2010-05-30 Sun
■ #398. 印欧語族は世界人口の半分近くを占める [indo-european][world_languages][statistics][demography]
印欧語族 ([2009-06-17-1]) は世界最大の語族であり,世界最大の母語話者人口を誇っている.他書(何だったか失念)では印欧語族は世界の 1/4 を占めると記されており,私もその概数をそのまま信じて本ブログでも [2009-08-05-1] で言及したことがあった.ところが Ethnologue の Table 4. Major language families of the world によると相当に異なる数値が提示されている.印欧語族に属する諸言語は,世界人口の 45.67% に相当する27億余りの人々によって話されているという.1/4 どころかほぼ半数であり,大きな違いだ.人口統計は様々な前提・仮定の上ではじき出されるものなのでなかなか評価が難しいが,Ethnologue に基づく限り,2位のシナ・チベット語族 ( Sino-Tibetan ) の人口 12.5 億人を大きく引き離してのトップである.昨日の記事[2010-05-29-1]でまとめた母語話者数による言語のランキング表でも,トップ10言語のなかで7言語までが印欧語族に属するので,世界における影響力が知れよう.
Ethnologue の Summary by language family によると,世界の言語は116の語族 ( language family ) に分かれ,そのなかの主要6語族のみで世界の言語の 2/3 を占め,世界の人口の 5/6 を占めるという.
また,Ethnologue の Indo-European の区分 では,印欧語族を Albanian, Armenian, Baltic, Celtic, Germanic, Greek, Indo-Iranian, Italic, Slavic の9語派に下位分類していることがわかる.
2010-05-29 Sat
■ #397. 母語話者数による世界トップ25言語 [statistics][world_languages][demography]
このブログでも何度も参照している Ethnologue の16版が2009年に出版された.オンライン版の Ethnologue で世界の言語にまつわる様々な数値を眺めていたら,英語の母語話者人口について新事実に出くわした.Table 3. Languages with at least 3 million first-language speakers によると,英語はスペイン語に僅差で追い越され,2位から3位に転落していたのである.すっかり見逃していた.
以下は上記のページから取った上位25位までの言語のデータを見やすくまとめたもの.右隅の列には,1996年出版の Ethnologue 13版に基づく数値を比較のために添えた( Graddol, p. 8 から埋められた部分のみ).Hindi については,Hindi と Urdu を一つとして扱った場合の数値をかっこ内に示した.
| Rank | Language | Primary Country | Countries | Speakers (16th ed, 2009) | (13th ed, 1996) |
|---|---|---|---|---|---|
| 1 | Chinese | China | 31 | 1,213 million | 1,123 |
| 2 | Spanish | Spain | 44 | 329 | 266 |
| 3 | English | United Kingdom | 112 | 328 | 322 |
| 4 | Arabic | Saudi Arabia | 57 | 221 | 202 |
| 5 | Hindi | India | 20 | 182 (242.6 with Urdu) | (236 with Urdu) |
| 6 | Bengali | Bangladesh | 10 | 181 | 189 |
| 7 | Portuguese | Portugal | 37 | 178 | 170 |
| 8 | Russian | Russian Federation | 33 | 144 | 288 |
| 9 | Japanese | Japan | 25 | 122 | 125 |
| 10 | German | Germany | 43 | 90.3 | 98 |
| 11 | Javanese | Indonesia | 5 | 84.6 | |
| 12 | Lahnda | Pakistan | 8 | 78.3 | |
| 13 | Telugu | India | 10 | 69.8 | |
| 14 | Vietnamese | Viet Nam | 23 | 68.6 | |
| 15 | Marathi | India | 5 | 68.1 | |
| 16 | French | France | 60 | 67.8 | 72 |
| 17 | Korean | South Korea | 33 | 66.3 | |
| 18 | Tamil | India | 17 | 65.7 | |
| 19 | Italian | Italy | 34 | 61.7 | 63 |
| 20 | Urdu | Pakistan | 23 | 60.6 | |
| 21 | Turkish | Turkey | 36 | 50.8 | |
| 22 | Gujarati | India | 20 | 46.5 | |
| 23 | Polish | Poland | 23 | 40.0 | |
| 24 | Malay | Malaysia | 14 | 39.1 | 47 |
| 25 | Bhojpuri | India | 3 | 38.5 |
この十数年の間で,トップを走っていた中国語と英語の母語話者数の伸び率は少ないが,4位につけていたスペイン語の伸び率は24%近くになる.一方,十数年前には3位につけていたロシア語が激減した.(ただし,これについては数え方の問題があるようで,別の独立した統計によれば当時のロシア語の母語話者数は 155 million ということだった.Ethnologue の 288 million とは著しい差である.)日本語はなんとかトップ10以内の座を守っているが,ヨーロッパの主要語とされるドイツ語やフランス語は低迷気味だ.
爆発的な影響力を誇るのはインドの言語である.Hindi を筆頭に,Telugu, Marathi, Tamil, Gujarati, Bhojpuri がトップ25位に入っている.トップ50位までに,主としてインドで行われている言語が14も入っているのだから驚きだ.Bengali や Lahnda などを合わせるとインド亜大陸の猛威を感じざるを得ない.
使用されている国の数でいうと,英語が群を抜いている.母語話者の数値だけでは表現されない実力があるということだろう.同様に,非母語話者の数を加えて評価すれば,相当に見栄えの異なるランキング表になるだろう.
英語使用国の人口増加率については[2010-05-07-1]を参照.
・ Graddol, David. The Future of English? The British Council, 1997. Digital version available at http://www.britishcouncil.org/learning-research-futureofenglish.htm.
2010-05-16 Sun
■ #384. 語彙数とゲルマン語彙比率で古英語と現代英語の語彙を比較する [oe][pde][loan_word][lexicology][statistics]
これまでも現代英語の語彙数と起源別割合については,グラフとともにいろいろなソースから具体的な数値を挙げてきた.
・ [2010-03-02-1]: 現代英語の基本語彙100語の起源と割合
・ [2009-11-15-1]: 現代英語の基本語彙600語の起源と割合
・ [2009-11-14-1]: 現代英語の借用語の起源と割合 (2)
それとは別に,語彙や起源別割合の通時的な増減やその他を扱った話題としては,以下のような記事を書いてきた.
・ [2009-08-22-1]: フランス借用語の年代別分布
・ [2009-08-19-1]: 初期近代英語の借用語の起源と割合
・ [2009-06-12-1]: 英語語彙にまつわる数値
語彙の数値というのは,参照する辞書などのソースを何にするのか,単語の頻度を考慮に入れるのか,などによって調査結果が大きく変わる可能性があり,なかなか難しい.起源言語別で数えるにしても,語源そのものが不詳だったり,フランス語なのかラテン語なのかなどで判断のつかないケースがあったりと,やはり難しい.ただ,予想される通り OED や SOED の情報に基づいた数値が多いようではある.
