2011-04-05 Tue
■ #708. Frequency Sorter CGI [corpus][bnc][statistics][web_service][cgi][lexicology][plural]
何らかの基準で集めた英単語のリストを,一般的な頻度の順に並び替えたいことがある.例えば,[2011-03-22-1]で論じたように,頻度と不規則な振る舞いとの関係を調べたいときに,注目する語(群)の一般的な頻度を知る必要がある.この目的には,[2010-03-01-1]で紹介したような大規模な汎用コーパスに基づく頻度表が有用である.BNC lemma-pos list (122KB) や ANC word-tagset list (7.2MB) などで問題の語を一つひとつ検索し,頻度数や頻度順位を調べてゆけばよいが,語数が多い場合には面倒だ.そこで,上記2つの頻度表から,入力した語(群)の頻度と順位を取り出す CGI を作成した.
改行でもスペースでもカンマでもよいのだが,区切られた単語リストを以下のボックスに入力し,"Frequency Sort Go!" をクリックする.出力結果を頻度順位の高い順にソートする場合には,"sort by rank?" をオンにする(デフォルトでオン.オフにすると,入力順に出力される).例えば,現代標準英語に残る純粋に i-mutation を示す複数形は以下の7語のみである(複合語,二重複数,[2011-04-01-1]で話題にした sister(e)n は除く).これをコピーしてボックスに入力する.
foot, goose, louse, man, mouse, tooth, woman
まず,BNC lemma-pos list による出力だが,この頻度表は約1億語の BNC 全体から,頻度にして800回以上現われる,上位6318位までの見出し語 ( lemma ) を収録している.したがって,それよりも頻度の下回る goose, louse については空欄となっている.頻度と不規則性の相関関係を考える際に参考になるだろう.
次に,ANC word-tagset list による出力が続くが,この頻度表は BNC のものよりも規模が大きく,かつきめ細かい.合計22,164,985語を有する ANC (American National Corpus) から,Penn Treebank Tagset によってクラス付与された単位で語形が列挙されたリストである.タグセットが細かいので読みにくいし,自動タグ付与に起因するエラーも少なからず含まれているが,BNC のものよりも低頻度の語(形)を収録しているので,goose や louse の頻度情報も現われる.こちらの頻度表では WORD FORM ごとの頻度も確認できるため,直接 geese や lice の頻度も確かめられる.
当初 Frequency Sorter の用途として想定していたのは,上記の不規則複数形を示す語群などの頻度と順位の一括調査だったが,他にも用途はあるかもしれない.以下に,思いつきをメモ.
・ 1単語から使えるので,like のような多品詞語を入力して,品詞(あるいはタグ付与されたクラス)ごとの頻度を取り出せる.
・ ヒット数だけを確認したい場合には,いちいちコーパスを立ち上げる必要がない.
・ 論文やプレゼンで,ある目的で集めた数百語の単語リストの中から典型的な例,分かりやすい例を10個ほど示したいときなど,頻度の高い10個を選べばよい.例えば,[2011-03-29-1]で列挙した sur- を接頭辞にもつ単語リストのうち,例示に最もふさわしい10個を選ぶなどの目的に.頻度に基づいた順番のほうが,ランダム順やアルファベット順よりも親切なことが多いだろう(今後,本ブログ執筆に活用する予定).
・ 英米それぞれの代表的なコーパスに基づく頻度表を利用しているので,綴字や形態などの頻度の英米差を確認するのに使える.
・ (実際には lemmatisation が必要だが)適当な英文を放り込んでみて,妙に頻度の低い語が含まれていないかを調べる.頻度のツールなので,その他,教育・学習目的にいろいろと使えるかもしれない.
2011-03-25 Fri
■ #697. Log-Likelihood Tester CGI [corpus][bnc][statistics][web_service][cgi][lltest][sociolinguistics]
昨日の記事[2011-03-24-1]で Log-Likelihood Test を話題にした.計算には Rayson 氏の Log-likelihood calculator を利用すればよいと述べたが,実際の検定の際に作業をもう少し自動化したいと思ったので CGI を自作してみた.細かい不備はあると思うが,とりあえず公開.
上のテキストボックスに入力すべきデータは,タブ区切りの表の形式.1行目(省略可)はコーパス名,2行目以降はキーワードと観察頻度数(ヒット数),最終行は各コーパスのサイズ(語数)."#" で始まる行はコメント行として無視される.1列目のキーワード列は省略可.
以下のテキストが入力サンプル.[2010-09-11-1]の記事で取り上げたテレビ広告で頻用される形容詞(比較級と最上級を含む)トップ20の頻度を,BNCweb の話し言葉サブコーパスから話者の性別に整理した表である.このままコピーして入力ボックスに貼り付けると,出力結果が確認できる.
BNC_Male_Speakers BNC_Female_Speakers new 149 91 good 408 310 free 173 75 fresh 84 118 delicious 12 34 full 210 107 sure 532 328 clean 197 223 wonderful 270 258 special 177 82 crisp 10 16 fine 347 215 big 470 415 great 203 96 real 163 80 easy 326 157 bright 113 110 extra 347 203 safe 182 92 rich 120 45 #-------- corpus_size 4949938 3290569
男女間で有意差の特に大きいのは,対応行が赤で塗りつぶされた fresh, delicious, clean, wonderful, big で,いずれも期待度数に基づいて計算された Diff_Co ( "Difference Coefficient" 「差異係数」 ) がマイナスであることから,女性に特徴的な形容詞ということになる.big は意外な気がしたが,おもしろい結果である.一方,男性に偏って有意差を示すのは黄色で示した easy や rich である.この結果はいろいろと読み込むことができそうだし,より詳細に調べることもできる.広告の形容詞という観点からは,話者ではなく聞き手の性別,年齢,社会階級などを軸に調査してもおもしろそうだ.いろいろと応用できる.
2011-03-24 Thu
■ #696. Log-Likelihood Test [corpus][bnc][statistics][lltest]
[2010-03-04-1]の記事で触れたが,コーパス言語学では各種の統計手法が用いられる.いくつかある手法のなかでも,ある表現のコーパス間の頻度を比較したり,collocation の度合いを測るのに広く用いられているのが Log-Likelihood Test ( LL Test, G Test, G2 Test などとも)呼ばれる検定である.コーパスサイズを考慮に入れた検定なのでサイズの異なるコーパス間での比較が可能であり,同じ目的で以前によく用いられていたカイ2乗検定 ( Chi-Squared Test ) よりもいくつかの点ですぐれた手法と評価されており,最近のコーパス研究では広く用いられている.(例えば,カイ2乗検定は期待頻度が5回より少ないとき,高頻度語を扱うとき,コーパスサイズが大きいものと小さいものを比較するときに信頼性が低くなるが,Log-Likelihood Test はこれらの影響を受けにくい [ Rayson and Garside 2 ] .)
Log-Likelihood Test の基本的な考え方は,コーパスサイズをもとにある表現の期待される出現頻度(期待頻度)を割り出し,その値と実際に出現する頻度(観察頻度)の差が単純な誤差と考えられるほどに近似しているかどうかを判定するというものである.例として,次のようなケース・スタディを試す.BNC ( The British National Corpus ) から話し言葉サブコーパスと書き言葉サブコーパスを区別し,両サブコーパス間で f*ck という four-letter word の頻度を比較する.BNCweb よりこのキーワードを検索すると,次のような結果が得られた.
| Category | No. of words | No. of hits | Dispersion (over files) | Frequency per million words |
|---|---|---|---|---|
| Spoken | 10,409,858 | 579 | 63/908 | 55.62 |
| Written | 87,903,571 | 743 | 172/3,140 | 8.45 |
| total | 98,313,429 | 1,322 | 235/4,048 | 13.45 |
統計処理をほどこすまでもなく最右列 "Frequency per million words" を見れば,f*ck が圧倒的に話し言葉で多く用いられることが分かるが,今回はこれを統計的に裏付ける.まず,帰無仮説として「話し言葉サブコーパスと書き言葉サブコーパスの間での f*ck の頻度差は誤差の範囲内であり,この語に関して両者に意味のある差はない」を設定する.その対立仮説は「話し言葉サブコーパスと書き言葉サブコーパスの間での f*ck の頻度差は誤差の範囲内でなく,この語に関して両者の差は意味がある」となる.帰無仮説が支持されるかどうかを決めるのが,検定の目的である.
| Corpus 1 | Corpus 2 | Total | |
|---|---|---|---|
| Frequency of word | a | b | a+b |
| Frequency of other words | c-a | d-b | c+d-a-b |
| Total | c | d | c+d |
Log-Likelihood Test に用いる Log-Likelihood ratio 「対数尤度比」は,上の表の要領で各サブコーパスの総語数 ( c, d ) と,各サブコーパスでの f*ck の頻度数 ( a, b ) を分割表にまとめた上で,それぞれの期待頻度 E1 と E2 を下の (1) の式で求め,その値を (2) の式に代入して求める.
