.
Log-Likelihood Test は以上のように進められるが,この検定を行なうにあたっての前提条件を知っておく必要がある.一般には,計算される期待頻度が 5 を下回るセルが1つでもある場合には,検定の精度は落ちるとされる.これは the Cochran rule と呼ばれているが,よりきめ細かなルールを提起した Rayson, Berridge, and Francis (8) によれば,期待頻度が満たすべき最低値は有意水準 5% で13 回,1% で 11 回,0.1% で 8 回だという.有意水準を 0.01% に設定すれば期待頻度 1 回にも耐える精度を得られるので,Rayson et al. はコーパス言語学で慣習的に用いられている3つの水準に加えて,0.01% の水準(対応するカイ二乗値は 15.13 )までの検定を推奨している.
統計には詳しくないが,ある表現の 2(サブ)コーパス間での頻度比較というシーンで簡単に用いることができる検定として,Log-Likelihood Test の応用範囲は広そうだ.計算自体は Rayson 氏の Log-likelihood calculator などに任せればよい(本記事はこのページの記述とリンク先の論文を参考にした).
BNC を用いた f*ck 関連語の分布の研究は,McEnery et al. (264--86) のケース・スタディに詳しい.
関連して,検定は行なわなかったが,かつて本ブログで扱った gorgeous の調査 ([2010-08-16-1], [2010-08-17-1],[2010-12-25-1]) なども参照.
・ Rayson, P., D. Berridge , and B. Francis. "Extending the Cochran Rule for the Comparison of Word Frequencies between Corpora." Le poids des mots: Proceedings of the 7th International Conference on Statistical Analysis of Textual Data (JADT 2004), Louvain-la-Neuve, Belgium, March 10-12, 2004. Ed. Purnelle G., Fairon C., and Dister A. Louvain: Presses universitaires de Louvain, 2004. 926--36. Available online at http://www.comp.lancs.ac.uk/computing/users/paul/publications/rbf04_jadt.pdf .
・ Rayson, P. and R. Garside. "Comparing Corpora Using Frequency Profiling". Proceedings of the Workshop on Comparing Corpora, Held in Conjunction with the 38th Annual Meeting of the Association for Computational Linguistics (ACL 2000), 1-8 October 2000, Hong Kong. 2000. 1--6. Available online at http://www.comp.lancs.ac.uk/computing/users/paul/phd/phd2003.pdf .
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
2011-03-12 Sat
■ #684. semantic prosody と文法カテゴリー [semantic_prosody][grammar][corpus][intensifier]
昨日起こった東北地方太平洋沖地震につきまして,被災者の方々に心よりお見舞い申し上げます.
[2011-03-03-1]の記事で,semantic prosody と文法カテゴリーとの間に関連があるという可能性に言及した.これは,happen の類義語,utterly を含む強意語の semantic prosody をコーパスによって調査した Partington の論文で指摘されていることである.
Partington は happen, set in, occur, come about, take place を調査し,この語群には程度の差はあれ,確かに unfavourable な semantic prosody が付随しているという証拠を挙げた(最も unfavourable なのは set in だという)(144) .同様に,utterly, absolutely, perfectly, totally, completely, entirely, thoroughly を調査し,それぞれの semantic prosody あるいは semantic preference を抽出した (148) .そして,いくつかの語句に付随している音色には,favourable vs. unfavourable という単純な価値基準の対立ではなく,一般には文法カテゴリーとして言及されるような特徴の対立が関与しているということがわかった.
具体的に言えば,happen は non-factuality を示す傾向が強い.法,疑問,条件といった文法カテゴリーとの関与が認められ,it is unclear why や to see what などの表現とともに用いられることが多い (140--41) .一方で,take place はむしろ factuality を示す傾向が強く,生じると予定されていることが実際に生じるという含意で用いられることが多い (143) .
強意語では,utterly は unfavourable semantic prosody を示すだけでなく,特徴の不在や状態変化を表わす語を修飾する傾向がある ( ex. utterly helpless / unable /forgotten / changed / different / destroyed ) .同じ傾向は,totally, completely, entirely にも見られる.entirely には (in)dependency というカテゴリーも関与しており,entirely dependent / self-sufficient / isolated などと用いられることが多い.absolutely は superlative を含意する語を修飾する ( ex. absolutely delighted / splendid / appalling ) .
factuality, absence, change, dependence, superlative というキーワードは,通常,文法カテゴリーに関連して言及されるラベルだが,語の意味,特に semantic prosody や semantic preference として言及される意味と深く関わっていることがわかる.
考えてみれば,語彙と文法の結びつきという視点は,新しくもなければ珍しくもない.例えば,ある動詞は受け身でしか用いられないとか,否定で用いられることが多いなどという事実は当たり前のように指摘されてきたし,学習者用辞書に広く反映されている.ある種の意味領域を表わす語が,後続する that 節内の動詞に subjunctive を要求するという文法項目も長い間論じられてきた ([2010-04-07-1]) .語彙と文法の関係は英語学ではよく知られていた事実だが,コーパス言語学という新しい角度からも同じ事実にたどり着いたということだろう.ただし,コーパス言語学の貢献は,factuality や absence などのカテゴリーを 0 か 1 かの binary な問題としてではなく,probabilistic な問題として取り扱うことができる点にあるように思われる.
英語史あるいは通時言語学の観点からは,ある語が文法カテゴリーと結びつきが認められる場合に,いつ,どのようにその結びつきが生じたのかに興味がある.例えば happen は英語史のいつ頃から unfavourable で non-factual な含蓄を得たのか.もしある時期にそのような含蓄を帯び始めたのであれば,その意味の場 ( semantic field ) を構成する他の類義語との関係も合わせて考える必要がある.そして,類義語との関係ということになれば,occur など借用語の圧力も考慮に入れなければならない.借用語による意味の場の再編成 → semantic prosody の滲出 → 文法カテゴリーへの結びつき,という流れがあるとすれば,おもしろい.speculation にすぎないが,例えば[2009-08-17-1]の記事で触れた語種と仮定法現在との関係にこの流れが見られないだろうか.
