2017-11-23 Thu
■ #3132. 暗号学と言語学 (2) [cryptology][linguistics][statistics][chaos_theory][information_theory]
最近,言語学とカオス理論 (chaos_theory) について少し調べているが,フラクタル図形「マンデルブロー集合」 (Mandelbrot set) で知られる数学者 Benoît Mandelbrot (1924--2010) が,情報理論や言語学に関する論考を著わしていることを知った(「マンデルブロー集合」については「#3123. カオスとフラクタル」 ([2017-11-14-1]) を参照).
Mandelbrot はその論考で,暗号学 (cryptology) と言語学の接点という話題にも触れている.本ブログでも「#2699. 暗号学と言語学」 ([2016-09-16-1]) の記事で,両分野の密接な関係について考えたことがあったので,ここで再び取り上げたい.その記事の第2段落で述べたことと Mandelbrot (552) の次の1節は,よく符合する.
. . . let us grant for the moment that the encoding and decoding machines may be as complicated as the designer may wish, and that the memory of the human links---using the common sense of the word "memory"---is unbounded. Under those ideal circumstances, it is obvious that any improvement of our understanding of the structure of language and of discourse will bring a possibility of improvement of the performance of the cryptographer or stenographer. For example, a knowledge of the rules of grammar will show that a given phrase will never be encountered in grammatically correct discourse; thus, if his employer were to speak only grammatical English, a stenographer would not need any special set of signs to designate the incorrect sentences. Similarly, a knowledge of the statistics of discourse will suggest that the "cliché" be represented by special short signs; in this way, the stenogram will be shortened and---since deciphering is very much helped by cliché---the code will be strengthened. That is, the ideal cryptographer and stenographer should make the utmost use of any available linguistic information.
暗号作成者は,言語の性質を知っていればいるほど,その性質の裏をかいた暗号文を作成できるし,逆に暗号解読者も,言語の性質を知っていればいるほど,そのように裏をかかれる可能性を減らすことができる.この意味で,暗号学は舞台を変えた言語学ともいえるのである.
・ Mandelbrot, Benoît. "Information Theory and Psycholinguistics." Scientific Psychology: Principles and Approaches. Ed. Benjamin B. Wolman and Ernest Nagel. New York: Basic Books, 1965. 550--62.
2017-09-14 Thu
■ #3062. 1665年のペストに関する Samuel Pepys の記録 [black_death][pepys][literature][history][demography][statistics]
17世紀のイングランドの海軍大臣 Samuel Pepys (1633--1703) は,1660--69年ロンドンでの出来事を記録した日記 The Diary of Samuel Pepys で知られる.1665--66年にロンドンを襲った腺ペスト (The Great Plague) についても,不安をもって記録している.関連する箇所をいくつか抜き出そう.
Sunday 30 April 1665 . . . . Great fears of the sickenesse here in the City, it being said that two or three houses are already shut up. God preserve as all!
Sunday 7 June 1665 . . . . This day, much against my will, I did in Drury Lane see two or three houses marked with a red cross upon the doors, and "Lord have mercy upon us" writ there; which was a sad sight to me, being the first of the kind that, to my remembrance, I ever saw. It put me into an ill conception of myself and my smell, so that I was forced to buy some roll-tobacco to smell to and chaw, which took away the apprehension.
Sunday 10 June 1665 . . . . In the evening home to supper; and there, to my great trouble, hear that the plague is come into the City (though it hath these three or four weeks since its beginning been wholly out of the City) . . . .
Saturday 16 September 1665 . . . . At noon to dinner to my Lord Bruncker, where Sir W. Batten and his Lady come, by invitation, and very merry we were, only that the discourse of the likelihood of the increase of the plague this weeke makes us a little sad, but then again the thoughts of the late prizes make us glad.
上の3つめの引用にあるとおり,ペストがシティに入ってきたのは6月10日頃である.6月下旬には,ロンドン市長と市参事会の連名でペスト条例が公布されている.当時のロンドンの人口は25万人ほどという説があるが,その1/5ほどがわずか1年のあいだに腺ペストに倒れたというから,その勢いは凄まじい(蔵持,pp. 219--226).ペストは翌1666年には下火になっていたものの,くすぶってはいた.ペストが完全に制圧されたのは,皮肉にも9月2日のロンドン大火によってだった.その日の Pepys の日記 (Sunday 2 September 1666) も参照されたい.
・ 蔵持 不三也 『ペストの文化誌 ヨーロッパの民衆文化と疫病』 朝日新聞社〈朝日選書〉,1995年.
2017-08-24 Thu
■ #3041. 近現代における semicolon の盛衰 [punctuation][statistics]
昨日の記事「#3040. 古英語から中英語にかけて用いられた「休止」を表わす句読記号」 ([2017-08-23-1]) に引き続き,句読記号 (punctuation) の話題.<;> (semicolon) は,「#2666. 初期近代英語の不安定な句読法」 ([2016-08-14-1]) で触れたように,16世紀後半になってようやく用いられるようになった新参者である.その後,句読記号を多用する "heavy style" 好みの18世紀にはおおいに活躍したが,現代にかけて衰退してきている.近現代にほける semicolon の盛衰に関して,Crystal (207) の文章が興味深い.
It's often been reported that the semicolon is going out of fashion, and the evidence (from the study of large collections of written material) does support a steady drop in frequency during the twentieth century. (They're much more common in British English than American English.) A typical finding is to see that 90 per cent of all punctuation marks are either periods or commas, and semicolons are just a couple of percent. The figure was much higher once. The semicolon had its peak in the eighteenth century, when long sentences were thought to be a feature of an elegant style, heavy punctuation was in vogue, and punctuation was becoming increasingly grammatical. The rot set in during the nineteenth century, when the colon became popular, and took over some of the semicolon's functions. The economics of the telegraph (the shorter the message, the cheaper) fostered short sentences. And today it has virtually disappeared from styles where sentences tend to be short, such as on the Internet.
最近の日本でも,Twitter などの影響で,単純な思考を短文で書くことしかできず,まとまった思考を長文で書くことができない人が増えているというコメントが聞かれるが,それと連動して文章を書くスタイルや用いられる句読記号の種類や頻度も変化するというのは確かにありそうである.semicolon という,ある意味で中途半端な句読記号の盛衰を追うことによって,むしろ各々の時代の文章スタイルの特徴が浮き彫りになるというのはおもしろい.今後,semicolon は限定されたテキストタイプでしかお目にかからないレアな句読記号になっていく可能性もありそうだ.
・ Crystal, David. Making a Point: The Pernickety Story of English Punctuation. London: Profile Books, 2015.