今回は,使用されている語彙リストのソース自体は不明なのだが,広く参照される可能性のある Encyclopedia of Linguistics に掲載されている数値を調べてみた.それぞれ "Old English" と "English" の項から関連箇所を引用する.
The recorded vocabulary of OE is estimated at approximately 30,000 words. Only about 3% of these were of non-Germanic origin. (779)
As a result of borrowing, the Gmc word stock is now a low 30% and the Romance one is 50%. (292)
後者では現代英語の総語彙を対象語彙としているようではあるが,その語数は記されていない.もし OED2 に準拠しているのであれば,定義・例説の与えられている語の数として 615,100 辺りを念頭においているのかもしれない ( see Dictionary facts ) .あるいは,定義されている語源の数である 219,800 辺りを念頭においているのだろうか.不明の点が多いが,現代英語の語彙数として仮に 615,100 という数を採用するとして,古英語と現代英語の語彙とそのなかのゲルマン語彙比率について比べる表を掲げよう.ゲルマン語彙とは,Anglo-Saxon 起源の本来語と(特に現代英語において)Old Norse 起源の借用語を合わせたものが中心になると考えてよいだろう.
| Old English | Present-Day English | |
|---|---|---|
| vocabulary | 30,000 | 615,100? |
| native words (%) | 97 | 30 |
語彙数がざっと20倍,ゲルマン語彙比率が1/3以下になったのだから,語彙体系の激変が起こったといってよい.大語彙推移 ( The Great Vocabulary Shift ) とでも呼びたくなる大変化だ.
・ Minkova, Donka. "Old English." Encyclopedia of Linguistics. Ed. Philip Strazny. New York: Fitzroy Dearborn, 2005. 777--80.
・ Leitner, Gerhard. "English." Encyclopedia of Linguistics. Ed. Philip Strazny. New York: Fitzroy Dearborn, 2005. 288--94.
2010-05-07 Fri
■ #375. 主要 ENL,ESL 国の人口増加率 [statistics][demography][elf][future_of_english]
ELF ( English as a Lingua Franca ) あるいは EIL ( English as an International Language ) としての英語の現状と未来を考えるうえで,人口統計は重要な示唆を与えてくれる.Crystal (71) では,2001年における人口統計により主要な ENL 国と ESL 国の人口および直近5年間の人口増加率が示され,前者が減少し後者が増加するという構図が鮮明に浮かび上がった.単純化していえば,英語母語話者の人口が減る一方で英語非母語話者の人口が増えているということであり,今後もこの傾向が続いてゆくとなると,[2009-10-17-1]で示した英語話者の分布において ENL 比率(円グラフの黄色部分)がますます圧迫されてゆくということになる.従来より規範的な変種として認められてきた British English や American English のブランドが,はたしてこの数的な圧迫のもとで今後も維持されてゆくのかどうか.英語の未来にかかわるエキサイティングな問題である.
Crystal の示した統計はすでに古くなったので,今回は最新版の統計を用いて Crystal と同様の表を作成してみた.ENS 国,ESL 国の詳しいリストは[2009-10-21-1]に掲げたとおりだが,今回は主要国に限った.ENS 国については7カ国(参考までに日本も加えた),ESL 国については原則として2010年年央時において人口2000万人を超える国を対象とした.統計値の典拠は UN, World Population Prospects: The 2008 Revision Population Database だが,これに基づいて作成された便利な表が国立社会保障・人口問題研究所のページから入手できたので,主にこれを利用した.人口の単位は1000人.人口増加率の読み方は,一年間に人口が1%ずつ増加する国は70年後には人口がほぼ2倍になる.
| ENL countries | population (2010) | population growth rate (2005-2010) (%) |
|---|---|---|
| USA | 317,641 | 0.96 |
| UK | 61,899 | 0.54 |
| South Africa | 50,492 | 0.98 |
| Canada | 33,890 | 0.96 |
| Australia | 21,512 | 1.07 |
| Ireland | 4,589 | 1.83 |
| New Zealand | 4,303 | 0.92 |
| Japan (for reference) | 126,995 | -0.07 |
| ESL countries | population (2010) | population growth rate (2005-2010) (%) |
|---|---|---|
| India | 1,214,464 | 1.43 |
| Pakistan | 184,753 | 2.16 |
| Bangladesh | 164,425 | 1.42 |
| Nigeria | 158,259 | 2.33 |
| the Philippines | 93,617 | 1.82 |
| Egypt | 84,474 | 1.81 |
| Tanzania | 45,040 | 2.88 |
| Kenya | 40,863 | 2.64 |
| Uganda | 33,796 | 3.27 |
| Nepal | 29,853 | 1.85 |
| Malaysia | 27,914 | 1.71 |
| Ghana | 24,333 | 2.09 |
| Sri Lanka | 20,410 | 0.88 |
ENL 国はいわゆる先進国なので,今後,人口は伸び悩む.一方,ESL 国には開発途上国が多いので,2%を超える増加率も珍しくない.とりわけインド亜大陸の爆発力がものすごいことは,今後の英語の行方に影響を与える可能性が高い ( see [2009-10-07-1] ).
2010-05-04 Tue
■ #372. 国際語としての英語の趨勢についての気になる事実(2005年版) [statistics][elf]
[2010-01-24-1]の記事でみたように,国際語としての英語という話題では,ELF ( English as a Lingua Franca ) や EIL ( English as an International Language ) という呼称がよく聞かれるようになってきた.英語話者数を始めとする国際語としての英語に関する最新の数値については,Crystal や Graddol がよく引き合いに出される.この種の統計値は最新のものが手に入りにくく,出版されるものは常に数年前のデータというのが普通である.
今回は,2005年時点でNewsweek が関連記事を掲載しているのをみつけたので,そこから世界英語の趨勢についての気になる事実・統計をいくつか抜き出してみたい.5年後の現在,すでに古くなっている情報もあるかもしれないのであしからず.
・ インド国内で英語学習産業は年間1億ドルのビジネスである
・ the British Council によると,10年以内に英語学習者数は20億人に達し,英語話者は30億人に達すると見込まれる
・ アジアの英語使用数は3億5千万人に達する(←アメリカ,イギリス,カナダの人口の和に相当する数)
・ 中国の1億人の子供たちが英語を学んでいる
・ インドは英語教師を中国や中東へ輸出し始めている(← [2009-10-07-1])
・ 反英語主義と結びつけられることの多いフランスでも,教育大臣が英語必修化に反対したものの,選択必修として96%の生徒がすでに英語を履修している(←事実上の必修科目)
・ 世界の電子情報の80%が英語で蓄積されている(← [2010-04-13-1] のイントロクイズで採用した問題.しかし,電子情報における英語の相対頻度は年々減ってきている.いつのデータかは本文内だけでは不明.)
