2021-01-04 Mon
■ #4270. 後期近代英語には -ly が2つ続く副詞 -lily がもっとあった [corpus][clmet][lmode][adverb][suffix][-ly][haplology]
「#4268. -ly が2つ続く副詞 -lily は稀である」 ([2021-01-02-1]) の記事で,接尾辞 -ly が2つついて -lily の形態を示す副詞が,現代英語においては稀であることを確認した.調音上の都合による haplology (重音脱落)の効果とみてよいだろう.
しかし,古い英語においても同じ「調音上の都合」が効いていたかどうかは別途調べなければならない.というのは,中英語テキストを読んでいると,-lily のような副詞に出会うことがままあるからだ.歴史の過程で haplology を経た形態が一般的になってきたのではないかと,私は疑っている.
まずは,現代の直近の時代である後期近代英語について調べてみたい.同時期のコーパス CLMET3.0 に登場してもらおう.このコーパスに対して,(いろいろ試行錯誤した挙げ句にたどりついた)"\B(?<!s)l[iy]l[yi](ch?)?(e(r|st)?)?\b" という Perl 対応の正規表現にて検索をかけてみた.その結果を,3つの時期ごとに整理したのが以下である.
・ 第1期(1710--1780年): surlily (11 times), livelily (3), sillily (2), immortalily (1), jollily (1) --- total 18 examples
・ 第2期(1780--1850年): surlily (13), holily (3), jollily (2), sillily (2), lovelily (1) --- total 21 examples
・ 第3期(1850--1920年): sillily (2), surlily (2), jollily (1), melancholily (1), lovelily (1), oilily (1), statelily (1) --- total 9 examples
前回の記事 ([2021-01-02-1]) で示した現代英語の BNCweb から取り出した事例と比べてみると分かるように,後期近代英語期にも -lily として現われる副詞の種類には緩い傾向がありそうだ.jollily, sillily, surlily などは低頻度ながらも,どの時期にも現われている.
約1億語からなる BNCweb から取り出せたのは実質的に15例,約3,400万語からなる CLMET から取り出せたのは48例.この単純な調査と比較だけで一般的に結論づけることはできないが,後期近代英語期では現代英語期よりも -lily 副詞が現われていた(許容されていた?)ようにみえる.
2020-12-29 Tue
■ #4264. XXX Made Easy というタイトル (2) [syntax][clmet][eebo][corpus]
昨日の記事 ([2020-12-28-1]) に引き続き続き,入門書などのタイトルに用いられる標記の表現について.昨今の本では定番文句となっているが,その走りがいつだったのか気になってきた.いくつかの歴史コーパスでざっと調べてみたが,そのうち2つを紹介.
まず現代にほど近い時期から.後期近代英語のコーパス CLMET3.0 で検索してみると,第3期 (1850--1929) から "Atheism made easy" が挙がってきた.さらにさかのぼって第1期 (1710--1780) からも Farriery made Easy なる例が得られた.
となれば,もっと早い時期の例を求めて初期近代英語期の EEBO corpus に当たってみたくなる.そこで探し出したのが,Thomas Edwards (1599--1647) なる著者が1644年に出した "Antapologia, or, A full answer to the Apologeticall narration of Mr. Goodwin, Mr. Nye, Mr. Sympson, Mr. Burroughs, Mr. Bridge, members of the Assembly of Divines wherein is handled many of the controversies of these times, viz. ... : humbly also submitted to the honourable Houses of Parliament" という本だ.(当時の本は,タイトルというよりは説明書きというべき,このように長いものが多い).その一部を引用する.
dialling made easy: or, tables calculated [.] # for the latitude of oxford, (but will serve without sensible difference for most parts of england:) by the help of which, and a line of chords, the hour-lines may quickly and exactly be described upon most sorts of useful dials: [.] # with some brief directions for making two sorts of spot-dials:
EEBO から取り出したこの文脈は完全なものではなく,明確には分からないところもあるのだが,dialling は日時計・羅針盤による時間測量の技術のことのようだ.すでに当時より XXX Made Easy が現代のような定番文句になっていたかどうかは怪しいにせよ,その走りの1例とみることはできるのかもしれない.
さらに中英語までさかのぼってみようと思ったが,ここで時間切れ.ここまででも十分にさかのぼった感あり.
2020-12-17 Thu
■ #4252. COCA と BNCweb でみる color vs colour [coca][bnc][corpus][ame_bre][spelling]
アメリカ式綴字 color とイギリス式綴字 colour をめぐる問題について,本ブログでは何度も取り上げてきた.綴字の米英差の代表例としてよく知られており,分かりやすい問題であるということもあるが,英語史的には意外と深掘りできる魅力的な問題だからでもある.
しかし,最も基本的な事実確認 --- 現代のアメリカ英語とイギリス英語で color と colour の各々の分布はどうなっているのかの調査 --- を行なわずいたことに気づいた.ということで,今回は現代アメリカ英語の代表的コーパス COCA と,イギリス英語の BNCweb で調べてみることにした.colo(u)r の屈折形,派生語,複合語を含めて網羅的に行なうのが理想だが,今回はレンマ検索を利用して,colo(u)r, colo(u)rs, colo(u)red (以上は屈折形として), colo(u)rful, colo(u)rless, discolo(u)r の6種類の語形の取り出しにとどめた.
| COCA による <color> と <colour> の頻度 | |||
| 語形 | <or> | <our> | <or> 比率 |
| COLOR | 124,778 | 4,792 | 0.9630 |
| COLORS | 33,225 | 1,886 | 0.9463 |
| COLORED | 5,553 | 179 | 0.9688 |
| COLORFUL | 10,871 | 412 | 0.9635 |
| COLORLESS | 1,000 | 57 | 0.9461 |
| DISCOLOR | 110 | 0 | 1.0000 |
| BNCweb による <color> と <colour> の頻度 | |||
| 語形 | <or> | <our> | <our> 比率 |
| COLOR | 115 | 11,332 | 0.9900 |
| COLORS | 24 | 4,396 | 0.9946 |
| COLORED | 14 | 2,432 | 0.9943 |
| COLORFUL | 6 | 1,093 | 0.9945 |
| COLORLESS | 4 | 166 | 0.9765 |
| DISCOLOR | 1 | 19 | 0.9500 |
COCA を用いたアメリカ英語の調査によれば,アメリカ式の <or> が,予想通りに圧倒的な95%前後の比率で用いられている.しかし,逆にいえば,5%ほどはイギリス式とされる <our> が用いられているというのも,とりわけ次のイギリス英語の状況と比較すると興味深い.
BNCweb を用いたイギリス英語の調査結果をみてみると,99%ほどというほぼ完全な比率でイギリス式の <our> が用いられている.アメリカ綴字を用いている少数の例を確認してみると,引用符に囲まれた短いタイトルらしきもの(アメリカ系由来の可能性があるもの)のなかで用いられているのが散見され,それを差し引いて考えることが許されるのであれば,さらに <our> は100%に近づく.この点では,イギリス英語のほうが綴字慣習についてより一貫しており,アメリカ英語は若干の寛容さを示すといえるかもしれない.
以上,標題の米英差の問題について事実確認した.