2017-07-23 Sun
■ #3009. 母語話者数による世界トップ25言語(2017年版) [statistics][world_languages][demography][japanese]
「#397. 母語話者数による世界トップ25言語」 ([2010-05-29-1]) を書いてから7年の年月が経った.Ethnologue (20th ed) の最新版が出たので,Summary by language size の表3により,母語話者数による世界トップ23言語の最新ランキングを示したい.
| Rank | Language | Primary Country | Countries | Speakers (20th ed, 2017) | Speakers (16th ed, 2009) | (13th ed, 1996) |
|---|---|---|---|---|---|---|
| 1 | Chinese | China | 37 | 1,284 million | 1,213 | 1,123 |
| 2 | Spanish | Spain | 31 | 437 | 329 | 266 |
| 3 | English | United Kingdom | 106 | 372 | 328 | 322 |
| 4 | Arabic | Saudi Arabia | 57 | 295 | 221 | 202 |
| 5 | Hindi | India | 5 | 260 | 182 (242.6 with Urdu) | (236 with Urdu) |
| 6 | Bengali | Bangladesh | 4 | 242 | 181 | 189 |
| 7 | Portuguese | Portugal | 13 | 219 | 178 | 170 |
| 8 | Russian | Russian Federation | 19 | 154 | 144 | 288 |
| 9 | Japanese | Japan | 2 | 128 | 122 | 125 |
| 10 | Lahnda | Pakistan | 6 | 119 | 78.3 | |
| 11 | Javanese | Indonesia | 3 | 84.4 | 84.6 | |
| 12 | Korean | Korea | 7 | 77.2 | 66.3 | |
| 13 | German | Germany | 27 | 76.8 | 90.3 | 98 |
| 14 | French | France | 53 | 76.1 | 67.8 | 72 |
| 15 | Telugu | India | 2 | 74.2 | 69.8 | |
| 16 | Marathi | India | 1 | 71.8 | 68.1 | |
| 17 | Turkish | Turkey | 8 | 71.1 | 50.8 | |
| 18 | Urdu | Pakistan | 6 | 69.1 | 60.6 | |
| 19 | Vietnamese | Viet Nam | 3 | 68.1 | 68.6 | |
| 20 | Tamil | India | 7 | 68.0 | 65.7 | |
| 21 | Italian | Italy | 13 | 63.4 | 61.7 | 63 |
| 22 | Persian | Iran | 30 | 61.9 | ||
| 23 | Malay | Malaysia | 16 | 60.8 | 39.1 | 47 |
2009年の16版の統計では2位スペイン語と3位英語の差はごくわずかで事実上のタイだったが,今回のデータによれば,2位のスペイン語が英語を勢いで引き離しにかかっていることがわかる.3位の英語は,むしろ今後は4位のアラビア語に詰め寄られることになりそうだ.
続くランキングで,9位につけている日本語までは,ここ数年で順位が変わっていないものの,10位だったドイツ語が13位まで順位を落としているのが印象的である.フランス語は,むしろ16位から14位へ若干順位を上げている.
近い将来,9位につけている日本語が徐々にランキングを下げていくことは必至である.日本以外に母語として使用される国がないこと,また日本の人口減の傾向が主たる要因である.ジャワ語やベトナム語などに肉薄されるのも時間の問題だろう.
「#274. 言語数と話者数」 ([2010-01-26-1]) で示したように,少数のトップ言語が世界人口の多くを担っているという事態は変わっていないどころか,傾向が加速化している.例えば,上の表の15位までの言語の母語話者の合計は約40億人となり,これは世界人口の6割近くに当たる.うち6言語は国連の公用語であり,これだけで148国をカバーする.言語の寡頭支配ぶりは明らかだろう.
2017-06-10 Sat
■ #2966. 英語語彙の世界性 (2) [lexicology][loan_word][borrowing][statistics][link]
英語語彙の世界性について,1年ほど前の記事 ([2016-06-24-1]) で様々なリンクを張ったが,その後書き足した記事もあるので,リンク等をアップデートしておきたい.記事を読み進めていけば,英語語彙史の概要が分かる.
1 数でみる英語語彙
1.1 語彙の規模の大きさ (#898)
1.2 語彙の種類の豊富さ (##756,309,202,429,845,1202,110,201,384)
1.3 英語語彙史の概略 (##37,1526,126,45)
2 語彙借用とは?
2.1 なぜ語彙を借用するのか? (##46,1794)
2.2 借用の5W1H:いつ,どこで,何を,誰から,どのように,なぜ借りたのか? (#37)
3 英語の語彙借用の歴史 (#1526)
3.1 大陸時代 (--449)
3.1.1 ラテン語 (#1437)
3.2 古英語期 (449--1100)
3.2.1 ケルト語 (##1216,2443)
3.2.2 ラテン語 (#32)
3.2.3 古ノルド語 (##2625,2693,340,818)
3.2.4 古英語本来語のその後 (##450,2556,648)
3.3 中英語期 (1100--1500)
3.3.1 フランス語 (##117,1210)
3.3.2 ラテン語 (##120,1211)
3.3.3 中英語の語彙の起源と割合 (#985)
3.4 初期近代英語期 (1500--1700)
3.4.1 ラテン語 (##478,114,1226)
3.4.2 ギリシア語 (#516)
3.4.3 ロマンス諸語 (##2385,2162,1411,1638)
3.5 後期近代英語期 (1700--1900) と現代英語期 (1900--)
3.5.1 語彙の爆発 (##203,616)
3.5.2 世界の諸言語 (##874,2165,2164)
4 現代の英語語彙にみられる歴史の遺産
4.1 フランス語とラテン語からの借用語 (#2162)
4.2 動物と肉を表わす単語 (##331,754)
4.3 語彙の3層構造 (##334,1296,335,1960)
4.4 日英語の語彙の共通点 (##1645,296,1630,1067)
5 現在そして未来の英語語彙
5.1 借用以外の新語の源泉 (##873,874,875)
5.2 語彙は時代を映し出す (##625,631,876,889)
英語語彙史を大づかみする上で最重要となる3点を指摘しておきたい.
(1) 英語語彙史は,英語と他言語の交流の歴史と連動している
(2) 語彙借用の動機づけは「必要性」のみではない
(3) 語彙借用により類義語が積み上げられていき,結果として3層構造が生じた
2017-03-12 Sun
■ #2876. 英語語彙の頻度分布に関する格差上位1%のシェア [lexicology][statistics][frequency][corpus]
昨日の記事「#2875. 英語語彙の頻度分布の格差をジニ係数とローレンツ曲線でみる」 ([2017-03-11-1]) に引き続き,英語語彙頻度の格差について考えてみたい.昨日扱ったジニ係数よりも直感的に格差を認識できる指標として,格差上位1%のシェアというものがある.経済学でいえば,トマス・ピケティも愛用している「トップ富裕層の所得シェア」である.大金持ちがどのくらい金持ちか,という指標と理解すればよい.英語語彙について言えば,生起頻度でトップ1%に入るそれほど多くない語によって,全体のどのくらいのシェアが占められているかを示す指標となる.
昨日と同じように,総頻度数が81.5万ほどの比較的小規模な GSL の語彙頻度表と,1850万ほどの巨大コーパス「#1424. CELEX2」 ([2013-03-21-1]) に基づく語彙頻度表で計算してみた.トップ1%とトップ0.1%での値は,以下の通り.
| GSL | CELEX2 | |
|---|---|---|
| 1% | 47.05% | 69.36% |
| 0.1% | 14.60% | 43.57% |
実際,ここまで高い値になるとは予想していなかった.英語学習という観点からみると,極端な話し,高頻度語のトップ1%を暗記すれば,5?7割ほどの語が認識できることになる.それでテキストを理解できるかというと,それはまったく別問題ではあるが,語彙学習の効率について再考させられる.