・ the British Council によると,世界中の科学者の66%が英語を読む
・ 中国は,一部 China English を Standard English に取り込む方向で英語のカリキュラムを検討しつつある
このような記事だけを読んでいると英語の勢いは止まらないという一方的な印象を受ける.しかし,実際には諸事情で英語の近未来像を明確に想像することは難しい.その諸事情については,Jenkins の著書がよくまとまっている.
・ "Not the Queen's English". Newsweek 145. 10. March 7, 2005, 41--45.
・ Crystal, David. English As a Global Language. 2nd ed. Cambridge: CUP, 2003.
・ Graddol, David. English Next. British Council, 2006. Digital version available at http://www.britishcouncil.org/learning-research-englishnext.htm.44--45.
・ Graddol, David. The Future of English? The British Council, 1997. Digital version available at http://www.britishcouncil.org/learning-research-futureofenglish.htm.
・ Jenkins, Jennifer. World Englishes: A Resource Book for Students. 2nd ed. London: Routledge, 2009.
2010-04-17 Sat
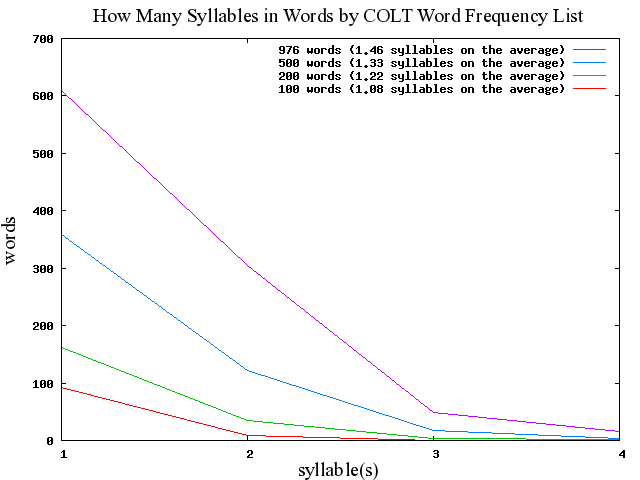
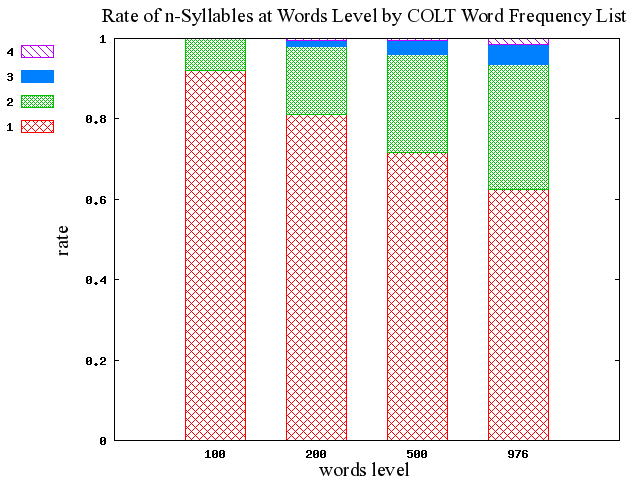
■ #355. COLT Word Frequency List による音節数の分布調査 [colt][syllable][lexicology][statistics]
昨日の記事[2010-04-16-1]で触れたように,COLT ベースの音節数分布調査をパイロット・スタディとして実施してみた.以下が結果.[2010-04-10-1], [2010-04-11-1]の BNC ベースの調査結果と比較するにはこちらのページへ.
BNC ベースの結果と比べて,100語,200語,500語,1000語(976語)のいずれのレベルでも,COLT のほうが平均音節数は少ない.1000語(976語)レベルで比べると,COLT は単音節語と二音節語だけで93%をカバーしているが,BNC はそのカバー率は約10%ほど少ない.口語コーパスに限定した COLT とそうでない BNC の差が関与していると考えられる.
2010-04-11 Sun
■ #349. BNC Word Frequency List による音節数の分布調査 (2) [syllable][lexicology][bnc][statistics]
今回は,昨日の記事[2010-04-10-1]で扱った音節数に関するデータを,角度を変えて見てみたい.100語レベルから6000語レベルまでの各頻度レベルの数値を標準化して,単音節語から7音節音語までの相対頻度を比べられるようにしたものである.(数値データはこのページのHTMLソースを参照.)
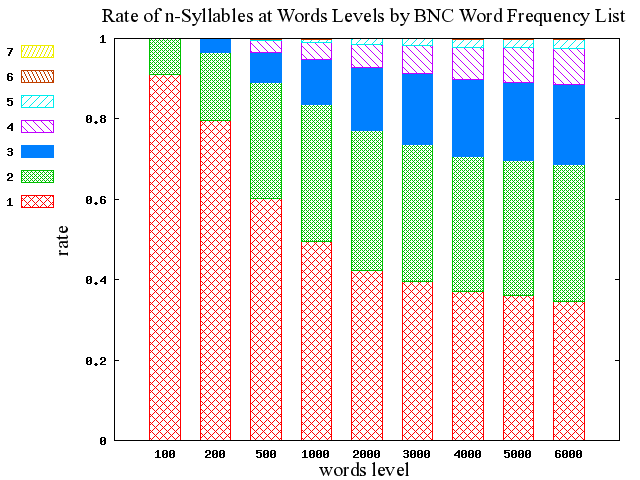
昨日のグラフだけでは読み取りにくかったいくつかのポイントが見えてきた.
・ 対象語彙が大きくなればなるほど単音節語の比率は減少するが,1000語レベル以上からの減り幅は比較的小さい
・ 2音節語の比率は,1000語レベル以上ではほとんど変化していない
・ 500語レベル以上からは3音節語と4音節語が存在感を増してくる
・ とはいえ,2000語レベル以上からは相対的な分布の変化は小さく,全体として安定しつつあるように見える
2010-04-10 Sat
■ #348. BNC Word Frequency List による音節数の分布調査 [syllable][lexicology][bnc][statistics]
昨日の記事[2010-04-09-1]に続く話題.BNC Word Frequency List の6318語の見出し語化された ( lemmatised ) 最頻語リストを材料として,音節数の分布がどのようになっているかを調査してみた.
まずはリストを頻度順に眺めてみるだけで,ある程度の検討はついた.[2010-03-02-1]の記事「現代英語の基本語彙100語の起源と割合」からも明らかなとおり,最頻基本語にはゲルマン系の本来語が多い.このことは,単音節語が多いということにもつながる.しかし,リストを下って頻度のより低い語に目をやると,徐々に2音節語,3音節語が目につくようになってくる.したがって,頻度で上位どのくらいまでを対象にするかによって,音節数の相対的な分布は変わってくることが予想される.そこで,まず6318語すべての音節数を出した上で,最頻100語,200語,500語,1000語,2000語,3000語,4000語,5000語,6000語というレベルで音節数の分布を調査した.レベル間の比較が可能となるようにグラフ化したのが下図である.(数値データはこのページのHTMLソースを参照.)