[ 固定リンク | 印刷用ページ ]
2020-12-04 Fri
■ #4239. oddly enough, interestingly enough などの表現における enough (2) [clmet][corpus][adverb][eurhythmy]
昨日の記事 ([2020-12-03-1]) に引き続き,文副詞となる oddly enough などの表現について.OED によると1704年に whimsically enough として初出したことが確認されるので,およそ後期近代英語期にかけて生まれ,育まれた表現である可能性が高い.とすれば,まず当たるべきコーパスは CLMET3.0 である.約3,400万語からなる,1710--1920年のイギリス英語のバランスコーパスだ.第1期 (1710--1780),第2期 (1780--1850),第3期 (1850--1929) と3期に分けて,関連する例を収集してみた.コンコーダンスラインはこちらからどうぞ(ただし,今回注目している用法ではなく「十分に?に」を意味する通常の用法の例も多く混じっているので精査する必要がある).
コンコーダンスラインをざっと眺めて気づくことは,18世紀の大半を含む第1期から,そこそこの数の例が挙がってくることだ.enough に前置される副詞として generously, gracefully, humorously などが散見される.いくつかランダムに例を示そう.
・ Generously enough, indeed, were I to be his; and had given him to believe that I would.--But that I have not done.
・ gracefully enough, I cannot but say; an advantage which travelled gentlemen have over other people.
・ These my father, humorously enough, called his beds of justice;
・ Footnote 82: Philelphus, absurdly enough, derives this Greek or Oriental jealousy from the manners of ancient Rome.
・ This was hastened by a temporary coalition between Fox and Pitt, which was occasioned, naturally enough, by the ill-treatment they had both received from the Duke of Newcastle.
第2期,第3期からも続々と例が挙がってくるが,現代的な oddly, strangely, curiously といった副詞との共起が目立ってくる.
・ Oddly enough, it happened. Mine honest friend Hector came in before dinner to ask a copy of my seal of Arms, with a sly kindliness of intimation that it was for some agreeable purpose.
・ Ha, ha, ha! [Taking Roope's arm.] Oddly enough---oddly enough, the story deals with the very subject we've been discussing.
・ His name was Agostino Mosti; and, strangely enough, he was the person who had raised a monument to Ariosto, of whom he was an enthusiastic admirer.
・ Strangely enough, Rogers was at first dissatisfied with the offer, holding that the sum should be paid for the new volumes alone.
・ Curiously enough, although Adam Smith was immersed in abstract speculations, his "homely sagacity" led him to the most practical results;
・ Curiously enough, this novel consists of two perfectly distinct narratives;
このようにコーパスによる調査結果を概観してみるだけでも,18世紀以降,共起する副詞の種類においても頻度においても,順調に分布を拡げ定着してきた表現といってよさそうである.enough を付加することでリズムがよくなるという効果 (eurhythmy) のほか,文副詞であることを明示する機能があるのかもしれない.
2020-12-03 Thu
■ #4238. oddly enough, interestingly enough などの表現における enough (1) [adverb][semantics][bnc][corpus][collocation][eurhythmy]
以前より不思議に思っていた表現がある.enough という卑近な副詞を用いた表現なのだが,典型的に -ly 副詞に enough が後置され,文頭位置あるいは挿入句として生起するものだ.例をみるのが早い.BNCweb より挙げてみよう(問題の句はイタリック体にしてある).なお,検索窓には "*ly_{ADV} enough" と入力した.
・ Oddly enough, many parliaments expect to modify government plans, which takes time.
・ Her large grin and knotted black curls were, strangely enough, more memorable.
・ I had a dream last night funnily enough about Leeds (I dont normally --- honest!).
・ Interestingly enough, even hens and rats have been found to consume more calories when they are offered a varied diet than when they are fed `the same old thing' all the time.
・ Naturally enough, those who commit crimes will tend to conceal their actions and protect themselves.
それぞれ「妙なことに」「奇妙なことに」「滑稽なことに」「興味深いことに」「当然のことに」を意味する,いわゆる文修飾の副詞句である.文修飾であるから,統語的には文頭に現われたり,挿入的に用いられたりすることは不思議ではない.理解しかねるのは,enough の役割である.なぜ「十分に」が添えられているのだろうか.enough が省略されたところで,前置されている副詞単体でも文修飾として同じように機能するのだ.副詞単体ではやや寂しく感じられ,たいした強調ともならない enough を添えることでリズムを良くする程度の効果 (eurhythmy) はありそうだが.
enough に前置されることの多い副詞の種類としては,ヒット数の多い順に20個を挙げると oddly, quickly, strangely, funnily, interestingly, early, easily, naturally, curiously, clearly, appropriately, only, seriously, barely, ironically, nearly, surprisingly, badly, reasonably, hardly となる.しかし,quickly, early, easily などは,今回注目する用法としてではない例(つまり「十分に素早く」などの通常の用法)によって頻度が高くなっているにすぎない.注目する用法で現われる最も典型的な10語を選べば,oddly, strangely, funnily, interestingly, naturally, curiously, appropriately, ironically, surprisingly, reasonably あたりとなる.
この用法が生起する分布に注意すると,書き言葉にも話し言葉にも現われており,メディアによる違いはないといってよい(いずれも 18 wpm 程度).使用者の男女差や世代差でみても,特に目立った分布上の特徴ははない.テキストタイプとしては Fiction and verse で相対的に高い値 (27.01 wpm) を示すが,際立っているわけでもない.多くの異なるレジスターで用いられているのが実態である.
改めて enough の意味の問題に立ち戻ろう.この enough は意味論的にはかなり薄いものと言わざるを得ない.実際『ジーニアス英和大辞典』によれば,この enough には「十分に」の意味はほどんどない旨,言及がある.また,OED の enough, adj., pron., and n., and adv. の C. adv. 2 にも "With the idea of satisfying a requirement reduced or absent." とあり,何のために「十分な」のかについて「何」の前提が薄くなってしまった語義が立てられている.その下位区分 (b) として与えられているのが,まさに今問題にしている用法で,次のように説明がある.
(b) With a sentence adverb, as in aptly enough.
See also funnily enough at FUNNILY adv. 2, oddly enough at ODDLY adv. 5b.
1704 W. Nicolson Diary 22 Nov. in London Diaries (1985) 231 The Text of the Book (whimsically enough) in Vermilion-Letters, instead of an Italic Character.
1783 Ld. Hailes Disquis. Antiq. Christian Church ii. 15 Which, aptly enough, might be denominated the journals of the senate.
1912 E. V. Baxter & L. J. Rintoul Rep. Sc. Ornithol. 3 Curiously enough, both the Common Nightingale .. and the Northern Nightingale .. were added in spring to the Scottish list.
2015 H. Scales Spirals in Time ix. 249 A mollusc named, appropriately enough, the Windowpane Oyster.
この用法での初例が1704年となっているので,はるばる古英語 geōg にさかのぼる古参の副詞とはいえ,別の副詞に前置される問題の表現は,なかなかモダンらしい.
2020-11-12 Thu
■ #4217. 後期近代英語期のイギリス英語における colour vs color [clmet][corpus][ame_bre][spelling]
綴字の英米差の典型例の1つとされる colour vs color の問題については,本ブログで以下の記事などで取り上げてきた.