参考までに,2000年の時点での日米の所得シェアを見てみると,アメリカではトップ0.1%の富裕層が所得全体の7%ほど,日本では2%ほどである(吉川,p. 226).近年,両国ともに格差は開いてきているようだが,さすがに語彙の世界ほどの格差に至ることはないだろう.語彙の社会は,あらためて不平等な社会である.
・ 吉川 洋 『人口と日本経済』 中央公論新社〈中公新書〉,2016年.
[ 固定リンク | 印刷用ページ ]
2017-03-11 Sat
■ #2875. 英語語彙の頻度分布の格差をジニ係数とローレンツ曲線でみる [lexicology][statistics][frequency][zipfs_law][corpus]
「#1103. GSL による Zipf's law の検証」 ([2012-05-04-1]) で,General Service List (GSL) の最頻2000語余りの語彙頻度表を用いて,zipfs_law が成立する様子を実演した.頻度順位の高い少数の語がただの高頻度語ではなく超高頻度語であること,一方でそれ以外の大多数の語がおしなべて低頻度語であるということが確認された.このことは,英語(そして,おそらくあらゆる言語)の語彙の頻度分布がきわめて不平等・不均衡であり,大きなばらつきと格差に特徴づけられていることを示すものである.
このような分布の格差を示す代表的な指標に,イタリアの経済学者ジニが所得や資産の分布の不平等を計測する指標として1936年に考案したジニ係数 (Gini's coefficient) がある.考え方は次の通りだ.X軸に沿って左から右へ最も頻度の低い語から高い語へと順に並べ,その累積頻度のシェアをY軸方向に取っていく.この点をつなげると,何らかの形の右肩上がりの曲線となる.これをローレンツ曲線 (Lorenz curve) という.すべての語が同頻度で現われるときにはローレンツ曲線は45度の右肩上がりの直線となり「完全平等」を示す.逆に,極端な例として,1つの語のみが生起頻度のすべてを占有し,他のすべての語が頻度ゼロの場合に「完全不平等」となり,ローレンツ曲線は左右逆L字型となる.普通は,ローレンツ曲線は,45度の右肩上がりの線の下部に,三日月形の弧として描かれる.ジニ係数は,三日月の面積と,45度の右肩上がりの線を直角の対辺とする直角二等辺三角形の比率として表現される.したがって,値0が完全平等,値1が完全不平等ということになる.
さて,GSL のデータファイルで計算した結果,ジニ係数は0.812と出た.ローレンツ曲線を描くと,以下のようになる.
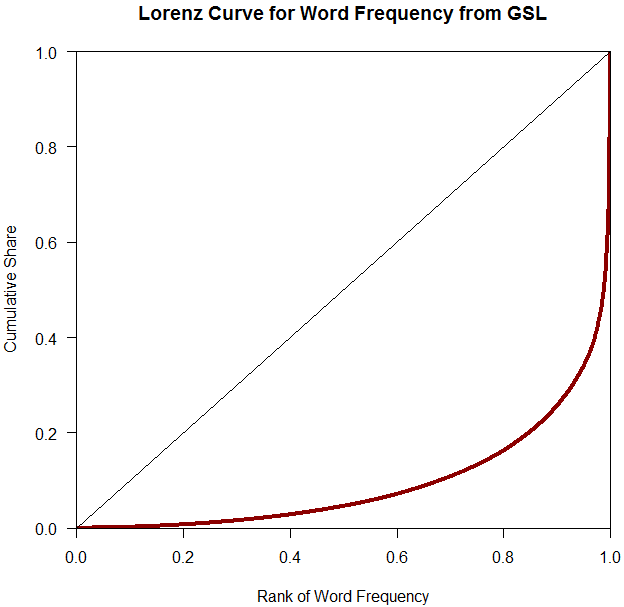
明らかに不平等な分布といえる.ちなみに,GSL よりも巨大なコーパスの語彙頻度表を使うと,さらにジニ係数は上がる(例えば,1790万語からなるコーパス「#1424. CELEX2」 ([2013-03-21-1]) に基づいた計算では,0.950 というすさまじい値が出た!).
参考までに,吉川 (122) に拠って2010年の諸国の所得格差を示すジニ係数をいくつか挙げると,日本が 0.336,アメリカが 0.380,チリが 0.510,アイスランドが 0.246 である.語彙の社会が極めて不平等な社会であることが分かるだろう.
・ 吉川 洋 『人口と日本経済』 中央公論新社〈中公新書〉,2016年.
2016-12-09 Fri
■ #2783. 世界で最も "popular" な言語は? [world_languages][demography][statistics]
現在,世界には7千ほどの言語が行なわれているとされるが,そのうち最も "popular" な言語は何だろうか.ほとんどの人々は「英語」と答えるかもしれない.しかし,実際には "popular" の定義を明確にしておかない限り,この質問に正確に答えるのは難しい.おそらく大多数の日本人にとって,"popular" な言語とは「世界中で広く話されている言語」のことと想定されるが,では「広く」とは何のことだろうか.それを常用している国の数か.あるいは,そのような国の面積か.それで用を足している人々の数か.それを共通語として採用している国際機関の数か.それを第2言語として教育している国の数か.いずれの観点かを定めさえすれば,"popular" の定義も定まり,最も "popular" な言語が何かという問いに答えを出すことができるだろう.しかし,どの観点が "popular" の定義として妥当なのかについて,満場一致はないように思われる."popular" を "top" や "significant" に置き換えたところで,問題は解決しない.
例えば,母語話者の数ということでいえば,英語は中国語,スペイン語についで第3位となる.しかし,第2言語として話す人口を加えれば,英語は第1位に躍り出る.しかし,ここでは「英語」の範囲が問題になり,例えば,英語を基盤としたピジン語やクレオール語の母語話者は英語話者に含めるのか,といった疑問が生じる.あるいは,どのピジン語やクレオール語を含め,どれを含めないのか.
また,その言語を主要言語とする国の経済力や技術力なども,考慮に入れる必要があるのではないか.その国が国際的に活躍していればいるほど,その言語も国際的に用いられやすいだろうし,世界的に "popular" ともなりうるからだ.しかし,そのような「国際性」は何によって計ればよいのか.経済活動か,軍事力か,文化力か,移民の割合か.何らかの重みづけをするにしても,その観点は無限である.
考えられる "popular" の指標をすべて計算に含めて総合点を出すという方法はあるだろうが,元となる統計値が現実的に得られないような指標も多いだろう.結局のところ,母語話者や第2言語話者の人口など,ある程度入手可能な既存のデータを中心にながら,主観的な「印象点」も加味して,最も "popular" な言語を割り出すということになならざるを得ない.「印象点」には,採点者次第で,個人的な好き嫌いが含まれるかもしれないし,政治的・イデオロギー的な好悪も埋め込まれるかもしれない.
言語ランキングを作るという作業は,一見簡単そうで実は難しい課題である.この問題については,Gooden (8--9) を参照されたい.本ブログ内では,「#397. 母語話者数による世界トップ25言語」 ([2010-05-29-1]),「#2263. 世界の主要言語の母語話者数の比較」 ([2015-07-08-1]),「#1591. Crystal による英語話者の人口」 ([2013-09-04-1]),「#1592. 英語話者の人口を推計することが難しい理由」 ([2013-09-05-1]) なども関連する.
