2015-09-07 Mon
■ #2324. n-gram [corpus][information_theory][coca][bnc][google_books][statistics][n-gram][collocation][frequency][link]
情報理論や自然言語処理の分野で用いられる n-gram という分析手法がある.コーパス言語学でもすでにお馴染みの概念であり,共起表現 (collocation) の研究などでは当たり前のように用いられるようになった.種々のコーパスのインターフェースにおいても採用されており,「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) では名前に含まれているほどだし,本ブログでも COCA (Corpus of Contemporary American English) の N-gram データベースを用いて「#956. COCA N-Gram Search」 ([2011-12-09-1]) を実装してきた(その応用は,「#953. 頭韻を踏む2項イディオム」 ([2011-12-06-1]),「#954. 脚韻を踏む2項イディオム」 ([2011-12-07-1]),「#955. 完璧な語呂合わせの2項イディオム」 ([2011-12-08-1]) を参照).BNC では,Explore Words and Phrases from the BNC が利用できる.
コンピュータを用いた分析手法というと難しそうに聞こえるが,n-gram の考え方は至って単純である.文字レベルの 2-gram (bigram) を考えてみよう.最長の英単語といわれる pneumonoultramicroscopicsilicovolcanoconiosis (「#63. 塵肺症は英語で最も重い病気?」 ([2009-06-30-1])) を例にとる.まず,先頭の2文字1組の pn を取り出す.次に,2文字目に進んで同じように ne を取り出す.3文字目に進んで eu を,4文字目に進んで um を得る.同じように,1文字ずつ右にずらしながら,最後の is まで2文字1組を次々と拾っていく.これで44組の2文字を得たことになる.この組のなかで,ic と co という組み合わせは各々3回起こり,os, si, no, on の組み合わせは各々2回現われ,それ以外の組み合わせはいずれも1度きりである.したがって,この単語において最高頻度の2文字1組は ic と co となる.
n-gram の単位は,このように文字である必要はなく,音素でもよいし,より大きな単位である形態素や語でもよく,さらに大きな句などのより大きな単位でもよい.英語コーパス言語学では,語という単位で考えるのが普通だろう.Martin Luther King, Jr. の I Have a Dream の演説のテキストで語単位の 4-gram を取ると,最も多い4語の組み合わせは,予想通り "I have a dream" の8回だが,"will be able to" も同じく8回現われる."Let freedom ring from" も7回とよく現われる,等々の分析が可能となる.ここでは4語という「窓」を設定したので 4-gram と呼ばれるが,隣接するいくつの文字を考慮するかにより 1-gram (unigram), 2-gram (bigram), 3-gram (trigram),そして 5-gram 以上ももちろん考えることができる(1-gram の場合,得られるリストは,事実上各語の生起頻度表である).
巨大コーパスから得られた 2-gram や 3-gram の一覧は,それ自体が共起表現の研究などでは基本データとなるため,ウェブ上でもいろいろと公開されている.日本語では「N-gram コーパス - 日本語ウェブコーパス 2010」があるし,現代英語では COCA の n-gram データベース がある.また,Bigram Plus では,歴史英語コーパスを含めた各種英語コーパスから N-Gram Search を行なえる機能を提供している.ほかにも任意のテキストやコーパスを対象に n-gram を取る各種のツールやソフトも,ウェブ上で入手可能だ.
n-gram 分析の言語分野への応用範囲は広い.次に来る語(音,文字)は何か,という予測可能性とも関係が深いため,機械による音声認識,統語分析,言語判定,自動翻訳,スペルチェック,剽窃探知,全文検索用インデックスの作成などに活用される.もちろん,共起表現の研究では,基本にして不可欠の手段となっている.一方,n-gram はもっぱら言語として表面化されたテキストを対象とし,深層にある構造にまったく触れることがないため,生成文法のような言語理論の方面からは批判があるようだ.詳しくは,n-gram in Wikipedia を参照.
n-gram は工夫次第で,まだまだ使い道がありそうだ.歴史英語テキストにも,応用していきたい.
(後記 2015/09/12(Sat): Sketch Engine より N-grams も参照.)