(1) E1 = c*(a+b)/(c+d); E2 = d*(a+b)/(c+d)
(2) LL = 2*((a*log(a/E1))+(b*log(b/E2)))
f*ck の数値で計算すると,以下のようになる.
E1 = 10409858*(579+743)/(10409858+87903571) = 139.979170861796
E2 = 87903571*(579+743)/(10409858+87903571) = 1182.0208291382
LL = 2*((579*log(579/139.979170861796))+(743*log(743/1182.0208291382))) = 954.2115
Log-likelihood ratio として 954.2115 という値が算出される.次にこの値を,適切な有意水準(通常は 5%, 1%, 0.1%)に対応するカイ二乗値と比較する.2 * 2 の分割表に対する計算では自由度1のカイ二乗値を用いることになっており,その値は有意水準 5%, 1%, 0.1% の順にそれぞれ 3.84, 6.63, 10.83 である.954.2115 の Log-Likelihood ratio は有意水準 0.1% に対応する 10.83 よりもずっと高いので,0.1% の有意水準で帰無仮説は棄却される.言い換えれば,統計的には帰無仮説が真である確率は 0.1% にも満たず,まず偽と考えてよいということである.このようにして対立仮説「話し言葉サブコーパスと書き言葉サブコーパスの間での f*ck の頻度差は誤差の範囲内でなく,この語に関して両者の差は意味がある」が採択されることになる.
Log-Likelihood Test は以上のように進められるが,この検定を行なうにあたっての前提条件を知っておく必要がある.一般には,計算される期待頻度が 5 を下回るセルが1つでもある場合には,検定の精度は落ちるとされる.これは the Cochran rule と呼ばれているが,よりきめ細かなルールを提起した Rayson, Berridge, and Francis (8) によれば,期待頻度が満たすべき最低値は有意水準 5% で13 回,1% で 11 回,0.1% で 8 回だという.有意水準を 0.01% に設定すれば期待頻度 1 回にも耐える精度を得られるので,Rayson et al. はコーパス言語学で慣習的に用いられている3つの水準に加えて,0.01% の水準(対応するカイ二乗値は 15.13 )までの検定を推奨している.
統計には詳しくないが,ある表現の 2(サブ)コーパス間での頻度比較というシーンで簡単に用いることができる検定として,Log-Likelihood Test の応用範囲は広そうだ.計算自体は Rayson 氏の Log-likelihood calculator などに任せればよい(本記事はこのページの記述とリンク先の論文を参考にした).
BNC を用いた f*ck 関連語の分布の研究は,McEnery et al. (264--86) のケース・スタディに詳しい.
関連して,検定は行なわなかったが,かつて本ブログで扱った gorgeous の調査 ([2010-08-16-1], [2010-08-17-1],[2010-12-25-1]) なども参照.
・ Rayson, P., D. Berridge , and B. Francis. "Extending the Cochran Rule for the Comparison of Word Frequencies between Corpora." Le poids des mots: Proceedings of the 7th International Conference on Statistical Analysis of Textual Data (JADT 2004), Louvain-la-Neuve, Belgium, March 10-12, 2004. Ed. Purnelle G., Fairon C., and Dister A. Louvain: Presses universitaires de Louvain, 2004. 926--36. Available online at http://www.comp.lancs.ac.uk/computing/users/paul/publications/rbf04_jadt.pdf .
・ Rayson, P. and R. Garside. "Comparing Corpora Using Frequency Profiling". Proceedings of the Workshop on Comparing Corpora, Held in Conjunction with the 38th Annual Meeting of the Association for Computational Linguistics (ACL 2000), 1-8 October 2000, Hong Kong. 2000. 1--6. Available online at http://www.comp.lancs.ac.uk/computing/users/paul/phd/phd2003.pdf .
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
2011-02-26 Sat
■ #670. 中英語ロマンスにおける formula の割合 [literature][romance][statistics][formula]
中世ロマンスの言語上の大きな特徴の1つに,formula の多用がある.stock phrase とも言われ「決まり文句,常套句」を指す.formula の定義には,表現の幅を限定したきわめて狭いものから,語彙や統語のレベルでの型に適合していればよいとする広いものまであるが,多くの formula 研究は Milman Parry の次の定義から出発している.
A formula is "a group of words which is regularly employed under the same metrical conditions to express a given essential idea." (qtd in Wittig, p. 15 as from "Studies in the Epic Technique of Oral Verse-Making. I: Homer and Homeric Style." Harvard Studies in Classical Philology 41 (1930). page 80.)
formula の具体例を挙げればきりがないが,"'Dame,' he said", "that hendi knight", "feyre and free" などの短いものから,"He was a bolde man and a stowt", "And he were neuer so blythe of mode", "For to make the lady glade / That was bothe gentyll and small" などの長いものまで様々である.Wittig によれば,中英語の韻文ロマンス25作品から Parry の条件を厳密に満たす formula を含む行を抜き出したところ,以下のような結果が得られた.
| POEM | LENGTH | VERSE TYPE | FORMULA RATE |
|---|---|---|---|
| Lai le freine | 340 lines | couplet | 10% |
| Sir Landeval | 500 | couplet | 11 |
| Sir Launfal | 1044 | tail-rhyme | 16 |
| King Horn | 1644 | couplet | 18 |
| Sir Degare | 1076 | couplet | 21 |
| Havelok | 2822 | couplet | 21 |
| Sir Isumbras | 804 | tail-rhyme | 22 |
| Sir Amadace | 864 | tail-rhyme | 22 |
| Sir Perceval | 2288 | tail-rhyme | 22 |
| Horn Child | 1138 | tail-rhyme | 24 |
| Roswall and Lillian | 885 | couplet | 25 |
| Ocatvian (southern) | 1962 | tail-rhyme | 25 |
| Sir Triamour | 1719 | tail-rhyme | 25 |
| Earl of Toulous | 1224 | tail-rhyme | 26 |
| Ywain and Gawayn | 4032 | couplet | 27 |
| Sir Eglamour | 1377 | tail-rhyme | 29 |
| Squyr of Lowe Degre | 1131 | couplet | 30 |
| Lebeaus Desconus | 2131 | tail-rhyme | 30 |
| Sir Torrent | 2669 | tail-rhyme | 31 |
| Bevis of Hampton | 4332 | couplet | 34 |
| Eger and Grime | 1474 | couplet | 35 |
| Sir Degrevant | 1920 | tail-rhyme | 38 |
| Octavian (northern) | 1731 | tail-rhyme | 39 |
| Floris and Blancheflur | 1083 | couplet | 41 |
| Emare | 1030 | tail-rhyme | 42 |
平均をとると,各テキストを構成する行数の26.56%が formula を含んでいることになる.couplet では平均が24.82%,tail-rhyme では27.93%だが,大差はない.また,テキストの長さと formula 行の割合には強い相関はない.Wittig の研究では,Arthur,Troy,Alexander ものなどの "cycle" は含まれていない.参照テキストを限定し,定義を厳密にし,あくまで低めに抑えられた数え上げなので,定義を緩くすれば相当に数値が上がるはずだという.
ロマンスのテキストの約1/4が formula から成っているとすると,聴衆にとって次にどのような文言が現われるかは予測可能ということになる.また,ロマンスは物語としての筋もおよそ決まっているので,聴衆にとって「新情報」を得る機会は非常に少ないと考えられる.では,そのようなロマンスが中世に大流行したのはなぜか.聴衆はロマンスに何を期待していたのだろうか.
・ Wittig, Susan. Stylistic and Narrative Structures in the Middle English Romances. Austin and London: U of Texas P, 1978.