・ Gooden, Philip. The Story of English: How the English Language Conquered the World. London: Quercus, 2009.
2016-09-22 Thu
■ #2705. カエサル暗号機(hellog 版) [cryptology][grammatology][cgi][web_service][statistics]
「#2704. カエサル暗号」 ([2016-09-21-1]) と関連して,文字遊びのために「カエサル暗号機」を作ってみた.まずは,最も単純な n 文字シフトの方針により,入力文字列を符号化 (encipher) あるいは復号化 (decipher) するだけの機能.バックエンドに Perl の Text::Cipher::KeywordAlphabet モジュールを利用している.
次に,下の暗号機は復号機能のみを実装しているが,英語の各文字の出現頻度に基づいた統計を利用して,n の値が不明でもカエサル暗号を解読してしまうことができる.
このカエサル暗号とその発展形は,西洋の古代・中世を通じて1500年以上ものあいだ最も普通に用いられたが,原理は驚くほど単純である.現在では暗号学者ならずとも普通の人にもコンピュータを使って簡単に解読できてしまい,暗号とは呼べないほどに安全性は低いが,メッセージを隠したいという人間の欲求の生み出した,本格的な暗号文化の幕開きを代表する手法だった.歴史的意義は大きい.
[ 固定リンク | 印刷用ページ ]
2016-09-16 Fri
■ #2699. 暗号学と言語学 [cryptology][linguistics][statistics][grammatology]
サイモン・シンの『暗号解読』を読んだ.暗号学 (cryptology) は言語学の1分野として言及されることもあるが,最も原始的な転置式暗号や,語や文字を置き換える換字式暗号を除けば,それ以降の暗号作成と解読は数学,統計学,物理学の応用そのものであり,言語学の扱う範囲から大きく逸脱しているように思われる.近代以降に開発されたヴィジュネル暗号,エニグマの暗号,公開鍵方式,量子暗号などは,高度な数学・物理学を利用した暗号であり,もはや言語学の出る幕ではないかのようだ.
しかし,いくつかの点で暗号学は言語学と密接な連係を保っているのは事実である.『暗号解読』により暗号の歴史を概観したところで,両分野の顕著な接点について考えてみた.1つ目は,当然といえば当然だが,暗号化して秘匿したいもとの材料はほぼ常に言語であるということだ.数字やその他の記号を秘匿したいという機会もあるだろうが,基本的には何らかの言語で書かれた文章が暗号化の対象であり,それゆえに「平文」と呼ばれる.暗号作成者は,この平文に何らかのスクランブル(暗号化するための演算)を施して無意味な文字列を得るわけだが,ここで行なっていることは,有意味で言語らしいテキストを無意味で言語らしからぬ文字列へ変換するという作業である.つまり,暗号作成者はなるべく平文のもつ言語らしさを取り除こうと努力する人にほかならず,暗号の成否は,その人が言語らしいとは何を指し,言語らしからぬとは何を指すのかについて,いかに深く理解しているかにかかっている.言語(とりわけ書き言葉)における文字の出現率などの統計的な事情に精通していればいるほど,暗号作成者は言語らしからぬ出力を得られるし,逆に暗号解読者はもとの平文を取り戻すことができる.隠したい元のものが言語テキストである以上,その後,いかに複雑な演算を加えようとも,何らかの言語的性質は着いて回らざるをえない.
2つ目に,暗号化や復号化に用いられる鍵もまた,暗号の歴史の大部分において,単語やその他の表現など言語的な単位だったという事実がある.現代の最も進んだ暗号においては鍵が数字であることが多いが,少なくとも鍵交換の問題が解決される以前の暗号においては,鍵は意味をなすキーワードやキーフレーズであり,ある言語の語彙に登録された単語やその他の表現であることが普通だった.それは,鍵が暗号者と復号者に共有されていなければならず,互いにとって既知である単語を鍵とし,それを暗記しておくのが,管理上もっとも便利だったからだ.数字や記号の羅列は暗記しにくいし,メモに書き留めておくという手はセキュリティ上問題がある.したがって,2人が最初から知っているもの,すなわち共通言語の何らかの単位を鍵とするのが自然である.逆にいえば,暗号解読者にとっては,鍵を突き止めるために,言語の語彙や表現のリストのなかから候補を絞り込むという戦略が妥当となる.このように,平文のみならず,暗号の鍵そのものも多くの場合,言語である.
3つ目に,諸言語は言語としての特性を共有しつつも互いに異なる恣意的な記号体系であるから,自言語と他言語の間の翻訳の作業は,暗号・復号の作業に近い.実際,第2次世界大戦では,アメリカは先住民ナヴァホ族の言語を用いたナヴァホ暗号なるものを生み出した.英語も話せるナヴァホ族が媒介となって,暗号化したい英語の平文をナヴァホ語へ変換し,そのナヴァホ語テキストを伝達したい相手に届ける.その相手は,お付きのナヴァホ族の人に頼んでそのテキストを英語へなおしてもらう.当時,敵国ドイツには,ナヴァホ語に関する研究は一切なく,ドイツ人の解読者がナヴァホ語から翻訳する術はなかった.既存のあまり知られていない自然言語は,それ自体が暗号のアルゴリズムになりうるという例だ.
最後に,未解読文字との関連もある.「#2427. 未解読文字」 ([2015-12-19-1]) で述べたように,いまだ解読されていない文字体系は少なくない.「#2486. 文字解読の歴史」 ([2016-02-16-1]) で触れたが,文字解読の歴史をひもとくと,そこで使われてきた手法は,現代に近づくほど,主として文字論を基礎とする統計学や数学を駆使する科学的な手法へと進化してきており,一般の暗号解読の手法ときわめてよく似ている.このことは,いずれも「平文」が何らかの言語で書かれたテキストであるということを前提としているのだから,不思議ではないだろう.暗号学の成果は,文字の解読におおいに貢献することができる.
さらに本質的で興味深い問いとして,人間はいつ,どこで,なぜ言語を暗号化する必要があるのだろうか.言語がコミュニケーションのために発達してきたことを前提とすると,メッセージを秘匿したいという行動や欲求は一種の矛盾ともいえる.言語と秘匿というテーマは,暗号学の哲学ともいうべきものになるだろう.
・ サイモン・シン(著),青木 薫(訳) 『暗号解読 上下巻』 新潮社,2017年.
2016-09-10 Sat
■ #2693. 古ノルド語借用語の統計 [lexicology][statistics][old_norse][french][loan_word][contact]
昨日の記事「#2692. 古ノルド語借用語に関する Gersum Project」 ([2016-09-09-1]) 紹介した Gersum Project の Norse Terms in English: A (basic!) Introduction に,フランス語からの借用語と対比しながら古ノルド語からの借用語に関する数値などが言及されていた.