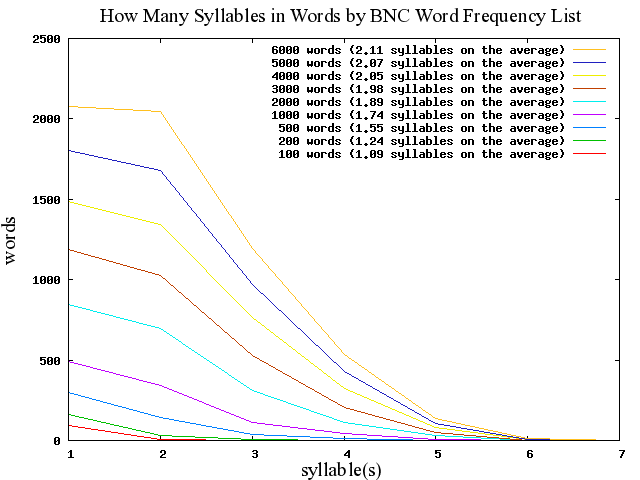
このグラフからいくつかの興味深い事実を読み取ることができる.
・ どのレベルでも単音節語が最も多い
・ 対象語彙が大きくなればなるほど,2音節語数が単音節語数に肉薄する
・ 英語語彙の圧倒的多数が単音節語か2音節語である
・ 対象語彙が大きくなればなるほど,平均音節数が漸増する
・ いずれにせよ英単語の平均音節数はせいぜい2音節ほどである
今回は最頻約6000語レベルの語彙で調査したが,対象語彙をどんどん大きくしてゆくとどのような結果が出るのか,おおいに気になった.やがては2音節語が単音節語を追い抜き,平均音節数も漸増を続けるのだろうか? あるいは平均音節数がこれ以上は変わらないという限界点が存在するのだろうか? non-lemmatised な語彙リストを材料にすると平均音節数はどのくらい変化するのだろうか? 次々に疑問が生じた.
ちなみに,最頻5000語レベルで初めて現れる7音節語が一つある.英語の平均音節数からすると異常に長い超多音節語だが,比較的よくお目にかかる単語ということになる.何であるか,想像できるだろうか? 答えは,4657番目に現れる
telecommunication
(←クリック)である.なるほど?.
2010-04-09 Fri
■ #347. 英単語の平均音節数はどのくらいか? [syllable][lexicology][compound][statistics]
ここ数ヶ月のあいだに取り組んでいる研究課題と関連して,標題の問いについて調査する必要が生じている.この問いの背後にある問題意識としては,単語の語源別の平均音節数を比較して,たとえば「ゲルマン系の単語はロマンス系の単語よりも○音節だけ短い」などという統計的な数値を得たいと思っているのだが,この問題は何段階かに分けてアプローチしてゆくのがよさそうである.標題の問いのままでは適切な問題設定とはいえないいくつかの理由がある.
一つは,言語学で最も悪名高い問題の一つである「単語とは何か」という問いに関係する.わかりやすい例として,合成語 ( compound ) を考えるとよい.school boy は1語なのだろうか,2語なのだろうか? さらに,固有名詞の New York City はどうだろうか? いずれも綴字上の慣習により複数の語とみなすこともできるが,一方で意味のまとまりとしては一つであるから1語だという理屈も成り立ちうる.kick the bucket のようなイディオムはどうだろうか? [2010-02-07-1], [2010-02-08-1]で触れた crane のような多義語 ( polysemy ) は,語義ごとに別の語と考えることもできるのではないか? 英単語の平均音節を考えるにあたっても,こうした基本的な問題は避けて通れない.
二つ目の理由は,英語語彙というときの範囲の問題である.OED には50万語ほどがエントリーされているが,辞書の保守性を考慮すると,実際にはその倍の語彙があるのではないかともいわれている.平均値を出すからには,理想的にはありったけの単語を考慮に入れることが必要である.となると,[2009-06-30-1]の記事でみた pneumonoultramicroscopicsilicovolcanoconiosis のような極端な語(19音節)も含めることになる.だが,そもそも現代英語語彙の総覧が存在しない以上,どこまで含めてどこから含めないかの判断は恣意的にならざるをえない.実際的な研究に際しては,どこかで強引に切る必要がある.
三つ目は,同一の語でも,変種によって1音節程度の増減が起こりうるという問題である.[2010-03-08-1]で触れたように,secretary は典型的な英米発音のあいだで音節数の揺れがある.もっとも,この問題は対象とする変種を定めてしまえば,上記の二つの問題ほど大きな問題にはならないかもしれない.
一つ目,二つ目の問題については当面の根本的な解決策はないが,そんなに難しいことを言っていては仕方がないというのも確かである.具体的に調査を進めてみようと思うと,[2010-03-01-1]で紹介した最頻英単語リスト辺りからスタートするのがよさそうである.ひとまずは,BNC Word Frequency List の6318語のリストから始めてみようと思う.
・ 齊藤 俊雄,中村 純作,赤野 一郎 編 『英語コーパス言語学?基礎と実践?』 研究社,1998年.110--13頁.
2010-03-12 Fri
■ #319. 英語話者人口の銀杏の葉モデル [elf][model_of_englishes][statistics][demography]
近代以降,特に19世紀から20世紀にかけて英語の話者人口が爆発的に増えてきたことは,本ブログでもたびたび話題に取りあげている.例えば,英語話者人口の様々な分類の仕方と問題点は[2009-10-17-1], [2009-11-30-1], [2009-12-05-1], [2010-01-24-1]で扱った.英語話者の分類はともかくとして話者人口そのものが増えてきた点に焦点をあてたとき,よく引き合いに出されるのがマッシュルームモデルである.最近では,Svartvik and Leech (8) でも掲載されたモデルである.
子供に図を見せて何に見えるかと尋ねたら,マッシュルームではなくイチョウの葉だというので,ここでは名称を改め「銀杏の葉モデル」と呼んでおきたい.これの意味するところは図を見れば一目瞭然だろう.
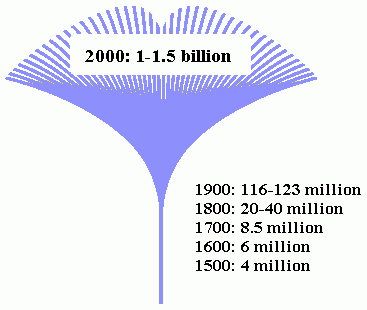
図中の数値は ENS, ESL, EFL を含めた概数だが,過去2世紀の間に約40倍も増えているのだから驚きだ.この図を見て思うところが3点あるので,コメントしておきたい.
