2015-03-29 Sun
■ #2162. OED によるフランス語・ラテン語からの借用語の推移 [oed][loan_word][statistics][french][latin][lexicology]
Wordorigins.org の "Where Do English Words Come From?" と題する記事では,OED をソースとした語種比率の通時的推移の調査報告がある.古英語から現代英語への各世紀に,語源別にどれだけの新語が語彙に加えられたかが解説とともにグラフで示されている.本文中にも述べられているように,見出し語の語源に関して OED の語源欄より引き出された情報は,眉に唾をつけて解釈しなければならない.というのは,語源欄にある言語が言及されていたとしても,それが借用元の語源を表すとは限らないからだ.しかし,およその参考になることは確かであり,通時的な概観のために有用であることには相違ない.
ここでは,CSV形式あるいはEXCEL形式で公開されている世紀別で語源別の数値を拝借し,フランス語とラテン語から英語語彙へ追加された借用語の推移をグラフ化して並べてみた.
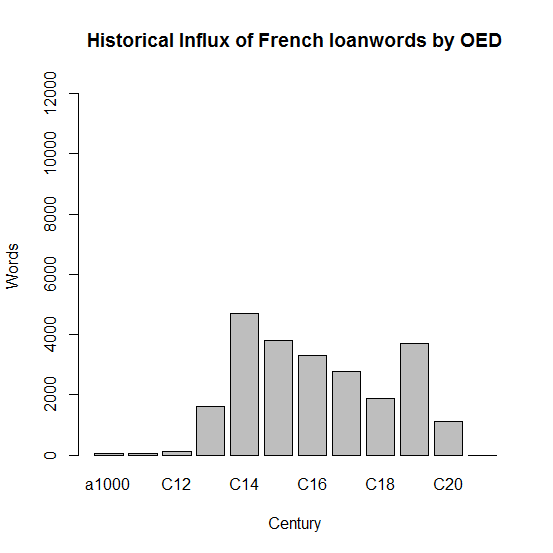 |
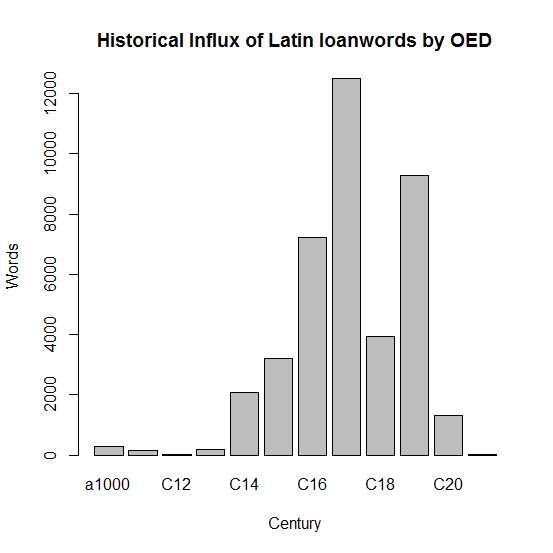 |
得られた傾向は,一般的な概説書で述べられているものと一致する.フランス語のピークは後期中英語,ラテン語のピークは初期近代英語である.比較すると,ラテン語の規模の著しさがよくわかる.フランス語とラテン語からの借用語に関連する統計については,すでに以下のように多くの記事で取り上げてきたので,そちらも参照されたい.
[2009-08-22-1]: #117. フランス借用語の年代別分布
[2009-11-15-1]: #202. 現代英語の基本語彙600語の起源と割合
[2010-06-30-1]: #429. 現代英語の最頻語彙10000語の起源と割合
[2010-12-12-1]: #594. 近代英語以降のフランス借用語の特徴
[2011-02-16-1]: #660. 中英語のフランス借用語の形容詞比率
[2011-08-20-1]: #845. 現代英語の語彙の起源と割合
[2011-09-18-1]: #874. 現代英語の新語におけるソース言語の分布
[2012-08-11-1]: #1202. 現代英語の語彙の起源と割合 (2)
[2012-08-18-1]: #1209. 1250年を境とするフランス借用語の区分
[2012-08-20-1]: #1211. 中英語のラテン借用語の一覧
[2012-09-03-1]: #1225. フランス借用語の分布の特異性
[2012-09-04-1]: #1226. 近代英語期における語彙増加の年代別分布
[2012-11-12-1]: #1295. フランス語とラテン語の2重語
[2014-08-24-1]: #1945. 古英語期以前のラテン語借用の時代別分類
また,OED の利用に際しては,以下の記事も参照されたい.
[2010-10-10-1] #:531. OED の引用データをコーパスとして使えるか
[2010-10-14-1] #:535. OED の引用データをコーパスとして使えるか (2)
[2010-10-15-1] #:536. OED の引用データをコーパスとして使えるか (3)
[2011-01-05-1] #:618. OED の検索結果から語彙を初出世紀ごとに分類する CGI
[2011-01-29-1] #:642. OED の引用データをコーパスとして使えるか (4)
2015-01-22 Thu
■ #2096. SUBTLEX-US Word Frequency List [frequency][statistics][corpus][lexicology][zipfs_law][cgi][web_service]
従来の英語学研究において,権威ある語彙頻度表といえばアメリカ英語に関する Kucera and Francis (1967) のものや,イギリス英語に比重を置いたより新しいものとして CELEX (1993) やその2版 (cf. 「#1424. CELEX2」 ([2013-03-21-1])) がよく用いられてきた.しかし,最近,これらを批判し,新しい手法に基づいたアメリカ英語の語彙頻度表が現われた.ベルギー,ヘント大学の実験心理学科の提供する SUBTLEXus である.左のHPから,SUBTLEXus の一群の頻度表のファイルや記述がダウンドーロできる.
SUBTLEXus の基盤にあるコーパスは,8388件の映画の字幕の集成であり,総語数は5100万語に及ぶ.SUBTLEXus の頻度表は,Kucera and Francis や CELEX の頻度表と比べて,いくつかの算出された指標においてすぐれていると主張されている.頻度は,見出し語 (lemma) ごとではなく語形 (word form) ごとに数えられており,例えば名詞であれば単数形と -s 語尾などをもつ複数形は別扱いされる(異なる語形は74,286種類).名詞と動詞など複数の品詞として用いられる語形については,それぞれの品詞ごとの頻度にもアクセスできるし,より優勢な品詞 (Dominant POS) のほうへ合算した頻度へもアクセスできる.データには,ほかに何件の映画に現われているか,小文字として現われているのは何回か,頻度の対数を取った指標,Zipf 指標 (cf. 「#1101. Zipf's law」 ([2012-05-02-1])) なども含まれている.これだけの種類のデータが含まれていると,目的とアイデア次第でおおいに有効に利用できるだろう.話し言葉ベースであることも顕著な特徴だ.
ダウンロードできるいくつかのデータのなかで "a zipped Excel file of SUBTLEX-US with the Zipf values included" をダウンロードし,少しいじってみた.例えば,(1) 全体的に多く現われ,かつ (2) 多くの映画にも現われる語形は,総合的な意味で頻度が高いと考えられるだろう.そこで (1) と (2) に関する対数の指標を掛け合わせて,それを降順に並べて最初の100語を取ると,正真正銘の最頻単語100語が得られるはずだ.省略形の片割れなども含まれているが,以下がそのリストである.
you, I, the, to, s, a, it, t, that, and, of, what, in, me, is, we, this, he, on, for, my, m, your, don, have, do, re, no, be, know, was, not, can, are, all, with, just, get, here, but, there, ll, so, they, like, right, out, go, up, about, she, if, him, got, at, now, come, oh, one, how, well, want, yeah, her, think, good, see, let, did, why, who, as, going, his, will, from, when, back, time, yes, look, d, take, an, where, man, would, them, been, some, or, tell, us, had, were, say, could, gonna, didn, hey
ほかには,最頻10語,25語,50語,100語,250語,500語,1,000語,2,500語,5,000語,10,000語,25,000語,50,000語,100,000語について,Dominant POS ごとに数え上げてみることもたやすい.「#666. COCA 最頻5000語で品詞別の割合は?」 ([2011-02-22-1]),「#667. COCA 最頻50万語で品詞別の割合は?」 ([2011-02-23-1]),「#1132. 英単語の品詞別の割合」 ([2012-06-02-1]) の記事でも,別のコーパスにより似たような調査を行ったが,SUBTLEX-US 版の調査結果は次のグラフにまとめられる.
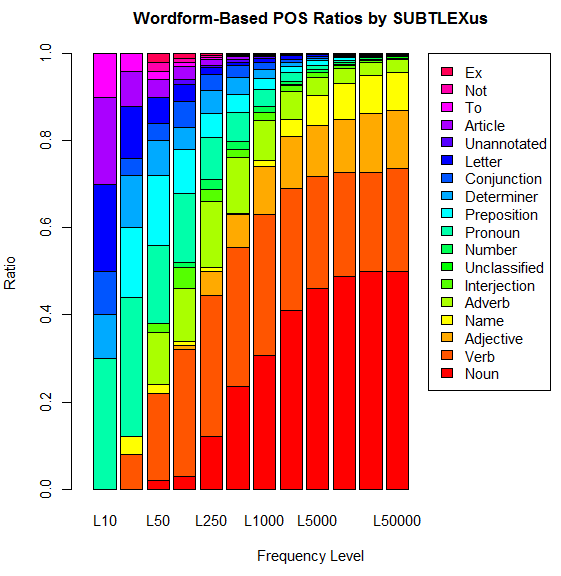
以下はおまけの検索ツール (SUBTLEX-US Word Frequency Extractor) .おまけなので,10例までしか結果が出力されない仕様です.SUBTLEXus の提供する複雑な検索も可能な,SUBTLEXus Online Search もどうぞ.
2014-09-18 Thu
■ #1970. 多義性と頻度の相関関係 [polysemy][zipfs_law][information_theory][frequency][statistics]
基本語彙と呼ばれるものの多面的な性質について「#1960. 英語語彙のピラミッド構造」 ([2014-09-08-1]) で触れた.基本語彙とは,日常的で頻度が高く,早期に習得され,変化しにくく,意味・用法が多岐にわたるなどの特徴をもつ.関連する話題は,「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1]),「#1089. 情報理論と言語の余剰性」 ([2012-04-20-1]),「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]),「#1101. Zipf's law」 ([2012-05-02-1]),「#1874. 高頻度語の語義の保守性」 ([2014-06-14-1]),「#1961. 基本レベル範疇」 ([2014-09-09-1]),「#1965. 普遍的な語彙素」 ([2014-09-13-1]) その他の記事でいろいろと扱ってきた.
今回は,この問題と関連して,高頻度語は多義的であるという命題について考えてみたい.頻度の高い語ほど語義を多くもち,頻度の低い語は語義を多くもたないということは言語使用の事実に照らして実証されるだろうか.また,理論的にいかに説明されるだろうか.Zipf's law で知られる Zipf は,情報理論の立場からこの課題に挑んだ.