When it comes to numbers, French influence, mainly as a result of the Norman Conquest, is much more significant: approximately 10,000 words were borrowed from French during the Middle English period (of which around 7,000 are still used), whereas there are about 2,000 Norse-derived terms recorded in medieval English texts. Of them, about 700 are still in use in Standard English, although many more can be found in dialects from areas such as the East Midlands, Yorkshire, Lancashire, and Cheshire. The significance of the Norse impact on (Standard) English lies instead in the fact that most of the Norse-derived terms do not have a technical character (consider, for instance, skirt, leg, window, ugly, ill, happy, scare, bask, die) and even include a number of grammatical terms, the most notable being the third person plural pronouns they, them and their (because personal pronouns are not easily borrowed between languages). The presence of these terms was probably facilitated by the similarity between Old English and Old Norse, both of which were Germanic languages. In fact, it seems very likely that the speakers of the two languages were able to understand each other by speaking their own language, of course with some careful lexical choices and a good deal of pointing and, when appropriate, smiling.
借用語彙の統計は,語源の不確かさの問題などが絡み,いきおい概数にならざるを得ないが,与えられていれば参考になる.ここに挙げられている数値も,他書のものと大きく異なっていない.中英語期の借用語に限定して数えると,フランス語からはおよそ1万語(うち約7千語が現在まで残る)が入り,古ノルド語からはおよそ2千語(うち約700語が現代標準英語に残る)が入ったとしている.古ノルド語からの借用語は絶対数も現在までの残存率も相対的に低いといえるが,英語語彙のコアにまで浸透しているという意味で,質的な深さはある.また,イングランド北部・東部の諸方言を考慮に入れれば,現在使われている古ノルド語借用語の数は著しく増えるということも銘記しておきたい.古英語話者と古ノルド語話者がある程度通じ合えたとの積極的な指摘も注目に値する.
その他,借用語に関する統計は cat:loan_word statistics の各記事を参照.
2016-09-07 Wed
■ #2690. N-gram Tool [cgi][n-gram][statistics][corpus][web_service][frequency][cgi]
n-gram は,言語統計やコーパス言語学の世界における基本的な概念・手段である(「#2324. n-gram」 ([2015-09-07-1]), 「#956. COCA N-Gram Search」 ([2011-12-09-1]) を参照).テキストを指定してその n-gram を得るツールはネットその他にも遍在しているが,あえて簡易ツールをCGIで実装してみた.バックエンドに Perl モジュールの Text::Ngrams を用いている.
使い方はおよそ自明だろう.適当な長さの英文テキストを投げ込めば,デフォルトでは単語ベースの 3-gram (およびそれ以下の 2-gram と 1-gram も含む)の一覧が絶対頻度の高い順に返される(出力行の制限はなし).オプションにより単語ベースではなく文字ベースにも変更でき,n-gram のサイズも変えられる.出力については,頻度順ではなくアルファベット順にすること,出力行に制限を設けること,絶対頻度ではなく相対頻度(各 n-gram 内で合計すると1.0となる)で返すことも可能.
なお,1-gram は入力テキストを構成する単語の頻度表となるので,その用途にも利用できる.簡易的な n-gram ツールとしてどうぞ.
[ 固定リンク | 印刷用ページ ]
2016-08-15 Mon
■ #2667. Chaucer の用いた語彙の10--15%がフランス借用語 [chaucer][french][loan_word][statistics][popular_passage][me_text]
Algeo and Pyles (280--81) に,Chaucer の The Canterbury Tales (Ellesmere 写本)から General Prologue の冒頭の27行について,フランス借用語にイタリック体を施して提示したものがある.以下に再現しよう,
Whan that Aprille with hise shoures soote
The droghte of March hath perced to the roote
And bathed every veyne in swich licour
Of which vertu engendred is the flour;
Whan Zephirus eek with his sweete breeth
Inspired hath in every hold and heeth
The tendre croppes, and the yonge sonne
Hath in the Ram his half[e] cours yronne,
And smale foweles maken melodye,
That slepen al the nyght with open eye---
So priketh hem nature in hir corages---
Thanne longen folk to goon on pilgrimages,
And Palmeres for to seken straunge strondes,
To ferne halwes kowthe in sondry londes
And specially fram every shires ende
Of Engelond to Caunterbury they wende
The hooly blisful martir for to seke
That hem hath holpen when þt they were seeke.
Bifil that in that seson on a day,
In southwerk at the Tabard as I lay
Redy to wenden on my pilgrymage
To Caunterbury with ful devout corage,
At nyght were come in to that hostelrye
Wel nyne and twenty in a compaignye
Of soundry folk by aventure yfalle
In felaweshipe, and pilgrimes were they alle
That toward Caunterbury wolden ryde.
27行で合計189語が用いられているが,2度現われる pilgrimage と corage を各1語と数え,異なり語数で計算すると,24語 (12.70%) までがフランス借用語である.この数字は,フランス語に堪能だった Chaucer ならではというわけではなく,おそらく14世紀後半の教養あるロンドンの英語に典型的な値といってよいだろう.Serjeantson (151) によれば,Chaucer の用いた語の10--15%はフランス借用語だったということだが,General Prologue の冒頭27行は Chaucer としても典型的,平均的な値を示しているといえる.
現代英語ではフランス借用語比率はどれくらいなのだろうか.当然ながら使用域によって異なるだろうが,標準的な文章語を対象に調査し,後期中英語の状況と比べるとおもしろそうだ.
General Prologue の冒頭については,「#534. The General Prologue の冒頭の現在形と完了形」 ([2010-10-13-1]),「#2275. 後期中英語の音素体系と The General Prologue」 ([2015-07-20-1]) を参照.
・ Algeo, John, and Thomas Pyles. The Origins and Development of the English Language. 5th ed. Thomson Wadsworth, 2005.
・ Serjeantson, Mary S. A History of Foreign Words in English. London: Routledge and Kegan Paul, 1935.
2016-08-09 Tue
■ #2661. Swadesh (1952) の選んだ言語年代学用の200語 [glottochronology][lexicology][frequency][statistics]
「基本語彙」 (basic vocabulary) という用語は,言語の調査や議論において様々な機会に出くわす.しかし,昨日の記事「#2660. glottochronology と基本語彙」 ([2016-08-08-1]) でも触れたように,個別言語においても,言語一般においても,基本語彙とは何なのか,どこまでの範囲を含むのかを客観的に定めることは難しい.
glottochronology に携わる人類言語学者は,独自の通言語的,通時的な観点から,基本語彙リストに相当するものを編集し,改訂してきた.例えば,この分野の草分けである Swadesh (456--57) は,完璧なリストは作り得ないということを認めつつ,次の200語からなる一覧を挙げている.その一覧を,Hymes ("Lexicostatistics" 6) 経由で掲げよう.
all, and, animal, ashes, at, back, bad, bark, because, belly, big, bird, bite, black, blood, blow, bone, breathe, burn, child, cloud, cold, come take, count, cut, day, die, dig, dirty, dog, drink, dry, dull, dust, ear, earth, eat, egg, eye, fall, far, fat-grease, father, fear, feather, few, fight, fire, fish, five, float, flow, flower, fly, fog, foot, four, freeze, fruit, give, good, grass, green, guts, hair, hand, he, head, hear, heart, heavy, here, hit, hold-take, how, hunt, husband, I, ice, if, in, kill, know, lake, laugh, leaf, leftside, leg, lie, live, liver, long, louse, man-male, many, meat-flesh, mother, mountain, mouth, name, narrow, near, neck, new, night, nose, not, old, one, other, person, play, pull, push, rain, red, right-correct, rightside, river, road, root, rope, rotten, rub, salt, sand, say, scratch, sea, see, seed, sew, sharp, short, sing, sit, skin, sky, sleep, small, smell, smoke, smooth, snake, snow, some, spit, split, squeeze, stab-pierce, stand, star, stick, stone, straight, suck, sun, swell, swim, tail, that, there, they, thick, thin, think, this, thou, three, throw, tie, tongue, tooth, tree, turn, two, vomit, walk, warm, wash, water, we, wet, what, when, where, white, who, wide, wife, wind, wing, wipe, with, woman, woods, worm, ye, year, yellow
この一覧は理論と実践を組み合わせたものであり,その後も数々の改訂を経ることになった.だが,もとより完璧な基本語彙リストは作り得ないのだから,何らかの言語調査を行なう場合に,この一覧を拠り所にするというのは,1つの便法ではある.なお,Swadesh が言語年代測定の診断のために用いたのは,別途厳選された100語のリストであり,それは「#1128. glottochronology」 ([2012-05-29-1]) で掲載した通りである(100語リストのほうが言語年代学的に有用性が高いという意見もある (Hymes, "More" 341)).