(1) 話者人口数を表すこの銀杏の葉モデルを側面図ととらえて,立体的に真上からのぞき込むと,話者人口の分類を表す同心円モデル([2009-11-30-1])に近くなるのではないか.透明の円錐をとがった方を下にして,上からのぞき込んだ感じである.話者人口増加にもっとも貢献しているのは,Outer Circle 及び Expanding Circle に所属する人々である.
(2) 銀杏の葉の上端にある筋状の葉脈の一つひとつが,英語の変種 ( variety ) に相当すると見ることができるのではないか.上端に近いほど筋は互いに離れていくが,実際には葉っぱ本体に埋め込まれている筋なので,つながっている.現代の英語の変種間に働く遠心力と求心力を思い起こさせる.
(3) 近代以前と以降とで英語史が二分されるというイメージ.近年,英語史研究の世界では,特に近代英語期以降に関する研究において,話者と言語との関係を意識した社会言語学なアプローチが活気づいている.また,変種間の微妙な違いに留意する研究も増えてきている.話者が増え,その分だけ変種も増え,現在に近いだけに言語現象の背後にある社会言語学的な情報にもアクセスできる,ということが関与していると思われる.
それに対して,中英語期の研究は,確かに社会言語学的な視点からのアプローチが増えてきているとはいえ,アクセスできる情報には限りがある.変種も地域変種(方言)の研究は盛んだが,地理的な広がりといえばイングランド(とせいぜいその周辺)に限られ,近代以降の世界中に展開する複雑きわまれる変種の分布とは規模が異なる.
だが,英語史をこのように二分する考え方が必ずしもいいとは思っていない.変種の規模や広がりこそ大きく異なるが,変種のあり方については近代も中世も古代もそれほど変わらない点があるのではないか.
あれやこれやと,この図から想像してみた.
・ Svartvik, Jan and Geoffrey Leech. English: One Tongue, Many Voices. Basingstoke: Palgrave Macmillan, 2006.
2010-03-02 Tue
■ #309. 現代英語の基本語彙100語の起源と割合 [loan_word][lexicology][statistics][pde]
昨日の記事[2010-03-01-1]で,現代英語の最頻英単語リストをいくつか紹介した.そのなかで,やや古いが広く参照されている GSL ( General Service List ) に基づき,最頻100語の語源別の内訳を調べてみた.
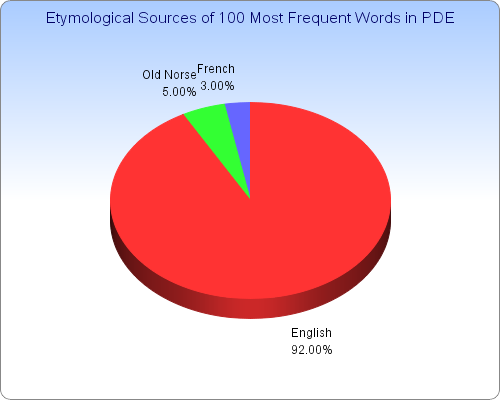
英語の本来語 ( native words ) の一人勝ちであることは一目瞭然である.借用語 ( loan words ) はわずかである.最頻語彙の血は紛れもなく Anglo-Saxon である.
古ノルド語由来の語は they, she, take, get, give の5語のみ.ただし,she の語源にはイングランド北部方言説など諸説がある.また,get と give については,語頭子音 /g/ こそ古ノルド語形に由来すると言ってよいが,対応する語は古英語にもあり,考え方によってはどちらの言語にも帰せられる.ここでは,いずれも古ノルド語由来として数えた.
フランス語由来の語は,state, use, people の3語のみ.
過去の記事でも類似する統計をいくつか載せているので,そちらも要参照.
・ [2009-11-15-1]: 現代英語の基本語彙600語の起源と割合
・ [2009-11-14-1]: 現代英語の借用語の起源と割合 (2)
・ [2009-08-15-1]: 現代英語の借用語の起源と割合
2010-03-01 Mon
■ #308. 現代英語の最頻英単語リスト [lexicology][corpus][link][academic_word_list][alphabet][frequency][statistics][letter_frequency]
現代英語の最頻英単語は何か.この話題についてはコーパス言語学,辞書学,計算機の発展により,様々な頻度表が作られてきた.ウェブ上でも簡単に手に入るので,いくつか代表的なリストや情報源へのリンクを掲げておく.語彙研究に活用したい.
[主要な頻度表]
・ GSL ( General Service List ): 最頻2000語を掲げたリスト.出版が1953年と古いが,現在でも広く参照されているリスト.
・ AWL ( Academic Word List ): 学術テキストに限定した最頻語リスト.2000年に出版され,GSLに含まれる語と重複しないように選ばれた570語を掲載.10のサブリストに分かれている.AWL の前身となる,1984年に出版された808語のリスト UWL ( University Word List ) も参照.
・ BNC Word Frequency Lists: BNC ( The British National Corpus ) による最頻6318語のリスト.頻度表の直接ダウンロードはこちらから.
・ Top 1000 words in UK English: 18人の著者,29作品,460万語のコーパスから抽出したイギリス英語の最頻1000語リスト.
・ Brown Corpus List: Brown Corpus によるアルファベット順リスト.
・ The Longman Defining Vocabulary: LDOCE の1988年版の定義語彙リスト.2000語以上.
[他のリストへのリンク集]
・ Work/Frequency List: 様々な頻度表へのリンク集.(2010/09/10(Fri)現在リンク切れ)
・ Famous Frequency Lists: 様々な頻度表へのリンク集.
・ Basic English and Common Words: ML上の最頻語頻度表についての議論.
[アルファベットの文字の頻度表]
・ Letter Frequencies (rankings for various languages): いくつかのランキング表がある.BNCでは "etaoinsrhldcumfpgwybvkxjqz" の順とある.
(後記 2010/03/07(Sun):American National Corpus に基づいた頻度表を見つけた.Written と Spoken で分別した頻度表もあり.)
(後記 2010/04/12(Mon):COLT: The Bergen Corpus Of London Teenage Language に基づいた最頻1000語のリストを見つけた.)
(後記 2011/02/14(Mon):Corpus of Contemporary American English (COCA) に基づいた Corpus-based word frequency lists, collocates, and n-grams を見つけた.Top 5,000 lemma, Top 500,000 word forms など.)
2010-01-26 Tue
■ #274. 言語数と話者数 [statistics][world_languages][language_death][demography]
[2010-01-22-1]で世界の言語の数を話題にした.今回は,言語数と各言語の母語話者数との関係を考えてみる.