2011-02-23 Wed
■ #667. COCA 最頻50万語で品詞別の割合は? [lexicology][corpus][french][loan_word][adjective][statistics][coca]
昨日の記事[2011-02-22-1]に引き続き,COCA ( Corpus of Contemporary American English ) に基づく単語の頻度リストを利用したパイロット・スタディ.今回は,こちらで最近になって追加された最頻50万語のリストを用いて,昨日と同様の品詞別割合を調べた.昨日のリストは見出し語 ( lemma ) に基づいた最頻5000語,今日のリストは語形 ( word form ) に基づいた最頻50万語(正確には497187語)で,性格が異なることに注意したい.
昨日とほぼ同じ作業だが,今回は2万語ずつで階級を区切り,L1からL25までの階級のそれぞれにおいて noun, verb, adj., adv., others の5区分で品詞別割合を出した.(数値データはこのページのHTMLソースを参照.)
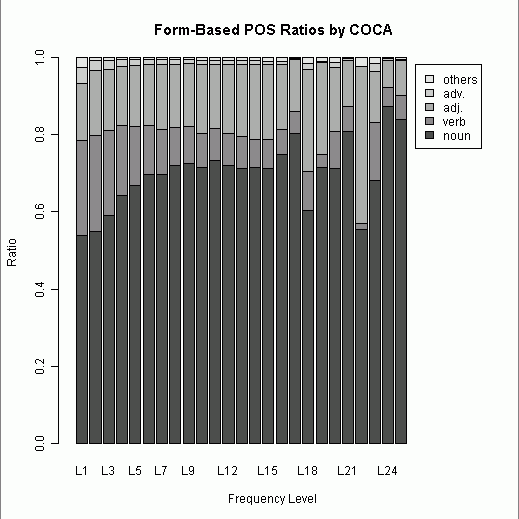
L6(12万語レベル)辺りから品詞別比率は安定期に入るといってよいだろう.L17(34万語レベル)辺りから変動期が始まるのが気になるが,階級幅を大きくしてみると(ならしてみると)直前のレベルから大きく逸脱していない.
[2011-02-16-1]の記事以来,形容詞の比率が気になっているが,今回のデータ全体から計算すると,0.1738という値がはじきだされた.昨日の lemma 調査では0.1678だったから,値は非常に近似している.ただし,名詞と動詞の lemma 対 word form の比率は,名詞が 0.5086 : 0.6985,動詞が 0.2000 : 0.1065 と大きく異なるので,形容詞の 0.1678 : 0.1738 という近似は偶然かもしれない.lemma 対 word form の品詞別割合には異なる傾向があるのかもしれないが,それでも大規模に調べると安定期と呼びうる区間が出現することは確かなようだ.
[2011-02-16-1]の記事で触れたように,中英語期のフランス借用語における形容詞比率は0.1768だった.今回の値0.1738と酷似しているが,主題の性質がまるで違うので,直接の関係を論じることは無理である.もとより昨日と今日の調査は,[2011-02-16-1]の調査とは無関係に始めたものである.しかし,偶然と思えるこの結果は,示唆的ではある.借用語彙といえば名詞が圧倒的なはずだと予想していたものの,フランス語や古ノルド語からはおよそ一定の割合の形容詞(それぞれ lemma 調査で0.1768と0.1817)が借用されていた.そして,その比率は時代が異なるとはいえ現代英語の比率と近似している.英語語彙全体における比率と借用語彙における比率が近似しているということは,もし偶然でないとしたら,何を意味するのだろうか.フランス借用語彙や古ノルド借用語彙が,英語に適応するような自然な比率で英語語彙へ溶け込んだということだろうか.これは,今回のパイロット・スタディの結果を受けての印象に基づく speculation にすぎない.今後も品詞別割合という観点に注目していきたい.
2011-02-22 Tue
■ #666. COCA 最頻5000語で品詞別の割合は? [lexicology][corpus][statistics][n-gram][coca]
COCA ( Corpus of Contemporary American English ) に基づいた各種語彙リストが Corpus-based word frequency lists, collocates, and n-grams から入手できる.そのなかで最も基本的なリストが,こちらの最頻5000語リストである.列挙されているのは見出し語 ( lemma ) 単位で,順位はコーパスに現われる頻度と分散の関数で計算されている.UCREL CLAWS7 Tagset の品詞コード表に基づいた粗い品詞情報も付与されており,品詞別の頻度などを手軽に分析することができる.
今回は,500語ごとに区切って頻度の高い順にL1からL10までの階級を設け,それぞれの階級における品詞別割合を出した.品詞は開いた語類 ( open class ) を中心とし,noun, verb, adj., adv., others の5区分とした.(数値データはこのページのHTMLソースを参照.)
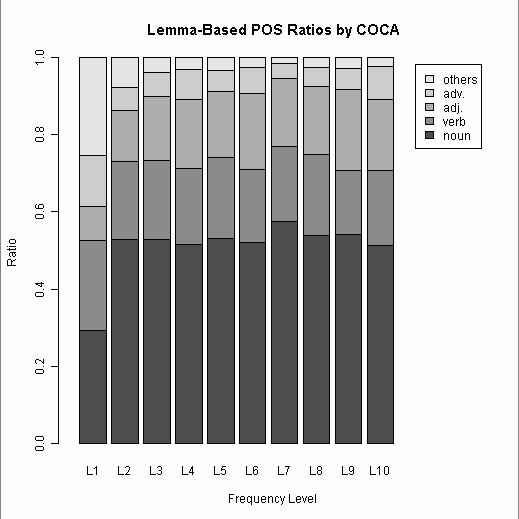
第1階級を除き,どの階級でも名詞が過半数を占めているのは予想できたことだが,第2階級以降に名詞の割合が思ったほど伸びていないことが分かった.動詞と形容詞が後半の階級でもおよそ一定の割合を占め続けているのも予想外だった.全体として,最頻5000語リストに限れば,名詞が飛び抜けつつも,開いた語類の内部比率はおよそ一定に保たれているといえよう.階級幅を様々に動かして試してみたが,およそ安定期に入るのは500語以降と見てよさそうだ.
[2011-02-16-1]の記事で中英語期のフランス借用語の品詞別割合をみたが,全体としての形容詞比率は0.1768だった.今回の現代英語の最頻5000語では,全体としての形容詞比率は0.1678.比べて意味のある数値かどうかは分からないが,英語(言語?)における品詞別比率の「安定感」のようなものはあるのだろうか.
COCA に基づくもの以外にオンラインで入手できる最頻英単語リストについては[2010-03-01-1]の記事を参照.頻度表を利用した別のパイロット・スタディとしては,単語の音節数を扱った[2010-04-17-1]の記事を参照.
2011-02-16 Wed
■ #660. 中英語のフランス借用語の形容詞比率 [french][loan_word][adjective][statistics]
クレパン (p. 113) に次のような記述があった.
中英語では,ラテン語およびフランス語からの借用語の流入が特徴的である.フランス語の借用語は,次例にみられるように,形容詞の領分に,とくに明白なあらわれ方をしている.
able covetous gracious pertinent simple abundant coy hardy plain single active cruel hasty pliant sober actual curious honest poor solid amiable debonair horrible precious special amorous double innocent principal stable barren eager jolly probable stout blank easy large proper strange brief faint liberal pure sturdy calm feeble luxurious quaint subtle certain fierce malicious real sudden chaste final mean rude supple chief firm moist safe sure clear foreign natural sage tender common frail nice savage treacherous contrary frank obedient scarce universal courageous gay original second usual courteous gentle perfect secret
どの言語からであっても借用語彙はその大半が名詞であるという前提が染みこんでいたので,その陰で特に形容詞が顕著であるなどと借用語彙を品詞別に見る視点は欠けていた.確かに上のように例を列挙されるとそのようにも思われてくる.
ある時期にある言語から入った借用語彙全体を1としたときに品詞別の比率はどのくらいか.この観点からの研究があったかどうかすぐには思いつかなかったので,OED を用いて自分で軽く調べてみることにした.中英語期に入ったフランス借用語彙の形容詞比率がどのくらいかを調べるのが主目的だが,出された数値を解釈するためには,何らかの比較が必要である.今回は,古ノルド語の対応する比率と比べることにした.OED の Advance Search で,名詞,形容詞,動詞の主要3品詞ごとに検索することにし,"language names" にそれぞれ "French" と "ON" を,"earliest date" に "1101-1500" を入力してAND検索した.その結果を,[2011-01-05-1]の記事で紹介した「OED の検索結果から語彙を初出世紀ごとに分類する CGI」に流し込み,得た数値を品詞ごとの語数で整理し,2種類のグラフを作成した.両言語でスケールが異なっていることに注意.(数値データはこのページのHTMLソースを参照.)