・ 「#3182. ARCHER で colour と color の通時的英米差を調査」 ([2018-01-12-1])
・ 「#3247. 講座「スペリングでたどる英語の歴史」の第5回「color か colour か? --- アメリカのスペリング」」 ([2018-03-18-1])
・ 「#4152. アメリカ英語の -our から -or へのシフト --- Webster の影響は限定的?」 ([2020-09-08-1])
・ 「#4161. アメリカ式 color はラテン語的,イギリス式 colour はフランス語的」 ([2020-09-17-1])
・ 「#4169. GloWbE --- Corpus of Global Web-Based English」 ([2020-09-25-1])
綴字に限らず英語における英米差の事例は多々あるが,歴史的にみると,これらの差異は,あるタイミングで突如として生じたというよりも,時間をかけて成立し,確立してきたというのが事実である.アメリカ英語的とされる color の綴字が定着するのにも,[2018-01-12-1], [2020-09-08-1] の記事でみたように,19世紀中の数十年という時間がかかっているし,イギリス英語的とされる colour にしても,後期近代英語期中にライバルの color を駆逐するには至っていない.後者の状況について,今回,1710--1920年のイギリス英語コーパスで,約3,400万語からなるジャンルを整理したバランスコーパス CLMET3.0 を用いて調査してみた.
調査対象は,colo(u)r のみならず,これを語幹にもつ各種の接頭辞や接尾辞を付した語形で,bicolor, colorless, colouration, discoloured など様々な種類をも含む.以下,3区分した時代別の頻度数を示す.
| Period (subcorpus size) | colour | color |
|---|---|---|
| 1710--1780 (10,480,431 words) | 1,273 (88.28%) | 169 |
| 1780--1850 (11,285,587) | 1,650 (83.71%) | 321 |
| 1850--1920 (12,620,207) | 3,242 (94.11%) | 203 |
3期を通じて colour 系が圧倒的であることは確認できるが,それでもライバルの color 系も完全に駆逐されてはおらず,なんとか持ちこたえていることが分かる.英語の英米差について,ともすれば A か B かというデジタルな問題のように思われがちだが,必ずしもそうではなく,程度のあるアナログの問題であることも多い.あるいは,たとえ共時的にはデジタル的な振る舞いを示しているようにみえたとしても,通時的にみればアナログ的に推移してきたことのほうが多いのである.
2020-10-30 Fri
■ #4204. コーパス言語学の基本的な用語を解説 --- concordance [terminology][corpus][hel_education][collocation]
昨日の記事 ([2020-10-29-1]) に引き続き,コーパス周りの用語を解説する.
concordance とは,もともとは「用語索引」ほどを意味し,ある本に出てくる単語を1つ1つ取り出してアルファベット順にリスト化したものである.その本に例えば the という単語が何回出現したか,さらに具体的にどこに出現したがが分かるような作りになっていることもあり,文献学研究や言語研究では馴染みのツールだった.聖書のコンコーダンスやChaucer のコンコーダンスなどがよく知られている.
しかし,電子コーパスが普及してからは,concordance という用語は別の意味でも用いられるようになった.昨今の電子コーパスで何らかの語なり表現なりを検索式の形にして検索すると,その条件にあった形式を含む例文がコーパス全体から収集され,ずらっと画面上に提示される.この全体が,その形式の concordance ということになる.そして,例文を含む個々の行のことを concordance line と呼ぶ.たとえていえば,ある単語を Google 検索して1万件ヒットしたという場合,その1万件全体が concordance ということになり,その1件1件が concordance line ということになる.
たいていのコーパス検索では,注目している形式の前後にどのような語が共起しているかを知りたいことが多いので,注目する形式が各 concordance line の中央に位置するように表示されると都合がよい.前後の文脈 (context) も合わせてその形式の用例を確認できることから,この表示法はコーパス研究ではある種のデフォルトといってよく,KWIC (= Key Word in Context) という名前すらついている.
昨日の記事で取り上げたが,BNCweb で "{love/V}" として検索してみると,14,195行もの concordance lines が得られる.その先頭の10行ほどを KWIC で表示すると,次のようになる.読みやすいし分析しやすい表示法であることがわかるだろう.
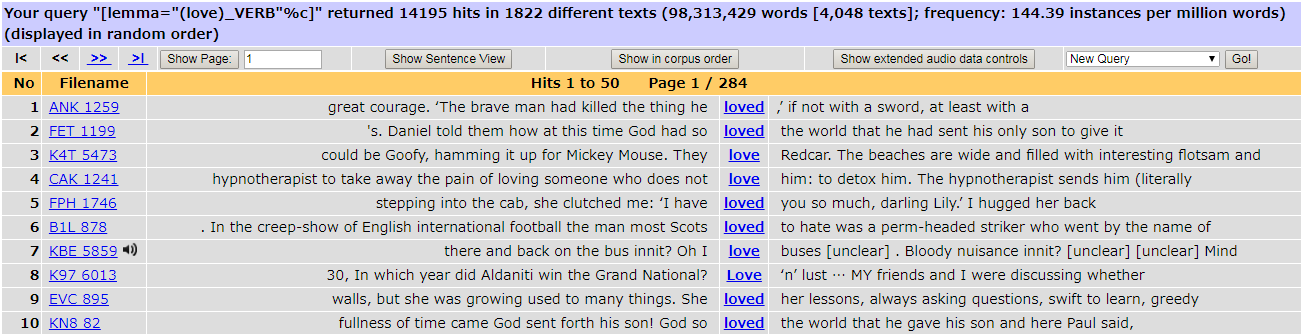
このように電子コーパスでは,ある形式の concordance が容易に得られる.もちろん concordance を産出するプログラムが背後で動いてくれているおかげであり,そのようなプログラムやアプリケーションを concordancer と呼んでいる.
2020-10-29 Thu
■ #4203. コーパス言語学の基本的な用語を解説 --- lemma [terminology][corpus][hel_education][lexicology][pos][verb][conjugation][inflection]
先日,大学の授業でコーパスセミナーを開催した.BNCweb, COCA, COHA, EEBO corpus などの代表的な共時的・通時的英語コーパスに初めて触れる学部生に,使用経験者である大学院生が講師としてコーパス利用のいろはを指南するという Zoom によるオンライン企画である.
一見,コーパス利用というのは初心者にはハードルが高いと思われがちが,適切な導入があれば,複雑な検索や応用的な利用法は別にしても,十分にその日から便利に使いこなすことができる.
しかし,意外と落とし穴となり得るのは,コーパス周りの用語 (terminology) かもしれない.例えば「love を動詞で POS 指定して lemma 検索をし,その concordance line を KWIC で表示させ,前後数語のフレームで collocation を取ってから log-likelihood を出しておいてね.必要に応じて noise をマニュアルで除去しておいてよ.」などという指示を,初心者の誰が理解できようか! ということで,コーパス周りの術語(というよりもジャーゴン)を少しずつ解説してきたい.
今回は lemma (レンマ,レマ)について.平たくいえば,辞書を念頭においた上でその「見出し語」だと思えばよい.動詞 love を例に取れば,実際の英文のなかでは,不定詞・現在形・命令形など love という裸の形態で生起することもあれば,3単現の loves として出現することもあるし,過去(分詞)形の loved や現在分詞・動名詞形の loving で現われることもあるだろう(「崩れた」lovin' 等として起こるかもしれない).love のこれらの諸形態は,確かに互いに少しずつ異なっているが,各々が異なる単語というわけではない.あくまで代表的・抽象的な love という動詞の,具体的な変化形にすぎないのである.このような代表的・抽象的な存在を lemma と呼んでいる.I love you. のように love という形態で出てきたとしても,これは love という lemma の,直説法1人称単数現在形の具体的な現われとしての love である.両者はたまたま形態的に一致しているけれども,あくまで前者は抽象的な love,後者は具体的な love として概念上は区別する必要がある.