・ Partington, A. "'Utterly content in each other's company': Semantic Prosody and Semantic Preference." International Journal of Corpus Linguistics 9.1 (2004): 131--56.
2011-03-05 Sat
■ #677. 現代英語における法助動詞の衰退 [auxiliary_verb][corpus][brown]
現代英語の法助動詞 ( modal auxiliary ) の体系が複雑なことについては,[2010-07-22-1], [2010-01-20-1], [2009-07-01-1], [2009-06-25-1]の記事で触れた.法助動詞は一般動詞と比較して統語形態上の振る舞いが特異であり,意味も多様化してきたので英語史を通じて不安定な語類であった.現代英語でも体系的な安定は得られておらず,再編成が進行中と考えられるが,再編成の様相それ自体が複雑である.現代英語の法助動詞の研究は数多いが,体系の変化の傾向を記述した研究として,The Brown family of corpora ([2010-06-29-1]) を利用した Leech et al. (Chapters 3--5) の研究がある.特に4章 (pp. 71--90) では,主要な11の法助動詞の頻度の変化が詳述されている.以下は,1961年の米英書き言葉を代表する Brown と LOB,そして1991/92年の米英書き言葉を代表する Frown と F-LOB により,約30年間にわたる法助動詞の頻度の通時変化を表わしたグラフである(Leech et al., p. 283 の数値表をもとに作成).数値データはこのページのHTMLソースを参照.will には 'll や won't などの省略形・否定形も含む.need は肯定形と否定形を両方含む.
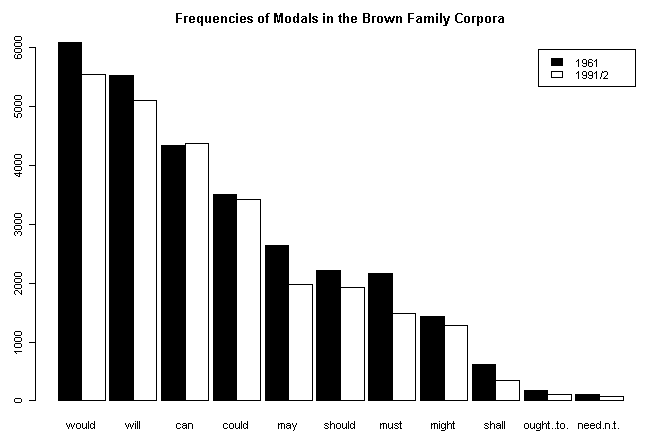
全体として30年の間に法助動詞の頻度が下がっていることが分かる.頻度の減少は,would, will, may, should, must, shall, ought (to) で p < 0.001 の非常に強い有意差を示し,might, need(n't) で p < 0.01 の強い有意差を示す.これは英米両変種をひっくるめた結果だが,変種で分けて調査すると,AmE のほうが BrE よりも減少の度合いが強く,BrE がその傾向を遅れて追いかけているかのような分布を示す (73) .
興味深いのは,もともと頻度の低い法助動詞ほど減少率も大きい "bottom-weighting" (73) の傾向が観察されることだ.減少率の全体平均は18.9%だが,上位4助動詞でみると4.7%,下位7助動詞でみると22.7%である.特に,shall の43.5%,ought (to) の37.5%,need(n't) の31.6%という減少率は著しい.
bottom-weighting の背景には,"paradigmatic atrophy" 「体系的な退化」(80--81) があるのではないかと指摘されている.上述のように,法助動詞は一般動詞と比べて多くの点で不完全であり変則的である.人称や数による屈折を欠いており,不定形が存在せず,時制変化もきわめて不規則である.shall は2人称代名詞を主語として現われることはほとんどなく,mayn't という否定形はきわめてまれである.法助動詞が全体的に "defective" な語類であることを考えれば,とりわけ頻度の低い法助動詞がいっそう機能不全に陥り,ますます低頻度になってゆくということは不思議ではない.法助動詞の再編成はグラフに見られるほど単純な現象ではないが,コーパスを用いた量的調査によって大きな潮流が明らかにされたと言えるだろう.
・ Leech, Geoffrey, Marianne Hundt, Christian Mair, and Nicholas Smith. Change in Contemporary English: A Grammatical Study. Cambridge: CUP, 2009.
2011-03-04 Fri
■ #676. コーパス研究の知見はどこまで解釈に役立つか? [semantics][corpus][semantic_prosody][passive]
[2011-03-02-1], [2011-03-03-1]の記事で semantic prosody を取りあげた.ある共起表現が(主に否定的な)評価を帯びる現象である.semantic prosody は単なる語句のレベルにとどまらず,統語的なレベルにも見られる.例えば,Stubbs (163--68) では be-passive に対する get-passive の意味特性に関するコーパス利用研究が紹介されており,get を用いた受動態は主語が不利益を被るという文脈(さらに場合によっては主語がその不利益に自ら責任があるという文脈)で頻繁に見られるという結果が報告されている.
get-passive が否定的な semantic prosody を帯びやすいということは,従来から文法書等で指摘されてきたことだが,コーパス研究の長所は具体的な数字を提供してくれる点にある.Stubbs の調査では,be-passive の約25%が "unpleasant" な結果を含意し,"pleasant" を含意するものも多いという.一方,get-passive では60%以上が "unpleasant" な結果を含意し,"pleasant" を含意するものはほんのわずかである.別のコーパスを用いた別の研究者による調査では,get-passage の "unpleasant" 含意率が話し言葉コーパスで約9割に達したという報告もあり,get-passive が否定的な semantic prosody をもっていることは明らかである.このような客観的な数値による裏付けが,corpus semantics の重要な特長であり役割である.