基本語彙の問題については,「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1]),「#1101. Zipf's law」 ([2012-05-02-1]),「#1961. 基本レベル範疇」 ([2014-09-09-1]),「#1965. 普遍的な語彙素」 ([2014-09-13-1]),「#2625. 古ノルド語からの借用語の日常性」 ([2016-07-04-1]) などの記事も要参照.
・ Swadesh, Morris. "Lexico-Statistic Dating of Prehistoric Ethnic Contacts: With Special Reference to North American Indians and Eskimos." Proceedings of the American Philosophical Society 96 (1952): 452--63.
・ Hymes, D. H. "Lexicostatistics So Far." Current Anthropology 1 (1960): 3--44.
・ Hymes, D. H. "More on Lexicostatistics." Current Anthropology 1 (1960): 338--45.
2016-08-08 Mon
■ #2660. glottochronology と基本語彙 [glottochronology][lexicology][statistics][history_of_linguistics][frequency][anthropology]
glottochronology の方法論を批評した Hymes (11) は,もう1人の人類言語学者 Gleason による1950年代の論著を参照しながら,語彙変化確率に関する3つの前提について解説している.
(1) Every lexical item at every given time has a certain probability of change.
(2) This probability of change is variable, and is influenced by both linguistic and non-linguistic factors.
(3) There exist certain sets of largely independent vocabulary items in which the probability of change within the group is large relative to the variability of that probability of change.
glottochronology では,(1) と (2) は当初から前提とされてきた.Hymes が特に重要だと指摘するのは (3) の仮定である.これによれば,語彙にはある種の閉じた語群がいくつかあり,ある語群は比較的安定し,その安定の度合いの揺れも比較的小さいが,別の語群は比較的不安定であり,その不安定の度合いの揺れも比較的大きいという.具体的にはいわゆる "basic vocabulary" と "non-basic vocabulary" などの区別を念頭においていることは間違いないが,必ずしも定義の明らかでない "(non-)basic" という用語を使わずに,集合論的,統計学的な手法で,それらに相当する語彙の部分集合を取り出せる可能性を示している.実際の検証には,多くの言語の語彙について調査し,それぞれについて長期間にわたる通時的な語彙変化確率を求め,それらを比較するという地道な作業が必要であり,すぐに結論が出るというものではないだろう.しかし,検証可能性は確保されているという点が重要である.
言語一般,あるいは個別言語において,基本語彙 (basic vocabulary) とは何かという問題は,客観的に答えるのが案外難しい.母語話者にとっては直感的に分かるものではあるが,その範囲を客観的に定めるのは難しい.昨日の記事「#2659. glottochronology と lexicostatistics」 ([2016-08-07-1]) でも触れたように,基本語彙の同定に関与する属性として (1) 共時的な commonness (or frequency), (2) 通言語的な universality (of semantic reference), (3) 通時的な (historical) persistence の3種が提案されており,これらが互いにおよその相関関係にあることも知られている.しかし,この3つの属性の各々にどの程度の重みをつけ最終的に基本語彙を決定すべきかについて,特に合意はない.
glottochronology にとっては,基本語彙とはあくまで言語の年代を測定するための材料ではあるが,むしろその材料探しの過程で,基本語彙とは何かという肝心な問題に,実践と理論の両側面から迫ることになったのではないかとも思われる.glottochronology という分野の前提と成果については多くの批判がなされてきたが,その過程で繰り広げられてきた議論はしばしば本質的であり,(人類)言語学史的な貢献は大きいといえるだろう.
glottochronology と基本語彙を巡る問題については,Hymes (32--33) が詳しく議論しているので,そちらを参照.
・ Hymes, D. H. "Lexicostatistics So Far." Current Anthropology 1 (1960): 3--44.
2016-08-07 Sun
■ #2659. glottochronology と lexicostatistics [glottochronology][lexicology][statistics][terminology][speed_of_change][frequency]
言語学の分野としての言語年代学 (glottochronology) と語彙統計学 (lexicostatistics) は,しばしば同義に用いられてきた.だが,glottochronology の創始者である Swadesh は,両用語を使い分けている.私自身も「#1128. glottochronology」 ([2012-05-29-1]) の記事で,両者は異なるとの前提に立ち,「glottochronology (言語年代学)は,アメリカの言語学者 Morris Swadesh (1909--67) および Robert Lees (1922--65) によって1940年代に開かれた通時言語学の1分野である.その手法は lexicostatistics (語彙統計学)と呼ばれる.」と述べた.今回は,この用語の問題について考えてみたい.
人類言語学者・社会言語学者の Hymes (4) は Swadesh に依拠しながら,両用語の区別を次のように理解している.
The terms "glottochronology" and "lexicostatistics" have often been used interchangeably. Recently several writers have proposed some sort of distinction between them . . . . I shall now distinguish them according to a suggestion by Swadesh.
Glottochronology is the study of rate of change in language, and the use of the rate for historical inference, especially for the estimation of time depths and the use of such time depths to provide a pattern of internal relationships within a language family. Lexicostatistics is the study of vocabulary statistically for historical inference. The contribution that has given rise to both terms is a glottochronologic method which is also lexicostatistic. Glottochronology based on rate of change in sectors of language other than vocabulary is conceivable, and lexicostatistic methods that do not involve rates of change or time exist . . . .
Lexicostatistics and glottochronology are thus best conceived as intersecting fields.
つまり,glottochronology と lexicostatistics は本来別物だが,両者の重なる部分,すなわち語彙統計により言語の年代を測定する部門が,いずれの分野にとっても最もよく知られた部分であるから,両者が事実上同義となっているということだ.ただし,Swadesh から80年近く経った現在では,lexicostatistics は,電子コーパスの発展により言語の年代測定とは無関係の諸問題をも扱う分野となっており,その守備範囲は広がっているといえるだろう.