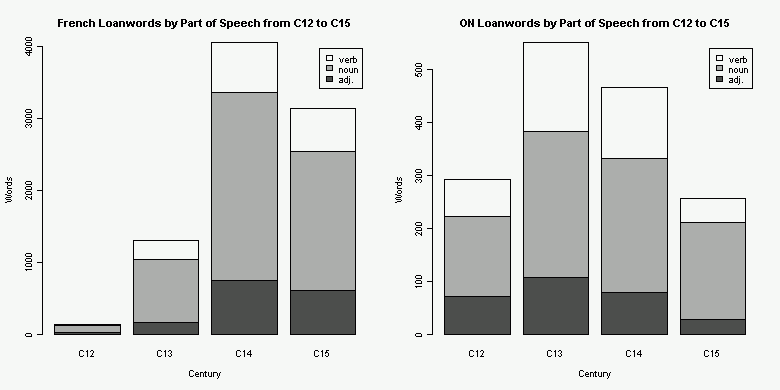
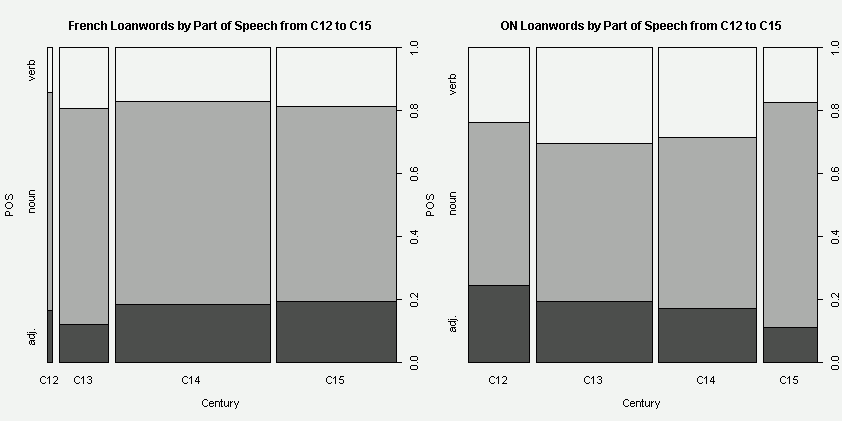
予想とはやや異なる結果が出た.前半2世紀でみたときには,形容詞比率に関しては古ノルド語のほうがフランス語よりも上回っている.一方,後半2世紀ではフランス語のほうが上回っている.両言語で借用語の最盛期が異なっていることを反映するかのように,フランス語ではおよそ上り調子,古ノルド語ではおよそ下り調子になっていることがわかるだろう.4世紀合計でみるとフランス語0.1768,古ノルド語0.1817で後者が僅差で勝っており,全体としてフランス語の形容詞が「とくに明白なあらわれ方をしている」ことは読み取れなかった.
ただし,これは荒いパイロット・スタディなので解釈には注意を要する.OED の検索には機能上の限界があり,そこから拾い出したデータには相当数の雑音が入っている.また,[2011-02-09-1]の記事で話題にしたように,ある借用語がフランス語からなのかラテン語からなのか区別がつけにくいケースも多いだろう.今回ラテン語借用語を比較対象に加えなかったのも同じ理由からである.
クレパンの「とくに明白なあらわれ方」とは,品詞別(特に対名詞)比率のことを指しているわけではないかもしれない.テキスト上での頻度が高いとか,目につく使われ方をしているとか,比率とは別の次元での顕著さのことを指しているのかもしれない.何よりも,形容詞の絶対数でいえばフランス語は古ノルド語の5倍以上もある.印象としては,Chaucer やロマンスのテキストでのフランス借用語形容詞の役割は確かに顕著だし,クレパンの指摘には首肯できる.
今後この問題を追究するのであれば,より精度の高い調査が必要だろう.手作業で借用元言語を確認し,古ノルド語だけでなくラテン語からの借用語彙も比較し,扱う時代範囲も前後に移動させる必要があろう.中英語テキストをジャンル別に検討するのもおもしろそうだ.
・ アンドレ・クレパン 著,西崎 愛子 訳 『英語史』 白水社〈文庫クセジュ〉,1980年.
2011-01-29 Sat
■ #642. OED の引用データをコーパスとして使えるか (4) [oed][corpus][statistics]
[2010-10-15-1]の記事に関連して,Brewer の論文から補足.その記事で OED の引用数を時代別にグラフ化したものを掲げたが,特に顕著な増加を示している箇所を数字で示した版を以下に示す.
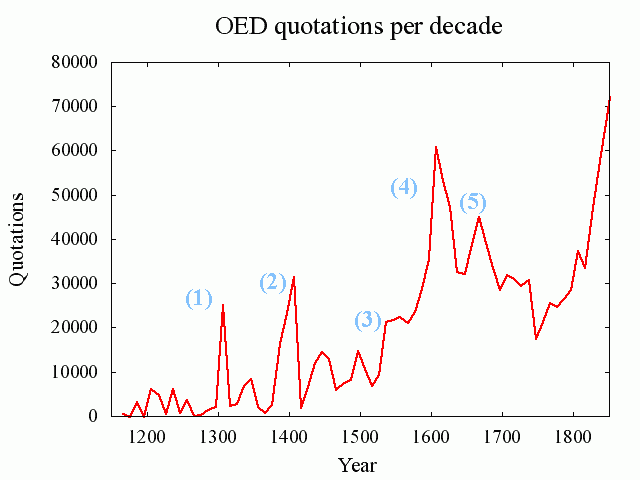
Brewer (58) によると,(1)--(5) の各増加は OED 編纂上の要因によるところが大きいとされる.それぞれの事情は以下の通りである.
(1) 1291--1300年の増加.1470年以前についてはしばしばテキストの年代が不明であり,そのような場合には便宜上各世紀の中央や両端に年代を仮設定するという編集上の方針があった.また,特にこの時代については,Robert of Gloucester (1297年,3222用例) や Cursor Mundi (1300年,10771用例で OED における被引用数第2位の作品) から,かなり集中的に引用が取り込まれているという事情もある.
(2) 1391--1400年の増加.(1) と同様の世紀終わりという理由に加え,Trevisa (1387/98年,6750用例) から大量に取り込まれているという事情がある.
(3) 1521--1530年の増加.Palsgrave の Lesclarcissement (1530年,5418用例) からの大量の引用により,半ば説明される.
(4) 1581--1600年の増加.Shakespeare (33304用例) の影響が相当に大きい.
(5) 1631--1660年の増加.おそらく革命期のパンフレットからの多数の引用が影響している.
この5点の増加についてだけでも編集上の背景を具体的に知っておくと,OED の引用データの使い方(少なくともその姿勢)は変わってくるだろうと思い,メモした次第.関連する記事としては以下を参照.
・ [2010-10-10-1]: #531. OED の引用データをコーパスとして使えるか
・ [2010-10-14-1]: #535. OED の引用データをコーパスとして使えるか (2)
・ [2010-10-15-1]: #536. OED の引用データをコーパスとして使えるか (3)
・ Brewer, Charlotte. "OED Sources." Lexicography and the OED: Pioneers in the Untrodden Forest. Ed. Lynda Mugglestone. Oxford: OUP, 2000. 40--58.
2011-01-04 Tue
■ #617. 近代英語期以前の専門5分野の語彙の通時分布 [scientific_english][lexicology][oed][statistics]
昨日の記事[2011-01-03-1]に引き続き,科学語彙など専門分野の語彙の初出世紀を OED で調べるという話題.近代以前に発展していた学術分野の語彙がどのような通時分布を示していたかについて,昨日は anatomy と math を例に挙げてグラフで示した.同じ手法で,やはり中世によく発達した music, astronomy, astrology, rhetoric, alchemy の各分野について語彙の初出世紀を整理してみた.definitions 欄に入れて検索した各分野の略記は "Mus.", "Astr." / "Astron.", "Astrol.", "Rhet.", "Alch." である.(数値データはこのページのHTMLソースを参照.)