別の角度からみれば,私たちが英単語学習の際に習得する主たるものは,個々の見出し形ともいえる lemma と,その具体的な諸変化形ということになる.これらのワンセットが内部で適切にヒモづけられ,頭の中で整理されていれば,その単語に関して習得が完了していることになる.このワンセットとそれにつけられた名前こそが lemma なのである.
「コーパスでlove を動詞で lemma 検索してね」というのは「動詞として用いられている love, loves, loved, loving などの例をすべて拾ってきてね」と言い換えられる.例えば BNCweb の場合には,検索式を "{love/V}" のように指定することで上記の lemma 検索が可能である.
2020-10-19 Mon
■ #4193. インド系英語における discuss about [verb][indian_english][glowbe][corpus][accommodation]
先月教えてもらったばかりの「#4169. GloWbE --- Corpus of Global Web-Based English」 ([2020-09-25-1]) を用いて,しかもつい数日前に院生の指摘からインスピレーションを受けた標題の話題について調べてみた.その意味では完全に人頼みの記事です(←ありがとうございます).
標準英語では discuss は他動詞であり,前置詞を伴わずに直後に目的語を要求する.日本語母語話者としては,訳語がたいてい「?について論じる」となるので,about 辺りの前置詞を介在させたくなり,discuss about としてしまうことがあるのだが,これは規範文法的には誤用とされる.しかし,実際には discuss about も耳にしたり目にする機会がある.インド英語などで広く行なわれる表現であるということは聞いたことがあった.
そこで,現代の世界英語変種を比較できるコーパス GloWbE (= Corpus of Global Web-Based English) の出番である.難しいことはない,検索欄に "discuss about" を入力するだけである.この超簡単な検索だけで,超おもしろい結果を味わうことができる.自動的に出力されたチャートは次の通り.

横方向のほぼ中央(ちょっとだけ左寄り)の一群で棒グラフが相対的に高い値を示している.この近辺はインド(亜大陸)系英語の数値である.統計学的な検定をかけるまでもなく,明らかに左右両端の英語変種とは異なる分布を示す.
バングラデシュやインド等の南アジア圏を相手とする21世紀の商談においては,accommodation 理論に従い,われわれ極東アジア人も "Shall we discuss about our business?" と始めたほうがビジネスの成功率は高そうだ.
コーパス利用はとかく苦手意識により敬遠されることが多いのだが,これくらいのところから始めてもよいのでは.
2020-09-25 Fri
■ #4169. GloWbE --- Corpus of Global Web-Based English [glowbe][corpus][ice][englishes][world_englishes][variety][ame_bre][spelling]
「#4166. 英語史の各時代のコーパスを比較すれば英語史がわかる(かも)」 ([2020-09-22-1]) で触れた World Englishes のコーパス GloWbE (= Corpus of Global Web-Based English) を少し試してみた.(先日の駒場英語史研究会にて本コーパスを導入していただきました菊地翔太先生(明海大学)には,改めて感謝します.)
このコーパスは20カ国からの英語変種を総合した19億語からなる巨大コーパスで,変種間の比較が容易に行なえる仕様となっている.変種間比較についていえば,私はこれまで「#517. ICE 提供の7種類の地域変種コーパス」 ([2010-09-26-1]),「#1743. ICE Frequency Comparer」 ([2014-02-03-1]) などで取り上げたように ICE (International Corpus of English) しか知らなかったのだが,コーパスの世界は急速に進化しているようだ.GloWbE のインターフェースは,COCA (Corpus of Contemporary American English) や COHA (Corpus of Historical American English) などと共通なので,そちらに慣れたユーザーであれば,とっついやすいはずだ.
きわめて単純な使い方ではあるが,GloWbE の最大の売りである変種間比較を color と colour のスペリングに関して行なってみた.一般に color はアメリカ式,colour はイギリス式のスペリングといわれるが,この2変種間の比較に満足せず,20変種間で比べてみようという試みだ.インターフェースより単純に Chart 出力機能を選択し,各々のスペリングで検索し,返された図表を眺めるだけなのだが,それだけでも十分におもしろい.まずは,アメリカ式 color の図表から.
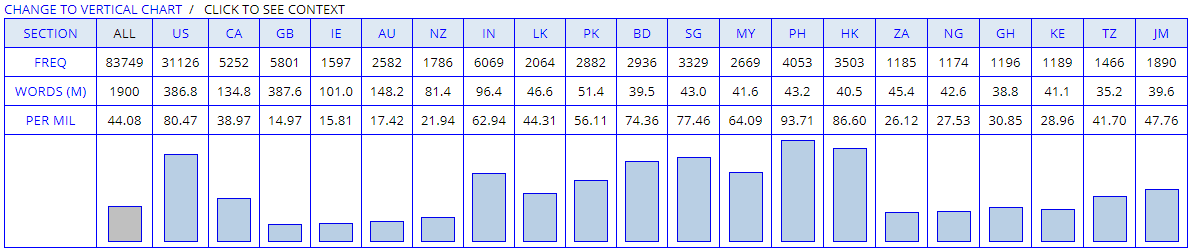
次に,イギリス式 colour の図表を挙げよう.
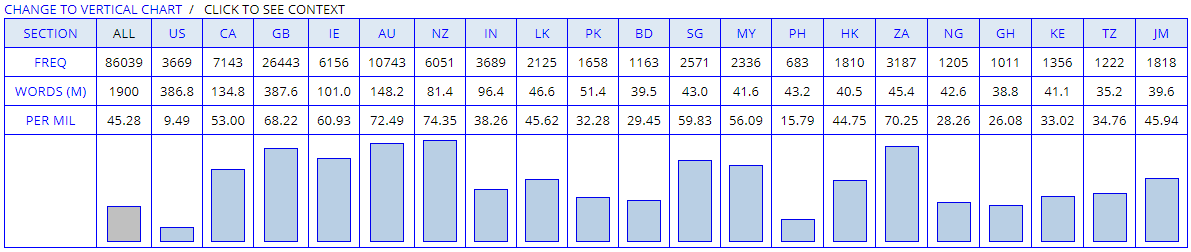
横方向の中央辺りに東南アジアの国々が集まっており,歴史的にはイギリス式が多いと予想される地域なわけだが,実はアメリカ式スペリングのほうが優勢のようだ.近年の英語のアメリカ化 (americanisation) の影響が疑われよう.一方,左側には(米国を除く)アングロサクソン系諸国が集まっており,そこでは予想通りにイギリス式が優勢である.右側に集まっているアフリカ諸国では,両スペリングの差はさほど大きくない.
color vs colour の問題を米英間の問題として論じる時代は過ぎ去りつつある.凄いツールが出てきたものである.
2020-09-22 Tue
■ #4166. 英語史の各時代のコーパスを比較すれば英語史がわかる(かも) [academic_conference][corpus][eebo][glowbe][laeme][lalme][historiography][standardisation]
一昨日の9月20日(日),2020年度駒場英語史研究会にて,特別企画「電子コーパスやオンライン・リソースを使った英語史研究 ― その実践と可能性」に発表者として参加しました.Zoom でのオンライン大会でしたが,円滑に会が進行しました.(企画のご提案から会の主催までお世話になりました寺澤盾先生(東京大学),発表者の家入葉子先生(京都大学)と菊地翔太先生(明海大学),および参加者すべての方々には,貴重な機会とインスピレーションをいただきました.お礼申し上げます.)