2012-11-22 Thu
■ #1305. 統語タグのついた Google Books Ngram Corpus [corpus][google_books][ame_bre]
[2010-12-25-1]の記事「#607. Google Books Ngram Viewer」で紹介した Google 提供のコーパスツールに,統語タグが付けられた.インターフェースである Google Books Ngram Viewer の見かけは変わらないが,検索欄へ統語標識つきの検索式を入力できるようになった.その紹介と利用法は,Syntactic Annotations for the Google Books Ngram Corpus で参照できる.
現在,Google Books Ngram Corpus は English, Spanish, French, German, Russian, Italian, Chinese, Hebrew の8言語のコーパスを含むが,英語コーパスに関する限り,4,541,627冊分,468,491,999,492 tokens からなる超巨大テキスト・データベースとなっている.データセットはこちらから入手可能.
実装された統語タグは,具体的にいえば,品詞 (POS) と修飾関係 (head-modifier) である.標識付けは統計学的に自動で行なわれている.品詞は以下の12種類が区別される.
NOUN (nouns), VERB (verbs), ADJ (adjectives), ADV (adverbs), PRON (pronouns), DET (determiners and articles), ADP (prepositions and postpositions), NUM (numerals), CONJ (conjunctions), PRT (particles), '.' (punctuation marks), X (a catch-all for other categories such as abbreviations or foreign words)
入力式としては,例えば "burnt" のように語形を入れることもできるし,"burnt_VERB" のように品詞を指定して入れることもできる.さらに 3-grams 以内の統語連鎖であれば "_ADJ_" のような一括指定も利用できる.以上のパターンを合わせて,"the _ADJ_ girl_NOUN" なども可能だ.修飾関係の指定では,"hair=>black", "read=>book" などと入力でき,冠詞やその他のノイズとなる要素をはじくことが可能となっている.
名詞と動詞の用法を共有している語について,品詞別に頻度変化をみたい場合を考えよう.travel は名詞でも動詞でもあるが,英語コーパス全体を対象とした検索によれば,20世紀に入って名詞用法が動詞用法を追い抜いたことがわかる.ただし,対象コーパスをアメリカ英語とイギリス英語に切り替えて比較すると,後者で名詞が動詞を頻度の上で追い抜くのは1960年代とずっと遅い.
ほかに,have a look 及び take a look という表現の拡大を調べようとする場合に,不定冠詞の後に形容詞などが挿入される可能性も考慮し,"have>=look, take>=look" などと検索してみた.アメリカ英語では take を用いた表現が1970年に追い抜いているが,イギリス英語では20世紀中に徐々に拡大こそしているが,いまだ have を用いた表現に追いついていない.
2011-09-16 Fri
■ #872. -ick or -ic [suffix][johnson][webster][corpus][google_books][spelling][n-gram]
現代英語の動詞 panic や picnic は,屈折語尾や派生語尾が付加されると,panicking, panicky, picnicked, picnicker などと <k> が挿入される.また,brick, kick, stick などの接尾辞ではない,語根の一部としての /-ɪk/ にも <k> が現われる.しかし,一般に接尾辞としての /-ɪk/ が語末に現われる場合,対応する綴字は -ick ではなく -ic である (ex. public, music, specific, basic, domestic, traffic, democratic, scientific, characteristic, academic) .
しかし,Johnson の A Dictionary of the English Language (1755) では,-ic 語はすべて,いまだ -ick として綴られていた.これを現代風の -ic へと改めたのはアメリカの辞書編纂者 Noah Webster だった.彼が The American Dictionary of the English Language (1828) で体現した改革により public の綴字が定着し,そのほかの多くの -ic 語の綴字も定着した.そして,これがアメリカ英語のみならずイギリス英語へも拡大していったのである (Potter 41) .
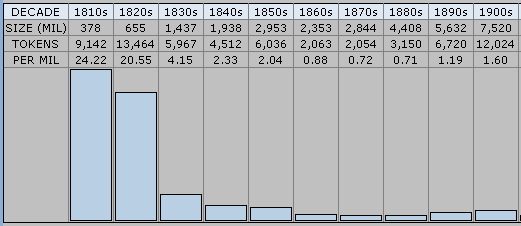
もっとも,Webster 以前に -ic の綴字がなかったわけではない.むしろ,ある程度の市民権を得ていたからこそ,Webster の一押しが効いたという側面がある.[2010-12-25-1]の記事で紹介した Google Books Ngram Viewer による public と publick の頻度の変遷を見れば,この状況が把握できる.AmE の変遷グラフ と BrE の変遷グラフ を確認されたい.同じデータを Mark Davies による Google Books: American English 経由で10年刻みに見ると,publick は1810--29年までは100万語辺りで20回以上現われていたが,1830年代には4.15回へ激減しているのが分かる.