以下の表は,世界に約6000言語が存在すると仮定し,その母語話者数との関係を一覧にしたものである.これは,1999年版の Ethnologue を参考に,Crystal がまとめたものである (14--15).
| Population of Native Speakers | Number of Languages | % | Cumulative downwards % | Cumulative upwards % |
|---|---|---|---|---|
| more than 100 million | 8 | 0.13 | 99.9 | |
| 10--99.9 million | 72 | 1.2 | 1.3 | 99.8 |
| 1--9.9 million | 239 | 3.9 | 5.2 | 98.6 |
| 100,000--999,999 | 795 | 13.1 | 18.3 | 94.7 |
| 10,000--99,999 | 1,605 | 26.5 | 44.8 | 81.6 |
| 1,000--9,999 | 1,782 | 29.4 | 74.2 | 55.1 |
| 100--999 | 1,075 | 17.7 | 91.9 | 25.7 |
| 10--99 | 302 | 5.0 | 96.9 | 8.0 |
| 1--9 | 181 | 3.0 | 99.9 |
この表あるいはこの表の背後にある事実から明らかなことは,第一言語に関する限り,ごく少数の言語が世界の人口の大部分をまかなっているということである.母語話者が1億人を超える言語は Mandarin (Chinese), Spanish, English, Bengali, Hindi, Portuguese, Russian, Japanese のわずか8言語に過ぎず,これだけで実に世界人口の4割ほど(24億人)がまかなわれているという.トップ20までの言語を考えると,それだけで世界人口の半分以上を占めるというから驚きである.
さらに象徴的な数字を示せば,世界の言語の4%が世界人口の96%を覆っているという.逆にいうと,世界の言語の96%が世界人口の4%に相当する数の話者にしか母語として使用されていないことになる.より具体的にいうと,一番右の列の数値をみれば,世界の言語の約25%が千人未満しか母語話者をもたず,世界の言語の半数以上が一万人未満しか母語話者をもたないことがわかる.世界の言語と母語話者の数は,まさにピラミッド状の分布を示すのである.
ピラミッドの中部以下に属する大多数の言語が消滅の危機にあることは明らかである.消滅の速度については様々な予想がなされているが,今後100年で世界の言語の半数が失われるだろうという推計がよく聞かれる (Crystal 19).この推計に基づいて簡単な算数をおこなうと,およそ12日に1言語の割合で消失が進んでいることになる.
・Crystal, David. Language Death. Cambridge: CUP, 2000.
2010-01-22 Fri
■ #270. 世界の言語の数はなぜ正確に把握できないか [statistics][world_languages][language_or_dialect]
世界に言語はいくつあるか? 論者によって3,000という数から10,000という数まで様々で,一定しない.だが,複数の論者の平均値としてもっともよく耳にする数が,6,000前後である.
だが,なぜ論者によって数値が違うのだろうか.言語は客観的に数えられないものなのだろうか.Crystal は世界の言語の数を正確に把握できない理由を5点挙げている (3--5).
(1) そもそも世界規模の調査が少ない.確かに20世紀後半からは Ethnologue などいくつかの機関が世界的な調査をおこなっているが,こうした試み自体が比較的新しいものであり,世界言語統計は始まったばかりというべきである.
(2) 多くの論者は上記の調査が不完全であることを知っているために,言語数を任意に切り上げたり切り下げたりしがちである.
(3) 消滅する言語の数とそれらが消滅する速度を正確に把握できない.
(4) 新たに発見される言語の数と発見の頻度を正確に把握できない.(もっとも,発見される「新言語」によって世界の言語数が劇的に増えるとは考えにくいので,影響は僅少だろうが.)
(5) ある変種を「言語」 ( language ) とみるか,ある言語の「方言」 ( dialect ) とみるかについて,明確な基準がない.
昨今,世界規模の調査も進められてきており,(1) から (4) の問題点については改善されてゆくだろう.だが,(5) は社会言語学上の古典的な問題であり,解決の糸口がない.
例えば,1990年には Serbo-Croatian という一言語だったものが現在では Serbian, Croatian, Bosnian と三言語に分裂している.言語が変わったわけではなく,旧ユーゴスラビアが政治的に分裂したがゆえの事態である.
同じように,英語が今後ますます多様化してゆくことを考えると,Indian English, Singapore English, Caribbean English などはすべて English から独立した別の言語として数えられるようになるかもしれない.
数えるって難しい.
・Crystal, David. Language Death. Cambridge: CUP, 2000.
2010-01-08 Fri
■ #256. 米国の Hispanification [spanish][hispanification][statistics][official_language]
昨日の記事[2010-01-07-1]の最後に,米国でスペイン語使用が増加している件 ( Hispanification ) に触れた.今回は,これと関連していくつかの数字を示したい.
現代世界において,米国が世界語としての英語の最強の推進者であることは論をまたないが,それは米国が英語一辺倒の国であることと同義ではない.米国が多民族国家であり多言語国家であることを忘れてはならない.Ethonologue (297) によると,アメリカ合衆国で現役で使用されている "living languages" は364言語を数える.そのなかで,近年もっとも勢力を伸ばしている言語はスペイン語である.スペイン語話者の数は1970年からみて6割以上も増加しているというから驚きの加速度である.具体的な数字を出せば,1990年の調査では 22,400,000 ほど,2000年の調査では 28,100,000 ほどのスペイン語話者人口が報告されており,その10年間だけで25%増加したことになる.New Mexico ではスペイン語は公的な地位を与えられており,それ以外の諸州においても official Spanish なる表現がよく聞かれるようになってきている.(以上の情報は,書籍版 Ethonologue に加え,Online 版の Ethnologue アメリカ合衆国の項 も参考にした.)
Graddol (26--27) では,1990年代に発表された米国商務省の統計に基づいた2050年の人口分布予測が紹介されている.それによると,2050年の米国では Hispanic 人口が全人口の約4分の1を占めるという.さらに Black や Native Americans を含む非白人の総計をとると,全人口の約半分を占めることになるという.こうした予測を背景に,1990年代の米国で英語公用語論が湧き出たのも自然なことだったといえよう.
U.S. English のサイトでは Official English について詳しい解説が与えられている.Crystal (127--40) にも関連する議論がある.参考までに.
・Graddol, David. The Future of English? The British Council, 1997. Digital version available at http://www.britishcouncil.org/learning-research-futureofenglish.htm.
・Gordon, Raymond G., Jr. ed. Ethnologue. 15th ed. Dallas: SIL International, 2005.
・Crystal, David. English As a Global Language. 2nd ed. Cambridge: CUP, 2003.
2009-11-16 Mon
■ #203. 1500--1900年における英語語彙の増加 [lexicology][statistics][soed]
近代英語期の英語語彙の増加について,(連日だが)Hughes の調査を参考にしつつ紹介.Hughes は,Shorter Oxford English Dictionary (1933 ed.) に基づいて編集された Chronological English Dictionary を利用して,1500年から1900年のあいだに英語に加わった語を10年ごとに集計してグラフを作成した (404).
以下のグラフは,Hughes のグラフを本ブログ用に改変したものである.Hughes にはグラフ作成のもとになる数値データは与えられていないので,グラフから目検討で数値を読み出し,それを頼りに再びグラフを作成した.したがって,ここに示されているものはあくまで参考までに.