トップバッターの私自身の発表では「LAEME & LALME を用いた英語史研究入門」と題して,中英語を代表する2つの姉妹コーパス LAEME と eLALME を紹介しました.続いて,家入先生の「データベースの利用によるコーパス言語学 --- Early English Books Online を中心に」と題する発表では,初期近代英語期を代表するコーパス EEBO corpus が紹介されました.最後に,菊地先生による「Corpus of Global Web-Based English(GloWbE)を用いた World Englishes 研究の可能性」という発表により,21世紀の World Englishes 時代を象徴する GloWbE が導入されました(←私にとって未知だったので驚きの連続でした).
各々の発表はコーパスの紹介とデモにとどまらず,その可能性や「利用上の注意」にまで触れた内容であり,発表後のディスカッションタイムでは,英語史研究においてコーパス利用はどのような意義をもつのかという方法論上の肝心な議論にまで踏み込めたように思います(時間が許せば,もっと議論したいところでした!).
中英語,近代英語,21世紀英語という3つの異なる時代の英語を対象としたコーパスを並べてみたわけですが,研究会が終わってからいろいろと考えが浮かんできました.同じ英語のコーパスとはいえ,対象とする時代が異なるだけで,なぜ検索の仕方も検索の結果もインターフェースもここまで異なるのだろうかということです.その答えは「各々の時代における英語の(社会)言語学的事情が大きく異なっているから,それと連動して(現代の研究者が編纂する)コーパスのあり方も大きく異ならざるを得ない」ということではないかと思い至りました.
逆からみれば,各時代のコーパスがどのように編纂され,どのように使用されているかを観察することにより,その時代の英語の(社会)言語学的事情が浮き彫りになってくるのではないか,ということです.そうして時代ごとの特徴がきれいに浮き彫りになってくるようであれば,それを並べてみれば,ある種の英語史記述となるにちがいない.換言すれば,各時代のコーパス検索に伴うクセや限界みたいなものを指摘していけば,その時代の背後にある言語事情が透けて見えてくるのではないかと.ここから「コーパスのあり方からみる英語史」のような試みが可能となってきそうです.
時代順にみていきます.中英語期は標準形が不在なので,ある単語を検索しようとしても,そもそもどの綴字で検索すればよいのかという出発点からして問題となります (cf. 「#1450. 中英語の綴字の多様性はやはり不便である」 ([2013-04-16-1])).実際,中英語辞書 MED である単語を引くにしても,そこそこ苦労することがあります.LAEME や LALME でも検索インターフェースには様々な工夫はなされていますが,やはり事前の知識や見当づけが必要ですので,検索が簡単であるとは口が裂けても言えません.現実に標準形がないわけですから,致し方がありません.
次に初期近代英語期ですが,EEBO は検索インターフェースが格段にとっつきやすく,一見すると検索そのものに問題があるようには見えません.しかし,英語史的にはあくまで標準化を模索している時代にとどまり,標準化が達成された現代とは事情が異なります.つまり,標準形とおぼしきものを検索欄に入れてクリックしたとしても,実は拾い漏れが多く生じてしまうのです.公式には実装されているとされる lemma 検索も,実際には思うほど精度は高くありません.落とし穴がいっぱいです.
最後に,21世紀英語の諸変種を対象とする GloWbE については,(ポスト)現代英語が相手ですから,当然ながら標準形を入力して検索できます.しかし,BNC や COCA のような「普通の」コーパスと異なるのは,返される検索結果が諸変種に由来する多様な例だということです.
大雑把にまとめると次のようになります.
| 代表コーパス | 検索法などに反映される「コーパスのあり方」 | (社会)言語学的事情 | |
|---|---|---|---|
| 中英語 | LAEME, LALME | 検索法が難しい | 標準形がない |
| 初期近代英語 | EEBO | 検索法が一見すると易しい | 標準形が中途半端にしかない |
| 21世紀英語 | GloWbE | 検索法が易しい | 標準形はあるが,その機能は変種によって多様 |
異なる時代のコーパスを比べてみると,英語史がみえてくるということがよく分かりました.駒場英語史研究会での発表の機会をいただき,改めて感謝します.
2020-06-25 Thu
■ #4077. MED の辞書としての特徴 [lexicography][dictionary][med][me][corpus][website][link][bibliography][onomastics]
昨日の記事「#4076. Dictionary of Old English と Dictionary of Old English Corpus」 ([2020-06-24-1]) に引き続き,英語史研究にはなくてはならないツールについて.中英語研究といえば,何をおいても MED を挙げなければならない (Kurath, Hans, Sherman M. Kuhn, John Reidy, and Robert E. Lewis. Middle English Dictionary. Ann Arbor: U of Michigan P, 1952--2001. Available online at http://quod.lib.umich.edu/m/med/) .昨日の DOE と DOEC の関係と同様に,MED にも関連する MEC というコーパスがあり,こちらもたいへん有用である (MEC = McSparran, Frances, ed. Middle English Compendium. Ann Arbor: U of Michigan P, 2006. Available online at http://quod.lib.umich.edu/m/mec/) .
MED は1952年に最初の小冊が出版され,1991年に最後の小冊が出版されて完成した.その後,2000年にオンライン版の Middle English Compendium に組み込まれ,使い勝手が大幅に向上した.細かな検索ができることはもちろん,hyperbibliography の充実振りが嬉しい.56,000件ほどの見出し語を誇る中英語最大の辞書であることはいうにおよばず,中英語研究史上の最大の成果物といえる.2018年にはほぼ20年振りの改訂版が公開され,現在も中英語研究の第一線を走っている.
MED には,使用に当たって知っておくべきいくつかの特徴がある.Durkin (1150--52) に拠って指摘しておこう.まず,MED は,語義に多くの注意を払う辞書だということだ.OED ではある語の語形を大きな基準として記述を仕分けているが,MED のエントリーの最大の構成原理は語義である.ある意味では語形の違いなどは方言差と割り切って,LALME や LAEME に委ねているといった風である.しかし,この語義優先という特徴により,語学的な研究のみならず,文化的,歴史的な研究にも資するツールとなっているという側面がある.
語義の重視と関連して,MED は該当語の固有名詞としての使用にも意を払っている.たいてい最後の語義として言及されるが,これは固有名詞研究や歴史研究に有用である.多言語テキストに記されている英語の地名なども拾い上げられており,他言語文献や言語接触の研究にも資する情報である.
MED で惜しむらく点は,語源記述が少ないことだ.直前の古英語形や借用語であればソース言語での形態などを挙げているにとどまり,深みがない.
最後に指摘しておくべきは,例文に付されている年代について,(1) 写本(証拠)そのものの年代と,(2) テキストが作成されたとおぼしき年代とが,分けて記されている点である(後者はカッコでくくられている).両年代を念頭におけば,例えば異写本間での語形の比較に際して貴重な判断材料となるだろう.この重要な情報は,diplomatic な読みを追求する文献学的な関心に答えてくれる可能性を秘めている.
関連して「#4016. 中英語研究のための基本的なオンライン・リソース」 ([2020-04-25-1]) も参照.
・ Durkin, Philip. "Resources: Lexicographic Resources." Chapter 73 of English Historical Linguistics: An International Handbook. 2 vols. Ed. Alexander Bergs and Laurel J. Brinton. Berlin: Mouton de Gruyter, 2012. 1149--63.
