2019-01-13 Sun
■ #3548. Parsed Corpus of Early English Correspondence (PCEEC) [corpus][emode][ceec]
現在取りかかっている研究テーマの調査のために,CoRD ( Corpus Resource Database ) の Parsed Corpus of Early English Correspondence (PCEEC) より情報を得て,The Oxford Text Archive (OTA) 経由で PCEEC を入手した.統語タグ付きコーパスとして提供されているものだが,複雑な統語環境の条件によるサーチは必要ないので,附属のプレーンテキストか品詞タグ付きテキストからなるコーパスで今回は十分に用を足しそうだ.しかし,必要とあらば検索ツール Corpus Search 2 を用いて凝ったサーチもできる.
このコーパスの元となっている Corpus of Early English Correspondence (CEEC) は,1996--98年にヘルシンキ大学にて編纂作業が進められたコーパスで,1410?--1681年の書簡テキストが送り手の情報とともに集積されている.96の書簡集からなり,書き手は778人,書簡は6039通,そして総語数が270万語に及ぶコーパスである.編纂の狙いは,社会言語学的な手法を歴史英語へ適用することにあった.
この CEEC からいくつかの姉妹コーパスが派生しており,その1つが統語タグ付きの PCEEC である.CEEC 自体は一般公開されておらず,一般に入手できるのは PCEEC と Corpus of Early English Correspondence Sampler (CEECS) のみである.PCEEC は,CEEC から著作権の関係で1/4ほどを取り除いたコーパスとなっている.
その他の(未公開)派生コーパスである,Corpus of Early English Correspondence Supplement (CEECSU) と Corpus of Early English Correspondence Extension (CEECE) も合わせて,量的な情報を一覧しておこう.
| Corpus | time covered | words | letters | writers | collections | published |
|---|---|---|---|---|---|---|
| CEEC | 1410?--1681 | 2.7 million | 6039 | 778 | 96 | ---- |
| CEECS | 1418--1680 | 0.45 million | 1147 | 194 | 23 | 1998 |
| PCEEC | 1410?--1681 | 2.2 million | 4979 | 657 | 84 | 2006 |
| CEECE | 1681--1800 | c. 2.2 million | c. 4900 | > 300 | 74 | ---- |
| CEECSU | 1402--1663 | c. 0.44 million | c. 900 | > 100 | 20 | ---- |
PCEEC について,時代区分を設けて語数をカウントすると以下の通り.
| Period | Date | Word count | Token count |
|---|---|---|---|
| M3 | 1350--1419 | 19,505 | 684 |
| M4 | 1420--1499 | 364,317 | 20,039 |
| E1 | 1500--1569 | 309,220 | 11,056 |
| E2 | 1570--1639 | 910,675 | 44,067 |
| E3 | 1640--1710 | 555,415 | 29,185 |
・ CEEC = Corpus of Early English Correspondence. Compiled by Terttu Nevalainen, Helena Raumolin-Brunberg, Jukka Keränen, Minna Nevala, Arja Nurmi and Minna Palander-Collin at the Department of Modern Languages, University of Helsinki. 1998.
・ PCEEC = Parsed Corpus of Early English Correspondence, parsed version. Annotated by Ann Taylor, Arja Nurmi, Anthony Warner, Susan Pintzuk, and Terttu Nevalainen. Compiled by the CEEC Project Team. York: University of York and Helsinki: University of Helsinki. 2006. Distributed through the Oxford Text Archive; Parsed Corpus of Early English Correspondence, tagged version. Annotated by Arja Nurmi, Ann Taylor, Anthony Warner, Susan Pintzuk, and Terttu Nevalainen. Compiled by the CEEC Project Team. York: University of York and Helsinki: University of Helsinki. 2006. Distributed through the Oxford Text Archive; Parsed Corpus of Early English Correspondence, text version. 2006. Compiled by Terttu Nevalainen, Helena Raumolin-Brunberg, Jukka Keränen, Minna Nevala, Arja Nurmi and Minna Palander-Collin, with additional annotation by Ann Taylor. Helsinki: University of Helsinki and York: University of York. 2006. Distributed through the Oxford Text Archive.
・ CEECS = Corpus of Early English Correspondence Sampler. Compiled by Compiled by Terttu Nevalainen, Helena Raumolin-Brunberg, Keränen, Minna Nevala, Arja Nurmi and Minna Palander-Collin at the Department of Modern Languages, University of Helsinki. 1998
[ 固定リンク | 印刷用ページ ]
2018-11-16 Fri
■ #3490. dreamt から dreamed へ [clmet][corpus][lmode][verb][conjugation][preterite][participle]
Is it 'Dreamed' or 'Dreamt'? と題する Merriam-Webster の語法記事を読んだ.dream の過去形(および過去分詞形)が dreamt から dreamed へと規則化してきた近現史に焦点が当てられている.
『メリアム・ウェブスター英英辞典』を含むいくつかの辞書では,dreamed の綴字のもとに /ˈdrɛmt, ˈdriːmd/ の2つの発音が記載されている.これは,動詞 dream の過去形・過去分詞形として dreamt/dreamed の両形態が交替可能であることを反映した併用・混用といえるだろうか.さすがに dreamt と綴って /ˈdriːmd/ と発音する旨の記述はない.(dreamt の発音の短母音については,「#2290. 形容詞屈折と長母音の短化」 ([2015-08-04-1]) を参照.)
上の語法記事には,19世紀前半にはすでに dreamed が優勢となっていたとの記述があったので,これを確かめるべく後期近代英語コーパス CLMET3.0 で例文を集めてみた(検索結果のテキストファイルはこちら).頻度を集計した結果は次の通り.
| Period (subcorpus size) | dreamt | dreamed |
|---|---|---|
| 1710--1780 (10,480,431 words) | 55 | 54 |
| 1780--1850 (11,285,587) | 75 | 137 |
| 1850--1920 (12,620,207) | 71 | 242 |
18世紀の大半を含む第1期には両形は互角だったが,確かに19世紀前半を中心とする第2期に dreamed が大きく伸張している.そして,19世紀後半以降には dreamed が dreamt をさらに圧倒していった.
とはいえ,現在に至るまで dreamt が「抹殺」されずにきたという事実を認識しておくことも重要である.言語変化は,個々の事例にもよるが,これほどゆっくり進むものである.
動詞の「規則化」あるいは「強弱移行」については,「#178. 動詞の規則活用化の略歴」 ([2009-10-22-1]) ,「#527. 不規則変化動詞の規則化の速度は頻度指標の2乗に反比例する?」 ([2010-10-06-1]) ,「#528. 次に規則化する動詞は wed !?」 ([2010-10-07-1]),「#764. 現代英語動詞活用の3つの分類法」 ([2011-05-31-1]),「#1287. 動詞の強弱移行と頻度」 ([2012-11-04-1]) を参照.逆の「不規則化」「弱強移動」については「#3385. 中英語に弱強移行した動詞」 ([2018-08-03-1]) を参照.
2018-10-24 Wed
■ #3467. 文献学における校訂の信頼性の問題 [philology][methodology][manuscript][punctuation][editing][corpus][evidence]
英語史・英語文献学に携わる者にとって,標題は本質的な問題,もっといえば死活問題でもある.この問題について,児馬 (31) が古英語資料との関係でポイントを要領よくまとめている.