上で引用した Hymes の論文は,言語における "basic vocabulary" とは何か,という根源的かつ物議を醸す問題について深く検討を加えており,一読の価値がある."basic vocabulary" は,commonness (or frequency), universality (of semantic reference), (historical) persistence のいずれかの属性,あるいはその組み合わせに基づくものと概ね受け取られているが,同論文はこの辺りの議論についても詳しい.基本語彙の問題については,「#1128. glottochronology」 ([2012-05-29-1]) や「#1965. 普遍的な語彙素」 ([2014-09-13-1]) の記事で直接に扱ったほか,「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1]),「#1089. 情報理論と言語の余剰性」 ([2012-04-20-1]),「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]),「#1101. Zipf's law」 ([2012-05-02-1]),「#1497. taboo が言語学的な話題となる理由 (2)」 ([2013-06-02-1]),「#1874. 高頻度語の語義の保守性」 ([2014-06-14-1]),「#1961. 基本レベル範疇」 ([2014-09-09-1]),「#1970. 多義性と頻度の相関関係」 ([2014-09-18-1]) なの記事で関与する問題に触れてきたので,そちらも参照されたい.
・ Hymes, D. H. "Lexicostatistics So Far." Current Anthropology 1 (1960): 3--44.
2016-07-25 Mon
■ #2646. オランダ借用語に関する統計 [loan_word][borrowing][dutch][flemish][afrikaans][statistics]
昨日の記事「#2645. オランダ語から借用された馴染みのある英単語」 ([2016-07-24-1]) 及び「#148. フラマン語とオランダ語」 ([2009-09-22-1]),「#149. フラマン語と英語史」 ([2009-09-23-1]) で取り上げてきたように,オランダ語と関連変種(フラマン語,低地ドイツ語,アフリカーンス語などを含み,オランダ語とともにすべて合わせて "Low Dutch" と呼ばれる)から英語に入った借用語は案外と多い.Durkin による OED3 による部分的な調査によれば,これらの言語からの借用語にまつわる数字を半世紀ごとにまとめると,以下のようになる (Durkin, p. 355 の "Loanwords from Dutch, Low German, and Afrikaans, as reflected by OED3 (A--ALZ and M-RZZ)" と題する表を再現した).
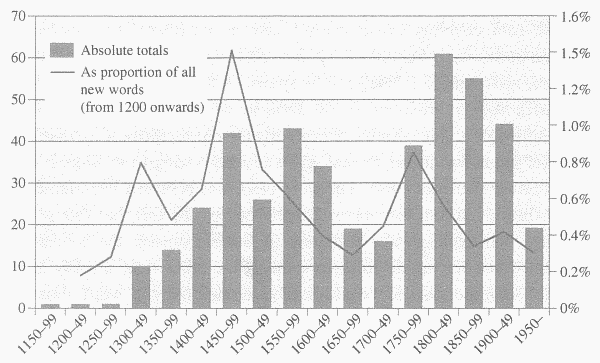
英語史を通じての全体的な数だけでいえば,Low Dutch からの借用語は,実に古ノルド語からの借用語よりも数が多いというのは意外かもしれない.「#126. 7言語による英語への影響の比較」 ([2009-08-31-1]) の表では,Dutch/Flemish からの語彙的影響は "minimal" と表現されているが,実際にはもう少し高めに評価する表現であってもよさそうだ.ただし,古ノルド語ほど英語の基本語彙に衝撃を与えたわけではなく,数だけで両ケースを比較することには注意しなければならない.ただし,Low Dutch からの語彙借用に関して顕著な特徴として,中世から現代まで途切れることなく語彙を供給している点は指摘しておきたい.
時代別にみると,借用語の絶対数では中世の合計は近現代の合計を下回るが,割合としては特に後期中英語に借用が盛んだったことがよくわかる.英語本来語と Low Dutch からの借用語とは語源的,形態的に区別のつかないことも多く,実際には古英語でも少なからぬ借用があった可能性があると想像すると,Low Dutch 借用語のもつ英語史上の潜在的な意義は小さくないように思われる.
Low Dutch 借用語の統計の問題について,Durkin (356--57) は次のように議論している.
The fullest study of words of Dutch or Low German origin in English remains that of Bense (1939), who drew his data chiefly from the first edition of the the (sic) OED. Bense's study groups loanwords from Dutch and Low German together under the collective heading 'Low Dutch', although at the level of individual word histories he frequently distinguishes between input from each language. His companion work, Bense (1925), provides a summary of the main historical contexts of contact. Bense discusses over 5,000 words, for most of which he considers Low Dutch origin at least plausible; this is thus much higher than the OED's etymologies suggest. His total includes some words ultimately of Dutch origin that have definitely entered English via other languages, e.g. plaque (from a French word that ultimately has a Dutch origin), and also many semantic loans; OED3 has over 150 of these in parts so far revised, e.g. household (a. 1399) or field-cornet (1800, after South African Dutch veldkornet). Nonetheless, Bense does make a case for direct borrowing from Dutch for many words for which the OED does not posit a Dutch etymon; even if one agrees with the OED's (generally more conservative) approach in all cases, Bense's suggestions are by no means absurd, and his work highlights very well the difficulty of being certain about the extent of the Dutch contribution to the lexis of English.
5000語を超えるという Bense の試算はやや大袈裟であっても,概数としては馬鹿げていないのではないかという Durkin の評価も,なかなか印象的である.
・ Durkin, Philip. Borrowed Words: A History of Loanwords in English. Oxford: OUP, 2014.
・ Bense, J. F. Anglo-Dutch Relations from the Earliest Times to the Death of William the Third. Den Haag: Martinus Nijhoff, 1925.
2016-06-30 Thu
■ #2621. ドイツ語の英語への本格的貢献は19世紀から [loan_word][borrowing][statistics][german]
「#2164. 英語史であまり目立たないドイツ語からの借用」 ([2015-03-31-1]) で触れたように,ドイツ語の英語への語彙的影響は案外少ない.安井・久保田 (20) は次のように述べている.
ドイツ語が1824年に至るまで,英国人に,ほとんどまったくといってよいくらい,顧みられなかったのも,驚くべきことである.ドイツ語からの借用語は16世紀からあるにはあるが,フランス語,オランダ語,スカンジナヴィア語などよりの借用語に比べると,じつに少ないのである.20世紀に入ってからでも,英国人のドイツ語に関する知識は満足すべき段階に達していない.
なお,引用中の1824年とは,Thomas Carlyle (1795--1881) が Göthe の Wilhelm Meister's Apprenticeship を翻訳出版した年である.
OED3 により借用語を研究した Durkin (362) によると,19世紀より前にはドイツ借用語は目立っていなかったが,19世紀前半に一気に伸張したという.19世紀後半にはその勢いがピークに達し,20世紀前半に半減した後,20世紀後半にかけて下火となるに至る. *
ドイツ借用語は全体として専門用語が多く,それが一般に目立たない理由だろう.Durkin (361) は Pfeffer and Cannon の先行研究を参照しながら,ドイツ語借用の性質と時期について次のように要約している.
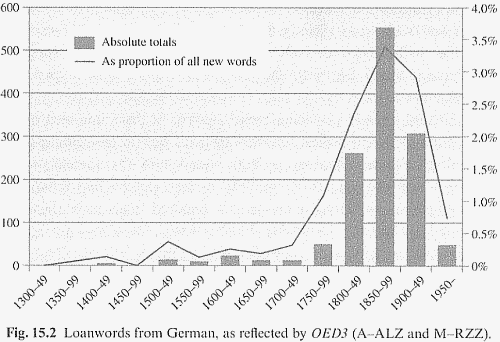{kind=link}
Pfeffer and Cannon provide a broad analysis of their data into subject areas; those with the highest numbers of items are (in descending order) mineralogy, chemistry, biology, geology, botany; only after these do we find two areas not belonging to the natural sciences: politics and music. The remaining areas that have more than a hundred items each (including semantic borrowings) are medicine, biochemistry, philosophy, psychology, the military, zoology, food, physics, and linguistics. Nearly all of these semantic areas reflect the importance of German as a language of culture and knowledge, especially in the latter part of the nineteenth century and early twentieth century.