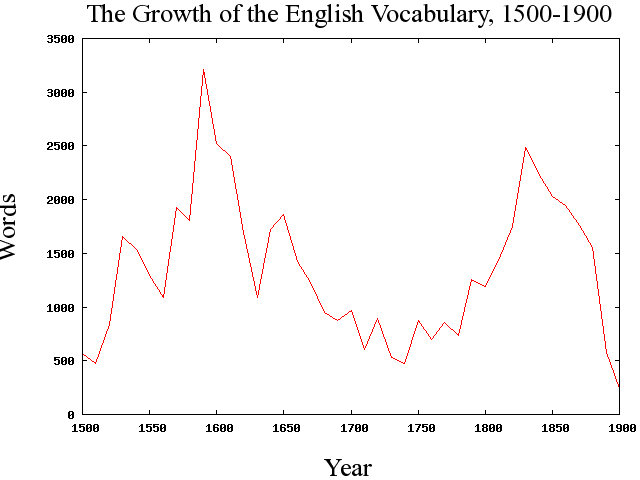
グラフには二つのピークがある.一つ目のピークは約1550?1630年の時期で,およそエリザベス朝の時代 ( Elizabethan Period ) を中心とする.二つ目のピークは約1790?1880年の時期で,およそロマン主義の時代 ( Romantic Period ) に相当する.間にはさまれた王政復古期 ( Restoration Period ) と新古典主義時代 ( Augustan Period ) は比較的,保守的だったとわかる.1450?1950年に加わった語彙の総数は6万語を超え,平均すると年に約120語ということになる.
なお,Hughes によると,年単位でみると1598年(590語)と1611年(844語)がもっとも際だっているという.
・Hughes, G. A History of English Words. Oxford: Blackwell, 2000. 403--04.
・Finkenstaedt, Thomas, E. Leisi, and D. Wolf. eds. A Choronological English Dictionary. Heidelberg: Carl Winter, 1970.
2009-11-15 Sun
■ #202. 現代英語の基本語彙600語の起源と割合 [loan_word][lexicology][statistics][pde][romancisation]
昨日の記事[2009-11-14-1]に引き続き,現代英語の語彙に関する統計値の話題.昨日は,借用語に限定し,そのソース言語の相対的割合を示すグラフを掲げた.今日は,本来語も借用語も含めた現代英語の語彙全体から基本語600語を取り出し,その語源をソース言語ごとに数え上げるという切り口による統計を紹介する.以下の数値と議論の出典は,昨日と同じく Hughes による.
数値をみる前に,基本語彙 ( core vocabulary ) を客観的に定義するのは難しいという問題に触れておきたい.話し言葉で考えるのか,書き言葉で考えるのか.個々の話し手,書き手によって基本語彙とは異なるものではないのか.世界英語のどの変種 ( variety ) を対象に考えるのか,イギリス英語か,アメリカ英語か,それ以外か.この問題に対して,Hughes は,LDOCE3 の頻度ラベルが S1 かつ W1 であるもの,すなわち話し言葉でも書き言葉でも最頻1000語に入っている語だけを選び出すことにした.この総数が600語であり,これを "the kernel of the core" (392) として調査対象にした.以下は,ソース言語別の割合をグラフ化したものである.
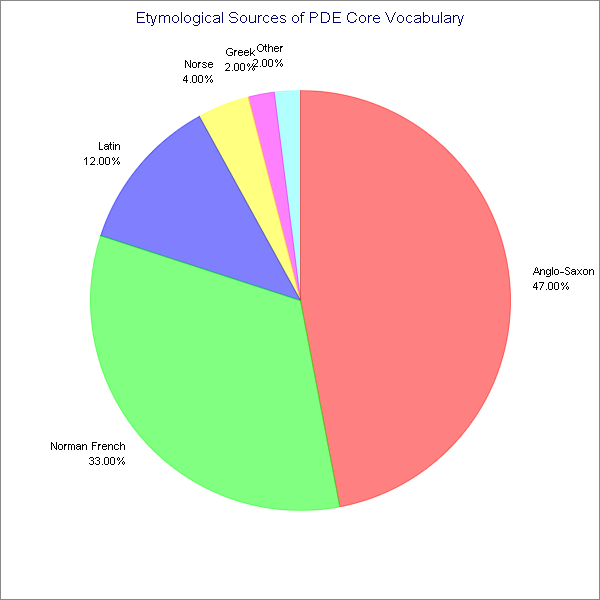
従来の類似調査や伝統的な英語史観からは,Anglo-Saxon 由来の本来語の割合はもっと高いはずではないか(6割?7割)と予想されるところだが,意外にも5割を切っている.話し言葉の記述に力を入れている LDOCE3 に基づく結果であるだけに,なおさらこの結果は意外である.
もう一つ興味深いのは,Anglo-Saxon と Norse を合わせた Germanic 連合軍と,Norman French と Latin と Greek を合わせた Latinate-Classic 連合軍とが,およそ半々に釣り合っていることだ.語彙に関しては,中英語以降,英語はゲルマン系からロマンス系へと舵を切っているということが英語史ではよくいわれる.現代において,語彙のロマンス化の傾向は維持されているのみならず,むしろ強まってきているということを,このデータは示唆するのではないか.
・ Hughes, G. A History of English Words. Oxford: Blackwell, 2000. 391--94.
・ Longman Dictionary of Contemporary English. 3rd ed. Harlow: Longman, 1995.
2009-11-14 Sat
■ #201. 現代英語の借用語の起源と割合 (2) [loan_word][lexicology][statistics][pde]
標題について[2009-08-15-1]で円グラフを示したが,そのときにグラフ作成に用いた数値は孫引きのデータだった.今回は OED (2nd ed.) で語彙調査をした Hughes の原典から直接データを取り込み,より精確なグラフを作成してみた.カウントの対象とされたソース言語は75言語,借用語総数は169327語である.
一つ目は円グラフで,現代英語の借用語全体を100としたときのソース言語の相対比率を示したものである.[2009-08-15-1]で示したグラフをより精確にしたものと理解されたい.
二つ目は棒グラフで,比率ではなく借用語数で,ソース言語別にプロットしたものである.
少数のソース言語が借用語の大多数を供給している実態がよくわかる.もとの数値データはこのページのHTMLソースを参照.
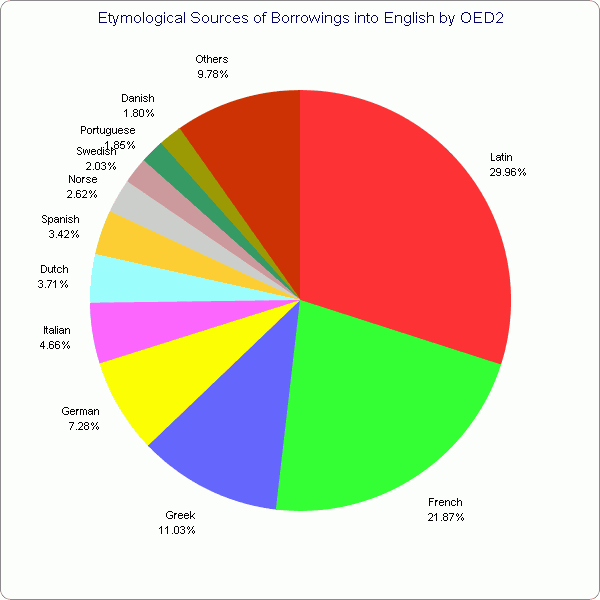

・Hughes, G. A History of English Words. Oxford: Blackwell, 2000. 370.