OE資料を使う際に,校訂の信頼性という問題は避けて通れない.歴史言語学で引用されているデータ(例文)の多くは写本研究,すなわち写本から校訂・編集を経て活字となった版 (edition) か,ないしは,特に最近はその版に基づいた電子コーパスに基づくことが多い.そうした文献学研究の多大な恩恵を受けて,歴史言語学研究が成り立っていることも忘れてはならないが,と同時に,校訂者 (editor) の介入がオリジナル写本を歪めることもありうるのである.一つの作品にいくつか複数の写本があって,異なる写本に基づいた複数の版が刊行されていることもあるので,その点は注意しなければならない.現代と同じように,構成素の切れ目をわかりやすくしたり,大・小文字の区別をする punctuation の明確な慣習はOE写本にはない.行の区切り,文単位の区切りなどが校訂者の判断でなされており,その判断は絶対ではないということを忘れてはならない.ここでは深入りしないが,それらの校訂本に基づいて作成された電子コーパスの信頼性もさらに問題となろう.少なくとも,歴史言語学で使用するデータに関しては,原典(本来は写本ということになるが,せいぜい校訂本)に当たることが不可欠である.
上で述べられていることは,古英語のみならず中英語にも,そしてある程度は近代英語以降の研究にも当てはまる.文献学における「証拠」を巡るメタな議論は非常に重要である.
関連して,「#681. 刊本でなく写本を参照すべき6つの理由」 ([2011-03-09-1]) ,「#682. ファクシミリでなく写本を参照すべき5つの理由」 ([2011-03-10-1]),「#2514. Chaucer と Gawain 詩人に対する現代校訂者のスタンスの違い」 ([2016-03-15-1]),「#1052. 英語史研究の対象となる資料 (2)」 ([2012-03-14-1]),「#2546. テキストの校訂に伴うジレンマ」 ([2016-04-16-1]) .
・ 児馬 修 「第2章 英語史概観」服部 義弘・児馬 修(編)『歴史言語学』朝倉日英対照言語学シリーズ[発展編]3 朝倉書店,2018年.22--46頁.
2018-10-16 Tue
■ #3459. 16--17世紀の君主の称号は Grace か Highness か Majesty か? [eebo][corpus][title][address_term][honorific][monarch]
標題は「#3095. Your Grace, Your Highness, Your Majesty」 ([2017-10-17-1]) で取り上げた話題である.初期近代英語期のトピックなので,EEBO (Early English Books Online) で調査するのにふさわしいと思い,Early English Books Online corpus のインターフェースを用いて検索してみた.
検索欄には "your|his|her majesty|majestie|highness|grace" を入力し,検索結果として出力されたデータについて,所有代名詞の種類や異綴字は一緒くたに扱いつつ,GRACE 系,Highness 系,Majesty 系の3つに整理した.本来であれば実際の指示対象が君主か否かをコンコーダンスラインで逐一確認する必要があるのだが,今回はあくまで傾向を知るための粗い調査なので,あしからず.
| 1470s | 1480s | 1490s | 1500s | 1510s | 1520s | 1530s | 1540s | 1550s | 1560s | 1570s | 1580s | 1590s | 1600s | 1610s | 1620s | 1630s | 1640s | 1650s | 1660s | 1670s | 1680s | 1690s | Total | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GRACE | 65 | 133 | 145 | 92 | 69 | 130 | 319 | 622 | 544 | 773 | 1169 | 2124 | 1174 | 1682 | 1664 | 1483 | 1790 | 2088 | 3222 | 2296 | 3200 | 4092 | 3216 | 32092 |
| HIGHNESS | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 6 | 0 | 0 | 0 | 7 | 31 | 0 | 38 | 1922 | 1252 | 1328 | 2727 | 1360 | 8671 |
| MAJESTY | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 18 | 21 | 88 | 142 | 592 | 1856 | 7919 | 7753 | 6102 | 5463 | 12735 | 9012 | 51701 |
| Total | 65 | 133 | 145 | 92 | 69 | 130 | 319 | 622 | 544 | 773 | 1175 | 2142 | 1195 | 1770 | 1813 | 2106 | 3646 | 10045 | 12897 | 9650 | 9991 | 19554 | 13588 | 92464 |
傾向は明確である.16世紀中は GRACE がほぼ唯一の称号だが,17世紀に入ると MAJESTY が加速度的に増え,1630年代には GRACE を追い抜く.MAJESTY は James I の治世 (1603--25) の後半に確立したとされてきたが,今回の結果もほぼそれに合致している.一方,HIGHNESS は17世紀半ばに突如として増えてはくるが,他の2つより優勢になったことはない.
[ 固定リンク | 印刷用ページ ]
2018-09-18 Tue
■ #3431. 各種の EEBO 検索インターフェース [eebo][corpus][emode][site][web_service][link][n-gram][kwic]
初期近代英語期の膨大なテキストを収録した EEBO (Early English Books Online) について,「#3117. EEBO corpus がリリース」 ([2017-11-08-1]) で BYU 提供の EEBO 検索インターフェース Early English Books Online corpus を紹介した.
それとは別に,Early Modern Print: Text Mining Early Printed English というサイトのプロジェクトで,n-gram や KWIC などの検索インターフェースが提供されていることを知ったので紹介しておきたい.全体的なイントロは,こちらのページをどうぞ.個々の具体的なツールは,次のリンクからアクセスできる.
・ EEBO N-Gram Browser (説明はこちら)
・ EEBO-TCP Key Words in Context (説明はこちら)
・ EEBO-TCP and ESTC Text Counts
・ EEBO-TCP Words Per Year
また,University of Michigan の提供する Early English Books Online の各種サーチや Lancaster University による EEBO on CQPweb (V3) も同様に有用.
各種インターフェースのいずれを用いるか迷うところだ.
2018-09-08 Sat
■ #3421. 英語ことわざの文体・語彙的特徴を示す統計値 [proverb][statistics][corpus][stylistics]
「#3419. 英語ことわざのキーワード」 ([2018-09-06-1]) と「#3420. キーワードを含む英語ことわざ」 ([2018-09-07-1]) に引き続き,英語ことわざの話題.安藤邦男(著)『ことわざから探る 英米人の知恵と考え方』の紹介ページより取り出した866件の英語ことわざについて,その文体的・語彙的な特徴を数字で示してみたい.特徴を浮き彫りにするには,英語ことわざコーパスを,より大きな一般的なコーパスと比較する必要があるので,昨日と同様に100万語規模の British English 06 (BE06) を使用した.結果として,次のような基本的な統計値が得られた. * *
| Corpus | Proverbs | BE06 |
|---|---|---|
| tokens (running words) in text | 6,276 | 1,011,020 |
| types (distinct words) | 1,616 | 45,298 |
| type/token ratio (TTR) | 25.75 | 4.48 |
| standardised TTR | 45.25 | 43.90 |
| STTR std.dev. | 46.42 | 54.62 |
| STTR basis | 1,000 | 1,000 |
| mean word length (in characters) | 4.09 | 4.69 |
| word length std.dev. | 1.92 | 2.58 |
| sentences | 869 | 53,466 |
| mean (in words) | 7.22 | 18.91 |
| std.dev. | 2.86 | 14.38 |
| 1-letter words | 292 | 38,775 |
| 2-letter words | 1,020 | 168,273 |
| 3-letter words | 1,345 | 205,211 |
| 4-letter words | 1,370 | 166,961 |
| 5-letter words | 996 | 110,856 |
| 6-letter words | 553 | 88,195 |
| 7-letter words | 359 | 79,174 |
| 8-letter words | 163 | 56,645 |
| 9-letter words | 96 | 39,767 |
| 10-letter words | 53 | 26,170 |
| 11-letter words | 17 | 15,493 |
| 12-letter words | 6 | 8,208 |
| 13-letter words | 4 | 4,557 |
| 14-letter words | 1 | 1,687 |
| 15-letter words | 1 | 623 |
見るべき点として,まず "type/token ratio" を指摘しておこう.この数値が高いほど,コーパス内で異なる語が多く用いられていると解釈できる.純粋に数値を見ると,一般コーパスよりもことわざコーパスのほうが高い値を示しており,語彙が多様であると解釈できそうだが,「#2336. Text Analyser --- 簡易テキスト統計分析器」 ([2015-09-19-1]) で示したように,コーパスサイズが互いに大きく異なるので,この指標単独ではそれほど情報量はない.