接尾辞 -ic に関連する話題としては,次の記事も参照.
・ [2009-08-02-1]: #97. 借用接尾辞「チック」
・ [2009-08-03-1]: #98. 「リック」や「ニック」ではなく「チック」で切り出した理由
・ [2009-08-10-1]: #105. 日本語に入った「チック」語
・ Potter, Simon. Changing English. London: Deutsch, 1969.
2010-12-25 Sat
■ #607. Google Books Ngram Viewer [corpus][web_service][ame_bre][google_books][n-gram][statistics][frequency][lexicology]
Google がものすごいコーパスツールを提供してきた.Google Books Ngram Viewer は Google Labs 扱いだが,その規模と可能性の大きさに驚いた.2004年以来1500万冊の本をデジタル化してきた Google が,そのサブセットとなる520万冊の本,5000億語をコーパス化した.英語のほかフランス語,ドイツ語,ロシア語,スペイン語,中国語が含まれているが,英語では British English, American English, English, English Fiction, English One Million からサブコーパスを選択できる.最大の特徴は,指定した5語までの検索語の頻度を過去5世紀(1500--2008年)にわたって追跡し,グラフで表示してくれることだ.Google からの公式な説明はこちらの記事にある.
規模が大きすぎてコーパスとしてどう評価すべきかも分からないが,ひとまずはいじるだけで楽しい.上記の記事内にいくつかのサンプルがあるが,英語史的な関心を引くサンプルとして burnt と burned の分布比較があったので,English, American English, British English の3サブコーパスをグラフを出してみた.
次に,本年度の卒論ゼミ生の扱った話題を拝借し,一般に AmE on the street, BrE in the street とされる前置詞使用の差異を Google Books Ngram Viewer で確認してみた.American English と British English のそれぞれのサブコーパスから出力されたグラフは以下の通り.
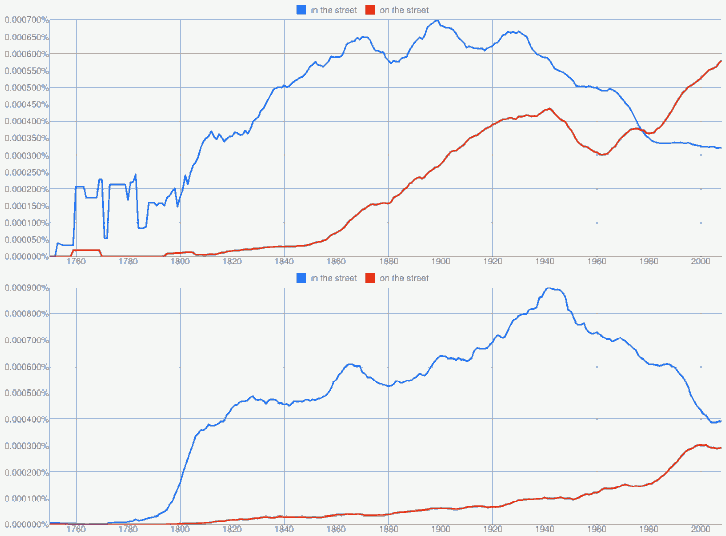
in と on の選択は句の意味(「街路で」か「失業して」か)などにも依存するため単純な形態の頻度比較では不十分だが,傾向はつかめる.
[2010-08-16-1], [2010-08-17-1]の記事で扱った gorgeous についても調べてみた.19世紀には流行っていたが20世紀には落ち目であったこの形容詞が,American English において1980年代以降,再び勢いを盛り返してきている状況がよくわかる.British English でも復調の兆しがあるだろうか?
コーパス言語学一般にいえるが,ツールの使用はアイデア次第である.文化史的な観点からは,[2009-12-28-1]の記事で紹介した American Dialect Society による "Words of the Century" や "Words of the Millennium" のノミネート語句を検索してみるとおもしろい.
他のオンラインコーパスについては[2010-11-16-1]を参照.
Powered by WinChalow1.0rc4 based on chalow