2020-06-24 Wed
■ #4076. Dictionary of Old English と Dictionary of Old English Corpus [lexicography][dictionary][doe][corpus][oe][website][link][bibliography]
標題の辞書は,目下進行中の古英語辞書編纂プロジェクトの所産である(cf. 「#3006. 古英語の辞書」 ([2017-07-20-1])).進行中なので未完成ということになるが,現在 The Dictionary of Old English (DOE) のサイト より,Dictionary of Old English: A to I online, ed. Angus Cameron, Ashley Crandell Amos, Antonette diPaolo Healey et al. (Toronto: Dictionary of Old English Project, 2018). の項目をオンラインで閲覧・参照できる(限定利用できる無料版あり).
この DOE と連動する形で古英語コーパス (DOEC) の編纂も同時に進行しており,Dictionary of Old English Web Corpus よりオンラインでアクセスできるようになっている(限定利用できる無料版あり).現存する古英語の文献資料は語数にして約300万語とされ,網羅的な目録を編纂し,網羅的な検索ツールを作ることは可能な範囲である.DOEC は,そのような目的の下,DOE 編纂プロジェクトの一環として,まず高頻度語を収録したマイクロフィッシュ版が1980年と1985年に公開された.その後,1997年にオンライン版が公開される一方,2005年には A--F までの項目を収録した CD-ROM 版も世に出た.その後も現在に至るまで,編纂者たちの地道な努力によって公開項目が増してきている.
DOE の各語のエントリーでは,文証されるスペリング,語義や用例,(翻訳テキストの場合)対応するラテン単語などの情報が得られ,OED への参照を含めた参考資料へのアクセスも提供されている.
この世に完璧なツールはないように,DOE(C) にも使用に際して注意すべき点はある.古英語テキストに複数のバージョンがある場合,文献学的には各々の単語の variants の情報が得られることが望ましいが,DOE(C) ではテキストによってその収録幅に揺れがある.また,語としての variants はおよそ拾い上げられているとしても,統語的,形態的,音韻的な意義をもつ variants にはさほど意が払われていない.さらに,書記上の省略が暗黙のうちに展開されているという点にも注意が必要である.語源情報が与えられていない点も,辞書として残念ではある.
それでも,古英語研究における DOE の重要性と期待の大きさは計りしれない.OED にも古英語単語は収録されているが,あくまで部分的であり,1150年を超えて生き延びた古英語単語に限定されている.編纂プロジェクトのインスピレーション自体は,OED の初版が完成されつつあった100年ほど前の Craigie のアイディアに由来するというから,実に息の長いプロジェクトなのである.応援していきましょう.
DOEC については,CoRD (Corpus Resource Database) よりこちらの情報もどうぞ.
・ Lowe, Kathryn A. "Resources: Early Textual Resources." Chapter 71 of English Historical Linguistics: An International Handbook. 2 vols. Ed. Alexander Bergs and Laurel J. Brinton. Berlin: Mouton de Gruyter, 2012. 1119--31.
・ Traxel, Oliver M. "Resources: Electronic/Online Resources." Chapter 72 of English Historical Linguistics: An International Handbook. 2 vols. Ed. Alexander Bergs and Laurel J. Brinton. Berlin: Mouton de Gruyter, 2012. 1131--48.
・ Durkin, Philip. "Resources: Lexicographic Resources." Chapter 73 of English Historical Linguistics: An International Handbook. 2 vols. Ed. Alexander Bergs and Laurel J. Brinton. Berlin: Mouton de Gruyter, 2012. 1149--63.
2020-04-25 Sat
■ #4016. 中英語研究のための基本的なオンライン・リソース [bibliography][website][link][corpus][dictionary][hel_education][auchinleck][oed][htoed][laeme][lalme][med][ceec][me]
標記について,Smith (47--48) の参考文献表よりいくつか抜き出し,整理し,リンクを張ってみた(現時点で生きたリンクであることを確認済み).本ブログでは,その他各種のオンライン・リソースも紹介してきたが,まとめきれないので link を参照.とりわけ Chaucer 関連のリンクは「#290. Chaucer に関する Web resources」 ([2010-02-11-1]) をどうぞ.
・ AM = Burnley, David and Alison Wiggins, eds. Auchinleck Manuscript. National Library of Scotland, 2003. Available online at http://www.nls.uk/auchinleck/ .
・ CEEC = Nevalainen, Terttu, Helena Raumolin-Brunberg, Jukka Keränen, Minna Nevala, Arja Nurmi, and Minna Palander-Collin. Corpus of Early English Correspondence (CEEC). Department of English, U of Helsinki. Available online at https://varieng.helsinki.fi/CoRD/corpora/CEEC/index.html .
・ CSC = Meurman-Solin, Anneli. Corpus of Scottish Correspondence. U of Helsinki, 2007. Available online at https://varieng.helsinki.fi/CoRD/corpora/CSC/ .
・ CTP = Robinson, Peter and Barbara Bordalejo. The Canterbury Tales Project. Institute of Textual Scholarship and Electronic Editing, U of Birmingham, 1996--. Available online at http://server30087.uk2net.com/canterburytalesproject.com/index.html .
・ HTOED = Kay, Christian, Jane Roberts, Michael Samuels, and Irené Wotherspoon, eds. Historical Thesaurus of the Oxford English Dictionary. Oxford: OUP, 2009. Available online via http://www.oed.com/ .
・ LAEME = Laing, Margaret and Roger Lass. LAEME: A Linguistic Atlas of Early Middle English, 1150--1325. U of Edinburgh, 2007. Available online at http://www.lel.ed.ac.uk/ihd/laeme2/laeme2.html .
・ LALME = McIntosh, Angus, Michael Samuels, and Michael Benskin, with Margaret Laing and Keith Williamson. A Linguistic Atlas of Late Mediaeval English (LALME). Aberdeen: Aberdeen UP, 1986. Available online as eLALME at http://www.lel.ed.ac.uk/ihd/elalme/elalme_frames.html .
・ LAOS = Williamson, Keith. A Linguistic Atlas of Older Scots, Phase 1: 1380--1500 (LAOS). 2007. Available online at http://www.lel.ed.ac.uk/ihd/laos1/laos1.html .
・ MEC = McSparran, Frances, ed. Middle English Compendium. Ann Arbor: U of Michigan P, 2006. Available online at http://quod.lib.umich.edu/m/mec/ .
・ MED = Kurath, Hans, Sherman M. Kuhn, John Reidy, and Robert E. Lewis. Middle English Dictionary. Ann Arbor: U of Michigan P, 1952--2001. Available online at http://quod.lib.umich.edu/m/med/ .
・ MEG-C = Stenroos, Merja, Martti Mákinen, Simon Horobin, and Jeremy Smith. The Middle English Grammar Corpus (MEG-C). Version 2011.2. Available online at https://www.uis.no/research/history-languages-and-literature/the-mest-programme/the-middle-english-grammar-corpus-meg-c/ .
・ OED = Simpson, John, ed. The Oxford English Dictionary. 3rd ed. Oxford UP, 2000--. Available online at http://www.oed.com/.
・ TOE = Edmonds, Flora, Christian Kay, Jane Roberts, and Irené Wotherspoon. Thesaurus of Old English. U of Glasgow, 2005. Available online at https://oldenglishthesaurus.arts.gla.ac.uk/ .