"mean word length" と "word length std.dev." は1語当たりの文字数である.両コーパス間の違いはそれほど大きくないが,示唆的ではある.ことわざコーパスのほうが一般コーパスよりも,より短い綴字の単語を好むと解釈できるが,どんなものだろうか.確かに,いたずらに長い単語は一般コーパスよりも出にくいようには感じられる.
最もなるほどと感じさせられるのは,1文がいくつの単語から成り立っているかを示す "mean (in words)" とその "std.dev." だろう.これらの数値もコーパスサイズに依存するとはいえ,ことわざでは平均して7.22語,一般では18.91語というのは,差が歴然としている.標準偏差も合わせて考えると,ことわざを構成する1文は全体的に短いことが分かる.「短く,語呂がよくてなんぼ」というのが,ある意味ではことわざの形式的な特徴でもあるから,この結果はまったく不思議ではないが,こうして客観的に数値を目の当たりにするとおもしろい.
・ 安藤 邦男 『ことわざから探る 英米人の知恵と考え方』 開拓社,2018年.
[ 固定リンク | 印刷用ページ ]
2018-09-06 Thu
■ #3419. 英語ことわざのキーワード [proverb][keyword][statistics][corpus]
今年6月に開拓社より出版された安藤邦男(著)『ことわざから探る 英米人の知恵と考え方』の紹介ページに,同著で言及された英語ことわざの索引や,その他の関連するリストが公開されている.こちらから英語のことわざ866件を取り出し,簡単にキーワード分析してみた. *
一般的な参照コーパスとして,British English 06 (BE06) を指定した.このコーパスについては「#1730. AmE-BrE 2006 Frequency Comparer」 ([2014-01-21-1]) で紹介しているが,端的にいえば2006年(頃)に出版されたイギリス英語の諸テキストからなる100万語規模のコーパスである.計算の結果,キーワード度数の高かった順に50の単語を挙げよう. *
is, makes, good, man, cannot, a, never, you, love, wise, better, thief, devil, ill, than, fool, horse, no, truth, fortune, sweet, adversity, evil, make, shall, travels, friend, every, don't, beauty, knows, not, money, neighbor, speak, words, will, worth, fair, hath, best, blind, deceives, dog, longest, comes, honor, man's, great, bread
上位語には機能語も多く入っているが,ことわざの文体の雰囲気をよく示しているように思われ,興味深い.cannot, never, you, than, no, shall, every, don't, not, hath などは,いかにもことわざと似合う機能語である.
それに劣らず内容語のラインナップもおもしろい.動詞では make, know, deceive というのがいかにもだし,名詞では man, thief, devil, fool, horse, truth, fortune, adversity, evil, friend, beauty, money, neighbor, words, dog, honor, bread など,思わず首肯してしまうものばかりだ.形容詞や副詞では,good, better, best, ill はもちろんのこと,wise, fair, blind, longest などには納得させられる.善悪,真偽,賢愚の対比や比較により,道徳上・生活上の知恵を授けるという英語ことわざの本質が見えてくるようなキーワードだ.
このような文体に関わるキーワード分析は,極めて客観的でありながら,往々にして直観に適う結果が出る(あるいはそれ以上に発見がある)という点でおもしろい.ほかにも,「いかにもなキーワード」シリーズの記事として,「#317. 拙著で自分マイニング(キーワード編)」 ([2010-03-10-1]),「#518. Singapore English のキーワードを抽出」 ([2010-09-27-1]),「#880. いかにもイギリス英語,いかにもアメリカ英語の単語」 ([2011-09-24-1]),「#2332. EEBO のキーワードを抽出」 ([2015-09-15-1]) を参照.歴史英語の通時的なキーワード分析については,初期中英語コーパス LAEME を利用した Hotta (2013) 論文もある.
・ 安藤 邦男 『ことわざから探る 英米人の知恵と考え方』 開拓社,2018年.
・ Hotta, Ryuichi. "Representativeness, Word Frequency, and Keywords in the LAEME Corpus." Journal of the Faculty of Letters: Language, Literature and Culture 112 (2013): 67--84.
2018-04-22 Sun
■ #3282. The Parsed Corpus of Middle English Poetry (PCMEP) [corpus][me][hc][ppcme][laeme][link]
中英語の韻文を集めた統語タグ付きコーパスをみつけた.The Parsed Corpus of Middle English Poetry より編纂者 Richard Zimmermann 氏の許可を得て利用できる.
現段階で,同コーパスは41のテキスト,160,432語からなっている(テキスト・リストはこちら).カバーする時代範囲は c. 1150--1420年,すなわち Helsinki Corpus の区分でいえば M1, M2, M3 に相当する時代である.統語タグは Penn Parsed Corpora of Historical English と同じ方法で付されており,Corpus Search 2 などのツールを用いて解析できる.
Related Corpora のページの情報も有用.そこにある中英語に関する各種コーパスやデータベースへのリンクを,以下にも張りつけておきたい.
・ The Penn-Parsed Corpus of Middle English
・ The Corpus of Middle English Prose and Verse
・ The Innsbruck Corpus of Middle English Prose
・ A Parsed Linguistic Atlas of Early Middle English (P-LAEME)
・ Database of Middle English Romance
アンテナ張りを怠っているうちに,いろいろなプロジェクトや成果物が現われていたのだなという感慨.
2018-03-11 Sun
■ #3240. Singapore English における used to (過去)ならぬ use to (現在) [singapore_english][auxiliary_verb][corpus][ice]
「#735. なぜ助動詞 used to に現在形がないか」 ([2011-05-02-1]) の記事で,「?したものだった」を意味する used to という過去の助動詞がありながら,なぜ「(現在)?する習慣がある」ほどを意味する現在の助動詞 use to がないのかについて考えた.そこでは,use to は実際のところ歴史的には文証されるのだが,現在までに廃用となったと述べた.
しかし,Milroy and Milroy (89) に次のような言及を見つけ,へぇーと感じた.
One syntactic feature which is very characteristic of Singaporean English and appears to be gaining currency, even in written varieties, is the expression use to as a mark of habitual aspect. Thus, all Europeans use to go there is glossed as 'Europeans commonly go there'.
ということで,「#518. Singapore English のキーワードを抽出」 ([2010-09-27-1]) で利用した Singapore English のコーパス (ICE-SIN) で調べてみたら,2例のみではあるが,関係する例文が見つかった.1つめの例は,Singlish の使用について複数の話者が討論している文脈からの例である.どのような場面で Singlish を用いるかという話題のなかで,話者 B が「(Singlish を)話すのが普通という時と場所があると思う」と述べている.
C: There are many informal situations in the home where Singlish is used. You see I feel very much that this discussion is kind of passe really is uh we're we're being a bit old-fashioned here in discussing discussing Singlish in the first place
B: No I think there's a time and place where I use to speak
D: There is a time and place precisely
もう1つの例文は,"Fortunately for me, nice and satisfied clients use to write me complimentary letters." である.前後の文脈が現在・習慣を表わすものであることは確認済みであり,過去の used to の発音・綴字上の代用としての use to ではない.