Zipf は,E. L. Thorndike の英語最頻20,000語と Thorndike-Century Senior Dictionary に基づき,語の頻度と語義数の相関関係を探った.この辞書は,古語や廃語などの特殊な register をもつ語義は掲載しておらず,一般的に用いられる語義のみを掲載している.丹念に調査した結果,ある頻度域と,そこに属する語が示す平均語義数との間に,明らかな相関関係が見いだされた.以下は,Zipf (253) に示されているグラフを再現したものである.両軸ともに対数軸であり,X軸は頻度順位を,Y軸は頻度域の平均語義数を表わす.
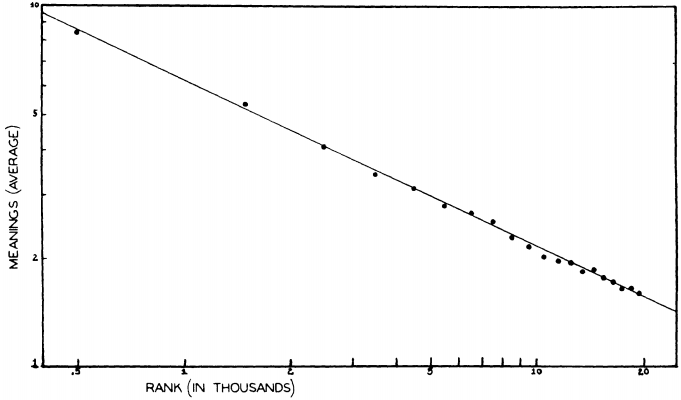
傾きはほぼ0.5に等しく,これは話者の発話と聴者の聴解にかかる費用に関する理論の予測と符合するという.その理論の数学的裏付けは私の理解を超えるので解説できないが,Zipf は結論として語の語義数と頻度(順位)の関係について次のように定式化した (Zipf 255) .
. . . different meanings of a word will tend to be equal to the square root of its relative frequencies (with the possible exception of the few dozen most frequent words)
背景には,多義の定義やある語の語義をいかに区分するかといった意味論の側で問うべき問題もおおいにあるが,示唆に富んだ結論である.関連して,「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]) や zipfs_law の各記事も参照されたい.
・ Zipf, G. K. "The Meaning-Frequency Relationship of Words." Journal of General Psychology 33 (1945): 251--66.
2014-09-07 Sun
■ #1959. 英文学史と日本文学史における主要な著書・著者の用いた語彙における本来語の割合 [statistics][lexicology][literature][style][japanese]
標題について,Hughes (42) は,Frederic T. Wood (An Outline History of the English Language. London: Heinemann, 1959. p.47) を参照して,数値を挙げている.以下にグラフ化して示そう.
King James Bible (1611) (94%): ********************************************************************************
Shakespeare (1564--1616) (90%): ****************************************************************************
Spenser (c1552--99) (86%): *************************************************************************
Milton (1608--74) (81%): ********************************************************************
Addison (1672--1719) (82%): *********************************************************************
Swift (1667--1745) (75%): ***************************************************************
Pope (1688--1744) (80%): ********************************************************************
Johnson (1709--84) (72%): *************************************************************
Hume (1711--76) (73%): **************************************************************
Gibbon (1737--94) (70%): ***********************************************************
Macaulay (1881--1958) (75%): ***************************************************************
Tennyson (1850--92) (77%): *****************************************************************
最高値を示す The King James Version が94%,最低値を示す Gibbon が70%だが,いずれにせよ相当に高い割合で本来語が用いられていることがわかる.話し言葉において本来語が高いことは容易に予想されるが,上記のような書き言葉において,しかも概して荘厳な文体が好まれた近代英語期に,ここまで本来語比率が高いという事実は注目に値する.特に Milton, Johnson, Gibbon などは難解な語彙を多く用いているという印象が強いが,英語史を通じて中核的であり続けた本来語彙の底力が際立っている.一方,最高値と最低値の間の20%ほどの幅は,それぞれの著者の時代や文体の相対的な差異を浮き彫りにしてくれることも確かである.
日本語の古典文学についても同様の調査を見てみよう.宮島達夫著『古典対称語い表』に基づいた加藤ほか (68, 73) に挙げられている数値を表にまとめて示す.
| 和語 | 漢語 | 混種語 | 語彙量(異なり語数) | |
|---|---|---|---|---|
| 万葉集(8世紀後半) | 99.6% | 0.3% | 0.1% | 6,505 |
| 竹取物語(9世紀末?10世紀初め) | 91.7% | 6.7% | 1.6% | 1,311 |
| 伊勢物語(10世紀初め?中ごろ) | 93.8% | 5.3% | 1.0% | 1,692 |
| 古今集(905年) | 99.9% | 0.1% | 0.1% | 1,994 |
| 土佐日記(935年) | 94.1% | 4.5% | 1.4% | 984 |
| 枕草子(1001年ごろ) | 84.1% | 12.2% | 3.6% | 5,247 |
| 源氏物語(11世紀初め) | 87.1% | 8.8% | 4.0% | 11,423 |
| 大鏡(12世紀初めごろ) | 67.6% | 27.6% | 4.8% | 4,819 |
| 方丈記(1212年) | 78.0% | 20.1% | 1.8% | 1,148 |
| 徒然草(1331年頃) | 68.6% | 28.1% | 3.3% | 4,242 |
和語についても,英文学史の場合と同様にグラフ化してみよう.日英語の間で通じるところが多いことに気づくだろう.
万葉集(8世紀後半) (99%): *******************************************************************************
竹取物語(9世紀末?10世紀初め) (91%): *************************************************************************
伊勢物語(10世紀初め?中ごろ) (93%): ***************************************************************************
古今集(905年) (99%): ********************************************************************************
土佐日記(935年) (94%): ***************************************************************************
枕草子(1001年ごろ) (84%): *******************************************************************
源氏物語(11世紀初め) (87%): *********************************************************************
大鏡(12世紀初めごろ) (67%): ******************************************************
方丈記(1212年) (78%): **************************************************************
徒然草(1331年頃) (68%): ******************************************************
関連して,「#1645. 現代日本語の語種分布」 ([2013-10-28-1]) とそこに張られているリンク,および「#1526. 英語と日本語の語彙史対照表」 ([2013-07-01-1]) を参照されたい.
・ Hughes, G. A History of English Words. Oxford: Blackwell, 2000.
・ 加藤 彰彦,佐治 圭三,森田 良行 編 『日本語概説』 おうふう,1989年.
2014-08-28 Thu
■ #1949. 語族ごとの言語数と話者数 [statistics][world_languages][language_family][demography]
「#270. 世界の言語の数はなぜ正確に把握できないか」 ([2010-01-22-1]),「#1060. 世界の言語の数を数えるということ」 ([2012-03-22-1]),「#274. 言語数と話者数」 ([2010-01-26-1]),「#398. 印欧語族は世界人口の半分近くを占める」 ([2010-05-30-1]) などの記事で,現代世界の言語の数やそれぞれの話者数を話題にしてきた.この種の統計の難しさは再三指摘してきたが,それを認めた上で,今回は語族 (language_family) ごとの言語数とその話者数の統計を示そう.とはいっても,W. Bright 編の言語学百科事典 (International Encyclopedia of Linguistics. New York and Oxford: OUP, 1992.) に拠っている Crystal (289) の統計値の受け売りにすぎない.1980年代後半現在の推計である.
| Language Family | Languages | Speakers |
|---|---|---|
| Indo-European | 386 | 2,500,000,000 |
| Sino-Tibetan | 272 | 1,088,000,000 |
| Austronesian | 1212 | 269,000,000 |
| Afro-Asiatic | 338 | 250,000,000 |
| Niger-Congo | 1354 | 206,000,000 |
| Dravidian | 70 | 165,000,000 |
| Japanese | 12 | 126,000,000 |
| Altaic | 60 | 115,000,000 |
| Austro-Asiatic | 173 | 75,000,000 |
| Tai | 61 | 75,000,000 |
| Korean | 1 | 60,000,000 |
| Nilo-Saharan | 186 | 28,000,000 |
| Uralic | 33 | 24,000,000 |
| Amerindian (North, Central, South America) | 985 | 22,400,000 |
| Caucasian | 38 | 7,800,000 |
| Miao-Yao | 15 | 5,600,000 |
| Indo-Pacific | 734 | 3,500,000 |
| Khoisan | 37 | 300,000 |
| Australian aborigine | 262 | 30,000 |
| Palaeosiberian | 8 | 18,000 |
| Isolates | 296 | 2,000,000 |
| Total | 6,533 | 5,022,648,000 |
言語数の推計には,310の死滅した言語,71の pidgin/creole,75の手話言語も含まれている.大雑把な推計であることを斟酌しつつも,印欧語族の話者は(当時の)世界人口の約半分を担う大語族であることが知れる.以下は,参考までに,上の図を割合を示す帯グラフにしたものである.

・ Crystal, David. The Cambridge Encyclopedia of Language. 2nd ed. Cambridge: CUP, 1997.
2014-08-24 Sun
■ #1945. 古英語期以前のラテン語借用の時代別分類 [typology][loan_word][latin][oe][christianity][borrowing][statistics]
「#32. 古英語期に借用されたラテン語」 ([2009-05-30-1]),「#1437. 古英語期以前に借用されたラテン語の例」 ([2013-04-03-1]) に続いて,古英語のラテン借用語の話題.古英語におけるラテン借用語の数は,数え方にもよるが,数百個あるといわれる.諸研究を参照した Miller (53) は,その数を600--700個ほどと見積もっている.
Old English had some 600--700 loanwords from Latin, about 500 of which are common to Northwest Germanic . . ., and 287 of which are ultimately from Greek, seventy-nine via Christianity . . . .
個数とともに確定しがたいのはそれぞれの借用語の借用年代である.[2013-04-03-1]の記事では,Serjeantson に従って借用年代を (i) 大陸時代,(ii) c. 450--c. 650, (iii) c. 650--c. 1100 と3分して示した.これは多くの論者によって採用されている伝統的な時代別分類である.これとほぼ重なるが,第4の借用の波を加えた以下の4分類も提案されている.
(1) continental borrowings
(2) insular borrowings during the settlement phase [c. 450--600]
(3) borrowings [600+] from christianization
(4) learned borrowings that accompanied and followed the Benedictine Reform [c10e]
この4分類をさらに細かくした Dennis H. Green (Language and History in the Early Germanic World. Cambridge: CUP, 1998.) による区分もあり,Miller (54) が紹介している.それぞれの特徴について Miller より引用し,さらに簡単に注を付す.
(1a) an early continental phase, when the Angles and Saxons were in Schleswig-Holstein (contact with merchants) and on the North Sea littoral as far as the mouth of the Ems (direct contact with the Romans)
数は少なく,主として商業語が多い.ローマからの商品,器,道具など.wine が典型例.
(1b) a later continental period, when the Angles and Saxons had penetrated to the litus Saxonicum (Flanders and Normandy)
ライン川河口以西でローマ人との直接接触して借用されたと思われる street, tile が典型例.
(2a) an early phase, featuring possible borrowing via Celtic
この時期に属すると思われる例は,ガリアで話されていた俗ラテン語と音声的に一致しており,ブリテン島での借用かどうかは疑わしいともいわれる.
(2b) a later phase, with loans from the continental Franks as part of their influence across the Channel, especially on Kent
(3) begins "with the coming of Augustine and his 40 companions in 597, and possibly even at an earlier date, with the arrival of Bishop Liudhard in the retinue of Queen Bertha of Kent in the 560s"
この時期の借用語は古英語期以前の音韻変化をほとんど示さない点で,他の時期のものと異なっている.多くは教会ラテン借用語である.