・ VARIENG = Nevalainen, Terttu, Irma Taavitsainen, and Sirpa Leppänen. The Research Unit for Variation, Contacts and Change in English (VARIENG). Department of English, U of Helsinki. Available online at https://varieng.helsinki.fi/index.html .
・ Smith, Jeremy J. "Periods: Middle English." Chapter 3 of English Historical Linguistics: An International Handbook. 2 vols. Ed. Alexander Bergs and Laurel J. Brinton. Berlin: Mouton de Gruyter, 2012. 32--48.
2020-03-07 Sat
■ #3967. コーパス利用の注意点 (3) [corpus][methodology][representativeness]
標題については,以下の記事を含む様々な機会に取り上げてきた.
・ 「#307. コーパス利用の注意点」 ([2010-02-28-1])
・ 「#367. コーパス利用の注意点 (2)」 ([2010-04-29-1])
・ 「#428. The Brown family of corpora の利用上の注意」 ([2010-06-29-1])
・ 「#1280. コーパスの代表性」 ([2012-10-28-1])
・ 「#2584. 歴史英語コーパスの代表性」 ([2016-05-24-1])
・ 「#2779. コーパスは英語史研究に使えるけれども」 ([2016-12-05-1])
コーパスを利用した英語(史)研究はますます盛んになってきており,学界でも当然視されるようになったが,だからこそ利用にあたって注意点を確認しておくことは大事である.主旨はおよそ繰り返しとなるが,今回は英語歴史統語論の概説書を著わした Fischer et al. (14) より,4点を指摘しよう.
(i) there can be tension between what is easily retrieved through corpus searches and what is thought to be linguistically most significant; a historical syntactic case in point involves patterns of co-reference of noun phrases . . . ; these have been largely neglected because they involve information status, which is currently not part of any standard annotation scheme;
(ii) when a data search yields large numbers of hits, there may be a temptation to interpret corpus results merely as numbers, which is a severely reductive approach; in cases of grammaticalization, for example, changes in frequency may act as tell-tale signs . . . , but an exclusive quantitative focus will mean that one is ignoring the changes in meaning and context that form the core of the process;
(iii) the substantial amounts of data that can be collected from a corpus can also blind researchers to the dangers of making generalizations about the language as a whole on the basis of a partial view of it; this is a particularly relevant problem for diachronic research, because we only have very incomplete evidence for the state of the language in any historical period . . . ;
(iv) trying to achieve greater representativness by collecting and comparing data from various corpora can also be tricky: principles guiding text inclusion vary widely, there is little standardization in user interfaces, and they can require a significant time investment to learn to operate.
この4点を私の言葉で超訳すれば,次のようになる.
(i) コーパスで遂行しやすい問題が,言語学的には必ずしも意味のある問題ではないかもしれない点に注意すべし
(ii) 量的な観点を重視する研究には役立ちそうだが,質的な観点が見過ごされてしまう危険性がある
(iii) 巨大なコーパスであったとしても,完全に representative であるわけではない(いわゆる歴史言語学における "bad-data problem")
(iv) コーパス編纂者の前提やインターフェース作成者の意図をつかんだ上で,使用法を心して習熟すべし
・ Fischer, Olga, Hendrik De Smet, and Wim van der Wurff. A Brief History of English Syntax. Cambridge: CUP, 2017.
2019-12-22 Sun
■ #3891. 現代英語の様々な句読記号の使用頻度 [punctuation][alphabet][diacritical_mark][net_speak][brown][corpus][frequency][statistics][exclamation_mark]
英語は同じローマン・アルファベットを用いる文字圏のなかでも,句読法 (punctuation) に関しては比較的単純な部類に入る.現代的な句読記号が出そろったのは500年前くらいであり,その数も多くない (cf. 「#575. 現代的な punctuation の歴史は500年ほど」 ([2010-11-23-1])) .また,文字そのものが26文字しかない上に,フランス語やドイツ語などにみられる,文字の周辺に付す特殊な発音区別符(号) (diacritical mark; cf. 「#870. diacritical mark」 ([2011-09-14-1])) も原則として用いられない.さらに,現代の印刷文化では句読記号が控えめに使われるようになってきているとも言われる.一方,net_speak などでは,新たな句読記号の使用法が生み出されていることも確かであり,句読法の発展が止まってしまったわけではないようだ (cf. 「#808. smileys or emoticons」 ([2011-07-14-1])) .
さて,約100万語のアメリカ英語の書き言葉コーパス Brown Corpus を用いた調査によると,英語の主要な句読記号の使用頻度 (%) は次の通りだという (Cook 92) .
| Commas | 47 |
| Full stops | 45 |
| Dashes | 2 |
| Parentheses | 2 |
| Semi-colons | 2 |
| Question marks | 1 |
| Colons | 1 |
| Exclamation marks | 1 |
用いられている句読記号の9割以上が <,> か <.> であるというのは,英語の読み手・書き手の直感としてうなづける.英語の読み書き学習の観点からいえば,まずはこの2つの句読記号に習熟することに努めればよいことになる.
ローマン・アルファベット文字圏の句読記号の変異について関心のある方は,Character design standards - Punctuation for Latin 1 などを参照されたい.
・ Cook, Vivian. The English Writing System. London: Hodder Education, 2004.
2019-07-09 Tue
■ #3725. 語彙力診断テストや語彙関連ツールなど [lexicology][bnc][coca][corpus][webservice][link]
以前「#833. 語彙力診断テスト」 ([2011-08-08-1]) を紹介したが,今回は中田(著)『英単語学習の科学』 (12) で取り上げられていた別の語彙診断力テスト Test Your Vocabulary Online With VocabularySize.com を紹介しよう.140問の4択問題をクリックしながら解き進めていくことで,word family ベースでの語彙力が判定できる.母語を日本語に設定して診断する.また,英語での出題のみとなるが,同じ語彙セットを用いた100問からなる語彙診断テストの改訂版もある.
関連して中田 (13) では,英単語の頻度レベルを調べるツールとして,Compleat Lexical Tutor の VocabProfilers が便利だとも紹介されている.BNC や COCA などを利用して,入力した単語(群)の頻度を1000語レベル,2000語レベルなどと千語単位で教えてくれる.ある程度の長さの英文を放り込むと,各単語を語彙レベルごとに色づけしてくれたり,分布の統計を返してくれる優れものだ.ただし,インターフェースがややゴチャゴチャしていて分かりにくい.
日本人の英語学習者にとっては,「標準語彙水準 SVL 12000」などに基づいて英文の語彙レベルを判定してくれる Word Level Checker も便利である.単語ごとにレベルを返してくれるわけではなく,入力した英文内の語彙レベルとその分布を返してくれるというツールである.
英文を入力すると,単語の語注をアルファベット順に自動作成してくれる Apps 4 EFL の Text to Flash というツールも便利だ.さらにこれの応用版で,単語をクリックすると意味がポップアップ表示される英文読解ページを簡単に作れる Pop Translation なるツールもある.世の中,便利になったものだなあ.
・ 中田 達也 『英単語学習の科学』 研究社,2019年.
2019-05-21 Tue
■ #3676. 英語コーパスの使い方 [corpus][hel_education][link][methodology]
たいそうな題名の記事ですが,これまでにコーパス利用について書いてきたブログ記事その他へのリンク集にすぎません.