なお,同コーパスでは,当然のことながら過去の used to の例も数多くヒットする.
・ Milroy, Lesley and James Milroy. Authority in Language: Investigating Language Prescription and Standardisation. 4th ed. London and New York: Routledge, 2012.
2018-02-01 Thu
■ #3202. 英語歴史語用論における有望な分野 [pragmatics][historical_pragmatics][speech_act][discourse_analysis][corpus]
英語歴史語用論の第1人者である Jucker が,ハンドブックの1節で,この分野において前途が明るいと考える話題を3つ挙げている.発話行為 (speech_act) の歴史的変化,対話 (dialogue) の形式の発展,談話の領域の発展である.研究課題を選ぶ際の参考となるよう,関連する箇所を引用しておきたい.
At present, three areas of research appear to be particularly promising. First, the research on the history of speech act has only just started to attract more than just occasional research efforts. . . .
Second, the research of the evolution of forms of dialogue is still in its infancy. . . . Culpeper and Kytö (2010: 2) [= Culpeper, Jonathan and Merja Kytö:. Early Modern English Dialogues: Spoken Interaction as Writing. Cambridge: CUP, 2010.] ask: "what was the spoken face-to-face interaction of past periods like?" in a systematic way and approach this question from various angles. In particular they look at the structure of conversations, at what they call "pragmatic noise", i.e. pragmatic interjections or discourse markers, and social roles and gender in interaction.
And third, the evolution of domains of discourse appears to be a very promising field of research. The existing work on courtroom discourse, the discourse of science and news discourse needs to be continued, and other domains should be tackled.
特に今世紀に入ってから,英語歴史語用論の研究を念頭においた,あるいはその目的で利用できるコーパスの編纂も多く行なわれるようになってきた.例えば,Corpora of Early English Correspondence (CEEC), Corpus of Early English Medical Writing (CEEM), Corpus of English Dialogues 1560-1760 (CED), Corpus of English Religious Prose (COERP), Old Bailey Corpus (OBC), The Corpus of Early English Recipes (CoER) などを挙げておこう.ほかにも Corpus Resource Database (CoRD) を探索されたい.
・ Jucker, Andreas H. "Linguistic Levels: Pragmatics and Discourse." Chapter 13 of English Historical Linguistics: An International Handbook. 2 vols. Ed. Alexander Bergs and Laurel J. Brinton. Berlin: Mouton de Gruyter, 2012. 197--212.
2018-01-12 Fri
■ #3182. ARCHER で colour と color の通時的英米差を調査 [ame_bre][spelling][archer][corpus][mode][webster]
意外と簡単にできる調査として,標題の例を紹介したい.近代英米語コーパス「#1802. ARCHER 3.2」 ([2014-04-03-1]) を用いて,綴字の英米差の通時的な調査を手軽に行える.例として,最も知られている <colour> と <color> の英米差を調べてみよう.
ARCHER Untagged にアクセスし,検索欄に "colour*" と "color*" 入れ,それぞれの結果を取り出す.それを「#1808. ARCHER 検索結果の時代×ジャンル仕分けツール (ARCHER Period-Genre Sorter)」 ([2014-04-09-1]) にかけて,自動的に4つの図表を作成させる.この図表により,両綴字の英米差について,1600--1999年を8区分した時代別に,そして12のジャンル別に比較することが可能となる.時代区分とジャンルは以下の通り.
・ P1 = 1600--49, P2 = 1650--99, P3 = 1700--49, P4 = 1750--99, P5 = 1800--49, P6 = 1850--99, P7 = 1900--49, P8 = 1950--99
・ a = advertising, d = drama, f = fiction, h = sermons, j = journals, l = legal, m = medicine, n = news, p = early prose, s = science, x = letters, y = diaries
では,まずイギリス英語からみていこう.上の図表が伝統的なイギリス式の <colour> の数値を示し,下が典型的にアメリカ式スペリングといわれる <color> の数値である.期待を裏切らず,イギリス英語では時代にかかわらず,ほぼ <colour> 一辺倒といってよい.
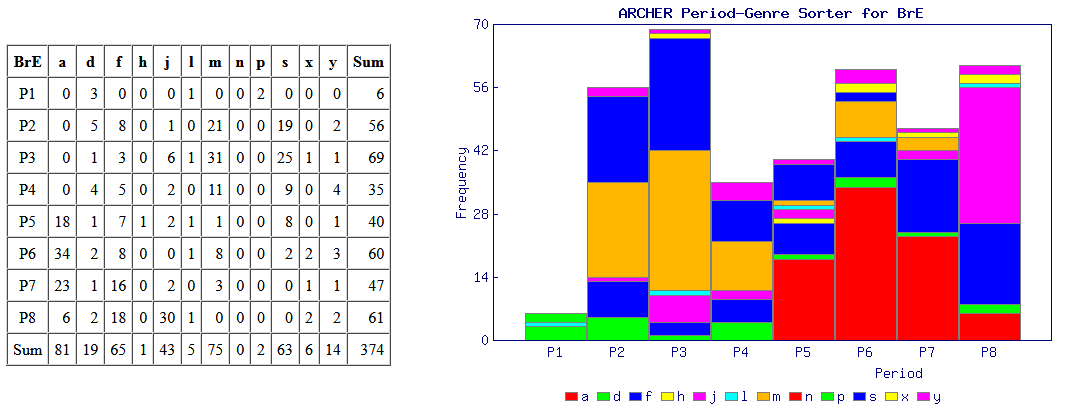
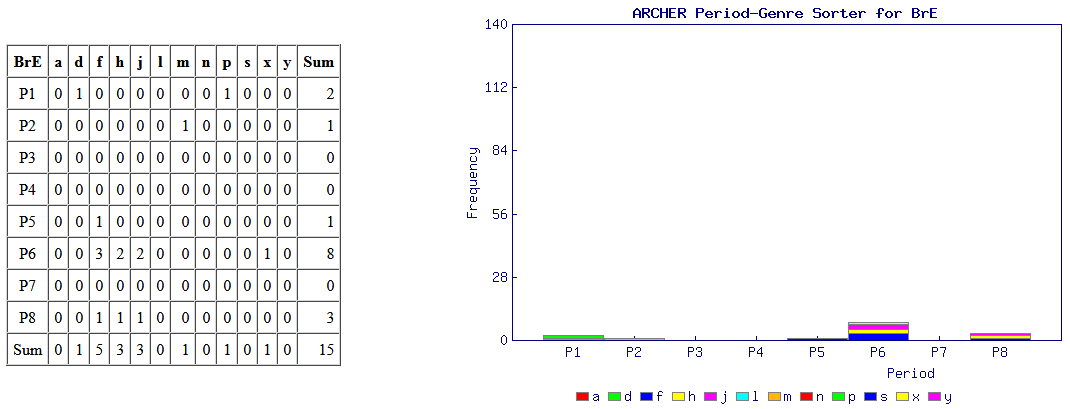
次にアメリカ英語の結果だが,こちらも英語史の期待を裏切らない.P4(1750--99年)までは伝統を受け継ぐ <colour> の綴字が圧倒的だが,P5 以降は著しく衰退し,代わりに <color> が伸びていく.P5 といえば,Noah Webster が An American Dictionary of the English Language を出版した1828年を含む半世紀の時代区分であり,米国式スペリングがその後数十年の時間をかけつつ定着していく様をよく表わしている.