しかし,コーパス研究によって得られた get-passive に関するこの知見は,get-passive を含む具体的な文の解釈にどのくらい役立つのだろうか.コーパスから得られたという次の文を考えよう.
I got praised for having a clean plate.
一見したところ特に "unpleasant" を含意する語句は含まれていない.しかし,get-passive が用いられているということは,ここでは "unpleasant" を含意する解釈,おそらくは皮肉的な読みが要求されているということなのだろうか.コーパスによる知見から言えることは,「否定的な semantic prosody を伴っている get-passive が用いられている以上,高い確率で "unpleasant" の読みがふさわしいだろうが,"pleasant or neutral" な例も皆無ではなかったのだからここでは例外的に "pleasant or neutral" な読みかもしれない」ほどだろうか.しかし,これでは常識的に知っていることと差がない.コーパスの知見がほとんど活かされていない.コーパス研究のジレンマは,大量の用例から傾向を探り出すことは得意だが,個々の用例の解釈を保証してはくれないということである.英文解釈のためにコーパスで注目表現の有無や頻度を調べるということは日常的に行なっているが,そこでいつも思うのが,その表現があったから,高頻度だったからといって,それが必ずしも正しい英文解釈へ導いてくれるとは限らないということである.「参考までに」で止まってしまうことが多く,じれったい.「参考までに」では参考にならないことが多いのだ.
この問題を semantic prosody の観点からとらえなおすと,ある共起表現において semantic prosody の含意する否定性がどの程度の強度,安定感,感染力をもっていれば,一見したところ中立的,肯定的な文脈が皮肉などの否定的な音色を帯びると考えられるのだろうか.それは probability の値として算出できるものなのだろうか.
個々の文脈で判断すべしと言ってしまえばそれまでだが,コーパス研究の成果が英文解釈という現実的な問題に貢献し得ないとなると,その価値は大幅に制限されてしまうのではないか.Stubbs の論文は,コーパス研究と解釈の関係について上記の問題を提起しているが,解決策については無言である.
・ Stubbs, M. "Texts, Corpora, and Problems of Interpretation: A Response to Widdowson." Applied Linguistics 22.2 (2001): 149--72.
2011-03-03 Thu
■ #675. collocation, colligation, semantic preference, semantic prosody [semantics][corpus][collocation][semantic_prosody]
昨日の記事[2011-03-02-1]で取りあげた semantic prosody に関連する話題.語と語の共起関係には4つの種類が区別される.以下,McEnery et al. (84--85, 149--52) を参照して,抽象度の低いものから高いものへと並べ,それぞれの概要を記す.
(1) collocation: 語彙項目と語彙項目との関係
(2) colligation: 語彙項目と文法カテゴリーとの関係.
(3) semantic preference: 語彙項目と,意味的に関連する語群との関係
(4) semantic prosody: 感情的意味を生み出す語彙項目の共起関係
(1) collocation は単純に語と語が共起するという関係を指し,基本的には統計的な概念と考えられている.しかし,どの程度の頻度をもって共起すれば "collocate" していると見なすことができるのかに関して,論者のあいだで統計的な基準は異なる( see [2010-03-23-1], [2010-03-04-1] ) .通常は,常識的に「高頻度」であれば collocation と呼んでいるようだ.
(2) 名詞 house と最も高頻度で共起する語に the や a などの冠詞があるが,これは collocation を研究する上であまり有意味でない.名詞であれば冠詞と共起するのは自明であり,house に限定された話しではないからだ.collocation を有意味な術語として保つためには,house と冠詞のような,語と文法カテゴリーの関係を表わす術語が必要となる.これが colligation である.
(3) semantic preference は,ある意味的特性を共有する,高頻度で共起する語の集合に関わる関係である.例えば,large は数量・規模を表わす語群 ( ex. number(s), scale, part, quantities, amount(s) ) と共起し,utterly は特徴の欠如や状態の変化を表わす語群 ( ex. helpless, useless, unable, forgotten; changed, different ) と共起する.large や utterly は共起する語句の意味範囲を選んでいる.
(4) semantic prosody の定義は昨日の記事[2011-03-02-1]で記した通りで,態度や評価といった感情的な意味を生み出す共起関係を指す.母語話者の意識に上らない,隠された含意であることが多い.semantic preference の特殊な現われと見ることもでき,その境目は必ずしも明確ではない.
いずれの種類の共起であれ,共起に関する詳細な研究は電子コーパスで一度に多数の例文を集められるようになったことにより発展してきた.semantic prosody の研究は,意味論の発展に貢献することはいうまでもないが,類義語間の区別を明らかにするのに役立つことが見込まれるので語学教育や辞書学の分野にも貢献することになるだろう.また,この種の研究は語彙論や意味論と強く結びつけられる研究ではあるが,先に utterly との関連で示した「特徴の欠如や状態の変化」という意味特性の関与を考えると,polarity や modality といった文法カテゴリーとの関連も示唆され,統語論との接点も見いだせそうだ.そして,繰り返し共起することにより特定の意味が定着してゆくという過程に焦点を当てれば,当然,通時的な研究対象にもなり得る.
semantic prosody は,このように広範な応用が期待できそうな話題である.McEnery et al. (84) に最近の研究の書誌があるので,参考までに以下に整理しておく.
・ Hunston, S. Corpora in Applied Linguistics. Cambridge: Cambridge UP, 2002.
・ Louw, B. "Irony in the Text or Insincerity in the Writer? The Diagnostic Potential of Semantic Prosodies." Text and Technology: In Honour of John Sinclair. Eds. M. Baker, G. Francis and E. Tognini-Bonelli. Amsterdam: John Benjamins, 1993. 157--76.
・ Louw, B. 2000. "Contextual Prosodic Theory: Bringing Semantic Prosodies to Life." Words in Context: A Tribute to John Sinclair on his Retirement. Eds. C. Heffer, H. Sauntson and G. Fox. Birmingham: U of Birmingham, 2000.