まず英語学でコーパスを利用しようと思ったら,様々な参考図書があるものの,まずは研究社のウェブサイトより「リレー連載 実践で学ぶ コーパス活用術」の連載記事(全37本)に目を通すのがよいと思います.筆者の堀田も影は薄いですが寄稿しています (cf. 「#2186. 研究社Webマガジンの記事「コーパスで探る英語の英米差 ―― 基礎編 ――」」 ([2015-04-22-1]) と「#2216. 研究社Webマガジンの記事「コーパスで探る英語の英米差 ―― 実践編」 ([2015-05-22-1])).
本ブログからは corpus の各記事をご覧いただきたいのですが,その中から特に重要な記事を選んでおきます.
・ 「#568. コーパスの定義と英語コーパス入門」 ([2010-11-16-1])
・ 「#307. コーパス利用の注意点」 ([2010-02-28-1])
・ 「#367. コーパス利用の注意点 (2)」 ([2010-04-29-1])
・ 「#2779. コーパスは英語史研究に使えるけれども」 ([2016-12-05-1])
・ 「#363. 英語コーパス発展の3軸」 ([2010-04-25-1])
・ 「#368. コーパスは研究の可能性を広げた」 ([2010-04-30-1])
・ 「#1165. 英国でコーパス研究が盛んになった背景」 ([2012-07-05-1])
・ 「#1280. コーパスの代表性」 ([2012-10-28-1])
・ 「#2584. 歴史英語コーパスの代表性」 ([2016-05-24-1])
・ 「#428. The Brown family of corpora の利用上の注意」 ([2010-06-29-1])
・ 「#517. ICE 提供の7種類の地域変種コーパス」 ([2010-09-26-1])
・ 「#271. 語彙研究ツールとしての辞書とコーパス」 ([2010-01-23-1])
歴史英語コーパスのハブというべきサイトといえば,「#506. CoRD --- 英語歴史コーパスの情報センター」 ([2010-09-15-1]) を挙げないわけにはいきません.現時点で最も有用な歴史英語の情報集積サイトです.
BNC, COCA, ICE, Brown Family, COHA, HC (= Helsinki Corpus), LAEME, EEBO, CLMET など個別の(歴史)コーパスについては,それぞれのタグをつけた bnc, coca, ice, brown, coha, hc, laeme, eebo, clmet もご参照ください.
その他,リンク集としては「コーパスで探る英語の英米差 ―― 基礎編 ――」」 ([2015-04-22-1]) の記事も参照.
2019-05-03 Fri
■ #3658. 歴史語用論の分類と課題 (2) [pragmatics][historical_pragmatics][hisopra][methodology][corpus]
「#2000. 歴史語用論の分類と課題」 ([2014-10-18-1]) に引き続いて.歴史語用論 (historical_pragmatics) は,ここ数年の間に国際的にも国内的にも知名度をあげてきた.国内では私も HiSoPra* (= HIstorical SOciolinguistics and PRAgmatics) 研究会に参加させてもらっているし,周囲の学生や研究者をみてみても確実に関心が広まってきているのを感じる.
歴史語用論の扱う領域は広く,従来の主流派言語学では取りこぼされてきた「雑多な」話題をカバーすることが多い.歴史語用論の研究領域を整理しようとする試みは,前の記事 ([2014-10-18-1]) でも紹介したように,いくつかある.今回は,Arnovick (96) が英語歴史語用論を念頭に置きつつ挙げている3分法を紹介しよう.
Pragmatic forms: discourse markers, terms of address, connectives, and interjections;
Interactional pragmatics: speech acts, politeness, impoliteness;
Discursive domains: scientific and medical discourse, journalism, religious and political discourse, courtroom discourse, literary discourse, public and private correspondence.
Arnovick の同じ論文では,英語歴史語用論とコーパス利用の親和性についても説かれている.導入的な文章となっているので,英語歴史語用論に初めて関心をもったら,ぜひ読んでもらいたい.
・ Arnovick, Leslie K. "Historical Pragmatics in the Teaching of the History of English." Chapter 9 of Approaches to Teaching the History of the English Language: Pedagogy in Practice. Introduction. Ed. Mary Heyes and Allison Burkette. Oxford: OUP, 2017. 93--105.
2019-02-22 Fri
■ #3588. -o で終わる名詞の複数形語尾 --- pianos か potatoes か? [plural][spelling][corpus]
-o で終わる加算名詞から規則的な複数形を作る場合に,綴字上 -s のみを付す pianos タイプと,-es とする potatoes タイプが区別される.
LGSWE (285) は,LGSWE Corpus によって両タイプの分布を調査した.両語尾の間で揺れを示すものもあるので,80%以上の生起率を基準にして,いずれかのタイプかに割り振ったリストである.別途『徹底例解ロイヤル英文法』から補った類例( * を付した)も含めつつ,以下に列挙しよう.
・ pianos タイプ: *autos, avocados, casinos, commandos, concertos, discos, *dynamos, embryos, Eskimos, *ghettos, jumbos, kilos, memos, pesos, photos, pianos, portfolios, radios, scenarios, shampoos, solos, stereos, studios, taboos, tacos, tattoos, *torsos, trios, twos, videos, weirdos, zeros, zoos
・ potatoes タイプ: buffaloes, cargoes, echoes, heroes, mangoes, mosquitoes, mottoes, negroes, potatoes, tomatoes, tornadoes, torpedoes, vetoes, volcanoes
一般論をいえば,-s のみを付す pianos タイプが原則である.特に,略語に由来する -o 語や最近の新語として加わった -o 語は -s で複数形を作るのがデフォルトである.また,語末が「母音字+ o」となる場合にも,綴字配列の都合と思われるが,-s のみを付けるのが規則である (e.g. bamboos, cameos, cuckoos, curios, folios, radios, studios, trios) .
一方,potatoes タイプはどちらかといえば「例外」の側になるわけだが,このタイプには英語化した度合いの比較的強い,日常語が含まれるので注意を要する.
また,-s と -es の間で揺れを示す名詞も少なくない.『徹底例解ロイヤル英文法』では,例として banjo(e)s, buffalo(e)s, cargo(e)s, fresco(e)s, ghetto(e)s, grotto(e)s, halo(e)s, mango(e)s, manifesto(e)s, mosquito(e)s, motto(e)s, tornado(e)s, volcano(e)s, zero(e)s が挙げられている.先に挙げたリストと重複する単語もあることから,-o 語の複数形をもっと細かく調査すれば,実際にはさらに広範な揺れが観察されるのかもしれない.
なお,この話題と関連して,単数形 potato の綴りを potatoe と誤って覚えていたアメリカ元副大統領 Dan Quayle のスキャンダル,通称「potato 事件」について,Horobin (2--3) あるいはその拙訳 (16--17) を参照.1文字のスペリング・ミス(だけではないが)で,政治生命が断たれることもあるという驚くべき事例である.pianos か potatoes かという問題は決して侮れない.
・ Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad, and Edward Finegan. Longman Grammar of Spoken and Written English. Harlow: Pearson Education, 1999.
・ 綿貫 陽(改訂・著);宮川幸久, 須貝猛敏, 高松尚弘(共著) 『徹底例解ロイヤル英文法』 旺文社,2000年.
・ Horobin, Simon. Does Spelling Matter? Oxford: OUP, 2013.
・ サイモン・ホロビン(著),堀田 隆一(訳) 『スペリングの英語史』 早川書房,2017年.
Powered by WinChalow1.0rc4 based on chalow