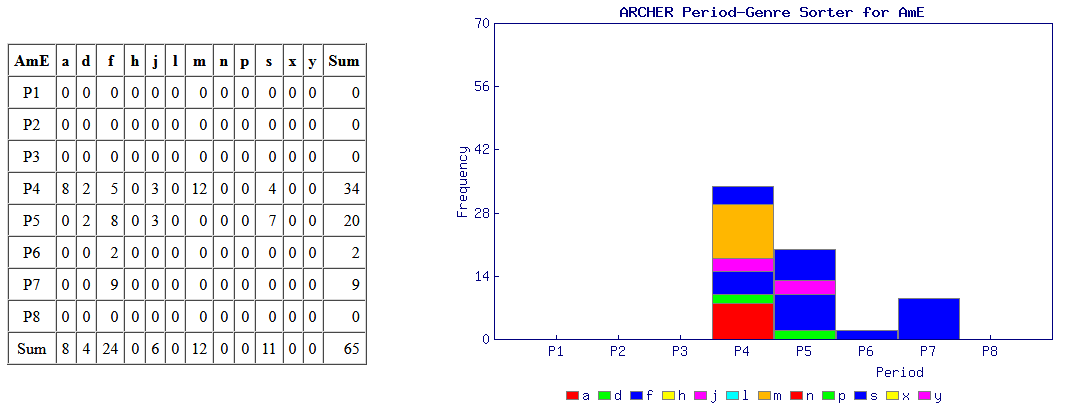
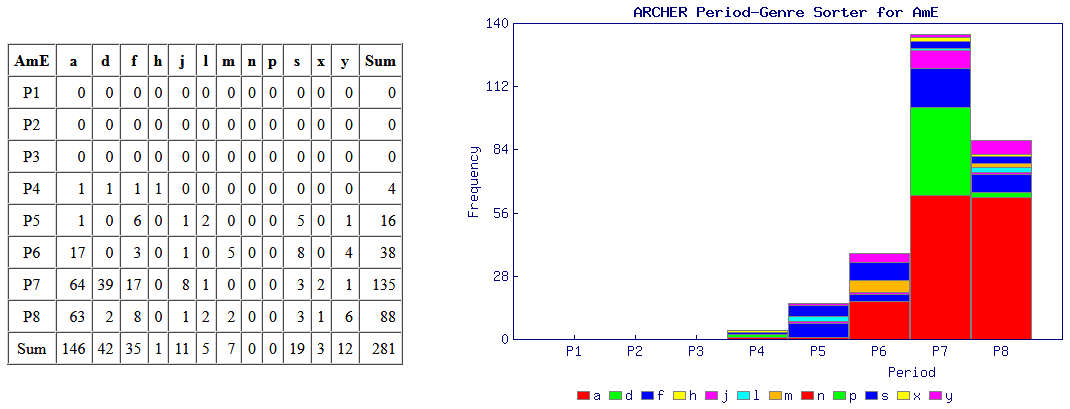
現在は超巨大な Google Books Ngram Viewer に簡単にアクセスできるため,ARCHER よりもさらに簡便に同じような調査を行えるようになっている.しかし,ARCHER ではコンコーダンス・ラインを引き出せるために文の中身を吟味することもできるし,ヒット件数が手作業でまかなえるほどに抑えられるというのも,考えようによっては利点といえる.要は使い方次第だ.ARCHER を使用した他の調査例として,「#1806. ARCHER で shew と show」 ([2014-04-07-1]),「#1807. ARCHER で between と betwixt」 ([2014-04-08-1]),「#1752. interpretor → interpreter (2)」 ([2014-02-12-1]) も参照.
2018-01-04 Thu
■ #3174. 高頻度語はスペリングが短い (2) [frequency][spelling][orthography][zipfs_law][statistics][lexicology][corpus]
昨日の記事 ([2018-01-03-1]) と同じ頻度とスペリングの長さに関するデータを,もう少し分析してみた.以下は,頻度ランキングのトップ100語,200語,500語,1000語,2000語,5000語,10000語,20000語,50000語について,それぞれ最低値,第1四分位数,中央値,平均値,第3四分位数,最大値を示した表である.英語の正書法を論じる上での基礎データとしてどうぞ.
| Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max. | |
|---|---|---|---|---|---|---|
| Top_100 | 1.0 | 2.0 | 3.0 | 3.1 | 4.0 | 5.0 |
| Top_200 | 1.00 | 3.00 | 4.00 | 3.77 | 4.00 | 10.00 |
| Top_500 | 1.000 | 4.000 | 4.000 | 4.498 | 5.000 | 10.000 |
| Top_1K | 1.000 | 4.000 | 5.000 | 4.968 | 6.000 | 15.000 |
| Top_2K | 1.000 | 4.000 | 5.000 | 5.406 | 7.000 | 15.000 |
| Top_5K | 1.000 | 5.000 | 6.000 | 6.014 | 7.000 | 16.000 |
| Top_10K | 1.000 | 5.000 | 6.000 | 6.488 | 8.000 | 16.000 |
| Top_20K | 1.000 | 5.000 | 7.000 | 6.954 | 8.000 | 17.000 |
| Top_50K | 1.000 | 6.000 | 7.000 | 7.622 | 9.000 | 20.000 |
これをもとに視覚化したのが,以下の箱ひげ図.
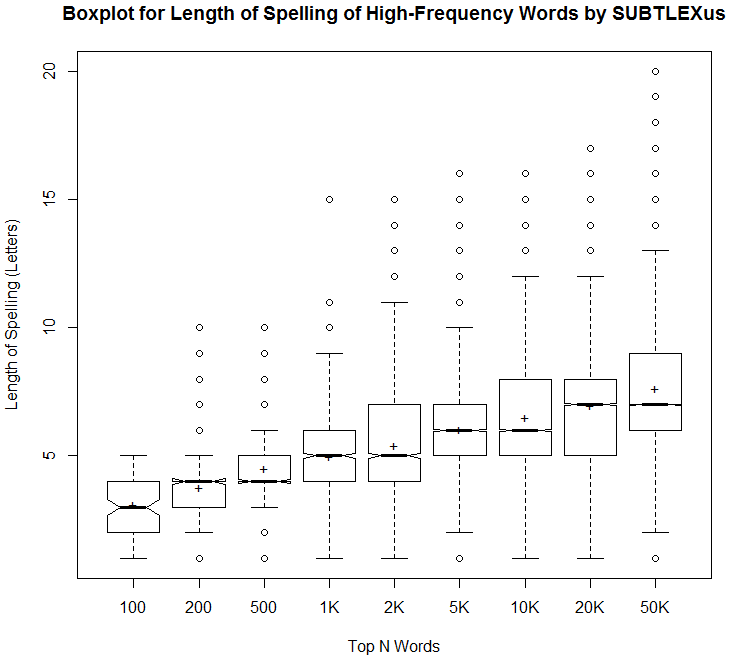
当然予想されたことだが,語数が増えるにしたがってスペリングの平均の長さは徐々に大きくなっていき,バラツキも広がっていく.しかし,トップ数万語でみても平均して7文字程度となっており,さほど長くないのだなという印象を受けた.