2009-10-22 Thu
■ #178. 動詞の規則活用化の略歴 [verb][conjugation][analogy][oe][statistics][sobokunagimon][dental_suffix]
現代英語の動詞は,規則動詞 ( regular verb ) と不規則動詞 ( irregular verb ) に大別される.
規則動詞は原則として動詞の原形に -ed という語尾を付加して過去形・過去分詞形を作る.発音は語幹末の音にしたがって /d/, /ɪd/, /t/ のいずれかとなるが,いずれも歯音接尾辞 ( dental suffix ) を含んでいる( ex. played, wanted, looked ).これはゲルマン諸語に共通する過去形・過去分詞形の形成である.
一方,不規則動詞 はいろいろと下位区分ができるが,多くは母音交替 ( ablaut or gradation ) によって過去形・過去分詞形を作る.swim -- swam -- swum, give -- gave -- given, come -- came -- come の類である.
不規則動詞には基本動詞が多いために,相当数の不規則動詞があるかのように錯覚しがちだが,実際には70個ほどしかない.それ以外の無数の動詞は -ed で過去形・過去分詞形を作る規則動詞である.
だが,昔からこのような分布だったわけではない.古英語では,およそ規則動詞に相当するものを弱変化動詞 ( weak verb ) と呼び,およそ不規則動詞に相当するものを強変化動詞 ( strong verb ) と呼んだが,後者は270語ほど存在したのである.だが,以降1000年の間に不規則動詞は激減した.この約270語がたどったパターンは以下のいずれかである.
(1) 不規則動詞(強変化動詞)としてとどまった
(2) 不規則動詞(強変化動詞)と規則動詞(弱変化動詞)の間で現在も揺れている
(3) 規則動詞化(弱変化動詞化)した
(4) 廃語として英語から消えた
それぞれの内訳は以下の通りである.おおまかにいって,古英語の強変化動詞の1/3は廃れ,1/3は規則動詞化し,1/3は不規則動詞にとどまったといえる.
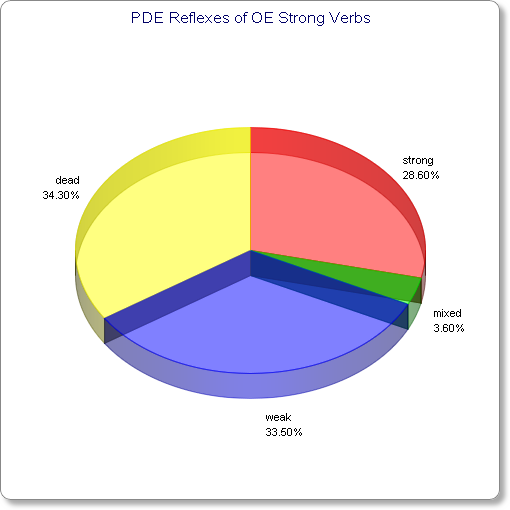
以下に簡単に具体例を挙げるが,定義上,(1) は現代英語に残っている不規則動詞であり,(4) は現代英語に残っていない語なので省略する.
(3) のパターンには,help がある.この動詞は古英語では helpan -- healp / hulpon -- holpen と母音交替によって活用していたが,現代英語では規則動詞となっている.その他,shave, step, yield などもかつては不規則動詞だった.
(2) のパターンには,mow -- mowed -- mowed / mown, show -- showed -- showed / shown, prove -- proved -- proved / proven などがある.傾向としては,-ed の付いた規則形が優勢である.このパターンに属する動詞では,不規則形が廃れていくのも時間の問題かもしれない.
・Görlach, Manfred. The Linguistic History of English. Basingstoke: Macmillan, 1997. 69--75.
2009-09-06 Sun
■ #132. 古英語から中英語への語順の発達過程 [word_order][syntax][lexical_diffusion][statistics]
古英語はで屈折により格が標示されたため,現代英語に比べて語順が自由だったことはよく知られている.例えば,SVO の構文は,特殊な倒置を除いて現代英語では揺るぎない規則といってよいが,古英語ではあくまでよくある傾向に過ぎなかった.従属節では SOV の語順が多かったし,主節でも目的語が代名詞であったり and で始まる文では SOV が多かった.つまり,古英語の語順は,緩やかな傾向をもった上で,比較的自由だったといえる.
だが,この状況が中英語期になって変化してくる.SVO の語順がにわかに発達してくるのである.以下は橋本先生の著書で引かれている Fries の調査結果に基づいた語順の推移である.およそ1000年から1500年までの英語を対象として,OV と VO の語順の比率を示したものである.(c1100のデータはなし.数値データはこのページのHTMLソースを参照.)
ここでは主節と従属節の区別をしていないこともあり,単純に結論づけることはできないものの,14世紀中に一気に SVO が成長したことは確かなようだ.発達曲線は slow-quick-quick-slow を示しており,典型的な 語彙拡散 ( Lexical Diffusion ) の発達過程を経ているように見える.
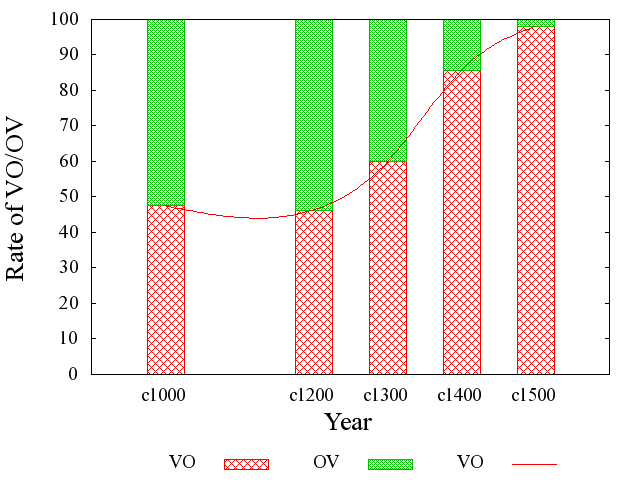
・Fries, Charles C. "On the Development of the Structural Use of Word-Order in Modern English." Language 16 (1940): 199--208.
・橋本 功 『英語史入門』 慶應義塾大学出版会,2005年. 176頁.
Powered by WinChalow1.0rc4 based on chalow