(4) of a learned nature, culled from classical Latin texts, and differ little from the classical written form
実際には,ここまで細かく枠を設定しても,ある借用語をいずれの枠にはめるべきかを確信をもって決することは難しい.continental か insular かという大雑把な分類ですら難しく,さらに曖昧に early か later くらいが精一杯ということも少なくない.
・ Miller, D. Gary. External Influences on English: From its Beginnings to the Renaissance. Oxford: OUP, 2012.
2014-06-21 Sat
■ #1881. 接尾辞 -ee の起源と発展 (2) [suffix][pde_language_change][lexicology][statistics][oed][productivity][agentive_suffix]
昨日の記事「#1880. 接尾辞 -ee の起源と発展 (1)」 ([2014-06-20-1]) に続き,当該接尾辞の現代英語にかけての質的な変化および量的な発展について,Isozaki に拠りながら考える.
Isozaki は,OED ほかの参考資料に当たり,現代英語から500を超える -ee 語を収集した.そして,これらを初出年代,統語・意味の種別,語幹の語源により分析し,後期近代英語から現代英語にかけての潮流を2点突き止めた.昨日の記事の終わりで述べた,(1) ロマンス系語幹ではなく本来語幹に接続する傾向が生じてきていること,および (2) standee のような動作主(主語)タイプが増えてきていること,の2つである.
(1) については,OED を用いた調査結果をグラフ化すると以下のようになる (Isozaki 7) .
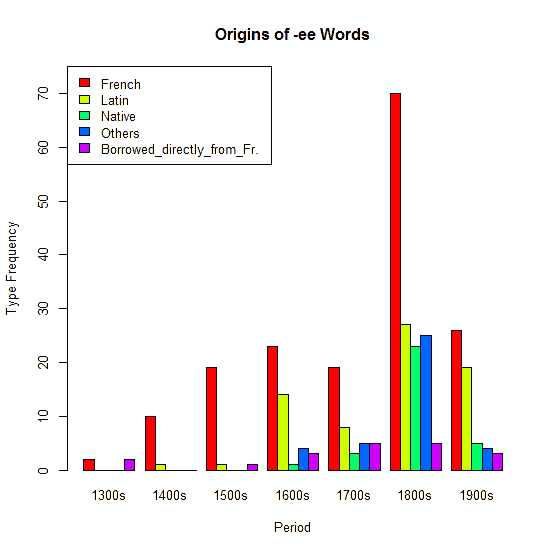
フランス語幹に接続する傾向が一貫して強いことは明らかである.しかし,本来語幹に接続する語例が後期近代より現われてきたことは注目に値する.なお,19世紀の爆発期の後で20世紀が地味に見えるのは,OED の語彙収録の特徴によるところが大きいかもしれない.
次に (2) についてだが,同じく OED を用いて,統語(意味)的な観点から分類した結果は以下の通りである (Isozaki 6) .グラフのなかで,DO は動詞の直接目的語,IO は間接目的語,PO は前置詞目的語,S は主語,Anom. は動詞とは直接に関係しない変則的なものである.
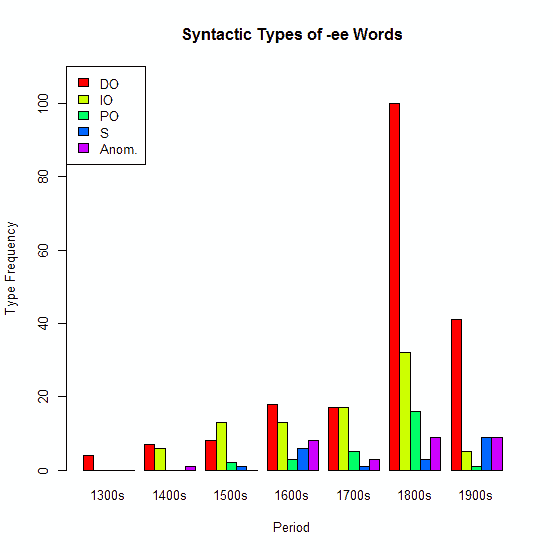
従来型の DO タイプが常に優勢であり続けていることが顕著であり,S タイプの拡張は特に目立たないようにみえる.しかし,OED を離れて,1900--2005年の種々の本や参考図書での出現を考慮に入れると,DO が117例,IO が23例,PO が4例,S が32例,Anom. が18例と,S (主語タイプ)の伸張が示唆される (Isozaki 6) .
-ee 語は臨時語的な使われ方が多いと想像され,使用域の一般化も進んでいるように思われる.今後は語用論的な調査も必要となってくるかもしれない.接辞の生産性 (productivity) という観点からも,アンテナを張っておきたい話題である.
・ Isozaki, Satoko. "520 -ee Words in English." Lexicon 36 (2006): 3--23.
2014-04-11 Fri
■ #1810. 変異のエントロピー [statistics][entropy][variation][consonant][speed_of_change][language_change][schedule_of_language_change][-ly]
昨今,エントロピー (entropy) というキーワードをよく聞くようになったが,言語との関連で,この概念が話題にされることはあまりない.本ブログでは,「#838. 言語体系とエントロピー」 ([2011-08-13-1]) をはじめとして,##838,1089,1090,1587,1693 の各記事でこの用語に触れてきたが,まだ具体的な問題に適用したことはなかった.
エントロピーとは,体系としての乱雑さの度合いを示す指標である.データがいかに一様に散らばっているかを表わす尺度と言い換えてもよい.言語への応用は,Gries (112) が少し触れている.
A simple measure for categorical data is relative entropy Hrel. Hrel is 1 when the levels of the relevant categorical variable are all equally frequent, and it is 0 when all data points have the same variable level. For categorical variables with n levels, Hrel is computed as shown in formula (16), in which pi corresponds to the frequency in percent of the i-th level of the variable:
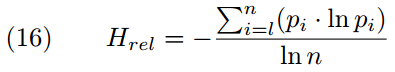
Gries は,300個の名詞句における冠詞の分布という例を挙げている.無冠詞164例,不定冠詞33例,定冠詞103例という内訳だった場合,Hrel = 0.8556091 となり,かなり不均質な分布を示すことになる.
ほかに散らばり具合が問題になるケースはいろいろと考えることができる.例えば,注目語句の出現頻度が,テキスト(のジャンル)に応じて一様か否かを測るということもできるだろう.
また,ある語に異形態や異綴字が認められる場合に,それぞれの変異形 (variants) の分布が均一か不均一かを計測することなどもできる.そのような変異の相対エントロピーが同時代の異なるテキスト(ジャンル)の間でどのくらい異なるのか,あるいは歴史的な関心からは,異なる時代のテキスト(ジャンル)の間でどのくらい異なるのかを,客観的に確かめることができるだろう.標準化その他の過程により,その変異が1つの形へ収斂してゆく場合,エントロピーが減少することになる.
具体的に考えるために,「#1773. ich, everich, -lich から語尾の ch が消えた時期」 ([2014-03-05-1]) で取り上げた,語尾の ch の脱落のデータを参照しよう.先の記事で Schlüter による集計結果の表を掲げたが,今回は,音声環境 (before V, before <h>, before C) の区別はせず,単純に ME II--ME IV の各時代に現れた変異形のトークン数のみを考慮に入れることにする.各変異形の各時代の Hrel を計算した結果の表を下に示す.
| I | 1150--1250 (ME I) | 1250--1350 (ME II) | 1350--1420 (ME III) | 1420--1500 (ME IV) |
|---|---|---|---|---|
| ich | 853 | 589 | 7 | 0 |
| I | 33 | 503 | 1397 | 2612 |
| Hrel | 0.2295 | 0.9955 | 0.04531 | 0.0000 |
| EVERY | 1150--1250 (ME I) | 1250--1350 (ME II) | 1350--1420 (ME III) | 1420--1500 (ME IV) |
| everich | - | 12 | 10 | 9 |
| everiche | - | 12 | 3 | 0 |
| every | - | 5 | 112 | 152 |
| Hrel | - | 0.9406 | 0.3550 | 0.1962 |
| -LY | 1150--1250 (ME I) | 1250--1350 (ME II) | 1350--1420 (ME III) | 1420--1500 (ME IV) |
| -lich | 106 | 33 | 31 | 3 |
| -''liche' | 689 | 168 | 70 | 44 |
| -ly | 12 | 19 | 1088 | 1444 |
| Hrel | 0.4225 | 0.6390 | 0.3123 | 0.1342 |
これの をプロットすると,次のようになる.
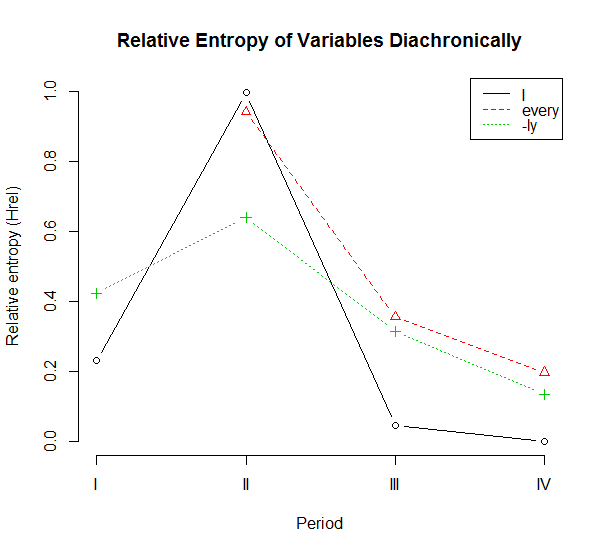
1人称単数代名詞主格 I の変異は,集束→発散→集束と推移しており,不安定期 II の突出が目立つ.安定していた体系が急激に乱され,そしてすぐに回復したという推移だ.第I期のデータを欠く every の変異は,I ほどではないものの,同じようにIIからIIIの時期にかけて急激な下落を示す.-ly の変異も,より緩やかではあるが,同時期に同様の下降を表わす.
Schlüter は,ich, everich, -lich の順で語尾の ch が脱落し,変異の収斂に向かっていったと評価しているが,これは第II期以降のエントロピーの減少率のことを指していると解釈できる.しかし,第I期からの推移も考慮に入れると,I の発散の開始は -ly の発散よりも後のようである.これは,早く始まった変化はゆっくりと進行するのに対し,遅く始まった変化は急速に進行するという,言語変化にしばしば見られるパターンを示唆する.エントロピー曲線の形状でいえば,前者は裾の長い富士山型,後者は先のとがったマッターホルン型ということになる.エントロピーという指標を用いて,言語変化のスピードについて何か一般化できることがあるかもしれない.
・ Gries, Stefan Th. Statistics for Linguistics with R: A Practical Introduction. Berlin: Mouton, 2009.
・ Schlüter, Julia. "Weak Segments and Syllable Structure in ME." Phonological Weakness in English: From Old to Present-Day English. Ed. Donka Minkova. Basingstoke: Palgrave Macmillan, 2009. 199--236.