[ 固定リンク | 印刷用ページ ]
2018-01-03 Wed
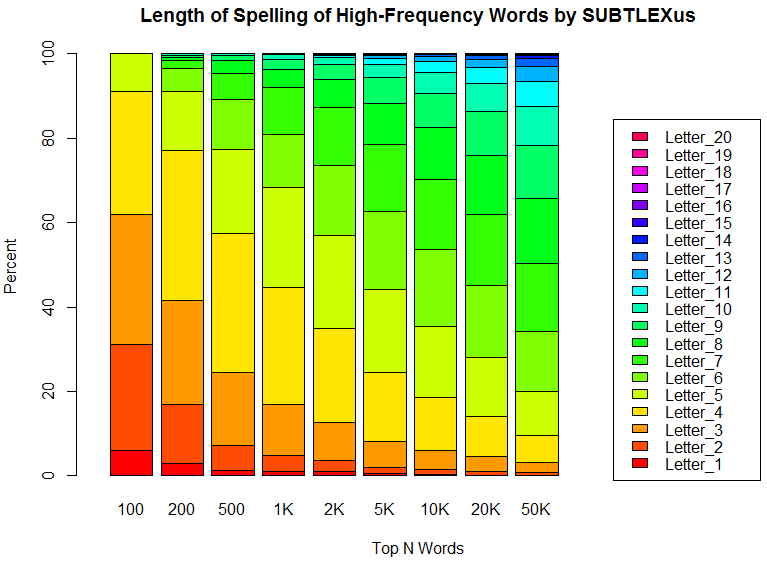
■ #3173. 高頻度語はスペリングが短い (1) [frequency][spelling][orthography][zipfs_law][statistics][lexicology][corpus][three-letter_rule]
標題は特に目新しい指摘ではなく,英語を読み書きする者には直感されていることだと思われる.「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]) や「#1102. Zipf's law と語の新陳代謝」 ([2012-05-03-1]) でも指摘したように,よく読み書きする単語のスペリングは短いほうが効率がよいと考えられるからだ.逆に,滅多に読み書きしない単語であれば少々長くても我慢できる.単語のスペリングに限らず,単語の音形についても同様の原理が作用していると思われる.
また,英語の正書法には内容語は3文字以上で綴られなければならないという「#2235. 3文字規則」 ([2015-06-10-1]) がある.これは機能語という頻度のきわめて高い語類については適用されない.したがって,この規則は上記の効率の問題とも関わる実用的な側面をもつといえる.
高頻度語であればあるほど,そのスペリングが平均的に短いことを示す方法の1つに,頻度ランキングのトップ100語,1000語,10000語などのリストに基づき,文字数別に単語を数え上げるというやり方がある.「#2096. SUBTLEX-US Word Frequency List」 ([2015-01-22-1]) から引き出した頻度ランキングを利用して,トップ100語,200語,500語,1000語,2000語,5000語,10000語,20000語,50000語について調査した.トップ100語のリストについては先の記事でリストを掲載している通りであり,なかには s, ll などコーパスの仕様に由来するとおぼしき怪しい「語」もあるが,結果の大勢には影響を及ぼさないだろう.
以下にグラフで整理した通り,結果は明白である(数値データはソースHTMLを参照).トップ100語の超高頻度語群では62.00%までが3文字以下のスペリングである.3文字以下の割合(下から3つ分のオレンジの帯まで)ということで比べていくと,トップ200語から50000語の調査結果まで,順に41.50%, 24.60%, 17.00%, 12.65%, 8.06%, 6.01%, 4.55%, 3.20%と目減りしていく.
2017-11-08 Wed
■ #3117. EEBO corpus がリリース [eebo][corpus][web_service][site]
本ブログでも何度か利用していたテキスト・データベース EEBO (Early English Books Online) が,BYU の Mark Davies 氏によりコーパス化され,この10月にオンラインで公開された.Early English Books Online corpus よりアクセスできる.
簡単にこのコーパスを紹介すると,まず規模としては "755 million words in more than 25,000 texts from the 1470s to the 1690s" を含む,巨大コーパスであることがわかる.時代としては初期近代英語をまるまるカバーしている.BYU系の他のコーパスと同様に,見出し語化がなされており,品詞タグや意味タグも賦与されている.コンコーダンス・ラインを出したり,共起表現を分析することはもとより,10年ごとに検索語句の頻度を自動的にグラフ化するなど,様々な機能が備わっている.
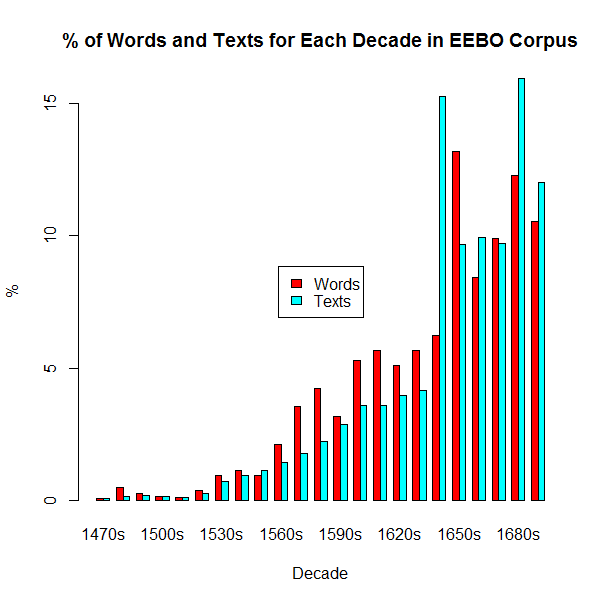
10年のまとまりごとのテキスト数や総語数の情報は,上のページのインフォメーションから容易に得られるが,第4列に1テキスト辺りの平均語数を加えた表を示そう.
| Decade | #words | #texts | #words/#texts |
|---|---|---|---|
| 1470s | 712,130 | 18 | 39,562.8 |
| 1480s | 3,706,937 | 43 | 86,207.8 |
| 1490s | 1,992,503 | 49 | 40,663.3 |
| 1500s | 1,288,091 | 45 | 28,624.2 |
| 1510s | 946,117 | 35 | 27,031.9 |
| 1520s | 3,042,934 | 73 | 41,684.0 |
| 1530s | 7,099,997 | 181 | 39,226.5 |
| 1540s | 8,709,681 | 239 | 36,442.2 |
| 1550s | 7,219,423 | 283 | 25,510.3 |
| 1560s | 16,084,901 | 361 | 44,556.5 |
| 1570s | 26,927,229 | 442 | 60,921.3 |
| 1580s | 31,955,245 | 558 | 57,267.5 |
| 1590s | 24,105,385 | 723 | 33,340.8 |
| 1600s | 40,031,223 | 898 | 44,578.2 |
| 1610s | 42,901,535 | 894 | 47,988.3 |
| 1620s | 38,550,967 | 994 | 38,783.7 |
| 1630s | 42,826,013 | 1,036 | 41,337.9 |
| 1640s | 47,129,000 | 3,805 | 12,386.1 |
| 1650s | 99,452,875 | 2,416 | 41,164.3 |
| 1660s | 63,491,742 | 2,481 | 25,591.2 |
| 1670s | 74,600,805 | 2,421 | 30,814.0 |
| 1680s | 92,583,947 | 3,977 | 23,279.8 |
| 1690s | 79,719,722 | 2,999 | 26,582.1 |
| TOTAL | 755,078,402 | 24,971 | 30,238.2 |
全期間にしめる各10年間の値を百分率でグラフ化してみた.赤は単語数,水色はテキスト数に基づいた数値である.いずれも16世紀から17世紀にかけてサブコーパスが大きくなっているのが分かるが,単語数は1650年代と1680年代,テキスト数は1640年代と1680年代が際立っていることを気に留めておきたい.