・ Partington, A. Patterns and Meanings. Amsterdam: John Benjamins, 1998.
・ Partington, A. "'Utterly content in each other's company': Semantic Prosody and Semantic Preference." International Journal of Corpus Linguistics 9.1 (2004): 131--56.
・ Schmitt, N. and R. Carter "Formulaic Sequences in Action: An Introduction." Formulaic Sequences. Ed. N. Schmitt. Amsterdam: John Benjamins, 2004. 1--22.
・ Stubbs, M. "Collocations and Semantic Profiles: On the Cause of the Trouble with Quantitative Methods." Function of Language 2.1 (1995): 1--33.
・ Stubbs, M. "Texts, Corpora, and Problems of Interpretation: A Response to Widdowson." Applied Linguistics 22.2 (2001): 149--72.
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
2011-03-02 Wed
■ #674. semantic prosody [semantics][corpus][collocation][semantic_prosody][terminology]
semantic prosody は,近年のコーパス言語学の興隆によって生み出された概念であり,研究課題としても注目されるようになってきた.同じくコーパス言語学によって注目を集めるようになった collocation とも深く関連している.Louw (57) によれば,semantic prosody の定義は "a form of meaning which is established through the proximity of a consistent series of collocates" である.もう少し分かりやすい定義として Crystal からも引用しよう.
A term sometimes used in corpus-based lexicology to describe a word which typically co-occurs with other words that belong to a particular semantic set. For example, utterly co-occurs regularly with words of negative evaluation (e.g. utterly appalling). (428)
例として utterly appalling が挙げられているように,utterly という強意の副詞は常に,否定的な性質を表わす語を強調する.他に,happen や set in という(句)動詞も不快な出来事を表わす名詞と共起することが多い.semantic prosody とは,共起によって強く顕現するこのような「意味上の音色」のことを指し,その主たる機能は話者の態度や評価を表わすことである.多くは否定的な評価に関するものであり,肯定的な評価の例は少ない(後者の例としては,否定的な強意副詞 utterly に対して肯定的な強意副詞 perfectly が挙げられよう).semantic prosody が collocation と強く結びつていることは,McEnery et al. (83) の挙げている personal price の例から明らかである.personal も price も単独ではその評価は中立的だが,共起すると通常否定的な意味上の音色を伴う.
特定の共起によって特定の semantic prosody が生じ,それが十分に定着してくると,その共起を故意に逸脱させることによって皮肉,偽善,ユーモアなどの特殊な効果を表わすことができるようにもなる.例えば,Cobuild written corpus に次のような例文がある.
Their relationship in fact was so complete that they were utterly content in each other's company.
semantic prosody に関して避けることのできない議論は,語と語の共起によってなぜ特定の音色(主に否定的な音色)が顕現するのか,あるいは歴史的に獲得されてきたのか,という問題である.utterly はなぜ否定的な音色を帯びるのか.この問いに対して,否定的な語と共起することが多かったから utterly 自体も否定の音色を帯びるようになったという答えがあるかもしれない.しかし,そもそも否定的な語と共起することが多かったのはなぜなのか.それは utterly 自体が本来的に否定的な音色を帯びていたからではないか.まさに鶏が先か卵が先かの問題に陥ってしまう.このような場合の常として,(1) 本来的に否定的な性質と (2) 特定の否定的な語との頻繁な共起,という2つの要因が相互に作用した結果だろうという説明がもっとも穏健かもしれない.しかし,比較的最近,接尾辞 -ish の否定的な含意の獲得について歴史的な研究を行なった私にとっては,この問題は悩ましい問題である.McEnery et al. (84) もこの問題に触れている.
It might be argued that the negative (or less frequently positive) prosody that belongs to an item is the result of the interplay between the item and its typical collocates. On the one hand, the item does not appear to have an affective meaning until it is in the context of its typical collocates. On the other hand, if a word has typical collocates with an affective meaning, it may take on that affective meaning even when used with atypical collocates. As the Chinese saying goes, 'he who stays near vermilion gets stained red, and he who stays near ink gets stained black' --- one takes on the colour of one's company --- the consequence of a word frequently keeping 'bad company' is that the use of the word alone may become enough to indicate something unfavourable . . . .
・ Crystal, David, ed. A Dictionary of Linguistics and Phonetics. 6th ed. Malden, MA: Blackwell, 2008. 295--96.
・ Louw, B. 2000. "Contextual Prosodic Theory: Bringing Semantic Prosodies to Life." Words in Context: A Tribute to John Sinclair on his Retirement. Eds. C. Heffer, H. Sauntson and G. Fox. Birmingham: U of Birmingham, 2000.
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
2011-02-23 Wed
■ #667. COCA 最頻50万語で品詞別の割合は? [lexicology][corpus][french][loan_word][adjective][statistics][coca]
昨日の記事[2011-02-22-1]に引き続き,COCA ( Corpus of Contemporary American English ) に基づく単語の頻度リストを利用したパイロット・スタディ.今回は,こちらで最近になって追加された最頻50万語のリストを用いて,昨日と同様の品詞別割合を調べた.昨日のリストは見出し語 ( lemma ) に基づいた最頻5000語,今日のリストは語形 ( word form ) に基づいた最頻50万語(正確には497187語)で,性格が異なることに注意したい.
昨日とほぼ同じ作業だが,今回は2万語ずつで階級を区切り,L1からL25までの階級のそれぞれにおいて noun, verb, adj., adv., others の5区分で品詞別割合を出した.(数値データはこのページのHTMLソースを参照.)