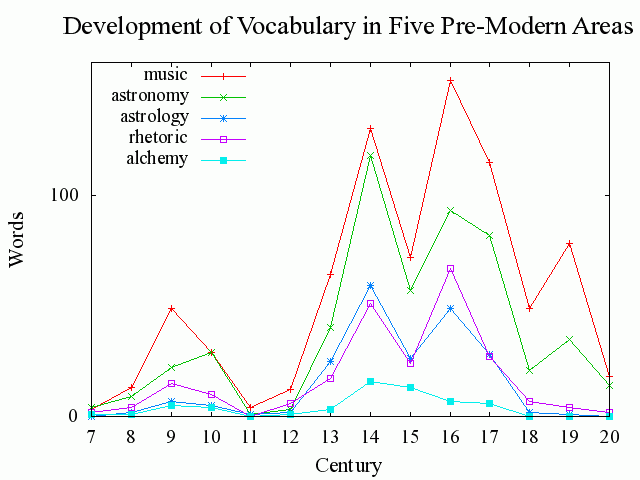
いずれも前近代的な専門分野らしく,近代科学の語彙が爆発する19世紀ではなく,14世紀や16世紀に初出のピークが来ている.それにしても,alchemy を除いた4分野のグラフが驚くほどきれいに平行しているのは示唆的である.15世紀にこぞって落ち込んでいる理由は分析していないが,各分野の発展史を参照して説明されるものなのか,あるいは OED の資料としての何らかの特徴が反映されているがゆえなのか.alchemy に関しては専門用語そのものの数が多くないので断定はできないが,14, 15世紀辺りにピークが来ている.
OED が文化史の研究に利用できるということは耳にしていたが,今回いろいろと具体的に作業してみて実感がわいてきた.語彙体系は文化の索引である.
2011-01-03 Mon
■ #616. 近代英語期の科学語彙の爆発 [scientific_english][lexicology][oed][statistics]
ルネサンス以降,近代英語期には科学語彙が爆発的に増殖した.特に19世紀は科学の発展がめざましく,おびただしい科学用語が出現することとなった.これには,18世紀後半から博物学でリンネの二名法が用いられるようになったことも影響している ( see [2010-09-21-1] ) .
科学の諸分野の発達とその語彙の増殖は連動していると考えられるので,OED で専門語彙の初出時期を調べてまとめれば,その分野の発展史の概略をつかむことができるのではないかと考えた.18世紀以前にすでに十分に発展していた分野もあるわけで,そのような分野では19世紀中の専門語彙の増殖は相対的に小さいはずである.そこで,18世紀以前に発展していたと分かっている解剖学と数学,19世紀に著しく発展したと分かっている化学と生物学に注目して,OED からそれぞれの分野からの専門用語を拾って整理してみた.
拾い方は,それぞれ ADVANCED SEARCH の definitions 欄に "Anat.", "Math.", "Chem.", "Biol." が含まれる語という粗い条件指定によるものであり,検索結果リストも逐一チェックはしていない.各語は初出年によって世紀ごとに振り分け,"a1866", "c1629", "15.." などはそれぞれ19, 17, 16世紀へ振り分けた.また,初出年の記載のないものは考慮から外している.このように大雑把な調査なので,あくまで参考までに.以下が,結果の表とグラフである.(数値データはこのページのHTMLソースを参照.)
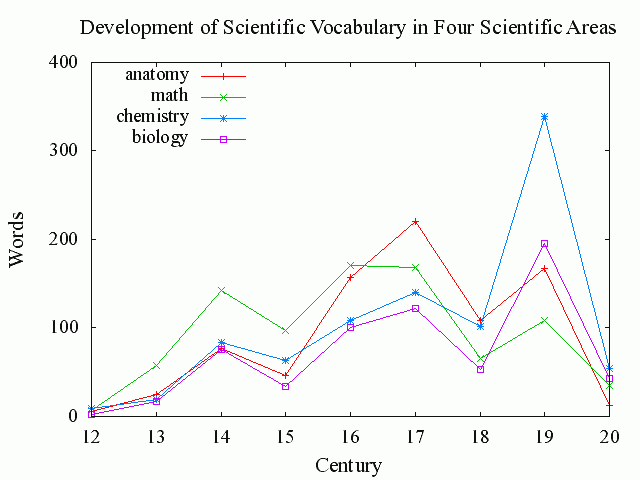
chemistry と biology は19世紀に初出語彙のピークが来ているが,anatomy と math はそれぞれ17, 16世紀にピークがある.後者2分野は確かに19世紀にも山があるので,科学語彙が爆発した世紀という一般論は当てはまるが,個々の分野によって語彙増殖の傾向の異なることがわかる.
今回はすでに発展史の概略がよく知られている4分野を取り上げ,OED によってその語彙増殖を確認したにすぎないが,他の専門分野で同様の調査を施してみるとおもしろい結果が出るかもしれない.関連する話題として,SOED を用いた「1500--1900年における英語語彙の増加」について,[2009-11-16-1]を参照.
・ Crystal, David. The Cambridge Encyclopedia of the English Language. 2nd ed. Cambridge: CUP, 2003. 87.
2010-12-31 Fri
■ #613. Academic Word List に含まれる本来語の割合 [lexicology][loan_word][statistics][academic_word_list]
昨日の記事[2010-12-30-1]で,Academic Word List (AWL) を導入した.この英語史ブログとして関心があるのは,AWL と銘打って収集されたこの語彙集のなかに本来語要素からなる語がどれだけ含まれているかという問題である.570語をざっと走査したら,以下の45語が挙がった.
acknowledge, albeit, aware, behalf, draft, forthcoming, furthermore, goal, hence, highlight, income, input, insight, layer, likewise, network, nevertheless, nonetheless, notwithstanding, offset, ongoing, outcome, output, overall, overlap, overseas, seek, shift, so-called, sole, somewhat, straightforward, tape, target, task, team, thereby, trend, undergo, underlie, undertake, welfare, whereas, whereby, widespread
570語中の45語で7.89%なので,予想通りに本来語の割合は少ない.しかし,数える前にはもっと小さい値が出るのではないかと踏んでいたので,意外に少なくないなと感じたのも事実である.Academic Word List というからには Greco-Latin の語がそれこそ100%に迫り,本来語は10語もあれば多いほうかと思い込んでいたのである.だが,本来語のリストを眺めていてなるほどど思った.out- や over- を接頭辞としてもつ実質的な語のカテゴリーが目立つ一方で,albeit, furthermore, hence, likewise, nevertheless, nonetheless, notwithstanding, thereby, whereas, whereby などの機能的・文法的なカテゴリーも目につく.forthcoming, ongoing, overall, so-called などの複合要素からなる形容詞も1カテゴリーをなしていると考えられるだろう.
ただし,本来語とはいっても古英語起源であるとは限らない.例えば,output などは1839年が初出である.上で最初に「本来語要素からなる語」と表現したのはそのためである.
なお,明確に本来語とはみなせないが Greco-Latin でもない語としては,古ノルド語からの借用語 bond, bulk, link, odd やオランダ語からの借用語 trigger があった.語源不詳のものとしては job もある.
現代英語の語彙数と起源別割合については,以下のリンクも参照.
・ [2010-06-30-1]: 現代英語の最頻語彙10000語の起源と割合
・ [2010-03-02-1]: 現代英語の基本語彙100語の起源と割合
・ [2009-11-15-1]: 現代英語の基本語彙600語の起源と割合
・ [2009-11-14-1]: 現代英語の借用語の起源と割合 (2)
2010-12-25 Sat
■ #607. Google Books Ngram Viewer [corpus][web_service][ame_bre][google_books][n-gram][statistics][frequency][lexicology]
Google がものすごいコーパスツールを提供してきた.Google Books Ngram Viewer は Google Labs 扱いだが,その規模と可能性の大きさに驚いた.2004年以来1500万冊の本をデジタル化してきた Google が,そのサブセットとなる520万冊の本,5000億語をコーパス化した.英語のほかフランス語,ドイツ語,ロシア語,スペイン語,中国語が含まれているが,英語では British English, American English, English, English Fiction, English One Million からサブコーパスを選択できる.最大の特徴は,指定した5語までの検索語の頻度を過去5世紀(1500--2008年)にわたって追跡し,グラフで表示してくれることだ.Google からの公式な説明はこちらの記事にある.
規模が大きすぎてコーパスとしてどう評価すべきかも分からないが,ひとまずはいじるだけで楽しい.上記の記事内にいくつかのサンプルがあるが,英語史的な関心を引くサンプルとして burnt と burned の分布比較があったので,English, American English, British English の3サブコーパスをグラフを出してみた.