2014-02-23 Sun
■ #1763. Shakespeare の作品と言語に関する雑多な情報 [shakespeare][statistics][link][timeline]
Shakespeare とその作品については,周知の通り,膨大な研究の蓄積がある.年表や統計の類いも多々あるが,Crystal and Crystal から適当に抜粋したものをいくつか載せておきたい.なお,Crystal and Crystal の種々の統計の元になっているデータベースは,Shakespeare's Words よりアクセスできる.その他の Shakespeare 関連のリンクについては,「#195. Shakespeare に関する Web resources」 ([2009-11-08-1]) を参照.
(1) Chronology of works (Crystal and Crystal 6)
| 1590--91 | The Two Gentlemen of Verona; The Taming of the Shrew |
| 1591 | Henry VI Part II; Henry VI Part III |
| 1592 | Henry VI Part I (perhaps with Thomas Nashe); Titus Andronicus (perhaps with George Peele) |
| 1592--3 | Richard III; Venus and Adonis |
| 1593--4 | The Rape of Lucrece |
| 1594 | The Comedy of Errors |
| 1594--5 | Love's Labour's Lost |
| by 1595 | King Edward III |
| 1595 | Richard II; Romeo and Juliet; A Midsummer Night's Dream |
| 1596 | King John |
| 1596--7 | The merchant of Venice; Henry IV Part I |
| 1597--8 | The Merry Wives of Windsor; Henry IV Part II |
| 1598 | Much Ado About Nothing |
| 1598--9 | Henry V |
| 1599 | Julius Caesar |
| 1599--1600 | As You Like It |
| 1600--1601 | Hamlet; Twelfth Night |
| by 1601 | The Phoenix and Turtle |
| 1602 | Troilus and Cressida |
| 1593--1603 | The Sonnets |
| 1603--4 | A Lover's Complaint; Sir Thomas More; Othello |
| 1603 | Measure for Measure |
| 1604--5 | All's Well that Ends Well |
| 1605 | Timon of Athens (with Thomas Middleton) |
| 1605--6 | King Lear |
| 1606 | Macbeth (revised by Middleton); Antony and Cleopatra |
| 1607 | Pericles (with George Wilkins) |
| 1608 | Coriolanus |
| 1609 | The Winter's Tale |
| 1610 | Cymbeline |
| 1611 | The Tempest |
| 1613 | Henry VIII (with John Fletcher); Cardenio (with John Fletcher) |
| 1613--14 | The Two Noble Kinsmen (with John Fletcher) |
(2) Top ten content words (Crystal and Crystal 153)
| good | 3995 |
| lord | 3164 |
| man | 3091 |
| love | 3047 |
| sir | 2548 |
| know | 2252 |
| give | 2114 |
| think/thought | 1911 |
| king | 1680 |
| speak | 1626 |
(3) Poetry or prose (Crystal and Crystal 165)
| Poetry (%) | No. of lines | Prose (%) | No. of lines | Play |
|---|---|---|---|---|
| 100 | 2752 | 0 | 0 | Richard II |
| 100 | 2569 | 0 | 0 | King John |
| 100 | 2493 | 0 | 0 | King Edward III |
| 99.7 | 2892 | 0.3 | 8 | Henry VI Part III |
| 99.5 | 2664 | 0.5 | 14 | Henry VI Part I |
| 98.6 | 2479 | 1.4 | 35 | Titus Andronicus |
| 97.6 | 3517 | 2.4 | 85 | Richard III |
| 97.4 | 2735 | 2.6 | 74 | Henry VIII |
| 94.5 | 2641 | 5.5 | 154 | The Two Noble Kinsmen |
| 93.5 | 1948 | 6.5 | 135 | Macbeth |
| 90.1 | 2208 | 9.9 | 244 | Julius Caesar |
| 89.8 | 2718 | 10.2 | 308 | Antony and Cleopatra |
| 86.9 | 2610 | 13.1 | 393 | Romeo and Juliet |
| 86.6 | 1543 | 13.4 | 239 | The Comedy of Errors |
| 85.2 | 2808 | 14.5 | 487 | Cymbeline |
| 83.7 | 2580 | 16.3 | 503 | Henry VI Part II |
| 81.2 | 1903 | 18.8 | 441 | Pericles |
| 80.6 | 2076 | 19.4 | 498 | The Taming of the Shrew |
| 80.6 | 1713 | 19.4 | 413 | A Midsummer Night's Dream |
| 80.4 | 2599 | 19.6 | 633 | Othello |
| 78.6 | 2025 | 21.4 | 551 | The Merchant of Venice |
| 77.2 | 2571 | 22.8 | 760 | Coriolanus |
| 76.5 | 1569 | 23.5 | 481 | The Tempest |
| 73.2 | 2181 | 26.8 | 800 | The Winter's Tale |
| 73.1 | 2345 | 26.9 | 865 | King Lear |
| 73.1 | 1707 | 26.9 | 627 | Timon of Athens |
| 73.1 | 1613 | 26.9 | 595 | The Two Gentlemen of Verona |
| 71.5 | 2742 | 28.5 | 1092 | Hamlet |
| 66.4 | 2250 | 33.6 | 1137 | Troilus and Cressida |
| 64.2 | 1716 | 35.8 | 955 | Love's Labour's Lost |
| 60.6 | 1634 | 39.4 | 1062 | Measure for Measure |
| 60.5 | 1943 | 39.5 | 1269 | Henry V |
| 55.6 | 1666 | 44.4 | 1332 | Henry IV Part I |
| 51.6 | 1447 | 48.4 | 1356 | All's Well that Ends Well |
| 47.6 | 1547 | 52.4 | 1700 | Henry IV Part II |
| 47.4 | 1276 | 52.6 | 1415 | As You Like It |
| 38.2 | 949 | 61.8 | 1532 | Twelfth Night |
| 28.3 | 739 | 71.7 | 1871 | Much Ado About Nothing |
| 12.5 | 338 | 87.5 | 2370 | The Merry Wives of Windsor |
(4) How long are the plays? (Crystal and Crystal 139)
| Total lines | Total words | Play | First Folio | Riverside |
|---|---|---|---|---|
| 3834 | 29,844 | Hamlet | 3906 | 4042 |
| 3602 | 28,439 | Richard III | 3887 | 3667 |
| 3387 | 25,730 | Troilus and Cressida | 3592 | 3531 |
| 3331 | 26,479 | Coriolanus | 3838 | 3752 |
| 3295 | 26,876 | Cymbeline | 3819 | 3707 |
| 3247 | 25,737 | Henry IV Part II | 3350 | 3326 |
| 3232 | 26,003 | Othello | 3685 | 3551 |
| 3212 | 25,623 | Henry V | 3381 | 3297 |
| 3210 | 25,341 | King Lear | 3302 | 3487 |
| 3083 | 24,490 | Henry VI Part II | 3355 | 3130 |
| 3026 | 23,726 | Antony and Cleopatra | 3636 | 3522 |
| 3003 | 24,023 | Romeo and Juliet | 3185 | 3099 |
| 2998 | 24,126 | Henry IV Part I | 3180 | 3081 |
| 2981 | 24,597 | The Winter's Tale | 3369 | 3348 |
| 2900 | 23,318 | Henry VI Part III | 3217 | 2915 |
| 2809 | 23,333 | Henry VIII | 3463 | 3221 |
| 2803 | 22,537 | All's Well that Ends Well | 3078 | 3013 |
| 2795 | 23,388 | The Two Noble Kinsmen | not in | 3261 |
| 2752 | 21,884 | Richard II | 2849 | 2796 |
| 2708 | 21,290 | The Merry Wives of Windsor | 2729 | 2891 |
| 2696 | 21,269 | Measure for Measure | 2938 | 2891 |
| 2691 | 21,477 | As You Like It | 2796 | 2810 |
| 2678 | 20,541 | Henry VI Part I | 2931 | 2695 |
| 2671 | 20,881 | Love's Labour's Lost | 2900 | 2829 |
| 2610 | 20,767 | Much Ado About Nothing | 2684 | 2787 |
| 2576 | 20,911 | The Merchant of Venice | 2737 | 2701 |
| 2574 | 20,552 | The Taming of the Shrew | 2750 | 2676 |
| 2569 | 20,472 | King John | 2729 | 2638 |
| 2514 | 19,888 | Titus Andronicus | 2708 | 2538 |
| 2493 | 19,406 | King Edward III | not in | not in |
| 2481 | 19,592 | Twelfth Night | 2579 | 2591 |
| 2452 | 19,149 | Julius Caesar | 2730 | 2591 |
| 2344 | 17,728 | Pericles | not in | 2459 |
| 2334 | 17,796 | Timon of Athens | 2607 | 2488 |
| 2208 | 16,936 | The Two Gentlemen of Verona | 2298 | 2288 |
| 2126 | 16,305 | A Midsummer Night's Dream | 2222 | 2192 |
| 2083 | 16,372 | Macbeth | 2529 | 2349 |
| 2050 | 16,047 | The Tempest | 2341 | 2283 |
| 1782 | 14,415 | The Comedy of Errors | 1918 | 1787 |
(5) Using you and thou (Crystal and Crystal 126)
| You-forms | Thou-forms | ||
| you | 14,244 | thou | 5,942 |
| ye | 352 | thee | 3,444 |
| your | 6,912 | thy | 4,429 |
| yours | 260 | thine | 510 |
| yourself | 289 | thyself | 251 |
| yourselves | 74 | ||
| Total | 22,131 | 14,576 | |
|---|---|---|---|
・ Crystal, David and Ben Crystal. The Shakespeare Miscellany. Woodstock & New York: Overlook, 2005.
2013-11-09 Sat
■ #1657. アメリカの英語公用語化運動 [sociolinguistics][language_planning][statistics][bilingualism][linguistic_right]
アメリカにもイギリスにも法律で定めた公用語というものはない.英語が事実上の公用語であることは明らかだが,まさに事実上そうであるという理由で,特に法律で明記する必要がないのである.いや,正確には,これまでは必要がなかったと言うべきだろう.1980年代以降,アメリカでは英語公用語化運動が繰り広げられてきた.
背景には,英語を話さないアメリカ人の増加という事情がある.U.S. Census Bureau の統計によると,5歳以上のアメリカ人で,英語がまったく話せない,あるいはうまく話せない人の数が,1980年では全人口の2%だったが,1990年では2.9%と増加し,最新の2011年のデータ (PDF)では4.65%に達している.ある試算によると2050年には6%に達するのではないかとも言われる.(Language Use - U.S. Census Bureau の各種統計を参照.)
アメリカでは1968年の2言語教育法の制定により,非英語話者が教育上不利にならないような配慮がなされてきた.非英語話者の子供には英語を学ぶ機会が必ず与えられるし,政府刊行物,公共の案内,運転免許の筆記試験などで英語以外の言語を選ぶこともできる.しかし,この言語政策には莫大な予算がかかる.さらに,国家統合の問題にもかかわる.増加する国民の英語離れは,アメリカが国家としての重要な求心力を失い始めている徴候ではないかと考える人々がいてもおかしくない.こうして,英語公用語論争が始まった.