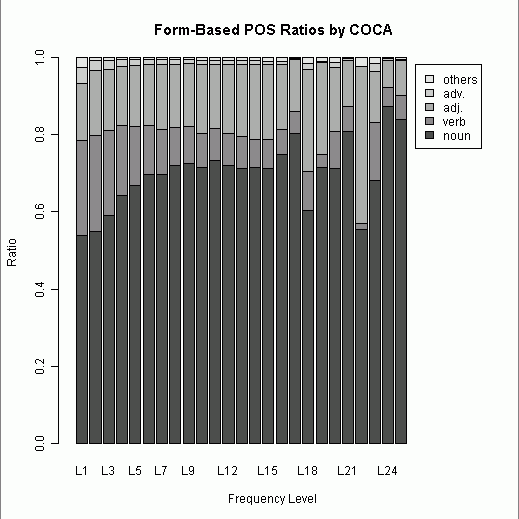
L6(12万語レベル)辺りから品詞別比率は安定期に入るといってよいだろう.L17(34万語レベル)辺りから変動期が始まるのが気になるが,階級幅を大きくしてみると(ならしてみると)直前のレベルから大きく逸脱していない.
[2011-02-16-1]の記事以来,形容詞の比率が気になっているが,今回のデータ全体から計算すると,0.1738という値がはじきだされた.昨日の lemma 調査では0.1678だったから,値は非常に近似している.ただし,名詞と動詞の lemma 対 word form の比率は,名詞が 0.5086 : 0.6985,動詞が 0.2000 : 0.1065 と大きく異なるので,形容詞の 0.1678 : 0.1738 という近似は偶然かもしれない.lemma 対 word form の品詞別割合には異なる傾向があるのかもしれないが,それでも大規模に調べると安定期と呼びうる区間が出現することは確かなようだ.
[2011-02-16-1]の記事で触れたように,中英語期のフランス借用語における形容詞比率は0.1768だった.今回の値0.1738と酷似しているが,主題の性質がまるで違うので,直接の関係を論じることは無理である.もとより昨日と今日の調査は,[2011-02-16-1]の調査とは無関係に始めたものである.しかし,偶然と思えるこの結果は,示唆的ではある.借用語彙といえば名詞が圧倒的なはずだと予想していたものの,フランス語や古ノルド語からはおよそ一定の割合の形容詞(それぞれ lemma 調査で0.1768と0.1817)が借用されていた.そして,その比率は時代が異なるとはいえ現代英語の比率と近似している.英語語彙全体における比率と借用語彙における比率が近似しているということは,もし偶然でないとしたら,何を意味するのだろうか.フランス借用語彙や古ノルド借用語彙が,英語に適応するような自然な比率で英語語彙へ溶け込んだということだろうか.これは,今回のパイロット・スタディの結果を受けての印象に基づく speculation にすぎない.今後も品詞別割合という観点に注目していきたい.
2011-02-22 Tue
■ #666. COCA 最頻5000語で品詞別の割合は? [lexicology][corpus][statistics][n-gram][coca]
COCA ( Corpus of Contemporary American English ) に基づいた各種語彙リストが Corpus-based word frequency lists, collocates, and n-grams から入手できる.そのなかで最も基本的なリストが,こちらの最頻5000語リストである.列挙されているのは見出し語 ( lemma ) 単位で,順位はコーパスに現われる頻度と分散の関数で計算されている.UCREL CLAWS7 Tagset の品詞コード表に基づいた粗い品詞情報も付与されており,品詞別の頻度などを手軽に分析することができる.
今回は,500語ごとに区切って頻度の高い順にL1からL10までの階級を設け,それぞれの階級における品詞別割合を出した.品詞は開いた語類 ( open class ) を中心とし,noun, verb, adj., adv., others の5区分とした.(数値データはこのページのHTMLソースを参照.)
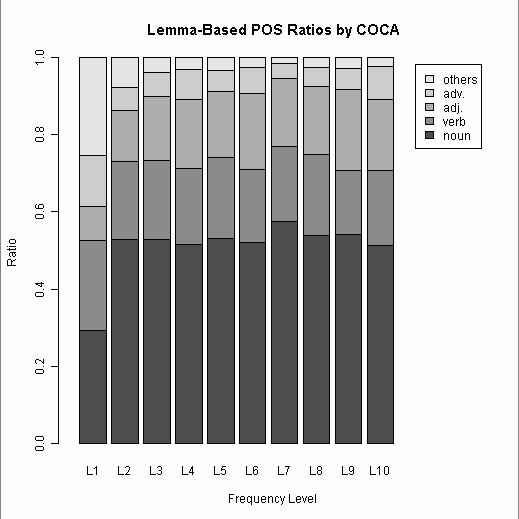
第1階級を除き,どの階級でも名詞が過半数を占めているのは予想できたことだが,第2階級以降に名詞の割合が思ったほど伸びていないことが分かった.動詞と形容詞が後半の階級でもおよそ一定の割合を占め続けているのも予想外だった.全体として,最頻5000語リストに限れば,名詞が飛び抜けつつも,開いた語類の内部比率はおよそ一定に保たれているといえよう.階級幅を様々に動かして試してみたが,およそ安定期に入るのは500語以降と見てよさそうだ.
[2011-02-16-1]の記事で中英語期のフランス借用語の品詞別割合をみたが,全体としての形容詞比率は0.1768だった.今回の現代英語の最頻5000語では,全体としての形容詞比率は0.1678.比べて意味のある数値かどうかは分からないが,英語(言語?)における品詞別比率の「安定感」のようなものはあるのだろうか.
COCA に基づくもの以外にオンラインで入手できる最頻英単語リストについては[2010-03-01-1]の記事を参照.頻度表を利用した別のパイロット・スタディとしては,単語の音節数を扱った[2010-04-17-1]の記事を参照.
2011-01-29 Sat
■ #642. OED の引用データをコーパスとして使えるか (4) [oed][corpus][statistics]
[2010-10-15-1]の記事に関連して,Brewer の論文から補足.その記事で OED の引用数を時代別にグラフ化したものを掲げたが,特に顕著な増加を示している箇所を数字で示した版を以下に示す.