次に,本年度の卒論ゼミ生の扱った話題を拝借し,一般に AmE on the street, BrE in the street とされる前置詞使用の差異を Google Books Ngram Viewer で確認してみた.American English と British English のそれぞれのサブコーパスから出力されたグラフは以下の通り.
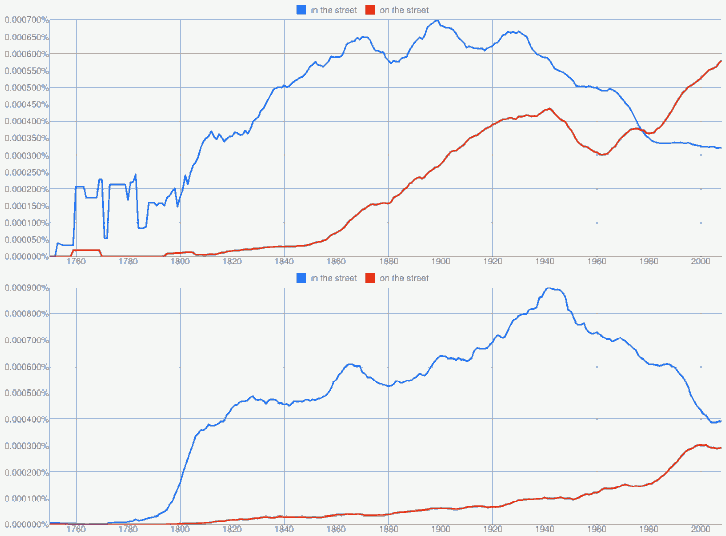
in と on の選択は句の意味(「街路で」か「失業して」か)などにも依存するため単純な形態の頻度比較では不十分だが,傾向はつかめる.
[2010-08-16-1], [2010-08-17-1]の記事で扱った gorgeous についても調べてみた.19世紀には流行っていたが20世紀には落ち目であったこの形容詞が,American English において1980年代以降,再び勢いを盛り返してきている状況がよくわかる.British English でも復調の兆しがあるだろうか?
コーパス言語学一般にいえるが,ツールの使用はアイデア次第である.文化史的な観点からは,[2009-12-28-1]の記事で紹介した American Dialect Society による "Words of the Century" や "Words of the Millennium" のノミネート語句を検索してみるとおもしろい.
他のオンラインコーパスについては[2010-11-16-1]を参照.
2010-12-12 Sun
■ #594. 近代英語以降のフランス借用語の特徴 [loan_word][french][statistics][history]
英語語彙史においてフランス借用語の果たしてきた役割の大きさは本ブログでも幾度となく取り上げてきた ( see french ) .しかし,しばしばフランス語借用はもっぱら中英語期の話題であると信じられているきらいがある.確かに[2009-08-22-1]の記事で掲げたグラフで示されている通り,15世紀以降はフランス語借用が一気に落ち込んでいる.しかしこれは13, 14世紀の絶頂期と比べての相対的な凋落であり,近現代に至るまで絶え間なく英語に語彙を供給してきた点は注目に値する.
英語史において絶え間ない語彙の供給源としては,ほかにラテン語とギリシア語が挙げられるが,この3言語のなかではフランス語が最も優勢のようである.数値を挙げよう.トゥルニエ (347) は The Shorter Oxford English Dictionary による調査で,1900--50年の間に英語に入った208の借用語のうち93例 (44.71%) がフランス語に関係しており,1961--75年では253例中の136 (53.75%) がフランス語であるという(ブランショ, p. 132--33).
英語語彙借用におけるフランス語の優位性はさることながら,借用語彙の分野が中世以来あまり変わっていないことも顕著である.その分野とは,貴族の生活,流行,美食,贅沢品,芸術,文学,軍事などで,まとめてしまえば「貴族的気取り」「知的流行」といったところだろうか.
近代英語期のフランス語借用に特徴的なのは,フランス語のまま入ってきているということである.つまり,発音や綴字が英語化されていない.フランス語らしさ,外国語らしさが保たれている.
古典期のフランス心酔は,1685年のナントの勅令の廃止後,フランスのプロテスタントの国外流出によって育まれたものである.これがフランス語に特権的な地位を与えるようになり,借用された語はもはや英語化されなくなる.それらの語は優先的に社会生活に関わるものである.例えば,à propos, ballet, chagrin, chaperon, double-entendre, étiquette, fête, moquette, naïve, intrigue, nom de plume, rendez-vous, rêverie などでは,そのままの採用が見られる.(ブランショ,p. 132)
ナントの勅令 ( L'Édit de Nante ) は,1598年4月13日にフランス国王アンリ4世がナントで発布した勅令で,限定的ながらも新教徒の権利を認めた寛容勅令の集大成だった.これにより30年以上続いた宗教戦争に一応の終止符が打たれたが,17世紀に絶対王権の強化とともにナントの勅令は形骸化していった.1685年,国王ルイ14世がナントの勅令を廃止すると,大量の新教徒が国外亡命することになった.この事件が,現代英語へフランス語ぽいフランス借用語がもたらされる契機となったのである.
・ ジャン=ジャック・ブランショ著,森本 英夫・大泉 昭夫 訳 『英語語源学』 〈文庫クセジュ〉 白水社,1999年. ( Blanchot, Jean-Jacques. L'Étymologie Anglaise. Paris: Presses Universitaires de France, 1995. )
2010-10-15 Fri
■ #536. OED の引用データをコーパスとして使えるか (3) [oed][corpus][statistics]
[2010-10-10-1], [2010-10-14-1]に引き続き,OED の引用データの話題.今回は,特に昨日の記事[2010-10-14-1]の (2), (3) で取り上げた年代別引用数の浮き沈みの問題を意識する上で,数値をグラフに視覚化しておくと便利だと考えた.
Brewer は10年ごとに OED の引用数の推移を調べており,実際にグラフ化もしている (48--49) .しかし,論文内に提示されているグラフは1470年を境に二分されており,目盛り尺度も互いに異なっているので比較するにはやや不便である.そこで,以下に目盛り尺度を揃えたグラフを改めて作成してみた.Brewer にはグラフ作成のもとになる数値データは与えられていないので,グラフから目検討で数値を読み出し,それを頼りに作成した(← 本当は自ら OED で改めて数字を出せばいいのだけれど).したがって,ここに示されているものはあくまで傾向をとらえるためのものとして参考までに.
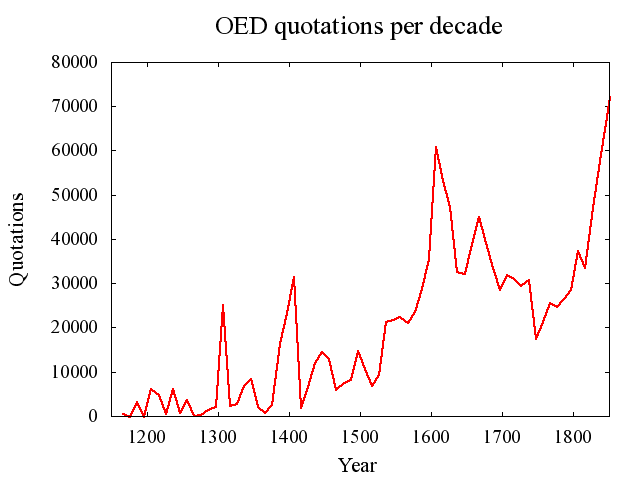
OED を通時コーパスとして用いる場合には,特に引用数が周囲より劇的に低かったり高かったりする時期からの引用に当たる際に注意が必要である.このグラフは,その際のお供として参照されたい.
・ Brewer, Charlotte. "OED Sources." Lexicography and the OED: Pioneers in the Untrodden Forest. Ed. Lynda Mugglestone. Oxford: OUP, 2000. 40--58.
2010-10-06 Wed
■ #527. 不規則変化動詞の規則化の速度は頻度指標の2乗に反比例する? [verb][conjugation][statistics][lexical_diffusion][speed_of_change][frequency]
言語進化論の立場からの驚くべき論文を読んだ.古英語の強変化動詞(不規則変化動詞)が時間とともに現在・未来に向かって規則化してゆく速度は,その動詞の頻度指標の2乗に反比例するというのである.不規則形の規則化と頻度に相関関係があることは多くの関連研究で明らかにされてきているが,この研究で驚かされるのは具体的な数式を挙げてきたことである.