連邦政府レベルで英語公用語運動が始まったのは,1981年である.カナダ生まれの日系人で言語学者であり連邦上院議員の S. I. Hayakawa が,英語を公用語とする修正条項を憲法に付加することを提案した.この提案は退けられたが,州レベルでは運動は続けられることになった.Nebraska, Illinois, Virginia, Indiana, Kentucky, Tennessee の6州で英語を公用語とする法律が成立したのに続き,1986年に California で英語公用語化法案 Proposition 63 が住民投票の結果,通された.メディアなどの前評判を覆して,賛成票73%での法案成立だった.それまでの他州での法案が実質的というよりは象徴的な意味合いをもつにすぎなかったのに対して,California Proposition 63 (or the English Is the Official Language of California Amendment) はより踏み込んだ法案となっていた.以下,抜粋しよう.
English is the common language of the people of the United States of America and of the State of California. . . . The legislature and officials of the State of California shall take all steps necessary to insure that the role of English as the common language of the State of California is preserved and enhanced. . . . Any person who is a resident of, or does business in the State of California shall have standing to sue the State of California to enforce this section . . .
この法案は,州政府に英語公用語化に向けてあらゆる措置を取らせる権限を与え,州民に英語公用語化に抵触する事態に面したときに起訴権を与えるというものである.さらにこの法案に特異なのは,US English という団体を中心とした一般州民の要望による住民投票で可決したという点である.
その後も,Arizona, Colorado, Florida などでも運動は成功したが,特に Arizona Proposition 106 はさらに突っ込んだ内容となっている."As the official language of this State, the English language is the language of the ballot, the public schools and all government functions and actions."
US English のような団体に反対する団体も現れている.English Plus Information Clearinghouse (EPIC) では,English Only ではなく English Plus の思想を打ち出し,言語権の擁護を訴えている.
以上,東 (197--205) を参照して執筆した.関連して,「#256. 米国の Hispanification」 ([2010-01-08-1]) を参照.
・ 東 照二 『社会言語学入門 改訂版』,研究社,2009年.
2013-10-28 Mon
■ #1645. 現代日本語の語種分布 [japanese][lexicology][statistics][etymology][loan_word][lexical_stratification]
英語語彙の語種別の割合について,これまで多くの記事で各種統計を示してきた.
・ [2012-09-03-1]: 「#1225. フランス借用語の分布の特異性」
・ [2012-08-11-1]: 「#1202. 現代英語の語彙の起源と割合 (2)」
・ [2012-01-07-1]: 「#985. 中英語の語彙の起源と割合」
・ [2011-09-18-1]: 「#874. 現代英語の新語におけるソース言語の分布」
・ [2011-08-20-1]: 「#845. 現代英語の語彙の起源と割合」
・ [2010-12-31-1]: 「#613. Academic Word List に含まれる本来語の割合」
・ [2010-06-30-1]: 「#429. 現代英語の最頻語彙10000語の起源と割合」
・ [2010-05-16-1]: 「#384. 語彙数とゲルマン語彙比率で古英語と現代英語の語彙を比較する」
・ [2010-03-02-1]: 「#309. 現代英語の基本語彙100語の起源と割合」
・ [2009-11-15-1]: 「#202. 現代英語の基本語彙600語の起源と割合」
・ [2009-11-14-1]: 「#201. 現代英語の借用語の起源と割合 (2)」
・ [2009-08-19-1]: 「#114. 初期近代英語の借用語の起源と割合」
・ [2009-08-15-1]: 「#110. 現代英語の借用語の起源と割合」
「#334. 英語語彙の三層構造」 ([2010-03-27-1]),「#335. 日本語語彙の三層構造」 ([2010-03-28-1]),「#1526. 英語と日本語の語彙史対照表」 ([2013-07-01-1]) で見たように,英語と日本語の語彙は比較される歴史をたどってきており,結果として現代の共時的な語彙構成にも共通点が見られる.今回は,現代英語との比較のために,現代日本語の語種別の割合をみよう.一般的にこの種の語彙統計を得るのは難しいが,『日本語百科大事典』 (420--21) に拠りながら3種の調査結果の概観を示す.
(1) 明治から昭和にかけての3種の国語辞典『言海』(明治22年;1889年),『例解国語辞典』(昭和31年;1956年),『例解国語辞典』(昭和44年;1969年)の収録語を語種別に数えた研究がある.総語数は,『言海』39,103,『例解国語辞典』40,393,『角川国語辞典』60,218 である.以下に割合を示す表と図を示そう.
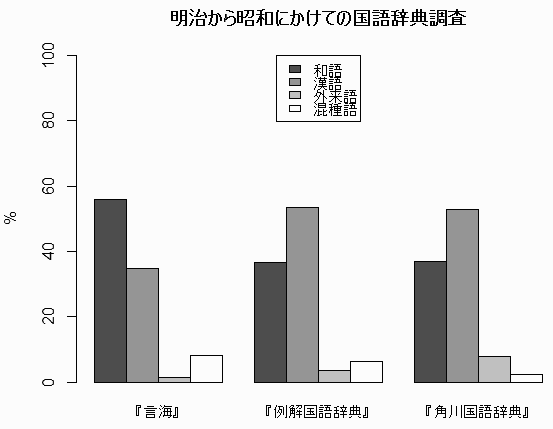
| 和語 | 漢語 | 外来語 | 混種語 | |
|---|---|---|---|---|
| 『言海』 | 55.8% | 34.7 | 1.4 | 8.1 |
| 『例解国語辞典』 | 36.6 | 53.6 | 3.5 | 6.2 |
| 『角川国語辞典』 | 37.1 | 52.9 | 7.8 | 2.2 |
時代が進むにつれて,和語に対する漢語と外来語の割合が高まってきているのがわかる.昭和では,1/2強が漢語,1/3強が和語という割合だ.
(2) 現代の書きことばについては,国立国語研究所の『現代雑誌九十種の用語用字』調査のデータがよく参照される.昭和31年(1956年)の雑誌から,助詞,助動詞,固有名詞を除いて語彙を収集したものである.得られた語彙は,異なり語数で30,331,延べ語数で411,972.21世紀の現在から見ると古いデータではあるが,質において比肩する新しい調査は行われていない.
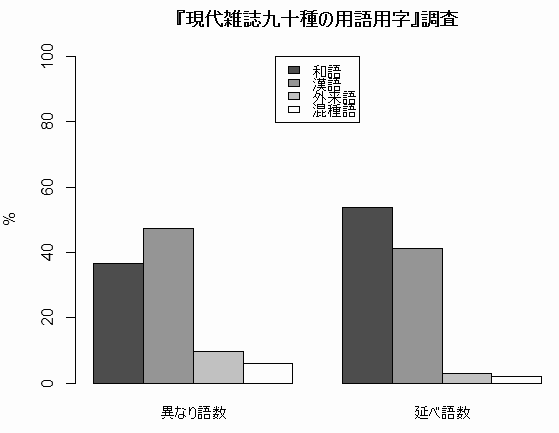
| 和語 | 漢語 | 外来語 | 混種語 | |
|---|---|---|---|---|
| 異なり語数 | 36.7% | 47.5 | 9.8 | 6.0 |
| 延べ語数 | 53.9 | 41.3 | 2.9 | 1.9 |
異なり語数と延べ語数では数値がかなり異なっており,特に和語と漢語の順位が入れ替わっているのが注目に値する.
(3) 現代の話しことばの調査としては,知識層を対象としたものがある.日本語教育および語学関係の研究者7人とその話し相手の会話を延べ42時間分録音し,分析したものである.異なり語数は4,617で,延べ語数は64,023.
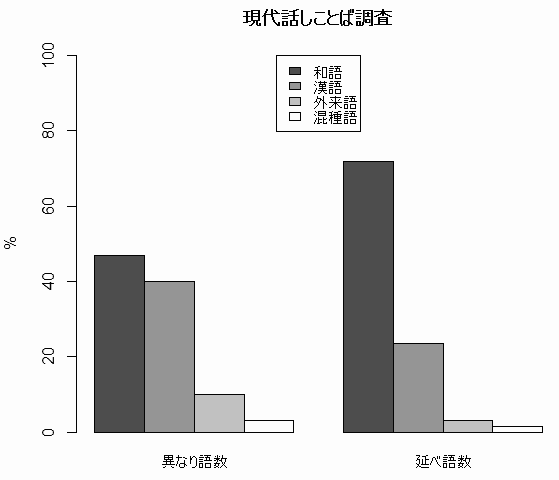
| 和語 | 漢語 | 外来語 | 混種語 | |
|---|---|---|---|---|
| 異なり語数 | 46.9% | 40.0 | 10.1 | 3.0 |
| 延べ語数 | 71.8 | 23.6 | 3.2 | 1.4 |
話しことばでは,書きことばと異なり,異なり語数と延べ語数の間で和漢語の順位入れ替えはない.いずれの数え方でも和語の割合が最も多いが,とりわけ延べ語数では和語が圧倒している.
この話しことばの調査では,公的な場面や私的な場面など場面別に分析がなされたが,全体的な傾向として,和語は (1) 私的な場面でのほうが多い,(2) 延べ語数でのほうが多い,(3) 使用頻度の高い語ほど多い,(4) 話し言葉でのほうが多い,という結果が出た.私的な話しことばで高頻度に用いられる語は,和語である確率が最も高いということになる.この結果は直感と一致するだろう.
英語においても本来語は「私的な場面の話しことばで高頻度に用いられる」確率が高いと想像されるが,これについては統計は見たことはなく,今後,実証してゆく必要があるかもしれない.
・ 『日本語百科大事典』 金田一 春彦ほか 編,大修館,1988年.
2013-09-05 Thu
■ #1592. 英語話者の人口を推計することが難しい理由 [statistics][demography][post-creole_continuum]
昨日の記事「#1591. Crystal による英語話者の人口」 ([2013-09-04-1]) で,Crystal による2001年付けでの英語話者人口の推計を示した.Crystal (69) の脚注に,最近の他の研究者による推計が触れられている.
It is interesting to compare estimates for first (L1), second (L2) and foreign (F) language use over the past 40 years.
-- in Quirk (1962: 6) the totals for first (L1), second (L2) and foreign (F) were 250 (L1) and 100 (L2/F);
-- during the 1970s these totals rose to 300 (L1), 300 (L2) and 100 (F) (cf. McArthur (1922: 355));
-- Kachru (1985: 212) has 300 (L1), 300--400 (L2) and 600--700 (F);
-- Ethnologue (1988) and Bright (1992: II.74), using a Time estimate in 1986, have 403 (L1), 397 (L2) and 800 (F);
-- during the 1990s the L1 and L2 estimates rise again, though with some variation. The Columbia Encyclopedia (1993) has 450 (L1), 400 and 850 (F). Ethnologue (1992), using a World Almanac estimate in 1991, has 450 (L1) and 350 (L2).
それぞれの推計の変動幅は決して小さくはなく,どれを信用すべきか迷うところだ.様々な推計の平均値をとるという方法も,1つの便宜的な方法かもしれない.
この種の人口統計はある程度の不確かさを伴うのが常だが,とりわけ英語話者数というような統計には多くの困難がついてまわる.その理由を挙げてみよう.
(1) この目的のために世界的な規模で利用できる統計がない (Crystal 61) .
(2) 昨日の Crystal の推計に関連して触れたように,主として Expanding Circle に属する EFL 話者の数を正確に把握することはとりわけ難しい.例えば,21世紀初頭において,世界的に英語学習者の増加率が高まってきていることは確かだが,具体的にどの程度の増加率かを正確に言い当てる直接的な方法はない.