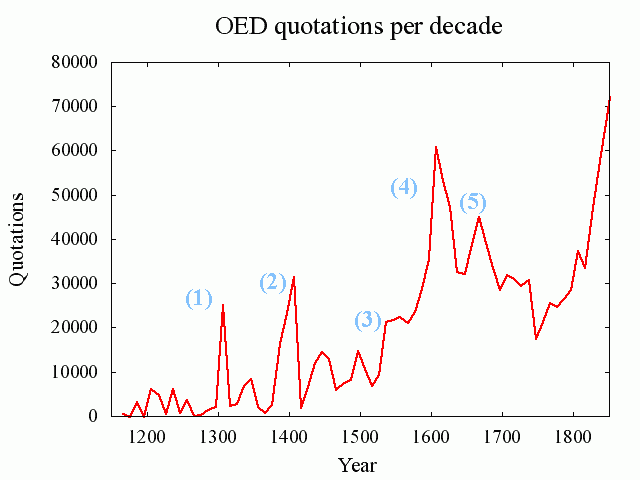
Brewer (58) によると,(1)--(5) の各増加は OED 編纂上の要因によるところが大きいとされる.それぞれの事情は以下の通りである.
(1) 1291--1300年の増加.1470年以前についてはしばしばテキストの年代が不明であり,そのような場合には便宜上各世紀の中央や両端に年代を仮設定するという編集上の方針があった.また,特にこの時代については,Robert of Gloucester (1297年,3222用例) や Cursor Mundi (1300年,10771用例で OED における被引用数第2位の作品) から,かなり集中的に引用が取り込まれているという事情もある.
(2) 1391--1400年の増加.(1) と同様の世紀終わりという理由に加え,Trevisa (1387/98年,6750用例) から大量に取り込まれているという事情がある.
(3) 1521--1530年の増加.Palsgrave の Lesclarcissement (1530年,5418用例) からの大量の引用により,半ば説明される.
(4) 1581--1600年の増加.Shakespeare (33304用例) の影響が相当に大きい.
(5) 1631--1660年の増加.おそらく革命期のパンフレットからの多数の引用が影響している.
この5点の増加についてだけでも編集上の背景を具体的に知っておくと,OED の引用データの使い方(少なくともその姿勢)は変わってくるだろうと思い,メモした次第.関連する記事としては以下を参照.
・ [2010-10-10-1]: #531. OED の引用データをコーパスとして使えるか
・ [2010-10-14-1]: #535. OED の引用データをコーパスとして使えるか (2)
・ [2010-10-15-1]: #536. OED の引用データをコーパスとして使えるか (3)
・ Brewer, Charlotte. "OED Sources." Lexicography and the OED: Pioneers in the Untrodden Forest. Ed. Lynda Mugglestone. Oxford: OUP, 2000. 40--58.
2011-01-14 Fri
■ #627. 2変種間の通時比較によって得られる言語的差異の類型論 [language_change][speed_of_change][corpus][brown][ame_bre]
[2010-06-29-1]の記事でみたように,The Brown family of corpora を構成する4コーパス ( Brown, Frown, LOB, F-LOB ) を用いることによって英語の英米変種間の30年間ほどの通時変化を比べることができる.このように信頼するに足る比較可能性を示す複数のコーパスを用いた通時研究は "diachronic comparative corpus linguistics" (Leech et al. 24) と呼ばれており,相互に30年ほどの間隔をあけた英米変種のコーパス群が過去と未来の両方向へ向かって編纂されてゆくものと思われる.
地域変種と年代という2つのパラメータによって得られる言語項目の頻度の差について,理論的な解釈は複数ありうる.Brown family の場合にはどのような解釈があり得るか,Mair (109--12) が論じている2変種間の通時比較によって得られる言語的差異(の有無)の類型論 ( "typology of contrasts" ) を改変した形で以下に示そう."=" は変化の出発点を,"+/-" は変化の生起とその方向を示す.
(1) nothing happening
BrE: = → =
AmE: = → =
(2) stable regional contrast
BrE: = → =
AmE: +/- → +/-
(3) parallel diachronic development
BrE: = → +/-
AmE: = → +/-
(4) convergence: Americanization
BrE: +/- → =
AmE: = → =
(5) convergence: 'Britishization'
BrE: = → =
AmE: +/- → =
(6) incipient divergence: British English innovating
BrE: = → +/-
AmE: = → =
(7) incipient divergence: American English innovating
BrE: = → =
AmE: = → +/-
(8) random fluctuation
BrE: = → +/-
AmE: +/- → +/-
(1), (8) は最も多いが観察者の関心を引かない平凡なタイプの差異(の欠如)である.(2) は確立された不動の英米差,例えば <honour> vs. <honor> の綴字や got vs. gotten の使用が例となる.(3) の例は Mair では挙げられていないが何があるだろうか.(4) は Americanization の事例,例えば help が原型不定詞を取るようになってきている傾向を思い浮かべることができる(ただし BrE でのこの傾向はすべてが Americanization に帰せられるというわけではない).(5) は非常にまれだが 'Britishization' の例である.例えば AmE での準助動詞表現 have got to の広がりは BrE に牽引されている可能性があると疑われている.(6) は,BrE で prevent が "O + from + V-ing" ではなく "O + V-ing" を好んで選択するようになり出している傾向が例に挙げられる.(7) は,AmE で begin が to 不定詞でなく V-ing を取る頻度が高まり出している傾向が例となる.
理論的には,さらに変化の速度を考慮しなければならない.例えば (3) のように両変種で同方向の通時変化が生じている場合でも,変種間で変化の速度に差があれば結果として平行にはならないだろう.上記の類型論に速度という観点を持ち込むと,相当に細かい場合分けが必要になるはずである.このように複雑な課題は残っているが,2変種2時点を比較する "diachronic comparative corpus linguistics" の理論的原型として,上記の "typology of contrasts" は有用だろう.もちろん,このタイポロジーは,BrE と AmE において30年ほどという短期間に生じた通時変化だけでなく,近代以降の両変種の通時的発達を記述するモデルとしても有効である.広くは,[2010-10-09-1]の記事で扱った世界英語の convergence と divergence の問題にも適用できると思われる.