2017-03-12 Sun
■ #2876. 英語語彙の頻度分布に関する格差上位1%のシェア [lexicology][statistics][frequency][corpus]
昨日の記事「#2875. 英語語彙の頻度分布の格差をジニ係数とローレンツ曲線でみる」 ([2017-03-11-1]) に引き続き,英語語彙頻度の格差について考えてみたい.昨日扱ったジニ係数よりも直感的に格差を認識できる指標として,格差上位1%のシェアというものがある.経済学でいえば,トマス・ピケティも愛用している「トップ富裕層の所得シェア」である.大金持ちがどのくらい金持ちか,という指標と理解すればよい.英語語彙について言えば,生起頻度でトップ1%に入るそれほど多くない語によって,全体のどのくらいのシェアが占められているかを示す指標となる.
昨日と同じように,総頻度数が81.5万ほどの比較的小規模な GSL の語彙頻度表と,1850万ほどの巨大コーパス「#1424. CELEX2」 ([2013-03-21-1]) に基づく語彙頻度表で計算してみた.トップ1%とトップ0.1%での値は,以下の通り.
| GSL | CELEX2 | |
|---|---|---|
| 1% | 47.05% | 69.36% |
| 0.1% | 14.60% | 43.57% |
実際,ここまで高い値になるとは予想していなかった.英語学習という観点からみると,極端な話し,高頻度語のトップ1%を暗記すれば,5?7割ほどの語が認識できることになる.それでテキストを理解できるかというと,それはまったく別問題ではあるが,語彙学習の効率について再考させられる.
参考までに,2000年の時点での日米の所得シェアを見てみると,アメリカではトップ0.1%の富裕層が所得全体の7%ほど,日本では2%ほどである(吉川,p. 226).近年,両国ともに格差は開いてきているようだが,さすがに語彙の世界ほどの格差に至ることはないだろう.語彙の社会は,あらためて不平等な社会である.
・ 吉川 洋 『人口と日本経済』 中央公論新社〈中公新書〉,2016年.
[ 固定リンク | 印刷用ページ ]
2017-03-11 Sat
■ #2875. 英語語彙の頻度分布の格差をジニ係数とローレンツ曲線でみる [lexicology][statistics][frequency][zipfs_law][corpus]
「#1103. GSL による Zipf's law の検証」 ([2012-05-04-1]) で,General Service List (GSL) の最頻2000語余りの語彙頻度表を用いて,zipfs_law が成立する様子を実演した.頻度順位の高い少数の語がただの高頻度語ではなく超高頻度語であること,一方でそれ以外の大多数の語がおしなべて低頻度語であるということが確認された.このことは,英語(そして,おそらくあらゆる言語)の語彙の頻度分布がきわめて不平等・不均衡であり,大きなばらつきと格差に特徴づけられていることを示すものである.
このような分布の格差を示す代表的な指標に,イタリアの経済学者ジニが所得や資産の分布の不平等を計測する指標として1936年に考案したジニ係数 (Gini's coefficient) がある.考え方は次の通りだ.X軸に沿って左から右へ最も頻度の低い語から高い語へと順に並べ,その累積頻度のシェアをY軸方向に取っていく.この点をつなげると,何らかの形の右肩上がりの曲線となる.これをローレンツ曲線 (Lorenz curve) という.すべての語が同頻度で現われるときにはローレンツ曲線は45度の右肩上がりの直線となり「完全平等」を示す.逆に,極端な例として,1つの語のみが生起頻度のすべてを占有し,他のすべての語が頻度ゼロの場合に「完全不平等」となり,ローレンツ曲線は左右逆L字型となる.普通は,ローレンツ曲線は,45度の右肩上がりの線の下部に,三日月形の弧として描かれる.ジニ係数は,三日月の面積と,45度の右肩上がりの線を直角の対辺とする直角二等辺三角形の比率として表現される.したがって,値0が完全平等,値1が完全不平等ということになる.
さて,GSL のデータファイルで計算した結果,ジニ係数は0.812と出た.ローレンツ曲線を描くと,以下のようになる.
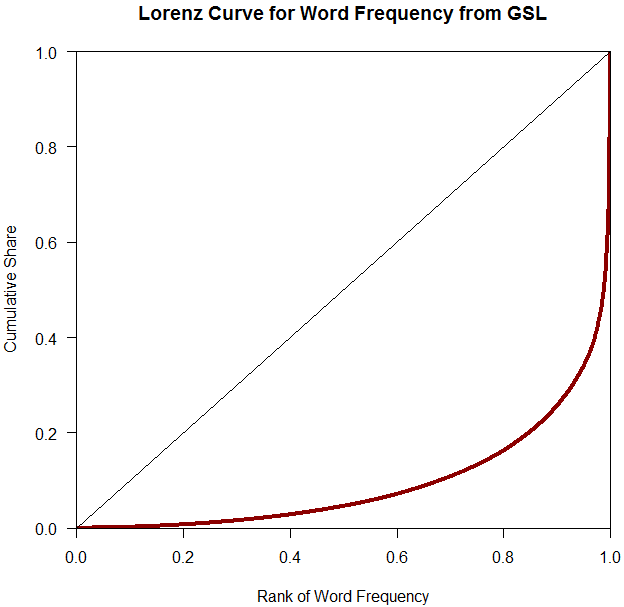
明らかに不平等な分布といえる.ちなみに,GSL よりも巨大なコーパスの語彙頻度表を使うと,さらにジニ係数は上がる(例えば,1790万語からなるコーパス「#1424. CELEX2」 ([2013-03-21-1]) に基づいた計算では,0.950 というすさまじい値が出た!).
参考までに,吉川 (122) に拠って2010年の諸国の所得格差を示すジニ係数をいくつか挙げると,日本が 0.336,アメリカが 0.380,チリが 0.510,アイスランドが 0.246 である.語彙の社会が極めて不平等な社会であることが分かるだろう.
・ 吉川 洋 『人口と日本経済』 中央公論新社〈中公新書〉,2016年.
2016-12-05 Mon
■ #2779. コーパスは英語史研究に使えるけれども [hel_education][corpus][methodology][philology][representativeness]
歴史言語学とコーパス使用とは相性がよいと言われる.例えば英語史で考えれば,歴史的なテキストは有限であるから,すべてを電子的に格納すれば,文字通り網羅的に調査することができる.従来の英語史記述研究も,電子的でこそなかったが,特定のテキスト群を調査対象としてきた点では,同じ「コーパス」研究だったという事情もある.現在では,ますます多くの研究者が電子コーパスとその関連ツールを用いて研究しているし,この潮流は間違いなく一層発展していくだろう.
しかし,注意すべきこともある.英語コーパス言語学の入門書を著わしたリンドクヴィスト (197) が次のように述べている.
1990年以降,歴史言語学者にとってコーパスは非常に重要なツールとなりました.手作業で文献から用例を収集しなければならなかった一昔前よりも,かなり効率よく用例を捜し,傾向を探る手助けになります.とはいえ,歴史言語学では,現代言語のコーパスを使った研究以上に,元の文献に立ち返り,精査する必要があります(ただし古い時代では,その「元の文献」すら必ずしも原本ではなく複写であるかもしれず,さらにはその複写も,複数の写字生がときに自らの方言で改編して残したものの一つにすぎない可能性があります).こうした状況から,この種の歴史的なコーパス言語学は,ここ二,三百年の言語の研究とは性質を異にします.学生が古い時代の英語コーパス研究をしたいならば,英語史の授業との関連で行うのがよいでしょう.