(3) 人口統計においても英語話者を ENL, ESL, EFL と区分するモデルが用いられることが多いが,その境目がはっきりしない.また,それぞれの国・地域が上記のいずれかの区分に当てはまるという前提が立てられているが,実際には両者は厳密に対応しないことも多い.ENL と ESL の国・地域では,英語が "special place" を占めていることが前提とされているが,"special place" とは実際の英語使用度や理解度によってではなく歴史的・政治的な要因によって与えられるものにすぎない.
(4) 「英語を話せる」レベルをどこに設定するか,客観的な基準がない.レベルを下げれば ESL や EFL の話者が数億人単位で増えるし,レベルを上げれば話者数は減る.
(5) どの変種を英語の一種とみなすかについて合意がない.ピジン英語やクレオール英語は英語の一種としてみなすべきだろうか.相互理解可能性を問題にするのであれば,多くのピジン英語やクレオール英語は英語でないという結論になりそうだが,「#1499. スカンジナビアの "semicommunication"」 ([2013-06-04-1]) でも触れたように,理解度は言語的な距離のほかに話し手と聞き手の態度も大きく影響する.また,「#385. Guyanese Creole の連続体」 ([2010-05-17-1]) で触れた post-creole continuum のように,どこからが標準変種でどこからがピジン・クレオール変種なのかが判然としない例もある.
・ Crystal, David. English As a Global Language. 2nd ed. Cambridge: CUP, 2003.
2013-09-04 Wed
■ #1591. Crystal による英語話者の人口 [statistics][demography][enl][esl][efl][elf][new_englishes][pidgin][creole]
昨日の記事で扱った「#1590. アジア英語の諸変種」 ([2013-09-03-1]) から世界の英語変種へ目を広げると,それこそおびただしい English varieties が,今現在,発展していることがわかる.英語変種の数ばかりでなく英語変種の話者の数もおびただしく,「#397. 母語話者数による世界トップ25言語」 ([2010-05-29-1]) の記事の終わりで触れたように,母語話者数と非母語話者を足し合わせると,英語は世界1の大言語となる.英語話者人口の過去,現在,未来については,以下の記事で扱ってきた.
・ 「#319. 英語話者人口の銀杏の葉モデル」 ([2010-03-12-1])
・ 「#427. 英語話者の泡ぶくモデル」 ([2010-06-28-1])
・ 「#933. 近代英語期の英語話者人口の増加」 ([2011-11-16-1])
・ 「#173. ENL, ESL, EFL の話者人口」 ([2009-10-17-1])
・ 「#375. 主要 ENL,ESL 国の人口増加率」 ([2010-05-07-1])
・ 「#759. 21世紀の世界人口の国連予測」 ([2011-05-26-1])
・ 「#414. language shift を考慮に入れた英語話者モデル」 ([2010-06-15-1])
現在の世界における英語話者人口を正確に把握することは難しい.Crystal (61, 65--67) で述べられているように,この種の人口統計には様々な現実的・理論的な制約が課されるからだ.Crystal (62--65) は,その制約のなかで2001年現在の英語人口を推計した.近年,最もよく引き合いに出される英語話者の人口統計である.
| Territory | L1 | L2 | Population (2001) |
|---|---|---|---|
| American Samoa | 2,000 | 65,000 | 67,000 |
| Antigua & Barbuda* | 66,000 | 2,000 | 68,000 |
| Aruba | 9,000 | 35,000 | 70,000 |
| Australia | 14,987,000 | 3,500,000 | 18,972,000 |
| Bahamas* | 260,000 | 28,000 | 298,000 |
| Bangladesh | 3,500,000 | 131,270,000 | |
| Barbados* | 262,000 | 13,000 | 275,000 |
| Belize* | 190,000 | 56,000 | 256,000 |
| Bermuda | 63,000 | 63,000 | |
| Botswana | 630,000 | 1,586,000 | |
| British Virgin Islands* | 20,000 | 20,800 | |
| Brunei | 10,000 | 134,000 | 344,000 |
| Cameroon* | 7,700,000 | 15,900,000 | |
| Canada | 20,000,000 | 7,000,000 | 31,600,000 |
| Cayman Islands* | 36,000 | 36,000 | |
| Cook Islands | 1,000 | 3,000 | 21,000 |
| Dominica* | 3,000 | 60,000 | 70,000 |
| Fiji | 6,000 | 170,000 | 850,000 |
| Gambia* | 40,000 | 1,411,000 | |
| Ghana* | 1,400,000 | 19,894,000 | |
| Gibraltar | 28,000 | 2,000 | 31,000 |
| Grenada* | 100,000 | 100,000 | |
| Guam | 58,000 | 100,000 | 160,000 |
| Guyana* | 650,000 | 30,000 | 700,000 |
| Hong Kong | 150,000 | 2,200,000 | 7,210,000 |
| India | 350,000 | 200,000,000 | 1,029,991,000 |
| Ireland | 3,750,000 | 100,000 | 3,850,000 |
| Jamaica* | 2,600,000 | 50,000 | 2,665,000 |
| Kenya | 2,700,000 | 30,766,000 | |
| Kiribati | 23,000 | 94,000 | |
| Lesotho | 500,000 | 2,177,000 | |
| Liberia* | 600,000 | 2,500,000 | 3,226,000 |
| Malawi | 540,000 | 10,548,000 | |
| Malaysia | 380,000 | 7,000,000 | 22,230,000 |
| Malta | 13,000 | 95,000 | 395,000 |
| Marshall Islands | 60,000 | 70,000 | |
| Mauritius | 2,000 | 200,000 | 1,190,000 |
| Micronesia | 4,000 | 60,000 | 135,000 |
| Montserrat* | 4,000 | 4,000 | |
| Namibia | 14,000 | 300,000 | 1,800,000 |
| Nauru | 900 | 10,700 | 12,000 |
| Nepal | 7,000,000 | 25,300,000 | |
| New Zealand | 3,700,000 | 150,000 | 3,864,000 |
| Nigeria* | 60,000,000 | 126,636,000 | |
| Northern Marianas* | 5,000 | 65,000 | 75,000 |
| Pakistan | 17,000,000 | 145,000,000 | |
| Palau | 500 | 18,000 | 19,000 |
| Papua New Guinea* | 150,000 | 3,000,000 | 5,000,000 |
| Philippine$ | 20,000 | 40,000,000 | 83,000,000 |
| Puerto Rico | 100,000 | 1,840,000 | 3,937,000 |
| Rwanda | 20,000 | 7,313,000 | |
| St Kitts & Nevis* | 43,000 | 43,000 | |
| St Lucia* | 31,000 | 40,000 | 158,000 |
| St Vincent & Grenadines* | 114,000 | 116,000 | |
| Samoa | 1,000 | 93,000 | 180,000 |
| Seychelles | 3,000 | 30,000 | 80,000 |
| Sierra Leone* | 500,000 | 4,400,000 | 5,427,000 |
| Singapore | 350,000 | 2,000,000 | 4,300,000 |
| Solomon Islands* | 10,000 | 165,000 | 480,000 |
| South Africa | 3,700,000 | 11,000,000 | 43,586,000 |
| Sri Lanka | 10,000 | 1,900,000 | 19,400,000 |
| Suriname* | 260,000 | 150,000 | 434,000 |
| Swaziland | 50,000 | 1,104,000 | |
| Tanzania | 4,000,000 | 36,232,000 | |
| Tonga | 30,000 | 104,000 | |
| Trinidad & Tobago* | 1,145,000 | 1,170,000 | |
| Tuvalu | 800 | 11,000 | |
| Uganda | 2,500,000 | 23,986,000 | |
| United Kingdom | 58,190,000 | 1,500,000 | 59,648,000 |
| UK Islands (Channel, Man) | 227,000 | 228,000 | |
| United States | 215,424,000 | 25,600,000 | 278,059,000 |
| US Virgin Islands* | 98,000 | 15,000 | 122,000 |
| Vanuatu* | 60,000 | 120,000 | 193,000 |
| Zambia | 110,000 | 1,800,000 | 9,770,000 |
| Zimbabwe | 250,000 | 5,300,000 | 11,365,000 |
| Other dependencies | 20,000 | 15,000 | 35,000 |
| Total | 329,140,800 | 430,614,500 | 2,236,730,800 |
* の付いている国・地域は,標準英語ではなく pidgin/creole 英語が主として話されている国・地域である.pidgin/creole 変種を英語の一種とみなすか否かは論争の的となっているので,立場に応じて数値を足し引きされたい(具体的には,L1 で主として西インド諸島の約700万人が,L2 で主として西アフリカの約8,000万人が関与する).また,L1 および L2 の人口は原則として少なめの推計とみてよい.さらにこの表には,「#217. 英語話者の同心円モデル」 ([2009-11-30-1]) の図でいうところの Expanding Circle の国・地域は含まれていないことにも注意されたい.
上で挙げた国・地域については,「#177. ENL, ESL, EFL の地域のリスト」 ([2009-10-21-1]) および「#215. ENS, ESL 地域の英語化した年代」 ([2009-11-28-1]) も参照.
・ Crystal, David. English As a Global Language. 2nd ed. Cambridge: CUP, 2003.
2013-05-14 Tue
■ #1478. 接頭辞と接尾辞 [affix][prefix][suffix][word_formation][morphology][lexicology][statistics][derivation]
今回は現代英語の接辞添加 (affixation) に関する一般的な話題.現代英語の語形成において利用される主たる接頭辞 (prefix) と接尾辞 (suffix) を,Quirk et al. (1539--58) にしたがい,接頭辞,接尾辞の順に列挙する.以下のリストでは,同一接辞の異形態も別々に挙げられているが,接頭辞,接尾辞ともにおよそ50個を数える.
A-, AN-, ANTI-, ARCH-, AUTO-, BE-, BI-, CO-, CONTRA-, COUNTER-, DE-, DEMI-, DI-, DIS-, EM-, EN-, EX-, EXTRA-, FORE-, HYPER-, IN-, INTER-, MAL-, MINI-, MIS-, MONO-, MULTI-, NEO-, NON-, OUT-, OVER-, PALEO-, PAN-, POLY-, POST-, PRE-, PRO-, PROTO-, PSEUDO-, RE-, SEMI-, SUB-, SUPER-, SUR-, TELE-, TRANS-, TRI-, ULTRA-, UN-, UNDER-, UNI-, VICE-
-(I)AN, -ABLE, -AGE, -AL, -ANT, -ATE, -ATION, -DOM, -ED, -EE, -EER, -EN, -ER, -ERY, -ESE, -ESQUE, -ESS, -ETTE, -FUL, -FY, -HOOD, -IAL, -IC, -ICAL, -IFY, -ING, -IOUS, -ISH, -ISM, -IST, -ITE, -ITY, -IVE, -IZE (-ISE), -LESS, -LET, -LIKE, -LING, -LY, -MENT, -NESS, -OCRACY, -OR, -OUS, -RY, -SHIP, -STER, -WARD(S), -WISE, -Y
同じく Quirk et al. にしたがい,意味や機能によるこれらの接辞の大雑把な分類を別ページに示したので,そちらも参照.