・ Leech, Geoffrey, Marianne Hundt, Christian Mair, and Nicholas Smith. Change in Contemporary English: A Grammatical Study. Cambridge: CUP, 2009.
・ Mair, Christian. Three Changing Patterns of Verb Complementation in Late Modern English: A Real-Time Study Based on Matching Text Corpora." English Language and Linguistics'' 6 (2002): 105--31.
2010-12-25 Sat
■ #607. Google Books Ngram Viewer [corpus][web_service][ame_bre][google_books][n-gram][statistics][frequency][lexicology]
Google がものすごいコーパスツールを提供してきた.Google Books Ngram Viewer は Google Labs 扱いだが,その規模と可能性の大きさに驚いた.2004年以来1500万冊の本をデジタル化してきた Google が,そのサブセットとなる520万冊の本,5000億語をコーパス化した.英語のほかフランス語,ドイツ語,ロシア語,スペイン語,中国語が含まれているが,英語では British English, American English, English, English Fiction, English One Million からサブコーパスを選択できる.最大の特徴は,指定した5語までの検索語の頻度を過去5世紀(1500--2008年)にわたって追跡し,グラフで表示してくれることだ.Google からの公式な説明はこちらの記事にある.
規模が大きすぎてコーパスとしてどう評価すべきかも分からないが,ひとまずはいじるだけで楽しい.上記の記事内にいくつかのサンプルがあるが,英語史的な関心を引くサンプルとして burnt と burned の分布比較があったので,English, American English, British English の3サブコーパスをグラフを出してみた.
次に,本年度の卒論ゼミ生の扱った話題を拝借し,一般に AmE on the street, BrE in the street とされる前置詞使用の差異を Google Books Ngram Viewer で確認してみた.American English と British English のそれぞれのサブコーパスから出力されたグラフは以下の通り.
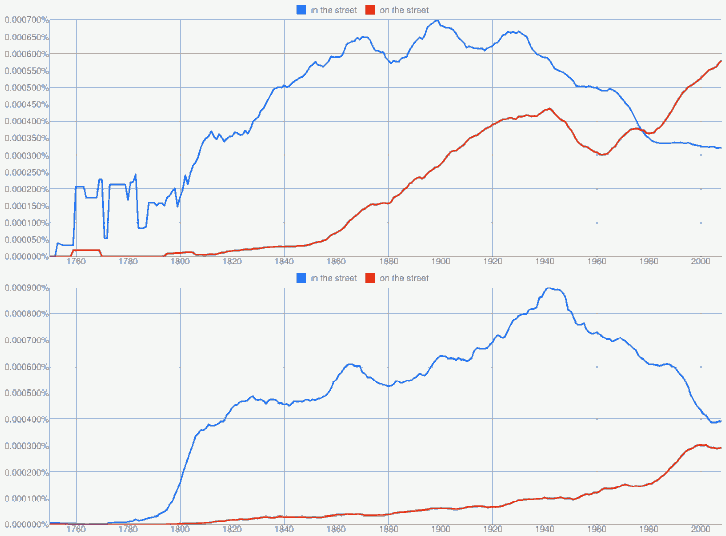
in と on の選択は句の意味(「街路で」か「失業して」か)などにも依存するため単純な形態の頻度比較では不十分だが,傾向はつかめる.
[2010-08-16-1], [2010-08-17-1]の記事で扱った gorgeous についても調べてみた.19世紀には流行っていたが20世紀には落ち目であったこの形容詞が,American English において1980年代以降,再び勢いを盛り返してきている状況がよくわかる.British English でも復調の兆しがあるだろうか?
コーパス言語学一般にいえるが,ツールの使用はアイデア次第である.文化史的な観点からは,[2009-12-28-1]の記事で紹介した American Dialect Society による "Words of the Century" や "Words of the Millennium" のノミネート語句を検索してみるとおもしろい.
他のオンラインコーパスについては[2010-11-16-1]を参照.
2010-11-16 Tue
■ #568. コーパスの定義と英語コーパス入門 [corpus][link][representativeness]
言語研究における corpus 「コーパス」は様々に定義されているが,McEnery et al. の定義が簡潔である.
. . . a corpus is a collection of (1) machine-readable (2) authentic texts (including transcripts of spoken data) which is (3) sampled to be (4) representative of a particular language or language variety.
(1) と (2) についてはおよそ研究者間にコンセンサスがあるが,(3) と (4) については何をもって "sampled" あるいは "representative" とみなすかについて様々な意見がある.しかし,大筋においてこの定義を受け入れることができるだろう.
手軽に英語コーパスを試すには,オンラインのものが便利である.以下は,(登録の必要なものもあるが)オンラインで簡便に利用できる英語コーパス.
・ British National Corpus (いくつかのインターフェースが提供されている)
* BNC ( The British National Corpus )
* BNCweb (要無料登録)
* BYU-BNC (要無料登録)
・ BYU Corpora ( Brigham Young University, Mark Davies 提供のその他のオンラインコーパス群)
* COCA ( Corpus of Contemporary American English ) (要無料登録)
* COHA ( Corpus of Historical American English ) (要無料登録)
* TIME Magazine Corpus of American English (要無料登録)
・ Cobuild Concordance and Collocations Sampler
その他,本ブログではコーパス関係の記事をいろいろと掲載しているので,参考にされたい.
・ hellog 内のコーパス情報の集約記事: [2010-09-15-1]
・ hellog 内のコーパス関連記事: corpus
・ hellog 内の BNC 関連記事: bnc
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
2010-10-15 Fri
■ #536. OED の引用データをコーパスとして使えるか (3) [oed][corpus][statistics]
[2010-10-10-1], [2010-10-14-1]に引き続き,OED の引用データの話題.今回は,特に昨日の記事[2010-10-14-1]の (2), (3) で取り上げた年代別引用数の浮き沈みの問題を意識する上で,数値をグラフに視覚化しておくと便利だと考えた.