古英語から取り出した177の不規則動詞(現在にまで廃語となっていないもののみ)のうち,中英語でも不規則のまま残ったのは145個,近代英語でも不規則のままなのは98個だという.また,未来に計算式を当てはめると西暦2500年までに不規則のまま残っているのは83個であると予測している.
この論文には計算に関わる数々の前提が説明されているが,細かくみればいろいろと疑問点がわき出てくる.
・ 現代英語における各動詞の頻度をコーパスで求めているのはよいとして,古英語と中英語における頻度の求め方は適切か.著者たちは中英語に関しては The Penn-Helsinki Parsed Corpus of Middle English を利用したと述べているが,現代英語の頻度を流用して計算している箇所もあった.もっとも,この流用による値の乱れは大きくないという議論は論文内で展開されてはいるが.
・ 現代英語については標準変種を想定して動詞を数えているが,過去の英語についてはどの変種を選んでいるのかが不明.おそらくは雑多な変種を含めたコーパスを対象としているのだろう.
・ 古英語から現代英語にかけておよそ一定の速度で規則化が起こっているという結果だが,近代期以降は「自然な」言語変化に干渉を加える規範文法の成立や教育の普及という社会的な出来事があった.こうした事情を考え合わせたうえで一定の速度であるということは何を意味するのか.
・ 規則形が現われだした時点ではなく,不規則形が最後に現われた(のちにもう現われないことになる)時点をカウントの基準にしているが,両形が共存している時期の長さについては何か言えることはあるのか.
ただ,非常に大きな視点からの研究なので,あまり細かい点を持ち出して評するのもどうかとは思う.そこで,細かいことは抜きにしてこのマクロな研究結果を好意的に受け入れてみることにして,次にこの研究の後に生じるはずの大きな課題を考えてみたい(論文中には特に further studies が示されていないかったので).
「規則化の速度が動詞の頻度指標の2乗に反比例する」という結果が出たが,この公式は英語の動詞の規則化だけに適用される単発の公式と考えてよいのだろうか.他のいくつかの(望むらくは多くの)言語的規則化にも一般的に適用できるのであればとても有意義だが,おそらくそれほどうまくは行かないだろう.そうすると,今回のように綺麗に公式が導き出される「理想的な」規則化の例は,逆に言うとどのような条件を備えているのだろうか.この条件を一般化することはできるのだろうか,また意味があるのだろうか.
私も「理想的な言語変化の推移」には関心があり,言語変化は slow-quick-quick-slow のパターンのS字曲線を描くとする語彙拡散 ( lexical diffusion ) という理論に注目しているが,上記と同じ課題を抱えている.現実には,理想的な言語変化の推移の起こることは稀だからである.この問題については今後もじっくり考えていきたい.
・ Lieberman, Erez, Jean-Baptiste Michel, Joe Jackson, Tina Tang, and Martin A. Nowak. "Quantifying the Evolutionary Dynamics of Language." Nature 449 (2007): 713--16.
2010-09-12 Sun
■ #503. 現代英語の綴字は規則的か不規則的か [spelling_pronunciation_gap][statistics]
現代英語の綴字と発音の関係は,母語話者にとっても非母語話者にとってもしばしば非難の対象になるが,[2010-02-05-1]の記事で少し触れたとおり,世間で酷評されるほどひどくないという主張がある.Crystal (72) によれば綴字が完全に不規則な日常英単語はわずか400語程度にすぎないという.また,以下のように綴字の規則性は75%?84%にも達するという推計もある.
English is much more regular in spelling than the traditional criticisms would have us believe. A major American study, published in the early 1970s, carried out a computer analysis of 17,000 words and showed that no less than 84 per cent of the words were spelled according to a regular pattern, and that only 3 per cent were so unpredictable that they would have to be learned by heart. Several other projects have reported comparable results of 75 per cent regularity or more. (Crystal, pp. 72--73)
この数値をみると,確かに巷で騒がれるほど英語の綴字はめちゃくちゃではないのだなと感じるかもしれない.しかし,こうした推計値は,解釈に際して2つの点で注意すべきである.1つは,推計値は調査対象とする語彙の範囲(例えば明らかに不規則性が多く観察される地名や人名などの固有名詞を含むかどうか)や規則性の計測の仕方(例えば meat, meet, mete の綴字はいずれもある意味で規則的と判断できるが,/mi:t/ を綴る可能性が3種類もあると考えれば予測不可能性は増し,その分不規則的ともいえる)などに大きく依存するという点である.何をどのように数えるかということが肝心である.
それでも,複数の推計で法外に大きく異なる値が出たわけではないので,ひとまず上の値を受け入れると仮定しよう.その場合でも,次の点を考慮する必要がある.数値が客観的であるとしても,その数値をどのように解釈すればよいかという基準が主観的あるいは相対的になることがありうるという点である.具体的に言えば,綴字の規則性を示す84%という上述の値は,本当に高いと評してよいのだろうか.綴字と発音の関係が例外なしの完璧な場合を100%と考えているのだろうが,その正反対である0%というのはローマ字のような表音文字 ( see [2010-06-23-1] ) を話題にしている限り,定義上ありえない.表語文字である漢字ですら,形声文字では,音読みに関する限り,読み方の予測可能性はかなり高いのである.つまり,100%の対極として0%を想定することは現実的にはありえない.取り得る値の範囲は,0--100% ではなく,例えば 50--100% くらいに落ち着くはずである.その中で84%という数値を評価する必要がある.
また,英語と同じローマ字を用いる他のヨーロッパ語を考えてみると,フランス語やドイツ語などで同じような推計をとると限りなく100%に近くなるのではないかと想像される.それと比較すると,英語の84%という値は相当に低いとも考えられる.「表音文字で綴られる言語」を標榜している限り,完璧な100%までは求めずともせめて95%くらいは欲しい,譲っても90%だなどと考えれば,84%では心許ないともいえる.「表音文字」であるから100%を建前としているし,取り得る値のボトムが0%でありえないという上記の前提を考慮すると,英語の84%という値の解釈は難しい.
出てきた数値はそれなりに客観的だとしても,その解釈は相対的にならざるを得ないと考える所以である.
・ Crystal, David. The English Language. 2nd ed. London: Penguin, 2002.
2010-09-06 Mon
■ #497. 5分で分かる英語の歴史と統計 [link][statistics][reestablishment_of_english][dictionary][elf]
こんな英語学習サイトを見つけた.English Language: All about the English language.この手のサイトは多数あるが,トップに英語史と英語の統計情報が簡単にまとまっているので目を引いた.
・ English language History
・ English language Statistics
前者の英語史の解説文の "Middle English" の節で,中英語期の英語の復権 ( see reestablishment_of_english ) がノルマン・コンクェスト後の50年くらいで早々と始まっていたという記述があった.
Various contemporary sources suggest that within fifty years most of the Normans outside the royal court had switched to English, with French remaining the prestige language largely out of social inertia. For example, Orderic Vitalis, a historian born in 1075 and the son of a Norman knight, said that he only learned French as a second language.
英語の復権を話題にするときには話し言葉か書き言葉か,庶民レベルか貴族レベルか,言語使用の状況が私的か公的かなど,視点によって復権の時期や程度が変わってくるのだが,従来の英語史ではフランス語のくびきの時代が中世のあいだに比較的長く続いたと記述されることが多かったように思う.しかし,事実としては上の解説文にあるとおり,中世イングランドでは庶民の実用上,英語は圧倒的な言語だったのであり,この事実を強調しておくことは重要だと思う.
英語の統計については本ブログでも statistics の各記事で取り上げてきたが,以下のものは驚きこそしないが,私にとって初耳だった.
・ English is the language of navigation, aviation and of Christianity; it is the ecumenical language of the World Council of Churches
・ Five of the largest broadcasting companies in the world (CBS, NBC, ABC, BBC and CBC) transmit in English, reaching millions and millions of people all over the world
・ Of the 163 member nations of the U.N., more use English as their official language than any other. . . . After English, 26 nations in the U.N. cite French as their official tongue, 21 Spanish and 17 Arabic.
・ People who count English as their mother tongue make up less than 10% of the world's population, but possess over 30% of the world's economic power
ただし,全体的に典拠は示されていない.また,2010年現在の国連加盟国は192カ国であり,上記の3点目の163カ国に基づく統計は1990年くらいの時点での数値かもしれない( see United Nations member States - Growth in United Nations membership, 1945-present ) .