Crystal (150) によれば,OED による見出し語サンプル調査の結果,これらの100を少し超えるほどの接頭辞,接尾辞のいずれかが,英語語彙全体の40--50%に現われるという.接辞添加が現代英語の新語形成の主たる手段であることは,「#873. 現代英語の新語における複合と派生のバランス」 ([2011-09-17-1]),「#875. Bauer による現代英語の新語のソースのまとめ」 ([2011-09-19-1]),「#878. Algeo と Bauer の新語ソース調査の比較」([2011-09-22-1]),「#879. Algeo の新語ソース調査から示唆される通時的傾向」([2011-09-23-1]) などで再三触れてきたが,歴史的に蓄積されてきた英語語彙全体をみても,やはり接辞添加の役割は非常に大きいということがわかる.
・ Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech, and Jan Svartvik. A Comprehensive Grammar of the English Language. London: Longman, 1985.
・ Crystal, David. The Stories of English. London: Penguin, 2005.
2013-04-06 Sat
■ #1440. 音節頻度ランキング [syllable][corpus][lexicon][phonetics][frequency][statistics]
「#1424. CELEX2」 ([2013-03-21-1]) で紹介した巨大データベースで何かしてみようと考え,Version 2 で新たに加えられた音節頻度 (English Frequency, Syllables) のサブデータベースにより,現代英語で最も多い音節タイプのランキングを得た.
これは,CELEX2 のもとになっているコーパス全体のうち,7.26%を構成する約130万語の話し言葉サブコーパスから引き出された音節頻度であり,タイプ頻度ではなくトークン頻度によるものである.つまり,話し言葉におけるある単語の頻度が高ければ,その分,その単語に含まれる音節タイプの頻度も高くなるということである.例えば,of を構成する "Ov" (= /ɒv/) と表現される音節は,第4位の頻度である.なお,強勢の有無は考慮せずに頻度を数えている.
以下のリストに挙げる音素表記は,IPA ではなく CELEX 仕様の独特の表記なので,先に対応表を挙げておこう.
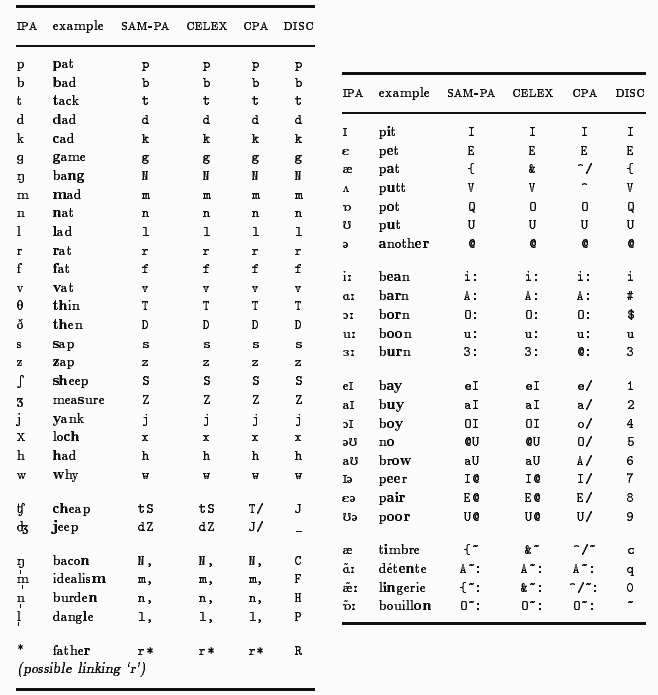
では,以下にランキング表でトップ50位までを掲載する.高頻度の単音節語の音節タイプがそのまま上位に反映されていて,あまりおもしろい表ではないが,何かの役に立つときもあるかもしれない.
| Rank | Syllable | Frequency |
|---|---|---|
| 1 | eI | 72971 |
| 2 | Di: | 60967 |
| 3 | tu: | 31446 |
| 4 | Ov | 30108 |
| 5 | In | 29906 |
| 6 | &nd | 28709 |
| 7 | aI | 23822 |
| 8 | lI | 19728 |
| 9 | @ | 19566 |
| 10 | rI | 14356 |
| 11 | ju: | 12598 |
| 12 | dI | 12465 |
| 13 | D&t | 12118 |
| 14 | It | 11504 |
| 15 | wOz | 10834 |
| 16 | fO:r* | 9778 |
| 17 | Iz | 9517 |
| 18 | tI | 9161 |
| 19 | fO | 9042 |
| 20 | Sn, | 8969 |
| 21 | hi: | 8928 |
| 22 | r@n | 8638 |
| 23 | bi: | 8505 |
| 24 | bI | 7936 |
| 25 | nI | 7068 |
| 26 | wID | 7046 |
| 27 | On | 7030 |
| 28 | &z | 6919 |
| 29 | O:l | 6569 |
| 30 | h&d | 6240 |
| 31 | E | 6165 |
| 32 | bl, | 6021 |
| 33 | sI | 5836 |
| 34 | @U | 5824 |
| 35 | t@r* | 5687 |
| 36 | &t | 5652 |
| 37 | hIz | 5564 |
| 38 | bVt | 5416 |
| 39 | mI | 5397 |
| 40 | s@ | 5391 |
| 41 | nOt | 5357 |
| 42 | D@r* | 5339 |
| 43 | I | 5283 |
| 44 | tId | 5259 |
| 45 | DeI | 5162 |
| 46 | IN | 5063 |
| 47 | t@ | 5053 |
| 48 | s@U | 4974 |
| 49 | baI | 4894 |
| 50 | h&v | 4769 |
全ランキング表を見たい方は,タブ区切り形式で Syllable Frequency Rank Table by CELEX2 を参照.ブラウザ上で閲覧したい方は,こちらからどうぞ.全体としては11492の異なる音節タイプが登録されており,頻度が1以上のものは7934タイプある.「#1023. 日本語の拍の種類と数」 ([2012-02-14-1]) の最後で,英語の音節タイプが日本語に比べて驚くほど多種多様であることに触れたが,この数をみれば納得できるだろう.関連して,syllable の各記事を参照.
なお,CELEX2 のマニュアルには以下の但し書きが記されていたので,再掲しておく.
Please note that the English corpus used by CELEX for deriving these frequencies contains only 7.3% spoken material. This means there is a rather tenuous relationship between the full frequency figures, which are based on written forms, and the syllable frequencies, which merely refer to phonemic conversions of these graphemic transcriptions. Of course it could be argued that frequencies of syllables, as lexical sub-units, are less liable to get skewed from differences in medium than full words, but it has to be taken into account that NO FIRM EVIDENCE ABOUT SPOKEN FREQUENCIES can be derived from these data.
2013-03-21 Thu
■ #1424. CELEX2 [corpus][dictionary][statistics][frequency][lexicology]
英単語の頻度に関連する諸研究(Betty Phillips など)で,CELEX という語彙データベースが使用されているのを見かけることがある.現在取りかかっている研究で,巨大コーパスに基づいた信頼できる語彙頻度統計が必要になったので,郵送料込みで350ドルするこの高価なデータベースを入手してみた.現行版は第2版であり,CELEX2 として購入できる.(なお,予想していなかったが,入手した CD-ROM には,LDC99T42 というデータベースも含まれていた.ここには tagged Brown Corpus, Wall Street Journal, Switchboard tagged など Treebank 系のコーパスが入っている.)
さて,CELEX2 には,英語語彙に関する複数のデータベースが納められている.それぞれのデータベースには,正書法,音韻,音節,形態,統語の各観点から,見出し語 (lemma) あるいは語形 (wordform) ごとに,ソース・コーパス内での頻度等の情報が格納されている.具体的には,次の11のデータベースが利用可能である.
ect (English Corpus Types)
efl (English Frequency, Lemmas)
efs (English Frequency, Syllables)
efw (English Frequency, Wordforms)
eml (English Morphology, Lemmas)
emw (English Morphology, Wordforms)
eol (English Orthography, Lemmas)
eow (English Orthography, Wordforms)
epl (English Phonology, Lemmas)
epw (English Phonology, Wordforms)
esl (English Syntax, Lemmas)
見出し語あるいは語形ごとの token 頻度の取り出しに強いデータベースという認識で購入したが,実際には,含まれている情報の種類は驚くほど豊富で,11のデータベースすべてを合わせたフィールド数はのべ250以上に及ぶ.行数は efl で52,447行,efw で160,595行という巨大さだ.検索用の SQLite DB をこしらえたら,容量にして90MBを超えてしまった.
CELEX2 のソースは,辞書情報については Oxford Advanced Learner's Dictionary (1974) 及び Longman Dictionary of Contemporary English (1978) であり,頻度情報については 1790万語からなる COBUILD/Birmingham corpus である.このコーパスの構成は,1660万語 (92.74%) が書き言葉コーパス,130万語 (7.26%) が話し言葉コーパスで,前者を構成する284テキストのうち44テキスト (15.49%) がアメリカ英語である.しかし,これらのアメリカ英語はほとんどがイギリス英語の綴字に直されていることに注意したい.
CELEX2 における "lemma" の定義は,以下の5点に依存する.
(1) orthography of the wordforms: peek vs peak
(2) syntactic class: meet (adj.) vs meet (adv.)
(3) inflectional paradigm: water (v.) vs water (n.)
(4) morphological structure: rubber (someone or something that rubs) vs rubber (the elastic substance)
(5) pronunciation of the wordforms: recount [ˈriː-kaʊnt] vs recount [rɪ-ˈkaʊnt]
したがって,通常異なる lexeme として扱われる bank (土手)と bank (銀行)などは,CELEX2 では同一の lemma として扱われているので注意が必要である.
このように CELEX2 は非常に強力な語彙頻度データベースだが,その他にも語彙頻度研究に資するデータベースやツールは存在する.本ブログで触れたものとしては,frequency statistics lexicology の各記事や,特に以下の記事が参考になるだろう.
・ 「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1])
・ 「#607. Google Books Ngram Viewer」 ([2010-12-25-1])
・ 「#708. Frequency Sorter CGI」 ([2011-04-05-1])
・ 「#1159. MRC Psycholinguistic Database Search」 ([2012-06-29-1])
・ Baayen R. H., R. Piepenbrock and L. Gulikers. CELEX2. CD-ROM. Philadelphia: Linguistic Data Consortium, 1996.