引用に述べられている通り,とりわけ古い時代の言語を対象とする場合には,注意を要する.現代の言語を扱うかのような前提のままでいると,数々の問題にぶつかるからだ.例えば,英語史でいえば,初期近代英語以前では綴字が安定していない.ある単語を検索しようとしても,標準的な綴字がないので,考え得る様々な異綴りで検索してみる必要がある.また,文法的なタグ付けがなされている場合にも,現代英語と古英語・中英語とでは文法範疇も異なっているし,屈折語尾の種類も相違しているので,検索するにあたって事前に古い文法の知識が必須となる.要するに,先に古い言語に習熟していることが求められるのである.
さらに,引用で言及されている通り,「元の文献」の深い理解が不可欠であるにもかかわらず,コーパスを表面的に用いることに慣れてくると,得てして問題の深みに意識が向かなくなりがちだ.換言すれば,本文批評 (textual criticism) や文献学的なアプローチから疎遠になってしまう傾向がある.もちろん,コーパス自体が悪いというわけではなく,研究する者が,このことを意識的に自覚していればよいということではあるのだが,簡単ではない.
もう1つ,電子コーパス時代ならずとも問題になるが,コーパスの代表性 (representativeness) の問題が常にある.古い言語の場合には,現在に伝わるテキストは偶然に生き残ってきたという致し方のない事情があり,代表性の問題はことさらに深い.
古い時代の言語をコーパスで調査するということは,理論的にも実践的にも,一見するほどたやすくないということを理解しておきたい.関連して,以下の記事も参照.
・ 「#568. コーパスの定義と英語コーパス入門」 ([2010-11-16-1])
・ 「#363. 英語コーパス発展の3軸」 ([2010-04-25-1])
・ 「#368. コーパスは研究の可能性を広げた」 ([2010-04-30-1])
・ 「#1165. 英国でコーパス研究が盛んになった背景」 ([2012-07-05-1])
・ 「#307. コーパス利用の注意点」 ([2010-02-28-1])
・ 「#367. コーパス利用の注意点 (2)」 ([2010-04-29-1])
・ 「#1280. コーパスの代表性」 ([2012-10-28-1])
・ 「#2584. 歴史英語コーパスの代表性」 ([2016-05-24-1])
・ ハーンス・リンドクヴィスト(著),渡辺 秀樹・大森 文子・加野 まきみ・小塚 良孝(訳) 『英語コーパスを活用した言語研究』 大修館,2016年.
2016-12-03 Sat
■ #2777. 語彙の14年周期説? [lexicology][language_change][speed_of_change][schedule_of_language_change][n-gram][corpus]
Language trends run in mysterious 14-year cycles と題する記事をみつけた.非常におもしろい. *
Marcelo Montemurro と Damián Zanette による調査結果である.2人は「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) とコンピュータ・プログラムを用いて,1700年から2008年の間の常用される名詞の "popularity" の推移を探った.すると,14年周期で英単語の "popularity" が上がっては下がるということが繰り返されていることが分かったという.意味的に関連する語群は盛衰をともにするというパターンも見つかっているし,英語に限らずフランス語,ドイツ語,イタリア語,ロシア語,スペイン語などの言語でも似たような周期が確認されるというから驚きだ.
では,なぜこのような周期があり,そしてなぜ14年前後という間隔なのか.いくつかの語については,政治を含めた社会的な変化との連動の可能性が指摘されうるが,一般論として,なぜこのような周期があるのかは不明である.もちろん,この周期が無作為変動の誤差の範囲にとどまっているのではないかという疑念は残っており,さらなる調査が必要ではあろう.しかし,もし何らかの要因があるとすれば,それはいったい何なのか.研究者の1人は "an obvious cultural connection" は見られないとしている.
人間行動の反復性,流行の周期,言語行動の慣れや飽き,などの問題と関わるのだろうか.いずれにせよ,非常に不思議で,興味をそそる現象である.
2016-09-11 Sun
■ #2694. EDD Online (2) [dialect][web_service][corpus][lmode][lexicography][edd][dictionary]
「#868. EDD Online」 ([2011-09-12-1]) で紹介したように,Joseph Wright による The English Dialect Dictionary の電子化プロジェクトが Innsbruck 大学で進められていたが,つい最近完成したとの知らせを受けた.これまでウェブ上のサービスではアカウント取得が必要だったが,これで直接自由にアクセスできるようになった.こちらの EDD Online からどうぞ.
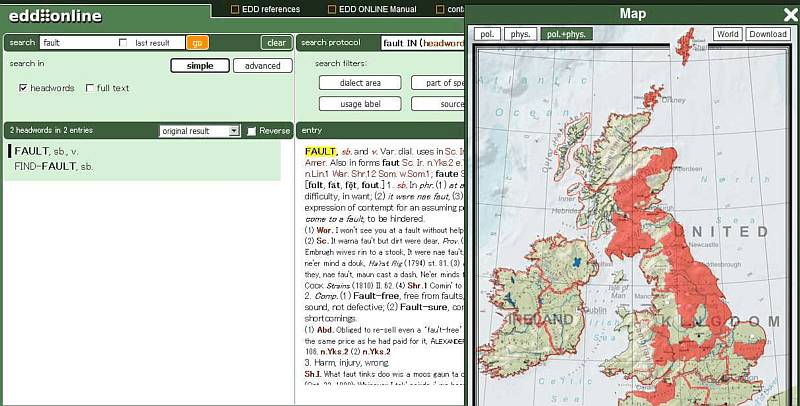
機能も充実しており,例えば上のスクリーンショットのように,検索語と関連して辞書内に言及されている方言地域を地図上で確認できる機能がある.ちょうど語源的綴字 (etymological_respelling) に関する調査の関係で,言及されている方言地域が地図上で確認できれば便利だろうと思っていた矢先だったので,嬉しい.
また,紙媒体の元祖 The English Dialect Dictionary のページをイメージとして確認することもできる.検索については,dialect area, part of speech, phonetic, etymology, usage label, source, morphemic, time span など各種カテゴリーによるサーチが可能.
利用マニュアルも閲覧できるので,参照しながらあれこれといじってみることをお薦めする.
・ Wright, Joseph, ed. The English Dialect Dictionary. 6 vols. Henry Frowde, 1898--1905.
2016-09-07 Wed
■ #2690. N-gram Tool [cgi][n-gram][statistics][corpus][web_service][frequency][cgi]
n-gram は,言語統計やコーパス言語学の世界における基本的な概念・手段である(「#2324. n-gram」 ([2015-09-07-1]), 「#956. COCA N-Gram Search」 ([2011-12-09-1]) を参照).テキストを指定してその n-gram を得るツールはネットその他にも遍在しているが,あえて簡易ツールをCGIで実装してみた.バックエンドに Perl モジュールの Text::Ngrams を用いている.
使い方はおよそ自明だろう.適当な長さの英文テキストを投げ込めば,デフォルトでは単語ベースの 3-gram (およびそれ以下の 2-gram と 1-gram も含む)の一覧が絶対頻度の高い順に返される(出力行の制限はなし).オプションにより単語ベースではなく文字ベースにも変更でき,n-gram のサイズも変えられる.出力については,頻度順ではなくアルファベット順にすること,出力行に制限を設けること,絶対頻度ではなく相対頻度(各 n-gram 内で合計すると1.0となる)で返すことも可能.
なお,1-gram は入力テキストを構成する単語の頻度表となるので,その用途にも利用できる.簡易的な n-gram ツールとしてどうぞ.
[ 固定リンク | 印刷用ページ ]
Powered by WinChalow1.0rc4 based on chalow