Brewer は10年ごとに OED の引用数の推移を調べており,実際にグラフ化もしている (48--49) .しかし,論文内に提示されているグラフは1470年を境に二分されており,目盛り尺度も互いに異なっているので比較するにはやや不便である.そこで,以下に目盛り尺度を揃えたグラフを改めて作成してみた.Brewer にはグラフ作成のもとになる数値データは与えられていないので,グラフから目検討で数値を読み出し,それを頼りに作成した(← 本当は自ら OED で改めて数字を出せばいいのだけれど).したがって,ここに示されているものはあくまで傾向をとらえるためのものとして参考までに.
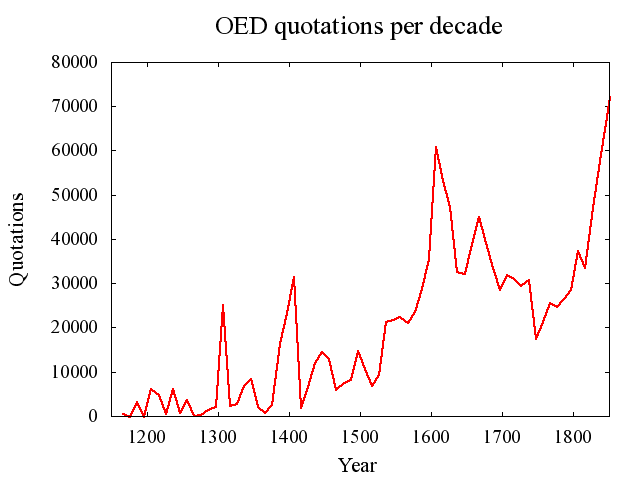
OED を通時コーパスとして用いる場合には,特に引用数が周囲より劇的に低かったり高かったりする時期からの引用に当たる際に注意が必要である.このグラフは,その際のお供として参照されたい.
・ Brewer, Charlotte. "OED Sources." Lexicography and the OED: Pioneers in the Untrodden Forest. Ed. Lynda Mugglestone. Oxford: OUP, 2000. 40--58.
2010-10-14 Thu
■ #535. OED の引用データをコーパスとして使えるか (2) [oed][corpus]
[2010-10-10-1]の記事では,Hoffmann の論文を参照して,OED の引用データは若干の注意は必要だが十分にコーパスとなりうるのではないかという説を見た.一方で,OED の引用は若干ではなく相当の注意を払わないと危ないという厳しい説がある.Brewer によれば,OED の引用データを,各時代を代表するコーパスとみなすことには慎重であるべきだという.Brewer は先行論文を参照しつつ様々な証拠を挙げて議論しているが,主なものを下にまとめてみる.
(1) 特定の文学作家,文学作品の引用が不釣り合いに多い.被引用数トップ5の作家は,Shakespeare, Walter Scott, Milton, Wycliffe, Chaucer.Shakespeare のカバー率は100%に近いと言われ,引用数は33304例を数える.第5位の Chaucer からの引用は11902例.被引用数トップの作品は,予想通りに聖書.第2位は1300年頃に書かれた長詩 Cursor Mundi で12772例を数える.有名な作家・作品についてはコンコーダンスが手に入りやすいために,引用が採用されやすいという事情があるという (45--47) .引用は言語を代表しているというよりも,編纂者の選択を表わしているというべきである.
Any inferences drawn from the OED coverage about the significance of these writers for the development and illustration of the English lexicon are flawed ones: the exceptionally full representation of their language in the dictionary is due at least as much to the lexicographers' consultation of the concordances as to the intrinsic qualities of these writers' diction. (51)
(2) 引用数を年代別にプロットすると c1581--1610 に引用が急激に増えている.また,19世紀前半も引用がうなぎ登りに増えている.この点については[2010-10-10-1]の (4) でも触れた.前者の時期については Shakespeare の引用が多いことと深く関連しており,必ずしもその時代の言語を代表しているということにはならないのではないか (47, 58) .後者の時期については,OED 制作のすぐ前の時代であり,必然的に容易に手に入る典拠の数が多いからである.
(3) 15世紀以前では 1291--1300, 1391--1400 の時期に引用のピークがあるが,1つには年代が不明確な作品については区切りのよい世紀の変わり目に切り上げたり切り下げたりすることがあり,それが反映された結果だという.別の理由としては,1300年頃に Robert of Gloucester (3222例)や Cursor Mundi (10771例)が,1400年頃に Trevisa (6750例)が集中したせいである (57--58) .
(4) OED に採用される見出し語は英語国のボランティア読者による単語収集とそのメモが元になっているが,ボランティアは普通でない語や普通でない意味を特に注意して集めるように指示されていた.". . . this resulted in partial reading and uneven representation of sources" (50).
(5) OED には初期近代英語期の辞書等から直接引用している見出し語が多くあるが,その辞書等の見出し語がすべて収録されているわけでなく,見出し語が取捨選択されている形跡がある.ある調査によると,1/5ほどが OED には収録されずに切り捨てられたという.ここでは,編纂者の恣意的な判断,おそらくは19世紀の進化観に裏打ちされた規範主義的な判断が入っていると考えられる (52--52) .
[2010-10-10-1]とあわせて OED の引用データをコーパスとしてみなしてよいかどうかについて賛否両論を見たが,1000年の歴史英語をカバーする扱いやすい通時コーパスが他に公開されていない以上,上に挙げたような点を意識したうえで OED を注意して用いる,ということ以外に答えはないように思える.
・ Brewer, Charlette. "OED Sources." Lexicography and the OED: Pioneers in the Untrodden Forest. Ed. Lynda Mugglestone. Oxford: OUP, 2000. 40--58.
Powered by WinChalow1.0rc4 based on chalow