2013-01-31 Thu
■ #1375. インターネットの使用言語トップ10 [elf][statistics][internet][demography][world_languages]
世界のインターネット使用が爆発的に増加している.Miniwatts Marketing Group による Internet World Stats: Usage and Population Statistics から Internet World Users by Language: Top 10 Languages のデータを参照すると,2000--2011年のあいだに全世界での使用者数が約5倍増えたと報告されている.では,インターネットの使用言語の分布についてはどうか.同ページより,インターネットにおけるトップ10言語の統計値を再掲しよう.2011年5月31日現在の数値である.
| TOP TEN LANGUAGES IN THE INTERNET | Internet Users by Language | Internet Penetration by Language | Growth in Internet (2000--2011) | Internet Users% of Total | World Population for this Language (2011 Estimate) |
|---|---|---|---|---|---|
| English | 565,004,126 | 43.4% | 301.4% | 26.8% | 1,302,275,670 |
| Chinese | 509,965,013 | 37.2% | 1,478.7% | 24.2% | 1,372,226,042 |
| Spanish | 164,968,742 | 39.0% | 807.4% | 7.8% | 423,085,806 |
| Japanese | 99,182,000 | 78.4% | 110.7% | 4.7% | 126,475,664 |
| Portuguese | 82,586,600 | 32.5% | 990.1% | 3.9% | 253,947,594 |
| German | 75,422,674 | 79.5% | 174.1% | 3.6% | 94,842,656 |
| Arabic | 65,365,400 | 18.8% | 2,501.2% | 3.3% | 347,002,991 |
| French | 59,779,525 | 17.2% | 398.2% | 3.0% | 347,932,305 |
| Russian | 59,700,000 | 42.8% | 1,825.8% | 3.0% | 139,390,205 |
| Korean | 39,440,000 | 55.2% | 107.1% | 2.0% | 71,393,343 |
| TOP 10 LANGUAGES | 1,615,957,333 | 36.4% | 421.2% | 82.2% | 4,442,056,069 |
| Rest of the Languages | 350,557,483 | 14.6% | 588.5% | 17.8% | 2,403,553,891 |
| WORLD TOTAL | 2,099,926,965 | 30.3% | 481.7% | 100.0% | 6,930,055,154 |
トップの言語は,いまだ英語である.トップを守っているという点では,「#1084. 英語の重要性を示す項目の一覧」 ([2012-04-15-1]) で見た通り,1980--90年代の状況と異ならない.しかし,増加率という点では,おそらく当時の勢いから大きく減退している.少なくとも,中国語,スペイン語,ポルトガル語,アラビア語,ロシア語などと比べて相対的に勢いは衰えているといえる([2009-10-08-1]の記事「#164. インターネットの非英語化」を参照).インターネット使用者数そのものでみれば,英語は早晩中国語に抜かれることは間違いないが,第3位のスペイン語との間にはまだ隔たりがある.現在は,英中ツートップの時代といえそうだ.
なお,最右列の言語話者の人口統計は U.S. Census Bureau に基づくものだというが,そこでは英語話者人口が約13億7千万とされている.これは,母語話者のみならず第2言語話者も含めた値であることは疑いない.
第2列と最右列の下の3行をみると,いかに少数の言語が世界の大部分を占めているかがわかる.関連して,「#274. 言語数と話者数」 ([2010-01-26-1]) のピラミッド状の分布を参照されたい.
ほかに英語話者人口にまつわる統計は,本ブログ内の以下の記事でも触れているので,参考までに.
・ 「#375. 主要 ENL,ESL 国の人口増加率」 ([2010-05-07-1])
・ 「#397. 母語話者数による世界トップ25言語」 ([2010-05-29-1])
・ 「#759. 21世紀の世界人口の国連予測」 ([2011-05-26-1])
2013-01-02 Wed
■ #1346. 付加疑問はどのくらいよく使われるか? [interrogative][tag_question][ame_bre][corpus][frequency][statistics]
現代英語の会話では,付加疑問がよく使われる.だが,具体的にどのくらいよく使われるのだろうか.そもそも一般的に疑問文はどのくらいの頻度で生起するのか.そのなかで,付加疑問はどれくらいの割合を占めるのか.このような疑問を抱いたら,まず当たるべきは Biber et al. の LGSWE である.
最初の問題については,p. 211 に解答が与えられている.疑問符の数による粗い調査だが,CONV(ERSATION) では40語に1つ疑問符が含まれているという.会話コーパスでは,転写上,疑問符が控えめに反映されている可能性が高く,実際には数値以上の頻度で疑問文が生起しているはずである.テキストタイプでいえば,次に大きく差を開けられて FICT(ION) が続き,NEWS と ACAD(EMIC) では疑問文の頻度は限りなく低い.
次に,各サブコーパスにおいて,疑問文全体における付加疑問の生起する割合はどのくらいか.p. 212 に掲載されている統計結果を以下のようにまとめた.各列を縦に足すと100%となる表である.
| (* = 5%; ~ = less than 2.5%) | CONV | FICT | NEWS | ACAD | |
|---|---|---|---|---|---|
| independent clause | wh-question | **** | ******* | ********* | ********** |
| yes/no-question | ***** | ***** | ******* | ******* | |
| alternative question | ~ | ~ | ~ | ~ | |
| declarative question | ** | * | ~ | ~ | |
| fragments | wh-question | * | ** | ** | * |
| other | *** | *** | * | * | |
| tag | positive | * | ~ | ~ | ~ |
| negative | **** | * | ~ | ~ | |
CONV において付加疑問の生起比率が高いことは当然のように予測されたが,同サブコーパスの疑問表現全体のなかで25%を占めるということは発見だった.そのなかでも,肯定の is it? よりも否定の isn't it? のタイプのほうがずっと多い.また,FICT が CONV におよそ準ずる分布を示すのは,フィクション内の会話部分の貢献だろう.一方,NEWS と ACAD で付加疑問の比率が低いのは,この表現と対話との結びつきを強く示唆するものである.また,この2つのサブコーパスでは,完全な独立節での疑問文,特に wh-question が相対的に多いのが注意を引く.
付加疑問の生起比率に関心をもったのは,実は,Schmitt and Marsden (192) に次のような記述を見つけたからだった.
Tag questions (i.e., regular questioning expressions tagged onto a sentence) exist in both American and British English, with British speakers perhaps using them more than Americans: "That's not very nice, is it?" Peremptory and aggressive tags tend to be used more in British English than in American English: "Well, I don't know, do I?" (192)
残念ながら,Biber et al. では付加疑問の頻度の英米差を確かめることはできない.別途,英米のコーパスで調べる必要があるだろう.
・ Schmitt, Norbert, and Richard Marsden. Why Is English Like That? Ann Arbor, Mich.: U of Michigan P, 2006.
・ Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad, and Edward Finegan. Longman Grammar of Spoken and Written English. Harlow: Pearson Education, 1999.
2012-11-11 Sun
■ #1294. 英語語源分析ツールの夢 [etymology][lexicology][statistics][web_service]
英文を投げ込むと,各単語(あるいは形態素)が語源別に色づけされて返ってくるような語源分析ツールがあるとよいなと思っている.しかも,各単語に語源辞書のエントリーへのリンクが張られているような.語彙研究や英語教育にも活かせるだろうし,出力を眺めているだけでもおもしろそうだ.このようなツールを作成するには精度の高い形態素分析プログラムと語源データベースの完備が欠かせないが,完璧を求めてしまうと実現は不可能だろう.
同じことを考える人はいるようだ.例えば,Visualizing English Word Origins はツールを公開こそしていないが,Douglas Harper による Online Etymology Dictionary に基づく自作のツールで,いくつかの短い英文一節を色づけ語源分析している.テキストの分野別に本来語やラテン語の割合が何パーセントであるかなどを示しており,およそ予想通りの結果が出されたとはいえ,実におもしろい.この分析に関して,The Economist に記事があった.
また,今は残念ながらリンク切れとなっているが,かつて http://huco.artsrn.ualberta.ca/~mburden/project/message.php?thread=Shakspere&id=174 に簡易的な語源分析ツールが公開されていた.こちらの紹介記事 にあるとおりで,なかなか有望なツールだった.私も少し利用した記憶があるのだが,どこへ消えてしまったのだろうか.
英語語源関連のオンライン・コンテンツも増えてきた.以下にいくつかをまとめておく.
・ 「#485. 語源を知るためのオンライン辞書」: [2010-08-25-1]
・ Etymology 関連の外部リンク集
・ 「#361. 英語語源情報ぬきだしCGI(一括版)」: [2010-04-23-1]
・ Behind the Name: The Etymology and History of First Names
・ Behind the Name: The Etymology and History of Surnames
・ 語源別語彙統計に関する本ブログ内の記事: lexicology loan_word statistics
・ Etymologic! The Toughest Word Game on the Web: 英語語源クイズ.
2012-11-04 Sun
■ #1287. 動詞の強弱移行と頻度 [frequency][analogy][verb][conjugation][lexical_diffusion][statistics]
昨日の記事「#1286. 形態音韻変化の異なる2種類の動機づけ」 ([2012-11-03-1]) で紹介した Hooper の論文では,調査の1つとして動詞の強弱移行(強変化動詞の弱変化化)が取り上げられていた.Hooper の議論は単純明快である.強弱移行は類推による水平化 (analogical leveling) の典型例であり,頻度の低い動詞から順に移行を遂げてきたのだという.
Hooper が調査対象とした動詞は古英語の強変化I, II, III類に由来する動詞のみであり,その現代英語における頻度情報については Kučera and Francis の頻度表が参照されている.頻度計算は lemma 単位での綴字のみを基準とした拾い出しであり,drive, ride などの語(下表で * の付いているもの)について品詞の区別を考慮していない荒削りなものだ.また,過去千年以上にわたる言語変化を話題にしているときに,現代英語における頻度のみを参照してよいのかという問題([2012-09-21-1]の記事「#1243. 語の頻度を考慮する通時的研究のために」)についても楽観的である (99) .全体として,解釈するのに参考までにという但し書きが必要だが,以下に Hooper (100) の表を見やすく改変したものを掲げよう.
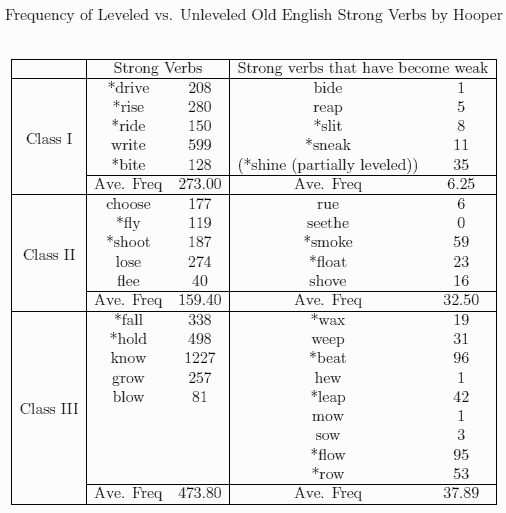
確かにこのように見ると,強弱移行を経た動詞は全体として頻度が相対的にずっと低いことがわかる.関連して,keep, *leave, *sleep や *creep, *leap, weep について,前者3語が伝統的な過去形を保持しているのに対して,後者3語には周辺的に creeped, leaped, weeped の異形も確認されるという.前者の頻度はそれぞれ 531, 792, 132 に対して後者はそれぞれ 37, 42, 31 だという (Hooper 100) .参考までにとはいっても,傾向としては明らかのように思われる.
動詞の強弱移行は英語史において基本的な話題であり,本ブログでも「#178. 動詞の規則活用化の略歴」 ([2009-10-22-1]) ,「#527. 不規則変化動詞の規則化の速度は頻度指標の2乗に反比例する?」 ([2010-10-06-1]) ,「#528. 次に規則化する動詞は wed !?」 ([2010-10-07-1]) などで触れてきたが,案外とわかっていないことも多い.今後の詳細な研究が俟たれる.
・ Hooper, Joan. "Word Frequency in Lexical Diffusion and the Source of Morphophonological Change." Current Progress in Historical Linguistics. Ed. William M. Christie Jr. Amsterdam: North-Holland, 1976. 95--105.
Powered by WinChalow1.0rc4 based on chalow