英語はゲルマン系 (Germanic) の言語であり,ドイツ語 (German) と「系統」関係にあるとは言えるが,上に見たように両言語は歴史的に(近現代に至ってすら)接触の機会が意外と乏しかったために,「影響」関係は僅少である.たまに「英語はドイツ語の影響を受けている」と言う人がいるが,これは系統関係と影響関係を取り違えているか,あるいは Germanic と German を同一視しているか,いずれにせよ誤解に基づいている.この誤解については「#369. 言語における系統と影響」 ([2010-05-01-1]),「#1136. 異なる言語の間で類似した語がある場合」 ([2012-06-06-1]),「#1930. 系統と影響を考慮に入れた西インドヨーロッパ語族の関係図」 ([2014-08-09-1]) を参照.
・ 安井 稔・久保田 正人 『知っておきたい英語の歴史』 開拓社,2014年.
・ Durkin, Philip. Borrowed Words: A History of Loanwords in English. Oxford: OUP, 2014.
2016-06-27 Mon
■ #2618. 文字をもたない言語の数は? (2) [world_languages][writing][statistics][language_planning][language_myth][medium]
「#1277. 文字をもたない言語の数は?」 ([2012-10-25-1]) で,この種の統計を得ることの難しさに触れた.今回は『世界民族百科事典』に「無文字言語」という項を見つけたので,その内容を要約したい.
無文字言語 (unwritten language) とは,「たんに文字に書かれることがないということではなく,研究者などによって書かれることがあるとしても社会に定着しておらず,それが通信や記録の媒体として機能していない言語」である.無文字言語の数については,本項を書いている梶 (186) も確かなことは言えないようで,Ethnologue による世界の言語の推計を参照しながら,漠然と「文字化された言語は,世界におそらく数%しかないのではないか.実際的に世界のほとんどの文字が無文字言語なのである」と述べている.
先の記事でも触れたが,無文字言語の母語話者が文字を知らないとは必ずしもいえないことに注意したい.非母語で教育を受け,その非母語の文字を習得している可能性はあるからだ.実際に,世界の多くの人々がそのような状況におかれている.逆に言えば,母語で(あるいは母国語で)教育を受けられる国というのは,少ないのである.
オーストラリアで無文字言語を話す少数民族の文化を無形文化財として保護しようとする運動が見られるなど,世界のいくつかの地域で少数言語の保持の試みがなされてはいる.しかし,このような言語政策 (language_planning) はいまだ一般的とはいえず,多くの言語が地域の強大な言語からの圧力や差別にさらされているのが実態だろう.
梶 (187) は,無文字言語に関する言語の神話 (language_myth) に言及しつつ,無文字社会にみられる口頭言語の役割の大きさを指摘している.
言語に文字がないと表現が散漫になるのではないかと考える向きもあるが,これはむしろ逆であることが多い.言語に文字がないからこそ,表現に一定の形式を与え,コミュニケーションを確かなものにしようという意識が働く.なぜアジアやアフリカの言語に民話が何千とあり,また諺も2,000も3,000もあるのか考えてみよう.例えば諺というのは,社会の英知をコンパクトに表現したものであるが,そこには韻を踏んだり対句を用いたりとさまざまな形式が導入されている.
〔中略〕文字言語は,さまざまなものを文字の代わりに用いることがある.例えば,人名や地名は出来事の記録媒体として機能することは世界の多くの地域でみられる.例えば,アフリカなどでは「葬式」という名前は,親族が死んで喪に服しているときに生まれた子供,「戦争」は戦いがあったときの子供,「道」は母親が産科に急いだのだが間に合わず道で産んだ子供といった具合である.これらの名前は個人を他の個人と区別するだけでなく同時に命名者(これは主として子供の親)にとって重要な出来事を,子供の名前の中に記録しているのである.また隣人に対して,あたかも手紙を書くようにメッセージを子供の名前に託したものも多い.
このように,無文字言語そして無文字社会においては,文字がないからこそ豊かな口承文芸が発達しているのである.そして文字の役割が大きくなればなるほど,口承文芸が衰退していくことは今,我々が目にしているとおりである.
関連して,「#1685. 口頭言語のもつ規範と威信」 ([2013-12-07-1]) を参照.
・ 梶 茂樹 「無文字言語」 『世界民族百科事典』 国立民族学博物館(編),丸善出版,2014年.186--87頁.
2016-06-24 Fri
■ #2615. 英語語彙の世界性 [lexicology][loan_word][borrowing][statistics][link]
英語語彙は世界的 (cosmopolitan) である.350以上の言語から語彙を借用してきた歴史をもち,現在もなお借用し続けている.英語語彙の世界性とその歴史について,以下に本ブログ (http://user.keio.ac.jp/~rhotta/hellog/) 上の関連する記事にリンクを張った.英語語彙史に関連するリンク集としてどうぞ.
1 数でみる英語語彙
1.1 語彙の規模の大きさ (#45)
1.2 語彙の種類の豊富さ (##756,309,202,429,845,1202,110,201,384)
2 語彙借用とは?
2.1 なぜ語彙を借用するのか? (##46,1794)
2.2 借用の5W1H:いつ,どこで,何を,誰から,どのように,なぜ借りたのか? (#37)
3 英語の語彙借用の歴史 (#1526)
3.1 大陸時代 (--449)
3.1.1 ラテン語 (#1437)
3.2 古英語期 (449--1100)
3.2.1 ケルト語 (##1216,2443)
3.2.2 ラテン語 (#32)
3.2.3 古ノルド語 (##340,818)
3.3 中英語期 (1100--1500)
3.3.1 フランス語 (##117,1210)
3.3.2 ラテン語 (#120)
3.4 初期近代英語期 (1500--1700)
3.4.1 ラテン語 (##114,478)
3.4.2 ギリシア語 (#516)
3.4.3 ロマンス諸語 (#2385)
3.5 後期近代英語期 (1700--1900) と現代英語期 (1900--)
3.5.1 世界の諸言語 (##874,2165)
4 現代の英語語彙にみられる歴史の遺産
4.1 フランス語とラテン語からの借用語 (#2162)
4.2 動物と肉を表わす単語 (##331,754)
4.3 語彙の3層構造 (##334,1296,335)
4.4 日英語の語彙の共通点 (##1526,296,1630,1067)
5 現在そして未来の英語語彙
5.1 借用以外の新語の源泉 (##873,875)
5.2 語彙は時代を映し出す (##625,631,876,889)
[ 参考文献 ]
・ Hughes, G. A History of English Words. Oxford: Blackwell, 2000.
・ Durkin, Philip. Borrowed Words: A History of Loanwords in English. Oxford: OUP, 2014.
Powered by WinChalow1.0rc4 based on chalow