このサイトには他にも English Dictionaries や English Literature などのページがある.
2010-08-26 Thu
■ #486. 迂言的 do の発達 [emode][syntax][statistics][do-periphrasis]
英語史で大きな統語上の問題はいくつかあるが,そのうちの1つに迂言的 do ( do-periphrasis ) の発達がある.現代英語では助動詞 do は疑問文,否定文,強調文で出現する最頻語だが,中英語以前はこれらの do の用法はいまだ確立していない.それ以前は,疑問文は Do you go? の代わりに Go you? であったし,否定文も I don't go. の代わりに I go not. などとすれば済んだ.do-periphrasis が初期近代英語期に確立した理由については諸説が提案されているが定説はなく,現在でも様々な方面から研究が続けられている.
しかし,do-periphrasis が確立した過程については,少なくとも頻度の変化という形で研究がなされてきた.疑問文や否定文を作るのに do を用いない従来型を単純形 ( simplex ) ,do を用いる革新型を迂言形 ( periphrastic ) とすると,迂言形の占める割合が初期近代英語期 ( 1500--1700年 ) に一気に増加したことが知られている.
以下は,英語史概説書を通じて広く知られている Ellegård による do-periphrasis の発達を示すグラフである.(中尾, p. 74 に再掲されている数値に基づいて作り直したもの.数値はHTMLソースを参照.)肯定平叙文 ( aff[irmative] declarative ) ,否定平叙文 ( neg[ative] declarative ) ,肯定疑問文 ( aff[irmative] interrogative ) ,否定疑問文 ( neg[ative] interrogative ) ,否定命令文 ( neg[ative] imperative ) と場合分けしてある.
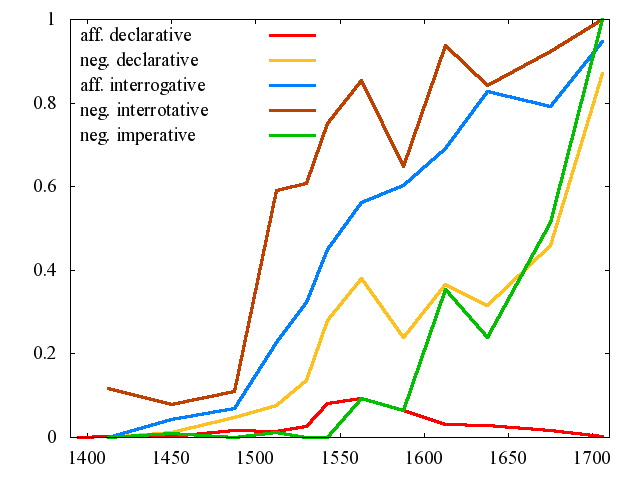
疑問文での do-periphrasis の使用が,全体的な発展を先導していったことがわかる.ただし,実際には個々の動詞によって do-periphrasis を受け入れる傾向は異なり,否定文では care, know, mistake などが,疑問文では come, do, hear, say などが迂言形の受け入れに保守的であった.Ogura によると,談話的な要因,社会・文体的要因,音素配列,動詞の頻度などが複雑に相互作用して do-periphrasis がこの時期に拡大していったようだ.
・ Ellegård, A. The Auxiliary Do. Stockholm: Almqvist and Wiksell, 1953.
・ 中尾 俊夫,児馬 修 編 『歴史的にさぐる現代の英文法』第3版,大修館,1997年.
・ Ogura, Mieko. "The Development of Periphrastic Do in English: A Case of Lexical Diffusion in Syntax. Diachronica'' 10 (1993): 51--85.
2010-07-21 Wed
■ #450. 現代英語に受け継がれた古英語の語彙はどのくらいあるか [oe][pde][lexicology][statistics][semantic_change]
古英語の語彙の多くが現代までに失われてしまっていることは,英語史でもよく話題にされる.背景には,特に中英語期以降,諸外国語から借用語が大量に流入して本来語彙を置き換えたという経緯がある.では,具体的に数でいうと,古英語語彙のどのくらいが現代までに死に絶え,どのくらいが受け継がれているのだろうか.参考になる数値が,Brinton and Arnovick (165--66) に掲載されていたので紹介する(数値の究極のソースは Cassidy and Ringler (4--7) に引用されている J. F Madden and F. P. Magoun, Jr である).
・ 古英詩での最頻1,000語のうち,半数を少々超えるほどの語しか現代に残っていない.
・ 古英語語彙の最頻100語のうち,76%が現代に残っている.
・ 古英語にあった数詞の100%,前置詞の82%,代名詞の80%,接続詞の75%が現代に残っている.
高頻度語や機能語ほど残存率が高いということは,これらの語群が失われる機会が少なく,他言語からの借用語で置換されにくいことによるだろう.だが,逆に言えば,内容語(名詞,動詞,形容詞,副詞)で同様の統計をとれば,死に絶えた語の数が劇的に増加するだろうことは予想できる.
ただ,古英語の語彙が現代まで残存している場合でも,意味や形態がほぼ古英語のままであるという保証はない.in, word, fæst "fast", nū "now" などは意味も形態もほぼそのままで受け継がれているが,brēad "bit" ( not "bread" ), sellan "to give" ( not "to sell" ) などは意味が変化している.また,古英語の意味や形態が,限られた使用域 ( register ) でのみ生きながらえているケースも少なくない.例えば,古英語 gāst 「魂,霊」の意味は,現代英語では the Holy Ghost 「聖霊」というキリスト教用語として限定的に生き残っているに過ぎず,一般的な意味は「幽霊」である.
もし仮に古英語より意味や使用域の変化を経た語は同一語とみなさないとするのであれば,古英語語彙の残存率は相当に低くなることだろう.千年を超える時間のなかでは,変化しない方が珍しいと考えるべきかもしれない.
・ Brinton, Laurel J. and Leslie K. Arnovick. The English Language: A Linguistic History. Oxford: OUP, 2006.
・ Cassidy, Frederic G and Richard N. Ringer, eds. Bright's Old English Grammar and Reader. 3rd ed. New York: Holt, Rinehart and Winston, 1971.
2010-06-30 Wed
■ #429. 現代英語の最頻語彙10000語の起源と割合 [loan_word][lexicology][statistics][pde]
現代英語の語彙の起源と割合については,[2010-05-16-1]でまとめたとおり,本ブログでも何度か扱ってきた.
・ [2010-03-02-1]: 現代英語の基本語彙100語の起源と割合
・ [2009-11-15-1]: 現代英語の基本語彙600語の起源と割合
・ [2009-11-14-1]: 現代英語の借用語の起源と割合 (2)
この種の英語語彙の語源調査については本格的なものは存在しないようだが,もう一つ関連する先行研究をみつけたので紹介したい.
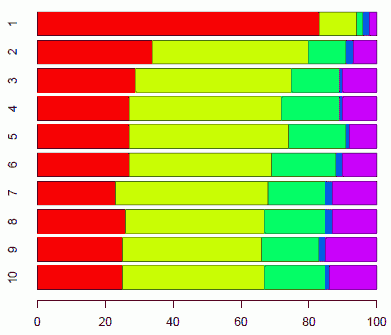
Williams (67--68) は,数千通の商用書簡から最頻1万語を取り出し,頻度の高い順に1000語単位で10のグループを設けた.各グループについて語源別に比率をまとめた表を Williams より再掲する(宇賀治,pp. 84--85 にも掲載あり).ついでに,見やすいように棒グラフも作った.
|
|
2000語,3000語レベルから早くも各言語の比率が落ち着いてくるのは,[2010-04-11-1]でみた音節数の分布とある程度は相関していそうでおもしろい.
"Other" グループは雑多あるいは語源不詳の語も含まれるが,そのなかで各1000語の語群のいずれかで1%を超えるものは Dutch 借用語のみだという.また,調査対象としたコーパスをひっくるめて token 頻度で調べると以下の通り.こうしてみると英語は英語なのだとわかる.
| English | 78.1% |
| French | 15.2 |
| Latin | 3.1 |
| Danish | 2.4 |
| Other (Greek, Dutch, Italian, Spanish, German, etc.) | 1.3 |
・ Williams, Joseph M. Origins of the English Language: A Social and Linguistic History. New York: The Free Press, 1975.
・ 宇賀治 正朋著 『英語史』 開拓社,2000年.
Powered by WinChalow1.0rc4 based on chalow